AWS customers often process petabytes of data using Amazon EMR on EKS. In enterprise environments with diverse workloads or varying operational requirements, customers frequently choose a multi-cluster setup due to the following advantages:
Better resiliency and no single point of failure – If one cluster fails, other clusters can continue processing critical workloads, maintaining business continuity
Better security and isolation – Increased isolation between jobs enhances security and simplifies compliance
Better scalability – Distributing workloads across clusters enables horizontal scaling to handle peak demands
Increased flexibility – You can enjoy straightforward experimentation and cost optimization through workload segregation to multiple clusters
However, one of the disadvantages of a multi-cluster setup is that there is no straightforward method to distribute workloads and support effective load balancing across multiple clusters. This post proposes a solution to this challenge by introducing the Batch Processing Gateway (BPG), a centralized gateway that automates job management and routing in multi-cluster environments.
Challenges with multi-cluster environments
In a multi-cluster environment, Spark jobs on Amazon EMR on EKS need to be submitted to different clusters from various clients. This architecture introduces several key challenges:
Endpoint management – Clients must maintain and update connections for each target cluster
Operational overhead – Managing multiple client connections individually increases the complexity and operational burden
Workload distribution – There is no built-in mechanism for job routing across multiple clusters, which impacts configuration, resource allocation, cost transparency, and resilience
Resilience and high availability – Without load balancing, the environment lacks fault tolerance and high availability
BPG addresses these challenges by providing a single point of submission for Spark jobs. BPG automates job routing to the appropriate EMR on EKS clusters, providing effective load balancing, simplified endpoint management, and improved resilience. The proposed solution is particularly beneficial for customers with multi-cluster Amazon EMR on EKS setups using the Spark Kubernetes Operator with or without Yunikorn scheduler.
However, although BPG offers significant benefits, it is currently designed to work only with Spark Kubernetes Operator. Additionally, BPG has not been tested with the Volcano scheduler, and the solution is not applicable in environments using native Amazon EMR on EKS APIs.
Solution overview
Martin Fowler describes a gateway as an object that encapsulates access to an external system or resource. In this case, the resource is the EMR on EKS clusters running Spark. A gateway acts as a single point to confront this resource. Any code or connection interacts with the interface of the gateway only. The gateway then translates the incoming API request into the API offered by the resource.
BPG is a gateway specifically designed to provide a seamless interface to Spark on Kubernetes. It’s a REST API service to abstract the underlying Spark on EKS clusters details from users. It runs in its own EKS cluster communicating to Kubernetes API servers of different EKS clusters. Spark users submit an application to BPG through clients, then BPG routes the application to one of the underlying EKS clusters.
The process for submitting Spark jobs using BPG for Amazon EMR on EKS is as follows:
The user submits a job to BPG using a client.
BPG parses the request, translates it into a custom resource definition (CRD), and submits the CRD to an EMR on EKS cluster according to predefined rules.
The Spark Kubernetes Operator interprets the job specification and initiates the job on the cluster.
The Kubernetes scheduler schedules and manages the run of the jobs.
The following figure illustrates the high-level details of BPG. You can read more about BPG in the GitHub README.
The proposed solution involves implementing BPG for multiple underlying EMR on EKS clusters, which effectively resolves the drawbacks discussed earlier. The following diagram illustrates the details of the solution.
Familiarity with Kubernetes, Amazon EKS, and Amazon EMR on EKS
Clone the repositories to your local machine
We assume that all repositories are cloned into the home directory (~/). All relative paths provided are based on this assumption. If you have cloned the repositories to a different location, adjust the paths accordingly.
Clone the BPG on EMR on EKS GitHub repo with the following command:
cd ~/
git clone [email protected]:aws-samples/batch-processing-gateway-on-emr-on-eks.git
The BPG repository is currently under active development. To provide a stable deployment experience consistent with the provided instructions, we have pinned the repository to the stable commit hash aa3e5c8be973bee54ac700ada963667e5913c865.
Before cloning the repository, verify any security updates and adhere to your organization’s security practices.
Clone the BPG GitHub repo with the following command:
git clone [email protected]:apple/batch-processing-gateway.git
cd batch-processing-gateway
git checkout aa3e5c8be973bee54ac700ada963667e5913c865
Create two EMR on EKS clusters
The creation of EMR on EKS clusters is not the primary focus of this post. For comprehensive instructions, refer to Running Spark jobs with the Spark operator. However, for your convenience, we have included the steps for setting up the EMR on EKS virtual clusters named spark-cluster-a-v and spark-cluster-b-v in the GitHub repo. Follow these steps to create the clusters.
After successfully completing the steps, you should have two EMR on EKS virtual clusters named spark-cluster-a-v and spark-cluster-b-v running on the EKS clusters spark-cluster-a and spark-cluster-b, respectively.
To verify the successful creation of the clusters, open the Amazon EMR console and choose Virtual clusters under EMR on EKS in the navigation pane.
Set up BPG on Amazon EKS
To set up BPG on Amazon EKS, complete the following steps:
Change to the appropriate directory:
cd ~/batch-processing-gateway-on-emr-on-eks/bpg/
Set up the AWS Region:
export AWS_REGION="<AWS_REGION>"
Create a key pair. Make sure you follow your organization’s best practices for key pair management.
By default, eksctl creates an EKS cluster in dedicated virtual private clouds (VPCs). To avoid reaching the default soft limit on the number of VPCs in an account, we use the --vpc-public-subnets parameter to create clusters in an existing VPC. For this post, we use the default VPC for deploying the solution. Modify the following code to deploy the solution in the appropriate VPC in accordance with your organization’s best practices. For official guidance, refer to Create a VPC.
For your convenience, we have provided the updated files in the batch-processing-gateway-on-emr-on-eks repository. You can copy these files into the batch-processing-gateway repository.
The ImagePullPolicy in the batch-processing-gateway GitHub repo is set to IfNotPresent. Update the image tag in case you need to update the image.
To verify the successful creation and upload of the Docker image, open the Amazon ECR console, choose Repositories under Private registry in the navigation pane, and locate the bpg repository:
To verify the successful creation of the RDS Regional cluster and Writer instance, on the Amazon RDS console, choose Databases in the navigation pane and check for the bpg database.
Set up network connectivity
Security groups for EKS clusters are typically associated with the nodes and the control plane (if using managed nodes). In this section, we configure the networking to allow the node security group of the bpg-cluster to communicate with spark-cluster-a, spark-cluster-b, and the bpg Aurora RDS cluster.
Identify the security groups of bpg-cluster, spark-cluster-a, spark-cluster-b, and the bpg Aurora RDS cluster:
# Identify Node Security Group of the bpg-cluster
BPG_CLUSTER_NODEGROUP_SG=$(aws ec2 describe-instances \
--filters Name=tag:eks:cluster-name,Values=bpg-cluster \
--query "Reservations[*].Instances[*].SecurityGroups[?contains(GroupName, 'eks-cluster-sg-bpg-cluster-')].GroupId" \
--region "$AWS_REGION" \
--output text | uniq)
# Identify Cluster security group of spark-cluster-a and spark-cluster-b
SPARK_A_CLUSTER_SG=$(aws eks describe-cluster --name spark-cluster-a --query "cluster.resourcesVpcConfig.clusterSecurityGroupId" --output text)
SPARK_B_CLUSTER_SG=$(aws eks describe-cluster --name spark-cluster-b --query "cluster.resourcesVpcConfig.clusterSecurityGroupId" --output text)
# Identify Cluster security group of bpg Aurora RDS cluster Writer Instance
BPG_RDS_WRITER_SG=$(aws ec2 describe-security-groups --filters "Name=group-name,Values=bpg-rds-securitygroup" --query "SecurityGroups[*].GroupId" --output text)
Allow the node security group of the bpg-cluster to communicate with spark-cluster-a, spark-cluster-b, and the bpg Aurora RDS cluster:
We deploy BPG for weight-based cluster selection. spark-cluster-a-v and spark-cluster-b-v are configured with a queue named dev and weight=50. We expect statistically equal distribution of jobs between the two clusters. For more information, refer to Weight Based Cluster Selection.
The helm chart for BPG requires a values.yaml file. This file includes various key-value pairs for each EMR on EKS clusters, EKS cluster, and Aurora cluster. Manually updating the values.yaml file can be cumbersome. To simplify this process, we’ve automated the creation of the values.yaml file.
Run the following script to generate the values.yaml file:
cd ~/batch-processing-gateway-on-emr-on-eks/bpg
chmod 755 create-bpg-values-yaml.sh
./create-bpg-values-yaml.sh
Use the following code to deploy the helm chart. Make sure the tag value in both values.template.yaml and values.yaml matches the Docker image tag specified earlier.
To test the solution, you can submit multiple Spark jobs by running the following sample code multiple times. The code submits the SparkPi Spark job to the BPG, which in turn submits the jobs to the EMR on EKS cluster based on the set parameters.
In this post, we explored the challenges associated with managing workloads on EMR on EKS cluster and demonstrated the advantages of adopting a multi-cluster deployment pattern. We introduced Batch Processing Gateway (BPG) as a solution to these challenges, showcasing how it simplifies job management, enhances resilience, and improves horizontal scalability in multi-cluster environments. By implementing BPG, we illustrated the practical application of the gateway architecture pattern for submitting Spark jobs on Amazon EMR on EKS. This post provides a comprehensive understanding of the problem, the benefits of the gateway architecture, and the steps to implement BPG effectively.
We encourage you to evaluate your existing Spark on Amazon EMR on EKS implementation and consider adopting this solution. It allows users to submit, examine, and delete Spark applications on Kubernetes with intuitive API calls, without needing to worry about the underlying complexities.
For this post, we focused on the implementation details of the BPG. As a next step, you can explore integrating BPG with clients such as Apache Airflow, Amazon Managed Workflows for Apache Airflow (Amazon MWAA), or Jupyter notebooks. BPG works well with the Apache Yunikorn scheduler. You can also explore integrating BPG to use Yunikorn queues for job submission.
About the Authors
Umair Nawaz is a Senior DevOps Architect at Amazon Web Services. He works on building secure architectures and advises enterprises on agile software delivery. He is motivated to solve problems strategically by utilizing modern technologies.
Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player.
Sri Potluri is a Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, ensuring scalable and reliable infrastructure tailored to each project’s unique challenges.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
If you have a customer facing application, you might want to enable self-service sign-up, which allows potential customers on the internet to create an account and gain access to your applications. While it’s necessary to allow valid users to sign up to your application, self-service options can open the door to unintended use or sign-ups. Bad actors might leverage the user sign-up process for unintended purposes, launching large-scale distributed denial of service (DDoS) attacks to disrupt access for legitimate users or committing a form of telecommunications fraud known as SMS pumping. SMS pumping is when bad actors purchase a block of high-rate phone numbers from a telecom provider and then coerces unsuspecting services into sending SMS messages to those numbers.
Amazon Cognito is a managed OpenID Connect (OIDC) identity provider (IdP) that you can use to add self-service sign-up, sign-in, and control access features to your web and mobile applications. AWS customers who use Cognito might encounter SMS pumping if SMS functions are enabled to send SMS messages, for example, perform user phone number verification during the registration process, to facilitate SMS multi-factor authentication (MFA) flows, or to support account recovery using SMS. In this blog post, we explore how SMS pumping may be perpetrated and options to reduce risks, including blocking unexpected user registration, detecting anomalies, and responding to risk events with your Cognito user pool.
Cognito user sign-up process
After a user has signed up in your application with an Amazon Cognito user pool, their account is placed in the Registered (unconfirmed) state in your user pool and the user won’t be able to sign in yet. You can use the Cognito-assisted verification and confirmation process to verify user-provided attributes (such as email or phone number) and then confirm the user’s status. This verified attribute is also used for MFA and account recovery purposes. If you choose to verify the user’s phone number, Cognito sends SMS messages with a one-time password (OTP). After a user has provided the correct OTP, their email or phone number is marked as verified and the user can sign in to your application.
Figure 1: Amazon Cognito sign-up process
If the sign-up process isn’t protected, bad actors can create scripts or deploy bots to sign up a large number of accounts, resulting in a significant volume of SMS messages sent in a short period of time. We dive deep into prevention, detection, and remediation mechanisms and strategies that you can apply to help protect against SMS pumping based on your use case.
Protect the sign-up flow
In this section, we review several prevention strategies to help protect against SMS sign-up frauds and help reduce the amount of SMS messages sent to bad actors.
Implement bot mitigation
Implementing bot mitigation techniques, such as CAPTCHA, can be very effective in preventing simple bots from pumping user creation flows. You can integrate a CAPTCHA framework on your application’s frontend and validate that the client initiating the sign-up request is operated by a human user. If the user has passed the verification, you then pass the CAPTCHA user response token in ClientMetadata together with user attributes to an Amazon Cognito SignUp API call. As part of the sign-up process, Cognito invokes an AWS Lambda function called pre sign-up Lambda trigger, which you can use to reject sign-up requests if there isn’t a valid CAPTCHA token presented. This will slow down bots and help reduce unintended account creation in your Cognito user pool.
Validate phone number before user sign-up
Another layer of mitigation is to identify the actor’s phone number early in your application’s sign-up process. You can validate the user provided phone number in the backend to catch incorrectly formatted phone numbers and add logic to help filter out unwanted phone numbers prior to sending text messages. Amazon Pinpoint offers a Phone Number Validate feature that can help you determine if a user-provided phone number is valid, determine phone number type (such as mobile, landline, or VoIP), and identify the country and service provider the phone number is associated with. The returned phone number metadata can be used to decide whether the user will continue the sign-up process and send an SMS message to that user. Note that there’s an additional charge for using the phone number validation service. For more information, see Amazon Pinpoint pricing.
To build this validation check into the Amazon Cognito sign-up process, you can customize the pre sign-up Lambda trigger, which Cognito uses to invoke your code before allowing users to sign-up and sending out an SMS OTP. The Lambda trigger invokes the Amazon Pinpoint phone number validate API, and based on the validation response, you can build a custom pattern that fits your application to continue or reject the user sign-up. For example, you can reject user sign-ups with VoIP numbers or reject users who provide a phone number that’s associated with countries that you don’t operate in, or even reject certain cellular service providers. After you reject a user sign-up using the Lambda trigger, Cognito will deny the user sign-up request and will not invoke user confirmation flow nor send out an SMS message.
When you send a request to the Amazon Pinpoint phone number validation service, it returns the following metadata about the phone number. The following example represents a valid mobile phone number data set:
Note that PhoneType includes type MOBILE, LANDLINE, VOIP, INVALID, or OTHER. INVALID phone numbers don’t include information about the carrier or location associated with the phone number and are unlikely to belong to actual recipients. This helps you decide when to reject user sign-ups and reduces SMS messages to undesired phone numbers. You can see details about other responses in the Amazon Pinpoint developer guide.
Example pre sign-up Lambda function to block user sign-up except with a valid MOBILE number
The following pre sign-up Lambda function example invokes the Amazon Pinpoint phone number validation service and rejects user sign-ups unless the validation service returns a valid mobile phone number.
import { PinpointClient, PhoneNumberValidateCommand } from "@aws-sdk/client-pinpoint"; // ES Modules import
const validatePhoneNumber = async (phoneNumber) => {
const pinpoint = new PinpointClient();
const input = { // PhoneNumberValidateRequest
NumberValidateRequest: { // NumberValidateRequest
PhoneNumber: phoneNumber,
},
};
const command = new PhoneNumberValidateCommand(input);
const response = await pinpoint.send(command);
return response;
};
const handler = async (event, context, callback) => {
const phoneNumber = event.request.userAttributes.phone_number;
const validationResponse = await validatePhoneNumber(phoneNumber);
if (validationResponse.NumberValidateResponse.PhoneType != "MOBILE") {
var error = new Error("Cannot register users without a mobile number");
// Return error to Amazon Cognito
callback(error, event);
}
// Return to Amazon Cognito
callback(null, event);
};
export { handler };
Use a custom user-initiated confirmation flow or alternative OTP delivery method
In your user pool configurations, you can opt out of using Amazon Cognito-assisted verification and confirmation to send SMS messages to confirm users. Instead, you can build a custom reverse OTP flow to ask your users to initiate the user confirmation process. For example, instead of automatically sending SMS messages to a user when they sign up, your application can display an OTP and direct the user to initiate the SMS conversation by texting the OTP to your service number. After your application has received the SMS message and confirmed the correct OTP is provided, invoke a service such as a Lambda function to call the AdminConfirmSignUp administrative API operation to confirm user, then call AdminUpdateUserAttributes to set the phone_number_verified attribute as true to indicate that the user phone number is verified.
You can also choose to deliver an OTP using other methods, such as email, especially if your application doesn’t require the user’s phone number. During the user sign-up process, you can configure a custom SMS sender Lambda trigger in Amazon Cognito to send a user verification code through email or another method. Additionally, you can use the Cognito email MFA feature to send MFA codes through email.
Detect SMS pumping
When you’re considering the various prevention options, it’s important to set up detection mechanisms to identify SMS pumping as they arise. In this section, we show you how to use AWS CloudTrail and Amazon CloudWatch to monitor your Amazon Cognito user pool and detect anomalies that could lead to SMS pumping. Note that building detection mechanism based on anomalies requires knowing your average or baseline traffic and the difference in metrics that represent regular activity and metrics that can indicate unauthorized or unintended activity.
Service quotas dashboard and CloudWatch alarms
Bad actors may attempt to leverage either the sign-up confirmation or the reset password functionality of Amazon Cognito. As shown previously in Figure 1, when a new user signs up to your Cognito user pool, the SignUp API operation is invoked. When the user provides the OTP confirmation code, the ConfirmSignUp API operation is invoked. The call rate of both APIs is tracked collectively under Rate of UserCreation requests under Amazon Cognito service in the service quotas dashboard.
You can set up Amazon CloudWatch alarms to monitor and issue notifications when you’re close to a quota value threshold. These alarms could be an early indication of a sudden usage increase, and you can use them to triage potential incidents.
Additionally, when your services are sending SMS messages, those transactions count towards the Amazon Simple Notification Service (Amazon SNS) service quota. You should set up alarms to monitor the Transactional SMS Message Delivery Rate per Second quota and the SMS Message Spending in USD quota.
CloudTrail event history
When bad actors plan SMS pumping, they are likely attempting to trick you to send as many SMS messages as possible rather than completing the user confirmation process. Under the context of a user sign-up event, you might notice in the CloudTrail event history that there are more SignUp and ResendConfirmationCode events—which send out SMS messages—than ConfirmSignUp operations; indicating a user has initiated but not completed the sign-up process. You can use Amazon Athena or CloudWatch Logs Insights to search and analyze your Amazon Cognito CloudTrail events and identify if there’s a significant reduction in finishing the user sign-up process.
Figure 2: SignUp API logged in CloudTrail event history
Similarly, you can apply this observability towards the user password reset flow by analyzing the ForgotPassword API and ConfirmForgotPassword API operations for deviations.
Note that the slight deviations in user completion flow in the CloudTrail event history alone might not be an indication of unauthorized activity, however a substantial deviation above the regular baseline might be a signal of unintended use.
Monitor excessive billing
Another opportunity for detecting and identifying unauthorized Amazon Cognito activity is by using AWS Cost Explorer. You can use this interface to visualize, understand, and manage your AWS costs and usage over time, which might assist by highlighting the source of excessive billing in your AWS account. Be aware that charges in your account can take up to 24 hours to be displayed, so while this method can help provide some assistance in identifying SMS pumping activity, it should only be used as a supplement to other detection methods.
In the navigation pane, under Cost Analysis, choose Cost Explorer.
In the Cost and Usage Report, under Report Parameters, select Date Range to include the start and end date of the time period that you want to apply a filter to. In Figure 3 that follows, we use an example date range between 2024-07-03 and 2024-07-17.
In the same Report Parameter area, under Filters, for Service, select SNS (Simple Notification Service). Because Amazon Cognito uses Amazon SNS for delivery of SMS messages, filtering on SNS can help you identify excessive billing.
Figure 3: Reviewing billing charges by service
Apply AWS WAF rules as mitigation approaches
It’s recommended that you apply AWS WAF with your Amazon Cognito user pool to protect against common threats. In this section, we show you a few advanced options using AWS WAF rules to block or throttle specific bad actor’s traffic when you have observed irregular sign-up attempts and suspect they were part of fraudulent activities.
Target a specific bad actor’s IP address
When building AWS WAF remediation strategies, you can start by building an IP deny list to block traffic from known malicious IP addresses. This method is straightforward and can be highly effective in preventing unwanted access. For detailed instructions on how to set up an IP deny list, see Creating an IP set.
Target a specific phone number area code regex pattern
In an SMS pumping scheme, bad actors often purchase blocks of cell phone numbers from a wireless service provider and use phone numbers with the same area code. If you observe a pattern and identify that these attempts use the same area code, you can apply an AWS WAF rule to block that specific traffic.
To configure an AWS WAF web ACL to block using an area code regex pattern:
Open the AWS WAF console.
In the navigation pane, under AWS WAF, choose WAF ACLs.
Choose Create web ACL. Under Web ACL details, select Regional resources, and select the AWS Region as your Amazon Cognito user pool. Under Associated AWS resources, select Add AWS resources, and choose your Cognito user pool. Choose Next.
On the Add rules and rule groups page, choose Add rules, Add my own rules and rule groups, and Rule builder.
Create a rule in Rule builder.
For If a request, select matches the statement.
For Inspect, select Body.
For Match type, select Matches regular expression.
For Regular expression, enter a match for the observed pattern. For example, the regular expression ^303|^\+1303|^001303 will match requests that include the digits 303, +1303, or 001303 at the beginning of any string in the body of a request:
Figure 4: Creating a web ACL
Under Action, choose Block. Then, choose Add rule.
Continue with Set rule priority and Configure metrics, then choose Create web ACL.
Be aware that this method will block all user sign-up requests that contain phone numbers matching the regex pattern for the target area code and could prevent legitimate users whose numbers match the defined pattern from signing up. For example, the rule above will apply to all users with phone numbers starting with 303, +1303, or 001303. You should consider implementing this method as an as-needed solution to address an ongoing SMS pumping attack.
Target a specific bad actor’s client fingerprint
Another method is to examine an actor’s TLS traffic. If your application UI is hosted using Amazon CloudFront or Application Load Balancer (ALB), you can build AWS WAF rules to match the client’s JA3 fingerprint. The JA3 fingerprint is a 32-character MD5 hash derived from the TLS three-way handshake when the client sends a ClientHello packet to the server. It serves as a unique identifier for the client’s TLS configuration because various attributes such as TLS version, cipher suites, and extensions are derived to calculate the fingerprint, allowing for the unique detection of clients even when the source IP and other commonly used identification information might have changed.
Fraudulent activities, such as SMS pumping, are typically carried out using automated tools and scripts. These tools often have a consistent SSL/TLS handshake pattern, resulting in a unique JA3 fingerprint. By configuring an AWS WAF web ACL rule to match the JA3 fingerprint associated with this traffic, you can identify clients with a high degree of accuracy, even if they change other attributes, such as IP addresses.
AWS WAF has introduced support for JA3 fingerprint matching, which you can use to identify and differentiate clients based on the way they initiate TLS connections, enabling you to inspect incoming requests for their JA3 fingerprints. You can build the remediation strategy by first evaluating AWS WAF logs to extract JA3 fingerprints for potential malicious hosts, then proceed with creating rules to block requests where the fingerprint matches the malicious JA3 fingerprint associated with previous attacks.
To configure an AWS WAF web ACL to block using JA3 fingerprint matching for CloudFront resources:
Open the AWS WAF console.
In the navigation pane, under AWS WAF, choose WAF ACLs.
Choose Create web ACL. Under Web ACL details, select Amazon CloudFront distributions. Under Associated AWS resources, select Add AWS resources, and select your CloudFront distribution. Choose Next.
On the Add rules and rule groups page, choose Add rules, Add my own rules and rule groups, and Rule builder.
In Rule builder:
For If a request, select matches the statement.
For Inspect, select JA3 fingerprint.
For Match type, keep Exactly matches string.
For String to match, enter the JA3 fingerprint that you want to block.
For Text transformation, choose None.
For Fallback for missing JA3 fingerprint, select a fallback match status for cases where no JA3 fingerprint is detected. We recommend choosing No match to prevent unintended traffic blocking.
If you need to block multiple JA3 fingerprints, include each one in the rule and for If a request select matches at least one of the statements (OR).
Figure 5: Creating an AWS WAF statement for a JA3 fingerprint
Under Action, select Block, and choose Add rule. You can choose other actions such as COUNT or CAPTCHA that suit your use case.
Continue with Set rule priority and Configure metrics, then choose Create web ACL.
Note that JA3 fingerprints can change over time due to the randomization of TLS ClientHello messages by modern browsers. It’s important to dynamically update your web ACL rules or manually review logs to update the JA3 fingerprint search string in your match rule when applicable.
AWS WAF remediation considerations
These AWS WAF remediation approaches help to block potential threats by providing mechanisms to filter out malicious traffic. It’s essential to continually review the effectiveness of these rules to minimize the risk of blocking legitimate sources and make dynamic adjustments to the rules when you detect new bad actors and patterns.
Summary
In this blog post, we introduced mechanisms that you can use to detect and protect your Amazon Cognito user pool against unintended user sign-up and SMS pumping. By implementing these strategies, you can enhance the security of your web and mobile applications and help to safeguard your services from potential abuse and financial loss. We suggest that you apply a combination of these prevention, detection, and mitigation approaches to protect your Cognito user pools.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that makes it easy to build and run Kafka clusters on Amazon Web Services (AWS). When working with Amazon MSK, developers are interested in accessing the service locally. This allows developers to test their application with a Kafka cluster that has the same configuration as production and provides an identical infrastructure to the actual environment without needing to run Kafka locally.
This post presents a practical approach to accessing your Amazon MSK environment for development purposes through a bastion host using a Secure Shell (SSH) tunnel (a commonly used secure connection method). Whether you’re working with Amazon MSK Serverless, where public access is unavailable, or with provisioned MSK clusters that are intentionally kept private, this post guides you through the steps to establish a secure connection and seamlessly integrate your local development environment with your MSK resources.
Solution overview
The solution allows you to directly connect to the Amazon MSK Serverless service from your local development environment without using Direct Connect or a VPN. The service is accessed with the bootstrap server DNS endpoint boot-<<xxxxxx>>.c<<x>>.kafka-serverless.<<region-name>>.amazonaws.com on port 9098, then routed through an SSH tunnel to a bastion host, which connects to the MSK Serverless cluster. In the next step, let’s explore how to set up this connection.
The flow of the solution is as follows:
The Kafka client sends a request to connect to the bootstrap server
The DNS query for your MSK Serverless endpoint is routed to a locally configured DNS server
The locally configured DNS server routes the DNS query to localhost.
The SSH tunnel forwards all the traffic on port 9098 from the localhost to the MSK Serverless server through the Amazon Elastic Compute Cloud (Amazon EC2) bastion host.
The following image shows the architecture diagram.
Prerequisites
Before deploying the solution, you need to have the following resources deployed in your account:
For Windows users, install Linux on Windows with Windows Subsystem for Linux 2 (WSL 2) using Ubuntu 24.04. For guidance, refer to How to install Linux on Windows with WSL.
This guide assumes an MSK Serverless deployment in us-east-1, but it can be used in every AWS Region where MSK Serverless is available. Furthermore, we are using OS X as operating system. In the following steps replace msk-endpoint-url with your MSK Serverless endpoint URL with IAM authentication. The MSK endpoint URL has a format like boot-<<xxxxxx>>.c<<x>>.kafka-serverless.<<region-name>>.amazonaws.com.
Solution walkthrough
To access your Amazon MSK environment for development purposes, use the following walkthrough.
Configure local DNS server OSX
Install Dnsmasq as a local DNS server and configure the resolver to resolve the Amazon MSK. The solution uses Dnsmasq because it can compare DNS requests against a database of patterns and use these to determine the correct response. This functionality can match any request that ends in kafka-serverless.us-east-1.amazonaws.com and send 127.0.0.1 in response. Follow these steps to install Dnsmasq:
Update brew and install Dnsmasq using brew
brew up
brew install dnsmasq
Start the Dnsmasq service
sudo brew services start dnsmasq
Reroute all traffic for Serverless MSK (kafka-serverless.us-east-1.amazonaws.com) to 127.0.0.1
Now that you have a working DNS server, you can configure your operating system to use it. Configure the server to send only .kafka-serverless.us-east-1.amazonaws.com queries to Dnsmasq. Most operating systems that are similar to UNIX have a configuration file called /etc/resolv.conf that controls the way DNS queries are performed, including the default server to use for DNS queries. Use the following steps to configure the OS X resolver:
OS X also allows you to configure additional resolvers by creating configuration files in the /etc/resolver/ This directory probably won’t exist on your system, so your first step should be to create it:
sudo mkdir -p /etc/resolver
Create a new file with the same name as your new top-level domain (kafka-serverless.us-east-1.amazonaws.com) in the /etc/resolver/ directory and add 127.0.0.1 as a nameserver to it by entering the following command.
sudo tee /etc/resolver/kafka-serverless.us-east-1.amazonaws.com >/dev/null <<EOF
nameserver 127.0.0.1
EOF
Configure local DNS server Windows
In Windows Subsystem for Linux, first install Dnsmasq, then configure the resolver to resolve the Amazon MSK and finally add localhost as the first nameserver.
Update apt and install Dnsmasq using apt. Install the telnet utility for later tests:
The next step is to create the SSH tunnel, which will allow any connections made to localhost:9098 on your local machine to be forwarded over the SSH tunnel to the target Kafka broker. Use the following steps to create the SSH tunnel:
Replace bastion-host-dns-endpoint with the public DNS endpoint of the bastion host, which comes in the style of <<xyz>>.compute-1.amazonaws.com, and replace ec2-key-pair.pem with the key pair of the bastion host. Then create the SSH tunnel by entering the following command.
Leave the SSH tunnel running and open a new terminal window.
Test the connection to the Amazon MSK server by entering the following command.
telnet <<msk-endpoint-url>> 9098
The output should look like the following example.
Trying 127.0.0.1...
Connected to boot-<<xxxxxxxx>>.c<<x>>.kafka-serverless.us-east-1.amazonaws.com.
Escape character is '^]'.
Testing
Now configure the Kafka client to use IAM Authentication and then test the setup. You find the latest Kafka installation at the Apache Kafka Download site. Then unzip and copy the content of the Dafka folder into ~/kafka.
Download the IAM authentication and unpack it
cd ~/kafka/libs
wget https://github.com/aws/aws-msk-iam-auth/releases/download/v2.2.0/aws-msk-iam-auth-2.2.0-all.jar
cd ~
Configure Kafka properties to use IAM as the authentication mechanism
cat <<EOF > ~/kafka/config/client-config.properties
# Sets up TLS for encryption and SASL for authN.
security.protocol = SASL_SSL
# Identifies the SASL mechanism to use.
sasl.mechanism = AWS_MSK_IAM
# Binds SASL client implementation.
sasl.jaas.config = software.amazon.msk.auth.iam.IAMLoginModule required;
# Encapsulates constructing a SigV4 signature based on extracted credentials.
# The SASL client bound by "sasl.jaas.config" invokes this class.
sasl.client.callback.handler.class = software.amazon.msk.auth.iam.IAMClientCallbackHandler
EOF
Enter the following command in ~/kafka/bin to create an example topic. Make sure that the SSH tunnel created in the previous section is still open and running.
To remove the solution, complete the following steps for Mac users:
Delete the file /etc/resolver/kafka-serverless.us-east-1.amazonaws.com
Delete the entry address=/kafka-serverless.us-east-1.amazonaws.com/127.0.0.1 in the file $(brew --prefix)/etc/dnsmasq.conf
Stop the Dnsmasq service sudo brew services stop dnsmasq
Remove the Dnsmasq service sudo brew uninstall dnsmasq
To remove the solution, complete the following steps for WSL users:
Delete the file /etc/dnsmasq.conf
Delete the entry nameserver 127.0.0.1 in the file /etc/resolv.conf
Remove the Dnsmasq service sudo apt remove dnsmasq
Remove the telnet utility sudo apt remove telnet
Conclusion
In this post, I presented you with guidance on how developers can connect to Amazon MSK Serverless from local environments. The connection is done using an Amazon MSK endpoint through an SSH tunnel and a bastion host. This enables developers to experiment and test locally, without needing to setup a separate Kafka cluster.
About the Author
Simon Peyer is a Solutions Architect at Amazon Web Services (AWS) based in Switzerland. He is a practical doer and passionate about connecting technology and people using AWS Cloud services. A special focus for him is data streaming and automations. Besides work, Simon enjoys his family, the outdoors, and hiking in the mountains.
In the context of Retrieval-Augmented Generation (RAG), knowledge retrieval plays a crucial role, because the effectiveness of retrieval directly impacts the maximum potential of large language model (LLM) generation.
Currently, in RAG retrieval, the most common approach is to use semantic search based on dense vectors. However, dense embeddings do not perform well in understanding specialized terms or jargon in vertical domains. A more advanced method is to combine traditional inverted-index(BM25) based retrieval, but this approach requires spending a considerable amount of time customizing lexicons, synonym dictionaries, and stop-word dictionaries for optimization.
In this post, instead of using the BM25 algorithm, we introduce sparse vector retrieval. This approach offers improved term expansion while maintaining interpretability. We walk through the steps of integrating sparse and dense vectors for knowledge retrieval using Amazon OpenSearch Service and run some experiments on some public datasets to show its advantages. The full code is available in the github repo aws-samples/opensearch-dense-spase-retrieval.
What’s Sparse vector retrieval
Sparse vector retrieval is a recall method based on an inverted index, with an added step of term expansion. It comes in two modes: document-only and bi-encoder. For more details about these two terms, see Improving document retrieval with sparse semantic encoders.
Simply put, in document-only mode, term expansion is performed only during document ingestion. In bi-encoder mode, term expansion is conducted both during ingestion and at the time of query. Bi-encoder mode improves performance but may cause more latency. The following figure demonstrates its effectiveness.
Neural sparse search in OpenSearch achieves 12.7%(document-only) ~ 20%(bi-encoder) higher NDCG@10, comparable to the TAS-B dense vector model.
With neural sparse search, you don’t need to configure the dictionary yourself. It will automatically expand terms for the user. Additionally, in an OpenSearch index with a small and specialized dataset, while hit terms are generally few, the calculated term frequency may also lead to unreliable term weights. This may lead to significant bias or distortion in BM25 scoring. However, sparse vector retrieval first expands terms, greatly increasing the number of hit terms compared to before. This helps produce more reliable scores.
Although the absolute metrics of the sparse vector model can’t surpass those of the best dense vector models, it possesses unique and advantageous characteristics. For instance, in terms of the NDCG@10 metric, as mentioned in Improving document retrieval with sparse semantic encoders, evaluations on some datasets reveal that its performance could be better than state-of-the-art dense vector models, such as in the DBPedia dataset. This indicates a certain level of complementarity between them. Intuitively, for some extremely short user inputs, the vectors generated by dense vector models might have significant semantic uncertainty, where overlaying with a sparse vector model could be beneficial. Additionally, sparse vector retrieval still maintains interpretability, and you can still observe the scoring calculation through the explanation command. To take advantage of both methods, OpenSearch has already introduced a built-in feature called hybrid search.
How to combine dense and sparse?
1. Deploy a dense vector model
To get more valuable test results, we selected Cohere-embed-multilingual-v3.0, which is one of several popular models used in production for dense vectors. We can access it through Amazon Bedrock and use the following two functions to create a connector for bedrock-cohere and then register it as a model in OpenSearch. You can get its model ID from the response.
2.1 On the OpenSearch Service console, choose Integrations in the navigation pane.
2.2 Under Integration with Sparse Encoders through Amazon SageMaker, choose to configure a VPC domain or public domain.
Next, you configure the AWS CloudFormation template.
2.3 Enter the parameters as shown in the following screenshot.
2.4 Get the sparse model ID from the stack output.
3. Set up pipelines for ingestion and search
Use the following code to create pipelines for ingestion and search. With these two pipelines, there’s no need to perform model inference, just text field ingestion.
4. Create an OpenSearch index with dense and sparse vectors
Use the following code to create an OpenSearch index with dense and sparse vectors. You must specify the default_pipeline as the ingestion pipeline created in the previous step.
For retrieval evaluation, we used to use the datasets from BeIR. But not all datasets from BeIR are suitable for RAG. To mimic the knowledge retrieval scenario, we choose BeIR/fiqa and squad_v2 as our experimental datasets. The schema of its data is shown in the following figures.
The following is a data preview of squad_v2.
The following is a query preview of BeIR/fiqa.
The following is a corpus preview of BeIR/fiqa.
You can find question and context equivalent fields in the BeIR/fiqa datasets. This is almost the same as the knowledge recall in RAG. In subsequent experiments, we input the context field into the index of OpenSearch as text content, and use the question field as a query for the retrieval test.
2. Test data ingestion
The following script ingests data into the OpenSearch Service domain:
import json
from setup_model_and_pipeline import get_aos_client
from beir.datasets.data_loader import GenericDataLoader
from beir import LoggingHandler, util
aos_client = get_aos_client(aos_endpoint)
def ingest_dataset(corpus, aos_client, index_name, bulk_size=50):
i=0
bulk_body=[]
for _id , body in tqdm(corpus.items()):
text=body["title"]+" "+body["text"]
bulk_body.append({ "index" : { "_index" : index_name, "_id" : _id } })
bulk_body.append({ "content" : text })
i+=1
if i % bulk_size==0:
response=aos_client.bulk(bulk_body,request_timeout=100)
try:
assert response["errors"]==False
except:
print("there is errors")
print(response)
time.sleep(1)
response = aos_client.bulk(bulk_body,request_timeout=100)
bulk_body=[]
response=aos_client.bulk(bulk_body,request_timeout=100)
assert response["errors"]==False
aos_client.indices.refresh(index=index_name)
url = f"https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/{dataset_name}.zip"
data_path = util.download_and_unzip(url, data_root_dir)
corpus, queries, qrels = GenericDataLoader(data_folder=data_path).load(split="test")
ingest_dataset(corpus, aos_client=aos_client, index_name=index_name)
3. Performance evaluation of retrieval
In RAG knowledge retrieval, we usually focus on the relevance of top results, so our evaluation uses recall@4 as the metric indicator. The whole test will include various retrieval methods to compare, such as bm25_only, sparse_only, dense_only, hybrid_sparse_dense, and hybrid_dense_bm25.
The following script uses hybrid_sparse_dense to demonstrate the evaluation logic:
In the context of RAG, usually the developer doesn’t pay attention to the metric NDCG@10; the LLM will pick up the relevant context automatically. We care more about the recall metric. Based on our experience of RAG, we measured recall@1, recall@4, and recall@10 for your reference.
The dataset BeIR/fiqa is mainly used for evaluation of retrieval, whereas squad_v2 is mainly used for evaluation of reading comprehension. In terms of retrieval, squad_v2 is much less complicated than BeIR/fiqa. In the real RAG context, the difficulty of retrieval may not be as high as with BeIR/fiqa, so we evaluate both datasets.
The hybird_dense_sparse metric is always beneficial. The following table shows our results.
Dataset
BeIR/fiqa
squad_v2
Method\Metric
Recall@1
Recall@4
Recall@10
Recall@1
Recall@4
Recall@10
bm25
0.112
0.215
0.297
0.59
0.771
0.851
dense
0.156
0.316
0.398
0.671
0.872
0.925
sparse
0.196
0.334
0.438
0.684
0.865
0.926
hybird_dense_sparse
0.203
0.362
0.456
0.704
0.885
0.942
hybird_dense_bm25
0.156
0.316
0.394
0.671
0.871
0.925
Conclusion
The new neural sparse search feature in OpenSearch Service version 2.11, when combined with dense vector retrieval, can significantly improve the effectiveness of knowledge retrieval in RAG scenarios. Compared to the combination of bm25 and dense vector retrieval, it’s more straightforward to use and more likely to achieve better results.
OpenSearch Service version 2.12 has recently upgraded its Lucene engine, significantly enhancing the throughput and latency performance of neural sparse search. But the current neural sparse search only supports English. In the future, other languages might be supported. As the technology continues to evolve, it stands to become a popular and widely applicable way to enhance retrieval performance.
About the Author
YuanBo Li is a Specialist Solution Architect in GenAI/AIML at Amazon Web Services. His interests include RAG (Retrieval-Augmented Generation) and Agent technologies within the field of GenAI, and he dedicated to proposing innovative GenAI technical solutions tailored to meet diverse business needs.
Charlie Yang is an AWS engineering manager with the OpenSearch Project. He focuses on machine learning, search relevance, and performance optimization.
River Xie is a Gen AI specialist solution architecture at Amazon Web Services. River is interested in Agent/Mutli Agent workflow, Large Language Model inference optimization, and passionate about leveraging cutting-edge Generative AI technologies to develop modern applications that solve complex business challenges.
Ren Guo is a manager of Generative AI Specialist Solution Architect Team for the domains of AIML and Data at AWS, Greater China Region.
This post is co-written with Sid Wray, Jade Koskela, and Ravi Bhattiprolu from SalesForce.
Amazon Redshift and Tableau empower data analysis. Amazon Redshift is a cloud data warehouse that processes complex queries at scale and with speed. Its advanced query optimization serves results to Tableau. Tableau’s extensive capabilities and enterprise connectivity help analysts efficiently prepare, explore, and share data insights company-wide.
Amazon Web Services (AWS) collaborated with Tableau to enable SSO support for accessing Amazon Redshift from Tableau. Both Tableau Desktop 2023.3.9 and Tableau Server 2023.3.9 releases support trusted identity propagation with IAM Identity Center. This SSO integration is available for Tableau Desktop, Tableau Server, and Tableau Prep.
This blog post provides a step-by-step guide to integrating IAM Identity Center with Microsoft Entra ID as the IdP and configuring Amazon Redshift as an AWS managed application. Additionally, you’ll learn how to set up the Amazon Redshift driver in Tableau, enabling SSO directly within Tableau Desktop.
Solution overview
The following diagram illustrates the architecture of the Tableau SSO integration with Amazon Redshift, IAM Identity Center, and Microsoft Entra ID.
Figure 1: Solution overview for Tableau integration with Amazon Redshift using IAM Identity Center and Microsoft Entra ID
The solution depicted in Figure 1 includes the following steps:
The user configures Tableau to access Amazon Redshift using IAM Identity Center.
On a user sign-in attempt, Tableau initiates a browser-based OAuth flow and redirects the user to the Microsoft Entra ID sign-in page to enter the sign-in credentials.
After successful authentication, Microsoft Entra ID issues authentication tokens (ID and access token) to Tableau.
The Amazon Redshift driver then makes a call to the Amazon Redshift-enabled Identity Center application and forwards the access token.
Amazon Redshift passes the token to IAM Identity Center for validation.
IAM Identity Center first validates the token using the OpenID Connect (OIDC) discovery connection to the trusted token issuer (TTI) and returns an IAM Identity Center generated access token for the same user. In Figure 1, the TTI is the Microsoft Entra ID server.
Amazon Redshift then uses the access token to obtain the user and group membership information from Identity Center.
The Tableau user will be able to connect with Amazon Redshift and access data based on the user and group membership returned from IAM Identity Center.
Prerequisites
Before you begin implementing the solution, you must have the following in place:
Install Tableau Server 2023.3.9 or above version. For Tableau Server installation, see Install and Configure Tableau Server.
Use an Entra ID account that has an active subscription. You need an admin role to set up the application on Entra ID. If you don’t have an Entra ID account, you can create an account for free.
Walkthrough
In this walkthrough, you will use the following steps to build the solution:
Set up the Microsoft Entra ID OIDC application
Collect Microsoft Entra ID information
Set up a trusted token issuer in IAM Identity Center
Set up client connections and trusted token issuers
Set up the Tableau OAuth config files for Microsoft Entra ID
Install the Tableau OAuth config file for Tableau Desktop
Set up the Tableau OAuth config file for Tableau Server or Tableau Cloud
Federate to Amazon Redshift from Tableau Desktop
Federate to Amazon Redshift from Tableau Server
Set up the Microsoft Entra ID OIDC application
To create your Microsoft Entra application and service principal, follow these steps:
In the navigation pane, choose Certificates & secrets.
Choose New client secret.
Enter a Description and select an expiration for the secret or specify a custom lifetime. For this example, keep the Microsoft recommended default expiration value of 6 months. Choose Add.
Copy the secret value. Note: It will only be presented one time; after that you cannot read it.
In the navigation pane, under Manage, choose Expose an API.
If you’re setting up for the first time, you can see Set to the right of Application ID URI.
Choose Set, and then choose Save.
After the application ID URI is set up, choose Add a scope.
For Scope name, enter a name. For example, redshift_login.
For Admin consent display name, enter a display name. For example, redshift_login.
For Admin consent description, enter a description of the scope.
To configure your IdP with IAM Identity Center and Amazon Redshift, collect the following parameters from Microsoft Entra ID. If you don’t have these parameters, contact your Microsoft Entra ID admin.
Tenant ID,Client ID and Audience value: To get these values:
Sign in to the Azure portal with your Microsoft account.
Under Manage, choose App registrations.
Choose the application that you created in previous sections.
On the left panel, choose Overview, a new page will appear containing the Essentials section. You can find the Tenant ID,Client ID and Audience value (Application ID URI) as shown in the following figure:
Figure 2: Overview section of OIDC application
Scope: To find your scope value:
In the navigation pane of the OIDC application, under Manage, choose Expose an API.
You will find the value under Scopes as shown in the following figure:
Figure 3: Application scope
Set up a trusted token issuer in IAM Identity Center
At this point, you have finished configurations in the Entra ID console; now you’re ready to add Entra ID as a TTI. You will start by adding a TTI so you can exchange tokens. In this step, you will create a TTI in the centralized management account. To create a TTI, follow these steps:
Open the AWS Management Console and navigate to IAM Identity Center, and then to the Settings
Select the Authentication tab and under Trusted token issuers, choose Create trusted token issuer.
On the Set up an external IdP to issue trusted tokens page, under Trusted token issuer details, do the following:
For Issuer URL, enter the OIDC discovery URL of the external IdP that will issue tokens for trusted identity propagation. The URL would be: https://sts.windows.net/<tenantid>/. To find your Microsoft Entra tenant ID, see Collect Microsoft Entra ID information.
For Trusted token issuer name, enter a name to identify this TTI in IAM Identity Center and in the application console.
Under Map attributes, do the following:
For Identity provider attribute, select an attribute from the list to map to an attribute in the Identity Center identity store. You can choose Email, Object Identifier, Subject, and Other. This example uses Other where we’re specifying the upn (user principal name) as the Identity provider attribute to map with Email from the IAM identity Center attribute.
For IAM Identity Center attribute, select the corresponding attribute for the attribute mapping.
Under Tags (optional), choose Add new tag, specify a value for Key, and optionally for Value. For information about tags, see Tagging AWS IAM Identity Center resources.
Figure 4 that follows shows the set up for TTI.
Figure 4: Create a trusted token issuer
Choose Create trusted token issuer.
Set up client connections and trusted token issuers
A third-party application (such as Tableau) that isn’t managed by AWS exchanges the external token (JSON Web Token (JWT) for an IAM Identity Center token before calling AWS services.
The JWT must contain a subject (sub) claim, an audience (aud) claim, an issuer (iss), a user attribute claim, and a JWT ID (JTI) claim. The audience is a value that represents the AWS service that the application will use, and the audience claim value must match the value that’s configured in the Redshift application that exchanges the token.
In this section, you will specify the audience claim in the Redshift application, which you will get from Microsoft Entra ID. You will configure the Redshift application in the member account where the Redshift cluster or serverless instance is.
Select IAM Identity Center connection from Amazon Redshift console menu.
Figure 5: Redshift IAM Identity Center connection
Select the Amazon Redshift application that you created as part of the prerequisites.
Select the Client connections tab and choose Edit.
Choose Yes under Configure client connections that use third-party IdPs.
Select the checkbox for Trusted token issuer that you created in the previous section.
Enter the aud claim value under Configure selected trusted token issuers. For example, api://1230a234-b456-7890-99c9-a12345bcc123. To get the audience value, see Collect Microsoft Entra ID information.
Choose Save.
Figure 6: Adding an audience claim for the TTI
Your IAM Identity Center, Amazon Redshift, and Microsoft Entra ID configuration is complete. Next, you need to configure Tableau.
Set up the Tableau OAuth config files for Microsoft Entra ID
To integrate Tableau with Amazon Redshift using IAM Identity Center, you need to use a custom XML. In this step, you use the following XML and replace the values starting with the $ sign and highlighted in bold. The rest of the values can be kept as they are, or you can modify them based on your use case. For detailed information on each of the elements in the XML file, see the Tableau documentation on GitHub.
Note: The XML file will be used for all the Tableau products including Tableau Desktop, Server, and Cloud. You can use the following XML or you can refer to Tableau’s github.
<?xml version="1.0" encoding="utf-8"?>
<pluginOAuthConfig>
<dbclass>redshift</dbclass>
<!-- For configs embedded in the connector package, don't prefix with "custom_". For external configs, always prefix with "custom_". -->
<oauthConfigId>custom_redshift_azure</oauthConfigId>
<clientIdDesktop>$copy_client_id_from_azure_oidc_app</clientIdDesktop>
<clientSecretDesktop>$copy_client_secret_from_azure_oidc_app</clientSecretDesktop>
<redirectUrisDesktop>http://localhost:55556/Callback</redirectUrisDesktop>
<redirectUrisDesktop>http://localhost:55557/Callback</redirectUrisDesktop>
<redirectUrisDesktop>http://localhost:55558/Callback</redirectUrisDesktop>
<redirectUrisDesktop>http://localhost:55559/Callback</redirectUrisDesktop>
<!-- For multitenant apps use the common endpoint, for single tenant apps use the directory specific endpoint. -->
<authUri>https://login.microsoftonline.com/$azure_tenant_id/oauth2/v2.0/authorize</authUri>
<tokenUri>https://login.microsoftonline.com/$azure_tenant_id/oauth2/v2.0/token</tokenUri>
<scopes>openid</scopes>
<scopes>offline_access</scopes>
<scopes>email</scopes>
<!-- An example with a custom API, which was required at the time of writing for integration with AWS IAM IDC. -->
<scopes>$scope_from_azure_oidc_app</scopes>
<capabilities>
<entry>
<key>OAUTH_CAP_REQUIRES_PROMPT_SELECT_ACCOUNT</key>
<value>true</value>
</entry>
<entry>
<key>OAUTH_CAP_REQUIRE_PKCE</key>
<value>true</value>
</entry>
<entry>
<key>OAUTH_CAP_PKCE_REQUIRES_CODE_CHALLENGE_METHOD</key>
<value>true</value>
</entry>
<entry>
<key>OAUTH_CAP_SUPPORTS_STATE</key>
<value>true</value>
</entry>
<entry>
<key>OAUTH_CAP_CLIENT_SECRET_IN_URL_QUERY_PARAM</key>
<value>false</value>
</entry>
<entry>
<key>OAUTH_CAP_SUPPORTS_GET_USERINFO_FROM_ID_TOKEN</key>
<value>true</value>
</entry>
<!-- Depending on the Azure application, dynamic ports may not be allowed. Enable this if not allowed. -->
<entry>
<key>OAUTH_CAP_FIXED_PORT_IN_CALLBACK_URL</key>
<value>true</value>
</entry>
</capabilities>
<accessTokenResponseMaps>
<entry>
<key>ACCESSTOKEN</key>
<value>access_token</value>
</entry>
<entry>
<key>REFRESHTOKEN</key>
<value>refresh_token</value>
</entry>
<entry>
<key>access-token-issue-time</key>
<value>issued_at</value>
</entry>
<entry>
<key>id-token</key>
<value>id_token</value>
</entry>
<entry>
<key>username</key>
<value>email</value>
</entry>
<entry>
<key>access-token-expires-in</key>
<value>expires_in</value>
</entry>
</accessTokenResponseMaps>
</pluginOAuthConfig>
The following is an example XML file:
<?xml version="1.0" encoding="utf-8"?>
<pluginOAuthConfig>
<dbclass>redshift</dbclass>
<!-- For configs embedded in the connector package, don't prefix with "custom_". For external configs, always prefix with "custom_". -->
<oauthConfigId>custom_redshift_azure</oauthConfigId>
<clientIdDesktop>1230a234-b456-7890-99c9-a12345bcc123</clientIdDesktop>
<clientSecretDesktop>RdQbc~1234559xFX~c65737wOwjsdfdsg123bg2</clientSecretDesktop>
<redirectUrisDesktop>http://localhost:55556/Callback</redirectUrisDesktop>
<redirectUrisDesktop>http://localhost:55557/Callback</redirectUrisDesktop>
<redirectUrisDesktop>http://localhost:55558/Callback</redirectUrisDesktop>
<redirectUrisDesktop>http://localhost:55559/Callback</redirectUrisDesktop>
<!-- For multitenant apps use the common endpoint, for single tenant apps use the directory specific endpoint. -->
<authUri>https://login.microsoftonline.com/e12a1ab3-1234-12ab-12b3-1a5012221d12/oauth2/v2.0/authorize</authUri>
<tokenUri>https://login.microsoftonline.com/e12a1ab3-1234-12ab-12b3-1a5012221d12/oauth2/v2.0/token</tokenUri>
<scopes>openid</scopes>
<scopes>offline_access</scopes>
<scopes>email</scopes>
<!-- An example with a custom API, which was required at the time of writing for integration with AWS IAM IDC. -->
<scopes>api://1230a234-b456-7890-99c9-a12345bcc123/redshift_login</scopes>
<capabilities>
<entry>
<key>OAUTH_CAP_REQUIRES_PROMPT_SELECT_ACCOUNT</key>
<value>true</value>
</entry>
<entry>
<key>OAUTH_CAP_REQUIRE_PKCE</key>
<value>true</value>
</entry>
<entry>
<key>OAUTH_CAP_PKCE_REQUIRES_CODE_CHALLENGE_METHOD</key>
<value>true</value>
</entry>
<entry>
<key>OAUTH_CAP_SUPPORTS_STATE</key>
<value>true</value>
</entry>
<entry>
<key>OAUTH_CAP_CLIENT_SECRET_IN_URL_QUERY_PARAM</key>
<value>false</value>
</entry>
<entry>
<key>OAUTH_CAP_SUPPORTS_GET_USERINFO_FROM_ID_TOKEN</key>
<value>true</value>
</entry>
<!-- Depending on the Azure application, dynamic ports may not be allowed. Enable this if not allowed. -->
<entry>
<key>OAUTH_CAP_FIXED_PORT_IN_CALLBACK_URL</key>
<value>true</value>
</entry>
</capabilities>
<accessTokenResponseMaps>
<entry>
<key>ACCESSTOKEN</key>
<value>access_token</value>
</entry>
<entry>
<key>REFRESHTOKEN</key>
<value>refresh_token</value>
</entry>
<entry>
<key>access-token-issue-time</key>
<value>issued_at</value>
</entry>
<entry>
<key>id-token</key>
<value>id_token</value>
</entry>
<entry>
<key>username</key>
<value>email</value>
</entry>
<entry>
<key>access-token-expires-in</key>
<value>expires_in</value>
</entry>
</accessTokenResponseMaps>
</pluginOAuthConfig>
Install the Tableau OAuth config file for Tableau Desktop
After the configuration XML file is created, it must be copied to a location to be used by Amazon Redshift Connector from Tableau Desktop. Save the file from the previous step as .xml and save it under Documents\My Tableau Repository\OAuthConfigs.
Note: Currently, this integration isn’t supported in macOS because the Redshift ODBC 2.X driver isn’t supported yet for MAC. It will be supported soon.
Set up the Tableau OAuth config file for Tableau Server or Tableau Cloud
To integrate with Amazon Redshift using IAM Identity Center authentication, you must install the Tableau OAuth config file in Tableau Server or Tableau Cloud.
Sign in to the Tableau Server or Tableau Cloud using admin credentials.
Navigate to Settings.
Go to OAuth Clients Registry and select Add OAuth Client
Choose following settings:
Connection Type: Amazon Redshift
OAuth Provider: Custom_IdP
Client Id: Enter your IdP client ID value
Client Secret: Enter your client secret value
Redirect URL: Enter http://localhost/auth/add_oauth_token. This example uses localhost for testing in a local environment. You should use the full hostname with https.
Choose OAuth Config File. Select the XML file that you configured in the previous section.
Select Add OAuth Client and choose Save.
Figure 7: Create an OAuth connection in Tableau Server or Cloud
Federate to Amazon Redshift from Tableau Desktop
Now you’re ready to connect to Amazon Redshift from Tableau as an Entra ID federated user. In this step, you create a Tableau Desktop report and publish it to Tableau Server.
Open Tableau Desktop.
Select Amazon Redshift Connector and enter the following values:
Server: Enter the name of the server that hosts the database and the name of the database you want to connect to.
Port: Enter 5439.
Database: Enter your database name. This example uses dev.
Authentication: Select OAuth.
Federation Type: Select Identity Center.
Identity Center Namespace: You can leave this value blank.
OAuth Provider: This value should automatically be pulled from your configured XML. It will be the value from the element oauthConfigId.
Select Require SSL.
Choose Sign in.
Figure 8: Tableau Desktop OAuth connection
Enter your IdP credentials in the browser pop-up window.
Figure 9: Microsoft Entra sign in page
When authentication is successful, you will see the message shown in Figure 10 that follows.
Figure 10: Successful authentication using Tableau
Congratulations! You’re signed in using the IAM Identity Center integration with Amazon Redshift. Now you’re ready to explore and analyze your data using Tableau Desktop.
Figure 11: Successful connection using Tableau Desktop
After signing in, you can create your own Tableau Report on the desktop version and publish it to your Tableau Server. For this example, we created and published a report named SalesReport.
Federate to Amazon Redshift from Tableau Server
After you have published the report from Tableau Desktop to Tableau Server, sign in as a non-admin user and view the published report (SalesReport in this example) using IAM Identity Center authentication.
Sign in to the Tableau Server site as a non-admin user.
Navigate to Explore and go to the folder where your published report is stored.
Select the report and choose Sign In.
Figure 12: User audit in sys_query_history
To authenticate, enter your non-admin Microsoft Entra ID (Azure) credentials in the browser pop-up.
Figure 13: Tableau Server sign In
After your authentication is successful, you can access the report.
Figure 14: Tableau report
Verify user identity from Amazon Redshift
As an optional step, you can audit the federated IAM Identity Center user from Amazon Redshift.
Figure 15 is a screenshot from the Amazon Redshift system table (sys_query_history) showing that user Ethan from Microsoft Entra ID is accessing the sales report.
select distinct user_id, pg.usename as username, trim(query_text) as query_text
from sys_query_history sys
join pg_user_info pg
on sys.user_id=pg.usesysid
where query_id=<query_id> and usesysid=<federateduser_id> and query_type='SELECT'
order by start_time desc
;
Figure 15: User audit in sys_query_history
Clean up
Complete the following steps to clean up your resources:
Delete the IdP applications that you created to integrate with IAM Identity Center.
Delete the IAM Identity Center configuration.
Delete the Amazon Redshift application and the Amazon Redshift provisioned cluster or serverless instance that you created for testing.
Delete the AWS Identity and Access Management (IAM) role and IAM policy that you created as part of the prerequisites for IAM Identity Center and Amazon Redshift integration.
Delete the permission set from IAM Identity Center that you created for Amazon Redshift Query Editor V2 in the management account.
Conclusion
This post explored a streamlined approach to access management for data analytics by using Tableau’s support for OIDC for SSO. The solution facilitates federated user authentication, where user identities from an external IdP are trusted and propagated to Amazon Redshift. You learned how to configure Tableau Desktop and Tableau Server to seamlessly integrate with Amazon Redshift using IAM Identity Center for SSO. By harnessing this integration between a third-party IdP and IAM Identity Center, users can securely access Amazon Redshift data sources within Tableau without managing separate database credentials.
The following are key resources to learn more about Amazon Redshift integration with IAM Identity Center:
Debu Panda is a Senior Manager, Product Management at AWS. He is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world.
Sid Wray is a Senior Product Manager at Salesforce based in the Pacific Northwest with nearly 20 years of experience in Digital Advertising, Data Analytics, Connectivity Integration and Identity and Access Management. He currently focuses on supporting ISV partners for Salesforce Data Cloud.
Adiascar Cisneros is a Tableau Senior Product Manager based in Atlanta, GA. He focuses on the integration of the Tableau Platform with AWS services to amplify the value users get from our products and accelerate their journey to valuable, actionable insights. His background includes analytics, infrastructure, network security, and migrations.
Jade Koskela is a Principal Software Engineer at Salesforce. He has over a decade of experience building Tableau with a focus on areas including data connectivity, authentication, and identity federation.
Harshida Patel is a Principal Solutions Architect, Analytics with AWS.
Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
Ravi Bhattiprolu is a Senior Partner Solutions Architect at AWS. He collaborates with strategic independent software vendor (ISV) partners like Salesforce and Tableau to design and deliver innovative, well-architected cloud products, integrations, and solutions to help joint AWS customers achieve their business goals.
In this blog post, I dive into a cross-Region replication (CRR) solution for card payment keys, with a specific focus on the powerful capabilities of AWS Payment Cryptography, showing how your card payment keys can be securely transported and stored.
In today’s digital landscape, where online transactions have become an integral part of our daily lives, ensuring the seamless operation and security of card payment transactions is of utmost importance. As customer expectations for uninterrupted service and data protection continue to rise, organizations are faced with the challenge of implementing robust security measures and disaster recovery strategies that can withstand even the most severe disruptions.
For large enterprises dealing with card payments, the stakes are even higher. These organizations often have stringent requirements related to disaster recovery (DR), resilience, and availability, where even a 99.99 percent uptime isn’t enough. Additionally, because these enterprises deliver their services globally, they need to ensure that their payment applications and the associated card payment keys, which are crucial for securing card data and payment transactions, are securely replicated and stored across AWS Regions.
Furthermore, I explore an event-driven, serverless architecture and the use of AWS PrivateLink to securely move keys through the AWS backbone, providing additional layers of security and efficiency. Overall, this blog post offers valuable insights into using AWS services for secure and resilient data management across AWS Regions.
Card payment key management
If you examine key management, you will notice that card payment keys are shared between devices and third parties today the same as they were around 40 years ago.
A key ceremony is the process held when parties want to securely exchange keys. It involves key custodians responsible for transporting and entering, key components that have been printed on pieces of paper into a hardware security module (HSM). This is necessary to share initial key encryption keys.
Let’s look at the main issues with the current key ceremony process:
It requires a secure room with a network-disconnected Payment HSM
The logistics are difficult: Three key custodians in the same place at the same time
Timewise, it usually takes weeks to have all custodians available, which can interfere with a project release
The cost of the operation which includes maintaining a secure room and the travel of the key custodians
Lost or stolen key components
Now, let’s consider the working keys used to encrypt sensitive card data. They rely on those initial keys to protect them. If the initial keys are compromised, their associated working keys are also considered compromised. I also see companies using key management standards from the 1990s, such as ANSI X9.17 / FIPS 171, to share working keys. NIST withdrew the FIPS 171 standard in 2005.
Analyzing the current scenario, you’ll notice security risks because of the way keys are shared today and sometimes because organizations are using deprecated standards.
So, let’s get card payment security into the twenty-first century!
Solution overview
AWS Payment Cryptography is a highly available and scalable service that currently operates within the scope of an individual Region. This means that the encryption keys and associated metadata are replicated across multiple Availability Zones within that Region, providing redundancy and minimizing the risk of downtime caused by failures within a single Region.
While this regional replication across multiple Availability Zones provides a higher level of availability and fault tolerance compared to traditional on-premises HSM solutions, some customers with stringent business continuity requirements have requested support for multi-Region replication.
By spanning multiple Regions, organizations can achieve a higher level of resilience and disaster recovery capabilities because data and services can be replicated and failover mechanisms can be implemented across geographically dispersed locations.
This Payment Cryptography CRR solution addresses the critical requirements of high availability, resilience, and disaster recovery for card payment transactions. By replicating encryption keys and associated metadata across multiple Regions, you can maintain uninterrupted access to payment services, even in the event of a regional outage or disaster.
Primary Region: Encryption keys are generated and managed in a primary Region using Payment Cryptography.
Replication: The generated encryption keys are securely replicated to a secondary Region, creating redundant copies for failover purposes.
Failover: In the event of a regional outage or disaster in the primary Region, payment operations can seamlessly failover to a secondary Region, using the replicated encryption keys to continue processing transactions without interruption.
This cross-Region replication approach enhances availability and resilience and facilitates robust disaster recovery strategies, allowing organizations to quickly restore payment services in a new Region if necessary.
When one of the events is detected, a Lambda function is launched to start key replication.
The Lambda function performs key export and import processes in a secure way using TR-31, which uses an initial key securely generated and shared using TR-34. This initial key is generated when the solution is enabled.
The CRR solution is deployed in several steps, and it’s essential to understand the underlying processes involved, particularly TR-34 (ANSI X9.24-2) and TR-31 (ANSI X9.143-2022), which play crucial roles in ensuring the secure replication of card payment keys across Regions.
Define which Region the AWS Cloud Development Kit (AWS CDK) stack will be deployed in. This is the primary Region that Payment Cryptography keys will be replicated from.
Enable CRR. This step involves the TR-34 process, which is a widely adopted standard for the secure distribution of symmetric keys using asymmetric techniques. In the context of this solution, TR-34 is used to securely exchange the initial key-encrypting key (KEK) between the primary and secondary Regions. This KEK is then used to encrypt and securely transmit the card payment keys (also called working keys) during the replication process. TR-34 uses asymmetric cryptographic algorithms, such as RSA, to maintain the confidentiality, integrity and authenticity of the exchanged keys.
Figure 2: TR-34 import key process
Create, import, and delete keys in the primary Region to check that keys will be automatically replicated. This step uses the TR-31 process, which is a standard for the secure exchange of cryptographic keys and related data. In this solution, TR-31 is employed to securely replicate the card payment keys from the primary Region to the secondary Region, using the previously established KEK for encryption. TR-31 incorporates various cryptographic algorithms, such as AES and HMAC, to protect the confidentiality and integrity of the replicated keys during transit
Figure 3: TR-31 import key process
Clean up when needed.
Detailed information about key blocks can be found on the related ANSI documentation. To summarize, the TR-31 key block specification and the TR-34 key block specification, which is based on the TR-31 key block specification, consists of three parts:
Key block header (KBH) – Contains attribute information about the key and the key block.
Encrypted data – This is the key (initial key encryption key for TR-34 and working key for TR-31) being exchanged.
Signature (MAC) – Calculated over the KBH and encrypted data.
Figure 4 presents the entire TR-31 and TR-34 key block parts. It is also called key binding method, which is the technique used to protect the key block secrecy and integrity. On both key blocks, the key, its length, and padding fields are encrypted, maintaining the key block secrecy. Signing of the entire key block fields verifies its integrity and authenticity. The signed result is appended to the end of the block.
Figure 4: TR-31 and TR-34 key block formats
By adhering to industry-standard protocols like TR-34 and TR-31, this solution helps to ensure that the replication of card payment keys across Regions is performed in a secure manner that delivers confidentiality, integrity, and authenticity. It’s worth mentioning that Payment Cryptography fully supports and implements these standards, providing a solution that adheres to PCI standards for secure key management and replication.
If you want to dive deep into this key management processes, see the service documentation page on import and export keys.
Prerequisites
The Payment Cryptography CRR solution will be deployed through the AWS CDK. The code was developed in Python and assumes that there is a python3 executable in your path. It’s also assumed that the AWS Command Line Interface (AWS CLI) and AWS CDK executables exist in the path system variable of your local computer.
Note: Tests and commands in the following sections where run on a MacOS operating system.
Deploy the primary resources
The solution is deployed in two main parts:
Primary Region resources deployment
CRR setup, where a secondary Region is defined for deployment of the necessary resources
This section will cover the first part:
Figure 5: Primary Region resources
Figure 5 shows the resources that will be deployed in the primary Region:
A CloudTrail trail for write-only log events.
CloudWatch Logs log group associated with the CloudTrail trail. An Amazon Simple Storage Service (Amazon S3) bucket is also created to store this trail’s log events.
A VPC, private subnets, a security group, Lambda functions, and VPC endpoint resources to address private communication inside the AWS backbone.
DynamoDB tables and DynamoDB Streams to manage key replication and orchestrate the solution deployment to the secondary Region.
Lambda functions responsible for managing and orchestrating the solution deployment and setup.
Some parameters can be configured before deployment. They’re located in the cdk.json file (part of the GitHub solution to be downloaded) inside the solution base directory.
The parameters reside inside the context.ENVIRONMENTS.dev key:
Note: You can change the parameters origin_vpc_cidr, origin_vpc_name and origin_subnets_prefix_name.
Validate that there aren’t VPCs already created with the same CIDR range as the one defined in this file. Currently, the solution is set to be deployed in only two Availability Zones, so the suggestion is to keep the origin_subnet_mask value as is.
To deploy the primary resources:
Download the solution folder from GitHub:
$ git clone https://github.com/aws-samples/automatically-replicate-your-card-payment-keys.git && cd automatically-replicate-your-card-payment-keys
Inside the solution directory, create a python virtual environment:
$ python3 -m venv .venv
Activate the python virtual environment:
$ source .venv/bin/activate
Install the dependencies:
$ pip install -r requirements.txt
If this is the first time deploying resources with the AWS CDK to your account in the selected AWS Region, run:
$ cdk bootstrap
Deploy the solution using the AWS CDK:
$ cdk deploy
Expected output:
Do you wish to deploy these changes (y/n)? y
apc-crr: deploying... [1/1]
apc-crr: creating CloudFormation changeset...
apc-crr
Deployment time: 307.88s
Stack ARN:
arn:aws:cloudformation:<aws_region>:<aws_account>:stack/apc-crr/<stack_id>
Total time: 316.06s
If the solution is correctly deployed, an AWS CloudFormation stack with the name apc-crr will have a status of CREATE_COMPLETE status. You can check that by running the following command:
You can change the dest_region, dest_vpc_name, dest_vpc_cidr, dest_subnet1_cidr, dest_subnet2_cidr, dest_subnets_prefix_name and dest_rt_prefix_name parameters.
Validate that there are no VPCs or subnets already created with the same CIDR ranges as are defined in this file.
To enable CRR and monitor its deployment process
Enable CRR.
From the solution base folder, navigate to the application directory:
$ cd application
Run the enable script.
$ ./enable-crr.sh
Expected output:
START RequestId: 8aad062a-ff0b-4963-8ca0-f8078346854f Version: $LATEST
Setup has initiated. A CloudFormation template will be deployed in us-west-2.
Please check the apcStackMonitor log to follow the deployment status.
You can do that by checking the CloudWatch Logs Log group /aws/apc-crr/apcStackMonitor in the Management Console,
or by typing on a shell terminal: aws logs tail "/aws/lambda/apcStackMonitor" --follow
You can also check the CloudFormation Stack in the Management Console: Account 111122223333, Region us-west-2
END RequestId: 8aad062a-ff0b-4963-8ca0-f8078346854f
REPORT RequestId: 8aad062a-ff0b-4963-8ca0-f8078346854f Duration: 1484.53 ms Billed Duration: 1485 ms Memory Size: 128 MB Max Memory Used: 79 MB Init Duration: 400.95 ms
This will launch a CloudFormation stack to be deployed in the AWS Region that the keys will be replicated to (secondary Region). Logs will be presented in the /aws/lambda/apcStackMonitor log (terminal from step 2).
If the stack is successfully deployed (CREATE_COMPLETE state), then the KEK setup will be invoked. Logs will be presented in the /aws/lambda/apcKekSetup log (terminal from step 3).
If the following message is displayed in the apcKekSetup log, then it means that the setup was concluded and new working keys created, deleted, or imported will be replicated.
Keys Generated, Imported and Deleted in <Primary (Origin) Region> are now being automatically replicated to <Secondary (Destination) Region>
There should be two keys created in the Region where CRR is deployed and two keys created where the working keys will be replicated. Use the following commands to check the keys:
Monitor the resources deployment in the secondary Region. Open a terminal to tail the apcStackMonitor Lambda log and check the deployment of the resources in the secondary Region.
2024-03-05T15:18:17.870000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac INIT_START Runtime Version: python:3.11.v29 Runtime Version ARN: arn:aws:lambda:us-east-1::runtime:2fb93380dac14772d30092f109b1784b517398458eef71a3f757425231fe6769
2024-03-05T15:18:18.321000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac START RequestId: 1bdd37b4-e95b-43bd-a49b-9da55e603845 Version: $LATEST
2024-03-05T15:18:18.933000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac Stack creation in progress. Status: CREATE_IN_PROGRESS
2024-03-05T15:18:24.017000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac Stack creation in progress. Status: CREATE_IN_PROGRESS
2024-03-05T15:18:29.108000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac Stack creation in progress. Status: CREATE_IN_PROGRESS
...
2024-03-05T15:21:32.302000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac Stack creation in progress. Status: CREATE_IN_PROGRESS
2024-03-05T15:21:37.390000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac Stack creation completed. Status: CREATE_COMPLETE
2024-03-05T15:21:38.258000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac Stack successfully deployed. Status: CREATE_COMPLETE
2024-03-05T15:21:38.354000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac END RequestId: 1bdd37b4-e95b-43bd-a49b-9da55e603845
2024-03-05T15:21:38.354000+00:00 2024/03/05/apcStackMonitor[$LATEST]6e6762b029cb4f7d8963c3206226deac REPORT RequestId: 1bdd37b4-e95b-43bd-a49b-9da55e603845Duration: 200032.11 ms Billed Duration: 200033 ms Memory Size: 128 MB Max Memory Used: 93 MB Init Duration: 450.87 ms
Monitor the setup of the KEKs between the primary and secondary Regions. Open another terminal to tail the apcKekSetup Lambda log and check the setup of the KEK between the key distribution host (Payment Cryptography in the primary Region) and the key receiving devices (Payment Cryptography in the secondary Region).
2024-03-12T14:58:18.954000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 INIT_START Runtime Version: python:3.11.v29 Runtime Version ARN: arn:aws:lambda:us-west-2::runtime:2fb93380dac14772d30092f109b1784b517398458eef71a3f757425231fe6769
2024-03-12T14:58:19.399000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 START RequestId: a9b60171-dfaf-433a-954c-b0a332d22f50 Version: $LATEST
2024-03-12T14:58:19.596000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 ##### Step 1. Generating Key Encryption Key (KEK) - Key that will be used to encrypt the Working Keys
2024-03-12T14:58:19.850000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 ##### Step 2. Getting APC Import Parameters from us-east-1
2024-03-12T14:58:21.680000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 ##### Step 3. Importing the Root Wrapping Certificates in us-west-2
2024-03-12T14:58:21.826000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 ##### Step 4. Getting APC Export Parameters from us-west-2
2024-03-12T14:58:23.193000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 ##### Step 5. Importing the Root Signing Certificates in us-east-1
2024-03-12T14:58:23.439000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 ##### Step 6. Exporting the KEK from us-west-2
2024-03-12T14:58:23.555000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 ##### Step 7. Importing the Wrapped KEK to us-east-1
2024-03-12T14:58:23.840000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 ##### Initial Key Exchange Successfully Completed.
2024-03-12T14:58:23.840000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 Keys Generated, Imported and Deleted in us-west-2 are now being automatically replicated to us-east-1
2024-03-12T14:58:23.840000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 Keys already present in APC won't be replicated. If you want to, it must be done manually.
2024-03-12T14:58:23.844000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 END RequestId: a9b60171-dfaf-433a-954c-b0a332d22f50
2024-03-12T14:58:23.844000+00:00 2024/03/12/apcKekSetup[$LATEST]ea4c6a7c85ac42da8a043aa8626d2897 REPORT RequestId: a9b60171-dfaf-433a-954c-b0a332d22f50 Duration: 4444.78 ms Billed Duration: 4445 ms Memory Size: 5120 MB Max Memory Used: 95 MB Init Duration: 444.73 ms
Testing
Now it’s time to test the solution. The idea is to simulate an application that manages keys in the service. You will use AWS CLI to send commands directly from a local computer to the Payment Cryptography public endpoints.
Check if the user or role being used has the necessary permissions to manage keys in the service. The following AWS Identity and Access Management (IAM) policy example shows an IAM policy that can be attached to the user or role that will run the commands in the service.
Prepare to monitor the replication processes. Open a new terminal to monitor the apcReplicateWk log and verify that keys are being replicated from one Region to the other.
Create, import, and delete working keys. Start creating and deleting keys in the account and Region where the CRR solution was deployed (primary Region).
Currently, the solution only listens to the CreateKey, ImportKey and DeleteKey commands. CreateAlias and DeleteAlias commands aren’t yet implemented, so the aliases won’t replicate.
It takes some time for the replication function to be invoked because it relies on the following steps:
A Payment Cryptography (CreateKey, ImportKey, or DeleteKey) log event is delivered to a CloudTrail trail.
The log event is sent to the CloudWatch Logs log group, which invokes the subscription filter and the Lambda function associated with it is run.
CloudTrail typically delivers logs within about 5 minutes of an API call. This time isn’t guaranteed. See the AWS CloudTrail Service Level Agreement for more information.
You can disable the solution (keys will stop being replicated, but the resources from the primary Region will remain deployed) or destroy the resources that were deployed.
Note: Completing only Step 3, destroying the stack, won’t delete the resources deployed in the secondary Region or the keys that have been generated.
Disable the CRR solution.
The KEKs created during the enablement process will be disabled and marked for deletion in both the primary and secondary Regions. The waiting period before deletion is 3 days.
From the base directory where the solution is deployed, run the following commands:
$ source .venv/bin/activate
$ cd application
$ ./disable-crr.sh
Expected output:
START RequestId: bc96659c-3063-460a-8b29-2aa21b967c9a Version: $LATEST
Deletion has initiated...
Please check the apcKekSetup log to check if the solution has been successfully disabled.
You can do that by checking the CloudWatch Logs Log group /aws/apc-crr/apcKekSetup in the Management Console,
or by typing on a shell terminal: aws logs tail "/aws/lambda/apcKekSetup" --follow
Please check the apcStackMonitor log to follow the stack deletion status.
You can do that by checking the CloudWatch Logs Log group /aws/apc-crr/apcStackMonitor in the Management Console,
or by typing on a shell terminal: aws logs tail "/aws/lambda/apcStackMonitor" --follow
END RequestId: bc96659c-3063-460a-8b29-2aa21b967c9a
REPORT RequestId: bc96659c-3063-460a-8b29-2aa21b967c9a Duration: 341.94 ms Billed Duration: 342 ms Memory Size: 128 MB Max Memory Used: 76 MB Init Duration: 429.87 ms
Keys created during the exchange of the KEK will be deleted and the logs will be presented in the /aws/lambda/apcKekSetup log group.
Expected output:
2024-03-05T16:40:23.510000+00:00 2024/03/05/apcKekSetup[$LATEST]1c97946d8bc747b19cc35d9b1472ff8d INIT_START Runtime Version: python:3.11.v28 Runtime Version ARN: arn:aws:lambda:us-east-1::runtime:7893bafe1f7e5c0681bc8da889edf656777a53c2a26e3f73436bdcbc87ccfbe8
2024-03-05T16:40:23.971000+00:00 2024/03/05/apcKekSetup[$LATEST]1c97946d8bc747b19cc35d9b1472ff8d START RequestId: fc10b303-f028-4a94-a2cf-b8c0a762ea16 Version: $LATEST
2024-03-05T16:40:23.971000+00:00 2024/03/05/apcKekSetup[$LATEST]1c97946d8bc747b19cc35d9b1472ff8d Disabling CRR and Deleting KEKs
2024-03-05T16:40:25.276000+00:00 2024/03/05/apcKekSetup[$LATEST]1c97946d8bc747b19cc35d9b1472ff8d Keys and aliases deleted from APC.
2024-03-05T16:40:25.294000+00:00 2024/03/05/apcKekSetup[$LATEST]1c97946d8bc747b19cc35d9b1472ff8d DB status updated.
2024-03-05T16:40:25.297000+00:00 2024/03/05/apcKekSetup[$LATEST]1c97946d8bc747b19cc35d9b1472ff8d END RequestId: fc10b303-f028-4a94-a2cf-b8c0a762ea16
2024-03-05T16:40:25.297000+00:00 2024/03/05/apcKekSetup[$LATEST]1c97946d8bc747b19cc35d9b1472ff8d REPORT RequestId: fc10b303-f028-4a94-a2cf-b8c0a762ea16 Duration: 1326.39 ms Billed Duration: 1327 ms Memory Size: 5120 MB Max Memory Used: 94 MB Init Duration: 460.29 ms
Second, the CloudFormation stack will be deleted with its associated resources. Logs will be presented in the /aws/lambda/apcStackMonitor Log group.
Expected output:
2024-03-05T16:40:25.854000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec START RequestId: 6b0b8207-19ae-40a1-b889-c92f8a5c243c Version: $LATEST
2024-03-05T16:40:26.486000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec De-provisioning Resources in the Destination Region. StackName: apc-setup-orchestrator-77aecbcf-1e4f-4e2a-8faa-6e3606a32690
2024-03-05T16:40:26.805000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Stack deletion in progress. Status: DELETE_IN_PROGRESS
2024-03-05T16:40:31.889000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Stack deletion in progress. Status: DELETE_IN_PROGRESS
2024-03-05T16:40:36.977000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Stack deletion in progress. Status: DELETE_IN_PROGRESS
2024-03-05T16:40:42.065000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Stack deletion in progress. Status: DELETE_IN_PROGRESS
2024-03-05T16:40:47.152000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Stack deletion in progress. Status: DELETE_IN_PROGRESS
...
2024-03-05T16:44:10.598000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Stack deletion in progress. Status: DELETE_IN_PROGRESS
2024-03-05T16:44:15.683000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Stack deletion in progress. Status: DELETE_IN_PROGRESS
2024-03-05T16:44:20.847000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Stack deletion completed. Status: DELETE_COMPLETE
2024-03-05T16:44:21.043000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec Resources successfully deleted. Status: DELETE_COMPLETE
2024-03-05T16:44:21.601000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec END RequestId: 6b0b8207-19ae-40a1-b889-c92f8a5c243c
2024-03-05T16:44:21.601000+00:00 2024/03/05/apcStackMonitor[$LATEST]2cb4c9044a08474894ff5fa81940dbec REPORT RequestId: 6b0b8207-19ae-40a1-b889-c92f8a5c243cDuration: 235746.42 ms Billed Duration: 235747 ms Memory Size: 128 MB Max Memory Used: 94 MB
Destroy the CDK stack.
$ cd ..
$ cdk destroy
Expected output:
Are you sure you want to delete: apc-crr (y/n)? y
apc-crr: destroying... [1/1]
apc-crr: destroyed
Delete all remaining working keys from the primary Region. If keys generated in the primary Region weren’t deleted before disabling the solution, then they’ll also exist in the secondary Region. To clean up keys in both Regions, get the key ARNS that have a status of CREATE_COMPLETE and delete them.
While using this Payment Cryptography CRR solution, it is crucial that you follow security best practices to maintain the highest level of protection for sensitive payment data:
Least privilege access: Implement strict access controls and follow the principle of least privilege, granting access to payment cryptography resources only to authorized personnel and services.
Encryption in transit and at rest: Make sure that sensitive data, including encryption keys and payment card data, is encrypted both in transit and at rest using industry-standard encryption algorithms.
Audit logging and monitoring: Activate audit logging and continuously monitor activity logs for suspicious or unauthorized access attempts.
Regular key rotation: Implement a key rotation strategy to periodically rotate encryption keys, reducing the risk of key compromise and minimizing potential exposure.
Incident response plan: Develop and regularly test an incident response plan to promote efficient and coordinated actions in the event of a security breach or data compromise.
Conclusion
In the rapidly evolving world of card payment transactions, maintaining high availability, resilience, robust security, and disaster recovery capabilities is crucial for maintaining customer trust and business continuity. AWS Payment Cryptography offers a solution that is tailored specifically for protecting sensitive payment card data.
By using the CRR solution, organizations can confidently address the stringent requirements of the payment industry, safeguarding sensitive data while providing continued access to payment services, even in the face of regional outages or disasters. With Payment Cryptography, organizations are empowered to deliver seamless and secure payment experiences to their customers.
To go further with this solution, you can modify it to fit your organization architecture by, for example, adding replication for the CreateAlias command. This will allow the Payment Cryptography keys alias to also be replicated between the primary and secondary Regions.
Amazon EMR on EC2 is a managed service that makes it straightforward to run big data processing and analytics workloads on AWS. It simplifies the setup and management of popular open source frameworks like Apache Hadoop and Apache Spark, allowing you to focus on extracting insights from large datasets rather than the underlying infrastructure. With Amazon EMR, you can take advantage of the power of these big data tools to process, analyze, and gain valuable business intelligence from vast amounts of data.
Cost optimization is one of the pillars of the Well-Architected Framework. It focuses on avoiding unnecessary costs, selecting the most appropriate resource types, analyzing spend over time, and scaling in and out to meet business needs without overspending. An optimized workload maximizes the use of all available resources, delivers the desired outcome at the most cost-effective price point, and meets your functional needs.
The current Amazon EMR pricing page shows the estimated cost of the cluster. You can also use AWS Cost Explorer to get more detailed information about your costs. These views give you an overall picture of your Amazon EMR costs. However, you may need to attribute costs at the individual Spark job level. For example, you might want to know the usage cost in Amazon EMR for the finance business unit. Or, for chargeback purposes, you might need to aggregate the cost of Spark applications by functional area. After you have allocated costs to individual Spark jobs, this data can help you make informed decisions to optimize your costs. For instance, you could choose to restructure your applications to utilize fewer resources. Alternatively, you might opt to explore different pricing models like Amazon EMR on EKS or Amazon EMR Serverless.
In this post, we share a chargeback model that you can use to track and allocate the costs of Spark workloads running on Amazon EMR on EC2 clusters. We describe an approach that assigns Amazon EMR costs to different jobs, teams, or lines of business. You can use this feature to distribute costs across various business units. This can assist you in monitoring the return on investment for your Spark-based workloads.
Solution overview
The solution is designed to help you track the cost of your Spark applications running on EMR on EC2. It can help you identify cost optimizations and improve the cost-efficiency of your EMR clusters.
The proposed solution uses a scheduled AWS Lambda function that operates on a daily basis. The function captures usage and cost metrics, which are subsequently stored in Amazon Relational Database Service (Amazon RDS) tables. The data stored in the RDS tables is then queried to derive chargeback figures and generate reporting trends using Amazon QuickSight. The utilization of these AWS services incurs additional costs for implementing this solution. Alternatively, you can consider an approach that involves a cron-based agent script installed on your existing EMR cluster, if you want to avoid the use of additional AWS services and associated costs for building your chargeback solution. This script stores the relevant metrics in an Amazon Simple Storage Service (Amazon S3) bucket, and uses Python Jupyter notebooks to generate chargeback numbers based on the data files stored in Amazon S3, using AWS Glue tables.
The following diagram shows the current solution architecture.
The Lambda function extracts Spark application run logs from the EMR cluster using the Resource Manager API. The following metrics are extracted as part of the process: vcore-seconds, memory MB-seconds, and storage GB-seconds.
The Lambda function captures the daily cost of EMR clusters from Cost Explorer.
The Lambda function also extracts EMR On-Demand and Spot Instance usage data using the Amazon Elastic Compute Cloud (Amazon EC2) Boto3 APIs.
Lambda function loads these datasets into an RDS database.
The cost of running a Spark application is determined by the amount of CPU resources it uses, compared to the total CPU usage of all Spark applications. This information is used to distribute the overall cost among different teams, business lines, or EMR queues.
The extraction process runs daily, extracting the previous day’s data and storing it in an Amazon RDS for PostgreSQL table. The historical data in the table needs to be purged based on your use case.
The solution is open source and available on GitHub.
You can use the AWS Cloud Development Kit (AWS CDK) to deploy the Lambda function, RDS for PostgreSQL data model tables, and a QuickSight dashboard to track EMR cluster cost at the job, team, or business unit level.
The following schema show the tables used in the solution which are queried by QuickSight to populate the dashboard.
emr_applications_execution_log_lz or public.emr_applications_execution_log – Storage for daily run metrics for all jobs run on the EMR cluster:
appdatecollect – Log collection date
app_id – Spark job run ID
app_name – Run name
queue – EMR queue in which job was run
job_state – Job running state
job_status – Job run final status (Succeeded or Failed)
starttime – Job start time
endtime – Job end time
runtime_seconds – Runtime in seconds
vcore_seconds – Consumed vCore CPU in seconds
memory_seconds – Memory consumed
running_containers – Containers used
rm_clusterid – EMR cluster ID
emr_cluster_usage_cost – Captures Amazon EMR and Amazon EC2 daily cost consumption from Cost Explorer and loads the data into the RDS table:
costdatecollect – Cost collection date
startdate – Cost start date
enddate – Cost end date
emr_unique_tag – EMR cluster associated tag
net_unblendedcost – Total unblended daily dollar cost
unblendedcost – Total unblended daily dollar cost
cost_type – Daily cost
service_name – AWS service for which the cost incurred (Amazon EMR and Amazon EC2)
emr_clusterid – EMR cluster ID
emr_clustername – EMR cluster name
loadtime – Table load date/time
emr_cluster_instances_usage – Captures the aggregated resource usage (vCores) and allocated resources for each EMR cluster node, and helps identify the idle time of the cluster:
instancedatecollect – Instance usage collect date
emr_instance_day_run_seconds – EMR instance active seconds in the day
emr_region – EMR cluster AWS Region
emr_clusterid – EMR cluster ID
emr_clustername – EMR cluster name
emr_cluster_fleet_type – EMR cluster fleet type
emr_node_type – Instance node type
emr_market – Market type (on-demand or provisioned)
emr_instance_type – Instance size
emr_ec2_instance_id – Corresponding EC2 instance ID
You must have the following prerequisites before implementing the solution:
An EMR on EC2 cluster.
The EMR cluster must have a unique tag value defined. You can assign the tag directly on the Amazon EMR console or using Tag Editor. The recommended tag key is cost-center along with a unique value for your EMR cluster. After you create and apply user-defined tags, it can take up to 24 hours for the tag keys to appear on your cost allocation tags page for activation
Activate the tag in AWS Billing. It takes about 24 hours to activate the tag if not done before. To activate the tag, follow these steps:
On the AWS Billing and Cost Management console, choose Cost allocation tags from navigation pane.
Select the tag key that you want to activate.
Choose Activate.
The Spark application’s name should follow the standardized naming convention. It consists of seven components separated by underscores: <business_unit>_<program>_<application>_<source>_<job_name>_<frequency>_<job_type>. These components are used to summarize the resource consumption and cost in the final report. For example: HR_PAYROLL_PS_PSPROD_TAXDUDUCTION_DLY_LD, FIN_CASHRECEIPT_GL_GLDB_MAIN_DLY_LD, or MKT_CAMPAIGN_CRM_CRMDB_TOPRATEDCAMPAIGN_DLY_LD. The application name must be supplied with the spark submit command using the --name parameter with the standardized naming convention. If any of these components don’t have a value, hardcode the values with the following suggested names:
frequency
job_type
Business_unit
The Lambda function should be able to connect to Cost Explorer, connect to the EMR cluster through the Resource Manager APIs, and load data into the RDS for PostgreSQL database. To do this, you need to configure the Lambda function as follows:
VPC configuration – The Lambda function should be able to access the EMR cluster, Cost Explorer, AWS Secrets Manager, and Parameter Store. If access is not in place already, you can do this by creating a virtual private cloud (VPC) that includes the EMR cluster and create VPC endpoint for Parameter Store and Secrets Manager and attach it to the VPC. Because there is no VPC endpoint available for Cost Explorer and in order to have Lambda connect to Cost Explorer, a private subnet and a route table are required to send VPC traffic to public NAT gateway. If your EMR cluster is in public subnet, you must create a private subnet including a custom route table and a public NAT gateway, which will allow the Cost Explorer connection to flow from the VPC private subnet. Refer to How do I set up a NAT gateway for a private subnet in Amazon VPC? for setup instructions and attach the newly created private subnet to the Lambda function explicitly.
IAM role – The Lambda function needs to have an AWS Identity and Access Management (IAM) role with the following permissions: AmazonEC2ReadOnlyAccess, AWSCostExplorerFullAccess, and AmazonRDSDataFullAccess. This role will be created automatically during AWS CDK stack deployment; you don’t need to set it up separately.
The AWS CDK should be installed on AWS Cloud9 (preferred) or another development environment such as VSCode or Pycharm. For more information, refer to Prerequisites.
You can choose to deploy the AWS CDK stack using AWS Cloud9 or any other development environment according to your needs. For instructions to set up AWS Cloud9, refer to Getting started: basic tutorials for AWS Cloud9.
Go to AWS Cloud9 and choose File and Upload local files upload the project folder.
Deploy the AWS CDK stack with the following code:
cd attribute-amazon-emr-costs-to-your-end-users/
pip install -r requirements.txt
cdk deploy –-all
The deployed Lambda function requires two external libraries: psycopg2 and requests. The corresponding layer needs to be created and assigned to the Lambda function. For instructions to create a Lambda layer for the requests module, refer to Step-by-Step Guide to Creating an AWS Lambda Function Layer.
Creation of the psycopg2 package and layer is tied to the Python runtime version of the Lambda function. Provided that the Lambda function uses the Python 3.9 runtime, complete the following steps to create the corresponding layer package for peycopog2:
Unzip and move the contents to a directory named python:
zip ‘python’ directory
Create a Lambda layer for psycopg2 using the zip file.
Assign the layer to the Lambda function by choosing Add a layer in the deployed function properties.
Validate the AWS CDK deployment.
Your Lambda function details should look similar to the following screenshot.
On the Systems Manager console, validate the Parameter Store content for actual values.
The IAM role details should look similar to the following code, which allows the Lambda function access to Amazon EMR and underlying EC2 instances, Cost Explorer, CloudWatch, Secrets Manager, and Parameter Store:
To test the solution, you can run a Spark job that combines multiple files in the EMR cluster, and you can do this by creating separate steps within the cluster. Refer to Optimize Amazon EMR costs for legacy and Spark workloads for more details on how to add the jobs as steps to EMR cluster.
Use the following sample command to submit the Spark job (emr_union_job.py). It takes in three arguments:
<input_full_path> – The Amazon S3 location of the data file that is read in by the Spark job. The path should not be changed. The input_full_path is s3://aws-blogs-artifacts-public/artifacts/BDB-2997/sample-data/input/part-00000-a0885743-e0cb-48b1-bc2b-05eb748ab898-c000.snappy.parquet
<output_path> – The S3 folder where the results are written to.
<number of copies to be unioned> – By changing the input to the Spark job, you can make sure the job runs for different amounts of time and also change the number of Spot nodes used.
The following screenshot shows the log of the steps run on the Amazon EMR console.
Run the deployed Lambda function from the Lambda console. This loads the daily application log, EMR dollar usage, and EMR instance usage details into their respective RDS tables.
The following screenshot of the Amazon RDS query editor shows the results for public.emr_applications_execution_log.
The following screenshot shows the results for public.emr_cluster_usage_cost.
The following screenshot shows the results for public.emr_cluster_instances_usage.
Cost can be calculated using the preceding three tables based on your requirements. In the following SQL query, you calculate the cost based on relative usage of all applications in a day. You first identify the total vcore-seconds CPU consumed in a day and then find out the percentage share of an application. This drives the cost based on overall cluster cost in a day.
Consider the following example scenario, where 10 applications ran on the cluster for a given day. You would use the following sequence of steps to calculate the chargeback cost:
Calculate the relative percentage usage of each application (consumed vcore-seconds CPU by app/total vcore-seconds CPU consumed).
Now you have the relative resource consumption of each application, distribute the cluster cost to each application. Let’s assume that the total EMR cluster cost for that date is $400.
app_id
app_name
runtime_seconds
vcore_seconds
% Relative Usage
Amazon EMR Cost ($)
application_00001
app1
10
120
5%
19.83
application_00002
app2
5
60
2%
9.91
application_00003
app3
4
45
2%
7.43
application_00004
app4
70
840
35%
138.79
application_00005
app5
21
300
12%
49.57
application_00006
app6
4
48
2%
7.93
application_00007
app7
12
150
6%
24.78
application_00008
app8
52
620
26%
102.44
application_00009
app9
12
130
5%
21.48
application_00010
app10
9
108
4%
17.84
A sample chargeback cost calculation SQL query is available on the GitHub repo.
You can use the SQL query to create a report dashboard to plot multiple charts for the insights. The following are two examples created using QuickSight.
The following is a daily bar chart.
The following shows total dollars consumed.
Solution cost
Let’s assume we’re calculating for an environment that runs 1,000 jobs daily, and we run this solution daily:
Lambda costs – One run requires 30 Lambda function invocations per month.
Amazon RDS cost – The total number of records in the public.emr_applications_execution_log table for a 30-day month would be 30,000 records, which translates to 5.72 MB of storage. If we consider the other two smaller tables and storage overhead, the overall monthly storage requirement would be approximately 12 MB.
In summary, the solution cost according to the AWS Pricing Calculator is $34.20/year, which is negligible.
Clean up
To avoid ongoing charges for the resources that you created, complete the following steps:
Delete the AWS CDK stacks:
cdk destroy –-all
Delete the QuickSight report and dashboard, if created.
Run the following SQL to drop the tables:
drop table public.emr_applications_execution_log_lz;
drop table public.emr_applications_execution_log;
drop table public.emr_cluster_usage_cost;
drop table public.emr_cluster_instances_usage;
Conclusion
With this solution, you can deploy a chargeback model to attribute costs to users and groups using the EMR cluster. You can also identify options for optimization, scaling, and separation of workloads to different clusters based on usage and growth needs.
You can collect the metrics for a longer duration to observe trends on the usage of Amazon EMR resources and use that for forecasting purposes.
If you have any thoughts or questions, leave them in the comments section.
About the Authors
Raj Patel is AWS Lead Consultant for Data Analytics solutions based out of India. He specializes in building and modernising analytical solutions. His background is in data warehouse/data lake – architecture, development and administration. He is in data and analytical field for over 14 years.
Ramesh Raghupathy is a Senior Data Architect with WWCO ProServe at AWS. He works with AWS customers to architect, deploy, and migrate to data warehouses and data lakes on the AWS Cloud. While not at work, Ramesh enjoys traveling, spending time with family, and yoga.
Gaurav Jain is a Sr Data Architect with AWS Professional Services, specialized in big data and helps customers modernize their data platforms on the cloud. He is passionate about building the right analytics solutions to gain timely insights and make critical business decisions. Outside of work, he loves to spend time with his family and likes watching movies and sports.
Dipal Mahajan is a Lead Consultant with Amazon Web Services based out of India, where he guides global customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings extensive experience on Software Development, Architecture and Analytics from industries like finance, telecom, retail and healthcare.
Moving and transforming data between databases is a common need for many organizations. Duplicating data from a production database to a lower or lateral environment and masking personally identifiable information (PII) to comply with regulations enables development, testing, and reporting without impacting critical systems or exposing sensitive customer data. However, manually anonymizing cloned information can be taxing for security and database teams.
You can use AWS Glue Studio to set up data replication and mask PII with no coding required. AWS Glue Studio visual editor provides a low-code graphic environment to build, run, and monitor extract, transform, and load (ETL) scripts. Behind the scenes, AWS Glue handles underlying resource provisioning, job monitoring, and retries. There’s no infrastructure to manage, so you can focus on rapidly building compliant data flows between key systems.
In this post, I’ll walk you through how to copy data from one Amazon Relational Database Service (Amazon RDS) for PostgreSQL database to another, while scrubbing PII along the way using AWS Glue. You will learn how to prepare a multi-account environment to access the databases from AWS Glue, and how to model an ETL data flow that automatically masks PII as part of the transfer process, so that no sensitive information will be copied to the target database in its original form. By the end, you’ll be able to rapidly build data movement pipelines between data sources and targets, that can hide PII in order to protect individual identities, without needing to write code.
Solution overview
The following diagram illustrates the solution architecture:
The solution uses AWS Glue as an ETL engine to extract data from the source Amazon RDS database. Built-in data transformations then scrub columns containing PII using pre-defined masking functions. Finally, the AWS Glue ETL job inserts privacy-protected data into the target Amazon RDS database.
This solution employs multiple AWS accounts. Having multi-account environments is an AWS best practice to help isolate and manage your applications and data. The AWS Glue account shown in the diagram is a dedicated account that facilitates the creation and management of all necessary AWS Glue resources. This solution works across a broad array of connections that AWS Glue supports, so you can centralize the orchestration in one dedicated AWS account.
It is important to highlight the following notes about this solution:
Following AWS best practices, the three AWS accounts discussed are part of an organization, but this is not mandatory for this solution to work.
This solution is suitable for use cases that don’t require real-time replication and can run on a schedule or be initiated through events.
Walkthrough
To implement this solution, this guide walks you through the following steps:
Enable connectivity from the AWS Glue account to the source and target accounts
Create AWS Glue components for the ETL job
Create and run the AWS Glue ETL job
Verify results
Prerequisites
For this walkthrough, we’re using Amazon RDS for PostgreSQL 13.14-R1. Note that the solution will work with other versions and database engines that support the same JDBC driver versions as AWS Glue. See JDBC connections for further details.
To follow along with this post, you should have the following prerequisites:
Three AWS accounts as follows:
Source account: Hosts the source Amazon RDS for PostgreSQL database. The database contains a table with sensitive information and resides within a private subnet. For future reference, record the associated virtual private cloud (VPC) ID, security group, and private subnets associated to the Amazon RDS database.
Target account: Contains the target Amazon RDS for PostgreSQL database, with the same table structure as the source table, initially empty. The database resides within a private subnet. Similarly, write down the associated VPC ID, security group ID and private subnets.
AWS Glue account: This dedicated account holds a VPC, a private subnet, and a security group. As mentioned in the AWS Glue documentation, the security group includes a self-referencing inbound rule for All TCP and TCP ports (0-65535) to allow AWS Glue to communicate with its components.
The following figure shows a self-referencing inbound rule needed on the AWS Glue account security group.
Make sure the three VPC CIDRs do not overlap with each other, as shown in the following table:
VPC
Private subnet
Source account
10.2.0.0/16
10.2.10.0/24
AWS Glue account
10.1.0.0/16
10.1.10.0/24
Target account
10.3.0.0/16
10.3.10.0/24
The VPC network attributes enableDnsHostnames and enableDnsSupport are set to true on each VPC. For details, see Using DNS with your VPC.
An Amazon Simple Storage Service (Amazon S3) endpoint on the AWS Glue account. AWS Glue requires this endpoint to store the ETL script. During the S3 endpoint set up, make sure you associate the endpoint with the route table assigned to the private subnet on the AWS Glue account. For details on creating an S3 endpoint, see Amazon VPC Endpoints for Amazon S3.
The following diagram illustrates the environment with all prerequisites:
To streamline the process of setting up the prerequisites, you can follow the directions in the README file on this GitHub repository.
Database tables
For this example, both source and target databases contain a customer table with the exact same structure. The former is prepopulated with data as shown in the following figure:
The AWS Glue ETL job you will create focuses on masking sensitive information within specific columns. These are last_name, email, phone_number, ssn and notes.
If you want to use the same table structure and data, the SQL statements are provided in the GitHub repository.
Step 1 – Enable connectivity from the AWS Glue account to the source and target accounts
When creating an AWS Glue ETL job, provide the AWS IAM role, VPC ID, subnet ID, and security groups needed for AWS Glue to access the JDBC databases. See AWS Glue: How it works for further details.
In our example, the role, groups, and other information are in the dedicated AWS Glue account. However, for AWS Glue to connect to the databases, you need to enable access to source and target databases from your AWS Glue account’s subnet and security group.
To enable access, first you inter-connect the VPCs. This can be done using VPC peering or AWS Transit Gateway. For this example, we use VPC peering. Alternatively, you can use an S3 bucket as an intermediary storage location. See Setting up network access to data stores for further details.
Follow these steps:
Peer AWS Glue account VPC with the database VPCs
Update the route tables
Update the database security groups
Peer AWS Glue account VPC with database VPCs
Complete the following steps in the AWS VPC console:
On the AWSGlueaccount, create two VPC peering connections as described in Create VPC peering connection, one for the source account VPC, and one for the target account VPC.
On the targetaccount, accept the VPC peering request as well.
On the AWSGlueaccount, enable DNS Settings on each peering connection. This allows AWS Glue to resolve the private IP address of your databases. For instructions, follow Enable DNS resolution for VPC peering connection.
After completing the preceding steps, the list of peering connections on the AWS Glue account should look like the following figure: Note that source and target account VPCs are not peered together. Connectivity between the two accounts isn’t needed.
Update subnet route tables
This step will enable traffic from the AWS Glue account VPC to the VPC subnets associate to the databases in the source and target accounts.
Complete the following steps in the AWS VPC console:
On the AWS Glue account’sroute table, for each VPC peering connection, add one route to each private subnet associated to the database. These routes enable AWS Glue to establish a connection to the databases and limit traffic from the AWS Glue account to only the subnets associated to the databases.
On the source account’sroute table of the private subnets associated to the database, add one route for the VPC peering with the AWS Glue account. This route will allow traffic back to the AWS Glue account.
Repeat step 2 on the target account’s route table.
This step is required to allow traffic from the AWS Glue account’s security group to the source and target security groups associated to the databases.
Connections enable AWS Glue to access your databases. The main benefit of creating AWS Glue connections is that connections save time by not making you have to specify all connection details every time you create a job. You can then reuse connections when creating jobs in AWS Glue Studio without having to manually enter connection details each time. This makes the job creation process more consistent and faster.
Complete these steps on the AWS Glue account:
On the AWS Glue console, choose the Data connections link on the navigation pane.
Choose Create connection and follow the instructions in the Create connection wizard:
In Choose data source, choose JDBC as data source.
In Configure connection:
For JDBC URL, enter the JDBC URL for the source database. For PostgreSQL, the syntax is:
You can find the database-endpoint on the Amazon RDS console on the source account.
Expand Network options. For VPC, Subnet and Security group, select the ones in the centralized AWS Glue account, as shown in the following figure:
In Set Properties, for Name enter Source DB connection-Postgresql.
Repeat steps 1 and 2 to create the connection to the target Amazon RDS database. Name the connection Target DB connection-Postgresql.
Now you have two connections, one for each Amazon RDS database.
Create AWS Glue crawlers
AWS Glue crawlers allow you to automate data discovery and cataloging from data sources and targets. Crawlers explore data stores and auto-generate metadata to populate the Data Catalog, registering discovered tables in the Data Catalog. This helps you to discover and work with the data to build ETL jobs.
To create a crawler for each Amazon RDS database, complete the following steps on the AWS Glue account:
On the AWS Glue console, choose Crawlers in the navigation pane.
Choose Create crawler and follow the instructions in the Add crawler wizard:
In Set crawler properties, for Name enter Source PostgreSQL database crawler.
In Chose data sources and classifiers, choose Not yet.
In Add data source, for Data source choose JDBC, as shown in the following figure:
For Connection, choose Source DB Connection - Postgresql.
For Include path, enter the path of your database including the schema. For our example, the path is sourcedb/cx/% where sourcedb is the name of the database, and cx the schema with the customer table.
In Configure security settings, choose the AWS IAM service role created a part of the prerequisites.
In Set output and scheduling, since we don’t have a database yet in the Data Catalog to store the source database metadata, choose Add database and create a database named sourcedb-postgresql.
Repeat steps 1 and 2 to create a crawler for the target database:
In Set crawler properties, for Name enter Target PostgreSQL database crawler.
In Add data source, for Connection, choose Target DB Connection-Postgresql, and for Include path enter targetdb/cx/%.
In Add database, for Name enter targetdb-postgresql.
Now you have two crawlers, one for each Amazon RDS database, as shown in the following figure:
Run the crawlers
Next, run the crawlers. When you run a crawler, the crawler connects to the designated data store and automatically populates the Data Catalog with metadata table definitions (columns, data types, partitions, and so on). This saves time over manually defining schemas.
From the Crawlers list, select both Source PostgreSQL database crawler and Target PostgreSQLdatabase crawler, and choose Run.
When finished, each crawler creates a table in the Data Catalog. These tables are the metadata representation of the customer tables.
You now have all the resources to start creating AWS Glue ETL jobs!
Step 3 – Create and run the AWS Glue ETL Job
The proposed ETL job runs four tasks:
Source data extraction – Establishes a connection to the Amazon RDS source database and extracts the data to replicate.
PII detection and scrubbing.
Data transformation – Adjusts and removes unnecessary fields.
Target data loading – Establishes a connection to the target Amazon RDS database and inserts data with masked PII.
Let’s jump into AWS Glue Studio to create the AWS Glue ETL job.
Choose Visual ETL as shown in the following figure:
Task 1 – Source data extraction
Add a node to connect to the Amazon RDS source database:
Choose AWS Glue Data Catalog from the Sources. This adds a data source node to the canvas.
On the Data source propertiespanel, select sourcedb-postgresql database and source_cx_customer table from the Data Catalog as shown in the following figure:
Task 2 – PII detection and scrubbing
To detect and mask PII, select Detect Sensitive Data node from the Transforms tab.
Let’s take a deeper look into the Transform options on the properties panel for the Detect Sensitive Data node:
First, you can choose how you want the data to be scanned. You can select Find sensitive data in each row or Find columns that contain sensitive data as shown in the following figure. Choosing the former scans all rows for comprehensive PII identification, while the latter scans a sample for PII location at lower cost.
Selecting Find sensitive data in each row allows you to specify fine-grained action overrides. If you know your data, with fine-grained actions you can exclude certain columns from detection. You can also customize the entities to detect for every column in your dataset and skip entities that you know aren’t in specific columns. This allows your jobs to be more performant by eliminating unnecessary detection calls for those entities and perform actions unique to each column and entity combination.
In our example, we know our data and we want to apply fine-grained actions to specific columns, so let’s select Find sensitive data in each row. We’ll explore fine-grained actions further below.
Next, you select the types of sensitive information to detect. Take some time to explore the three different options.
In our example, again because we know the data, let’s select Select specific patterns. For Selected patterns, choose Person’s name, Email Address, Credit Card, Social Security Number (SSN) and US Phone as shown in the following figure. Note that some patterns, such as SSNs, apply specifically to the United States and might not detect PII data for other countries. But there are available categories applicable to other countries, and you can also use regular expressions in AWS Glue Studio to create detection entities to help meet your needs.
Next, select the level of detection sensitivity. Leave the default value (High).
Next, choose the global action to take on detected entities. Select REDACT and enter **** as the Redaction Text.
Next, you can specify fine-grained actions (overrides). Overrides are optional, but in our example, we want to exclude certain columns from detection, scan certain PII entity types on specific columns only, and specify different redaction text settings for different entity types.
Choose Add to specify the fine-grained action for each entity as shown in the following figure:
Task 3 – Data transformation
When the Detect Sensitive Data node runs, it converts the id column to string type and it adds a column named DetectedEntities with PII detection metadata to the output. We don’t need to store such metadata information in the target table, and we need to convert the id column back to integer, so let’s add a Change Schema transform node to the ETL job, as shown in the following figure. This will make these changes for us.
Note: You must select the DetectedEntities Drop checkbox for the transform node to drop the added field.
Task 4 – Target data loading
The last task for the ETL job is to establish a connection to the target database and insert the data with PII masked:
Choose AWS Glue Data Catalog from the Targets. This adds a data target node to the canvas.
On the Data target properties panel, choose targetdb-postgresql and target_cx_customer, as shown in the following figure.
Save and run the ETL job
From the Job details tab, for Name, enter ETL - Replicate customer data.
For IAM Role, choose the AWS Glue role created as part of the prerequisites.
Choose Save, then choose Run.
Monitor the job until it successfully finishes from Job run monitoring on the navigation pane.
Step 4 – Verify the results
Connect to the Amazon RDS target database and verify that the replicated rows contain the scrubbed PII data, confirming sensitive information was masked properly in transit between databases as shown in the following figure:
And that’s it! With AWS Glue Studio, you can create ETL jobs to copy data between databases and transform it along the way without any coding. Try other types of sensitive information for securing your sensitive data during replication. Also try adding and combining multiple and heterogenous data sources and targets.
Clean up
To clean up the resources created:
Delete the AWS Glue ETL job, crawlers, Data Catalog databases, and connections.
Delete the VPC peering connections.
Delete the routes added to the route tables, and inbound rules added to the security groups on the three AWS accounts.
On the AWS Glue account, delete associated Amazon S3 objects. These are in the S3 bucket with aws-glue-assets-account_id-region in its name, where account-id is your AWS Glue account ID, and region is the AWS Region you used.
Delete the Amazon RDS databases you created if you no longer need them. If you used the GitHub repository, then delete the AWS CloudFormation stacks.
Conclusion
In this post, you learned how to use AWS Glue Studio to build an ETL job that copies data from one Amazon RDS database to another and automatically detects PII data and masks the data in-flight, without writing code.
By using AWS Glue for database replication, organizations can eliminate manual processes to find hidden PII and bespoke scripting to transform it by building centralized, visible data sanitization pipelines. This improves security and compliance, and speeds time-to-market for test or analytics data provisioning.
About the Author
Monica Alcalde Angel is a Senior Solutions Architect in the Financial Services, Fintech team at AWS. She works with Blockchain and Crypto AWS customers, helping them accelerate their time to value when using AWS. She lives in New York City, and outside of work, she is passionate about traveling.
Amazon CodeCatalyst is a unified software development service for development teams to quickly build, deliver and scale applications on AWS while adhering to organization-specific best practices. Developers can automate development tasks and innovate faster with generative AI capabilities, and spend less time setting up project tools, managing CI/CD pipelines, provisioning and configuring various development environments or coordinating with team members.
It can integrate with services like AWS CodeArtifact, which is a managed artifact repository service that lets you securely store, publish, and share software packages. In this blog post we will show you how to use Publish to AWS CodeArtifact action in a CodeCatalyst workflow to publish packages to AWS Code Artifact.
In Amazon CodeCatalyst, an action is the main building block of a workflow, and defines a logical unit of work to perform during a workflow run. Typically, a workflow includes multiple actions that run sequentially or in parallel depending on how you’ve configured them. Amazon CodeCatalyst provides a library of pre-built actions that you can use in your workflows, such as for building, testing, deploying applications, as well as the ability to create custom actions for specific tasks not covered by the pre-built options.
Following are the instructions on using Publish to AWS CodeArtifact action in Amazon CodeCatalyst workflow.
Prerequisites
To follow along with this walkthrough, you will need:
A domain and repository created in AWS CodeArtifact for publishing your package. See Create a repository.
An AWS account associated with your space and have the IAM role in that account that has permissions to publish our package to AWS Code Artifact. For more information about the role and role policy, see Creating a CodeCatalyst service role. Make sure that the role includes the following permissions policy:
In the trust policy, we have specified two AWS services in the Principal element. Service principals are defined by the service. The following service principals are defined for CodeCatalyst:
amazonaws.com – This service principal is used for a role that will grant CodeCatalyst access to AWS.
codecatalyst-runner.amazonaws.com – This service principal is used for a role that will grant CodeCatalyst access to AWS resources in deployments for CodeCatalyst workflows.
Walkthrough
In this example, we are going to publish a npm package to a CodeArtifact repository called ‘myapp-frontend in the domain ‘myapp-artifacts. Amazon CodeCatalyst is available in two regions at the moment i.e. Europe (Ireland) and US West (Oregon). We will use ‘us-west-2’ for all the resources in this walkthrough.
Here are the steps to create your workflow.
In the navigation pane, choose CI/CD, and then choose Workflows.
Choose Create workflow.
The workflow definition file appears in the CodeCatalyst console’s YAML editor.
To configure your workflow
You can configure your workflow in the Visual editor, or the YAML editor. Let’s start with the YAML editor and then switch to the visual editor.
Choose + Actions to see a list of workflow actions that you can add to your workflow.
In the Build action, choose + to add the action’s YAML to your workflow definition file. Your workflow now looks similar to the following. You can follow the below code by editing in YAML editor.
The following code shows the newly created workflow.
Name: CodeArtifactWorkflow
SchemaVersion: "1.0"
# Optional - Set automatic triggers.
Triggers:
- Type: Push
Branches:
- main
# Required - Define action configurations.
Actions:
Build:
# Identifies the action. Do not modify this value.
Identifier: aws/[email protected]
# Specifies the source and/or artifacts to pass to the action as input.
Inputs:
# Optional
Sources:
- WorkflowSource # This specifies that the action requires this Workflow as a source
Outputs:
Artifacts:
- Name: ARTIFACT
Files:
- "**/*"
# Defines the action's properties.
Configuration:
# Required - Steps are sequential instructions that run shell commands
Steps:
- Run: cd integration/npm/npm-package-example-main
- Run: npm pack
- Run: ls
Compute:
Type: EC2
Environment:
Connections:
- Role: CodeCatalystWorkflowDevelopmentRole-action-workshop
Name: codecatalystconnection
Name: action-builder
In this build action, we are using ‘npm pack’ command to create a compressed tarball (.tgz) file of our package’s source code and configuration files. We are creating an output artifact named ‘ARTIFACT’ and our files are in this directory integration/npm/npm-package-example-master.
Now, we are going to select publish-to-code-artifact action from the action’s dropdown list.
The following code shows the newly added action in the workflow file.
If you chose ‘Visual’ option to view the workflow definition file in the visual editor. This is going to look as shown in the image below. The fields in the visual editor let you configure the YAML properties shown in the YAML editor.
How the “Publish to AWS CodeArtifact” action works:
The “Publish to AWS CodeArtifact” action works as follows at runtime:
Checks if the PackageFormat, PackagePath, RepositoryName, DomainNameand AWSRegionis specified, validates the configuration, and configures AWS credentials based on the Environment, Connection, and Role specified.
Looks for package files to publish in the path configured in the PackagePathfield in the WorkflowSource If no source is configured in Sources, but an artifact is configured in Arifacts, then the action looks for the files in the configured artifact folder.
Publishes the package to AWS CodeArtifact.
Cleanup
If you have been following along with this workflow, you should delete the resources you deployed so that you do not continue to incur charges.
Delete the published package in AWS CodeArtifact by following these instructions.
Delete the repository in AWS CodeArtifact by following these instructions.
Delete the domain in AWS CodeArtifact by following these instructions.
For Amazon CodeCatalyst, if you created a new project for this tutorial, delete it. For instructions, see Deleting a project. Deleting the project also deletes the source repository and workflow.
Conclusion
In this post, we demonstrated how to use an Amazon CodeCatalyst workflow to publish packages to AWS CodeArtifact by utilizing the Publish to AWS CodeArtifact action. By following the steps outlined in this blog post, you can ensure that your packages are readily available for your projects while maintaining version control and security.
For further reading, see Working with actions in the CodeCatalyst documentation.
About the Authors
Muhammad Shahzad is a Solutions Architect at AWS. He is passionate about helping customers achieve success on their cloud journeys, enjoys designing solutions and helping them implement DevSecOps by explaining principles, creating automated solutions and integrating best practices in their journey to the cloud. Outside of work, Muhammad plays badminton regularly, enjoys various other sports, and has a passion for hiking scenic trails.
Alexander Schueren is a Senior Specialist Solutions Architect at AWS, dedicated to modernizing legacy applications and building event-driven serverless solutions. With a focus on simplifying complexity and bringing clarity to technical challenges, Alexander is on a mission to empower developers with the tools they need for success. As the maintainer of the open-source project “Powertools for AWS Lambda (TypeScript),” he is committed to driving innovation in serverless technologies. In his free time, Alexander channels his creativity through street photography, capturing decisive moments in the urban landscape.
According to the Well-Architected DevOps Guidance, “A peer review process for code changes is a strategy for ensuring code quality and shared responsibility. To support separation of duties in a DevOps environment, every change should be reviewed and approved by at least one other person before merging.” Development teams often implement the peer review process in their Software Development Lifecycle (SDLC) by leveraging Pull Requests (PRs). Amazon CodeCatalyst has recently released three new features to facilitate a robust peer review process. Pull Request Approval Rules enforce a minimum number of approvals to ensure multiple peers review a proposed change prior to a progressive deployment. Amazon Q pull request summaries can automatically summarize code changes in a PR, saving time for both the creator and reviewer. Lastly, Nested Comments allows teams to organize conversations and feedback left on a PR to ensure efficient resolution.
This blog will demonstrate how a DevOps lead can leverage new features available in CodeCatalyst to accomplish the following requirements covering best practices: 1. Require at least two people to review every PR prior to deployment, and 2. Reduce the review time to merge (RTTM).
Prerequisites
If you are using CodeCatalyst for the first time, you’ll need the following to follow along with the steps outlined in the blog post:
A Project in a CodeCatalyst Space. If you don’t have one, you can create a new space.
Approval rules can be configured for branches in a repository. When you create a PR whose destination branch has an approval rule configured for it, the requirements for the rule must be met before the PR can be merged.
In this section, you will implement approval rules on the default branch (main in this case) in the application’s repository to implement the new ask from leadership requiring that at least two people review every PR before deployment.
Step 1: Creating the application Pull Request approval rules work with every project but in this blog, we’ll leverage the Modern three-tier web application blueprint for simplicity to implement PR approval rules for merging to the main branch.
Figure 1: Creating a new Modern three-tier application Blueprint
First, within your space click “Create Project” and select the Modern three-tier web application CodeCatalyst Blueprint as shown above in Figure 1.
Enter a Project name and select: Lambda for the Compute Platform and Amplify Hosting for Frontend Hosting Options. Additionally, ensure your AWS account is selected along with creating a new IAM Role.
Finally, click Create Project and a new project will be created based on the Blueprint.
Once the project is successfully created, the application will deploy via a CodeCatalyst workflow, assuming the AWS account and IAM role were setup correctly. The deployed application will be similar to the Mythical Mysfits website.
Step 2: Creating an approval rule
Next, to satisfy the new requirement of ensuring at least two people review every PR before deployment, you will create the approval rule for members when they create a pull request to merge into the main branch.
Navigate to the project you created in the previous step.
In the navigation pane, choose Code, and then choose Source repositories.
Next, choose the mysfits repository that was created as part of the Blueprint.
On the overview page of the repository, choose Branches.
For the main branch, click View under the Approval Rules column.
In Minimum number of approvals, the number corresponds to the number of approvals required before a pull request can be merged to that branch.
Now, you’ll change the approval rule to satisfy the requirement to ensure at least 2 people review every PR. Choose Manage settings. On the settings page for the source repository, in Approval rules, choose Edit.
In Destination Branch, from the drop-down list, choose main as the name of the branch to configure an approval rule. In Minimum number of approvals, enter 2, and then choose Save.
Figure 2: Creating a new approval rule
Note: You must have the Project administrator role to create and manage approval rules in CodeCatalyst projects. You cannot create approval rules for linked repositories.
When implementing approval rules and branch restrictions in your repositories, ensure you take into consideration the following best practices:
For branches deemed critical or important, ensure only highly privileged users are allowed to Push to the Branch and Delete the Branch in the branch rules. This prevents accidental deletion of critical or important branches as well as ensuring any changes introduced to the branch are reviewed before deployment.
Ensure Pull Request approval rules are in place for branches your team considers critical or important. While there is no specific recommended number due to varying team size and project complexity, the minimum number of approvals is recommended to be at least one and research has found the optimal number to be two.
In this section, you walked through the steps to create a new approval rule to satisfy the requirement of ensuring at least two people review every PR before deployment on your CodeCatalyst repository.
Amazon Q pull request summaries
Now, you begin exploring ways that can help development teams reduce MTTR. You begin reading about Amazon Q pull request summaries and how this feature can automatically summarize code changes and start to explore this feature in further detail.
While creating a pull request, in Pull request description, you can leverage the Write description for me feature, as seen in Figure 5 below, to have Amazon Q create a description of the changes contained in the pull request.
Figure 3: Amazon Q write description for me feature
Once the description is generated, you can Accept and add to description, as seen in Figure 6 below. As a best practice, once Amazon Q has generated the initial PR summary, you should incorporate any specific organizational or team requirements into the summary before creating the PR. This allows developers to save time and reduce MTTR in generating the PR summary while ensuring all requirements are met.
Figure 4: PR Summary generated by Amazon Q
CodeCatalyst offers an Amazon Q feature that summarizes pull request comments, enabling developers to quickly grasp key points. When many comments are left by reviewers, it can be difficult to understand common themes in the feedback, or even be sure that you’ve addressed all the comments in all revisions. You can use the Create comment summary feature to have Amazon Q analyze the comments and provide a summary for you, as seen in Figure 5 below.
Figure 5: Comment summary
Nested Comments
When reviewing various PRs for the development teams, you notice that feedback and subsequent conversations often happen within disparate and separate comments. This makes reviewing, understanding and addressing the feedback cumbersome and time consuming for the individual developers. Nested Comments in CodeCatalyst can organize conversations and reduce MTTR.
You’ll leverage the existing project to walkthrough how to use the Nested Comments feature:
Step 1: Creating the PR
Click the mysifts repository, and on the overview page of the repository, choose More, and then choose Create branch.
Edit the file to update the text in the <title> block to Mythical Mysfits new title update! and Commit the changes.
Create a pull request by using test-branch as the Source branch and main as the Destination branch. Your PR should now look similar to Figure 6 below:
Figure 6: Pull Request with updated Title
Step 2: Review PR and add Comments
Review the PR, ensure you are on the Changes tab (similar to Figure 3), click the Comment icon and leave a comment. Normally this would be done by the Reviewer but you will simulate being both the Reviewer and Developer in this walkthrough.
With the comment still open, hit Reply and add another comment as a response to the initial comment. The PR should now look similar to Figure 7 below.
Figure 7: PR with Nested Comments
When leaving comments on PR in CodeCatalyst, ensure you take into consideration the following best practices :
Feedback or conversation focused on a specific topic or piece of code should leverage the nested comments feature. This will ensure the conversation can be easily followed and that context and intent are not lost in a sea of individual comments.
Author of the PR should address all comments by either making updates to the code or replying to the comment. This indicates to the reviewer that each comment was reviewed and addressed accordingly.
Feedback should be constructive in nature on PRs. Research has found that, “destructive criticism had a negative impact on participants’ moods and motivation to continue working.”
Clean-up
As part of following the steps in this blog post, if you upgraded your space to Standard or Enterprise tier, please ensure you downgrade to the Free tier to avoid any unwanted additional charges. Additionally, delete any projects you may have created during this walkthrough.
Conclusion
In today’s fast-paced software development environment, maintaining a high standard for code changes is crucial. With its recently introduced features, including Pull Request Approval Rules, Amazon Q pull request summaries, and nested comments, CodeCatalyst empowers development teams to ensure a robust pull request review process is in place. These features streamline collaboration, automate documentation tasks, and facilitate organized discussions, enabling developers to focus on delivering high-quality code while maximizing productivity. By leveraging these powerful tools, teams can confidently merge code changes into production, knowing that they have undergone rigorous review and meet the necessary standards for reliability and performance.
In this blog post, I’ll explain how to use a Microsoft Entra ID and Visual Studio Code editor to access Amazon Q developer service and speed up your development. Additionally, I’ll explain how to minimize the time spent on repetitive tasks and quickly integrate users from external identity sources so they can immediately use and explore Amazon Web Services (AWS).Generative AI on AWS holds great ability for businesses seeking to unlock new opportunities and drive innovation. AWS offers a robust suite of tools and capabilities that can revolutionize software development, generate valuable insights, and deliver enhanced customer value. AWS is committed to simplifying generative AI for businesses through services like Amazon Q, Amazon Bedrock, Amazon SageMaker, Data foundation & AI infrastructure.
Amazon Q Developer is a generative AI-powered assistant that helps developers and IT professionals with all of their tasks across the software development lifecycle. Amazon Q Developer assists with coding, testing, and upgrading to troubleshooting, performing security scanning and fixes, optimizing AWS resources, and creating data engineering pipelines.
A common request from Amazon Q Developer customers is to allow developer sign-ins using established identity providers (IdP) such as Entra ID. Amazon Q Developer offers authentication support through AWS Builder ID or AWS IAM Identity Center. AWS Builder ID is a personal profile for builders. IAM Identity Center is ideal for an enterprise developer working with Amazon Q and employed by organizations with an AWS account. When using the Amazon Q Developer Pro tier, the developer should authenticate with the IAM Identity Center. See the documentation, Understanding tiers of service for Amazon Q Developer for more information.
How it works
The flow for accessing Amazon Q Developer through the IAM Identity Center involves the authentication of Entra ID users using Security Assertion Markup Language (SAML) 2.0 authentication (Figure 1).
Figure 1 – Solution Overview
The flow for accessing Amazon Q Developer through the IAM Identity Center involves the authentication of Entra ID users using SAML 2.0 authentication. (Figure 1).
IAM Identity Center synchronizes users and groups information from Entra ID into IAM Identity Center using the System for Cross-domain Identity Management (SCIM) v2.0 protocol.
Developers with an Entra ID account connect to Amazon Q Developer through IAM Identity Center using the VS Code IDE.
If a developer isn’t already authenticated, they will be redirected to the Entra ID account login. The developer will sign in using their Entra ID credentials.
If the sign-in is successful, Entra ID processes the request and sends a SAML response containing the developer identity and authentication status to IAM Identity Center.
If the SAML response is valid and the developer is authenticated, IAM Identity Center grants access to Amazon Q Developer.
The developer can now securely access and use Amazon Q Developer.
Prerequisites
In order to perform the following procedure, make sure the following are in place.
Configure Entra ID and AWS IAM Identity Center integration
In this section, I will show how you can create a SAML base connection between Entra ID and AWS Identity Center so you can access AWS generative AI services using your Entra ID.
Note: You need to switch the console between Entra ID portal and AWS IAM Identity center. I recommend to open new browser tabs for each console.
Step 1 – Prepare your Microsoft tenant
Perform the below steps in the Entra identity provider section.
Navigate to Identity > Applications > Enterprise applications, and then choose New application.
On the Browse Microsoft Entra Gallery page, enter AWS IAM Identity Center in the search box.
Select AWS IAM Identity Center from the results area.
Choose Create.
Now you have created AWS IAM Identity Center application, set up single sign-on to enable users to sign into their applications using their Entra ID credentials. Select the Single sign-on tab from the left navigation plane and select Setup single sign on.
Step 2 – Collect required service provider metadata from IAM Identity Center
In this step, you will launch the Change identity source wizard from within the IAM Identity Center console and retrieve the metadata file and the AWS specific sign-in URL. You will need this to enter when configuring the connection with Entra ID in the next step.
IAM Identity Center.
You need to enable this in order to configure SSO.
Navigate to Services –> Security, Identity, & Compliance –> AWS IAM Identity Center.
Choose Enable (Figure 2).
Figure 2 – Get started with AWS IAM Identity Center
In the left navigation pane, choose Settings.
On the Settings page, find Identity source, select Actions pull-down menu, and select Change identity source.
On the Change identity source page, choose External identity provider (Figure 3).
Figure 3 – Select External identity provider
On the Configure external identity provider page, under Service provider metadata, select Download metadata file (XML file).
In the same section, locate the AWS access portal sign-in URL value and copy it. You will need to enter this value when prompted in the next step (Figure 4).
Figure 4 – Copy provider metadata URLs
Leave this page open, and move to the next step to configure the AWS IAM Identity Center enterprise application in Entra ID. Later, you will return to this page to complete the process.
Step 3 – Configure the AWS IAM Identity Center enterprise application in Entra ID
This procedure establishes one-half of the SAML connection on the Microsoft side using the values from the metadata file and Sign-On URL you obtained in the previous step.
In the Microsoft Entra admin center console, navigate to Identity > Applications > Enterprise applications and then choose AWS IAM Identity Center.
On the left, choose Single sign-on.
On the Set up Single sign on with SAML page, choose Upload metadata file, choose the folder icon, select the service provider metadata file that you downloaded in the previous step 2.6, and then choose Add.
On the Basic SAML Configuration page, verify that both the Identifier and Reply URL values now point to endpoints in AWS that start with https://<REGION>.signin.aws.amazon.com/platform/saml/.
Under Sign on URL (Optional), paste in the AWS access portal sign-in URL value you copied in the previous step (Step 2.7), choose Save, and then choose X to close the window.
If prompted to test single sign-on with AWS IAM Identity Center, choose No I’ll test later. You will do this verification in a later step.
On the Set up Single Sign-On with SAML page, in the SAML Certificates section, next to Federation Metadata XML, choose Download to save the metadata file to your system. You will need to upload this file when prompted in the next step.
Step 4 – Configure the Entra ID external IdP in AWS IAM Identity Center
Next you will return to the Change identity source wizard in the IAM Identity Center console to complete the second-half of the SAML connection in AWS.
Return to the browser session you left open in the IAM Identity Center console.
On the Configure external identity provider page, in the Identity provider metadata section, under IdP SAML metadata, choose the Choose file button, and select the identity provider metadata file that you downloaded from Microsoft Entra ID in the previous step, and then choose Open (Figure 5).
Figure 5 – AWS IAM Identity center metadata
Choose Next
After you read the disclaimer and are ready to proceed, enter ACCEPT
Choose Change identity source to apply your changes (Figure 6).
Figure 6 – AWS IAM Identity center metadata
Confirm the changes (Figure 7).
Figure 7 – AWS IAM Identity center metadata configuration changes progress console.
Step 5 – Configure and test your SCIM synchronization
In this step, you will set up automatic provisioning (synchronization) of user and group information from Microsoft Entra ID into IAM Identity Center using the SCIM v2.0 protocol. You configure this connection in Microsoft Entra ID using your SCIM endpoint for AWS IAM Identity Center and a bearer token that is created automatically by AWS IAM Identity Center.
To enable automatic provisioning of Entra ID users to IAM Identity Center, follow these steps using the IAM Identity Center application in Entra ID. For testing purposes, you can create a new user (TestUser) in Entra ID with details like First Name, Last Name, Email ID, Department, and more. Once you’ve configured SCIM synchronization, you can verify that this user and their relevant attributes were successfully synced to AWS IAM Identity Center.
In this procedure, you will use the IAM Identity Center console to enable automatic provisioning of users and groups coming from Entra ID into IAM Identity Center.
Open the IAM Identity Center console and Choose Setting in the left navigation pane.
On the Settings page, under the Identity source tab, notice that Provisioning method is set to Manual (Figure 8).
Figure 8 – AWS IAM Identity center console with provisioning method configuration details
Locate the Automatic provisioning information box, and then choose Enable. This immediately enables automatic provisioning in IAM Identity Center and displays the necessary SCIM endpoint and access token information.
In the Inbound automatic provisioning dialog box, copy each of the values for the following options. You will need to paste these in the next step when you configure provisioning in Entra ID.
SCIM endpoint – For example, https://scim.us-east-2.amazonaws.com/11111111111-2222-3333-4444-555555555555/scim/v2/
Access token – Choose Show token to copy the value (Figure 9).
Figure 9 – AWS IAM Identity center automatic provisioning info
Choose Close.
Under the Identity source tab, notice that Provisioning method is now set to SCIM.
Step 6 – Configure automatic provisioning in Entra ID
Now that you have your test user in place and have enabled SCIM in IAM Identity Center, you can proceed with configuring the SCIM synchronization settings in Entra ID.
In the Microsoft Entra admin center console, navigate to Identity > Applications > Enterprise applications and then choose AWS IAM Identity Center.
Choose Provisioning, under Manage, choose Provisioning
In Provisioning Mode select
For Admin Credentials, in Tenant URL paste in the SCIM endpoint URL value you copied earlier. In Secret Token, paste in the Access token value (Figure 10).
Figure 10 – Azure Enterprise AWS IAM Identity center application provisioning configuration tab
Choose Test Connection. You should see a message indicating that the tested credentials were successfully authorized to enable provisioning (Figure 11).
Figure 11 – Azure Enterprise AWS IAM Identity center application provisioning testing status
Choose Save.
Under Manage, choose Users and groups, and then choose Add user/group.
On the Add Assignment page, under Users, choose None Selected.
Select TestUser, and then choose Select.
On the Add Assignment page, choose
Choose Overview, and then choose Start provisioning (Figure 12).
Figure 12 – AWS IAM Identity center application Start provisioning tab
Note : The default provisioning interval is set to 40 minutes. Our users (Figure 13) are successfully provisioned and are now available in the AWS IAM Identity Center console.
In this section, you will verify that TestUser user was successfully provisioned and that all attributes are displayed in IAM Identity Center (Figure 13).
Figure 13 – AWS IAM Identity center application user console example
In the Identity source in IDC section, enable Identity-aware console sessions (Figure 14). This enables AWS IAM Identity Center user and session IDs to be included in users’ AWS console sessions when they sign in. For example, Amazon Q Developer Pro uses identity-aware console sessions to personalize the service experience.
I have completed Entra ID and AWS Identity Center configuration. You can see Entra ID identity synced successfully with AWS IAM identity center.
Step 7 – Set up AWS Toolkit with IAM Identity Center
To use Amazon Q Developer, you will now set up the AWS Toolkit within integrated development environments (IDE) to establish authentication with the IAM Identity Center.
AWS Toolkit for Visual Studio Code is an open-source plug-in for VS Code that makes it easier for developers by providing an integrated experience to create, debug, and deploy applications on AWS. Getting started with Amazon Q Developer in VS Code is simple.
Open the AWS Toolkit for Visual Studio Code extension in your VS Code IDE. Install AWS Toolkit for VS Code, which is available as a download from the VS Code Marketplace.
From the AWS Toolkit for Visual Studio Code extension in the VS Code Marketplace, choose Install to begin the installation process.
When prompted, choose to restart VS Code to complete the installation process.
Step 8 – Setup Amazon Q Developer service with VS Code using AWS IAM identity center.
After installing the Amazon Q extension or plugin, authenticate through IAM Identity Center or AWS Builder ID.
After your identity has been subscribed to Amazon Q Developer Pro, complete the following steps to authenticate.
Choose the Amazon Q icon from the sidebar in your IDE
Choose Use with Pro license and select Continue (Figure 15).
Figure 15 – Visual Studio code Amazon Q Developer extension
Enter the IAM Identity Center URL you previously copied into the Start URL
Set the appropriate region, example us-east-1, and select Continue
Click Copy Code and Proceed to copy the code from the resulting pop-up.
When prompted by the Do you want Code to open the external website? pop-up, select Open
Paste the code copied in Step 6 and select Next
Enter your Entra ID credentials and select Sign in
Select Allow Access toAWS IDE Extensions for VSCode to access Amazon Q Developer (Figure 16).
Figure 16 – Allow VS Code to access Amazon Q Developer
When the connection is complete, a notification indicates that it is safe to close your browser. Close the browser tab and return to your IDE.
You are now all set to use Amazon Q Developer from within IDE, authenticated with your Entra ID credentials.
Step 9 – Test configuration examples
Now you have configured IAM identity Center access with VS code now you can chat, get inline code suggestions, check for security vulnerabilities with Amazon Q Developer to learn about, build, and operate AWS applications. I have mentioned a few examples of Amazon Q Suggestions, Code suggestions, Security Vulnerabilities during development for your reference (Figures 17 ,18 ,19 ,20).
Figure 17 – Amazon Q suggestion examples
Example of developers get the recommendations using Amazon Q developer.
Figure 18 – Amazon Q Developer example
Figure 19 – Generate code, explain code, and get answers to questions about software development.
Example of integrating secure coding practices early in the software development lifecycle using Amazon Q developer.
Figure 20 – Analyze and fix security vulnerabilities in your project example
Cleanup
Configuring AWS and Azure services from this blog will provision resources which incur cost. It is a best practice to delete configurations and resources that you are no longer using so that you do not incur unintended charges.
Conclusion
In this blog post, you learned how to integrate AWS IAM Identity Center and Entra ID IdP for accessing Amazon Q Developer service using VS Code IDE, which speeds up development. Next, you set up the AWS Toolkit to establish a secure connection to AWS using Entra ID credentials, granting you access to the Amazon Q Developer Professional Tier. Using SCIM automatic provisioning for user provisioning and access assignment saves time and speeds up onboarding, allowing for immediate use of AWS services using you own identity. Using Amazon Q, developers get the recommendations and information within their working environment in the IDE, enabling them to integrate secure coding practices early in the software development lifecycle. Developers can proactively scan their existing code using Amazon Q and remediate the security vulnerabilities found in the code.
In the rapidly evolving landscape of Generative AI, the ability to deploy and iterate on features quickly and reliably is paramount. We, the Amazon Q Developer service team, relied on several offline and online testing methods, such as evaluating models on datasets, to gauge improvements. Once positive results are observed, features were rolled out to production, introducing a delay until the change affected 100% of customers.
This blog post delves into the impact of A/B testing and Multi-Model hosting on deploying Generative AI features. By leveraging these powerful techniques, our team has been able to significantly accelerate the pace of experimentation, iteration, and deployment. We have not only streamlined our development process but also gained valuable insights into model performance, user preferences, and the potential impact of new features. This data-driven approach has allowed us to make informed decisions, continuously refine our models, and provide a user experience that resonates with our customers
What is A/B Testing?
A/B testing is a controlled experiment, and a widely adopted practice in the tech industry. It involves simultaneously deploying multiple variants of a product or feature to distinct user segments. In the context of Amazon Q Developer, the service team leverages A/B testing to evaluate the impact of new model variants on the developer experience. This helps in gathering real-world feedback from a subset of users before rolling out changes to the entire user base.
Control group: Developers in the control group continue to receive the base Amazon Q Developer experience, serving as the benchmark against which changes are measured.
Treatment group: Developers in the treatment group are exposed to the new model variant or feature, providing a contrasting experience to the control group.
To run an experiment, we take a random subset of developers and evenly split it into two groups: The control group continues to receive the base Amazon Q Developer experience, while the treatment group receives a different experience.
By carefully analyzing user interactions and telemetry metrics of the control group and comparing them to those from the treatment group, we can make informed decisions about which variant performs better, ultimately shaping the direction of future releases.
How do we split the users?
Whenever a user request is received, we perform consistent hashing on the user identity and assign the user to a cohort. Irrespective on which machine the algorithm runs, the user will be assigned the same cohort. This means that we can scale horizontally – user A’s request can be served by any machine and user A will always be assigned to group A from the beginning to the end of the experiment.
Individuals in the two groups are, on average, balanced on all dimensions that will be meaningful to the test. This means that we do not expose a cohort to have more than one experiment at any given time. This enables us to conduct multivariate experiments where one experiment does not impact the result of another.
The above diagram illustrates the process of user assignment to cohorts in a system conducting multiple parallel A/B experiments.
How do we enable segmentation?
For some A/B experiments, we want to perform A/B experiments for users matching certain criteria. Assume we want to exclusively target Amazon Q Developer customers using the Visual Studio Code Integrated Development Environment (IDE). For such scenarios, we perform cohort allocation only for users who meet the criteria. In this example, we would divide a subset of Visual Studio Code IDE users into control and treatment cohorts.
How do we route the traffic between different models ?
The above diagram depicts how Application Load Balancer redirects traffic to various models based on path-based routing. Where path1 is routing to control model and path2 is routing to treatment model 1 etc.
How do we enable different IDE experiences for different groups?
The IDE plugin polls the service endpoint asking if the developer belongs to the control or treatment group. Based on the response the user will be served the control or treatment experience.
The above diagram depicts how the IDE plugin provides different experience based on control or treatment group.
How do we ingest data?
From the plugin, we publish telemetry metrics to our data plane. We honor opt-out settings of our users. If the user is opted-out, we do not store their data. In the data plane, we check the cohort of the caller. We publish telemetry metrics with cohort metadata to Amazon Data Firehose, which delivers the data to an Amazon OpenSearch Serverless destination.
The above diagram depicts how metrics are captured via the data plane into Amazon OpenSearch Serverless.
How do we analyze the data?
We publish the aggregated metrics to OpenSearch Serverless. We leverage OpenSearch Serverless to ingest and index various metrics to compare and contrast between control and treatment cohorts. We enable filtering based on metadata such as programming language and IDE.
Additionally, we publish data and metadata to a data lake to view, query and analyze the data securely using Jupyter Notebooks and dashboards. This enables our scientists and engineers to perform deeper analysis.
Conclusion
This post has focused on challenges Generative AI services face when it comes to fast experimentation cycles, the basics of A/B testing and the A/B testing capabilities built by the Amazon Q Developer service team to enable multi-variate service and client-side experimentation. We can gain valuable insights into the effectiveness of the new model variants on the developer experience within Amazon Q Developer. Through rigorous experimentation and data-driven decision-making, we can empower teams to iterate, innovate, and deliver optimal solutions that resonate with the developer community.
We hope you are as excited as us about the opportunities with Generative AI! Give Amazon Q Developer and Amazon Q Developer Customization a try today:
AWS partners often have a requirement to create resources, such as cross-account roles, in their customers’ accounts. A good choice for consistently provisioning these resources is AWS CloudFormation, an Infrastructure as Code (IaC) service that allows you to specify your architecture in a template file written in JSON or YAML. CloudFormation also makes it easy to deploy resources across a range of regions and accounts in parallel with StackSets, which is an invaluable feature that helps customers who are adopting multi-account strategies.
The challenge for partners is in choosing the right technique to deliver the templates to customers, and how to update the deployed resources when changes or additions need to be made. CloudFormation offers a simple, one-click experience to launch a stack based on a template with a quick-create link, but this does not offer an automated way to update the stack at a later date. In the post, I will discuss how you can use the CloudFormation Git sync feature to give customers maximum control and flexibility when it comes to deploying partner defined resources in their accounts.
CloudFormation Git sync allows you to configure a connection to your Git repository that will be monitored for any changes on the selected branch. Whenever you push a change to the template file, a stack deployment automatically occurs. This is a simple and powerful automation feature that is easier than setting up a full CI/CD pipeline using a service like AWS CodePipeline. A common practice with Git repositories is to operate off of a fork, which is a copy of a repository that you make in your own account and is completely under your control. You could choose to make modifications to the source code in your fork, or simply fetch from the “upstream” repository and merge into your repository when you are ready to incorporate updates made to the original.
A diagram showing a partner repository, a customer’s forked repository, and a stack with Git sync enabled
In the diagram above, the AWS partner’s Git repository is represented on the left. This repository is where the partner maintains the latest version of their CloudFormation template. This template may change over time as requirements for the resources needed in customer accounts change. In the middle is the customer’s forked repository, which holds a copy of the template. The customer can choose to customize the template, and the customer can also fetch and merge upstream changes from the partner. This is an important consideration for customers who want fine-grained control and internal review of any resources that get created or modified in accounts they own. On the right is the customer account, where the resources get provisioned. A CloudFormation stack with Git sync configured via a CodeConnection automatically deploys any changes merged into the forked repository.
Note that forks of public GitHub repositories are public by nature, even if forked into a private GitHub Organization. Never commit sensitive information to a forked or public repository, such as environment files or access keys.
Another common scenario is creating resources in multiple customer accounts at once. Many customers are adopting a multi-account strategy, which offers benefits like isolation of workloads, insulation from exhausting account service quotas, scoping of security boundaries, and many more. Some architectures call for a standard set of accounts (development, staging, production) per micro-service, which can lead to a customer running in hundreds or thousands of accounts. CloudFormation StackSets solves this problem by allowing you to write a CloudFormation template, configure the accounts or Organizational Units you want to deploy it to, and then the CloudFormation service handles the heavy lifting for you to consistently install those resources in each target account or region. Since stack sets can be defined in a CloudFormation template using the AWS::CloudFormation::StackSet resource type, the same Git sync solution can be used for this scenario.
A diagram showing a customer’s forked repository and a stack set being deployed to multiple accounts.
In the diagram above, the accounts on the right could scale to any number, and you can also deploy to multiple regions within those accounts. If the customer uses AWS Organizations to manage those accounts, configuration is much simpler, and newly added accounts will automatically receive the resources defined in the stack. When the partner makes changes to the original source template, the customer follows the same fetch-and-merge process to initiate the automatic Git sync deployment. Note that in order to use Git sync for this type of deployment, you will need to use the TemplateBody parameter to embed the content of the child stack into the parent template.
Conclusion
In this post, I have introduced an architectural option for partners and customers who want to work together to provide a convenient and controlled way to install and configure resources inside a customer’s accounts. Using AWS CloudFormation Git sync, along with CloudFormation StackSets, allows for updates to be rolled out consistently and at scale using Git as the basis for operational control.
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the data warehouse. However, you might need to automatically scale compute resources based on factors like query complexity and data volume to meet price-performance targets, irrespective of query queuing. To address this requirement, Redshift Serverless launched the artificial intelligence (AI)-driven scaling and optimization feature, which scales the compute not only based on the queuing, but also factoring data volume and query complexity.
In this post, we describe how Redshift Serverless utilizes the new AI-driven scaling and optimization capabilities to address common use cases. This post also includes example SQLs, which you can run on your own Redshift Serverless data warehouse to experience the benefits of this feature.
Solution overview
The AI-powered scaling and optimization feature in Redshift Serverless provides a user-friendly visual slider to set your desired balance between price and performance. By moving the slider, you can choose between optimized for cost, balanced performance and cost, or optimized for performance. Based on where you position the slider, Amazon Redshift will automatically add or remove resources to ensure better behavior and perform other AI-driven optimizations like automatic materialized views and automatic table design optimization to meet your selected price-performance target.
The slider offers the following options:
Optimized for cost – Prioritizes cost savings. Redshift attempts to automatically scale up compute capacity when doing so and doesn’t incur additional charges. And it will also attempt to scale down compute for lower cost, despite longer runtime.
Balanced – Offers balance between performance and cost. Redshift scales for performance with a moderate cost increase.
Optimized for performance – Prioritizes performance. Redshift scales aggressively for maximum performance, potentially incurring higher costs.
In the following sections, we illustrate how the AI-driven scaling and optimization feature can intelligently predict your workload compute needs and scale proactively for three scenarios:
Use case 1 – A long-running complex query. Compute scales based on query complexity.
Use case 2 – A sudden spike in ingestion volume (a three-fold increase, from 720 million to 2.1 billion). Compute scales based on data volume.
Use case 3 – A data lake query scanning large datasets (TBs). Compute scales based on the expected data to be scanned from the data lake. The expected data scan is predicted by machine learning (ML) models based on prior historical run statistics.
In the existing auto scaling mechanism, the use cases don’t increase compute capacity automatically unless queuing is identified across the instance.
Prerequisites
To follow along, complete the following prerequisites:
We use TPC-DS 1TB Cloud Data Warehouse Benchmark data to demonstrate this feature. Run the SQL statements to create tables and load the TPC-DS 1TB data.
Use case 1: Scale compute based on query complexity
The following query analyzes product sales across multiple channels such as websites, wholesale, and retail stores. This complex query typically takes about 25 minutes to run with the default 128 RPUs. Let’s run this workload on the preview workgroup created as part of prerequisites.
When a query is run for the first time, the AI scaling system may make a suboptimal decision regarding resource allocation or scaling as the system is still learning the query and data characteristics. However, the system learns from this experience, and when the same query is run again, it can make a more optimal scaling decision. Therefore, if the query didn’t scale during the first run, it is recommended to rerun the query. You can monitor the RPU capacity used on the Redshift Serverless console or by querying the SYS_SERVERLSS_USAGE system view.
The results cache is turned off in the following queries to avoid fetching results from the cache.
SET enable_result_cache_for_session TO off;
with /* TPC-DS demo query */
ws as
(select d_year AS ws_sold_year, ws_item_sk, ws_bill_customer_sk
ws_customer_sk, sum(ws_quantity) ws_qty, sum(ws_wholesale_cost) ws_wc,
sum(ws_sales_price) ws_sp from web_sales left join web_returns on
wr_order_number=ws_order_number and ws_item_sk=wr_item_sk join date_dim
on ws_sold_date_sk = d_date_sk where wr_order_number is null group by
d_year, ws_item_sk, ws_bill_customer_sk ),
cs as
(select d_year AS cs_sold_year,
cs_item_sk, cs_bill_customer_sk cs_customer_sk, sum(cs_quantity) cs_qty,
sum(cs_wholesale_cost) cs_wc, sum(cs_sales_price) cs_sp from catalog_sales
left join catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_sk
join date_dim on cs_sold_date_sk = d_date_sk where cr_order_number is
null group by d_year, cs_item_sk, cs_bill_customer_sk ),
ss as
(select
d_year AS ss_sold_year, ss_item_sk, ss_customer_sk, sum(ss_quantity)
ss_qty, sum(ss_wholesale_cost) ss_wc, sum(ss_sales_price) ss_sp
from store_sales left join store_returns on sr_ticket_number=ss_ticket_number
and ss_item_sk=sr_item_sk join date_dim on ss_sold_date_sk = d_date_sk
where sr_ticket_number is null group by d_year, ss_item_sk, ss_customer_sk
)
select
ss_customer_sk,round(ss_qty/(coalesce(ws_qty+cs_qty,1)),2)
ratio,ss_qty store_qty, ss_wc store_wholesale_cost, ss_sp store_sales_price,
coalesce(ws_qty,0)+coalesce(cs_qty,0) other_chan_qty,coalesce(ws_wc,0)+coalesce(cs_wc,0)
other_chan_wholesale_cost,coalesce(ws_sp,0)+coalesce(cs_sp,0) other_chan_sales_price
from ss left join ws on (ws_sold_year=ss_sold_year and ws_item_sk=ss_item_sk
and ws_customer_sk=ss_customer_sk)left join cs on (cs_sold_year=ss_sold_year
and cs_item_sk=cs_item_sk and cs_customer_sk=ss_customer_sk)where coalesce(ws_qty,0)>0
and coalesce(cs_qty, 0)>0 order by ss_customer_sk, ss_qty desc, ss_wc
desc, ss_sp desc, other_chan_qty, other_chan_wholesale_cost, other_chan_sales_price,
round(ss_qty/(coalesce(ws_qty+cs_qty,1)),2);
When the query is complete, run the following SQL to capture the start and end times of the query, which will be used in the next query:
select query_id,query_text,start_time,end_time, elapsed_time/1000000.0 duration_in_seconds
from sys_query_history
where query_text like '%TPC-DS demo query%'
and query_text not like '%sys_query_history%'
order by start_time desc
Let’s assess the compute scaled during the preceding start_time and end_time period. Replace start_time and end_time in the following query with the output of the preceding query:
select * from sys_serverless_usage
where end_time >= 'start_time'
and end_time <= DATEADD(minute,1,'end_time')
order by end_time asc
-- Example
--select * from sys_serverless_usage
--where end_time >= '2024-06-03 00:17:12.322353'
--and end_time <= DATEADD(minute,1,'2024-06-03 00:19:11.553218')
--order by end_time asc
The following screenshot shows an example output.
You can notice the increase in compute over the duration of this query. This demonstrates how Redshift Serverless scales based on query complexity.
Use case 2: Scale compute based on data volume
Let’s consider the web_sales ingestion job. For this example, your daily ingestion job processes 720 million records and completes in an average of 2 minutes. This is what you ingested in the prerequisite steps.
Due to some event (such as month end processing), your volumes increased by three times and now your ingestion job needs to process 2.1 billion records. In an existing scaling approach, this would increase your ingestion job runtime unless the queue time is enough to invoke additional compute resources. But with AI-driven scaling, in performance optimized mode, Amazon Redshift automatically scales compute to complete your ingestion job within usual runtimes. This helps protect your ingestion SLAs.
Run the following job to ingest 2.1 billion records into the web_sales table:
copy web_sales from 's3://redshift-downloads/TPC-DS/2.13/3TB/web_sales/' iam_role default gzip delimiter '|' EMPTYASNULL region 'us-east-1';
Run the following query to compare the duration of ingesting 2.1 billion records and 720 million records. Both ingestion jobs completed in approximately a similar time, despite the three-fold increase in volume.
select query_id,table_name,data_source,loaded_rows,duration/1000000.0 duration_in_seconds , start_time,end_time
from sys_load_history
where
table_name='web_sales'
order by start_time desc
Run the following query with the start times and end times from the previous output:
select * from sys_serverless_usage
where end_time >= 'start_time'
and end_time <= DATEADD(minute,1,'end_time')
order by end_time asc
The following is an example output. You can notice the increase in compute capacity for the ingestion job that processes 2.1 billion records. This illustrates how Redshift Serverless scaled based on data volume.
Use case 3: Scale data lake queries
In this use case, you create external tables pointing to TPC-DS 3TB data in an Amazon Simple Storage Service (Amazon S3) location. Then you run a query that scans a large volume of data to demonstrate how Redshift Serverless can automatically scale compute capacity as needed.
In the following SQL, provide the ARN of the default IAM role you attached in the prerequisites:
-- Create external schema
create external schema ext_tpcds_3t
from data catalog
database ext_tpcds_db
iam_role '<ARN of the default IAM role attached>'
create external database if not exists;
Create external tables by running DDL statements in the following SQL file. You should see seven external tables in the query editor under the ext_tpcds_3t schema, as shown in the following screenshot.
Run the following query using external tables. As mentioned in the first use case, if the query didn’t scale during the first run, it is recommended to rerun the query, because the system will have learned from the previous experience and can potentially provide better scaling and performance for the subsequent run.
The results cache is turned off in the following queries to avoid fetching results from the cache.
SET enable_result_cache_for_session TO off;
with /* TPC-DS demo data lake query */
ws as
(select d_year AS ws_sold_year, ws_item_sk, ws_bill_customer_sk
ws_customer_sk, sum(ws_quantity) ws_qty, sum(ws_wholesale_cost) ws_wc,
sum(ws_sales_price) ws_sp from ext_tpcds_3t.web_sales left join ext_tpcds_3t.web_returns on
wr_order_number=ws_order_number and ws_item_sk=wr_item_sk join ext_tpcds_3t.date_dim
on ws_sold_date_sk = d_date_sk where wr_order_number is null group by
d_year, ws_item_sk, ws_bill_customer_sk ),
cs as
(select d_year AS cs_sold_year,
cs_item_sk, cs_bill_customer_sk cs_customer_sk, sum(cs_quantity) cs_qty,
sum(cs_wholesale_cost) cs_wc, sum(cs_sales_price) cs_sp from ext_tpcds_3t.catalog_sales
left join ext_tpcds_3t.catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_sk
join ext_tpcds_3t.date_dim on cs_sold_date_sk = d_date_sk where cr_order_number is
null group by d_year, cs_item_sk, cs_bill_customer_sk ),
ss as
(select
d_year AS ss_sold_year, ss_item_sk, ss_customer_sk, sum(ss_quantity)
ss_qty, sum(ss_wholesale_cost) ss_wc, sum(ss_sales_price) ss_sp
from ext_tpcds_3t.store_sales left join ext_tpcds_3t.store_returns on sr_ticket_number=ss_ticket_number
and ss_item_sk=sr_item_sk join ext_tpcds_3t.date_dim on ss_sold_date_sk = d_date_sk
where sr_ticket_number is null group by d_year, ss_item_sk, ss_customer_sk)
SELECT ss_customer_sk,round(ss_qty/(coalesce(ws_qty+cs_qty,1)),2)
ratio,ss_qty store_qty, ss_wc store_wholesale_cost, ss_sp store_sales_price,
coalesce(ws_qty,0)+coalesce(cs_qty,0) other_chan_qty,coalesce(ws_wc,0)+coalesce(cs_wc,0) other_chan_wholesale_cost,coalesce(ws_sp,0)+coalesce(cs_sp,0) other_chan_sales_price
FROM ss left join ws on (ws_sold_year=ss_sold_year and ws_item_sk=ss_item_sk and ws_customer_sk=ss_customer_sk)left join cs on (cs_sold_year=ss_sold_year and cs_item_sk=cs_item_sk and cs_customer_sk=ss_customer_sk)
where coalesce(ws_qty,0)>0
and coalesce(cs_qty, 0)>0
order by ss_customer_sk, ss_qty desc, ss_wc desc, ss_sp desc, other_chan_qty, other_chan_wholesale_cost, other_chan_sales_price, round(ss_qty/(coalesce(ws_qty+cs_qty,1)),2);
Review the total elapsed time of the query. You need the start_time and end_time from the results to feed into the next query.
select query_id,query_text,start_time,end_time, elapsed_time/1000000.0 duration_in_seconds
from sys_query_history
where query_text like '%TPC-DS demo data lake query%'
and query_text not like '%sys_query_history%'
order by start_time desc
Run the following query to see how compute scaled during the preceding start_time and end_time period. Replace start_time and end_time in the following query from the output of the preceding query:
select * from sys_serverless_usage
where end_time >= 'start_time'
and end_time <= DATEADD(minute,1,'end_time')
order by end_time asc
The following screenshot shows an example output.
The increased compute capacity for this data lake query shows that Redshift Serverless can scale to match the data being scanned. This demonstrates how Redshift Serverless can dynamically allocate resources based on query needs.
Considerations when choosing your price-performance target
You can use the price-performance slider to choose your desired price-performance target for your workload. The AI-driven scaling and optimizations provide holistic optimizations using the following models:
Query prediction models – These determine the actual resource needs (memory, CPU consumption, and so on) for each individual query
Scaling prediction models – These predict how the query would behave on different capacity sizes
Let’s consider a query that takes 7 minutes and costs $7. The following figure shows the query runtimes and cost with no scaling.
A given query might scale in a few different ways, as shown below. Based on the price-performance target you chose on the slider, AI-driven scaling predicts how the query trades off performance and cost, and scales it accordingly.
The slider options yield the following results:
Optimized for cost – When you choose Optimized for cost, the warehouse scales up if there is no additional cost or lesser costs to the user. In the preceding example, the superlinear scaling approach demonstrates this behavior. Scaling will only occur if it can be done in a cost-effective manner according to the scaling model predictions. If the scaling models predict that cost-optimized scaling isn’t possible for the given workload, then the warehouse won’t scale.
Balanced – With the Balanced option, the system will scale in favor of performance and there will be a cost increase, but it will be a limited increase in cost. In the preceding example, the linear scaling approach demonstrates this behavior.
Optimized for performance – With the Optimized for performance option, the system will scale in favor of performance even though the costs are higher and non-linear. In the preceding example, the sublinear scaling approach demonstrates this behavior. The closer the slider position is to the Optimized for performance position, the more sublinear scaling is permitted.
The following are additional points to note:
The price-performance slider options are dynamic and they can be changed anytime. However, the impact of these changes will not be realized immediately. The impact of this is effective as the system learns how to scale the current workload and any additional workloads better.
The price-performance slider options, Max capacity and Max RPU-hours are designed to work together. Max capacity and Max RPU-hours are the controls to limit maximum RPUs the data warehouse allowed to scale and maximum RPU hours allowed to consume respectively. These controls are always honored and enforced regardless of the settings on the price-performance target slider.
The AI-driven scaling and optimization feature dynamically adjusts compute resources to optimize query runtime speed while adhering to your price-performance requirements. It considers factors such as query queueing, concurrency, volume, and complexity. The system can either run queries on a compute resource with lower concurrent queries or spin up additional compute resources to avoid queueing. The goal is to provide the best price-performance balance based on your choices.
Monitoring
You can monitor the RPU scaling in the following ways:
Review the RPU capacity used graph on the Amazon Redshift console.
Monitor the ComputeCapacity metric under AWS/Redshift-Serverless and Workgroup in Amazon CloudWatch.
Query the SYS_QUERY_HISTORY view, providing the specific query ID or query text to identify the time period. Use this time period to query the SYS_SERVERLSS_USAGE system view to find the compute_capacity The compute_capacity field will show the RPUs scaled during the query runtime.
Delete the Redshift Serverless associated namespace.
Conclusion
In this post, we discussed how to optimize your workloads to scale based on the changes in data volume and query complexity. We demonstrated an approach to implement more responsive, proactive scaling with the AI-driven scaling feature in Redshift Serverless. Try this feature in your environment, conduct a proof of concept on your specific workloads, and share your feedback with us.
About the Authors
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Ashish Agrawal is a Principal Product Manager with Amazon Redshift, building cloud-based data warehouses and analytics cloud services. Ashish has over 25 years of experience in IT. Ashish has expertise in data warehouses, data lakes, and platform as a service. Ashish has been a speaker at worldwide technical conferences.
Davide Pagano is a Software Development Manager with Amazon Redshift based out of Palo Alto, specialized in building cloud-based data warehouses and analytics cloud services solutions. He has over 10 years of experience with databases, out of which 6 years of experience tailored to Amazon Redshift.
On November 1, 2023, the New York State Department of Financial Services (NYDFS) issued its Second Amendment (the Amendment) to its Cybersecurity Requirements for Financial Services Companies adopted in 2017, published within Section 500 of 23 NYCRR 500 (the Cybersecurity Requirements; the Cybersecurity Requirements as amended by the Amendment, the Amended Cybersecurity Requirements). In the introduction to its Cybersecurity Resource Center, the Department explains that the revisions are aimed at addressing the changes in the increasing sophistication of threat actors, the prevalence of and relative ease in running cyberattacks, and the availability of additional controls to manage cyber risks.
This blog post focuses on the revision to the encryption in transit requirement under section 500.15(a). It outlines the encryption capabilities and secure connectivity options offered by Amazon Web Services (AWS) to help customers demonstrate compliance with this updated requirement. The post also provides best practices guidance, emphasizing the shared responsibility model. This enables organizations to design robust data protection strategies that address not only the updated NYDFS encryption requirements but potentially also other security standards and regulatory requirements.
The target audience for this information includes security leaders, architects, engineers, and security operations team members and risk, compliance, and audit professionals.
Note that the information provided here is for informational purposes only; it is not legal or compliance advice and should not be relied on as legal or compliance advice. Customers are responsible for making their own independent assessments and should obtain appropriate advice from their own legal and compliance advisors regarding compliance with applicable NYDFS regulations.
500.15 Encryption of nonpublic information
The updated requirement in the Amendment states that:
As part of its cybersecurity program, each covered entity shall implement a written policy requiring encryption that meets industry standards, to protect nonpublic information held or transmitted by the covered entity both in transit over external networks and at rest.
To the extent a covered entity determines that encryption of nonpublic information at rest is infeasible, the covered entity may instead secure such nonpublic information using effective alternative compensating controls that have been reviewed and approved by the covered entity’s CISO in writing. The feasibility of encryption and effectiveness of the compensating controls shall be reviewed by the CISO at least annually.
This section of the Amendment removes the covered entity’s chief information security officer’s (CISO) discretion to approve compensating controls when encryption of nonpublic information in transit over external networks is deemed infeasible. The Amendment mandates that, effective November 2024, organizations must encrypt nonpublic information transmitted over external networks without the option of implementing alternative compensating controls. While the use of security best practices such as network segmentation, multi-factor authentication (MFA), and intrusion detection and prevention systems (IDS/IPS) can provide defense in depth, these compensating controls are no longer sufficient to replace encryption in transit over external networks for nonpublic information.
However, the Amendment still allows for the CISO to approve the use of alternative compensating controls where encryption of nonpublic information at rest is deemed infeasible. AWS is committed to providing industry-standard encryption services and capabilities to help protect customer data at rest in the cloud, offering customers the ability to add layers of security to their data at rest, providing scalable and efficient encryption features. This includes the following services:
Flexible key management options, including AWS Key Management Service (AWS KMS), which allow you to choose whether to have AWS manage the encryption keys or keep complete control over your keys.
Dedicated, hardware-based cryptographic key storage using AWS CloudHSM, to help you adhere to compliance requirements
While the above highlights encryption-at-rest capabilities offered by AWS, the focus of this blog post is to provide guidance and best practice recommendations for encryption in transit.
AWS guidance and best practice recommendations
Cloud network traffic encompasses connections to and from the cloud and traffic between cloud service provider (CSP) services. From an organization’s perspective, CSP networks and data centers are deemed external because they aren’t under the organization’s direct control. The connection between the organization and a CSP, typically established over the internet or dedicated links, is considered an external network. Encrypting data in transit over these external networks is crucial and should be an integral part of an organization’s cybersecurity program.
AWS implements multiple mechanisms to help ensure the confidentiality and integrity of customer data during transit and at rest across various points within its environment. While AWS employs transparent encryption at various transit points, we strongly recommend incorporating encryption by design into your architecture. AWS provides robust encryption-in-transit capabilities to help you adhere to compliance requirements and mitigate the risks of unauthorized disclosure and modification of nonpublic information in transit over external networks.
Additionally, AWS recommends that financial services institutions adopt a secure by design (SbD) approach to implement architectures that are pre-tested from a security perspective. SbD helps establish control objectives, security baselines, security configurations, and audit capabilities for workloads running on AWS.
Security and Compliance is a shared responsibility between AWS and the customer. Shared responsibility can vary depending on the security configuration options for each service. You should carefully consider the services you choose because your organization’s responsibilities vary depending on the services used, the integration of those services into your IT environment, and applicable laws and regulations. AWS provides resources such as service user guides and AWS Customer Compliance Guides, which map security best practices for individual services to leading compliance frameworks, including NYDFS.
Protecting connections to and from AWS
We understand that customers place a high priority on privacy and data security. That’s why AWS gives you ownership and control over your data through services that allow you to determine where your content will be stored, secure your content in transit and at rest, and manage access to AWS services and resources for your users. When architecting workloads on AWS, classifying data based on its sensitivity, criticality, and compliance requirements is essential. Proper data classification allows you to implement appropriate security controls and data protection mechanisms, such as Transport Layer Security (TLS) at the application layer, access control measures, and secure network connectivity options for nonpublic information over external networks. When it comes to transmitting nonpublic information over external networks, it’s a recommended practice to identify network segments traversed by this data based on your network architecture. While AWS employs transparent encryption at various transit points, it’s advisable to implement encryption solutions at multiple layers of the OSI model to establish defense in depth and enhance end-to-end encryption capabilities. Although requirement 500.15 of the Amendment doesn’t mandate end-to-end encryption, implementing such controls can provide an added layer of security and can help demonstrate that nonpublic information is consistently encrypted during transit.
AWS offers several options to achieve this. While not every option provides end-to-end encryption on its own, using them in combination helps to ensure that nonpublic information doesn’t traverse open, public networks unprotected. These options include:
Client-side encryption of data before sending it to AWS
AWS Direct Connect with MACsec encryption
AWS Direct Connect provides direct connectivity to the AWS network through third-party colocation facilities, using a cross-connect between an AWS owned device and either a customer- or partner-owned device. Direct Connect can reduce network costs, increase bandwidth throughput, and provide a more consistent network experience than internet-based connections. Within Direct Connect connections (a physical construct) there will be one or more virtual interfaces (VIFs). These are logical entities and are reflected as industry-standard 802.1Q VLANs on the customer equipment terminating the Direct Connect connection. Depending on the type of VIF, they will use either public or private IP addressing. There are three different types of VIFs:
Public virtual interface – Establish connectivity between AWS public endpoints and your data center, office, or colocation environment.
Transit virtual interface – Establish private connectivity between AWS Transit Gateways and your data center, office, or colocation environment. Transit Gateways is an AWS managed high availability and scalability regional network transit hub used to interconnect Amazon Virtual Private Cloud (Amazon VPC) and customer networks.
Private virtual interface – Establish private connectivity between Amazon VPC resources and your data center, office, or colocation environment.
By default, a Direct Connect connection isn’t encrypted from your premises to the Direct Connect location because AWS cannot assume your on-premises device supports the MACsec protocol. With MACsec, Direct Connect delivers native, near line-rate, point-to-point encryption, ensuring that data communications between AWS and your corporate network remain protected. MACsec is supported on 10 Gbps and 100 Gbps dedicated Direct Connect connections at selected points of presence. Using Direct Connect with MACsec-enabled connections and combining it with the transparent physical network encryption offered by AWS from the Direct Connect location through the AWS backbone not only benefits you by allowing you to securely exchange data with AWS, but also enables you to use the highest available bandwidth. For additional information on MACsec support and cipher suites, see the MACsec section in the Direct Connect FAQs.
Figure 1: Sample architecture for using Direct Connect with MACsec encryption
In the sample architecture, you can see that Layer 2 encryption through MACsec only encrypts the traffic from your on-premises systems to the AWS device in the Direct Connect location, and therefore you need to consider additional encryption solutions at Layer 3, 4, or 7 to get closer to end-to-end encryption to the device where you’re comfortable for the packets to be decrypted. In the next section, let’s review an option for using network layer encryption using AWS Site-to-Site VPN.
Direct Connect with Site-to-Site VPN
AWS Site-to-Site VPN is a fully managed service that creates a secure connection between your corporate network and your Amazon VPC using IP security (IPsec) tunnels over the internet. Data transferred between your VPC and the remote network routes over an encrypted VPN connection to help maintain the confidentiality and integrity of data in transit. Each VPN connection consists of two tunnels between a virtual private gateway or transit gateway on the AWS side and a customer gateway on the on-premises side. Each tunnel supports a maximum throughput of up to 1.25 Gbps. See Site-to-Site VPN quotas for more information.
You can use Site-to-Site VPN over Direct Connect to achieve secure IPsec connection with the low latency and consistent network experience of Direct Connect when reaching resources in your Amazon VPCs.
Figure 2: Encrypted connections between the AWS Cloud and a customer’s network using VPN
While Direct Connect with MACsec and Site-to-Site VPN with IPsec can provide encryption at the physical and network layers respectively, they primarily secure the data in transit between your on-premises network and the AWS network boundary. To further enhance the coverage for end-to-end encryption, it is advisable to use TLS encryption. In the next section, let’s review mechanisms for securing API endpoints on AWS using TLS encryption.
Secure API endpoints
APIs act as the front door for applications to access data, business logic, or functionality from other applications and backend services.
While requests to public AWS service API endpoints use HTTPS by default, a few services, such as Amazon S3 and Amazon DynamoDB, allow using either HTTP or HTTPS. If the client or application chooses HTTP, the communication isn’t encrypted. Customers are responsible for enforcing HTTPS connections when using such AWS services. To help ensure secure communication, you can establish an identity perimeter by using the IAM policy condition key aws:SecureTransport in your IAM roles to evaluate the connection and mandate HTTPS usage.
As enterprises increasingly adopt cloud computing and microservices architectures, teams frequently build and manage internal applications exposed as private API endpoints. Customers are responsible for managing the certificates on private customer-owned endpoints. AWS helps you deploy private customer-owned identities (that is, TLS certificates) through the use of AWS Certificate Manager (ACM)private certificate authorities (PCA) and the integration with AWS services that offer private customer-owned TLS termination endpoints.
ACM is a fully managed service that lets you provision, manage, and deploy public and private TLS certificates for use with AWS services and internal connected resources. ACM minimizes the time-consuming manual process of purchasing, uploading, and renewing TLS certificates. You can provide certificates for your integrated AWS services either by issuing them directly using ACM or by importing third-party certificates into the ACM management system. ACM offers two options for deploying managed X.509 certificates. You can choose the best one for your needs.
AWS Certificate Manager (ACM) – This service is for enterprise customers who need a secure web presence using TLS. ACM certificates are deployed through Elastic Load Balancing (ELB), Amazon CloudFront, Amazon API Gateway, and other integrated AWS services. The most common application of this type is a secure public website with significant traffic requirements. ACM also helps to simplify security management by automating the renewal of expiring certificates.
AWS Private Certificate Authority (Private CA) – This service is for enterprise customers building a public key infrastructure (PKI) inside the AWS Cloud and is intended for private use within an organization. With AWS Private CA, you can create your own certificate authority (CA) hierarchy and issue certificates with it for authenticating users, computers, applications, services, servers, and other devices. Certificates issued by a private CA cannot be used on the internet. For more information, see the AWS Private CA User Guide.
You can use a centralized API gateway service, such as Amazon API Gateway, to securely expose customer-owned private API endpoints. API Gateway is a fully managed service that allows developers to create, publish, maintain, monitor, and secure APIs at scale. With API Gateway, you can create RESTful APIs and WebSocket APIs, enabling near real-time, two-way communication applications. API Gateway operations must be encrypted in-transit using TLS, and require the use of HTTPS endpoints. You can use API Gateway to configure custom domains for your APIs using TLS certificates provisioned and managed by ACM. Developers can optionally choose a specific TLS version for their custom domain names. For use cases that require mutual TLS (mTLS) authentication, you can configure certificate-based mTLS authentication on your custom domains.
Pre-encryption of data to be sent to AWS
Depending on the risk profile and sensitivity of the data that’s being transferred to AWS, you might want to choose encrypting data in an application running on your corporate network before sending it to AWS (client-side encryption). AWS offers a variety of SDKs and client-side encryption libraries to help you encrypt and decrypt data in your applications. You can use these libraries with the cryptographic service provider of your choice, including AWS Key Management Service or AWS CloudHSM, but the libraries do not require an AWS service.
The AWS Encryption SDK is a client-side encryption library that you can use to encrypt and decrypt data in your application and is available in several programming languages, including a command-line interface. You can use the SDK to encrypt your data before you send it to an AWS service. The SDK offers advanced data protection features, including envelope encryption and additional authenticated data (AAD). It also offers secure, authenticated, symmetric key algorithm suites, such as 256-bit AES-GCM with key derivation and signing.
The AWS Database Encryption SDK is a set of software libraries developed in open source that enable you to include client-side encryption in your database design. The SDK provides record-level encryption solutions. You specify which fields are encrypted and which fields are included in the signatures that help ensure the authenticity of your data. Encrypting your sensitive data in transit and at rest helps ensure that your plaintext data isn’t available to a third party, including AWS. The AWS Database Encryption SDK for DynamoDB is designed especially for DynamoDB applications. It encrypts the attribute values in each table item using a unique encryption key. It then signs the item to protect it against unauthorized changes, such as adding or deleting attributes or swapping encrypted values. After you create and configure the required components, the SDK transparently encrypts and signs your table items when you add them to a table. It also verifies and decrypts them when you retrieve them. Searchable encryption in the AWS Database Encryption SDK enables you search encrypted records without decrypting the entire database. This is accomplished by using beacons, which create a map between the plaintext value written to a field and the encrypted value that is stored in your database. For more information, see the AWS Database Encryption SDK Developer Guide.
The Amazon S3 Encryption Client is a client-side encryption library that enables you to encrypt an object locally to help ensure its security before passing it to Amazon S3. It integrates seamlessly with the Amazon S3 APIs to provide a straightforward solution for client-side encryption of data before uploading to Amazon S3. After you instantiate the Amazon S3 Encryption Client, your objects are automatically encrypted and decrypted as part of your Amazon S3 PutObject and GetObject requests. Your objects are encrypted with a unique data key. You can use both the Amazon S3 Encryption Client and server-side encryption to encrypt your data. The Amazon S3 Encryption Client is supported in a variety of programming languages and supports industry-standard algorithms for encrypting objects and data keys. For more information, see the Amazon S3 Encryption Client developer guide.
Encryption in-transit inside AWS
AWS implements responsible and sophisticated technical and physical controls that are designed to help prevent unauthorized access to or disclosure of your content. To protect data in transit, traffic traversing through the AWS network that is outside of AWS physical control is transparently encrypted by AWS at the physical layer. This includes traffic between AWS Regions (except China Regions), traffic between Availability Zones, and between Direct Connect locations and Regions through the AWS backbone network.
Network segmentation
When you create an AWS account, AWS offers a virtual networking option to launch resources in a logically isolated virtual private network (VPN), Amazon Virtual Private Cloud (Amazon VPC). A VPC is limited to a single AWS Region and every VPC has one or more subnets. VPCs can be connected externally using an internet gateway (IGW), VPC peering connection, VPN, Direct Connect, or Transit Gateways. Traffic within the your VPC is considered internal because you have complete control over your virtual networking environment, including selection of your own IP address range, creation of subnets, and configuration of route tables and network gateways.
As a customer, you maintain ownership of your data, and you select which AWS services can process, store, and host your data, and you choose the Regions in which your data is stored. AWS doesn’t automatically replicate data across Regions, unless the you choose to do so. Data transmitted over the AWS global network between Regions and Availability Zones is automatically encrypted at the physical layer before leaving AWS secured facilities. Cross-Region traffic that uses Amazon VPC and Transit Gateway peering is automatically bulk-encrypted when it exits a Region.
Encryption between instances
AWS provides secure and private connectivity between Amazon Elastic Compute Cloud (Amazon EC2) instances of all types. The Nitro System is the underlying foundation for modern Amazon EC2 instances. It’s a combination of purpose-built server designs, data processors, system management components, and specialized firmware that provides the underlying foundation for EC2 instances launched since the beginning of 2018. Instance types that use the offload capabilities of the underlying Nitro System hardware automatically encrypt in-transit traffic between instances. This encryption uses Authenticated Encryption with Associated Data (AEAD) algorithms, with 256-bit encryption and has no impact on network performance. To support this additional in-transit traffic encryption between instances, instances must be of supported instance types, in the same Region, and in the same VPC or peered VPCs. For a list of supported instance types and additional requirements, see Encryption in transit.
Conclusion
The second Amendment to the NYDFS Cybersecurity Regulation underscores the criticality of safeguarding nonpublic information during transmission over external networks. By mandating encryption for data in transit and eliminating the option for compensating controls, the Amendment reinforces the need for robust, industry-standard encryption measures to protect the confidentiality and integrity of sensitive information.
AWS provides a comprehensive suite of encryption services and secure connectivity options that enable you to design and implement robust data protection strategies. The transparent encryption mechanisms that AWS has built into services across its global network infrastructure, secure API endpoints with TLS encryption, and services such as Direct Connect with MACsec encryption and Site-to-Site VPN, can help you establish secure, encrypted pathways for transmitting nonpublic information over external networks.
By embracing the principles outlined in this blog post, financial services organizations can address not only the updated NYDFS encryption requirements for section 500.15(a) but can also potentially demonstrate their commitment to data security across other security standards and regulatory requirements.
AWS offers regulated customers tools, guidance and third-party audit reports to help meet compliance requirements. Regulated industry customers often require a service-by-service approval process when adopting cloud services to make sure that each adopted service aligns with their regulatory obligations and risk tolerance. How financial institutions can approve AWS services for highly confidential data walks through the key considerations that customers should focus on to help streamline the approval of cloud services. In this post we cover how regulated customers, especially FSI customers, can approach secrets management on Amazon Elastic Kubernetes Service (Amazon EKS) to help meet data protection and operational security requirements. Amazon EKS gives you the flexibility to start, run, and scale Kubernetes applications in the AWS Cloud or on-premises.
Applications often require sensitive information such as passwords, API keys, and tokens to connect to external services or systems. Kubernetes has secrets objects for managing these types of sensitive information. Additional tools and approaches have evolved to supplement the Kubernetes Secrets to help meet the compliance requirements of regulated organizations. One of the driving forces behind the evolution of these tools for regulated customers is that the native Kubernetes Secrets values aren’t encrypted but encoded as base64 strings; meaning that their values can be decoded by a threat actor with either API access or authorization to create a pod in a namespace containing the secret. There are options such as GoDaddy Kubernetes External Secrets, AWS Secrets and Configuration Provider (ASCP) for the Kubernetes Secrets Store CSI Driver, Hashicorp Vault, and Bitnami Sealed secrets that you can use to can help to improve the security, management, and audibility of your secrets usage.
Security and compliance is a shared responsibility between AWS and the customer. The AWS Shared Responsibility Model describes this as security of the cloud and security in the cloud:
AWS responsibility – Security of the cloud: AWS is responsible for protecting the infrastructure that runs the services offered in the AWS Cloud. For Amazon EKS, AWS is responsible for the Kubernetes control plane, which includes the control plane nodes and etcd database. Amazon EKS is certified by multiple compliance programs for regulated and sensitive applications. The effectiveness of the security controls are regularly tested and verified by third-party auditors as part of the AWS compliance programs.
Customer responsibility – Security in the cloud: Customers are responsible for the security and compliance of customer configured systems and services deployed on AWS. This includes responsibility for securely deploying, configuring and managing ESO within their Amazon EKS cluster. For Amazon EKS, the customer responsibility depends upon the worker nodes you pick to run your workloads and cluster configuration as shown in Figure 1. In the case of Amazon EKS deployment using Amazon Elastic Compute Cloud (Amazon EC2) hosts, the customer responsibility includes the following areas:
The security configuration of the data plane, including the configuration of the security groups that allow traffic to pass from the Amazon EKS control plane into the customer virtual private cloud (VPC).
The configuration of the nodes and the containers themselves.
The nodes’ operating system, including updates and security patches.
Other associated application software:
Setting up and managing network controls, such as firewall rules.
The sensitivity of your data, such as personally identifiable information (PII), keys, passwords, and tokens
Customers are responsible for enforcing access controls to protect their data and secrets.
Customers are responsible for monitoring and logging activities related to secrets management including auditing access, detecting anomalies and responding to security incidents.
Your company’s requirements, applicable laws and regulations
When using AWS Fargate, the operational overhead for customers is reduced in the following areas:
The customer is not responsible for updating or patching the host system.
Fargate manages the placement and scaling of containers.
Figure 1: AWS Shared Responsibility Model with Fargate and Amazon EC2 based workflows
As an example of the Shared Responsibility Model in action, consider a typical FSI workload accepting or processing payments cards and subject to PCI DSS requirements. PCI DSS v4.0 requirement 3 focuses on guidelines to secure cardholder data while at rest and in transit:
Control ID
Control description
3.6
Cryptographic keys used to protect stored account data are secured.
3.6.1.2
Store secret and private keys used to encrypt and decrypt cardholder data in one (or more) of the following forms:
Encrypted with a key-encrypting key that is at least as strong as the data-encrypting key, and that is stored separately from the data-encrypting key.
Stored within a secure cryptographic device (SCD), such as a hardware security module (HSM) or PTS-approved point-of-interaction device.
Has at least two full-length key components or key shares, in accordance with an industry-accepted method. Note: It is not required that public keys be stored in one of these forms.
3.6.1.3
Access to cleartext cryptographic key components is restricted to the fewest number of custodians necessary.
NIST frameworks and controls are also broadly adopted by FSI customers. NIST Cyber Security Framework (NIST CSF) and NIST SP 800-53 (Security and Privacy Controls for Information Systems and Organizations) include the following controls that apply to secrets:
Regulation or framework
Control ID
Control description
NIST CSF
PR.AC-1
Identities and credentials are issued, managed, verified, revoked, and audited for authorized devices, users and processes.
NIST CSF
PR.DS-1
Data-at-rest is protected.
NIST 800-53.r5
AC-2(1) AC-3(15)
Secrets should have automatic rotation enabled. Delete unused secrets.
Based on the preceding objectives, the management of secrets can be categorized into two broad areas:
Identity and access management ensures separation of duties and least privileged access.
Strong encryption, using a dedicated cryptographic device, introduces a secure boundary between the secrets data and keys, while maintaining appropriate management over the cryptographic keys.
Choosing your secrets management provider
To help choose a secrets management provider and apply compensating controls effectively, in this section we evaluate three different options based on the key objectives derived from the PCI DSS and NIST controls described above and other considerations such as operational overhead, high availability, resiliency, and developer or operator experience.
Architecture and workflow
The following architecture and component descriptions highlight the different architectural approaches and responsibilities of each solution’s components, ranging from controllers and operators, command-line interface (CLI) tools, custom resources, and CSI drivers working together to facilitate secure secrets management within Kubernetes environments.
External Secrets Operator (ESO) extends the Kubernetes API using a custom resource definition (CRD) for secret retrieval. ESO enables integration with external secrets management systems such as AWS Secrets Manager, HashiCorp Vault, Google Secrets Manager, Azure Key Vault, IBM Cloud Secrets Manager, and various other systems. ESO watches for changes to an external secret store and keeps Kubernetes secrets in sync. These services offer features that aren’t available with native Kubernetes Secrets, such as fine-grained access controls, strong encryption, and automatic rotation of secrets. By using these purpose-built tools outside of a Kubernetes cluster, you can better manage risk and benefit from central management of secrets across multiple Amazon EKS clusters. For more information, see the detailed walkthrough of using ESO to synchronize secrets from Secrets Manager to your Amazon EKS Fargate cluster.
ESO is comprised of a cluster-side controller that automatically reconciles the state within the Kubernetes cluster and updates the related secrets anytime the external API’s secret undergoes a change.
Figure 2: ESO workflow
Sealed Secrets is an open source project by Bitnami comprised of a Kubernetes controller coupled with a client-side CLI tool with the objective to store secrets in Git in a secure fashion. Sealed Secrets encrypts your Kubernetes secret into a SealedSecret, which can also be deployed to a Kubernetes cluster using kubectl. For more information, see the detailed walkthough of using tools from the Sealed Secrets open source project to manage secrets in your Amazon EKS clusters.
Sealed Secrets comprises of three main components: First, there is an operator or a controller which is deployed onto a Kubernetes cluster. The controller is responsible for decrypting your secrets. Second, you have a CLI tool called Kubeseal that takes your secret and encrypts it. Third, you have a CRD. Instead of creating regular secrets, you create SealedSecrets, which is a CRD defined within Kubernetes. That is how the operator knows when to perform the decryption process within your Kubernetes cluster.
Upon startup, the controller looks for a cluster-wide private-public key pair and generates a new 4096-bit RSA public-private key pair if one doesn’t exist. The private key is persisted in a secret object in the same namespace as the controller. The public key portion of this is made publicly available to anyone wanting to use Sealed Secrets with this cluster.
Figure 3: Sealed Secrets workflow
The AWS Secrets Manager and Config Provider (ASCP) for Secret Store CSI driver is an open source tool from AWS that allows secrets from Secrets Manager and Parameter Store, a capability of AWS Systems Manager, to be mounted as files inside Amazon EKS pods. It uses a CRD called SecretProviderClass to specify which secrets or parameters to mount. Upon a pod start or restart, the CSI driver retrieves the secrets or parameters from AWS and writes them to a tmpfs volume mounted in the pod. The volume is automatically cleaned up when the pod is deleted, making sure that secrets aren’t persisted. For more information, see the detailed walkthrough on how to set up and configure the ASCP to work with Amazon EKS.
ASCP comprises of a cluster-side controller acting as the provider, allowing secrets from Secrets Manager, and parameters from Parameter Store to appear as files mounted in Kubernetes pods. Secrets Store CSI Driver is a DaemonSet with three containers: node-driver-registrar, which registers the CSI driver with Kubelet; secrets-store, which implements the CSI Node service gRPC services for mounting and unmounting volumes during pod creation and deletion; and liveness-probe, which monitors the health of the CSI driver and reports to Kubernetes for automatic issue detection and pod restart.
Figure 4: AWS Secrets Manager and configuration provider
In the next section, we cover some of the key decisions involved in choosing whether to use ESO, Sealed Secrets, or ASCP for regulated customers to help meet their regulatory and compliance needs.
Comparing ESO, Sealed Secrets, and ASCP objectives
All three solutions address different aspects of secure secrets management and aim to help FSI customers meet their regulatory compliance requirements while upholding the protection of sensitive data in Kubernetes environments.
ESO synchronizes secrets from external APIs into Kubernetes, targeting the cluster operator and application developer personas. The cluster operator is responsible for setting up ESO and managing access policies. The application developer is responsible for defining external secrets and the application configuration.
Sealed Secrets encrypts your Kubernetes secrets before storing them in version control systems such as public Git repositories. This is the case if you decide to check in your Kubernetes manifest to a Git repository granting access to your sensitive secrets to anyone who has access to the Git repository. This is ultimately the reason why Sealed Secrets was created and the sealed secret can be decrypted only by the controller running in the target cluster.
Using ASCP, you can securely store and manage your secrets in Secrets Manager and retrieve them through your applications running on Kubernetes without having to write custom code. Secrets Manager provides features such as rotation, auditing, and access control that can help FSI customers meet regulatory compliance requirements and maintain a robust security posture.
Installation
The deployment and configuration details that follow highlight the different approaches and resources used by each solution to integrate with Kubernetes and external secret stores, catering to the specific requirements of secure secrets management in containerized environments.
ESO provides Helm charts for ease of operator deployment. External Secrets provides custom resources like SecretStore and ExternalSecret for configuring the required operator functionality to synchronize external secrets to your cluster. For instance, SecretStore can be used by the cluster operator to be able to connect to AWS Secrets Manager using appropriate credentials to pull in the secrets.
To install Sealed Secrets, you can deploy the Sealed Secrets Controller onto the Kubernetes cluster. You can deploy the manifest by itself or you can use a Helm chart to deploy the Sealed Secrets Controller for you. After the controller is installed, you use the Kubeseal client-side utility to encrypt secrets using asymmetric cryptography. If you don’t already have the Kubeseal CLI installed, see the installation instructions.
ASCP provides Helm charts to assist in operator deployment. The ASCP operator provides custom resources such as SecretProviderClass to provide provider-specific parameters to the CSI driver. During pod start and restart, the CSI driver will communicate with the provider using gRPC to retrieve the secret content from the external secret store you specified in the SecretProviderClass custom resource. Then the volume is mounted in the pod as tmpfs and the secret contents are written to the volume.
Encryption and key management
These solutions use robust encryption mechanisms and key management practices provided by external secret stores and AWS services such as AWS Key Management Service (AWS KMS) and Secrets Manager. However, additional considerations and configurations might be required to meet specific regulatory requirements, such as PCI DSS compliance for handling sensitive data.
ESO relies on encryption features within the external secrets management system. For instance, Secrets Manager supports envelope encryption with AWS KMS which is FIPS 140-2 Level 3 certified. Secrets Manager has several compliance certifications making it a great fit for regulated workloads. FIPS 140-2 Level 3 ensures only strong encryption algorithms approved by NIST can be used to protect data. It also defines security requirements for the cryptographic module, creating logical and physical boundaries.
Both AWS KMS and Secrets Manager help you to manage key lifecycle and to integrate with other AWS Services. In terms of key rotation, both provide automatic rotation of secrets that runs on a schedule (which you define), and abstract the complexity of managing different versions of keys. For AWS managed keys, the key rotation happens automatically once every year by default. With customer managed keys (CMKs), automatic key rotation is available but not enabled by default.
When using SealedSecrets, you use the Kubeseal tool to convert a standard Kubernetes Secret into a Sealed Secrets resource. The contents of the Sealed Secrets are encrypted with the public key served by the Sealed Secrets Controller as described in the Sealed Secrets project homepage.
In the absence of cloud native secrets management integration, you might have to add compensating controls to achieve the regulatory standards required by your organization. In cases where the underlying SealedSecrets data is sensitive in nature, such as cardholder PII, PCI requires that you store sensitive secrets in a cryptographic device such as a hardware security module (HSM). You can use Secrets Manager to store the master key generated to seal the secrets. However, this you will have to enable additional integration with Amazon EKS APIs to fetch the master key securely from the EKS cluster. You will also have to modify your deployment process to use a master key from Secrets Manager. The applications running in the EKS cluster must have permissions to fetch the SealedSecret and master key from Secrets Manager. This might involve configuring the application to interact with Amazon EKS APIs and Secrets Manager. For non-sensitive data, Kubeseal can be used directly within the EKS cluster to manage secrets and sealing keys.
For key rotation, you can store the controller generated private key in Parameter Store as a SecureString. You can use the advanced tier in Parameter Store if the file containing the private keys exceeds the Standard tier limit of up to 4,096 characters. In addition, if you want to add key rotation, you can use AWS KMS.
The ASCP relies on encryption features within the chosen secret store, such as Secrets Manager. Secrets Manager supports integration with AWS KMS for an additional layer of security by storing encryption keys separately. The Secrets Store CSI Driver facilitates secure interaction with the secret store, but doesn’t directly encrypt secrets. Encrypting mounted content can provide further protection, but introduces operational overhead related to key management.
ASCP relies on Secrets Manager and AWS KMS for encryption and decryption capabilities. As a recommendation, you can encrypt mounted content to further protect the secrets. However, this introduces the additional operational overhead of managing encryption keys and addressing key rotation.
Additional considerations
These solutions address various aspects of secure secrets management, ranging from centralized management, compliance, high availability, performance, developer experience, and integration with existing investments, catering to the specific needs of FSI customers in their Kubernetes environments.
ESO can be particularly useful when you need to manage an identical set of secrets across multiple Kubernetes clusters. Instead of configuring, managing, and rotating secrets at each cluster level individually, you can synchronize your secrets across your clusters. This simplifies secrets management by providing a single interface to manage secrets across multiple clusters and environments.
External secrets management systems typically offer advanced security features such as encryption at rest, access controls, audit logs, and integration with identity providers. This helps FSI customers ensure that sensitive information is stored and managed securely in accordance with regulatory requirements.
FSI customers usually have existing investments in their on-premises or cloud infrastructure, including secrets management solutions. ESO integrates seamlessly with existing secrets management systems and infrastructure, allowing FSI customers to use their investment in these systems without requiring significant changes to their workflow or tooling. This makes it easier for FSI customers to adopt and integrate ESO into their existing Kubernetes environments.
ESO provides capabilities for enforcing policies and governance controls around secrets management such as access control, rotation policies, and audit logging when using services like Secrets Manager. For FSI customers, audits and compliance are critical and ESO verifies that access to secrets is tracked and audit trails are maintained, thereby simplifying the process of demonstrating adherence to regulatory standards. For instance, secrets stored inside Secrets Manager can be audited for compliance with AWS Config and AWS Audit Manager. Additionally, ESO uses role-based access control (RBAC) to help prevent unauthorized access to Kubernetes secrets as documented in the ESO security best practices guide.
High availability and resilience are critical considerations for mission critical FSI applications such as online banking, payment processing, and trading services. By using external secrets management systems designed for high availability and disaster recovery, ESO helps FSI customers ensure secrets are available and accessible in the event of infrastructure failure or outages, thereby minimizing service disruption and downtime.
FSI workloads often experience spikes in transaction volumes, especially during peak days or hours. ESO is designed to efficiently managed a large volume of secrets by using external secrets management that’s optimized for performance and scalability.
In terms of monitoring, ESO provides Prometheus metrics to enable fine-grained monitoring of access to secrets. Amazon EKS pods offer diverse methods to grant access to secrets present on external secrets management solutions. For example, in non-production environments, access can be granted through IAM instance profiles assigned to the Amazon EKS worker nodes. For production, using IAM roles for service accounts (IRSA) is recommended. Furthermore, you can achieve namespace level fine-grained access control by using annotations.
ESO also provides options to configure operators to use a VPC endpoint to comply with FIPS requirements.
Additional developer productivity benefits provided by ESO include support for JSON objects (Secret key/value in the AWS Management console) or strings (Plaintext in the console). With JSON objects, developers can programmatically update multiple values atomically when rotating a client certificate and private key.
The benefit of Sealed Secrets, as discussed previously, is when you upload your manifest to a Git repository. The manifest will contain the encrypted SealedSecrets and not the regular secrets. This assures that no one has access to your sensitive secrets even when they have access to your Git repository. Sealed Secrets offer a few benefits to developers in terms of developer experience. Sealed Secrets gives you access to manage your secrets, making them more readily available to developers. Sealed Secrets offers VSCode extension to assist in integrating it into the software development lifecycle (SDLC). Using Sealed Secrets, you can store the encrypted secrets in the version control systems such as Gitlab and GitHub. Sealed Secrets can reduce operational overhead related to updating dependent objects because whenever a secret resource is updated, the same update is applied to the dependent objects.
ASCP integration with the Kubernetes Secrets Store CSI Driver on Amazon EKS offers enhanced security through seamless integration with Secrets Manager and Parameter Store, ensuring encryption, access control, and auditing. It centralizes management of sensitive data, simplifying operations and reducing the risk of exposure. The dynamic secrets injection capability facilitates secure retrieval and injection of secrets into Kubernetes pods, while automatic rotation provides up-to-date credentials without manual intervention. This combined solution streamlines deployment and management, providing a secure, scalable, and efficient approach to handling secrets and configuration settings in Kubernetes applications.
Consolidated threat model
We created a threat model based on the architecture of the three solution offerings. The threat model provides a comprehensive view of the potential threats and corresponding mitigations for each solution, allowing organizations to proactively address security risks and ensure the secure management of secrets in their Kubernetes environments.
X = Mitigations applicable to the solution
Threat
Mitigations
ESO
Sealed Secrets
ASCP
Unauthorized access or modification of secrets
Implement least privilege access principles
Rotate and manage credentials securely
Enable RBAC and auditing in Kubernetes
X
X
X
Insider threat (for example, a rogue administrator who has legitimate access)
Implement least privilege access principles
Enable auditing and monitoring
Enforce separation of duties and job rotation
X
X
Compromise of the deployment process
Secure and harden the deployment pipeline
Implement secure coding practices
Enable auditing and monitoring
X
Unauthorized access or tampering of secrets during transit
Enable encryption in transit using TLS
Implement mutual TLS authentication between components
Use private networking or VPN for secure communication
X
X
X
Compromise of the Kubernetes API server because of vulnerabilities or misconfiguration
Secure and harden the Kubernetes API server
Enable authentication and authorization mechanisms (for example, mutual TLS and RBAC)
Keep Kubernetes components up-to-date and patched
Enable Kubernetes audit logging and monitoring
X
Vulnerability in the external secrets controller leading to privilege escalation or data exposure
Keep the external secrets controller up-to-date and patched
Regularly monitor for and apply security updates
Implement least privilege access principles
Enable auditing and monitoring
X
Compromise of the Secrets Store CSI Driver, node-driver-registrar, Secrets Store CSI Provider, kubelet, or Pod could lead to unauthorized access or exposure of secrets
Implement least privilege principles and role-based access controls
Regularly patch and update the components
Monitor and audit the component activities
X
Unauthorized access or data breach in Secrets Manager could expose sensitive secrets
Implement strong access controls and access logging for Secrets Manager
Encrypt secrets at rest and in transit
Regularly rotate and update secrets
X
X
Shortcomings and limitations
The following limitations and drawbacks highlight the importance of carefully evaluating the specific requirements and constraints of your organization before adopting any of these solutions. You should consider factors such as team expertise, deployment environments, integration needs, and compliance requirements to promote a secure and efficient secrets management solution that aligns with your organization’s needs.
ESO doesn’t include a default way to restrict network traffic to and from ESO using network policies or similar network or firewall mechanisms. The application team is responsible for properly configuring network policies to improve the overall security posture of ESO within your Kubernetes cluster.
Any time an external secret associated with ESO is rotated, you must restart the deployment that uses that particular external secret. Given the inherent risks associated with integrating an external entity or third-party solution into your system, including ESO, it’s crucial to implement a comprehensive threat model similar to the Kubernetes Admission Control Threat Model.
Also, ESO set up is complicated and the controller must be installed on the Kubernetes cluster.
SealedSecrets cannot be reused across namespaces unless they’re re-encrypted or made cluster-wide, which makes it challenging to manage secrets across multiple namespaces consistently. The need to manually rotate and re-encrypt SealedSecrets with new keys can introduce operational overhead, especially in large-scale environments with numerous secrets. The old sealing keys pose a potential risk of misuse by unauthorized users, which increases the risk. To mitigate both risks (high overhead and old secrets), you should implement additional controls such as deleting older keys as part of the key rotation process or periodically rotate sealing keys and make sure that old sealed secret resources are re-encrypted with the new keys. Sealed Secrets doesn’t support external secret stores such as HashiCorp Vault, or cloud provider services such as Secrets Manager, Parameter Store, or Azure Key Vault. Sealed Secrets requires a Kubeseal client-side binary to encrypt secrets. This can be a concern in FSI environments where client-side tools are restricted by security policies.
While ASCP provides seamless integration with Secrets Manager and Parameter Store, teams unfamiliar with these AWS services might need to invest some additional effort to fully realize the benefits. This additional effort is justified by the long-term benefits of centralized secrets management and access control provided by these services. Additionally, relying primarily on AWS services for secrets management can potentially limit flexibility in deploying to alternative cloud providers or on-premises environments in the future. These factors should be carefully evaluated based on the specific needs and constraints of the application and deployment environment.
Conclusion
We have provided a summary of three options for managing secrets in Amazon EKS, ESO, Sealed Secrets, and AWS Secrets and Configuration Provider (ASCP), and the key considerations for FSI customers when choosing between them. The choice depends on several factors including existing investments in secrets management systems, specific security needs and compliance requirements, preference for a Kubernetes native solution or willingness to accept vendor lock-in.
The guidance provided here covers the strengths, limitations, and trade-offs of each option, allowing regulated institutions to make an informed decision based on their unique requirements and constraints. This guidance can be adapted and tailored to fit the specific needs of an organization, providing a secure and efficient secrets management solution for their Amazon EKS workloads, while aligning with the stringent security and compliance standards of the regulated institutions.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Customers across diverse industries rely on Amazon OpenSearch Service for interactive log analytics, real-time application monitoring, website search, vector database, deriving meaningful insights from data, and visualizing these insights using OpenSearch Dashboards. Additionally, customers often seek out capabilities that enable effortless sharing of visual dashboards and seamless embedding of these dashboards within their applications, further enhancing user experience and streamlining workflows.
In this post, we show how to embed a live Amazon Opensearch dashboard in your application, allowing your end customers to access a consolidated, real-time view without ever leaving your website.
Solution overview
We demonstrate how to deploy a sample flight data dashboard using OpenSearch Dashboards and embed it into your application through an iFrame. The following diagram provides a high-level overview of the end-to-end solution.
The workflow includes the following steps:
The user requests for the embedded dashboard by opening the static web server’s endpoint in a browser.
The request reaches the NGINX endpoint. The NGINX endpoint routes the traffic to the self-managed OpenSearch Dashboards server. The OpenSearch Dashboards server acts as the UI layer that connects to the OpenSearch Service domain as the server.
The self-managed OpenSearch Dashboards server interacts with the Amazon managed OpenSearch Service domain to fetch the required data.
The requested data is sent to the OpenSearch Dashboards server.
The requested data is sent from the self-managed OpenSearch Dashboards server to the web server using the NGINX proxy.
The dashboard renders the visualization with the data and displays it on the website.
Prerequisites
You will launch a self-managed OpenSearch Dashboards server on an Amazon Elastic Compute Cloud (Amazon EC2) instance and link it to the managed OpenSearch Service domain to create your visualization. The self-managed OpenSearch Dashboards server acts as the UI layer that connects to the OpenSearch Service domain as the server. The post assumes the presence of a VPC with public as well as private subnets.
Create an OpenSearch Service domain
If you already have an OpenSearch Service domain set up, you can skip this step.
For instructions to create an OpenSearch Service domain, refer to Getting started with Amazon OpenSearch Service. The domain creation takes around 15–20 minutes. When the domain is in Active status, note the domain endpoint, which you will need to set up a proxy in subsequent steps.
Deploy an EC2 instance to act as the NGINX proxy to the OpenSearch Service domain and OpenSearch Dashboards
In this step, you launch an AWS CloudFormation stack that deploys the following resources:
A security group for the EC2 instance
An ingress rule for the security group attached to the OpenSearch Service domain that allows the traffic on port 443 from the proxy instance
An EC2 instance with the NGINX proxy and self-managed OpenSearch Dashboards set up
Complete the following steps to create the stack:
Choose Launch Stack to launch the CloudFormation stack with some preconfigured values in us-east-1. You can change the AWS Region as required.
Provide the parameters for your OpenSearch Service domain.
Choose Create stack. The process may take 3–4 minutes to complete as it sets up an EC2 instance and the required stack. Wait until the status of the stack changes to CREATE_COMPLETE.
On the Outputs tab of the stack, note the value for DashboardURL.
Access OpenSearch Dashboards using the NGINX proxy and set it up for embedding
In this step, you create a new dashboard in OpenSearch Dashboards, which will be used for embedding. Because you launched the OpenSearch Service domain within the VPC, you don’t have direct access to it. To establish a connection with the domain, you use the NGINX proxy setup that you configured in the previous steps.
Navigate to the link for DashboardURL (as demonstrated in the previous step) in your web browser.
Enter the user name and password you configured while creating the OpenSearch Service domain.
You will use a sample dataset for ease of demonstration, which has some preconfigured visualizations and dashboards.
Import the sample dataset by choosing Add data.
Choose the Sample flight data dataset and choose Add data.
To open the newly imported dashboard and get the iFrame code, choose Embed Code on the Share menu.
Under Generate the link as, select Snapshot and choose Copy iFrame code.
The iFrame code will look similar to the following code:
Copy the code to your preferred text editor, remove the /_dashboards part, and change the frame height and width from height="600" width="800" to height="800" width="100%".
Wrap the iFrame code with HTML code as shown in the following example and save it as an index.html file on your local system:
The next step is to host the index.html file. The index.html file can be served from any local laptop or desktop with Firefox or Chrome browser for a quick test.
There are different options available to host the web server, such as Amazon EC2 or Amazon S3. For instructions to host the web server on Amazon S3, refer to Tutorial: Configuring a static website on Amazon S3.
The following screenshot shows our embedded dashboard.
Clean up
If you no longer need the resources you created, delete the CloudFormation stack and the OpenSearch Service domain (if you created a new one) to prevent incurring additional charges.
Vibhu Pareek is a Sr. Solutions Architect at AWS. Since 2016, he has guided customers in cloud adoption using well-architected, repeatable patterns. With his specialization in databases, data analytics, and AI, he thrives on transforming complex challenges into innovative solutions. Outside work, he enjoys short treks and sports like badminton, football, and swimming.
Kamal Manchanda is a Senior Solutions Architect at AWS, specializing in building and designing data solutions with focus on lake house architectures, data governance, search platforms, log analytics solutions as well as generative AI solutions. In his spare time, Kamal loves to travel and spend time with family.
Adesh Jaiswal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available, and secure solutions in the AWS Cloud. In his free time, he enjoys watching movies, TV series, and of course, football.
Amazon Simple Storage Service (Amazon S3) is a widely used object storage service known for its scalability, availability, durability, security, and performance. When sharing data between organizations, customers need to treat incoming data as untrusted and assess it for malicious files before ingesting it into their downstream processes. This traditionally requires setting up secure staging buckets, deploying third-party anti-virus and anti-malware scanning software, and managing a complex data pipeline and processing architecture.
To address the need for malware protection in Amazon S3, Amazon Web Services (AWS) has launched Amazon GuardDuty Malware Protection for Amazon S3. This new feature provides malicious object scanning for objects uploaded to S3 buckets, using multiple AWS-developed and industry-leading third-party malware scanning engines. It eliminates the need for customers to manage their own isolated data pipelines, compute infrastructure, and anti-virus software across accounts and AWS Regions, providing malware detection without compromising the scale, latency, and resiliency of S3 usage.
In this blog post, we share a solution that uses Amazon EventBridge, AWS Lambda, and Amazon S3 to copy scanned S3 objects to a destination S3 bucket. EventBridge is a serverless event bus that you can use to build event-driven architectures and automate your business workflows. In this solution, we allow events to be invoked from an object that is being placed in an S3 bucket. The events can be processed by a serverless function in Lambda to invoke a malware scan. We then show you how to extend this solution for other use cases specific to your organization.
Feature overview
GuardDuty Malware Protection for Amazon S3 provides a malware and anti-virus detection service for new objects uploaded to an S3 bucket. Malware Protection for S3 is enabled from within the AWS Management Console for GuardDuty and GuardDuty threat detection is not required to be enabled to use this feature. If GuardDuty threat detection is enabled, security findings for detected malware are also sent to GuardDuty. This allows customer development or application teams and security teams to work together and oversee malware protection for S3 buckets throughout the organization.
When your AWS account has GuardDuty enabled in an AWS Region, your account is associated to a unique regional entity called a detector ID. All findings that GuardDuty generates and API operations that are performed are associated with this detector ID. If you don’t want to use GuardDuty with your AWS account, Malware Protection for S3 is available as an independent feature. Used independently, Malware Protection for S3 will not create an associated detector ID.
When a malware scan identifies a potentially malicious object and you don’t have a detector ID, no GuardDuty finding will be generated in your AWS account. GuardDuty will publish the malware scan results to your default EventBridge event bus and metrics to an Amazon CloudWatch namespace for you to use for automating additional tasks.
GuardDuty manages error handling and reprocessing of event creation and publication as needed to make sure that each object is properly evaluated before being accessed by downstream resources. GuardDuty supports configuring Amazon S3 object tagging actions to be performed throughout the process.
Figure 1 shows the high-level overview of the S3 object scanning process.
Figure 1: S3 object scanning process
The object scanning process is the following:
An object is uploaded to an S3 bucket that has been configured for malware detection. If the object is uploaded as a multi-part upload, then a new object notification will be generated on completion of the upload.
The malware scan service receives a notification that a new object has been detected in the bucket.
The malware scan service downloads the object by using AWS PrivateLink. This will be automatically created when malware detection is enabled on an S3 bucket. No additional configuration is required.
The malware detection service then reads, decrypts, and scans this object in an isolated VPC with no internet access within the GuardDuty service account. Encryption at rest is used for customer data that is scanned during this process. After the malware detection scan is complete, the object is deleted from the malware scanning environment.
The malware scan result event is sent to the EventBridge default event bus in your AWS account and Region where malware detection has been enabled. When malware is detected, an EventBridge notification is generated that includes details of which S3 object was flagged as malicious and supporting information such as the malware variant and known use cases for the malicious software.
Scan metrics such as number of objects scanned and bytes scanned are sent to Amazon CloudWatch.
If malware is detected, the service sends a finding to the GuardDuty detector ID in the current Region.
If you have configured object tagging, GuardDuty adds a predefined tag with key GuardDutyMalwareScanStatus and a potential scan result value of your scanned S3 object.
IAM permissions
Enabling and using GuardDuty Malware Protection for S3 requires you to add AWS Identity and Access Manager (IAM) role permissions and a specific trust policy for GuardDuty to perform the malware scan on your behalf. GuardDuty provides you flexibility to enable this feature for your entire bucket, or limit the scope of the malware scan to specific object prefixes where GuardDuty scans each uploaded object that starts with up to five selected prefixes.
To allow GuardDuty Malware Protection for S3 to scan and add tags to your S3 objects, you need an IAM role that includes permissions to perform the following tasks:
A trust policy to allow Malware Protection to assume the IAM role.
Allow EventBridge actions to create and manage the EventBridge managed rule to allow Malware Protection for S3 to listen to your S3 object notifications.
Allow Amazon S3 and EventBridge actions to send notification to EventBridge for events in the S3 bucket.
Allow Amazon S3 actions to access the uploaded S3 object and add a predefined tag GuardDutyMalwareScanStatus to the scanned S3 object.
If you’re encrypting S3 buckets with AWS Key Management System (AWS KMS) keys, you must allow AWS KMS key actions to access the object before scanning and putting a test object in S3 buckets with the supported encryption.
This IAM policy is required each time you enable Malware Protection for S3 for a new bucket in your account. Alternatively, update an existing IAM PassRole policy to include the details of another S3 bucket resource each time you enable Malware Protection. See the AWS documentation for example policies and permissions required.
The example S3 bucket policy in the AWS GuardDuty user guide stops anyone other than the GuardDuty Malware scan service principal from reading objects from the specific S3 bucket that aren’t tagged GuardDutyMalwareScanStatus with a value NO_THREATS_FOUND. The policy also helps prevent other roles or users other than GuardDuty from adding the GuardDutyMalwareScanStatus tag.
Configure optional access for other IAM roles that are allowed to override the GuardDutyMalwareScanStatus tag after an object is tagged. Achieve this by replacing <IAM-role-name> in the following example S3 bucket policy.
Change the policy if you are required to allow certain principals or roles to read failed or skipped objects. You can permit a special role to read the malicious object if needed as part of your existing incident response process. Do this by adding an additional statement into the S3 bucket policy and replacing the <IAM-role-name>value in the following example.
This solution is designed to streamline the deployment of GuardDuty Malware Protection for S3, helping you to maintain a secure and reliable S3 storage environment while minimizing the risk of malware infections and their potential consequences. The solution provides several configuration options, allowing you to create a new S3 bucket or use an existing one, enable encryption with a new or existing AWS KMS key, and optionally set up a function to copy objects with a defined tag to a destination S3 bucket. The copy function feature offers an additional layer of protection by separating potentially malicious files from clean ones, allowing you to maintain a separate repository of safe data for continued business operations or further analysis.
The high-level workflow of the solution is as follows:
An object is uploaded to an S3 bucket that has been configured for malware detection.
The malware scan service receives a notification that a new object has been detected in the bucket and then GuardDuty reads, decrypts, and scans the object in an isolated environment.
An EventBridge rule is configured to listen for events that match the pattern of completed scans for the monitored bucket that have a scan result of NO_THREATS_FOUND.
When the matched event pattern occurs, the copy object Lambda function is invoked.
The Lambda copy object function copies the object from the monitored S3 bucket to the target bucket.
In this solution, you will use the follow AWS services and features:
Event tracking: This solution uses an EventBridge rule to listen for completed malware scan result events for a specific S3 bucket, which has been enabled for malware scanning. When the EventBridge rule finds a matched event, the rule passes the required parameters and invokes the Lambda function required to copy the S3 object from the source malware protected bucket to a destination clean bucket. The event pattern used in this solution uses the following format:
Note: Replace the value of the bucketName attribute with the bucket in your account.
Task orchestration: A Lambda function handles the logic for copying the S3 object from the source bucket to the destination bucket which has just been scanned by GuardDuty. If the object was created within a new S3 prefix, the prefix and the object will be copied. If the object was tagged by GuardDuty, then the object tag will be copied.
Deploy the solution
The solution CloudFormation template provides you with multiple deployment scenarios so you can choose which best applies to your use case.
Deploy the CloudFormation template
For this next step, make sure that you deploy the CloudFormation template provided in the AWS account and Region where you want to test this solution.
To deploy the CloudFormation template
Choose the Launch Stack button to launch a CloudFormation stack in your account. Note that the stack will launch in the N. Virginia (us-east-1) Region. To deploy this solution in other Regions, download the solution’s CloudFormation template, modify it, and deploy it to the selected Regions.
Choose the appropriate scenario and complete the parameters information questions as shown in Figure 3.
Figure 3: CloudFormation template parameters
Each of the following scenarios and their parameter information (from Figure 3) can be evaluated to make sure that the CloudFormation template deploys successfully:
Deployment scenario
Create a new bucket or use an existing bucket?
If ”new”, should a KMS key be created for the new bucket?
Would you like to create the copy function to a destination bucket? Create the Lambda copy function from the protected bucket to the clean bucket.
Post scan file copy function
This will be used as the basis for the copy function and EventBridge rule to invoke the function: Copy files to the clean bucket with either the THREATS or NO_THREATS_FOUND tagged value.
Existing S3 bucket configuration – not used for new S3 buckets
Enter the bucket name that you would like to be your scanned bucket: Enter the existing S3 bucket name that will be enabled for GuardDuty Malware Protection for S3.
Enter the bucket name that you would like to be your scanned bucket: Enter the S3 bucket name to be used as the copy destination for S3 objects.
Is the existing bucket using a KMS key? Is the existing S3 bucket encrypted with an existing KMS key?
ARN of the existing KMS key to be used: Provide the existing KMS key Amazon Resource Name (ARN) to be used for KMS encryption. IAM policies will be configured for this KMS key name.
Lambda Copy Function clean bucket: Create a new S3 bucket with the Lambda copy function from the protected bucket to the clean bucket.
Review the stack name and the parameters for the template.
On the Quick create stack screen, scroll to the bottom and select I acknowledge that AWS CloudFormation will create IAM resources.
Choose Create stack. The deployment of the CloudFormation stack will take 3–4 minutes.
After the CloudFormation stack has deployed successfully, the solution will be available for use in the same Region where you deployed the CloudFormation stack. The solution deploys a specific Lambda function and EventBridge rule to match the name of the source S3 bucket.
Follow the readme contained within the repository to deploy the solution or individual components depending your requirements.
Extend the solution
In this section, you’ll find options for extending the solution.
Copy alternative status results
The solution can be extended to copy S3 objects with a scan result status that you define. To change the scan result used to invoke the copy function, update the scanresultstatus in the event pattern defined in EventBridge rule created as part of the solution named S3Malware-CopyS3Object-<DOC-EXAMPLE-BUCKET-111122223333>.
"scanResultDetails": {
"scanResultStatus": ["<scan result status>"]
Delete source S3 objects
To delete the object from the source after the copy was successful, you will need to update the Lambda function code and the IAM role used by the Lambda function.
The IAM role used by the Lambda function requires a new statement added to the existing role. The JSON formatted statement is provided in the following example.
To remove malicious objects from the S3 bucket to help prevent accidental download or access, implement a tag-based lifecycle rule to delete the object after a specific number of days. To achieve this follow the steps in Setting a lifecycle configuration on a bucket to configure a lifecycle rule and make sure the tag key is GuardDutyMalwareScanStatus and value is THREATS_FOUND.
Figure 4: Tag based S3 lifecycle rule
Align the lifecycle policy with your organization’s current S3 object malware investigation procedures. Deleting objects prematurely might hinder security teams’ ability to analyze potentially malicious content. When using bucket versioning instead of permanently deleting the object, Amazon S3 inserts a delete marker that becomes the current version of the object.
AWS Transfer Family integration
If you’re using the AWS Transfer Family service with Secure File Transfer Protocol (SFTP) connector for S3, it’s recommended to scan external uploads for malware before using the received files. This helps ensure the security and integrity of data transferred into your S3 buckets using SFTP.
Figure 5: AWS Transfer Family S3 workflow
To implement malware scanning, configure a file processing workflow configuration to copy the uploaded objects into an S3 bucket that has GuardDuty Malware Protection for S3 enabled.
Figure 6: Transfer Family configuration workflow
Summary
Amazon GuardDuty Malware Protection for S3 is now available to assess untrusted objects for malicious files before being ingested by downstream processes within your organization. Customers can automatically scan their S3 objects for malware and take appropriate actions, such as quarantining or remediating infected files. This proactive approach helps mitigate the risks associated with malware infections, data breaches, and potential financial losses. The solution provided offers an additional layer of protection by separating potentially malicious files from clean ones, allowing customers to maintain a separate repository of safe data for continued business operations or further analysis. Visit the 2024 re:Inforce session or the what’s new blog post to understand additional service details.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Unlocking the true value of data often gets impeded by siloed information. Traditional data management—wherein each business unit ingests raw data in separate data lakes or warehouses—hinders visibility and cross-functional analysis. A data mesh framework empowers business units with data ownership and facilitates seamless sharing.
However, integrating datasets from different business units can present several challenges. Each business unit exposes data assets with varying formats and granularity levels, and applies different data validation checks. Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate data warehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
In this post, we explore a robust architecture pattern of a data sharing mechanism by bridging the gap between data lake and data warehouse using Amazon DataZone and Amazon Redshift.
Solution overview
Amazon DataZone is a data management service that makes it straightforward for business units to catalog, discover, share, and govern their data assets. Business units can curate and expose their readily available domain-specific data products through Amazon DataZone, providing discoverability and controlled access.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Thousands of customers use Amazon Redshift data sharing to enable instant, granular, and fast data access across Amazon Redshift provisioned clusters and serverless workgroups. This allows you to scale your read and write workloads to thousands of concurrent users without having to move or copy the data. Amazon DataZone natively supports data sharing for Amazon Redshift data assets. With Amazon Redshift Spectrum, you can query the data in your Amazon Simple Storage Service (Amazon S3) data lake using a central AWS Glue metastore from your Redshift data warehouse. This capability extends your petabyte-scale Redshift data warehouse to unbounded data storage limits, which allows you to scale to exabytes of data cost-effectively.
The following figure shows a typical distributed and collaborative architectural pattern implemented using Amazon DataZone. Business units can simply share data and collaborate by publishing and subscribing to the data assets.
The Central IT team (Spoke N) subscribes the data from individual business units and consumes this data using Redshift Spectrum. The Central IT team applies standardization and performs the tasks on the subscribed data such as schema alignment, data validation checks, collating the data, and enrichment by adding additional context or derived attributes to the final data asset. This processed unified data can then persist as a new data asset in Amazon Redshift managed storage to meet the SLA requirements of the business units. The new processed data asset produced by the Central IT team is then published back to Amazon DataZone. With Amazon DataZone, individual business units can discover and directly consume these new data assets, gaining insights to a holistic view of the data (360-degree insights) across the organization.
The Central IT team manages a unified Redshift data warehouse, handling all data integration, processing, and maintenance. Business units access clean, standardized data. To consume the data, they can choose between a provisioned Redshift cluster for consistent high-volume needs or Amazon Redshift Serverless for variable, on-demand analysis. This model enables the units to focus on insights, with costs aligned to actual consumption. This allows the business units to derive value from data without the burden of data management tasks.
This streamlined architecture approach offers several advantages:
Single source of truth – The Central IT team acts as the custodian of the combined and curated data from all business units, thereby providing a unified and consistent dataset. The Central IT team implements data governance practices, providing data quality, security, and compliance with established policies. A centralized data warehouse for processing is often more cost-efficient, and its scalability allows organizations to dynamically adjust their storage needs. Similarly, individual business units produce their own domain-specific data. There are no duplicate data products created by business units or the Central IT team.
Eliminating dependency on business units – Redshift Spectrum uses a metadata layer to directly query the data residing in S3 data lakes, eliminating the need for data copying or relying on individual business units to initiate the copy jobs. This significantly reduces the risk of errors associated with data transfer or movement and data copies.
Eliminating stale data – Avoiding duplication of data also eliminates the risk of stale data existing in multiple locations.
Incremental loading – Because the Central IT team can directly query the data on the data lakes using Redshift Spectrum, they have the flexibility to query only the relevant columns needed for the unified analysis and aggregations. This can be done using mechanisms to detect the incremental data from the data lakes and process only the new or updated data, further optimizing resource utilization.
Federated governance – Amazon DataZone facilitates centralized governance policies, providing consistent data access and security across all business units. Sharing and access controls remain confined within Amazon DataZone.
Enhanced cost appropriation and efficiency – This method confines the cost overhead of processing and integrating the data with the Central IT team. Individual business units can provision the Redshift Serverless data warehouse to solely consume the data. This way, each unit can clearly demarcate the consumption costs and impose limits. Additionally, the Central IT team can choose to apply chargeback mechanisms to each of these units.
In this post, we use a simplified use case, as shown in the following figure, to bridge the gap between data lakes and data warehouses using Redshift Spectrum and Amazon DataZone.
The underwriting business unit curates the data asset using AWS Glue and publishes the data asset Policies in Amazon DataZone. The Central IT team subscribes to the data asset from the underwriting business unit.
We focus on how the Central IT team consumes the subscribed data lake asset from business units using Redshift Spectrum and creates a new unified data asset.
Prerequisites
The following prerequisites must be in place:
AWS accounts – You should have active AWS accounts before you proceed. If you don’t have one, refer to How do I create and activate a new AWS account? In this post, we use three AWS accounts. If you’re new to Amazon DataZone, refer to Getting started.
Amazon Data Zone resources – You need a domain for Amazon DataZone, an Amazon DataZone project, and a new Amazon DataZone environment (with a custom AWS service blueprint).
Data lake asset – The data lake asset Policies from the business units was already onboarded to Amazon DataZone and subscribed by the Central IT team. To understand how to associate multiple accounts and consume the subscribed assets using Amazon Athena, refer to Working with associated accounts to publish and consume data.
Central IT environment – The Central IT team has created an environment called env_central_team and uses an existing AWS Identity and Access Management (IAM) role called custom_role, which grants Amazon DataZone access to AWS services and resources, such as Athena, AWS Glue, and Amazon Redshift, in this environment. To add all the subscribed data assets to a common AWS Glue database, the Central IT team configures a subscription target and uses central_db as the AWS Glue database.
IAM role – Make sure that the IAM role that you want to enable in the Amazon DataZone environment has necessary permissions to your AWS services and resources. The following example policy provides sufficient AWS Lake Formation and AWS Glue permissions to access Redshift Spectrum:
As shown in the following screenshot, the Central IT team has subscribed to the data Policies. The data asset is added to the env_central_team environment. Amazon DataZone will assume the custom_role to help federate the environment user (central_user) to the action link in Athena. The subscribed asset Policies is added to the central_db database. This asset is then queried and consumed using Athena.
The goal of the Central IT team is to consume the subscribed data lake asset Policies with Redshift Spectrum. This data is further processed and curated into the central data warehouse using the Amazon Redshift Query Editor v2 and stored as a single source of truth in Amazon Redshift managed storage. In the following sections, we illustrate how to consume the subscribed data lake asset Policies from Redshift Spectrum without copying the data.
Automatically mount access grants to the Amazon DataZone environment role
Amazon Redshift automatically mounts the AWS Glue Data Catalog in the Central IT Team account as a database and allows it to query the data lake tables with three-part notation. This is available by default with the Admin role.
To grant the required access to the mounted Data Catalog tables for the environment role (custom_role), complete the following steps:
Log in to the Amazon Redshift Query Editor v2 using the Amazon DataZone deep link.
In the Query Editor v2, choose your Redshift Serverless endpoint and choose Edit Connection.
For Authentication, select Federated user.
For Database, enter the database you want to connect to.
Get the current user IAM role as illustrated in the following screenshot.
Connect to Redshift Query Editor v2 using the database user name and password authentication method. For example, connect to dev database using the admin user name and password. Grant usage on the awsdatacatalog database to the environment user role custom_role (replace the value of current_userwith the value you copied):
GRANT USAGE ON DATABASE awsdatacatalog to "IAMR:current_user"
Query using Redshift Spectrum
Using the federated user authentication method, log in to Amazon Redshift. The Central IT team will be able to query the subscribed data asset Policies (table: policy) that was automatically mounted under awsdatacatalog.
Aggregate tables and unify products
The Central IT team applies the necessary checks and standardization to aggregate and unify the data assets from all business units, bringing them at the same granularity. As shown in the following screenshot, both the Policies and Claims data assets are combined to form a unified aggregate data asset called agg_fraudulent_claims.
These unified data assets are then published back to the Amazon DataZone central hub for business units to consume them.
The Central IT team also unloads the data assets to Amazon S3 so that each business unit has the flexibility to use either a Redshift Serverless data warehouse or Athena to consume the data. Each business unit can now isolate and put limits to the consumption costs on their individual data warehouses.
Because the intention of the Central IT team was to consume data lake assets within a data warehouse, the recommended solution would be to use custom AWS service blueprints and deploy them as part of one environment. In this case, we created one environment (env_central_team) to consume the asset using Athena or Amazon Redshift. This accelerates the development of the data sharing process because the same environment role is used to manage the permissions across multiple analytical engines.
Clean up
To clean up your resources, complete the following steps:
Delete any S3 buckets you created.
On the Amazon DataZone console, delete the projects used in this post. This will delete most project-related objects like data assets and environments.
Delete the Amazon DataZone domain.
On the Lake Formation console, delete the Lake Formation admins registered by Amazon DataZone along with the tables and databases created by Amazon DataZone.
If you used a provisioned Redshift cluster, delete the cluster. If you used Redshift Serverless, delete any tables created as part of this post.
Conclusion
In this post, we explored a pattern of seamless data sharing with data lakes and data warehouses with Amazon DataZone and Redshift Spectrum. We discussed the challenges associated with traditional data management approaches, data silos, and the burden of maintaining individual data warehouses for business units.
In order to curb operating and maintenance costs, we proposed a solution that uses Amazon DataZone as a central hub for data discovery and access control, where business units can readily share their domain-specific data. To consolidate and unify the data from these business units and provide a 360-degree insight, the Central IT team uses Redshift Spectrum to directly query and analyze the data residing in their respective data lakes. This eliminates the need for creating separate data copy jobs and duplication of data residing in multiple places.
The team also takes on the responsibility of bringing all the data assets to the same granularity and process a unified data asset. These combined data products can then be shared through Amazon DataZone to these business units. Business units can only focus on consuming the unified data assets that aren’t specific to their domain. This way, the processing costs can be controlled and tightly monitored across all business units. The Central IT team can also implement chargeback mechanisms based on the consumption of the unified products for each business unit.
To learn more about Amazon DataZone and how to get started, refer to Getting started. Check out the YouTube playlist for some of the latest demos of Amazon DataZone and more information about the capabilities available.
About the Authors
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
Data quality is crucial in data pipelines because it directly impacts the validity of the business insights derived from the data. Today, many organizations use AWS Glue Data Quality to define and enforce data quality rules on their data at rest and in transit. However, one of the most pressing challenges faced by organizations is providing users with visibility into the health and reliability of their data assets. This is particularly crucial in the context of business data catalogs using Amazon DataZone, where users rely on the trustworthiness of the data for informed decision-making. As the data gets updated and refreshed, there is a risk of quality degradation due to upstream processes.
Amazon DataZone is a data management service designed to streamline data discovery, data cataloging, data sharing, and governance. It allows your organization to have a single secure data hub where everyone in the organization can find, access, and collaborate on data across AWS, on premises, and even third-party sources. It simplifies the data access for analysts, engineers, and business users, allowing them to discover, use, and share data seamlessly. Data producers (data owners) can add context and control access through predefined approvals, providing secure and governed data sharing. The following diagram illustrates the Amazon DataZone high-level architecture. To learn more about the core components of Amazon DataZone, refer to Amazon DataZone terminology and concepts.
To address the issue of data quality, Amazon DataZone now integrates directly with AWS Glue Data Quality, allowing you to visualize data quality scores for AWS Glue Data Catalog assets directly within the Amazon DataZone web portal. You can access the insights about data quality scores on various key performance indicators (KPIs) such as data completeness, uniqueness, and accuracy.
By providing a comprehensive view of the data quality validation rules applied on the data asset, you can make informed decisions about the suitability of the specific data assets for their intended use. Amazon DataZone also integrates historical trends of the data quality runs of the asset, giving full visibility and indicating if the quality of the asset improved or degraded over time. With the Amazon DataZone APIs, data owners can integrate data quality rules from third-party systems into a specific data asset. The following screenshot shows an example of data quality insights embedded in the Amazon DataZone business catalog. To learn more, see Amazon DataZone now integrates with AWS Glue Data Quality and external data quality solutions.
In this post, we show how to capture the data quality metrics for data assets produced in Amazon Redshift.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. Amazon DataZone natively supports data sharing for Amazon Redshift data assets.
With Amazon DataZone, the data owner can directly import the technical metadata of a Redshift database table and views to the Amazon DataZone project’s inventory. As these data assets gets imported into Amazon DataZone, it bypasses the AWS Glue Data Catalog, creating a gap in data quality integration. This post proposes a solution to enrich the Amazon Redshift data asset with data quality scores and KPI metrics.
Solution overview
The proposed solution uses AWS Glue Studio to create a visual extract, transform, and load (ETL) pipeline for data quality validation and a custom visual transform to post the data quality results to Amazon DataZone. The following screenshot illustrates this pipeline.
The pipeline starts by establishing a connection directly to Amazon Redshift and then applies necessary data quality rules defined in AWS Glue based on the organization’s business needs. After applying the rules, the pipeline validates the data against those rules. The outcome of the rules is then pushed to Amazon DataZone using a custom visual transform that implements Amazon DataZone APIs.
The custom visual transform in the data pipeline makes the complex logic of Python code reusable so that data engineers can encapsulate this module in their own data pipelines to post the data quality results. The transform can be used independently of the source data being analyzed.
Each business unit can use this solution by retaining complete autonomy in defining and applying their own data quality rules tailored to their specific domain. These rules maintain the accuracy and integrity of their data. The prebuilt custom transform acts as a central component for each of these business units, where they can reuse this module in their domain-specific pipelines, thereby simplifying the integration. To post the domain-specific data quality results using a custom visual transform, each business unit can simply reuse the code libraries and configure parameters such as Amazon DataZone domain, role to assume, and name of the table and schema in Amazon DataZone where the data quality results need to be posted.
In the following sections, we walk through the steps to post the AWS Glue Data Quality score and results for your Redshift table to Amazon DataZone.
IAM role – If you want to follow in your own environment and your Amazon DataZone domain has associated additional producer accounts, make sure that you have an AWS Identity and Access Management (IAM) role in the Amazon DataZone domain account with Amazon DataZone write privileges that your AWS Glue role can assume.
A custom visual transform lets you define, reuse, and share business-specific ETL logic with your teams. Each business unit can apply their own data quality checks relevant to their domain and reuse the custom visual transform to push the data quality result to Amazon DataZone and integrate the data quality metrics with their data assets. This eliminates the risk of inconsistencies that might arise when writing similar logic in different code bases and helps achieve a faster development cycle and improved efficiency.
For the custom transform to work, you need to upload two files to an Amazon Simple Storage Service (Amazon S3) bucket in the same AWS account where you intend to run AWS Glue. Download the following files:
Copy these downloaded files to your AWS Glue assets S3 bucket in the folder transforms (s3://aws-glue-assets–<account id>-<region>/transforms). By default, AWS Glue Studio will read all JSON files from the transforms folder in the same S3 bucket.
In the following sections, we walk you through the steps of building an ETL pipeline for data quality validation using AWS Glue Studio.
Create a new AWS Glue visual ETL job
You can use AWS Glue for Spark to read from and write to tables in Redshift databases. AWS Glue provides built-in support for Amazon Redshift. On the AWS Glue console, choose Author and edit ETL jobs to create a new visual ETL job.
Establish an Amazon Redshift connection
In the job pane, choose Amazon Redshift as the source. For Redshift connection, choose the connection created as prerequisite, then specify the relevant schema and table on which the data quality checks need to be applied.
Apply data quality rules and validation checks on the source
The next step is to add the Evaluate Data Quality node to your visual job editor. This node allows you to define and apply domain-specific data quality rules relevant to your data. After the rules are defined, you can choose to output the data quality results. The outcomes of these rules can be stored in an Amazon S3 location. You can additionally choose to publish the data quality results to Amazon CloudWatch and set alert notifications based on the thresholds.
Preview data quality results
Choosing the data quality results automatically adds the new node ruleOutcomes. The preview of the data quality results from the ruleOutcomes node is illustrated in the following screenshot. The node outputs the data quality results, including the outcomes of each rule and its failure reason.
Post the data quality results to Amazon DataZone
The output of the ruleOutcomes node is then passed to the custom visual transform. After both files are uploaded, the AWS Glue Studio visual editor automatically lists the transform as mentioned in post_dq_results_to_datazone.json (in this case, Datazone DQ Result Sink) among the other transforms. Additionally, AWS Glue Studio will parse the JSON definition file to display the transform metadata such as name, description, and list of parameters. In this case, it lists parameters such as the role to assume, domain ID of the Amazon DataZone domain, and table and schema name of the data asset.
Fill in the parameters:
Role to assume is optional and can be left empty; it’s only needed when your AWS Glue job runs in an associated account
For Domain ID, the ID for your Amazon DataZone domain can be found in the Amazon DataZone portal by choosing the user profile name
Table name and Schema name are the same ones you used when creating the Redshift source transform
Data quality ruleset name is the name you want to give to the ruleset in Amazon DataZone; you could have multiple rulesets for the same table
Max results is the maximum number of Amazon DataZone assets you want the script to return in case multiple matches are available for the same table and schema name
Edit the job details and in the job parameters, add the following key-value pair to import the right version of Boto3 containing the latest Amazon DataZone APIs:
--additional-python-modules
boto3>=1.34.105
Finally, save and run the job.
The implementation logic of inserting the data quality values in Amazon DataZone is mentioned in the post Amazon DataZone now integrates with AWS Glue Data Quality and external data quality solutions . In the post_dq_results_to_datazone.py script, we only adapted the code to extract the metadata from the AWS Glue Evaluate Data Quality transform results, and added methods to find the right DataZone asset based on the table information. You can review the code in the script if you are curious.
After the AWS Glue ETL job run is complete, you can navigate to the Amazon DataZone console and confirm that the data quality information is now displayed on the relevant asset page.
Conclusion
In this post, we demonstrated how you can use the power of AWS Glue Data Quality and Amazon DataZone to implement comprehensive data quality monitoring on your Amazon Redshift data assets. By integrating these two services, you can provide data consumers with valuable insights into the quality and reliability of the data, fostering trust and enabling self-service data discovery and more informed decision-making across your organization.
If you’re looking to enhance the data quality of your Amazon Redshift environment and improve data-driven decision-making, we encourage you to explore the integration of AWS Glue Data Quality and Amazon DataZone, and the new preview for OpenLineage-compatible data lineage visualization in Amazon DataZone. For more information and detailed implementation guidance, refer to the following resources:
Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada.
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance.
Varsha Velagapudi is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about simplifying customers’ AI/ML and analytics journey to help them succeed in their day-to-day tasks. Outside of work, she enjoys nature and outdoor activities, reading, and traveling.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.






 Umair Nawaz is a Senior DevOps Architect at Amazon Web Services. He works on building secure architectures and advises enterprises on agile software delivery. He is motivated to solve problems strategically by utilizing modern technologies.
Umair Nawaz is a Senior DevOps Architect at Amazon Web Services. He works on building secure architectures and advises enterprises on agile software delivery. He is motivated to solve problems strategically by utilizing modern technologies. Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player.
Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player. Sri Potluri is a Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, ensuring scalable and reliable infrastructure tailored to each project’s unique challenges.
Sri Potluri is a Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, ensuring scalable and reliable infrastructure tailored to each project’s unique challenges. Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.





 Simon Peyer is a Solutions Architect at Amazon Web Services (AWS) based in Switzerland. He is a practical doer and passionate about connecting technology and people using AWS Cloud services. A special focus for him is data streaming and automations. Besides work, Simon enjoys his family, the outdoors, and hiking in the mountains.
Simon Peyer is a Solutions Architect at Amazon Web Services (AWS) based in Switzerland. He is a practical doer and passionate about connecting technology and people using AWS Cloud services. A special focus for him is data streaming and automations. Besides work, Simon enjoys his family, the outdoors, and hiking in the mountains.






 YuanBo Li is a Specialist Solution Architect in GenAI/AIML at Amazon Web Services. His interests include RAG (Retrieval-Augmented Generation) and Agent technologies within the field of GenAI, and he dedicated to proposing innovative GenAI technical solutions tailored to meet diverse business needs.
YuanBo Li is a Specialist Solution Architect in GenAI/AIML at Amazon Web Services. His interests include RAG (Retrieval-Augmented Generation) and Agent technologies within the field of GenAI, and he dedicated to proposing innovative GenAI technical solutions tailored to meet diverse business needs. Charlie Yang is an AWS engineering manager with the OpenSearch Project. He focuses on machine learning, search relevance, and performance optimization.
Charlie Yang is an AWS engineering manager with the OpenSearch Project. He focuses on machine learning, search relevance, and performance optimization. River Xie is a Gen AI specialist solution architecture at Amazon Web Services. River is interested in Agent/Mutli Agent workflow, Large Language Model inference optimization, and passionate about leveraging cutting-edge Generative AI technologies to develop modern applications that solve complex business challenges.
River Xie is a Gen AI specialist solution architecture at Amazon Web Services. River is interested in Agent/Mutli Agent workflow, Large Language Model inference optimization, and passionate about leveraging cutting-edge Generative AI technologies to develop modern applications that solve complex business challenges. Ren Guo is a manager of Generative AI Specialist Solution Architect Team for the domains of AIML and Data at AWS, Greater China Region.
Ren Guo is a manager of Generative AI Specialist Solution Architect Team for the domains of AIML and Data at AWS, Greater China Region.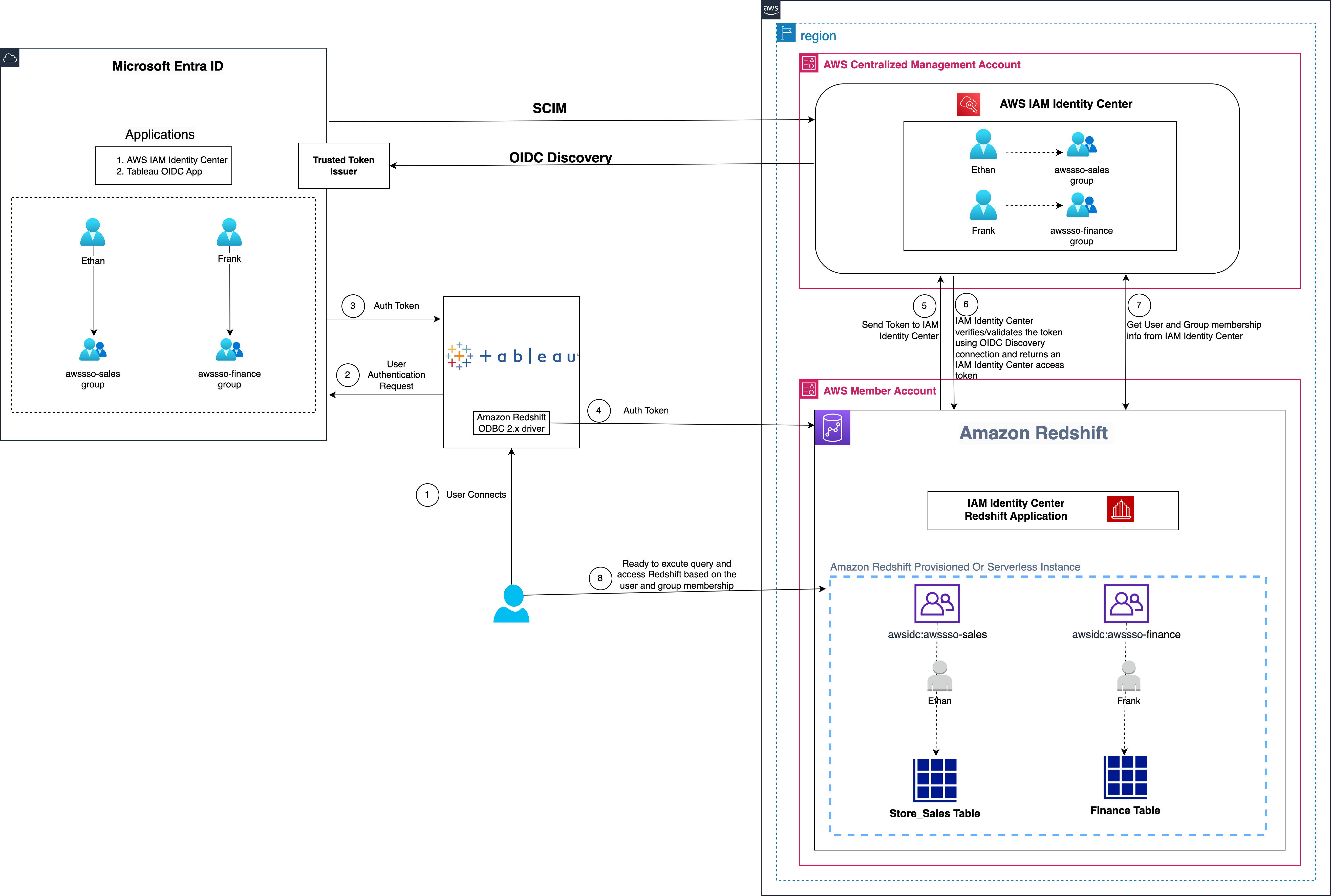

























 apc-crr
apc-crr
 Deployment time: 307.88s
Stack ARN:
arn:aws:cloudformation:<aws_region>:<aws_account>:stack/apc-crr/<stack_id>
Deployment time: 307.88s
Stack ARN:
arn:aws:cloudformation:<aws_region>:<aws_account>:stack/apc-crr/<stack_id>


































 Alexander Schueren is a Senior Specialist Solutions Architect at AWS, dedicated to modernizing legacy applications and building event-driven serverless solutions. With a focus on simplifying complexity and bringing clarity to technical challenges, Alexander is on a mission to empower developers with the tools they need for success. As the maintainer of the open-source project “Powertools for AWS Lambda (TypeScript),” he is committed to driving innovation in serverless technologies. In his free time, Alexander channels his creativity through street photography, capturing decisive moments in the urban landscape.
Alexander Schueren is a Senior Specialist Solutions Architect at AWS, dedicated to modernizing legacy applications and building event-driven serverless solutions. With a focus on simplifying complexity and bringing clarity to technical challenges, Alexander is on a mission to empower developers with the tools they need for success. As the maintainer of the open-source project “Powertools for AWS Lambda (TypeScript),” he is committed to driving innovation in serverless technologies. In his free time, Alexander channels his creativity through street photography, capturing decisive moments in the urban landscape.
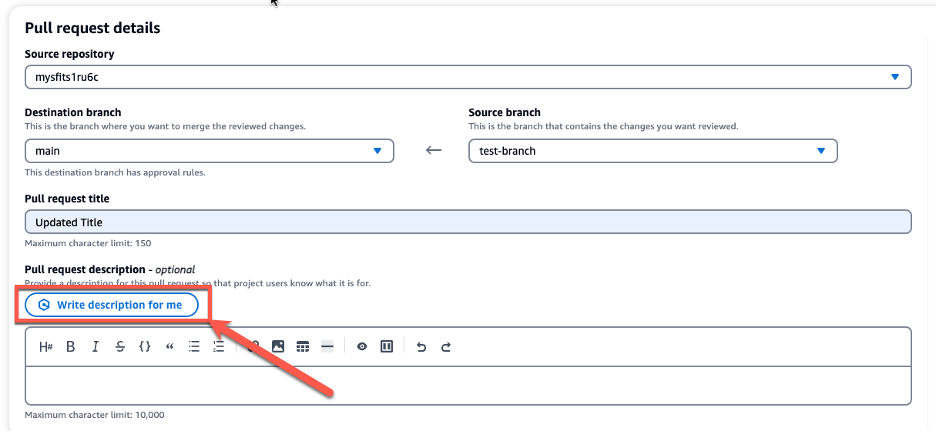
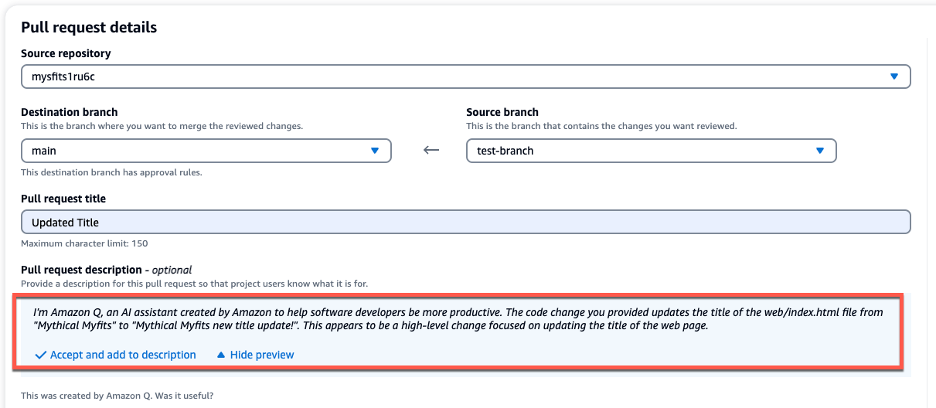
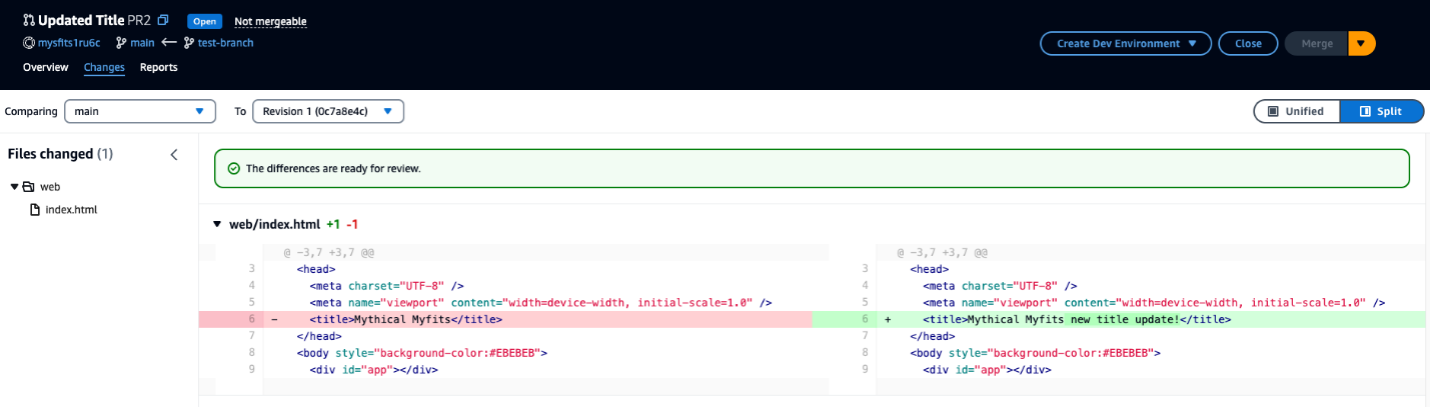
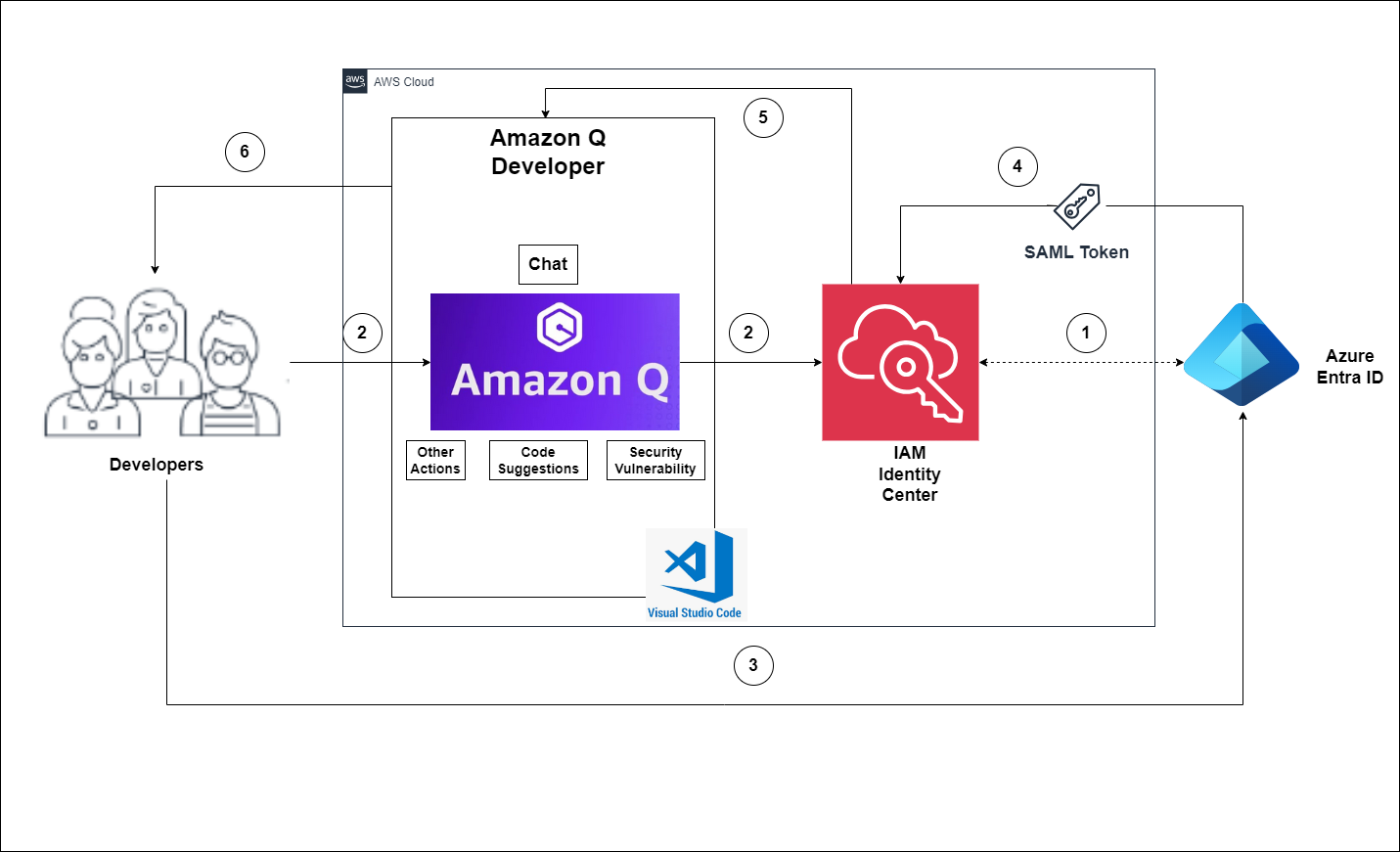











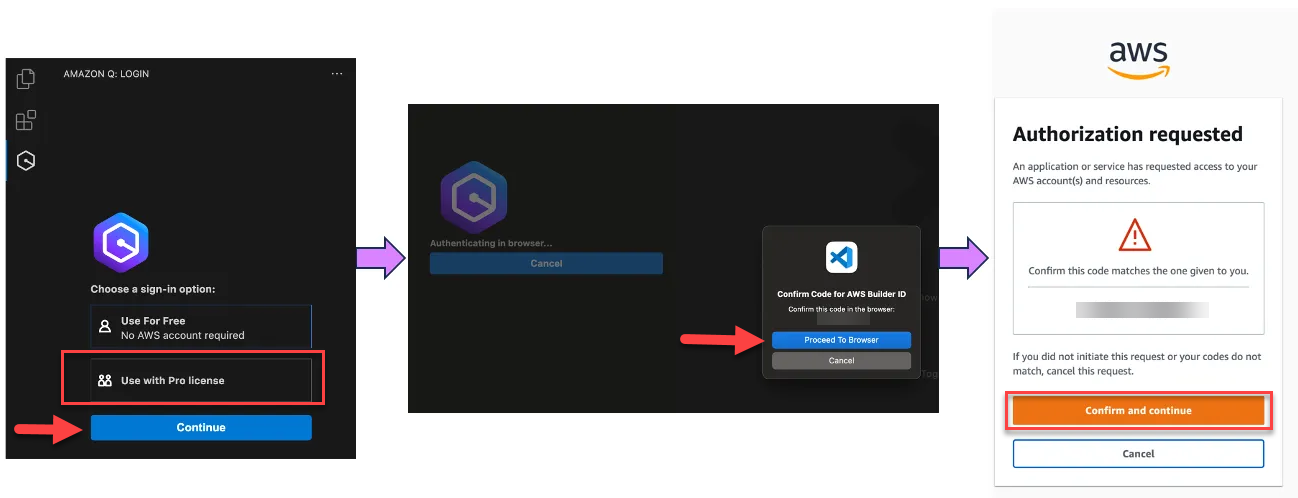

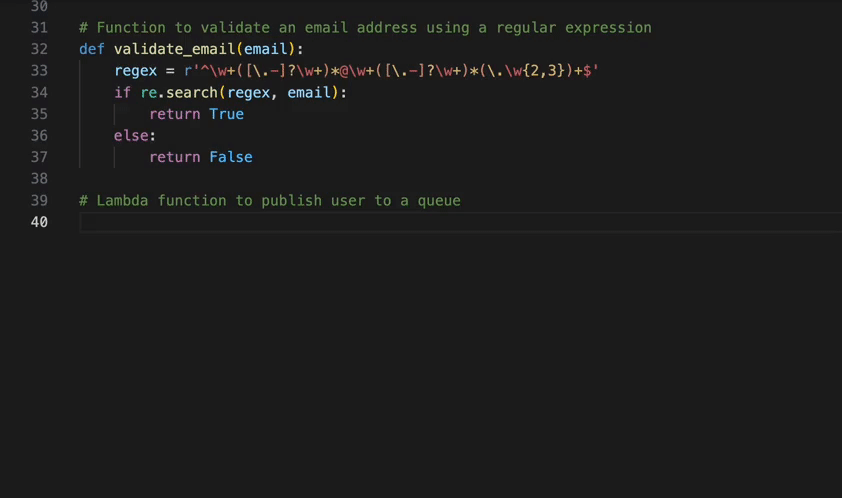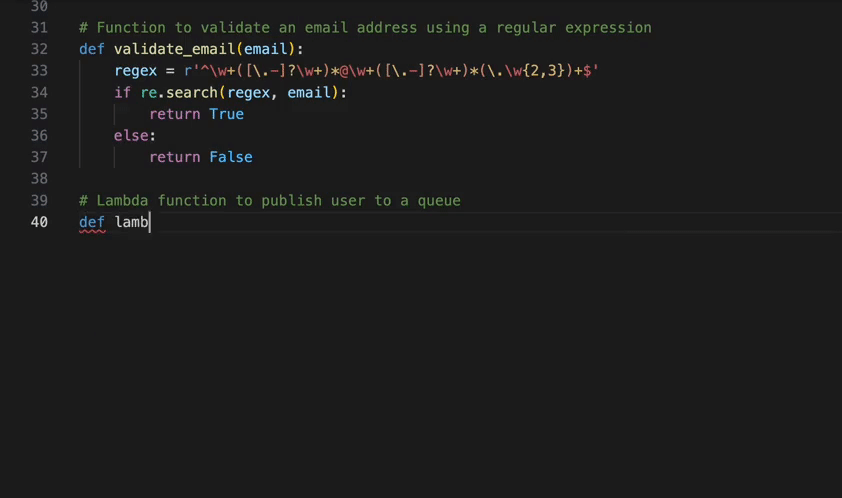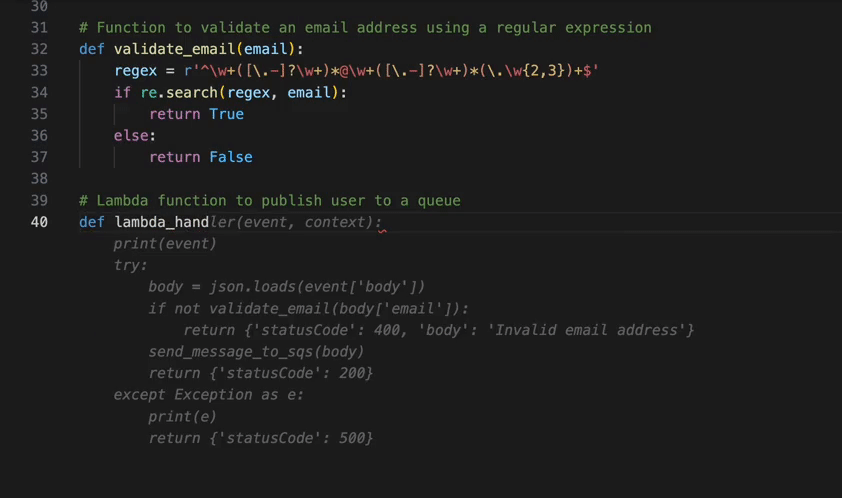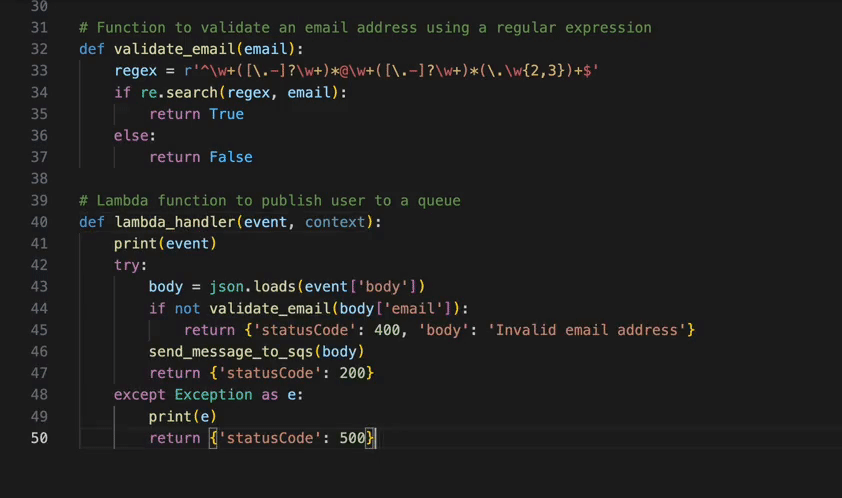
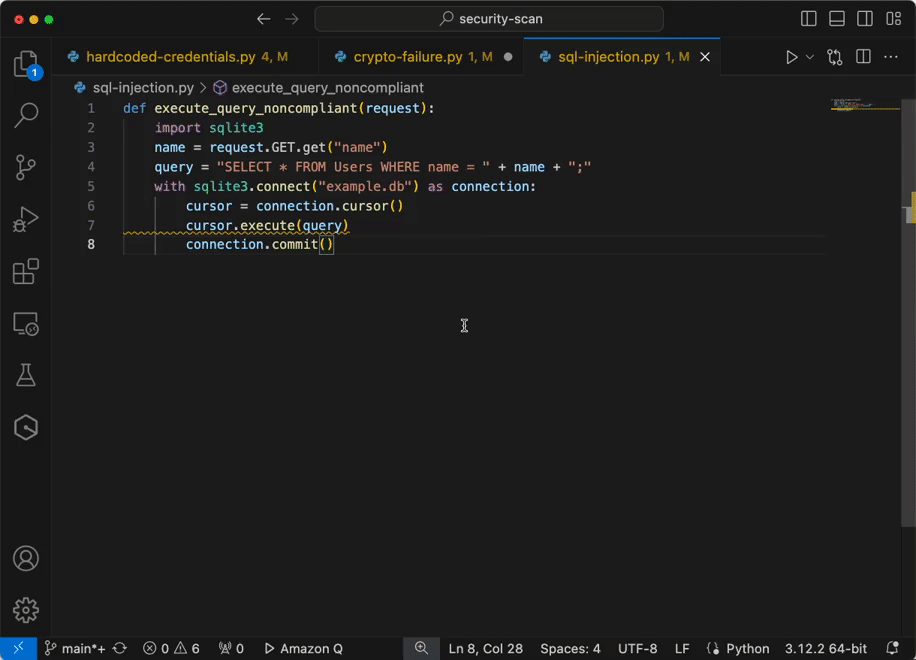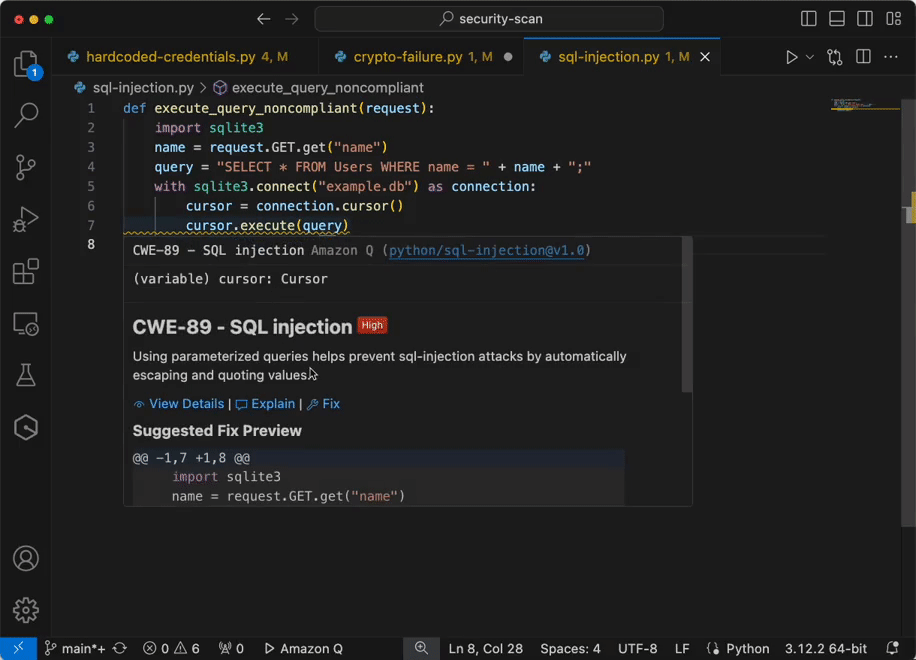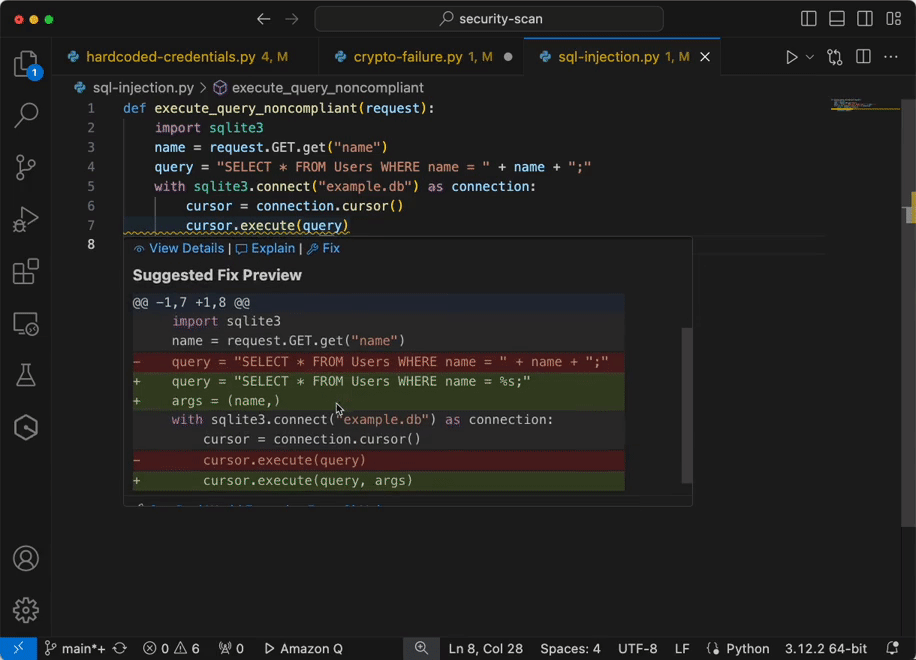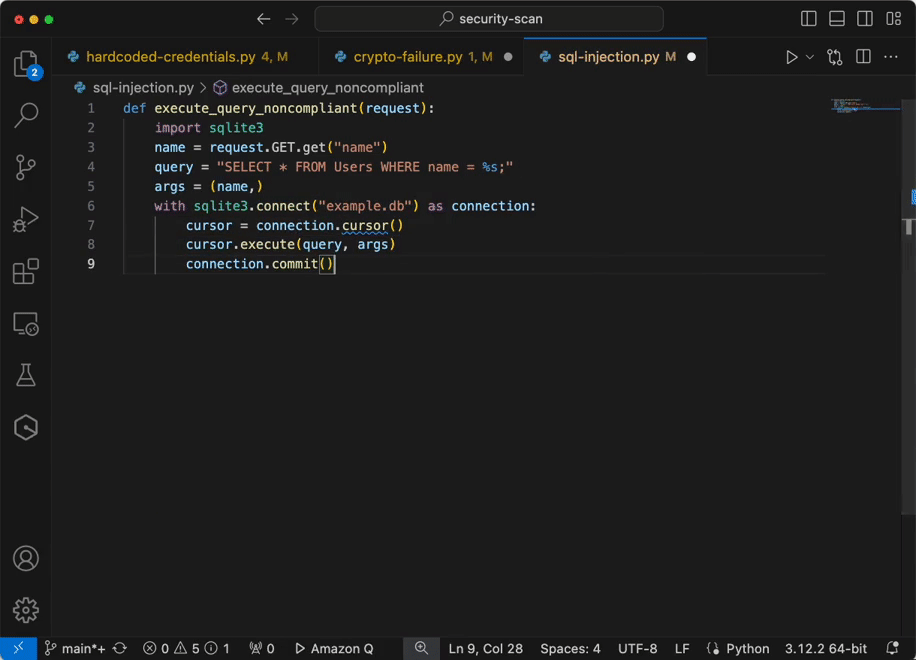













 Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe. Ashish Agrawal is a Principal Product Manager with Amazon Redshift, building cloud-based data warehouses and analytics cloud services. Ashish has over 25 years of experience in IT. Ashish has expertise in data warehouses, data lakes, and platform as a service. Ashish has been a speaker at worldwide technical conferences.
Ashish Agrawal is a Principal Product Manager with Amazon Redshift, building cloud-based data warehouses and analytics cloud services. Ashish has over 25 years of experience in IT. Ashish has expertise in data warehouses, data lakes, and platform as a service. Ashish has been a speaker at worldwide technical conferences. Davide Pagano is a Software Development Manager with Amazon Redshift based out of Palo Alto, specialized in building cloud-based data warehouses and analytics cloud services solutions. He has over 10 years of experience with databases, out of which 6 years of experience tailored to Amazon Redshift.
Davide Pagano is a Software Development Manager with Amazon Redshift based out of Palo Alto, specialized in building cloud-based data warehouses and analytics cloud services solutions. He has over 10 years of experience with databases, out of which 6 years of experience tailored to Amazon Redshift.











 Vibhu Pareek is a Sr. Solutions Architect at AWS. Since 2016, he has guided customers in cloud adoption using well-architected, repeatable patterns. With his specialization in databases, data analytics, and AI, he thrives on transforming complex challenges into innovative solutions. Outside work, he enjoys short treks and sports like badminton, football, and swimming.
Vibhu Pareek is a Sr. Solutions Architect at AWS. Since 2016, he has guided customers in cloud adoption using well-architected, repeatable patterns. With his specialization in databases, data analytics, and AI, he thrives on transforming complex challenges into innovative solutions. Outside work, he enjoys short treks and sports like badminton, football, and swimming. Kamal Manchanda is a Senior Solutions Architect at AWS, specializing in building and designing data solutions with focus on lake house architectures, data governance, search platforms, log analytics solutions as well as generative AI solutions. In his spare time, Kamal loves to travel and spend time with family.
Kamal Manchanda is a Senior Solutions Architect at AWS, specializing in building and designing data solutions with focus on lake house architectures, data governance, search platforms, log analytics solutions as well as generative AI solutions. In his spare time, Kamal loves to travel and spend time with family. Adesh Jaiswal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available, and secure solutions in the AWS Cloud. In his free time, he enjoys watching movies, TV series, and of course, football.
Adesh Jaiswal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available, and secure solutions in the AWS Cloud. In his free time, he enjoys watching movies, TV series, and of course, football.










 Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance.
Lakshmi Nair is a Senior Analytics Specialist Solutions Architect at AWS. She specializes in designing advanced analytics systems across industries. She focuses on crafting cloud-based data platforms, enabling real-time streaming, big data processing, and robust data governance. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.









 Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada.
Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada. Varsha Velagapudi is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about simplifying customers’ AI/ML and analytics journey to help them succeed in their day-to-day tasks. Outside of work, she enjoys nature and outdoor activities, reading, and traveling.
Varsha Velagapudi is a Senior Technical Product Manager with Amazon DataZone at AWS. She focuses on improving data discovery and curation required for data analytics. She is passionate about simplifying customers’ AI/ML and analytics journey to help them succeed in their day-to-day tasks. Outside of work, she enjoys nature and outdoor activities, reading, and traveling.