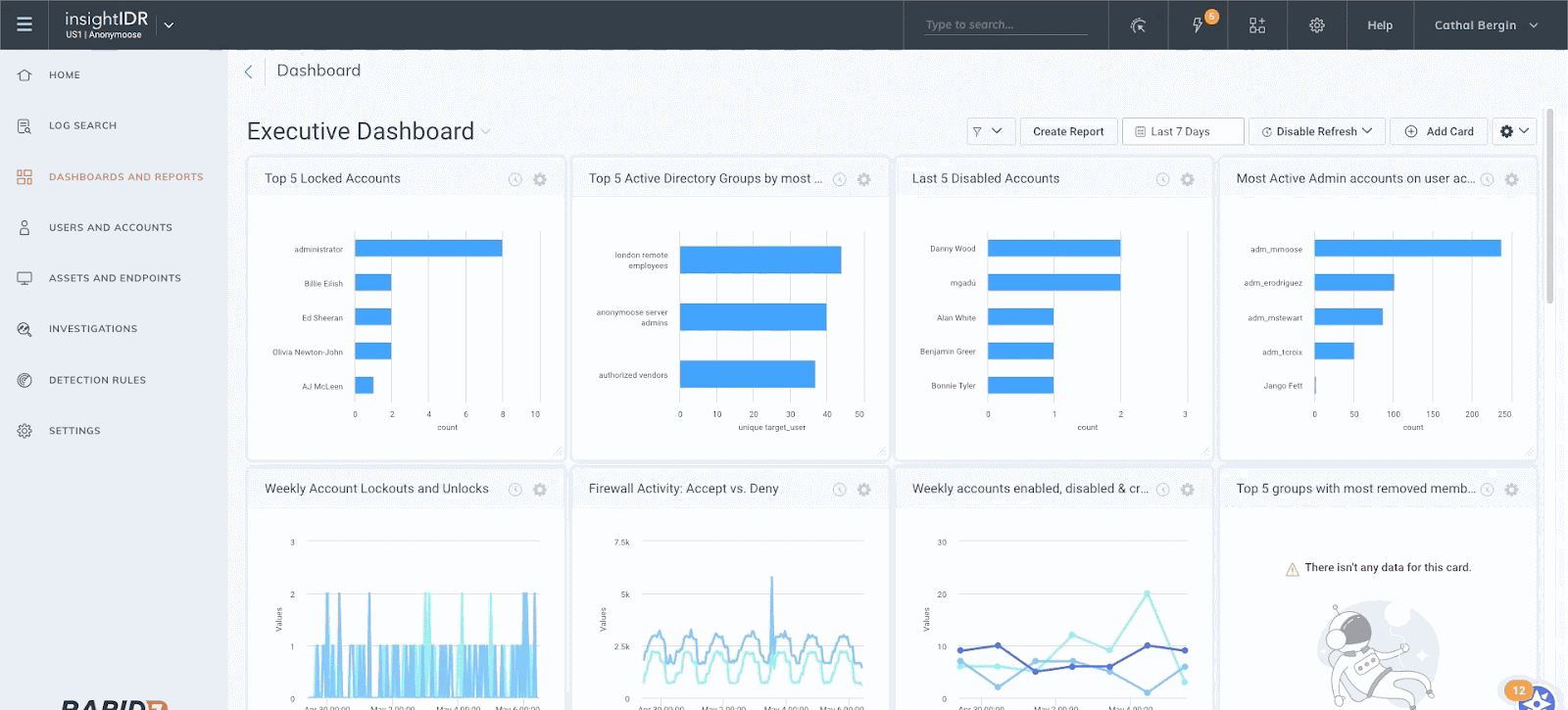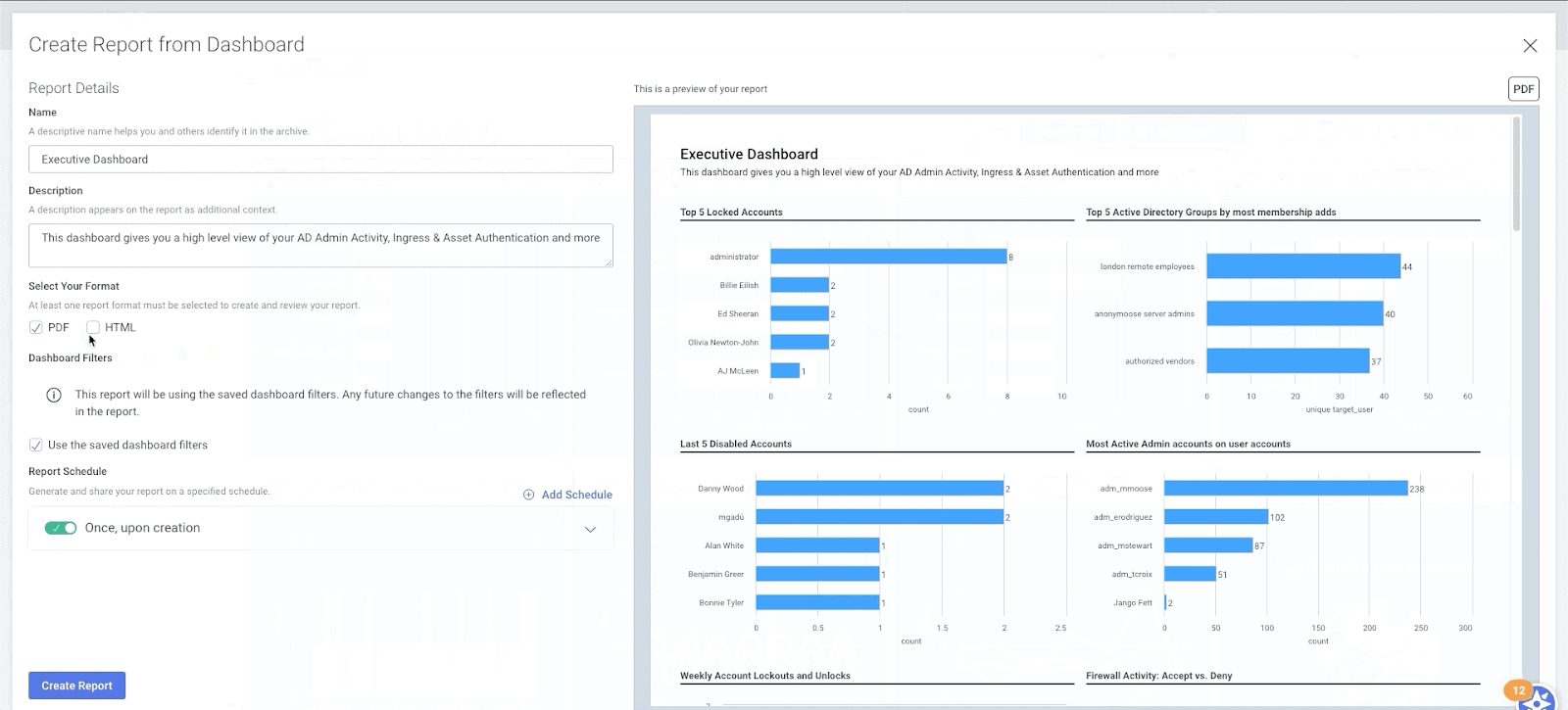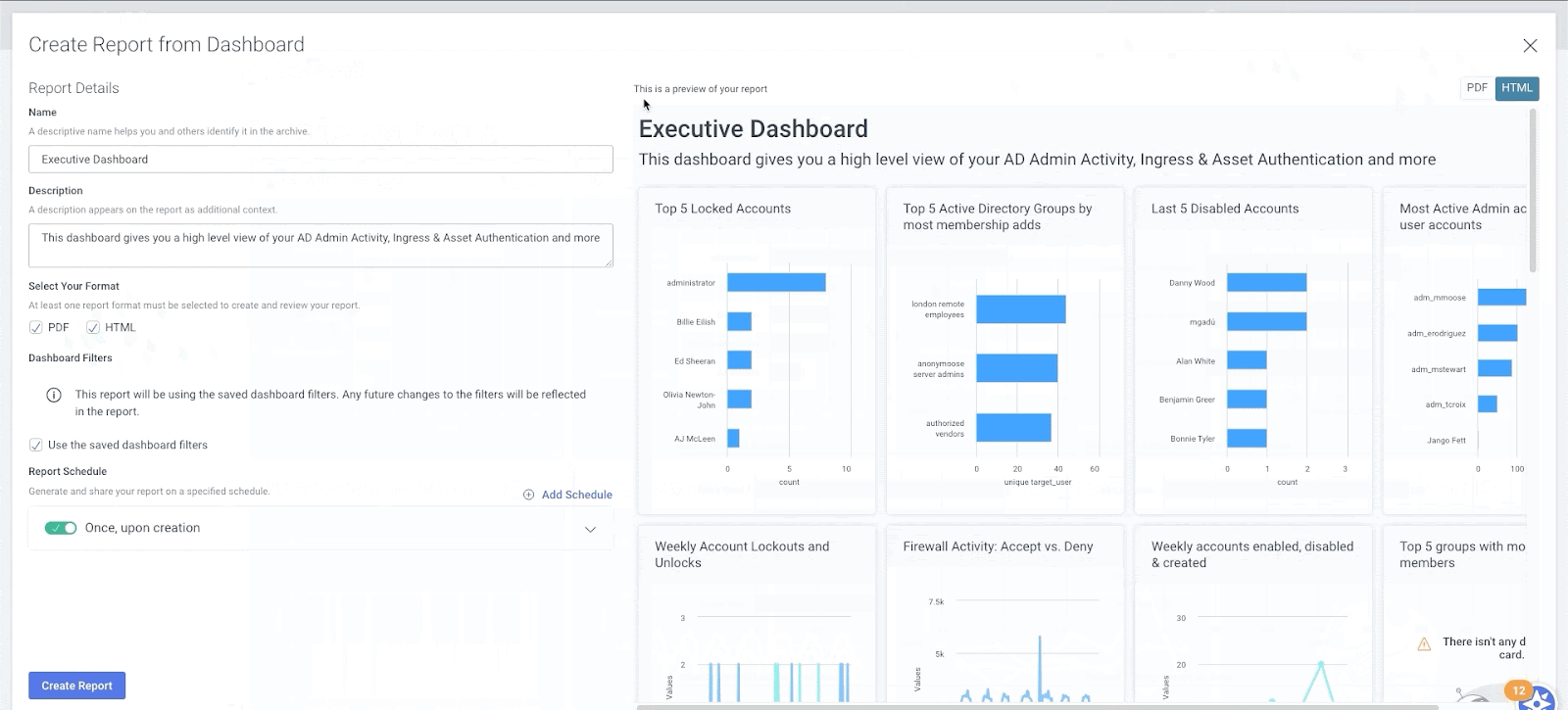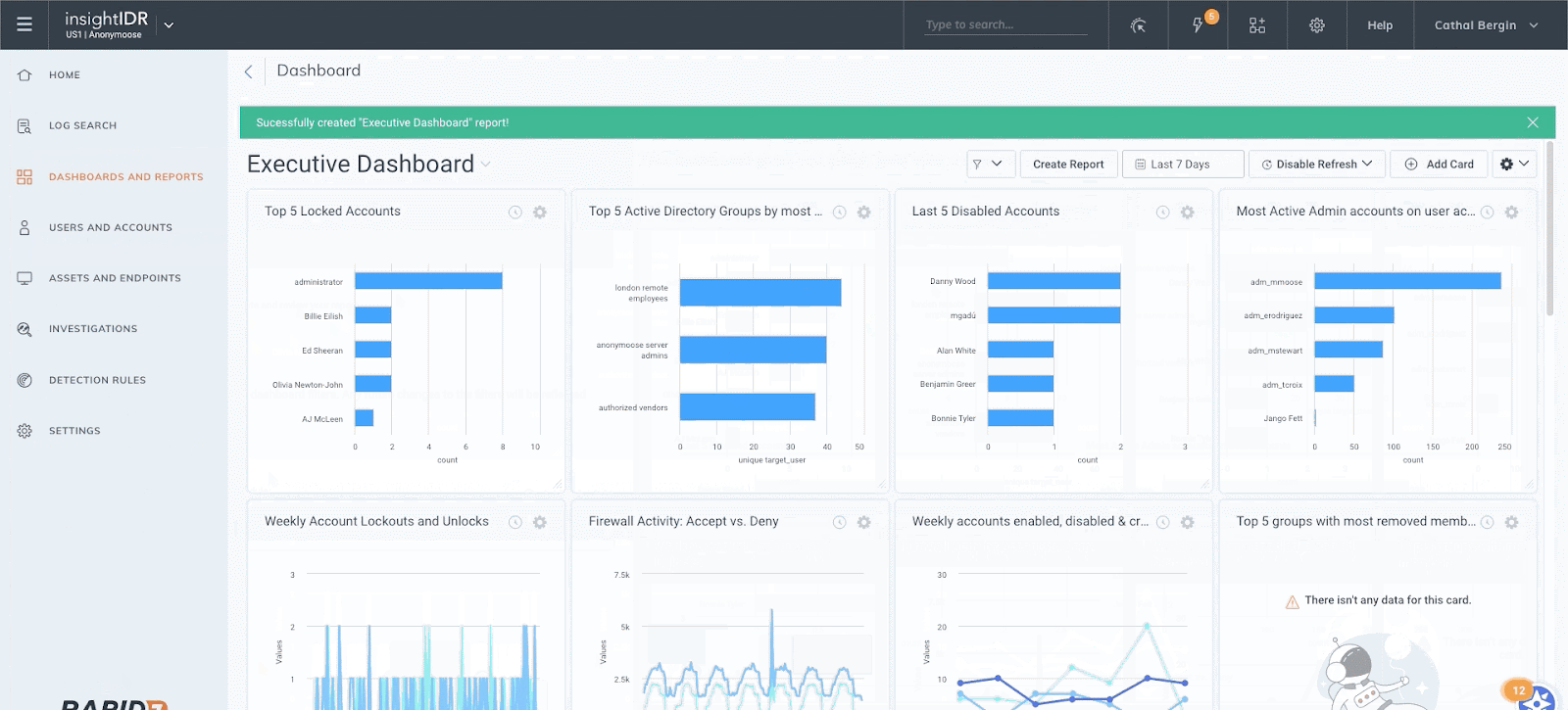
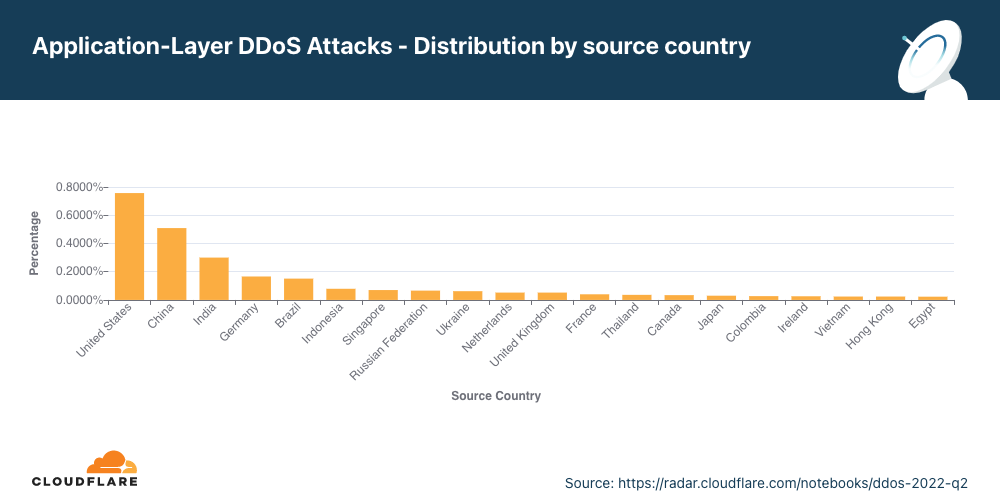
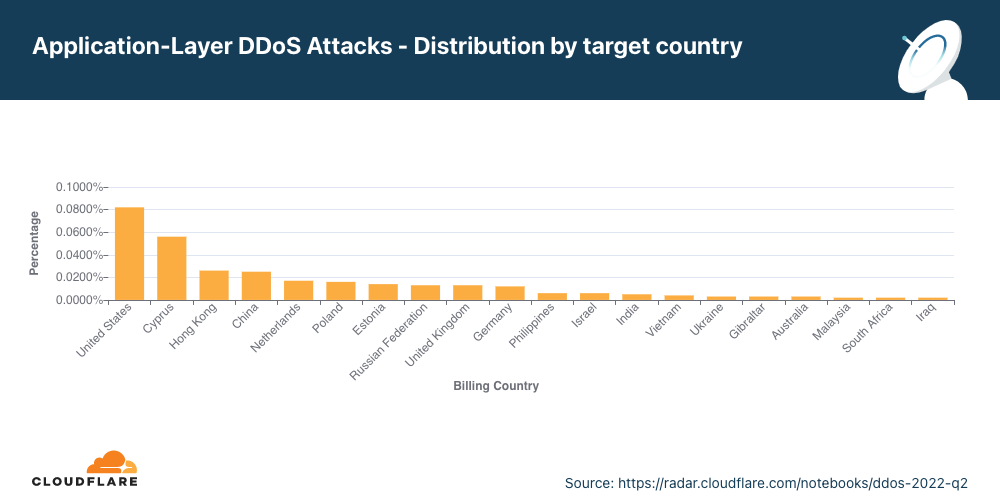
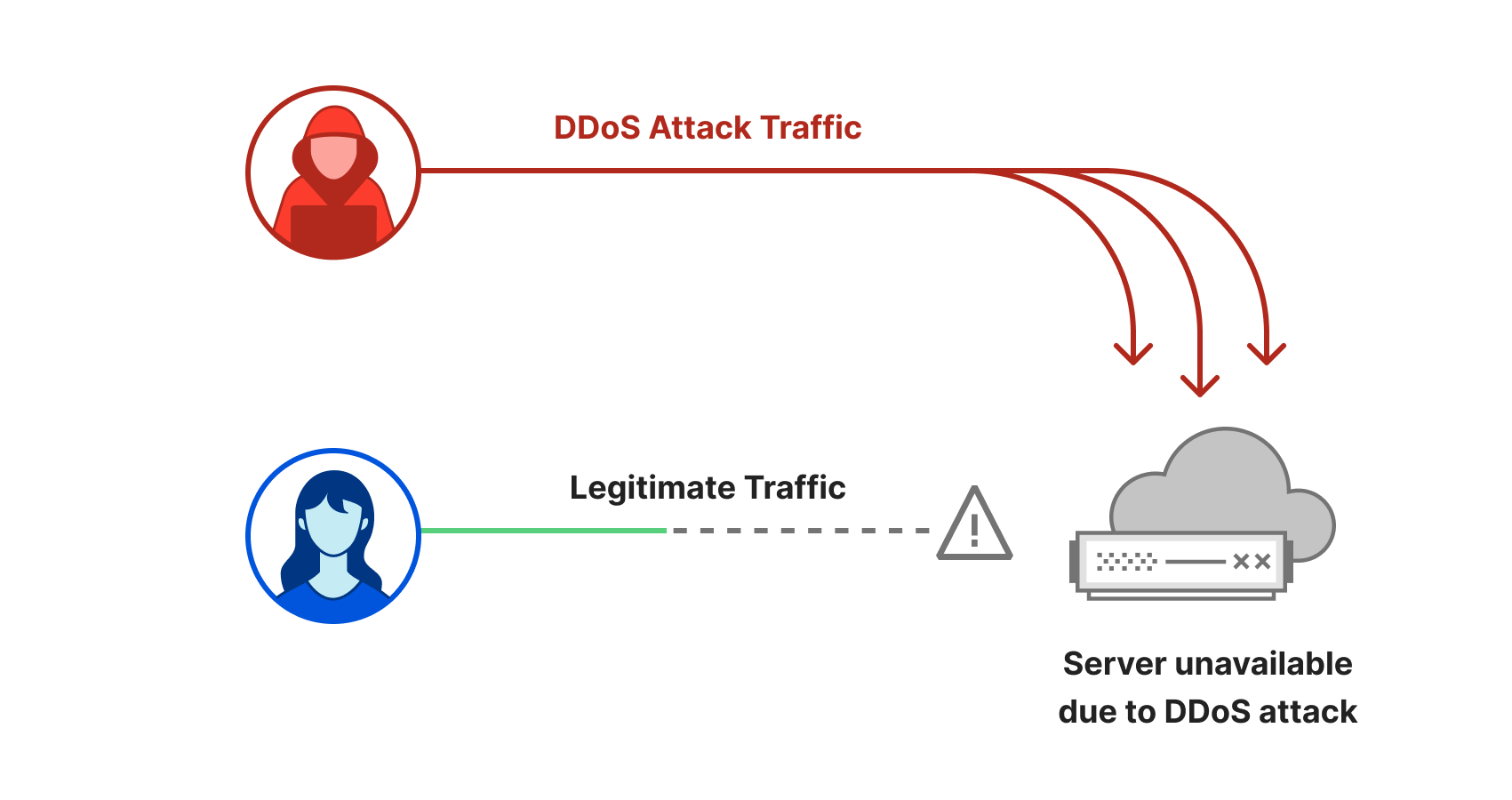
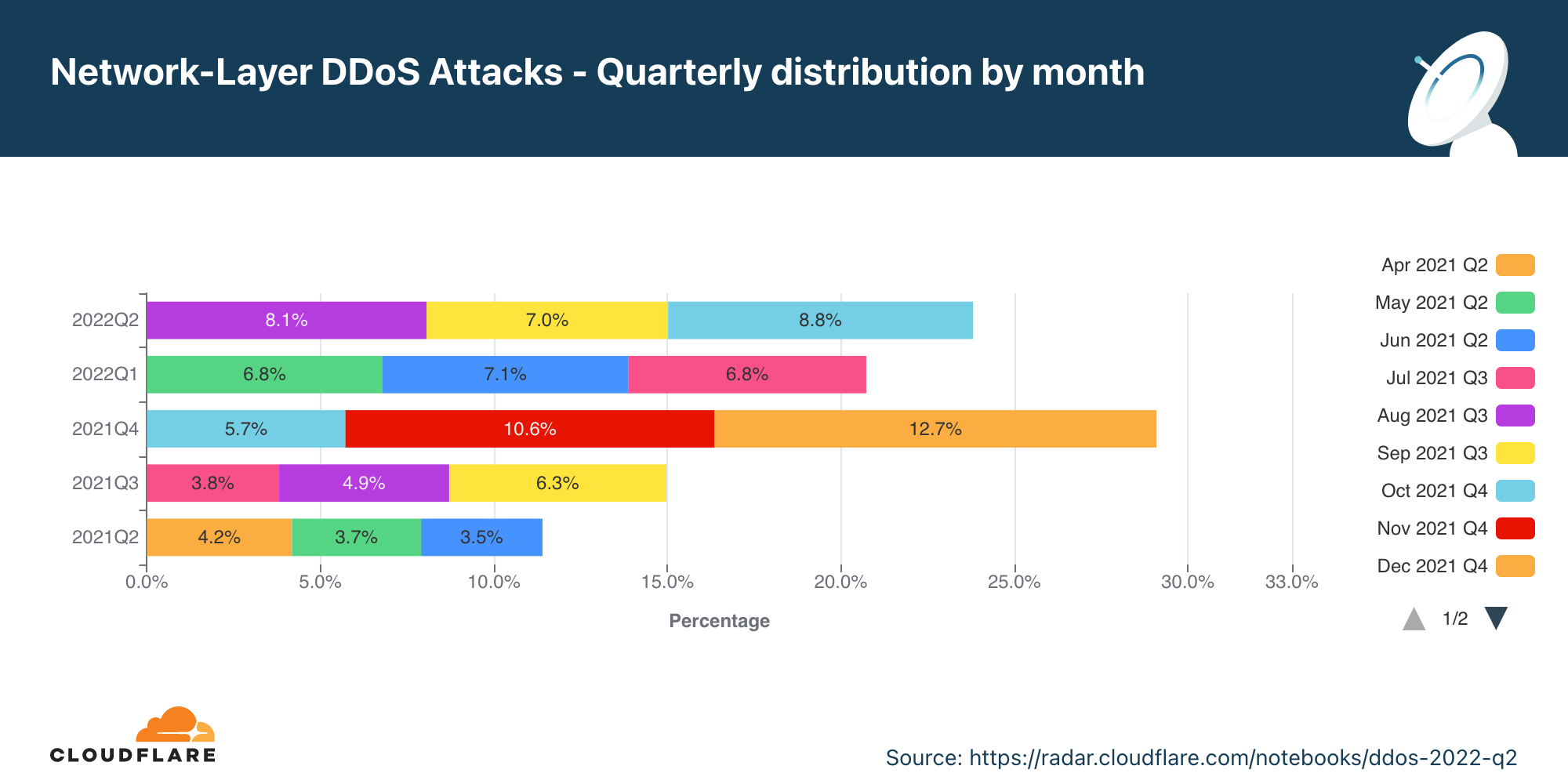
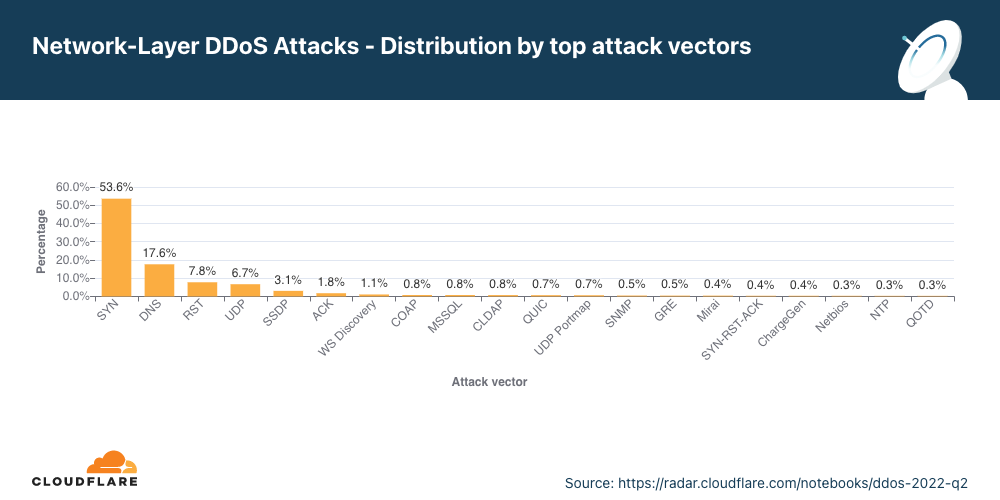
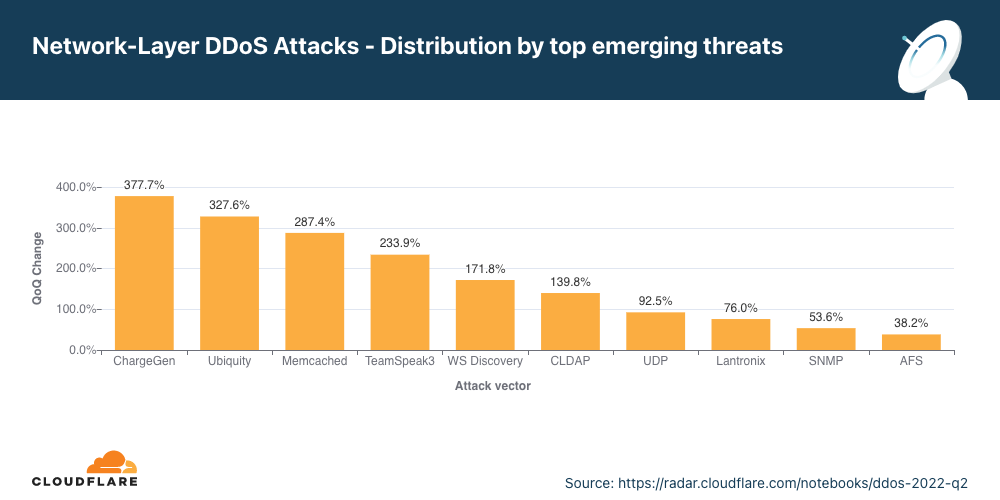
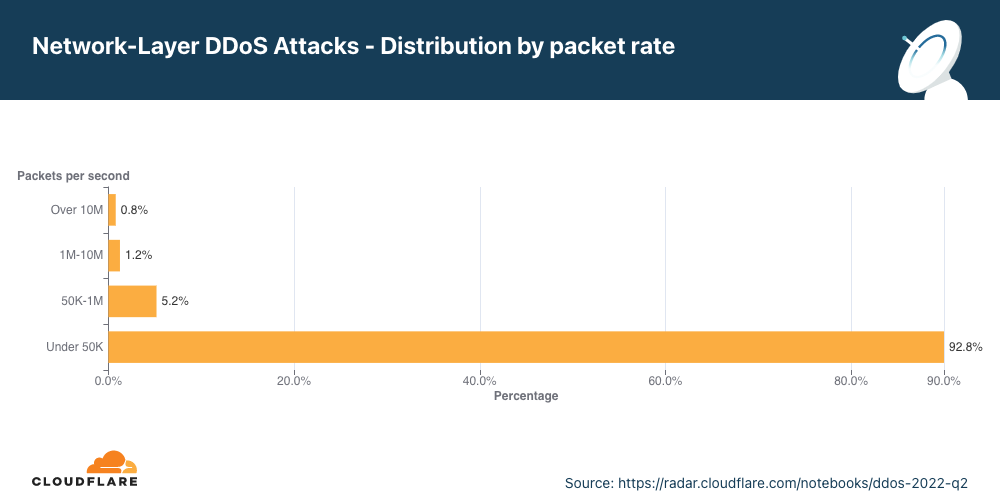
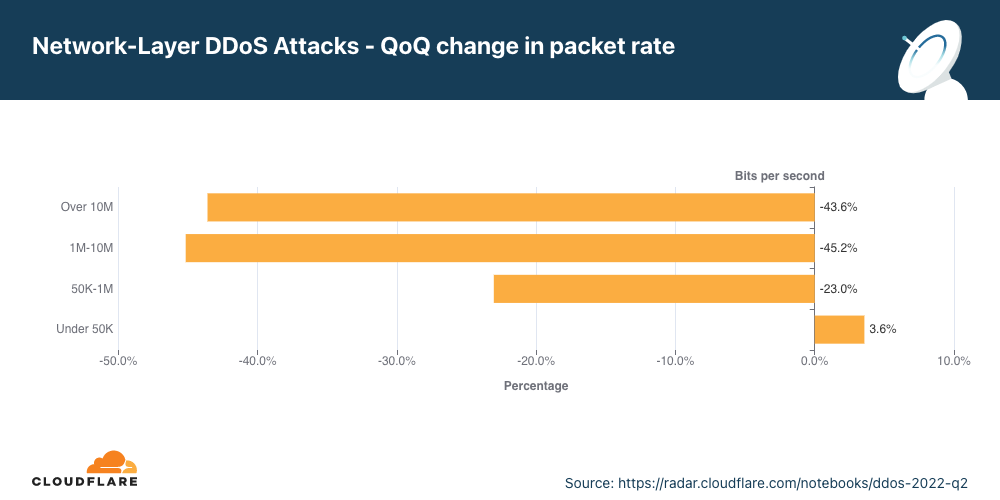
Cloudflare is expanding our WAF’s threat intelligence capabilities by adding four new managed IP lists that can be used as part of any custom firewall rule.
Managed lists are created and maintained by Cloudflare and are built based on threat intelligence feeds collected by analyzing patterns and trends observed across the Internet. Enterprise customers can already use the Open SOCKS Proxy list (launched in March 2021) and today we are adding four new IP lists: “VPNs”, “Botnets, Command and Control Servers”, “Malware” and “Anonymizers”.
You can check what rules are available in your plan by navigating to Manage Account → Configuration → Lists.
Customers can reference these lists when creating a custom firewall rule or in Advanced Rate Limiting. For example, you can choose to block all traffic generated by IPs we categorize as VPNs, or rate limit traffic generated by all Anonymizers. You can simply incorporate managed IP lists in the powerful firewall rule builder. Of course, you can also use your own custom IP list.
Managed IP Lists can be used in WAF rules to manage incoming traffic from these IPs.
Where do these feeds come from?
These lists are based on Cloudflare-generated threat feeds which are made available as IP lists to be easily consumed in the WAF. Each IP is categorized by combining open source data as well as by analyzing the behavior of each IP leveraging the scale and reach of Cloudflare network. After an IP has been included in one of these feeds, we verify its categorization and feed this information back into our security systems and make it available to our customers in the form of a managed IP list. The content of each list is updated multiple times a day.
In addition to generating IP classifications based on Cloudflare’s internal data, Cloudflare curates and combines several data sources that we believe provide reliable coverage of active security threats with a low false positive rate. In today’s environment, an IP belonging to a cloud provider might today be distributing malware, but tomorrow might be a critical resource for your company.
Some IP address classifications are publicly available, OSINT data, for example Tor exit nodes, and Cloudflare takes care of integrating this into our Anonymizer list so that you don’t have to manage integrating this list into every asset in your network. Other classifications are determined or vetted using a variety of DNS techniques, like lookup, PTR record lookup, and observing passive DNS from Cloudflare’s network.
Our malware and command-and-control focused lists are generated from curated partnerships, and one type of IP address we target when we select partners is data sources that identify security threats that do not have DNS records associated with them.
Our Anonymizer list encompasses several types of services that perform anonymization, including VPNs, open proxies, and Tor nodes. It is a superset of the more narrowly focused VPN list (known commercial VPN nodes), and the Cloudflare Open Proxies list (proxies that relay traffic without requiring authentication).
In dashboard IP annotations
Using these lists to deploy a preventative security policy for these IPs is great, but what about knowing if an IP that is interacting with your website or application is part of a Botnet or VPN? We first released contextual information for Anonymizers as part of Security Week 2022, but we are now closing the circle by extending this feature to cover all new lists.
As part of Cloudflare’s threat intelligence feeds, we are exposing the IP category directly into the dashboard. Say you are investigating requests that were blocked by the WAF and that looked to be probing your application for known software vulnerabilities. If the source IP of these requests is matching with one of our feeds (for example part of a VPN), contextual information will appear directly on the analytics page.
When the source IP of a WAF event matches one of the threat feeds, we provide contextual information directly onto the Cloudflare dashboard.
This information can help you see patterns and decide whether you need to use the managed lists to handle the traffic from these IPs in a particular way, for example by creating a rate limiting rule that reduces the amount of requests these actors can perform over a period of time.
Who gets this?
The following table summarizes what plans have access to each one of these features. Any paying plans will have access to the contextual in-dash information, while Enterprise will be able to use different managed lists. Managed lists can be used only on Enterprise zones within an Enterprise account.
FREE
PRO
BIZ
ENT
Advanced ENT *
Annotations
x
✅
✅
✅
✅
Open Proxies
x
x
x
✅
✅
Anonymizers
x
x
x
x
✅
VPNs
x
x
x
x
✅
Botnets, command and control
x
x
x
x
✅
Malware
x
x
x
x
✅
* Contact your customer success manager to learn how to get access to these lists.
Future releases
We are working on enriching our threat feeds even further. In the next months we are going to provide more IP lists, specifically we are looking into lists for cloud providers and Carrier-grade Network Address Translation (CG-NAT).
Today we share the second report in our series of findings from the Gender Balance in Computing research programme, which we’ve been running as part of the National Centre for Computing Education and with various partners. In this £2.4 million research programme, funded by the Department for Education in England, we aim to identify ways to encourage more female learners to engage with Computing and choose to study it further.
Previously, we shared the evaluation report about our pilot study of using a storytelling approach with very young computing learners. This new report, again coming from the Behavioural Insights Team (BIT) which acts as the programme’s independent evaluator, describes our study of another teaching approach.
Existing research suggests that computing is not always taught in a way that is engaging for girls in particular [1], and that we can improve this. With the intervention at hand, we wanted to explore the effects of using a pair programming teaching approach with primary school learners aged 8 to 11. We have critically and carefully examined the findings, which show mixed outcomes regarding the effectiveness of the approach, and we believe that the research provides insights that increase our shared understanding of how to teach computing effectively to young learners.
Computing education through a collaborative lens
Many people think that writing computer programs is a task carried out by people working individually. A 2017 study of 8- and 9-year-olds [2] confirms this: when asked to draw a picture of a computer scientist doing work, 90% of the children drew a picture of one person working alone. This stereotype is present in teaching and learning about computing and computer science; many computer programming lessons take place in a way that promotes solitary working, with individual students sitting in front of separate computers, working on their own code and debugging their own errors.
Professional software development rarely happens like this. For example, at the Raspberry Pi Foundation, our software engineers work collaboratively on design and often pair up to solve problems. Computing education research also has identified the importance of looking at computer programming through a collaborative lens. This viewpoint allows us to see computing as a subject with scope for collaborative group work in which students create useful applications together and are part of a community where programming has a shared social context [3].
Researching collaborative learning in the primary computing classroom
One teaching approach in computing that promotes collaborative learning is pair programming (a practice also used in industry). This is a structured way of working on programming tasks where learners are paired up and take turns acting as the driver or the navigator. The driver controls the keyboard and mouse and types the code. The navigator reads the instructions, supports the driver by watching out for errors in the code, and thinks strategically about next steps and solutions to problems. Learners swap roles every 5 to 10 minutes, to ensure that both partners can contribute equally and actively to the collaborative learning.
As one part of the Gender Balance in Computing programme, we designed a project to explore the effect of pair programming on girls’ attitudes towards computing. This project builds on research from the USA which suggests that solving problems collaboratively increases girls’ persistence when they encounter difficulties in programming tasks [4].
In the Pair Programming project, we worked with teachers of Year 4 (ages 8–9) and Year 6 (ages 10–11) in schools in England. From January to March 2020, we ran a pilot study with 10 schools and used the resulting teacher feedback to finalise the training and teaching materials for a full randomised controlled trial. Due to the coronavirus pandemic, we trained teachers in the pair programming approach using an online course instead of face-to-face training.
A tweet from a school about taking part in the pair programming study.
The randomised controlled trial ran from September to December 2021 with 97 schools. Schools were randomly allocated to either the intervention group and used the pair programming training and the scheme of work we designed, or to the control group and taught Computing in their usual way, not aware that we were investigating the effects of pair programming. Due to the coronavirus pandemic, our training of teachers in the pair programming approach had to take place via an online course instead of face to face.
Teachers in both groups delivered 12 weeks of Computing lessons, in which learners used Scratch programming to draw shapes and create animations. The lessons covered computing concepts from Key Stage 2 (ages 7–11), such as using sequences, selection, and repetition in programs, as well as digital literacy skills such as using technology respectfully.
What can we learn about pair programming from the study?
The findings about this particular intervention were limited by the amount of data the independent evaluators at BIT were able to collect amongst learners and teachers given the ongoing pandemic. BIT’s evaluation was primarily based on quantitative data collected from learners at the start and the end of the intervention. To collect the data, they used a validated instrument called the Student Computer Science Attitude Survey (SCSAS), which asks learners about their attitudes towards Computing. The evaluators compared the datasets gathered from the intervention group (who took part in pair programming lessons) and the control group (who took part in Computing lessons taught with a ‘business as usual’ model).
The evaluators’ data analysis found no statistically significant evidence that the pair programming approach positively affected girls’ attitudes towards computing or their intention to study computing in the future. The lack of statistically significant results, called a null result in research projects, can appear disappointing at first. But our work involves careful reflection and critical thinking about all outcomes of our research, and the result of this project is no exception. These are factors that may have contributed towards the result:
The independent evaluators suggested that the intervention may lead to different findings if it were implemented again without the disruptions caused by the pandemic. One of their recommendations was to revert to our original planned model of providing face-to-face training to teachers delivering the pair programming approach, and we believe this would embed a deeper understanding of the approach.
Our research built upon a prior study [4] that suggested a connection between pair programming and increased confidence about problem-solving in girls of a similar age. That study took place in a non-formal setting in an all-girls group, whereas our research was situated in formal education in mixed gender groups. It may be that these differences are significant.
It may be that there is no causal link between using the pair programming approach and an increase in girls’ attitudes towards computing, or that the link may only become apparent over a longer time-scale, or that the pair programming approach needs to be combined with other strategies to achieve a positive effect.
The evaluators also gathered qualitative data by running teacher and learner interviews, and we were pleased that this data provided some rich insights into the benefits of using a pair programming approach in the primary classroom, and gave some promising indications of possible benefits for female learners in particular.
Teachers spoke positively about the use of paired activities, and felt that having the defined roles of driver and navigator helped both partners to contribute equally to the programming tasks. Learners said that they enjoyed working in pairs, even though there could be some moments of frustration. Some of the teachers were even planning to integrate pair programming into future lessons. This suggests that the approach was effective both in engaging and motivating learners, as well as in facilitating the planned learning outcomes of the lessons, and that it can be used more widely in primary computing teaching.
“I don’t know why I’ve never thought to do computing like that, actually, because it’s a really good vehicle for the fact that there are two roles, clearly defined. There’s all your conversation, and knowledge comes through that, and then they’re both equally having a turn.” — Primary school teacher (report, p. 38)
“I like working with both [both as a partner and by yourself] because when you do pair programming, you’re collaborating with your partner, making links, and you have to tell them what to do. But if you have a really good idea and then they put the wrong thing in the wrong place, it’s quite annoying.” — Female learner (report, p. 40)
Both teachers and learners felt that having the support of a partner boosted learners’ confidence, which echoes previous research in the field [5, 6]. In computing, boys more accurately assess their capabilities, whereas girls tend to underestimate their performance [7]. When learners feel a positive emotion such as confidence towards a subject, combined with a belief that they can succeed in tasks related to that subject, this shows self-efficacy [8]. Our findings suggest that, through the use of the pair programming approach, both boys and girls improved their sense of self-efficacy towards Computing, which is corroborated by quotes from learners themselves. This is interesting because a sense of self-efficacy in Computing is linked to the decisions to pursue further study in the subject [9]. More research could build on this observation.
“I do think that having that equal time to have a go at both, thinking of the girls I’ve got, will have helped my girls, because they lack a bit of confidence. They were learning very quickly that, ‘Actually, yes, we are sure. We can do this.’” — Primary teacher (report, p. 44)
“It might be easier to do pair programming [compared to ‘normal’ lessons] because if you’re stuck, your partner can be helpful.” — Female learner (report, p. 43)
Watch this short video that shows pair programming being used in a primary classroom.
Read the evaluation report of the pair programming intervention, where you’ll also find more quotes from teachers and learners.
Try the free training course on pair programming we designed and used for this project. It also includes links to the lesson plans that teachers worked with.
Collaboration in our research
We will continue to publish evaluation reports and our reflections on the other projects in the Gender Balance in Computing programme. If you would like to stay up-to-date with the programme, you can sign up to the newsletter.
The insights gained from this trial will feed forwards into our future work. Through the process of working with schools on this project, we have increased our understanding of the process of research in educational settings in many ways. We are very grateful for the input from teachers who took part in the first stage of the trial, with whom we developed an effective co-production model for developing resources, a model we will use in future research projects. Teachers who took part in the second stage of the project told us that the resources we provided were of good quality, which demonstrates the success of this co-production approach to developing resources.
In our new Raspberry Pi Computing Education Research Centre, created with the University of Cambridge Department of Computer Science and Technology, we will collaborate closely with teachers and schools when implementing and evaluating research projects. You are invited to the free in-person launch event of the Centre on 20 July in Cambridge, UK, where we hope to meet many teachers, researchers, and other education practitioners to strengthen a collaborative community around computing education research.
References
[1] Goode, J., Estrella, R., & Margolis, J. (2018). Lost in Translation: Gender and High School Computer Science. In Women and Information Technology. https://doi.org/10.7551/mitpress/7272.003.0005
[2] Alexandria K. Hansen, Hilary A. Dwyer, Ashley Iveland, Mia Talesfore, Lacy Wright, Danielle B. Harlow, and Diana Franklin. 2017. Assessing Children’s Understanding of the Work of Computer Scientists: The Draw-a-Computer-Scientist Test. In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education (SIGCSE ’17). Association for Computing Machinery, New York, NY, USA, 279–284. https://doi.org/10.1145/3017680.3017769
[3] Yasmin B. Kafai and Quinn Burke. 2013. The social turn in K-12 programming: moving from computational thinking to computational participation. In Proceeding of the 44th ACM technical symposium on Computer science education (SIGCSE ’13). Association for Computing Machinery, New York, NY, USA, 603–608. https://doi.org/10.1145/2445196.2445373
[5] Charlie McDowell, Linda Werner, Heather E. Bullock, and Julian Fernald. 2006. Pair programming improves student retention, confidence, and program quality. Commun. ACM 49, 8 (August 2006), 90–95. https://doi.org/10.1145/1145287.1145293
[6] Denner, J., Werner, L., Campe, S., & Ortiz, E. (2014). Pair programming: Under what conditions is it advantageous for middle school students? Journal of Research on Technology in Education, 46(3), 277–296. https://doi.org/10.1080/15391523.2014.888272
[7] Maria Kallia and Sue Sentance. 2018. Are boys more confident than girls? the role of calibration and students’ self-efficacy in programming tasks and computer science. In Proceedings of the 13th Workshop in Primary and Secondary Computing Education (WiPSCE ’18). Association for Computing Machinery, New York, NY, USA, Article 16, 1–4. https://doi.org/10.1145/3265757.3265773
[9] Allison Mishkin. 2019. Applying Self-Determination Theory towards Motivating Young Women in Computer Science. In Proceedings of the 50th ACM Technical Symposium on Computer Science Education (SIGCSE ’19). Association for Computing Machinery, New York, NY, USA, 1025–1031. https://doi.org/10.1145/3287324.3287389
Управленската програма за следващите шест месеца, подготвяна от „Продължаваме промяната“, „Демократична България“ и БСП, е онова, което не успяха да свършат в предишните шест – добавили са срокове. Не че ги нямаше и в коалиционното споразумение, но все пак то беше разчетено за пълен четиригодишен мандат, а спорните теми бяха отложени с анализи. Сега, след изгубеното време, се явява нов кандидат за министър-председател – Асен Василев, с подновен кабинет и програма с дати, чието съдържание ще се променя до последния момент.
Програмата е микс от стари проекти и идеи и нови предложения. Прави впечатление концентрацията на контролни функции в Министерския съвет, респективно премиера, тъй като към МС се предвижда да премине Изпълнителната агенция по горите с всички горски стопанства и Българската агенция по безопасност на храните (двете сега са подопечни на Министерството на земеделието) и Дирекцията за национален строителен контрол (досега към МРРБ). Трите структури контролират огромни сектори от икономиката – горския и дърводобивния, хранително-вкусовия, строителния – и винаги са били обект на големи интереси и корупционен натиск.
Енергетика
Разумното предложение тук е да се въведат две тарифи за ток и парно, като първата да покрива базово потребление на по-ниска цена. Не е фиксирано какъв ще е прагът.
Договорено е да се ускори изграждането на нови ядрени мощности и преминаване на АЕЦ „Козлодуй“ на алтернативно ядрено гориво, както и гарантиране на сигурността на газовите доставки – чрез диверсификация и дългосрочни договори за доставка. Само че нито може да се ускори „изграждането“ на нови мощности за шест месеца, нито АЕЦ да мине на алтернативно гориво за същото време, а то бездруго си е планирано.
Първо, управляващите (все едно кои) трябва да решат каква да е новата ядрена мощност – в коалиционното споразумение пише, че ще стане след анализ, а такъв дори не е започнат. Но наред с това и процедурата за АЕЦ „Белене“ не е прекратена – а БСП със сигурност ще настоява именно за втора АЕЦ с руските реактори. Второ, още от февруари м.г., на база подписано споразумение между АEЦ „Koзлoдyй“ и „Уecтингxayc Eлeĸтpиĸ Швeция“, е планирано алтернативното ядрено гориво. Ако Агенцията за ядрено регулиране лицензира горивото, постепенно ще бъдат заменяни част от касетките с руско гориво в V блок. Постепенно. А VI блок е подготвен с руско гориво до 2026 г.
Какво значи дългосрочни договори за доставка?
В контекста на призива на председателката на ЕК Урсула фон дер Лайен Европа да се готви за спиране на руския газ, това може да означава само едно: доставки на втечнен газ и увеличаване на количествата неруски газ. Министърът на енергетиката в оставка Александър Николов потвърди пред журналисти, че се водят преговори за азерски газ над договорените сега количества от 1 млрд. куб.м на година – „но трябва да се прави разлика между 25-годишен договор и търговски преговори, които включват доставка сега, веднага, на пазарна цена“. България вече получава в пълен размер азерския газ, но това е една трета от общото потребление, което е около 3 млрд. куб.м годишно. А изглежда, че намерението за общи газови доставки на ЕС няма да се осъществи.
Газовото уравнение обаче ще трябва да бъде решено – все едно вписано ли е, или не – в 6-месечната управленска програма. Макар че там фигурира и запълване на капацитета на газохранилището в Чирен, което сега е 35% запълнено, а има и срок – до 30 септември. Как ще бъде решено това уравнение? Обемът на хранилището е 550 млн. куб.м, от които остават близо 358 млн. куб.м за запълване. Максималният капацитет за нагнетяване е 3,2 млн. куб.м на ден, което означава, че ще са необходими 112 дни – и то при условие че има достатъчно количества синьо гориво.
След по-малко от 4 месеца започва отоплителният сезон –
индустрията, битовите абонати, болниците, детските градини, газифицираните общини трябва да са наясно гарантиран ли е газът за зимата. Ето с изпълнението на този належащ приоритет правителството трябва да се заеме най-напред. Само че първо в коалицията ще е нужно да са постигнали разбирателство по въпроса, със или без руски газ в микса.
Кирил Петков и Асен Василев недвусмислено заявиха, че няма да бъде подновен изтичащият в края на 2022 г. договор с компанията „Газпром“, която едностранно спря руския газ за България. БСП и нейната лидерка Корнелия Нинова винаги са били на противното мнение. Като аргумент Нинова изтъква, че бизнесът иска по-евтин газ. По-рано днес по БНР председателят на Асоциацията на индустриалния капитал Васил Велев определи настоящата ситуация като „доста шизофренна“:
Имаме договор, който не е прекратен, с „Газпром експорт“, на по-ниски цени от тези на спот пазара, от порядъка на 25-30% по-ниски. Плащаме по този договор транспорта на този газ и в същото време не потребяваме газ, рискувайки да го платим след това, нищо че не сме го потребили – поради клаузата в договора „вземи или плати“.
Депутатът от БСП Борислав Гуцанов обясни по БНТ, че по време на преговорите социалистите са поставили въпроса, че трябва да бъдат направени „всички усилия“ да бъдат нормализирани дипломатическите отношения между България и Русия и да бъдат подновени преговорите с „Газпром“. И това беше прието от „Продължаваме промяната“, заяви Гуцанов. Ако от ПП наистина са приели да има нови преговори с „Газпром“, пропуснали са го съобщят публично.
Инфраструктура
По темата „инфраструктура“ се предвиждадовършване на магистрала „Струма“, така че да не бъдат загубени европейски средства. Това не е възможно не само в близките шест месеца, но би било чудо, ако се случи до края на настоящия програмен период – 2027 г. За първите шест месеца управляващата четворна коалиция така и не се разбра по основния въпрос за „Струма“ – 13-километров тунел през Кресненското дефиле или изграждане на източен обход на Кресна за движението от Гърция към София. Спорът тече от 2007-ма, а в настоящото управление въпросът беше оставен за разрешаване на коалиционен съвет – който така и не го реши. Така че, ако смятат да довършват „Струма“, би следвало ПП, ДБ и БСП поне да са се разбрали кой вариант избират до 30 септември.
Заложено е и до 31 декември да се подпише споразумение с Румъния за проектиране и изграждане на 5 моста над Дунав,
обещани още в предизборната кампания на „Продължаваме промяната“. В последния си, трети мандат премиерът и лидер на ГЕРБ Бойко Борисов говореше за три моста и дори обяви, че ще има първа копка на третия – между Свищов и Зимнич. Въпреки настойчивостта му, от другата страна на Дунав така и не уточниха къде да бъде третият мост. Така че амбицията за пет моста е смехотворна – още повече при липсата на добри пътища и жп връзки в България след преминаването им.
Възлагане на проектирането на тунели при Петрохан и Прохода на Републиката, възлагане за довършването на проектирането на магистрала „Хемус“ и продължението на „Черно море“. Тези проекти бяха обявени за приоритетни от министъра на регионалното развитие и благоустройство в оставка Гроздан Караджов още през януари. По време на парламентарен контрол през март т.г. той съобщи докъде е стигнала работата по три тунела – за този под връх Шипка текат процедури по съгласуване с МОСВ по определяне на екомерките; за Петрохан се работи за разширен идеен проект; третият е по трасето на бъдещия аутобан „Черно море“ и за него има разширен идеен проект, стигнал до втори етап – да се определят екомерките, което ще отнеме още около една година. А договорът за проектиране на „Черно море“ е сключен през октомври 2020 г. с ДЗЗД „Екип проект АМ Черно море“ – за 9,5 млн. лв. и една година срок, така че
на хартия проект трябваше да има още миналата есен.
Предлага се до 31 октомври да бъдат въведени германски изисквания за пътно строителство, включително стандартите за текущ ремонт и поддръжка. Също така до края на годината да се намери решение за инхаус поръчките от ерата „Борисов“ – с което досега управлението така и не се справи, а и не поиска да се справи.
Ред и право
С най-голям шанс за осъществяване е приоритетът, който от „Продължаваме промяната“ винаги слагат най-отпред – сегашният министър на вътрешните работи в оставка Бойко Рашков да оглави КПКОНПИ. Срокът за това е до края на юли, тоест преди парламентът да се разпусне за обичайната си лятна ваканция, каквато не иска да пропусне и този път. До 23 септември е предвидено да бъде приет и законопроект за противодействие на корупцията, който разделя комисията на две – противодействие на корупцията и установяване на конфликт на интереси, от една страна, и отнемане на незаконно придобито имущество, от друга; предвиждат се и правомощия за разследване и използване на събраните доказателства в наказателно производство.
Разписани са срокове за номинации,
за да бъде променен съставът на Комисията за защита на конкуренцията, Комисията за финансов надзор и Българската народна банка – през септември и ноември. През първите си шест месеца разпадналата се четворна коалиция се разтресе от разногласия заради двамата си кандидати за гуверньор на БНБ, но сега отново няма решение за обща кандидатура – всяка от трите политически сили ще излезе със своя номинация.
Конституционно мнозинство за избор на 11 нови членове от парламентарната квота във ВСС няма, както и за нов състав на Инспектората към ВСС.
Законодателната програма, която включва приемане на 21 законопроекта, изисквани заради средствата по Плана за възстановяване и устойчивост, и още толкова заради други промени, е твърде амбициозна на фона на досегашната парламентарна леност.
Новите предложения
Сред брадясалите проекти и идеи има и нови предложения. Едно от най-съществените сред тях е Дирекция „Финансово разузнаване“ да бъде извадена от системата на ДАНС и да се върне в Министерството на финансите. Дирекцията беше към МФ до момента, в който тройната коалиция с премиер Сергей Станишев създаде ДАНС и я вкара там. В резултат активността по отношение на мерките срещу изпирането на пари рязко се понижи и Европейската комисия неколкократно отбелязва тази слабост на България.
Друга нова инициатива е въвеждане на фонд за радио и телевизия, който да бъде заложен в бюджета за 2023 г. Едва ли може да се мине без социалните теми – увеличение на вдовишките добавки и на добавките за пенсионирани учители, безплатни учебници до ХII клас включително, по-високи стипендии за ученици и студенти, оптимизиране на екипите по спешна помощ, обещано още по време на предизборната кампания миналата есен, и пр.
Най-напред обаче следващото правителство ще трябва да се заеме с газовите доставки – докато е лято, за да гарантира енергийната сигурност през зимата. В противен случай твърдото приземяване му е гарантирано.
A regular feature of the Embedded
Linux Conference (ELC) has been an update on the state of embedded Linux from
conference organizer Tim Bird. It has been quite a few years since I had
the opportunity to sit in on one, so I took one at the
2022 Open
Source Summit North America (OSSNA) in Austin, Texas. OSSNA is an
umbrella conference that contains ELC and a whole lot more these days.
Bird gave a look at recent kernel features from an embedded perspective,
talked a bit about some different technology areas and their impact on
embedded Linux, and
also tried to answer a question that Andrew Morton posed in a keynote at ELC in 2008.
AWS Identity and Access Management (IAM) has now made it easier for you to use IAM roles for your workloads that are running outside of AWS, with the release of IAM Roles Anywhere. This feature extends the capabilities of IAM roles to workloads outside of AWS. You can use IAM Roles Anywhere to provide a secure way for on-premises servers, containers, or applications to obtain temporary AWS credentials and remove the need for creating and managing long-term AWS credentials.
In this post, I will briefly discuss how IAM Roles Anywhere works. I’ll mention some of the common use cases for IAM Roles Anywhere. And finally, I’ll walk you through an example scenario to demonstrate how the implementation works.
Background
To enable your applications to access AWS services and resources, you need to provide the application with valid AWS credentials for making AWS API requests. For workloads running on AWS, you do this by associating an IAM role with Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), or AWS Lambda resources, depending on the compute platform hosting your application. This is secure and convenient, because you don’t have to distribute and manage AWS credentials for applications running on AWS. Instead, the IAM role supplies temporary credentials that applications can use when they make AWS API calls.
IAM Roles Anywhere enables you to use IAM roles for your applications outside of AWS to access AWS APIs securely, the same way that you use IAM roles for workloads on AWS. With IAM Roles Anywhere, you can deliver short-term credentials to your on-premises servers, containers, or other compute platforms. When you use IAM Roles Anywhere to vend short-term credentials you can remove the need for long-term AWS access keys and secrets, which can help improve security, and remove the operational overhead of managing and rotating the long-term credentials. You can also use IAM Roles Anywhere to provide a consistent experience for managing credentials across hybrid workloads.
In this post, I assume that you have a foundational knowledge of IAM, so I won’t go into the details here about IAM roles. For more information on IAM roles, see the IAM documentation.
How does IAM Roles Anywhere work?
IAM Roles Anywhere relies on public key infrastructure (PKI) to establish trust between your AWS account and certificate authority (CA) that issues certificates to your on-premises workloads. Your workloads outside of AWS use IAM Roles Anywhere to exchange X.509 certificates for temporary AWS credentials. The certificates are issued by a CA that you register as a trust anchor (root of trust) in IAM Roles Anywhere. The CA can be part of your existing PKI system, or can be a CA that you created with AWS Certificate Manager Private Certificate Authority (ACM PCA).
Your application makes an authentication request to IAM Roles Anywhere, sending along its public key (encoded in a certificate) and a signature signed by the corresponding private key. Your application also specifies the role to assume in the request. When IAM Roles Anywhere receives the request, it first validates the signature with the public key, then it validates that the certificate was issued by a trust anchor previously configured in the account. For more details, see the signature validation documentation.
After both validations succeed, your application is now authenticated and IAM Roles Anywhere will create a new role session for the role specified in the request by calling AWS Security Token Service (AWS STS). The effective permissions for this role session are the intersection of the target role’s identity-based policies and the session policies, if specified, in the profile you create in IAM Roles Anywhere. Like any other IAM role session, it is also subject to other policy types that you might have in place, such as permissions boundaries and service control policies (SCPs).
There are typically three main tasks, performed by different personas, that are involved in setting up and using IAM Roles Anywhere:
Initial configuration of IAM Roles Anywhere – This task involves creating a trust anchor, configuring the trust policy of the role that IAM Roles Anywhere is going to assume, and defining the role profile. These activities are performed by the AWS account administrator and can be limited by IAM policies.
Provisioning of certificates to workloads outside AWS – This task involves ensuring that the X.509 certificate, signed by the CA, is installed and available on the server, container, or application outside of AWS that needs to authenticate. This is performed in your on-premises environment by an infrastructure admin or provisioning actor, typically by using existing automation and configuration management tools.
Using IAM Roles Anywhere – This task involves configuring the credential provider chain to use the IAM Roles Anywhere credential helper tool to exchange the certificate for session credentials. This is typically performed by the developer of the application that interacts with AWS APIs.
I’ll go into the details of each task when I walk through the example scenario later in this post.
Common use cases for IAM Roles Anywhere
You can use IAM Roles Anywhere for any workload running in your data center, or in other cloud providers, that requires credentials to access AWS APIs. Here are some of the use cases we think will be interesting to customers based on the conversations and patterns we have seen:
Send security findings from on-premises sources to AWS Security Hub
Enable hybrid workloads to access AWS services over the course of phased migrations
Example scenario and walkthrough
To demonstrate how IAM Roles Anywhere works in action, let’s walk through a simple scenario where you want to call S3 APIs to upload some data from a server in your data center.
Prerequisites
Before you set up IAM Roles Anywhere, you need to have the following requirements in place:
The certificate bundle of your own CA, or an active ACM PCA CA in the same AWS Region as IAM Roles Anywhere
An end-entity certificate and associated private key available on the on-premises server
Administrator permissions for IAM roles and IAM Roles Anywhere
Setup
Here I demonstrate how to perform the setup process by using the IAM Roles Anywhere console. Alternatively, you can use the AWS API or Command Line Interface (CLI) to perform these actions. There are three main activities here:
Create a trust anchor
Create and configure a role that trusts IAM Roles Anywhere
Under Trust anchors, choose Create a trust anchor.
On the Create a trust anchor page, enter a name for your trust anchor and select the existing AWS Certificate Manager Private CA from the list. Alternatively, if you want to use your own external CA, choose External certificate bundle and provide the certificate bundle.
Figure 1: Create a trust anchor in IAM Roles Anywhere
To create and configure a role that trusts IAM Roles Anywhere
Using the AWS Command Line Interface (AWS CLI), you are going to create an IAM role with appropriate permissions that you want your on-premises server to assume after authenticating to IAM Roles Anywhere. Save the following trust policy as rolesanywhere-trust-policy.json on your computer.
Save the following identity-based policy as onpremsrv-permissions-policy.json. This grants the role permissions to write objects into the specified S3 bucket.
You can optionally use condition statements based on the attributes extracted from the X.509 certificate to further restrict the trust policy to control the on-premises resources that can obtain credentials from IAM Roles Anywhere. IAM Roles Anywhere sets the SourceIdentity value to the CN of the subject (onpremsrv01 in my example). It also sets individual session tags (PrincipalTag/) with the derived attributes from the certificate. So, you can use the principal tags in the Condition clause in the trust policy as additional authorization constraints.
For example, the Subject for the certificate I use in this post is as follows.
Subject: … O = Example Corp., OU = SecOps, CN = onpremsrv01
So, I can add condition statements like the following into the trust policy (rolesanywhere-trust-policy.json):
On the Create a profile page, enter a name for the profile.
For Roles, select the role that you created in the previous step (ExampleS3WriteRole).
5. Optionally, you can define session policies to further scope down the sessions delivered by IAM Roles Anywhere. This is particularly useful when you configure the profile with multiple roles and want to restrict permissions across all the roles. You can add the desired session polices as managed policies or inline policy. Here, for demonstration purpose, I add an inline policy to only allow requests coming from my specified IP address.
Figure 2: Create a profile in IAM Roles Anywhere
At this point, IAM Roles Anywhere setup is complete and you can start using it.
Use IAM Roles Anywhere
IAM Roles Anywhere provides a credential helper tool that can be used with the process credentials functionality that all current AWS SDKs support. This simplifies the signing process for the applications. See the IAM Roles Anywhere documentation to learn how to get the credential helper tool.
To test the functionality first, run the credential helper tool (aws_signing_helper) manually from the on-premises server, as follows.
Figure 3: Running the credential helper tool manually
You should successfully receive session credentials from IAM Roles Anywhere, similar to the example in Figure 3. Once you’ve confirmed that the setup works, update or create the ~/.aws/config file and add the signing helper as a credential_process. This will enable unattended access for the on-premises server. To learn more about the AWS CLI configuration file, see Configuration and credential file settings.
To verify that the config works as expected, call the aws sts get-caller-identity AWS CLI command and confirm that the assumed role is what you configured in IAM Roles Anywhere. You should also see that the role session name contains the Serial Number of the certificate that was used to authenticate (cc:c3:…:85:37 in this example). Finally, you should be able to copy a file to the S3 bucket, as shown in Figure 4.
Figure 4: Verify the assumed role
Audit
As with other AWS services, AWS CloudTrail captures API calls for IAM Roles Anywhere. Let’s look at the corresponding CloudTrail log entries for the activities we performed earlier.
The first log entry I’m interested in is CreateSession, when the on-premises server called IAM Roles Anywhere through the credential helper tool and received session credentials back.
You can see that the cert, along with other parameters, is sent to IAM Roles Anywhere and a role session along with temporary credentials is sent back to the server.
The next log entry we want to look at is the one for the s3:PutObject call we made from our on-premises server.
In addition to the CloudTrail logs, there are several metrics and events available for you to use for monitoring purposes. To learn more, see Monitoring IAM Roles Anywhere.
Additional notes
You can disable the trust anchor in IAM Roles Anywhere to immediately stop new sessions being issued to your resources outside of AWS. Certificate revocation is supported through the use of imported certificate revocation lists (CRLs). You can upload a CRL that is generated from your CA, and certificates used for authentication will be checked for their revocation status. IAM Roles Anywhere does not support callbacks to CRL Distribution Points (CDPs) or Online Certificate Status Protocol (OCSP) endpoints.
Another consideration, not specific to IAM Roles Anywhere, is to ensure that you have securely stored the private keys on your server with appropriate file system permissions.
Conclusion
In this post, I discussed how the new IAM Roles Anywhere service helps you enable workloads outside of AWS to interact with AWS APIs securely and conveniently. When you extend the capabilities of IAM roles to your servers, containers, or applications running outside of AWS you can remove the need for long-term AWS credentials, which means no more distribution, storing, and rotation overheads.
I mentioned some of the common use cases for IAM Roles Anywhere. You also learned about the setup process and how to use IAM Roles Anywhere to obtain short-term credentials.
If you have any questions, you can start a new thread on AWS re:Post or reach out to AWS Support.
In this episode of Security Nation, Jen and Tod are joined again by Pete Cooper and Irene Pontisso of the UK Cabinet Office for a follow-up on the cybersecurity culture challenge they launched in 2021. Pete and Irene run us through the results, what kinds of interventions participants came up with, and what has them excited about building a more resilient government security culture in the years to come.
Stick around for our Rapid Rundown, where Tod and Jen talk about a recent write-up that takes a deep dive into a curious form of phishing: pig-butchering scams. Spoiler: They have nothing to do with actual pigs but everything to do with highly specific text messages from numbers you don’t recognize.
Pete Cooper
Pete is Deputy Director Cyber Defence within the Government Security Group in the UK Cabinet Office where he looks over the whole of the Government sector and is responsible for the Government Cyber Security Strategy, standards, and policies, as well as responding to serious or cross-government cyber incidents. With a diverse military, private sector, and government background, he has worked on everything ranging from cyber operations, global cybersecurity strategies, advising on the nature of state-versus-state cyber conflict to leading cybersecurity change across industry, public sector and the global hacker community, including founding and leading the Aerospace Village at DEF CON. A fast jet pilot turned cyber operations advisor, who on leaving the military in 2016 founded the UK’s first multi-disciplinary cyber strategy competition, he is passionate about tackling national and international cybersecurity challenges through better collaboration, diversity, and innovative partnerships. He has a Post Grad in Cyberspace Operations from Cranfield University. He is a Non-Resident Senior Fellow at the Cyber Statecraft Initiative of the Scowcroft Centre for Strategy and Security at the Atlantic Council and a Visiting Senior Research Fellow in the Dept of War Studies, King’s College London.
Irene Pontisso
Irene is Assistant Head of Engagement and Information within the Government Security Group in the UK Cabinet Office. Irene is responsible for the design and strategic oversight of cross-government security education, awareness, and culture-related initiatives. She is also responsible for leading cross-government engagement and press activities for Government Security and the Government Chief Security Officer. Irene started her career in policy and international relations through her roles at the United Nations Platform for Space-based Information for Disaster Management and Emergency Response (UN-SPIDER). Irene also has significant industry and third sector experience, and she partnered with the world’s leading law firms to provide free access to legal advice for NGOs on international development projects. She also has experience in leading large-scale exhibitions and policy research in corporate environments. She holds a MSc in International Relations from the University of Bristol and a BSc from the University of Turin.
Read the paper on the UK government’s cybersecurity strategy through 2030.
Rapid Rundown links
Check out the article on so-called pig-butchering scams.
Like the show? Want to keep Jen and Tod in the podcasting business? Feel free to rate and review with your favorite podcast purveyor, like Apple Podcasts.
Want More Inspiring Stories From the Security Community?
In Part 1 of this two-part series, we shared an overview of some of the most important 2021 Amazon Web Services (AWS) Security service and feature launches. In this follow-up, we’ll dive deep into additional launches that are important for security professionals to be aware of and understand across all AWS services. There have already been plenty in the first half of 2022, so we’ll highlight those soon, as well.
AWS Identity
You can use AWS Identity Services to build Zero Trust architectures, help secure your environments with a robust data perimeter, and work toward the security best practice of granting least privilege. In 2021, AWS expanded the identity source options, AWS Region availability, and support for AWS services. There is also added visibility and power in the permission management system. New features offer new integrations, additional policy checks, and secure resource sharing across AWS accounts.
AWS Single Sign-On
For identity management, AWS Single Sign-On (AWS SSO) is where you create, or connect, your workforce identities in AWS once and manage access centrally across your AWS accounts in AWS Organizations. In 2021, AWS SSO announced new integrations for JumpCloud and CyberArk users. This adds to the list of providers that you can use to connect your users and groups, which also includes Microsoft Active Directory Domain Services, Okta Universal Directory, Azure AD, OneLogin, and Ping Identity.
For access management, there have been a range of feature launches with AWS Identity and Access Management (IAM) that have added up to more power and visibility in the permissions management system. Here are some key examples.
IAM made it simpler to relate a user’s IAM role activity to their corporate identity. By setting the new source identity attribute, which persists through role assumption chains and gets logged in AWS CloudTrail, you can find out who is responsible for actions that IAM roles performed.
IAM added support for policy conditions, to help manage permissions for AWS services that access your resources. This important feature launch of service principal conditions helps you to distinguish between API calls being made on your behalf by a service principal, and those being made by a principal inside your account. You can choose to allow or deny the calls depending on your needs. As a security professional, you might find this especially useful in conjunction with the aws:CalledVia condition key, which allows you to scope permissions down to specify that this account principal can only call this API if they are calling it using a particular AWS service that’s acting on their behalf. For example, your account principal can’t generally access a particular Amazon Simple Storage Service (Amazon S3) bucket, but if they are accessing it by using Amazon Athena, they can do so. These conditions can also be used in service control policies (SCPs) to give account principals broader scope across an account, organizational unit, or organization; they need not be added to individual principal policies or resource policies.
Another very handy new IAM feature launch is additional information about the reason for an access denied error message. With this additional information, you can now see which of the relevant access control policies (for example, IAM, resource, SCP, or VPC endpoint) was the cause of the denial. As of now, this new IAM feature is supported by more than 50% of all AWS services in the AWS SDK and AWS Command Line Interface, and a fast-growing number in the AWS Management Console. We will continue to add support for this capability across services, as well as add more features that are designed to make the journey to least privilege simpler.
IAM Access Analyzer also launched the ability to generate fine-grained policies based on analyzing past AWS CloudTrail activity. This feature provides a great new capability for DevOps teams or central security teams to scope down policies to just the permissions needed, making it simpler to implement least privilege permissions. IAM Access Analyzer launched further enhancements to expand policy checks, and the ability to generate a sample least-privilege policy from past activity was expanded beyond the account level to include an analysis of principal behavior within the entire organization by analyzing log activity stored in AWS CloudTrail.
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) helps you securely share your resources across unrelated AWS accounts within your organization or organizational units (OUs) in AWS Organizations. Now you can also share your resources with IAM roles and IAM users for supported resource types. This update enables more granular access using managed permissions that you can use to define access to shared resources. In addition to the default managed permission defined for each shareable resource type, you now have more flexibility to choose which permissions to grant to whom for resource types that support additional managed permissions. Additionally, AWS RAM added support for global resource types, enabling you to provision a global resource once, and share that resource across your accounts. A global resource is one that can be used in multiple AWS Regions; the first example of a global resource is found in AWS Cloud WAN, currently in preview as of this publication. AWS RAM helps you more securely share an AWS Cloud WAN core network, which is a managed network containing AWS and on-premises networks. With AWS RAM global resource sharing, you can use the Cloud WAN core network to centrally operate a unified global network across Regions and accounts.
AWS Directory Service
AWS Directory Service for Microsoft Active Directory, also known as AWS Managed Microsoft Active Directory (AD), was updated to automatically provide domain controller and directory utilization metrics in Amazon CloudWatch for new and existing directories. Analyzing these utilization metrics helps you quantify your average and peak load times to identify the need for additional domain controllers. With this, you can define the number of domain controllers to meet your performance, resilience, and cost requirements.
Amazon Cognito
Amazon Cognitoidentity pools (federated identities) was updated to enable you to use attributes from social and corporate identity providers to make access control decisions and simplify permissions management in AWS resources. In Amazon Cognito, you can choose predefined attribute-tag mappings, or you can create custom mappings using the attributes from social and corporate providers’ access and ID tokens, or SAML assertions. You can then reference the tags in an IAM permissions policy to implement attribute-based access control (ABAC) and manage access to your AWS resources. Amazon Cognito also launched a new console experience for user pools and now supports targeted sign out through refresh token revocation.
Governance, control, and logging services
There were a number of important releases in 2021 in the areas of governance, control, and logging services.
This approach provides a powerful new middle ground between the older security models of prevention (which provide developers only an access denied message, and often can’t distinguish between an acceptable and an unacceptable use of the same API) and a detect and react model (when undesired states have already gone live). The Cfn-Guard 2.0 model gives builders the freedom to build with IaC, while allowing central teams to have the ability to reject infrastructure configurations or changes that don’t conform to central policies—and to do so with completely custom error messages that invite dialog between the builder team and the central team, in case the rule is unnuanced and needs to be refined, or if a specific exception needs to be created.
For example, a builder team might be allowed to provision and attach an internet gateway to a VPC, but the team can do this only if the routes to the internet gateway are limited to a certain pre-defined set of CIDR ranges, such as the public addresses of the organization’s branch offices. It’s not possible to write an IAM policy that takes into account the CIDR values of a VPC route table update, but you can write a Cfn-Guard 2.0 rule that allows the creation and use of an internet gateway, but only with a defined and limited set of IP addresses.
AWS Systems Manager Incident Manager
An important launch that security professionals should know about is AWS Systems Manager Incident Manager. Incident Manager provides a number of powerful capabilities for managing incidents of any kind, including operational and availability issues but also security issues. With Incident Manager, you can automatically take action when a critical issue is detected by an Amazon CloudWatch alarm or Amazon EventBridge event. Incident Manager runs pre-configured response plans to engage responders by using SMS and phone calls, can enable chat commands and notifications using AWS Chatbot, and runs automation workflows with AWS Systems Manager Automation runbooks. The Incident Manager console integrates with AWS Systems Manager OpsCenter to help you track incidents and post-incident action items from a central place that also synchronizes with third-party management tools such as Jira Service Desk and ServiceNow. Incident Manager enables cross-account sharing of incidents using AWS RAM, and provides cross-Region replication of incidents to achieve higher availability.
Amazon Simple Storage Service (Amazon S3) is one of the most important services at AWS, and its steady addition of security-related enhancements is always big news. Here are the 2021 highlights.
Access Points aliases
Amazon S3 introduced a new feature, Amazon S3 Access Points aliases. With Amazon S3 Access Points aliases, you can make the access points backwards-compatible with a large amount of existing code that is programmed to interact with S3 buckets rather than access points.
To understand the importance of this launch, we have to go back to 2019 to the launch of Amazon S3 Access Points. Access points are a powerful mechanism for managing S3 bucket access. They provide a great simplification for managing and controlling access to shared datasets in S3 buckets. You can create up to 1,000 access points per Region within each of your AWS accounts. Although bucket access policies remain fully enforced, you can delegate access control from the bucket to its access points, allowing for distributed and granular control. Each access point enforces a customizable policy that can be managed by a particular workgroup, while also avoiding the problem of bucket policies needing to grow beyond their maximum size. Finally, you can also bind an access point to a particular VPC for its lifetime, to prevent access directly from the internet.
With the 2021 launch of Access Points aliases, Amazon S3 now generates a unique DNS name, or alias, for each access point. The Access Points aliases look and acts just like an S3 bucket to existing code. This means that you don’t need to make changes to older code to use Amazon S3 Access Points; just substitute an Access Points aliases wherever you previously used a bucket name. As a security team, it’s important to know that this flexible and powerful administrative feature is backwards-compatible and can be treated as a drop-in replacement in your various code bases that use Amazon S3 but haven’t been updated to use access point APIs. In addition, using Access Points aliases adds a number of powerful security-related controls, such as permanent binding of S3 access to a particular VPC.
S3 Bucket Keys were launched at the end of 2020, another great launch that security professionals should know about, so here is an overview in case you missed it. S3 Bucket Keys are data keys generated by AWS KMS to provide another layer of envelope encryption in which the outer layer (the S3 Bucket Key) is cached by S3 for a short period of time. This extra key layer increases performance and reduces the cost of requests to AWS KMS. It achieves this by decreasing the request traffic from Amazon S3 to AWS KMS from a one-to-one model—one request to AWS KMS for each object written to or read from Amazon S3—to a one-to-many model using the cached S3 Bucket Key. The S3 Bucket Key is never stored persistently in an unencrypted state outside AWS KMS, and so Amazon S3 ultimately must always return to AWS KMS to encrypt and decrypt the S3 Bucket Key, and thus, the data. As a result, you still retain control of the key hierarchy and resulting encrypted data through AWS KMS, and are still able to audit Amazon S3 returning periodically to AWS KMS to refresh the S3 Bucket Keys, as logged in CloudTrail.
Returning to our review of 2021, S3 Bucket Keys gained the ability to use Amazon S3 Inventory and Amazon S3 Batch Operations automatically to migrate objects from the higher cost, slightly lower-performance SSE-KMS model to the lower-cost, higher-performance S3 Bucket Keys model.
To understand this launch, we need to go in time to the origins of Amazon S3, which is one of the oldest services in AWS, created even before IAM was launched in 2011. In those pre-IAM days, a storage system like Amazon S3 needed to have some kind of access control model, so Amazon S3 invented its own: Amazon S3 access control lists (ACLs). Using ACLs, you could add access permissions down to the object level, but only with regard to access by other AWS account principals (the only kind of identity that was available at the time), or public access (read-only or read-write) to an object. And in this model, objects were always owned by the creator of the object, not the bucket owner.
After IAM was introduced, Amazon S3 added the bucket policy feature, a type of resource policy that provides the rich features of IAM, including full support for all IAM principals (users and roles), time-of-day conditions, source IP conditions, ability to require encryption, and more. For many years, Amazon S3 access decisions have been made by combining IAM policy permissions and ACL permissions, which has served customers well. But the object-writer-is-owner issue has often caused friction. The good news for security professionals has been that a deny by either type of access control type overrides an allow by the other, so there were no security issues with this bi-modal approach. The challenge was that it could be administratively difficult to manage both resource policies—which exist at the bucket and access point level—and ownership and ACLs—which exist at the object level. Ownership and ACLs might potentially impact the behavior of only a handful of objects, in a bucket full of millions or billions of objects.
With the features released in 2021, Amazon S3 has removed these points of friction, and now provides the features needed to reduce ownership issues and to make IAM-based policies the only access control system for a specified bucket. The first step came in 2020 with the ability to make object ownership track bucket ownership, regardless of writer. But that feature applied only to newly-written objects. The final step is the 2021 launch we’re highlighting here: the ability to disable at the bucket level the evaluation of all existing ACLs—including ownership and permissions—effectively nullifying all object ACLs. From this point forward, you have the mechanisms you need to govern Amazon S3 access with a combination of S3 bucket policies, S3 access point policies, and (within the same account) IAM principal policies, without worrying about legacy models of ACLs and per-object ownership.
Additional database and storage service features
AWS Backup Vault Lock
AWS Backup added an important new additional layer for backup protection with the availability of AWS Backup Vault Lock. A vault lock feature in AWS is the ability to configure a storage policy such that even the most powerful AWS principals (such as an account or Org root principal) can only delete data if the deletion conforms to the preset data retention policy. Even if the credentials of a powerful administrator are compromised, the data stored in the vault remains safe. Vault lock features are extremely valuable in guarding against a wide range of security and resiliency risks (including accidental deletion), notably in an era when ransomware represents a rising threat to data.
ACM Private CA achieved FedRAMP authorization for six additional AWS Regions in the US.
Additional certificate customization now allows administrators to tailor the contents of certificates for new use cases, such as identity and smart card certificates; or to securely add information to certificates instead of relying only on the information present in the certificate request.
Additional capabilities were added for sharing CAs across accounts by using AWS RAM to help administrators issue fully-customized certificates, or revoke them, from a shared CA.
Integration with Kubernetes provides a more secure certificate authority solution for Kubernetes containers.
Online Certificate Status Protocol (OCSP) provides a fully-managed solution for notifying endpoints that certificates have been revoked, without the need for you to manage or operate infrastructure yourself.
Network and application protection
We saw a lot of enhancements in network and application protection in 2021 that will help you to enforce fine-grained security policies at important network control points across your organization. The services and new capabilities offer flexible solutions for inspecting and filtering traffic to help prevent unauthorized resource access.
AWS WAF
AWS WAF launched AWS WAF Bot Control, which gives you visibility and control over common and pervasive bots that consume excess resources, skew metrics, cause downtime, or perform other undesired activities. The Bot Control managed rule group helps you monitor, block, or rate-limit pervasive bots, such as scrapers, scanners, and crawlers. You can also allow common bots that you consider acceptable, such as status monitors and search engines. AWS WAF also added support for custom responses, managed rule group versioning, in-line regular expressions, and Captcha. The Captcha feature has been popular with customers, removing another small example of “undifferentiated work” for customers.
AWS Shield Advanced
AWS Shield Advanced now automatically protects web applications by blocking application layer (L7) DDoS events with no manual intervention needed by you or the AWS Shield Response Team (SRT). When you protect your resources with AWS Shield Advanced and enable automatic application layer DDoS mitigation, Shield Advanced identifies patterns associated with L7 DDoS events and isolates this anomalous traffic by automatically creating AWS WAF rules in your web access control lists (ACLs).
Amazon CloudFront
In other edge networking news, Amazon CloudFront added support for response headers policies. This means that you can now add cross-origin resource sharing (CORS), security, and custom headers to HTTP responses returned by your CloudFront distributions. You no longer need to configure your origins or use custom Lambda@Edge or CloudFront Functions to insert these headers.
Following Route 53 Resolver’s much-anticipated launch of DNS logging in 2020, the big news for 2021 was the launch of its DNS Firewall capability. Route 53 Resolver DNS Firewall lets you create “blocklists” for domains you don’t want your VPC resources to communicate with, or you can take a stricter, “walled-garden” approach by creating “allowlists” that permit outbound DNS queries only to domains that you specify. You can also create alerts for when outbound DNS queries match certain firewall rules, allowing you to test your rules before deploying for production traffic. Route 53 Resolver DNS Firewall launched with two managed domain lists—malware domains and botnet command and control domains—enabling you to get started quickly with managed protections against common threats. It also integrated with Firewall Manager (see the following section) for easier centralized administration.
AWS Network Firewall and Firewall Manager
Speaking of AWS Network Firewall and Firewall Manager, 2021 was a big year for both. Network Firewall added support for AWS Managed Rules, which are groups of rules based on threat intelligence data, to enable you to stay up to date on the latest security threats without writing and maintaining your own rules. AWS Network Firewall features a flexible rules engine enabling you to define firewall rules that give you fine-grained control over network traffic. As of the launch in late 2021, you can enable managed domain list rules to block HTTP and HTTPS traffic to domains identified as low-reputation, or that are known or suspected to be associated with malware or botnets. Prior to that, another important launch was new configuration options for rule ordering and default drop, making it simpler to write and process rules to monitor your VPC traffic. Also in 2021, Network Firewall announced a major regional expansion following its initial launch in 2020, and a range of compliance achievements and eligibility including HIPAA, PCI DSS, SOC, and ISO.
Elastic Load Balancing now supports forwarding traffic directly from Network Load Balancer (NLB) to Application Load Balancer (ALB). With this important new integration, you can take advantage of many critical NLB features such as support for AWS PrivateLink and exposing static IP addresses for applications that still require ALB.
The AWS Networking team also made Amazon VPC private NAT gateways available in both AWS GovCloud (US) Regions. The expansion into the AWS GovCloud (US) Regions enables US government agencies and contractors to move more sensitive workloads into the cloud by helping them to address certain regulatory and compliance requirements.
Compute
Security professionals should also be aware of some interesting enhancements in AWS compute services that can help improve their organization’s experience in building and operating a secure environment.
Amazon Elastic Compute Cloud (Amazon EC2) launched the Global View on the console to provide visibility to all your resources across Regions. Global View helps you monitor resource counts, notice abnormalities sooner, and find stray resources. A few days into 2022, another simple but extremely useful EC2 launch was the new ability to obtain instance tags from the Instance Metadata Service (IMDS). Many customers run code on Amazon EC2 that needs to introspect about the EC2 tags associated with the instance and then change its behavior depending on the content of the tags. Prior to this launch, you had to associate an EC2 role and call the EC2 API to get this information. That required access to API endpoints, either through a NAT gateway or a VPC endpoint for Amazon EC2. Now, that information can be obtained directly from the IMDS, greatly simplifying a common use case.
Amazon EC2 launched sharing of Amazon Machine Images (AMIs) with AWS Organizations and Organizational Units (OUs). Previously, you could share AMIs only with specific AWS account IDs. To share AMIs within AWS Organizations, you had to explicitly manage sharing of AMIs on an account-by-account basis, as they were added to or removed from AWS Organizations. With this new feature, you no longer have to update your AMI permissions because of organizational changes. AMI sharing is automatically synchronized when organizational changes occur. This feature greatly helps both security professionals and governance teams to centrally manage and govern AMIs as you grow and scale your AWS accounts. As previously noted, this feature was also added to EC2 Image Builder. Finally, Amazon Data Lifecycle Manager, the tool that manages all your EBS volumes and AMIs in a policy-driven way, now supports automatic deprecation of AMIs. As a security professional, you will find this helpful as you can set a timeline on your AMIs so that, if the AMIs haven’t been updated for a specified period of time, they will no longer be considered valid or usable by development teams.
Looking ahead
In 2022, AWS continues to deliver experiences that meet administrators where they govern, developers where they code, and applications where they run. We will continue to summarize important launches in future blog posts. If you’re interested in learning more about AWS services, join us for AWS re:Inforce, the AWS conference focused on cloud security, identity, privacy, and compliance. AWS re:Inforce 2022 will take place July 26–27 in Boston, MA. Registration is now open. Register now with discount code SALxUsxEFCw to get $150 off your full conference pass to AWS re:Inforce. For a limited time only and while supplies last. We look forward to seeing you there!
To stay up to date on the latest product and feature launches and security use cases, be sure to read the What’s New with AWS announcements (or subscribe to the RSS feed) and the AWS Security Blog.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
NIST’s post-quantum computing cryptography standard process is entering its final phases. It announced the first four algorithms:
For general encryption, used when we access secure websites, NIST has selected the CRYSTALS-Kyber algorithm. Among its advantages are comparatively small encryption keys that two parties can exchange easily, as well as its speed of operation.
For digital signatures, often used when we need to verify identities during a digital transaction or to sign a document remotely, NIST has selected the three algorithms CRYSTALS-Dilithium, FALCON and SPHINCS+ (read as “Sphincs plus”). Reviewers noted the high efficiency of the first two, and NIST recommends CRYSTALS-Dilithium as the primary algorithm, with FALCON for applications that need smaller signatures than Dilithium can provide. The third, SPHINCS+, is somewhat larger and slower than the other two, but it is valuable as a backup for one chief reason: It is based on a different math approach than all three of NIST’s other selections.
NIST has not chosen a public-key encryption standard. The remaining candidates are BIKE, Classic McEliece, HQC, and SIKE.
I have a lot to say on this process, and have written an essay for IEEE Security & Privacy about it. It will be published in a month or so.
In June, we experienced four incidents resulting in significant impact and degraded state of availability to multiple GitHub.com services. This report also sheds light into an incident that impacted multiple GitHub.com services in May.
June 1 09:40 UTC (lasting 48 minutes)
During this incident, customers experienced delays in the start up of their GitHub Actions workflows. The cause of these delays was excessive load on a proxy server that routes traffic to the database.
At 09:37 UTC, Actions service noticed a marked increase in the time it takes customer jobs to start. Our on-call engineer was paged and Actions was statused red. Once we started to investigate, we noticed that the pods running the proxy server for the database were crash-looping due to out-of-memory errors. A change was created to increase the available memory to these pods, which fully rolled out by 10:08 UTC. We started to see recovery in Actions even before 10:08 UTC, and statused to yellow at 10:17 UTC. By 10:28 UTC, we were confident that the memory increase had mitigated the issue, and statused Actions green.
Ultimately, this issue was traced back to a set of data analysis queries being pointed at an incorrect database. The large load they placed on the database caused the crash loops and the broader impact. These queries have been moved to a dedicated analytics setup that does not serve production traffic.
We are adding alerts to identify increases in load to the proxy server to catch issues like this early. We are also investigating how we can put in guardrails to ensure production database access is limited to services that own the data.
June 21 17:02 UTC (lasting 1 hour and 10 minutes)
During this incident, shortly after the GA of Copilot, users with either a Marketplace or Sponsorship plan were unable to use Copilot. Users with those subscriptions received an error from our API responsible for creating authentication tokens. This impacted a little less than 20% of our active users at the time.
At approximately 16:45 UTC, we were alerted and noticed elevated error rates in the API and began investigating causes. We were able to identify the issue and statused red. Our engineers worked quickly to roll out a fix to the API endpoint and we saw API error rates begin lowering at approximately 17:45 UTC. By 18:00 UTC, we were no longer seeing this issue but decided to wait for 10 more minutes to status back to green to ensure there were no regressions.
We have increased our testing around this particular combination of subscription types, added these scenarios to our user testing and will add additional data shape testing before future rollouts.
June 28 17:16 UTC (lasting 26 minutes)
Our alerting systems detected degraded availability for Codespaces during this time. Due to the recency of this incident, we are still investigating the contributing factors and will provide a more detailed update on the causes and remediations in the July Availability Report, which will be published the first Wednesday of August.
June 29 14:48 UTC (lasting 1 hour and 27 minutes)
During this incident, services including GitHub Actions, API Requests, Codespaces, Git Operations, GitHub Packages, and GitHub Pages were impacted. As we continue to investigate the contributing factors, we will provide a more detailed update in the July Availability Report. We will also share more about our efforts to minimize the impact of similar incidents in the future.
Follow up to May 27 04:26 UTC (lasting 21 minutes) and May 27 07:36 UTC (lasting 1 hour and 21 minutes)
As mentioned in the May Availability Report, we are now providing a more detailed update on this incident following further investigation.
Both instances that occurred at 04:26 and 07:36 UTC were caused by the same contributing factors. In the first instance, an individual service team noticed higher than normal load and an increase in error rate on API requests and statused red. The load was particularly high on our login endpoint. While this did elevate error rates, it was not enough to cause a widespread outage and we should have likely statused yellow in this instance.
After follow-up that indicated the load pattern had subsided, our on-call team determined it was safe to report the situation was mitigated and began to investigate further.
However, three hours later, we again experienced a degradation of service from a sustained high load in traffic. This was again concentrated on our login endpoint. We statused all services red, since we were seeing sustained error rates for a variety of clients and situations, and then updated individual service statuses based on their SLOs. Services that were affected by the load pattern statused to yellow, while services that were not impacted statused back to green.
The duration of impact to GitHub.com from the second instance of the load pattern lasted about 15 minutes. We continued to see elevated traffic during this time and waited until a network-level mitigation was rolled out before statusing all affected services back to green.
In addition to network mitigation, we were able to use the data from this incident to add additional mitigations on the application side for a sustained load of this type, as well as inform architectural changes we can make in the future to make our services more resilient.
Following this incident, we are improving our on-call procedures to ensure we always report the correct status level based on SLO review. While we always want to over-communicate issues with customers for awareness, we want to only status red when necessary.
In summary
We will continue to keep you updated on the progress and investments we’re making to ensure the reliability of our services. To receive real-time updates on status changes, please follow our status page. You can also learn more about what we’re working on on the GitHub Engineering Blog.
In business, data loss is unavoidable unless you have good server backups. Files get deleted accidentally, servers crash, computers fail, and employees make mistakes.
However, those aren’t the only dangers. You could also lose your company data in a natural disaster or cybersecurity attack. Ransomware is a serious concern for small to medium-sized businesses as well as large enterprises. Smart companies plan ahead to avoid data loss.
This post will discuss server backup basics, the different types of server backup, why it’s critical to keep your data backed up, and how to create a solid backup strategy for your company. Read on to learn everything you ever wanted to know about server backups.
Check out the other posts in our Server Backup 101 series:
A server is a virtual or physical device that performs a function to support other computers and users. Sometimes servers are dedicated machines used for a single purpose, and sometimes they serve multiple functions. Other computers or devices that connect to the server are called “clients.” Typically, clients use special software to communicate with the server and reply to requests. This communication is referred to as the server/client model. Some common uses for this setup include:
Web Server: Hosts web pages and online applications.
Email Server: Manages email for a company.
Database Server: Hosts various databases and controls access.
Application Server: Allows users to share applications.
File Server: Used to host files shared on a network.
DNS Server: Used to decode web addresses and deliver the user to the correct address.
FTP Server: Used specifically for hosting files for shared use.
Proxy Server: Adds a layer of security between client and server.
Servers run on many operating systems (OS) such as Windows, Linux, Mac, Apache, Unix, NetWare, and FreeBSD. The OS handles access control, user connections, memory allocation, and network functions. Each OS offers varying degrees of control, security, flexibility, and scalability.
Why It’s Important to Back Up Your Server
Did you know that roughly 40% of small and medium-sized businesses (SMBs) will be attacked by cybercriminals within a year, and 61% of all SMBs have already been attacked? Additionally, statistics show that 93% of companies that lost data for more than 10 days were forced into bankruptcy within a year. More than half of them filed immediately, and most shut down.
Company data is vulnerable to fire, theft, natural disasters, hardware failure, and cybercrime. Backups are an essential prevention tool.
Types of Servers
Within the realm of servers, there are many different types for virtually any purpose and environment. However, the primary function of most servers is data storage and processing. Some examples of servers include:
Physical Servers: These are hardware devices (usually computers) that connect users, share resources, and control access.
Virtual Servers: Using special software (called a hypervisor), you can set up multiple virtual servers on one physical machine. Each server acts like a physical server while the hypervisor manages memory and allocates other system resources as needed.
Hybrid Servers: Hybrids are servers combining physical servers and virtual servers. They offer the speed and efficiency of a physical server combined with the flexibility of cloud-hosted resources.
NAS Devices: Network-attached storage (NAS) devices store data and are accessed directly through the network without first connecting to a computer. These hardware devices contain a storage drive, processor, and OS, and can be accessed remotely.
SAN Server: Although not technically a server, a storage area network (SAN) connects multiple storage devices to multiple servers expanding the network and controlling connections.
Cloud Servers: Cloud servers exist in a virtual online environment, and you can access them through web portals, applications, and specialized software.
Regardless of how you save your data and where, backups are essential to protecting yourself from loss.
How to Back Up a Server
You have options for backing up data, and the methods vary. First, let’s talk about terminology.
Backup vs. Archive
Backing up is copying your data, whereas an archive is a historical copy that you keep for retention purposes, often for long periods. Archives are typically used to save old, inactive data for compliance reasons.
Here are two examples that illustrate backups vs. an archives. An example of a backup is when your mobile phone backs up to the cloud, and if you factory reset the phone, you can restore all your applications, settings, and data from the backup copy. An example of an archive is a tape backup of old HR files that have long since been deleted from the server.
Backup vs. Sync
Sometimes people confuse the word backup with sync. They are not the same thing. A backup is a copy of your data you can use to restore lost files. Syncing is the automatic updating and merging of two file sources. Cloud computing often uses syncing to keep files in one location identical to files in another.
To prevent data loss, backups are the process to use. Syncing overwrites files with the latest version; a backup can restore back to a single point in time, so you don’t lose anything valuable.
Backup Destinations
When selecting a backup destination, you have many mediums to choose from. There are pros and cons for each type. Some popular backup destinations and their pros and cons are as follows:
Destination
Pros
Cons
External Media (USB, CD, Removable Hard Drives, Flash Drives, etc.)
Quick, easy, affordable.
Fragile if dropped, crushed, or exposed to magnets; very small capacity.
NAS
Always available on the network, small size, and great for SMBs.
Vulnerable to on-premises threats and non-scalable due to limits.
Network or SAN Storage
High speed, view connected drives as local, good security, failover protection, excellent disk utilization, and high-end disaster recovery options.
Can be expensive, doesn’t work with all types of servers, and is vulnerable to attacks on the network.
Tape
Dependable (robust, not fragile), can be kept for years, low cost, and simple to replicate.
High initial setup costs, limited scalability, potential media corruption over time, and time consuming to manage.
FTP
Excellent for large files, copy multiple files at once, can resume if the connection is lost, schedule backups and recover lost data.
No security, vendors vary widely, not all solutions include encryption, and vulnerable to attacks.
Cloud backups are an altogether different type of backup; typically, you have two options available: all-in-one tools or integrated solutions.
All-in-one Tools
All-in-one tools like Carbonite Safe, Carbonite Server, Acronis, IDrive, CrashPlan, and SpiderOak combine both the backup software and the backend cloud storage in one offering. They have the ability to back up entire operating systems, files, images, videos, and sometimes even mobile device data. Depending on the tool you choose, you may be able to back up an unlimited number of devices, or you may have limits. However, most of these all-in-one solutions are expensive and can be complex to use. All those bells and whistles often come at a price—a steep learning curve.
Integrated Solutions (Backup Software Paired With Cloud Storage)
Pairing software and cloud storage is another option that combines the best of both worlds. It allows users to choose the software they want with the features they need and fast, reliable cloud storage. Cloud storage is scalable, so you will never run out of space as your business grows. Using your chosen software, it’s fast and easy to restore your files. Although it may seem counterintuitive, it’s often more affordable to use two integrated solutions versus an all-in-one tool. Another big bonus of using cloud storage is that it integrates with many popular software options. For example, Backblaze works seamlessly with:
An important factor to consider when choosing the right backup software and cloud storage is compatibility. Research which platforms your software will back up and what types of backups it offers (file, image, system, etc.). You also need to think about the restore process and your options (e.g., file, folder, bare metal/image, virtual, etc.). User-friendliness is important when deciding. Some programs like rClone require a working knowledge of command line. Choose a software program that is best for you.
Think about scalability and how much storage it can handle now and in the future as your business grows. A few other things to consider are pricing, security, and support. Your backup files are no good if they are vulnerable to attack. Compare prices and check out the support options before making your final decision.
Creating a Solid Backup Strategy
A solid backup strategy is the best way to protect your company against data loss. Again, you have options. The 3-2-1 strategy is the gold standard, but some companies are choosing options like a 3-2-1-1-0 option or even a 4-3-2 scheme. Learn more about how each plan works.
Before determining your strategy, you must consider what data you need to back up. For example, will you be backing up just servers or also workstations and dedicated servers, such as email servers or SaaS data devices?
Another concern is how you will get your data into the cloud. You need to figure out which method will work best for you. You have the option of direct transfer over internet bandwidth or using a rapid ingest device (e.g., the Backblaze Fireball rapid ingest device).
Universal Data Migration
Migrating your data can seem like an insurmountable task. We launched our Universal Data Migration service to make migrating to Backblaze just as easy as it is to use Backblaze. You can migrate from virtually any source to Backblaze B2 Cloud Storage, and it’s free to new customers who have 10TB of data or more to migrate with a one-year commitment.
How Often Should You Back Up Your Data?
Should you run full backups regularly? Or rely on incremental backups? The answer is that both have their place.
To fully protect yourself, performing regular full backups and keeping them safe is essential. Full backups can be scheduled for slow times or performed overnight when no one is using the data. Remember that full backups take the longest to complete and are the costliest but the easiest to restore.
A full backup backs up the entire server. An incremental backup only backs up files that have changed or been added since the last backup, saving storage space. The cadence of full versus incremental backups might look different for each organization. Learn more about full vs. incremental, differential, and full synthetic backups.
How Long Should You Keep Your Previous Backups?
You also must consider how long you want to keep your previous backups. Will you keep them for a specific amount of time and overwrite older backups?
By overwriting the files, you can save space, but you may not have an old enough backup when you need it. Also, keep in mind that many cloud storage vendors have minimum retention policies for deleted files. While “retention” sounds like a good thing, in this case it’s not. They might be charging you for data storage for 30, 60, or even 90 days even if you deleted it after storing it for just one day. That may also factor into your decision about how long you should keep your previous backup files. Some experts recommend three months, but that may not be enough in some situations.
You need to keep full backups for as long as you might need to recover from various issues. If, for example, you are infiltrated by a cybercriminal and don’t discover it for two months, will your oldest backup be enough to restore your system back to a clean state?
Another question to think about is if you’ll keep an archive. As a refresher, an archive is a backup of historical data that you keep long-term even if the files have already been deleted from the server. Most sources say you should plan to keep archives forever unless you have no use for the data in the future, but your company might have a different appetite for retention timeframes. Forever probably seems like…well, a long time, but keep in mind that the security of having those files available may be worth it.
How Will You Monitor Your Backup?
It’s not enough to just schedule your backups and walk away. You need to monitor them to ensure they are occurring on schedule. You should also test your ability to restore and fully understand the options you have for restoring your data. A backup is only as good as its ability to restore. You must test this out periodically to ensure you have a solid disaster recovery plan in place.
Special Considerations for Backing Up
When backing up servers with different operating systems, you need to consider the constraints of that system. For example, SQL servers can handle differential backups, whereas other servers cannot. Some backup software like Veeam integrates easily with all the major operating systems and therefore supports backups of multiple servers using different platforms.
If you are backing up a single server, things are easy. You have only one OS to worry about. However, if you are backing up multiple servers with different platforms and applications running on them, things could get more complex. Be sure to research all your options and use a vendor that can easily handle groups management and SaaS-managed backup services so that you can view all your data through a single pane of glass. You want consolidation and easy delineation if you need to pinpoint a single system to restore. You can use groups to easily manage different servers with similar operating systems to keep things organized and streamline your backup strategy.
As you can see, there are many facets to server backups, and you have options. If you have questions or want to learn more about Backblaze backup solutions, contact us today. Or, click here if you’re ready to get started backing up your server.
This Q2 2022 recap post takes a look at some of the latest investments we’ve made to InsightIDR to drive detection and response forward for your organization.
New interactive HTML reports
InsightIDR’s new HTML reports incorporate the interactive features you know and love from our dashboards delivered straight to your inbox. The HTML report file is sent as an email attachment and allows you to scroll through tables, drill in and out of cards, and sort tables in the same way you would explore dashboards.
Increased visibility into malware activity
Traditional intrusion detection systems (IDS) can be noisy. Rapid7’s Threat Intelligence and Detection Engineering (TIDE) team has carefully analyzed thousands of IDS events to curate a list of only the most critical and actionable events. We’ve recently expanded our library to include over 4,500 curated IDS detection rules to help customers detect activity associated with thousands of common pieces of malware.
Catch data exfiltration attempts with Anomalous Data Transfer
Anomalous Data Transfer (ADT) is a new Attacker Behavior Analytics (ABA) detection rule that uses the Insight Network Sensor to identify large transfers of data sent by assets on a network. ADT outputs data exfiltration alerts which make it easier for you to monitor transfer activity and identify unusual behavior to stay ahead of threats. These new detections are available for select InsightIDR packages — see more details here in our documentation.
Build stronger integrations and quickly triage investigations with new InsightIDR APIs
Investigation management APIs
Our new APIs allow you to extract more extensive data from within your investigation and use it to integrate with third-party tools, or build automation workflows to help you save time analyzing and closing investigations. View our documentation to learn more.
Update one or more Investigation fields through a single API call
Retrieve a sortable list of Investigations
Search Investigations
Create a Manual Investigation
User, accounts, and asset APIs
We are excited to release new APIs to allow you to programmatically interface with InsightIDR users, accounts, local accounts, and assets. You can use these APIs to configure new automations that further contextualize alerts generated by InsightIDR or third-party tools and help you to create more actionable views of alert data.
Relative Activity: A new way to analyze detection rules
We’ve introduced a new score called Relative Activity to ABA detection rules that analyzes how often the Rule Logic matches data in your environment based on certain parameters. The Relative Activity score is calculated over a rolling 24-hour period and can help you:
Identify detection rules that might cause frequent investigations or notable events if switched on
Determine which rules may benefit from tuning, either by changing the Rule Action or adding exceptions
New Relative Activity score for detection rules
Log Search improvements
Enrich Log Search results with new Quick Actions: Earlier this year InsightIDR and InsightConnect teamed up to create Quick Actions, a new feature that provides instant automation within InsightIDR to reduce time to respond to investigations, all with the click of a button. We’ve recently released new Quick Actions to enable pre-configured actions within InsightIDR’s Log Search for InsightIDR Ultimate and InsightIDR legacy customers. Quick Actions are available for select InsightIDR packages, see more details here in our documentation.
Use AWS S3 as a collection method for custom logs: Now customers have the choice to use either Cisco Umbrella or AWS S3 as a collection method when setting up custom logs. Alongside this update, we’ve also refactored the data source to make it more resilient and effective.
A growing library of actionable detections
In Q2, we added 290 new ABA detection rules to InsightIDR. See them in-product or visit the Detection Library for actionable descriptions and recommendations.
Stay tuned!
As always, we’re continuing to work on exciting product enhancements and releases throughout the year. Keep an eye on our blog and release notes as we continue to highlight the latest in detection and response at Rapid7.
Organizations have been using data warehouse and business intelligence (DWBI) workloads to support business decision making for many years. These workloads are brought to the Amazon Web Services (AWS) platform to utilize the benefit of AWS cloud. However, these workloads are built using multiple vendor tools and technologies, and the customer faces the burden of administrative overhead.
This post provides architectural guidance to consolidate multiple DWBI technologies to AWS Managed Services to help reduce the administrative overhead, bring operational ease, and business efficiency. Two scenarios are explored:
Upstream transactional databases are already on AWS
Upstream transactional databases are present at on-premise datacenter
Challenges faced by an organization
Organizations are engaged in managing multiple DWBI technologies due to acquisitions, mergers, and the lift-and-shift of workloads. These workloads use extract, transform, and load (ETL) tools to read relational data from upstream transactional databases, process it, and store it in a data warehouse. Thereafter, these workloads use business intelligence tools to generate valuable insight and present it to users in form of reports and dashboards.
These DWBI technologies are generally installed and maintained on their own server. Figure 1 demonstrates the increased the administrative overhead for the organization but also creates challenges in maintaining the team’s overall knowledge.
Figure 1. DWBI workload with multiple tools
Therefore, organizations are looking to consolidate technology usage and continue supporting important business functions.
Scenario 1
As we know, three major functions of DWBI workstream are:
ETL data using a tool
Store/manage the data in a data warehouse
Generate information from the data using business intelligence
Each of these functions can be performed efficiently using an AWS service. For example, AWS Glue can be used for ETL, Amazon Redshift for data warehouse, and Amazon QuickSight for business intelligence.
With the use of mentioned AWS services, organizations will be able to consolidate their DWBI technology usage. Organizations also will be able to quickly adapt to these services, as their engineering team can more easily use their DWBI knowledge with these services. For example, using SQL knowledge in AWS Glue jobs with SprakSQL, in Amazon Redshift queries, and in Amazon QuickSight dashboards.
Figure 2 demonstrates the redesigned the architecture of Figure 1 using AWS services. In this architecture, ETL functions are consolidated in AWS Glue. An AWS Glue crawler is used to auto-catalogue the source and target table metadata; then, AWS Glue ETL jobs use these catalogues to read data from source and write to target (data warehouse). AWS Glue jobs also apply necessary transformations (such as join, filter, and aggregate) to the data before writing. Additionally, an AWS Glue trigger is used to schedule the job executions. Alternatively, AWS Managed Workflows for Apache Airflow can be used to schedule jobs.
Figure 2. Consolidated workload with source on AWS
Similarly, data warehousing function is consolidated with Amazon Redshift. Amazon Redshift is used to store and organize enriched data and also enforce appropriate data access control for both workloads and users.
Lastly, business intelligence functions are consolidated using Amazon QuickSight. It used to create necessary dashboards that source data from Amazon Redshift and apply complex business logic to produce necessary charts and graphs needed for business insights. It is also used to implement necessary access restrictions to dashboards and data.
Scenario 2
In situation where source databases are in on-premises datacenter, the overall solution will be similar to Scenario 1, with an additional step to move the data continually from on-premise database to an Amazon Simple Storage Service (Amazon S3) bucket. The data movement can be efficiently handled by AWS Database Migration Service (AWS DMS).
To make the source database accessible to AWS DMS, a connection needs to established between the AWS cloud and on-premise network. Based on performance and throughput needs, the organization can choose either AWS Direct Connect service or AWS Site-to-Site VPN service to securely move the data. For the purpose of this discussion, we are considering AWS Direct Connect.
In Figure 3, AWS DMS task is used to perform a full-load followed by change data capture to continuously move the data to an S3 bucket. In this scenario, AWS Glue is used to catalogue and read the data from S3 bucket. The remaining portion of the dataflow is the same as the one mentioned in Scenario 1.
Figure 3. Consolidated workload with source at datacenter
Scaling
Both of the updated architectures provide necessary scaling:
Auto scaling feature can be used to scale-up or -down AWS Glue ETL job resources
Concurrency scaling feature can be used to support virtually unlimited concurrent users and queries in Amazon Redshift
Amazon QuickSight resources (web server, Amazon QuickSight engine, and SPICE) are auto scaled by design
Security, monitoring, and auditing
Also, the updated architectures provide necessary security by using access control, data encryption at-rest and in transit, monitoring, and auditing.
AWS CloudTrail can be used for tracking user activity and API usage for auditing and troubleshooting.
Amazon CloudWatch can be used to monitor Amazon Redshift service and log generated by AWS Glue jobs.
Amazon Simple Notification Service can be used for sending notifications from AWS cloud. For example, AWS Glue jobs’ execution status, Amazon QuickSight SPICE data failure notification.
Additionally, both Amazon Redshift and Amazon QuickSight provides their own authentication and access controls. Therefore, a user can be a local user or a federated one. With the help of these authentications, an organization will be able to control access to data in Amazon Redshift and also access to the dashboard in Amazon QuickSight.
Conclusion
In this blog post, we discussed how AWS Glue, Amazon Redshift, and Amazon QuickSight can be used to consolidate DWBI technologies. We also have discussed how an architecture can help an organization build a scalable, secure workload with auto scaling, access control, log monitoring and activity auditing.
Security updates have been issued by Debian (ldap-account-manager), Fedora (openssl1.1, thunderbird, and yubihsm-connector), Mageia (curl, cyrus-imapd, firefox, ruby-git, ruby-rack, squid, and thunderbird), Oracle (firefox, kernel, and thunderbird), Slackware (openssl), SUSE (dpdk, haproxy, and php7), and Ubuntu (gnupg2 and openssl).
Welcome to our 2022 Q2 DDoS report. This report includes insights and trends about the DDoS threat landscape — as observed across the global Cloudflare network. An interactive version of this report is also available on Radar.
In Q2, we’ve seen some of the largest attacks the world has ever seen including a 26 million request per second HTTPS DDoS attacks that Cloudflare automatically detected and mitigated. Furthermore, attacks against Ukraine and Russia continue, whilst a new Ransom DDoS attack campaign emerged.
The Highlights
Ukrainian and Russian Internet
The war on the ground is accompanied by attacks targeting the spread of information.
Broadcast Media companies in the Ukraine were the most targeted in Q2 by DDoS attacks. In fact, all the top five most attacked industries are all in online/Internet media, publishing, and broadcasting.
In Russia on the other hand, Online Media drops as the most attacked industry to the third place. Making their way to the top, Banking, Financial Services and Insurance (BFSI) companies in Russia were the most targeted in Q2; almost 45% of all application-layer DDoS attacks targeted the BFSI sector. Cryptocurrency companies in Russia were the second most attacked.
We’ve seen a new wave of Ransom DDoS attacks by entities claiming to be the Fancy Lazarus.
In June 2022, ransom attacks peaked to the highest of the year so far: one out of every five survey respondents who experienced a DDoS attack reported being subject to a Ransom DDoS attack or other threats.
Overall in Q2, the percent of Ransom DDoS attacks increased by 11% QoQ.
Application-layer DDoS attacks
In 2022 Q2, application-layer DDoS attacks increased by 72% YoY.
Organizations in the US were the most targeted, followed by Cyprus, Hong Kong, and China. Attacks on organizations in Cyprus increased by 166% QoQ.
The Aviation & Aerospace industry was the most targeted in Q2, followed by the Internet industry, Banking, Financial Services and Insurance, and Gaming / Gambling in fourth place.
Network-layer DDoS attacks
In 2022 Q2, network-layer DDoS attacks increased by 109% YoY. Attacks of 100 Gbps and larger increased by 8% QoQ, and attacks lasting more than 3 hours increased by 12% QoQ.
The top attacked industries were Telecommunications, Gaming / Gambling and the Information Technology and Services industry.
Organizations in the US were the most targeted, followed by China, Singapore, and Germany.
This report is based on DDoS attacks that were automatically detected and mitigated by Cloudflare’s DDoS Protection systems. To learn more about how it works, check out this deep-dive blog post.
A note on how we measure DDoS attacks observed over our network
To analyze attack trends, we calculate the “DDoS activity” rate, which is either the percentage of attack traffic out of the total traffic (attack + clean) observed over our global network, or in a specific location, or in a specific category (e.g., industry or billing country). Measuring the percentages allows us to normalize data points and avoid biases reflected in absolute numbers towards, for example, a Cloudflare data center that receives more total traffic and likely, also more attacks.
Ransom Attacks
Our systems constantly analyze traffic and automatically apply mitigation when DDoS attacks are detected. Each DDoS’d customer is prompted with an automated survey to help us better understand the nature of the attack and the success of the mitigation.
For over two years now, Cloudflare has been surveying attacked customers — one question on the survey being if they received a threat or a ransom note demanding payment in exchange to stop the DDoS attack.
The number of respondents reporting threats or ransom notes in Q2 increased by 11% QoQ and YoY. During this quarter, we’ve been mitigating Ransom DDoS attacks that have been launched by entities claiming to be the Advanced Persistent Threat (APT) group “Fancy Lazarus”. The campaign has been focusing on financial institutions and cryptocurrency companies.
The percentage of respondents reported being targeted by a ransom DDoS attack or that have received threats in advance of the attack.
Drilling down into Q2, we can see that in June one out of every five respondents reported receiving a ransom DDoS attack or threat — the highest month in 2022, and the highest since December 2021.
Application-layer DDoS attacks
Application-layer DDoS attacks, specifically HTTP DDoS attacks, are attacks that usually aim to disrupt a web server by making it unable to process legitimate user requests. If a server is bombarded with more requests than it can process, the server will drop legitimate requests and — in some cases — crash, resulting in degraded performance or an outage for legitimate users.
Application-layer DDoS attacks by month
In Q2, application-layer DDoS attacks increased by 72% YoY.
Overall, in Q2, the volume of application-layer DDoS attacks increased by 72% YoY, but decreased 5% QoQ. May was the busiest month in the quarter. Almost 41% of all application-layer DDoS attacks took place in May, whereas the least number of attacks took place in June (28%).
Application-layer DDoS attacks by industry
Attacks on the Aviation and Aerospace industry increased by 493% QoQ.
In Q2, Aviation and Aerospace was the most targeted industry by application-layer DDoS attacks. After it, was the Internet industry, Banking, Financial Institutions and Insurance (BFSI) industry, and in fourth place the Gaming / Gambling industry.
Ukraine and Russia cyberspace
Media and publishing companies are the most targeted in Ukraine.
As the war in Ukraine continues on the ground, in the air and on the water, so does it continue in cyberspace. Entities targeting Ukrainian companies appear to be trying to silence information. The top five most attacked industries in the Ukraine are all in broadcasting, Internet, online media, and publishing — that’s almost 80% of all DDoS Attacks targeting Ukraine.
On the other side of the war, the Russian Banks, Financial Institutions and Insurance (BFSI) companies came under the most attacks. Almost 45% of all DDoS attacks targeted the BFSI sector. The second most targeted was the Cryptocurrency industry, followed by Online media.
In both sides of the war, we can see that the attacks are highly distributed, indicating the use of globally distributed botnets.
Application-layer DDoS attacks by source country
In Q2, attacks from China shrank by 78%, and attacks from the US shrank by 43%.
To understand the origin of the HTTP attacks, we look at the geolocation of the source IP address belonging to the client that generated the attack HTTP requests. Unlike network-layer attacks, source IP addresses cannot be spoofed in HTTP attacks. A high percentage of DDoS activity in a given country doesn’t mean that that specific country is launching the attacks but rather indicates the presence of botnets operating from within the country’s borders.
For the second quarter in a row, the United States tops the charts as the main source of HTTP DDoS attacks. Following the US is China in second place, and India and Germany in the third and fourth. Even though the US remained in the first place, attacks originating from the US shrank by 48% QoQ while attacks from other regions grew; attacks from India grew by 87%, from Germany by 33%, and attacks from Brazil grew by 67%.
Application-layer DDoS attacks by target country
In order to identify which countries are targeted by the most HTTP DDoS attacks, we bucket the DDoS attacks by our customers’ billing countries and represent it as a percentage out of all DDoS attacks.
HTTP DDoS attacks on US-based countries increased by 67% QoQ pushing the US back to the first place as the main target of application-layer DDoS attacks. Attacks on Chinese companies plunged by 80% QoQ dropping it from the first place to the fourth. Attacks on Cyprus increase by 167% making it the second most attacked country in Q2. Following Cyprus is Hong Kong, China, and the Netherlands.
Network-layer DDoS attacks
While application-layer attacks target the application (Layer 7 of the OSI model) running the service that end users are trying to access (HTTP/S in our case), network-layer attacks aim to overwhelm network infrastructure (such as in-line routers and servers) and the Internet link itself.
Network-layer DDoS attacks by month
In Q2, network-layer DDoS attacks increased by 109% YoY, and volumetric attacks of 100 Gbps and larger increased by 8% QoQ.
In Q2, the total amount of network-layer DDoS attacks increased by 109% YoY and 15% QoQ. June was the busiest month of the quarter with almost 36% of the attacks occurring in June.
Network-layer DDoS attacks by industry
In Q2, attacks on Telecommunication companies grew by 66% QoQ.
For the second consecutive quarter, the Telecommunications industry was the most targeted by network-layer DDoS attacks. Even more so, attacks on Telecommunication companies grew by 66% QoQ. The Gaming industry came in second place, followed by Information Technology and Services companies.
Network-layer DDoS attacks by target country
Attacks on US networks grew by 95% QoQ.
In Q2, the US remains the most attacked country. After the US came China, Singapore and Germany.
Network-layer DDoS attacks by ingress country
In Q2, almost a third of the traffic Cloudflare observed in Palestine and a fourth in Azerbaijan was part of a network-layer DDoS attack.
When trying to understand where network-layer DDoS attacks originate, we cannot use the same method as we use for the application-layer attack analysis. To launch an application-layer DDoS attack, successful handshakes must occur between the client and the server in order to establish an HTTP/S connection. For a successful handshake to occur, the attacks cannot spoof their source IP address. While the attacker may use botnets, proxies, and other methods to obfuscate their identity, the attacking client’s source IP location does sufficiently represent the attack source of application-layer DDoS attacks.
On the other hand, to launch network-layer DDoS attacks, in most cases, no handshake is needed. Attackers can spoof the source IP address in order to obfuscate the attack source and introduce randomness into the attack properties, which can make it harder for simple DDoS protection systems to block the attack. So if we were to derive the source country based on a spoofed source IP, we would get a ‘spoofed country’.
For this reason, when analyzing network-layer DDoS attack sources, we bucket the traffic by the Cloudflare data center locations where the traffic was ingested, and not by the (potentially) spoofed source IP to get an understanding of where the attacks originate from. We are able to achieve geographical accuracy in our report because we have data centers in over 270 cities around the world. However, even this method is not 100% accurate, as traffic may be back hauled and routed via various Internet Service Providers and countries for reasons that vary from cost reduction to congestion and failure management.
Palestine jumps from the second to the first place as the Cloudflare location with the highest percentage of network-layer DDoS attacks. Following Palestine is Azerbaijan, South Korea, and Angola.
To view all regions and countries, check out the interactive map.
Attack vectors
In Q2, DNS attacks increased making it the second most frequent attack vector.
An attack vector is a term used to describe the method that the attacker uses to launch their DDoS attack, i.e., the IP protocol, packet attributes such as TCP flags, flooding method, and other criteria.
In Q2, 53% of all network-layer attacks were SYN floods. SYN floods remain the most popular attack vector. They abuse the initial connection request of the stateful TCP handshake. During this initial connection request, servers don’t have any context about the TCP connection as it is new and without the proper protection may find it hard to mitigate a flood of initial connection requests. This makes it easier for the attacker to consume an unprotected server’s resources.
After the SYN floods are attacks targeting DNS infrastructure, RST floods again abusing TCP connection flow, and generic attacks over UDP.
Emerging threats
In Q2, the top emerging threats included attacks over CHARGEN, Ubiquiti and Memcached.
Identifying the top attack vectors helps organizations understand the threat landscape. In turn, this may help them improve their security posture to protect against those threats. Similarly, learning about new emerging threats that may not yet account for a significant portion of attacks, can help mitigate them before they become a significant force.
In Q2, the top emerging threats were amplification attacks abusing the Character Generator Protocol (CHARGEN), amplification attacks reflecting traffic off of exposed Ubiquiti devices, and the notorious Memcached attack.
Abusing the CHARGEN protocol to launch amplification attacks
In Q2, attacks abusing the CHARGEN protocol increased by 378% QoQ.
Initially defined in RFC 864 (1983), the Character Generator (CHARGEN) protocol is a service of the Internet Protocol Suite that does exactly what it says it does – it generates characters arbitrarily, and it doesn’t stop sending them to the client until the client closes the connection. Its original intent was for testing and debugging. However, it’s rarely used because it can so easily be abused to generate amplification/reflection attacks.
An attacker can spoof the source IP of their victim and fool supporting servers around the world to direct a stream of arbitrary characters “back” to the victim’s servers. This type of attack is amplification/reflection. Given enough simultaneous CHARGEN streams, the victim’s servers, if unprotected, would be flooded and unable to cope with legitimate traffic — resulting in a denial of service event.
Amplification attacks exploiting the Ubiquiti Discovery Protocol
In Q2, attacks over Ubiquity increased by 327% QoQ.
Ubiquiti is a US-based company that provides networking and Internet of Things (IoT) devices for consumers and businesses. Ubiquiti devices can be discovered on a network using the Ubiquiti Discovery protocol over UDP/TCP port 10001.
Similarly to the CHARGEN attack vector, here too, attackers can spoof the source IP to be the victim’s IP address and spray IP addresses that have port 10001 open. Those would then respond to the victim and essentially flood it if the volume is sufficient.
Memcached DDoS attacks
In Q2, Memcached DDoS attacks increased by 287% QoQ.
Memcached is a database caching system for speeding up websites and networks. Similarly to CHARGEN and Ubiquiti, Memcached servers that support UDP can be abused to launch amplification/reflection DDoS attacks. In this case, the attacker would request content from the caching system and spoof the victim’s IP address as the source IP in the UDP packets. The victim will be flooded with the Memcache responses which can be amplified by a factor of up to 51,200x.
Network-layer DDoS attacks by attack rate
Volumetric attacks of over 100 Gbps increase by 8% QoQ.
There are different ways of measuring the size of an L3/4 DDoS attack. One is the volume of traffic it delivers, measured as the bit rate (specifically, terabits per second or gigabits per second). Another is the number of packets it delivers, measured as the packet rate (specifically, millions of packets per second).
Attacks with high bit rates attempt to cause a denial-of-service event by clogging the Internet link, while attacks with high packet rates attempt to overwhelm the servers, routers, or other in-line hardware appliances. These devices dedicate a certain amount of memory and computation power to process each packet. Therefore, by bombarding it with many packets, the appliance can be left with no further processing resources. In such a case, packets are “dropped,” i.e., the appliance is unable to process them. For users, this results in service disruptions and denial of service.
Distribution by packet rate
The majority of network-layer DDoS attacks remain below 50,000 packets per second. While 50 kpps is on the lower side of the spectrum at Cloudflare scale, it can still easily take down unprotected Internet properties and congest even a standard Gigabit Ethernet connection.
When we look at the changes in the attack sizes, we can see that packet-intensive attacks above 50 kpps decreased in Q2, resulting in an increase of 4% in small attacks.
Distribution by bitrate
In Q2, most of the network-layer DDoS attacks remain below 500 Mbps. This too is a tiny drop in the water at Cloudflare scale, but can very quickly shut down unprotected Internet properties with less capacity or at the very least cause congestion for even a standard Gigabit Ethernet connection.
Interestingly enough, large attacks between 500 Mbps and 100 Gbps decreased by 20-40% QoQ, but volumetric attacks above 100 Gbps increased by 8%.
Network-layer DDoS attacks by duration
In Q2, attacks lasting over three hours increased by 9%.
We measure the duration of an attack by recording the difference between when it is first detected by our systems as an attack and the last packet we see with that attack signature towards that specific target.
In Q2, 52% of network-layer DDoS attacks lasted less than 10 minutes. Another 40% lasted 10-20 minutes. The remaining 8% include attacks ranging from 20 minutes to over three hours.
One important thing to keep in mind is that even if an attack lasts only a few minutes, if it is successful, the repercussions could last well beyond the initial attack duration. IT personnel responding to a successful attack may spend hours and even days restoring their services.
While most of the attacks are indeed short, we can see an increase of over 15% in attacks ranging between 20-60 minutes, and a 12% increase of attacks lasting more than three hours.
Short attacks can easily go undetected, especially burst attacks that, within seconds, bombard a target with a significant number of packets, bytes, or requests. In this case, DDoS protection services that rely on manual mitigation by security analysis have no chance in mitigating the attack in time. They can only learn from it in their post-attack analysis, then deploy a new rule that filters the attack fingerprint and hope to catch it next time. Similarly, using an “on-demand” service, where the security team will redirect traffic to a DDoS provider during the attack, is also inefficient because the attack will already be over before the traffic routes to the on-demand DDoS provider.
It’s recommended that companies use automated, always-on DDoS protection services that analyze traffic and apply real-time fingerprinting fast enough to block short-lived attacks.
Summary
Cloudflare’s mission is to help build a better Internet. A better Internet is one that is more secure, faster, and reliable for everyone — even in the face of DDoS attacks. As part of our mission, since 2017, we’ve been providing unmetered and unlimited DDoS protection for free to all of our customers. Over the years, it has become increasingly easier for attackers to launch DDoS attacks. But as easy as it has become, we want to make sure that it is even easier — and free — for organizations of all sizes to protect themselves against DDoS attacks of all types.
Not using Cloudflare yet? Start now with our Free and Pro plans to protect your websites, or contact us for comprehensive DDoS protection for your entire network using Magic Transit.
Bem-vindo ao nosso relatório de DDoS do segundo trimestre de 2022. Este relatório inclui informações e tendências sobre o cenário de ameaças DDoS — conforme observado em toda a Rede global da Cloudflare. Uma versão interativa deste relatório também está disponível no Radar.
A guerra no terreno é acompanhada por ataques direcionados à distribuição de informações.
Empresas de mídia de radiodifusão na Ucrânia foram as mais visadas por ataques DDoS no segundo trimestre. Na verdade, todos os seis principais setores vitimados estão na mídia on-line/internet, publicações e radiodifusão.
Por outro lado, na Rússia, a mídia on-line deixou de ser o setor mais atacado e caiu para o terceiro lugar. No topo, estão empresas como bancos, serviços financeiros e seguros (BFSI, na sigla em inglês) do país, que foram as mais visadas no segundo trimestre; sendo vítimas de quase 50% de todos os ataques DDoS na camada de aplicativos. O segundo lugar é das empresas de criptomoedas.
Em junho de 2022, houve o maior pico do ano nos ataques DDoS com pedido de resgate até agora: um em cada cinco participantes na pesquisa que passaram por um ataque DDoS relataram ter recebido um pedido de resgate ou outras ameaças.
No T2 em geral, o percentual de ataques DDoS com pedido de resgate aumentou 11% na comparação com o trimestre anterior.
Ataques DDoS na camada de aplicativos
No segundo trimestre de 2022, houve um aumento de 44% em termos anuais nos ataques DDoS na camada de aplicativos.
Empresas nos EUA foram as maiores vítimas, seguidas por outras no Chipre, em Hong Kong e na China. Os ataques à empresas do Chipre aumentaram 171% na comparação trimestral.
O setor de aviação e aeronáutica foi o mais visado no segundo trimestre, seguido por: internet, bancos, serviços financeiros, seguros, jogos e apostas.
Ataques DDoS na camada de rede
No segundo trimestre de 2022, houve um aumento de 75% em termos anuais nos ataques DDoS na camada de rede. Ataques de 100 Gbps e mais cresceram 19% em termos trimestrais; e ataques com mais de três horas aumentaram em 9% no mesmo período.
Os setores mais atacados foram: telecomunicações, jogos/apostas e tecnologia e serviços de informação.
Empresas nos EUA foram as maiores vítimas, seguidas por outras em Singapura, na Alemanha e na China.
Este relatório é baseado nos ataques DDoS detectados e mitigados automaticamente pelos sistemas de proteção contra DDoS da Cloudflare. Para saber mais sobre como isso funciona, confira este post no blog com mais detalhes.
Uma observação sobre como medimos os ataques DDoS observados em nossa Rede
Para analisar tendências de ataques, calculamos a taxa de “atividade DDoS”, que é o percentual do tráfego de ataque com relação ao tráfego total (ataque + limpo) observado em nossa Rede global, em um local específico ou em uma determinada categoria (por exemplo, setor ou país de faturamento). Medir os percentuais nos permite normalizar os pontos de dados e evitar uma abordagem tendenciosa em números absolutos, envolvendo, por exemplo, um data center da Cloudflare que recebe mais tráfego total e, provavelmente, mais ataques.
Ataques com pedido de resgate
Nossos sistemas estão constantemente analisando o tráfego e ao detectar ataques DDoS, automaticamente aplicam a mitigação. Cada cliente que sofre um ataque DDoS recebe uma pesquisa automatizada a fim de nos ajudar a entender melhor a natureza do ataque e o êxito da mitigação.
Há mais de dois anos a Cloudflare realiza pesquisas junto a clientes que foram atacados — uma das perguntas da pesquisa destina-se a saber se eles receberam ameaças ou pedidos de resgate exigindo pagamento em troca de parar o ataque DDoS.
O número de participantes que relatou ameaças ou pedidos de resgate no segundo trimestre aumentou 11% em termos trimestrais e anuais. Durante este trimestre, mitigamos ataques DDoS com pedido de resgate realizados por entidades que alegavam ser o grupo de ameaças avançadas permanentes (APT, na sigla em inglês) conhecido como “Fancy Lazarus”. A iniciativa se concentrou em instituições financeiras e empresas de criptomoedas.
O percentual de entrevistados que relatou ter sido alvo de um ataque DDoS com resgate ou ter recebido ameaças antes do ataque.
Analisando o segundo trimestre em mais detalhes, é possível ver que em junho um em cada cinco participantes relataram ataques DDoS com pedido de resgate ou ameaças — o mês com maior volume em 2022, o mais alto desde dezembro de 2021.
Ataques DDoS na camada de aplicativos
Ataques DDoS na camada de aplicativos, especificamente ataques DDoS por HTTP, são ataques que normalmente buscam interromper um servidor web tornando-o incapaz de processar solicitações legítimas dos usuários. Se um servidor é bombardeado com mais solicitações do que consegue processar, ele descartará solicitações legítimas e — em alguns casos — irá travar, resultando na deterioração da performance ou em uma interrupção para os usuários legítimos.
Ataques DDoS na camada de aplicativos por mês
No segundo trimestre, houve um aumento de 44% em termos anuais nos ataques DDoS na camada de aplicativos.
No T2 em geral, o volume de ataques DDoS na camada de aplicativos aumentou 44% na comparação anual, mas caiu 16% em termos trimestrais. Maio foi o mês mais movimentado no trimestre. Quase 47% de todos os ataques DDoS na camada de aplicativos ocorreu em maio, ao passo que o mês de junho foi o que teve o menor número de ataques (18%).
Ataques DDoS na camada de aplicativos por setor
Ataques ao setor de aviação e aeronáutica cresceram 256% em termos trimestrais
No segundo trimestre, o setor de aviação e aeronáutica foi o mais visado com ataques DDoS na camada de aplicativos. Depois, estão os setores de bancos, instituições financeiras e seguros (BFSI), e em terceiro lugar o setor de jogos/apostas.
Espaços cibernéticos da Ucrânia e da Rússia
Empresas de mídia e publicação são as mais visadas na Ucrânia.
Enquanto a guerra na Ucrânia continua em campo, no ar e na água, outra guerra é travada no espaço cibernético. Entidades que visam empresas ucranianas parecem estar tentando silenciar informações. Os seis setores mais atacados na Ucrânia estão todos em radiodifusão, internet, mídia on-line e publicação — quase 80% de todos os ataques DDoS ao país.
No outro lado da guerra, bancos, instituições financeiras e empresas de seguro (BFSI) da Rússia são os que sofreram mais ataques. Quase 50% de todos os ataques DDoS foram contra o setor de BFSI. O segundo setor mais visado é o de criptomoedas, seguido por mídia on-line.
Em ambos os lados da guerra, é possível ver que os ataques são altamente distribuídos, o que indica o uso de botnets distribuídas globalmente.
Ataques DDoS na camada de aplicativos por país de origem
No segundo trimestre, os ataques da China aumentaram 112, enquanto dos EUA diminuíram 43%.
Para entender a origem dos ataques HTTP, analisamos a geolocalização do endereço de IP de origem do cliente que gerou as solicitações HTTP de ataque. Ao contrário dos ataques na camada de rede, os IPs de origem não podem ser falsificados em ataques HTTP. Uma alta porcentagem de atividade DDoS em um determinado país não indica que os ataques estão vindo desse local, mas significa que há botnets funcionando dentro das fronteiras da nação em questão.
Pelo segundo trimestre consecutivo, os Estados Unidos estão no topo da lista como principal origem de ataques DDoS por HTTP. Logo depois estão China, Índia e Alemanha. Mesmo que os EUA tenham permanecido em primeiro lugar, os ataques com origem no país tiveram uma queda de 43% em termos trimestrais, ao passo que os originados em outras regiões aumentaram (China em 112%, Índia em 89% e Alemanha em 80%).
Ataques DDoS na camada de aplicativos por país-alvo
A fim de identificar quais países eram visados pela maioria dos ataques DDoS por HTTP, agrupamos os ataques DDoS pelos países de faturamento de nossos clientes e os representamos como porcentagem em relação ao total de ataques DDoS.
Ataques DDoS por HTTP em países baseados nos EUA aumentaram 45% na comparação trimestral, levando os EUA ao primeiro lugar como principal alvo de ataques DDoS na camada de aplicativos. Ataques a empresas chinesas diminuíram 79% em termos trimestrais, aindo do primeiro para o quarto lugar. Ataques no Chipre aumentaram 171%, o que tornou o país o segundo mais atacado no segundo trimestre, seguido por Hong Kong, China e Polônia.
Ataques DDoS na camada de rede
Enquanto os ataques na camada de aplicativo visam o aplicativo (Camada 7 do Modelo OSI) que executa o serviço que os usuários finais estão tentando acessar (HTTP/S em nosso caso), os ataques na camada de rede visam sobrecarregar a infraestrutura de rede (como roteadores e servidores internos) e a próprio link com da internet.
Ataques DDoS na camada de rede por mês
No segundo trimestre, houve um aumento de 75% em termos anuais nos ataques DDoS na camada de rede; e uma alta de 19% na comparação trimestral em ataques volumétricos de 100 Gbps e mais.
No segundo trimestre, o número total de ataques DDoS à camada de rede aumentou 75% em termos anuais, mas não mudou muito em comparação com o trimestre anterior. Abril foi o mês mais movimentado do trimestre, com quase 40% dos ataques.
Ataques DDoS na camada de rede por setor
No segundo trimestre, ataques a empresas de telecomunicações cresceram 45% em termos trimestrais.
Pelo segundo trimestre consecutivo, o setor de telecomunicações foi o mais visado por ataques DDoS na camada de rede. Além disso, os ataques a empresas de telecomunicações cresceram 45% em termos trimestrais. O setor de jogos ficou em segundo lugar, seguido por empresas de tecnologia e serviços de informação.
Ataques DDoS na camada de rede por país-alvo
Aumento de 70% em termos trimestrais nos ataques a redes dos EUA
No segundo trimestre, os EUA continuaram sendo o país mais atacado, seguido por Singapura, que saltou para o segundo lugar em relação ao quarto no trimestre anterior. Logo depois, em terceiro, está a Alemanha, seguida por China, Maldivas e Coreia do Sul.
Ataques DDoS na camada de rede por país de entrada
No segundo trimestre, quase um terço do tráfego observado pela Cloudflare na Palestina e no Azerbaijão foi parte de um ataque DDoS à camada de rede.
Ao tentar entender onde fica a origem de ataques DDoS na camada de rede, não podemos seguir o mesmo método usado para a análise de ataques na camada de aplicativos. Para que um ataque DDoS na camada de aplicativos aconteça, é preciso ocorrer handshakes bem-sucedidos entre o cliente e o servidor, a fim de estabelecer uma conexão HTTP/S. E para um handshake bem-sucedido acontecer, os ataques não podem falsificar o endereço de IP da origem. Embora o invasor possa usar botnets, proxies e outros métodos para ofuscar a identidade, o local do IP de origem do cliente, que faz o ataque, representa adequadamente a origem de ataques DDoS na camada de aplicativos.
Por outro lado, para lançar ataques DDoS na camada de rede, na maioria dos casos, não é necessário nenhum handshake. Os invasores podem falsificar o endereço de IP de origem para ofuscar a origem do ataque e introduzir aleatoriedade nas propriedades do ataque, o que pode dificultar que sistemas simples de proteção contra DDoS bloqueiem o ataque. Dessa forma, se formos tentar descobrir o país de origem com base em um endereço de IP falsificado, obteríamos um “país falsificado”.
Por esse motivo, ao analisar origens de ataques DDoS na camada de rede, dividimos o tráfego pelos locais de data centers da Cloudflare em que o tráfego foi ingerido, e não pelo IP de origem (possivelmente) falsificado, para entender melhor de onde os ataques vêm. Conseguimos ter precisão geográfica em nosso relatório porque temos data centers em mais de 270 cidades em todo o mundo. No entanto, até esse método não é 100% preciso, pois o tráfego pode passar por backhaul e ser direcionado por meio de diversos provedores de internet e países, por motivos que variam da redução de custos até à gestão de falhas e congestionamentos.
A Palestina saiu do segundo para o primeiro lugar como local da Cloudflare com maior percentual de ataques DDoS à camada de rede, seguida por Azerbaijão, Coreia do Sul e Angola.
Para visualizar todas as regiões e países, confira o mapa interativo.
Vetores de ataque
No segundo trimestre, houve um aumento dos ataques de DNS, e essa modalidade se tornou o segundo vetor de ataque mais frequente.
Vetor de ataque é o termo usado para descrever o método usado pelo invasor para lançar um ataque DDoS. Por exemplo, o protocolo IP, atributos de pacote, como sinalizadores TCP, método de inundação e outros critérios.
No segundo trimestre, 56% de todos os ataques na camada de rede foram inundações SYN, que ainda são o vetor de ataque mais popular e exploram a solicitação de conexão inicial do handshake TCP com estado. Durante essa solicitação de conexão inicial, os servidores não têm nenhum contexto sobre a conexão TCP, pois ela é nova; e sem a proteção adequada, pode ser difícil mitigar uma inundação de solicitações de conexão inicial. Assim fica mais fácil para o invasor consumir os recursos de um servidor desprotegido.
Após as inundações SYN, estão os ataques direcionados à infraestrutura DNS, inundações RST que exploram o fluxo de conexão TCP e ataques genéricos por UDP.
Ameaças emergentes
No segundo trimestre, as principais ameaças emergentes incluíram ataques por CHARGEN, Ubiquiti e Memcached.
Identificar os principais vetores de ataques ajuda as empresas a entender o cenário de ameaças. Por sua vez, isso as ajuda a melhorar a postura de segurança para se protegerem contra essas ameaças. Da mesma forma, aprender sobre novas ameaças emergentes, que ainda não representam uma parte significativa dos ataques, pode ajudar a mitigá-los antes que se tornem uma força expressiva.
No segundo trimestre, as principais ameaças emergentes foram ataques de amplificação que exploram o protocolo gerador de caracteres (CHARGEN), que desviam o tráfego de dispositivos Ubiquiti expostos e o conhecido ataque Memcached.
Abuso do protocolo CHARGEN para realizar ataques de amplificação
No segundo trimestre, ataques ao protocolo CHARGEN aumentaram 378% em termos trimestrais.
Definido inicialmente em RFC 864 (1983), o protocolo gerador de caracteres (CHARGEN) é um serviço da pilha de protocolos de internet que faz exatamente isso: gera caracteres de forma aleatória e não para de enviá-los ao cliente até ele encerrar a conexão. A intenção original era fazer teste e depuração. No entanto, é raramente usado, porque é muito fácil de explorar para gerar ataques de reflexão/amplificação.
Um invasor pode falsificar o IP de origem da vítima e enganar os servidores de apoio em todo o mundo para direcionar um fluxo de caracteres aleatórios “de volta” os servidores da vítima. Esse tipo de ataque é de reflexão/amplificação. Dependendo do número de fluxos CHARGEN simultâneos, se os servidores da vítima estiverem desprotegidos, serão inundados e não conseguirão processar o tráfego legítimo — resultando em um evento de negação de serviço.
Ataques de amplificação que exploram o protocolo de descoberta Ubiquiti
No segundo trimestre, ataques por Ubiquiti aumentaram 313% em termos trimestrais.
Ubiquiti é uma empresa americana que oferece dispositivos de Internet of Things (IoT) a consumidores e empresas. Os dispositivos da Ubiquiti podem ser descobertos em uma rede pelo protocolo de descoberta Ubiquiti na porta UDP/TCP 10001.
Semelhante ao vetor de ataque CHARGEN, os invasores podem falsificar o IP de origem para o endereço de IP da vítima e pulverizar os endereços de IP que estão com a porta 10001 aberta. Esses então responderiam à vítima e inundariam se o volume for suficiente.
Ataque DDoS ao Memcached
No segundo trimestre, ataques DDoS ao Memcached cresceram 281% em termos trimestrais.
Memcached é um sistema de caching de banco de dados para acelerar sites e redes. Semelhante ao CHARGEN e Ubiquiti, os servidores Memcached compatíveis com UDP podem ser aproveitados para iniciar ataques DDoS de amplificação/reflexão. Nesse caso, o invasor solicita conteúdo do sistema de caching e falsificam o endereço de IP da vítima como IP de origem nos pacotes UDP. A vítima será inundada com as respostas Memcache, que podem ser amplificadas por um fator de até 51.200x.
Ataques DDoS na camada de rede por taxa de ataque
Ataques volumétricos de mais de 100 Gbps aumentaram 19% em termos trimestrais. Ataques com mais de três horas cresceram 9%.
Existem diferentes maneiras de medir o tamanho de um ataque DDoS nas camadas 3 e 4. Uma é o volume de tráfego que ele fornece, medido como taxa de bits (especificamente, terabits por segundo ou gigabits por segundo). Outra é o número de pacotes que ele entrega, medido como taxa de pacotes (especificamente, milhões de pacotes por segundo).
Os ataques com altas taxas de bits tentam causar um evento de negação de serviço saturando a conexão com a internet, enquanto os ataques com altas taxas de pacotes tentam sobrecarregar os servidores, roteadores ou outros dispositivos de hardware em linha. Os dispositivos dedicam uma certa quantidade de memória e capacidade de computação para processar cada pacote. Portanto, ao bombardeá-los com muitos pacotes, os dispositivos podem ficar sem recursos de processamento. Nesse caso, os pacotes são “descartados,” ou seja, o dispositivo não consegue processá-los. Para os usuários, isso resulta em interrupções e em negação de serviço.
Distribuição por taxa de pacotes
A maioria dos ataques DDoS na camada de rede permanecem abaixo de 50 mil pacotes por segundo. Embora 50 kpps esteja no lado inferior do espectro na escala da Cloudflare, isto ainda pode derrubar facilmente ativos da internet desprotegidos e congestionar até mesmo uma conexão Ethernet Gigabit padrão.
Ao analisar as mudanças nos tamanhos dos ataques, vemos que houve uma queda em ataques com uso intenso de pacotes acima de 50 kpps no segundo trimestre, resultando em um aumento de 4% nos ataques menores.
Distribuição por taxa de bits
No segundo trimestre, a maioria dos ataques DDoS na camada de rede ficaram abaixo de 500 Mbps. Também é uma gota no oceano se pensarmos na escala da Cloudflare, mas que pode desconectar rapidamente ativos da internet desprotegidos com menos capacidade ou até congestionar uma conexão Ethernet Gigabit padrão.
É interessante ver que ataques grandes entre 500 Mbps e 100 Gbps diminuíram de 20% a 40% em termos trimestrais, mas ataques volumétricos acima de 100 Gbps cresceram 8%.
Ataques DDoS na camada de rede por duração
No segundo trimestre, ataques com mais de três horas aumentaram 9%.
Medimos a duração de um ataque registrando a diferença entre quando ele foi detectado pela primeira vez por nossos sistemas como um ataque e o último pacote que vimos com a assinatura desse ataque no alvo específico.
No segundo trimestre, 51% dos ataques DDoS à camada de rede duraram menos de 10 minutos, e 41% duraram de 10 a 20 minutos. Os 8% restantes incluem ataques que vão de 20 minutos até mais de 3 horas.
Vale lembrar que mesmo quando um ataque tem apenas alguns minutos, se ele for bem-sucedido, as consequências podem durar mais do que o próprio ataque. Os profissionais de TI que lidam com ataques bem-sucedidos podem passar horas e até dias restaurando serviços.
Embora a maioria dos ataques realmente sejam curtos, é possível ver um aumento de mais de 15% em ataques de 20 a 60 minutos, bem como um crescimento de 12% em ataques com mais de 3 horas.
Ataques curtos podem facilmente passar despercebidos, especialmente ataques burst que, em segundos, bombardeiam um alvo com um número significativo de pacotes, bytes ou solicitações. Nesse caso, os serviços de proteção contra DDoS, que contam com mitigação manual por meio de análise de segurança, não conseguem mitigar o ataque a tempo. Eles podem apenas aprender com esse ataque durante a análise pós-ataque e, em seguida, implantar uma nova regra que filtre o identificador do ataque, esperando capturá-lo na próxima vez. Da mesma forma, também é ineficiente usar um serviço “sob demanda”, em que a equipe de segurança redireciona o tráfego para um provedor de DDoS durante o ataque, uma vez que o ataque já terá terminado antes que o tráfego seja encaminhado para o provedor de DDoS sob demanda.
É recomendável que as empresas utilizem serviços de proteção contra DDoS automatizados sempre ativos, que analisem o tráfego e apliquem a identificação em tempo real com rapidez suficiente para bloquear ataques de curta duração.
Resumo
A missão da Cloudflare é ajudar a construir uma internet melhor, ou seja, mais segura, mais rápida e mais confiável para todos, até mesmo ao enfrentar ataques DDoS. Como parte de nossa missão, desde 2017 oferecemos proteção contra DDoS ilimitada e sem restrições, além de gratuita, para todos os nossos clientes. Ao longo dos anos, tornou-se cada vez mais fácil para os invasores lançar ataques DDoS. Para combater a vantagem do invasor, queremos garantir que também seja fácil e gratuito para organizações de todos os tamanhos se protegerem contra ataques DDoS de todos os tipos. Ainda não usa a Cloudflare? Comece agora com os planos Free e Pro para proteger sites ou fale conosco para ter uma proteção contra DDoS mais abrangente para toda a rede usando o Magic Transit.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


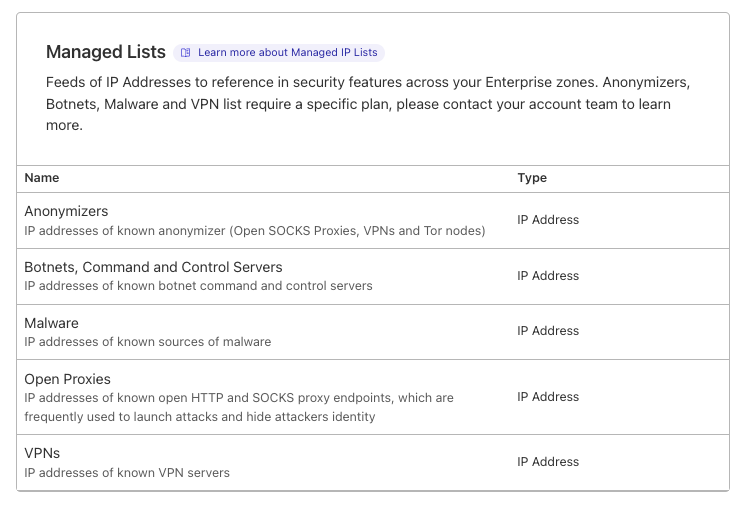
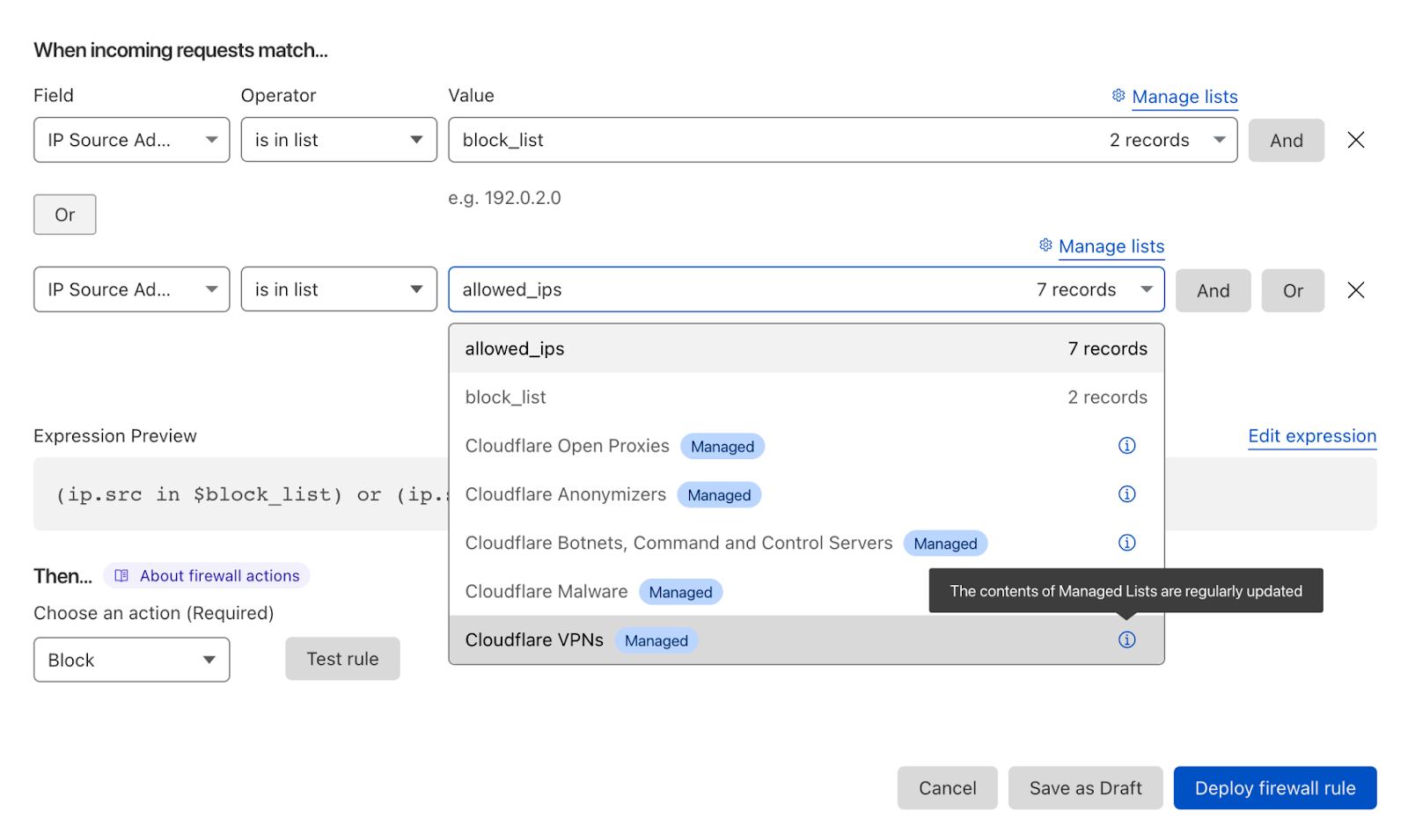











![[Security Nation] Pete Cooper and Irene Pontisso on the Results of the UK Government’s Security Culture Challenge](https://blog.rapid7.com/content/images/2022/07/image1.jpg)
![[Security Nation] Pete Cooper and Irene Pontisso on the Results of the UK Government’s Security Culture Challenge](https://blog.rapid7.com/content/images/2022/07/irene.jpg)