As customers increasingly seek to harness the power of generative AI (GenAI) and machine learning to deliver cutting-edge applications, the need for a flexible, intuitive, and scalable development platform has never been greater. In this landscape, Streamlit has emerged as a standout tool, making it easy for developers to prototype, build, and deploy GenAI-powered apps with minimal friction. It is an open-source Python framework designed to simplify the development of custom web applications for data science, machine learning, and GenAI projects. With Streamlit, developers can quickly transform Python scripts into interactive dashboards, LLM-powered chatbots, and web apps, using just a few lines of code. Its unique combination of simplicity, interactivity, and speed is the perfect complement to the rapid advancements in AI.
When deploying Streamlit applications, customers often face the challenge of ensuring their applications are highly available and can scale to meet a variable amount of demand. To achieve these goals, customers are looking at serverless approaches to deploying their Streamlit apps. With a serverless application, you only pay for the resources required and do not want have to worry about managing servers or capacity planning.
In this post, we will walk you through deploying containerized, serverless Streamlit applications automatically via HashiCorp Terraform, an Infrastructure as Code (IaC) tool that enables users to define and provision infrastructure across cloud platforms.
Solution Overview
For this solution, we have the Streamlit app running on an Amazon Elastic Container Service (ECS) cluster across multiple availability zones (AZs), using AWS Fargate to manage the compute. Fargate is a serverless, pay-as-you-go compute engine that lets you focus on building apps without managing servers. Using Fargate helps reduce the undifferentiated heavy lifting that can come with building and maintaining web applications. It is also often desirable to use a Content Delivery Network (CDN) to ensure low latency for users globally by caching the content at edge locations closer to where the users are geographically located.
Let’s zoom in on the two architectures – the Streamlit App hosting architecture, and the Streamlit App deployment pipeline.
Streamlit app hosting
In the above architecture, the following flow applies:
Users access the Streamlit App using the public DNS endpoint for an Amazon CloudFront distribution.
Using an Internet Gateway (IGW), user requests are routed to a public-facing Application Load Balancer (ALB).
This ALB has target groups which map to ECS task nodes that are part of an ECS cluster running in two AZs (us-east-1a and us-east-1b in this example).
Fargate will automatically scale the underlying compute nodes in the ECS cluster based on the demand.
Streamlit app deployment pipeline
In the above architecture, the following flow applies:
User develops a local Streamlit App and defines the path of these assets in the module configuration, then runs terraform apply to generate a local .zip file comprised of the Streamlit App directory, and upload this to an Amazon S3 bucket (Streamlit Assets) with versioning enabled, which is configured to trigger the Streamlit CI/CD pipeline to run.
AWS CodePipeline (Streamlit CI/CD pipeline) begins running. The pipeline copies the .zip file from the Streamlit Assets S3 Bucket, stores the contents in a connected CodePipeline Artifacts S3 bucket, and passes the asset to the AWS CodeBuild project that is also part of the pipeline.
CodeBuild (Streamlit CodeBuild Project) configures a compute/build environment and fetches a Python Docker Image from a public Amazon ECR repository. CodeBuild uses Docker to build a new Streamlit App image based on what is defined in the Dockerfile within the .zip file, and pushes the new image to a private ECR repository. It tags the image with latest, an app_version (user-defined in Terraform), as well as the S3 Version ID of the .zip file and pushes the image to ECR.
ECS has a task definition that references the image in ECR based on the S3 Version ID tag which will always be a unique value, as it is generated whenever a new version of the file is created. This also serves as data lineage so versions of the Streamlit App .zip files in S3 can be linked to versions of the image stored in ECR. Once a new image is pushed to ECR (with a unique image tag), the task definition is updated and the ECS service begins a new deployment using the new version of the Streamlit App.
When a new image is pushed to ECR, the Terraform Module is configured to use the local-exec provisioner to run an AWS CLI command that creates a CloudFront invalidation. This enables users of the Streamlit app to use the new version without waiting for the time-to-live (TTL) of the cached file to expire on the edge locations (default is 24 hours). Both of these pipelines are built and packaged into a Terraform module that can be reused efficiently with only a few lines of code.
Both of these pipelines are built and packaged into a Terraform module that can be reused efficiently with only a few lines of code.
Prerequisites
This solution requires the following prerequisites:
An AWS account. If you don’t have an account, you can sign up for one.
Terraform v1.0.0 or newer installed.
python v3.8 or newer installed.
A Streamlit app. If you don’t have a Streamlit project already, you can download this app directory as a sample Streamlit app for this post and save it to a local folder.
Your folder structure will look something like this:
In the same folder where you have the your Streamlit app saved, in the above example in the terraform_streamlit_folder, you will create and initialize a new Terraform project.
In your preferred terminal, create a new file named main.tf by running the following command on Unix/Linux machines, or an equivalent command on Windows machines:
touch main.tf
Open up the main.tf file and add the following code to it:
module "serverless-streamlit-app" {
source = "aws-ia/serverless-streamlit-app/aws"
app_name = "streamlit-app"
app_version = "v1.1.0"
path_to_app_dir = "./app" # Replace with path to your app
}
This code utilizes a module block with a source pointing to the Terraform module, and the appropriate input variables passed in. When Terraform encounters a module block, it loads and processes that module’s configuration files using the source. The Serverless Streamlit App Terraform module has many optional input variables. If you have existing resources, such as an existing VPC, subnets, and security groups that you’d like to reuse instead of deploying new ones, you can use the module’s input variables to reference your existing resources. However, in this post, we’re deploying all of the resources in the above architecture from scratch. Here, we simply define the source that references the module hosted in the Terraform Registry, provide an app_name that will be used as a prefix for naming your resources, the app_version that is used for tracking changes to your app, and the path_to_app_dir which is the path to the local directory where the assets for your Streamlit app are stored.
Save the file.
To initialize the Terraform working directory, run the following command in your terminal:
terraform init
The output will contain a successful message like the following:
"Terraform has been successfully initialized"
Output the CloudFront URL
To be able to easily access the Cloudfront URL of the deployed Streamlit application, you can add the URL as a Terraform output.
In your terminal, create a new file named outputs.tf by running the following command on Unix/Linux machines, or an equivalent command on Windows machines:
touch outputs.tf
Open up the outputs.tf file and add the following code to it:
output "streamlit_cloudfront_distribution_url" {
value = module.serverless-streamlit-app.streamlit_cloudfront_distribution_url
}
Save the file. Now, your folder structure will look like:
Now you can use Terraform to deploy the resources defined in your main.tf file.
In your terminal, run the following command to apply to deploy the infrastructure. This includes the hosting for your Streamlit application using ECS and CloudFront, as well as the pipeline that is used to push updates.
terraform apply
When the apply command finishes running, you’ll see the Terraform outputs displayed in the terminal.
Navigate to the streamlit_cloudfront_distribution_url to see your Streamlit application that is hosted on AWS.
When you make changes to your Streamlit codebase, you can go ahead and re-run terraform apply to push your new changes to your cloud environment.
When updating the Streamlit codebase, the CodePipeline and CodeBuild processes kick off to automatically update your new changes, which get reflected on your Streamlit application. CodePipeline automates the entire software release process, managing stages like source retrieval, building, testing, and deployment. It integrates with AWS services and third-party tools (such as GitHub and Jenkins) to enhance automation, speed, and security. CodeBuild focuses on automating code compilation, testing, and packaging, supporting multiple languages and custom Docker environments, while integrating with CodePipeline for scalable, secure builds. With this CI/CD pipeline, when you make changes to your code, all you need to run is terraform apply to update your cloud environment. For an example buildspec, see the example in the repo.
You can find full examples of deploying the infrastructure with and without existing resources in the GitHub repository.
Clean up
When you no longer need the resources deployed in this post, you can clean up the resources by using the Terraform destroy command. Simply run terraform destroy . This will remove all of the resources you have deployed in this post with Terraform.
Conclusion
Building serverless Streamlit applications with Terraform on AWS offers a powerful combination of scalability, efficiency, and automation. As you continue to build and refine your Streamlit applications, Terraform’s flexibility ensures that your infrastructure can evolve seamlessly, supporting rapid innovation and agile development. With Streamlit and Terraform, you have the tools to create dynamic, serverless applications that scale effortlessly and operate reliably in the cloud.
Organizations that are looking to establish secure communication networks at the edge often encounter challenges. The use of disparate collaboration tools on personal and government-issued devices can make it difficult to protect sensitive data and avoid communication gaps.
This blog post highlights four common communication issues that customers encounter when operating in disconnected (or intermittently connected) environments, and how end-to-end encrypted messaging and collaboration service AWS Wickr can help you address them.
Issue 1: Seamless communication—multiple agencies and partners need to collaborate effectively.
Federal, state, and local organizations tend to use different means and mechanisms to communicate both internally and externally with third parties, which often leads to interoperability challenges. They need to seamlessly coordinate and connect with mission partners—including government agencies, military teams, medical professionals, and first responders—even in disconnected environments in order to work together effectively.
Issue 2: Out-of-band communication—teams need a way to ensure that communication is possible when primary channels are down or compromised.
Network disruptions, security events, and system failures can impact communication channels. The use of a separate, secure, out-of-band communication tool that can be used as a backup when primary channels are unavailable or compromised is critical to protecting sensitive information, maintaining business continuity, and coordinating incident response activities.
Issue 3: Data retention—messages and files need to be retained to help meet recordkeeping requirements, and facilitate after-action reports.
Virtually all federal, state, and local government agencies must adhere to various data retention and records management policies, regulations, and laws. Many are subject to Federal Records Act (FRA) and National Archives and Records Administration (NARA) regulations that require them to collect, store, and manage federal records that are created, received, and used in daily operations. For those subject to Freedom of Information Act (FOIA) requests and U.S. Department of Defense (DOD) Instruction 8170.01—which prescribes procedures for the collection, distribution, storage, and processing of DOD information through electronic messaging services—effectively retaining messages is about more than supporting security and compliance; it’s about maintaining public trust.
Issue 4: Security and control—communications must be adequately protected and administrative control must be maintained, no matter the environment.
The transmission of sensitive and mission-critical data through messaging apps and collaboration tools that lack critical encryption and security protocols increases the likelihood of a security incident. Popular consumer messaging apps don’t provide controls that allow for individual devices or accounts to be suspended or removed, increasing the threat of data exposure stemming from a lost or stolen device. Enterprise collaboration apps lack the advanced security provided by end-to-end encryption.
How AWS Wickr can help
AWS Wickr is a secure messaging and collaboration service that protects one-to-one and group messaging, voice and video calling, file sharing, screen sharing, and location sharing with 256-bit encryption.
Wickr combines the security and privacy of end-to-end encryption with the data retention and administrative controls you need to accelerate collaboration, even in disconnected environments.
Wickr provides the following capabilities to help you address common communication challenges:
Seamless communication: Federation and guest access features allow you to exchange sensitive information with mission partners, without the need to connect to a virtual private network (VPN). You can assign groups of users to specific federation rules, restrict access to select agencies and partners, and allow or disable the guest user access feature for individual security groups.
Out-of-band communication: Wickr provides a communication channel outside of existing systems that can help you keep teams connected and protect sensitive information, even when primary channels are down or compromised. The user interface is intuitive; response teams can simply open the application on their device and start collaborating, without special software or training.
Data retention: Wickr network administrators can configure and apply data retention to both internal and external communications in a Wickr network. This includes conversations with guest users, external teams, and other partner networks, so you can retain messages and files sent to and from the organization to help meet requirements. Data retention is implemented as an always-on recipient that is added to conversations, similar to the blind carbon copy (BCC) feature in email. The data retention process can run anywhere Docker workloads are supported: on-premises, on an Amazon Elastic Compute Cloud (Amazon EC2) virtual machine, or at a location of your choice.
Security and control: With Wickr, each message gets a unique Advanced Encryption Standard (AES) private encryption key, and a unique Elliptic-curve Diffie–Hellman (ECDH) public key to negotiate the key exchange with recipients. Message content—including text, files, audio, or video—is encrypted on the sending device using the message-specific AES key. This key is then exchanged via the ECDH key exchange mechanism so that no one other than intended recipients can decrypt the content (not even AWS). Fine-grained administrative controls allow you to organize users into security groups with restricted access to features and content at their level. You can apply policies to each group that are custom-tailored to meet desired outcomes. Wickr app data can be deleted remotely both by administrators, and end users.
Communicating at the edge
Wickr is available in two deployment models: cloud-native AWS Wickr and AWS WickrGov, which are available through the AWS Management Console, and self-hosted Wickr Enterprise. Wickr Enterprise offers the same secure collaboration features as AWS Wickr and AWS WickrGov, but can be self-hosted on any private on-premises infrastructure (such as an AWS Outpost or Snowball Edge device), private cloud infrastructure, or in a multi-cloud deployment. Wickr Enterprise can maintain secure communications when internet access (via broadband, mobile, 5G, or satellite) to cloud-based networks fails. You can run Wickr Enterprise without any internet connectivity and it supports architectural resiliency, such as deploying a fully managed network backhaul that is capable of federating with AWS Wickr users when internet connectivity is available.
Figure 1 illustrates a hybrid architecture that combines AWS Wickr and Wickr Enterprise. The Snowball Edge device running Wickr allows disconnected communications at the edge between Wickr Enterprise users. When internet connectivity becomes available, Wickr Enterprise users can federate with AWS Wickr users and send data retention logs to Amazon S3 or any customer-defined storage.
Figure 1: Hybrid of Wickr Enterprise self-hosted on Snowball Edge and AWS Wickr in the Cloud. A hybrid solution federates AWS Wickr in the cloud with a local deployment of Wickr Enterprise for extended resilience and redundancy.
Collaborate with confidence
Securing communications at the edge is critical to protecting sensitive data and maintaining operational resilience. AWS Wickr offers a secure, simple-to-use, reliable solution that can help you address common challenges and collaborate effectively, even in the harshest environments. By choosing the features and deployment options that meet your needs, you can facilitate secure and compliant communications everywhere, and seamlessly collaborate with mission partners.
AWS Wickr has been authorized for Department of Defense Cloud Computing Security Requirements Guide Impact Level 4 and 5 (DoD CC SRG IL4 and IL5) in the AWS GovCloud (US-West) Region. It is also Federal Risk and Authorization Management Program (FedRAMP) authorized at the Moderate impact level in the AWS US East (N. Virginia) Region, FedRamp High authorized in the AWS GovCloud (US-West) Region, and meets compliance programs and standards such as Health Insurance Portability and Accountability Act (HIPAA) eligibility, International Organization for Standardization (ISO) 27001, and System and Organization Controls (SOC) 1,2, and 3.
Erik is a Principal Worldwide Go-to-Market (GTM) Specialist for Amazon Web Services (AWS) and is based in Montana. He focuses on global customers and leads the global GTM plan for AWS Wickr. Erik has 15-plus years of experience working across industries from national security, federal/SLED sales, healthcare, and technology. He holds a master’s degree in microbiology from California State University Long Beach and a bachelor’s degree in Biological Sciences from the University of California Irvine.
Anne Grahn
Anne is a Senior Worldwide Security GTM Specialist at AWS, based in Chicago. She has more than 13 years of experience in the security industry, and focuses on effectively communicating cybersecurity risk. She maintains a Certified Information Systems Security Professional (CISSP) certification.
Customers who use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) often need Python dependencies that are hosted in private code repositories. Many customers opt for public network access mode for its ease of use and ability to make outbound Internet requests, all while maintaining secure access. However, private code repositories may not be accessible via the Internet. It’s also a best practice to only install Python dependencies where they are needed. You can use Amazon MWAA startup scripts to selectively install Python dependencies required for running code on workers, while avoiding issues due to web server restrictions.
This post demonstrates a method to selectively install Python dependencies based on the Amazon MWAA component type (web server, scheduler, or worker) from a Git repository only accessible from your virtual private cloud (VPC).
Solution overview
This solution focuses on using a private Git repository to selectively install Python dependencies, although you can use the same pattern demonstrated in this post with private Python package indexes such as AWS CodeArtifact. For more information, refer to Amazon MWAA with AWS CodeArtifact for Python dependencies.
The Amazon MWAA architecture allows you to choose a web server access mode to control whether the web server is accessible from the internet or only from your VPC. You can also control whether your workers, scheduler, and web servers have access to the internet through your customer VPC configuration. In this post, we demonstrate an environment such as the one shown in the following diagram, where the environment is using public network access mode for the web servers, and the Apache Airflow workers and schedulers don’t have a route to the internet from your VPC.
There are up to four potential networking configurations for an Amazon MWAA environment:
Public routing and public web server access mode
Private routing and public web server access mode (pictured in the preceding diagram)
Public routing and private web server access mode
Private routing and private web server access mode
We focus on one networking configuration for this post, but the fundamental concepts are applicable for any networking configuration.
The solution we walk through relies on the fact that Amazon MWAA runs a startup script (startup.sh) during startup on every individual Apache Airflow component (worker, scheduler, and web server) before installing requirements (requirements.txt) and initializing the Apache Airflow process. This startup script is used to set an environment variable, which is then referenced in the requirements.txt file to selectively install libraries.
The following steps allow us to accomplish this:
Create and install the startup script (startup.sh) in the Amazon MWAA environment. This script sets the environment variable for selectively installing dependencies.
Create and install global Python dependencies (requirements.txt) in the Amazon MWAA environment. This file contains the global dependencies required by all Amazon MWAA components.
Create and install component-specific Python dependencies in the Amazon MWAA environment. This step involves creating separate requirements files for each component type (worker, scheduler, web server) to selectively install the necessary dependencies.
Prerequisites
For this walkthrough, you should have the following prerequisites:
Create and install the startup script in the Amazon MWAA environment
Create the startup.sh file using the following example code:
#!/bin/sh
echo "Printing Apache Airflow component"
echo $MWAA_AIRFLOW_COMPONENT
if [[ "${MWAA_AIRFLOW_COMPONENT}" != "webserver" ]]
then
sudo yum -y install libaio
fi
if [[ "${MWAA_AIRFLOW_COMPONENT}" == "webserver" ]]
then
echo "Setting extended python requirements for webservers"
export EXTENDED_REQUIREMENTS="webserver_reqs.txt"
fi
if [[ "${MWAA_AIRFLOW_COMPONENT}" == "worker" ]]
then
echo "Setting extended python requirements for workers"
export EXTENDED_REQUIREMENTS="worker_reqs.txt"
fi
if [[ "${MWAA_AIRFLOW_COMPONENT}" == "scheduler" ]]
then
echo "Setting extended python requirements for schedulers"
export EXTENDED_REQUIREMENTS="scheduler_reqs.txt"
fi
Upload startup.sh to the S3 bucket for your Amazon MWAA environment:
Browse the CloudWatch log streams for your workers and view the worker_console log. Notice the startup script is now running and setting the environment variable.
Create and install global Python dependencies in the Amazon MWAA environment
Your requirements file must include a –constraint statement to make sure the packages listed in your requirements are compatible with the version of Apache Airflow you are using. The statement beginning with -r references the environment variable you set in your startup.sh script based on the component type.
The following code is an example of the requirements.txt file:
Create and install component-specific Python dependencies in the Amazon MWAA environment
For this example, we want to install the Python package scrapy on workers and schedulers from our private Git repository. We also want to install pprintpp on the web server from the public Python packages indexes. To accomplish that, we need to create the following files (we provide example code):
Browse the CloudWatch log streams for your workers and view the requirements_install log. Notice the startup script is now running and setting the environment variable.
Conclusion
In this post, we demonstrated a method to selectively install Python dependencies based on the Amazon MWAA component type (web server, scheduler, or worker) from a Git repository only accessible from your VPC.
We hope this post provided you with a better understanding of how startup scripts and Python dependency management work in an Amazon MWAA environment. You can implement other variations and configurations using the concepts outlined in this post, depending on your specific network setup and requirements.
About the Author
Tim Wilhoit is a Sr. Solutions Architect for the Department of Defense at AWS. Tim has over 20 years of enterprise IT experience. His areas of interest are serverless computing and ML/AI. In his spare time, Tim enjoys spending time at the lake and rooting on the Oklahoma State Cowboys. Go Pokes!
Many organizations continuously receive security-related findings that highlight resources that aren’t configured according to the organization’s security policies. The findings can come from threat detection services like Amazon GuardDuty, or from cloud security posture management (CSPM) services like AWS Security Hub, or other sources. An important question to ask is: How, and how soon, are your teams notified of these findings?
Often, security-related findings are streamed to a single centralized security team or Security Operations Center (SOC). Although it’s a best practice to capture logs, findings, and metrics in standardized locations, the centralized team might not be the best equipped to make configuration changes in response to an incident. Involving the owners or developers of the impacted applications and resources is key because they have the context required to respond appropriately. Security teams often have manual processes for locating and contacting workload owners, but they might not be up to date on the current owners of a workload. Delays in notifying workload owners can increase the time to resolve a security incident or a resource misconfiguration.
This post outlines a decentralized approach to security notifications, using a self-service mechanism powered by AWS Service Catalog to enhance response times. With this mechanism, workload owners can subscribe to receive near real-time Security Hub notifications for their AWS accounts or workloads through email. The notifications include those from Security Hub product integrations like GuardDuty, AWS Health, Amazon Inspector, and third-party products, as well as notifications of non-compliance with security standards. These notifications can better equip your teams to configure AWS resources properly and reduce the exposure time of unsecured resources.
End-user experience
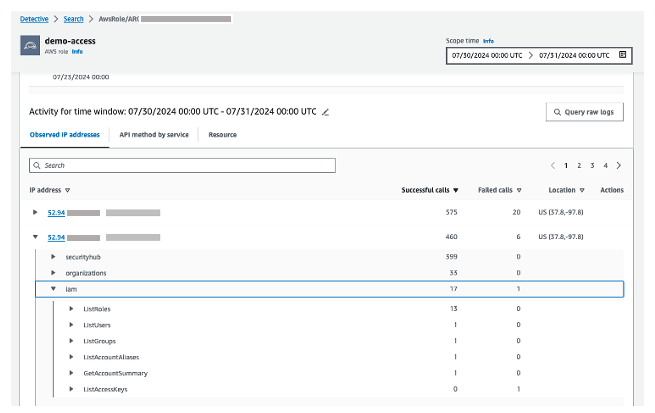
After you deploy the solution in this post, users in assigned groups can access a least-privilege AWS IAM Identity Center permission set, called SubscribeToSecurityNotifications, for their AWS accounts (Figure 1). The solution can also work with existing permission sets or federated IAM roles without IAM Identity Center.
Figure 1: IAM Identity Center portal with the permission set to subscribe to security notifications
After the user chooses SubscribeToSecurityNotifications, they are redirected to an AWS Service Catalog product for subscribing to security notifications and can see instructions on how to proceed (Figure 2).
Figure 2: AWS Service Catalog product view
The user can then choose the Launch product utton and enter one or more email addresses and the minimum severity level for notifications (Critical, High, Medium, or Low). If the AWS account has multiple workloads, they can choose to receive only the notifications related to the applications they own by specifying the resource tags. They can also choose to restrict security notifications to include or exclude specific security products (Figure 3).
Figure 3: Service Catalog security notifications product parameters
You can update the Service Catalog product configurations after provisioning by doing the following:
In the Service Catalog console, in the left navigation menu, choose Provisioned products.
Select the provisioned product, choose Actions, and then choose Update.
Update the parameters you want to change.
For accounts that have multiple applications, each application owner can set up their own notifications by provisioning an additional Service Catalog product. You can use the Filter findings by tag parameters to receive notifications only for a specific application. The example shown in Figure 3 specifies that the user will receive notifications only from resources with the tag key app and the tag value BigApp1 or AnotherApp.
After confirming the subscription, the user starts to receive email notifications for new Security Hub findings in near real-time. Each email contains a summary of the finding in the subject line, the account details, the finding details, recommendations (if any), the list of resources affected with their tags, and an IAM Identity Center shortcut link to the Security Hub finding (Figure 4). The email ends with the raw JSON of the finding.
Figure 4: Sample email showing details of the security notification
Choosing the link in the email takes the user directly to the AWS account and the finding in Security Hub, where they can see more details and search for related findings (Figure 5).
Figure 5: Security Hub finding detail page, linked from the notification email
Solution overview
We’ve provided two deployment options for this solution; a simpler option and one that is more advanced.
Figure 6 shows the simpler deployment option of using the requesting user’s IAM permissions to create the resources required for notifications.
Figure 6: Architecture diagram of the simpler configuration of the solution
The solution involves the following steps:
Create a central Subscribe to AWS Security Hub notifications Service Catalog product in an AWS account which is shared with the entire organization in AWS Organizations or with specific organizational units (OUs). Configure the product with the names of IAM roles or IAM Identity Center permission sets that can launch the product.
Users who sign in through the designated IAM roles or permission sets can access the shared Service Catalog product from the AWS Management Console and enter the required parameters such as their email address and the minimum severity level for notifications.
The Service Catalog product creates an AWS CloudFormation stack, which creates an Amazon Simple Notification Service (Amazon SNS) topic and an Amazon EventBridge rule that filters new Security Hub finding events that match the user’s parameters, such as minimum severity level. The rule then formats the Security Hub JSON event message to make it human-readable by using native EventBridge input transformers. The formatted message is then sent to SNS, which emails the user.
We also provide a more advanced and recommended deployment option, shown in Figure 7. This option involves using an AWS Lambda function to enhance messages by doing conversions from UTC to your selected time zone, setting the email subject to the finding summary, and including an IAM Identity Center shortcut link to the finding. To not require your users to have permissions for creating Lambda functions and IAM roles, a Service Catalog launch role is used to create resources on behalf of the user, and this role is restricted by using IAM permissions boundaries.
Figure 7: Architecture diagram of the solution when using the calling user’s permissions
The architecture is similar to the previous option, but with the following changes:
Create a CloudFormation StackSet in advance to pre-create an IAM role and an IAM permissions boundary policy in every AWS account. The IAM role is used by the Service Catalog product as a launch role. It has permissions to create CloudFormation resources such as SNS topics, as well as to create IAM roles that are restricted by the IAM permissions boundary policy that allows only publishing SNS messages and writing to Amazon CloudWatch Logs.
Users who want to subscribe to security notifications require only minimal permissions; just enough to access Service Catalog and to pass the pre-created role (from the preceding step) to Service Catalog. This solution provides a sample AWS Identity Center permission set with these minimal permissions.
The Service Catalog product uses a Lambda function to format the message to make it human-readable. The stack creates an IAM role, limited by the permissions boundary, and the role is assumed by the Lambda function to publish the SNS message.
Security Hub enabled in the accounts you are monitoring.
An AWS account to host this solution, for example the Security Hub administrator account or a shared services account. This cannot be the management account.
One or more AWS accounts to consume the Service Catalog product.
Authentication that uses AWS IAM Identity Center or federated IAM role names in every AWS account for users accessing the Service Catalog product.
(Optional, only required when you opt to use Service Catalog launch roles) CloudFormation StackSet creation access to either the management account or a CloudFormation delegated administrator account.
This solution supports notifications coming from multiple AWS Regions. If you are operating Security Hub in multiple Regions, for a simplified deployment evaluate the Security Hub cross-Region aggregation feature and enable it for the applicable Regions.
Walkthrough
There are four steps to deploy this solution:
Configure AWS Organizations to allow Service Catalog product sharing.
(Optional, recommended) Use CloudFormation StackSets to deploy the Service Catalog launch IAM role across accounts.
Service Catalog product creation to allow users to subscribe to Security Hub notifications. This needs to be deployed in the specific Region you want to monitor your Security Hub findings in, or where you enabled cross-Region aggregation.
(Optional, recommended) Provision least-privileged IAM Identity Center permission sets.
Step 1: Configure AWS Organizations
Service Catalog organizations sharing in AWS Organizations must be enabled, and the account that is hosting the solution must be one of the delegated administrators for Service Catalog. This allows the Service Catalog product to be shared to other AWS accounts in the organization.
To enable this configuration, sign in to the AWS Management Console in the management AWS account, launch the AWS CloudShell service, and enter the following commands. Replace the <Account ID> variable with the ID of the account that will host the Service Catalog product.
# Enable AWS Organizations integration in Service Catalog
aws servicecatalog enable-aws-organizations-access
# Nominate the account to be one of the delegated administrators for Service Catalog
aws organizations register-delegated-administrator --account-id <Account ID> --service-principal servicecatalog.amazonaws.com
Step 2: (Optional, recommended) Deploy IAM roles across accounts with CloudFormation StackSets
The following steps create a CloudFormation StackSet to deploy a Service Catalog launch role and permissions boundary across your accounts. This is highly recommended if you plan to enable Lambda formatting, because if you skip this step, only users who have permissions to create IAM roles will be able to subscribe to security notifications.
To deploy IAM roles with StackSets
Sign in to the AWS Management Console from the management AWS account, or from a CloudFormation delegated administrator
Choose Create stack, and then choose With new resources (standard).
Choose Upload a template file and upload the CloudFormation template that you downloaded earlier:SecurityHub_notifications_IAM_role_stackset.yaml. Then choose Next.
Enter the stack name SecurityNotifications-IAM-roles-StackSet.
Enter the following values for the parameters:
AWS Organization ID: Start AWS CloudShell and enter the command provided in the parameter description to get the organization ID.
Organization root ID or OU ID(s): To deploy the IAM role and permissions boundary to every account, enter the organization root ID using CloudShell and the command in the parameter description. To deploy to specific OUs, enter a comma-separated list of OU IDs. Make sure that you include the OU of the account that is hosting the solution.
Current Account Type: Choose either Management account or Delegated administrator account, as needed.
Formatting method: Indicate whether you plan to use the Lambda formatter for Security Hub notifications, or native EventBridge formatting with no Lambda functions. If you’re unsure, choose Lambda.
Choose Next, and then optionally enter tags and choose Submit. Wait for the stack creation to finish.
Step 3: Create Service Catalog product
Next, run the included installation script that creates the CloudFormation templates that are required to deploy the Service Catalog product and portfolio.
To run the installation script
Sign in to the console of the AWS account and Region that will host the solution, and start the AWS CloudShell service.
In the terminal, enter the following commands:
git clone https://github.com/aws-samples/improving-security-incident-response-times-by-decentralizing-notifications.git
cd improving-security-incident-response-times-by-decentralizing-notifications
./install.sh
The script will ask for the following information:
Whether you will be using the Lambda formatter (as opposed to the native EventBridge formatter).
The timezone to use for displaying dates and times in the email notifications, for example Australia/Melbourne. The default is UTC.
The Service Catalog provider displayname, which can be your company, organization, or team name.
The Service Catalog product version, which defaults to v1. Increment this value if you make a change in the product CloudFormation template file.
Whether you deployed the IAM role StackSet in Step 2, earlier.
The principal type that will use the Service Catalog product. If you are using IAM Identity Center, enter IAM_Identity_Center_Permission_Set. If you have federated IAM roles configured, enter IAM role name.
If you entered IAM_Identity_Center_Permission_Set in the previous step, enter the IAM Identity Center URL subdomain. This is used for creating a shortcut URL link to Security Hub in the email. For example, if your URL looks like this: https://d-abcd1234.awsapps.com/start/#/, then enter d-abcd1234.
The principals that will have access to the Service Catalog product across the AWS accounts. If you’re using IAM Identity Center, this will be a permission set name. If you plan to deploy the provided permission set in the next step (Step 4), press enter to accept the default value SubscribeToSecurityNotifications. Otherwise, enter an appropriate permission set name (for example AWSPowerUserAccess) or IAM role name that users use.
The script creates the following CloudFormation stacks:
SecurityHub_notifications_SC-Bucket.yaml: This stack creates an Amazon Simple Storage (Amazon S3) bucket that contains the file SecurityHub-Notifications.yaml, which is the CloudFormation template file associated with the Service Catalog product. The script modifies the Mappings section of the template file that has the configuration details depending on the answers to the installation script questions, and then uploads the file to the bucket.
SecurityHub_notifications_ServiceCatalog_Portfolio.yaml: This stack creates a Service Catalog portfolio and product using the Amazon S3 bucket from the previous step and gives permissions to the required principals to launch the product.
After the script finishes the installation, it outputs the Service Catalog Product ID, which you will need in the next step. The script then asks whether it should automatically share this Service Catalog portfolio with the entire organization or a specific account, or whether you will configure sharing to specific OUs manually.
(Optional) To manually configure sharing with an OU
In the Service Catalog console, choose Portfolios.
Choose Subscribe to AWS Security Hub notifications.
On the Share tab, choose Add a share.
Choose AWS Organization, and then select the OU. The product will be shared to the accounts and child OUs within the selected OU.
Select Principal sharing, and then choose Share.
To expand this solution across Regions, enable Security Hub cross-Region aggregation. This results in the email notifications coming from the linked Regions that are configured in Security Hub, even though the Service Catalog product is instantiated in a single Region. If cross-Region aggregation isn’t enabled and you want to monitor multiple Regions, you must repeat the preceding steps in all the Regions you are monitoring.
Step 4: (Optional, recommended) Provision IAM Identity Center permission sets
This step requires you to have completed Step 2 (Deploy IAM roles across accounts with CloudFormation StackSets).
If you’re using IAM Identity Center, the following steps create a custom permission set, SubscribeToSecurityNotifications, that provides least-privileged access for users to subscribe to security notifications. The permission set redirects to the Service Catalog page to launch the product.
To provision Identity Center permission sets
Sign in to the AWS Management Console from the management AWS account, or from an IAM Identity Center delegated administrator
Choose Create stack, and then choose With new resources (standard).
Choose Upload a template file and upload the CloudFormation template you downloaded earlier: SecurityHub_notifications_PermissionSets.yaml. Then choose Next.
Enter the stack name SecurityNotifications-PermissionSet.
Enter the following values for the parameters:
AWS IAM Identity Center Instance ARN: Use the AWS CloudShell command in the parameter description to get the IAM Identity Center ARN.
Permission set name: Use the default value SubscribeToSecurityNotifications.
Service Catalog product ID: Use the last output line of the install.sh script in Step 3, or alternatively get the product ID from the Service Catalog console for the product account.
Choose Next. Then optionally enter tags and choose Next Wait for the stack creation to finish.
Next, go to the IAM Identity Center console, select your AWS accounts, and assign access to the SubscribeToSecurityNotifications permission set for your users or groups.
Testing
To test the solution, sign in to an AWS account, making sure to sign in with the designated IAM Identity Center permission set or IAM role. Launch the product in Service Catalog to subscribe to Security Hub security notifications.
Wait for a Security Hub notification. For example, if you have the AWS Foundational Security Best Practices (FSBP) standard enabled, creating an S3 bucket with no server access logging enabled should generate a notification within a few minutes.
Consider enabling Security Hub consolidated control findings so you don’t receive multiple email notifications for a control that applies to multiple standards.
To remove unneeded resources after testing the solution, follow these steps:
In the workload account or accounts where the product was launched:
Go to the Service Catalog provisioned products page and terminate each associated provisioned product. This stops security notifications from being sent to the email address associated with the product.
In the AWS account that is hosting the directory:
In the Service Catalog console, choose Portfolios, and then choose Subscribe to AWS Security Hub notifications. On the Share tab, select the items in the list and choose Actions, then choose Unshare.
In the CloudFormation console, delete the SecurityNotifications-Service-Catalog stack.
In the Amazon S3 console, for the two buckets starting with securitynotifications-sc-bucket, select the bucket and choose Empty to empty the bucket.
In the CloudFormation console, delete the SecurityNotifications-SC-Bucket stack.
If applicable, go to the management account or the CloudFormation delegated administrator account and delete the SecurityNotifications-IAM-roles-StackSet stack.
If applicable, go to the management account or the IAM Identity Center delegated administrator account and delete the SecurityNotifications-PermissionSet stack.
Conclusion
This solution described in this blog post enables you to set up a self-service standardized mechanism that application or workload owners can use to get security notifications within minutes through email, as opposed to being contacted by a security team later. This can help to improve your security posture by reducing the incident resolution time, which reduces the time that a security issue remains active.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Web Services (AWS) prioritizes the security, privacy, and performance of its services. AWS is responsible for the security of the cloud and the services it offers, and customers own the security of the hosts, applications, and services they deploy in the cloud. AWS has also been introducing quantum-resistant key exchange in common transport protocols used by our customers in order to provide long-term confidentiality. In this blog post, we elaborate how customer compliance and security configuration responsibility will operate in the post-quantum migration of secure connections to the cloud. We explain how customers are responsible for enabling quantum-resistant algorithms or having these algorithms enabled by default in their applications that connect to AWS. We also discuss how AWS will honor and choose these algorithms (if they are supported on the server side) even if that means the introduction of a small delay to the connection.
Secure connectivity
Security and compliance is a shared responsibility between AWS and the customer. This Shared Responsibility Model can help relieve the customer’s operational burden as AWS operates, manages, and controls the components from the host operating system and virtualization layer down to the physical security of the facilities in which the service operates. The customer assumes responsibility and management of the guest operating system and other associated application software, as well as the configuration of the AWS provided security group firewall. AWS has released Customer Compliance Guides (CCGs) to support customers, partners, and auditors in their understanding of how compliance requirements from leading frameworks map to AWS service security recommendations.
In the context of secure connectivity, AWS makes available secure algorithms in encryption protocols (for example, TLS, SSH, and VPN) for customers that connect to its services. That way AWS is responsible for enabling and prioritizing modern cryptography in connections to the AWS Cloud. Customers, on the other hand, use clients that enable such algorithms and negotiate cryptographic ciphers when connecting to AWS. It is the responsibility of the customer to configure or use clients that only negotiate the algorithms the customer prefers and trusts when connecting.
Prioritizing quantum-resistance or performance?
AWS has been in the process of migrating to post-quantum cryptography in network connections to AWS services. New cryptographic algorithms are designed to protect against a future cryptanalytically relevant quantum computer (CRQC) which could threaten the algorithms we use today. Post-quantum cryptography involves introducing post-quantum (PQ) hybrid key exchanges in protocols like TLS 1.3 or SSH/SFTP. Because both classical and PQ-hybrid exchanges need to be supported for backwards compatibility, AWS will prioritize PQ-hybrid exchanges for clients that support it and classical for clients that have not been upgraded yet. We don’t want to switch a client to classical if it advertises support for PQ.
PQ-hybrid key establishment leverages quantum-resistant key encapsulation mechanisms (KEMs) used in conjunction with classical key exchange. The client and server still do an ECDH key exchange, which gets combined with the KEM shared secret when deriving the symmetric key. For example, clients could perform an ECDH key exchange with curve P256 and post-quantum Kyber-768 from NIST’s PQC Project Round 3 (TLS group identifier X25519Kyber768Draft00) when connecting to AWS Certificate Manager (ACM), AWS Key Management Service (AWS KMS), and AWS Secrets Manager. This strategy combines the high assurance of a classical key exchange with the quantum-resistance of the proposed post-quantum key exchanges, to help ensure that the handshakes are protected as long as the ECDH or the post-quantum shared secret cannot be broken. The introduction of the ML-KEM algorithm adds more data (2.3 KB) to be transferred and slightly more processing overhead. The processing overhead is comparable to the existing ECDH algorithm, which has been used in most TLS connections for years. As shown in the following table, the total overhead of hybrid key exchanges has been shown to be immaterial in typical handshakes over the Internet. (Sources: Blog posts How to tune TLS for hybrid post-quantum cryptography with Kyber and The state of the post-quantum Internet)
Data transferred (bytes)
CPU processing (thousand ops/sec)
Client
Server
ECDH with P256
128
17
17
X25519
64
31
31
ML-KEM-768
2,272
13
25
The new key exchanges introduce some unique conceptual choices that we didn’t have before, which could lead to the peers negotiating classical-only algorithms. In the past, our cryptographic protocol configurations involved algorithms that were widely trusted to be secure. The client and server configured a priority for their algorithms of choice and they picked the more appropriate ones from their negotiated prioritized order. Now, the industry has two families of algorithms, the “trusted classical” and the “trusted post-quantum” algorithms. Given that a CRQC is not available, both classical and post-quantum algorithms are considered secure. Thus, there is a paradigm shift that calls for a decision in the priority vendors should enforce on the client and server configurations regarding the “secure classical” or “secure post-quantum” algorithms.
Figure 1 shows a typical PQ-hybrid key exchange in TLS.
Figure 1: A typical TLS 1.3 handshake
In the example in Figure 1, the client advertises support for PQ-hybrid algorithms with ECDH curve P256 and quantum-resistant ML-KEM-768, ECDH curve P256 and quantum-resistant Kyber-512 Round 3, and classical ECDH with P256. The client also sends a Keyshare value for classical ECDH with P256 and for PQ-hybrid P256+MLKEM768. The Keyshare values include the client’s public keys. The client does not include a Keyshare for P256+Kyber512, because that would increase the size of the ClientHello unnecessarily and because ML-KEM-768 is the ratified version of Kyber Round 3, and so the client chose to only generate and send a P256+MLKEM768 public key. Now let’s say that the server supports ECDH curve P256 and PQ-hybrid P256+Kyber512, but not P256+MLKEM768. Given the groups and the Keyshare values the client included in the ClientHello, the server has the following two options:
Use the client P256 Keyshare to negotiate a classical key exchange, as shown in Figure 1. Although one might assume that the P256+Kyber512 Keyshare could have been used for a quantum-resistant key exchange, the server can pick to negotiate only classical ECDH key exchange with P256, which is not resistant to a CRQC.
Send a Hello Retry Request (HRR) to tell the client to send a PQ-hybrid Keyshare for P256+Kyber512 in a new ClientHello (Figure 2). This introduces a round trip, but it also forces the peers to negotiate a quantum-resistant symmetric key.
Note: A round-trip could take 30-50 ms in typical Internet connections.
Previously, some servers were using the Keyshare value to pick the key exchange algorithm (option 1 above). This generally allowed for faster TLS 1.3 handshakes that did not require an extra round-trip (HRR), but in the post-quantum scenario described earlier, it would mean the server does not negotiate a quantum-resistant algorithm even though both peers support it.
Such scenarios could arise in cases where the client and server don’t deploy the same version of a new algorithm at the same time. In the example in Figure 1, the server could have been an early adopter of the post-quantum algorithm and added support for P256+Kyber512 Round 3. The client could subsequently have upgraded to the ratified post-quantum algorithm with ML-KEM (P256+MLKEM768). AWS doesn’t always control both the client and the server. Some AWS services have adopted the earlier versions of Kyber and others will deploy ML-KEM-768 from the start. Thus, such scenarios could arise while AWS is in the post-quantum migration phase.
Note: In these cases, there won’t be a connection failure; the side-effect is that the connection will use classical-only algorithms although it could have negotiated PQ-hybrid.
These intricacies are not specific to AWS. Other industry peers have been thinking about these issues, and they have been a topic of discussion in the Internet Engineering Task Force (IETF) TLS Working Group. The issue of potentially negotiating a classical key exchange although the client and server support quantum-resistant ones is discussed in the Security Considerations of the TLS Key Share Prediction draft (draft-davidben-tls-key-share-prediction). To address some of these concerns, the Transport Layer Security (TLS) Protocol Version 1.3 draft (draft-ietf-tls-rfc8446bis), which is the draft update of TLS 1.3 (RFC 8446), introduces text about client and server behavior when choosing key exchange groups and the use of Keyshare values in Section 4.2.8. The TLS Key Share Prediction draft also tries to address the issue by providing DNS as a mechanism for the client to use a proper Keyshare that the server supports.
Prioritizing quantum resistance
In a typical TLS 1.3 handshake, the ClientHello includes the client’s key exchange algorithm order of preferences. Upon receiving the ClientHello, the server responds by picking the algorithms based on its preferences.
Figure 2 shows how a server can send a HelloRetryRequest (HRR) to the client in the previous scenario (Figure 1) in order to request the negotiation of quantum-resistant keys by using P256+Kyber512. This approach introduces an extra round trip to the handshake.
Figure 2: An HRR from the server to request the negotiation of mutually supported quantum-resistant keys with the client
AWS services that terminate TLS 1.3 connections will take this approach. They will prioritize quantum resistance for clients that advertise support for it. If the AWS service has added quantum-resistant algorithms, it will honor a client-supported post-quantum key exchange even if that means that the handshake will take an extra round trip and the PQ-hybrid key exchange will include minor processing overhead (ML-KEM is almost performant as ECDH). A typical round trip in regionalized TLS connections today is usually under 50 ms and won’t have material impact to the connection performance. In the post-quantum transition, we consider clients that advertise support for quantum-resistant key exchange to be clients that take the CRQC risk seriously. Thus, the AWS server will honor that preference if the server supports the algorithm.
Pull Request 4526 introduces this behavior in s2n-tls, the AWS open source, efficient TLS library built over other crypto libraries like OpenSSL libcrypto or AWS libcrypto (AWS-LC). When built with s2n-tls, s2n-quic handshakes will also inherit the same behavior. s2n-quic is the AWS open source Rust implementation of the QUIC protocol.
What AWS customers can do to verify post-quantum key exchanges
AWS services that have already adopted the behavior described in this post include AWS KMS, ACM, and Secrets Manager TLS endpoints, which have been supporting post-quantum hybrid key exchange for a few years already. Other endpoints that will deploy quantum-resistant algorithms will inherit the same behavior.
AWS customers that want to take advantage of new quantum-resistant algorithms introduced in AWS services are expected to enable them on the client side or the server side of a customer-managed endpoint. For example, if you are using the AWS Common Runtime (CRT) HTTP client in the AWS SDK for Java v2, you would need to enable post-quantum hybrid TLS key exchanges with the following.
The AWS KMS and Secrets Manager documentation includes more details for using the AWS SDK to make HTTP API calls over quantum-resistant connections to AWS endpoints that support post-quantum TLS.
To confirm that a server endpoint properly prioritizes and enforces the PQ algorithms, you can use an “old” client that sends a PQ-hybrid Keyshare value that the PQ-enabled server does not support. For example, you could use s2n-tls built with AWS-LC (which supports the quantum-resistant KEMs). You could use a client TLS policy (PQ-TLS-1-3-2023-06-01) that is newer than the server’s policy (PQ-TLS-1-0-2021-05-24). That will lead the server to request the client by means of an HRR to send a new ClientHello that includes P256+MLKEM768, as shown following.
The hrr-capture.pcap packet capture will show the negotiation and the HRR from the server.
To confirm that a server endpoint properly implements the post-quantum hybrid key exchanges, you can use a modern client that supports the key exchange and connect against the endpoint. For example, using the s2n-tls client built with AWS-LC (which supports the quantum-resistant KEMs), you could try connecting to a Secrets Manager endpoint by using a post-quantum TLS policy (for example, PQ-TLS-1-2-2023-12-15) and observe the PQ hybrid key exchange used in the output, as shown following.
./bin/s2nc -c PQ-TLS-1-2-2023-12-15 secretsmanager.us-east-1.amazonaws.com 443
CONNECTED:
Handshake: NEGOTIATED|FULL_HANDSHAKE|MIDDLEBOX_COMPAT
Client hello version: 33
Client protocol version: 34
Server protocol version: 34
Actual protocol version: 34
Server name: secretsmanager.us-east-1.amazonaws.com
Curve: NONE
KEM: NONE
KEM Group: SecP256r1Kyber768Draft00
Cipher negotiated: TLS_AES_128_GCM_SHA256
Server signature negotiated: RSA-PSS-RSAE+SHA256
Early Data status: NOT REQUESTED
Wire bytes in: 6699
Wire bytes out: 1674
s2n is ready
Connected to secretsmanager.us-east-1.amazonaws.com:443
Cryptographic migrations can introduce intricacies to cryptographic negotiations between clients and servers. During the migration phase, AWS services will mitigate the risks of these intricacies by prioritizing post-quantum algorithms for customers that advertise support for these algorithms—even if that means a small slowdown in the initial negotiation phase. While in the post-quantum migration phase, customers who choose to enable quantum resistance have made a choice which shows that they consider the CRQC risk as important. To mitigate this risk, AWS will honor the customer’s choice, assuming that quantum resistance is supported on the server side.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Security, Identity, & Compliance re:Post or contact AWS Support. For more details regarding AWS PQC efforts, refer to our PQC page.
Amazon Web Services (AWS) customers of various sizes across different industries are pursuing initiatives to better classify and protect the data they store in Amazon Simple Storage Service (Amazon S3). Amazon Macie helps customers identify, discover, monitor, and protect sensitive data stored in Amazon S3. However, it’s important that customers evaluate and test the capabilities of Macie to verify that they can meet their specific data identification and protection goals. In this post, we show you how to define and run a proof of concept (POC) to validate using Macie and automated discovery to enhance your current data protection strategies. The POC steps demonstrate how you can use Macie to detect and alert you to sensitive data discovered in your AWS environment and help you determine the value of using Macie to enhance your current data protection strategies.
Note: This POC uses some features that offer a 30-day free trial and other features that will incur minimal charges during the POC phase. We highlight and summarize these throughout this post.
Data security business challenges
Data security is a broad concept that revolves around protecting digital information from unauthorized access, corruption, theft, and other forms of malicious activity throughout its lifecycle. There’s an exponential growth of digital data and organizations are grappling with not only managing it but also determining where their sensitive data exists. Additionally, many organizations have compliance requirements from government regulators and industry standards, such as PCI DSS or HIPAA. Organizations want to move fast, which means giving developers the tools to build quickly to stay ahead, while making sure that the correct data classification policies are defined and enforced.
Macie features
Amazon Macie is a data security service that discovers sensitive data using machine learning and pattern matching, provides visibility into data security risks, and enables automated protection against those risks. The following is a summary of the key features of Macie, many of which will be used in this POC. The core capabilities of Macie are focused on the security of your S3 buckets and helping to identify sensitive data including financial data, personal data, and credentials as well as sensitive data that’s unique to your organization, such as intellectual property.
S3 bucket security
Customers use Amazon S3 for a variety of use cases and store various types of data in S3 buckets, including sensitive data. Continuously monitoring these buckets for the presence of sensitive data is a vital part of a data protection strategy. Macie gives you visibility into your S3 bucket inventory and the security and access controls associated with your buckets. This visibility includes if the bucket is publicly accessible, the encryption level of the bucket, and if the bucket is shared with other accounts. Whenever the security posture of one of your buckets is reduced, Macie generates a finding about the change, enabling you to respond. These findings are consumable through the AWS Management Console for Macie, through Macie APIs, as Amazon EventBridge messages, or through AWS Security Hub.
Sensitive data discovery jobs
Sensitive data discovery jobs provide a way to target a specific S3 bucket or group of buckets to do a deep analysis of the objects in those buckets and identify if sensitive data is present in the objects and if so, the type of data. These jobs can run on a daily, weekly, or monthly basis for new or changed data or once for on-demand analysis.
Automated data discovery
Macie offers an automated data discovery feature that can continually discover sensitive data within your S3 buckets. This feature is intended to help customers who have large amounts of S3 buckets and data better understand where sensitive data might be stored without having to scan all their data. By using automated data discovery, you can focus your resources on deeper investigations of the security of buckets identified to have sensitive data. Macie selects samples of the objects within S3 buckets and inspects them for the presence of sensitive data daily, providing insight into where sensitive data might reside in your overall Amazon S3 data estate.
POC overview
This POC is intended to help you gain an understanding of what Macie is capable of and how you can use it to achieve your data discovery goals. The POC in this post includes the following tasks in Macie:
Reviewing managed data identifiers
Defining custom data identifiers
Staging POC data
Running a sensitive data discovery job
Reviewing the output of the discovery job
Enabling and reviewing the output of automated data discovery
Note: The amount of time required for each task depends on your preparation and analysis for each stage. Note that, in the automated data discovery phase, it will take 24–48 hours for Macie to perform the first scan after the feature is enabled.
Enable Macie
Macie must be enabled before you can proceed with the POC. If you haven’t yet enabled Macie, see Enable Macie for instructions.
Note: When you enable Macie and the 30-day free trial for S3, monitoring S3 bucket security and privacy is automatically enabled. There’s also a 30-day free trial for automated data discovery, which is covered later in this post. There is no free trial for running targeted data discovery jobs. Review the Macie pricing page for details.
Review managed data identifiers
A successful POC of Macie includes understanding what data Macie can detect. Macie comes with over 150 managed data identifiers that are designed to identify sensitive data in your S3 objects. It’s important to first understand the available managed data identifiers and which ones align with the use cases you want to address. Examples of Macie managed data identifiers include credit card numbers, AWS secret access keys, and national identification numbers. Macie offers a default collection of recommend managed data identifiers to use for detecting general categories and types of sensitive data while optimizing data discovery results and reducing noise.
Keywords are an important component for Macie to be able to detect sensitive data. Many managed data identifiers require keywords to be in proximity of the data for Macie to be able to detect findings. Understanding the keywords that are used as part of sensitive data detection is important when it comes to building test data for a POC.
Prior to beginning your POC, review the list of managed data identifiers and determine which ones you feel will be necessary to use for your data discovery requirements. Additionally, identify which managed data identifiers, which are applicable to your POC, fall outside of the default list of identifiers.
Define custom data identifiers
Macie covers a wide number of use cases with its managed data identifiers, but some use cases need custom data identifiers for data types that aren’t included in the managed data identifiers. For example, customers might need to identify sensitive data that’s specific to their company, such as an employee ID or project number. Other customers might operate in industries that have data types unique to that industry, such as a known traveler number in the airline industry. If your requirements for identifying sensitive data include detecting sensitive data that isn’t part of the current list of managed data identifiers, then you can create custom data identifiers for those data types. For a POC, you might not want to create a custom data identifier for every additional detection. Instead, you can create a few to help confirm that you can use custom data identifiers for sensitive data detection and that Macie can support your data discovery goals. Building custom data identifiers has a thorough explanation of how to define a custom data identifier. Similar to managed data identifiers, custom data identifiers have keyword requirements. Defining detection criteria for custom data identifiers provides details for the types of data that require keywords.
Stage POC data
After reviewing the managed data identifiers provided by Macie and creating the custom data identifiers needed for your POC, it’s time to stage data sets that will help demonstrate the capabilities of these identifiers and better understand how Macie identifies sensitive data. We recommend that you stage data sets that contain sensitive data as well as data sets that do not to gain a full understanding of how Macie detects and reports on each of these situations. You can stage a variety of data sets to use for your POC using just a few GB of data to help keep your initial POC scans’ cost low. Staged data must be in file formats that Macie supports.
When preparing data to stage, keep in mind the keyword requirements for many of the Macie managed data identifiers. To determine which managed data identifiers have keyword requirements, see Managed data identifiers by type. When you’re staging your data, reference the keywords that are supported for the managed data identifiers you are using to help ensure that the data can be identified in your POC tests.
We recommend staging the data in one S3 bucket that’s dedicated to the POC and to use S3 server-side encryption on the bucket. If you want to use a customer managed AWS KMS key to encrypt the S3 data at rest, follow the instructions in Allowing Macie to use a customer managed AWS KMS key to give Macie access to decrypt the data in the bucket. You should also follow best practices for the S3 bucket related to not allowing public access and implementing least privilege access.
You can use one or more of the following approaches to identify and stage data for your POC:
Stage data files created by synthetic data generator tools with sensitive data included. There are many tools available for generating sensitive data. The following are two that you can use to generate test data.
Stage data files from public data repositories. There are various repositories staged with information that could be used for sensitive data detection. These repositories are often comprised of publicly available data sets or were created to help with testing machine learning models or sensitive data detection.
Stage data files of your own data with sensitive information. Because the goal is to use Macie to identify sensitive information in your S3 buckets, including examples of your own data that contains sensitive information can be helpful to test the capabilities of Macie.
Stage data files that don’t contain sensitive information. This can help you understand how Macie handles data that you believe doesn’t contain sensitive information. With the managed data identifiers that Macie offers, you should stage data files that you believe don’t contain information that aligns to the managed data identifiers. The staged data files could be log files, documents, or data sets that meet the criteria of this step.
Stage data that contains information that’s representative of data that you would want to detect using custom data identifiers.
Run a data classification job
Now that you’ve reviewed the managed data identifiers, defined custom data identifiers, and staged sample data, it’s time to run a sensitive data discovery job. When configuring the job scope, we recommend the following:
A specific S3 bucket where the POC data is staged.
The scope is set to be a one-time job.
Leave the sampling depth at 100 percent. Most customers leave this value at 100 percent, but some will lower it if they want a smaller random sample scan of their data. Most customers use automated data discovery to get sample scans instead of adjusting the sampling depth for individual jobs.
Select the recommended managed data identifiers. If your testing requires that Macie identify additional sensitive data types that are offered as managed data identifiers but aren’t part of the recommended list, choose the Custom option and select the managed data identifiers that you need. Make sure that the recommended managed data identifiers are part of the custom list that you construct.
Choose the custom data identifiers that you want to be used in the job.
After you configure your job, give it a name, review the final configuration, and then submit the job to run. A job that uses a data set of a few GB should complete within 30 minutes.
Review the findings from your job
After the job completes, it’s time to review what Macie found in the data. Objects that Macie found with sensitive data will be presented as Findings in the Macie console. From the Jobs screen, choose the job you submitted. In the right-hand window, you will see the overview information for the job. From the overview window you can choose Show results menu and then select Show findings to view a list of the findings that were generated by the job.
Figure 1: Viewing Macie job findings
Each object where Macie found sensitive data will be listed as a single finding. If there were multiple types of sensitive data found in the object, each type of sensitive data and a count will be included in the details. Choose each of the findings that was produced and review the details to confirm what sensitive data was identified and if the sensitive data was discovered as you expected. Additionally, confirm that you don’t have findings for objects that you staged that were not supposed to have sensitive data so that you can confirm how Macie handles these types of objects. If you created custom data identifiers, review findings for the objects that included the custom data that you detect to confirm that the data was detected.
Enable automated discovery
Now that you understand how to use Macie to discover sensitive data, the next step in the POC is to enable automated discovery and use Macie to discover sensitive data across a larger collection of your existing S3 data.
You will be enabling automated discovery in Macie as a 30-day free trial. For the free trial, the scope of total data storage to be evaluated will be 150 GB. Use the following steps to guide your setup of the automated discovery feature:
After your delegated administrator account is configured, enable automated discovery. As part of enabling automated discovery, pay extra attention to the following items:
Set managed data identifiers. Ideally, choose the recommended data identifiers to help reduce noise. If there are specific managed data identifiers that you really want to see, then choose Custom to choose the ones you want.
Include custom data identifiers that you want to be used to evaluate your sensitive data.
Exclude buckets that you don’t want included in the scope for identifying sensitive data.
Include or exclude specific accounts that should be part of the POC. Step 5 of Enable automated discovery covers how to enable it for specific accounts.
You will see the first set of results 24 to 48 hours after you enable automated discovery. After that, you will see updates to the automated discovery results every 24 hours.
After automated discovery starts producing results, you will start seeing data in the Automated Discovery section of the Macie summary page in the console. The summary includes metrics for the total number of buckets eligible for discovery, counts for the number of buckets where sensitive data was or was not found, and how many of these buckets are public.
Figure 2: Example automated discovery summary metrics
Choosing a link for one of the counts will take you to the S3 buckets view with the appropriate filters applied.
After reviewing the summary screen, choose S3 buckets from the navigation pane to see a heatmap that shows each account and the buckets within each account.
Figure 3: S3 bucket heatmap view in Macie
The heatmap provides point-in-time insights into the data that Macie has scanned, and in which buckets sensitive data has been identified or no sensitive data has been found.
Over time, this heatmap might change as automated data discovery continues sampling the data in each bucket. The heatmap view provides information on each organizational member account and insight about sensitive data within each bucket in the account.
The console displays the results as a set of colored squares for each account. Each square represents a bucket in that account and the color of the square indicates whether sensitive data was discovered in that bucket. Red indicates that some type of sensitive data has been found in the bucket, while blue indicates no sensitive data has been identified. If a bucket is blue, that means only that automated data discovery hasn’t identified sensitive data up to the point in time of the last scan, not that there is no sensitive data in the bucket.
Hover over each bucket to see a summary of the sensitivity score of the bucket along with statistics about the data in the bucket. Choosing a bucket in the heatmap will open a window that provides more information about the bucket. This information includes the sensitivity score of the bucket, a summary of the types of sensitive data found in the bucket, which objects within the bucket have been sampled, statistics related to the data that has been scanned and data that is still to be scanned, and other information about the bucket.
Figure 4: S3 bucket sensitivity information in Macie
As part of your POC, it’s recommended that you investigate buckets that are reported to contain sensitive data. For your investigation, validate if the data identified is sensitive based on your organization’s data classification policy. Each Macie finding contains not only the details on the types of sensitive data identified, but also the location within the file where the sensitive data is located so that you can confirm the identified data is sensitive. The following is an example of a Macie finding in an Excel file where bank account numbers were found. This example shows the row and column where the sensitive data was found.
Investigating sensitive data with findings has detailed guidance around locating sensitive data from Macie findings, retrieving the sensitive data, and the schema for sensitive data locations. If the findings are true positives, make sure that the bucket has the right level of security configurations and permissions based on the data stored in the bucket.
In addition to reviewing the bucket level statistics that are generated by automated discovery, you can view the individual findings that were generated for each S3 object that was identified as having sensitive data. You can view the findings through the Findings tab in Macie or by choosing the sensitive data type when looking at the summary detections for a bucket.
Next steps
With the preceding POC, you should now have a more complete understanding of how Macie identifies sensitive data and how you can use the information that Macie provides about that data identified. As you complete your POC, there are a few next steps that other customers have taken after completing their POC with Macie.
Operationalize Macie output
In the POC steps, we outlined how to view the findings and the insights that the automated discovery provides. Before you proceed with Macie, you should have a plan for how you will operationalize the Macie output. This will help ensure that the remediation steps for identified sensitive data are directed to the correct parties.
Depending on what operational tools you have in place, the steps that you take to operationalize the output of Macie will vary. Many customers implement operational processes that cover the following areas:
The privacy or security team that’s responsible for Macie does an initial triage on the findings to confirm if there are true positives.
The privacy or security team defines their operational processes related to the summary dashboard and bucket sensitivity information that’s provided by automated discovery.
The team that owns the bucket where the sensitive data is located is provided the information needed to investigate the identified data and provide a response. Responses will vary but could include removal of the data, correcting the application that is writing the data, or applying additional security to the bucket.
A key part of operationalizing Macie output is also how you are getting and reviewing the signals related to Macie findings. As outlined in this post, you can view and investigate findings in the Macie console. At a steady state, customers find it beneficial to consume Macie findings using Amazon EventBridge, through Macie APIs, or through the integration of Macie with AWS Security Hub. These options can be used to incorporate the findings that are reported by Macie into the operational workflows and tools that work best for your organization and allow you to consume and address findings at scale. Monitoring and processing findings provides more insight into these integration approaches.
Store and retain sensitive data discovery results
As you move forward with Macie, it’s important to enable logging for each of the S3 objects that Macie has scanned. Macie creates an analysis record for each S3 object that’s in scope for a data discovery job or an automated discovery scan. These records are an audit of every object that Macie attempted to scan, including objects that didn’t contain sensitive data. Data discovery results are written to an S3 bucket that you own and where you control the data retention. These data discovery results can assist with analysis of records over time or to get a broader sense of what data Macie has scanned and which objects had sensitive data and which did not.
The data discovery scan results are stored as JSON Lines files. You can use multiple approaches to analyze and query these log files. The Amazon Macie Results Analytics GitHub repository provides instructions on how to configure Amazon Athena with tables that allow you to query the results of Macie discovery scan files.
Define the scope for Macie use
After a POC with Macie, you can set the scope of how you will use Macie in production by deciding which buckets don’t need to be evaluated and so can be excluded, such as buckets used for AWS logs and buckets deemed not in scope for sensitive data identification.
You can also refine the managed data identifiers that are required for detecting sensitive data. Based on what they learned from the POC. You can create custom data identifiers to help meet your data detection needs if necessary.
As you identify the sensitive data discovery jobs to run as part of your production use of Macie, keep in mind that these jobs are immutable. To edit an existing scheduled job, you must create a copy of the job with the updated configuration and cancel the original job for changes to take effect. Depending on the updated criteria for your job, you must do one of the following to help avoid re-scanning objects that were covered by the previous job:
Clear include existing objects when setting the scope. This will cause the new job to schedule only objects that were created between when it was first created and when it was run for the first time.
When setting the job scope, set the object attributes so that the object last modified date is the date of the last time the previous job ran. This helps ensure that when the new scheduled job runs, it evaluates only objects that weren’t covered by the previous job.
Clean up
To avoid incurring additional charges, disable Macie while you evaluate the value of the additional data protection provided. If S3 buckets were created for this POC, those should also be deleted.
Call to action
After the POC is complete, evaluate the results to determine how much using Macie can strengthen your organization’s data protection program. Based on that evaluation, you can identify how and where to use Macie for maximum effectiveness. Also consider how the information provided can be factored into operational workflows to get additional value from Macie.
Conclusion
This post outlined how you can use a POC to better understand how Amazon Macie can help meet your data discovery and classification needs. A well thought-out and implemented POC can provide valuable early insights and help you develop a more thorough understanding of what your data discovery and classification strategy should be. Planning your POC using the guidance in this post can help you determine more quickly if Macie is a fit for your company.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
As organizations increasingly adopt Amazon Q Developer, understanding how developers use it is essential. Diving into specific telemetry events and user-level data clarifies how users interact with Amazon Q Developer, offering insights into feature usage and developer behaviors. This granular view, accessible through logs, is vital for identifying trends, optimizing performance, and enhancing the overall developer experience. This blog is intended to give visibility to key telemetry events logged by Amazon Q Developer and how to explore this data to gain insights.
To help you get started, the following sections will walk through several practical examples that showcase how to extract meaningful insights from AWS CloudTrail. By reviewing the logs, organizations can track usage patterns, identify top users, and empower them to train and mentor other developers, ultimately fostering broader adoption and engagement across teams.
Although the examples here focus on Amazon Athena for querying logs, the methods can be adapted to integrate with other tools like Splunk or Datadog for further analysis. Through this exploration, readers will learn how to query the log data to understand better how Amazon Q Developer is used within your organization.
Solution Overview
This solution leverages Amazon Q Developer’s logs from the Integrated Development Environment (IDE) and terminal, captured in AWS CloudTrail. The logs will be queried directly using Amazon Athena from Amazon Simple Storage Service (Amazon S3) to analyze feature usage, such as in-line code suggestions, chat interactions, and security scanning events.
Analyzing Telemetry Events in Amazon Q Developer
Amazon Athena is used to query the CloudTrail logs directly to analyze this data. By utilizing Athena, queries can be run on existing CloudTrail records, making it simple to extract insights from the data in its current format.
Ensuring CloudTrail is set up to log the data events.
Navigate to the AWS CloudTrail Console.
Edit an Existing Trail:
If you have a trail, verify it is configured to log data events for Amazon CodeWhisperer.
Note: As of 4/30/24, CodeWhisperer has been renamed to Amazon Q Developer. All the functionality previously provided by CodeWhisperer is now part of Amazon Q Developer. However, for consistency, the original API names have been retained.
Click on your existing trail in CloudTrail. Find the Data Events section and click edit.
For CodeWhisperer:
Data event type: CodeWhisperer
Log selector template: Log all events
Save your changes.
Note your “Trail log location.” This S3 bucket will be used in our Athena setup.
If you don’t have an existing trail, follow the instructions in the AWS CloudTrail User Guide to set up a new trail.
Below is a screenshot of the data events addition:
Steps to Create an Athena Table from CloudTrail Logs: This step aims to turn CloudTrail events into a queryable Athena table.
1. Navigate to the AWS Management Console > Athena > Editor.
2. Click on the plus to create a query tab.
3. Run the following query to create a database and table. Note to update the location to your S3 bucket.
-- Step 1: Create a new database (if it doesn't exist)
CREATE DATABASE IF NOT EXISTS amazon_q_metrics;
-- Step 2: Create the external table explicitly within the new database
CREATE EXTERNAL TABLE amazon_q_metrics.cloudtrail_logs (
userIdentity STRUCT<
accountId: STRING,
onBehalfOf: STRUCT<
userId: STRING,
identityStoreArn: STRING
>
>,
eventTime STRING,
eventSource STRING,
eventName STRING,
requestParameters STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING
>>,
recipientAccountId STRING
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://{Insert Bucket Name from CloudTrail}/'
TBLPROPERTIES ('classification'='cloudtrail');
4. Click Run
5. Run a quick query to view the data.
SELECT
eventTime,
userIdentity.onBehalfOf.userId AS user_id,
eventName,
requestParameters
FROM
amazon_q_metrics.cloudtrail_logs AS logs
WHERE
eventName = 'SendTelemetryEvent'
LIMIT 10;
In this section, the significance of the telemetry events captured in the requestParameters field will be explained. The query begins by displaying key fields and their data, offering insights into how users interact with various features of Amazon Q Developer.
Query Breakdown:
eventTime: This field captures the time the event was recorded, providing insights into when specific user interactions took place.
userIdentity.onBehalfOf.userId: This extracts the userId of the user. This is critical for attributing interactions to the correct user, which will be covered in more detail later in the blog.
eventName: The query is filtered on SendTelemetryEvent. Telemetry events are triggered when the user interacts with particular features or when a developer uses the service.
requestParameters: The requestParameters field is crucial because it holds the details of the telemetry events. This field contains a rich set of information depending on the type of interaction and feature the developer uses, which programming languages are used, completion types, or code modifications.
In the context of the SendTelemetryEvent, various telemetry events are captured in the requestParameters field of CloudTrail logs. These events provide insights into user interactions, overall usage, and the effectiveness of Amazon Q Developer’s suggestions. Here are the key telemetry events along with their descriptions:
UserTriggerDecisionEvent
Description: This event is triggered when a user interacts with a suggestion made by Amazon Q Developer. It captures whether the suggestion was accepted or rejected, along with relevant metadata.
Key Fields:
completionType: Whether the completion was a block or a line.
suggestionState: Whether the user accepted, rejected, or discarded the suggestion.
programmingLanguage: The programming language associated with the suggestion.
generatedLine: The number of lines generated by the suggestion.
CodeScanEvent
Description: This event is logged when a code scan is performed. It helps track the scope and result of the scan, providing insights into security and code quality checks.
Key Fields:
codeAnalysisScope: Whether the scan was performed at the file level or the project level.
programmingLanguage: The language being scanned.
CodeScanRemediationsEvent
Description: This event captures user interactions with Amazon Q Developer’s remediation suggestions, such as applying fixes or viewing issue details.
Key Fields:
CodeScanRemediationsEventType: The type of remediation action taken (e.g., viewing details or applying a fix).
includesFix: A boolean indicating whether the user applied a fix.
ChatAddMessageEvent
Description: This event is triggered when a new message is added to an ongoing chat conversation. It captures the user’s intent which refers to the purpose or goal the user is trying to achieve with the chat message. The intent can include various actions, such as suggesting alternate implementations of the code, applying common best practices, improving the quality or performance of the code.
Key Fields:
conversationId: The unique identifier for the conversation.
messageId: The unique identifier for the chat message.
userIntent: The user’s intent, such as improving code or explaining code.
programmingLanguage: The language related to the chat message.
ChatInteractWithMessageEvent
Description: This event captures when users interact with chat messages, such as copying code snippets, clicking links, or hovering over references.
Key Fields:
interactionType: The type of interaction (e.g., copy, hover, click).
interactionTarget: The target of the interaction (e.g., a code snippet or a link).
acceptedCharacterCount: The number of characters from the message that were accepted.
acceptedSnippetHasReference: A boolean indicating if the accepted snippet included a reference.
TerminalUserInteractionEvent
Description: This event logs user interactions with terminal commands or completions in the terminal environment.
Key Fields:
terminalUserInteractionEventType: The type of interaction (e.g., terminal translation or code completion).
isCompletionAccepted: A boolean indicating whether the completion was accepted by the user.
terminal: The terminal environment in which the interaction occurred.
shell: The shell used for the interaction (e.g., Bash, Zsh).
Telemetry events are key to understanding how users engage with Amazon Q Developer. They track interactions such as code completion, security scans, and chat-based suggestions. Analyzing the data in the requestParameters field helps reveal usage patterns and behaviors that offer valuable insights.
By exploring events such as UserTriggerDecisionEvent, ChatAddMessageEvent, TerminalUserInteractionEvent, and others in the schema, organizations can assess the effectiveness of Amazon Q Developer and identify areas for improvement.
Example Queries for Analyzing Developer Engagement
To gain deeper insights into how developers interact with Amazon Q Developer, the following queries can help analyze key telemetry data from CloudTrail logs. These queries track in-line code suggestions, chat interactions, and code-scanning activities. By running these queries, you can uncover valuable metrics such as the frequency of accepted suggestions, the types of chat interactions, and the programming languages most frequently scanned. This analysis helps paint a clear picture of developer engagement and usage patterns, guiding efforts to enhance productivity.
These four examples only cover a sample set of the available telemetry events, but they serve as a starting point for further exploration of Amazon Q Developer’s capabilities.
SELECT
eventTime,
userIdentity.onBehalfOf.userId AS user_id,
eventName,
json_extract_scalar(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.suggestionState') AS suggestionState,
json_extract_scalar(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.completionType') AS completionType
FROM
amazon_q_metrics.cloudtrail_logs
WHERE
eventName = 'SendTelemetryEvent'
AND json_extract(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent') IS NOT NULL
AND json_extract_scalar(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.suggestionState') = 'ACCEPT';
Use Case:This use case focuses on how developers interact with in-line code suggestions by analyzing accepted snippets. It helps identify which users are accepting suggestions, the type of snippets being accepted (blocks or lines), and the programming languages involved. Understanding these patterns can reveal how well Amazon Q Developer aligns with the developers’ expectations.
Query Explanation: The query retrieves the event time, user ID, event name, suggestion state (filtered to show only ACCEPT), and completion type. TotalGeneratedLinesBlockAccept and totalGeneratedLinesLineAccept or discarded suggestions are not included, but this gives an idea of the developers using the service for in-line code suggestions and the lines or blocks they have accepted. Additionally, the programming language field can be extracted to see which languages are used during these interactions.
Query 2: Analyzing Chat Interactions
SELECT
userIdentity.onBehalfOf.userId AS userId,
json_extract_scalar(requestParameters, '$.telemetryEvent.chatInteractWithMessageEvent.interactionType') AS interactionType,
COUNT(*) AS eventCount
FROM
amazon_q_metrics.cloudtrail_logs
WHERE
eventName = 'SendTelemetryEvent'
AND json_extract(requestParameters, '$.telemetryEvent.chatInteractWithMessageEvent') IS NOT NULL
GROUP BY
userIdentity.onBehalfOf.userId,
json_extract_scalar(requestParameters, '$.telemetryEvent.chatInteractWithMessageEvent.interactionType')
ORDER BY
eventCount DESC;
Use Case: This use case looks at how developers use chat options like upvoting, downvoting, and copying code snippets. Understanding the chat usage patterns shows which interactions are most used and how developers engage with Amazon Q Developer chat. As an organization, this insight can help support other developers in successfully leveraging this feature.
Query Explanation: The query provides insights into chat interactions within Amazon Q Developer by retrieving user IDs, interaction types, and event counts. This query aggregates data based on the interactionType field within chatInteractWithMessageEvent, showcasing various user actions such as UPVOTE, DOWNVOTE, INSERT_AT_CURSOR, COPY_SNIPPET, COPY, CLICK_LINK, CLICK_BODY_LINK, CLICK_FOLLOW_UP, and HOVER_REFERENCE.
This analysis highlights how users engage with the chat feature and the interactions, offering a view of interaction patterns. By focusing on the interactionType field, you can better understand how developers interact with the chat feature of Amazon Q Developer.
Query 3: Analyzing Code Scanning Jobs Across Programming Languages
SELECT
userIdentity.onBehalfOf.userId AS userId,
json_extract_scalar(requestParameters, '$.telemetryEvent.codeScanEvent.programmingLanguage.languageName') AS programmingLanguage,
COUNT(json_extract_scalar(requestParameters, '$.telemetryEvent.codeScanEvent.codeScanJobId')) AS jobCount
FROM
amazon_q_metrics.cloudtrail_logs
WHERE
eventName = 'SendTelemetryEvent'
AND json_extract(requestParameters, '$.telemetryEvent.codeScanEvent') IS NOT NULL
GROUP BY
userIdentity.onBehalfOf.userId,
json_extract_scalar(requestParameters, '$.telemetryEvent.codeScanEvent.programmingLanguage.languageName')
ORDER BY
jobCount DESC;
Use Case: Amazon Q Developer includes security scanning, and this section helps determine how the security scanning feature is being used across different users and programming languages within the organization. Understanding these trends provides valuable insights into which users actively perform security scans and the specific languages targeted for these scans.
Query Explanation: The query provides insights into the distribution of code scanning jobs across different programming languages in Amazon Q Developer. It retrieves user IDs and the count of code-scanning jobs by programming language. This analysis focuses on the CodeScanEvent, aggregating data to show the total number of jobs executed per language.
By summing up the number of code scanning jobs per programming language, this query helps to understand which languages are most frequently analyzed. It provides a view of how users are leveraging the code-scanning feature. This can be useful for identifying trends in language usage and optimizing code-scanning practices.
Query 4: Analyzing User Activity across features.
SELECT
userIdentity.onBehalfOf.userId AS user_id,
COUNT(DISTINCT CASE
WHEN json_extract(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent') IS NOT NULL
THEN eventId END) AS inline_suggestions_count,
COUNT(DISTINCT CASE
WHEN json_extract(requestParameters, '$.telemetryEvent.chatInteractWithMessageEvent') IS NOT NULL
THEN eventId END) AS chat_interactions_count,
COUNT(DISTINCT CASE
WHEN json_extract(requestParameters, '$.telemetryEvent.codeScanEvent') IS NOT NULL
THEN eventId END) AS security_scans_count,
COUNT(DISTINCT CASE
WHEN json_extract(requestParameters, '$.telemetryEvent.terminalUserInteractionEvent') IS NOT NULL
THEN eventId END) AS terminal_interactions_count
FROM
amazon_q_metrics.cloudtrail_logs
WHERE
eventName = 'SendTelemetryEvent'
GROUP BY
userIdentity.onBehalfOf.userId
Use Case:This use case looks at how developers use Amazon Q Developer across different features: in-line code suggestions, chat interactions, security scans, and terminal interactions. By tracking usage, organizations can see overall engagement and identify areas where developers may need more support or training. This helps optimize the use of Amazon Q Developer and helps teams get the most out of the tool.
Query Explanation: Let’s take the other events from the prior queries and additional events to get more detail overall and tie it all together. This expanded query provides a comprehensive view of user activity within Amazon Q Developer by tracking the number of in-line code suggestions, chat interactions, security scans, and terminal interactions performed by each user. By analyzing these events, organizations can gain a better understanding of how developers are using these key features.
By summing up the interactions for each feature, this query helps identify which users are most active in each category, offering insights into usage patterns and areas where additional training or support may be needed.
Enhancing Metrics with Display Names and Usernames
The previous queries had userid as a field; however, many customers would prefer to see a user alias (such as username or display name). The following section illustrates enhancing these metrics by augmenting user IDs with display names and usernames from the AWS IAM Identity Center. This will provide more human-readable user names.
In this example, the export is run locally to enhance user metrics with IAM Identity Center for simplicity. This method works well for demonstrating how to access and work with the data, but it provides a static snapshot of the users at the time of export. In a production environment, an automated solution would be preferable to capture newly added users continuously. For the purposes of this blog, this straightforward approach is used to focus on data access.
To proceed, install Python 3.8+ and Boto3, and configure AWS credentials via the CLI. Then, run the following Python script locally to export the data:
import boto3, csv
# replace this with the region of your IDC instance
RegionName='us-east-1'
# client creation
idstoreclient = boto3.client('identitystore', RegionName)
ssoadminclient = boto3.client('sso-admin', RegionName)
Instances= (ssoadminclient.list_instances()).get('Instances')
InstanceARN=Instances[0].get('InstanceArn')
IdentityStoreId=Instances[0].get('IdentityStoreId')
# query
UserDigestList = []
ListUserResponse = idstoreclient.list_users(IdentityStoreId=IdentityStoreId)
UserDigestList.extend([[user['DisplayName'], user['UserName'], user['UserId']] for user in ListUserResponse['Users']])
NextToken = None
if 'NextToken' in ListUserResponse.keys(): NextToken = ListUserResponse['NextToken']
while NextToken is not None:
ListUserResponse = idstoreclient.list_users(IdentityStoreId=IdentityStoreId, NextToken=NextToken)
UserDigestList.extend([[user['DisplayName'], user['UserName'], user['UserId']] for user in ListUserResponse['Users']])
if 'NextToken' in ListUserResponse.keys(): NextToken = ListUserResponse['NextToken']
else: NextToken = None
# write the query results to IDCUserInfo.csv
with open('IDCUserInfo.csv', 'w') as CSVFile:
CSVWriter = csv.writer(CSVFile, quoting=csv.QUOTE_ALL)
HeaderRow = ['DisplayName', 'UserName', 'UserId']
CSVWriter.writerow(HeaderRow)
for UserRow in UserDigestList:
CSVWriter.writerow(UserRow)
This script will query the IAM Identity Center for all users and write the results to a CSV file, including DisplayName, UserName, and UserId. After generating the CSV file, upload it to an S3 bucket. Please make note of this S3 location.
Steps to Create an Athena Table from the above CSV output: Create a table in Athena to join the existing table with the user details.
1. Navigate to the AWS Management Console > Athena > Editor.
2. Click on the plus to create a query tab.
3. Run the following query to create our table. Note to update the location to your S3 bucket.
CREATE EXTERNAL TABLE amazon_q_metrics.user_data (
DisplayName STRING,
UserName STRING,
UserId STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '"'
)
STORED AS TEXTFILE
LOCATION 's3://{Update to your S3 object location}/' -- Path containing CSV file
TBLPROPERTIES ('skip.header.line.count'='1');
4. Click Run
5. Now, let’s run a quick query to verify the data in the new table.
SELECT * FROM amazon_q_metrics.user_data limit 10;
The first query creates an external table in Athena from user data stored in a CSV file in S3. The user_data table has three fields: DisplayName, UserName, and UserId. To specify the correct parsing of the CSV, separatorChar is specified as a comma and quoteChar as a double quote. Additionally, the TBLPROPERTIES (‘skip.header.line.count’=’1’) flag skips the header row in the CSV file, ensuring that column names aren’t treated as data.
The user_data table holds key details: DisplayName (full name), UserName (username), and UserId (unique identifier). This table will be joined with the cloudtrail_q_metrics table using the userId field from the onBehalfOf struct, enriching the interaction logs with human-readable user names and display names instead of user IDs.
In the previous analysis of in-line code suggestions, the focus was on retrieving key metrics related to user interactions with Amazon Q Developer. The query below follows a similar structure but now includes a join with the user_data table to enrich insights with additional user details such as DisplayName and Username.
To include a join with the user_data table in the query, it is necessary to define a shared key between the cloudtrail_logs_amazon_q and user_data tables. For this example, user_id will be used.
SELECT
logs.eventTime,
user_data.displayname, -- Additional field from user_data table
user_data.username, -- Additional field from user_data table
json_extract_scalar(logs.requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.suggestionState') AS suggestionState,
json_extract_scalar(logs.requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.completionType') AS completionType
FROM
amazon_q_metrics.cloudtrail_logs AS logs -- Specified database for cloudtrail_logs
JOIN
amazon_q_metrics.user_data -- Specified database for user_data
ON
logs.userIdentity.onBehalfOf.userId = user_data.userid
WHERE
logs.eventName = 'SendTelemetryEvent'
AND json_extract_scalar(logs.requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.suggestionState') = 'ACCEPT';
This approach allows for a deeper analysis by integrating user-specific information with the telemetry data, helping you better understand how different user roles interact with the in-line suggestions and other features of Amazon Q Developer.
Cleanup
If you have been following along with this workflow, it is important to clean up the resources to avoid unnecessary charges. You can perform the cleanup by running the following query in the Amazon Athena console:
-- Step 1: Drop the tables
DROP TABLE IF EXISTS amazon_q_metrics.cloudtrail_logs;
DROP TABLE IF EXISTS amazon_q_metrics.user_data;
-- Step 2: Drop the database after the tables are removed
DROP DATABASE IF EXISTS amazon_q_metrics CASCADE;
This query removes both the cloudtrail_logs and user_data tables, followed by the amazon_q_metrics database.
Remove the S3 objects used to store the CloudTrail logs and user data by navigating to the S3 console, selecting the relevant buckets or objects, and choosing “Delete.”
If a new CloudTrail trail was created, consider deleting it to stop further logging. For instructions, see Deleting a Trail. If an existing trail was used, remove the CodeWhisperer data events to prevent continued logging of those events.
Conclusion
By tapping into Amazon Q Developer’s logging capabilities, organizations can unlock detailed insights that drive better decision-making and boost developer productivity. The ability to analyze user-level interactions provides a deeper understanding of how the service is used.
Now that you have these insights, the next step is leveraging them to drive improvements. For example, organizations can use this data to identify opportunities for Proof of Concepts (PoCs) and pilot programs that further demonstrate the value of Amazon Q Developer. By focusing on areas where engagement is high, you can support the most engaged developers as champions to advocate for the tool across the organization, driving broader adoption.
The true potential of these insights lies in the “art of the possible.” With the data provided, it is up to you to explore how to query or visualize it further. Whether you’re examining metrics for in-line code suggestions, interactions, or security scanning, this foundational analysis is just the beginning.
As Amazon Q Developer continues to evolve, staying updated with emerging telemetry events is crucial for maintaining visibility into the available metrics. You can do this by regularly visiting the official Amazon Q Developer documentation and the Amazon Q Developer’s Changelog to stay up-to-date latest information and insights.
Externalized authorization for custom applications is a security approach where access control decisions are managed outside of the application logic. Instead of embedding authorization rules within the application’s code, these rules are defined as policies, which are evaluated by a separate system to make an authorization decision. This separation enhances an application’s security posture by aligning with Zero Trust principles of continual real-time authorization, simplifies the management of security policies, and enables consistent policy enforcement across multiple applications. Amazon Verified Permissions is a scalable permissions management and fine-grained authorization service that you can use to externalize application authorization.
Two common access control models that you might consider when implementing your authorization system are role-based access control (RBAC) and attribute-based access control (ABAC). RBAC grants permissions to users based on their assigned roles within an organization, simplifying the management of access by grouping permissions into roles that correspond to job functions. ABAC grants permissions based on a set of attributes associated with users, resources, and the context, allowing for more fine-grained and dynamic authorization decisions. However, as systems become more complex and have more interconnected data—especially in environments like social networks, collaborative environments, and multi-tenant applications—the limitations of RBAC and ABAC become apparent. These models often fail to effectively capture the relationships between entities. Relationship-based access control (ReBAC) offers a more nuanced approach by using the relationships between users and resources to make decisions about permitted actions, thus addressing scenarios more efficiently than other models.
In this blog post, we show you how to implement ReBAC using Verified Permissions and Amazon Neptune, a managed, serverless graph database on AWS.
What is relationship-based access control?
The core principle of ReBAC is that authorization decisions are based on the relationships between the principal requesting access and the resource being accessed. These relationships can be of several types—ownership, collaboration, or membership relationships—that form hierarchical structures. Examples of ReBAC can be found in multiple domains, including social media sites, project management tools, and content management systems. For example, in a social media application, ReBAC can be used to control who can view, comment, or share a post based on the relationships between the poster, their connections, and the content itself.
Conceptually, roles are types of relationships, and relationships are subsets of attributes.
Benefits of ReBAC
In some types of applications, relationships change dynamically. For example, in a collaborative or social media application, relationships such as contributor or co-owner are continually being established between individual users and resources. Compared to traditional access control models, ReBAC offers the following benefits in these use cases.
Fine-grained access control – ReBAC grants access at the level of an individual resource based on a user’s relationship with that resource. For example, a user can update individual photo albums with which they have a contributor relationship.
Scalability and adaptability – Relationships can change dynamically. Access permissions are updated automatically when a relationship changes. For example, when the contributor relationship is removed, the user no longer has access.
Support for hierarchies – ReBAC can handle hierarchical relationships. For example, the contributor relationship can be inherited down through an album hierarchy, permitting the user to update photo albums that are members of the album with which they have the relationship.
Common relationship models in ReBAC
Here are some common relationship models, also shown in Figure 1, for consideration when building the application and its authorization system:
Resource ownership – Permissions to access or manipulate a resource are granted based on whether a user owns that resource. For example, you can delete a GitHub repository if you are the owner of the repository.
Resource hierarchies – Permissions to access or manipulate a resource are granted based on the permissions that a principal has for the parent resource. For example, a GitHub repository contributor can close issues that belong to that repository.
User hierarchies – These are similar to AWS Identity and Access Management (IAM) user groups. Principals that belong to a group will have the permissions granted to that group.
Figure 1: Common relationship models in ReBAC
In a relationship model, direct relationships represent clear, explicit links between users and resources, such as an employee owns their expense reports or a file is a member of a folder. These connections are straightforward and simply definable.
However, relationship models often extend beyond these direct links to include hierarchical structures. These create indirect relationships that are more complex in nature. For example, team managers might have access to all expense reports filed by their subordinates, even though they don’t directly own these reports. Similarly, folder owners might have access to all files within their subfolders, regardless of who created those files.
These indirect relationships are derived from a series of direct relationships. They form a relationship chain that, while not explicitly defined, is implied by the hierarchical structure. Because of their complexity and potential for far-reaching implications, these indirect relationships require careful consideration when designing an authorization system.
In this blog post, we focus on the implementation of the relationship models that use resource ownership and resource hierarchies, and relationship hierarchies in these models.
Example scenario
Consider a video application that allows users to manage and share videos of their pets. Alice and Bob are individual users within the environment and so they only have access permissions to their own directory or videos. Because Alice and Bob directly own their resources, they have direct OWNER relationships to these resources, represented as solid lines in Figure 2. aliceCatVideo.mp4 is a video resource stored in the aliceVideoDirectory directory. There is a MemberOf relationship between these resources.
Figure 2: Alice has direct relationship to resources that she has direct ownership
Charlie has direct OWNER relationship to the root directory petVideosDirectory. Because aliceVideoDirectory is a subdirectory of petVideosDirectory, Charlie inherits an OWNER relationship to aliceVideoDirectory and the video resource aliceCatVideo.mp4 inside. This indirect OWNER relationship is inherited through the MemberOf relationship between resources and is represented as dotted lines in Figure 3.
Figure 3: Charlie has indirect relationship to resources that inherited from the MemberOf relationship
When implementing access control for this scenario, both RBAC and ABAC offer distinct approaches. In RBAC, you might define roles such as OWNER and VIEWER, and grant Charlie full access to each resource through the OWNER role. While initially straightforward, this method can become inflexible as the application grows, potentially leading to role proliferation. For example, you might want to have separate roles to manage different resources (such as photos or videos) for each type of pet (such as cats or dogs). In ABAC, you might assign attributes such as OWNER and VIEWER and grant each user permissions to resources with specific attributes. This approach offers more flexibility, but fine-grained control can be more complex to set up and manage. As the application’s hierarchy becomes more intricate, both models face challenges in maintaining scalability while maintaining proper access control.
ReBAC addresses these limitations by implementing an access control model that uses direct and indirect relationships between principals and resources. In the example scenario, when Charlie requests access to the video resource aliceCatVideo.mp4, the application traverses the relationship graph in Neptune to retrieve the inherited OWNER relationship through the MemberOf relationship and make the authorization decision.
Overview of a ReBAC application
In this solution, relationship data is stored in Neptune. Prior to requesting an authorization decision from Verified Permissions, the application runs a Neptune query that traverses the relationship graph to retrieve the set of principals that have a specific relationship with the resource. The application then constructs an authorization request for Verified Permissions, using the results of this query to populate the entity data in the request.
In the Cedar schema, the resource has an attribute—named for the relationship—that contains the set of principals that have that relationship with the resource. In our sample application, entities of type Video have an attribute called OWNER, which contains the set of users that have an owner relationship, directly or indirectly, with a video. Each potential relationship is represented by a distinct resource attribute and requires a dedicated query to fetch the set of principals that have that relationship.
See the GitHub repository for the step-by-step walkthrough. In this post, we focus on the key concepts of the solution.
Architecture
Figure 4: Solution architecture
The solution architecture, as shown in Figure 4, includes the following:
The user authenticates with Amazon Cognito and obtains an access token and an ID token.
The user accesses the application through Amazon API Gateway with the provided token.
An application AWS Lambda function traverses the relationship graph in Neptune and returns the set of principals that have a specific relationship with the resource.
The application Lambda function constructs the requests by putting relationship data in the entities field and passes the requests to Verified Permissions. Verified Permissions acts as the policy decision point (PDP) and evaluates the Cedar policies to arrive at an authorization decision.
The application Lambda function acts as the policy enforcement point (PEP) to enforce the authorization decision returned by Verified Permissions by allowing or denying access to the API.
Data modelling and queries in Neptune
Relationships between entities are created and stored in Neptune as a property graph. A property graph is a set of vertices and edges with respective properties (key-value pairs). The vertices represent entities such as User, Directory, and Video in our example, and the edges represent directional relationships between vertices. Each edge has a label that denotes the type of relationship.
Neptune supports multiple graph query languages, including Gremlin, openCypher, and SPARQL, to access a graph. In this solution, we use Gremlin as the graph query language. For more information about Gremlin, see the documentation from Apache TinkerPop. You can use Neptune graph notebooks to work with a Neptune graph.
You can visualize the relationship graph (Figure 5) using the following query. We use elementMap() to include attributes to represent a vertex or an edge.
# Visualizing the relationship graph and extracting the attributes of each vertex and edge
%%gremlin -p v,oute,inv
g.V().outE().inV().path().by(elementMap('name','directoryId','videoId','ownerName','ownerId','userId','isPublic').order().by(keys))
Figure 5: Relationship graph in Neptune
The following code snippet shows how to add a vertex for entity and an edge for relationship in a relationship graph. Static attributes such as ownerId, ownerName, and isPublic are defined as properties of a vertex. In our example, we will define two relationships—MEMBEROF and OWNER—to denote the direct relationships between resources-to-resources and resources-to-users respectively.
It’s a best practice to assign universally unique identifiers (UUIDs) for all principal and resource identifiers. Another best practice is to not include personally identifying, confidential, or sensitive information as part of the unique identifier for your principals or resources.
To traverse the relationship graph to obtain the owner vertex of a resource vertex, you can use the following query. This query returns the vertex that has a direct OWNER relationship to the resource vertex aliceCatVideo.mp4.
# Retrieve the direct owner of a specific video
g.V().hasLabel('video').has('name', 'aliceCatVideo.mp4').in('OWNER').values(‘name’)
You can use the following query to discover inherited OWNER relationships through MemberOf relationships between resources. The query traverses the relationship graph starting from a video vertex and return the OWNER vertex of each resource vertex along the path to the root directory petVideosDirectory. It outputs the set of owners after deduplication. This query discovers the inherited OWNER in the file system hierarchy and includes them in the entities list of authorization requests.
# Retrieve the direct and transitive owners of a specific video
g.V().hasLabel('video').has('videoId',video_id).union(in('OWNER'),repeat(out('MEMBEROF')).until(has('name', 'petVideosDirectory')).in('OWNER')).dedup().values('userId').toList()
Cedar policy design
Verified Permissions uses the Cedar policy language to define fine-grained permissions. The default decision for an authorization response is DENY. The first policy permits a principal to perform actions in the action group OwnerActions on resources in petVideosDirectory only when the same principal is included in the set of resource owners.
// Resource owner and related persons can access the resources
permit (
principal,
action in [PetVideosApp::Action::"OwnerActions"],
resource in PetVideosApp::Directory::<petVideosDirectory_UUID> )
when {
resource has owner &&
principal in resource.owner };
The second policy is an ABAC policy that permits a principal to perform actions in the action group PublicActions on resources in petVideosDirectory only when the resource has the static attribute isPublic and its value is true.
// Allow public access to the resources
permit (
principal,
action in [PetVideosApp::Action::"PublicActions"],
resource in PetVideosApp::Directory::<petVideosDirectory_UUID> )
when {
resource has isPublic &&
resource.isPublic == true };
Implementing ReBAC using this Cedar design pattern in conjunction with a relationship graph requires the careful construction of queries. Verified Permissions will validate that the Cedar policies are correct, based on the Cedar schema, but cannot validate that the Neptune queries correctly traverse the graph to return the correct set of principals with the referenced relationship.
When designing your policies and queries, take account of the following guidelines.
Each Cedar policy governs the behaviors of a specific relationship, in this case OWNER. Use a distinct Cedar policy for each relationship in your use cases.
Define action groups for each relationship in your use cases.
Each new relationship referenced in a Cedar policy requires its own query, and the application needs to run this query if the relationship is relevant to the authorization request. Policy writers must collaborate closely with the application developer to help ensure that the application fetches all data that’s relevant to the authorization request.
Indirect relationships can be hard to intuit and prone to errors. The example here of an OWNER relationship inherited through the MEMBEROF relationship is relatively intuitive. However, we recommend avoiding policies that rely on indirect relationships that are derived from multiple different types of direct relationship.
Indirect relationships can be over-permissive when there is no permission boundary defined. In our example, the boundary for inherited relationship is defined at the root level of the directory (petVideosDirectory). Follow the least privilege principle to limit inherited relationship within a clearly defined permission boundary.
Use MEMBEROF to denote the parent relationship in your graph to align with Cedar policy terminology. However, remember that Verified Permissions cannot auto-discover the Neptune graph, so your queries will still need to be designed to traverse it correctly.
Authorization request to Verified Permissions
The following example shows the structure of an authorization request made to Verified Permissions. In the example, Amazon Cognito is used as the identity source of the Verified Permissions policy store. Cognito user ID claims are mapped to the user entity PetVideosApp::User. Tokens issued by Cognito are mapped to a principal ID in the format <user pool ID>|<sub> by Verified Permissions.
The following request was made for action ViewVideo to the video resource entity with UUID 878c101a-ca0e-4733-904d-af3f252abf50 (the video ID of aliceCatVideo.mp4) using the ID token of alice. The user IDs for alice and charlie were returned after traversing the relationship graph in Neptune to fetch users with the OWNER relationship and include these in the owner attribute in the entities field. The entities field is an array of attributes that Verified Permissions can examine when evaluating the policies. The resource hierarchy of this video resource was shown by including the parent directories (petVideosDirectory and aliceVideosDirectory) as the parent entities in the authorization request.
With reference to the Cedar policy <Resource owner and related persons can access the resources>, the following authorization request returns an ALLOW decision.
ReBAC policies are a great fit when you want to create access based on a relationship between the principal and the resource. However, there can be cases where an ABAC policy is a more intuitive expression of a business rule. For example, in the sample application, you might want to grant all principals permission to view any public resource.
With ReBAC, you would need to create a vertex public in the relationship graph, create MEMBEROF relationships between all public resources and this vertex, and then create a VIEWER relationship between all principals and the vertex public.
With Cedar, you can create a policy store that is a mix of ReBAC and ABAC policies, enabling you to express this access rule with a single ABAC policy that allows public access to resources, as described in the section Cedar Policy Design. This policy grants broad access on resources with the attribute isPublic set to true.
You can use the following Gremlin query to modify the static property isPublic of the video resource vertex bobDogVideo.mp4 to true.
# Set the property "isPublic" to "true" for a specific video
g.V().hasLabel('video').has('name','bobDogVideo.mp4').property(single,'isPublic',true)
You can verify the value of property isPublic of bobDogVideo.mp4 with the following Gremlin query.
# Verify the value of property "isPublic" of a specific video
g.V().hasLabel('video').has('name','bobDogVideo.mp4').values('isPublic')
The following authorization request is made to Verified Permissions using the principal alice after you have set the isPublic property of the video resource bobDogVideo.mp4. In the entities field, there is the attribute isPublic with true as the value.
With reference to the Cedar policy <Allow public access to the resources>, the following authorization request returns ALLOW.
In this post, we showed you what ReBAC is and its benefits and demonstrated the implementation of ReBAC using Amazon Verified Permissions and Amazon Neptune. We also reviewed Cedar policy design patterns and considerations, in addition to the authorization request structure for a ReBAC application. You also saw how to combine ReBAC policies with ABAC policies.
Amazon CodeCatalyst is a unified service that streamlines the entire software development lifecycle, empowering teams to build, deliver, and scale applications on AWS.
DevSecOps is the practice of integrating security into all stages of software development. Rather than prioritizing features, it injects security into an earlier phase of the development process – baking it into design, coding, testing, deployment, and operations from the start. Extensive automation like policy checks, scanning, and more proactively uncovers risks.
Amazon Inspector Scan is a CodeCatalyst Action, a logical unit of work to be performed during a workflow run, which leverages software bill of materials (SBOM) generator (sbomgen) to produce a SBOM and ScanSbom to scan a provided CycloneDX 1.5 SBOM and report on any vulnerabilities discovered in that SBOM. An SBOM inventories third-party and open-source components in an application, documenting names, versions, licenses, dependencies, and more. It enables vital DevSecOps initiatives, such as checking an SBOM against CVE databases to rapidly identify vulnerable libraries needing remediation.
Introduction
This blog talks about the benefits of DevSecOps in general and the SBOM in particular. It provides a walkthrough of adding SBOM generation and scanning as a CodeCatalyst Action to an existing CodeCatalyst Workflow. A workflow is an automated procedure that describes how to build, test, and deploy your code as part of a CI/CD system. First, you will create a new Amazon CodeCatalyst project in the CodeCatalyst console. Next, you will modify the workflow to add the Amazon Inspector Scan action. Lastly, you will run the workflow and view the SBOM and vulnerabilities report.
An AWS Identity and Access Management (IAM) role (that will be added to the Amazon CodeCatalyst space later) to provide Amazon CodeCatalyst service permissions to build and deploy applications.
First, you will create a project using CodeCatalyst Blueprints. Blueprints setup a code repository with a working sample app, define cloud infrastructure and run pre-configured CI/CD workflows for your project.
Create a project from a blueprint
Go to your space by clicking your space name in the CodeCatalyst console. From your space, click Create Project. Upon selecting Start with a blueprint, you will select the Single-page application blueprint and click Next as shown in figure 1.
You will then pick a suitable name for your project, for this post I will use SafeWebShip. Select the AWS IAM role associated with the space and account connection, then click on Create Project.
Next, you will take a look at the current workflow and add the Amazon Inspector Scan action to identify the packages and libraries that make up a software application and scan for vulnerabilities from the associated packages and libraries.
Review the current workflow
A workflow defines a series of steps, or actions, to take during a workflow run and can be assembled using YAML or a visual editor. Actions which require interaction with AWS resources like creation, modification, reading, and deletion occur in the customer’s AWS account, such as creating an Amazon Inspector task to scan an SBOM report.
Add SBOM generation and scanning to the workflow
To add the Amazon Inspector Scan action to the workflow:
Navigate to the CI/CD menu on the left side of your screen, and then click Workflows
Click on the onPushToMainPipeline workflow
Click the edit button to make changes to the workflow
Ensure the Visual tab is selected, then add a CodeCatalyst Action by clicking Actions at the top left of the screen
In the new Actions catalog pop-up, search Amazon Inspector Scan. Click the + at the bottom right of the action card as shown in figure 2
Figure 2 Amazon CodeCatalyst Actions Catalog
Click the Configuration tab of the action and rename the action to inspector_sbom by clicking the pencil under action name
Select the environment from the Environment dropdown, AWS account connection and the Role you created earlier in the pre-requisite
Scroll down to Path and ensure it is “./” which represents the root of the source repository. The tool will traverse all of the directories of the source repository for supported manifest files to scan
The Scan Source should be REPO. The action can scan directories or source repository and a container image. For the purpose of this blog, you will be scanning an existing source repository
The tool can be configured to run scanners that will inspect container images, packages, archive, directory, and binary scanners. For the purpose of this blog, you will be using javascript-nodejs scanner. You can skip the rest of the scanners. You can read the action’s documentation from the action’s catalog page for a full list of supported scanners
Scroll down to Severity Threshold, type medium to fail the action if a vulnerability of medium or greater is found
Skip Files determines the files to skip and should be public/ since you are scanning a public repository
Depth specifies the depth of directory traversal when generating the SBOM. You should pick Depth as 1 to scan all the files in the root directory of the public repository. Other inputs that are relevant to container images can be ignored as the source repository is only being scanned
The action produces two files, the SBOM in CycloneDX v1.5 format from sbomgen and the vulnerability report from ScanSbom. Click the Outputs tab of the action, under Artifacts click Add artifact
Name the Build artifact name as SBOM
Paste the Files produced by build with the followinginspector_sbom_report.json
Click Add artifact again
Name the Build artifact name as SBOM_VULNERABILITIES
Paste the Files produced by build with the following
inspector_scan_report.json
Figure 3 Amazon CodeCatalyst Workflow Screen
As a best practice, you don’t want to build your project unless it has passed the security scan.
Do the following:
From the visual diagram of the workflow, click the Build action
With new menu pop-up to the right, in the pre-loaded inputs tab, and under Depends on – optional, select the Add actions dropdown menu and select the inspector_sbom action
Click x next to the action name to leave the action input menu
Finally, in order to save our changes to the workflow do the following:
Click Validate
Once you see a banner at the top of the page that says the workflow definition is valid, click Commit then click Commit once more to publish the changes to the workflow.
Run the workflow and view artifacts
After committing your changes to the workflow. There should be a new workflow run automatically as the trigger to the workflow is a code push.
Currently, SBOM CycloneDX v1.5 is not supported via CodeCatalyst Reports. Therefore, the report can not be visualized under the Reports feature of Amazon CodeCatalyst. However, the SBOM in CycloneDX v1.5 and the scan report are provided as artifacts for you to download and are stored as part of a workflow run.
To access the reports, do the following:
Navigate to the CI/CD menu on the left side of your screen, and then click Workflows
Click on the onPushToMainPipeline workflow
The current view is the Latest state, Click Runs
When the workflow, or CI/CD pipeline, runs, it is referred to as a run. Runs that are in progress are under Active runs and Runs history contains all previous workflow runs. Click the Run ID under latest run
Once the workflow run page loads, click Artifacts
On the Artifacts page, you should notice SBOM, CycloneDX v1.5, and SBOM_VULNERABILITIES, scan of the SBOM for vulnerabilities as shown in figure 4. Both of these artifacts can be downloaded and viewed on your local machine
The SBOM report will be downloaded as inspector_sbom_report.json. In the SBOM report, all the components that make up the software application are available to view. Each listed component is identified by its name and version as shown in figure 5.
Figure 5 Amazon Inspector Scan SBOM Artifact
The scan of the SBOM report for vulnerabilities will be downloaded as inspector_scan_report.json. In the scan report example below, there are 41 medium vulnerabilities and 32 high vulnerabilities. Since the threshold was set to “medium,” the build failed so these vulnerabilities can be addressed.
The scan report details the vulnerabilities, links to the affected components, and contains information on the vulnerability like description and CVE reference identifier as shown in figure 6 and figure 7.
Figure 7 Amazon Inspector Scan Vulnerability Artifact continued
Clean Up
If you have been following along with building this workflow, you should delete the resources you deployed so you do not continue to incur charges.
First, delete the stack titled DevelopmentFrontendStack-* that has been deployed from the AWS CloudFormation console in the AWS account you associated when you launched the blueprint. Second, delete the project from CodeCatalyst by navigating to Project settings and clicking the Delete project button
Conclusion
In this blog, we demonstrated how you can integrate security practices into a development pipeline using Amazon CodeCatalyst and Amazon Inspector. You created a project from a blueprint that came pre-configured with a workflow. Next, you modified the workflow to add DevSecOps practices to the pipeline through SBOM generation and scanning. Finally, you ran the workflow and viewed the SBOM and vulnerabilities report. It is essential to secure application dependencies during modern software development. For improved software supply chain security, Amazon CodeCatalyst and Amazon Inspector connect effortlessly. Add this action to your existing or new workflows to improve code security. This is necessary in today’s circumstances to protect your software supply chain. Learn more about Amazon CodeCatalyst and get started today!
Sending automated transactional emails, such as account verifications and password resets, is a common requirement for web applications hosted on Amazon EC2 instances. Amazon SES provides multiple interfaces for sending emails, including SMTP, API, and the SES console itself. The type of SES credential you use with Amazon SES depends on the method through which you are sending the emails.
In this blog post, we describe how to leverage IAM roles for EC2 instances to securely send emails via the Amazon SES API, without the need to embed IAM credentials directly in the application code, link to a shared credentials file, or manage IAM credentials within the EC2 instance. By adopting the approach outlined in this blog, you can enhance security by eliminating the risk of credential exposure and simplify credential management for your web applications.
Solution Overview
Below we provide step-by-step instructions to configure an IAM role with SES permissions to use on your EC2 instance. This allows the EC2 hosted web application to securely send emails via Amazon SES without storing or managing IAM credentials within the EC2 instance. We present an option for running EC2 and SES in the same AWS account, as well as an option to accommodate running EC2 and SES in different AWS accounts. Both options offer a way to enhance security and simplify credential management.
Either option begins with creating an IAM role with SES permissions. Next, the IAM role is attached to your EC2 instance, providing it with the necessary permissions for SES without needing to embed IAM credentials in your application code or on a file in the EC2 instance. In option 2, we’ll add cross-account permissions that allow the code on the EC2 instance in account “A” to send email via the SES API in account “B”. We also provide a sample Python script that demonstrates how to send an email from your EC2 instance using the attached IAM role.
Option 1 – SES and EC2 are in a single AWS account
In a typical scenario where an EC2 instance is operating in the same AWS account as SES, the process of using an IAM role to send emails via SES is straightforward. In the steps below, you’ll configure and attach an IAM role to the EC2 instance. You’ll then update a sample Python script to use the permissions provided by the attached IAM role to send emails via SES. This direct access simplifies the SES sending process, as no explicit credential management is required in the code, nor do you need to include a shared credentials file on the EC2 instance.
EC2 & SES in the same AWS Account
Prerequisites – single AWS account for EC2 and SES
Make note of a verified sending email address here: ___________
EC2 instance (Linux) in running state
If you don’t have a EC2 instance create one (Linux)
Administrative Access to Amazon SES, IAM and EC2 consoles.
Access to a recipient email address to receive test emails from the python script.
Make note of a SES verified recipient email address to send test emails here: ___________
Step 1 – Create IAM Role for EC2 instance with SES Permissions
To start, create an IAM role that grants the necessary permissions to send emails using Amazon SES by following these steps:
Sign in to the AWS Management Console and open the IAM console.
In the navigation pane, choose “Roles,” and then choose “Create role.”
Choose the trusted entity type as “AWS service” and select “EC2” as the service that will use this role, then click ‘Next’
Search for and select the “AmazonSESFullAccess” policy from the list (or create a custom policy with the necessary SES permissions), then click ‘Next’.
Provide a name for your role (e.g., EC2_SES_SendEmail_Role).
In the navigation pane, choose “Instances,” and select the running EC2 instance to which you want to attach the IAM role.
With the instance selected, choose “Actions,” then “Security,” and “Modify IAM role.“
Choose the IAM role you created (EC2_SES_SendEmail_Role) from the drop-down menu and click “Update IAM role.”
Step 3 – Create a sample python script that sends emails from the EC2 instance with the attached role.
Now that your EC2 instance is configured with the necessary permissions, you can set up an example Python script to send emails via Amazon SES using the IAM Role. Here, we’re using the AWS SDK for Python (Boto3), a powerful and versatile library to interact with the SES API endpoint. Before running the example script, ensure that Python, pip (the package installer for Python), and the Boto3 library are installed on your EC2 instance:
Run the ‘python3 –version‘ command to check if Python is installed on your EC2 instance. If Python is installed, the version will be displayed, otherwise you’ll receive a ‘command not found’ or similar error message.
If python is not installed, run the command ‘sudo yum install python3 -y‘
Run the ‘pip3 --version‘ command to check if pip is installed on your EC2 instance. If pip3 is installed, is installed, the version will be displayed, otherwise you’ll receive a ‘command not found’ or similar error message.
If pip3 is not installed, run the command ‘sudo yum install python3-pip‘
Install the Boto3 Library which allows Python scripts to interact with AWS services including SES. Run the command ‘pip3 install boto3‘ to install (or update) Boto3 using pip.
Save the code below as a Python file named ‘sesemail.py‘ on your EC2 instance.
Edit 'sesemail.py‘ and replace the placeholder values of SENDER, RECIPIENT, and AWS_REGION with your values (see prerequisites). Do not modify any “” marks.
[copy]
import boto3
from botocore.exceptions import ClientError
SENDER = "[email protected]"
RECIPIENT = "[email protected]"
#CONFIGURATION_SET = "ConfigSet"
AWS_REGION = "us-west-2"
SUBJECT = "Amazon SES Test Email (SDK for Python) using IAM Role"
BODY_TEXT = ("Amazon SES Test (Python)\r\n"
"This email was sent with Amazon SES using the "
"AWS SDK for Python (Boto)."
)
BODY_HTML = """<html>
<head></head>
<body>
<h1>Amazon SES Test (SDK for Python) using IAM Role</h1>
<p>This email was sent with
<a href='https://aws.amazon.com/ses/'>Amazon SES</a> using the
<a href='https://aws.amazon.com/sdk-for-python/'>
AWS SDK for Python (Boto)</a>.</p>
</body>
</html>
"""
CHARSET = "UTF-8"
client = boto3.client('ses',region_name=AWS_REGION)
try:
response = client.send_email(
Destination={
'ToAddresses': [
RECIPIENT,
],
},
Message={
'Body': {
'Html': {
'Charset': CHARSET,
'Data': BODY_HTML,
},
'Text': {
'Charset': CHARSET,
'Data': BODY_TEXT,
},
},
'Subject': {
'Charset': CHARSET,
'Data': SUBJECT,
},
},
Source=SENDER,
)
except ClientError as e:
print(e.response['Error']['Message'])
else:
print("Email sent! Message ID:"),
print(response['MessageId'])
Run ‘python3 sesmail.py‘ to execute the Python script.
When ‘python3 sesmail.py‘ runs successfully, an email is sent to the RECIPIENT(check the inbox), and the command line will display the sent Message ID.
Option 2 – SES and EC2 are in different AWS accounts
In some scenarios, your EC2 instance might operate in a different AWS account than SES. Let’s call the EC2 AWS account “A” and SES AWS account “B”. Because the AWS resources in account A don’t automatically have permission to access AWS resources account B, we need some way to allow the code on EC2 to assume a role in the SES Account using the AWS Security Token Service (STS). This involves a method that generates temporary credentials that include an access key, secret access key, and session token, which are only valid for a limited time.
EC2 & SES in different AWS Accounts
In the steps below, you’ll configure and attach an IAM role to the EC2 instance in account “A” such that it can run an example Python script. This Python script can use the permissions provided by the attached IAM role to send emails via SES in account “B”. This approach leverages cross-account access and simplifies sending email from the EC2 in account A via SES in account B. As with Option 1, no explicit credential management is required in the code running on EC2, nor do you need to include a shared credentials file on the Ec2 instance.
Prerequisites – different AWS accounts for EC2 and SES (use cross-account access)
Make note of a verified sending email address here: ___________
Administrative Access to Amazon SES and IAM consoles.
Make note of your “B” AWS account ID here: ________________
In the steps below, you will create a “SES_Role_for_account_A” role.
Make note of the ARN of the “SES_Role_for_account_A” role here: ___________
Access to a recipient email address to receive test emails from the python script.
Make note of a SES verified recipient email address to send test emails here: ___________
Step 1 – Create IAM Role in the SES “B” account
Sign in to the SES “B” account via the AWS Management Console and open the IAM console.
In the navigation pane, choose “Roles,” and then choose “Create role“.
Choose the trusted entity type as ‘AWS account’ and select ‘Another AWS account’.
Add the AWS account ID where your EC2 instance resides (AWS account “A” in the prerequisites) and click ‘Next’.
Search for and select the “AmazonSESFullAccess” policy or create a custom policy with the necessary SES permissions, then click ‘Next’.
Provide a name for your role (e.g., ‘SES_Role_for_account_A').
Click “Create role“.
Copy the arn for the new SES_Role_for_account_A (you’ll need the arn in the next step).
Step 2 – Create a IAM policy in the EC2 “A” account that allows this role to assume the SES_Role_for_account_A role you just created in the SES “B” Account.
Sign in to the EC2 “A” account via the AWS Management Console and open the IAM console.
In the navigation pane, choose “Policies,” and then choose “Create Policy”.
Choose the service as ‘EC2’ and select policy editor as JSON.
Copy the policy below, and in the policy editor, replace the Resource with the arn of theSES_Role_for_account_A in the SES account “B” (you created this in step 1).
[copy, paste into policy editor & replace the arn with SES_Role_for_account_A]
Click ‘Next’ and provide a name for your role (e.g., EC2_Policy_for_account_B).
Click ‘Create the Policy’
Step 3 – Create an IAM role in the EC2 “A” account, and attach the previously created IAM policy (EC2_Policy_for_account_B) to it.
In the EC2 “A” account IAM console navigation pane, choose “Roles,” and then choose “Create role.”
Choose the trusted entity type as “AWS service” and select “EC2” as the service, then click ‘Next’.
Filter by type “customer managed”, search for (EC2_Policy_for_account_B) and select that policy and ‘Next’ (note – if you are using AWS Session Manger to remotely connect to your EC2 instance, you may need to add the “AmazonSSMManagedInstanceCore” policy to the role).
Provide a name for your role (e.g., EC2_SES_in_account_B_role).
Click “Create role“.
Step 4 – Attach the IAM Role (EC2_SES_in_account_B_role) to the EC2 instance in AWS account “A”.
In the navigation pane, choose “Instances,” and select the instance to which you want to attach the EC2_SES_in_account_B_role IAM role.
With the instance selected, choose “Actions,” then “Security,” and “Modify IAM role.”
Choose the IAM role you created (EC2_SES_in_account_B_role) from the drop-down menu.
Click “Update IAM role.”
Step 5 – Create a sample python script that sends emails via SES in AWS account “B” from the EC2 instance in AWS account “A” using the EC2 attached role.
Now that your EC2 instance is configured with the necessary permissions, you can set up an example Python script to send emails via Amazon SES in AWS Account “B” using the IAM Role on EC2 in AWS Account “A”. We’ll use the AWS SDK for Python (Boto3), a powerful and versatile library to interact with the SES API endpoint. Before running the example script, ensure that Python, pip (the package installer for Python), and the Boto3 library are installed on your EC2 instance:
Run the ‘python3 –version‘ command to check if Python is installed on your EC2 instance. If Python is installed, the version will be displayed, otherwise you’ll receive a ‘command not found’ or similar error message.
If python is not installed, run the command ‘sudo yum install python3 -y‘
Run the ‘pip3 --version‘ command to check if pip is installed on your EC2 instance. If pip3 is installed, is installed, the version will be displayed, otherwise you’ll receive a ‘command not found’ or similar error message.
If pip3 is not installed, run the command ‘sudo yum install python3-pip‘
Install the Boto3 Library which allows Python scripts to interact with AWS services including SES. Run the command ‘pip3 install boto3‘ to install (or update) Boto3 using pip.
Save the code below as a Python file named cross_sesemail.py on your EC2 instance. 4b. Edit cross_sesemail.py and replace the placeholder values of the ROLE_ARN with ARN of the SES_Role_for_account_A you created in SES Account “B” (see prerequisites), SENDER, RECIPIENT, and AWS_REGION with your values (see prerequisites). Do not modify any “” marks.
[copy, edit & replace the ROLE_ARN]
import boto3
from botocore.exceptions import ClientError
# Replace with your role ARN in SES Account
ROLE_ARN = "arn:aws:iam::<Account_ID>:role/<Role_Name>"
# Create an STS client
sts_client = boto3.client('sts')
# Assume the role
assumed_role = sts_client.assume_role(
RoleArn=ROLE_ARN,
RoleSessionName="SESSession"
)
# Extract the temporary credentials
credentials = assumed_role['Credentials']
# Create an SES client using the assumed role credentials
ses_client = boto3.client(
'ses',
region_name='us-west-2',
aws_access_key_id=credentials['AccessKeyId'],
aws_secret_access_key=credentials['SecretAccessKey'],
aws_session_token=credentials['SessionToken']
)
# Email parameters
SENDER = "[email protected]"
RECIPIENT = "[email protected]"
SUBJECT = "Amazon SES Test (SDK for Python) using cross-account IAM Role"
BODY_TEXT = ("Amazon SES Test (Python)\r\n"
"This email was sent with Amazon SES using the "
"AWS SDK for Python (Boto) using IAM Role."
)
BODY_HTML = """<html>
<head></head>
<body>
<h1>Amazon SES Test (SDK for Python) using IAM Role</h1>
<p>This email was sent with
<a href='https://aws.amazon.com/ses/'>Amazon SES</a> using the
<a href='https://aws.amazon.com/sdk-for-python/'>
AWS SDK for Python (Boto)</a> using IAM Role.</p>
</body>
</html>
"""
CHARSET = "UTF-8"
# Send the email
try:
response = ses_client.send_email(
Destination={
'ToAddresses': [RECIPIENT],
},
Message={
'Body': {
'Html': {
'Charset': CHARSET,
'Data': BODY_HTML,
},
'Text': {
'Charset': CHARSET,
'Data': BODY_TEXT,
},
},
'Subject': {
'Charset': CHARSET,
'Data': SUBJECT,
},
},
Source=SENDER,
)
except ClientError as e:
print(e.response['Error']['Message'])
else:
print("Email sent! Message ID:"),
print(response['MessageId'])
Run the python script python3 cross_sesemail.py. When the email is sent successfully, the command line output will display the message ID of the sent email, and the recipient will receive an email.
Conclusion:
By implementing IAM roles for EC2 instances with SES permissions, you can securely send emails via the SES APIs from your web applications without the need to store or manage IAM credentials within the EC2 instance or application code. This approach not only enhances security by eliminating the risk of credential exposure, but also simplifies the management of credentials. With the step-by-step guide provided in this blog post, you can easily configure IAM roles for your EC2 instances and start sending emails via the Amazon SES API in a secure and efficient manner, regardless of whether your EC2 and SES resources reside in the same or different AWS accounts.
Next Steps:
Sign up for the AWS Free Tier and try out Amazon SES with IAM roles for EC2 instances as demonstrated in this blog post.
Join the AWS Community Forums to ask questions, share experiences, and learn from other AWS users who have implemented similar solutions for secure email sending from their web applications.
About the Authors
Manas Murali M
Manas Murali M is a Cloud Support Engineer II at AWS and subject matter expert in Amazon Simple Email Service (SES) and Amazon CloudFront. With over 5 years of experience in the IT industry, he is passionate about resolving technical issues for customers. In his free time, he enjoys spending time with friends, traveling, and exploring emerging technologies.
Zip
Zip is an Amazon Pinpoint and Amazon Simple Email Service Sr. Specialist Solutions Architect at AWS. Outside of work he enjoys time with his family, cooking, mountain biking and plogging.
Organizations are collecting and storing vast amounts of structured and unstructured data like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset. For many organizations, this centralized data store follows a data lake architecture. Although data lakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. End-users often struggle to find relevant information buried within extensive documents housed in data lakes, leading to inefficiencies and missed opportunities.
Surfacing relevant information to end-users in a concise and digestible format is crucial for maximizing the value of data assets. Automatic document summarization, natural language processing (NLP), and data analytics powered by generative AI present innovative solutions to this challenge. By generating concise summaries of large documents, performing sentiment analysis, and identifying patterns and trends, end-users can quickly grasp the essence of the information without the need to sift through vast amounts of raw data, streamlining information consumption and enabling more informed decision-making.
This is where Amazon Bedrock comes into play. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. This post shows how to integrate Amazon Bedrock with the AWS Serverless Data Analytics Pipeline architecture using Amazon EventBridge, AWS Step Functions, and AWS Lambda to automate a wide range of data enrichment tasks in a cost-effective and scalable manner.
Solution overview
The AWS Serverless Data Analytics Pipeline reference architecture provides a comprehensive, serverless solution for ingesting, processing, and analyzing data. At its core, this architecture features a centralized data lake hosted on Amazon Simple Storage Service (Amazon S3), organized into raw, cleaned, and curated zones. The raw zone stores unmodified data from various ingestion sources, the cleaned zone stores validated and normalized data, and the curated zone contains the final, enriched data products.
Building upon this reference architecture, this solution demonstrates how enterprises can use Amazon Bedrock to enhance their data assets through automated data enrichment. Specifically, it showcases the integration of the powerful FMs available in Amazon Bedrock for generating concise summaries of unstructured documents, enabling end-users to quickly grasp the essence of information without sifting through extensive content.
The enrichment process begins when a document is ingested into the raw zone, invoking an Amazon S3 event that initiates a Step Functions workflow. This serverless workflow orchestrates Lambda functions to extract text from the document based on its file type (text, PDF, Word). A Lambda function then constructs a payload with the document’s content and invokes the Amazon Bedrock Runtime service, using state-of-the-art FMs to generate concise summaries. These summaries, encapsulating key insights, are stored alongside the original content in the curated zone, enriching the organization’s data assets for further analysis, visualization, and informed decision-making. Through this seamless integration of serverless AWS services, enterprises can automate data enrichment, unlocking new possibilities for knowledge extraction from their valuable unstructured data.
The serverless nature of this architecture provides inherent benefits, including automatic scaling, seamless updates and patching, comprehensive monitoring capabilities, and robust security measures, enabling organizations to focus on innovation rather than infrastructure management.
The following diagram illustrates the solution architecture.
Let’s walk through the architecture chronologically for a closer look at each step.
Initiation
The process is initiated when an object is written to the raw zone. In this example, the raw zone is a prefix, but it could also be a bucket. Amazon S3 emits an object created event and matches an EventBridge rule. The event invokes a Step Functions state machine. The state machine runs for each object in parallel, so the architecture scales horizontally.
Workflow
The Step Functions state machine provides a workflow to handle different file types for text summarization. Files are first preprocessed based on the file extension and corresponding Lambda function. Next, the files are processed by another Lambda function that summarizes the preprocessed content. If the file type is not supported, the workflow fails with an error. The workflow consists of the following states:
CheckFileType – The workflow starts with a Choice state that checks the file extension of the uploaded object. Based on the file extension, it routes the workflow to different paths:
If the file extension is .txt, it goes to the IngestTextFile state.
If the file extension is .pdf, it goes to the IngestPDFFile state.
If the file extension is .docx, it goes to the IngestDocFile state.
If the file extension doesn’t match any of these options, it goes to the UnsupportedFileType state and fails with an error.
IngestTextFile, IngestPDFFile, and IngestDocFile – These are Task states that invoke their respective Lambda functions to ingest (or process) the file based on its type. After ingesting the file, the job moves to the SummarizeTextFile state.
SummarizeTextFile – This is another Task state that invokes a Lambda function to summarize the ingested text file. The function takes the source key (object key) and bucket name as input parameters. This is the final state of the workflow.
You can extend this code sample to account for different types of files, including audio, pictures, and video files, by using services like Amazon Transcribe or Amazon Rekognition.
Preprocessing
Lambda enables you to run code without provisioning or managing servers. This solution contains a Lambda function for each file type. These three functions are part of a larger workflow that processes different types of files (Word documents, PDFs, and text files) uploaded to an S3 bucket. The functions are designed to extract text content from these files, handle any encoding issues, and store the extracted text as new text files in the same S3 bucket with a different prefix. The functions are as follows:
Word document processing function:
Downloads a Word document (.docx) file from the S3 bucket
Uses the python-docx library to extract text content from the Word document by iterating over its paragraphs
Stores the extracted text as a new text file (.txt) in the same S3 bucket with a cleaned prefix
PDF processing function:
Downloads a PDF file from the S3 bucket
Uses the PyPDF2 library to extract text content from the PDF by iterating over its pages
Stores the extracted text as a new text file (.txt) in the same S3 bucket with a cleaned prefix
Text file processing function:
Downloads a text file from the S3 bucket
Uses the chardet library to detect the encoding of the text file
Decodes the text content using the detected encoding (or UTF-8 if encoding can’t be detected)
Encodes the decoded text content as UTF-8
Stores the UTF-8 encoded text as a new text file (.txt) in the same S3 bucket with a cleaned prefix
All three functions follow a similar pattern:
Download the source file from the S3 bucket.
Process the file to extract or convert the text content.
Store the extracted and converted text as a new text file in the same S3 bucket with a different prefix.
Return a response indicating the success of the operation and the location of the output text file.
Processing
After the content has been extracted to the cleaned prefix, the Step Functions state machine initiates the Summarize_text Lambda function. This function acts as an orchestrator in a workflow designed to generate summaries for text files stored in an S3 bucket. When it’s invoked by a Step Functions event, the function retrieves the source file’s path and bucket location, reads the text content using the Boto3 library, and generates a concise summary using Anthropic Claude 3 on Amazon Bedrock. After obtaining the summary, the function encapsulates the original text, generated summary, model details, and a timestamp into a JSON file, which is uploaded back to the same S3 bucket with a specified prefix, providing organized storage and accessibility for further processing or analysis.
Summarization
Amazon Bedrock provides a straightforward way to build and scale generative AI applications with FMs. The Lambda function sends the content to Amazon Bedrock with directions to summarize it. The Amazon Bedrock Runtime service plays a crucial role in this use case by enabling the Lambda function to integrate with the Anthropic Claude 3 model seamlessly. The function constructs a JSON payload containing the prompt, which includes a predefined prompt stored in an environment variable and the input text content, along with parameters like maximum tokens to sample, temperature, and top-p. This payload is sent to the Amazon Bedrock Runtime service, which invokes the Anthropic Claude 3 model and generates a concise summary of the input text. The generated summary is then received by the Lambda function and incorporated into the final JSON file.
If you use this solution for your own use case, you can customize the following parameters:
modelId – The model you want Amazon Bedrock to run. We recommend testing your use case and data with different models. Amazon Bedrock has a lot of models to offer, each with their own strengths. Models also vary by context window, which is how much data you can send with a single prompt.
prompt – The prompt that you want Anthropic Claude 3 to complete. Customize the prompt for your use case. You can set the prompt in the initial deployment steps as described in the following section.
max_tokens_to_sample – The maximum number of tokens to generate before stopping. This sample is currently set at 300 to manage cost, but you will likely want to increase it.
Temperature – The amount of randomness injected into the response.
top_p – In nucleus sampling, Anthropic’s Claude 3 computes the cumulative distribution over all the options for each subsequent token in decreasing probability order and cuts it off when it reaches a particular probability specified by top_p.
The best way to determine the best parameters for a specific use case is to prototype and test. Fortunately, this can be a quick process by using the following code example or the Amazon Bedrock console. For more details about models and parameters available, refer to Anthropic Claude Text Completions API.
AWS SAM template
This sample is built and deployed with AWS Serverless Application Model (AWS SAM) to streamline development and deployment. AWS SAM is an open source framework for building serverless applications. It provides shorthand syntax to express functions, APIs, databases, and event source mappings. You define the application you want with just a few lines per resource and model it using YAML. In the following sections, we guide you through the process of a sample deployment using AWS SAM that exemplifies the reference architecture.
Prerequisites
For this walkthrough, you should have the following prerequisites:
This walkthrough uses AWS CloudShell to deploy the solution. CloudShell is a browser-based shell environment provided by AWS that allows you to interact with and manage your AWS resources directly from the AWS Management Console. It offers a pre-authenticated command line interface with popular tools and utilities pre-installed, such as the AWS Command Line Interface (AWS CLI), Python, Node.js, and git. CloudShell eliminates the need to set up and configure your local development environments or manage SSH keys, because it provides secure access to AWS services and resources through a web browser. You can run scripts, run AWS CLI commands, and manage your cloud infrastructure without leaving the AWS console. CloudShell is free to use and comes with 1 GB of persistent storage for each AWS Region, allowing you to store your scripts and configuration files. This tool is particularly useful for quick administrative tasks, troubleshooting, and exploring AWS services without the need for additional setup or local resources.
Complete the following steps to set up the CloudShell environment:
Open the CloudShell console.
If this is your first time using CloudShell, you may see a “Welcome to AWS CloudShell” page.
Choose the option to open an environment in your Region (the Region listed may vary based on your account’s primary Region).
It may take several minutes for the environment to fully initialize if this is your first time using CloudShell.
The display resembles a CLI suitable for deploying AWS SAM sample code.
Download and deploy the solution
This code sample is available on Serverless Land and GitHub. Deploy it according to the directions in the GitHub README on the CloudShell console:
git clone https://github.com/aws-samples/step-functions-workflows-collection
cd step-functions-workflows-collection/s3-sfn-lambda-bedrock
sam build
sam deploy –-guided
For the guided deployment process, use the default values. Also, enter a stack name. AWS SAM will deploy the sample code.
Run the following code to set up the required prefix structure:
bucket=$(aws s3 ls | grep sam-app | cut -f 3 -d ' ') && for each in raw cleaned curated; do aws s3api put-object --bucket $bucket --key $each/; done
The sample application has now been deployed and you’re ready to begin testing.
EventBridge will monitor for new file additions to the raw S3 bucket, invoking the Step Functions workflow.
You can navigate to the Step Functions console and view the state machine. You can observe the status of the job and when it’s complete.
The Step Functions workflow verifies the file type, subsequently invoking the appropriate Lambda function for processing or raising an error if the file type is unsupported. Upon successful content extraction, a second Lambda function is invoked to summarize the content using Amazon Bedrock.
The workflow employs two distinct functions: the first function extracts content from various file types, and the second function processes the extracted information with the assistance of Amazon Bedrock, receiving data from the initial Lambda function.
Upon completion, the processed data is stored back in the curated S3 bucket in JSON format.
The process creates a JSON file with the original_content and summary fields. The following screenshot shows an example of the process using the Containers On AWS whitepaper. Results can vary depending on the large language model (LLM) and prompt strategies selected.
Clean up
To avoid incurring future charges, delete the resources you created. Run sam delete from CloudShell.
Solution benefits
Integrating Amazon Bedrock into the AWS Serverless Data Analytics Pipeline for data enrichment offers numerous benefits that can drive significant value for organizations across various industries:
Scalability – This serverless approach inherently scales resources up or down as data volumes and processing requirements fluctuate, providing optimal performance and cost-efficiency. Organizations can handle spikes in demand seamlessly without manual capacity planning or infrastructure provisioning.
Cost-effectiveness – With the pay-per-use pricing model of AWS serverless services, organizations only pay for the resources consumed during data enrichment. This avoids upfront costs and ongoing maintenance expenses of traditional deployments, resulting in substantial cost savings.
Ease of maintenance – AWS handles the provisioning, scaling, and maintenance of serverless services, reducing operational overhead. Organizations can focus on developing and enhancing data enrichment workflows rather than managing infrastructure.
Across industries, this solution unlocks numerous use cases:
Research and academia – Summarizing research papers, journals, and publications to accelerate literature reviews and knowledge discovery
Legal and compliance – Extracting key information from legal documents, contracts, and regulations to support compliance efforts and risk management
Healthcare – Summarizing medical records, studies, and patient reports for better patient care and informed decision-making by healthcare professionals
Enterprise knowledge management – Enriching internal documents and repositories with summaries, topic modeling, and sentiment analysis to facilitate information sharing and collaboration
Customer experience management – Analyzing customer feedback, reviews, and social media data to identify sentiment, issues, and trends for proactive customer service
Marketing and sales – Summarizing customer data, sales reports, and market analysis to uncover insights, trends, and opportunities for optimized campaigns and strategies
With Amazon Bedrock and the AWS Serverless Data Analytics Pipeline, organizations can unlock their data assets’ potential, driving innovation, enhancing decision-making, and delivering exceptional user experiences across industries.
The serverless nature of the solution provides scalability, cost-effectiveness, and reduced operational overhead, empowering organizations to focus on data-driven innovation and value creation.
Conclusion
Organizations are inundated with vast information buried within documents, reports, and complex datasets. Unlocking the value of these assets requires innovative solutions that transform raw data into actionable insights.
This post demonstrated how to use Amazon Bedrock, a service providing access to state-of-the-art LLMs, within the AWS Serverless Data Analytics Pipeline. By integrating Amazon Bedrock, organizations can automate data enrichment tasks like document summarization, named entity recognition, sentiment analysis, and topic modeling. Because the solution utilizes a serverless approach, it handles fluctuating data volumes without manual capacity planning, paying only for resources consumed during enrichment and avoiding upfront infrastructure costs.
This solution empowers organizations to unlock their data assets’ potential across industries like research, legal, healthcare, enterprise knowledge management, customer experience, and marketing. By providing summaries, extracting insights, and enriching with metadata, you efficiency add innovative features that provide differentiated user experiences.
Explore the AWS Serverless Data Analytics Pipeline reference architecture and take advantage of the power of Amazon Bedrock. By embracing serverless computing and advanced NLP, organizations can transform data lakes into valuable sources of actionable insights.
About the Authors
Dave Horne is a Sr. Solutions Architect supporting Federal System Integrators at AWS. He is based in Washington, DC, and has 15 years of experience building, modernizing, and integrating systems for public sector customers. Outside of work, Dave enjoys playing with his kids, hiking, and watching Penn State football!
Robert Kessler is a Solutions Architect at AWS supporting Federal Partners, with a recent focus on generative AI technologies. Previously, he worked in the satellite communications segment supporting operational infrastructure globally. Robert is an enthusiast of boats and sailing (despite not owning a vessel), and enjoys tackling house projects, playing with his kids, and spending time in the great outdoors.
AWS IAM Identity Center manages user access to Amazon Web Services (AWS) resources, including both AWS accounts and applications. You can use IAM Identity Center to create and manage user identities within the Identity Center identity store or to connect seamlessly to other identity sources.
Organizations might change the configuration of their identity source in IAM Identity Center for various reasons. These include switching identity providers (IdPs), expanding their identity footprint, adopting new features, and so on. These transitions can disrupt user access and require planning to minimize downtime.
In this blog post, we walk you through the process of switching from one identity source to another and provide sample code that you can use to assist with the transition.
Background
The identity source configured in IAM Identity Center determines where users and groups are created and managed. Each organization can connect to only one identity source at a time. Identity Center supports three main identity source options:
Identity Center directory: This is the default identity store for IAM Identity Center. You can use it to directly create and administer your users and groups within Identity Center without relying on an external provider.
Active Directory: You can configure integration with an on-premises Active Directory or with AWS Managed Microsoft AD using AWS Directory Service. This integration enables you to use your existing Active Directory identities and group memberships.
External IdP: You can continue using your current third-party IdPs that support SAML 2.0, such as Okta Universal Directory or Microsoft Entra ID (formerly Azure AD).
Understanding these identity source options can help you choose the source that best fits your user management needs based on your existing infrastructure and authentication requirements.
Figure 1 explains the flow of users and groups accessing AWS resources. This access is granted through the following:
Assignment of permission sets to users and groups in your directory, which enables assume role access to AWS accounts.
Figure 1: Granting access to AWS resources for users and groups managed by an identity source in IAM Identity Center
When you change the identity source, the work required varies depending on the original and new sources. AWS documentation details these considerations. In minimal impact scenarios, assignments remain intact, although you need to force password resets or verify correct assertions from the new source. More disruptive scenarios delete users, groups, and their assignments. In those scenarios, you need to restore the deleted entries after changing the identity source.
Sample deployment
This deployment covers permission sets and application assignments’ backup and restore. These scripts associate assignments with unique user attributes such as UserName, and group attributes such as DisplayName. Attributes that might change during the user and group restoration process, such as UserId and GroupId, aren’t used.
What isn’t covered includes users, groups, permission sets, and applications backup and restore.
Users and groups backup and restore aren’t covered because they depend heavily on the format of the source and target IdPs.
Because we’re working with identity source switching, the permission sets will remain unchanged and applications will not be deleted.
The sample scripts and detailed steps are available on GitHub.
Note: This solution is available in the GitHub aws-samples repository. You can report bugs or make feature requests through GitHub Issues. The builders of this solution can help with GitHub issues. Enterprise Support customers can reach out to their Technical Account Manager (TAM) for further questions or feature requests.
Walkthrough
In this section, we walk you through the process of transitioning to a new identity source in IAM Identity Center.
Step 1: Backup users, groups, and assignments from the current identity source
This step is critical to preserve users’ information and their associated access scope.
Note: For some external IdPs, there are native integrations with Active Directory, such as Okta AD integration and Ping One AD Connect. You can set up a native integration and sync users and groups data without needing to backup and restore that data.
Assignments can be backed up by running the backup.py file from GitHub. Replace <IDC_STORE_ID> with your Identity Store ID (it looks like d-1234567890), and replace <IDC_ARN> with the Amazon Resource Name (ARN) for your IAM Identity Center instance.
This script uses both IAM Identity Center APIs and Identity Store APIs as shown in Figure 2 that generates permission set assignments backup files (UserAssignments.json and GroupAssignments.json) and an application assignments backup file (AppAssignments.json).
Figure 2: APIs used for backing up assignments
Step 2: Restore and validate the backed-up users and groups in the target identity source
The target will become the new authoritative identity source. When done, verify that the group memberships and attributes have been correctly transferred.
WARNING: While the directory is being rebuilt, your users will not have access to AWS accounts or applications through IAM Identity Center until all assignments are restored in Step 4.
Step 4: Restore assignments to users and groups in the new identity source
The APIs used to restore assignments are as shown in Figure 3.
Figure 3: APIs used for restoring assignments
Assignments can be restored by running the restore.py file from GitHub. Replace <NEW_IDC_STORE_ID> with your newly configured Identity Store ID (it looks like d-1234567890) and replace <IDC_ARN> with the ARN for your IAM Identity Center instance.
This script uses the APIs illustrated in Figure 2 and picks up backup files (UserAssignments.json, GroupAssignments.json, and AppAssignments.json) from Step 1 by default. Account permission set assignment results are automatically retrieved five times using exponential backoff. If the result is other than SUCCEEDED after five retries, the principal ID will be marked as failed and exported in error logs.
Note: For AWS managed applications that maintain a separate identity source, using the CreateApplicationAssignments API to restore application assignments will not preserve user access. These applications typically have dependencies on the original identity source ID, or dependencies on UserId and GroupId from the original identity source. This dependency is represented by importing users or groups from IAM Identity Center during the AWS managed application creation process. Example AWS managed applications include Amazon SageMaker Studio and Amazon Q Developer. These applications must be restored on a case-by-case basis and can require redeployment of the application.
Step 5: Validate user access using the new identity source
Make sure that users can still access the expected accounts and applications.
Conclusion
Transitioning your identity source in IAM Identity Center requires careful planning and implementation. This post outlined the steps to manage this transition. By following these steps, you can streamline the transition process, providing a smooth and efficient transfer of user access with minimal downtime. To get started, see the GitHub repository. For related posts, visit the AWS Security Blog channel and search for IAM Identity Center.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
AWS customers often look for ways to run their systems within or under budget, avoiding unnecessary costs. This post offers practical advice on designing scalable and cost-efficient three-tier architectures by using serverless technologies within the AWS Free Tier.
With AWS, you can start small and scale cost-effectively as your business demand increases. You can begin with minimal investments by using the Free Tier to build a minimum viable product (MVP). Then you can expand resources as your user base grows and your needs evolve, and transition to a full-fledged, large-scale application.
In this blog post, you will learn how to build a three-tier architecture that predominantly relies on AWS service usage within the Free Tier, resulting in a highly affordable architecture.
Note: The Free Tier offerings mentioned within this blog post are subject to change. Always check the AWS Free Tier page for the most current information.
Background: Understanding the AWS Free Tier
The Free Tier provides users with access to a range of AWS services at no cost within predefined monthly usage limits. This offering helps users to run experimentation, development, and even production workloads without charges. The Free Tier is available for more than 100 AWS products today, including Amazon Simple Storage Service (Amazon S3), Amazon Elastic Compute Cloud (Amazon EC2), and Amazon Relational Database Service (Amazon RDS). Depending on the product, there are three types of Free Tier offers:
Free trials – Short-term trial offers that start when the first usage begins. After the trial period expires, you pay standard service rates.
12 months free – Offers available to new AWS customers for 12 months following their sign-up date. After the 12-month free term expires, you pay standard service rates.
Always free – Offers available to both existing and new AWS customers indefinitely.
For example, the AWS Lambda Free Tier includes one million free requests per month and 400,000 GB-seconds of compute time per month usable for functions across both x86 and AWS Graviton processors. The AWS Lambda Free Tier falls under the always free category.
Walkthrough: Three-tier architecture on AWS
Cost efficiency is a prominent advantage of using AWS serverless services. These services decrease the need for provisioning and managing servers, reducing operational overhead and labor costs. Serverless services like AWS Lambda and Amazon API Gateway use a pay-as-you-go model. This way, you only pay for the resources you consume, providing significant savings compared to maintaining idle infrastructure. Serverless technologies also feature automatic scaling and built-in high availability to increase agility and optimize costs.
A three-tier architecture is a popular implementation of a multi-tier architecture and consists of a presentation tier, business logic tier, and data tier. A three-tier architecture separates an application’s functionality into distinct layers (presentation, business logic, and data) to enable scalability, modularity, and flexibility in software development. This type of architecture is suitable for building a wide range of applications such as web applications, enterprise systems, and mobile apps.
The following image is an example of a three-tier architecture fully built with AWS serverless services. In this example, users authenticate and navigate to the website in the presentation tier. They call APIs, which invoke Lambda functions at the business logic tier. Data is stored in DynamoDB at the data tier.
Figure 1: Example of a three-tier architecture on AWS
In the following sections, we explore how to use AWS serverless services within the Free Tier to build a similar architecture.
Note: The Free Tier offerings mentioned within this blog post are subject to change. Always check the AWS Free Tier page for the most current information.
Presentation tier
The presentation tier is where your users interact with your offering, such as a webpage or an app. You can use the following services within the Free Tier to build your presentation tier.
Use with Amazon S3 for a faster and more performant distribution of your assets to end users. CloudFront gives you access to the AWS content delivery network with more than 410 points of presence worldwide.
CloudFront includes an Always Free Tier, with 1 TB of data transfer out to the internet per month and 10 million HTTP(S) requests per month. See Amazon CloudFront pricing for details.
Use Amazon Cognito user pools to authenticate your users. You can also integrate Amazon Cognito within your application’s UI for a seamless login experience.
Amazon Cognito has an Always Free Tier, including up to 50,000 monthly active users. It also includes 10 GBs of cloud sync storage and 1 million sync operations per month, valid for the first 12 months after sign-up. See Amazon Cognito pricing for details.
*as of September 2024
Business logic tier
The business logic tier is where code translates user actions to application functionality. You can use the following services within the Free Tier to build your business logic tier.
Use AWS Lambda for a serverless compute environment that integrates with API Gateway. You can embed your business logic into functions that run on AWS without the need for you to run and manage infrastructure.
The Always Free Tier offers 1 million free requests and 400,000 GB-seconds of compute time per month. See AWS Lambda pricing for details.
*as of September 2024
Data tier
The data tier is where your data is stored. You can use the following service within the Free Tier to build your data tier.
Use this serverless NoSQL database for storing data and tracking transactions. In the context of a three-tier architecture, DynamoDB stores and manages the application’s data, providing reliable and secure data access to the business logic tier.
Walkthrough: Monitoring your usage to avoid unexpected charges
If you use consolidated billing or AWS Organizations, the Free Tier usage accumulates at the management account level. Each management account receives one quota of the Free Tier.
To monitor your Free Tier usage and avoid unexpected charges, you can use the following resources:
See the Free Tier page in the AWS Billing and Cost Management console. The Free Tier page provides detailed insights into current usage per service, Region, and type.
The following image shows an example of the Free Tier page in the AWS Billing and Cost Management console.
Figure 2: AWS Free Tier view in the Cost and Usage Report
We also recommend configuring a zero spend budget within the AWS Billing and Cost Management console. With this budget, you receive notifications when your usage exceeds the Free Tier limits, helping you to avoid unexpected charges. The following image shows an example of this budget setup.
Figure 3: Zero spend budget
Conclusion
In this post, we explored how to use AWS serverless services within the Free Tier to build a three-tier application. We also explored how to monitor your Free Tier usage. The Free Tier offers a chance to experiment and develop without additional costs, helping businesses minimize infrastructure expenses early on. AWS serverless architectures bring benefits like cost savings, flexibility, and scalability.
Beyond using services within the Free Tier, you can further optimize the cost of your AWS serverless application. For instance, to prevent incurring unnecessary inter-Region data transfer costs, we recommend starting with a single Region deployment for your application.
To learn more about the Free Tier and which services it offers, check out the AWS Free Tier FAQs.
Many AWS customers run their mission-critical workloads across multiple AWS regions to serve geographically dispersed customer base, meet disaster recovery objectives or address local laws and regulations. Amazon CodeCatalyst is a unified software development service designed to streamline and accelerate the process of building and delivering applications on AWS. It is an all-in-one platform for managing your entire development lifecycle, from planning and collaboration to continuous integration, deployment, and scaling. Amazon CodeCatalyst aims to boost developer productivity, ensure consistency, and improve the overall software development experience on AWS. By leveraging Amazon CodeCatalyst for multi-region deployments, AWS customers can ensure high availability and disaster recovery and comply with various regulatory requirements, all while improving their development and deployment process.
In this post, we will walk you through a solution which allows you to easily control updates to applications that are deployed across multiple AWS regions using Amazon CodeCatalyst.
Architecture
In this post, we are going to consider a containerized application running on Amazon Elastic Container Service (Amazon ECS) deployed in two different regions us-east-1 and us-west-2. We will walk you through how to configure an Amazon CodeCatalyst workflow to perform the deployment in stages, limiting the deployment scope to one region at a time (Figure 1).
Figure 1: Amazon ECS Multi Region deployment
Here are the high-level steps in the multi-region deployment process.
The developer makes updates to the application code base and pushes the code changes to the source repository hosted in Amazon CodeCatalyst
This code push invokes an Amazon CodeCatalyst workflow for the multi-region deployment. In this example, the workflow deploys changes to containerized application running on Amazon ECS in two regions.
The deployment to different regions happens in stages. In Step 3, the updates get deployed to region 1. This staged approach allows for initial testing and validation in one AWS region before proceeding.
Once the deployment (and any associated validation steps) is completed successfully in region 1, the workflow proceeds with deployment to the second AWS region.
Limiting the scope of each individual deployment limits the potential impact on customers from failed production deployments and prevents a multi-region impact.
Prerequisites
You need access to an AWS account. If you don’t have one, you can create a new AWS account.
Follow Amazon ECS Multi-Region Workshop to deploy a simple containerized application across two different AWS regions. Clone the repository and then follow steps to deploy the foundation, data and backend stack. Note the outputs from workshop-backend-main & workshop-backend-secondary, we’ll use them later on in this post.
Follow the Amazon ECR user guide to create an Amazon Elastic Container Registry (Amazon ECR) repository named codecatalyst-ecs-image-repo.
Create an Amazon CodeCatalyst space, with an empty Amazon CodeCatalyst project named codecatalyst-ecs-project and an Amazon CodeCatalyst environment called codecatalyst-ecs-environment. Associate your AWS account to the CodeCatalyst space. Follow the Amazon CodeCatalyst tutorial to set these up.
An AWS Identity and Access Management (IAM) role in the Amazon CodeCatalyst space to provide Amazon CodeCatalyst service permissions to build and deploy applications. Note the name of this role as you’ll use it later in this post.
Create an Amazon CodeCatalyst source repository titled ecs-multi-region-repo following the instructions in the documentation.
Step 1: Create an Amazon CodeCatalyst Dev Environment
In this step, you will create an Amazon CodeCatalyst Dev Environment directly linked to your source repository ecs-multi-region-repo allowing you to work on your Amazon ECS Multi Region application code and configuration files.
Open Amazon CodeCatalyst and navigate to your project
In the left navigation pane, choose Code and then choose Source repositories
Choose the source repository ecs-multi-region-repo for the Amazon ECS multi-region application
Choose Create Dev Environment
Choose Visual Studio Code from the drop-down menu
In Create Dev Environment and open with Visual Studio Code page (Figure 2), choose Create to create a Visual Studio Code development environment
Figure 2: Create Dev Environment in Amazon CodeCatalyst
Choose Open in Visual Studio Code when prompted (Figure 3), this establishes a remote connection to Dev Environment from your local Visual Studio Code. Keep this window open as you will need it for Step 2
Figure 3: Open Dev Environment with Visual Studio Code
Step 2: Add Source files to Amazon CodeCatalyst source repository
In this step you will add the necessary source files source files to the Amazon CodeCatalyst repository you created in the pre-requisites, including the sample Amazon ECS multi-region application and the Amazon ECS task definition file.
Inside the Visual Studio Code IDE, choose Terminal in the top menu.
Select New Terminal or use an existing terminal window if you prefer.
Clone the Github project inside your project folder by running the below commands in the terminal.
You need to create an Amazon ECS task definition file for the sample application. Create a file named task.json inside the app folder. Paste the below contents into the task.json replacing placeholder <Account_ID> with your AWS Account ID and <ecsTaskExecutionRole> with your role from workshop-backend-main outputs.
Commit the changes to the Amazon CodeCatalyst repository by issuing the following commands inside the Visual Studio Code IDE terminal window. You will need to update the <your_email> and <your_name> with your email and name.
In this example, we are using a single task definition file (task.json) which Amazon CodeCatalyst will use to render task definitions in both regions. But, if your workload requires different task definition files across different regions (e.g. region specific resource requirements, compliance requirements, environment specific configurations etc), you can create multiple task definition files in Amazon CodeCatalyst repository and configure RenderAmazonECStaskdefinition action for each regions with different task definition files.
Step 3: Create Amazon CodeCatalyst Workflow for multi-region deployment
Amazon CodeCatalyst workflow is an automated procedure that describes how to build, test, and deploy your code as part of a continuous integration and continuous delivery (CI/CD) system. A workflow defines a series of steps, or actions, to be executed during a workflow run. You can group actions into action groups to keep your workflow organized and configure dependencies between different groups.
In the navigation pane, choose CI/CD, and then choose Workflows
Choose Create workflow. Select ecs-multi-region-repo from the Source repository dropdown
Choose main in the branch. Select Create (Figure 4). The workflow definition file appears in the Amazon CodeCatalyst console’s YAML editor
Figure 4: Create Workflow page in Amazon CodeCatalyst
In the YAML editor, you will replace the default content with the below provided workflow definition. Replace <Account_ID> with your AWS account ID.
Replace <EcsRegionNameMain>, <EcsClusterNameMain>, <EcsServiceNameMain>, <EcsRegionNameSecondary>, <EcsClusterNameSecondary>, <EcsServiceNameSecondary>. For values with “main” refer to output from workshop-backend-main, and values with “secondary” refer to output from workshop-backend-secondary.
Otherwise use your own Amazon ECS Region, Amazon ECS Cluster ARN, Amazon ECS Service Name values.
Replace <CodeCatalyst-Dev-Admin-Role> with the Role Name from the pre-requisite
Name: BuildAndDeployToECS
SchemaVersion: "1.0"
# Set automatic triggers on code push.
Triggers:
- Type: Push
Branches:
- main
Actions:
Build_application_Multi_Region:
Identifier: aws/build@v1
Inputs:
Sources:
- WorkflowSource
Variables:
- Name: region
Value: <EcsRegionNameMain>
- Name: registry
Value: <Account_ID>.dkr.ecr.<EcsRegionNameMain>.amazonaws.com
- Name: image
Value: codecatalyst-ecs-image-repo
Outputs:
AutoDiscoverReports:
Enabled: false
Variables:
- IMAGE
Compute:
Type: EC2
Environment:
Connections:
- Role: <CodeCatalyst-Dev-Admin-Role>
Name: "<Account_ID>"
Name: codecatalyst-ecs-environment
Configuration:
Steps:
- Run: export account=`aws sts get-caller-identity --output text | awk '{ print $1
}'`
- Run: aws ecr get-login-password --region ${region} | docker login --username AWS
--password-stdin ${registry}
- Run: docker build -t appimage app
- Run: docker tag appimage ${registry}/${image}:${WorkflowSource.CommitId}
- Run: docker push --all-tags ${registry}/${image}
- Run: export IMAGE=${registry}/${image}:${WorkflowSource.CommitId}
build-deploy-region-one:
Actions:
RenderAmazonECStaskdefinition_Region_One:
Identifier: aws/ecs-render-task-definition@v1
Configuration:
image: ${Build_application_Multi_Region.IMAGE}
container-name: web
task-definition: app/task.json
Outputs:
Artifacts:
- Name: TaskDefinitionOne
Files:
- task-definition*
DependsOn:
- Build_application_Multi_Region
Inputs:
Sources:
- WorkflowSource
DeploytoAmazonECS_Region_One:
Identifier: aws/ecs-deploy@v1
Configuration:
task-definition: /artifacts/build-deploy-region-one@DeploytoAmazonECS_Region_One/TaskDefinitionOne/${RenderAmazonECStaskdefinition_Region_One.task-definition}
service: <EcsServiceNameMain>
cluster: <EcsClusterNameMain>
region: <EcsRegionNameMain>
Compute:
Type: EC2
Fleet: Linux.x86-64.Large
Environment:
Connections:
- Role: <CodeCatalyst-Dev-Admin-Role>
Name: "<Account_ID>"
Name: codecatalyst-ecs-environment
DependsOn:
- RenderAmazonECStaskdefinition_Region_One
Inputs:
Artifacts:
- TaskDefinitionOne
Sources:
- WorkflowSource
build-deploy-region-two:
DependsOn:
- build-deploy-region-one
Actions:
RenderAmazonECSTaskDefinition_Region_Two:
# Identifies the action. Do not modify this value.
Identifier: aws/[email protected]
# Defines the action's properties.
Configuration:
image: ${Build_application_Multi_Region.IMAGE}
container-name: web
task-definition: app/task.json
Outputs:
Artifacts:
- Name: TaskDefinitionTwo
Files:
- task-definition*
DependsOn:
- Build_application_Multi_Region
# Specifies the source and/or artifacts to pass to the action as input.
Inputs:
# Optional
Sources:
- WorkflowSource # This specifies that the action requires this Workflow as a source
DeployToAmazonECS_Region_Two:
Identifier: aws/[email protected] # Defines the action's properties.
Configuration:
task-definition: /artifacts/build-deploy-region-two@DeployToAmazonECS_Region_Two/TaskDefinitionTwo/${RenderAmazonECSTaskDefinition_Region_Two.task-definition}
service: <EcsServiceNameSecondary>
cluster: <EcsClusterNameSecondary>
region: <EcsRegionNameSecondary>
# Required; You can use an environment to access AWS resources.
Environment:
Connections:
- Role: <CodeCatalyst-Dev-Admin-Role>
Name: "<Account_ID>"
Name: codecatalyst-ecs-environment
DependsOn:
- RenderAmazonECSTaskDefinition_Region_Two
# Specifies the source and/or artifacts to pass to the action as input.
Inputs:
Artifacts:
- TaskDefinitionTwo
# Optional
Sources:
- WorkflowSource # This specifies that the action requires this Workflow as a source
Figure 5: Amazon CodeCatalyst Workflow Screen
The workflow above (Figure 5) does the following:
Whenever code changes are pushed to the repository, a Build action is invoked automatically. The Build action builds a container image and pushes the image to the Amazon Elastic Container Registry (Amazon ECR) repository in the primary region. In this example, we are storing the container image only within the primary region. If you are implementing multi-region for disaster recovery, enable cross-region replication on Amazon ECR to automatically replicate images to repositories in other regions. You will also need to update the task definition files to reference the Amazon ECR repository in the same region where the task will run
Once the Build stage is complete, the Amazon ECS task definition is updated with the new Amazon ECR repository image
The DeployToECS action then deploys the new image to Amazon ECS in the first region
Once the first action group execution succeeds, the Amazon CodeCatalyst workflow invokes second action group repeating the last two steps (Render Task Definition, Deploy) for the second region.
As you may have noticed, the build action is separated from the deployment actions in this example. This way, we are building the container image only once and deploying the same image across multiple regions. But, if you have specific build steps that are region-specific, you can include those actions in the region-specific action groups. This allows for customizations based on regional requirements while maintaining overall consistency.
To check the syntax and structure of your workflow definition:
Choose the Validate button. It should add a green banner with “The workflow definition is valid” at the top
Select Commit to add the workflow to the repository (Figure 6)
Figure 6: Commit workflow page in Amazon CodeCatalyst
The workflow file is stored in a ~/.codecatalyst/workflows/ folder in the root of your source repository. The file can have a .yml or .yaml extension.
Using the URL of the Application Load Balancer you noted from the pre-requisite from either of the two regions, add /healthcheck to load the health check page in your browser. You’ll to see the message in the health check page as shown in figure 7.
Figure 7: ECS Multi Region Application (US-West-1)
Step 4: Validate the setup
To validate the setup, you will make a small change to the Health check of the sample application.
Open Amazon CodeCatalyst dev environment (Visual Studio Code) that you created in Step 1.
Update your local copy of the repository. In the terminal run the below command
git pull
Inside the Visual Studio Code IDE, open app.py present inside the app folder.
Inside healthcheck() method, on line 13, update the string from ok to ok v1
Commit the changes to the repository using the below commands:
After the change is commit, the Amazon CodeCatalyst workflow should start running automatically. Once the Amazon CodeCatalyst workflow finishes execution, paste the Application Load Balancer URL for region and add /healthcheck to reach the check page. You will be able to see the updated message in the health check page as shown in figure 8 and 9.
Figure 8: ECS Multi Region Application (US-East-1)
Figure 9: ECS Multi Region Application (US-West-1)
Considerations for multi-region deployments
In this post, we considered a deployment scenario across two regions. Many organizations have workload running across many regions, serving customers across the globe. The Amazon CodeCatalyst workflow, that we created in this post, can be extended to more than two regions.
Amazon CodeCatalyst allows fine-grained control for progressive wave-based deployments across multiple regions. This is achieved by using multiple action groups and sequencing those action groups using dependencies in the Amazon CodeCatalyst workflow. For example, in the workflow discussed in Step 3, you defined two action groups build-deploy-region-oneand build-deploy-region-two. We setup build-deploy-region-two to depend on build-deploy-region-one using DependsOn: property, so that the deployment to the second region starts only after the completion of the first region. This approach allows for staggered deployments, mitigating risks by preventing issues in one AWS region from impacting others.
For workloads spanning multiple regions, the same staggering deployment approach can be extended with more action groups. Each action group can contain a list of regions to deploy to in parallel. Dependencies between action groups ensures the deployment happens sequentially. Below is a high-level architecture (Figure 10) of the setup of 3-stage deployment process for a workload running across 6 regions.
Figure 10: Staggered Deployment architecture
Cleanup
If you have been following along with the post, you should delete the resources you deployed so you do not continue to incur charges.
Manually delete Amazon CodeCatalyst dev environment, source repository and project from your CodeCatalyst Space.
In conclusion, we demonstrated how you can setup multi-region deployments for Amazon ECS workloads using Amazon CodeCatalyst workflows. We showed how to configure the Amazon CodeCatalyst workflow to deploy to one region at a time, allowing for validation before proceeding to additional regions. The pattern can be extended to more than two AWS regions using additional action groups and dependencies. This solution addresses key challenges in multi-region deployments like maintaining consistency while ensuring high availability. Learn more about multi region in AWS Multi-Region Fundamentals Whitepaper
The betting and gaming industry has grown into a data-rich landscape that presents an enticing target for sophisticated bots. The sensitive personally identifiable information (PII) that is collected and the financial data involved in betting and in-game economies is especially valuable. Microtransactions and in-game purchases are frequently targeted, making them an ideal case for safeguarding with AWS WAF.
In this blog post, we’ll explore some of these threats in more detail and explain how a layered bot mitigation strategy that uses AWS WAF can minimize the risk and impact of bot activity.
Understanding common automated threats
Automations deployed by threat actors can perform web scraping, perform betting arbitrage to gain an unfair advantage, and use automated techniques to undermine fair competition. Aggressive web scraping can also lead to application overload, service disruptions, and degraded user experience. At AWS, we routinely identify and mitigate automated threats for betting and gaming customers. Some of the common tactics we see in this space include the following:
Scraping tactics
Scraper bots often use fake accounts or compromised credentials to systematically harvest betting odds and other competitive data from multiple sites. A common example of scraping is arbitrage betting, where the scraped data is used to place simultaneous bets in different venues in order to make profits from tiny differences in the asset’s listed price. There are also competitive scraper bots that use this data to improve their betting applications.
Account-related tactics
Account creation fraud aims at claiming sign-up bonuses or other incentives at scale by using bot-generated accounts. Account takeover fraud aims at logging into user accounts to change account details, make purchases, withdraw funds, steal personal information or loyalty points, or use this data to access other accounts on different websites. A common form of this tactic is automated brute force login techniques, such as credential stuffing.
Denial-of-service tactics
Volumetric floods can cause betting and gaming sites to experience slow page-loads, downtime, and damaged brand reputation. DDoS attacks are another common security concern for many customers.
In-game tactics
In-game bots can use automated cheating or expediting techniques to manipulate resources and gain unfair advantages. These bots typically manipulate client applications and make malicious API requests.
AWS WAF intelligent threat mitigation features
To help protect customers from such automated tactics, AWS WAF offers the following intelligent threat mitigation features.
AWS WAF Common Bot Control managed rule group
The AWS WAF Common Bot Control managed rule group uses static analysis to identify web requests and header information that is correlated with known good bots and bad bots. These techniques are helpful in detecting a variety of self-identifying bots, such as web scraping frameworks, search engines, and automated browsers. Using these predetermined patterns and signatures can help gaming customers to identify and block known bot behaviors.
CAPTCHA and challenge rule actions
CAPTCHA rule action – Configured rules in AWS WAF can have a CAPTCHA action. When a rule is configured with a CAPTCHA action, users are required to solve a puzzle to prove that a human being is sending the request. When a user successfully solves a CAPTCHA challenge, a token is placed on their browser so it won’t challenge future requests, using a configurable immunity time. Learn about best practices for configuring CAPTCHA.
Challenge rule action – Challenge scripts run a silent challenge that requires the client session to verify that it’s a browser and not a bot. The verification runs in the background without involving the end user. Challenge-based bot detection can check each visitor’s ability to run JavaScript and store cookies. When a challenge is solved correctly, AWS WAF vends out an AWS WAF token, as seen in Figure 1, which allows bot control to track user activity across sessions. A reduced ability to process these challenges is a sign of bot traffic. The challenge action is a good option for verifying clients that you suspect of being invalid. You can use this feature by setting a selected AWS WAF rule action to CHALLENGE or by using a targeted bot control managed rule group. To learn more about protecting against bots with the AWS WAF challenge and CAPTCHA actions, see this blog post.
Figure 1: A sequence diagram explaining the flow of requests when Challenge is set as a rule action for an AWS WAF rule
Client application integration
AWS WAF provides the following levels of integration.
Intelligent threat integration
To improve the user experience and reduce latency for mobile and API-driven applications, AWS WAF provides client-side application APIs to integrate with your application. These integrations help verify that the client applications that send web requests to your protected resources are the intended clients and that your end users are human beings. This functionality is available for JavaScript and for Android and iOS mobile applications. As shown in Figure 2, the token acquisition process is similar to a challenge action, but slightly different. The basic approach for using the SDK is to create a token provider by using a configuration object, then to use the token provider to retrieve tokens from AWS WAF. By default, the token provider includes the retrieved tokens in your web requests to your protected resource. The intelligent threat integration APIs work with web access control lists (ACLs) that use the intelligent threat rule groups to enable the full functionality of these advanced managed rule groups. You can use the AWS WAF mobile SDKs to implement AWS WAF intelligent threat integration SDKs for Android and iOS mobile applications.
Figure 2: A sequence diagram explaining the flow of requests when AWS WAF intelligent threat mitigation SDKs are configured
CAPTCHA JavaScript integration
You can also verify end users by making them solve customized CAPTCHA puzzles that you manage in your application. This is similar to the functionality provided by the AWS WAF CAPTCHA rule action, but with added control over the puzzle placement and behavior. This integration uses the JavaScript intelligent threat integration to run silent challenges and provide AWS WAF tokens to the customer’s page.
AWS WAF Targeted Bot Control
The AWS WAF Targeted Bot Control tier includes the common-level protections described earlier and adds targeted detection for sophisticated bots that don’t self-identify. Targeted protections mitigate bot activity by using a combination of rate limiting and CAPTCHA and background browser challenges. Targeted protections use detection techniques such as the following:
Implementing browser fingerprinting – Browser fingerprinting is a powerful tracking and identification technique employed by online gaming sites to gain deep insights into their players’ computing setups. This technique involves probing the unique characteristics and configuration of each gamer’s browser. By collecting dozens of browser data points, a fingerprint can be generated that allows the requests coming from that specific browser to be identified and tracked across gaming sessions. Even if players try to randomize or spoof some browser attributes, perhaps in an attempt to bypass certain restrictions or gain an unfair advantage, the overall fingerprint still allows detection of such attempts. For example, if the user agent claims to be Chrome on Windows but other fingerprint attributes indicate Linux and Firefox, that suggests an attempted spoofing by the player, which can then be flagged by the gaming site’s security measures.
By using browser fingerprinting and looking for discrepancies, gaming and betting sites gain tools to help detect and block sophisticated bots even when the bots try to mask their true identity and intent. AWS WAF uses tokens for detecting browser inconsistencies, such as when the characteristics of a browser do not match the user agent. The AWS Targeted Bot Control rule group offers this functionality by emitting labels like TGT_SignalBrowserInconsistency, and the recommended mitigation action for inconsistent browsers is to serve a CAPTCHA puzzle.
Detecting browser automation – Many threat actors who operate automated programs use scripting languages to carry out their tasks, such as data scraping or launching exploits. They often employ tools that mimic the behavior of a web browser to bypass security measures. To address these challenges, AWS WAF Bot Control offers solutions to help detect and block automated software that simulates browser activity. It uses specific rules like TGT_SignalAutomatedBrowser to examine requests for signs that suggest the browser is not operated by a human, helping to identify and mitigate potential threats from automated systems.
Understand normal volumetric activity with unique browser ID tracking – AWS WAF Targeted Bot Control monitors application visitors by assigning each one a unique browser ID (UBID) embedded in a token. It establishes baselines for the number of requests a client sends within a five-minute session and sets three thresholds per device: high, medium, and low. The system identifies clients that exceed normal request rates and challenges them with a CAPTCHA puzzle using the TGT_VolumetricSession rule. For verified bots, the rule group takes no action but labels the traffic with awswaf:managed:aws:bot-control:bot:verified.
Using real-time machine learning models for clustering and behavior analysis – Traditional solutions to fight advanced bots faced limitations: handling massive amounts of player traffic, accurately identifying bots without labeling every request (ground truth), and staying cost-effective. To address these challenges, the AWS WAF team created a machine learning model. This model finds hidden bot networks by analyzing patterns in website traffic. It automatically analyzes traffic statistics to identify suspicious activity that suggests coordinated bot activity.
The model aggregates data at different levels, including the client, session, and behavioral cluster levels. It uses features like session statistics, behavioral cluster information (derived from clustering), and relative entropy to identify suspicious behavior. This feature analyzes web traffic every few minutes and optimizes the analysis for the detection of low intensity, long-duration bots that are distributed across many IP addresses. AWS WAF emits the labels TGT_ML_CoordinatedActivityMedium and TGT_ML_CoordinatedActivityHigh, based on the confidence level of the detection.
This machine learning capability is included by default in the AWS WAF Targeted Bot Control rules, but you can choose to disable it if needed.
Fraudulent account creation involves the creation of fake accounts for activities such as bonus abuse, impersonation, and phishing. These fake accounts can damage your reputation and expose you to financial fraud. To help prevent account creation fraud, we recommend using the AWS WAF Fraud Control account creation fraud prevention (ACFP) feature. This feature is available in the AWS Managed Rules rule group AWSManagedRulesACFPRuleSet, along with companion application integration SDKs. By integrating this feature into your system, you can effectively monitor and control account creation attempts, helping to provide a safer and more secure environment for your customers.
Threat actors might try to gain unauthorized access to a player’s account by using stolen credentials, guessing passwords through brute-force exploits, or other means. After they gain access, they can steal money, information, or services, or even pose as the victim to gain access to other accounts. This can lead to financial loss and damage to your reputation. To help prevent account takeovers, we recommend using the AWS WAF Fraud Control account takeover prevention (ATP) feature. This feature is available in the AWS Managed Rules rule group AWSManagedRulesATPRuleSet, along with companion application integration SDKs.
Conclusion
Bot management involves choosing controls to identify traffic coming from bots, and then blocking undesired traffic. The more threat actors are motivated to target a web application, the more they will invest in detection evasion techniques, requiring more advanced mitigation capabilities. We recommend that you adopt a layered approach to managing bots, with differentiated tooling that is adapted to specific bot tactics.
Ready to start putting the tools in place to protect your gaming or betting application from sophisticated bot threats? Check out our solution overview guide for AWS WAF and the Implementing a bot control strategy on AWS whitepaper to learn more about deploying a layered bot mitigation strategy on AWS. You can also sign up for an AWS Activation Day to work directly with our experts on implementing capabilities like AWS WAF, AWS WAF Bot Control, and AWS Shield for your specific use case. For hands-on experience, try our bot mitigation workshops—you can enable managed rule groups like Bot Control in just a few steps. Start your proof-of-concept by contacting your AWS account representative today.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
AWS Transfer Family is a secure transfer service that lets you transfer files directly into and out of Amazon Web Services (AWS) storage services using popular protocols such as AS2, SFTP, FTPS, and FTP. When you launch a Transfer Family server, there are multiple options that you can choose depending on what you need to do. In this blog post, I describe six security configuration options that you can activate to fit your needs and provide instructions for each one.
Use our latest security policy to help protect your transfers from newly discovered vulnerabilities
By default, newly created Transfer Family servers use our strongest security policy, but for compatibility reasons, existing servers require that you update your security policy when a new one is issued. Our latest security policy, including our FIPS-based policy, can help reduce your risks of known vulnerabilities such as CVE-2023-48795, also known as the Terrapin Attack. In 2020, we had already removed support for the ChaCha20-Poly1305 cryptographic construction and CBC with Encrypt-then-MAC (EtM) encryption modes, so customers using our later security policies did not need to worry about the Terrapin Attack. Transfer Family will continue to publish improved security policies to offer you the best possible options to help ensure the security of your Transfer Family servers. See Edit server details for instructions on how to update your Transfer Family server to the latest security policy.
Use slashes in session policies to limit access
If you’re using Amazon Simple Storage Service (Amazon S3) as your data store with a Transfer Family server, the session policy for your S3 bucket grants and limits access to objects in the bucket. Amazon S3 is an object store and not a file system, so it has no concept of directories, only prefixes. You cannot, for example, set permissions on a directory the way you might on a file system. Instead, you set session policies on prefixes.
Even though there isn’t a file system, the slash character still plays an important role. Imagine you have a bucket named DailyReports and you’re trying to authorize certain entities to access the objects in that bucket. If your session policy is missing a slash in the Resource section, such as arn:aws:s3:::$DailyReports*, then you should add a slash to make it arn:aws:s3:::$DailyReports/*. Without the slash (/) before the asterisk (*), your session policy might allow access to buckets you don’t intend. For example, if you also have buckets named DailyReports-archive and DailyReports-testing, then a role with permission arn:aws:s3:::$DailyReports* will also grant access to objects in those buckets, which is probably not what you want. A role with permission arn:aws:s3:::$DailyReports/* won’t grant access to objects in your DailyReports-archive bucket, because the slash (/) makes it clear that only objects whose prefix begins with DailyReports/ will match, and all objects in DailyReports-archive will have a prefix of DailyReports-archive/, which won’t match your pattern. To check to see if this is an issue, follow the instructions in Creating a session policy for an Amazon S3 bucket to find your AWS Identity and Access Management (IAM) session policy.
Use scope down policies to back up logical directory mappings
When creating a logical directory mapping with a role that has more access than you intend to give your users, it’s important to use session policies to tailor the access appropriately. This provides an extra layer of protection against accidental changes to your logical directory mapping opening access to files you didn’t intend.
Don’t place NLBs in front of a Transfer Family server
We’ve spoken with many customers who have configured a Network Load Balancer (NLB) to route traffic to their Transfer Family server. Usually, they’ve done this either because they created their server before we offered a way to access it from both inside their VPC and from the internet, or to support FTP on the internet. This not only increases the cost for the customer, it can cause other issues, which we describe in this section.
If you’re using this configuration, we encourage you to move to a VPC endpoint and use an Elastic IP. Placing an NLB in front of your Transfer Family server removes your ability to see the source IP of your users, because Transfer Family will see only the IP address of your NLB. This not only degrades your ability to audit who is accessing your server, it can also impact performance. Transfer Family uses the source IP to shard your connections across our data plane. In the case of FTPS, this means that instead of being able to have 10,000 simultaneous connections, a Transfer Family server with an NLB in front of it would be limited to only 300 simultaneous connections. If you have a use case that requires you to place an NLB in front of your Transfer Family server, reach out to the Transfer Family Product Management team through AWS Support or discuss issues on AWS re:Post, so we can look for options to help you take full advantage of our service.
One of the security challenges with FTPS is that it uses two separate ports to process read/write requests. An analogy to this in the physical world would be going through a drive-thru window where you pay for your food and someone else can cut in front of you to receive your order at the second window. For this reason, security measures have been added to the FTPS protocol over time. In a client-server protocol, there are server-side configurations and client-side configurations.
TLS session resumption helps protect client connections as they hand off between the FTPS control port and the data port. The server sends a unique identifier for each session on the control port, and the client is meant to send that same session identifier back on the data port. This gives the server confidence that it’s talking to the same client on the data port that initiated the session on the control port. Transfer Family endpoints provide three options for session resumption:
Disabled – The server ignores whether the client sends a session ID and doesn’t check that it’s correct, if it is sent. This option exists for backward compatibility reasons, but we don’t recommend it.
Enabled – The server will transmit session IDs and will enforce session IDs if the client uses them, but clients who don’t use session IDs are still allowed to connect. We only recommend this as a transitional state to Enforced to verify client compatibility.
Enforced – Clients must support TLS session resumption, or the server won’t transmit data to them. This is our default and recommended setting.
To use the console to see your TLS session resumption settings:
Sign in to the AWS Management Console in the account where your transfer server runs and go to AWS Transfer Family. Be sure to select the correct AWS Region.
To find your Transfer Family server endpoint, find your Transfer Family server in the console and choose Main Server Details.
Select Additional Details.
Under TLS Session Resumption, you will see if your server is enforcing TLS session resumption.
If some of your users don’t have access to modern FTPS clients that support TLS, you can choose Edit to choose a different option.
Conclusion
Transfer Family offers many benefits to help secure your managed file transfer (MFT) solution as the threat landscape evolves. The steps in this post can help you get the most out of Transfer Family to help protect your file transfers. As the requirements for a secure, compliant architecture for file transfers evolve and threats become more sophisticated, Transfer Family will continue to offer optimized solutions and provide actionable advice on how you can use them. For more information, see Security in AWS Transfer Family and take our self-paced security workshop.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Transfer Family re:Post or contact AWS Support.
Amazon OpenSearch Service is a managed service that makes it easy to deploy, operate, and scale OpenSearch domains in AWS to perform interactive log analytics, real-time application monitoring, website search, and more. Understanding OpenSearch service spend per domain is crucial for effective cost management, optimization, and informed decision-making. Amazon OpenSearch Service Pricing is based on three dimensions: instances, storage, and data transfer. Storage pricing depends on the chosen storage type and also the storage tier. Visibility into domain-level charges enables accurate budgeting, efficient resource allocation, fair cost attribution across projects, and overall cost transparency.
In this post, we show you how to view the OpenSearch Service domain-level cost using AWS Cost Explorer. For example, the account in the following screenshot has five OpenSearch Service domains deployed.
Using AWS Cost Explorer, you can see the cost at the service level by default but not at an individual domain level. However, users can still breakdown the cost using a dimension like Usage type. The simplest approach to gain domain level visibility is by enabling resource-level data in AWS Cost Explorer. There are no additional charges for enabling resource-level data at daily granularity in AWS Cost Explorer. If you need domain-level cost data beyond 14 days then either you can setup a Data Export/CUR or you can use user-defined cost allocation tags. User-defined cost allocation tags offer benefits such as cost categorization and cost allocation to categorize and group your AWS costs across cost centers and based on criteria that are meaningful to your organization, such as projects, departments, environments, or applications. This provides better visibility and granularity into your cost breakdown compared to just looking at resource-level costs.
Overview
This post demonstrates how to use user-defined cost allocation tags attached to a cluster using these high-level steps:
Add a user-defined cost allocation tag to an OpenSearch Service domain
Activate the user-defined cost allocation tag
Analyze OpenSearch Service domain costs using AWS Cost Explorer and tags
Prerequisites
For this walkthrough, you should have the following prerequisites:
1. Add a user-defined cost allocation tag to an OpenSearch Service domain
The user-defined cost allocation tags are key-value pairs and user will need to define both a key and a value to an OpenSearch Service domain using one of the following methods:
To add a user-defined cost allocation tag using the AWS Management Console, follow these steps:
In the AWS Management Console, under Analytics, choose Amazon OpenSearch Service.
Select the domain you want to add tags to and go to the Tags
Choose Add tags and then Add new tag.
Enter a tag and an optional value.
Choose Save.
The following screenshot shows the Add tags window.
AWS CLI
To add a user-defined cost allocation tag using the AWS CLI, you can use the aws opensearch add-tags command to add tags to an OpenSearch Service domain. The command requires the domain Amazon Resource Name (ARN) and a list of tags to be added. Use the following syntax.
You can use the Amazon OpenSearch Service configuration API to create, configure, and manage OpenSearch Service domains. Use the following AddTags command to tag an OpenSearch Service domain.
You can programmatically add tags to an OpenSearch Service domain using the AWS OpenSearch SDK. The SDK provides methods to interact with Amazon OpenSearch Service API and manage tags. For example, Python client can use the client.add_tags command to tag a domain. You must provide values for domain_arn, tag_key, and tag_value.
When provisioning an OpenSearch Service domain using CloudFormation or Terraform, you can define the tags as part of the resource configuration by using AWS::OpenSearchService::Domain Tag.
The add-tags command can fail in the following scenarios, so make sure all the values are entered correctly:
Invalid resource ARN – The command will fail if the provided ARN for the OpenSearch Service domain is invalid or does not exist.
Insufficient permissions – Verify that the IAM user or role you’re using to run the OpenSearch Service commands has the necessary permissions to access the OpenSearch Service domain and perform the desired actions, such as adding tags.
Exceeded tag limit – The OpenSearch Service domain has limit of up to 10 tags, so if the number of tags you are trying to add exceeds this limit, the command will fail.
For ease of use and best results, use the Tag Editor to create and apply user-defined tags. The Tag Editor provides a central, unified way to create and manage your user-defined tags. For more information, refer to Working with Tag Editor in the AWS Resource Groups User Guide.
2. Activate the user-defined cost allocation tag
User-defined cost allocation tags are tags that you define, create, and apply to resources, and it may take up to 24 hours for the tag keys to appear on your cost allocation tags page for activation in the Billing and Cost Management console. After you select your tags for activation, it can take an additional 24 hours for tags to activate and be available for use in Cost Explorer. Use the following steps to activate the user-defined cost allocation tags you created in previous steps.
As shown in the following screenshot, on the Billing and Cost Management dashboard, in the navigation pane, select Cost Allocation Tags.
To activate the tag, under User-defined cost allocation tags, enter opensearchdomain to search for your tag name, select it, and choose Activate. This confirms that Cost Explorer and your AWS Cost and Usage Reports (CUR) will include these tags.
In general, cost allocation tags cannot be deleted and can only be deactivated. However, you can exclude the tag that you do not want in the CUR report or in AWS Cost Explorer and only include tags that are needed.
3. Analyze OpenSearch Service domain cost using AWS Cost Explorer and tags
AWS Cost Explorer only displays tags starting from the date when you have enabled user-defined cost allocation tags and not from when the resource was tagged. Therefore, even if your resources had tags for a long time, AWS Cost Explorer will show “No tag key” for all of the previous days until the date when tag was enabled, but users can request to backfill tags. To analyze OpenSearch Service domain costs using AWS Cost Explorer and tags, follow these steps:
On the Billing and Cost Management console, in the navigation pane, under Cost analysis, choose Cost Explorer.
In the Report parameters help panel on the right, under Group by, for Dimension, select Tag. Under Tag, choose the opensearchtestdomain tag key that you created.
Under Applied filters, choose OpenSearch Service.
The following screenshot shows the CUR dashboard.
Costs
There is no additional fee or charge for using the user-defined cost allocation tags in AWS Cost Explorer. However, an excessive number of tags can increase the size of your CUR file. Your CUR file contains your usage and cost data, including tags you apply, so more tags mean more data in the file. CUR data is stored in Amazon Simple Storage Service (Amazon S3), so larger CUR file could increase storage cost.
The best practice is to be selective about which tags you enable and how many you use. Start with tags that provide the most value for attributes such as cost allocation and analytics. Monitor your CUR file size over time and add and remove tags thoughtfully.
Conclusion
This post outlines a solution for AWS customers to gain visibility into their OpenSearch Service workload costs on a per-domain basis using AWS Cost Explorer and user-defined cost allocation tags. This approach enables greater cost transparency and control, making it easier to allocate costs accurately and make informed decisions about Amazon OpenSearch service workload usage. The process involves adding a cost allocation tag to each OpenSearch Service domain, activating the user-defined tag, and then analyzing the costs in AWS Cost Explorer based on the tag. By implementing this solution, customers can obtain granular insights into OpenSearch Service workload costs at the domain level, facilitating precise cost attribution and better alignment of costs with business requirements.
Nikhil Agarwal is a Sr. Technical Manager with Amazon Web Services. He is passionate about helping customers achieve operational excellence in their cloud journey and actively working on technical solutions. He is an artificial intelligence (AI/ML) and analytics enthusiastic, he deep dives into customer’s ML and OpenSearch service specific use cases. Outside of work, he enjoys traveling with family and exploring different gadgets.
Rick Balwani is an Enterprise Support Manager responsible for leading a team of Technical Account Mangers (TAMs) supporting AWS independent software vendor (ISV) customers. He works to ensure customers are successful on AWS and can build cutting-edge solutions. Rick has a background in DevOps and system engineering.
Ashwin Barve is a Sr. Technical Manager with Amazon Web Services. In his role, Ashwin leverages his experience to help customers align their workloads with AWS best practices and optimize resources for maximum cost savings. Ashwin is dedicated to assisting customers through every phase of their cloud adoption, from accelerating migrations to modernizing workloads.
As a security team lead, your goal is to manage security for your organization at scale and ensure that your team follows AWS Identity and Access Management (IAM)security best practices, such as the principle of least privilege. As your developers build on AWS, you need visibility across your organization to make sure that teams are working with only the required privileges. Now, AWS Identity and Access Management Analyzer offers prescriptive recommendations with actionable guidance that you can share with your developers to quickly refine unused access.
In this post, we show you how to use IAM Access Analyzer recommendations to refine unused access. To do this, we start by focusing on the recommendations to refine unused permissions and show you how to generate the recommendations and the actions you can take. For example, we show you how to filter unused permissions findings, generate recommendations, and remediate issues. Now, with IAM Access Analyzer, you can include step-by-step recommendations to help developers refine unused permissions quickly.
Unused access recommendations
IAM Access Analyzer continuously analyzes your accounts to identify unused access and consolidates findings in a centralized dashboard. The dashboard helps review findings and prioritize accounts based on the volume of findings. The findings highlight unused IAM roles and unused access keys and passwords for IAM users. For active IAM roles and users, the findings provide visibility into unused services and actions. You can learn more about unused access analysis through the IAM Access Analyzer documentation.
For unused IAM roles, access keys, and passwords, IAM Access Analyzer provides quick links in the console to help you delete them. You can use the quick links to act on the recommendations or use export to share the details with the AWS account owner. For overly permissive IAM roles and users, IAM Access Analyzer provides policy recommendations with actionable steps that guide you to refine unused permissions. The recommended policies retain resource and condition context from existing policies, helping you update your policies iteratively.
Throughout this post, we use an IAM role in an AWS account and configure the permissions by doing the following:
We use an inline policy to demonstrate that IAM Access Analyzer unused access recommendations are applicable for that use case. The recommendations are also applicable when using AWS managed policies and customer managed policies.
In your AWS account, after you have configured an unused access analyzer, you can select an IAM role that you have used recently and see if there are unused access permissions findings and recommendations.
In this post we explore three options for generating recommendations for IAM Access Analyzer unused permissions findings: the console, AWS CLI, and AWS API.
Generate recommendations for unused permissions using the console
After you have created an unused access analyzer as described in the prerequisites, wait a few minutes to see the analysis results. Then use the AWS Management Console to view the proposed recommendations for the unused permissions.
To list unused permissions findings
Go to the IAM console and under Access Analyzer, choose Unused access from the navigation pane.
Search for active findings with the type Unused permissions in the search box.
Select Active from the Status drop-down list.
In the search box, select Findings type under Properties.
Select Equals as Operators.
Select Findings Type = Unused permissions.
This list shows the active findings for IAM resources with unused permissions.
Figure 1: Filter on unused permissions in the IAM console
Select a finding to learn more about the unused permissions granted to a given role or user.
To obtain recommendations for unused permissions
On the findings detail page, you will see a list of the unused permissions under Unused permissions.
Following that, there is a new section called Recommendations. The Recommendations section presents two steps to remediate the finding:
Review the existing permissions on the resource.
Create new policies with the suggested refined permissions and detach the existing policies.
Figure 2: Recommendations section
The generation of recommendations is on-demand and is done in the background when you’re using the console. The message Analysis in progress indicates that recommendations are being generated. The recommendations exclude the unused actions from the recommended policies.
When an IAM principal, such as an IAM role or user, has multiple permissions policies attached, an analysis of unused permissions is made for each of permissions policies:
If no permissions have been used, the recommended action is to detach the existing permissions policy.
If some permissions have been used, only the used permissions are kept in the recommended policy, helping you apply the principle of least privilege.
The recommendations are presented for each existing policy in the column Recommended policy. In this example, the existing policies are:
AmazonBedrockReadOnly
AmazonS3ReadOnlyAccess
InlinePolicyListLambda
And the recommended policies are:
None
AmazonS3ReadOnlyAccess-recommended
InlinePolicyListLambda-recommended
Figure 3: Recommended policies
There is no recommended policy for AmazonBedrockReadOnly because the recommended action is to detach it. When hovering over None, the following message is displayed: There are no recommended policies to create for the existing permissions policy.
AmazonS3ReadOnlyAccess and InlinePolicyListLambda and their associated recommended policy can be previewed by choosing Preview policy.
To preview a recommended policy
IAM Access Analyzer has proposed two recommended policies based on the unused actions.
To preview each recommended policy, choose Preview policy for that policy to see a comparison between the existing and recommended permissions.
Choose Preview policy for AmazonS3ReadOnlyAccess-recommended.
The existing policy has been analyzed and the broad permissions—s3:Get* and s3:List*—have been scoped down to detailed permissions in the recommended policy.
The permissions s3:Describe*, s3-object-lambda:Get*, and s3-object-lambda:List* can be removed because they weren’t used.
Figure 4: Preview of the recommended policy for AmazonS3ReadOnlyAccess
Choose Preview policy for InlinePolicyListLambda-recommended to see a comparison between the existing inline policy InlinePolicyListLambda and its recommended version.
The existing permissions, lambda:ListFunctions and lambda:ListLayers, are kept in the recommended policy, as well as the existing condition.
The permissions in lambda:ListAliases and lambda:ListFunctionUrlConfigs can be removed because they weren’t used.
Figure 5: Preview the recommended policy for the existing inline policy InlinePolicyListLambda
To download the recommended policies file
Choose Download JSON to download the suggested recommendations locally.
Figure 6: Download the recommended policies
A .zip file that contains the recommended policies in JSON format will be downloaded.
Figure 7: Downloaded recommended policies as JSON files
The content of the AmazonS3ReadOnlyAccess-recommended-1-2024-07-22T20/08/44.793Z.json file the same as the recommended policy shown in Figure 4.
Generate recommendations for unused permissions using AWS CLI
Use the following code to refine the results by filtering on the type UnusedPermission and selecting only the active findings. Copy the Amazon Resource Name (ARN) of your unused access analyzer and use it to replace the ARN in the following code:
This command provides the following results. For more information about the meaning and structure of the recommendations, see Anatomy of a recommendation later in this post.
Note: The recommendations consider AWS managed policies, customer managed policies, and inline policies. The IAM conditions in the initial policy are maintained in the recommendations if the actions they’re related to are used.
The remediations suggested are to do the following:
Detach AmazonBedrockReadOnly policy because it is unused: DETACH_POLICY
Create a new recommended policy with scoped down permissions from the managed policy AmazonS3ReadOnlyAccess: CREATE_POLICY
Detach AmazonS3ReadOnlyAccess: DETACH_POLICY
Embed a new recommended policy with scoped down permissions from the inline policy: CREATE_POLICY
To generate recommendations for unused permissions using the IAM Access Analyzer API
The findings are generated on-demand. For that purpose, IAM Access Analyzer API GenerateFindingRecommendation can be called with two parameters: the ARN of the analyzer and the finding ID.
After the recommendations are generated, they can be obtained by calling the API GetFindingRecommendation with the same parameters: the ARN of the analyzer and the finding ID.
Use AWS SDK for Python (boto3) for the API call as follows:
The recommendations are generated as actionable guidance that you can follow. They propose new IAM policies that exclude the unused actions, helping you rightsize your permissions.
Anatomy of a recommendation
The recommendations are usually presented in the following way:
Date and time: startedAt, completedAt. Respectively when the API call was made and when the analysis was completed and the results were provided.
Resource ARN: The ARN of the resource being analyzed.
Recommended steps: The recommended steps, such as creating a new policy based on the actions used and detaching the existing policy.
Status: The status of retrieving the finding recommendation. The status values include SUCCEEDED, FAILED, and IN_PROGRESS.
For more information about the structure of recommendations, see the output section of get-finding-recommendation.
Recommended policy review
You must review the recommended policy. The recommended actions depend on the original policy. The original policy will be one of the following:
An AWS managed policy: You need to create a new IAM policy using recommendedPolicy. Attach this newly created policy to your IAM role. Then detach the former policy.
A customer managed policy or an inline policy: Review the policy, verify its scope, consider how often it’s attached to other principals (customer managed policy only), and when you are confident to proceed, use the recommended policy to create a new policy and detach the former policy.
Use cases to consider when reviewing recommendations
During your review process, keep in mind that the unused actions are determined based on the time defined in your tracking period. The following are some use cases you might have where a necessary role or action might be identified as unused (this is not an exhaustive list of use cases). It’s important to review the recommendations based on your business needs. You can also archive some findings related to the use cases such as the ones that follow:
Backup activities: If your tracking period is 28 days and you have a specific role for your backup activities running at the end of each month, you might discover that after 29 days some of the permissions for that backup role are identified as unused.
IAM permissions associated to an infrastructure as code deployment pipeline: You should also consider the permissions associated to specific IAM roles such an IAM for infrastructure as code (IaC) deployment pipeline. Your pipeline can be used to deploy Amazon Simple Storage Service (Amazon S3) buckets based on your internal guidelines. After deployment is complete, the pipeline permissions can become unused after your tracking period, but removing those unused permissions can prevent you from updating your S3 buckets configuration or from deleting it.
IAM roles associated with disaster recovery activities: While it’s recommended to have a disaster recovery plan, the IAM roles used to perform those activities might be flagged by IAM Access Analyzer for having unused permissions or being unused roles.
To apply the suggested recommendations
Of the three original policies attached to IAMRole_IA2_Blog_EC2Role, AmazonBedrockReadOnly can be detached and AmazonS3ReadOnlyAccess and InlinePolicyListLambda can be refined.
DetachAmazonBedrockReadOnly
No permissions are used in this policy, and the recommended action is to detach it from your IAM role. To detach it, you can use the IAM console, the AWS CLI, or the AWS API.
Create a new policy called AmazonS3ReadOnlyAccess-recommended and detach AmazonS3ReadOnlyAccess.
The unused access analyzer has identified unused permissions in the managed policy AmazonS3ReadOnlyAccess and proposed a new policy AmazonS3ReadOnlyAccess-recommended that contains only the used actions. This is a step towards least privilege because the unused actions can be removed by using the recommended policy.
Create a new IAM policy named AmazonS3ReadOnlyAccess-recommended that contains only the following recommended policy or one based on the downloaded JSON file.
Embed a new inline policy InlinePolicyListLambda-recommended and delete InlinePolicyListLambda. This inline policy lists AWS Lambda aliases, functions, layers, and function URLs only when coming from a specific source IP address.
After updating the policies based on the Recommended policy proposed, the finding Status will change from Active to Resolved.
Figure 9: The finding is resolved
Pricing
There is no additional pricing for using the prescriptive recommendations after you have enabled unused access findings.
Conclusion
As a developer writing policies, you can use the actionable guidance provided in recommendations to continually rightsize your policies to include only the roles and actions you need. You can export the recommendations through the console or set up automated workflows to notify your developers about new IAM Access Analyzer findings.
This new IAM Access Analyzer unused access recommendations feature streamlines the process towards least privilege by selecting the permissions that are used and retaining the resource and condition context from existing policies. It saves an impressive amount of time by the actions used by your principals and guiding you to refine them.
By using the IAM Access Analyzer findings and access recommendations, you can quickly see how to refine the permissions granted. We have shown in this blog post how to generate prescriptive recommendations with actionable guidance for unused permissions using AWS CLI, API calls, and the console.
Uncovering AWS Identity and Access Management (IAM) users and roles potentially involved in a security event can be a complex task, requiring security analysts to gather and analyze data from various sources, and determine the full scope of affected resources.
Amazon Detective includes Detective Investigation, a feature that you can use to investigate IAM users and roles to help you determine if a resource is involved in a security event and obtain an in-depth analysis. It automatically analyzes resources in your Amazon Web Services (AWS) environment using machine learning and threat intelligence to identify potential indicators of compromise (IoCs) or suspicious activity. This allows analysts to identify patterns and identify which resources are impacted by security events, offering a proactive approach to threat identification and mitigation. Detective Investigation can help determine if IAM entities have potentially been compromised or involved in known tactics, techniques, and procedures (TTPs) from the MITRE ATT&CK framework, a well adopted framework for security and threat detection. MITRE TTPs are the terms used to describe the behaviors, processes, actions, and strategies used by threat actors engaged in cyberattacks.
In this post, I show you how to use Detective Investigation and how to interpret and use the information provided from an IAM investigation.
Prerequisites
The following are the prerequisites to follow along with this post:
Access to the AWS Management Console with an active AWS account.
Use Detective Investigation to investigate IAM users and roles
To get started with an investigation, sign in to the console. The walkthrough uses three scenarios:
Automated investigations
Investigator persona
Threat hunter persona
In addition to Detective, some of these scenarios also use Amazon GuardDuty, which is an intelligent threat detection service.
Scenario 1: Automated investigations
Automatic investigations are available in Detective. Detective only displays investigation information when you’re running an investigation. You can use the Detective console to see the number of IAM roles and users that were impacted by security events over a set period. In addition to the console, you can use the StartInvestigation API to initiate a remediation workflow or collect information about IAM entities involved or AWS resources compromised.
The Detective summary dashboard, shown in Figure 1, automatically shows you the number of critical investigations, high investigations, and the number of IAM roles and users found in suspicious activities over a period of time. Detective Investigation uses machine learning models and threat intelligence to surface only the most critical issues, allowing you to focus on high-level investigations. It automatically analyzes resources in your AWS environment to identify potential indicators of compromise or suspicious activity.
To get to the dashboard using the Detective console, choose Summary from the navigation pane.
Figure 1: AWS roles and users impacted by a security event
Note: If you don’t have automatic investigations listed in Detective, the View active investigations link won’t display any information. To run a manual investigation, follow the steps in Running a Detective Investigation using the console or API.
If you have an active automatic investigation, choose View active investigations on the Summary dashboard to go to the Investigations page (shown in Figure 2), which shows potential security events identified by Detective. You can select a specific investigation to view additional details in the investigations report summary.
Figure 2: Active investigations that are related to IAM entities
Select a report ID to view its details. Figure 3 shows the details of the selected event under Indicators of compromise along with the AWS role that was involved, period of time, role name, and the recommended mitigation action. The indicators of compromise list includes observed tactics from the MITRE ATT&CK framework, flagged IP addresses involved in potential compromise (if any), impossible travel under the indicators, and the finding group. You can continue your investigation by selecting and reviewing the details of each item from the list of indicators of compromise.
Figure 3: Summary of the selected investigation
Figure 4 shows the lower portion of the selected investigation. Detective maps the investigations to TTPs from the MITRE ATT&CK framework. TTPs are classified according to their severity. The console shows the techniques and actions used. When selecting a specific TTP, you can see the details in the right pane. In this example, the valid cloud credential has IP addresses involved in 34 successful API call attempts.
Figure 4: TTP mappings
Scenario 2: Investigator persona
For this scenario, you have triaged the resources associated with a GuardDuty finding informing you that an IAM user or role has been identified in an anomalous behavior. You need to investigate and analyze the impact this security issue might have had on other resources and ensure that nothing else needs to be remediated.
The example for this use case starts by going to the GuardDuty console and choosing Findings from the navigation pane, selecting a GuardDuty IAM finding, and then choosing the Investigate with Detective link.
Figure 5: List of findings in GuardDuty
Let’s now investigate an IAM user associated with the GuardDuty finding. As shown in Figure 6, you have multiple options for pivoting to Detective, such as the GuardDuty finding itself, the AWS account, the role session, and the internal and external IP addresses.
Figure 6: Options for pivoting to Detective
From the list of Detective options, you can choose Role session, which will help you investigate the IAM role session that was in use when the GuardDuty finding was created. Figure 7 shows the IAM role session page.
Before moving on to the next section, you would scroll down to Resources affected in the GuardDuty finding details panel on the right side of the screen and take note of the Principal ID.
Figure 7: IAM role session page in Detective
A role session consists of an instantiation of an IAM role and the associated set of short-term credentials. A role session involves the following:
When investigating a role session, consider the following questions:
How long has the role been active?
Is the role routinely used?
Has activity changed over that use?
Was the role assumed by multiple users?
Was it assumed by a large number of users? A narrowly used role session might guide your investigation differently from a role session with overlapping use.
You can use the principal ID to get more in-depth details using the Detective search function. Figure 8 shows the search results of an IAM role’s details. To use the search function, choose Search from the navigation pane, select Role session as the type, and enter an exact identifier or identifier with wildcard characters to search for. Note that the search is case sensitive.
When you select the assumed role link, additional information about the IAM role will be displayed, helping to verify if the role has been involved in suspicious activities.
Figure 8: Results of an IAM role details search
Figure 9 shows other findings related to the role. This information is displayed by choosing the Assumed Role link in the search results.
Now you should see a new screen with information specific to the role entity that you selected. Look through the role information and gather evidence that would be important to you if you were investigating this security issue.
Were there other findings associated to the role? Was there newly observed activity during this time in terms of new behavior? Were there resource interaction associated with the role? What permissions did this role have?
Figure 9: Other findings related to the role
In this scenario, you used Detective to investigate an IAM role session. The information that you have gathered about the security findings will help give you a better understanding of other resources that need to be remediated, how to remediate, permissions that need to be scoped down, and root cause analysis insight to include in your action reports.
Scenario 3: Threat hunter persona
Another use case is to aid in threat hunting (searching) activities. In this scenario, suspicious activity has been detected in your organization and you need to find out what resources (that is, what IAM entities) have been communicating with a command-and-control IP address. You can check from the Detective summary page for roles and users with the highest API call volume, which automatically lists the IAM roles and users that were impacted by security events over a set time scope, as shown in Figure 10.
Figure 10: Roles and users with the highest API call volume
From the list of Principal (role or user) options, choose the user or role that you find interesting based on the data presented. Things to consider when choosing the role or user to examine:
Is there a role with a large amount of failed API calls?
Is there a role with an unusual data trend?
After choosing a role from the DetectiveSummary page, you’re taken to the role overview page. Scroll down to the Overall API call volume section to view the overall volume of API calls issued by the resource during the scope time. Detective presents this information to you in a graphical interface without the need to create complex queries.
Figure 11: Graph showing API call volume
In the Overall API call volume, choose the display details for time scope button at the bottom of the section to search through the observed IP addresses, API method by service, and resource.
Figure 12: Overall API call volume during the specified scope time
To see the details for a specific IP address, use the Overall API call volume panel to search through different locations and to determine where the failed API calls came from. Select an IP address to get more granular details (as shown in Figure 13). When looking through this information, think about what this might tell you in your own environment.
Do you know who normally uses this role?
What is this role used for?
Should this role be making calls from various geolocations?
Figure 13: Granular details for the selected IP address
In this scenario, you used Detective to review potentially suspicious activity in your environment related to information assumed to be malicious. If adversaries have assumed the same role with different session names, this gives you more information about how this IAM role was used. If you find information related to the suspicious resources in question, you should conduct a formal search according to your internal incident response playbooks.
Conclusion
In this blog post, I walked you through how to investigate IAM entities (IAM users or rules) using Amazon Detective. You saw different scenarios on how to investigate IAM entities involved in a security event. You also learned about the Detective investigations for IAM feature, which you can use to automatically investigate IAM entities for indicators of compromise (IOCs), helping security analysts determine whether IAM entities have potentially been compromised or involved in known TTPs from the MITRE ATT&CK framework.
In this blog post, I take you on a deep dive into Amazon GuardDuty Runtime Monitoring for EC2 instances and key capabilities that are part of the feature. Throughout the post, I provide insights around deployment strategies for Runtime Monitoring and detail how it can deliver security value by detecting threats against your Amazon Elastic Compute Cloud (Amazon EC2) instances and the workloads you run on them. This post builds on the post by Channy Yun that outlines how to enable Runtime Monitoring, how to view the findings that it produces, and how to view the coverage it provides across your EC2 instances.
Amazon Web Services (AWS) launched Amazon GuardDuty at re:Invent 2017 with a focus on providing customers managed threat detection capabilities for their AWS accounts and workloads. When enabled, GuardDuty takes care of consuming and processing the necessary log data. Since its launch, GuardDuty has continued to expand its threat detection capabilities. This expansion has included identifying new threat types that can impact customer environments, identifying new threat tactics and techniques within existing threat types and expanding the log sources consumed by GuardDuty to detect threats across AWS resources. Examples of this expansion include the ability to detect EC2 instance credentials being used to invoke APIs from an IP address that’s owned by a different AWS account than the one that the associated EC2 instance is running in, and the ability to identify threats to Amazon Elastic Kubernetes Services (Amazon EKS) clusters by analyzing Kubernetes audit logs.
GuardDuty has continued to expand its threat detection capabilities beyond AWS log sources, providing a more comprehensive coverage of customers’ AWS resources. Specifically, customers needed more visibility around threats that might occur at the operating system level of their container and compute instances. To address this customer need, GuardDuty released the Runtime Monitoring feature, beginning with support on Amazon Elastic Kubernetes Service (Amazon EKS) workloads. Runtime Monitoring provides operating system insight for GuardDuty to use in detecting potential threats to workloads running on AWS and enabled the operating system visibility that customers were asking for. At re:Invent 2023, GuardDuty expanded Runtime Monitoring to include Amazon Elastic Container Service (Amazon ECS)—including serverless workloads running on AWS Fargate, and previewed support for Amazon EC2, which became generally available earlier this year. The release of EC2 Runtime Monitoring enables comprehensive compute coverage for GuardDuty across containers and EC2 instances, delivering breadth and depth for threat detection in these areas.
Features and functions
GuardDuty EC2 Runtime Monitoring relies on a lightweight security agent that collects operating system events—such as file access, processes, command line arguments, and network connections—from your EC2 instance and sends them to GuardDuty. After the operating system events are received by GuardDuty, they’re evaluated to identify potential threats related to the EC2 instance. In this section, we explore how GuardDuty is evaluating the runtime events it receives and how GuardDuty presents identified threat information.
Command arguments and event correlation
The runtime security agent enables GuardDuty to create findings that can’t be created using the foundational data sources of VPC Flow Logs, DNS logs, and CloudTrail logs. The security agent can collect detailed information about what’s happening at the instance operating system level that the foundational data sources don’t contain.
With the release of EC2 Runtime Monitoring, additional capabilities have been added to the runtime agent and to GuardDuty. The additional capabilities include collecting command arguments and correlation of events for an EC2 instance. These new capabilities help to rule out benign events and more accurately generate findings that are related to activities that are associated with a potential threat to your EC2 instance.
Command arguments
The GuardDuty security agent collects information on operating system runtime commands (curl, systemctl, cron, and so on) and uses this information to generate findings. The security agent now also collects the command arguments that were used as part of running a command. This additional information gives GuardDuty more capabilities to detect threats because of the additional context related to running a command.
For example, the agent will not only identify that systemctl (which is used to manage services on your Linux instance) was run but also which parameters the command was run with (stop, start, disable, and so on) and for which service the command was run. This level of detail helps identify that a threat actor might be changing security or monitoring services to evade detection.
Event correlation
GuardDuty can now also correlate multiple events collected using the runtime agent to identify scenarios that present themselves as a threat to your environment. There might be events that happen on your instance that, on their own, don’t present themselves as a clear threat. These are referred to as weak signals. However, when these weak signals are considered together and the sequence of commands aligns to malicious activity, GuardDuty uses that information to generate a finding. For example, a download of a file would present itself as a weak signal. If that download of a file is then piped to a shell command and the shell command begins to interact with additional operating system files or network configurations, or run known malware executables, then the correlation of all these events together can lead to a GuardDuty finding.
GuardDuty finding types
GuardDuty Runtime Monitoring currently supports 41 finding types to indicate potential threats based on the operating system-level behavior from the hosts and containers in your Amazon EKS clusters on Amazon EC2, Amazon ECS on Fargate and Amazon EC2, and EC2 instances. These findings are based on the event types that the security agent collects and sends to the GuardDuty service.
Five of these finding types take advantage of the new capabilities of the runtime agent and GuardDuty, which were discussed in the previous section of this post. These five new finding types are the following:
Each GuardDuty finding begins with a threat purpose, which is aligned with MITRE ATT&CK tactics. The Execution finding types are focused on observed threats to the actual running of commands or processes that align to malicious activity. The DefenseEvasion finding types are focused on situations where commands are run that are trying to disable defense mechanisms on the instance, which would normally be used to identify or help prevent the activity of a malicious actor on your instance.
In the following sections, I go into more detail about the new Runtime Monitoring finding types and the types of malicious activities that they are identifying.
Identifying suspicious tools and commands
The SuspiciousTool, SuspiciousCommand, and PtraceAntiDebugging finding types are focused on suspicious activities, or those that are used to evade detection. The approach to identify these types of activities is similar. The SuspiciousTool finding type is focused on tools such as backdoor tools, network scanners, and network sniffers. GuardDuty helps to identify the cases where malicious activities related to these tools are occurring on your instance.
The SuspiciousCommand finding type identifies suspicious commands with the threat purposes of DefenseEvasion or Execution. The DefenseEvasion findings are an indicator of an unauthorized user trying to hide their actions. These actions could include disabling a local firewall, modifying local IP tables, or removing crontab entries. The Execution findings identify when a suspicious command has been run on your EC2 instance. The findings related to Execution could be for a single suspicious command or a series of commands, which, when combined with a series of other commands along with additional context, becomes a clearer indicator of suspicious activity. An example of an Execution finding related to combining multiple commands could be when a file is downloaded and is then run in a series of steps that align with a known malicious pattern.
For the PtraceAntiDebugging finding, GuardDuty is looking for cases where a process on your instance has used the ptrace system call with the PTRACE_TRACEME option, which causes an attached debugger to detach from the running process. This is a suspicious activity because it allows a process to evade debugging using ptrace and is a known technique that malware uses to evade detection.
Identifying running malicious files
The updated GuardDuty security agent can also identify when malicious files are run. With the MaliciousFileExecuted finding type, GuardDuty can identify when known malicious files might have been run on your EC2 instance, providing a strong indicator that malware is present on your instance. This capability is especially important because it allows you to identify known malware that might have been introduced since your last malware scan.
Finding details
All of the findings mentioned so far are consumable through the AWS Management Console for GuardDuty, through the GuardDuty APIs, as Amazon EventBridge messages, or through AWS Security Hub. The findings that GuardDuty generates are meant to not only tell you that a suspicious event has been observed on your instance, but also give you enough context to formulate a response to the finding.
The GuardDuty security agent collects a variety of events from the operating system to use for threat detection. When GuardDuty generates a finding based on observed runtime activities, it will include the details of these observed events, which can help with confirmation on what the threat is and provide you a path for possible remediation steps based on the reported threat. The information provided in a GuardDuty runtime finding can be broken down into three main categories:
Information about the impacted AWS resource
Information about the observed processes that were involved in the activity
Context related to the runtime events that were observed
Impacted AWS resources
In each finding that GuardDuty produces, information about the impacted AWS resource will be included. For EC2 Runtime Monitoring, the key information included will be information about the EC2 instance (such as name, instance type, AMI, and AWS Region), tags that are assigned to the instance, network interfaces, and security groups. This information will help guide your response and investigation to the specific instance that’s identified for the observed threat. It’s also useful in assessing key network configurations of the instance that could assist with confirming whether the network configuration of the instance is correct or assessing how the network configuration might factor into the response.
Process details
For each runtime finding, GuardDuty includes the details that were observed about the process attributed to the threat that the finding is for. Common items that you should expect to see include the name of the executable and the path to the executable that resulted in the finding being created, the ID of the operating system process, when the process started, and which operating system user ran the process. Additionally, process lineage is included in the finding. Process lineage helps identify operating system processes that are related to each other and provides insight into the parent processes that were run leading up to the identified process. Understanding this lineage can give you valuable insight into what the root cause of the malicious process identified in the finding might be; for example, being able to identify which other commands were run that ultimately led to the activation of the executable or command identified in the finding. If the process attributed to the finding is running inside a container, the finding also provides container details such as the container ID and image.
Runtime context
Runtime context provides insight on things such as file system type, flags that were used to control the behavior of the event, name of the potentially suspicious tool, path to the script that generated the finding, and the name of the security service that was disabled. The context information in the finding is intended to help you further understand the runtime activity that was identified as a threat and determine its potential impact and what your response might be. For example, a command that is detected by using the systemctl command to disable the apparmor utility would report the process information related to running the systemctl command, and then the runtime context would contain the name of the actual service that was impacted by the systemctl command call and the options used with the command.
See Runtime Monitoring finding details for a full list of the process and context details that might be present in your runtime findings.
Responding to runtime findings
With GuardDuty findings, it’s a best practice to enable an event-based response that can be invoked as soon as the runtime finding is generated. This approach holds true for runtime related findings as well. For every runtime finding that GuardDuty generates, a copy of the finding is sent to EventBridge. If you use Security Hub, a copy of the finding is sent to Security Hub as well. With EventBridge, you can define a rule with a pattern that matches the finding attributes you want to prioritize and respond to. This pattern could be very broad in looking for all runtime-related findings. Or, it could be more specific, only looking for certain finding types, findings of a certain severity, or even certain attributes related to the process or runtime context of a finding.
After the rule pattern is established, you can define a target that the finding should be sent to. This target can be one of over 20 AWS services, which gives you lots of flexibility in routing the finding into the operational tools or processes that are used by your company. The target could be an AWS Lambda function that’s responsible for evaluating the finding, adding some additional data to the finding, and then sending it to a ticketing or chat tool. The target could be an AWS Systems Manager runbook, which would be used on the actual operating system to perform additional forensics or to isolate or disable any processes that are identified in the finding.
Many customers take a stepped approach in their response to GuardDuty findings. The first step might be to make sure that the finding is enriched with as many supporting details as possible and sent to the right individual or team. This helps whoever’s investigating the finding to confirm that the finding is a true positive, further informing the decision on what action to take.
In addition to having an event-based response to GuardDuty findings, you can investigate each GuardDuty runtime finding in the GuardDuty or Security Hub console. Through the console, you can research the details of the finding and use the information to inform the next steps to respond to or remediate the finding.
Speed to detection
With its close proximity to your workloads, the GuardDuty security agent can produce findings more quickly when compared to processing log sources such as VPC Flow Logs and DNS logs. The security agent collects operating system events and forwards them directly to the GuardDuty service, examining events and generating findings more quickly. This helps you to formulate a response sooner so that you can isolate and stop identified threats to your EC2 instances.
Let’s examine a finding type that can be detected by both the runtime security agent and by the foundational log sources of AWS CloudTrail, VPC Flow Logs, and DNS logs. Backdoor:EC2/C&CActivity.B!DNS and Backdoor:Runtime/C&CActivity.B!DNS are the same finding with one coming from DNS logs and one coming from the runtime security agent. While GuardDuty doesn’t have a service-level agreement (SLA) on the time it takes to consume the findings for a log source or the security agent, testing for these finding types reveals that the runtime finding is generated in just a few minutes. Log file-based findings will take around 15 minutes to produce because of the latency of log file delivery and processing. In the end, these two findings mean the same thing, but the runtime finding will arrive faster and with additional process and context information, helping you implement a response to the threat sooner and improve your ability to isolate, contain, and stop the threat.
Runtime data and flow logs data
When exploring the Runtime Monitoring feature and its usefulness for your organization, a key item to understand is the foundational level of protection for your account and workloads. When you enable GuardDuty the foundational data sources of VPC Flow Logs, DNS logs, and CloudTrail logs are also enabled, and those sources cannot be turned off without fully disabling GuardDuty. Runtime Monitoring provides contextual information that allows for more precise findings that can help with targeted remediation compared to the information provided in VPC Flow Logs. When the Runtime Monitoring agent is deployed onto an instance, the GuardDuty service still processes the VPC Flow Logs and DNS logs for that instance. If, at any point in time, an unauthorized user tampers with your security agent or an instance is deployed without the security agent, GuardDuty will continue to use VPC Flow Logs and DNS logs data to monitor for potential threats and suspicious activity, providing you defense in depth to help ensure you have visibility and coverage for detecting threats.
Note: GuardDuty doesn’t charge you for processing VPC Flow Logs while the Runtime Monitoring agent is active on an instance.
Deployment strategies
There are multiple strategies that you can use to install the GuardDuty security agent on an EC2 instance, and it’s important to use the one that fits best based on how you deploy and maintain instances in your environment. The following are agent installation options that cover managed installation, tag-based installation, and manual installation techniques. The managed installation approach is a good fit for most customers, but the manual options are potentially better if you have existing processes that you want to maintain or you want the more fine-grained features provided by agent installation compared to the managed approach.
Note: GuardDuty requires that each VPC, with EC2 instances running the GuardDuty agent, has a VPC endpoint that allows the agent to communicate with the GuardDuty service. You aren’t charged for the cost of these VPC endpoints. When you’re using the GuardDuty managed agent feature, GuardDuty will automatically create and operate these VPC endpoints for you. For the other agent deployment options listed in this section, or other approaches that you take, you must manually configure the VPC endpoint for each VPC where you have EC2 instances that will run the GuardDuty agent. See Creating VPC endpoint manually for additional details.
GuardDuty-managed installation
If you want to use security agents to monitor runtime activity on your EC2 instances but don’t want to manage the installation and lifecycle of the agent on specific instances, then Automated agent configuration is the option for you. For GuardDuty to successfully manage agent installation, each EC2 instance must meet the operating system architectural requirements of the security agent. Additionally, each instance must have the Systems Manager agent installed and configured with the minimal instance permissions that System Manager requires.
In addition to making sure that your instances are configured correctly, you also need to enable automated agent configuration for your EC2 instances in the Runtime Monitoring section of the GuardDuty console. Figure 1 shows what this step looks like.
Figure 1: Enable GuardDuty automated agent configuration for Amazon EC2
After you have enabled automated agent configuration and have your instances correctly configured, GuardDuty will install and manage the security agent for every instance that is configured.
GuardDuty-managed with explicit tagging
If you want to selectively manage installation of the GuardDuty agent but still want automated deployment and updates, you can use inclusion or exclusion tags to control which instances the agent is installed to.
Inclusion tags allow you to specify which EC2 instances the GuardDuty security agent should be installed to without having to enable automated agent configuration. To use inclusion tags, each instance where the security agent should be installed needs to have a key-value pair of GuardDutyManaged/true. While you don’t need to turn on automated agent configuration to use inclusion tags, each instance that you tag for agent installation needs to have the Systems Manager agent installed and the appropriate permissions attached to the instance using an instance role.
Exclusion tags allow you to enable automated agent configuration, and then selectively manage which instances the agent shouldn’t be deployed to. To use exclusion tags, each instance that shouldn’t have an instance installed needs to have a key-value pair of GuardDutyManaged/false.
You can use selective installation for a variety of use cases. If you’re doing a proof of concept with EC2 Runtime Monitoring, you might want to deploy the solution to a subset of your instances and then gradually onboard additional instances. At times, you might want to limit agent installation to instances that are deployed into certain environments or applications that are a priority for runtime monitoring. Tagging resources associated with these workloads helps ensure that monitoring is in place for resources that you want to prioritize for runtime monitoring. This strategy gives you more fine-grained control but also requires more work and planning to help ensure that the strategy is implemented correctly.
With a tag-based strategy it is important to understand who is allowed to add or remove tags to your EC2 instances as this influences when security controls are enabled or disabled. A review of your IAM roles and policies for tagging permissions is recommended to help ensure that the appropriate principals have access to this tagging capability. This IAM document provides an example of how you may limit tagging capabilities within a policy. The approach you take will depend on how you are using policies within your environment.
Manual agent installation options
If you don’t want to run the Systems Manager agent that powers the automated agent configuration, or if you have your own strategy to install and configure software on your EC2 instances, there are other deployment options that are better suited for your situation. The following are multiple approaches that you can use to manually install the GuardDuty agent for Runtime Monitoring. See Installing the security agent manually for general pointers on the recommended manual installation steps. With manual installation, you’re responsible for updating the GuardDuty security agent when new versions of the agent are released. Updating the agent can often be performed using the same techniques as installing the agent.
EC2 Image Builder
Your EC2 deployment strategy might be to build custom Amazon EC2 machine images that are then used as the approved machine images for your organization’s workloads. One option for installing the GuardDuty runtime agent as part of a machine image build is to use EC2 Image Builder. Image Builder simplifies the building, testing, and deployment of virtual machine and container images for use on AWS. With Image Builder, you define an image pipeline that includes a recipe with a build component for installing the GuardDuty Runtime Monitoring RPM. This approach with Image Builder helps ensure that your pre-built machine image includes the necessary components for EC2 Runtime Monitoring so that the necessary security monitoring is in place as soon as your instances are launched.
Bootstrap
Some customers prefer to configure their EC2 instances as they’re launched. This is commonly done through the user data field of an EC2 instance definition. For EC2 Runtime Monitoring agent installation, you would add the steps related to download and install of the runtime RPM as part of your user data script. The steps that you would add to your user data script are outlined in the Linux Package Managers method of Installing the security agent manually.
Other tools
In addition to the preceding steps, there are other tools that you can use when you want to incorporate the installation of the GuardDuty runtime monitoring agent. Tools such as Packer for building EC2 images, and Ansible, Chef, and Puppet for instance automation can be used to run the necessary steps to install the runtime agent onto the necessary EC2 instances. See Installing the security agent manually for guidance on the installation commands you would use with these tools.
Conclusion
Through customer feedback, GuardDuty has enhanced its threat detection capabilities with the Runtime Monitoring feature and you can now use it to deploy the same security agent across different compute services in AWS for runtime threat detection. Runtime monitoring provides an additional level of visibility that helps you achieve your security goals for your AWS workloads.
This post outlined the GuardDuty EC2 Runtime Monitoring feature, how you can implement the feature on your EC2 instances, and the security value that the feature provides. The insight provided in this post is intended to help you better understand how EC2 Runtime Monitoring can benefit you in achieving your security goals related to identifying and responding to threats.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.




 Erik Iwanski
Erik Iwanski Anne Grahn
Anne Grahn



 Tim Wilhoit is a Sr. Solutions Architect for the Department of Defense at AWS. Tim has over 20 years of enterprise IT experience. His areas of interest are serverless computing and ML/AI. In his spare time, Tim enjoys spending time at the lake and rooting on the Oklahoma State Cowboys. Go Pokes!
Tim Wilhoit is a Sr. Solutions Architect for the Department of Defense at AWS. Tim has over 20 years of enterprise IT experience. His areas of interest are serverless computing and ML/AI. In his spare time, Tim enjoys spending time at the lake and rooting on the Oklahoma State Cowboys. Go Pokes!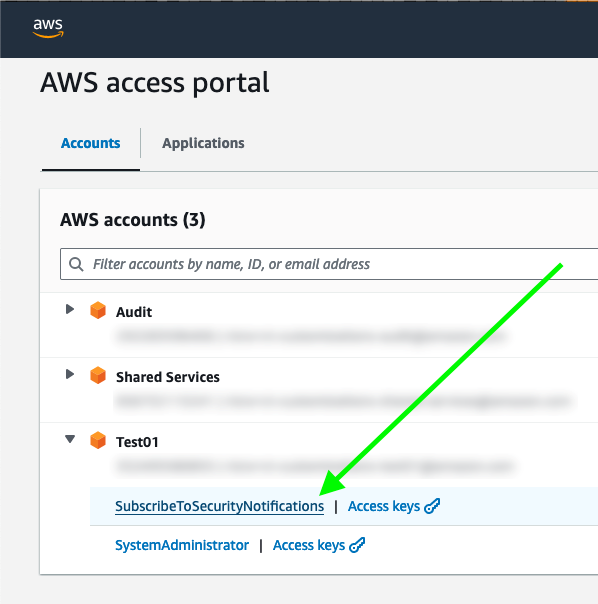
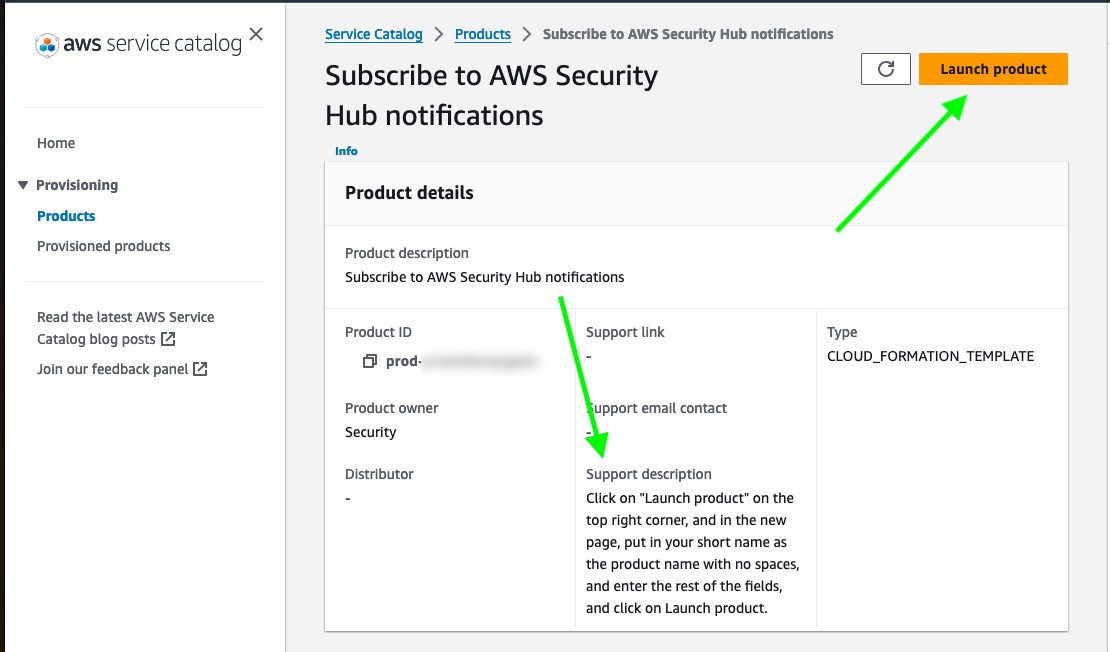
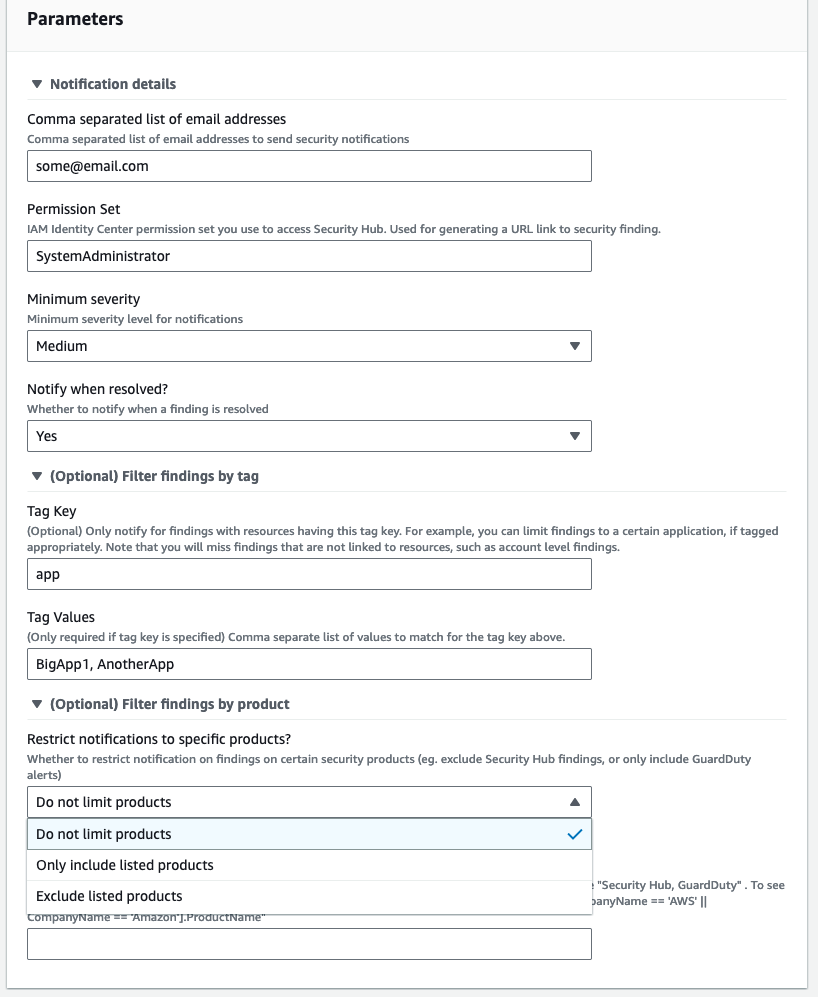
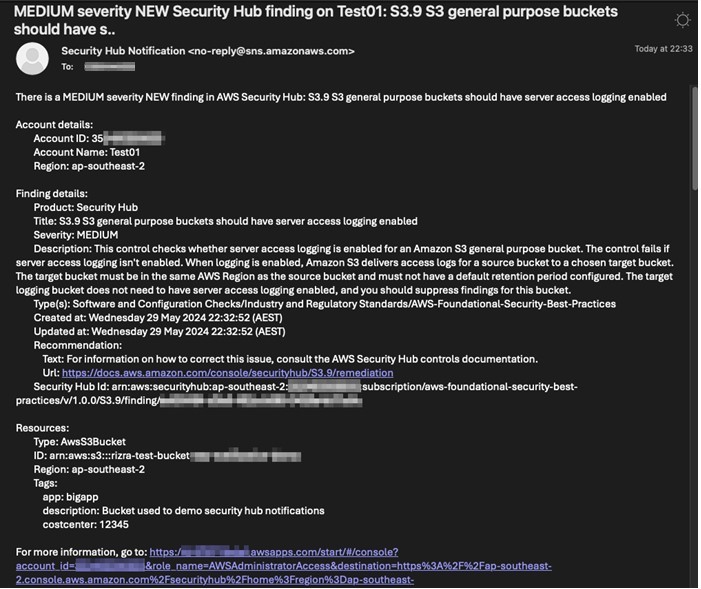
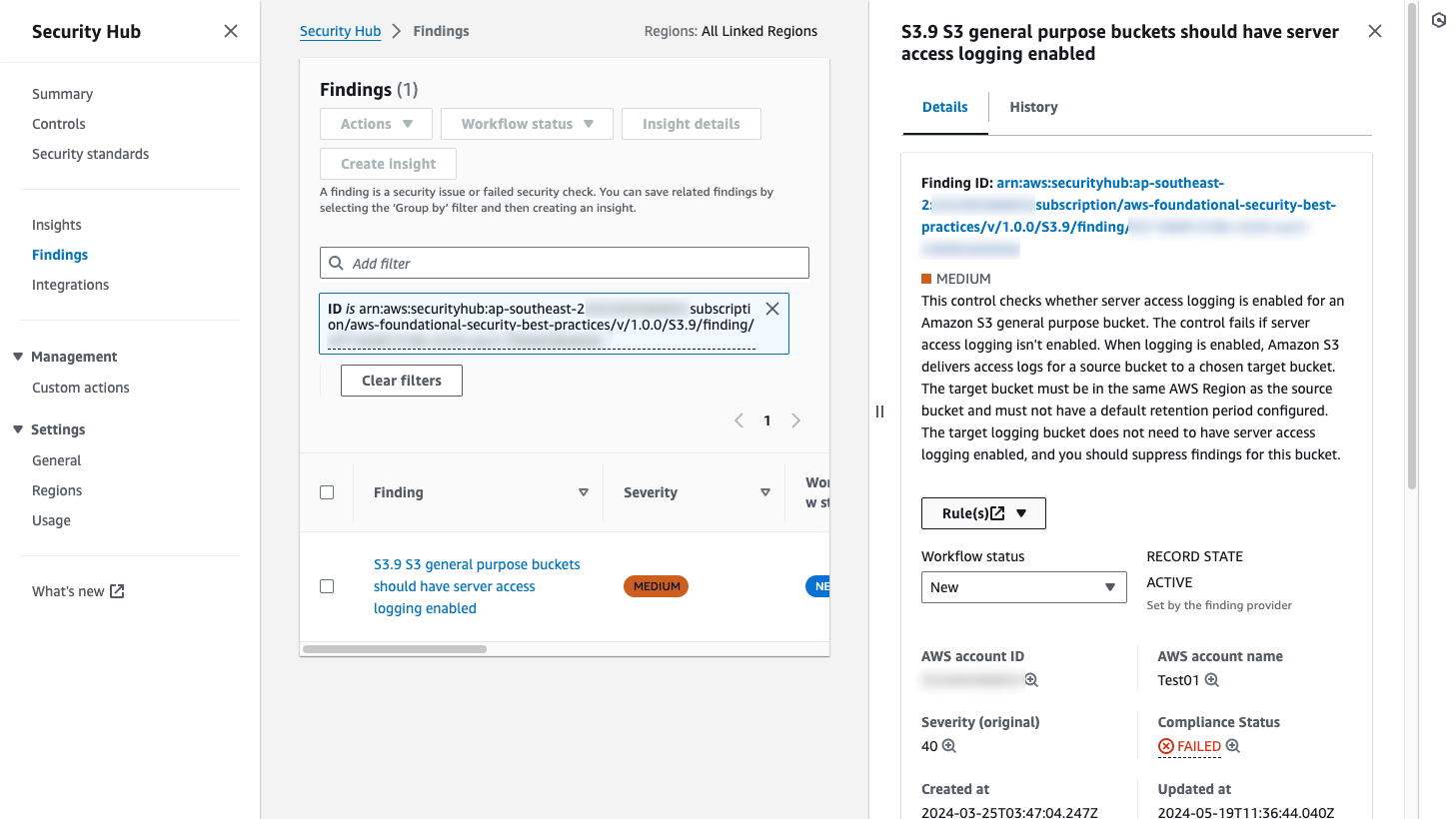
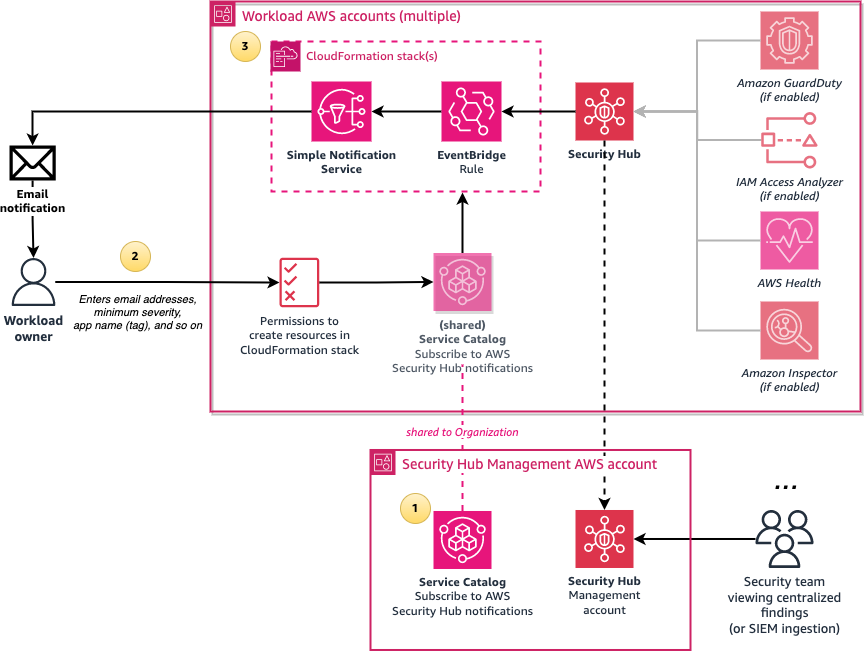
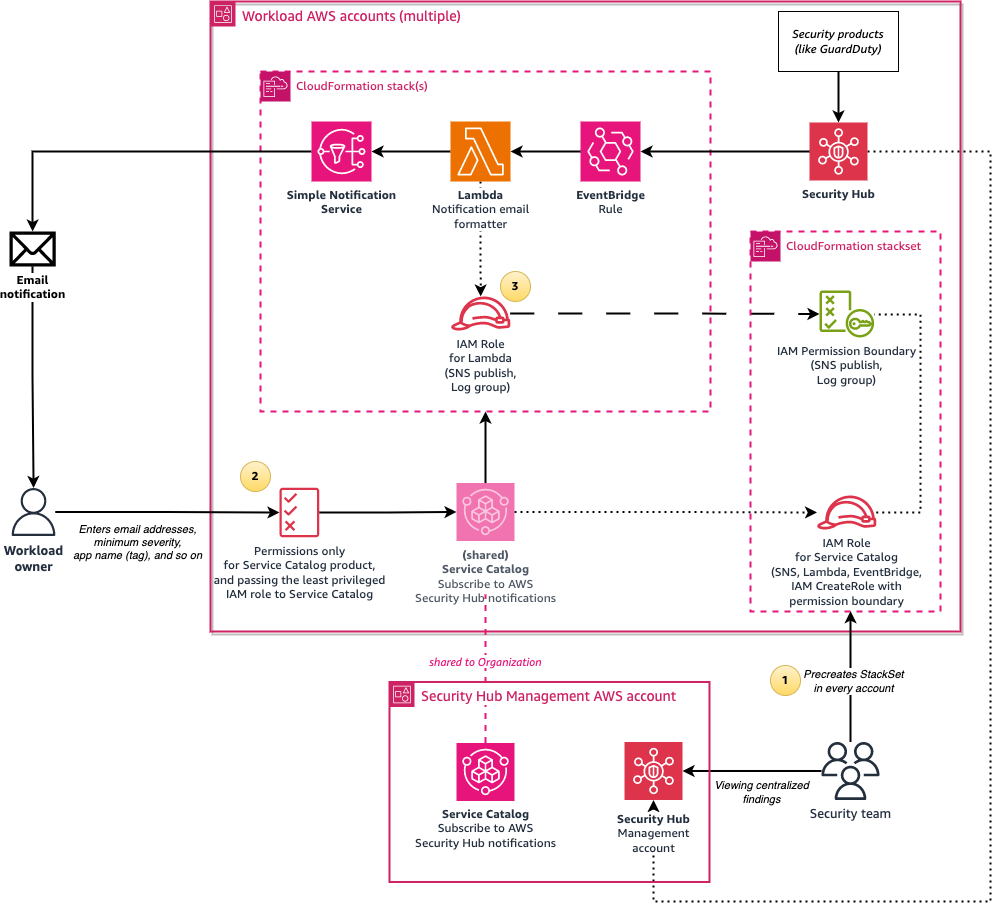


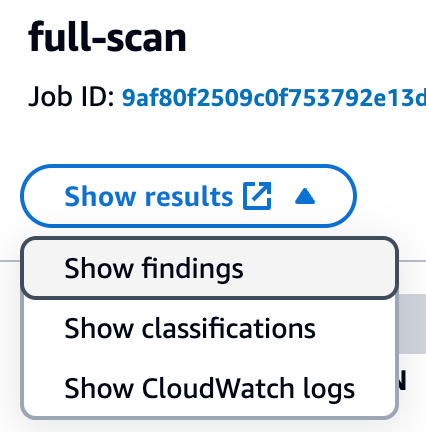
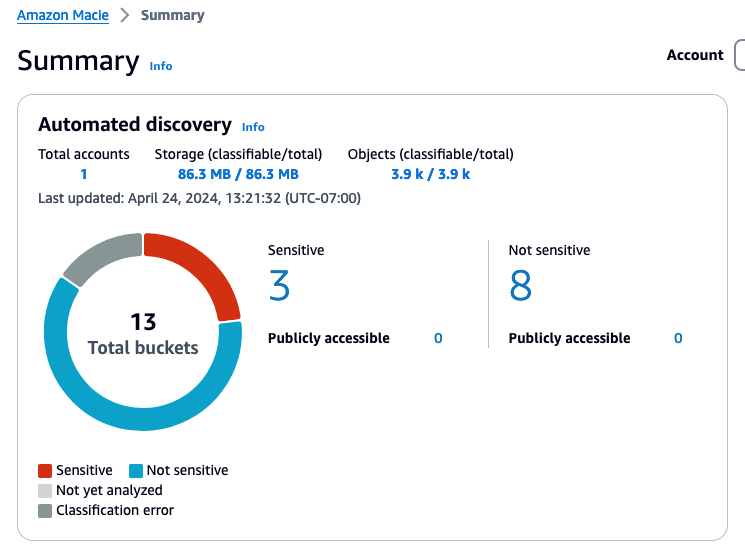
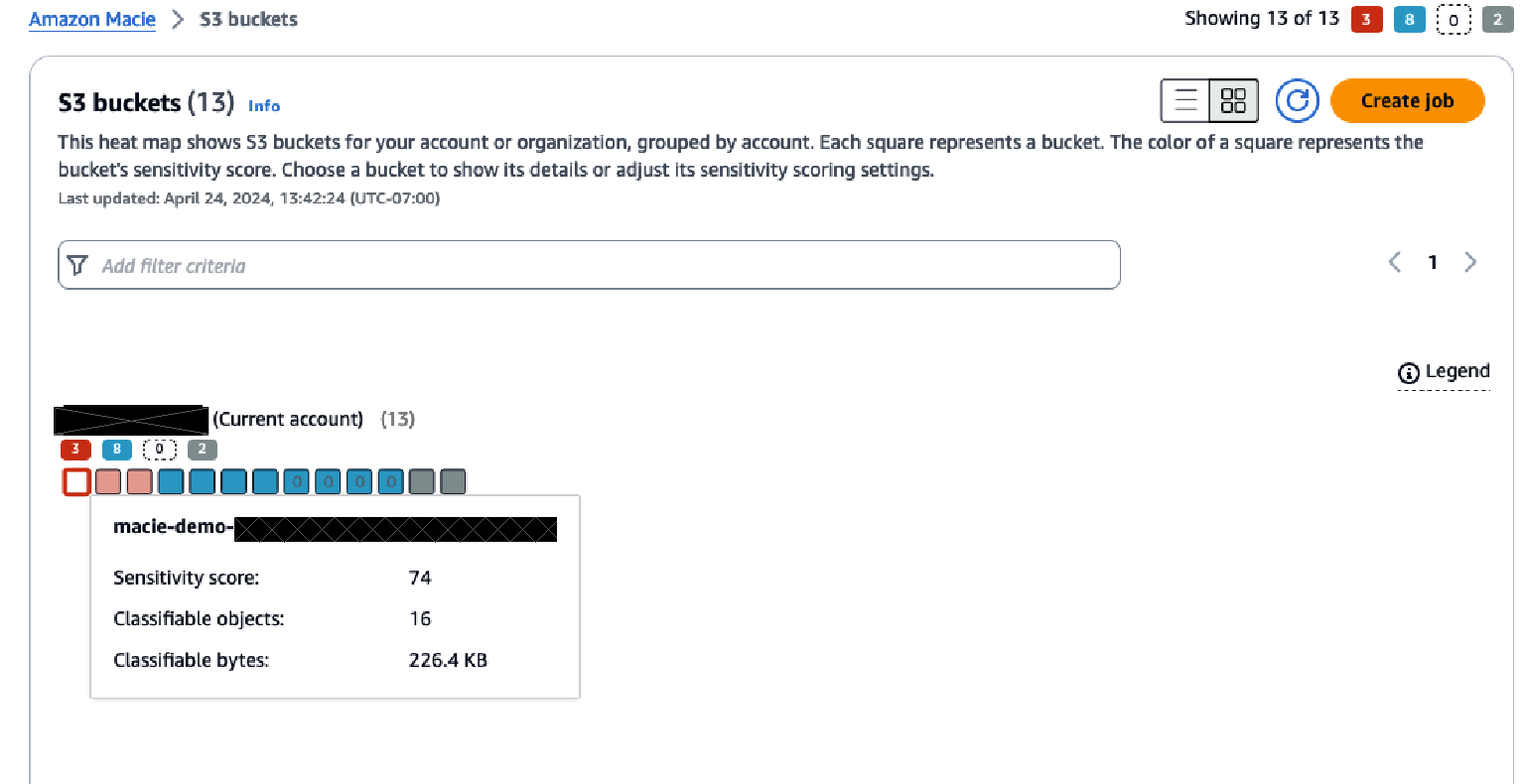
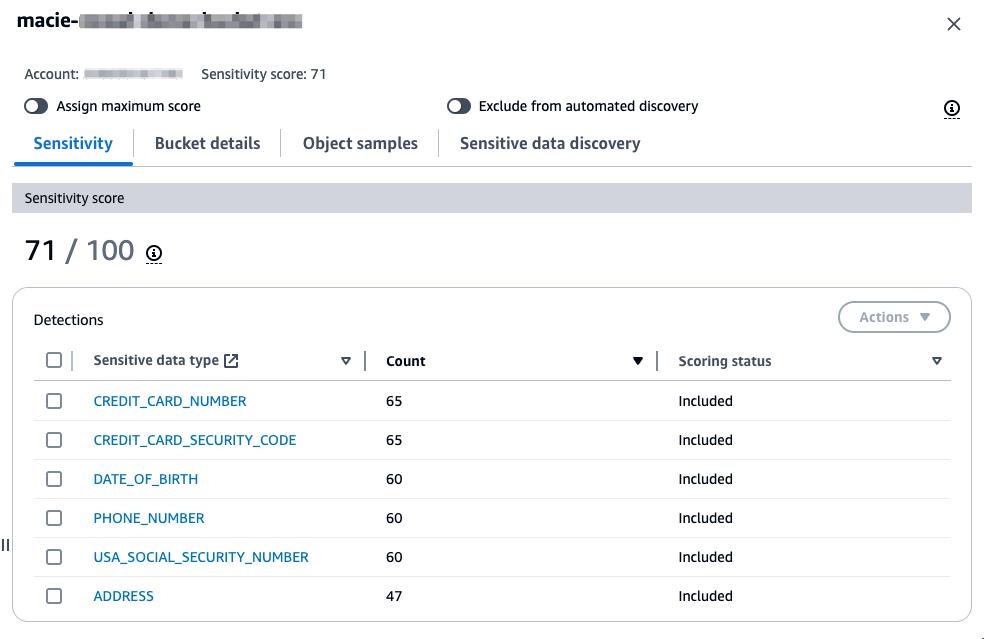
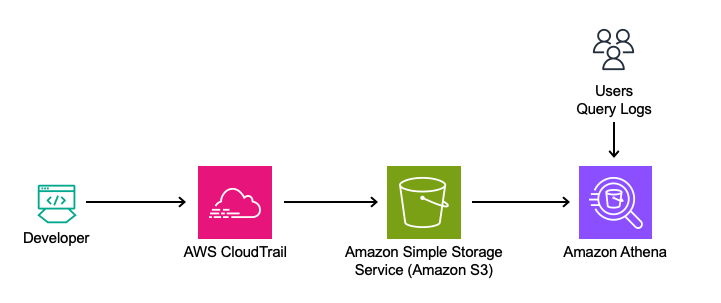












































 Dave Horne is a Sr. Solutions Architect supporting Federal System Integrators at AWS. He is based in Washington, DC, and has 15 years of experience building, modernizing, and integrating systems for public sector customers. Outside of work, Dave enjoys playing with his kids, hiking, and watching Penn State football!
Dave Horne is a Sr. Solutions Architect supporting Federal System Integrators at AWS. He is based in Washington, DC, and has 15 years of experience building, modernizing, and integrating systems for public sector customers. Outside of work, Dave enjoys playing with his kids, hiking, and watching Penn State football! Robert Kessler is a Solutions Architect at AWS supporting Federal Partners, with a recent focus on generative AI technologies. Previously, he worked in the satellite communications segment supporting operational infrastructure globally. Robert is an enthusiast of boats and sailing (despite not owning a vessel), and enjoys tackling house projects, playing with his kids, and spending time in the great outdoors.
Robert Kessler is a Solutions Architect at AWS supporting Federal Partners, with a recent focus on generative AI technologies. Previously, he worked in the satellite communications segment supporting operational infrastructure globally. Robert is an enthusiast of boats and sailing (despite not owning a vessel), and enjoys tackling house projects, playing with his kids, and spending time in the great outdoors.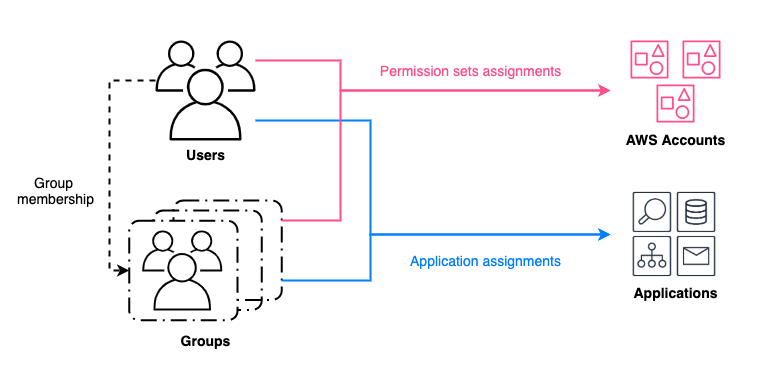
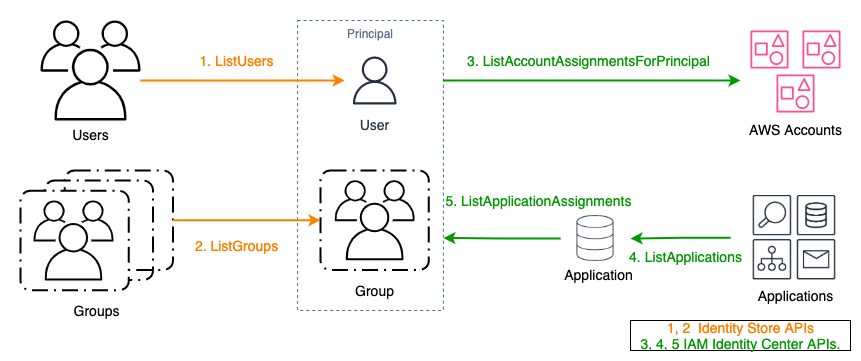
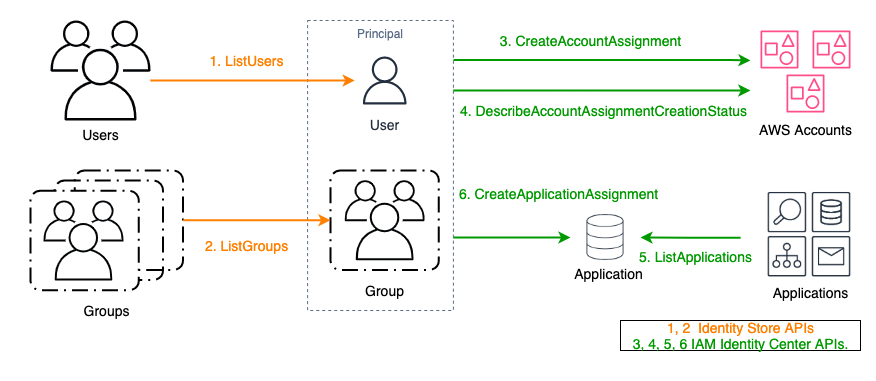


















 Nikhil Agarwal is a Sr. Technical Manager with Amazon Web Services. He is passionate about helping customers achieve operational excellence in their cloud journey and actively working on technical solutions. He is an artificial intelligence (AI/ML) and analytics enthusiastic, he deep dives into customer’s ML and OpenSearch service specific use cases. Outside of work, he enjoys traveling with family and exploring different gadgets.
Nikhil Agarwal is a Sr. Technical Manager with Amazon Web Services. He is passionate about helping customers achieve operational excellence in their cloud journey and actively working on technical solutions. He is an artificial intelligence (AI/ML) and analytics enthusiastic, he deep dives into customer’s ML and OpenSearch service specific use cases. Outside of work, he enjoys traveling with family and exploring different gadgets. Rick Balwani is an Enterprise Support Manager responsible for leading a team of Technical Account Mangers (TAMs) supporting AWS independent software vendor (ISV) customers. He works to ensure customers are successful on AWS and can build cutting-edge solutions. Rick has a background in DevOps and system engineering.
Rick Balwani is an Enterprise Support Manager responsible for leading a team of Technical Account Mangers (TAMs) supporting AWS independent software vendor (ISV) customers. He works to ensure customers are successful on AWS and can build cutting-edge solutions. Rick has a background in DevOps and system engineering. Ashwin Barve is a Sr. Technical Manager with Amazon Web Services. In his role, Ashwin leverages his experience to help customers align their workloads with AWS best practices and optimize resources for maximum cost savings. Ashwin is dedicated to assisting customers through every phase of their cloud adoption, from accelerating migrations to modernizing workloads.
Ashwin Barve is a Sr. Technical Manager with Amazon Web Services. In his role, Ashwin leverages his experience to help customers align their workloads with AWS best practices and optimize resources for maximum cost savings. Ashwin is dedicated to assisting customers through every phase of their cloud adoption, from accelerating migrations to modernizing workloads.








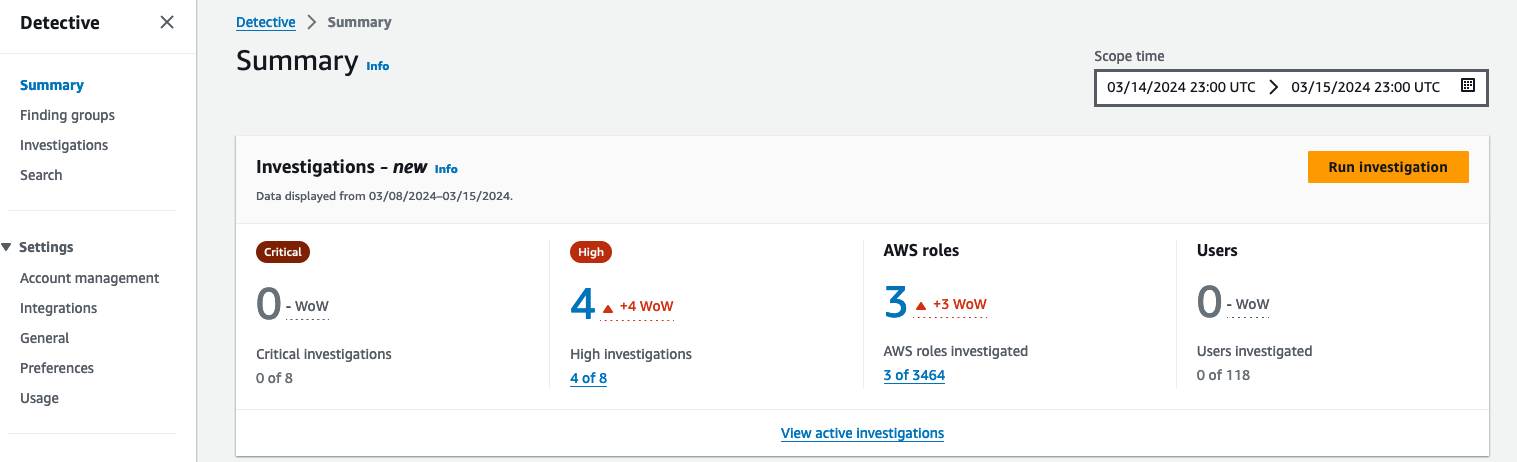
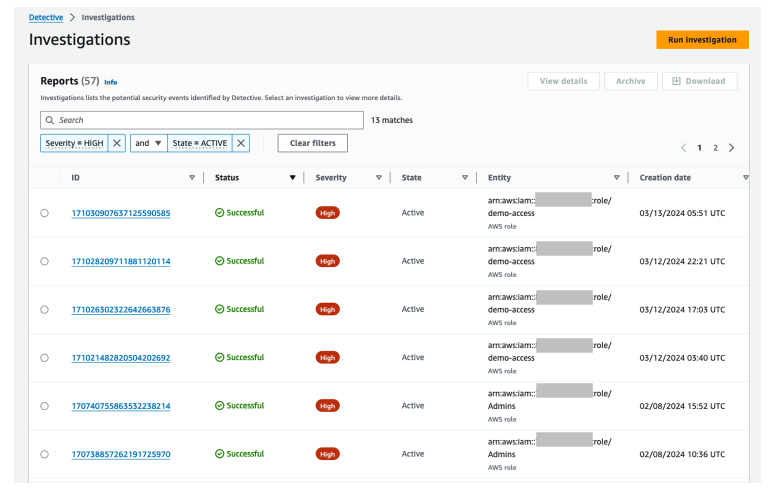
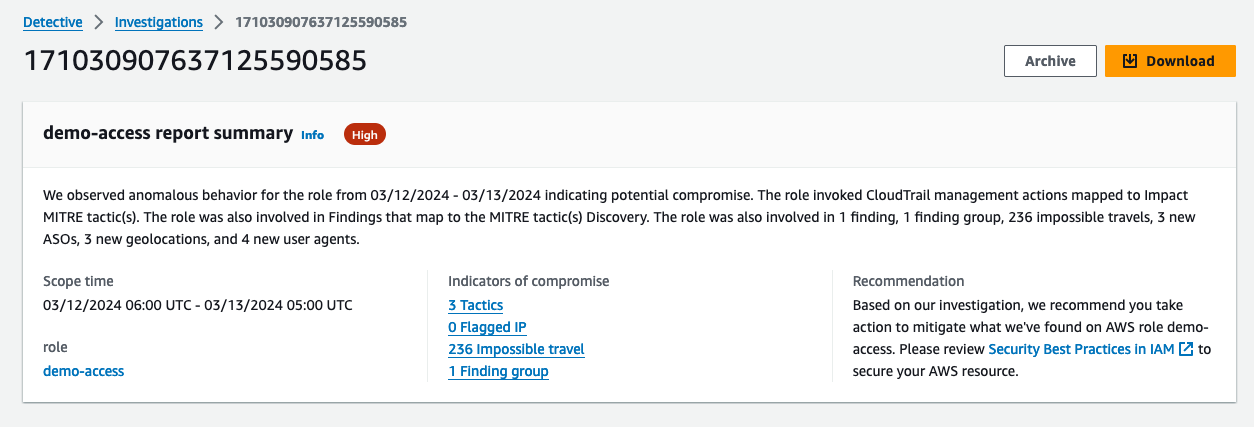
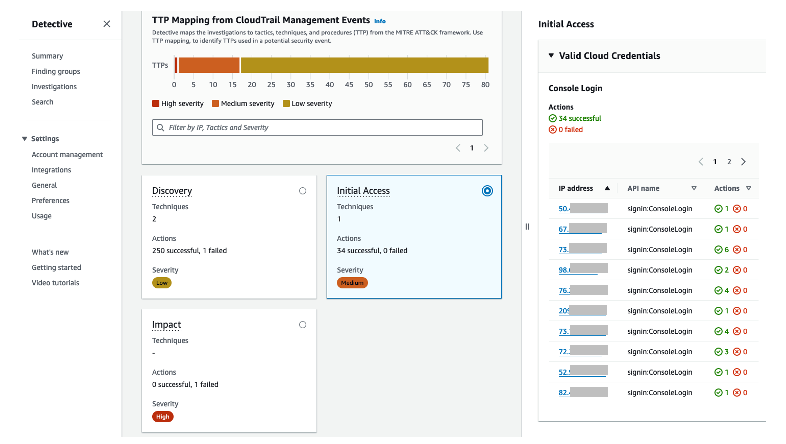
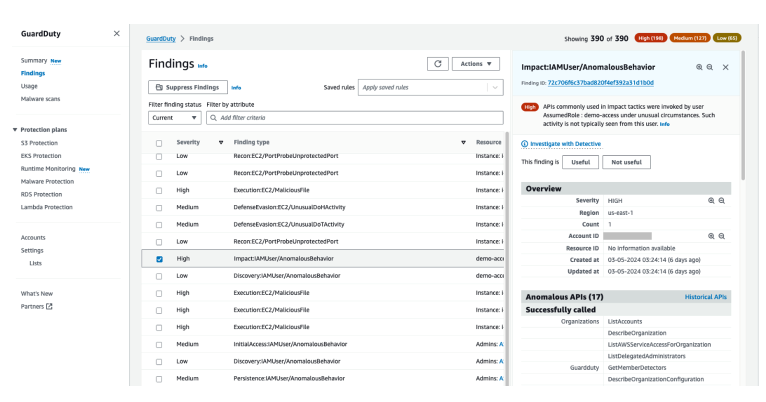
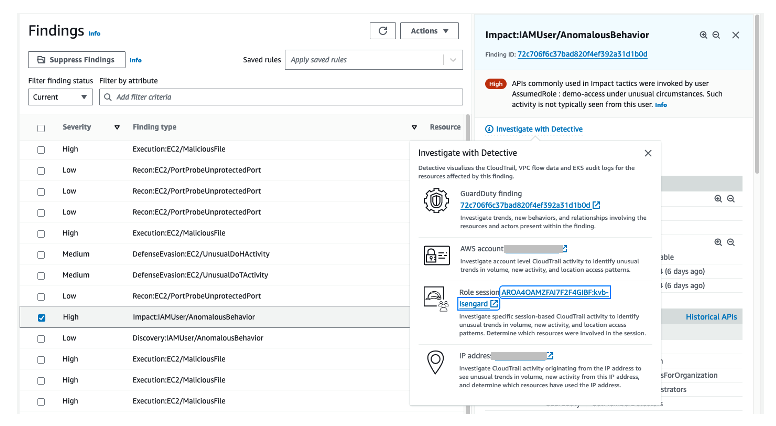
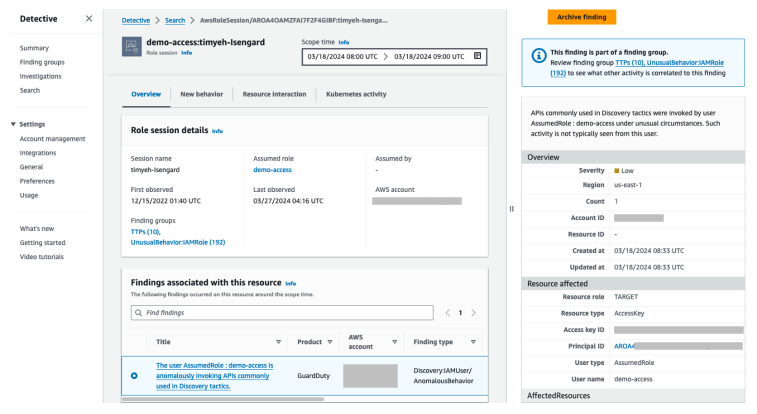
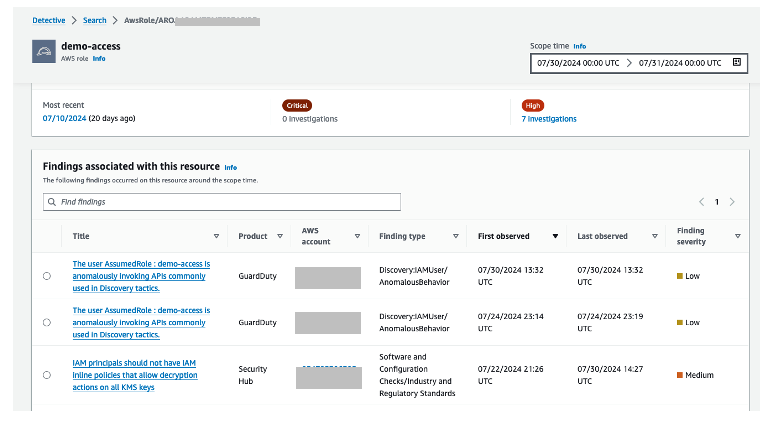
 Figure 12: Overall API call volume during the specified scope time
Figure 12: Overall API call volume during the specified scope time