Every day, millions of applications seamlessly connect users to the digital services they need through DNS queries. These queries act as an interface to the internet’s address book, translating familiar domain names like amazon.com into the IP addresses that computers use to appropriately route traffic. The DNS landscape presents unique security challenges and opportunities in Amazon Virtual Private Cloud (Amazon VPC) environments. First, DNS resolution acts as an early checkpoint that you can use to control network traffic before it even begins. Second, DNS queries in your VPC follow a distinct path through the Amazon Route 53 Resolver that operates independently from your standard internet gateway, bypassing other network security controls.
To address this, Amazon Route 53 Resolver DNS Firewall provides protection for DNS traffic, starting with traditional domain lists where you can explicitly allow or deny DNS resolution of specific domains. Also, included are AWS Managed Domain Lists, which automatically block known malicious domains identified through Amazon Threat Intelligence and our trusted security partners. While this approach works effectively to help prevent known threats, sophisticated bad actors are increasingly using techniques that traditional blocklists can’t catch.
Instead of relying solely on static lists, Amazon Route 53 Resolver DNS Firewall Advanced provides intelligent protection alongside these traditional controls. These advanced rules work like a skilled security analyst, watching for suspicious patterns in DNS queries in real time. By examining characteristics such as query length, entropy, and frequency, the service can spot potentially malicious activity even when encountering previously unknown domains. This approach enables detecting and blocking advanced threats like DNS tunneling and domain generation algorithms (DGAs)—techniques that bad actors use to establish hidden communication channels or connect malware to their control servers.
In this post, we take you on a practical journey exploring these DNS-based threats and tools to help prevent them. You’ll learn how to set up effective Route 53 Resolver DNS Firewall Advanced rules, and we provide a ready-to-deploy CloudFormation template with our recommended configurations. Finally, we demonstrate an example of real-world threat detection and show you how the service integrates with AWS Security Hub to improve visibility of alerts. By the time you finish reading this post, you’ll have a clear understanding of how to deploy Route 53 Resolver DNS Firewall rules to add an intelligent, proactive layer of security to your AWS environment.
Understanding the risks of DNS tunneling and DGAs
As mentioned earlier, the Route 53 Resolver provides a service-managed path to the internet that operates independently from your VPC’s internet gateway. While this architecture enables efficient DNS resolution, it can be exploited through techniques such as DNS tunneling. Let’s explore how these techniques work and why they present unique challenges.
DNS tunneling takes advantage of the DNS protocol’s basic function—asking questions about domain names and receiving answers from the authoritative nameserver for the domain. But instead of using DNS for its intended purpose of domain name resolution, tunneling encodes other types of data within DNS queries and responses. For example, rather than asking simply what is the IP address for example.com?, a tunneling exploit might embed data within a query like secretdata123.attacker.com, where secretdata123 contains encoded information. This can lead to DNS being used as a two-way communications command and control channel. Detecting and blocking DNS tunneling is a vital control for stopping data exfiltration and command and control (C2) communications.
DGAs represent a different challenge for DNS security. Rather than using a fixed, predictable domain name that can be quickly blocked, DGAs automatically create many possible domain names using mathematical formulas, which are then used as a destination for C2 traffic. For instance, a DGA might generate domains like xkt7py.com today and mn9qrs.com tomorrow. This makes it difficult to maintain effective blocklists, because the domains change frequently and appear random. Traditional threat intelligence feeds, which rely on identifying and blocking known malicious domains, struggle to keep pace with DGA-generated domains.
How DNS Firewall Advanced works
When examining a domain name, Route 53 Resolver DNS Firewall Advanced looks at multiple characteristics that help distinguish between legitimate and suspicious domains. For example, legitimate domain names typically use real words and follow predictable patterns that are designed to facilitate a human’s ability to recall and enter them accurately. In contrast, domains used for tunneling or generated by DGAs often contain random-looking strings of characters or unusual patterns.
Route 53 Resolver DNS Firewall Advanced builds its intelligence on extensive analysis of real-world domain usage patterns. It learns what legitimate domain names look like by studying the most resolved domains on the internet, combined with actual domain resolution patterns from across AWS. This real-world training data helps establish a baseline for normal domain name characteristics. DNS Firewall Advanced then contrasts these patterns against known techniques used in DNS tunneling and domain generation to identify suspicious activity.
The service analyzes various aspects of each domain name, including:
How the domain name is structured and broken into parts
The patterns of letters and numbers used
How closely the domain resembles natural language
The presence of common words versus random character combinations
The service analyzes queries in real time, processing each one in less than a millisecond, which maintains strong security controls without affecting your applications’ performance.
Route 53 Resolver DNS Firewall Advanced has customized protection levels that you can use to choose how aggressively you want to detect and respond to suspicious domains through confidence thresholds:
High confidence: This setting focuses on the most obvious threats, minimizing false positives. It’s ideal for production environments where blocking legitimate traffic could be disruptive.
Medium confidence: Provides balanced protection, suitable for most environments.
Low confidence: Offers the most detection but might require more tuning to avoid false positives. This setting is useful for high-security environments or for initial monitoring to understand traffic patterns.
You can combine these confidence levels with different actions (block or alert) to create a defense strategy that matches your security needs.
Manually create a DNS Firewall Advanced rule:
To start, we show you how to manually create a Route 53 Resolver DNS Firewall Advanced rule in the AWS Management Console. This rule will block DNS queries that it has detected to be DNS tunneling with high confidence.
To manually create a rule:
In the Route 53 console, choose Rules in the navigation pane, and then choose Add rule.
Figure 1: Rules in the Route 53 console
Enter a name for the rule and select DNS Firewall Advanced protections.
Figure 2: Add a rule
Under DNS Firewall Advanced protection:
Select DNS tunneling detection.
For Confidence threshold, select High.
Leave the Query type empty so that the rule applies to all query types.
Figure 3: Select DNS protection options
Under Action:
Select Block.
For the response, select OVERRIDE.
For the Record value, enter dns-firewall-advanced-block.
For the Record type, select CNAME.
Choose Add rule.
Figure 4: Configure actions for the rule
Deploy the recommended DNS Firewall Rule group using CloudFormation (OPTIONAL)
We’ve created an AWS CloudFormation stack that deploys the following recommended Route 53 Resolver DNS Firewall rules in a DNS Firewall rule group. We recommend this configuration because it provides a balanced security approach—blocking high-confidence threats immediately while generating alerts for lower-confidence detections.
The inclusion of the AWS Managed Aggregate Threat List is particularly valuable because it combines domains from multiple threat categories (malware, ransomware, botnet, spyware, and DNS tunneling) into a blocklist. This consolidated list includes the domains from other AWS Managed Domain Lists, including those identified by GuardDuty threat intelligence systems, giving you broad protection against known malicious domains while the Route 53 DNS Firewall Advanced rules catch previously unseen threats.
For enterprise environments, you can scale this protection across your entire organization by using AWS Firewall Manager to automatically deploy and manage this rule group configuration consistently across the VPCs in your organization.
BLOCK – Aggregate Threat List (domains associated with multiple DNS threat categories including malware, ransomware, botnet, spyware, and DNS tunneling to help block multiple types of threats)
BLOCK – DNS Tunneling | Confidence: HIGH
BLOCK – DGAs | Confidence: HIGH
ALERT – DNS Tunneling | Confidence: LOW
ALERT – DGAs | Confidence: LOW
To deploy this rule group using a CloudFormation stack:
Navigate to the CloudFormation console, choose Stacks from the navigation pane. Choose Create Stack in the upper right and select With new resources (standard).
Figure 5: Create a stack
Download the CloudFormation template. Select Choose an existing template and then select Upload a template file and upload the CloudFormation stack. Choose Next.
Figure 6: Use the CloudFormation template
Enter a stack name and choose Next.
Figure 7: Enter a stack name
Leave the default values for all options, select Next, and then choose Submit.
Navigate to the Route 53 Resolver DNS Firewall by visiting the Amazon VPC console, scroll down to the DNS firewall section, and select the Rule groups tab.
Select the newly created rule group.
Select the Associated VPCs tab, choose Associate VPC, and then associate a VPC you want to protect and choose Associate.
Figure 8: Associate a VPC
Observability
Route 53 Resolver query logging provides detailed visibility into DNS queries made from resources associated with your VPCs, enabling you to monitor and analyze your DNS traffic for security and compliance purposes. By configuring query logging, you can capture essential information about each DNS request, including the domain name being queried, the record type, the response code, and the originating VPC and instance. Query logging is particularly valuable when used in conjunction with Route 53 Resolver DNS Firewall, because it helps you track blocked queries and fine-tune your security rules based on actual DNS traffic patterns in your environment. The following are examples of log entries generated when DNS Firewall detects and responds to suspicious activities, showing the detailed information available for security analysis and incident response.
Example log entry: DNS tunneling block
The following is an example of a DNS tunneling block.
Security Hub provides you with a view of your security state in AWS and helps you to check your environment against security industry standards and best practices. Security Hub collects security data from across AWS accounts, AWS services, and supported third-party partner products, and helps you to analyze security trends and identify the highest priority security issues. It enables findings from both the Amazon: Route 53 Resolver DNS Firewall – AWS List and Amazon: Route 53 Resolver DNS Firewall Advanced list by default, so you’ll automatically receive these alerts without additional configuration. You only need to manually enable Amazon: Route 53 Resolver DNS Firewall – Custom List findings if you’re using custom domain lists in your rule groups. See Sending findings from Route 53 Resolver DNS Firewall to Security Hub for more information.
The following figure is an example of how Route 53 Resolver DNS Firewall Advanced findings appear in the Security Hub console, providing you with actionable security intelligence directly in your centralized dashboard.
Figure 9: DNS Firewall Advanced findings in Security Hub
Select a finding to view details such as Finding ID, Types, Workflow status, and so on.
Figure 10: Findings details
Conclusion
Amazon Route 53 Resolver DNS Firewall Advanced represents a significant step forward in protecting organizations against sophisticated DNS-based threats. As mentioned, DNS queries sent to the Route 53 Resolver follow a unique path that bypasses traditional AWS security controls like security groups, NACLs, and even AWS Network Firewall—creating a security gap in many environments. Throughout this post, we’ve explored how DNS tunneling and DGA-based exploits take advantage of this blind spot, and how you can use Route 53 Resolver DNS Firewall Advanced to protect from these threats through real-time pattern analysis and anomaly detection. You learned how to configure the service in the AWS console and use the provided CloudFormation template with recommended rules that balance blocking high-confidence threats while alerting on potential issues. And you saw how query logging provides valuable visibility into your DNS traffic and how Security Hub integration centralizes your security findings. Implementing these capabilities helps you protect your infrastructure from sophisticated DNS-based exploits that traditional domain blocklists cannot catch, strengthening your cloud security posture while maintaining operational efficiency.
If you have feedback about this post, submit comments in the Comments section below.
In the cloud security landscape, organizations benefit from aligning their controls and practices with industry standard frameworks such as MITRE ATT&CK®, MITRE EngageTM, and MITRE D3FENDTM. MITRE frameworks are structured, openly accessible models that document threat actor behaviors to help organizations improve threat detection and response.
Figure 1: Interaction between the various MITRE frameworks
Figure 1 showcases how the frameworks interact with each other to identify threatening behavior and provide actionable defensive measures. MITRE ATT&CK provides insights into threat actor behavior while D3FEND translates insights from ATT&CK into actionable defensive measures. MITRE Engage uses both ATT&CK and D3FEND to plan proactive engagement strategies that disrupt threat actor activity. As organizations use AWS to enhance their operational capabilities, implementing comprehensive security strategies becomes an important part of cloud adoption.
This blog post explores how AWS security services align with the MITRE frameworks to provide a systematic approach for threat detection and mitigation. We’ll examine how organizations can use AWS security tools such as Amazon GuardDuty, Amazon Security Lake, and AWS Security Hub in conjunction with MITRE frameworks to implement security controls across different stages of their cloud security operations.
Understanding MITRE frameworks
Today’s security teams face increasingly sophisticated threats, with actors continuously evolving their tactics, techniques, and procedures (TTPs). To help organizations strengthen their security posture, industry frameworks such as MITRE ATT&CK, D3FEND, and Engage provide structured methodologies for understanding and responding to these threats.
Understanding these threats through a risk lifecycle approach is crucial for security teams. This structured methodology enables teams to detect anomalies early, map threats to known risk stages, and implement proactive defense mechanisms. By following a risk lifecycle approach, organizations can enhance threat intelligence, improve incident response, and minimize dwell time, ultimately strengthening their security posture against evolving cyber threats.
The integration of MITRE ATT&CK, D3FEND, and Engage frameworks offers organizations a comprehensive approach across the security operations lifecycle. At the foundation, MITRE ATT&CK provides a common language for describing threat actor TTPs. This knowledge base is invaluable during threat modeling and risk assessment, helping teams identify potential vulnerabilities and threat vectors.
Building upon ATT&CK, MITRE D3FEND complements the tactical knowledge with a framework for defensive countermeasures. It suggests proactive security controls, such as implementing least privilege access or securing system configurations. This allows organizations to align their defenses directly with known exploit patterns.
MITRE Engage then adds a layer of active defense capabilities. It guides security teams in planning and implementing strategies that can help in three different ways and potentially simultaneously. Defenders can expose threat actors by detecting them as they attempt to access or operate on infrastructure. Defenders can use Engage to help impose costs by causing threat actors to focus on fake infrastructure rather than legitimate assets. Finally, defenders can set up enticing fake targets to lure threat actors into exploiting them and thereby revealing tradecraft.
A MITRE operation that was run in conjunction with a partner might clarify how this is valuable. MITRE worked with a partner to set up a fake network to appear as a specific type of entity. The goal was to elicit TTPs from a specific advanced persistent threat (APT) for which MITRE and the partner had a recent malware sample. MITRE ran the sample on the fake network and observed the APT’s activities. From that operation, MITRE gathered a list of specific TTPs that were executed by a script in a particular order that helped the partner develop a novel analytic. Plus, in reviewing event traces, MITRE found a flaw in a well-known security tool that missed a specific type of process-tampering event. This was disclosed to the vendor, who fixed that in later versions. Finally, every minute of operating in this environment imposed a cost on the APT by diverting resources from real victims. Full details of the exercise were presented at Shmoocon 2022.
As we move through the security operations lifecycle, these three MITRE frameworks continue to work in concert:
During detection and monitoring, ATT&CK informs threat hunting and log analysis and correlation, D3FEND strengthens real-time detection and anomaly tracking, and Engage enables strategic detection through deception techniques.
When responding to incidents, ATT&CK helps map incident progression, D3FEND automates response actions, and Engage provides methods to gather additional intelligence about threat activities.
In the post-incident phase, ATT&CK helps map the incident chain for better detection tuning, D3FEND refines security controls, and Engage expands deception tactics based on lessons learned. By integrating these efforts, organizations can implement a systematic approach to security operations that combines tactical knowledge, defensive measures, and strategic engagement capabilities.
Aligning AWS to MITRE frameworks
AWS offers a broad set of cloud services with high security at global scale, and has proven experience helping businesses innovate faster. Customers use AWS services in various configurations to build solutions for their bespoke business needs. A fundamental aspect of using AWS is understanding the Shared Responsibility Model, shown in Figure 2 that follows.
Figure 2: AWS Shared Responsibility Model
AWS is responsible for security of the cloud, while customers are responsible for security in the cloud. This means that AWS is responsible for protecting the infrastructure that runs the services offered in the AWS Cloud, while customer responsibility is determined by the AWS Cloud services that a customer selects. As customers embark on their cloud security journey, we help them understand two important concepts of cloud-scale environments:
Interconnected resources and configurations: Cloud architectures consist of interconnected entities—ranging from virtual machines using Amazon Elastic Compute Cloud (Amazon EC2) to serverless functions using AWS Lambda. To help customers maintain visibility and control, AWS offers native tools designed for cloud-scale management.
Dynamic access management and least privilege: Cloud environments require robust authentication mechanisms and fine-grained permissions. AWS provides comprehensive identity and access management tools to implement least privilege access and manage dynamic workloads effectively.
To support our customers’ security needs, AWS offers native security services that align with industry-standard frameworks like MITRE ATT&CK, D3FEND, and Engage. Here’s how these services map across the security lifecycle:
For threat modeling and risk assessment, Security Lake aggregates logs for MITRE ATT&CK-based analytics, while Amazon Inspector scans for vulnerabilities mapped to threat actor techniques. Amazon Macie detects sensitive data exposure across AWS resources.
When implementing preventive controls, implementing least privilege for access is fundamental. AWS Identity and Access Management (IAM) and AWS Organizations provide capabilities to enforce least privilege across your AWS environment. You can use IAM permissions and service control policies (SCPs) to build an identity perimeter. AWS Web Application Firewall (AWS WAF) provides application-layer protections, while you can use AWS Secrets Manager to store honey tokens. Secrets Manager is an AWS service that you can use to centrally manage the lifecycle of secrets. Honey tokens act as digital decoys that simulate legitimate credentials or sensitive data, enticing threat actors to reveal their presence when they interact with them. When triggered, these tokens generate real-time alerts and detailed event logs, enabling swift investigation and deeper insights into threat actor tactics. Deploying honey tokens on AWS involves creating decoy credentials or sensitive data entries that serve no legitimate purpose yet are closely monitored for unauthorized access attempts. One common approach is to use Secrets Manager to store fake secrets that mimic real credentials. When such tokens, stored in Secrets Manager, are accessed, the service generates detailed event logs with AWS CloudTrail and Amazon CloudWatch. You can continuously monitor these logs and events and configure them to alert you if the decoys are ever accessed.
During the detection and monitoring phase, GuardDuty identifies unusual activity patterns across your AWS accounts and workloads, Amazon Detective helps investigate these anomalies by analyzing root causes and plotting out the incident scope in an interactive way, while Security Hub centralizes security alerts and enables automated responses across your environment.
For incident response, containment, and recovery, Lambda and Step Functions help automate responses when security events occur. AWS Shield and WAF work together to provide real-time threat mitigation against denial-of-service type threats like distributed denial of service (DDoS), while Security Lake and Detective provide the necessary data and tools for conducting thorough forensic analysis. In 2024, AWS announced the AWS Security Incident Response service that uses automated monitoring and investigation through the AWS Customer Incident Response Team to prepare for, respond to, and recover from security events. You can use the service to augment your cloud-based security response function aligned with AWS security best practices.
By blocking malicious traffic, Shield and WAF provide real-time DDoS mitigation. AWS deception tactics could include redirecting threat actors to honeypots or deploying decoy Amazon Simple Storage Service (Amazon S3) files to enhance engagement strategies, like the honey token deployment and storage using Secrets Manager explained earlier in this post. Post incident, Security Lake and Detective assist in forensic analysis, while Security Hub and IAM policies refine security controls based on past exploit trends. MITRE Engage tactics can further evolve by analyzing honeypot interactions. By integrating these AWS security services, you can detect, prevent, and deceive threat actors effectively, strengthening your organization’s overall security posture. The following table maps MITRE lifecycle stages to AWS services and tools.
Lifecycle stage
AWS tools for MITRE ATT&CK (detect and map)
AWS tools for MITRE D3FEND (prevent and contain)
AWS tools for MITRE Engage (deceive and disrupt)
Threat modeling and risk assessment
Security Lake, Amazon Inspector, Macie, and Security Hub
IAM policies and AWS WAF
Secrets Manager and honey tokens
Detection and monitoring
GuardDuty, CloudTrail, and Security Hub
Detective, auto-remediation using AWS services such as Amazon EventBridge, Lambda, and Step Functions.
You can use Table 1 as a guide to understand how AWS services map to the various lifecycle stages in the incident response lifecycle. We will now demonstrate how GuardDuty, an AWS security service that continuously monitors your AWS accounts and workloads to provide automated threat detection, works in line with the MITRE ATT&CK framework.
GuardDuty: MITRE framework integration in action
In 2024, AWS worked extensively with MITRE to create new techniques and sub-techniques, and to update some of the existing detection objects in the MITRE ATT&CK cloud matrix. The work that AWS did with MITRE drew from real-world threat actor techniques performed against AWS customers and helped to provide more detailed information and specific detections on how threat actors abuse AWS services. For example, AWS threat detection teams observed a new tactic in the cloud environment (T1485.001 | Data Destruction: Lifecycle-Triggered Deletion) where threat actors could modify lifecycle policies for S3 buckets to delete all objects stored in the bucket. This technique, along with associated mitigations, detection, and references was submitted back to the MITRE ATT&CK framework.
AWS security services such as AWS Security Incident Response and GuardDuty use MITRE ATT&CK to provide threat intelligence and detailed information on threats identified in an AWS account. You can examine how these AWS security services integrate with MITRE ATT&CK through a specific example. GuardDuty Extended Threat Detection helps customers with contextual threat detection in their AWS environment and aligns the signals with the MITRE ATT&CK lifecycle. GuardDuty automatically detects and correlates individual findings with connected resources to produce an attack sequence finding. Consider an attack sequence finding generated by GuardDuty detecting data compromise in your AWS account. We will use this as an example in this post.
To begin, the finding summary includes a textual description of the sequence of events and the TTPs detected, as shown in Figure 3. It also shows a summary of the observed TTP identifiers, AWS API calls, and IP addresses.
Figure 3: GuardDuty finding summary visible in the service console
As seen in Figure 4, every attack sequence finding highlights the signals and the MITRE tactic associated with the activity. The finding shown in Figure 4 shows the full lifecycle of the threat from discovery to impact.
Figure 4: Signals and MITRE tactics alignment
Diving deeper into each signal reveals the specific MITRE tactic associated with the activity and the technique identifier. Another interesting feature is that you can see the correlation between the AWS API call associated with the resources involved in the attack sequence and the user agent.
Figure 5 shows one of the signals associated with the attack sequence in the previous finding. A data exfiltration activity has been reported because of the nature of the AWS API call (s3:GetObject) and the user agent (Kali Linux) that was used to perform the activity. The level of detail for each signal is contextual based on the type of activity and tactic.
Figure 5: Details for a single signal within a GuardDuty attack sequence finding
Figure 6 shows another signal from the same finding, but in this case the level of detail includes the malicious IP lists and suspicious network activity detected in relation to the signal and associated resources.
Figure 6: Details of TTPs associated with an indicator within a GuardDuty attack sequence finding
This information can be downloaded in a JSON-formatted file. The information from the JSON document can be used to automate responses and remediations for the detections.
Conclusion
AWS security services work together to support the implementation of MITRE frameworks—ATT&CK for threat detection, D3FEND for preventative security, and Engage for threat actor engagement across the cybersecurity lifecycle. As demonstrated through the GuardDuty Extended Threat Detection example, these integrations provide customers with practical, actionable security capabilities across their AWS environment. The alignment of AWS security services with MITRE frameworks helps you build security operations using industry-standard methodologies, implement automated detection and response capabilities, maintain visibility across your AWS environment, and continuously enhance your security controls.
Through this integration of AWS security services with MITRE frameworks, you can implement comprehensive security operations that evolve with your organization’s business needs. To get started, visit the GuardDuty console to enable Extended Threat Detection, and explore our documentation to learn more about implementing these security capabilities in your AWS environment. Join us at AWS re:Inforce 2025 to learn more about AWS security services, including deep dives into the integration of Amazon GuardDuty with MITRE frameworks and hands-on workshops with AWS security experts.
If you have feedback about this post, submit comments in the Comments section below.
Many organizations build and operate enterprise-wide data mesh architectures using the AWS GlueData Catalog and AWS Lake Formation for their Amazon Simple Storage Service (Amazon S3) based data lakes. Now, with Amazon SageMaker Lakehouse, these organizations can unify their data analytics and AI/ML workflows while maintaining secure cross-account access without data replication. By centralizing access to a single copy of data and using the secure fine-grained permissions of Lake Formation, enterprises can accelerate their analytics initiatives while reducing operational complexity across business units.
SageMaker Lakehouse organizes data using logical containers called catalogs, enabling teams to seamlessly query and analyze data across their entire ecosystem—from S3 data lakes to Amazon Redshift warehouses—using familiar Apache Iceberg compatible tools. Organizations can either mount their existing data warehouse to the lakehouse or create new catalogs using Amazon Redshift managed storage. Built-in zero-ETL connectors reduce data silos by integrating various data sources, enabling unified analytics across teams. This seamless integration particularly benefits existing AWS customers who already use the Data Catalog and Lake Formation, because they can immediately take advantage of SageMaker Lakehouse capabilities.
AWS Glue is a serverless service that makes data integration simpler, faster, and cheaper. We launched AWS Glue 5.0 with upgraded Apache Spark 3.5.4 and Python 3.11. AWS Glue 5.0 adds support for SageMaker Lakehouse to unify your data across S3 data lakes and Redshift data warehouses.
In our previous blog post, we demonstrated the process of creating tables in both the Amazon Redshift managed catalog and Amazon Redshift federated catalog within a single AWS account. In this post, we show you how to share a Redshift table and Amazon S3 based Iceberg table from the account that owns the data to another account that consumes the data. In the recipient account, we run a join query on the shared data lake and data warehouse tables using Spark in AWS Glue 5.0. We walk you through the complete cross-account setup and provide the Spark configuration in a Python notebook.
Solution overview
To demonstrate the functionality of SageMaker Lakehouse multi-catalog tables using AWS Glue 5.0 Spark, let’s assume the retail company Example Retail Corp launches a campaign to understand their market and drive growth by country of operation. Their infrastructure consists of a Redshift data warehouse for structured data and an S3 data lake for structured and semi-structured data. The marketing team realizes that customer data is spread across those two systems and wants to use the support of their data engineering and analysts to analyze and provide insights. As a company, they prefer unified governance for managing data access while enabling a secure sharing mechanism for business and engineering teams.
Let’s see how they can achieve the goal using SageMaker Lakehouse. The solution is represented in the following diagram.
The setup could be extended to enterprise data meshes where a data producer account will own the Redshift clusters, catalog the tables in a central governance account, and share with any number of consumer accounts from the central account. Multiple consumer accounts could analyze the shared Redshift tables using the SageMaker Lakehouse integrated analytics engines.
The solution also works for cross-Region table access. You would create a resource link for the catalog tables in an AWS Region where you want to run your analyses and create dashboards. For cross-Region resource link setup, refer to Setting up cross-Region table access.
Prerequisites
To implement this solution, you need the following prerequisites:
Two sample datasets, orders and returns, in CSV format. This is Example Retail Corp’s data on their customer purchase and return trends. Their marketing team has collected these data in a Redshift table and Amazon S3 from various systems. The instructions to create these tables are provided in the appendix at the end of this post. After completing the steps in the appendix, you should have customerdb.returnstbl_iceberg in your default catalog and ordersdb.orderstbl in your Redshift Serverless application default namespace.
An IAM role, Glue-execution-role, in the consumer account, with the following policies:
AWS managed policies AWSGlueServiceRole and AmazonRedshiftDataFullAccess.
Create a new in-line policy with the following permissions and attach it:
For the producer account setup, you can either use your IAM administrator role added as Lake Formation administrator or use a Lake Formation administrator role with permissions added as discussed in the prerequisites. For illustration purposes, we use the IAM admin role Admin added as Lake Formation administrator.
Configure your catalog
Complete the following steps to set up your catalog:
After the registration is initiated, you will see the invite from Amazon Redshift on the Lake Formation console.
Select the pending catalog invitation and choose Approve and create catalog.
On the Set catalog details page, configure your catalog:
For Name, enter a name (for this post, redshiftserverless1-uswest2).
Select Access this catalog from Apache Iceberg compatible engines.
Choose the IAM role you created for the data transfer.
Choose Next.
On the Grant permissions – optional page, choose Add permissions.
Grant the Admin user Super user permissions for Catalog permissions and Grantable permissions.
Choose Add.
Verify the granted permission on the next page and choose Next.
Review the details on the Review and create page and choose Create catalog.
Wait a few seconds for the catalog to show up.
Choose Catalogs in the navigation pane and verify that the redshiftserverless1-uswest2 catalog is created.
Explore the catalog detail page to verify the ordersdb.public database.
On the database View dropdown menu, view the table and verify that the orderstbl table shows up.
As the Admin role, you can also query the orderstbl in Amazon Athena and confirm the data is available.
Grant permissions on the tables from the producer account to the consumer account
In this step, we share the Amazon Redshift federated catalog database redshiftserverless1-uswest2:ordersdb.public and table orderstbl as well as the Amazon S3 based Iceberg table returnstbl_iceberg and its database customerdb from the default catalog to the consumer account. We can’t share the entire catalog to external accounts as a catalog-level permission; we just share the database and table.
On the Lake Formation console, choose Data permissions in the navigation pane.
Choose Grant.
Under Principals, select External accounts.
Provide the consumer account ID.
Under LF-Tags or catalog resources, select Named Data Catalog resources.
For Catalogs, choose the account ID that represents the default catalog.
For Databases, choose customerdb.
Under Database permissions, select Describe under Database permissions and Grantable permissions.
Choose Grant.
Repeat these steps and grant table-level Select and Describe permissions on returnstbl_iceberg.
Repeat these steps again to grant database- and table-level permissions for the ordertbl table of the federated catalog database redshiftserverless1-uswest2/ordersdb.
The following screenshots show the configuration for database-level permissions.
The following screenshots show the configuration for table-level permissions.
Choose Data permissions in the navigation pane and verify that the consumer account has been granted database- and table-level permissions for both orderstbl from the federated catalog and returnstbl_iceberg from the default catalog.
Register the Amazon S3 location of the returnstbl_iceberg with Lake Formation.
In this step, we register the Amazon S3 based Iceberg table returnstbl_iceberg data location with Lake Formation to be managed by Lake Formation permissions. Complete the following steps:
On the Lake Formation console, choose Data lake locations in the navigation pane.
Choose Register location.
For Amazon S3 path, enter the path for your S3 bucket that you provided while creating the Iceberg table returnstbl_iceberg.
For IAM role, provide the user-defined role LakeFormationS3Registration_custom that you created as a prerequisite.
For Permission mode, select Lake Formation.
Choose Register location.
Choose Data lake locations in the navigation pane to verify the Amazon S3 registration.
With this step, the producer account setup is complete.
Steps for consumer account setup
For the consumer account setup, we use the IAM admin role Admin, added as a Lake Formation administrator.
The steps in the consumer account are quite involved. In the consumer account, a Lake Formation administrator will accept the AWS Resource Access Manager (AWS RAM) shares and create the required resource links that point to the shared catalog, database, and tables. The Lake Formation admin verifies that the shared resources are accessible by running test queries in Athena. The admin further grants permissions to the role Glue-execution-role on the resource links, database, and tables. The admin then runs a join query in AWS Glue 5.0 Spark using Glue-execution-role.
Accept and verify the shared resources
Lake Formation uses AWS RAM shares to enable cross-account sharing with Data Catalog resource policies in the AWS RAM policies. To view and verify the shared resources from producer account, complete the following steps:
Log in to the consumer AWS console and set the AWS Region to match the producer’s shared resource Region. For this post, we use us-west-2.
Open the Lake Formation console. You will see a message indicating there is a pending invite and asking you accept it on the AWS RAM console.
When the invite status changes to Accepted, choose Shared resources under Shared with me in the navigation pane.
Verify that the Redshift Serverless federated catalog redshiftserverless1-uswest2, the default catalog database customerdb, the table returnstbl_iceberg, and the producer account ID under Owner ID column display correctly.
On the Lake Formation console, under Data Catalog in the navigation pane, choose Databases.
Search by the producer account ID. You should see the customerdb and public databases. You can further select each database and choose View tables on the Actions dropdown menu and verify the table names
You will not see an AWS RAM share invite for the catalog level on the Lake Formation console, because catalog-level sharing isn’t possible. You can review the shared federated catalog and Amazon Redshift managed catalog names on the AWS RAM console, or using the AWS Command Line Interface (AWS CLI) or SDK.
Create a catalog link container and resource links
A catalog link container is a Data Catalog object that references a local or cross-account federated database-level catalog from other AWS accounts. For more details, refer to Accessing a shared federated catalog. Catalog link containers are essentially Lake Formation resource links at the catalog level that reference or point to a Redshift cluster federated catalog or Amazon Redshift managed catalog object from other accounts.
In the following steps, we create a catalog link container that points to the producer shared federated catalog redshiftserverless1-uswest2. Inside the catalog link container, we create a database. Inside the database, we create a resource link for the table that points to the shared federated catalog table <<producer account id>>:redshiftserverless1-uswest2/ordersdb.public.orderstbl.
On the Lake Formation console, under Data Catalog in the navigation pane, choose Catalogs.
Choose Create catalog.
Provide the following details for the catalog:
For Name, enter a name for the catalog (for this post, rl_link_container_ordersdb).
For Type, choose Catalog Link container.
For Source, choose Redshift.
For Target Redshift Catalog, enter the Amazon Resource Name (ARN) of the producer federated catalog (arn:aws:glue:us-west-2:<<producer account id>>:catalog/redshiftserverless1-uswest2/ordersdb).
Under Access from engines, select Access this catalog from Apache Iceberg compatible engines.
For IAM role, provide the Redshift-S3 data transfer role that you had created in the prerequisites.
Choose Next.
On the Grant permissions – optional page, choose Add permissions.
Grant the Admin user Super user permissions for Catalog permissions and Grantable permissions.
Choose Add and then choose Next.
Review the details on the Review and create page and choose Create catalog.
Wait a few seconds for the catalog to show up.
In the navigation pane, choose Catalogs.
Verify that rl_link_container_ordersdb is created.
Create a database under rl_link_container_ordersdb
Complete the following steps:
On the Lake Formation console, under Data Catalog in the navigation pane, choose Databases.
On the Choose catalog dropdown menu, choose rl_link_container_ordersdb.
Choose Create database.
Alternatively, you can choose the Create dropdown menu and then choose Database.
Provide details for the database:
For Name, enter a name (for this post, public_db).
For Catalog, choose rl_link_container_ordersdb.
Leave Location – optional as blank.
Under Default permissions for newly created tables, deselect Use only IAM access control for new tables in this database.
Choose Create database.
Choose Catalogs in the navigation pane to verify that public_db is created under rl_link_container_ordersdb.
Create a table resource link for the shared federated catalog table
A resource link to a shared federated catalog table can reside only inside the database of a catalog link container. A resource link for such tables will not work if created inside the default catalog. For more details on resource links, refer to Creating a resource link to a shared Data Catalog table.
Complete the following steps to create a table resource link:
On the Lake Formation console, under Data Catalog in the navigation pane, choose Tables.
On the Create dropdown menu, choose Resource link.
Provide details for the table resource link:
For Resource link name, enter a name (for this post, rl_orderstbl).
For Destination catalog, choose rl_link_container_ordersdb.
For Database, choose public_db.
For Shared table’s region, choose US West (Oregon).
For Shared table, choose orderstbl.
After the Shared table is selected, Shared table’s database and Shared table’s catalog ID should get automatically populated.
Choose Create.
In the navigation pane, choose Databases to verify that rl_orderstbl is created under public_db, inside rl_link_container_ordersdb.
Create a database resource link for the shared default catalog database.
Now we create a database resource link in the default catalog to query the Amazon S3 based Iceberg table shared from the producer. For details on database resource links, refer Creating a resource link to a shared Data Catalog database.
Though we are able to see the shared database in the default catalog of the consumer, a resource link is required to query from analytics engines, such as Athena, Amazon EMR, and AWS Glue. When using AWS Glue with Lake Formation tables, the resource link needs to be named identically to the source account’s resource. For additional details on using AWS Glue with Lake Formation, refer to Considerations and limitations.
Complete the following steps to create a database resource link:
On the Lake Formation console, under Data Catalog in the navigation pane, choose Databases.
On the Choose catalog dropdown menu, choose the account ID to choose the default catalog.
Search for customerdb.
You should see the shared database name customerdb with the Owner account ID as that of your producer account ID.
Select customerdb, and on the Create dropdown menu, choose Resource link.
Provide details for the resource link:
For Resource link name, enter a name (for this post, customerdb).
The rest of the fields should be already populated.
Choose Create.
In the navigation pane, choose Databases and verify that customerdb is created under the default catalog. Resource link names will show in italicized font.
Verify access as Admin using Athena
Now you can verify your access using Athena. Complete the following steps:
In the navigation pane, verify both the default catalog and federated catalog tables by previewing them.
You can also run a join query as follows. Pay attention to the three-point notation for referring to the tables from two different catalogs:
SELECT
returns_tb.market as Market,
sum(orders_tb.quantity) as Total_Quantity
FROM rl_link_container_ordersdb.public_db.rl_orderstbl as orders_tb
JOIN awsdatacatalog.customerdb.returnstbl_iceberg as returns_tb
ON orders_tb.order_id = returns_tb.order_id
GROUP BY returns_tb.market;
This verifies the new capability of SageMaker Lakehouse, which enables accessing Redshift cluster tables and Amazon S3 based Iceberg tables in the same query, across AWS accounts, through the Data Catalog, using Lake Formation permissions.
Grant permissions to Glue-execution-role
Now we will share the resources from the producer account with additional IAM principals in the consumer account. Usually, the data lake admin grants permissions to data analysts, data scientists, and data engineers in the consumer account to do their job functions, such as processing and analyzing the data.
We set up Lake Formation permissions on the catalog link container, databases, tables, and resource links to the AWS Glue job execution role Glue-execution-role that we created in the prerequisites.
Resource links allow only Describe and Drop permissions. You need to use the Grant on target configuration to provide database Describe and table Select permissions.
Complete the following steps:
On the Lake Formation console, choose Data permissions in the navigation pane.
Choose Grant.
Under Principals, select IAM users and roles.
For IAM users and roles, enter Glue-execution-role.
Under LF-Tags or catalog resources, select Named Data Catalog resources.
For Catalogs, choose rl_link_container_ordersdb and the consumer account ID, which indicates the default catalog.
Under Catalog permissions, select Describe for Catalog permissions.
Choose Grant.
Repeat these steps for the catalog rl_link_container_ordersdb:
On the Databases dropdown menu, choose public_db.
Under Database permissions, select Describe.
Choose Grant.
Repeat these steps again, but after choosing rl_link_container_ordersdb and public_db, on the Tables dropdown menu, choose rl_orderstbl.
Under Resource link permissions, select Describe.
Choose Grant.
Repeat these steps to grant additional permissions to Glue-execution-role.
For this iteration, grant Describe permissions on the default catalog databases public and customerdb.
Grant Describe permission on the resource link customerdb.
Grant Select permission on the tables returnstbl_iceberg and orderstbl.
The following screenshots show the configuration for database public and customerdb permissions.
The following screenshots show the configuration for resource link customerdb permissions.
The following screenshots show the configuration for table returnstbl_iceberg permissions.
The following screenshots show the configuration for table orderstbl permissions.
In the navigation pane, choose Data permissions and verify permissions on Glue-execution-role.
Run a PySpark job in AWS Glue 5.0
Download the PySpark script LakeHouseGlueSparkJob.py. This AWS Glue PySpark script runs Spark SQL by joining the producer shared federated orderstbl table and Amazon S3 based returns table in the consumer account to analyze the data and identify the total orders placed per market.
Replace <<consumer_account_id>> in the script with your consumer account ID. Complete the following steps to create and run an AWS Glue job:
On the AWS Glue console, in the navigation pane, choose ETL jobs.
Choose Create job, then choose Script editor.
For Engine, choose Spark.
For Options, choose Start fresh.
Choose Upload script.
Browse to the location where you downloaded and edited the script, select the script, and choose Open.
On the Job details tab, provide the following information:
For Name, enter a name (for this post, LakeHouseGlueSparkJob).
Under Basic properties, for IAM role, choose Glue-execution-role.
For Glue version, select Glue 5.0.
Under Advanced properties, for Job parameters, choose Add new parameter.
Add the parameters --datalake-formats = iceberg and --enable-lakeformation-fine-grained-access = true.
Save the job.
Choose Run to execute the AWS Glue job, and wait for the job to complete.
Review the job run details from the Output logs
Clean up
To avoid incurring costs on your AWS accounts, clean up the resources you created:
Delete the Lake Formation permissions, catalog link container, database, and tables in the consumer account.
Delete the AWS Glue job in the consumer account.
Delete the federated catalog, database, and table resources in the producer account.
Delete the Redshift Serverless namespace in the producer account.
Delete the S3 buckets you created as part of data transfer in both accounts and the Athena query results bucket in the consumer account.
Clean up the IAM roles you created for the SageMaker Lakehouse setup as part of the prerequisites.
Conclusion
In this post, we illustrated how to bring your existing Redshift tables to SageMaker Lakehouse and share them securely with external AWS accounts. We also showed how to query the shared data warehouse and data lakehouse tables in the same Spark session, from a recipient account, using Spark in AWS Glue 5.0.
We hope you find this useful to integrate your Redshift tables with an existing data mesh and access the tables using AWS Glue Spark. Test this solution in your accounts and share feedback in the comments section. Stay tuned for more updates and feel free to explore the features of SageMaker Lakehouse and AWS Glue versions.
Appendix: Table creation
Complete the following steps to create a returns table in the Amazon S3 based default catalog and an orders table in Amazon Redshift:
Download the CSV format datasets orders and returns.
Upload them to your S3 bucket under the corresponding table prefix path.
Create an Iceberg format table in the default catalog and insert data from the CSV format table:
CREATE TABLE customerdb.returnstbl_iceberg(
`returned` string,
`order_id` string,
`market` string)
LOCATION 's3://<your-producer-account-bucket>/returnstbl_iceberg/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
INSERT INTO customerdb.returnstbl_iceberg
SELECT *
FROM returnstbl_csv;
SELECT * FROM customerdb.returnstbl_iceberg LIMIT 10;
To create the orders table in the Redshift Serverless namespace, open the Query Editor v2 on the Amazon Redshift console.
Connect to the default namespace using your database admin user credentials.
Run the following commands in the SQL editor to create the database ordersdb and table orderstbl in it. Copy the data from your S3 location of the orders data to the orderstbl:
Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She collaborates with the service team to enhance product features, works with AWS customers and partners to architect lakehouse solutions, and establishes best practices for data governance.
Subhasis Sarkar is a Senior Data Engineer with Amazon. Subhasis thrives on solving complex technological challenges with innovative solutions. He specializes in AWS data architectures, particularly data mesh implementations using AWS CDK components.
On August 20, 2024, we announced the general availability of the new AWS CloudHSM instance type hsm2m.medium (hsm2). This new type comes with additional features compared to the previous AWS CloudHSM instance type, hsm1.medium (hsm1), such as support for Federal Information Processing Standard (FIPS) 140-3 Level 3, the ability to run clusters in non-FIPS mode, increased storage capacity of 16,666 total keys, and support for mutual transport layer security (mTLS) between the client and CloudHSM.
The hsm1 instance type is reaching end-of-life and will be unavailable for service on December 1, 2025. See the hsm1 deprecation notification.
To address this, starting April 2025, AWS will attempt to automatically migrate existing hsm1 clusters to hsm2. During the migration, the hsm1 cluster will operate in limited-write mode.
If you want to use automatic migration and can accommodate restrictions on operations during the migration, make sure that your environment meets the prerequisites for automatic migration.
If you want to manage the migration yourself, you can do so before the automatic migration begins. In this post, we provide a few options for migration so you can choose the method that’s best for your situation and available resources.
To help facilitate high availability during migration, you can use a blue/green deployment strategy. If high availability isn’t a priority, there are two approaches: one where write operations are restricted and a second where you incur some downtime on operations. We also cover different use cases based on the operations performed during migration and provide rollback strategies.
Important considerations
When planning a migration to hsm2, consider the following:
Backup: We recommend keeping a backup of hsm1 until you have confirmed that all the required keys have been migrated to hsm2. You can configure a CloudHSM backup retention policy to manage backups.
Availability and rollback: This post presents two main migration approaches. One that preserves availability but might become complex depending on the type of keys used and operations performed during the migration period. The other approach is less complicated but might impact availability for a short time. Choose the migration process based on your availability requirements.
Blue/Green strategy: You can use a blue/green deployment strategy using an enterprise-specific method or a CloudHSM multi-cluster configuration.
Note: Multi-cluster configuration is supported for CloudHSM CLI, JCE, and PKCS11.
Client SDK version: Instance type hsm2 is compatible only with Client SDK version 5.9.0 and later. Upgrade your client SDK before starting migration. We recommend using the latest version.
Known issues: See the known issues with hsm2 to amend your tests and metrics as needed after migration.
Limited availability
There are two options: customer triggered and customer managed. Choose the approach that best fits your requirements. Note that for both options, you need to satisfy the migration criteria. See Prerequisites for migrating to hsm2m.medium.
Customer triggered
You can trigger migration of your hsm1 cluster from the AWS Management Console for CloudHSM or the AWS Command Line Interface (AWS CLI), and AWS will manage the migration process. Follow the detailed steps in Migrating from hsm1.medium to hsm2m.medium. This approach is suitable if you don’t perform frequent write operations such as creating or deleting users or keys. During the migration, the hsm1 cluster enters limited-write mode where write operations will be rejected until migration is complete. Write operations performed by your application, if any, will fail during the migration. Read operations remain unaffected. If a rollback is required, it will be managed by AWS. If necessary, you can roll back the migration within 24 hours of starting it. The customer triggered migration process is straightforward because no configuration changes are required. If your application requires write operations during migration you can follow the customer managed option.
Customer managed
This approach is suitable if you can schedule a brief downtime to perform migration. For this process, you create a new hsm2 cluster using the latest hsm1 backup. After you add the same number of HSMs to the hsm2 cluster as are in the hsm1 cluster, stop the application, reconfigure the CloudHSM client library to hsm2, and restart the application.
Create an hsm2 cluster from backup: CloudHSM makes periodic backups of your cluster at least once every 24 hours. If you need a more recent backup, follow the steps in Cluster backups in AWS CloudHSM to trigger a backup. If you created a backup retention policy when you created the cluster, that will determine how long the backups are retained before being purged. The default is 90 days.
After you have identified the backup, create an hsm2 cluster from the CloudHSM console or AWS CLI. For the console, choose HSM type hsm2m.medium and Cluster source as Restore cluster from existing backup and choose the designated backup of hsm1.
Update cluster for high availability: The new hsm2 cluster will have only one HSM instance. You can now add the same number of instances as hsm1 to this cluster. See adding an HSM to CloudHSM cluster. Based on your workload, add more HSMs to the cluster to ensure high availability. This is a good time to review the cluster to be sure that it follows best practices.
Reconfigure client SDKs: During the maintenance window, stop your application that is integrated with the CloudHSM client SDK, reconfigure the appropriate client SDK to talk to the new hsm2 cluster, and then restart the application. See Bootstrap the Client SDK to reconfigure the SDKs. An alternative to stopping and reconfiguring existing applications is to launch a new application instance with the CloudHSM client configured to talk to hsm2 and decommission the old application instance.
Monitor the application: Monitor your application’s health metrics and logs to verify that operations run against the new hsm2 cluster are successful. If you see increased errors, you can roll back to the hsm1 cluster and contact AWS Support for assistance.
Rollback: You can roll back by reconfiguring your application to communicate with the hsm1 cluster, similar to how you configured your application to talk to the hsm2 cluster.
Delete the hsm1 cluster: After you’re satisfied with your new hsm2 cluster, you can delete the hsm1 cluster to reduce costs. This action will create a backup that will be retained—CloudHSM doesn’t delete a cluster’s last backup.
High availability
If you need your CloudHSM cluster to be highly available during migration, AWS recommends that you follow the blue/green deployment methodology. The fundamental idea behind blue/green deployment is to shift traffic between two identical environments that are running different versions of a service or application. The blue environment represents the current version serving production traffic—the hsm1 cluster. The green environment is staged in parallel, running a different version of the service—an hsm2 cluster. After the green environment is ready and tested, production traffic is redirected from blue to green. If problems are identified, you can roll back by reverting traffic back to the blue environment.
We discuss two blue/green approaches in this post. Approach 1 uses a load balancer to route traffic between the blue and green configurations. Approach 2 uses CloudHSM multi-cluster configuration and requires application code changes. Each has pros and cons in terms of effort and cost.
If you have already implemented a multi-cluster configuration in your application, you can follow Approach 2; otherwise, we recommend Approach 1.
A few important things to keep in mind when you implement either of these approaches.
You need to create the hsm2 cluster from the hsm1 backup as described in Customer managed.
If you need to support write operations during migration, you will need to run additional processes to make sure the data is in sync between the blue and green clusters. See Use cases to learn about different scenarios and plan accordingly.
Approach 1
For this approach, you create two separate but identical client environments. One environment (blue) runs the current application and the client SDK that connects to the hsm1 cluster. The other environment (green) runs the same application with the client SDK configured to talk to the hsm2 cluster. You then use a load balancer—such as Application Load Balancer (ALB)—to selectively route traffic between blue and green using the weighted target groups routing feature of ALB or an equivalent feature in your load balancer.
You can start by directing a small percentage of your application traffic to green. When you’re confident that green is performing well and is stable, shift traffic to green and shut down blue.
Figure 1: Blue/green migration architecture
The following are the steps of the migration architecture shown in Figure 1:
Create an hsm2 cluster from an hsm1 backup as described in Customer managed. Make sure you create the new cluster in the same Availability Zones as the existing CloudHSM cluster. This will be your green environment.
Spin up new application instances in the green environment and configure them to connect to the new hsm2 cluster.
Add the new client instances to a new target group for the ALB.
Next, use the weighted target groups routing feature of ALB to route traffic to the newly configured environment.
Each target group weight is a value from 0 to 999. Requests that match a listener rule with weighted target groups are distributed to these target groups based on their weights.
You can follow the canary deployment pattern to roll out an hsm2 cluster integrated application to a subset of users before making it widely available while the hsm1 integrated application serves most of the users. To start, you can configure blue target group with a weight of 90 and green with 10; the ALB will route 90 percent of the traffic to the blue target group and 10 percent to green.
Monitor applications to verify that operations to green are successful (see Monitoring). After you’re satisfied with the response from green, you can update the weights to 0 and 100 for blue and green to completely switch over to green and then shut down blue.
This approach uses a single application environment that talks to both the hsm1 and hsm2 clusters. To shift traffic between blue and green environments, you will use the CloudHSM multi-cluster configuration, which allows a single client SDK to communicate with two or more CloudHSM clusters. Your application code needs to be modified to communicate with both blue and green clusters. In this post, we use a JCE SDK multi-cluster configuration, shown in Figure 2 that follows.
Figure 2: Multi-cluster migration architecture
The solution uses the basic blue/green deployment steps using a multi-cluster configuration and is designed for common use cases based on the type of CloudHSM operations performed during migration. We also cover how keys can be synchronized between the blue and green clusters and how to roll back.
Create an hsm2 cluster from an hsm1 backup
As described in Customer managed, create an hsm2 cluster from an hsm1 backup. Make sure you create the new cluster in the same Availability Zones as the existing CloudHSM cluster. This will be your green environment.
Modify the application to talk to both blue and green
In this step, you modify the application to use multi-cluster configuration to talk to both blue and green. When using a multi-cluster configuration, you need to configure the CloudHSM provider in the code instead of using the default config file.
In the application code, instantiate two providers: providerHsm1 pointing to blue cluster and providerHsm2 pointing to green cluster. Then update the business logic to switch traffic between blue and green using these providers.
Monitor the application to verify that operations on green are successful. See the Monitoring section. Once you are satisfied with response from green, you can update the application code to completely switch over to green.
Monitoring
During migration to hsm2, it’s important to monitor your application to confirm it’s working as expected and roll back if you notice increased errors. You can use your application logs and the CloudHSM client SDK logs to monitor the application.
Depending on the type of operations you perform on your CloudHSM cluster during migration, you need to run additional processes to make sure the data is in sync between the blue and green clusters. This will help avoid the split-brain scenario where blue and green clusters are in an inconsistent state if a write operation is performed during migration.
Read-only operations
During migration, if you only need to perform read operations—meaning you aren’t creating token keys—then the data between the clusters will be consistent. You can switch over to green completely following the blue/green-deployment methodology in Approach 1 or Approach 2.
Create/delete operations
If token keys need to be created during migration, the blue and green clusters need to be synchronized to make sure that read operations to the clusters are successful.
Write to blue: Initially, create operations can be directed to blue and read operations to both blue and green. In this case, the newly created keys need to be replicated to green. You can use the CloudHSM CLI key replicate command to synchronize keys. See Replicate keys.
Write to green: After you gain confidence in the read capability of the green cluster, you could begin swapping over the application to do write operations against the green cluster. In this case, if you’re still reading from both blue and green, you can replicate keys to blue using the CloudHSM CLI key replicate. See Replicate keys.
Replicate keys
Keys can be replicated between CloudHSM clusters that are created from the same backup using CloudHSM CLI with multi-cluster configuration.
Make sure that key owners and users that the key is shared with exist in the destination. Also, the crypto user or admin performing the operation needs to sign in to both clusters.
Run the key replicate command to replicate the keys from blue to green or vice versa as shown in the following example.
List keys in hsm1:
crypto_user@cluster-<hsm1ClusterID> > key list --cluster-id cluster-<hsm1ClusterID>
List keys in hsm2:
crypto-user@cluster-<hsm1ClusterID> > key list --cluster-id cluster-<hsm2ClusterID>
The complexity of a rollback will depend on the stage of the migration and what keys were created. Normally, whether it’s during the migration or after, if you aren’t using hsm2-specific features such as new key attributes, then the rollback is straightforward. During the migration, if a rollback is needed, you can point your application back toward the hsm1 cluster. Through this approach, reads and writes will revert to happening on just the hsm1 and the rollback will be complete. If you created keys in only hsm2, you can replicate them back to hsm1.
The other scenario for a rollback is if you cannot replicate keys back to the hsm1 cluster. This can happen if you have fully migrated your application to hsm2 and have created more than 3,300 keys (the limit for hsm1) or are using hsm2-specific features. In this scenario, you need to make application changes to return to a multi-cluster setup where reads are performed against both hsm1 and hsm2 clusters (in case the keys exist in only hsm2), but write operations happen solely on the hsm1. In this case, the recommendation is to continue talking to both clusters and keep them in sync until non-replicable keys are no longer needed and the cluster can be scaled back down.
Conclusion
In this post, we described strategies to migrate a hsm1.medium CloudHSM cluster to hsm2m.medium. We explored commonly used blue/green deployments and AWS CloudHSM provided options. We also explored common use cases, steps to avoid common pitfalls, and rollback options.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Network monitoring provides essential visibility into cloud application traffic patterns across large organizations. It enables security and compliance teams to detect anomalies and maintain compliance, while allowing development teams to troubleshoot issues, optimize performance, and track costs in multi-tenant software as a service (SaaS) environments. Implementing robust network monitoring allows organizations to effectively manage their security, compliance, and operational requirements while continuously enhancing their applications.
In this post, you will learn methods for network monitoring in AWS Lambda functions and how to apply them to your scenarios.
Overview
Lambda is a secure and highly scalable serverless compute service where each function operates in an isolated execution environment with strict security boundaries. This architecture delivers key advantages, such as enhanced security, automatic compute capacity scaling, and minimal operational overhead. Minimizing infrastructure management allows Lambda to enable organizations to redirect their focus from managing servers to other critical aspects, such as performance optimization and network traffic analysis. In turn, these enable organizations to build more secure and efficient applications.
Lambda network monitoring addresses diverse organizational needs, such as compliance requirements for audit logs and anomaly detection, business needs for traffic metering and customer billing, and development needs for troubleshooting network issues. Traditional agent-based or host-based monitoring methods often aren’t compatible with the strongly isolated, ephemeral execution environment of Lambda, which necessitates alternative approaches to meet these critical requirements.
You can use AWS-native, integrated network monitoring solutions, such as Amazon Virtual Private Cloud (Amazon VPC) Flow Logs, or build your own custom solution, as detailed in this post. Each solution offers distinct capabilities with varying levels of granularity and real-time visibility. When choosing an approach, you must evaluate key factors such as the desired data granularity, operational complexity, latency tolerance, and cost implications.
Using VPC Flow Logs
VPC Flow Logs is the AWS-recommended tool for network activity monitoring. If your scenario necessitates monitoring of the network activity of Lambda functions, then you can attach these functions to a VPC and enable Flow Logs. This captures detailed network traffic data, such as source and destination IPs, ports, protocols, and traffic volume for all traffic flowing through the network interfaces used by your functions.
When you attach your functions to a VPC, the Lambda service automatically creates an Elastic Network Interface (ENI) for functions to communicate with VPC-based resources. By default, VPC-attached functions can only access private resources within the VPC. If you need your functions to communicate with other AWS services, then you should use VPC Endpoints. If your function needs to communicate with the public internet, then you should use an NAT Gateway for egress traffic. The following diagram shows how you can use VPC Flow Logs for Lambda functions.
Flow Logs provide detailed insights into the IP traffic flowing to and from the network interfaces within a VPC, offering valuable data for network audits and activity monitoring. This approach promotes a clear separation of concerns between application and networking layers, with VPC constructs typically managed by a dedicated operations or infrastructure team.
VPC Flow Logs provides a robust network monitoring solution. However, when using it with Lambda functions, you should evaluate the following considerations:
It captures ENI-level information. ENIs can be reused across multiple functions, thus it won’t provide per-function or per-invoke granularity.
It only logs IP addresses, not DNS names (if capturing DNS names is a requirement for you).
It introduces infrastructure management into your serverless applications. You must learn VPC constructs or involve your infrastructure team.
The following sections explore Lambda network monitoring methods that can either be augmented with VPC Flow Logs for better granularity or used without attaching your functions to a VPC.
Proxying network traffic
You can configure the Lambda runtime to route egress network traffic through a side-car proxy that runs as a Lambda layer within the Lambda execution environment and logs network activity. The proxy layer should be agnostic to the language runtime. AWS recommends that you use compiled languages such as Rust or Golang for maximum reusability and minimal added latency. The following diagram shows emitting logs from a network proxy layer.
Applying proxy configuration differs across language runtimes. In Python you set proxy_http and proxy_https environment variables. Java uses JVM flags. Node.js doesn’t provide a native way to configure proxy using command line flags or environment variables. Therefore, you need to make code changes, such as configuring a proxy for your AWS SDK or using a third-party open source libraries such as global-agent or Interceptors.
The proxy approach is most suitable if you’re okay with making function code or configuration changes that might vary across runtimes. Furthermore, adding a network proxy server process inside the execution environment consumes resources shared with the function code, which can add network latency.
Following techniques use the fact that the Lambda execution environment is a Linux-based micro-VM. Lambda runtimes operate within a restricted user space that prevents the use of traditional OS-level monitoring tools needing elevated privileges, such as tcpdump, iptables, ptrace, or eBPF. The following techniques are specifically designed to work under these user space constraints, allowing their use without needing elevated privileges.
Reading OS networking layer information from procfs
Use this method when you need to obtain the OS-level information, such as metering transferred bytes, or see all open connections. You can use it to implement tenant chargebacks or detect network traffic pattern changes. The method is based on the proc pseudo-filesystem (also known as procfs) available in Linux OS, which provides an interface to kernel data and allows you to read OS-level information. For example, /proc/cpuinfo and /proc/meminfo pseudo-files provide information about current CPU and memory usage, while /proc/net/* provides you with network layer information. Reading /proc/net/tcp and /proc/net/udp gives you a list of active TCP/UDP connections, such as remote IP addresses and ports. Reading /proc/net/dev provides the list of network devices with detailed usage statistics, such as bytes transferred and received.
“The procfs method provides a simple but powerful way to collect critical network telemetry data from Lambda functions, such as up-to-date network statistics and file descriptor counts, which enables us to monitor outbound connections from Lambda functions. Better yet, it enables us to support multiple Lambda runtimes with a single implementation in our Rust-based, next-generation Lambda Extension”—AJ Stuyvenberg, Staff Engineer at Datadog.
The sample project provides the LambdaNetworkMonitor-Procfs stack to show this technique. For every invocation, the function reads /proc/net/dev, and sends network statistics to log and Amazon CloudWatch Metrics, as shown in the following figure.
Reading the /proc/net/dev pseudo-file is a simple and effective way to monitor Lambda functions networking without adding latency. However, it doesn’t capture DNS names and the IP addresses to which they resolve.
Intercepting network-related libc calls
Low-level network operations in Linux, such as DNS lookup and connection creation, are managed by the C Standard Library (libc). You can intercept libc function calls made by Lambda runtimes to monitor network traffic at the OS level. This is a significantly more advanced and complex mechanism, enabling visibility into OS-level activities, as shown in the following figure.
Intercepting libc function calls, such as getaddrinfo (DNS lookup) and connect, allows you to log details such as DNS name, IP addresses, ports, and protocols at a granular level, as shown in the following figure. This method allows you to capture comprehensive information about DNS queries and initiated network connections. It can provide precise per-function and per-invoke network monitoring, such as hostnames and IP addresses.
The runtime calls libc getaddrinfo to resolve the DNS name.
You intercept this call, log the DNS name, and forward the call to the original libc getaddrinfo.
The original libc getaddrinfo returns resolved IP addresses. You log them and return to the runtime.
The runtime calls libc connect method to create a new connection.
You intercept this call, log the IP address, forward the call to the original libc connect, and so on.
To implement this technique, you need to use a language that compiles to a shared object (.so) file. To implement libc method signatures you should use a language such as C, C++, or Rust. The following sample code uses Rust for its strong safety guarantees and implements overriding the getaddrinfo libc function (DNS lookup).
The method signature fully matches the libc function signature of the same name.
The node and service arguments would commonly be DNS name and port.
At the end, the function invokes the real libc getaddrinfo and returns the result.
When compiled to an .so file, you must package it as a Lambda layer, attach the layer to your functions, and configure the execution environment to use it through the Linux dynamic linker capability called preloading. Set the LD_PRELOAD environment variable to point to your .so file to instruct the OS to preload it before it loads any other library, such as libc. You can configure this either as a function environment variable or through a wrapper script, as shown in the following figure.
This technique allows you to get detailed connection-level monitoring such as DNS lookups, resolved IP addresses, ports, protocols, and count bytes transferred. Depending on your requirements, it can be adapted to track further network-related information as needed.
The sample project provides the LambdaNetworkMonitor-LdPreload stack to show this technique, as shown in the following figure. For every invocation, the function prints intercepted libc functions, DNS names, and connection IP addresses.
Considerations
OS-level techniques necessitate strong understanding of Linux fundamentals and careful implementation. AWS recommends that you closely evaluate which methods to use and keep your solution minimally invasive.
LD_PRELOAD is an advanced low-level technique that allows you to override libc methods and OS behavior. Incorrectly implemented hooks could lead to undefined behavior and crashes. Make sure your code is robust to recursion and thread-safe. Test it thoroughly in a controlled environment before using it in production.
The LD_PRELOAD technique relies on dynamic linking. It works with dynamically linked runtimes such as Node.js, Python, and Java. It doesn’t work with runtimes that use static linking, such as Golang.
When using runtime-dependent functionality, consider using Lambda runtime update controls to make sure that runtimes are only updated when the next function update occurs.
Always install layers from trusted sources only. Use infrastructure as code (IaC) tools to attach and audit layer configurations, such as AWS Identity and Access Management (IAM) permissions.
Conclusion
Monitoring network traffic in Lambda functions is a common requirement for many organizations. In case you need to audit IP-level network logs, AWS recommends that you to attach your functions to a VPC and use Flow Logs. If you need per-function or per-invoke granularity, then you can augment it with techniques described in this post.
These techniques provide valuable insights for debugging, auditing, and monitoring, but they also necessitate a solid understanding of Linux fundamentals and careful implementation. They offer a practical solution for organizations that need Lambda network monitoring, allowing them to troubleshoot issues and maintain compliance.
To learn more about Serverless architectures and asynchronous Lambda invocation patterns, go to Serverless Land.
Because security logging data sources continually grow, organizations need to provide a mechanism for their security teams to understand and query those data sources. You might have existing investigation and response playbooks that your security teams need to be well-versed in and know when to use. It can take security teams an extended period of time to onboard and understand the available security data sources and playbooks and how to efficiently use them to reduce the mean time to respond.
In this post, we show you how to extend the functionality from the previous post. You will learn how to deploy a security chatbot with a graphical user interface (GUI) and a serverless backend powered by an Amazon Bedrock agent that incorporates existing playbooks to investigate or respond to a security event. The chatbot demonstrates purpose-built Amazon Bedrock agents that help address security concerns depending on the user’s natural language input. The solution has a single GUI that provides a direct interface with the Amazon Bedrock agent to create and invoke SQL queries or provide recommendations for internal incident response playbooks to investigate or respond to possible security events.
The Lambda function invokes the Amazon Bedrock agent with the user’s query.
The Amazon Bedrock agent (using Anthropic’s Claude 3 Sonnet) processes the query and decides between retrieving information from the playbooks or by querying Security Lake using Amazon Athena.
For playbook knowledge base queries:
The Amazon Bedrock agent queries the playbooks knowledge base and retrieves relevant results.
For Security Lake data queries:
The Amazon Bedrock agent queries the schema knowledge base and retrieves the Security Lake table schemas to create an SQL query.
The Amazon Bedrock agent invokes the SQL query action from the Amazon Bedrock action group, passing the SQL query as a parameter.
The action group invokes the Execute SQL on Athena Lambda function, which executes the query on Athena and returns the results to the Amazon Bedrock agent.
After retrieving results from the knowledge base or action group:
The Amazon Bedrock agent uses the retrieved information to formulate the final response and sends it back to the Invoke Agent Lambda function.
The Lambda function sends the response back to the client using an API Gateway WebSocket API.
API Gateway delivers the response to the React UI using a WebSocket connection to the client.
The agent’s response is displayed to the user in the chat interface.
Prerequisites
Before deploying the sample solution, complete the following prerequisites:
Create a database link in AWS Lake Formation in the subscriber AWS account and grant access for the Athena tables in the Security Lake AWS account.
Grant Anthropic’s Claude v3 model access for Amazon Bedrock in the AWS subscriber account where you will deploy the solution. If you try to use a model before you enable it in your AWS account, you will get an error message.
With the prerequisites in place, the sample solution architecture provisions the following resources:
A Lambda function to invoke the Amazon Bedrock agent.
An Amazon Bedrock agent with a knowledge base.
An Amazon Bedrock agent action group to generate and invoke SQL queries on Athena.
An Amazon Bedrock knowledge base to reference example Athena table schemas in Security Lake. Although the Amazon Bedrock agent can get rows directly from the Athena table, providing example table schemas improves SQL query generation accuracy for table columns in Security Lake.
An Amazon Bedrock knowledge base to reference existing incident response playbooks. By incorporating this knowledge base, the Amazon Bedrock agent can suggest actions for investigation or response based on existing playbooks that have already been approved by your organization.
Cost
Before deploying the sample solution and walking through this post, it’s important to understand the cost of the AWS services being used. The cost will largely depend on the amount of data you interact with in Amazon Bedrock and by querying Security Lake with Athena.
Amazon Bedrock on-demand pricing is based on the selected large language model (LLM) and the number of input and output tokens. A token is comprised of a few characters and refers to the basic unit of text that a model learns to understand the user input and prompts. For more details, see Amazon Bedrock pricing.
The SQL queries generated by Amazon Bedrock are invoked using Athena. Athena cost is based on the amount of data scanned within Security Lake for that query. For more details, see Athena pricing.
Build and deploy the app using the following commands:
npm install -g aws-cdk
npm install
cdk synth
Run the following commands in your terminal while signed in to your subscriber AWS account. Replace <INSERT_AWS_ACCOUNT> with your account number and replace <INSERT_REGION> with the AWS Region that you want the solution deployed to.
As part of the CDK deployment, there is an Output value for the React Application URL (FrontendAppStack.ReactAppUrl). You will use this value to interact with the GenAI application. Wait up to 5 mins for the URL to be live.
Post-deployment configuration steps
Now that you’ve deployed the solution, you need to add permissions to allow the Lambda function’s AWS Identity and Access Management (IAM) role and Amazon Bedrock to interact with your Security Lake data.
Grant permission to the Security Lake database
Copy the Lambda’s role ARN from the “BedrockAppStack” CloudFormation stack. The resource in the stack is named “athenaAgentSecurityLakeActionGroupLambdaServiceRole********”.
Go to the Lake Formation console.
Select the amazon_security_lake_glue_db_<YOUR-REGION> database. For example, if your Security Lake is in us-east-1, the value would be amazon_security_lake_glue_db_us_east_1
For Actions, select Grant.
In Grant Data Permissions, select SAML Users and Groups.
Paste the Lambda function IAM role ARN from Step 1.
In Database Permissions, select Describe, and then choose Grant.
Grant permission to Security Lake tables
You must repeat the following steps for each source configured within Security Lake. For example, if you have four sources configured within Security Lake, you must grant permissions for the Lambda function IAM role to each table. If you have multiple sources that are in separate Regions and you don’t have a rollup Region configured in Security Lake, you must repeat the steps for each source in each Region.
The following example grants permissions to the Security Hub table within Security Lake. For more information about granting table permissions, see the AWS Lake Formation user guide.
Copy the Lambda’s role ARN from the “BedrockAppStack” CloudFormation stack. The resource in the stack is named as “athenaAgentSecurityLakeActionGroupLambdaServiceRole********”.
Go to the Lake Formation console.
Select the amazon_security_lake_glue_db_<YOUR-REGION> database. For example, if your Security Lake database is in us-east-1, the value would be amazon_security_lake_glue_db_us_east-1
Choose View Tables.
Select the amazon_security_lake_table_<YOUR-REGION>_sh_findings_1_0 table. For example, if your Security Lake table is in us-east-1, the value would be amazon_security_lake_table_us_east_1_sh_findings_1_0
Note: Each table must be granted access individually. Selecting All Tables won’t grant the access needed to query Security Lake.
For Actions, select Grant.
In Grant Data Permissions, select SAML Users and Groups.
Paste the Lambda function IAM role ARN from Step 1.
In Table Permissions, select Describe, and then Grant.
Sync data sources
After you deploy the infrastructure, you need to sync the data sources in the Amazon Bedrock knowledge bases so that the data in Amazon S3 can be vectorized and made available in Amazon OpenSearch Serverless, which is the service used as a vector source by the knowledge bases in this solution.
In the Amazon Bedrock console, select Knowledge base and find the two Amazon Bedrock knowledge bases deployed in this solution: gen-ai-sec-lake-table-schema and gen-ai-sec-lake-runbooks. Navigate to each knowledge base and its data source. Then choose Sync for each data source.
In the Stacks section, select the FrontendAppStack.
Select the Outputs tab.
Copy the value ReactAppUrl.
Investigate with your security chatbot
Now that you’ve deployed the sample solution and configured the appropriate permissions, you’re ready to use natural language input to generate and invoke SQL queries and to recommend internal incident response playbooks.
Generate and invoke SQL queries
Although most security professionals already know how to create and invoke SQL queries, time is extremely important during a possible security event. Adding natural-language-to-SQL capability to the security agent can help reduce your mean time to respond, which can reduce the overall impact of a security event. Furthermore, you can use these same techniques for threat hunting in your AWS environment.
Question 1: Which AWS accounts have the most security findings for EC2 instances in the last 7 days?
Answer 1: The query results show the top two AWS accounts with the most security findings related to EC2 instances in the last 7 days. The account with ID XXXXXX10 had the highest number of findings at 252, followed by account XXXXXX28 with 197 findings.
The query covered the key requirements, so I provided the final answer summarizing the top accounts and their finding counts.
The question and response are shown in Figure 2.
Figure 2: Response for most EC2 security findings
The more context you provide to the chatbot, the better the query that will be generated. Providing a time window also gives a smaller data set to review and give quicker results.
Question 2: In those AWS accounts, what were the top EC2 security finding types?
Answer 2: Based on the query results, the top EC2 security finding types in the AWS accounts with the most EC2 instance findings in the last 7 days were:
For account XXXXXX10:
“Compliance Finding: Update” with 252 findings
For account XXXXXX28:
“Compliance Finding Update” with 166 findings
“Compliance Finding Create” with 24 findings
“Vulnerability Finding: Update” with 2 findings
“Vulnerability Finding: Create” with 2 findings.
The question and response are shown in Figure 3.
Figure 3: Response for top EC2 security finding types
The results show that the issues are primarily around Security Hub controls mapped to the type_name OCSF column. If you want to look at a different column, you can provide additional instructions or update the question.
Question 3: Which EC2 instances had vulnerability security findings?
Answer 3: Based on the query results, the following EC2 instances had vulnerability security findings in the AWS account with the most EC2 instance findings in the last 7 days:
As part of this sample solution, we used the AWS Incident Response Playbook Samples GitHub repository and uploaded them to an S3 bucket. Alternatively, you can create or reference your own playbooks to investigate and respond to various security events to refer to. After each question, the chatbot provides an answer along with an Amazon S3 URL to the playbook. The security analyst must have the appropriate permissions to download the playbook from Amazon S3.
Question 1: Do I have any playbooks that would help investigate a compromised EC2 instance for crypto mining or malware?
Answer 1: Yes, the search results include a relevant playbook for investigating a potentially compromised EC2 instance that could be used for crypto mining, malware, or ransomware. The key steps outlined in the playbook are:
Acquire, preserve, and document evidence – Identify indicators of compromise, determine attack vector, document impacted applications/users
Contain the incident – Isolate the compromised instance if possible without service disruption, remove from auto-scaling group if applicable
Eradicate the incident – Follow the steps to remove the malware/crypto miner, restore from known good backups/AMIs
Recovery – Spin up new instances from trusted AMIs, restore the data, and monitor for persistence of the threat
Lessons learned – Analyze the incident, identify root causes, and implement preventative measures
The playbook provides detailed guidance on each of these phases in the context of an EC2 ransomware incident, but the overall process can be adapted for investigating crypto mining, malware, or other threats on EC2 as well.
The question and response are shown in Figure 5.
Figure 5: Response for EC2 IR playbooks
The previous threat-hunting exercise identified two EC2 instances that had vulnerabilities present. After further investigation, if a security analyst believes the EC2 instance is compromised, they can ask for an IR playbook to respond to the security event. Once they determine which playbook makes the most sense, they can either click on the S3 URL or look at other playbooks to use.
Question 2: Do I have any playbooks that would help respond to ransomware in my S3 bucket?
Answer 2: Yes, the search results include a playbook that can help respond to a ransomware incident involving an S3 bucket. The “Incident Response Playbook Template for Unintended Access to an Amazon S3 Bucket” outlines steps for:
Gathering evidence of the unintended access
Containing the incident by restricting access to the affected bucket(s)
Eradicating the issue by removing any malicious data/objects and restoring from backup
Recovering by re-enablement access to the bucket for legitimate users
Conducting post-incident activities like reviewing logs, determining root cause, and implementing preventative measures
While focused on generic unintended access rather than ransomware specifically, many of these steps could be adapted and applied to a ransomware scenario targeting data in S3. The playbook provides a solid framework for incident response on S3.
Additionally, the general “Ransomware Incident Response Playbook” template covers common steps for any ransomware incident, such as:
Acquiring and preserving evidence of the ransomware infection
Containing the incident by isolating affected systems
Identifying and remove the ransomware
Recovering data from backups or known good sources
Conducting post-incident review
While not S3-specific, this playbook provides complementary guidance that could be used in conjunction with the S3 access playbook for an S3 ransomware incident.
The question and response are shown in Figure 6.
Figure 6: Response for S3 ransomware IR playbooks
The response provides a high-level overview of the specific playbook that’s being referenced to provide the analyst with context before diving deeper into any single playbook.
Adding functionality to the security chatbot
This sample solution was developed to show the art of the possible. Each customer uses AWS resources to address their business needs in their own way, and security teams must be appropriately equipped to help secure their respective environments. Here are some possible enhancements that you can incorporate into the sample solution to align to your security use-cases and needs.
Incorporate an Amazon DynamoDB table to use as part of reporting interactions tied to a specific event or finding GUID. By incorporating an audit trail, you can tie actions taken by the agent and associated resources to a security event and validate the outcome of the investigation before taking action.
Tuning the backend chatbot agent to take natural language requests and respond with detectors or correlation rules for Amazon OpenSearch or query language for custom detections in your security information and event management (SIEM) tool.
Adding a new data source to Athena, such as AWS Config, to provide the analyst with additional capabilities to query AWS resource configuration across the AWS environment that might have been impacted by a security event. For example, if a security finding shows that an S3 bucket has been made public, querying what and when other configuration changes were made to the S3 bucket.
Incorporating multi-agent-orchestration to scale the use of multiple Amazon Bedrock agents that can be tuned towards niche security use cases by respective teams. The chatbot can speak directly to a classifier or controller, which then addresses the user’s natural language request and orchestrates across one or more agents to generate a response. For example, if a user asks which EC2 instances might have been impacted by a security event and which playbook to use to respond, the classifier agent could direct the initial query to the agent in this sample solution. In the same chat window, the analyst could ask if there are any open CVEs for the EC2 instances in scope to get a list of CVEs to address within the AWS account.
If you deployed the security chatbot sample solution by using the Launch Stack button and the console with the CloudFormation template security_genai_chatbot_cfn, do the following to clean up:
In the CloudFormation console for the account and Region where you deployed the solution, choose the SecurityGenAIChatbot stack.
Choose the option to Delete the stack.
If you deployed the solution by using the AWS CDK, run the command cdk destroy --all.
Conclusion
The sample solution demonstrates how you can use task-oriented Amazon Bedrock agents and natural language input to help accelerate investigation and analysis and increase your overall security posture. We provided an example of a sample solution with a user interface that is powered by an Amazon Bedrock agent, which you can extend to add additional task-oriented agents, each with their own instructions, knowledge bases, and models. By extending the use of AI-powered agents, you can help your security team operate more efficiently across multiple security domains within your AWS environment.
The backend for the chatbot to investigate security events uses Security Lake, which normalizes data into Open Cybersecurity Schema Framework (OCSF); as long as the data schema is normalized, the solution can be applied to other data lakes within your AWS environment.
To learn more, see the other posts in this series:
Organizations often need to securely share files with external parties over the internet. Allowing public access to a file transfer server exposes the organization to potential threats, such as malware-infected files uploaded by threat actors or inadvertently by genuine users. To mitigate this risk, companies can take steps to help make sure that files received through public channels are scanned for malware before processing.
This post demonstrates how to use AWS Transfer Family and Amazon GuardDuty to scan files uploaded through a secure FTP (SFTP) server for malware as part of an overall transfer workflow. For readers who might have read an earlier blog post on this topic, the key difference is that this solution is fully managed and doesn’t require the deployment of compute resources. GuardDuty automatically updates malware signatures every 15 minutes instead of using a container image for scanning, avoiding the need for manual patching to keep the signatures up to date.
Prerequisites
To deploy the solution in this post, you will need:
An AWS account: You need access to AWS to deploy this solution. If you don’t have an account that you can use, see Start building on AWS today.
AWS CLI: Install and configure the AWS Command Line Interface (AWS CLI) to be authenticated to your AWS account. Set up the environment variables for your AWS account using the access token and secret access key for your environment.
Git: You will use Git to pull down the example code from GitHub.
Terraform: You’ll use Terraform to run the automation. Follow the Terraform installation instructions to download and set up Terraform.
Solution overview
This solution uses Transfer Family and GuardDuty. Transfer Family provides a secure file transfer service that you can use to set up an SFTP server, and GuardDuty is an intelligent threat detection service. GuardDuty monitors for malicious activity and anomalous behavior to protect AWS accounts, workloads, and data. At a high level, the solution uses the following steps:
A user uploads a file through a Transfer Family SFTP server.
The workflow begins only after a successful file upload.
Partial uploads to the SFTP server will invoke an error handling Lambda function to report a partial upload error.
A step function state machine invokes a Lambda function to move uploaded files to an Amazon Simple Storage Service (Amazon S3) bucket for processing and then starts scanning using GuardDuty.
The GuardDuty scan result is sent as a callback to the step function.
Infected files are moved or cleaned.
The workflow sends the user the results through an Amazon Simple Notification Service (Amazon SNS) topic. This can be a notification of an error or malicious upload during the scan or notification of a successful upload and a clean scan for further processing.
Solution architecture and walkthrough
The solution uses GuardDuty Malware Protection for S3 to scan newly uploaded objects to the S3 bucket. You can use this feature of GuardDuty to set up a malware protection plan for an S3 bucket at the bucket level or to watch for specific object prefixes.
Figure 1: Solution architecture
The following steps (shown in Figure 1) describe the workflow for this solution starting from the point the file is uploaded until it’s scanned and marked as safe or as infected, leading to subsequent steps that can be customized based on your use case.
A file is uploaded using the SFTP protocol through Transfer Family.
If the file is successfully uploaded, Transfer Family uploads the file to the S3 bucket called Unscanned and the Managed Workflow Complete workflow is triggered. This is the workflow used to handle successful uploads and invokes the Step Function Invoker Lambda function.
The Step Function Invoker starts the state machine and kicks off the first step in the process by invoking the GuardDuty – Scan Lambda function.
The GuardDuty – Scan function moves the file to the Processing bucket. This is the bucket from which the files will be scanned.
When an object upload activity is detected, GuardDuty automatically scans the object. In this implementation, a malware protection plan is created for the Processing bucket.
When a scan completes, GuardDuty publishes the scan result to Amazon EventBridge.
An EventBridge rule has been created to invoke a Lambda Callback function whenever a scan event has completed. EventBridge will invoke the function with an event that contains the scan results. See Monitoring S3 object scans with Amazon EventBridge for an example.
The Lambda Callback function notifies the GuardDuty – Scan task using the callback task integration pattern. The results of the GuardDuty scan are returned to the GuardDuty – Scan function and these results are passed to the Move File task.
If the result is a clean scan with no threats detected, the Move File task will place the file in the Clean S3 bucket, indicating that the file is successfully scanned and safe for further processing.
At this point, the Move File function publishes a notification to the Success SNS topic to notify the subscribers.
If the result indicates that the file is malicious, the Move File function will instead move the file to the Quarantine S3 bucket for further investigation. The function will also delete the file from the Processing bucket and publish a notification in the Error topic in SNS to notify the user of a potential malicious file being uploaded.
If the file upload is unsuccessful and the file isn’t fully uploaded, then Transfer Family will trigger the Managed Workflow Partial workflow.
Managed Workflow Partial is an error handling workflow and invokes the Error Publisher function, which is used for reporting errors that occur anywhere in the workflow.
The Error Publisher function identifies the type of error—whether it’s because of the partial upload or an issue elsewhere in the workflow—and sets the error status accordingly. It will then publish an error message to Error Topic in SNS.
The GuardDuty – Scan task has a timeout to make sure that an event is published to Error Topic to prompt a manual intervention to investigate further if the file isn’t successfully scanned. If the GuardDuty – Scan task fails, the Error clean up Lambda function is invoked.
Finally, there’s an S3 Lifecycle policy attached to the Processing bucket. This is to make sure that no file is left in the Processing bucket for more than one day.
Code repository
The GitHub AWS-samples repository has a sample implementation developed using Terraform and Python-based Lambda functions to implement this solution. The same solution can also be implemented using AWS CloudFormation. The code has the components needed to deploy the entire workflow to demonstrate the abilities of Transfer Family and the GuardDuty malware protection plan.
Install the solution
Use the following steps to deploy this solution to your test environment.
Clone the repository to your working directory using Git.
Navigate to the root directory of your cloned project directory.
Update the terraform locals.tf file with the values of your choice for the S3 bucket names, SFTP server names, and other variables.
Run terraform plan.
If everything looks good, run a terraform apply and enter yes to create the resources.
Clean up
After testing and exploring the solution, it’s important to clean up the resources you created to avoid incurring unnecessary costs. To delete the resources created by this solution, navigate to the root directory of your cloned project and run the following command:
terraform destroy
This command will remove the resources created by Terraform, including the SFTP server, S3 buckets, Lambda functions, and other components. Confirm the deletion by entering yes when prompted.
Conclusion
By using the approach outlined in the post, you can make sure that the files received over SFTP and uploaded to your S3 bucket are scanned for threats and are safe for further processing. The solution reduces the exposure surface by making sure that public uploads are scanned in a safe environment before they’re sent to other components of your system.
If you have feedback about this post, submit comments in the Comments section below.
Introduced at re:Invent 2022, SnapStart is a performance optimization that makes it easier to build highly responsive and scalable applications using AWS Lambda. The largest contributor to startup latency (often referred to as cold-start time) is the time spent initializing a function. This includes loading the function’s code and initializing dependencies. For latency-sensitive workloads such as APIs and real-time data processing applications, high startup latency can result in a suboptimal end user experience. Lambda SnapStart can reduce startup duration from several seconds to as low as sub-second, with minimal or no code changes. This post discusses ‘Priming’, a technique to further optimize startup times for AWS Lambda functions built using Java and Spring Boot.
Spring Boot applications typically experience high cold start latency during JVM and framework initialization, where significant time is spent loading classes and performing Just-In-Time (JIT) compilation of Java bytecode. This blog post uses a Spring Boot application as an example that retrieves 10 records from a ‘UnicornEmployee’ table in an Amazon RDS for PostgreSQL database, where each employee record includes employee name, location, and hire date.
The sample application uses Amazon API Gateway which triggers an AWS Lambda function that connects to the database through RDS Proxy to return the employee data. While this sample application uses dummy employee data for demonstration, the patterns and optimization techniques discussed in this post are applicable to real-world scenarios with similar data access patterns. Sample code for this implementation can be found in our GitHub repository at lambda-priming-crac-java-cdk.
Background: How SnapStart works
The post assumes familiarity with SnapStart and provides a short background. For additional details, refer to the SnapStart documentation.
To quickly recap, the INIT phase for a Lambda function involves downloading the function’s code, starting the runtime and any external dependencies, and running the function’s initialization code. For functions that don’t use SnapStart, this phase occurs each time your application scales up to create a new execution environment. When SnapStart is activated, the INIT phase happens when you publish a function version.
The following image shows a comparison of a Lambda request lifecycle with and without SnapStart.
Figure 1 – comparison of a Lambda request lifecycle with and without SnapStart
At the end of the INIT phase, Lambda executes your before-checkpoint runtime hooks. Lambda then snapshots the memory and disk state of the initialized execution environment, persists the encrypted snapshot, and caches it for low-latency access. When the function is subsequently invoked, new execution environments are resumed from the cached snapshot (during the RESTORE phase), speeding up function startup.
Figure 2 – new execution environments are resumed from the cached snapshot.
You can validate this speedup by comparing the RESTORE duration with the INIT duration recorded before SnapStart in your Lambda function’s Amazon CloudWatch Logs. As demonstrated in the following table, enabling SnapStart reduces the startup latency of our sample Spring Boot application by 4.3x from 6.1s to 1.4s. The 6.1s cold start latency for ON_DEMAND is primarily due to the combination of (1) initializing the JVM and Spring Boot framework, (2) JIT compilation of lazy loaded application code during initial invocation and (3) the time needed to establish a database connection with RDS through Amazon RDS Proxy. By enabling SnapStart, Lambda initializes the JVM and Spring Boot prior to the function invocation – resulting in the significantly reduced latency of 1.4s.
Method
Cold Start Invocations
p50
P90
P99
p99.9
PrimingLogGroup-1_ON_DEMAND
128
5047.94 ms
5386.78 ms
6158.80 ms
6195.84 ms
PrimingLogGroup-2_SnapStart_NO_PRIMING
111
1177.87 ms
1288.73 ms
1419.94 ms
1425.63 ms
You can reduce cold starts even further for your latency-sensitive Spring Boot applications by using priming techniques on Lambda functions. Let’s explore how to implement priming techniques.
Priming explained
Priming is the process of preloading dependencies and initializing resources during the INIT phase, rather than during the INVOKE phase to further optimize startup performance with SnapStart. This is required because Java frameworks that use dependency injection load classes into memory when these classes are explicitly invoked, which typically happens during Lambda’s INVOKE phase. You can proactively load classes using Java runtime hooks, that are part of the open source CRaC (Coordinated Restore at Checkpoint) project. This post demonstrates how to use this hook, called beforeCheckpoint(), to prime SnapStart-enabled Java functions, in two ways:
Invoke Priming: This approach involves directly invoking application endpoints or methods in your pre-snapshotting hook so that they are JIT compiled during the INIT phase and included in the snapshot. This can include operations such as invoking API Gateway endpoints or fetching data from an S3 bucket or RDS database to proactively execute the code paths, ensuring that the underlying classes are included in the snapshot.
Class Priming: This approach involves proactive initialization of classes during the INIT phase, ensuring that they are included in the function’s snapshot without risking unwanted changes to application state or data. This can be achieved by leveraging Java’s forName() method, which loads, links, and initializes the specified class. Initialization refers to the JVM process of loading the class definition into memory, verifying the bytecode, preparing static fields with default values, and executing static initializers. This is different from instantiation, which creates objects of the class using constructors. To generate a list of the classes required for pre-loading, you can use the following VM option, writing the list to a file called classes-loaded.txt: -Xlog:class+load=info:classes-loaded.txt
While invoke priming can offer better performance, it requires additional effort to ensure that the actions performed are idempotent and do not have unintended side effects, for instance processing financial transactions in a banking application. For this reason, invoke priming should only be used when code executed during priming is either idempotent or does not modify state. For scenarios where this is not possible, class priming provides a safer alternative by only initializing classes without executing their methods. Note that this assumes your application does not execute state-modifying code during class initialization.
With this context, let’s look at how to implement Invoke and Class priming for a Spring Boot sample application.
Example priming Implementation using CRaC runtime hooks before taking a Lambda snapshot
This post demonstrates both Invoke priming and Class priming using the sample Spring Boot application. The choice between the two approaches depends on the specific requirements and complexities of your application.
Step 1: Set up your Spring Boot Application using the aws-serverless-springboot3-archetype as explained in our Quick Start Spring Boot3 guide, adding database connectivity code, or simply clone the sample project from GitHub repository.
Create a Spring Boot Application.
// src/main/java/software/amazon/awscdk/examples/unicorn/UnicornApplication.java
package software.amazon.awscdk.examples.unicorn;
…
@Import({ UnicornConfig.class })
@SpringBootApplication
public class UnicornApplication {
private static final Logger log = LoggerFactory.getLogger(UnicornApplication.class);
public static void main(String... arguments) {
SpringApplication.run(UnicornApplication.class, arguments);
}
}
Add all the necessary Maven dependencies for Spring Boot, AWS Lambda, and Database Connection in your pom.xml file. The following, highlighted, dependency contains the classes required to use the CRaC runtime hooks.
Step 2: Implement Lambda Function Handler with CRaC runtime hooks and Invoke Priming Approach:
Create Lambda Function Handler and integrate CRaC runtime hooks to execute beforeCheckpoint() and afterRestore() methods in your application for before taking and after restoring the snapshot.
Implement the RequestHandler<UnicornRequest, UnicornResponse> interface in the Lambda function handler class.
Implement the CRaC resource interface with two methods: beforeCheckpoint() and afterRestore(), which defines actions performed before Lambda creates the snapshot and after the snapshot is restored.
Add invoke priming by creating a UnicornRequest object with a GET request to a specific endpoint (such as, /unicorn) and call the handleRequest(unicornRequest, null) method.
This ensures that the code paths associated with the specified endpoint are JIT compiled and optimized for faster execution during the first invocation after the snapshot is restored.
/src/main/java/software/amazon/awscdk/examples/unicorn/handler/InvokePriming.java
package software.amazon.awscdk.examples.unicorn.handler;
import org.crac.Core;
import org.crac.Resource;
...
public class InvokePriming implements RequestHandler<APIGatewayV2HTTPEvent, APIGatewayV2HTTPResponse>, Resource {
...
@Override
public APIGatewayV2HTTPResponse handleRequest(APIGatewayV2HTTPEvent event, Context context) {
var awsLambdaInitializationType = System.getenv("AWS_LAMBDA_INITIALIZATION_TYPE");
var unicorns = getUnicorns();
var body = gson.toJson(unicorns);
return APIGatewayV2HTTPResponse.builder().withStatusCode(200).withBody(body).build();
}
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context)
throws Exception {
var event = APIGatewayV2HTTPEvent.builder().build();
handleRequest(event, null);
}
...
}
Step 3: Implement Class priming Approach:
The class priming approach focuses on pre-loading required classes to achieve optimal performance. To implement class priming, generate the list of classes that are loaded during the application startup and function execution by running the application locally using the following JVM argument: -Xlog:class+load=info:classes-loaded.txt
Ensure that your application classes included in the generated classes-loaded.txt file are not mutating state during static initialization. Note: the generated classes-loaded.txt contains class entries in the following format:
Read a file (such as, /classes-loaded.txt) that contains a list of classes that have been loaded during the application’s execution in the beforeCheckpoint() method.
Use the Class.forName() method to load and initialize the class, ensuring that it is ready during the snapshot. Note: by systematically pre-loading these classes, the Class priming approach simplifies the optimization process and reduces the complexities associated with Invoke priming.
//src/main/java/software/amazon/awscdk/examples/unicorn/handler/ClassPriming.java
package software.amazon.awscdk.examples.unicorn.handler;
...
import org.crac.Core;
import org.crac.Resource;
public class ClassPriming implements RequestHandler<APIGatewayV2HTTPEvent, APIGatewayV2HTTPResponse>, Resource {
...
ConfigurableApplicationContext configurableApplicationContext =
SpringApplication.run(UnicornApplication.class);
this.unicornService = configurableApplicationContext.getBean(UnicornService.class);
this.gson = configurableApplicationContext.getBean(Gson.class);
Core.getGlobalContext().register(this);
}
@Override
public APIGatewayV2HTTPResponse handleRequest(APIGatewayV2HTTPEvent event, Context context) {
var unicorns = getUnicorns();
var body = gson.toJson(unicorns);
return APIGatewayV2HTTPResponse.builder().withStatusCode(200).withBody(body).build();
}
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context)
throws Exception {
ClassLoaderUtil.loadClassesFromFile();
}
...
}
Step 4: AWS CDK Infrastructure Setup
Before proceeding, review the prerequisites in the project README file.
The CDK stack deploys a serverless application and required infrastructure for testing different Lambda optimization strategies. It creates a VPC with private subnets, an RDS for PostgreSQL instance with a database proxy, and five Lambda functions implementing different optimization approaches (ON_DEMAND without SnapStart, SnapStart without priming, SnapStart with invoke priming, and SnapStart with class priming). Each Lambda function is integrated with API Gateway for HTTP access, configured with Java 21 runtime on ARM64 architecture, and includes CloudWatch log groups for monitoring.
Step 6: Compare the load test results for On-demand (non-SnapStart), SnapStart, Invoke priming, and Class priming
The performance test results in the table below are sorted from slowest to fastest startup latency. The function without SnapStart performs the slowest due to JVM initialization, class loading and JIT compilation that occurs when the function is invoked. Notice a 4.3x improvement with SnapStart, which resumes invocations from a pre-initialized snapshot thereby avoiding JVM initialization and initial JIT compilation. SnapStart with class priming achieves a 1.4x speed-up over SnapStart, by proactively loading/initializing classes during INIT so that they are included in your function’s snapshot. Finally, SnapStart with invoke priming achieves the fastest performance – with a 781.68ms p99.9 cold-start latency that is 1.8x faster than SnapStart. This is because in addition to initializing classes, it also executes methods on the instances of those classes, resulting in even more components being included in the function’s snapshot.
Note that with invoke priming, any application code you execute must either be idempotent or modify stub data only. For instance, consider application code that triggers a financial transaction. If this code is executed during invoke priming with real user data, it may drive unintended effects with potentially serious consequences. Class priming avoids this, since application classes are initialized rather than being instantiated and their methods executed. This assumes that application code does not execute state modifying logic during class initialization. We recommend that you keep these considerations in mind when using invoke and/or class priming, and choose the appropriate approach for your use case.
Method
Cold Start Invocations
p50
P90
P99
p99.9
PrimingLogGroup-1_ON_DEMAND
128
5047.94 ms
5386.78 ms
6158.80 ms
6195.84 ms
PrimingLogGroup-2_SnapStart_NO_PRIMING
111
1177.87 ms
1288.73 ms
1419.94 ms
1425.63 ms
PrimingLogGroup-4_SnapStart_CLASS_PRIMING
82
857.81 ms
997.49 ms
1085.94 ms
1085.94 ms
PrimingLogGroup-3_SnapStart_INVOKE_PRIMING
66
608.42 ms
688.88 ms
781.68 ms
781.68 ms
Conclusion
This post showed how AWS Lambda SnapStart, enhanced by CRaC runtime hooks, unlocks granular control over cold-start optimization for Java applications through two distinct priming strategies:
Invoke Priming: improves performance by executing critical endpoints during snapshot creation, ideal for idempotent workflows.
Class Priming: preloads classes without triggering business logic, mitigating side-effect risks.
To implement these optimization techniques in your applications evaluate your use case and opt for the optimal priming approach. Track latency reductions and resource utilization of your application via Amazon CloudWatch metrics to quantify performance improvements. By integrating these strategies, developers can achieve sub-second cold starts while maintaining the scalability and cost-efficiency of serverless architecture using Java.
This post is co-written with Haya Axelrod Stern, Zion Rubin and Michal Urbanowicz from Natural Intelligence.
Many organizations turn to data lakes for the flexibility and scale needed to manage large volumes of structured and unstructured data. However, migrating an existing data lake to a new table format such as Apache Iceberg can bring significant technical and organizational challenges
Natural Intelligence (NI) is a world leader in multi-category marketplaces. NI’s leading brands, Top10.com and BestMoney.com, help millions of people worldwide to make informed decisions every day. Recently, NI embarked on a journey to transition their legacy data lake from Apache Hive to Apache Iceberg.
In this blog post, NI shares their journey, the innovative solutions developed, and the key takeaways that can guide other organizations considering a similar path.
This article details NI’s practical approach to this complex migration, focusing less on Apache Iceberg’s technical specifications, but rather on the real-world challenges and solutions encountered during the transition to Apache Iceberg, a challenge that many organizations are grappling with.
Why Apache Iceberg?
The architecture at NI followed the commonly used medallion architecture, comprised of a bronze-silver-gold layered framework, shown in the figure that follows:
Silver layer: Contains cleaned and enriched data, processed using Apache Flink.
Gold layer: Holds analytics-ready datasets designed for business intelligence (BI) and reporting, produced using Apache Spark pipelines, and consumed by services such as Snowflake, Amazon Athena, Tableau, and Apache Druid. The data is stored in Apache Parquet format with AWS Glue Catalog providing metadata management.
While this architecture supported NI analytical needs, it lacked the flexibility required for a truly open and adaptable data platform. The gold layer was coupled only with query engines that supported Hive and AWS Glue Data Catalog. It was possible to use Amazon Athena however Snowflake required maintaining another catalog in order to query those external tables. This issue made it difficult to evaluate or adopt alternative tools and engines without costly data duplication, query rewrite data catalog synchronization. As business scaled, NI needed a data platform that could seamlessly support multiple query engines simultaneously with a single data catalog and avoiding any vendor lock-in.
The power of Apache Iceberg
Apache Iceberg emerged as the perfect solution—a flexible, open table format that aligns with NI’s approach of Data Lake First. Iceberg offers several critical advantages such as ACID transactions, schema evolution, time travel, performance improvements and more. But the key strategic benefits lay in the ability to support multiple query engines simultaneously. It also has the following advantages:
Decoupling of storage and compute: The open table format enables you to separate the storage layer from the query engine, allowing an easy swap and support for multiple engines concurrently without data duplication.
Vendor independence: As an open table format, Apache Iceberg prevents vendor lock-in, giving you the flexibility to adapt to changing analytics needs.
Vendor adoption: Apache Iceberg is widely supported by major platforms and tools, providing seamless integration and long-term ecosystem compatibility.
By transitioning to Iceberg, NI was able to embrace a truly open data platform, providing long-term flexibility, scalability, and interoperability while maintaining a unified source of truth for all analytics and reporting needs.
Challenges faced
Migrating a live production data lake to Iceberg was challenging because of operational complexities and legacy constraints. The data service at NI runs hundreds of Spark and machine learning pipelines, manages thousands of tables, and supports over 400 dashboards—all operating 24/7. Any migration would need to be done without production interruptions; and coordinating such a migration while operations continue seamlessly was daunting.
NI needed to accommodate diverse users with varying requirements and timelines from data engineers to data analysts all the way to data scientists and BI teams.
Adding to the challenge were legacy constraints. Some of the existing tools didn’t fully support Iceberg, so there was a need to maintain Hive-backed tables for compatibility. As NI realized that not all consumers could adopt Iceberg immediately. A plan was required to allow for incremental transitions without downtime or disruption to ongoing operations.
Key pillars for migration
To help ensure a smooth and successful transition, six critical pillars were defined:
Support ongoing operations: Maintain uninterrupted compatibility with existing systems and workflows during the migration process.
User transparency: Minimize disruption for users by preserving existing table names and access patterns.
Gradual consumer migration: Allow consumers to adopt Iceberg at their own pace, avoiding a forced, simultaneous switchover.
ETL flexibility: Migrate ETL pipelines to Iceberg without imposing constraints on development or deployment.
Cost effectiveness: Minimize storage and compute duplication and overhead during the migration period.
Minimize maintenance: Reduce the operational burden of managing dual table formats (Hive and Iceberg) during the transition.
Evaluating traditional migration approaches
Apache Iceberg supports two main approaches for migration: In-place and rewrite-based migration.
In-place migration
How it works: Converts an existing dataset into an Iceberg table without duplicating data by creating Iceberg metadata on top of the existing files while preserving their layout and format.
Advantages:
Cost-effective in terms of storage (no data duplication)
Simplified implementation
Maintains existing table names and locations
No data movement and minimal compute requirements, translating into lower cost
Disadvantages:
Downtime required: All write operations must be paused during conversion, which was unacceptable in NI cases because data and analytics are considered mission critical and run 24/7
No gradual adoption: All consumers must switch to Iceberg simultaneously, increasing the risk of disruption
Limited validation: No opportunity to validate data before cutover; rollback requires restoring from backups
Technical constraints: Schema evolution during migration can be challenging; data type incompatibilities can halt the entire process
Rewrite-based migration
How it works: Rewrite-based migration in Apache Iceberg involves creating a new Iceberg table by rewriting and reorganizing existing dataset files into Iceberg’s optimized format and structure for improved performance and data management.
Advantages:
Zero downtime during migration
Supports gradual consumer migration
Enables thorough validation
Simple rollback mechanism
Disadvantages:
Resource overhead: Double storage and compute costs during migration
Maintenance complexity: Managing two parallel data pipelines increases operational burden
Consistency challenges: Maintaining perfect consistency between the two systems is challenging
Performance impact: Increased latency because of dual writes; potential pipeline slowdowns
Why neither option alone was good enough
NI decided that neither option could meet all critical requirements:
In-place migration fell short because of unacceptable downtime and lack of support for gradual migration.
Rewrite-based migration fell short because of prohibitive cost overhead and complex operational management.
This analysis led NI to develop a hybrid approach that combines the advantages of both methods while mitigating and minimizing limitations.
The hybrid solution
The hybrid migration strategy was designed around five foundational elements, using AWS analytical services for orchestration, processing, and state management.
Hive-to-Iceberg CDC: Automatically synchronize Hive tables with Iceberg using a custom change data capture (CDC) process to support existing consumers. Unlike traditional CDC focusing on row-level changes, the process was done at the partition-level to preserve Hive’s behavior of updating tables by overwriting partitions. This helps ensure that data consistency is maintained between Hive and Iceberg without logic changes at the migration phase, making sure that the same data exists on both tables.
Continuous schema synchronization: Schema evolution during the migration introduced maintenance challenges. Automated schema sync processes compared Hive and Iceberg schemas, reconciling differences while maintaining type compatibility.
Iceberg-to-Hive reverse CDC: To enable the data team to transition extract, transform, and load (ETL) jobs to write directly to Iceberg while maintaining compatibility with existing Hive-based processes not yet migrated, a reverse CDC from Iceberg to Hive was implemented. This allowed ETLs to write to Iceberg while maintaining Hive tables for downstream processes that had not yet migrated and still relied on them during the migration period.
Alias management in Snowflake: Snowflake aliases made sure that Iceberg tables retained their original names, making the transition transparent to users. This approach minimized reconfiguration efforts across dependent teams and workflows.
Table replacement: Swap production tables while retaining original names, completing the migration.
Technical deep dive
The migration to from Hive to Iceberg was constructed of several steps:
1. Hive-to-Iceberg CDC pipeline
Objective: Keep Hive and Iceberg tables synchronized without duplicating effort.
The preceding figure demonstrates how every partition written to the Hive table is automatically and transparently copied to the Iceberg table using a CDC process. This process makes sure that both tables are synchronized, enabling a seamless and incremental migration without disrupting downstream systems. NI chose partition-level synchronization because the legacy Hive ETL jobs already wrote updates by overwriting entire partitions and updating the partition location. Adopting that same approach in the CDC pipeline helped ensure that it remained consistent with how data was originally managed, making the migration smoother and avoiding the need to rework row-level logic.
Implementation:
To keep Hive and Iceberg tables synchronized without duplicating effort, a streamlined pipeline was implemented. Whenever partitions in Hive tables are updated, the AWS Glue Catalog emits events such as UpdatePartition. Amazon EventBridge captured these events, filtered them for the relevant databases and tables according to the event bridge rule, and triggered an AWS Lambda This function parsed the event metadata and sent the partition updates to an Apache Kafka topic.
A Spark job running on Amazon EMR consumed the messages from Kafka, which contained the updated partition details from the Data Catalog events. Using that event metadata, the Spark job queried the relevant Hive table, and wrote it to Iceberg table in Amazon S3 using the Spark Iceberg overwritePartitions API, as shown in the following example:
{
"id":"10397e54-c049-fc7b-76c8-59e148c7cbfc",
"detail-type":"Glue Data Catalog Table State Change",
"source":"aws.glue",
"time":"2024-10-27T17:16:21Z",
"region":"us-east-1",
"detail":{
"databaseName":"dlk_visitor_funnel_dwh_production",
"changedPartitions":[
"2024-10-27"
],
"typeOfChange":"UpdatePartition",
"tableName":"fact_events"
}
}
By targeting only modified partitions, the pipeline (shown in the following figure) significantly reduced the need for costly full-table rewrites. Iceberg’s robust metadata layers, including snapshots and manifest files, were seamlessly updated to capture these changes, providing efficient and accurate synchronization between Hive and Iceberg tables.
2. Iceberg-to-Hive reverse CDC pipeline
Objective: Support Hive consumers while allowing ETL pipelines to transition to Iceberg.
The preceding figure shows the reverse process, where every partition written to the Iceberg table is automatically and transparently copied to the Hive table using a CDC mechanism. This process helps ensure synchronization between the two systems, enabling seamless data updates for legacy systems that still rely on Hive while transitioning to Iceberg.
Implementation:
Synchronizing data from Iceberg tables back to Hive tables presented a different challenge. Unlike Hive tables, Data Catalog doesn’t track partition updates for Iceberg tables because partitions in Iceberg are managed internally and not within the catalog. This meant NI couldn’t rely on Glue Catalog events to detect partition changes.
To address this, NI implemented a solution similar to the previous flow but adapted to Iceberg’s architecture. Apache Spark was used to query Iceberg’s metadata tables—specifically the snapshots and entries tables—to identify the partitions modified since the last synchronization. The query used was:
SELECT e.data_file.partition, MAX(s.committed_at) AS last_modified_time
FROM $target_table.snapshots JOIN $target_table.entries e ON s.snapshot_id = e.snapshot_id
WHERE s.committed_at &gt; '$last_sync_time'
GROUP BY e.data_file.partition;
This query returned only the partitions that had been updated since the last synchronization, enabling it to focus exclusively on the changed data. Using this information, similar to the earlier process, a Spark job retrieved the updated partitions from Iceberg and wrote them back to the corresponding Hive table, providing seamless synchronization between both tables.
3. Continuous schema synchronization
Objective: Automate schema updates to maintain consistency across Hive and Iceberg.
The preceding figure shows how the automatic schema sync process helps ensure consistency between Hive and Iceberg tables schemas by automatically synchronizing schema changes. In this example adding the Channel column, minimizing manual work and double maintenance during the extended migration period.
Implementation:
To handle schema changes between Hive and Iceberg, a process was implemented to detect and reconcile differences automatically. When a schema change happens in a Hive table, Data Catalog emits an UpdateTable event. This event triggers a Lambda function (routed through EventBridge), which retrieves the updated schema from Data Catalog for the Hive table and compares it to the Iceberg schema. It’s important to call out that in NI’s setup, schema changes originate from Hive because the Iceberg table is hidden behind aliases across the system. Because Iceberg is primarily used for Snowflake, a one-way sync from Hive to Iceberg is sufficient. As a result, there is no mechanism to detect or handle schema changes made directly in Iceberg, because they aren’t needed in the current workflow.
During the schema reconciliation (shown in the following figure), data types are normalized to help ensure compatibility—for example, converting Hive’s VARCHAR to Iceberg’s STRING. Any new fields or type changes are validated and applied to the Iceberg schema using a Spark job running on Amazon EMR. Amazon DynamoDB stores schema synchronization checkpoints which allow tracking changes over time and maintain consistency between the Hive and Iceberg schemas.
By automating this schema synchronization, maintenance overhead was significantly reduced and freed developers from manually keeping schemas in sync, making the long migration period significantly more manageable.
The preceding figure depicts an automated workflow to maintain schema consistency between Hive and Iceberg tables. AWS Glue captures table state change events from Hive, which trigger an EventBridge event. The event invokes a Lambda function that fetches metadata from DynamoDB and compares schemas fetched from AWS Glue for both Hive and Iceberg tables. If a mismatch is detected, the schema in Iceberg is updated to help ensure alignment, minimizing manual intervention and supporting smooth operation during the migration.
4. Alias management in Snowflake
Objective: Enable Snowflake consumers to adopt Iceberg without changing query references.
The preceding figure shows how Snowflake aliases enable seamless migration by mapping queries like SELECT platform, COUNT(clickouts) FROM funnel.clickouts to Iceberg tables in the Glue Catalog. Even with suffixes added during the Iceberg migration, existing queries and workflows remain unchanged, minimizing disruption for BI tools and analysts.
Implementation:
To help ensure a seamless experience for BI tools and analysts during the migration, Snowflake aliases were used to map external tables to the Iceberg metadata stored in Data Catalog. By assigning aliases that matched the original Hive table names, existing queries and reports were preserved without interruption. For example, an external table was created in Snowflake and aliased it to the original table name, as shown in the following query:
CREATE OR REPLACE ICEBERG TABLE dlk_visitor_funnel_dwh_production.aggregated_cost
EXTERNAL_VOLUME = 's3_dlk_visitor_funnel_dwh_production_iceberg_migration'
CATALOG = 'glue_dlk_visitor_funnel_dwh_production_iceberg_migration'
CATALOG_TABLE_NAME = 'aggregated_cost';
ALTER ICEBERG TABLE dlk_visitor_funnel_dwh_production.aggregated_cost REFRESH;
When migration was completed, a simple change back to the alias was done to point to the new location or schema, making the transition seamless and minimizing any disruption to user workflows.
5. Table replacement
Objective: When all ETLs and related data workflows were successfully transitioned to use Apache Iceberg’s capabilities, and everything was functioning correctly with the synchronization flow, it was time to move on to the final phase of the migration. The primary objective was to maintain the original table names, avoiding the use of any prefixes like those employed in the earlier, intermediate migration steps. This helped ensure that the configuration remained tidy and free from unnecessary naming complications.
The preceding figure shows the table replacement to complete the migration, where Hive on Amazon EMR was used to register Parquet files as Iceberg tables while preserving original table names and avoiding data duplication, helping to ensure a seamless and tidy migration.
Implementation:
One of the challenges was that renaming tables isn’t possible within AWS Glue, which prevents the use of a straightforward renaming approach for the existing synchronization flow tables. In addition, AWS Glue doesn’t support the Migrate procedure, which creates Iceberg metadata on top of the existing data file while preserving the original table name. The strategy to overcome this limitation was to use a Hive metastore on an Amazon EMR cluster. By using Hive on Amazon EMR, NI was able to create the final tables with their original names because it operates in a separate metastore environment, giving the flexibility to define any required schema and table names without interference.
The add_files procedure was used to methodically register all the existing Parquet files, thus constructing all necessary metadata within Hive. This was a crucial step, because it helped ensure that all data files were appropriately cataloged and linked within the metastore.
The preceding figure shows the transition of a production table to Iceberg by using the add_files procedure to register existing Parquet files and create Iceberg metadata. This helped ensure a smooth migration while preserving the original data and avoiding duplication.
This setup allowed the use of existing Parquet files without duplicating data, thus saving resources. Although the sync flow used separate buckets for the final architecture, NI chose to maintain the original buckets and cleaned the intermediate files. This resulted in a different folder structure on Amazon S3. The historical data had subfolders for each partition under the root table directory, while the new Iceberg data organizes subfolders within a data folder. This difference was acceptable to avoid data duplication and preserve the original Amazon S3 buckets.
Technical recap
The AWS Glue Data Catalog served as the primary source of truth for schema and table updates, with Amazon EventBridge capturing Data Catalog events to trigger synchronization workflows. AWS Lambda parsed event metadata and managed schema synchronization, while Apache Kafka buffered events for real-time processing. Apache Spark on Amazon EMR handled data transformations and incremental updates, and Amazon DynamoDB maintained state, including synchronization checkpoints and table mappings. Finally, Snowflake seamlessly consumed Iceberg tables via aliases without disrupting existing workflows.
Migration outcome
The migration was completed with zero downtime; continuous operations were maintained throughout the migration, supporting hundreds of pipelines and dashboards without interruption. The migration was done with a cost optimized mindset with incremental updates and partition-level synchronization that minimized the usage of compute and storage resources. Lastly, NI Established a modern, vendor-neutral platform that enables scaling their evolving analytics and machine learning needs. It enables seamless integration with multiple compute and query engines, supporting flexibility and further innovation.
Conclusion
Natural intelligence migration to Apache Iceberg was a pivotal step in modernizing the company’s data infrastructure. By adopting a hybrid strategy and using the power of event-driven architectures, NI helped ensure a seamless transition that balanced innovation with operational stability. The journey underscored the importance of careful planning, understanding the data ecosystem, and focusing on an organization-first approach.
Above all, business was kept in focus and continuity prioritized the user experience. By doing so, NI unlocked the flexibility and scalability of their data lake while minimizing disruption, allowing teams to use cutting-edge analytics capabilities, positioning the company at the forefront of modern data management and readiness for the future.
If you’re considering an Apache Iceberg migration or facing similar data infrastructure challenges, we encourage you to explore the possibilities. Embrace open formats, use automation, and design with your organization’s unique needs in mind. The journey might be complex, but the rewards in scalability, flexibility, and innovation are well worth the effort. You can use the AWS prescriptive guide to help learn more about how to best use Apache Iceberg for your organization
About the Authors
Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. Yonatan is an Apache Iceberg evangelist.
Haya Stern is a Senior Director of Data at Natural Intelligence. She leads the development of NI’s large-scale data platform, with a focus on enabling analytics, streamlining data workflows, and improving dev efficiency. In the past year, she led the successful migration from the previous data architecture to a modern lake house based on Apache Iceberg and Snowflake.
Zion Rubin is a Data Architect at Natural Intelligence with ten years of experience architecting large‑scale big‑data platforms, now focused on developing intelligent agent systems that turn complex data into real‑time business insight.
Michał Urbanowicz is a Cloud Data Engineer at Natural Intelligence with expertise in migrating data warehouses and implementing robust retention, cleanup, and monitoring processes to ensure scalability and reliability. He also develops automations that streamline and support campaign management operations in cloud-based environments.
AWS Outposts Rack is a fully managed service that extends AWS infrastructure, services, and APIs to user managed locations. Although you may be used to the seemingly infinite capacity that AWS offers in region, those using Outposts rack for their workloads are limited to the capacity that they order. You will need to closely manage and monitor usage of the available resources as part of capacity management. It is also important to make sure that there is sufficient available capacity in the event of an impactful hardware failure. Although spare capacity is often planned for in the initial Outposts rack configuration order, scaling events and deployments of new workloads can often lead to capacity shortages that only become visible during a failure event.
In this post, we review best practices for capacity management and fault tolerance with Outposts rack followed by an example of how the Outposts API can be used to build an automated monitoring and alerting system to highlight potential resiliency issues.
When looking to determine resiliency levels, we refer to having N+M capacity, where N represents the number of deployed hosts of a particular instance family (such as C5 or M5), and M represents the number of hosts that can fail while still meeting workload capacity requirements.
The capacity configuration that is applied to each host will impact the necessary recovery process in the event of a failure, depending on the number of configured or running instances. With this in mind, there are three potential recovery scenarios that can apply in the event of a host hardware failure:
Sufficient capacity exists within all instance pools to tolerate the failure of M hosts. This is the most ideal operational position to be in because, in the event of a failure, instances can be recovered to free capacity quickly either through automated features, such as EC2 Auto Scaling groups and instance recovery, or through manual stop/start of the instances.
The required instance type is not available within the available instance pools, however, there is sufficient vCPU available to execute capacity tasks to create the required instance capacity to fulfill the shortfall. As this requires changes to existing capacity, this results in a longer recovery time overall
Insufficient capacity within the Outpost at both the instance pool and vCPU level means that either workloads need to be stopped to fit within the available capacity, or more Outpost hardware needs to be added. This further extends the recovery time for workloads.
Consider the following example of an Outpost configured with four M5 hosts that have been designed with an N+1 resiliency model.
Figure 1: Example configuration with sufficient instance pool capacity
In this example, there are five configured instance pools with the following usages:
Instance size
Total instance pool capacity
Total free instance pool capacity
Max configured instances per host
M5.large
16
6
4
M5.xlarge
8
3
2
M5.2xlarge
8
3
2
M5.4xlarge
8
3
2
M5.8xlarge
4
2
1
For all instance pools, the number of available instances is greater than the maximum number of instances configured on a single host. Therefore, in the event of a failure of any host, instances can be moved to the existing available capacity without any reconfiguration.
We can consider another scenario of running instances on the same set of hosts:
Figure 2: Example configuration with sufficient vCPU capacity
With the usage as shown, four of the configured instance pools have sufficient available capacity. However, the m5.4xlarge instance pool only has one available instance placement, resulting in no tolerance to a single host failure. A single m5 host has a total of 96 vCPU, and in this example the overall capacity of the available slots is 156 vCPU. This means that, with the execution of a capacity task to rebalance the available slots, instances could be restarted after a host failure.
Automating a capacity observability solution
With the release of the capacity task functionality for Outposts, details of instance placement and slot configuration per host are now available within both the AWS Management Console and through the API. With the addition of capacity tasks for Outposts, an automated solution can be created to query this data and provide notifications when the N+M resiliency requirements for your workloads are at risk.
CloudWatch alarms continually monitor for changes to Outpost capacity.
In the event of alarm thresholds being breached, a Lambda function is invoked to send notifications via SNS to the user defined endpoints.
At the core of the solution are two Lambda functions:
Monitoring stack manager: This Lambda function sets up the dynamic monitoring of the desired N+M resiliency level. It achieves this by creating and updating CloudWatch alarms based on the current capacity configuration of the Outposts being monitored, and the capacity usage for each instance family and type. The function generates detailed reports for each Outpost, identifying any potential resiliency issues for each instance family based on the M value that is specified at the time of deployment.
The detailed report, which is issued via the configured SNS topic, starts with an overall summary that clearly details the status of each instance family and the resiliency status.
Figure 4: Resiliency report summary section
Following the overall summary section, a more detailed analysis is provided for each instance family, looking at resiliency from both instance type and vCPU capacity perspectives. As part of this detailed analysis, the level of risk for each capacity pool is provided alongside a review of available instance capacity and suggested mitigation options.
Figure 5: Resiliency report instance pool analysis section
Figure 6: Resiliency report vCPU analysis section
This summary report is generated on every execution of the Monitoring Stack Manager function, with the default configuration that is triggered by the EventBridge Scheduler set to daily.
Process alarm: When the alarm that is configured by the Monitoring Stack Manager Lambda triggers, the Process Alarm Lambda analyzes Outpost capacity, checking for available free vCPUs within the hosts running the affected instance family. Then, a report is sent via SNS to immediately draw attention to the capacity risk, providing guidance if the resiliency risk can be mitigated through the application of an alternate capacity configuration.
Figure 7: Resiliency alarm notification report
Similar to the report generated by the Monitoring Stack Manager function, a more detailed breakdown of the capacity issue is provided that allows for easy identification of any necessary follow up actions. These actions are recommendations for manual resolution of the issue and require you to take action to implement.
When the available capacity returns to a level that matches the N+M resiliency requirements you defined, a further notification report is sent to confirm this, and the alarm is reset.
The sample solution provided has been designed to work for users who are operating Outposts at any scale. However, there are some considerations for deploying:
The deployment is AWS Region-specific. Therefore, it would need to be deployed in each AWS Region you’re using Outposts in.
Each stack deployment supports dedicated N+M configuration monitoring, allowing you to create separate deployments to match the desired resilience requirements across multiple Outposts.
Cleaning up
Because this solution is implemented through AWS SAM, the only clean up required is to execute the AWS SAM deployment using the cleanup parameter as documented in the code repository readme file.
Conclusion
In this post, we reviewed how to calculate N+M resilience for Outposts rack deployments, and provided a sample solution that can dynamically monitor and report on capacity constraints. Making sure that there is sufficient available capacity within an Outpost rack to tolerate failures is critical to running resilient applications and minimizing any potential downtime. Combining good capacity management practices with service functionality, such as EC2 Auto Scaling, automatic instance recovery, and placement groups, gives you several options to make sure workloads can continue to run even during failure events. If you need any assistance calculating your Outposts rack resiliency, or further information on deploying and running fault tolerant workloads, reach out to your AWS Account team.
Effective tracing enables developers and operators to quickly identify performance bottlenecks, troubleshoot issues across service boundaries, and make sure of optimal end-user experiences. This makes it crucial for maintaining and optimizing distributed serverless applications. This post explores the importance of distributed tracing for operating serverless applications and announces an important update to tracing behavior for AWS Lambda, which streamlines how trace context is handled in PassThrough mode. This blog post will demonstrate how this change gives you better control over how your Lambda functions handle tracing with AWS X-Ray through practical examples. Whether you’re building new applications or operating existing ones, this update helps you achieve more predictable and efficient tracing across your serverless applications built using Lambda.
Overview
Distributed serverless applications spanning numerous AWS services require robust monitoring as they scale. Traditional troubleshooting approaches fall short due to Lambda’s ephemeral nature, making it difficult for development teams to track requests across components, understand performance bottlenecks, and optimize costs by eliminating unnecessary function invocations. Without end-to-end visibility, production issues become increasingly time-consuming to resolve.
X-Ray addresses these observability challenges by providing powerful distributed tracing capabilities that help developers understand how their Lambda functions interact with other AWS services and identify performance issues. As serverless architectures grow in complexity, having fine-grained control over tracing behavior becomes crucial for maintaining efficient and cost-effective observability strategies that enable teams to effectively operate production workloads.
Lambda and X-Ray have steadily enhanced tracing capabilities in recent years to improve observability for serverless applications. In November 2022, X-Ray introduced trace linking between Amazon Simple Queue Service (Amazon SQS) and Lambda, enabling end-to-end tracing for event-driven applications. In February 2023, X-Ray added active tracing support for Amazon Simple Notification Service (Amazon SNS), allowing you to trace messages that flow through SNS topics to Lambda functions. In May 2023, X-Ray added tracing support to SnapStart-enabled Lambda functions, helping you troubleshoot and optimize the performance of latency-sensitive Java applications built using SnapStart-enabled functions. In November 2023, Lambda launched a unified experience in the Lambda console that brings together metrics, logs, and traces in a single view, allowing you to more directly troubleshoot and optimize your functions.
Building upon these enhancements, Lambda has now rolled out streamlined trace sampling behavior, which gives you better control over how your functions handle tracing with X-Ray. This launch makes an important change to tracing behavior in Lambda when the tracing configuration is set to PassThrough mode. With this launch, Lambda propagates the tracing context as is without any modifications in PassThrough mode. This means that Lambda won’t create any trace segments or subsegments for functions set to PassThrough mode, even if the incoming invocation contains a decision to sample the request. However, Lambda service does propagate the tracing context as received by the function.
This change to the X-Ray PassThrough mode for Lambda gives you more control and predictability over your tracing configuration. This enables you to optimize your tracing strategy and better understand the performance and behavior of your serverless applications. This post shows three different scenarios to demonstrate the new tracing behavior.
Understanding the Lambda/X-Ray tracing behavior: before and after
Tracing in Lambda with X-Ray is a powerful tool for gaining insights into the performance and behavior of serverless applications. Enabling tracing allows you to identify bottlenecks, troubleshoot issues, and optimize your Lambda functions. Lambda supports two tracing modes for X-Ray: Active and PassThrough. With Active tracing, Lambda automatically creates trace segments for function invocations and sends them to X-Ray. On the other hand, PassThrough mode propagates the tracing context to downstream services.
Previously, if you enabled tracing in an upstream service that invokes your function, Lambda would follow this sampling decision and send traces to X-Ray automatically, even in the case where the Lambda function was configured to use PassThrough mode. The following figure shows this process. This behavior could result in unexpected trace segments, which could become an overhead, particularly in high throughput scenarios.
Figure 1. Previous behavior: Lambda sends traces to X-Ray even when function tracing configuration is set to PassThrough
The updated X-Ray PassThrough mode for Lambda provides a more intuitive and consistent tracing experience. You can now expect Lambda to respect the incoming tracing context (if it exists) and propagate it without any modifications. In turn, downstream services can make their own tracing decisions based on their configuration. The following figure shows this updated behavior.
Figure 2. New behavior: When function tracing configuration is set to PassThrough, Lambda doesn’t send traces to X-Ray or modify sampling decision
PassThrough tracing configuration with upstream sampling
To configure your Lambda function to use PassThrough tracing mode in the console, complete the following steps:
In the Lambda console, navigate to your function.
On the Configuration tab, choose Monitoring and operations tools in the left pane.
Confirm that X-Ray active tracing shows as Not enabled. If it’s enabled, then choose Edit.
Under X-Ray, turn off Active tracing, then choose Save, as shown in the following figure.
Figure 3. Lambda console showing function with active tracing disabled
You can also make use of the AWS Command Line Interface (AWS CLI) to achieve the aforementioned setting:
This configuration allows your Lambda function to propagate the tracing context received from the upstream service without any changes. If you were previously using this configuration, then you no longer see trace segments created by the Lambda function on the X-Ray console. This configuration is useful when you want to propagate the tracing context without generating trace segments, in scenarios that need optimizing for tracing costs or overhead. The following figure shows the workflow.
Figure 4. A tracing map that shows the UpstreamFunction Lambda function isn’t displayed on the trace map, because it’s configured to use PassThrough tracing mode after this change
If you want to see trace segments for your Lambda function, then you need to set the tracing mode to Active.
Active tracing configuration
When you configure your Lambda function to use active tracing mode, and if there is no sampling decision from the upstream request, Lambda samples requests at the rate of one request per second and 5% of further requests. If there is a decision not to sample, then Lambda respects this sampling decision.
To configure your Lambda function to use active tracing mode, complete the following steps:
On the Lambda console, navigate to the AWS X-Ray section on the Lambda function’s configuration page, as described in the previous section.
Turn on Active tracing, then choose Save, as shown in the following figure.
Figure 5: Lambda console showing active tracing enabled
You can also use the AWS CLI to set this configuration:
With active tracing mode, you can always see traces for sampled requests for your Lambda function on the X-Ray console. This mode is particularly useful when you want to have complete visibility into the performance and behavior of your Lambda function. The following figure shows the workflow for upstream and downstream Lambda functions with active tracing enabled.
Figure 6. A trace map showing both the UpstreamFunction and DownstreamFunction Lambda functions. This is because both functions have active tracing enabled.
The following screenshot shows a full trace corresponding to the preceding trace workflow with both upstream and downstream Lambda functions. Detailed insights gained from comprehensive tracing can be invaluable for troubleshooting, performance optimization, and understanding the end-to-end behavior of your serverless application.
Figure 7. A full trace corresponding to the preceding trace map with both upstream and downstream Lambda functions
PassThrough tracing configuration without upstream sampling
When you configure your Lambda function to use PassThrough tracing mode, and the upstream service has sampling turned off, Lambda continues to propagate the tracing context without any modifications, and without generating traces.
To configure your Lambda function to use PassThrough tracing mode, complete the following steps:
On the Lambda console, navigate to the AWS X-Ray section on the Lambda function’s configuration page.
Under X-Ray, turn off Active tracing, then choose Save, as shown in the following figure.
Figure 8. Lambda console showing active tracing disabled
This configuration remains the same in the updated PassThrough configuration and is particularly useful when you want to allow downstream services to make their own tracing decisions.
Conclusion
The new streamlined trace sampling behavior for AWS Lambda functions provides you with more control and flexibility over insights into your applications. Whether you choose to use PassThrough mode with upstream sampling on or off, or active tracing mode, you can now configure your Lambda functions to handle tracing in a way that best suits your application’s needs.
This update empowers you to optimize your tracing setup, balance tracing costs and benefits, and gain valuable insights into the performance and behavior of your serverless applications.
This change in tracing behavior now applies to all new and existing functions in all AWS Regions where Lambda and AWS X-Ray are available, at no further cost. To learn more about the new tracing sampling behavior for Lambda, see the post Visualize Lambda function invocations using AWS X-Ray.
For more serverless learning resources, visit Serverless Land.
Note: This post was first published April 21, 2016. The updated version aligns with the latest version of AWS WAF (AWS WAF v2) and includes screenshots that reflect the changes in the AWS console experience.
AWS WAF Classic has been deprecated and will be end-of-life (EOL) in September 2025. This update describes how to use the latest version of AWS WAF (WAFv2) to help prevent hotlinking. Updates have been made to the screenshots to reflect the changes in the AWS Management Console for AWS WAF.
Hotlinking—also known as inline linking—is a form of content leeching where an unauthorized third-party website embeds links to resources originally referenced in a primary site’s HTML. The third-party website doesn’t incur the cost of hosting the content, which means that your website can be charged for the content other sites use. It also results in slow loading times, lost revenue, and potential legal issues.
Now, you can use AWS WAF to help prevent hotlinking. AWS WAF is a web application firewall that’s closely integrated with Amazon CloudFront—a content delivery network (CDN)—and can help protect your web applications from common web exploits that could affect application availability, compromise security, and consume excessive resources. In this blog post, I show you how to help prevent hotlinking by using header inspection in AWS WAF, while still taking advantage of the improved user experience from a CDN such as CloudFront.
Solution overview
You can address hotlinking in various ways. For instance, you can validate the Referer header (sent by a browser to indicate to the server which page the visitor was referred from) at your web server (for example, by using the Apache module mod_rewrite), and either issue a redirect back to your site’s main page or return a 403 Forbidden error to the visitor’s browser.
If you’re using a CDN such as CloudFront to speed up your site’s delivery of content, validating the Referer header at the web server becomes less practical. The CDN stores a copy of your content in the edge of its network of servers, so even if your web server validates the original request’s headers (in this case, the referer), additional requests for that content must be validated by the CDN itself, because they are unlikely to reach the origin web server.
Figure 1 illustrates this process.
Figure 1: Request – response flow showing instances of a cache-miss and a cache-hit
The process shown in Figure 1 is as follows:
A request is received from a user client (1) at a CloudFront edge location (2).
The edge location attempts to return a cached copy of the file requested. This request, if fulfilled from the cache, is considered a cache hit.
In the case of a cache miss—when the content is either not in the edge or is not valid (for example, if the content is out of date)—the request is forwarded to the origin (3) (such as an Amazon Simple Storage Service (Amazon S3) bucket) for a new copy of the object.
In the case of a cache hit, the origin cannot apply validation logic to the user’s request, because the edge server doesn’t need to contact the origin to fulfil the user’s request.
In the next section, I show you how to inspect the client-request headers using AWS WAF to allow or block requests at the CDN.
Solution implementation—two approaches
This post includes two ways to set up AWS WAF to help prevent hotlinking:
Using a separate subdomain: Static files (such as images or styling components) to be protected are moved to a separate subdomain such as static.example.com so that you only need to validate the Referer header.
Using the same domain: Static files are located under a directory on the same domain. This solution includes how to extend this example to check for an empty Referer header.
The choice of approach will depend on how your site is structured and the level of protection you want to implement. The first approach enables you to set up a Referer header check to make sure that requests for the images only come from an allowlisted sub-domain, while the second approach has an additional check for an empty Referer header. The second approach extends the first approach and allows for some flexibility for users to share direct links to the image while still preventing unaffiliated third-party sites from embedding the image links on their websites.
Terms
The following list includes key terms used in this post:
AWS WAF configurations consist of a web access control list (web ACL), associated with a given CloudFront distribution.
Each web ACL is a collection of one or more rules, and each rule can have one or more match conditions.
Match conditions are made up of one or more filters, which inspect components of the request (such as its headers or URI) to match for certain conditions.
Case-sensitivity: HTTP header names are case-insensitive. Referer and referer point to the same HTTP header. HTTP header values, however, are case-sensitive.
Prerequisites
You must have a CloudFront distribution set up before configuring an AWS WAF web ACL. For information about how to set up a CloudFront distribution with an S3 bucket as an origin, see Configure distributions.
Approach 1: A separate subdomain
In this example, you create an AWS WAF rule set that contains a single rule with a single match condition, which in turn has a single filter. The match condition checks the Referer header and verifies that it contains a given value. If the request matches the condition specified in the rule, the traffic is allowed. Otherwise, the AWS WAF rule blocks the traffic.
For this example, because all the static files are on a separate subdomain (static.example.com) accessed only from the site example.com, you will block hotlinking for any file that don’t have a referer that ends with example.com.
Use the following steps to set this up using the AWS WAF console.
If you have not created a web ACL before, Choose Create web ACL on the AWS WAF console landing page.
Because you want to associate the web ACL with a CloudFront distribution, select Amazon CloudFront distributions as the Resource type.
Enter a Name for the web ACL that you’re creating. For this example, I used the name sample-webacl. The page will automatically populate an associated Amazon CloudWatch metric name. CloudWatch is a monitoring service that allows you to gather and report on metrics of various services. This CloudWatch metric can be used later to report on how your newly created AWS WAF configuration is being used.
After you have supplied the name of the web ACL, you can select the available AWS resources to be protected by this web ACL. In this example, you will fill that in later, so leave this field blank for now.
By default, AWS WAF can inspect up to 16 KB of the web request body with additional values of 32, 48, and 64 KB for an additional cost. Leave the web request Body sizelimit at the default value of 16 KB.
Choose Next.
Figure 2: Describing the web ACL and associating it to resources
Step 2: Create a string match condition on Referer header
AWS WAF ACLs can use AWS managed rule groups, rule groups from AWS Marketplace providers, or you can write your own rules and rule groups. For this example, you will create your own rules and rule groups.
In the AWS WAF console, choose Add rules, and select Add my own rules and rule groups to create the string match condition.
Figure 3: Add rules and rule groups
This will bring you to the Rule visual editor page. The default Rule type will be set to Rule builder which you can leave unchanged. In the Rule builder section, select Regular rule.
Figure 4: Rule type and Rule builder
The next step is to construct a string match condition to match on the Referer header. Under Name, enter a name for the rule, such as Referer-check. Make sure that If a request is set to doesn’t match the statement (NOT). The string match condition is a negative match which means that if the Referer header field value does not match the value specified in the rule, the request will be blocked. This makes sure that requests for static.example.com which only originate from example.com are allowed. In the Statement section, use the following settings:
Inspect: Select Single header.
Header field name: Enter referer as the value.
Match type: Select Exactly matches string.
String to match: Enter example.com as the value.
Text transformation: Select Lowercase. This isn’t required for most modern browsers, but is a good practice because HTTP header field values are case sensitive.
Figure 5: Rule name and statement
In the Action section, select Block as the Action. Choose Add Rule.
Figure 6: Rule Action
In the preceding rule statement, you’re configuring AWS WAF to inspect a header with the name Referer and checking if the value of the header matches the static string example.com. If the value of the Referer header is not example.com, then the request is blocked.
The next page is Add rules and rule groups. It shows the following attributes of the web ACL:
AWS WAF rules that have been added to the web ACL.
Because you’re only adding one rule to this web ACL, choose Next.
Figure 7: Rules and rule groups, WCUs, and default web ACL action
On the next page, you will set the rule priority. Because you added only one rule, you will not need to adjust the rule priority. If there is more than one rule, you can select a particular rule and use the Move up or Move down options to organize the rule order. Choose Next.
Figure 8: Set rule priority
The Configure metrics page details can be left at the default values. Choose Next to proceed to the final step.
Figure 9: Configure metrics
The final step is to review the web ACL details. If you need to change one of the settings of the web ACL, you can choose Edit step for the corresponding step. Choose Create web ACL to finalize creating the AWS WAF web ACL.
Figure 10: Review and create web ACL
Step 3: Associate the new rule with the relevant CloudFront distribution
You can now associate AWS resources with the web ACL that you created in the previous steps. In this case, the AWS resource is a CloudFront distribution.
In the AWS WAF console, choose Web ACLs in the navigation pane. Select the web ACL named sample-webacl that you created previously.
Figure 11: Select a Web ACL to configure
Choose Add AWS resources.
Figure 12: Add AWS resources
Eligible AWS resources will be displayed in the pop-up page. Select the CloudFront distribution from the Resources list. Choose Add to associate the ACL sample-webacl with the CloudFront distribution.
Figure 13: Select CloudFront distribution to associate with sample-webacl
The next page is the Web ACLs page, which will show the CloudFront distribution selected in the previous step in the Associated AWS resources section.
Figure 14: Web ACLs and Associated AWS resources
Test the referer check rule
You’re ready to test the web ACL that you created by issuing a cURL command from the command line and confirming that the referer check is matched correctly. When you request files without the allowlisted Referer header, the requests are blocked at the CDN. However, valid requests still are allowed through.
When a third party embeds your content (request blocked at the CDN)
Note: With Approach 1, you must make the request with an allowlisted Referer header. In this example, all paths are filtered.
Approach 2: All content under the same domain, with filtering by path
In the second approach, you allow a blank Referer header and filter by a given URL path. To do this, you will create an AWS WAF web ACL that contains multiple rules with additional match conditions, which in turn are comprised of multiple filters. As with the first approach, the match condition looks at the Referer header; however, you will validate the header in two ways. First, you validate whether the request contains the expected header, and if it does not, you apply the second validation, which checks to see whether it has a URL style Referer header. This enables you to access the assets directly in a browser when the assets aren’t embedded elsewhere in a website but still provides protection against hotlinking.
Accessing an image directly in the browser can be useful in situations where users might want to share the link to the image directly, thus helping to prevent a negative user experience when sharing the image link with other users. This approach makes it an improvement over the first approach where requests for the images must originate from the sub-domain.
You will also validate the path used in the request (in this example /wp-content), which allows AWS WAF to protect individual folders under a single domain name.
Step 1: Decide what to protect
As in the first approach, rather than filter on everything under a domain, you will filter based on the path. In this case, /wp-content. This allows you to protect your uploaded content that sits under /wp-content, but without having to put the content into a separate subdomain.
Step 2: Create and name a new web ACL
You can use the web ACL that you created for Approach 1, or you can repeat Step 1 of Approach 1 to create a new web ACL.
Step 3: Create string match conditions on the referer
For Approach 2, the assumption is that everything exists under a single domain, so instead of using the catch-all example.com, use the more secure https://example.com/ and mark the header as Starting withhttps://example.com.
Because you’re explicitly filtering on one header, you must watch out for two things:
Switching between www.example.com and example.com in your application.
Switching between https:// and http:// in your application.
If either of these switches occurs, you will see a 403 Forbidden error returned instead of your embedded files. In this example, all content is delivered directly through https://example.com/.
For this example, you will construct two rules, each of which will contain multiple string match conditions. AWS WAF allows for conditional match conditions within a rule so you can create nested logic statements. For example, a rule evaluation is true if all the statements within a rule statement are evaluated to true.
First rule: Validate a Referer header:
For this rule, you will set the following match conditions and AWS WAF actions:
Rule name: Validate-Referer-header
If Referer header value starts with https://example.com
AND
If URI path starts with /wp-content
THEN
ALLOW request
Open the AWS Management Console for AWS WAF and navigate to WAF & Shield.
Choose Web ACLs in the navigation pane and select Global (CloudFront) as the AWS Region.
Figure 15: Web ACLs and AWS Regions
The page will refresh to show the Web ACL sample-webacl that you created in the preceding Step 2. Select sample-webacl.
Figure 16: Web ACLs list
Select the Rules tab.
Figure 17: Web ACL rules
Choose Add rules and select Add my own rules and rule groups. If you’re reusing the web ACL created in Approach 1, delete the Referer-check rule before adding new rules.
Figure 18: Add rules and rule groups
For Rule type, select Rule builder.
Figure 19: Rule type
In the Rule section, use the following settings:
Name: Enter Validate-referer-header as the value.
Type: Select Regular rule.
If a request: Select matches all the statements (AND).
Figure 20: Rule name and match condition
In the Statement 1 section, use the following settings:
Inspect: Select Single header.
Header field name: Enter referer as the value.
Match type: Select Starts with string.
String to match: Enter https://example.com as the value.
Text transformation: Select Lowercase.
Figure 21: First string match condition
Create the second string match condition (Statement 2). For the URL itself, you want to protect content under /wp-content, so you will create a string match to validate that case using the same steps as for the first string match condition, with two changes:
For Inspect, select URI path.
For String to match, enter /wp-content as the value.
Figure 22: Second string match condition
Change the Action to Allow and choose Add Rule at the bottom of the page.
Figure 23: Set the Action to Allow
In the Set rule priority page, choose Save.
Figure 24: Save the rule
Second rule: Validate without a Referer header
For the second rule, you will set the following match conditions and rule actions:
Rule name: Validate- with-no-Referer-header
If Referer header contains ://
AND
If URI path starts with /wp-content
THEN
BLOCK request
The second rule is similar to the first rule, but it matches when the Referer header value includes ://. You use this match condition to check whether the Referer header has been set at all. If it has, you block the request.
In the Web ACL page, choose Add rules and select Add my own rules and rule groups to be taken to the Rule type page.
Figure 25: Create the second rule
For Rule type and Rule builder, use the following settings:
Rule type: Select Rule builder.
Name: Enter Validate-with-no_Referer-header as the value.
Type: Select Regular rule.
If a request: Select matches all the statements (AND).
Figure 26: Set the rule type and matching
For Statement 1, use the following settings:
Inspect: Select Single header.
Header field name: Enter Referer as the value.
Match type: Select Contains string.
String to match: Enter ://
Figure 27: Configure Statement 1
For Statement 2, use the following settings:
Inspect: Select URI path.
Match type: Select Starts with string.
String to match: Enter /wp-content as the value.
Figure 28: Configure Statement 2
For Action, keep the default setting of Block and choose Add Rule.
Figure 29: Add rule
The resulting Set rule priority page will list the rules in the sample-webacl web ACL and will look like the following figure. It shows the name of the rule, the rule priority, the web capacity units (WCUs) and the AWS WAF response. Choose Save.
Figure 30: Rule priority and web ACL units used the web ACL.
The Rules tab will now show both of the rules that you added with their corresponding AWS WAF actions in addition to the default action of Allow for requests that don’t match one of the rules.
Figure 31: Rules tab of sample-webacl web ACL
Step 4: Associate the new rules with the relevant CloudFront distribution
Select the Associated AWS Resources tab and choose Add AWS resources.
Figure 32: Add AWS resources
Select the relevant CloudFront distribution and choose Add.
Figure 33: Select the CloudFront distribution
The web ACLs page will show the CloudFront distribution in the Associated AWS resources tab.
Figure 34: Associated AWS resources
Test the rules
Similar to Approach 1, you have filtering at the CDN, but this time the filtering is based on the path and direct linking is allowed (without a Referer header).
You can use cURL to verify that the new AWS WAF web ACL correctly protects your content. Use the –H argument to send a different Referer header to the CloudFront distribution, which allows you to test as if you are embedding the website content in an unauthorized page.
AWS WAF is a web application firewall that lets you monitor and control the HTTP(S) requests that are forwarded to your protected web application resources. In this post, you saw how to use the AWS WAF custom rule builder feature to prevent content hotlinking to protect your website’s content hosted in an Amazon S3 bucket.
The two approaches demonstrated in this post provide you with ways to implement a robust referer check solution that helps prevent unauthorized third-party websites from linking back to static assets on your website, thus helping to prevent increased bandwidth costs, bad user experience, and degraded performance because of resource leeching. Following the concept of least privilege, you can further restrict the AWS WAF rules to apply only to certain image file extensions (such as .jpg or .png).
While referer checking helps prevent unaffiliated sites from backlinking to your site’s images and benefitting by using your site’s bandwidth, more sophisticated exploits can carefully craft a request to bypass the referer check. Other web request mechanisms, such as web browser plugins, server-to-server requests that forge referer header values, or privacy-based web browsers may also cause inconsistencies in accurately evaluating the referer header value. Be aware of such inconsistencies and consider using additional private content mechanisms such as signed URLs and token authentication.
You can use AWS WAF to build on top of the referer check to implement more advanced content protection solutions such as rate-limiting, bot mitigation, and DDOS mitigations to further secure your website against a wide range of exploits.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this solution or its implementation, start a new thread on the AWS WAF forum.
Alex Smith was the original author of this post in 2016.
OpenID Foundation’s AuthZEN Working Group is currently drafting a new specification (version 1.0, draft 03 at the time of publication) and associated standard mechanisms, protocols, and formats to communicate authorization-related information between components involved in access control and authorization.
Traditionally, application developers built their own authorization logic within the application code to evaluate access to resources. Reviewing the authorization rules requires reviewing the application code, and changing the authorization rules requires changing and deploying a new version of the application. Customers using this pattern often find it challenging to consistently enforce their authorization rules, track changes to these rules, and update rules as their application evolves.
To solve these challenges, modern application designs have shifted their authorization capabilities and decoupled them from application code. This strategy accelerates application development and grants fine-grained permissions within applications in a more repeatable and dynamic way that developers can apply consistently. Fine-grained permissions are typically designed based on:
Subject role assignments following role-based access control (RBAC)
Attribute values of the subject or the requested resources following attribute-based access control (ABAC)
Relationships between subjects and resources following relationship-based access control (ReBAC)
A hybrid model using a combination of the preceding methods
Expressions of these access control rules are called policies, which lead to the policy-based access control (PBAC) approach.
To support these access control approaches, customers implement solutions that follow the guidance of NIST SP 800-162 – A guide to ABAC.
Figure 1: Access control components and interactions
Figure 1 illustrates the architecture of an advanced access control mechanism that consists of several key components that work together to manage and enforce authorization policies.
At the heart of this system is the policy decision point (PDP), which serves as the rules or policy engine. The PDP is responsible for evaluating rules and policies to determine whether a particular access request should be allowed or denied. This component interacts closely with the policy enforcement point (PEP), which acts as the gatekeeper for resource access.
The PEP, typically integrated into your application, receives access requests for subjects (users or systems) and enforces the decisions made by the PDP. It either allows or denies access to the requested resource based on the PDP’s determination.
To make informed decisions, the PDP might need to retrieve additional metadata or attributes. A policy information point (PIP) acts as an interface to external data sources, such as subject attribute and resource attribute stores. These could include databases such as your HR system, providing crucial contextual information to aid in the decision-making process.
The diagram also shows other important elements:
The policy store, which stores the authorization policies.
The policy administration point (PAP), used for managing and updating policies in the policy store.
Environment conditions, which can influence access decisions based on factors like time, location, or system status.
All these components collaborate within the authorization services framework to provide a comprehensive and flexible access control system. The AuthZEN specification provides a standardized way to communicate authorization requests from the PEP to the PDP and to communicate authorization decisions from the PDP to the PEP.
Interoperability with Verified Permissions
Verified Permissions offers organizations a fully managed service that combines the roles of both a PDP engine and a policy store with a PAP. AWS manages the underlying infrastructure, scaling automatically with application demands and maintaining consistent performance across distributed systems.
Verified Permissions uses Cedar, an open-source policy language that brings mathematically provable access control. When integrated into an application’s architecture, Verified Permissions serves as the central decision-making engine for authorization requests sent through its IsAuthorized() API. Verified Permissions evaluates requests against defined policies while considering information such as principal attributes, resource properties, type of action, and environmental conditions. The service also offers the ability to group common authorization requests into one API call and to validate OAuth 2.0 JSON Web Token with the OpenID Connect provider that issued it when provided as principal information.
This reference implementation enables interoperability and seamless integration between OpenID’s AuthZEN protocol and Verified Permissions. It can help you standardize authorization patterns across different services hosted on AWS.
Architecture overview
The architecture of the proposed AuthZEN interface for Verified Permissions is illustrated in Figure 2.
Figure 2: Architecture overview
The workflow for this architecture is as follows:
The application, serving as PEP, makes an authenticated authorization API call for access requests in AuthZEN-compliant format.
Note: In this solution, you will manage access to the API using a secret generated by AWS Secrets Manager. Review your threat model and adopt additional authentication mechanisms that fit your workload such as OAuth 2.0 bearer tokens, client certificate authentication, or AWS Identity and Access Management (IAM) temporary credentials.
After successful authentication, API Gateway propagates the request to a Lambda function integration.
The Lambda function queries the entity store, which is a PIP, to retrieve additional metadata and attributes about the entities in the authorization request. The entities are representing the principals and the resources.
The Lambda function integration transforms the authorization requests in AuthZEN format into a Verified Permissions IsAuthorized() formatted request.
Verified Permissions evaluates the authorization request and returns the authorization decision, then a Lambda function transforms the authorization decision to an AuthZEN formatted decision back to the application.
Create a Verified Permissions policy store to store your authorization policies. You can create a new policy store using the AWS Management Console for Verified Permissions or deploy the sample policy store by using AWS CDK. The sample policy store contains Cedar policies and entities to support AuthZEN’s authorization scenarios.
To deploy the policy store stack using AWS CDK:
Navigate to the project root folder, bootstrap your environment, and deploy the policy store by using the following commands. Replace <account-id> and <region> with your AWS account number and the AWS Region you want to deploy in.
You then deploy a sample AuthZEN PDP interface that’s connected to the Verified Permissions policy store. The PDP includes the API Gateway REST API, the Lambda authorizer, and the Lambda function integration.
To deploy the PDP by using AWS CDK:
Deploy the PDP stack by using the following commands:
The PASS REQ results indicate this deployment has met AuthZEN interoperability test scenarios requirements. You can also view the latest results at OpenID AuthZEN Interop results summary site.
It’s your turn to build
In this post, we introduced an open-source AuthZEN interface for Amazon Verified Permissions that’s based on the OpenID Foundation’s AuthZEN working group specifications. This implementation provides developers with a transparent way to adopt industry-standard authorization practices while maintaining the security and scalability benefits of the managed authorization service provided by AWS.
If you’re interested in learning more about Cedar and Verified Permissions, see the following references:
AWS Network Firewall is a managed, stateful network firewall and intrusion detection and prevention service. It allows you to implement security rules for fine-grained control of your VPC network traffic. In this blog post, we discuss flow capture and flow flush, new features of AWS Network Firewall that enhance network visibility and security policy enforcement. Flow capture provides comprehensive visibility into active network flows for monitoring and troubleshooting, while flow flush enables selective termination of specific flows or all flows. These capabilities are valuable for routine network monitoring, troubleshooting, and policy updates, as well as during security incidents, where quick isolation of potentially compromised systems is crucial.
Once the traffic flow is allowed by the firewall, that decision remains in effect for the lifetime of the flow. When you modify firewall rules—for example, changing from a broader to a more targeted firewall policy—you may want to review and re-apply the new policy on the existing flows to maintain compliance with your updated security requirements. This is particularly valuable in dynamic cloud environments where security policies are regularly updated, or during security incidents requiring rapid response. These new features provide additional visibility and control of this fundamental aspect of firewall behavior by providing a native capability to identify active flows and selectively flush their connection details from firewall’s inspection engine. As a result, you can maintain consistent policy enforcement across your network during planned security updates or while flushing suspicious network traffic flows during security events.
Before we dive into how to use these new features, let’s go over some of the terms that are introduced.
Understanding the terminologies:
Active flow: A flow in AWS Network Firewall is a tracked network connection identified by a unique 5-tuple (source IP, destination IP, source port, destination port, and protocol). In the context of flow capture and flush features, an active flow refers to a network flow that is not in a CLOSED state. For example, for TCP, this includes a session in the NEW or ESTABLISHED state.
Flow filter: A set of parameters that defines which active network flows to match based on one or more criteria (such as source IP address, destination IP address, source port, destination port, or protocol). A single flow filter can match multiple network flows that meet the defined criteria.
Flow capture: A firewall operation that generates a point-in-time snapshot of active flows based on the defined flow filter(s). You can use this feature to gain network traffic visibility, analyze security events, and validate flows before flush operation.
Flow flush: A firewall operation that flushes selected active flows from the firewall flow table at a specific point in time based on your defined flow filter(s). Subsequent packets after the flush are treated as midstream flows and are re-evaluated against the stream exception policy.
Overview: Flow capture and flow flush operations workflow
AWS Network Firewall uses the open-source intrusion detection and prevention system (IDS/IPS) Suricata for stateful inspection. When inspecting your VPC traffic, the firewall maintains detailed connection state information in a flow table. This means that rather than examining individual packets in isolation, the firewall understands the full context of each network connection. You might need to flush flows in two common scenarios: either to clear all active flows (for example, during troubleshooting or maintenance) or to selectively flush specific flows (for example, when you update your firewall rules and want to flush long-running flows) based on flow filter criteria like IP address, port, or protocol. You can either capture flows first to review them before flushing, or directly flush flows using specified filters. You can monitor and verify the status and details of your capture and flush operations through the firewall operation history.
Let’s see flow capture and flush features in action:
To access these features via console:
Sign in to the AWS management console and open Amazon VPC console.
In the navigation pane, under Network Firewall, select Firewalls.
Under Firewalls, select the name of the Firewall you want to capture/flush flows from.
In the Firewall operations section, you can see the Configure flow capture and Configure flow flush options.
Figure 1: Firewall operations
Flow capture
In this section, you will learn how to capture active flows based on full or partial 5-tuple filters. In this setup, traffic between subnets 10.0.1.0/24 and 10.0.2.0/24, both within the same VPC, is configured to go through AWS Network Firewall for inspection. The goal here is to identify active flows from source subnet 10.0.1.0/24 to destination subnet 10.0.2.0/24 on TCP port 80, and then flush these identified flows.
Figure 2: Network setup
To start flow capture via the console:
Select Configure flow capture to identify active flows as shown in figure 1. This opens a new window, as shown in figure 3.
Select Availability Zone.
Enter Source or Destination address (at least one field is required).
Optionally, enter Minimum age of flow, Source Port, Destination Port, and Protocol (ICMP, TCP, UDP, IPv6-ICMP, or SCTP).
Click Add filter. You can add up to 20 filters using full or partial 5-tuple combinations.
Choose Start capture as shown in figure 3.
In figure 3, only the first filter is needed to capture traffic from subnet 10.0.1.0/24 to 10.0.2.0/24 on TCP port 80. Additional filters are shown to demonstrate other filter possibilities. Using more specific filters results in faster operation times.
Figure 3: Start capture operation
Once capture is complete, the flow operation displays the flows captured by the filter, as shown in figure 4.
Figure 4: Flow capture operation result
Flow flush
In this section, you will learn how to flush flows based on a full or partial 5-tuple. When you need to identify active flows before flushing them, first use the capture operation described in the previous section. Alternatively, you can initiate a new flow flush operation by defining new filters to flush specific active flows.
To start flow flush via the console:
Option 1: Capture then flush
Select Configure flow flush from figure 4 to flush the flows matching your previously defined Filters in the Configure flow capture operation.
Select Start flush in figure 5 to start the flush operation.
Figure 5: Start flush from previous flow capture filter
Option 2: Direct flush
Select Configure flow flush in Firewall operations as shown in figure 1.
Configure the Filter properties as shown in figure 3.
Initiate the Start flush operation.
After the flow flush operation is complete using either option, you can see the flushed flows as shown in figure 6.
Figure 6: Flow flush operation result
For additional verification of flow flushing, you can perform a flow capture operation followed by a flow flush. When flows are flushed, clients typically attempt to reconnect. These retry attempts are recorded in the firewall’s flow table and appear in flow capture results. You can use the Minimum age parameter as a filter to help prevent retry flows from cluttering your flow capture data.
Additionally, if you have AWS Network Firewall flow logs configured for your firewall’s stateful engine, the flow logs display entries for flushed flows. These entries show the reason’ field as flushed and include the last state of the flow before it was flushed.
Figure 7: AWS Network Firewall Flow logs when flow is flushed
Firewall operation history
The Firewall operation history displays the capture and flush operations from the past 12 hours with unique operation IDs for the selected Availability Zone (AZ). Operations older than 12 hours are automatically purged. By clicking on a specific Flow operation ID, you can see the details of each capture or flush flow operation.
Figure 8: Firewall operation history
Things to know:
You can perform one operation (either flow capture or flow flush) at a time per AZ per firewall. If your firewall endpoints are deployed in multiple AZs, you can run a flow capture or flow flush operation simultaneously in multiple AZs.
Use the Minimum age parameter in Filter properties to identify or flush long-running flows. For example, setting Minimum age to 300 seconds includes only flows that are active for 5+ minutes.
The firewall policy’s stream exception policy is applied to packets that arrive at the firewall after their corresponding flow state is flushed. For most applications, we recommend the reject stream exception policy.
Due to the distributed nature of the firewall infrastructure, the actual execution of flow capture and flush operations may vary slightly across different firewall hosts. Both capture and flush operations roll across the firewall infrastructure rather than executing as point-in-time operations.
These features support both IPv4 and IPv6 flows.
AWS CloudTrail records flow capture and flush operations as Management events for auditing.
Conclusion
In this post, you learned how the flow capture and flush features allow you to identify and flush existing flows and validate your security configurations, including stream exception policy implementations, on demand. By using these enhanced features, organizations can actively monitor their network traffic, quickly respond to security events, and verify that their updated security policies are consistently enforced across active connections. There is no additional cost to use these features, and they are enabled by default for existing and new customers.
To learn more about AWS Network Firewall, see the AWS Network Firewall product page and the service documentation. To see which Regions AWS Network Firewall is available in, visit the AWS Region Table.
If you have feedback about this post, submit comments in the comments section below. If you have questions about this post, contact AWS Support.
Today’s organizations rely heavily on secure and reliable communication channels and digital certificates play a crucial role in securing internal and external-facing infrastructure by establishing trust and enabling encrypted communication. While public certificates are commonly used to secure internet applications, many organizations prefer private certificates for internal resources to maintain confidentiality and enable custom configurations that public certificates don’t support. AWS Private Certificate Authority (AWS Private CA) offers a comprehensive solution to create and manage private certificate hierarchies within an organization’s public key infrastructure (PKI). AWS handles the heavy lifting of certificate authority (CA) management, allowing organizations to issue certificates for various use cases, including creating encrypted communication channels, authenticating clients, and cryptographically signing code. These certificates remain trusted within the organization, helping to ensure internal security without exposing them to the public internet.
AWS Certificate Manager (ACM) and AWS Private CA provide robust tools to issue and manage certificates seamlessly within AWS. However, as workloads evolve—spanning cloud native microservices, containerized environments, and hybrid edge deployments—the default certificate configurations might not meet every need. For instance, private TLS certificates requested using ACM come with a fixed 13-month validity period, which ACM tracks and renews automatically. But what if your organization requires certificates with custom validity periods such as short-lived certificates for ephemeral containers or certificates with extended durations for your on-premises systems? This is a common scenario for enterprises using modern architectures. You can gain significant advantages by creating and updating your certificates through AWS Command Line Interface (AWS CLI) or AWS SDKs. These powerful tools offer enhanced flexibility and integrate seamlessly with existing workflows.
Taking this efficiency even further, you can optimize your certificate management by bypassing the AWS Management Console, using the AWS CLI or SDK to generate certificates programmatically through their custom PKI pipelines.
You can use this automation-friendly approach to maintain full control over your certificate lifecycle, though it’s worth noting that ACM doesn’t inherently track the expiration of certificates that are issued using the acm-pca:IssueCertificate API, and aren’t requested using ACM. Lack of oversight on certificate expiration can lead to operational disruptions and compromise the accessibility of your applications. The AWS Private CA offers a powerful option to address this gap: the Generate audit report option. This option produces a detailed report of the certificates issued by your certificate hierarchy—including their expiration dates—regardless of how they were generated. However, with organizations managing vast numbers of certificates across multiple certificate hierarchies, manual report generation and review becomes impractical and unsustainable.
In this blog post, we guide you through a custom automation workflow that harnesses AWS Private CA audit reports to monitor certificate expirations proactively. The solution uses Amazon EventBridge, AWS Lambda, Amazon Simple Storage Service (Amazon S3), Amazon Simple Notification Service (Amazon SNS), and AWS Security Hub to generate daily reports, review them for expiring certificates, notify stakeholders, and generate log findings for centralized visibility. We’ve also included an AWS CloudFormation template to deploy this solution in your AWS environments, complete with step-by-step instructions. This approach can help ensure that you stay ahead of certificate expirations.
The challenge: Certificate management beyond the defaults
To understand why this solution matters, let’s explore the evolving needs of certificate management.
Certificates requested using ACM that are issued by your private CA through the console default to a 13-month validity period; a reasonable middle ground for many workloads. ACM tracks these certificates, monitors their expiration, and even automates renewals. This hands-off approach works well for standard cloud applications, but modern IT environments are rarely standard because of the diverse requirements of real-world use cases.
Consider these real-world examples:
Short-lived certificates: in containerized environments running on EKS or Amazon Elastic Container Service (Amazon ECS) certificates with validity periods of a few hours or days are increasingly common. Service meshes like Istio or Linkerd rely on short-lived certificates to secure pod-to-pod communication, reducing the threat surface if a key is compromised. A 13-month certificate might not be optimal for this use case.
Long-lived certificates: On the other hand, some workloads—often found in traditional or resource-constrained environments—benefit from certificates with extended validity periods. For instance, systems deployed in locations with unreliable or restricted network access might require longer-lived certificates to minimize the challenges of frequent renewals, which could disrupt operations or require manual intervention. Likewise, infrastructures running critical applications with minimal automation might lean towards multi-year certificates to reduce the administrative burden and maintain consistent security over time. In such cases, long-lived certificates offer a dependable solution, balancing security needs with operational simplicity and minimizing the frequency of maintenance tasks.
To address these needs, many organizations turn to their own continuous integration and delivery (CI/CD) pipelines and custom automation using AWS Private CA and ACM. Using AWS CLI or SDKs, you can use AWS Private CA to issue certificates that have custom validity periods tailored to their workload requirements.
Even if certificates aren’t requested using ACM, you can optionally re-import the certificates into ACM. After the certificates have been imported, ACM begins tracking and monitoring them. However, you have the flexibility to decide which certificates to import. Certificates that aren’t imported into ACM will not be tracked by the service. These certificates won’t appear in the ACM console, their expiration events won’t trigger Amazon CloudWatch Logs and managed renewals of these certificates aren’t supported by ACM.
Without a centralized view, you must manually monitor expiration dates, a task that quickly becomes unmanageable as certificate volume grows. An expired certificate can lead to downtime (for example, a load balancer rejecting traffic). This is where the ability to generate an audit report from AWS Private CA can help you. It provides a comprehensive list of all the certificates issued by your CA, including serial numbers, issuance dates, and expiration dates. However, generating this report manually using the console and reviewing it daily isn’t scalable.
In the following section, we show you how to set up a more scalable, automated solution that will notify you when certificates need to be renewed.
Prerequisites
For this walkthrough, you need to have the following:
An AWS account
A private CA from AWS Private CA
An externally created certificate imported into ACM
Solution overview
This audit generation solution provides an automated, scalable, and integrated approach to generating and analyzing audit reports for certificates issued by AWS Private CA. It uses AWS services to monitor certificate statuses, detect impending expirations, and notify administrators while integrating findings into Security Hub for centralized security monitoring. The solution helps ensure timely awareness of expiring certificates; enhancing compliance and operational security.
The following figure shows the solution architecture. The process begins with an EventBridge rule (PCAReportRule) that triggers the audit report generation on a user-defined schedule (for example: daily). This rule invokes the first of the two Lambda functions: PCAauditReportLambdaGenerator. This function interacts with the AWS boto3 SDK to generate an audit report, capturing details of issued certificates. The report is formatted as a CSV file (with optional JSON support configurable in the Lambda function) and stored in a designated S3 bucket. To simulate expiration alerts for demonstration purposes, certificates can be issued with a validity period of less than 30 days, as opposed to the default 13-month validity of AWS Private CA certificates.
Figure 1: Solution architecture
After the audit report is uploaded to the S3 bucket, an S3:PutObject event notification triggers the second Lambda function, PCAAuditReportLambdaProcessor. This function downloads the most recent report, parses the data in the CSV file, and analyzes the details to identify certificates that are expiring within the 30-day threshold. Upon identifying expiring certificates, the function sends a consolidated notification using an Amazon SNS topic PCASNSTopic, which supports subscriptions such as an email or an optional Amazon Simple Queue Service (Amazon SQS) queue for further processing. Simultaneously, the function integrates findings into Security Hub, providing a centralized view of expiring certificates for compliance tracking and security monitoring.
The architecture is deployed using a CloudFormation template, automating the setup of the core components—EventBridge, Lambda functions, an S3 bucket, an SNS topic, and Security Hub integration—into a cohesive system. Security Hub serves as a cloud security posture management service that provides organizations with a consolidated view of their security alerts and compliance status across your AWS accounts. It functions as a central dashboard where security data from various sources and AWS services is aggregated, enabling automatic assessment of resources against established security standards while helping teams prioritize security concerns throughout their environment. This design helps ensure scalability, flexibility, and minimal manual intervention, enabling users to modify the Lambda functions to support additional report formats (such as JSON) or adjust notification thresholds as required. It’s also worth noting that you can generate a report every 30 minutes.
Deploy the solution
With the prerequisites in place and an understanding of the architecture, you’re ready to deploy and test the automation workflow and run an audit report on-demand.
Deploy the CloudFormation template
To get started, clone the following GitHub repo.
~ $ curl -O https://aws-security-blog-content.s3.us-east-1.amazonaws.com/public/sample/2526-monitor-private-ca-issued-certificates-aws-private-certificate-authority-eventbridge/ACM-PCA-Monitoring-cfn.yml
~ $ ls
ACM-PCA-Monitoring-cfn.yml
The ACM-PCA-Monitoring-cfn.yml CloudFormation template includes the following parameters, which allow you to customize the deployment:
CertificateAuthorityArn: The Amazon Resource Name (ARN) (<ARN_of_your_PrivateCA>) of your pre-existing private CA for which the audit report is generated.
S3BucketName: A new S3 bucket (<Name_of_s3_bucket>) where the audit report will be stored.
EventBridgeRuleName: The name of the EventBridge rule (<Name_of_EventBridgeRule>) to trigger the Lambda function (default value: PCAReportRule).
CronJobExpression: A cron expression (<Frequency_of_running_evaluation>) to define the schedule for report generation (default value: cron(0 21 * * ? *)).
SNSName: The name of a new Amazon SNS topic (<Name_of_SNS_Topic>) for expiration alerts (default value: PCASNSTopic).
SQSName: The name of a new Amazon SQS queue (<Name_of_SQS>) for expiration alerts (default value PCASQS).
EmailAddress: The email address for receiving notifications (<Email_to_Receive_alerts>).
CertificateExpirationThreshold: The threshold value in days (<Expiration_threshold_in_days>) to monitor for your certificate’s expiration (default value: 30).
Run the following command to create the CloudFormation stack. Stack creation will take 2–3 minutes to complete.
When stack creation is complete, you’ll get an email asking you to confirm your subscription to the specified SNS topic from the previous step.
Figure 2: Sample notification email sent by Amazon SNS
Test the automation workflow
Test the automation workflow by creating a private certificate that will trigger your expiration alert system. To do this, you’ll generate a private certificate using your private CA with an intentionally short expiration period. The certificate should expire before the threshold you set in the CloudFormation template (the default is 30 days). For example, if you kept the default 30-day threshold, the following code will generate a certificate that expires in 20 days, which should trigger the notification system:
Note: You’ll receive alerts for all certificates that are approaching expiration, even for certificates that are requested using ACM, which support managed renewal. You can compare the ARN of the expiring certificate to your list of requested certificates in the ACM console, or to the results of the acm:ListCertificates API.
With the audit report infrastructure deployed and a test certificate created within your expiration threshold, the next step is to trigger the automation workflow to generate and process the audit report.
Run an audit report on-demand
To test the EventBridge rule PCAReportRule, you’ll temporarily modify it to run every 30 minutes. When you’re done testing, you can revert it back to the original scheduled that you specified in the CloudFormation template parameters.
In the Amazon EventBridge console, choose Rules in the navigation pane. Select PCAReportRule and then choose Edit rule.
Select Define schedule.
Under Schedule pattern, select A schedule that runs at a regular rate…
Under Rate expression, for Value enter 30, and for Unit, select Minutes.
Choose Next.
Figure 3: Edit the schedule of PCAReportRule for the test
For an immediate test, you can also trigger this workflow from the Lambda console.
In the Lambda console, choose Functions in the navigation pane, and then select the PCAauditReportLambdaGenerator Lambda function.
Choose the Test tab, leave the default values for the Event JSON.
Choose Test at the top of the window.
Figure 4: Use the console to trigger a test
This Lambda function generates an AWS Private CA audit report and saves it to the specified S3 bucket at the audit-report prefix. To verify this, navigate to the Amazon S3 console and choose Buckets from the navigation pane.
Select the bucket that you created when you ran the CloudFormation template and verify the reports in the audit-report folder.
Figure 5: The audit report is saved to the specified S3 bucket
When an audit report is uploaded to the S3 bucket, it automatically triggers the PCAAuditReportLambdaProcessor Lambda function through S3 event notifications. The function analyzes the audit report to identify any certificates approaching expiration. If certificates are found that will expire within the specified threshold (30 days by default), the function automatically creates detailed findings in Security Hub for tracking and monitoring purposes. These findings include important details such as the certificate ARN, expiration date, and severity level.
Because you created a test certificate that expires in 20 days (which is within the test threshold), the automation workflow will detect this and generate corresponding findings in Security Hub. To see the results go to the Security Hub console and choose Findings in the navigation pane.
Figure 6: View the audit report findings in Security Hub
After creating Security Hub findings, the Lambda function sends detailed certificate expiration alerts through Amazon SNS. You’ll receive an email notification at the address you provided in the CloudFormation parameters. The email will contain important information about the certificates approaching expiration, including their ARNs and exact expiration dates. Here’s an example of the email notification format
Figure 7: Sample notification email sent by Amazon SNS
Conclusion
Certificate management is crucial for maintaining security across modern workloads, and AWS Private CA plays a vital role in issuing certificates with custom validity periods. The solution in this post delivers a robust, automated approach to certificate lifecycle management by seamlessly integrating several AWS services.
The solution combines Amazon EventBridge for scheduled execution of audit reports, AWS Lambda for automated processing and analysis, Amazon S3 for secure storage of audit reports, Amazon SNS for immediate notification delivery, and AWS Security Hub for centralized monitoring and tracking. This powerful integration creates a comprehensive automation workflow that actively monitors certificate expirations and provides timely alerts across your cloud, hybrid, and edge deployments.
By implementing this CloudFormation template, you can:
Automate the generation and processing of AWS Private CA audit reports at scheduled intervals
Receive immediate notifications when certificates approach their expiration threshold
Maintain centralized visibility through detailed Security Hub findings
Track certificate lifecycles across your entire infrastructure
Help ensure compliance with organizational security policies
Minimize the risk of service disruptions due to expired certificates
The solution transforms traditional certificate management from a manual, error-prone process into a streamlined, automated workflow. It provides security teams with the tools they need to proactively manage certificate lifecycles, maintain compliance requirements, and respond quickly to potential certificate-related issues. The automated notifications and centralized monitoring through Security Hub help ensure that no certificate expiration goes unnoticed, allowing teams to take timely action before service disruptions occur.
The result is a scalable, reliable system that simplifies certificate management and strengthens your organization’s overall security posture through consistent monitoring and proactive management of certificate lifecycles.
If you have feedback about this post, submit comments in the Comments section below.
This blog is co-authored by JamesLe, Head of Developer Experience – TwelveLabs
The exponential growth of video content has created both opportunities and challenges. Content creators, marketers, and researchers are now faced with the daunting task of efficiently searching, analyzing, and extracting valuable insights from vast video libraries. Traditional search methods such as keyword-based text search often fall short when dealing with video content to analyze the visual content, spoken words, or contextual elements within the video itself, leaving organizations struggling to effectively search through and unlock the full potential of their multimedia assets.
In this blog post, we show you the process of integrating TwelveLabs Embed API with OpenSearch Service to create a multimodal search solution. You’ll learn how to generate rich, contextual embeddings from video content and use OpenSearch Service’s vector database capabilities to enable search functionalities. By the end of this post, you’ll be equipped with the knowledge to implement a system that can transform the way your organization handles and extracts value from video content.
TwelveLabs’ multimodal embeddings process visual, audio, and text signals together to create unified representations, capturing the direct relationships between these modalities. This unified approach delivers precise, context-aware video search that matches human understanding of video content. Whether you’re a developer looking to enhance your applications with advanced video search capabilities, or a business leader seeking to optimize your content management strategies, this post will provide you with the tools and steps to implement multimodal search for your organizational data.
About TwelveLabs
TwelveLabs is an Advanced AWS Partner and AWS Marketplace Seller that offers video understanding solutions. Embed API is designed to revolutionize how you interact with and extract value from video content.
At its core, the Embed API transforms raw video content into meaningful, searchable data by using state-of-the-art machine learning models. These models extract and represent complex video information in the form of dense vector embeddings, each a standard 1024-dimensional vector that captures the essence of the video content across multiple modalities (image, text, and audio).
Key features of TwelveLabs Embed API
Below are the key features of TwelveLabs Embed API:
Multimodal understanding: The API generates embeddings that encapsulate various aspects of the video, including visual expressions, body language, spoken words, and overall context.
Temporal coherence: Unlike static image-based models, TwelveLabs’ embeddings capture the interrelations between different modalities over time, providing a more accurate representation of video content.
Flexibility: The API supports native processing of all modalities present in videos, eliminating the need for separate text-only or image-only models.
High performance: By using a video-native approach, the Embed API provides more accurate and temporally coherent interpretation of video content compared to traditional CLIP-like models.
Benefits and use cases
The Embed API offers numerous advantages for developers and businesses working with video content:
Enhanced Search Capabilities: Enable powerful multimodal search across video libraries, allowing users to find relevant content based on visual, audio, or textual queries.
Content Recommendation: Improve content recommendation systems by understanding the deep contextual similarities between videos.
Scene Detection and Segmentation: Automatically detect and segment different scenes within videos for easier navigation and analysis.
Content Moderation: Efficiently identify and flag inappropriate content across large video datasets.
However, the use case can be expanded to various other segments. For example, the news organization struggles with:
Needle-in-haystack searches through thousands of hours of archival footage
Manual metadata tagging that misses nuanced visual and audio context
Cross-modal queries such as querying a video collection using text or audio descriptions
Rapid content retrieval for breaking news tie-ins
By integrating TwelveLabs Embed API with OpenSearch Service, you can:
Generate 1024-dimensional embeddings capturing each video’s visual concepts. The embeddings are also capable of extracting spoken narration, on-screen text, and audio cues.
Enable multimodal search capabilities allowing users to:
Find specific demonstrations using text-based queries.
Locate activities through image-based queries.
Identify segments using audio pattern matching.
Reduce search time from hours to seconds for complex queries.
Before you proceed further, verify that the following prerequisites are met:
Confirm that you have an AWS account. Sign in to the AWS account.
Create a TwelveLabs account because it will be required to get the API Key. TwelveLabs offer free tier pricing but you can upgrade if necessary to meet your requirement.
Have an Amazon OpenSearch Service domain. If you don’t have an existing domain, you can create one using the steps outlined in our public documentation for Creating and Managing Amazon OpenSearch Service Domain. Make sure that the OpenSearch Service domain is accessible from your Python environment. You can also use Amazon OpenSearch Serverless for this use case and update the interactions to OpenSearch Serverless using AWS SDKs.
Step 1: Set up the TwelveLabs SDK
Start by setting up the TwelveLabs SDK in your Python environment:
Follow steps here to create a secret in AWS Secrets Manager. For example, name the secret as TL_API_Key.Note down the ARN or name of the secret (TL_API_Key) to retrieve. To retrieve a secret from another account, you must use an ARN.For an ARN, we recommend that you specify a complete ARN rather than a partial ARN. See Finding a secret from a partial ARN.Use this value for the SecretId in the code block below.
Use the Embed API to create multimodal embeddings that are contextual vector representations for your videos and texts. TwelveLabs video embeddings capture all the subtle cues and interactions between different modalities, including the visual expressions, body language, spoken words, and the overall context of the video, encapsulating the essence of all these modalities and their interrelations over time.
To create video embeddings, you must first upload your videos, and the platform must finish processing them. Uploading and processing videos require some time. Consequently, creating embeddings is an asynchronous process comprised of three steps:
Upload and process a video: When you start uploading a video, the platform creates a video embedding task and returns its unique task identifier.
Monitor the status of your video embedding task: Use the unique identifier of your task to check its status periodically until it’s completed.
Retrieve the embeddings: After the video embedding task is completed, retrieve the video embeddings by providing the task identifier. Learn more in the docs.
Video processing implementation
This demo depends upon some video data. To use this, you will download two mp4 files and upload it to an Amazon S3 bucket.
Download the 21723-320725678_small.mp4 and 2946-164933125_small.mp4 files.
Create an S3 bucket if you don’t have one already. Follow the steps in the Creating a bucket doc. Note down the name of the bucket and replace it the code block below (Eg., MYS3BUCKET).
Upload the 21723-320725678_small.mp4 and 2946-164933125_small.mp4 video files to the S3 bucket created in the step above by following the steps in the Uploading objects doc. Note down the name of the objects and replace it the code block below (Eg., 21723-320725678_small.mp4 and 2946-164933125_small.mp4)
s3_client=boto3.client("s3")
bird_video_data=s3_client.download_file(Bucket='MYS3BUCKET', Key='21723-320725678_small.mp4', Filename='robin-bird.mp4')
island_video_data=s3_client.download_file(Bucket='MYS3BUCKET', Key='2946-164933125_small.mp4', Filename='island.mp4')
def print_segments(segments: List[SegmentEmbedding], max_elements: int = 1024):
for segment in segments:
print(
f" embedding_scope={segment.embedding_scope} start_offset_sec={segment.start_offset_sec} end_offset_sec={segment.end_offset_sec}"
)
print(f" embeddings: {segment.embeddings_float[:max_elements]}")
# Initialize client with API key
twelvelabs_client = TwelveLabs(api_key=TL_API_KEY)
video_files=["robin-bird.mp4", "island.mp4"]
tasks=[]
Embedding generation process
With the SDK configured, generate embeddings for your video and monitor task completion with real-time updates. Here you use the Marengo 2.7 model to generate the embeddings:
for video in video_files:
# Create embedding task
task = twelvelabs_client.embed.task.create(
model_name="Marengo-retrieval-2.7",
video_file=video
)
print(
f"Created task: id={task.id} engine_name={task.model_name} status={task.status}"
)
def on_task_update(task: EmbeddingsTask):
print(f" Status={task.status}")
status = task.wait_for_done(
sleep_interval=2,
callback=on_task_update
)
print(f"Embedding done: {status}")
# Retrieve and inspect results
task = task.retrieve()
if task.video_embedding is not None and task.video_embedding.segments is not None:
print_segments(task.video_embedding.segments)
tasks.append(task)
Key features demonstrated include:
Multimodal capture: 1024-dimensional vectors encoding visual, audio, and textual features
Model specificity: Using Marengo-retrieval-2.7 optimized for scientific content
Progress tracking: Real-time status updates during embedding generation
Set up the OpenSearch client with your host details and authentication credentials:
from opensearchpy import OpenSearch, RequestsHttpConnection, helpers
from requests_aws4auth import AWS4Auth
from requests.auth import HTTPBasicAuth
# OpenSearch connection configuration
# host = 'your-host.aos.us-east-1.on.aws'
host = 'search-new-domain-mbgs7wth6r5w6hwmjofntiqcge.aos.us-east-1.on.aws'
port = 443 # Default HTTPS port
# Get OpenSearch username secret from Secrets Manager
opensearch_username=secrets_manager_client.get_secret_value(
SecretId="AOS_username"
)
opensearch_username_string=json.loads(opensearch_username["SecretString"])["AOS_username"]
# Get OpenSearch password secret from Secrets Manager
opensearch_password = secrets_manager_client.get_secret_value(
SecretId="AOS_password"
)
opensearch_password_string=json.loads(opensearch_password["SecretString"])["AOS_password"]
auth=(opensearch_username_string, opensearch_password_string)
# Create the client configuration
client_aos = OpenSearch(
hosts=[{'host': host, 'port': port}],
http_auth=auth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection
)
# Test the connection
try:
# Get cluster information
cluster_info = client_aos.info()
print("Successfully connected to OpenSearch")
print(f"Cluster info: {cluster_info}")
except Exception as e:
print(f"Connection failed: {str(e)}")
Expected output
If the connection is successful, you should see a message like the following:
Successfully connected to OpenSearch
Cluster info: {'name': 'bb36e8d98ee7bd517891ecd714bfb9d7', ...}
This confirms that your OpenSearch client is properly configured and ready for use.
Step 4: Create an index in OpenSearch Service
Next, you create an index optimized for vector search to store the embeddings generated by the TwelveLabs Embed API.
Define the index configuration
The index is configured to support k-nearest neighbor (kNN) search with a 1024-dimensional vector field. You will these values for this demo but follow these best practices to find appropriate values for your application. Here’s the code:
Use the following code to create the index in OpenSearch Service:
# Create the index in OpenSearch
response = client_aos.indices.create(index=index_name, body=new_vector_index_definition, ignore=400)
# Retrieve and display index details to confirm creation
index_info = client_aos.indices.get(index=index_name)
print(index_info)
Expected output
After running this code, you should see details of the newly created index. For example:
The following screenshot confirms that an index named twelvelabs_index has been successfully created with a knn_vector field of dimension 1024 and other specified settings. With these steps completed, you now have an operational OpenSearch Service domain configured for vector search. This index will serve as the repository for storing embeddings generated from video content, enabling advanced multimodal search capabilities.
Step 5: Ingest embeddings to the created index in OpenSearch Service
With the TwelveLabs Embed API successfully generating video embeddings and the OpenSearch Service index configured, the next step is to ingest these embeddings into the index. This process helps ensure that the embeddings are stored in OpenSearch Service and made searchable for multimodal queries.
Embedding ingestion process
The following code demonstrates how to process and index the embeddings into OpenSearch Service:
from opensearchpy.helpers import bulk
def generate_actions(tasks, video_files):
count = 0
for task in tasks:
# Check if video embeddings are available
if task.video_embedding is not None and task.video_embedding.segments is not None:
embeddings_doc = task.video_embedding.segments
# Generate actions for bulk indexing
for doc_id, elt in enumerate(embeddings_doc):
yield {
'_index': index_name,
'_id': doc_id,
'_source': {
'embedding_field': elt.embeddings_float,
'video_title': video_files[count],
'segment_start': elt.start_offset_sec,
'segment_end': elt.end_offset_sec,
'segment_id': doc_id
}
}
print(f"Prepared bulk indexing data for task {count}")
count += 1
# Perform bulk indexing
try:
success, failed = bulk(client_aos, generate_actions(tasks, video_files))
print(f"Successfully indexed {success} documents")
if failed:
print(f"Failed to index {len(failed)} documents")
except Exception as e:
print(f"Error during bulk indexing: {e}")
Explanation of the code
Embedding extraction: The video_embedding.segments object contains a list of segment embeddings generated by the TwelveLabs Embed API. Each segment represents a specific portion of the video.
Document creation: For each segment, a document is created with a key (embedding_field) that stores its 1024-dimensional vector, video_title with the title of the video, segment_start and segment_end indicating the timestamp of the video segment, and a segment_id.
Indexing in OpenSearch: The index() method uploads each document to the twelvelabs_index created earlier. Each document is assigned a unique ID (doc_id) based on its position in the list.
Expected output
After the script runs successfully, you will see:
A printed list of embeddings being indexed.
A confirmation message:
Prepared bulk indexing data for task 0
Prepared bulk indexing data for task 1
Successfully indexed 6 documents
Result
At this stage, all video segment embeddings are now stored in OpenSearch and ready for advanced multimodal search operations, such as text-to-video or image-to-video queries. This sets up the foundation for performing efficient and scalable searches across your video content.
Step 6: Perform vector search in OpenSearch Service
After embeddings are generated, you use it as a query vector to perform a kNN search in the OpenSearch Service index. Below are the functions to perform vector search and format the search results:
# Function to perform vector search
def search_similar_segments(query_vector, k=5):
query = {
"size": k,
"_source": ["video_title", "segment_start", "segment_end", "segment_id"],
"query": {
"knn": {
"embedding_field": {
"vector": query_vector,
"k": k
}
}
}
}
response = client_aos.search(
index=index_name,
body=query
)
results = []
for hit in response['hits']['hits']:
result = {
'score': hit['_score'],
'title': hit['_source']['video_title'],
'start_time': hit['_source']['segment_start'],
'end_time': hit['_source']['segment_end'],
'segment_id': hit['_source']['segment_id']
}
results.append(result)
return (results)
# Function to format search results
def print_search_results(results):
print("\nSearch Results:")
print("-" * 50)
for i, result in enumerate(results, 1):
print(f"\nResult {i}:")
print(f"Video: {result['title']}")
print(f"Time Range: {result['start_time']} - {result['end_time']}")
print(f"Similarity Score: {result['score']:.4f}")
Key points:
The _source field contains the video title, segment start, segment end, and segment id corresponding to the video embeddings.
The embedding_field in the query corresponds to the field where video embeddings are stored.
The k parameter specifies how many top results to retrieve based on similarity.
Step 7:Performing text-to-video search
You can use text-to-video search to retrieve video segments that are most relevant to a given textual query. In this solution, you will do this by using TwelveLabs’ text embedding capabilities and OpenSearch’s vector search functionality. Here’s how you can implement this step:
Generate text embeddings
To perform a search, you first need to convert the text query into a vector representation using the TwelveLabs Embed API:
from typing import List
from twelvelabs.models.embed import SegmentEmbedding
def print_segments(segments: List[SegmentEmbedding], max_elements: int = 1024):
for segment in segments:
print(
f" embedding_scope={segment.embedding_scope} start_offset_sec={segment.start_offset_sec} end_offset_sec={segment.end_offset_sec}"
)
print(f" embeddings: {segment.embeddings_float[:max_elements]}")
# Create text embeddings for the query
text_res = twelvelabs_client.embed.create(
model_name="Marengo-retrieval-2.7",
text="Bird eating food", # Replace with your desired query
)
print("Created a text embedding")
print(f" Model: {text_res.model_name}")
# Extract and inspect the generated text embeddings
if text_res.text_embedding is not None and text_res.text_embedding.segments is not None:
print_segments(text_res.text_embedding.segments)
vector_search = text_res.text_embedding.segments[0].embeddings_float
print("Generated Text Embedding Vector:", vector_search)
Key points:
The Marengo-retrieval-2.7 model is used to generate a dense vector embedding for the query.
The embedding captures the semantic meaning of the input text, enabling effective matching with video embeddings.
Perform vector search in OpenSearch Service
After the text embedding is generated, you use it as a query vector to perform a kNN search in the OpenSearch index:
The following illustrates similar results retrieved from OpenSearch.
Search Results:
--------------------------------------------------
Result 1:
Video: robin-bird.mp4
Time Range: 18.0 - 21.087732
Similarity Score: 0.4409
Result 2:
Video: robin-bird.mp4
Time Range: 12.0 - 18.0
Similarity Score: 0.4300
Result 3:
Video: island.mp4
Time Range: 0.0 - 6.0
Similarity Score: 0.3624
Insights from results
Each result includes a similarity score indicating how closely it matches the query, a time range indicating the start and end offset in seconds, and the video title.
Observe that the top 2 results correspond to the robin bird video segments matching the Bird eating food query.
This process demonstrates how textual queries such as Bird eating food can effectively retrieve relevant video segments from an indexed library using TwelveLabs’ multimodal embeddings and OpenSearch’s powerful vector search capabilities.
Step 8: Perform audio-to-video search
You can use audio-to-video search to retrieve video segments that are most relevant to a given audio input. By using TwelveLabs’ audio embedding capabilities and OpenSearch’s vector search functionality, you can match audio features with video embeddings in the index. Here’s how to implement this step:
Generate audio embeddings
To perform the search, you first convert the audio input into a vector representation using the TwelveLabs Embed API:
# Create audio embeddings for the input audio file
audio_res = twelvelabs_client.embed.create(
model_name="Marengo-retrieval-2.7",
audio_file="audio-data.mp3", # Replace with your desired audio file
)
# Print details of the generated embedding
print(f"Created audio embedding: model_name={audio_res.model_name}")
print(f" Model: {audio_res.model_name}")
# Extract and inspect the generated audio embeddings
if audio_res.audio_embedding is not None and audio_res.audio_embedding.segments is not None:
print_segments(audio_res.audio_embedding.segments)
# Store the embedding vector for search
vector_search = audio_res.audio_embedding.segments[0].embeddings_float
print("Generated Audio Embedding Vector:", vector_search)
Key points:
The Marengo-retrieval-2.7 model is used to generate a dense vector embedding for the input audio.
The embedding captures the semantic features of the audio, such as rhythm, tone, and patterns, enabling effective matching with video embeddings
Perform vector search in OpenSearch Service
After the audio embedding is generated, you use it as a query vector to perform a k-nearest neighbor (kNN) search in OpenSearch:
The following shows video segments retrieved from OpenSearch Service based on their similarity to the input audio.
Search Results:
--------------------------------------------------
Result 1:
Video: island.mp4
Time Range: 6.0 - 12.0
Similarity Score: 0.2855
Result 2:
Video: robin-bird.mp4
Time Range: 18.0 - 21.087732
Similarity Score: 0.2841
Result 3:
Video: robin-bird.mp4
Time Range: 12.0 - 18.0
Similarity Score: 0.2837
Result 4:
Video: island.mp4
Time Range: 0.0 - 6.0
Similarity Score: 0.2835
Here notice that segments from both videos are returned with a low similarity score.
Step 9: Performing images-to-video search
You can use image-to-video search to retrieve video segments that are visually similar to a given image. By using TwelveLabs’ image embedding capabilities and OpenSearch Service’s vector search functionality, you can match visual features from an image with video embeddings in the index. Here’s how to implement this step:
Generate Image Embeddings
To perform the search, you first convert the input image into a vector representation using the TwelveLabs Embed API:
# Create image embeddings for the input image file
image_res = twelvelabs_client.embed.create(
model_name="Marengo-retrieval-2.7",
image_file="image-data.jpg", # Replace with your desired image file
)
# Print details of the generated embedding
print(f"Created image embedding: model_name={image_res.model_name}")
print(f" Model: {image_res.model_name}")
# Extract and inspect the generated image embeddings
if image_res.image_embedding is not None and image_res.image_embedding.segments is not None:
print_segments(image_res.image_embedding.segments)
# Store the embedding vector for search
vector_search = image_res.image_embedding.segments[0].embeddings_float
print("Generated Image Embedding Vector:", vector_search)
Key points:
The Marengo-retrieval-2.7 model is used to generate a dense vector embedding for the input image.
The embedding captures visual features such as shapes, colors, and patterns, enabling effective matching with video embeddings
Perform vector search in OpenSearch
After the image embedding is generated, you use it as a query vector to perform a k-nearest neighbor (kNN) search in OpenSearch:
The following shows video segments retrieved from OpenSearch based on their similarity to the input image.
Search Results:
--------------------------------------------------
Result 1:
Video: island.mp4
Time Range: 6.0 - 12.0
Similarity Score: 0.5616
Result 2:
Video: island.mp4
Time Range: 0.0 - 6.0
Similarity Score: 0.5576
Result 3:
Video: robin-bird.mp4
Time Range: 12.0 - 18.0
Similarity Score: 0.4592
Result 4:
Video: robin-bird.mp4
Time Range: 18.0 - 21.087732
Similarity Score: 0.4540
Observe that image of an ocean was used to search the videos. Video clips from the island video are retrieved with a higher similarity score in the first 2 results.
Clean up
To avoid charges, delete resources created while following this post. For Amazon OpenSearch Service domains, navigate to the AWS Management Console for Amazon OpenSearch Service dashboard and delete the domain.
Conclusion
The integration of TwelveLabs Embed API with OpenSearch Service provides a cutting-edge solution for advanced video search and analysis, unlocking new possibilities for content discovery and insights. By using TwelveLabs’ multimodal embeddings, which capture the intricate interplay of visual, audio, and textual elements in videos, and combining them with OpenSearch Service’s robust vector search capabilities, this solution enables highly nuanced and contextually relevant video search.
As industries increasingly rely on video content for communication, education, marketing, and research, this advanced search solution becomes indispensable. It empowers businesses to extract hidden insights from their video content, enhance user experiences in video-centric applications and make data-driven decisions based on comprehensive video analysis
This integration not only addresses current challenges in managing video content but also lays the foundation for future innovations in how we interact with and derive value from video data.
Get started
Ready to explore the power of TwelveLabs Embed API? Start your free trial today by visiting TwelveLabs Playground to sign up and receive your API key.
For developers looking to implement this solution, follow our detailed step-by-step guide on GitHub to integrate TwelveLabs Embed API with OpenSearch Service and build your own advanced video search application.
Unlock the full potential of your video content today!
About the Authors
James Le runs the Developer Experience function at TwelveLabs. He works with partners, developers, and researchers to bring state-of-the-art video foundation models to various multimodal video understanding use cases.
Gitika is an Senior WW Data & AI Partner Solutions Architect at Amazon Web Services (AWS). She works with partners on technical projects, providing architectural guidance and enablement to build their analytics practice.
Kruthi is a Senior Partner Solutions Architect specializing in AI and ML. She provides technical guidance to AWS Partners in following best practices to build secure, resilient, and highly available solutions in the AWS Cloud.
Before you start using IAM Roles Anywhere, it’s important to plan how you’ll integrate it with your PKI and with your applications running outside of AWS. In this blog post, we share considerations and best practices for integrating IAM Roles Anywhere with your PKI and applications.
Placing your trust anchor within your PKI
The first step when you configure IAM Roles Anywhere is to create a trust anchor. A trust anchor is a resource that represents your certificate authority (CA). A trust anchor can be a root CA or an intermediate or issuing CA.
The choice of which CA to use as your trust anchor within your PKI has implications for which end-entity certificates can be used with IAM Roles Anywhere and the security of your IAM Roles Anywhere deployment. Any valid end-entity certificate issued by your trust anchor, or a valid end-entity certificate issued by a CA that is beneath your trust anchor in your PKI’s hierarchy, can be used with IAM Roles Anywhere.
For example, in a three-level PKI where you select your root CA as your trust anchor, an end-entity certificate issued by your root, or an intermediate certificate authority below your root, can be used with this trust anchor for IAM Roles Anywhere, as shown in Figure 1.
Figure 1: The useable end-entity certificates if you select a root CA as a trust anchor
As shown in Figure 2, if you select Intermediate CA 2 (a CA two levels below the root) as your trust anchor for IAM Roles Anywhere, only end-entity certificates issued from Intermediate CA 2 could be used to get temporary AWS credentials with your IAM Roles Anywhere deployment.
Figure 2: The useable end entity certificates if you select a lower level or issuing certificate authority as a trust anchor
In Figure 2, we selected Intermediate CA as our trust anchor and only end-entity certificates issued by Intermediate CA 2 can be used with IAM Roles Anywhere.
Selecting a root or higher-level intermediate CA will give you more flexibility when it comes to rotation of lower-level CAs, but might allow for more certificates than you intend to be able to access your AWS resources. Using a lower-level issuing CA will not allow certificates issued by other CAs within your PKI to be able to use IAM Roles Anywhere, even if they have identical attributes.
To use the certificate revocation list (CRL) functionality of IAM Roles Anywhere, the certificate used as a trust anchor MUST also contain the CRL Sign for key usage.
The certificate must not be issued by a public CA, or be a public CA.
Choosing your trust anchor: AWS Private CA compared to a self-managed PKI
If you already have an existing PKI and the capability to distribute certificates to your workloads, it’s likely that your existing PKI (which you have experience managing) will be a good choice to use as your IAM Roles Anywhere trust anchor.
However, if you’re looking to establish a PKI without the investment and maintenance costs of operating an on-premises CA, consider using AWS Private Certificate Authority (AWS Private CA). When you use this service, AWS hosts your CAs and allows you to issue certificates by using AWS API requests.
Consider the following when deciding whether to use AWS Private CA for your PKI:
Automatic rotation of your trust anchor: AWS Private CA is designed to integrate quickly with IAM Roles Anywhere, so you don’t need additional rotation of trust anchor certificates within IAM Roles Anywhere—this will be entirely managed in AWS Private CA.
Cost: There’s a cost to using AWS Private CA, which can make reusing your existing PKI more cost effective, if you have one. However, there are benefits to using AWS Private CA, such as automatic rotation, scalability, and resiliency, which can offset the cost of the service.
Scalability and availability: AWS Private CA is a highly scalable and available service across many AWS Regions. AWS Private CA also integrates with AWS Certificate Manager, so that you can conveniently manage certificate issuance and automate certificate renewals.
Resiliency: You can configure an identical AWS Private CA setup in another supported Region.
AWS API integration: You can use AWS Private CA to manage and issue certificates with AWS credentials, using IAM roles and temporary security credentials that are subject to the relevant AWS policies.
Technology integrations: AWS Private CA can integrate with technologies such as third-party certificate management services.
For more information about implementing IAM Roles Anywhere with AWS Private CA, see this Security Blog post.
Working with end-entity certificates with IAM Roles Anywhere
In IAM Roles Anywhere, end-entity X.509 certificates are used to authenticate with the CreateSession API call. These end-entity certificates must meet the following constraints:
The certificates MUST be X.509v3.
Basic constraints MUST include CA: false.
The key usage MUST include Digital Signature.
The signing algorithm MUST include SHA256 or stronger. MD5 and SHA1 signing algorithms are rejected.
Most certificates issued today, such as those used to serve HTTPS requests or to perform mutual TLS (mTLS) authentication, meet these constraints. Those certificates could be used with IAM Roles Anywhere without changes.
Each end-entity’s certificate serial number doesn’t need to be unique, but it’s a best practice for each certificate issued by your certificate authority to have a unique serial number. The serial number of a certificate is used as the role session name of the IAM role session IAM Roles Anywhere creates, and this number can be used to associate events logged to AWS CloudTrail back to the end-entity certificate that was used to assume an IAM role.
IAM roles and workload identity
After you’ve planned for integration with your PKI, the next step when you set up IAM Roles Anywhere is to plan for how your workload identity will integrate with IAM Roles Anywhere and your PKI. The IAM role session that is created by calling CreateSession represents the identity and permissions of your external workloads within AWS.
To help you achieve least privilege, AWS recommends that you use a dedicated IAM role for each of your applications so that you can give each application only the permissions it requires to operate. For example, if you had two applications, Red and Blue, you would create a separate IAM role for each application and grant each role the IAM permissions it needs to do its job.
To make sure that the Red and Blue applications cannot access each other’s roles, you can restrict access by using X.509 attributes as tags in the trust policy for each IAM role. (See Certificate attribute mapping for more information on attributes.) For this example, we will use the Common Name (CN) attribute to restrict access for the Red application.
The following is a sample IAM role trust policy that lets the Red certificate from a trust anchor named ExampleCorpAnchor assume the role from IAM Roles Anywhere:
The role session created will have the SourceIdentity value in AWS set to be equal to the CN of the certificate. For example, the Red certificate would have a SourceIdentity value of CN=Red.
You can find a complete list of session tags and attributes used in IAM Roles Anywhere in the IAM Roles Anywhere documentation The session tags set on roles created with IAM Roles Anywhere are transitive and will be present on any further roles assumed by a role session that is created by IAM Roles Anywhere.
Rotating trust anchor certificates
When you’re using IAM Roles Anywhere with a self-hosted PKI for your trust anchor, you’re responsible for updating your trust anchor with the new CA certificate.
IAM Roles Anywhere supports up to two certificates configured within a trust anchor at a time. When it comes time to rotate the certificate authority used as your trust anchor, you can add your new certificate into the trust anchor so that certificates issued from either CA certificate can be used with IAM Roles Anywhere.
After you have both CA certificates in your trust anchor, you can migrate your workloads over to end-entity certificates issued by your new CA for a seamless migration without the need to update code or configurations on your workloads. After your workloads have migrated to your new certificate authority, you can remove the unused certificate from your trust anchor configuration.
IAM Roles Anywhere profiles and session policies
When you set up IAM Roles Anywhere, you create a profile to associate IAM roles with. A profile allows you to optionally apply a session policy.
Most customers deploy IAM Roles Anywhere by creating one profile for each IAM role that they configure. This gives you the flexibility to apply session policies to each application or IAM role in IAM Roles Anywhere without impacting other roles or applications. We recommend that customers use the one-profile-per-role approach to achieve more operational flexibility.
By using one profile across many different IAM roles, you can minimize configuration work and have a common session policy for the different IAM roles you have set up with IAM Roles Anywhere. This approach requires management of fewer AWS resources, but means that changes to the profile will impact a larger number of applications.
When you set a session policy on a profile, we recommend that you use a managed policy Amazon Resource Name (ARN), rather than the default in-line session policy ARN, because this allows you to have more IAM policy space. The most common use case we’ve seen for applying session policies with IAM Roles Anywhere profiles is restricting the IAM Roles Anywhere session to only expected IP address ranges, such as your on-premises data centers.
The role sessions created by IAM Roles Anywhere are subject to all relevant AWS policies, such as resource control policies (RCPs), service control policies (SCPs), resource policies, permissions boundaries, and VPC endpoint policies.
Working with distributed applications
If you have multiple deployments of an application, we recommend that, wherever possible, you use a unique certificate and key for each instance of that application. For example, this would apply if Blue is a distributed application, and each instance of the Blue application has a requirement to communicate with AWS resources. Sharing a key across distributed applications increases the risk a key could accidentally be made available to unauthorized parties when it’s copied and stored over a network.
By using a unique certificate and key for each instance, you can keep the private key on the server that is using IAM Roles Anywhere instead of needing to distribute the private key over the network, which is a best practice to help prevent exposure of a private key. IAM Roles Anywhere can use private keys and certificates that are stored in Trusted Platform Modules (TPMs), Windows and MacOS certificate stores, files on a file system, or in a hardware security module (HSM) that is accessible with the PKCS #11 protocol.
Because the certificates that are issued to each instance typically have different serial numbers, you can associate events in CloudTrail back to the actual instance of a workload that was issued a certificate. The IAM role session created by a certificate uses the certificate’s serial number as the role session name, which is visible in CloudTrail logs for actions taken by that role session.
Comparing short-lived and long-lived end entity certificates
X.509 certificates have an expiration date. The longer a credential is used, the greater the chance that it might come under the control of an unauthorized person.
We recommend that the certificates you issue to your workloads expire as quickly as your operational tolerances can withstand. For example, if you’re experienced in operating a PKI and can allow applications to request certificates through self-service, we recommend that the certificates issued have a relatively short expiration time so that new certificates must be requested frequently.
If your PKI certificates are issued or distributed manually, you might need to issue longer-lived certificates to ease your operational burden and give yourself longer periods of overlap in validity so that certificates can be rotated without disrupting your business.
It’s possible for multiple end-entity certificates to be valid at the same time with identical attributes. For example, if there were multiple non-expired, non-revoked CN=Red certificates, any of those CN=Red certificates can be used to access the CreateSessions API with IAM Roles Anywhere.
Certificate revocation
Traditionally, certificates are given a long validity period which helps reduce the operational burden for systems engineers who support certificates manually. However, sometimes you might need to revoke certificates for security reasons such as a compromised private key, a change in certificate fields, or a certificate that has been issued incorrectly. Certificate revocation helps maintain the trust and integrity of the PKI system.
A CRL is one of the primary mechanisms to help maintain the health of your PKI. The CRL contains information about the certificates that have been revoked due to security or other reasons.
IAM Roles Anywhere checks the validity of your certificates against your CRL. Using your PKI, after your certificate has been added to the CRL, you can import the CRL to IAM Roles Anywhere by using the using ImportCrl API operation or the import-crl CLI command. A copy of the CRL you import is hosted within IAM Roles Anywhere. After the CRL has been updated, IAM Roles Anywhere validates the certificate against your CRL before issuing credentials.
The fact that your CRL is hosted within IAM Roles Anywhere helps to mitigate a common scenario where the CRL is the target of a denial-of-service (DoS) attempt, causing applications to either deny all access because they’re unable to check the status of a cert against a CRL, or to let unauthorized users use revoked certificates to access services that are configured to ignore the CRL if it isn’t reachable.
Deployment patterns: centralized or decentralized
There are two approaches you can choose when deploying IAM Roles Anywhere: centralized or decentralized. We’ll look at the pros and cons of both.
Centralized trust anchor pattern
The following image describes how a centralized trust anchor would be deployed. First, a central trust anchor is deployed in a dedicated IAM account. Workloads then authenticate to IAM Roles Anywhere in a centralized account, and the workload performs role chaining to access the workload account.
In Figure 3, the workload running in the on-premises datacenter uses its certificate to get temporary AWS credentials from IAM Roles Anywhere in the IAM Roles Anywhere landing account. It then uses those credentials to assume a role into the workload account that hosts its AWS resources.
We recommend a centralized trust anchor pattern if you’re just getting started with IAM Roles Anywhere. This pattern simplifies the management and governance of IAM Roles Anywhere and allows you to scale with fewer resources to manage.
If you have more than one CA that you want to use with IAM Roles Anywhere, you can scale this pattern with multiple trust anchors in the same IAM Roles Anywhere landing account.
Pros of the centralized trust anchor pattern:
A simplified setup and fewer IAM Roles Anywhere resources to manage: Administrators only need to configure IAM Roles Anywhere profiles, roles, and trust anchors in one AWS account per Region.
Easier to manage CRLs: Because IAM Roles Anywhere is centralized, administrators only need to update the CRL in one account per Region.
Minimal application setup: Applications will need to set up role chaining to access their workloads accounts. Later in this post, we show you how to set up role chaining with IAM Roles Anywhere and the various AWS SDKs using a configuration that allows you to access other accounts without writing custom code.
Scaling: Based on the number of CAs you have, you can add additional trust anchors for additional CAs you want to use with IAM Roles Anywhere.
Cons of the centralized trust anchor pattern:
Cross-account access: The account that you’re creating for IAM Roles Anywhere will have access to other AWS accounts hosting your workloads. This might not meet your isolation requirements because it introduces cross-account access. However, remember that you can use certificate attributes in a role-trust policy to limit which workloads can access which AWS accounts.
Considerations of the centralized trust anchor pattern:
Multiple trust anchors: IAM Roles Anywhere supports two certificates per trust anchor, to help with rotation of certificates, so that you don’t have to update the ARNs during certificate rotation.
However, if there was a requirement to support multiple CAs, then it would be best to create separate trust anchors. For example, if you have a root CA and three issuing CAs, instead of creating a bundle of four certificates, you could create a trust anchor with a root CA, which would trust all certificates. Alternatively, you could create three different trust anchors per each issuing CA. So, it’s recommended to consider your PKI hierarchy during this process.
Auditing: If you have multiple trust anchors for different CAs deployed into the IAM Roles Anywhere account, you might need to use the aws:SourceARN condition key in role-trust policies to specify that that only a specific trust anchor can be used to assume a role with IAM Roles Anywhere.
When you use the centralized trust anchor pattern, you can use the certificate attributes to segregate access based on workloads, as described in the IAM roles and workload identity section earlier in this post.
Distributed trust anchor pattern
If you have more advanced security and compliance requirements, you can achieve greater isolation and granular access control by using a distributed (multi-trust-anchor, multi-account) approach with IAM Roles Anywhere.
In Figure 4, you see a distributed pattern where multiple trust anchors have been deployed based on which workloads and applications need access. In this model, the on-premises resource would call the respective trust anchor that has been mapped to each application to gain access to the AWS resource.
Based on your strategy, it’s possible to migrate from the centralized architecture to a distributed architecture as your organization grows or your operating model changes. Let’s looks at some of the considerations for this approach.
Pros of the distributed trust anchor pattern:
Better isolation: This pattern doesn’t require cross-account roles to be set up, and therefore AWS accounts and workloads are better isolated.
PKI flexibility: If you have different subordinate or issuing CAs that align with specific workloads or compliance requirements, you can have a distributed IAM Roles Anywhere setup for each workload in each AWS account.
Cons of the distributed trust anchor pattern:
Additional setup and AWS resources to manage: Trust anchors, profiles, and CRLs need to be set up in each AWS account that you want to use with IAM Roles Anywhere.
Additional configuration of applications: IAM Roles Anywhere ARNs will be different across accounts, and you will need to update the configuration of your applications that use IAM Roles Anywhere with the correct trust anchor and profile ARNs for each account.
Considerations of the distributed trust anchor pattern:
Scale: Infrastructure as code, such as AWS CloudFormation StackSets, can be used to scale the distributed pattern. Administrators can use AWS CloudFormation StackSets as a convenient way to implement trust anchors and profiles across accounts.
Working with IAM Roles Anywhere in your applications
Your applications integrate with IAM Roles Anywhere by using the aws signing helper (also known as the credential helper) with the AWS SDK. The signing helper is a lightweight executable written in Go that uses your private keys and certificate to authenticate to the IAM Roles Anywhere API and request temporary AWS credentials, and then delivers the credentials to your application.
The signing helper uses Go’s cryptographic libraries and doesn’t need specific versions of cryptographic software to be deployed into the environment where it runs, which helps it to run seamlessly and without conflict to other applications. The signing helper can use certificates and keys from OS certificate stores, TPMs, or locations on the file system.
In most cases, we recommend that customers use the signing helper with the credential_process setting because this allows you to use IAM Roles Anywhere without setting up environment variables and also allows you to configure role chaining seamlessly. The AWS SDK will automatically attempt to refresh credentials that are retrieved by the signing helper when the helper is used with the credential_process setting when the AWS credentials are nearing expiration.
If you set up the [default] profile in the AWS configuration file (~.aws/credentials on Linux and MacOS, C:\Users\ USERNAME \.aws\credentials on Windows), the AWS SDK default credentials provider chain will be used by IAM Roles Anywhere, provided that there are no other AWS credentials configured in that environment in a higher priority in the default credential providers chain.
Note: As described in the AWS SDK documentation, the default credential providers will vary slightly based on the language and AWS SDK used. However, many credential providers support using the credential_process setting in the default profile.
Here’s an example default profile that will use IAM Roles Anywhere:
You can also use a non-default profile and call that profile explicitly in your code when creating a credential providers or session object. How your application calls the AWS profile and IAM Roles Anywhere will vary depending on which AWS SDK you use, but we recommend checking the documentation for each SDK, and wherever possible, reuse clients, sessions, or credential providers to avoid unneeded calls to the IAM Roles Anywhere service to get new credentials. Otherwise, workloads may use up more CreateSession quota than expected or introduce unexpected latency to your application while making unnecessary calls to get AWS credentials when it already has some.
Note: AWS SDKs call the IAM Roles Anywhere credential_process to get credentials each time a new credential provider, session, or client is created, depending on the SDK.
Many applications that are written using the AWS SDK use the default credentials providers chain, and might be compatible with IAM Roles Anywhere without additional configuration or code change when using the default profile.
As a best practice, if you have multiple different applications running on the same host and accessing AWS that have totally different security requirements, you should have them run as separate users on that host and avoid sharing configuration files.
Configuring role chaining with IAM Roles Anywhere
Role chaining means to use a role to assume a second role through the AWS Command Line Interface (AWS CLI) or API. For example, RoleA has permission to assume RoleB. You can enable User1 to assume RoleA by using User1’s long-term user credentials in the AssumeRole API operation. This returns RoleA short-term credentials. With role chaining, you can use RoleA’s short-term credentials to enable User1 to assume RoleB.
You can set up role chaining with IAM Roles Anywhere by using profiles in the AWS configuration file, without writing code to manage role chaining or sessions. In the following example, there is a default profile that references the rolesanywhere profile. Applications that use the default profile will automatically use the credentials from the rolesanywhere profile to assume the role specified by the role_arn value, without writing code to manage credentials.
The diagram in Figure 5 describes what happens when the AWS SDK performs role chaining with SDK configuration.
Figure 5: A work sequence diagram detailing the interactions that happen when the AWS SDK reads the preceding config file
The flow in Figure 5 is as follows:
The AWS SDK reads the default profile and discovers it must get credentials from the specified source_profile.
The AWS SDK reads the source profile and uses the configuration to request credentials from IAM Roles Anywhere.
The AWS SDK then uses the credentials retrieved from the source_profile to call STS AssumeRole on the role workload role defined in the default profile.
The AWS SDK returned the temporary AWS credentials for workload role, which can now be used to access AWS resources in the workload account.
Logging and monitoring
Teams and security analysts typically prefer to have visibility into all actions taken. To help with this goal, logging and monitoring is available across different notification channels for IAM Roles Anywhere.
CA certificate expiry: Checks whether the certificate in the trust anchor is due for expiry.
End entity certificate expiry: Checks whether the certificate used for vending temporary security credentials is due for expiry.
Using such information, you can set up alarms and email notifications to remind administrators or developers to rotate the certificates before they expire. It’s especially important to monitor the expiry of the certificates for the trust anchor so that workloads that use IAM Roles Anywhere can continue operations without business disruption.
Using notification events to help with certificate revocation, you can use automations to help with other certificate expiry events. Note that if you’re using AWS Certificate Manager, rotation is automatically handled for you. For more information, see Managed certificate renewal in AWS Certificate Manager.
Tip: IAM Roles Anywhere logs also include the field SourceIdentity, which can help when you’re trying to trace back which workloads are taking what actions in AWS. The SourceIdentity field is usually the common name (CN) of the certificate.
IAM Roles Anywhere and AWS Regions
IAM Roles Anywhere is a regional AWS service. Meaning that configurations for resources like profiles and trust anchors exist in the Region in which you configure them.
As a best practice, we recommend setting up IAM Roles Anywhere in the same Region as the resources you will be accessing (for example, if you’re using IAM Roles Anywhere to access AWS resources in the us-west-2 Region, you should configure IAMRA in the us-west-2 Region).
Credentials issued by IAM Roles Anywhere, like other AWS credentials, can be used to access resources in other Regions (for example, credentials acquired from IAM Roles Anywhere in the us-west-2 Region can be used to access resources in the ca-central-1 Region).
If required, you can have your application introduce logic to try to use IAM Roles Anywhere in different Regions by having different profiles defined for your IAM Roles Anywhere deployment in different Regions. The following Python example will attempt to get credentials from the profile rolesanywhere-uswest2 for IAM roles anywhere in the us-west-2 Region, and if that fails, it will then attempt to get credentials with the rolesanywhere-cacentral1 profile for the ca-central-1 Region.
import boto3
def get_session():
try:
#tries to create a session using the profile “rolesanywhere-uswest2”
#add additional logic and logging, per your requirements
return boto3.Session(profile_name='rolesanywhere-uswest2')
except:
#tries to create a session using the profile “rolesanywhere-cacentral1”
#add additional logic and logging, per your requirements
return boto3.Session(profile_name='rolesanywhere-cacentral1')
session = get_session()
sts_client = session.client('sts')
print(sts_client.get_caller_identity())
Conclusion
In this blog post, we showed you the considerations for selecting a CA to use as your trust anchor, considerations for mapping your workload identity to IAM roles, patterns for deploying IAM Roles Anywhere, and how to integrate IAM Roles Anywhere with your applications.
IAM Roles Anywhere is a great solution for companies that have a PKI and want to access AWS resources from outside AWS, without needing to use long-lived credentials for IAM users.
Resilience has always been a top priority for customers running mission-critical Apache Kafka applications. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is deployed across multiple Availability Zones and provides resilience within an AWS Region. However, mission-critical Kafka deployments require cross-Region resilience to minimize downtime during service impairment in a Region. With Amazon MSK Replicator, you can build multi-Region resilient streaming applications to provide business continuity, share data with partners, aggregate data from multiple clusters for analytics, and serve global clients with reduced latency. This post explains how to use MSK Replicator for cross-cluster data replication and details the failover and failback processes while keeping the same topic name across Regions.
MSK Replicator overview
Amazon MSK offers two cluster types: Provisioned and Serverless. Provisioned cluster supports two broker types: Standard and Express. With the introduction of Amazon MSK Express brokers, you can now deploy MSK clusters that significantly reduce recovery time by up to 90% while delivering consistent performance. Express brokers provide up to 3 times the throughput per broker and scale up to 20 times faster compared to Standard brokers running Kafka. MSK Replicator works with both broker types in Provisioned clusters and along with Serverless clusters.
MSK Replicator supports an identical topic name configuration, enabling seamless topic name retention during both active-active or active-passive replication. This avoids the risk of infinite replication loops commonly associated with third-party or open source replication tools. When deploying an active-passive cluster architecture for regional resilience, where one cluster handles live traffic and the other acts as a standby, an identical topic configuration simplifies the failover process. Applications can transition to the standby cluster without reconfiguration because topic names remain consistent across the source and target clusters.
To set up an active-passive deployment, you have to enable multi-VPC connectivity for the MSK cluster in the primary Region and deploy an MSK Replicator in the secondary Region. The replicator will consume data from the primary Region’s MSK cluster and asynchronously replicate it to the secondary Region. You connect the clients initially to the primary cluster but fail over the clients to the secondary cluster in the case of primary Region impairment. When the primary Region recovers, you deploy a new MSK Replicator to replicate data back from the secondary cluster to the primary. You need to stop the client applications in the secondary Region and restart them in the primary Region.
Because replication with MSK Replicator is asynchronous, there is a possibility of duplicate data in the secondary cluster. During a failover, consumers might reprocess some messages from Kafka topics. To address this, deduplication should occur on the consumer side, such as by using an idempotent downstream system like a database.
In the next sections, we demonstrate how to deploy MSK Replicator in an active-passive architecture with identical topic names. We provide a step-by-step guide for failing over to the secondary Region during a primary Region impairment and failing back when the primary Region recovers. For an active-active setup, refer to Create an active-active setup using MSK Replicator.
Solution overview
In this setup, we deploy a primary MSK Provisioned cluster with Express brokers in the us-east-1 Region. To provide cross-Region resilience for Amazon MSK, we establish a secondary MSK cluster with Express brokers in the us-east-2 Region and replicate topics from the primary MSK cluster to the secondary cluster using MSK Replicator. This configuration provides high resilience within each Region by using Express brokers, and cross-Region resilience is achieved through an active-passive architecture, with replication managed by MSK Replicator.
The following diagram illustrates the solution architecture.
The primary Region MSK cluster handles client requests. In the event of a failure to communicate to MSK cluster due to primary region impairment, you need to fail over the clients to the secondary MSK cluster. The producer writes to the customer topic in the primary MSK cluster, and the consumer with the group ID msk-consumer reads from the same topic. As part of the active-passive setup, we configure MSK Replicator to use identical topic names, making sure that the customer topic remains consistent across both clusters without requiring changes from the clients. The entire setup is deployed within a single AWS account.
In the next sections, we describe how to set up a multi-Region resilient MSK cluster using MSK Replicator and also show the failover and failback strategy.
This will create the virtual private cloud (VPC), subnets, and the MSK Provisioned cluster with Express brokers within the VPC configured with AWS Identity and Access Management (IAM) authentication in each Region. It will also create a Kafka client Amazon Elastic Compute Cloud (Amazon EC2) instance, where we can use the Kafka command line to create and view a Kafka topic and produce and consume messages to and from the topic.
Configure multi-VPC connectivity in the primary MSK cluster
After the clusters are deployed, you need to enable the multi-VPC connectivity in the primary MSK cluster deployed in us-east-1. This will allow MSK Replicator to connect to the primary MSK cluster using multi-VPC connectivity (powered by AWS PrivateLink). Multi-VPC connectivity is only required for cross-Region replication. For same-Region replication, MSK Replicator uses an IAM policy to connect to the primary MSK cluster.
MSK Replicator uses IAM authentication only to connect to both primary and secondary MSK clusters. Therefore, although other Kafka clients can still continue to use SASL/SCRAM or mTLS authentication, for MSK Replicator to work, IAM authentication has to be enabled.
To enable multi-VPC connectivity, complete the following steps:
On the Amazon MSK console, navigate to the MSK cluster.
On the Properties tab, under Network settings, choose Turn on multi-VPC connectivity on the Edit dropdown menu.
For Authentication type, select IAM role-based authentication.
Choose Turn on selection.
Enabling multi-VPC connectivity is a one-time setup and it can take approximately 30–45 minutes depending on the number of brokers. After this is enabled, you need to provide the MSK cluster resource policy to allow MSK Replicator to talk to the primary cluster.
Under Security settings¸ choose Edit cluster policy.
Select Include Kafka service principal.
Now that the cluster is enabled to receive requests from MSK Replicator using PrivateLink, we need to set up the replicator.
Create a MSK Replicator
Complete the following steps to create an MSK Replicator:
In the secondary Region (us-east-2), open the Amazon MSK console.
Choose Replicators in the navigation pane.
Choose Create replicator.
Enter a name and optional description.
In the Source cluster section, provide the following information:
For Cluster region, choose us-east-1.
For MSK cluster, enter the Amazon Resource Name (ARN) for the primary MSK cluster.
For cross-Region setup, the primary cluster will appear disabled if the multi-VPC connectivity is not enabled and the cluster resource policy is not configured in the primary MSK cluster. After you choose the primary cluster, it automatically selects the subnets associated with primary cluster. Security groups are not required because the primary cluster’s access is governed by the cluster resource policy.
Next, you select the target cluster. The target cluster Region is defaulted to the Region where the MSK Replicator is created. In this case, it’s us-east-2.
In the Target cluster section, provide the following information:
For MSK cluster, enter the ARN of the secondary MSK cluster. This will automatically select the cluster subnets and the security group associated with the secondary cluster.
For Security groups, choose any additional security groups.
Make sure that the security groups have outbound rules to allow traffic to your secondary cluster’s security groups. Also make sure that your secondary cluster’s security groups have inbound rules that accept traffic from the MSK Replicator security groups provided here.
Now let’s provide the MSK Replicator settings.
In the Replicator settings section, enter the following information:
For Topics to replicate, we keep the topics to replicate as a default value that replicates all topics from the primary to secondary cluster.
For Replication starting position, we choose Earliest, so that we can get all the events from the start of the source topics.
For Copy settings, select Keep the same topic names to configure the topic name in the secondary cluster as identical to the primary cluster.
This makes sure that the MSK clients don’t need to add a prefix to the topic names.
For this example, we keep the Consumer group replication setting as default and set Target compression type as None.
Also, MSK Replicator will automatically create the required IAM policies.
Choose Create to create the replicator.
The process takes around 15–20 minutes to deploy the replicator. After the MSK Replicator is running, this will be reflected in the status.
Configure the MSK client for the primary cluster
Complete the following steps to configure the MSK client:
On the Amazon EC2 console, navigate to the EC2 instance of the primary Region (us-east-1) and connect to the EC2 instance dr-test-primary-KafkaClientInstance1 using Session Manager, a capability of AWS Systems Manager.
After you have logged in, you need to configure the primary MSK cluster bootstrap address to create a topic and publish data to the cluster. You can get the bootstrap address for IAM authentication on the Amazon MSK console under View Client Information on the cluster details page.
Configure the bootstrap address with the following code:
sudo su - ec2-user
export BS_PRIMARY=<<MSK_BOOTSTRAP_ADDRESS>>
Configure the client configuration for IAM authentication to talk to the MSK cluster:
This will consume both the sample messages from the topic.
Press Ctrl+C to exit the console prompt.
Configure the MSK client for the secondary MSK cluster
Go to the EC2 cluster of the secondary Region us-east-2 and follow the previously mentioned steps to configure an MSK client. The only difference from the previous steps is that you should use the bootstrap address of the secondary MSK cluster as the environment variable. Configure the variable $BS_SECONDARY to configure the secondary Region MSK cluster bootstrap address.
Verify replication
After the client is configured to talk to the secondary MSK cluster using IAM authentication, list the topics in the cluster. Because the MSK Replicator is now running, the customer topic is replicated. To verify it, let’s see the list of topics in the cluster:
By default, MSK Replicator replicates the details of all the consumer groups. Because you used the default configuration, you can verify using the following command if the consumer group ID msk-consumer is also replicated to the secondary cluster:
Now that we have verified the topic is replicated, let’s understand the key metrics to monitor.
Monitor replication
Monitoring MSK Replicator is very important to make sure that replication of data is happening fast. This reduces the risk of data loss in case an unplanned failure occurs. Some important MSK Replicator metrics to monitor are ReplicationLatency, MessageLag, and ReplicatorThroughput. For a detailed list, see Monitor replication.
To understand how many bytes are processed by MSK Replicator, you should monitor the metric ReplicatorBytesInPerSec. This metric indicates the average number of bytes processed by the replicator per second. Data processed by MSK Replicator consists of all data MSK Replicator receives. This includes the data replicated to the target cluster and filtered by MSK Replicator. This metric is applicable if you use Keep same topic name in the MSK Replicator copy settings. During a failback scenario, MSK Replicator starts to read from the earliest offset and replicates records from the secondary back to the primary. Depending on the retention settings, some data might exist in the primary cluster. To prevent duplicates, MSK Replicator processes the data but automatically filters out duplicate data.
Fail over clients to the secondary MSK cluster
In the case of an unexpected event in the primary Region in which clients can’t connect to the primary MSK cluster or the clients are receiving unexpected produce and consume errors, this could be a sign that the primary MSK cluster is impacted. You may notice a sudden spike in replication latency. If the latency continues to rise, it could indicate a regional impairment in Amazon MSK. To verify this, you can check the AWS Health Dashboard, though there is a chance that status updates may be delayed. Once you identify signs of a regional impairment in Amazon MSK, you should prepare to fail over the clients to the secondary region.
For critical workloads we recommend not taking a dependency on control plane actions for failover. To mitigate this risk, you could implement a pilot light deployment, where essential components of the stack are kept running in a secondary region and scaled up when the primary region is impaired. Alternatively, for faster and smoother failover with minimal downtime, a hot standby approach is recommended. This involves pre-deploying the entire stack in a secondary region so that, in a disaster recovery scenario, the pre-deployed clients can be quickly activated in the secondary region.
Failover process
To perform the failover, you first need to stop the clients pointed to the primary MSK cluster. However, for the purpose of the demo, we are using console producer and consumers, so our clients are already stopped.
In a real failover scenario, using primary Region clients to communicate with the secondary Region MSK cluster is not recommended, as it breaches fault isolation boundaries and leads to increased latency. To simulate the failover using the preceding setup, let’s start a producer and consumer in the secondary Region (us-east-2). For this, run a console producer in the EC2 instance (dr-test-secondary-KafkaClientInstance1) of the secondary Region.
The following diagram illustrates this setup.
Complete the following steps to perform a failover:
Create a console producer using the following code:
This is the 3rd message to the topic.
This is the 4th message to the topic.
Now, let’s create a console consumer. It’s important to make sure the consumer group ID is exactly the same as the consumer attached to the primary MSK cluster. For this, we use the group.idmsk-consumer to read the messages from the customer topic. This simulates that we are bringing up the same consumer attached to the primary cluster.
Create a console consumer with the following code:
Although the consumer is configured to read all the data from the earliest offset, it only consumes the last two messages produced by the console producer. This is because MSK Replicator has replicated the consumer group details along with the offsets read by the consumer with the consumer group ID msk-consumer. The console consumer with the same group.id mimic the behaviour that the consumer is failed over to the secondary Amazon MSK cluster.
Fail back clients to the primary MSK cluster
Failing back clients to the primary MSK cluster is the common pattern in an active-passive scenario, when the service in the primary region has recovered. Before we fail back clients to the primary MSK cluster, it’s important to sync the primary MSK cluster with the secondary MSK cluster. For this, we need to deploy another MSK Replicator in the primary Region configured to read from the earliest offset from the secondary MSK cluster and write to the primary cluster with the same topic name. The MSK Replicator will copy the data from the secondary MSK cluster to the primary MSK cluster. Although the MSK Replicator is configured to start from the earliest offset, it will not duplicate the data already present in the primary MSK cluster. It will automatically filter out the existing messages and will only write back the new data produced in the secondary MSK cluster when the primary MSK cluster was down. The replication step from secondary to primary wouldn’t be required if you don’t have a business requirement of keeping the data same across both clusters.
After the MSK Replicator is up and running, monitor the MessageLag metric of MSK Replicator. This metric indicates how many messages are yet to be replicated from the secondary MSK cluster to the primary MSK cluster. The MessageLag metric should come down close to 0. Now you should stop the producers writing to the secondary MSK cluster and restart connecting to the primary MSK cluster. You should also allow the consumers to read data from the secondary MSK cluster until the MaxOffsetLag metric for the consumers is not 0. This makes sure that the consumers have already processed all the messages from the secondary MSK cluster. The MessageLag metric should be 0 by this time because no producer is producing records in the secondary cluster. MSK Replicator replicated all messages from the secondary cluster to the primary cluster. At this point, you should start the consumer with the same group.id in the primary Region. You can delete the MSK Replicator created to copy messages from the secondary to the primary cluster. Make sure that the previously existing MSK Replicator is in RUNNING status and successfully replicating messages from the primary to secondary. This can be confirmed by looking at the ReplicatorThroughput metric, which should be greater than 0.
Failback process
To simulate a failback, you first need to enable multi-VPC connectivity in the secondary MSK cluster (us-east-2) and add a cluster policy for the Kafka service principal like we did before.
Deploy the MSK Replicator in the primary Region (us-east-1) with the source MSK cluster pointed to us-east-2 and the target cluster pointed to us-east-1. Configure Replication starting position as Earliest and Copy settings as Keep the same topic names.
The following diagram illustrates this setup.
After the MSK Replicator is in RUNNING status, let’s verify there is no duplicate while replicating the data from the secondary to the primary MSK cluster.
Run a console consumer without the group.id in the EC2 instance (dr-test-primary-KafkaClientInstance1) of the primary Region (us-east-1):
This should show the four messages without any duplicates. Although in the consumer we specify to read from the earliest offset, MSK Replicator makes sure the duplicate data isn’t replicated back to the primary cluster from the secondary cluster.
This is a customer topic
This is the 2nd message to the topic.
This is the 3rd message to the topic.
This is the 4th message to the topic.
You can now point the clients to start producing to and consuming from the primary MSK cluster.
Clean up
At this point, you can tear down the MSK Replicator deployed in the primary Region.
Conclusion
This post explored how to enhance Kafka resilience by setting up a secondary MSK cluster in another Region and synchronizing it with the primary cluster using MSK Replicator. We demonstrated how to implement an active-passive disaster recovery strategy while maintaining consistent topic names across both clusters. We provided a step-by-step guide for configuring replication with identical topic names and detailed the processes for failover and failback. Additionally, we highlighted key metrics to monitor and outlined actions to provide efficient and continuous data replication.
Subham Rakshit is a Senior Streaming Solutions Architect for Analytics at AWS based in the UK. He works with customers to design and build streaming architectures so they can get value from analyzing their streaming data. His two little daughters keep him occupied most of the time outside work, and he loves solving jigsaw puzzles with them. Connect with him on LinkedIn.
Amazon Web Services (AWS) provides service reference information in JSON format to help you automate policy management workflows. With the service reference information, you can access available actions across AWS services from machine-readable files. The service reference information helps to address a key customer need: keeping up with the ever-growing list of services and actions in AWS. As new services launch and existing services expand their capabilities, you can now conveniently identify and incorporate available actions, resources, and condition keys for each AWS service into your policy authoring and validation workflows. As your business expands and your AWS footprint grows, you might decide to automate your policy management workflows. With the service authorization reference, you can build custom tools to make it easier to evaluate and use new actions, resources, and condition keys that AWS services introduce.
Getting started with service reference information
The service reference information is static information about the actions, resources, and condition keys available for each service in AWS. To obtain the list of AWS services for which reference information is available, go to the following URL: https://servicereference.us-east-1.amazonaws.com/v1/service-list.json
This URL endpoint provides a JSON file that contains an up-to-date catalog of AWS services with available reference information. By querying this endpoint, you can retrieve the most current list of services supported by the AWS Service Reference Information feature.
To retrieve the list of actions, resources, and condition keys for a specific AWS service, go to the following URL: https://servicereference.us-east-1.amazonaws.com/v1/<service-name>/<service-name>.json
Replace <service-name> with the name of the desired AWS service (for example, “s3” for Amazon Simple Storage service (Amazon S3) or “ec2” for Amazon Elastic Compute Cloud (Amazon EC2)). This URL endpoint provides a JSON file that contains the comprehensive list of actions, resources, and condition keys that are available for that particular service.
The following example shows the format of the output from the service-list.json file, which contains the service names and URLs for each service’s reference information:
You can navigate to the service information page by using the url field to view the list of permissions for the service. You can also download the JSON file to use in your policy authoring workflows. For example, you can download the permissions for Amazon S3 by following this URL: https://servicereference.us-east-1.amazonaws.com/v1/s3/s3.json
The following example shows a partial output of the permissions for Amazon S3. The AWS Identity and Access Management (IAM) actions are available in JSON format, and each action is its own JSON object. The Name field for those objects provides the name of the IAM action, the ActionConditionKeys field provides the available condition keys for this action, and the Resources field provides the available resources for this action.
What can you build with the service reference information?
Let’s explore how you can make use of the service reference information through practical examples. To help you get started, here are two custom tools that use the service reference information. You can find these tools in our GitHub repository, ready for you to use and adapt to your specific needs. You can download the source code for these tools by visiting the following links:
The SCP pre-processor provides a convenient way to write SCPs. You run the SCP pre-processor as a command-line tool. The tool takes a single, monolithic JSON file and runs a series of transformations and optimizations, then outputs a collection of valid service control policies that fit within policy size quotas. The tool uses AWS service reference information data in order to optimize lists of IAM actions.
Notification tool for new or removed IAM actions
You might find yourself needing to update various policies throughout your AWS environment when new IAM actions or services are released. You can use this tool to notify you when new services or new actions are added or removed. It works by downloading the service reference information and comparing it to the previous version of the file when the tool last ran. You can use these notifications to perform actions like automatically updating IAM policies when new actions are added or manually reviewing the notifications for new, sensitive actions.
The AWS service reference information makes it easier for you to create automation for policy authoring and validation. By providing the AWS service actions reference in JSON format, this feature enables you to create custom tools for policy authoring and management.
We’re excited to know what kind of policy authoring tools you can think up.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
While helping our customers build systems on AWS, we found out that a large number of enterprise customers who pay great attention to data security and compliance, such as B2C FinTech enterprises, build data-sensitive applications on premises and use other applications on AWS to take advantage AWS managed services. Using AWS managed services can greatly simplify daily operation and maintenance, as well as help you achieve optimized resource utilization and performance.
This post discusses a decoupled approach of building a serverless data lakehouse using AWS Cloud-centered services, including Amazon EMR Serverless, Amazon Athena, Amazon Simple Storage Service (Amazon S3), Apache DolphinScheduler (an open source data job scheduler) as well as PingCAP TiDB, a third-party data warehouse product that can be deployed either on premises or on the cloud or through a software as a service (SaaS).
Solution overview
For our use case, an enterprise data warehouse with business data is hosted on an on-premises TiDB platform, an AWS Global Partner that is also available on AWS through AWS Marketplace.
The data is then processed by an Amazon EMR Serverless Job to achieve data lakehouse tiering logic. Different tiering data are stored in separate S3 buckets or separate S3 prefixes under the same S3 bucket. Typically, there are four layers in terms of data warehouse design.
Operational data store layer (ODS) – This layer stores raw data of the data warehouse
Data warehouse stage layer (DWS) – This layer is a temporary staging area within the data warehousing architecture where data from various sources is loaded, cleaned, transformed, and prepared before being loaded into the data warehouse database layer;
Data warehouse database layer (DWD) – This layer is the central repository in a data warehousing environment where data from various sources is integrated, transformed, and stored in a structured format for analytical purposes;
Analytical data store (ADS) – This layer is a subset of the data warehousing that is specifically designed and optimized for a particular business function, department, or analytical purpose.
For this post, we only use ODS and ADS layers to demonstrate the technical feasibility.
The schema of this data is managed through the AWS Glue Data Catalog, and can be queried using Athena. The EMR Serverless Jobs are orchestrated using Apache DolphinScheduler deployed in cluster mode on Amazon Elasctic Compute Cloud (Amazon EC2) instances, with meta data stored in an Amazon Relational Database Service (Amazon RDS) for MySQL instance.
Using DolphinScheduler as the data lakehouse job orchestrator offers the following advantages:
Its distributed architecture allows for better scalability, and the visual DAG designer makes workflow creation more intuitive for team members with varying technical expertise
It provides more granular task-level controls and supports a wider range of task types out-of-the-box, including Spark, Flink, and machine learning (ML) workflows, without requiring additional plugin installations;
Its multi-tenancy feature enables better resource isolation and access control across different teams within an organization.
However, DolphinScheduler requires more initial setup and maintenance effort, making it more suitable for organizations with strong DevOps capabilities and a desire for complete control over their workflow infrastructure.
The following diagram illustrates the solution architecture.
Prerequisites
You need to create an AWS account and set up an AWS Identity and Access Management (IAM) user as a prerequisite for the following implementation. Complete the following steps:
For AWS account signing up, please follow up the actions guided per page link.
Create an AWS account.
Sign in to the account using the root user for the first time.
One the IAM console, create an IAM user with AdministratorAccess Policy.
Use this IAM user to log in AWS Management Console rather the root user.
On the IAM console, choose Users in the navigation pane.
Navigate to your user, and on the Security credentials tab, create an access key.
Store the access key and secret key in a secure place and use them for further API access of the resources of this AWS account.
Set up DolphinScheduler, IAM configuration, and the TiDB Cloud table
In this section, we walk through the steps to install DolphinScheduler, complete additional IAM configurations to enable the EMR Serverless job, and provision the TiDB Cloud table.
Install DolphinScheduler on an EC2 instance with an RDS for MySQL instance storing DolphinScheduler metadata. The production deployment mode of DolphinScheduler is cluster mode. In this blog, we use pseudo cluster mode which has the same installation steps as cluster mode, and could achieve resource economy. We name the EC2 instance ds-pseudo.
Make sure the inbound rule of the security group attached to the EC2 instance allows port 12345’s TCP traffic. Then complete the following steps:
Log in to Amazon EC2 as the root user, and install jvm:
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz
cd apache-zookeeper-3.8.0-bin/conf
cp zoo_sample.cfg zoo.cfg
cd ..
nohup bin/zkServer.sh start-foreground &> nohup_zk.out &
bin/zkServer.sh status
Check the Python version:
python3 --version
The version should be 3.9 or above. It is recommended that you use Amazon Linux 2023 or later as the Amazon EC2 operating system (OS); Python version 3.9 meets the requirement. For detail information, refer to Python in AL2023.
Install Dolphinscheduler
Download the dolphinscheduler package:
cd /usr/local/src
wget https://dlcdn.apache.org/dolphinscheduler/3.1.9/apache-dolphinscheduler-3.1.9-bin.tar.gz
tar -zxvf apache-dolphinscheduler-3.1.9-bin.tar.gz
mv apache-dolphinscheduler-3.1.9-bin apache-dolphinscheduler
Download the mysql connector package:
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.31.tar.gz
tar -zxvf mysql-connector-j-8.0.31.tar.gz
Copy specific mysql connector JAR file to the following destinations:
On the Amazon RDS console, provision an RDS for MySQL instance with the following configurations:
For Database Creation Method, select Standard create.
For Engine options, choose MySQL.
For Edition: choose MySQL 8.0.35.
For Templates: select Dev/Test.
For Availability and durability, select Single DB instance.
For Credentials management, select Self-managed.
For Connectivity, select Connect to an EC2 compute resource, and choose the EC2 instance created earlier.
For Database Authentication: choose Password Authentication.
Navigate to the ds- mysql database details page, and under Connectivity & security, copy the RDS for MySQL endpoint.
Configure the intance:
mysql -h <RDS for mysql Endpoint> -u admin -p
mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
mysql> exit;
Configure the dolphinscheduler configuration file:
On the Amazon EC2 console, navigate to the instance details page and copy the private IP address.
Revise install_env.sh:
vim bin/env/install_env.sh
ips=${ips:-"<private ip address of ds-pseudo EC2 instance>"}
masters=${masters:-"<private ip address of ds-pseudo EC2 instance>"}
workers=${workers:-" private ip address of ds-pseudo EC2 instance:default"}
alertServer=${alertServer:-" private ip address of ds-pseudo EC2 instance "}
apiServers=${apiServers:-" private ip address of ds-pseudo EC2 instance "}
installPath=${installPath:-"~/dolphinscheduler"}
export JAVA_HOME=${JAVA_HOME:-/usr/lib/jvm/jre-1.8.0-openjdk}
export PYTHON_HOME=${PYTHON_HOME:-/bin/python3}
Configure the dolphinscheduler configuration file:
cd /usr/local/src/apache-dolphinscheduler/
bash tools/bin/upgrade-schema.sh
Install DolphinScheduler:
cd /usr/local/src/apache-dolphinscheduler/
su dolphinscheduler
bash ./bin/install.sh
Start DolphinScheduler after installation:
cd /usr/local/src/apache-dolphinscheduler/
su dolphinscheduler
bash ./bin/start-all.sh
Open the DolphinScheduler console:
http://<ec2 ip address>:12345/dolphinscheduler/ui/login
After input the initial username and password, press Login button to enter into the dashboard shown as below.
initial user/password admin/dolphinscheduler123
Configure IAM role to enable the EMR serverless job
The EMR serverless job role needs to have permission to access a specific S3 bucket to read job scripts and potentially write results, and also have permission to access AWS Glue to read the Data Catalog which stores the tables’ meta data. For detailed guidance, please refer to Grant permission to use EMR Serverless or EMR Serverless Samples.
The following screenshot shows the IAM role configured with the trust policy attached.
The IAM role should have the following permissions policies attached, as shown in the following screenshot.
Provision the TiDB Cloud table
To provision the TiDB Cloud table, complete the following steps:
Register for TiDB Cloud.
Create a serverless cluster, as shown in the following screenshot. For this post, we name the cluster Cluster0.
Choose Cluster0, then choose SQL Editor to create a database named test:
create table testtable (id varchar(255));
insert into testtable values (1);
insert into testtable values (2);
insert into testtable values (3);
Synchronize data between on-premises TiDB and AWS
In this section, we discuss how to synchronize historical data as well as incremental data between TiDB and AWS.
Use TiDB Dumpling to sync historical data from TiDB to Amazon S3
Use the commands in this section to dump data stored in TiDB as CSV files into a S3 bucket. For full details on how to achieve a data sync from on-premises TiDB to Amazon S3, see Export data to Amazon S3 cloud storage. For this post, we use TiDB tool Dumpling. Complete the following steps:
Log in to the EC2 instance created earlier as root.
Run the following command to install TiUP:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
cd /root
source .bash_profile
tiup --version
Run the following command to install Dumpling:
tiup install dumpling
Run the following command to achieve target database table dumpling to the specific S3 bucket.
To acquire the TiDB serverless connection information, navigate to the TiDB Cloud console and choose Connect.
You can collect the specific connection information of test database from the following screenshot.
Yan can view the data stored in the S3 bucket on the Amazon S3 console.
You can use Amazon S3 Select to query the data and get results similar to the following screenshot, confirming that the data has been ingested into testtable.
Use TiDB Dumpling with a self-managed checkpoint to sync incremental data from TiDB to Amazon S3
To achieve incremental data synchronization using TiDB Dumpling, it’s essential to self-manage the check point of the target synchronized data. One recommended way is to store the ID of the final ingested record into a certain media (such as Amazon ElastiCache for Redis, Amazon DynamoDB) to achieve a self-managing checkpoint when running the shell/Python job that trigges TiDB Dumpling. The prerequisite for implementing this is that the target table has a monotonically increasing id field as its primary key.
Use the TiDB CDC connector to sync incremental data from TiDB to Amazon S3
The advantage of using TiDB CDC connector to achieve incremental data synchronization from TiDB to Amazon S3 is that there is built-in change data capture (CDC) mechanism, and because the backend engine is Flink, the performance is fast. However, there is one trade-off: you need to create several Flink tables to map the ODS tables on AWS.
For instructions to implement the TiDB CDC connector, refer to TiDB CDC.
Use an EMR serverless job to sync historical and incremental data from a Data Catalog table to the TiDB table
Data usually flows from on premises to the AWS Cloud. However, in some cases, the data might flow from the AWS Cloud to your on-premises database.
After landing on AWS, the data will be wrapped up and managed by the Data Catalog by created Athena tables with the specific tables’ schema. The table DDL script is as follows:
CREATE EXTERNAL TABLE IF NOT EXISTS `testtable`(
`id` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
LOCATION 's3://<bucket_name>/<prefix_name>/';
The screenshot below showcases the DDL running result using Athena console.
The data stored in testtable table is queried using select * from testable SQL. The query result is shown as follows:
In this case, an EMR serverless spark job can accomplish the work of synchronizing data from an AWS Glue table to your on premises table.
If the Spark job is written in Scala, the sample code is as below:
package com.example
import org.apache.spark.sql.{DataFrame, SparkSession}
object Main {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("<specific app name>")
.enableHiveSupport()
.getOrCreate()
spark.sql("show databases").show()
spark.sql("use default")
var df=spark.sql("select * from testtable")
df.write
.format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://<tidbcloud_endpoint>:4000/namespace")
.option("dbtable", "<table_name>")
.option("user", "<user_name>")
.option("password", "<password_string>")
.save()
spark.close()
}
}
You can acquire the TiDB serverless endpoint connection information on the TiDB console by choosing Connect, as shown earlier in this post.
After you have wrapped the Scala code as JAR file using SBT, you can submit the job to EMR Serverless with the following AWS Command Line Interface (AWS CLI) command:
The preceding PySpark code and AWS CLI command achieves outbound parameter input as well: the table name (specifically testspark) is ingested into the SQL sentence when submitting the job.
EMR Serverless job pperation essentials
An EMR Serverless application is a resource pool concept. An application holds a certain capacity of compute, memory, and storage resources for jobs running on it to use. You can configure the resource capacity using AWS CLI or the console. Because it’s a resource pool, EMR Serverless application creation is usually a one-time action with the initial capacity and maximum capacity being configured.
An EMR Serverless job is a working unit that actually processes the compute task. In order for a job to work, you need to set the EMR Serverless application ID, the execution IAM role (discussed previously), and the specific application configuration (the resources the job is planning to use). Although you can create the EMR Serverless job on the console, it’s recommended to create the EMR Serverless job using the AWS CLI for further integration with the scheduler and scripts.
DolphinScheduler integration and job orchestration
DolphinScheduler is a modern data orchestration platform. It’s agile to create high- performance workflows with low code. It also provides a powerful UI, dedicated to solving complex task dependencies in the data pipeline and providing various types of jobs out of the box.
DolphinScheduler is developed and maintained by WhaleOps, and available in AWS Marketplace as WhaleStudio.
DolphinScheduler has been natively integrated with Hadoop: DolphinScheduler cluster mode is by default recommended to be deployed on a Hadoop cluster (usually on HDFS data nodes), and the HQL scripts uploaded to DolphinScheduler Resource Manager are stored by default on HDFS, and can be orchestrated using the following native Hive shell command:
Hive -f example.sql
Moreover, for specific case in which the orchestration DAGs are quite complicated, each DAG consists of several jobs (for example, more than 300), and almost all the jobs are HQL scripts stored in DolphinScheduler Resource Manager.
Complete the steps listed in this section to achieve a seamless integration between DolphinScheduler and EMR Serverless.
Switch the storage layer of DolphinScheduler Resource Center from HDFS to Amazon S3
Edit the common.properties files under directories /usr/local/src/apache-dolphinscheduler/api-server/ and directory /usr/local/src/apache-dolphinscheduler/worker-server/conf. The following code snippet shows the part of the file that needs to be revised:
# resource storage type: HDFS, S3, OSS, NONE
#resource.storage.type=NONE
resource.storage.type=S3
# resource store on HDFS/S3 path, resource file will store to this base path, self configuration, please make sure the directory exists on hdfs and have read write permissions. "/dolphinscheduler" is recommended
resource.storage.upload.base.path=/dolphinscheduler
# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.access.key.id=AKIA************
# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.secret.access.key=lAm8R2TQzt*************
# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.region=us-east-1
# The name of the bucket. You need to create them by yourself. Otherwise, the system cannot start. All buckets in Amazon S3 share a single namespace; ensure the bucket is given a unique name.
resource.aws.s3.bucket.name=dolphinscheduler-shiyang
# You need to set this parameter when private cloud s3. If S3 uses public cloud, you only need to set resource.aws.region or set to the endpoint of a public cloud such as S3.cn-north-1.amazonaws.com.cn
resource.aws.s3.endpoint=s3.us-east-1.amazonaws.com
After editing and saving the two files, restart the api-server and worker-server by running the following commands, under folder path /usr/local/src/apache-dolphinscheduler/
You can validate whether switching the storage layer to Amazon S3 was successful by uploading a script using DolphinScheduler Resource Center Console, check if the file appears in relevant S3 bucket folder.
Before verifying that Amazon S3 is now the storage location of DolphinScheduler, you need to create a tenant on the DolphinScheduler console and bundle the admin user with the tenant, as illustrated in the following screenshots:
After that, you can create a folder on the DolphinScheduler console, and check whether the folder is visible on the Amazon S3 console.
Make sure the job scripts uploaded from Amazon S3 are available in the DolphinScheduler Resource Center
After accomplishing the first task, you can upload the scripts from the DolphinScheduler Resource Center console, and confirm that the scripts are stored in Amazon S3. However, in practice, you need to migrate all scripts directly to Amazon S3. You can find and modify the scripts stored in Amazon S3 using DolphinScheduler Resource Center console. To do so, you can revise the metadata table t_ds_resources by inserting all the scripts’ metadata. The table schema of table t_ds_resources is shown in the following screenshot.
Now there are two records in the table t_ds_resoruces.
You can access relevant records on the DolphinScheduler console.
The following screenshot shows the files on the Amazon S3 console.
Make the DolphinScheduler DAG orchestrator aware of the jobs’ status so the DAG can move forward or take relevant actions
As mentioned earlier, DolphinScheduler is natively integrated with the Hadoop ecosystem, and the HQL scripts can be orchestrated by the DolphinScheduler DAG orchestrator via Hive -f xxx.sql command. As a result, when the scripts changed to shell scripts or Python scripts (EMR Severless jobs needs to be orchestrated via shell scripts or Python scripts rather than the simple Hive command), the DAG orchestrator can start the job, but can’t get the real time status of the job, and therefore can’t continue the workflow to further steps. Because the DAGs in this case are very complicated, it’s not feasible to amend the DAGs; instead we follow a lift-and-shift strategy.
We use the following scripts to capture jobs’ status and take appropriate actions.
Persist the application ID list with the following code:
In this post, we discussed how EMR Serverless, as AWS managed serverless big data compute engine, integrates with popular OSS products like TiDB and DolphinScheduler. We discussed how to achieve data synchronization between TiDB and the AWS Cloud, and how to use DolphineScheduler to orchestrate EMR Serverless jobs.
Try out the solution with your own use case, and share your feedback in the comments.
About the Author
Shiyang Wei is Senior Solutions Architect at Amazon Web Services. He is specializing in cloud system architecture and solution design for the financial industry. Particularly, he focused on big data and machine learning applications in finance, as well as the impact of regulatory compliance on cloud architecture design in the financial sector. He has over 10 years of experience in data domain development and architectural design.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.










































































































 Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. Yonatan is an Apache Iceberg evangelist.
Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. Yonatan is an Apache Iceberg evangelist. Haya Stern is a Senior Director of Data at Natural Intelligence. She leads the development of NI’s large-scale data platform, with a focus on enabling analytics, streamlining data workflows, and improving dev efficiency. In the past year, she led the successful migration from the previous data architecture to a modern lake house based on Apache Iceberg and Snowflake.
Haya Stern is a Senior Director of Data at Natural Intelligence. She leads the development of NI’s large-scale data platform, with a focus on enabling analytics, streamlining data workflows, and improving dev efficiency. In the past year, she led the successful migration from the previous data architecture to a modern lake house based on Apache Iceberg and Snowflake. Data Architect at Natural Intelligence with ten years of experience architecting large‑scale big‑data platforms, now focused on developing intelligent agent systems that turn complex data into real‑time business insight.
Data Architect at Natural Intelligence with ten years of experience architecting large‑scale big‑data platforms, now focused on developing intelligent agent systems that turn complex data into real‑time business insight. Michał Urbanowicz is a Cloud Data Engineer at Natural Intelligence with expertise in migrating data warehouses and implementing robust retention, cleanup, and monitoring processes to ensure scalability and reliability. He also develops automations that streamline and support campaign management operations in cloud-based environments.
Michał Urbanowicz is a Cloud Data Engineer at Natural Intelligence with expertise in migrating data warehouses and implementing robust retention, cleanup, and monitoring processes to ensure scalability and reliability. He also develops automations that streamline and support campaign management operations in cloud-based environments.














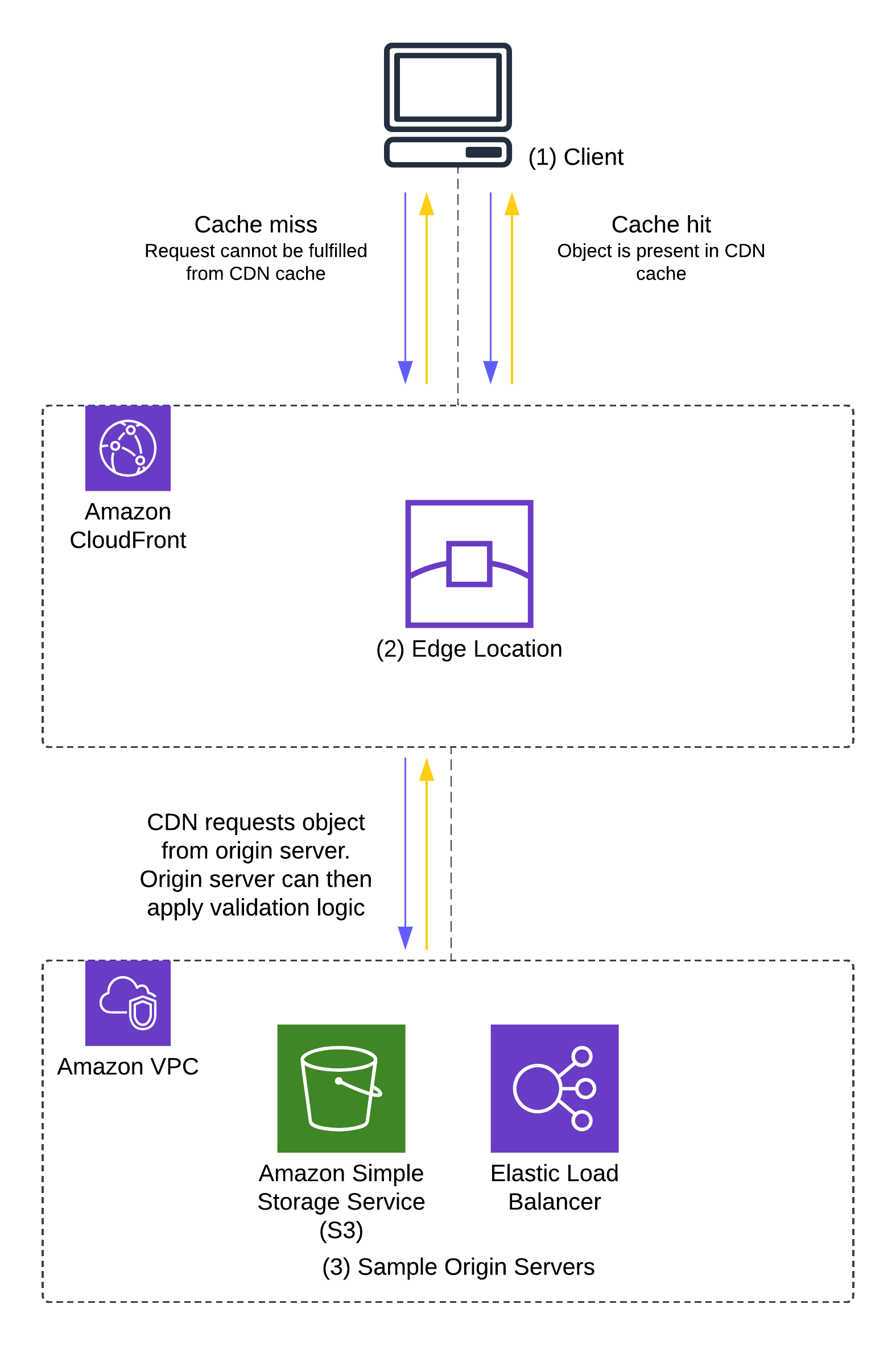



























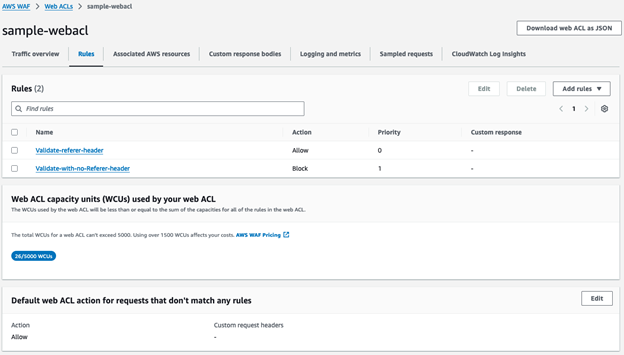

































































 Shiyang Wei is Senior Solutions Architect at Amazon Web Services. He is specializing in cloud system architecture and solution design for the financial industry. Particularly, he focused on big data and machine learning applications in finance, as well as the impact of regulatory compliance on cloud architecture design in the financial sector. He has over 10 years of experience in data domain development and architectural design.
Shiyang Wei is Senior Solutions Architect at Amazon Web Services. He is specializing in cloud system architecture and solution design for the financial industry. Particularly, he focused on big data and machine learning applications in finance, as well as the impact of regulatory compliance on cloud architecture design in the financial sector. He has over 10 years of experience in data domain development and architectural design.