Post Syndicated from Biff Gaut original https://aws.amazon.com/blogs/devops/rapid-flexible-infrastructure-with-solutions-constructs-cdk/
Introduction
As workloads move to the cloud and all infrastructure becomes virtual, infrastructure as code (IaC) becomes essential to leverage the agility of this new world. JSON and YAML are the powerful, declarative modeling languages of AWS CloudFormation, allowing you to define complex architectures using IaC. Just as higher level languages like BASIC and C abstracted away the details of assembly language and made developers more productive, the AWS Cloud Development Kit (AWS CDK) provides a programming model above the native template languages, a model that makes developers more productive when creating IaC. When you instantiate CDK objects in your Typescript (or Python, Java, etc.) application, those objects “compile” into a YAML template that the CDK deploys as an AWS CloudFormation stack.
AWS Solutions Constructs take this simplification a step further by providing a library of common service patterns built on top of the CDK. These multi-service patterns allow you to deploy multiple resources with a single object, resources that follow best practices by default – both independently and throughout their interaction.
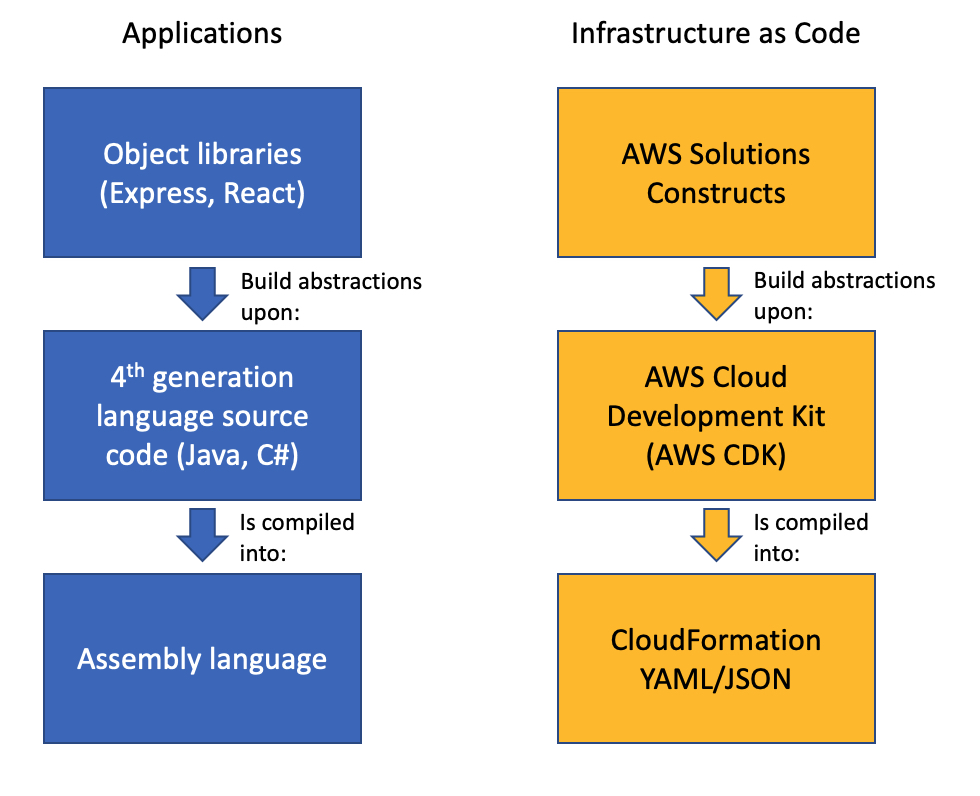
Application Development Stack vs. IaC Development Stack
Solution overview
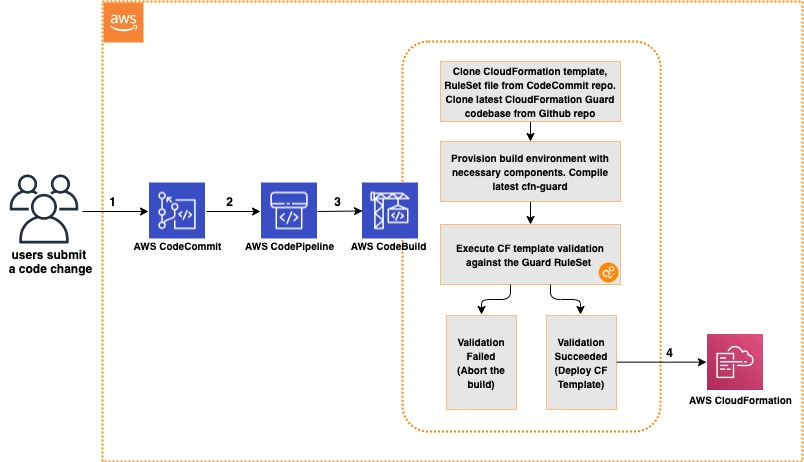
To demonstrate how using Solutions Constructs can accelerate the development of IaC, in this post you will create an architecture that ingests and stores sensor readings using Amazon Kinesis Data Streams, AWS Lambda, and Amazon DynamoDB.

Prerequisite – Setting up the CDK environment
Tip – If you want to try this example but are concerned about the impact of changing the tools or versions on your workstation, try running it on AWS Cloud9. An AWS Cloud9 environment is launched with an AWS Identity and Access Management (AWS IAM) role and doesn’t require configuring with an access key. It uses the current region as the default for all CDK infrastructure.
To prepare your workstation for CDK development, confirm the following:
- Node.js 10.3.0 or later is installed on your workstation (regardless of the language used to write CDK apps).
- You have configured credentials for your environment. If you’re running locally you can do this by configuring the AWS Command Line Interface (AWS CLI).
- TypeScript 2.7 or later is installed globally (
npm -g install typescript)
Before creating your CDK project, install the CDK toolkit using the following command:
npm install -g aws-cdk
Create the CDK project
- First create a project folder called
stream-ingestionwith these two commands:
mkdir stream-ingestion
cd stream-ingestion
- Now create your CDK application using this command:
npx [email protected] init app --language=typescript
Tip – This example will be written in TypeScript – you can also specify other languages for your projects.
At this time, you must use the same version of the CDK and Solutions Constructs. We’re using version 1.68.0 of both based upon what’s available at publication time, but you can update this with a later version for your projects in the future.
Let’s explore the files in the application this command created:
bin/stream-ingestion.ts– This is the module that launches the application. The key line of code is:
new StreamIngestionStack(app, 'StreamIngestionStack');
This creates the actual stack, and it’s in StreamIngestionStack that you will write the CDK code that defines the resources in your architecture.
lib/stream-ingestion-stack.ts– This is the important class. In the constructor ofStreamIngestionStackyou will add the constructs that will create your architecture.
During the deployment process, the CDK uploads your Lambda function to an Amazon S3 bucket so it can be incorporated into your stack.
- To create that S3 bucket and any other infrastructure the CDK requires, run this command:
cdk bootstrap
The CDK uses the same supporting infrastructure for all projects within a region, so you only need to run the bootstrap command once in any region in which you create CDK stacks.
- To install the required Solutions Constructs packages for our architecture, run the these two commands from the command line:
npm install @aws-solutions-constructs/[email protected]
npm install @aws-solutions-constructs/[email protected]
Write the code
First you will write the Lambda function that processes the Kinesis data stream messages.
- Create a folder named
lambdaunderstream-ingestion - Within the
lambdafolder save a file calledlambdaFunction.jswith the following contents:
var AWS = require("aws-sdk");
// Create the DynamoDB service object
var ddb = new AWS.DynamoDB({ apiVersion: "2012-08-10" });
AWS.config.update({ region: process.env.AWS_REGION });
// We will configure our construct to
// look for the .handler function
exports.handler = async function (event) {
try {
// Kinesis will deliver records
// in batches, so we need to iterate through
// each record in the batch
for (let record of event.Records) {
const reading = parsePayload(record.kinesis.data);
await writeRecord(record.kinesis.partitionKey, reading);
};
} catch (err) {
console.log(`Write failed, err:\n${JSON.stringify(err, null, 2)}`);
throw err;
}
return;
};
// Write the provided sensor reading data to the DynamoDB table
async function writeRecord(partitionKey, reading) {
var params = {
// Notice that Constructs automatically sets up
// an environment variable with the table name.
TableName: process.env.DDB_TABLE_NAME,
Item: {
partitionKey: { S: partitionKey }, // sensor Id
timestamp: { S: reading.timestamp },
value: { N: reading.value}
},
};
// Call DynamoDB to add the item to the table
await ddb.putItem(params).promise();
}
// Decode the payload and extract the sensor data from it
function parsePayload(payload) {
const decodedPayload = Buffer.from(payload, "base64").toString(
"ascii"
);
// Our CLI command will send the records to Kinesis
// with the values delimited by '|'
const payloadValues = decodedPayload.split("|", 2)
return {
value: payloadValues[0],
timestamp: payloadValues[1]
}
}
We won’t spend a lot of time explaining this function – it’s pretty straightforward and heavily commented. It receives an event with one or more sensor readings, and for each reading it extracts the pertinent data and saves it to the DynamoDB table.
You will use two Solutions Constructs to create your infrastructure:

aws-kinesisstreams-lambdacreates the Kinesis data stream and Lambda function that subscribes to that stream. To support this, it also creates other resources, such as IAM roles and encryption keys.

aws-lambda-dynamodbcreates an Amazon DynamoDB table and a Lambda function with permission to access the table.
- To deploy the first of these two constructs, replace the code in
lib/stream-ingestion-stack.tswith the following code:
import * as cdk from "@aws-cdk/core";
import * as lambda from "@aws-cdk/aws-lambda";
import { KinesisStreamsToLambda } from "@aws-solutions-constructs/aws-kinesisstreams-lambda";
import * as ddb from "@aws-cdk/aws-dynamodb";
import { LambdaToDynamoDB } from "@aws-solutions-constructs/aws-lambda-dynamodb";
export class StreamIngestionStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const kinesisLambda = new KinesisStreamsToLambda(
this,
"KinesisLambdaConstruct",
{
lambdaFunctionProps: {
// Where the CDK can find the lambda function code
runtime: lambda.Runtime.NODEJS_10_X,
handler: "lambdaFunction.handler",
code: lambda.Code.fromAsset("lambda"),
},
}
);
// Next Solutions Construct goes here
}
}
Let’s explore this code:
- It instantiates a new
KinesisStreamsToLambdaobject. This Solutions Construct will launch a new Kinesis data stream and a new Lambda function, setting up the Lambda function to receive all the messages in the Kinesis data stream. It will also deploy all the additional resources and policies required for the architecture to follow best practices. - The third argument to the constructor is the properties object, where you specify overrides of default values or any other information the construct needs. In this case you provide properties for the encapsulated Lambda function that informs the CDK where to find the code for the Lambda function that you stored as
lambda/lambdaFunction.jsearlier.
- Now you’ll add the second construct that connects the Lambda function to a new DynamoDB table. In the same
lib/stream-ingestion-stack.tsfile, replace the line// Next Solutions Construct goes herewith the following code:
// Define the primary key for the new DynamoDB table
const primaryKeyAttribute: ddb.Attribute = {
name: "partitionKey",
type: ddb.AttributeType.STRING,
};
// Define the sort key for the new DynamoDB table
const sortKeyAttribute: ddb.Attribute = {
name: "timestamp",
type: ddb.AttributeType.STRING,
};
const lambdaDynamoDB = new LambdaToDynamoDB(
this,
"LambdaDynamodbConstruct",
{
// Tell construct to use the Lambda function in
// the first construct rather than deploy a new one
existingLambdaObj: kinesisLambda.lambdaFunction,
tablePermissions: "Write",
dynamoTableProps: {
partitionKey: primaryKeyAttribute,
sortKey: sortKeyAttribute,
billingMode: ddb.BillingMode.PROVISIONED,
removalPolicy: cdk.RemovalPolicy.DESTROY
},
}
);
// Add autoscaling
const readScaling = lambdaDynamoDB.dynamoTable.autoScaleReadCapacity({
minCapacity: 1,
maxCapacity: 50,
});
readScaling.scaleOnUtilization({
targetUtilizationPercent: 50,
});
Let’s explore this code:
- The first two
constobjects define the names and types for the partition key and sort key of the DynamoDB table. - The
LambdaToDynamoDBconstruct instantiated creates a new DynamoDB table and grants access to your Lambda function. The key to this call is the properties object you pass in the third argument.- The first property sent to LambdaToDynamoDB is
existingLambdaObj– by setting this value to the Lambda function created by KinesisStreamsToLambda, you’re telling the construct to not create a new Lambda function, but to grant the Lambda function in the other Solutions Construct access to the DynamoDB table. This illustrates how you can chain many Solutions Constructs together to create complex architectures. - The second property sent to LambdaToDynamoDB tells the construct to limit the Lambda function’s access to the table to write only.
- The third property sent to LambdaToDynamoDB is actually a full properties object defining the DynamoDB table. It provides the two attribute definitions you created earlier as well as the billing mode. It also sets the
RemovalPolicytoDESTROY. This policy setting ensures that the table is deleted when you delete this stack – in most cases you should accept the default setting to protect your data.
- The first property sent to LambdaToDynamoDB is
- The last two lines of code show how you can use statements to modify a construct outside the constructor. In this case we set up auto scaling on the new DynamoDB table, which we can access with the
dynamoTableproperty on the construct we just instantiated.
That’s all it takes to create the all resources to deploy your architecture.
- Save all the files, then compile the Typescript into a CDK program using this command:
npm run build
- Finally, launch the stack using this command:
cdk deploy
(Enter “y” in response to Do you wish to deploy all these changes (y/n)?)
You will see some warnings where you override CDK default values. Because you are doing this intentionally you may disregard these, but it’s always a good idea to review these warnings when they occur.
Tip – Many mysterious CDK project errors stem from mismatched versions. If you get stuck on an inexplicable error, check package.json and confirm that all CDK and Solutions Constructs libraries have the same version number (with no leading caret ^). If necessary, correct the version numbers, delete the
package-lock.jsonfile andnode_modulestree and runnpm install. Think of this as the “turn it off and on again” first response to CDK errors.
You have now deployed the entire architecture for the demo – open the CloudFormation stack in the AWS Management Console and take a few minutes to explore all 12 resources that the program deployed (and the 380 line template generated to created them).
Feed the Stream
Now use the CLI to send some data through the stack.
Go to the Kinesis Data Streams console and copy the name of the data stream. Replace the stream name in the following command and run it from the command line.
Tip – If you are using the AWS CLI v2, the previous command will result in an “Invalid base64…” error because v2 expects the inputs to be Base64 encoded by default. Adding the argument
--cli-binary-format raw-in-base64-outwill fix the issue.
To confirm that the messages made it through the service, open the DynamoDB console – you should see the two records in the table.
Now that you’ve got it working, pause to think about what you just did. You deployed a system that can ingest and store sensor readings and scale to handle heavy loads. You did that by instantiating two objects – well under 60 lines of code. Experiment with changing some property values and deploying the changes by running npm run build and cdk deploy again.
Cleanup
To clean up the resources in the stack, run this command:
cdk destroy
Conclusion
Just as languages like BASIC and C allowed developers to write programs at a higher level of abstraction than assembly language, the AWS CDK and AWS Solutions Constructs allow us to create CloudFormation stacks in Typescript, Java, or Python instead JSON or YAML. Just as there will always be a place for assembly language, there will always be situations where we want to write CloudFormation templates manually – but for most situations, we can now use the AWS CDK and AWS Solutions Constructs to create complex and complete architectures in a fraction of the time with very little code.
AWS Solutions Constructs can currently be used in CDK applications written in Typescript, Javascript, Java and Python and will be available in C# applications soon.
About the Author
 Biff Gaut has been shipping software since 1983, from small startups to large IT shops. Along the way he has contributed to 2 books, spoken at several conferences and written many blog posts. He is now a Principal Solutions Architect at AWS working on the AWS Solutions Constructs team, helping customers deploy better architectures more quickly.
Biff Gaut has been shipping software since 1983, from small startups to large IT shops. Along the way he has contributed to 2 books, spoken at several conferences and written many blog posts. He is now a Principal Solutions Architect at AWS working on the AWS Solutions Constructs team, helping customers deploy better architectures more quickly.


































































 Ease of development
Ease of development