Post Syndicated from Vineeth Nair original https://aws.amazon.com/blogs/devops/automate-lambda-code-signing-with-amazon-codecatalyst-and-aws-signer/
Amazon CodeCatalyst is an integrated service for software development teams adopting continuous integration and deployment practices into their software development process. CodeCatalyst puts the tools you need all in one place. You can plan work, collaborate on code build, test, and deploy applications with continuous integration/continuous delivery (CI/CD) tools. You can also integrate AWS resources with your projects by connecting your AWS accounts to your CodeCatalyst space. By managing all of the stages and aspects of your application lifecycle in one tool, you can deliver software quickly and confidently.
Introduction
In this post we will focus on how development teams can use Amazon CodeCatalyst with AWS Signer to fully manage the code signing process to ensure the trust and integrity of code assets. We will describe the process of building the AWS Lambda code using a CodeCatalyst workflow, we will then demonstrate the process of signing the code using a signer profile and deploying the signed code to our Lambda function.
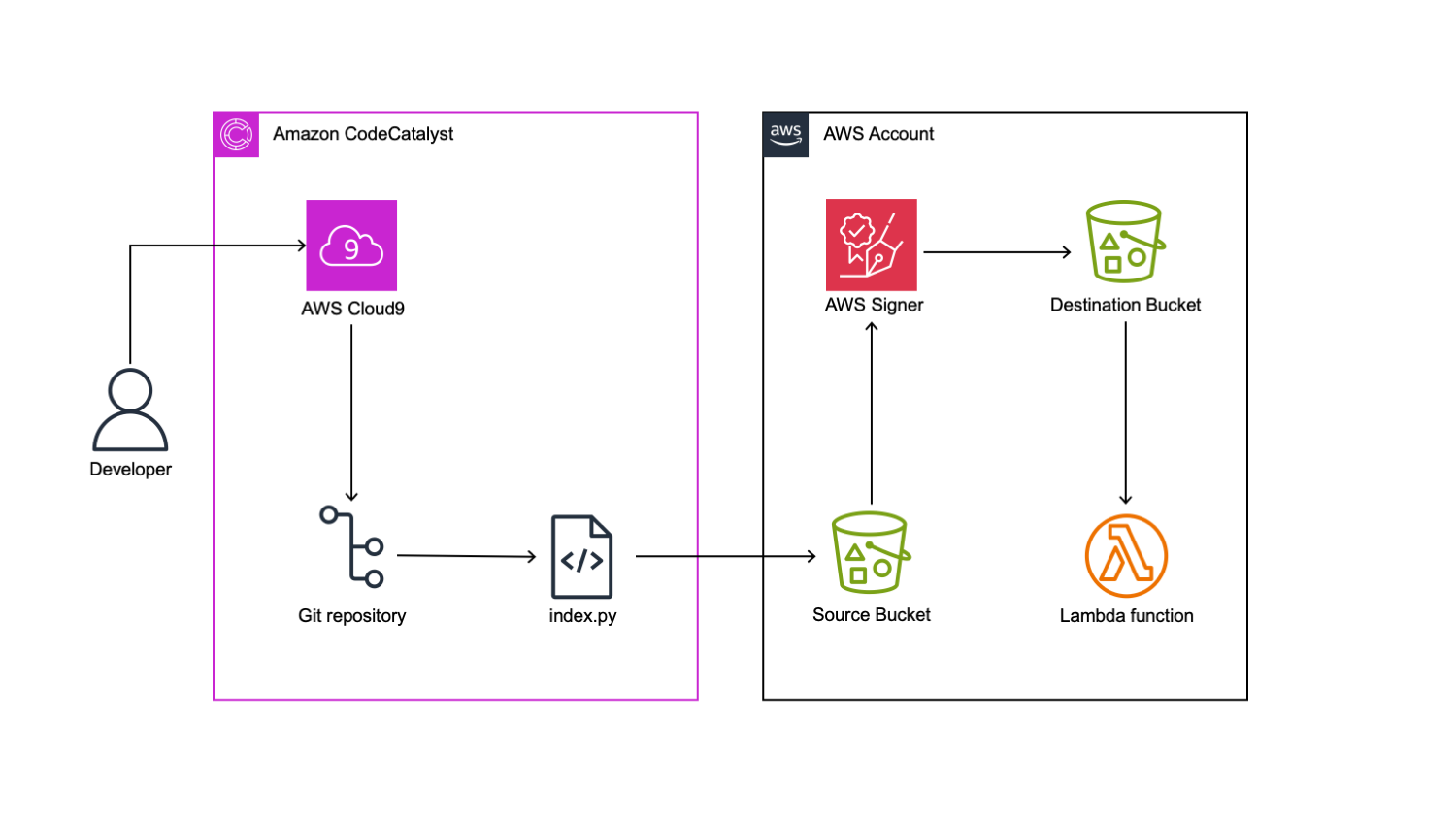
Figure 1: Architecture Diagram.
Prerequisites
To follow along with the post, you will need the following items:
- An AWS Builder ID for signing in to CodeCatalyst.
- A CodeCatalyst space
- Have the Space administrator role assigned in your CodeCatalyst space
- Have an AWS account associated with your space along with an associated IAM role
- A CodeCatalyst project with a source repository
- A CodeCatalyst environment connected to an AWS account
- A CodeCatalyst IAM role associated with the target AWS account
- If you are using the CodeCatalystWorkflowDevelopmentRole-project_name you will need to add the relevant AWS Signer permissions. In our demo environment we used signer:* S3-*IAM permission.
- CDK v2 installed
Walkthrough
During this tutorial, we will create a step-by-step guide to constructing a workflow utilizing CodeCatalyst. The objective is to employ the AWS Signer service to retrieve Python code from a specified source Amazon S3 bucket, compress and sign the code, and subsequently store it in a destination S3 bucket. Finally, we will utilize the signed code to deploy a secure Lambda function.
Create the base workflow
To begin we will create our workflow in the CodeCatalyst project.
Select CI/CD → Workflows → Create workflow:

Figure 2: Create workflow.
Leave the defaults for the Source Repository and Branch, select Create. We will have an empty workflow:

Figure 3: Empty workflow.
We can edit the workflow from the CodeCatalyst console, or use a Dev Environment. Initially, we will create an initial commit of this workflow file, ignore any validation errors at this stage:

Figure 4: Commit workflow with workflow file name, message repository and branch name.
Connect to CodeCatalyst Dev Environment
We will use an AWS Cloud9 Dev Environment. Our first step is to connect to the dev environment.
Select Code → Dev Environments. If you do not already a Dev Instance you can create an instance by selecting Create Dev Environment.

Figure 5: Create Dev Environment.
We already have a Dev Environment, so will go ahead and select Resume Instance. A new browser tab opens for the IDE and will be available in less than one minute. Once the IDE is ready, we can go ahead and start building our workflow. First, open a terminal. You can then change into the source repository directory and pull the latest changes. In our example, our Git source repository name is lambda-signer
cd lambda-signer && git pull. We can now edit this file in our IDE.
Initially, we will create a basic Lambda code under artifacts directory:
The previous command block creates our index.py file which will go inside the AWS Lambda function. When we testing the Lambda Function, we should see message “Testing Lambda Code Signing using Signer” in the console log.
As a next step, we will create the CDK directory and initiate it:
The previous command will create a directory called ‘cdk’ and then initiate cdk inside this directory. As a result, we will see another directory named ‘cdk’. We then need to update files inside this directory as per the following screenshot.

Figure 6: Repository file structure.
Update the content of the files as per the code following snippets:
(Note: Update your region name by replacing the placeholder <Region Name> )
cdk_stack.py:
lambda_stack.py:
app.py:
Finally, we will work on Workflow:
In our example, our workflow is Workflow_d892. We will locate Workflow_d892.yaml in the .codecatalyst\workflows directory in our repository.

Figure 7: Workflow yaml file.
Update workflow with remaining steps
We can assign our workflow a name and configure the action. We have five stages in this workflow:
- CDKBootstrap: Prepare AWS Account for CDK deployment.
- CreateSignerResources: Deploys Signer resources into AWS Account
- ZipLambdaCode: Compresses the index.py file and store it in the source S3 bucket
- SignCode: Sign the compressed python file and push it to the destination S3 bucket
- Createlambda: Creates the Lambda Function using the signed code from destination S3 bucket.
Please insert the following values for your environment into the workflow file. The environment configuration will be as per the pre-requisite configuration for CodeCatalyst environment setup:
- <Name of your Environment>: The Name of your CodeCatalyst environment
- <AWS Account>: The AWS Account connection ID
- <Role Name>: The CodeCatalyst role that is configured for the environment
(Note: Feel free to update the region configuration to meet your deployment requirements. Supported regions are listed here)
We can copy/paste this code into our workflow. To save our changes, we select File -> Save. We can then commit these to our git repository by typing the following at the terminal:
The previous command will commit and push the changes that we have made to the CodeCatalyst source repository. As we have a branch trigger for main defined, this will trigger a run of the workflow. We can monitor the status of the workflow in the CodeCatalyst console by selecting CICD -> Workflows. Locate your workflow and click on Runs to view the status.

Figure 8: Successful workflow execution.
To validate that our newly created Lambda function is using AWS Signed code, we can open the AWS Console in our target region > Lambda > click on the sample-signer-function to inspect the properties.

Figure 9: AWS Lambda function with signed code.
Under the Code Source configuration property, you should see an informational message advising that ‘Your function has signed cofde and can’t be edited inline’. This confirms that the Lambda function is successfully using signed code.
Cleaning up
If you have been following along with this workflow, you should delete the resources that you have deployed to avoid further chargers. In the AWS Console > CloudFormation, locate the LambdaStack, then select and click Delete to remove the stack. Complete the same steps for the CDK stack.
Conclusion
In this post, we explained how development teams can easily get started signing code with AWS Signer and deploying it to Lambda Functions using Amazon CodeCatalyst. We outlined the stages in our workflow that enabled us to achieve the end-to-end release cycle. We also demonstrated how to enhance the developer experience of integrating CodeCatalyst with our AWS Cloud9 Dev Environment and leveraging the power of AWS CDK to use familiar programming languages such as Python to define our infrastructure as code resources.































 Ravi Itha is a Principal Consultant at AWS Professional Services with specialization in data and analytics and generalist background in application development. Ravi helps customers with enterprise data strategy initiatives across insurance, airlines, pharmaceutical, and financial services industries. In his 6-year tenure at Amazon, Ravi has helped the AWS builder community by publishing approximately 15 open-source solutions (accessible via
Ravi Itha is a Principal Consultant at AWS Professional Services with specialization in data and analytics and generalist background in application development. Ravi helps customers with enterprise data strategy initiatives across insurance, airlines, pharmaceutical, and financial services industries. In his 6-year tenure at Amazon, Ravi has helped the AWS builder community by publishing approximately 15 open-source solutions (accessible via  Srinivas Kandi is a Data Architect at AWS Professional Services. He leads customer engagements related to data lakes, analytics, and data warehouse modernizations. He enjoys reading history and civilizations.
Srinivas Kandi is a Data Architect at AWS Professional Services. He leads customer engagements related to data lakes, analytics, and data warehouse modernizations. He enjoys reading history and civilizations.



































 Virendhar (Viru) Sivaraman is a strategic Senior Big Data & Analytics Architect with Amazon Web Services. He is passionate about building scalable big data and analytics solutions in the cloud. Besides work, he enjoys spending time with family, hiking & mountain biking.
Virendhar (Viru) Sivaraman is a strategic Senior Big Data & Analytics Architect with Amazon Web Services. He is passionate about building scalable big data and analytics solutions in the cloud. Besides work, he enjoys spending time with family, hiking & mountain biking. Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a Bigdata enthusiast and holds 14 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation.
Vivek Shrivastava is a Principal Data Architect, Data Lake in AWS Professional Services. He is a Bigdata enthusiast and holds 14 AWS Certifications. He is passionate about helping customers build scalable and high-performance data analytics solutions in the cloud. In his spare time, he loves reading and finds areas for home automation.






