Post Syndicated from Asser Moustafa original https://aws.amazon.com/blogs/big-data/power-enterprise-grade-data-vaults-with-amazon-redshift-part-2/
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than any other cloud data warehouses.
As with all AWS services, Amazon Redshift is a customer-obsessed service that recognizes there isn’t a one-size-fits-all for customers when it comes to data models, which is why Amazon Redshift supports multiple data models such as Star Schemas, Snowflake Schemas and Data Vault. This post discusses the most pressing needs when designing an enterprise-grade Data Vault and how those needs are addressed by Amazon Redshift in particular and AWS cloud in general. The first post in this two-part series discusses best practices for designing enterprise-grade data vaults of varying scale using Amazon Redshift.
Whether it’s a desire to easily retain data lineage directly within the data warehouse, establish a source-system agnostic data model within the data warehouse, or more easily comply with GDPR regulations, customers that implement a data vault model will benefit from this post’s discussion of considerations, best practices, and Amazon Redshift features as well as the AWS cloud capabilities relevant to the building of enterprise-grade data vaults. Building a starter version of anything can often be straightforward, but building something with enterprise-grade scale, security, resiliency, and performance typically requires knowledge and adherence to battle-tested best practices, and using the right tools and features in the right scenario.
Data Vault overview
For a brief review of the core Data Vault premise and concepts, refer to the first post in this series.
In the following sections, we discuss the most common areas of consideration that are critical for Data Vault implementations at scale: data protection, performance and elasticity, analytical functionality, cost and resource management, availability, and scalability. Although these areas can also be critical areas of consideration for any data warehouse data model, in our experience, these areas present their own flavor and special needs to achieve data vault implementations at scale.
Data protection
Security is always priority-one at AWS, and we see the same attention to security every day with our customers. Data security has many layers and facets, ranging from encryption at rest and in transit to fine-grained access controls and more. In this section, we explore the most common data security needs within the raw and business data vaults and the Amazon Redshift features that help achieve those needs.
Data encryption
Amazon Redshift encrypts data in transit by default. With the click of a button, you can configure Amazon Redshift to encrypt data at rest at any point in a data warehouse’s lifecycle, as shown in the following screenshot.

You can use either AWS Key Management Service (AWS KMS) or Hardware Security Module (HSM) to perform encryption of data at rest. If you use AWS KMS, you can either use an AWS managed key or customer managed key. For more information, refer to Amazon Redshift database encryption.
You can also modify cluster encryption after cluster creation, as shown in the following screenshot.


Moreover, Amazon Redshift Serverless is encrypted by default.
Fine-grained access controls
When it comes to achieving fine-grained access controls at scale, Data Vaults typically need to use both static and dynamic access controls. You can use static access controls to restrict access to databases, tables, rows, and columns to explicit users, groups, or roles. With dynamic access controls, you can mask part or all portions of a data item, such as a column based on a user’s role or some other functional analysis of a user’s privileges.
Amazon Redshift has long supported static access controls through the GRANT and REVOKE commands for databases, schemas, and tables, at row level and column level. Amazon Redshift also supports row-level security, where you can further restrict access to particular rows of the visible columns, as well as role-based access control, which helps simplify the management of security privileges in Amazon Redshift.
In the following example, we demonstrate how you can use GRANT and REVOKE statements to implement static access control in Amazon Redshift.
- First, create a table and populate it with credit card values:
-- Create the credit cards table
CREATE TABLE credit_cards
( customer_id INT,
is_fraud BOOLEAN,
credit_card TEXT);
--populate the table with sample values
INSERT INTO credit_cards
VALUES
(100,'n', '453299ABCDEF4842'),
(100,'y', '471600ABCDEF5888'),
(102,'n', '524311ABCDEF2649'),
(102,'y', '601172ABCDEF4675'),
(102,'n', '601137ABCDEF9710'),
(103,'n', '373611ABCDEF6352');
- Create the user
user1 and check permissions for user1 on the credit_cards table. We use SET SESSION AUTHORIZATION to switch to user1 in the current session:
-- Create user
CREATE USER user1 WITH PASSWORD '1234Test!';
-- Check access permissions for user1 on credit_cards table
SET SESSION AUTHORIZATION user1;
SELECT * FROM credit_cards; -- This will return permission defined error
- Grant SELECT access on the
credit_cards table to user1:
RESET SESSION AUTHORIZATION;
GRANT SELECT ON credit_cards TO user1;
- Verify access permissions on the table
credit_cards for user1:
SET SESSION AUTHORIZATION user1;
SELECT * FROM credit_cards; -- Query will return rows
RESET SESSION AUTHORIZATION;
Data obfuscation
Static access controls are often useful to establish hard boundaries (guardrails) of the user communities that should be able to access certain datasets (for example, only those users that are part of the marketing user group should be allowed access to marketing data). However, what if access controls need to restrict only partial aspects of a field, not the entire field? Amazon Redshift supports partial, full, or custom data masking of a field through dynamic data masking. Dynamic data masking enables you to protect sensitive data in your data warehouse. You can manipulate how Amazon Redshift shows sensitive data to the user at query time without transforming it in the database by using masking policies.
In the following example, we achieve a full redaction of credit card numbers at runtime using a masking policy on the previously used credit_cards table.
- Create a masking policy that fully masks the credit card number:
CREATE MASKING POLICY mask_credit_card_full
WITH (credit_card VARCHAR(256))
USING ('000000XXXX0000'::TEXT);
- Attach
mask_credit_card_full to the credit_cards table as the default policy. Note that all users will see this masking policy unless a higher priority masking policy is attached to them or their role.
ATTACH MASKING POLICY mask_credit_card_full
ON credit_cards(credit_card) TO PUBLIC;
- Users will see credit card information being masked when running the following query
SELECT * FROM credit_cards;
Centralized security policies
You can achieve a great deal of scale by combining static and dynamic access controls to span a broad swath of user communities, datasets, and access scenarios. However, what about datasets that are shared across multiple Redshift warehouses, as might be done between raw data vaults and business data vaults? How can scale be achieved with access controls for a dataset that resides on one Redshift warehouse but is authorized for use across multiple Redshift warehouses using Amazon Redshift data sharing?
The integration of Amazon Redshift with AWS Lake Formation enables centrally managed access and permissions for data sharing. Amazon Redshift data sharing policies are established in Lake Formation and will be honored by all of your Redshift warehouses.
Performance
It is not uncommon for sub-second SLAs to be associated with data vault queries, particularly when interacting with the business vault and the data marts sitting atop the business vault. Amazon Redshift delivers on that needed performance through a number of mechanisms such as caching, automated data model optimization, and automated query rewrites.
The following are common performance requirements for Data Vault implementations at scale:
- Query and table optimization in support of high-performance query throughput
- High concurrency
- High-performance string-based data processing
Amazon Redshift features and capabilities for performance
In this section, we discuss Amazon Redshift features and capabilities that address those performance requirements.
Caching
Amazon Redshift uses multiple layers of caching to deliver subsecond response times for repeat queries. Through Amazon Redshift in-memory result set caching and compilation caching, workloads ranging from dashboarding to visualization to business intelligence (BI) that run repeat queries experience a significant performance boost.
With in-memory result set caching, queries that have a cached result set and no changes to the underlying data return immediately and typically within milliseconds.
The current generation RA3 node type is built on the AWS Nitro System with managed storage that uses high performance SSDs for your hot data and Amazon S3 for your cold data, providing ease of use, cost-effective storage, and fast query performance. In short, managed storage means fast retrieval for your most frequently accessed data and automated/managed identification of hot data by Amazon Redshift.
The large majority of queries in a typical production data warehouse are repeat queries, and data warehouses with data vault implementations observe the same pattern. The most optimal run profile for a repeat query is one that avoids costly query runtime interpretation, which is why queries in Amazon Redshift are compiled during the first run and the compiled code is cached in a global cache, providing repeat queries a significant performance boost.
Materialized views
Pre-computing the result set for repeat queries is a powerful mechanism for boosting performance. The fact that it automatically refreshes to reflect the latest changes in the underlying data is yet another powerful pattern for boosting performance. For example, consider the denormalization queries that might be run on the raw data vault to populate the business vault. It’s quite possible that some less-active source systems will have exhibited little to no changes in the raw data vault since the last run. Avoiding the hit of rerunning the business data vault population queries from scratch in those cases could be a tremendous boost to performance. Redshift materialized views provide that exact functionality by storing the precomputed result set of their backing query.
Queries that are similar to the materialized view’s backing query don’t have to rerun the same logic each time, because they can pull records from the existing result set. Developers and analysts can choose to create materialized views after analyzing their workloads to determine which queries would benefit. Materialized views also support automatic query rewriting to have Amazon Redshift rewrite queries to use materialized views, as well as auto refreshing materialized views, where Amazon Redshift can automatically refresh materialized views with up-to-date data from its base tables.
Alternatively, the automated materialized views (AutoMV) feature provides the same performance benefits of user-created materialized views without the maintenance overhead because Amazon Redshift automatically creates the materialized views based on observed query patterns. Amazon Redshift continually monitors the workload using machine learning and then creates new materialized views when they are beneficial. AutoMV balances the costs of creating and keeping materialized views up to date against expected benefits to query latency. The system also monitors previously created AutoMVs and drops them when they are no longer beneficial. AutoMV behavior and capabilities are the same as user-created materialized views. They are refreshed automatically and incrementally, using the same criteria and restrictions.
Also, whether the materialized views are user-created or auto-generated, Amazon Redshift automatically rewrites queries, without users to change queries, to use materialized views when there is enough of a similarity between the query and the materialized view’s backing query.
Concurrency scaling
Amazon Redshift automatically and elastically scales query processing power to provide consistently fast performance for hundreds of concurrent queries. Concurrency scaling resources are added to your Redshift warehouse transparently in seconds, as concurrency increases, to process read/write queries without wait time. When workload demand subsides, Amazon Redshift automatically shuts down concurrency scaling resources to save you cost. You can continue to use your existing applications and BI tools without any changes.
Because Data Vault allows for highly concurrent data processing and is primarily run within Amazon Redshift, concurrency scaling is the recommended way to handle concurrent transformation operations. You should avoid operations that aren’t supported by concurrency scaling.
Concurrent ingestion
One of the key attractions of Data Vault 2.0 is its ability to support high-volume concurrent ingestion from multiple source systems into the data warehouse. Amazon Redshift provides a number of options for concurrent ingestion, including batch and streaming.
For batch- and microbatch-based ingestion, we suggest using the COPY command in conjunction with CSV format. CSV is well supported by concurrency scaling. In case your data is already on Amazon S3 but in Bigdata formats like ORC or Parquet, always consider the trade-off of converting the data to CSV vs. non-concurrent ingestion. You can also use workload management to prioritize non-concurrent ingestion jobs to keep the throughput high.
For low-latency workloads, we suggest using the native Amazon Redshift streaming capability or the Amazon Redshift Zero ETL capability in conjunction with Amazon Aurora. By using Aurora as a staging layer for the raw data, you can handle small increments of data efficiently and with high concurrency, and then use this data inside your Redshift data warehouse without any extract, transform, and load (ETL) processes. For stream ingestion, we suggest using the native streaming feature (Amazon Redshift streaming ingestion) and have a dedicated stream for ingesting each table. This might require a stream processing solution upfront, which splits the input stream into the respective elements like the hub and the satellite record.
String-optimized compression
The Data Vault 2.0 methodology often involves time-sensitive lookup queries against potentially very large satellite tables (in terms of row count) that have low-cardinality hash/string indexes. Low-cardinality indexes and very large tables tend to work against time-sensitive queries. Amazon Redshift, however, provides a specialized compression method for low-cardinality string-based indexes called BYTEDICT. Using BYTEDICT creates a dictionary of the low-cardinality string indexes that allow Amazon Redshift to reads the rows even in a compressed state, thereby significantly improving performance. You can manually select the BYTEDICT compression method for a column, or alternatively rely on Amazon Redshift automated table optimization facilities to select it for you.
Support of transactional data lake frameworks
Data Vault 2.0 is an insert-only framework. Therefore, reorganizing data to save money is a challenge you may face. Amazon Redshift integrates seamlessly with S3 data lakes allowing you to perform data lake queries in your S3 using standard SQL as you would with native tables. This way, you can outsource less frequently used satellites to your S3 data lake, which is cheaper than keeping it as a native table.
Modern transactional lake formats like Apache Iceberg are also an excellent option to store this data. They ensure transactional safety and therefore ensure that your audit trail, which is a fundamental feature of Data Vault, doesn’t break.
We also see customers using these frameworks as a mechanism to implement incremental loads. Apache Iceberg lets you query for the last state for a given point in time. You can use this mechanism to optimize merge operations while still making the data accessible from within Amazon Redshift.
Amazon Redshift data sharing performance considerations
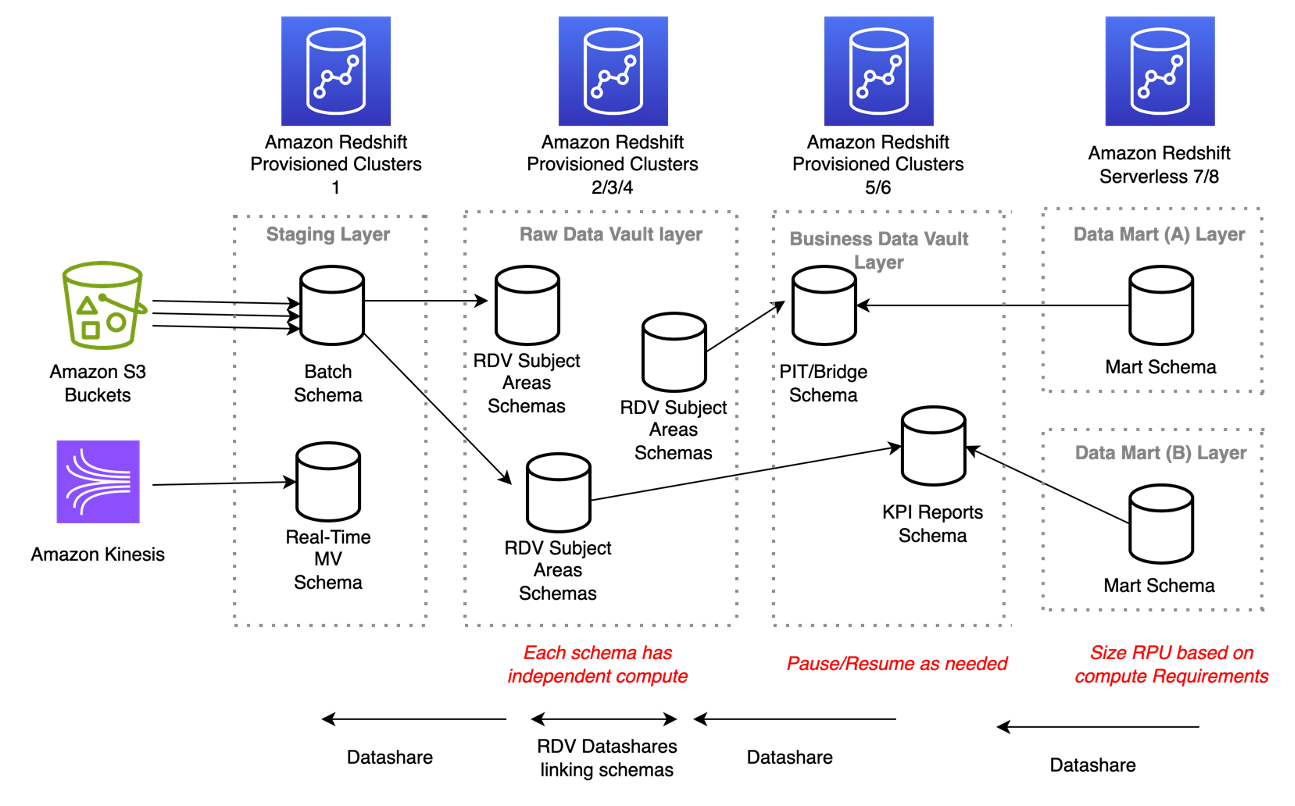
For large-scale Data Vault implementation, one of the preferred design principals is to have a separate Redshift data warehouse for each layer (staging, raw Data Vault, business Data Vault, and presentation data mart). These layers have separate Redshift provisioned or serverless warehouses according to their storage and compute requirements and use Amazon Redshift data sharing to share the data between these layers without physically moving the data.
Amazon Redshift data sharing enables you to seamlessly share live data across multiple Redshift warehouses without any data movement. Because the data sharing feature serves as the backbone in implementing large-scale Data Vaults, it’s important to understand the performance of Amazon Redshift in this scenario.
In a data sharing architecture, we have producer and consumer Redshift warehouses. The producer warehouse shares the data objects to one or more consumer warehouse for read purposes only without having to copy the data.
Producer/consumer Redshift cluster performance dependency
From a performance perspective, the producer (provisioned or serverless) warehouse is not responsible for query performance running on the consumer (provisioned or serverless) warehouse and has zero impact in terms of performance or activity on the producer Redshift warehouse. It depends on the consumer Redshift warehouse compute capacity. The producer warehouse is only responsible for the shared data.
Result set caching on the consumer Redshift cluster
Amazon Redshift uses result set caching to speed up the retrieval of data when it knows that the data in the underlying table has not changed. In a data sharing architecture, Amazon Redshift also uses result set caching on the consumer Redshift warehouse. This is quite helpful for repeatable queries that commonly occur in a data warehousing environment.
Best practices for materialized views in Data Vault with Amazon Redshift data sharing
In Data Vault implementation, the presentation data mart layer typically contains views or materialized views. There are two possible routes to create materialized views for the presentation data mart layer. First, create the materialized views on the producer Redshift warehouse (business data vault layer) and share materialized views with the consumer Redshift warehouse (dedicated data marts). Alternatively, share the table objects directly from the business data vault layer to the presentation data mart layer and build the materialized view on the shared objects directly on the consumer Redshift warehouse.
The second option is recommended in this case, because it gives us the flexibility of creating customized materialized views of data on each consumer according to the specific use case and simplifies the management because each data mart user can create and manage materialized views on their own Redshift warehouse rather than be dependent on the producer warehouse.
Table distribution implications in Amazon Redshift data sharing
Table distribution style and how data is distributed across Amazon Redshift plays a significant role in query performance. In Amazon Redshift data sharing, the data is distributed on the producer Redshift warehouse according to the distribution style defined for table. When we associate the data via a data share to the consumer Redshift warehouse, it maps to the same disk block layout. Also, a bigger consumer Redshift warehouse will result in better query performance for queries running on it.
Concurrency scaling
Concurrency scaling is also supported on both producer and consumer Redshift warehouses for read and write operations.
Cost and resource management
Given that multiple source systems and users will interact heavily with the data vault data warehouse, it’s a prudent best practice to enable usage and query limits to serve as guardrails against runaway queries and unapproved usage patterns. Furthermore, it often helps to have a systematic way for allocating service costs based on usage of the data vault to different source systems and user groups within your organization.
The following are common cost and resource management requirements for Data Vault implementations at scale:
- Utilization limits and query resource guardrails
- Advanced workload management
- Chargeback capabilities
Amazon Redshift features and capabilities for cost and resource management
In this section, we discuss Amazon Redshift features and capabilities that address those cost and resource management requirements.
Utilization limits and query monitoring rules
Runaway queries and excessive auto scaling are likely to be the two most common runaway patterns observed with data vault implementations at scale.
A Redshift provisioned cluster supports usage limits for features such as Redshift Spectrum, concurrency scaling, and cross-Region data sharing. A concurrency scaling limit specifies the threshold of the total amount of time used by concurrency scaling in 1-minute increments. A limit can be specified for a daily, weekly, or monthly period (using UTC to determine the start and end of the period).
You can also define multiple usage limits for each feature. Each limit can have a different action, such as logging to system tables, alerting via Amazon CloudWatch alarms and optionally Amazon Simple Notification Service (Amazon SNS) subscriptions to that alarm (such as email or text), or disabling the feature outright until the next time period begins (such as the start of the month). When a usage limit threshold is reached, events are also logged to a system table.
Redshift provisioned clusters also support query monitoring rules to define metrics-based performance boundaries for workload management queues and the action that should be taken when a query goes beyond those boundaries. For example, for a queue dedicated to short-running queries, you might create a rule that cancels queries that run for more than 60 seconds. To track poorly designed queries, you might have another rule that logs queries that contain nested loops.
Each query monitoring rule includes up to three conditions, or predicates, and one query action (such as stop, hop, or log). A predicate consists of a metric, a comparison condition (=, <, or >), and a value. If all of the predicates for any rule are met, that rule’s action is triggered. Amazon Redshift evaluates metrics every 10 seconds and if more than one rule is triggered during the same period, Amazon Redshift initiates the most severe action (stop, then hop, then log).
Redshift Serverless also supports usage limits where you can specify the base capacity according to your price-performance requirements. You can also set the maximum RPU (Redshift Processing Units) hours used per day, per week, or per month to keep the cost predictable and specify different actions, such as write to system table, receive an alert, or turn off user queries when the limit is reached. A cross-Region data sharing usage limit is also supported, which limits how much data transferred from the producer Region to the consumer Region that consumers can query.
You can also specify query limits in Redshift Serverless to stop poorly performing queries that exceed the threshold value.
Auto workload management
Not all queries have the same performance profile or priority, and data vault queries are no different. Amazon Redshift workload management (WLM) adapts in real time to the priority, resource allocation, and concurrency settings required to optimally run different data vault queries. These queries could consist of a high number of joins between the hubs, links, and satellites tables; large-scale scans of the satellite tables; or massive aggregations. Amazon Redshift WLM enables you to flexibly manage priorities within workloads so that, for example, short or fast-running queries won’t get stuck in queues behind long-running queries.
You can use automatic WLM to maximize system throughput and use resources effectively. You can enable Amazon Redshift to manage how resources are divided to run concurrent queries with automatic WLM. Automatic WLM manages the resources required to run queries. Amazon Redshift determines how many queries run concurrently and how much memory is allocated to each dispatched query.
Chargeback metadata
Amazon Redshift provides different pricing models to cater to different customer needs. On-demand pricing offers the greatest flexibility, whereas Reserved Instances provide significant discounts for predictable and steady usage scenarios. Redshift Serverless provides a pay-as-you-go model that is ideal for sporadic workloads.
However, with any of these pricing models, Amazon Redshift customers can attribute cost to different users. To start, Amazon Redshift provides itemized billing like many other AWS services in AWS Cost Explorer to attain the overall cost of using Amazon Redshift. Moreover, the cross-group collaboration (data sharing) capability of Amazon Redshift enables a more explicit and structured chargeback model to different teams.
Availability
In the modern data organization, data warehouses are no longer used purely to perform historical analysis in batches overnight with relatively forgiving SLAs, Recovery Time Objectives (RTOs), and Recovery Point Objectives (RPOs). They have become mission-critical systems in their own right that are used for both historical analysis and near-real-time data analysis. Data Vault systems at scale very much fit that mission-critical profile, which makes availability key.
The following are common availability requirements for Data Vault implementations at scale:
- RTO of near-zero
- RPO of near-zero
- Automated failover
- Advanced backup management
- Commercial-grade SLA
Amazon Redshift features and capabilities for availability
In this section, we discuss the features and capabilities in Amazon Redshift that address those availability requirements.
Separation of storage and compute
AWS and Amazon Redshift are inherently resilient. With Amazon Redshift, there’s no additional cost for active-passive disaster recovery. Amazon Redshift replicates all of your data within your data warehouse when it is loaded and also continuously backs up your data to Amazon S3. Amazon Redshift always attempts to maintain at least three copies of your data (the original and replica on the compute nodes, and a backup in Amazon S3).
With separation of storage and compute and Amazon S3 as the persistence layer, you can achieve an RPO of near-zero, if not zero itself.
Cluster relocation to another Availability Zone
Amazon Redshift provisioned RA3 clusters support cluster relocation to another Availability Zone in events where cluster operation in the current Availability Zone is not optimal, without any data loss or changes to your application. Cluster relocation is available free of charge; however, relocation might not always be possible if there is a resource constraint in the target Availability Zone.
Multi-AZ deployment
For many customers, the cluster relocation feature is sufficient; however, enterprise data warehouse customers require a low RTO and higher availability to support their business continuity with minimal impact to applications.
Amazon Redshift supports Multi-AZ deployment for provisioned RA3 clusters.
A Redshift Multi-AZ deployment uses compute resources in multiple Availability Zones to scale data warehouse workload processing as well as provide an active-active failover posture. In situations where there is a high level of concurrency, Amazon Redshift will automatically use the resources in both Availability Zones to scale the workload for both read and write requests using active-active processing. In cases where there is a disruption to an entire Availability Zone, Amazon Redshift will continue to process user requests using the compute resources in the sister Availability Zone.
With features such as multi-AZ deployment, you can achieve a low RTO, should there ever be a disruption to the primary Redshift cluster or an entire Availability Zone.
Automated backup
Amazon Redshift automatically takes incremental snapshots that track changes to the data warehouse since the previous automated snapshot. Automated snapshots retain all of the data required to restore a data warehouse from a snapshot. You can create a snapshot schedule to control when automated snapshots are taken, or you can take a manual snapshot any time.
Automated snapshots can be taken as often as once every hour and retained for up to 35 days at no additional charge to the customer. Manual snapshots can be kept indefinitely at standard Amazon S3 rates. Furthermore, automated snapshots can be automatically replicated to another Region and stored there as a disaster recovery site also at no additional charge (with the exception of data transfer charges across Regions) and manual snapshots can also be replicated with standard Amazon S3 rates applying (and data transfer costs).
Amazon Redshift SLA
As a managed service, Amazon Redshift frees you from being the first and only line of defense against disruptions. AWS will use commercially reasonable efforts to make Amazon Redshift available with a monthly uptime percentage for each Multi-AZ Redshift cluster during any monthly billing cycle, of at least 99.99% and for multi-node cluster, at least 99.9%. In the event that Amazon Redshift doesn’t meet the Service Commitment, you will be eligible to receive a Service Credit.
Scalability
One of the major motivations of organizations migrating to the cloud is improved and increased scalability. With Amazon Redshift, Data Vault systems will always have a number of scaling options available to them.
The following are common scalability requirements for Data Vault implementations at scale:
- Automated and fast-initiating horizontal scaling
- Robust and performant vertical scaling
- Data reuse and sharing mechanisms
Amazon Redshift features and capabilities for scalability
In this section, we discuss the features and capabilities in Amazon Redshift that address those scalability requirements.
Horizontal and vertical scaling
Amazon Redshift uses concurrency scaling automatically to support virtually unlimited horizontal scaling of concurrent users and concurrent queries, with consistently fast query performance. Furthermore, concurrency scaling requires no downtime, supports read/write operations, and is typically the most impactful and used scaling option for customers during normal business operations to maintain consistent performance.
With Amazon Redshift provisioned warehouse, as your data warehousing capacity and performance needs to change or grow, you can vertically scale your cluster to make the best use of the computing and storage options that Amazon Redshift provides. Resizing your cluster by changing the node type or number of nodes can typically be achieved in 10–15 minutes. Vertical scaling typically occurs much less frequently in response to persistent and organic growth and is typically performed during a planned maintenance window when the short downtime doesn’t impact business operations.
Explicit horizontal or vertical resize and pause operations can be automated per a schedule (for example, development clusters can be automatically scaled down or paused for the weekends). Note that the storage of paused clusters remains accessible to clusters with which their data was shared.
For resource-intensive workloads that might benefit from a vertical scaling operation vs. concurrency scaling, there are also other best-practice options that avoid downtime, such as deploying the workload onto its own Redshift Serverless warehouse while using data sharing.
Redshift Serverless measures data warehouse capacity in RPUs, which are resources used to handle workloads. You can specify the base data warehouse capacity Amazon Redshift uses to serve queries (ranging from as little as 8 RPUs to as high as 512 RPUs) and change the base capacity at any time.
Data sharing
Amazon Redshift data sharing is a secure and straightforward way to share live data for read purposes across Redshift warehouses within the same or different accounts and Regions. This enables high-performance data access while preserving workload isolation. You can have separate Redshift warehouses, either provisioned or serverless, for different use cases according to your compute requirement and seamlessly share data between them.
Common use cases for data sharing include setting up a central ETL warehouse to share data with many BI warehouses to provide read workload isolation and chargeback, offering data as a service and sharing data with external consumers, multiple business groups within an organization, sharing and collaborating on data to gain differentiated insights, and sharing data between development, test, and production environments.
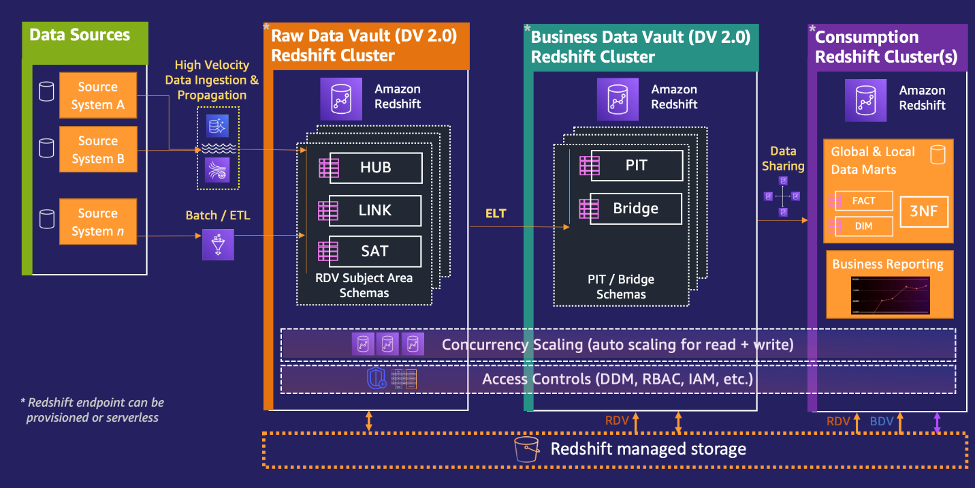
Reference architecture
The diagram in this section shows one possible reference architecture of a Data Vault 2.0 system implemented with Amazon Redshift.
We suggest using three different Redshift warehouses to run a Data Vault 2.0 model in Amazon Redshift. The data between these data warehouses is shared via Amazon Redshifts data sharing and allows you to consume data from a consumer data warehouse even if the provider data warehouse is inactive.
- Raw Data Vault – The RDV data warehouse hosts hubs, links, and satellite tables. For large models, you can additionally slice the RDV into additional data warehouses to even better adopt the data warehouse sizing to your workload patterns. Data is ingested via the patterns described in the previous section as batch or high velocity data.
- Business Data Vault – The BDV data warehouse hosts bridge and point in time (PIT) tables. These tables are computed based on the RDV tables using Amazon Redshift. Materialized or automatic materialized views are straightforward mechanisms to create those.
- Consumption cluster – This data warehouse contains query-optimized data formats and marts. Users interact with this layer.
If the workload pattern is unknown, we suggest starting with a Redshift Serverless warehouse and learning the workload pattern. You can easily migrate between a serverless and provisioned Redshift cluster at a later stage based on your processing requirements, as discussed in Part 1 of this series.

Best practices building a Data Vault warehouse on AWS
In this section, we cover how the AWS Cloud as a whole plays its role in building an enterprise-grade Data Vault warehouse on Amazon Redshift.
Education
Education is a fundamental success factor. Data Vault is more complex than traditional data modeling methodologies. Before you start the project, make sure everyone understands the principles of Data Vault. Amazon Redshift is designed to be very easy to use, but to ensure the most optimal Data Vault implementation on Amazon Redshift, gaining a good understanding of how Amazon Redshift works is recommended. Start with free resources like reaching out to your AWS account representative to schedule a free Amazon Redshift Immersion Day or train for the AWS Analytics specialty certification.
Automation
Automation is a major benefit of Data Vault. This will increase efficiency and consistency across your data landscape. Most customers focus on the following aspects when automating Data Vault:
- Automated DDL and DML creation, including modeling tools especially for the raw data vault
- Automated ingestion pipeline creation
- Automated metadata and lineage support
Depending on your needs and skills, we typically see three different approaches:
- DSL – This is a common tool for generating data vault models and flows with Domain Specific Languages (DSL). Popular frameworks for building such DSLs are EMF with Xtext or MPS. This solution provides the most flexibility. You directly build your business vocabulary into the application and generate documentation and business glossary along with the code. This approach requires the most skill and biggest resource investment.
- Modeling tool – You can build on an existing modeling language like UML 2.0. Many modeling tools come with code generators. Therefore, you don’t need to build your own tool, but these tools are often hard to integrate into modern DevOps pipelines. They also require UML 2.0 knowledge, which raises the bar for non-tech users.
- Buy – There are a number of different third-party solutions that integrate well into Amazon Redshift and are available via AWS Marketplace.
Whichever approach of the above-mentioned approaches you choose, all three approaches offer multiple benefits. For example, you can take away repetitive tasks from your development team and enforce modeling standards like data types, data quality rules, and naming conventions. To generate the code and deploy it, you can use AWS DevOps services. As part of this process, you save the generated metadata to the AWS Glue Data Catalog, which serves as a central technical metadata catalog. You then deploy the generated code to Amazon Redshift (SQL scripts) and to AWS Glue.
We designed AWS CloudFormation for automation; it’s the AWS-native way of automating infrastructure creation and management. A major use case for infrastructure as code (IaC) is to create new ingestion pipelines for new data sources or add new entities to existing one.
You can also use our new AI coding tool Amazon CodeWhisperer, which helps you quickly write secure code by generating whole line and full function code suggestions in your IDE in real time, based on your natural language comments and surrounding code. For example, CodeWhisperer can automatically take a prompt such as “get new files uploaded in the last 24 hours from the S3 bucket” and suggest appropriate code and unit tests. This can greatly reduce development effort in writing code, for example for ETL pipelines or generating SQL queries, and allow more time for implementing new ideas and writing differentiated code.
Operations
As previously mentioned, one of the benefits of Data Vault is the high level of automation which, in conjunction with serverless technologies, can lower the operating efforts. On the other hand, some industry products come with built-in schedulers or orchestration tools, which might increase operational complexity. By using AWS-native services, you’ll benefit from integrated monitoring options of all AWS services.
Conclusion
In this series, we discussed a number of crucial areas required for implementing a Data Vault 2.0 system at scale, and the Amazon Redshift capabilities and AWS ecosystem that you can use to satisfy those requirements. There are many more Amazon Redshift capabilities and features that will surely come in handy, and we strongly encourage current and prospective customers to reach out to us or other AWS colleagues to delve deeper into Data Vault with Amazon Redshift.
About the Authors
 Asser Moustafa is a Principal Analytics Specialist Solutions Architect at AWS based out of Dallas, Texas. He advises customers globally on their Amazon Redshift and data lake architectures, migrations, and visions—at all stages of the data ecosystem lifecycle—starting from the POC stage to actual production deployment and post-production growth.
Asser Moustafa is a Principal Analytics Specialist Solutions Architect at AWS based out of Dallas, Texas. He advises customers globally on their Amazon Redshift and data lake architectures, migrations, and visions—at all stages of the data ecosystem lifecycle—starting from the POC stage to actual production deployment and post-production growth.
Philipp Klose is a Global Solutions Architect at AWS based in Munich. He works with enterprise FSI customers and helps them solve business problems by architecting serverless platforms. In this free time, Philipp spends time with his family and enjoys every geek hobby possible.
Saman Irfan is a Specialist Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies.


 Buddhike de Silva is a Senior Specialist Solutions Architect at Amazon Web Services. Buddhike helps customers run large scale streaming analytics workloads on AWS and make the best out of their cloud journey.
Buddhike de Silva is a Senior Specialist Solutions Architect at Amazon Web Services. Buddhike helps customers run large scale streaming analytics workloads on AWS and make the best out of their cloud journey.






 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
 Kinshuk Pahare is a leader in AWS Glue’s product management team. He drives efforts on the platform, developer experience, and big data processing frameworks like Apache Spark, Ray, and Python Shell.
Kinshuk Pahare is a leader in AWS Glue’s product management team. He drives efforts on the platform, developer experience, and big data processing frameworks like Apache Spark, Ray, and Python Shell.

 testproject-dev: destroyed
testproject-dev: destroyed


 Shaila Mathias is a Business Development lead for AWS Clean Rooms at Amazon Web Services.
Shaila Mathias is a Business Development lead for AWS Clean Rooms at Amazon Web Services. Allison Milone is a Product Marketer for the Advertising & Marketing Industry at Amazon Web Services.
Allison Milone is a Product Marketer for the Advertising & Marketing Industry at Amazon Web Services. Ryan Malecky is a Senior Solutions Architect at Amazon Web Services. He is focused on helping customers build gain insights from their data, especially with AWS Clean Rooms.
Ryan Malecky is a Senior Solutions Architect at Amazon Web Services. He is focused on helping customers build gain insights from their data, especially with AWS Clean Rooms.












 Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect and AWS Glue expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding. Follow Kamen on LinkedIn to keep up to date with the latest AWS Glue news!
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect and AWS Glue expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding. Follow Kamen on LinkedIn to keep up to date with the latest AWS Glue news! Sean Bjurstrom is a Technical Account Manager in ISV accounts at Amazon Web Services, where he specializes in analytics technologies and draws on his background in consulting to support customers on their analytics and cloud journeys. Sean is passionate about helping businesses harness the power of data to drive innovation and growth. Outside of work, he enjoys running and has participated in several marathons.
Sean Bjurstrom is a Technical Account Manager in ISV accounts at Amazon Web Services, where he specializes in analytics technologies and draws on his background in consulting to support customers on their analytics and cloud journeys. Sean is passionate about helping businesses harness the power of data to drive innovation and growth. Outside of work, he enjoys running and has participated in several marathons. Vinod Jayendra is an Enterprise Support Lead in ISV accounts at Amazon Web Services, where he helps customers solve their architectural, operational, and cost-optimization challenges. With a particular focus on serverless technologies, he draws from his extensive background in application development to help customers build top-tier solutions. Beyond work, he finds joy in quality family time, embarking on biking adventures, and coaching youth sports teams.
Vinod Jayendra is an Enterprise Support Lead in ISV accounts at Amazon Web Services, where he helps customers solve their architectural, operational, and cost-optimization challenges. With a particular focus on serverless technologies, he draws from his extensive background in application development to help customers build top-tier solutions. Beyond work, he finds joy in quality family time, embarking on biking adventures, and coaching youth sports teams. Doug Mbaya is a Senior Partner Solution architect with a focus in analytics and machine learning. Doug works closely with AWS partners and helps them integrate their solutions with AWS analytics and machine learning solutions in the cloud.
Doug Mbaya is a Senior Partner Solution architect with a focus in analytics and machine learning. Doug works closely with AWS partners and helps them integrate their solutions with AWS analytics and machine learning solutions in the cloud.













 Seshadri Senthamaraikannan is a data architect with AWS professional services team based in London, UK. He is well experienced and specialised in Data Analytics and works with customers focusing on building innovative and scalable solutions in AWS Cloud to meet their business goals. In his spare time, he enjoys spending time with his family and play sports.
Seshadri Senthamaraikannan is a data architect with AWS professional services team based in London, UK. He is well experienced and specialised in Data Analytics and works with customers focusing on building innovative and scalable solutions in AWS Cloud to meet their business goals. In his spare time, he enjoys spending time with his family and play sports. Mohamed Hamdy is a Senior Big Data Architect with AWS Professional Services based in London, UK. He has over 15 years of experience architecting, leading, and building data warehouses and big data platforms. He helps customers develop big data and analytics solutions to accelerate their business outcomes through their cloud adoption journey. Outside of work, Mohamed likes travelling, running, swimming and playing squash.
Mohamed Hamdy is a Senior Big Data Architect with AWS Professional Services based in London, UK. He has over 15 years of experience architecting, leading, and building data warehouses and big data platforms. He helps customers develop big data and analytics solutions to accelerate their business outcomes through their cloud adoption journey. Outside of work, Mohamed likes travelling, running, swimming and playing squash.























 Asser Moustafa is a Principal Analytics Specialist Solutions Architect at AWS based out of Dallas, Texas. He advises customers globally on their Amazon Redshift and data lake architectures, migrations, and visions—at all stages of the data ecosystem lifecycle—starting from the POC stage to actual production deployment and post-production growth.
Asser Moustafa is a Principal Analytics Specialist Solutions Architect at AWS based out of Dallas, Texas. He advises customers globally on their Amazon Redshift and data lake architectures, migrations, and visions—at all stages of the data ecosystem lifecycle—starting from the POC stage to actual production deployment and post-production growth. Philipp Klose is a Global Solutions Architect at AWS based in Munich. He works with enterprise FSI customers and helps them solve business problems by architecting serverless platforms. In this free time, Philipp spends time with his family and enjoys every geek hobby possible.
Philipp Klose is a Global Solutions Architect at AWS based in Munich. He works with enterprise FSI customers and helps them solve business problems by architecting serverless platforms. In this free time, Philipp spends time with his family and enjoys every geek hobby possible. Saman Irfan is a Specialist Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies.
Saman Irfan is a Specialist Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies.