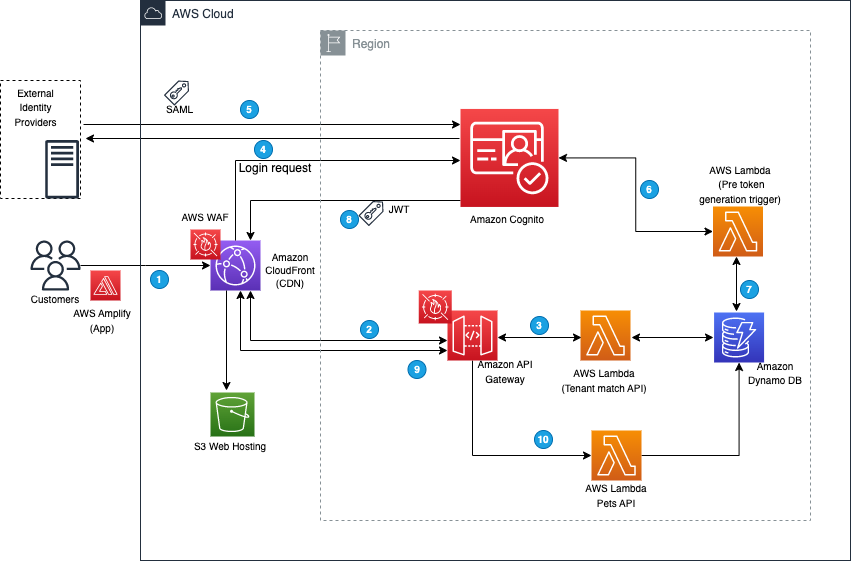
Post Syndicated from Cody Penta original https://aws.amazon.com/blogs/security/iam-roles-anywhere-with-an-external-certificate-authority/
AWS Identity and Access Management Roles Anywhere allows you to use temporary Amazon Web Services (AWS) credentials outside of AWS by using X.509 Certificates issued by your certificate authority (CA). Faraz Angabini goes deep into using IAM Roles Anywhere in his blog post Extend AWS IAM roles to workloads outside of AWS with IAM Roles Anywhere. In this blog post, I take a step back from his post and first define what public key infrastructure (PKI) is and help you set one up for use for IAM Roles Anywhere.
I focus on setting up local PKI for testing purposes by building a basic, minimal certificate authority using openssl. I chose openssl as it’s a standard industry tool for cryptography and is often installed by default on many operating systems. However, you can achieve similar results in a simpler manner using open source tools such as cfssl. In this blog post, we create a local PKI for non-production use cases only for the sake of brevity and to focus more on understanding the core fundamentals. As I go along, I’ll point out what I left out and where to find more information.
Overview
The overall flow of this blog is as follows, there’s some new terminology, so please use this as a map to refer to as you read along to understand the flow. If you’re taking cornell notes, now would be the right time to write key words you see below such as key, certificate, end-entity certificate, certificate authority, CA, trust, IAM Roles Anywhere, and others that pop out to you.
- Explain the concepts of keys and certificates and their uses.
- Using what you learn about keys and certificates, create a CA.
- Import your certificate authority into IAM Roles Anywhere and establish trust between your certificate authority and IAM Roles Anywhere.
- Create an end-entity certificate.
- Exchange your end-entity certificate for IAM credentials using IAM Roles Anywhere.
Background
IAM Roles Anywhere is compatible with existing PKIs, and for demonstration purposes, you’ll create local infrastructure using openssl to get a deep understanding of the terminology and concepts. Existing PKIs such as AWS Certificate Manager (ACM) and third-party certificate authority services often abstract and simplify this process. With that being said, you have to start somewhere, so let’s start with a key.
What exactly is a key? The National Institute of Standards and Technology (NIST) defines a key as “a parameter used in conjunction with a cryptographic algorithm that determines the specific operation of that algorithm,” which is a formal way of saying for anything you would put inside the key parameter in a function like encrypt(key, data), decrypt(key, data), or sign(key, data). The definition cleverly avoids defining the key by its structure—such as, “It’s a sequence of 256 truly random bits” — as that’s not always the case. For example, in asymmetric encryption you have two keys. One key is private and should not, under any circumstances, be shared outside of your control; while another key is public and can be safely shared with the outside world. To illustrate this, let’s look at actual commands to generate keys:
openssl genpkey -out private.key \
-algorithm RSA \
-pkeyopt rsa_keygen_bits:2048 # 2048 minimum key size for RSA, later we use 4096
NOTE: The key is printed in PKCS#8 format, which is a file format for the private key along with some metadata
You can inspect this key with:
cat private.key
-----BEGIN PRIVATE KEY-----
MIIEvgIBADANBgkqhkiG9w0BAQEFAASCBKgwggSkAgEAAoIBAQC/BWpcJqlVDJkC
wr+qrwEgNPSpXM2iSQQAfjS81pll4I5yp//7lm1UqKeBTbaYp9rVec1uzKQrw3xt
...36 lines removed for brevity
mx2sovZyFB7Xe4/99TGLQuHTtgLYYVEN/iFtvsbjPjR7X+R76GWPLdUFdRes0gPo
dlsfnsVKVkUUJKZy0Y2nOrwb2gNSUd/NjcgV9XHEW4y+Sclk/EkdAML1d3aGM0VQ
AaLL8xb75To0VqSQPW12URJM
-----END PRIVATE KEY-----
The public key is embedded inside the private key and you can even pull the public part from the private key.
openssl pkey -in private.key -pubout -out public.key
And like the private key, you can inspect it:
cat public.key
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAvwVqXCapVQyZAsK/qq8B
IDT0qVzNokkEAH40vNaZZeCOcqf/+5ZtVKingU22mKfa1XnNbsykK8N8bSY9J4r5
f9DVDN8YmRh1+YEYB8pkFTjZBuz158F9GVRK9r/6Lr2Ft0RAinGiN4LoO+V++Ofk
LITgB0rqMk1UH8XyUJwHkS5btr5M7v7zudiQiUDW4vRpWTJ/I4mb9Y2brMfMxJpg
nJ0ni1pm8Yz8zcVjFklvkdtQD+wx4DXf4/7o2EDBNPc1gW+9gIpCI1h5TMwXWURH
lY9cM03SqKwj6SzHxRdOjcMC1Zie3+8OKr1HYpMT0AIM85T3q1iUif8s0TQ3Mk9o
jQIDAQAB
-----END PUBLIC KEY-----
While you must keep your private key a secret, you can openly share your public key. You can even copy the key multiple times and rename each copy to designate an individual whom you would hand the public key out to.
cp public.key alice-public.key
cp public.key bob-public.key
ls
alice-public.key bob-public.key private.key public.key
Now here’s the most critical question that I cannot stress enough:
Who owns these keys?
Does the server that generated this private key own it? Do I, as the author of this blog, own it? Does Amazon, as the company, own this private key?
What about the public keys? Who exactly is Alice (alice-public.key)? Who is Bob (bob-public.key)? How are Bob and Alice different if they have the same public key? These are all rhetorical questions you should be asking yourself when working with cryptographic keys. It helps answer who is responsible for this key and ultimately any data encrypted/unencrypted with that key.
At its core, public key infrastructure (PKI) can be explained as assigning an identity to someone or something and using cryptographic keys to ensure that identity can be verified. In the case of internal PKIs, the someone or something is often a hierarchy of assets belonging to your company. For example, a flow could be:
- Your company
- Your company’s business unit
- business unit servers
- business unit load balancers
- business unit clients
- Another business unit
Step 1: Set up a root certificate authority
You need to start somewhere, right? To get a publicly trusted identity, you often need to go through a certificate management service like AWS Certificate Manager (ACM) or a third-party vendor. These vendors go through several audits with operating system providers to have their identity trusted on the operating system itself. For example, on MacOS, you can open the Keychain Access app, go to System Roots, and look at the Certificates tab to see identities that are managed on your behalf.
In this use case with IAM Roles Anywhere, you don’t have to worry about interacting with operating system providers, because you’re creating your own internal PKI—your own internal identity. You do this by creating a certificate authority.
But hold on now, what exactly is a certificate authority? For that matter, what is a certificate?
A certificate is a wrapper around a public key that assigns metadata to an entity. Remember how you can copy the public key and just rename it to alice-public.key? You’ll need a little more metadata than that but the concept is the same. Examples of metadata include “Who are you?” “Who gave you this key?” “When should this key expire?” “Here is what you’re allowed to use this key for,” and various other attributes. As you can imagine, you don’t want just anybody to provide you this type of metadata. You want trusted authorities to assign or validate that metadata for you, and so the term certificate authorities. Certificate authorities also sign these certificates using a digital signing algorithm such as RSA so that consumers of these certificates can verify that the metadata inside hasn’t been tampered with.
You want to be the certificate authority within your own internal network. So how do you go about doing that? Turns out, you’ve already completed the most critical step: creating a private key. By creating a cryptographically strong, random private key, you can assert that whoever owns this private key, represents our company. You can do so because it’s highly improbable that anyone could guess or brute-force this key. However, that means every mechanism you use to protect this private key is critical.
Remember though, you need an identity, and simply naming your private key anycompany.private.key and public key usecase.public.key isn’t ideal. It’s not ideal because you need a lot more metadata than a file name. You need metadata like you would have in the earlier certificate example. You need a certificate that represents your certificate authority, a sort of ID for your root certificate. To facilitate that, there’s a field in certificates called IsCA that’s either true or false. Meaning whether or not a certificate is simply a certificate or a certificate authority is determined by a flag inside the certificate. We’ll start by writing out an openssl configuration file that is used throughout multiple certificate management commands.
NOTE: What’s the difference between a root certificate and a root certificate authority? You can think of a root certificate authority as a person who stamps other certificates. This person themselves needs an ID card. That ID card is the root certificate.
# NOTE: Examples derived from Ivans Ristic's Github
# https://github.com/ivanr/bulletproof-tls
# You may also use `man ca` at the CLI for more examples
# Basic Info about the CA
[default]
name = root-ca
domain_suffix = example.com
default_ca = ca_default
name_opt = utf8,esc_ctrl,multiline,lname,align
[ca_dn]
countryName = "US"
organizationName = "Any Company Corp"
commonName = "internal.anycompany.com"
# How the CA Should operate
[ca_default]
home = root-ca
database = $home/db/index
serial = $home/db/serial
certificate = $home/$name.crt
private_key = $home/private/$name.key
RANDFILE = $home/private/random
new_certs_dir = $home/certs
unique_subject = no
copy_extensions = none
default_days = 3650
default_md = sha256
policy = policy_c_o_match
[policy_c_o_match]
countryName = match
stateOrProvinceName = optional
organizationName = match
organizationalUnitName = optional
commonName = supplied
emailAddress = optional
# Configuration for `req` command
[req]
default_bits = 4096
encrypt_key = yes
default_md = sha256
utf8 = yes
string_mask = utf8only
prompt = no
distinguished_name = ca_dn
req_extensions = ca_ext
[ca_ext]
basicConstraints = critical,CA:true
keyUsage = critical,keyCertSign
subjectKeyIdentifier = hash
# create-root-ca.sh
mkdir -p root-ca/certs # New Certificates issued are stored here
mkdir -p root-ca/db # Openssl managed database
mkdir -p root-ca/private # Private key dir for the CA
chmod 700 root-ca/private
touch root-ca/db/index
# Give our root-ca a unique identifier
openssl rand -hex 16 > root-ca/db/serial
# Create the certificate signing request
openssl req -new \
-config root-ca.conf \
-out root-ca.csr \
-keyout root-ca/private/root-ca.key
# Sign our request
openssl ca -selfsign \
-config root-ca.conf \
-in root-ca.csr \
-out root-ca.crt \
-extensions ca_ext
But there are a few things I have to point out:
- Most certificates start their lives as a certificate signing request (CSR). They contain most of the data an actual certificate does and only become a certificate when signed either by the same entity that created it (self-signed certificate) or by another entity (external certificate authority). This is why you see
openssl req followed by openssl ca -selfsign.
- Everything under
root-ca/ must now be protected, especially anything generated under root-ca/private/.
- I skipped quite a few steps for the sake of brevity, including creating a subordinate certificate authority and keeping the root certificate authority offline, as well as adding a certificate revocation list and Online Certificate Status Protocol (OSCP) capabilities. These can be their own book and I would instead recommend reading Bulletproof TLS and PKI by Ivan Ristic. In this post, I include the bare minimum to import a certificate and get started with IAM Roles Anywhere. As a side note, if you’re importing a certificate from a certificate authority managed outside of AWS, it should come with these capabilities as well.
It’s good practice to inspect the actual root-ca.crt that was returned to you.
openssl x509 -in root-ca.crt -text -noout
Note: If you want to inspect and compare the root-ca.crt with the certificate signing request root-ca.csr, you can use openssl req -text -noout -verify -in root-ca.csr.
What you look for in the following output are that fields such as Subject, Public-Key Algorithm, and the CA:TRUE flag are set and correspond to the configuration you passed in earlier. Additional things to look for are Issuer (yourself since it’s self-signed), and Key Usage (what the public key included in the certificate is allowed to be used for).
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
95:77:30:1a:1b:bc:ce:70:f3:e7:ff:1c:12:d2:01:c7
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = US, O = Any Company Corp, CN = internal.anycompany.com
Validity
Not Before: Jul 5 20:52:33 2023 GMT
Not After : Jul 2 20:52:33 2033 GMT
Subject: C = US, O = Any Company Corp, CN = internal.anycompany.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (4096 bit)
...
X509v3 extensions:
X509v3 Basic Constraints: critical
CA:TRUE
X509v3 Key Usage: critical
Certificate Sign
...
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
...
Now why is this certificate especially important? This is your root certificate. When you’re asked “Does this certificate belong to your company?” this is the certificate that you must use in order to prove that it belongs to your company, including any certificates derived from this root certificate (remember, you can have a hierarchy) and also end-entity certificates (shown later). All certificates derived from this root certificate are cryptographically linked to it through a digital signing algorithm that combines hashing and encryption to sign the certificate (the example above uses sha256WithRSAEncryption).
With your root CA successfully set up, it’s time to integrate it with IAM Roles Anywhere.
Step 2: Set up IAM Roles Anywhere
Step 1: Set up a root certificate authority (root CA) was a prerequisite for using IAM Roles Anywhere. Remember, you set up all this infrastructure to eventually use it. In step 2, you start going through how to effectively use the root CA you set up to issue AWS credentials outside of the AWS ecosystem.
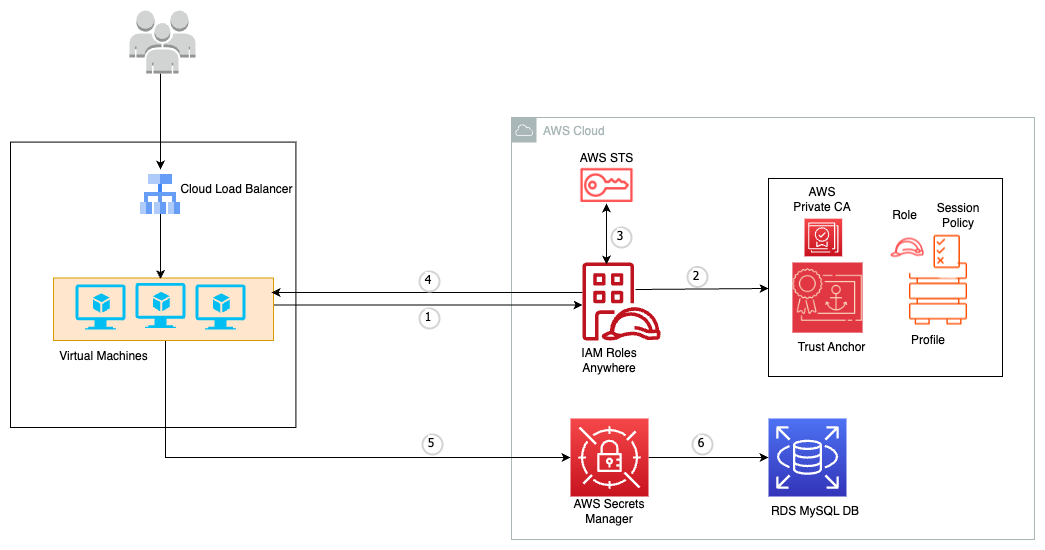
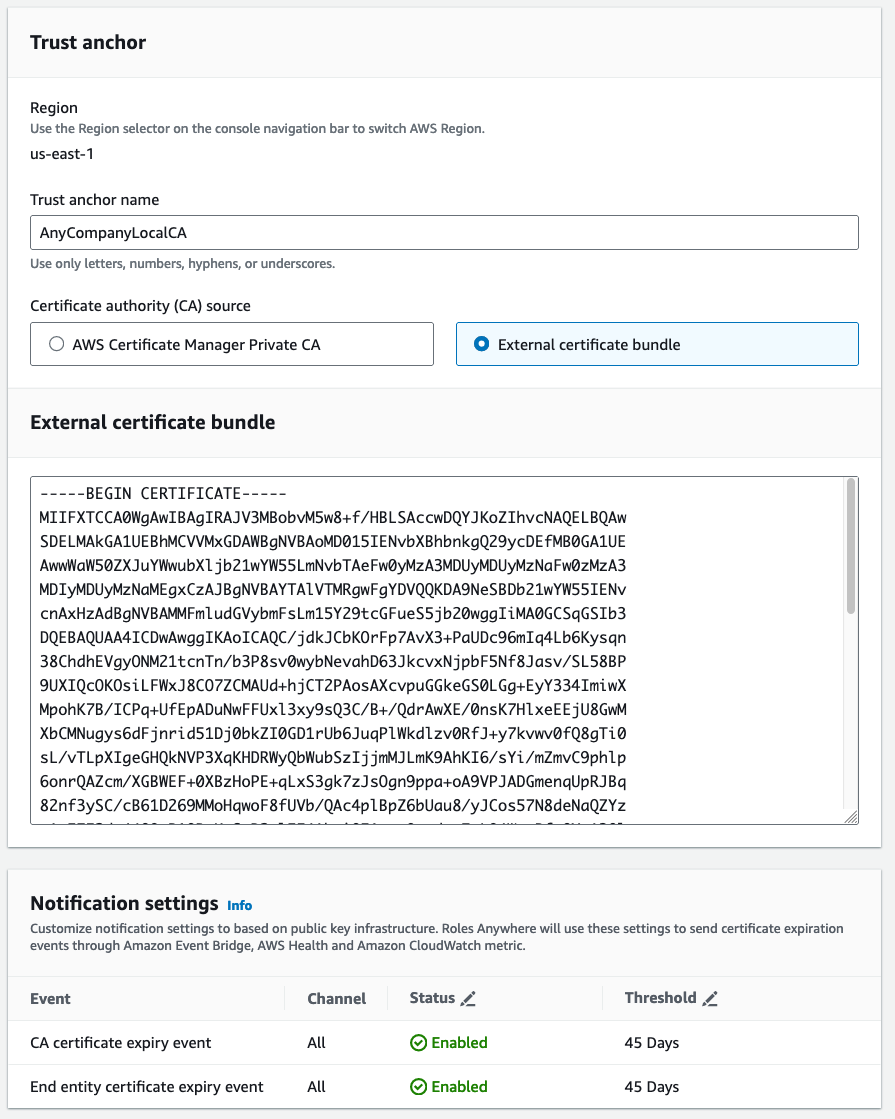
But before you do that, you must bind the IAM Roles Anywhere service to your private certificate authority (private CA). You do this by setting up a trust between the two. When you set up trust between two things, you’re essentially saying “I don’t have the information to verify this is a valid request, so I’m going to trust that the downstream component (in this case, your private CA) knows this information.” Another way of saying it is “if the private CA says it’s good, then it’s a valid request”. You can set up this trust with your newly created root CA by copying the encoded section of your root-ca.crt in the IAM Roles Anywhere console.
To set up the trust
- Go the the IAM Roles Anywhere console.
- Under External certificate bundle, paste the encoded section of your
root-ca.crt.
- Submit the form.
tail -n 31 root-ca.crt
-----BEGIN CERTIFICATE-----
MIIFXTCCA0WgAwIBAgIRAJV3MBobvM5w8+f/HBLSAccwDQYJKoZIhvcNAQELBQAw
SDELMAkGA1UEBhMCVVMxGDAWBgNVBAoMD015IENvbXBhbnkgQ29ycDEfMB0GA1UE
...lines removed for brevitity
iCmHNvGCkBMBo08PLPuynuY69IJCdbjv6iudspBQDdu9aYNPF8BWR3dsTjPpsbOw
ef33wuHiCj4nH96wCrSmPoIUfc4UEp7eZiS0A9xHw8TkT5Uzyq9ZThSaTqBZfojD
zGtnpprPTg/lCHDmoTbGmrOp9ByWU3qQUK7ZtzxSjhjT
-----END CERTIFICATE-----

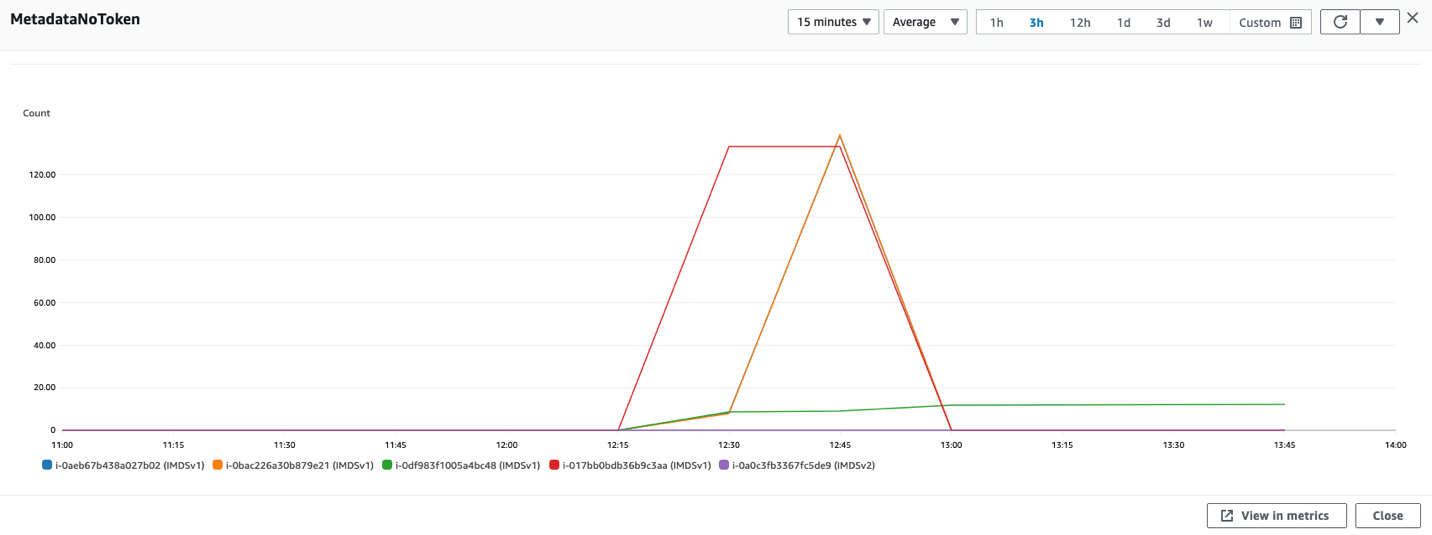
Figure 1: Use the console to set up a trust between IAM Roles Anywhere and the private CA
What you just set up is a trust anchor, which is a representation of your certificate authority inside of IAM Roles Anywhere. With this trust anchor in place, you can start tying in IAM roles to your authentication. Let’s start with something simple but practical, imagine an on-premises virtual machine (VM) that needs to have read access to Amazon Simple Storage Service (Amazon S3). Not only that, but it must have read only access to a specific folder in Amazon S3 and only that folder.
The first thing you need to do is create an IAM role that trusts IAM Roles Anywhere. But you need to be more specific than that. You need to create a role that trusts IAM Roles Anywhere only when the certificate presented to IAM Roles Anywhere contains the common name MyOnpremVM. If this is unclear, that’s okay, after you have all of the prerequisites set up, you’ll walk through the entire process step by step. The following is the trust section in an IAM policy that can be created in the IAM console.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"rolesanywhere.amazonaws.com"
]
},
"Action": [
"sts:AssumeRole",
"sts:TagSession",
"sts:SetSourceIdentity"
],
"Condition": {
"ArnEquals": {
"aws:SourceArn": [
"arn:aws:rolesanywhere:us-east-1:111222333444:trust-anchor/d5302884-5212-4f8d-9b17-24be63a5ae85"
]
},
"StringEquals": {
"aws:PrincipalTag/x509Subject/CN": "MyOnpremVM"
}
}
}
]
}
The second thing you need to create is the actual Amazon S3 permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListObjectsInBucket",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::DOC-EXAMPLE-BUCKET",
"Condition": {
"StringLike": {
"s3:prefix": [
"MyOnPremVM/*"
]
}
}
},
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::DOC-EXAMPLE-BUCKET/MyOnPremVM",
"arn:aws:s3:::DOC-EXAMPLE-BUCKET/MyOnPremVM/*"
]
}
]
}
Note: There are other certificate fields you might want to key off as well. See Trust policy in the documentation for more examples.
The last thing to do before moving on is to tie a set of roles to a profile. You can think of it as a container of multiple possible roles with the ability to further restrict them using session policies. Note that you use the role ARN for the S3 role you just created.
aws rolesanywhere create-profile --name DefaultProfile --role-arns arn:aws:iam::111222333444:role/RolesAnywhereS3Role
{
"profile": {
"createdAt": "2023-05-01T22:29:36.088864+00:00",
"createdBy": "arn:aws:sts::111222333444:assumed-role/<role-name>",
"durationSeconds": 3600,
"enabled": false,
"name": "DefaultProfile",
"profileArn": "arn:aws:rolesanywhere:us-east-1:111222333444:profile/2845dde5-9c82-480d-a6a6-f61240e42d4a",
"profileId": "2845dde5-9c82-480d-a6a6-f61240e42d4a",
"roleArns": [
"arn:aws:iam::111222333444:role/RolesAnywhereS3"
],
"updatedAt": "2023-05-01T22:29:36.088864+00:00"
}
}
Profiles are created disabled by default, you can enable them later as needed. You could also enable a profile on creation by using the --enabled flag, but I want to highlight the ability to create it as disabled and then enabled it later for awareness. This becomes relevant in cases when you need to disable access, such as during a security event. Use the following command to enable the profile after creating it:
aws rolesanywhere enable-profile --profile-id 2845dde5-9c82-480d-a6a6-f61240e42d4a
Now that all your infrastructure is in place, it’s time to provision an end-entity certificate and assume the role you created earlier.
Creating an end-entity certificate
The first thing you must do is obtain an end-entity certificate. This is called end-entity because a certificate can have an entire chain of certificates that are linked together. The end-entity certificate is at the end of the chain, which commonly represents individual entities, and so the term end-entity certificate.
Similar to how you set up your root certificate, it’s mostly a two-step process. You first create a certificate signing request and then ask someone to sign it (or sign it yourself). You can create a certificate signing request for your on-premises VM with:
# Make your private key specific to your client machine
openssl genpkey -out client.key \
-algorithm RSA \
-pkeyopt rsa_keygen_bits:2048
# Using your newly generated private key make a certificate signing request
openssl req -new -key client.key -out client.csr
# You'll be presented an interactive session to enter details for the CSR
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:US
State or Province Name (full name) []:WA
Locality Name (eg, city) [Default City]:Seattle
Organization Name (eg, company) [Default Company Ltd]:Any Company Corp
Organizational Unit Name (eg, section) []:Sales
Common Name (eg, your name or your server's hostname) []:MyOnpremVM
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
As always, let’s inspect the certificate we made.
openssl req -text -noout -verify -in client.csr
The client name (common name (CN) in the certificate) is what’s most important here, after all this is how we uniquely identify this specific VM.
Certificate Request:
Data:
Version: 0 (0x0)
Subject: C=US, ST=WA, L=Seattle, O=Any Company Corp, OU=Sales, CN=MyOnpremVM
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (4096 bit)
Modulus:
00:ae:d0:ab:2d:20:2d:44:b5:36:ad:de:dd:23:ac:
...32 lines removed for brevity
89:98:ef:b6:86:bf:c2:16:08:55:2d:5e:45:af:24:
17:45:cb
Exponent: 65537 (0x10001)
Attributes:
a0:00
Signature Algorithm: sha256WithRSAEncryption
08:b4:86:66:14:1f:03:12:0b:36:15:42:2b:ae:56:7b:ba:99:
...27 lines removed for brevity
00:bb:06:88:6b:c7:c2:53
Signing an end-entity certificate
Now that you have your certificate signing request, the certificate must be signed. Let’s have your private root CA that you created in Step 1 sign this certificate.
NOTE: You might have to move your root-ca.crt file into whatever $home is inside of your root-ca.conf file before running the following command.
openssl ca \
-config root-ca.conf \
-in client.csr \
-out client.crt \
-extensions client_ext
You’ll be asked to manually verify the certificate you’re about to sign. The key things you need to pay attention to for the purposes of IAM Roles Anywhere are:
Common Name because that’s how permissions and to what S3 bucket are decided.Key usage specifies Digital Signature, and basic constraints specify CA:FALSE. Both are required to work with IAM Roles Anywhere.
Certificate:
Data:
Version: 1 (0x0)
Serial Number:
95:77:30:1a:1b:bc:ce:70:f3:e7:ff:1c:12:d2:01:c8
Issuer:
countryName = US
organizationName = Any Company Corp
commonName = internal.anycompany.com
Validity
Not Before: Jul 6 14:46:49 2023 GMT
Not After : Jul 3 14:46:49 2033 GMT
Subject:
countryName = US
stateOrProvinceName = WA
organizationName = Any Company Corp
organizationalUnitName = Sales
commonName = MyOnpremVM
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
...
X509v3 extensions:
...
X509v3 Basic Constraints: critical
CA:FALSE
X509v3 Key Usage: critical
Digital Signature
...
Certificate is to be certified until Jul 3 14:46:49 2033 GMT (3650 days)
Sign the certificate? [y/n]:
After verification, you can commit the certificate to the local database and move on to the next step.
Swapping an end-entity certificate for AWS credentials
Now it’s time for the moment of truth. To review, you have:
- Created a local CA
- Uploaded the CA certificate into IAM Roles Anywhere and created a trust anchor
- Created an IAM role that trusts IAM Roles Anywhere, which in turn trusts your CA certificate
- Created an end-entity certificate for a specific server that has been signed by your CA
It’s time to swap this certificate for IAM credentials.
The API you call to swap credentials is CreateSession for IAM Roles Anywhere. This API serves as a wrapper around STS AssumeRole but requires that you pass in certificate information first. You, as the end user, don’t directly call this API. Instead, you use the IAM Roles Anywhere credential helper.
You can get the binary for this helper using the following example command (for Linux).
NOTE: The URL in the example uses version 1.0.4 of the credential helper as there isn’t a latest path. Verify that you’re getting the latest version using the table found inside of IAM roles anywhere documentation.
curl https://rolesanywhere.amazonaws.com/releases/1.0.4/X86_64/Linux/aws_signing_helper --output aws_signing_helper
Then use the credential helper tool to successfully swap for AWS credentials.
NOTE: You pass in the private key, but the private key doesn’t leave the host, it’s used to sign the request to CreateSession. See the signing process to learn more. The signing process is also why you use the credentials helper instead of making a call directly to CreateSession.
./aws_signing_helper credential-process \
--certificate client.crt \
--private-key client.key \
--role-arn arn:aws:iam::111222333444:role/RolesanywhereS3Role \
--trust-anchor-arn arn:aws:rolesanywhere:us-east-1:111222333444:trust-anchor/d5302884-5212-4f8d-9b17-24be63a5ae85
--profile-arn arn:aws:rolesanywhere:us-east-1:111222333444:profile/e341077c-4ee6-48e8-8d05-d900eb26b367
{
"Version":1,
"AccessKeyId":"ASIAEXAMPLEID",
"SecretAccessKey":"wWPZTXfKdp8UF6HDpfbTEboEXAMPLESECRETKEY",
"SessionToken":"IQoJb3JpZ2luX2VjEK///EXAMPLESESSIONTOKEN",
"Expiration":"2023-05-01T23:37:10Z"
}
You can write the command you just ran into your AWS Config file instead of manually parsing the JSON response into environment variables, or run the serve command to set up a local credential-serving endpoint that’s compatible with the AWS SDK and AWS Command Line Interface (AWS CLI).
./aws_signing_helper serve \
--certificate client.crt \
--private-key client.key \
--role-arn arn:aws:iam::111222333444:role/RolesanywhereS3Role \
--trust-anchor-arn arn:aws:rolesanywhere:us-east-1:111222333444:trust-anchor/d5302884-5212-4f8d-9b17-24be63a5ae85 \
--profile-arn arn:aws:rolesanywhere:us-east-1:111222333444:profile/e341077c-4ee6-48e8-8d05-d900eb26b367 \
& # Start the process in the background
Then export the AWS_EC2_METADATA_SERVICE_ENDPOINT environment variable to point the AWS SDKs and AWS CLI to a local mock EC2 metadata endpoint instead of the endpoint normally found inside EC2 instances.
export AWS_EC2_METADATA_SERVICE_ENDPOINT=http://127.0.0.1:9911/
Then finally, confirm that you assumed the right role with:
aws sts get-caller-identity
{
"UserId": "AROARIEKBWA5HJMA7JDOJ:00bd58e6934d37bf2c3e19afb4c8cac58c",
"Account": "111222333444",
"Arn": "arn:aws:sts::111222333444:assumed-role/RolesAnywhereS3/00bd58e6934d37bf2c3e19afb4c8cac58c"
}
And from here, you can use the AWS CLI or SDKs to make calls into AWS with the permissions you set up. For example, test your permissions by writing an object to Amazon S3 at a location you should be able to write to and a location you shouldn’t be.
# Failure case
aws s3 cp client.crt s3://DOC-EXAMPLE-BUCKET/notme/client.crt
upload failed: ./client.crt to s3://DOC-EXAMPLE-BUCKET/notme/client.crt An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
# Passing Case
aws s3 cp client.crt s3://DOC-EXAMPLE-BUCKET/MyOnPremVM/client.crt
upload: ./client.crt to s3://DOC-EXAMPLE-BUCKET/MyOnPremVM/client.crt
Conclusion
To summarize, I started off this blog post discussing core concepts related to public key infrastructure. I talked about the purpose of keys (being improbable to guess) and certificates (tying an identity to a key, among other important concepts such as digital signing). I then discussed and showed you how to create a local certificate authority (CA), then use that CA to vend out end-entity certificates. Finally, you learned how to establish a trust relationship between your CA and IAM Roles Anywhere to allow IAM Roles Anywhere to verify end-entity certificates and exchange them with AWS credentials.
I encourage you to explore any other openssl commands and scenarios you can imagine. For example, how would you use this information to handle two different fleets of VMs, each with their own unique set of permissions? Another avenue to explore would be using cfssl instead of openssl to create a CA or using a provider such as AWS Private Certificate Authority. You can use an AWS account to try AWS Private Certificate Authority with a 30-day trial. See AWS Private CA Pricing to learn more.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.

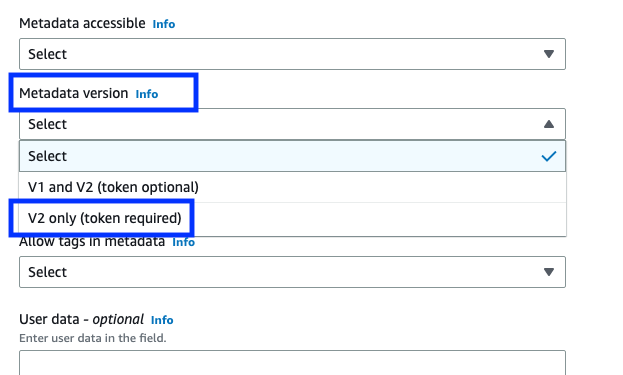
 Don’t be surprised if you have seen the Certificate Update in the
Don’t be surprised if you have seen the Certificate Update in the