This is a guest post by Valdiney Gomes, Hélio Leal, and Flávia Lima from Dafiti.
Data and its various uses is increasingly evident in companies, and each professional has their preferences about which technologies to use to visualize data, which isn’t necessarily in line with the technological needs and infrastructure of a company. At Dafiti, a Brazilian fashion and style e-commerce retailer, it was no different. Five tools were used by different sectors of the company, which caused misalignment and management overhead, spreading our resources thin to support them. Looking for a tool that would enable us to democratize our data, we chose Amazon QuickSight, a cloud-native, serverless business intelligence (BI) service that powers interactive dashboards that lets us make better data-driven decisions, as a corporate solution for data visualization.
In this post, we discuss why we chose QuickSight and how we implemented it.
Why we chose QuickSight
We had specific requirements for our BI solution and looked at many different options. The following factors guided our decision:
Tool close to data – It was important to have the data visualization tool as close to the data as possible. At Dafiti, the entire infrastructure is on AWS, and we use Amazon Redshift as our Data Warehouse. QuickSight, when using SPICE (Super-fast, Parallel, In-memory Calculation Engine), extracts data from Amazon Redshift as efficiently as possible using UNLOAD, which optimizes the use of Amazon Redshift.
Highly available and accessible solution – We wanted to be able to be access the tool by web or mobile interface, in addition to being able to do almost anything through API calls.
Serverless solution – All the other data visualization solutions that were used at Dafiti were on premises, which created unnecessary cost and effort to maintain these services, taking the focus away from what was most important to us: data.
Flexible pricing model – We needed a pricing model that would allow us to provide access to everyone in the company and at a price defined by usage and not by license. Thanks to AWS pay-as-you-go pricing, with more than double the number of users we had on our previous main data visualization solution, our cost with QuickSight is about 10 times lower.
Robust documentation – The material provided by AWS proved to be helpful, allowing our team to put the project into production.
Unifying our solution
We were previously using Qlikview, Sisense, Tableau, SAP, and Excel to analyze our data across different teams. We were already using other AWS services and learning about QuickSight when we hosted a Data Battle with AWS, a hybrid event for more than 230 Dafiti employees. This event had a hands-on approach with a workshop followed by a friendly QuickSight competition. Participants had to get information in their own dashboard to answer correctly. This 5-hour event flew by, accelerated the learning path of technical and business teams, and proved that QuickSight was the right tool for us.
QuickSight has brought all of our teams into one tool, while lowering costs by 80% and enabling us to do so much more together. Currently, over 400 employees, including our CEO, across nine different business units are using QuickSight as their sole source of truth on a daily basis. This includes human resources, auditing, and customer service, which previously had their analyses spread across several sources.
Data democratization
Data democratization is one of Dafiti’s main objectives. We believe that allowing everyone to analyze the data, following Brazilian, Argentinean, and Colombian privacy laws, unlocks potential for improving decision-making processes by extracting value from the data generated by the company. However, the democratization of data comes with the responsible use of resources. Yes, we want all users to be able to access and extract value from the data, but the cost can never be greater than the value that this generates.
How we organized the project
Data democratization drives Dafiti’s strategy. When implementing QuickSight, the obsession of becoming an even more data-driven company (we talk about this at the AWS Summit SP 2022) and having data increasingly accessible was what guided the project.
We organized QuickSight by folders, as can be seen in the following figure, and each folder represents a business area. This makes it easier to grant access and ensures that all people from the same area have access to exactly the same set of data and reports.
In this model, people from the corporate data area can view and edit any resource from any area, while customer service users can view and edit resources only for customer service.
Expanding the model a bit, the reports created by one area can be shared with others, as can be seen in the following figure, in which the SAC report was shared with Support, creating what we call a reporting portfolio.
In this way, all users who join any of the groups will have exactly the same view as any of their peers, eliminating privileges in accessing data. In addition, the portfolio is enriched every day with reports that are created and maintained by other areas, but which may be of interest to areas other than the one responsible for creating it.
For this to work correctly, a certain rigidity is necessary in relation to the few naming and documentation standards that have been defined. On the other hand, designers have complete freedom to define the characteristics of their reports.
Another highlight in this model is that no report can be shared directly with a specific user; this restriction was defined using custom permissions in QuickSight. Therefore, the reports are always shared only through the folders. After all, we want the data to be accessible equally to everyone in the company.
Technical configurations
QuickSight offers a comprehensive API, and all the activities we carry out on a daily basis take place through these APIs. Among these activities, we highlight the granting of access and the monitoring of various aspects of the tool.
The QuickSight visual interface allows most of the tool’s maintenance activities to be performed and integration with Active Directory or the use of AWS Identity and Access Management (IAM) users is possible, but we understand that it wouldn’t be the ideal choice to grant access. Therefore, we defined an access grant flow for users and groups based on the QuickSight API, as can be seen in the following figure. In this model, the creation and removal of users is done through a JSON file with the following structure:
Whenever a user needs to be added or changed, the file is edited and a pull request is submitted to GitHub. If the request is approved, an action is triggered to send the file to an Amazon Simple Storage Service (Amazon S3) bucket. From this, an AWS Lambda function is triggered that performs two activities: the first is the maintenance of users and groups, and the second is the sending of an invitation through Amazon Simple Email Service (Amazon SES) for users to join QuickSight. In our case, we opted for a personalized invitation model that would emphasize the data democratization initiative that is being conducted.
To monitor the tool, we implemented the architecture shown in the following figure, in which we used AWS CloudTrail to pull out the QuickSight logs and the QuickSight API to extract information from the tool’s resources, such as reports, users, datasets, data sources, and more. All of this data is processed by Glove, our data integration tool, stored in Amazon Redshift, and analyzed in QuickSight itself. This allows us to understand the behavior of our users and concentrate efforts on the most-used resources, in addition to allowing optimal cost control and the use of SPICE.
To update the datasets, we don’t use the QuickSight internal scheduler, due to the large volume of data and the complexity of the DAGs. We prefer updating the datasets within our ETL (extract, transform, and load) and ELT process orchestration flow. For this purpose, we use Hanger, our orchestration tool. This approach allows the datasets to be updated only when the data source is changed and the data quality processes are executed. This model is represented by the following figure.
Conclusion
Choosing a data visualization tool is not a simple task. It involves many considerations, and several aspects must be analyzed in order for the choice to fit the characteristics of the company and to be consistent with the profile of business users.
For Dafiti, QuickSight was a natural choice from the moment we learned about its features. We needed a service that was in the same cloud as our main data sources, extremely fast using SPICE, and solved the maintenance and cost problem of on-premises applications. In terms of functionalities that are necessary for our business, it met our needs perfectly.
Do you want to know more about what we are doing in the data area here at Dafiti? Check out the following videos:
Valdiney Gomes is Data Engineering Coordinator at Dafiti. He worked for many years in software engineering, migrated to data engineering, and currently leads an amazing team responsible for the data platform for Dafiti in Latin America.
Hélio Leal is a Data Engineering Specialist at Dafiti, responsible for maintaining and evolving the entire data platform at Dafiti using AWS solutions.
Flávia Lima is a Data Engineer at Dafiti, responsible for sustaining the data platform and providing the data from many sources to internal customers.
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. It allows you to access diverse data sources, build business intelligence dashboards, build AI and machine learning (ML) models to provide customized customer experiences, and accelerate the curation of new datasets for consumption by adopting a modern data architecture or data mesh architecture.
However, many use cases, like performing change data capture (CDC) from an upstream relational database to an Amazon S3-based data lake, require handling data at a record level. Performing an operation like inserting, updating, and deleting individual records from a dataset requires the processing engine to read all the objects (files), make the changes, and rewrite entire datasets as new files. Furthermore, making the data available in the data lake in near-real time often leads to the data being fragmented over many small files, resulting in poor query performance and compaction maintenance.
In 2022, we announced that you can enforce fine-grained access control policies using AWS Lake Formation and query data stored in any supported file format using table formats such as Apache Iceberg, Apache Hudi, and more using Amazon Athena queries. You get the flexibility to choose the table and file format best suited for your use case and get the benefit of centralized data governance to secure data access when using Athena.
In this post, we show you how to configure Lake Formation using Iceberg table formats. We also explain how to upsert and merge in an S3 data lake using an Iceberg framework and apply Lake Formation access control using Athena.
Iceberg is an open table format for very large analytic datasets. Iceberg manages large collections of files as tables, and it supports modern analytical data lake operations such as record-level insert, update, delete, and time travel queries. The Iceberg specification allows seamless table evolution such as schema and partition evolution, and its design is optimized for usage on Amazon S3. Iceberg also helps guarantee data correctness under concurrent write scenarios.
Solution overview
To explain this setup, we present the following architecture, which integrates Amazon S3 for the data lake (Iceberg table format), Lake Formation for access control, AWS Glue for ETL (extract, transform, and load), and Athena for querying the latest inventory data from the Iceberg tables using standard SQL.
The solution workflow consists of the following steps, including data ingestion (Steps 1–3), data governance (Step 4), and data access (Step 5):
We use AWS Database Migration Service (AWS DMS) or a similar tool to connect to the data source and move incremental data (CDC) to Amazon S3 in CSV format.
An AWS Glue PySpark job reads the incremental data from the S3 input bucket and performs deduplication of the records.
The job then invokes Iceberg’s MERGE statements to merge the data with the target S3 bucket.
We use the AWS Glue Data Catalog as a centralized catalog, which is used by AWS Glue and Athena. An AWS Glue crawler is integrated on top of S3 buckets to automatically detect the schema. Lake Formation allows you to centrally manage permissions and access control for Data Catalog resources in your S3 data lake. You can use fine-grained access control in Lake Formation to restrict access to data in query results.
We use Athena integrated with Lake Formation to query data from the Iceberg table using standard SQL and validate table- and column-level access on Iceberg tables.
For this solution, we assume that the raw data files are already available in Amazon S3, and focus on processing the data using AWS Glue with Iceberg table format. We use sample item data that has the following attributes:
op – This represents the operation on the source record. This shows values I to represent insert operations, U to represent updates, and D to represent deletes. You need to make sure this attribute is included in your CDC incremental data before it gets written to Amazon S3. Make sure you capture this attribute, so that your ETL logic can take appropriate action while merging it.
product_id – This is the primary key column in the source data table.
category – This column represents the category of an item.
product_name – This is the name of the product.
quantity_available – This is the quantity available in the inventory. When we showcase the incremental data for UPSERT or MERGE, we reduce the quantity available for the product to showcase the functionality.
last_update_time – This is the time when the item record was updated at the source data.
We demonstrate implementing the solution with the following steps:
Create an S3 bucket for input and output data.
Create input and output tables using Athena.
Insert the data into the Iceberg table from Athena.
Query the Iceberg table using Athena.
Upload incremental (CDC) data for further processing.
Run the AWS Glue job again to process the incremental files.
Query the Iceberg table again using Athena.
Define Lake Formation policies.
Prerequisites
For Athena queries, we need to configure an Athena workgroup with engine version 3 to support Iceberg table format.
To validate cross-account access through Lake Formation for Iceberg table, in this post we used two accounts (primary and secondary).
Now let’s dive into the implementation steps.
Create an S3 bucket for input and output data
Before we run the AWS Glue job, we have to upload the sample CSV files to the input bucket and process them with AWS Glue PySpark code for the output.
To create an S3 bucket, complete the following steps:
On the Amazon S3 console, choose Buckets in the navigation pane.
Choose Create bucket.
Specify the bucket name asiceberg-blog and leave the remaining fields as default.
S3 bucket names are globally unique. While implementing the solution, you may get an error saying the bucket name already exists. Make sure to provide a unique name and use the same name while implementing the rest of the implementation steps. Formatting the bucket name as<Bucket-Name>-${AWS_ACCOUNT_ID}-${AWS_REGION_CODE}might help you get a unique name.
On the bucket details page, choose Create folder.
Create two subfolders. For this post, we createiceberg-blog/raw-csv-input andiceberg-blog/iceberg-output.
The following screenshot provides a sample of the input dataset.
Create input and output tables using Athena
To create input and output Iceberg tables in the AWS Glue Data Catalog, open the Athena query editor and run the following queries in sequence:
-- Create database for the demo
CREATE DATABASE iceberg_lf_db;
As we explain later in this post, it’s essential to record the data locations when incorporating Lake Formation access controls.
-- Create external table in input CSV files. Replace the S3 path with your bucket name
CREATE EXTERNAL TABLE iceberg_lf_db.csv_input(
op string,
product_id bigint,
category string,
product_name string,
quantity_available bigint,
last_update_time string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://glue-iceberg-demo/raw-csv-input/'
TBLPROPERTIES (
'areColumnsQuoted'='false',
'classification'='csv',
'columnsOrdered'='true',
'compressionType'='none',
'delimiter'=',',
'typeOfData'='file');
-- Create output Iceberg table with partitioning. Replace the S3 bucket name with your bucket name
CREATE TABLE iceberg_lf_db.iceberg_table_lf (
product_id bigint,
category string,
product_name string,
quantity_available bigint,
last_update_time timestamp)
PARTITIONED BY (category, bucket(16,product_id))
LOCATION 's3://glue-iceberg-demo/iceberg_blog/iceberg-output/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet',
'write_target_data_file_size_bytes'='536870912'
);
-- Validate the input data
SELECT * FROM iceberg_lf_db.csv_input;
SELECT * FROM iceberg_lf_db.iceberg_table_lf;
Alternatively, you can use an AWS Glue crawler to create the table definition for the input files.
Insert the data into the Iceberg table from Athena
Optionally, we can insert data into the Iceberg table through Athena using the following code:
insert into iceberg_lf_demo.iceberg_lf_output_athena (product_id,category,product_name,quantity_available,last_update_time) values (200,'Mobile','Mobile brand 1',25,cast('2023-01-19 09:51:40' as timestamp));
insert into iceberg_lf_demo.iceberg_lf_output_athena (product_id,category,product_name,quantity_available,last_update_time) values (201,'Laptop','Laptop brand 1',20,cast('2023-01-19 09:51:40' as timestamp));
insert into iceberg_lf_demo.iceberg_lf_output_athena (product_id,category,product_name,quantity_available,last_update_time) values (202,'Tablet','Kindle',30,cast('2023-01-19 09:51:41' as timestamp));
insert into iceberg_lf_demo.iceberg_lf_output_athena (product_id,category,product_name,quantity_available,last_update_time) values (203,'Speaker','Alexa',10,cast('2023-01-19 09:51:42' as timestamp));
insert into iceberg_lf_demo.iceberg_lf_output_athena (product_id,category,product_name,quantity_available,last_update_time) values (204,'Speaker','Alexa',50,cast('2023-01-19 09:51:43' as timestamp));
For this post, we load the data using an AWS Glue job. Complete the following steps to create the job:
On the AWS Glue console, choose Jobs in the navigation pane.
Choose Create job.
Select Visual with ablank canvas.
Choose Create.
Choose Editscript.
Replace the script with the following script:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import *
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql.window import Window
from pyspark.sql.functions import rank, max
from pyspark.conf import SparkConf
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
conf = SparkConf()
## spark.sql.catalog.job_catalog.warehouse can be passed as an ## runtime argument with value as the S3 path
## Please make sure to pass runtime argument –
## iceberg_job_catalog_warehouse with value as the S3 path
conf.set("spark.sql.catalog.job_catalog.warehouse", args['iceberg_job_catalog_warehouse'])
conf.set("spark.sql.catalog.job_catalog", "org.apache.iceberg.spark.SparkCatalog")
conf.set("spark.sql.catalog.job_catalog.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog")
conf.set("spark.sql.catalog.job_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO")
conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
conf.set("spark.sql.iceberg.handle-timestamp-without-timezone","true")
sc = SparkContext(conf=conf)
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
## Read Input Table
## glueContext.create_data_frame.from_catalog can be more
## performant and can be replaced in place of
## create_dynamic_frame.from_catalog.
IncrementalInputDyF = glueContext.create_dynamic_frame.from_catalog(database = "iceberg_lf_db", table_name = "csv_input", transformation_ctx = "IncrementalInputDyF")
IncrementalInputDF = IncrementalInputDyF.toDF()
if not IncrementalInputDF.rdd.isEmpty():
## Apply De-duplication logic on input data, to pickup latest record based on timestamp and operation
IDWindowDF = Window.partitionBy(IncrementalInputDF.product_id).orderBy(IncrementalInputDF.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize)
# Add new columns to capture OP value and what is the latest timestamp
inputDFWithTS= IncrementalInputDF.withColumn("max_op_date",max(IncrementalInputDF.last_update_time).over(IDWindowDF))
# Filter out new records that are inserted, then select latest record from existing records and merge both to get deduplicated output
NewInsertsDF = inputDFWithTS.filter("last_update_time=max_op_date").filter("op='I'")
UpdateDeleteDf = inputDFWithTS.filter("last_update_time=max_op_date").filter("op IN ('U','D')")
finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf)
# Register the deduplicated input as temporary table to use in Iceberg Spark SQL statements
finalInputDF.createOrReplaceTempView("incremental_input_data")
finalInputDF.show()
## Perform merge operation on incremental input data with MERGE INTO. This section of the code uses Spark SQL to showcase the expressive SQL approach of Iceberg to perform a Merge operation
IcebergMergeOutputDF = spark.sql("""
MERGE INTO job_catalog.iceberg_lf_db.iceberg_table_lf t
USING (SELECT op, product_id, category, product_name, quantity_available, to_timestamp(last_update_time) as last_update_time FROM incremental_input_data) s
ON t.product_id = s.product_id
WHEN MATCHED AND s.op = 'D' THEN DELETE
WHEN MATCHED THEN UPDATE SET t.quantity_available = s.quantity_available, t.last_update_time = s.last_update_time
WHEN NOT MATCHED THEN INSERT (product_id, category, product_name, quantity_available, last_update_time) VALUES (s.product_id, s.category, s.product_name, s.quantity_available, s.last_update_time)
""")
job.commit()
On the Job details tab, specify the job name (iceberg-lf).
For IAM Role, assign an AWS Identity and Access Management (IAM) role that has the required permissions to run an AWS Glue job and read and write to the S3 bucket.
For Glue version, choose Glue 4.0 (Glue 3.0 is also supported).
For Language, choose Python 3.
Make sure Job bookmark has the default value of Enable.
For Job parameters, add the following:
Add the key--datalake-formatswith the valueiceberg.
Add the key--iceberg_job_catalog_warehouse with the value as your S3 path (s3://<bucket-name>/<iceberg-warehouse-path>).
Choose Save and then Run, which should write the input data to the Iceberg table with a MERGE statement.
Query the Iceberg table using Athena
After you have successfully run the AWS Glue job, you can validate the output in Athena with the following SQL query:
SELECT * FROM iceberg_lf_db.iceberg_table_lf limit 10;
The output of the query should match the input, with one difference: the Iceberg output table doesn’t have theopcolumn.
Upload incremental (CDC) data for further processing
After we process the initial full load file, let’s upload an incremental file.
This file includes updated records on two items.
Run the AWS Glue job again to process incremental files
Because the AWS Glue job has bookmarks enabled, the job picks up the new incremental file and performs a MERGE operation on the Iceberg table.
To run the job again, complete the following steps:
On the AWS Glue console, choose Jobs in the navigation pane.
Query the Iceberg table using Athena after incremental data processing
When the incremental data processing is complete, you can run the same SELECT statement again and validate that the quantity value is updated for items 200 and 201.
The following screenshot shows the output.
Define Lake Formation policies
For data governance, we use Lake Formation. Lake Formation is a fully managed service that simplifies data lake setup, supports centralized security management, and provides transactional access on top of your data lake. Moreover, it enables data sharing across accounts and organizations. There are two ways to share data resources in Lake Formation: named resource access control (NRAC) and tag-based access control (TBAC). NRAC uses AWS Resource Access Manager (AWS RAM) to share data resources across accounts using Lake Formation V3. Those are consumed via resource links that are based on created resource shares. Lake Formation tag-based access control (LF-TBAC) is another approach to share data resources in Lake Formation, which defines permissions based on attributes. These attributes are called LF-tags.
In this example, we create databases in the primary account. Our NRAC database is shared with a data domain via AWS RAM. Access to data tables that we register in this database will be handled through NRAC.
Configure access controls in the primary account
In the primary account, complete the following steps to set up access controls using Lake Formation:
On the Lake Formation console, choose Data lake locations in the navigation pane.
Choose Register location.
Update the Iceberg Amazon S3 location path shown in the following screenshot.
Grant access to the database to the secondary account
To grant database access to the external (secondary) account, complete the following steps:
On the Lake Formation console, navigate to your database.
On the Actions menu, choose Grant.
Choose External accounts and enter the secondary account number.
Select Named data catalog resources.
Verify the database name.
The first grant should be at database level, and the second grant is at table level.
For Database permissions, specify your permissions (for this post, we select Describe).
Choose Grant.
Now you need to grant permissions at the table level.
Select External accounts and enter the secondary account number.
Select Named data catalog resources.
Verify the table name.
For Table permissions, specify the permissions you want to grant. For this post, we select Select and Describe.
Choose Grant.
If you see the following error, you must revokeIAMAllowedPrincipalsfrom the data lake permissions.
To do so, select IAMAllowedPrincipals and choose Revoke.
Choose Revoke again to confirm.
After you revoke the data permissions, the permissions should appear as shown in the following screenshot.
Add AWS Glue IAM role permissions
Because the IAM principal role was revoked, the AWS Glue IAM role that was used in the AWS Glue job needs to be added exclusively to grant access as shown in the following screenshot.
You need to repeat these steps for the AWS Glue IAM role at table level.
Verify the permissions granted to the AWS Glue IAM role on the Lake Formation console.
Grant access to the Iceberg table to the external account
In the secondary account, complete the following steps to grant access to the Iceberg table to external account.
On the AWS RAM console, choose Resource shares in the navigation pane.
Choose the resource shares invitation sent from the primary account.
Choose Accept resource share.
The resource status should now be active.
Next, you need to create a resource link for the shared Iceberg table and access through Athena.
On the Lake Formation console, choose Tables in the navigation pane.
Select the Iceberg table (shared from the primary account).
On the Actions menu, choose Create resource link.
For Resource link name, enter a name (for this post,iceberg_table_lf_demo).
For Database, choose your database and verify the shared table and database are automatically populated.
Choose Create.
Select your table and on the Actions menu, choose View data.
You’re redirected to the Athena console, where you can query the data.
Grant column-based access in the primary account
For column-level restricted access, you need to grant access at the column level on the Iceberg table. Complete the following steps:
On the Lake Formation console, navigate to your database.
On the Actions menu, choose Grant.
Select External accounts and enter the secondary account number.
Select Named data catalog resources.
Verify the table name.
For Table permissions, choose the permissions you want to grant. For this post, we select Select.
Under Data permissions, choose Column-based access.
Select Include columns and choose your permission filters (for this post, Category and Quantity_available).
Choose Grant.
Data with restricted columns can now be queried through the Athena console.
Clean up
To avoid incurring ongoing costs, complete the following steps to clean up your resources:
In your secondary account, log in to the Lake Formation console.
Drop the resource share table.
In your primary account, log in to the Lake Formation console.
Revoke the access you configured.
Drop the AWS Glue tables and database.
Delete the AWS Glue job.
Delete the S3 buckets and any other resources that you created as part of the prerequisites for this post.
Conclusion
This post explains how you can use the Iceberg framework with AWS Glue and Lake Formation to define cross-account access controls and query data using Athena. It provides an overview of Iceberg and its features and integration approaches, and explains how you can ingest data, grant cross-account access, and query data through a step-by-step guide.
We hope this gives you a great starting point for using Iceberg to build your data lake platform along with AWS analytics services to implement your solution.
About the Authors
Vikram Sahadevan is a Senior Resident Architect on the AWS Data Lab team. He enjoys efforts that focus around providing prescriptive architectural guidance, sharing best practices, and removing technical roadblocks with joint engineering engagements between customers and AWS technical resources that accelerate data, analytics, artificial intelligence, and machine learning initiatives.
Suvendu Kumar Patra possesses 18 years of experience in infrastructure, database design, and data engineering, and he currently holds the position of Senior Resident Architect at Amazon Web Services. He is a member of the specialized focus group, AWS Data Lab, and his primary duties entail working with executive leadership teams of strategic AWS customers to develop their roadmaps for data, analytics, and AI/ML. Suvendu collaborates closely with customers to implement data engineering, data hub, data lake, data governance, and EDW solutions, as well as enterprise data strategy and data management.
Many of our customers use Amazon Cognito user pools to add authentication, authorization, and user management capabilities to their web and mobile applications. You can enable the built-in advanced security in Amazon Cognito to detect and block the use of credentials that have been compromised elsewhere, and to detect unusual sign-in activity and then prompt users for additional verification or block sign-ins. Additionally, you can associate an AWS WAF web access control list (web ACL) with your user pool to allow or block requests to Amazon Cognito user pools, based on security rules.
In this post, we’ll show how you can use AWS WAF with Amazon Cognito user pools and provide a sample set of rate-based rules and advanced AWS WAF rule groups. We’ll also show you how to test and tune the rules to help protect your user pools from common threats.
Rate-based rules for Amazon Cognito user pool endpoints
The following are endpoints exposed publicly by an Amazon Cognito user pool that you can protect with AWS WAF:
Public API operations — These generate a request to Cognito API actions that are either unauthenticated or authenticated with a session string or access token, but not with AWS credentials.
A good way to protect these endpoints is to deploy rate-based AWS WAF rules. These rules will detect and block requests with high rates that could indicate an attempt to exceed your Amazon Cognito API request rate quotas and that could subsequently impact requests from legitimate users.
When you apply rate limits, it helps to group Amazon Cognito API actions into four action categories. You can set specific rate limits per action category giving you traffic visibility for each category.
User Creation — This category includes operations that create new users in Cognito. Setting a rate limit for this category provides visibility for traffic of these operations and threats such as fake users being created in Cognito, which drives up your Monthly Active User (MAU) costs for Cognito.
Sign-in — This category includes operations to initiate a sign-in operation. Setting a rate limit for this category can provide visibility into the abuse of these operations. This could indicate high frequency, automated attempts to guess user credentials, sometimes referred to as credential stuffing.
Account Recovery — This category includes operations to recover accounts, including “forgot password” flows. Setting a rate limit for this category can provide visibility into the abuse of these operations, malicious activity can include: sending fake reset attempts, which might result in emails and SMS messages being sent to users.
Default — This is a catch-all rate limit that applies to an operation that is not in one of the prior categories. Setting a default rate limit can provide visibility and mitigation from request flooding attacks.
Table 1 below shows selected Hosted UI endpoint paths (the equivalent of individual API actions) and the recommended rate-based rule limit category for each.
Additionally, the rate-based rules we provide in this post include the following:
Two IP sets that represent allow lists for IPv4 and IPv6. You can add IPs that represent your trusted source IP addresses to these IP sets so that other AWS WAF rules don’t apply to requests that originate from these IP addresses.
Two IP sets that represent deny lists for IPv4 and IPv6. Add IPs to these IP sets that you want to block in all cases, regardless of the result of other rules.
An AWS managed IP reputation rule group: The AWS managed IP reputation list rule group contains rules that are based on Amazon internal threat intelligence, to identify IP addresses typically associated with bots or other threats. You can limit requests that match rules in this rule group to a specific rate limit.
Deploy rate-based rules
You can deploy the rate-based rules described in the previous section by using the AWS CloudFormation template that we provide here.
To deploy rate-based rules using the template
(Optional but recommended) If you want to enable AWS WAF logging and resources to analyze request rates, create an Amazon Simple Storage Service (Amazon S3) bucket in the same AWS Region as your Amazon Cognito user pool, with a bucket name starting with the prefix aws-waf-logs-. If you previously created an S3 bucket for AWS WAF logs, you can choose to reuse it, or you can create a new bucket to store AWS WAF logs for Amazon Cognito.
Choose the following Launch Stack button to launch a CloudFormation stack in your account.
Note: The stack will launch in the N. Virginia (us-east-1) Region. To deploy this solution into other AWS Regions, download the solution’s CloudFormation template and deploy it to the selected Region.
This template creates the following resources in your AWS account:
A rule group for the rate-based rules, according to the limits shown in Tables 1 and 2.
Four IP sets for an allow list and deny list for IPv4 and IPv6 addresses.
A web ACL that includes the rule group that is created, IP set based rules, and the AWS managed IP reputation rule group.
(Optional) The template enables AWS WAF logging for the web ACL to an S3 bucket that you specify.
(Optional) The template creates resources to help you analyze AWS WAF logs in S3 to calculate peak request rates that you can use to set rate limits for the rate-based rules.
Set the template parameters as needed. The following table shows the default values for the parameters. We recommend that you deploy the template with the default values and with TestMode set to Yes so that all rules are set to Count. This allows all requests but emits Amazon CloudWatch metrics and AWS WAF log events for each rule that matches. You can then follow the guidance in the next section to analyze the logs and tune the rate limits to match the traffic patterns to your user pool. When you are satisfied with the unique rate limits for each parameter, you can update the stack and set TestMode to No to start blocking requests that exceed the rate limits.
The rate limits for AWS WAF rate-based rules are configured as the number of requests per 5-minute period per unique source IP. The value of the rate limit can be between 100 and 2,000,000,000 (2 billion).
Table 3: Default values for template parameters
Parameter name
Description
Default value
Allowed values
Request rate limits by action category
UserCreationRateLimit
Rate limit applied to User Creation actions
2000
100–2,000,000,000
SignInRateLimit
Rate limit applied to Sign-in actions
4000
100–2,000,000,000
AccountRecoveryRateLimit
Rate limit applied to Account Recovery actions
1000
100–2,000,000,000
IPReputationRateLimit
Rate limit applied to requests that match the AWS Managed IP reputation list
1000
100–2,000,000,000
DefaultRateLimit
Default rate limit applied to actions that are not in any of the prior categories
6000
100–2,000,000,000
Test mode
TestMode
Set to Yes to test rules by overriding rule actions to Count. Set to No to apply the default actions for rules after you’ve tested the impact of these rules.
Yes
Yes or No
AWS WAF logging and rate analysis
EnableWAFLogsAndRateAnalysis
Set to Yes to enable logging for the AWS WAF web ACL to an S3 bucket and create resources for request rate analysis. Set to No to disable AWS WAF logging and skip creating resources for rate analysis. If No, the rest of the parameter values in this section are ignored. If Yes, choose values for the rest of the parameters in this section.
Yes
Yes or No
WAFLogsS3Bucket
The name of an existing S3 bucket where AWS WAF logs are delivered. The bucket name must start with aws-waf-logs- and can end with any suffix. Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
None
Name of an existing S3 bucket that starts with the prefix aws-waf-logs-
DatabaseName
The name of the AWS Glue database to create, which will contain the request rate analysis tables created by this template. (Important: The name cannot contain hyphens.) Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
rate_analysis
WorkgroupName
The name of the Amazon Athena workgroup to create for rate analysis. Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
rate_analysis
WAFLogsTableName
The name of the AWS Glue table for AWS WAF logs. Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
waf_logs
WAFLogsProjectionStartDate
The earliest date to analyze AWS WAF logs, in the format YYYY/MM/DD (example: 2023/02/28). Only used if the parameter EnableWAFLogsAndRateAnalysis is set to Yes.
None
Set this to the current date, in the format YYYY/MM/DD
Wait for the CloudFormation template to be created successfully.
Go to the AWS WAF console and choose the web ACL created by the template. It will have a name ending with CognitoWebACL.
Choose the Associated AWS resources tab, and then choose Add AWS resource.
For Resource type, choose Amazon Cognito user pool, and then select the Amazon Cognito user pools that you want to protect with this web ACL.
Choose Add.
Now that your user pool is being protected by the rate-based rules in the web ACL you created, you can proceed to tune the rate-based rule limits by analyzing AWS WAF logs.
Tune AWS WAF rate-based rule limits
As described in the previous section, the rate-based rules give you the ability to set separate rate limit values for each category of Amazon Cognito API actions.
Although the CloudFormation template has default starting values for these rate limits, it is important that you tune these values to match the traffic patterns for your user pool. To begin the tuning process, deploy the template with default values for all parameters, including Yes for TestMode. This overrides all rule actions to Count, allowing all requests but emitting CloudWatch metrics and AWS WAF log events for each rule that matches.
After you collect AWS WAF logs for a period of time (this period can vary depending on your traffic, from a couple of hours to a couple of days), you can analyze them, as shown in the next section, to get peak request rates to tune the rate limits to match observed traffic patterns for your user pool.
Query AWS WAF logs to calculate peak request rates by request type
You can calculate peak request rates by analyzing information that is present in AWS WAF logs. One way to analyze these is to send AWS WAF logs to S3 and to analyze the logs by using SQL queries in Amazon Athena. If you deploy the template in this post with default values, it creates the resources you need to analyze AWS WAF logs in S3 to calculate peak requests rates by request type.
If you are instead ingesting AWS WAF logs into your security information and event management (SIEM) system or a different analytics environment, you can create equivalent queries by using the query language for your SIEM or analytics environment to get similar results.
To access and edit the queries built by the CloudFormation template for use
Open the Athena console and switch to the Athena workgroup that was created by the template (the default name is rate_analysis).
On the Saved queries tab, choose the query named Peak request rate per 5-minute period by source IP and request category. The following SQL query will be loaded into the edit panel.
-- Gets the top 5 source IPs sending the most requests in a 5-minute period per request category
‐‐ NOTE: change the start and end timestamps to match the duration of interest
SELECT request_category, from_unixtime(time_bin*60*5) AS date_time, client_ip, request_count FROM (
SELECT *, row_number() OVER (PARTITION BY request_category ORDER BY request_count DESC, time_bin DESC) AS row_num FROM (
SELECT
CASE
WHEN ip_reputation_labels.name IN (
'awswaf:managed:aws:amazon-ip-list:AWSManagedIPReputationList',
'awswaf:managed:aws:amazon-ip-list:AWSManagedReconnaissanceList',
'awswaf:managed:aws:amazon-ip-list:AWSManagedIPDDoSList'
) THEN 'IPReputation'
WHEN target.value IN (
'AWSCognitoIdentityProviderService.InitiateAuth',
'AWSCognitoIdentityProviderService.RespondToAuthChallenge'
) THEN 'SignIn'
WHEN target.value IN (
'AWSCognitoIdentityProviderService.ResendConfirmationCode',
'AWSCognitoIdentityProviderService.SignUp',
'AWSCognitoIdentityProviderService.ConfirmSignUp'
) THEN 'UserCreation'
WHEN target.value IN (
'AWSCognitoIdentityProviderService.ForgotPassword',
'AWSCognitoIdentityProviderService.ConfirmForgotPassword'
) THEN 'AccountRecovery'
WHEN httprequest.uri IN (
'/login',
'/oauth2/authorize'
) THEN 'SignIn'
WHEN httprequest.uri IN (
'/signup',
'/confirmUser',
'/resendcode'
) THEN 'UserCreation'
WHEN httprequest.uri IN (
'/forgotPassword',
'/confirmForgotPassword'
) THEN 'AccountRecovery'
ELSE 'Default'
END AS request_category,
httprequest.clientip AS client_ip,
FLOOR("timestamp"/(1000*60*5)) AS time_bin,
COUNT(*) AS request_count
FROM waf_logs
LEFT OUTER JOIN UNNEST(FILTER(httprequest.headers, h -> h.name = 'x-amz-target')) AS t(target) ON TRUE
LEFT OUTER JOIN UNNEST(FILTER(labels, l -> l.name like 'awswaf:managed:aws:amazon-ip-list:%')) AS t(ip_reputation_labels) ON TRUE
WHERE
from_unixtime("timestamp"/1000) BETWEEN TIMESTAMP '2022-01-01 00:00:00' AND TIMESTAMP '2023-01-01 00:00:00'
GROUP BY 1, 2, 3
ORDER BY 1, 4 DESC
)
) WHERE row_num <= 5 ORDER BY request_category ASC, row_num ASC
Scroll down to Line 48 in the Query Editor and edit the timestamps to match the start and end time of the time window of interest.
Run the query to calculate the top 5 peak request rates per 5-minute period by source IP and by action category.
The results show the action category, source IP, time, and count of requests. You can use the request count to tune the rate limits for each action category.
The lowest rate limit you can set for AWS WAF rate-based rules is 100 requests per 5-minute period. If your query results show that the peak request count is less than 100, set the rate limit as 100 or higher.
After you have tuned the rate limits, you can apply the changes to your web ACL by updating the CloudFormation stack.
To update the CloudFormation stack
On the CloudFormation console, choose the stack you created earlier.
Choose Update. For Prepare template, choose Use current template, and then choose Next.
Update the values of the parameters with rate limits to match the tuned values from your analysis.
You can choose to enable blocking of requests by setting TestMode to No. This will set the action to Block for the rate-based rules in the web ACL and start blocking traffic that exceeds the rate limits you have chosen.
Choose Next and then Next again to update the stack.
Now the rate-based rules are updated with your tuned limits, and requests will be blocked if you set TestMode to No.
Protect endpoints with user interaction
Now that we’ve covered the bases with rate-based rules, we’ll show you some more advanced AWS WAF rules that further help protect your user pool. We’ll explore two sample scenarios in detail, and provide AWS WAF rules for each. You can use the rules provided as a guideline to build others that can help with similar use cases.
Rules to verify human activity
The first scenario is protecting endpoints where users have interaction with the page. This will be a browser-based interaction, and a human is expected to be behind the keyboard. This scenario applies to the Hosted UI endpoints such as /login, /signup, and /forgotPassword, where a CAPTCHA can be rendered on the user’s browser for the user to solve. Let’s take the login (sign-in) endpoint as an example, and imagine you want to make sure that only actual human users are attempting to sign in and you want to block bots that might try to guess passwords.
To illustrate how to protect this endpoint with AWS WAF, we’re sharing a sample rule, shown in Figure 1. In this rule, you can take input from prior rules like the Amazon IP reputation list or the Anonymous IP list (which are configured to Count requests and add labels) and combine that with a CAPTCHA action. The logic of the rule says that if the request matches the reputation rules (and has received the corresponding labels) and is going to the /login endpoint, then the AWS WAF action should be to respond with a CAPTCHA challenge. This will present a challenge that increases the confidence that a human is performing the action, and it also adds a custom label so you can efficiently identify and have metrics on how many requests were matched by this rule. The rule is provided in the CloudFormation template and is in JSON format, because it has advanced logic that cannot be displayed by the console. Learn more about labels and CAPTCHA actions in the AWS WAF documentation.
Figure 1: Login sample rule flow
Note that the rate-based rules you created in the previous section are evaluated before the advanced rules. The rate-based rules will block requests to the /login endpoint that exceed the rate limit you have configured, while this advanced rule will match requests that are below the rate limit but match the other conditions in the rule.
Rules for specific activity
The second scenario explores activity on specific application clients within the user pool. You can spot this activity by monitoring the logs provided by AWS WAF, or other traffic logs like Application Load Balancer (ALB) logs. The application client information is provided in the call to the service.
In the Amazon Cognito user pool in this scenario, we have different application clients and they’re constrained by geography. For example, for one of the application clients, requests are expected to come from the United States at or below a certain rate. We can create a rule that combines the rate and geographical criteria to block requests that don’t meet the conditions defined.
The flow of this rule is shown in Figure 2. The logic of the rule will evaluate the application client information provided in the request and the geographic information identified by the service, and apply the selected rate limit. If blocked, the rule will provide a custom response code by using HTTP code 429 Too Many Requests, which can help the sender understand the reason for the block. For requests that you make with the Amazon Cognito API, you could also customize the response body of a request that receives a Block response. Adding a custom response helps provide the sender context and adjust the rate or information that is sent.
Figure 2: AppClientId sample rule flow
AWS WAF can detect geo location with Region accuracy and add specific labels for the location. These can then be used in other rule evaluations. This rule is also provided as a sample in the CloudFormation template.
Advanced protections
To build on the rules we’ve shared so far, you can consider using some of the other intelligent threat mitigation rules that are available as managed rules—namely, bot control for common or targeted bots. These rules offer advanced capabilities to detect bots in sensitive endpoints where automation or non-browser user agents are not expected or allowed. If you receive machine traffic to the endpoint, these rules will result in false positives that would need to be tuned. For more information, see Options for intelligent threat mitigation.
The sample rule flow in Figure 3 shows an example for our Hosted UI, which builds on the first rule we built for specific activity and adds signals coming from the Bot Control common bots managed rule, in this case the non-browser-user-agent label.
Figure 3: Login sample rule with advanced protections
Adding the bot detection label will also add accuracy to the evaluation, because AWS WAF will consider multiple different sources of information when analyzing the request. This can also block attacks that come from a small set of IPs or easily recognizable bots.
We’ve shared this rule in the CloudFormation template sample. The rule requires you to add AWS WAF Bot Control (ABC) before the custom rule evaluation. ABC has additional costs associated with it and should only be used for specific use cases. For more information on ABC and how to enable it, see this blog post.
After adding these protections, we have a complete set of rules for our Hosted UI–specific needs; consider that your traffic and needs might be different. Figure 4 shows you what the rule priority looks like. All rules except the last are included in the provided CloudFormation template. Managed rule evaluations need to have higher priority and be in Count mode; this way, a matching request can get labels that can be evaluated further down the priority list by using the custom rules that were created. For more information, see How labeling works.
Figure 4: Summary of the rules discussed in this post
Conclusion
In this post, we examined the different protections provided by the integration between AWS WAF and Amazon Cognito. This integration makes it simpler for you to view and monitor the activity in the different Amazon Cognito endpoints and APIs, while also adding rate-based rules and IP reputation evaluations. For more specific use cases and advanced protections, we provided sample custom rules that use labels, as well as an advanced rule that uses bot control for common bots. You can use these advanced rules as examples to create similar rules that apply to your use cases.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the re:Post with tag AWS WAF or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In this blog post, we will explore the process of creating a Continuous Integration/Continuous Deployment (CI/CD) pipeline for a .NET AWS Lambda function using the CDK Pipelines. We will cover all the necessary steps to automate the deployment of the .NET Lambda function, including setting up the development environment, creating the pipeline with AWS CDK, configuring the pipeline stages, and publishing the test reports. Additionally, we will show how to promote the deployment from a lower environment to a higher environment with manual approval.
Background
AWS CDK makes it easy to deploy a stack that provisions your infrastructure to AWS from your workstation by simply running cdk deploy. This is useful when you are doing initial development and testing. However, in most real-world scenarios, there are multiple environments, such as development, testing, staging, and production. It may not be the best approach to deploy your CDK application in all these environments using cdk deploy. Deployment to these environments should happen through more reliable, automated pipelines. CDK Pipelines makes it easy to set up a continuous deployment pipeline for your CDK applications, powered by AWS CodePipeline.
The AWS CDK Developer Guide’s Continuous integration and delivery (CI/CD) using CDK Pipelines page shows you how you can use CDK Pipelines to deploy a Node.js based Lambda function. However, .NET based Lambda functions are different from Node.js or Python based Lambda functions in that .NET code first needs to be compiled to create a deployment package. As a result, we decided to write this blog as a step-by-step guide to assist our .NET customers with deploying their Lambda functions utilizing CDK Pipelines.
In this post, we dive deeper into creating a real-world pipeline that runs build and unit tests, and deploys a .NET Lambda function to one or multiple environments.
Architecture
CDK Pipelines is a construct library that allows you to provision a CodePipeline pipeline. The pipeline created by CDK pipelines is self-mutating. This means, you need to run cdk deploy one time to get the pipeline started. After that, the pipeline automatically updates itself if you add new application stages or stacks in the source code.
The following diagram captures the architecture of the CI/CD pipeline created with CDK Pipelines. Let’s explore this architecture at a high level before diving deeper into the details.
Figure 1: Reference architecture diagram
The solution creates a CodePipeline with a AWS CodeCommit repo as the source (CodePipeline Source Stage). When code is checked into CodeCommit, the pipeline is automatically triggered and retrieves the code from the CodeCommit repository branch to proceed to the Build stage.
Build stage compiles the CDK application code and generates the cloud assembly.
Update Pipeline stage updates the pipeline (if necessary).
Publish Assets stage uploads the CDK assets to Amazon S3.
After Publish Assets is complete, the pipeline deploys the Lambda function to both the development and production environments. For added control, the architecture includes a manual approval step for releases that target the production environment.
Before you use AWS CDK to deploy CDK Pipelines, you must bootstrap the AWS environments where you want to deploy the Lambda function. An environment is the target AWS account and Region into which the stack is intended to be deployed.
In this post, you deploy the Lambda function into a development environment and, optionally, a production environment. This requires bootstrapping both environments. However, deployment to a production environment is optional; you can skip bootstrapping that environment for the time being, as we will cover that later.
This is one-time activity per environment for each environment to which you want to deploy CDK applications. To bootstrap the development environment, run the below command, substituting in the AWS account ID for your dev account, the region you will use for your dev environment, and the locally-configured AWS CLI profile you wish to use for that account. See the documentation for additional details.
‐‐profile specifies the AWS CLI credential profile that will be used to bootstrap the environment. If not specified, default profile will be used. The profile should have sufficient permissions to provision the resources for the AWS CDK during bootstrap process.
‐‐cloudformation-execution-policies specifies the ARNs of managed policies that should be attached to the deployment role assumed by AWS CloudFormation during deployment of your stacks.
For this post, you will use CodeCommit to store your source code. First, create a git repository named dotnet-lambda-cdk-pipeline in CodeCommit by following these steps in the CodeCommit documentation.
After you have created the repository, generate git credentials to access the repository from your local machine if you don’t already have them. Follow the steps below to generate git credentials.
Sign in to the AWS Management Console and open the IAM console.
Next. open the user details page, choose the Security Credentials tab, and in HTTPS Git credentials for AWS CodeCommit, choose Generate.
Download credentials to download this information as a .CSV file.
Clone the recently created repository to your workstation, then cd into dotnet-lambda-cdk-pipeline directory.
git clone <CODECOMMIT-CLONE-URL>
cd dotnet-lambda-cdk-pipeline
Alternatively, you can use git-remote-codecommit to clone the repository with git clone codecommit::<REGION>://<PROFILE>@<REPOSITORY-NAME> command, replacing the placeholders with their original values. Using git-remote-codecommit does not require you to create additional IAM users to manage git credentials. To learn more, refer AWS CodeCommit with git-remote-codecommit documentation page.
Initialize the CDK project
From the command prompt, inside the dotnet-lambda-cdk-pipeline directory, initialize a AWS CDK project by running the following command.
cdk init app --language csharp
Open the generated C# solution in Visual Studio, right-click the DotnetLambdaCdkPipeline project and select Properties. Set the Target framework to .NET 6.
Create a CDK stack to provision the CodePipeline
Your CDK Pipelines application includes at least two stacks: one that represents the pipeline itself, and one or more stacks that represent the application(s) deployed via the pipeline. In this step, you create the first stack that deploys a CodePipeline pipeline in your AWS account.
From Visual Studio, open the solution by opening the .sln solution file (in the src/ folder). Once the solution has loaded, open the DotnetLambdaCdkPipelineStack.cs file, and replace its contents with the following code. Note that the filename, namespace and class name all assume you named your Git repository as shown earlier.
Note: be sure to replace “<CODECOMMIT-REPOSITORY-NAME>” in the code below with the name of your CodeCommit repository (in this blog post, we have used dotnet-lambda-cdk-pipeline).
using Amazon.CDK;
using Amazon.CDK.AWS.CodeBuild;
using Amazon.CDK.AWS.CodeCommit;
using Amazon.CDK.AWS.IAM;
using Amazon.CDK.Pipelines;
using Constructs;
using System.Collections.Generic;
namespace DotnetLambdaCdkPipeline
{
public class DotnetLambdaCdkPipelineStack : Stack
{
internal DotnetLambdaCdkPipelineStack(Construct scope, string id, IStackProps props = null) : base(scope, id, props)
{
var repository = Repository.FromRepositoryName(this, "repository", "<CODECOMMIT-REPOSITORY-NAME>");
// This construct creates a pipeline with 3 stages: Source, Build, and UpdatePipeline
var pipeline = new CodePipeline(this, "pipeline", new CodePipelineProps
{
PipelineName = "LambdaPipeline",
SelfMutation = true,
// Synth represents a build step that produces the CDK Cloud Assembly.
// The primary output of this step needs to be the cdk.out directory generated by the cdk synth command.
Synth = new CodeBuildStep("Synth", new CodeBuildStepProps
{
// The files downloaded from the repository will be placed in the working directory when the script is executed
Input = CodePipelineSource.CodeCommit(repository, "master"),
// Commands to run to generate CDK Cloud Assembly
Commands = new string[] { "npm install -g aws-cdk", "cdk synth" },
// Build environment configuration
BuildEnvironment = new BuildEnvironment
{
BuildImage = LinuxBuildImage.AMAZON_LINUX_2_4,
ComputeType = ComputeType.MEDIUM,
// Specify true to get a privileged container inside the build environment image
Privileged = true
}
})
});
}
}
}
In the preceding code, you use CodeBuildStep instead of ShellStep, since ShellStep doesn’t provide a property to specify BuildEnvironment. We need to specify the build environment in order to set privileged mode, which allows access to the Docker daemon in order to build container images in the build environment. This is necessary to use the CDK’s bundling feature, which is explained in later in this blog post.
Open the file src/DotnetLambdaCdkPipeline/Program.cs, and edit its contents to reflect the below. Be sure to replace the placeholders with your AWS account ID and region for your dev environment.
using Amazon.CDK;
namespace DotnetLambdaCdkPipeline
{
sealed class Program
{
public static void Main(string[] args)
{
var app = new App();
new DotnetLambdaCdkPipelineStack(app, "DotnetLambdaCdkPipelineStack", new StackProps
{
Env = new Amazon.CDK.Environment
{
Account = "<DEV-ACCOUNT-ID>",
Region = "<DEV-REGION>"
}
});
app.Synth();
}
}
}
Note: Instead of committing the account ID and region to source control, you can set environment variables on the CodeBuild agent and use them; see Environments in the AWS CDK documentation for more information. Because the CodeBuild agent is also configured in your CDK code, you can use the BuildEnvironmentVariableType property to store environment variables in AWS Systems Manager Parameter Store or AWS Secrets Manager.
After you make the code changes, build the solution to ensure there are no build issues. Next, commit and push all the changes you just made. Run the following commands (or alternatively use Visual Studio’s built-in Git functionality to commit and push your changes):
Then navigate to the root directory of repository where your cdk.json file is present, and run the cdk deploy command to deploy the initial version of CodePipeline. Note that the deployment can take several minutes.
The pipeline created by CDK Pipelines is self-mutating. This means you only need to run cdk deploy one time to get the pipeline started. After that, the pipeline automatically updates itself if you add new CDK applications or stages in the source code.
After the deployment has finished, a CodePipeline is created and automatically runs. The pipeline includes three stages as shown below.
Source – It fetches the source of your AWS CDK app from your CodeCommit repository and triggers the pipeline every time you push new commits to it.
Build – This stage compiles your code (if necessary) and performs a cdk synth. The output of that step is a cloud assembly.
UpdatePipeline – This stage runs cdk deploy command on the cloud assembly generated in previous stage. It modifies the pipeline if necessary. For example, if you update your code to add a new deployment stage to the pipeline to your application, the pipeline is automatically updated to reflect the changes you made.
Figure 2: Initial CDK pipeline stages
Define a CodePipeline stage to deploy .NET Lambda function
In this step, you create a stack containing a simple Lambda function and place that stack in a stage. Then you add the stage to the pipeline so it can be deployed.
To create a Lambda project, do the following:
In Visual Studio, right-click on the solution, choose Add, then choose New Project.
In the New Project dialog box, choose the AWS Lambda Project (.NET Core – C#) template, and then choose OK or Next.
For Project Name, enter SampleLambda, and then choose Create.
From the Select Blueprint dialog, choose Empty Function, then choose Finish.
Next, create a new file in the CDK project at src/DotnetLambdaCdkPipeline/SampleLambdaStack.cs to define your application stack containing a Lambda function. Update the file with the following contents (adjust the namespace as necessary):
using Amazon.CDK;
using Amazon.CDK.AWS.Lambda;
using Constructs;
using AssetOptions = Amazon.CDK.AWS.S3.Assets.AssetOptions;
namespace DotnetLambdaCdkPipeline
{
class SampleLambdaStack: Stack
{
public SampleLambdaStack(Construct scope, string id, StackProps props = null) : base(scope, id, props)
{
// Commands executed in a AWS CDK pipeline to build, package, and extract a .NET function.
var buildCommands = new[]
{
"cd /asset-input",
"export DOTNET_CLI_HOME=\"/tmp/DOTNET_CLI_HOME\"",
"export PATH=\"$PATH:/tmp/DOTNET_CLI_HOME/.dotnet/tools\"",
"dotnet build",
"dotnet tool install -g Amazon.Lambda.Tools",
"dotnet lambda package -o output.zip",
"unzip -o -d /asset-output output.zip"
};
new Function(this, "LambdaFunction", new FunctionProps
{
Runtime = Runtime.DOTNET_6,
Handler = "SampleLambda::SampleLambda.Function::FunctionHandler",
// Asset path should point to the folder where .csproj file is present.
// Also, this path should be relative to cdk.json file.
Code = Code.FromAsset("./src/SampleLambda", new AssetOptions
{
Bundling = new BundlingOptions
{
Image = Runtime.DOTNET_6.BundlingImage,
Command = new[]
{
"bash", "-c", string.Join(" && ", buildCommands)
}
}
})
});
}
}
}
Building inside a Docker container
The preceding code uses bundling feature to build the Lambda function inside a docker container. Bundling starts a new docker container, copies the Lambda source code inside /asset-input directory of the container, runs the specified commands that write the package files under /asset-output directory. The files in /asset-output are copied as assets to the stack’s cloud assembly directory. In a later stage, these files are zipped and uploaded to S3 as the CDK asset.
Building Lambda functions inside Docker containers is preferable than building them locally because it reduces the host machine’s dependencies, resulting in greater consistency and reliability in your build process.
Bundling requires the creation of a docker container on your build machine. For this purpose, the privileged: true setting on the build machine has already been configured.
Adding development stage
Create a new file in the CDK project at src/DotnetLambdaCdkPipeline/DotnetLambdaCdkPipelineStage.cs to hold your stage. This class will create the development stage for your pipeline.
using Amazon.CDK;
using Constructs;
namespace DotnetLambdaCdkPipeline
{
public class DotnetLambdaCdkPipelineStage : Stage
{
internal DotnetLambdaCdkPipelineStage(Construct scope, string id, IStageProps props = null) : base(scope, id, props)
{
Stack lambdaStack = new SampleLambdaStack(this, "LambdaStack");
}
}
}
Edit src/DotnetLambdaCdkPipeline/DotnetLambdaCdkPipelineStack.cs to add the stage to your pipeline. Add the bolded line from the code below to your file.
using Amazon.CDK;
using Amazon.CDK.Pipelines;
namespace DotnetLambdaCdkPipeline
{
public class DotnetLambdaCdkPipelineStack : Stack
{
internal DotnetLambdaCdkPipelineStack(Construct scope, string id, IStackProps props = null) : base(scope, id, props)
{
var repository = Repository.FromRepositoryName(this, "repository", "dotnet-lambda-cdk-application");
// This construct creates a pipeline with 3 stages: Source, Build, and UpdatePipeline
var pipeline = new CodePipeline(this, "pipeline", new CodePipelineProps
{
PipelineName = "LambdaPipeline",
.
.
.
});
var devStage = pipeline.AddStage(new DotnetLambdaCdkPipelineStage(this, "Development"));
}
}
}
Next, build the solution, then commit and push the changes to the CodeCommit repo. This will trigger the CodePipeline to start.
When the pipeline runs, UpdatePipeline stage detects the changes and updates the pipeline based on the code it finds there. After the UpdatePipeline stage completes, pipeline is updated with additional stages.
Let’s observe the changes:
An Assets stage has been added. This stage uploads all the assets you are using in your app to Amazon S3 (the S3 bucket created during bootstrapping) so that they could be used by other deployment stages later in the pipeline. For example, the CloudFormation template used by the development stage, includes reference to these assets, which is why assets are first moved to S3 and then referenced in later stages.
A Development stage with two actions has been added. The first action is to create the change set, and the second is to execute it.
Figure 3: CDK pipeline with development stage to deploy .NET Lambda function
After the Deploy stage has completed, you can find the newly-deployed Lambda function by visiting the Lambda console, selecting “Functions” from the left menu, and filtering the functions list with “LambdaStack”. Note the runtime is .NET.
Right click on the solution, choose Add, then choose New Project.
In the New Project dialog box, choose the xUnit Test Project template, and then choose OK or Next.
For Project Name, enter SampleLambda.Tests, and then choose Create or Next. Depending on your version of Visual Studio, you may be prompted to select the version of .NET to use. Choose .NET 6.0 (Long Term Support), then choose Create.
Right click on SampleLambda.Tests project, choose Add, then choose Project Reference. Select SampleLambda project, and then choose OK.
Next, edit the src/SampleLambda.Tests/UnitTest1.cs file to add a unit test. You can use the code below, which verifies that the Lambda function returns the input string as upper case.
using Xunit;
namespace SampleLambda.Tests
{
public class UnitTest1
{
[Fact]
public void TestSuccess()
{
var lambda = new SampleLambda.Function();
var result = lambda.FunctionHandler("test string", context: null);
Assert.Equal("TEST STRING", result);
}
}
}
You can add pre-deployment or post-deployment actions to the stage by calling its AddPre() or AddPost() method. To execute above test cases, we will use a pre-deployment action.
To add a pre-deployment action, we will edit the src/DotnetLambdaCdkPipeline/DotnetLambdaCdkPipelineStack.cs file in the CDK project, after we add code to generate test reports.
To run the unit test(s) and publish the test report in CodeBuild, we will construct a BuildSpec for our CodeBuild project. We also provide IAM policy statements to be attached to the CodeBuild service role granting it permissions to run the tests and create reports. Update the file by adding the new code (starting with “// Add this code for test reports”) below the devStage declaration you added earlier:
using Amazon.CDK;
using Amazon.CDK.Pipelines;
...
namespace DotnetLambdaCdkPipeline
{
public class DotnetLambdaCdkPipelineStack : Stack
{
internal DotnetLambdaCdkPipelineStack(Construct scope, string id, IStackProps props = null) : base(scope, id, props)
{
// ...
// ...
// ...
var devStage = pipeline.AddStage(new DotnetLambdaCdkPipelineStage(this, "Development"));
// Add this code for test reports
var reportGroup = new ReportGroup(this, "TestReports", new ReportGroupProps
{
ReportGroupName = "TestReports"
});
// Policy statements for CodeBuild Project Role
var policyProps = new PolicyStatementProps()
{
Actions = new string[] {
"codebuild:CreateReportGroup",
"codebuild:CreateReport",
"codebuild:UpdateReport",
"codebuild:BatchPutTestCases"
},
Effect = Effect.ALLOW,
Resources = new string[] { reportGroup.ReportGroupArn }
};
// PartialBuildSpec in AWS CDK for C# can be created using Dictionary
var reports = new Dictionary<string, object>()
{
{
"reports", new Dictionary<string, object>()
{
{
reportGroup.ReportGroupArn, new Dictionary<string,object>()
{
{ "file-format", "VisualStudioTrx" },
{ "files", "**/*" },
{ "base-directory", "./testresults" }
}
}
}
}
};
// End of new code block
}
}
}
Finally, add the CodeBuildStep as a pre-deployment action to the development stage with necessary CodeBuildStepProps to set up reports. Add this after the new code you added above.
devStage.AddPre(new Step[]
{
new CodeBuildStep("Unit Test", new CodeBuildStepProps
{
Commands= new string[]
{
"dotnet test -c Release ./src/SampleLambda.Tests/SampleLambda.Tests.csproj --logger trx --results-directory ./testresults",
},
PrimaryOutputDirectory = "./testresults",
PartialBuildSpec= BuildSpec.FromObject(reports),
RolePolicyStatements = new PolicyStatement[] { new PolicyStatement(policyProps) },
BuildEnvironment = new BuildEnvironment
{
BuildImage = LinuxBuildImage.AMAZON_LINUX_2_4,
ComputeType = ComputeType.MEDIUM
}
})
});
Build the solution, then commit and push the changes to the repository. Pushing the changes triggers the pipeline, runs the test cases, and publishes the report to the CodeBuild console. To view the report, after the pipeline has completed, navigate to TestReports in CodeBuild’s Report Groups as shown below.
Figure 4: Test report in CodeBuild report group
Deploying to production environment with manual approval
CDK Pipelines makes it very easy to deploy additional stages with different accounts. You have to bootstrap the accounts and Regions you want to deploy to, and they must have a trust relationship added to the pipeline account.
To bootstrap an additional production environment into which AWS CDK applications will be deployed by the pipeline, run the below command, substituting in the AWS account ID for your production account, the region you will use for your production environment, the AWS CLI profile to use with the prod account, and the AWS account ID where the pipeline is already deployed (the account you bootstrapped at the start of this blog).
The --trust option indicates which other account should have permissions to deploy AWS CDK applications into this environment. For this option, specify the pipeline’s AWS account ID.
Use below code to add a new stage for production deployment with manual approval. Add this code below the “devStage.AddPre(...)” code block you added in the previous section, and remember to replace the placeholders with your AWS account ID and region for your prod environment.
var prodStage = pipeline.AddStage(new DotnetLambdaCdkPipelineStage(this, "Production", new StageProps
{
Env = new Environment
{
Account = "<PROD-ACCOUNT-ID>",
Region = "<PROD-REGION>"
}
}), new AddStageOpts
{
Pre = new[] { new ManualApprovalStep("PromoteToProd") }
});
To support deploying CDK applications to another account, the artifact buckets must be encrypted, so add a CrossAccountKeys property to the CodePipeline near the top of the pipeline stack file, and set the value to true (see the line in bold in the code snippet below). This creates a KMS key for the artifact bucket, allowing cross-account deployments.
var pipeline = new CodePipeline(this, "pipeline", new CodePipelineProps
{
PipelineName = "LambdaPipeline",
SelfMutation = true,
CrossAccountKeys = true,EnableKeyRotation = true, //Enable KMS key rotation for the generated KMS keys
// ...
}
After you commit and push the changes to the repository, a new manual approval step called PromoteToProd is added to the Production stage of the pipeline. The pipeline pauses at this step and awaits manual approval as shown in the screenshot below.
Figure 5: Pipeline waiting for manual review
When you click the Review button, you are presented with the following dialog. From here, you can choose to approve or reject and add comments if needed.
Figure 6: Manual review approval dialog
Once you approve, the pipeline resumes, executes the remaining steps and completes the deployment to production environment.
Figure 7: Successful deployment to production environment
Clean up
To avoid incurring future charges, log into the AWS console of the different accounts you used, go to the AWS CloudFormation console of the Region(s) where you chose to deploy, select and click Delete on the stacks created for this activity. Alternatively, you can delete the CloudFormation Stack(s) using cdk destroy command. It will not delete the CDKToolkit stack that the bootstrap command created. If you want to delete that as well, you can do it from the AWS Console.
Conclusion
In this post, you learned how to use CDK Pipelines for automating the deployment process of .NET Lambda functions. An intuitive and flexible architecture makes it easy to set up a CI/CD pipeline that covers the entire application lifecycle, from build and test to deployment. With CDK Pipelines, you can streamline your development workflow, reduce errors, and ensure consistent and reliable deployments. For more information on CDK Pipelines and all the ways it can be used, see the CDK Pipelines reference documentation.
Have you ever wanted to initiate change in an Amazon Web Services (AWS) account after you update a GitHub repository, or deploy updates in an AWS application after you merge a commit, without the use of AWS Identity and Access Management (IAM) user access keys? If you configure an OpenID Connect (OIDC) identity provider (IdP) inside an AWS account, you can use IAM roles and short-term credentials, which removes the need for IAM user access keys.
In this blog post, we will walk you through the steps needed to configure a specific GitHub repo to assume an individual role in an AWS account to preform changes. You will learn how to create an OIDC-trusted connection that is scoped to an individual GitHub repository, and how to map the repository to an IAM role in your account. You will create the OIDC connection, IAM role, and trust relationship two ways: with the AWS Management Console and with the AWS Command Line Interface (AWS CLI).
This post focuses on creating an IAM OIDC identity provider for GitHub and demonstrates how to authorize access into an AWS account from a specific branch and repository. You can use OIDC IdPs for workflows that support the OpenID Connect standard, such as Google or Salesforce.
Prerequisites
To follow along with this blog post, you should have the following prerequisites in place:
GitHub is an external provider that is independent from AWS. To use GitHub as an OIDC IdP, you will need to complete four steps to access AWS resources from your GitHub repository. Then, for the fifth and final step, you will use AWS CloudTrail to audit the role that you created and used in steps 1–4.
Create an OIDC provider in your AWS account. This is a trust relationship that allows GitHub to authenticate and be authorized to perform actions in your account.
Create an IAM role in your account. You will then scope the IAM role’s trust relationship to the intended parts of your GitHub organization, repository, and branch for GitHub to assume and perform specific actions.
Assign a minimum level of permissions to the role.
Create a GitHub Actions workflow file in your repository that can invoke actions in your account.
Audit the role’s use with Amazon CloudTrail logs.
Step 1: Create an OIDC provider in your account
The first step in this process is to create an OIDC provider which you will use in the trust policy for the IAM role used in this action.
(Optional) For Add tags, you can add key–value pairs to help you identify and organize your IdPs. To learn more about tagging IAM OIDC IdPs, see Tagging OpenID Connect (OIDC) IdPs.
Verify the information that you entered. Your console should match the screenshot in Figure 1. After verification, choose Add provider.
Note: Each provider is a one-to-one relationship to an external IdP. If you want to add more IdPs to your account, you can repeat this process.
Figure 1: Steps to configure the identity provider
Once you are taken back to the Identity providers page, you will see your new IdP as shown in Figure 2. Select your provider to view its properties, and make note of the Amazon Resource Name (ARN). You will use the ARN later in this post. The ARN will look similar to the following:
You can add GitHub as an IdP in your account with a single AWS CLI command. The following code will perform the previous steps outlined for the console, with the same results. For the value —thumbprint-list, you will use the GitHub OIDC thumbprint 938fd4d98bab03faadb97b34396831e3780aea1.
aws iam create-open-id-connect-provider --url
"https://token.actions.GitHubusercontent.com" --thumbprint-list
"6938fd4d98bab03faadb97b34396831e3780aea1" --client-id-list
'sts.amazonaws.com'
Both of the preceding methods will add an IdP in your account. You can view the provider on the Identity providers page in the IAM console.
Step 2: Create an IAM role and scope the trust policy
You can create an IAM role with either the IAM console or the AWS CLI. If you choose to create the IAM role with the AWS CLI, you will scope the Trust Relationship Policy before you create the role.
In the IAM console, on the Identity providers screen, choose the Assign role button for the newly created IdP.
Figure 3: Assign a role to the identity provider
In the Assign role for box, choose Create a new role, and then choose Next, as shown in the following figure.
Figure 4: Create a role from the Identity provider page
The Create role page presents you with a few options. Web identity is already selected as the trusted entity, and the Identity provider field is populated with your IdP. In the Audience list, select sts.amazonaws.com, and then choose Next.
On the Permissions page, choose Next. For this demo, you won’t add permissions to the role.
(Optional) On the Tags page, add tags to this new role, and then choose Next: Review.
On the Create role page, add a role name. For this demo, enter GitHubAction-AssumeRoleWithAction. Optionally add a description.
To create the role, choose Create role.
Next, you’ll scope the IAM role’s trust policy to a single GitHub organization, repository, and branch.
To scope the trust policy (IAM console)
In the IAM console, open the newly created role and choose Edit trust relationship.
On the Edit trust policy page, modify the trust policy to allow your unique GitHub organization, repository, and branch to assume the role. This example trusts the GitHub organization <aws-samples>, the repository named <EXAMPLEREPO>, and the branch named <ExampleBranch>. Update the Federated ARN with the GitHub IdP ARN that you copied previously.
In the AWS CLI, use the example trust policy shown above for the console. This policy is designed to limit access to a defined GitHub organization, repository, and branch.
Create and save a JSON file with the example policy to your local computer with the file name trustpolicyforGitHubOIDC.json.
Run the following command to create the role.
aws iam create-role --role-name GitHubAction-AssumeRoleWithAction --assume-role-policy-document file://C:\policies\trustpolicyforGitHubOIDC.json
Step 3: Assign a minimum level of permissions to the role
For this example, you won’t add permissions to the IAM role, but will assume the role and call STS GetCallerIdentity to demonstrate a GitHub action that assumes the AWS role.
If you’re interested in performing additional actions in your account, you can add permissions to the role you created, GitHubAction-AssumeRoleWithAction. Common actions for workflows include calling AWS Lambda functions or pushing files to an Amazon Simple Storage Service (Amazon S3) bucket. For more information about using IAM to apply permissions, see Policies and permissions in IAM.
Step 4: Create a GitHub action to invoke the AWS CLI
GitHub actions are defined as methods that you can use to automate, customize, and run your software development workflows in GitHub. The GitHub action that you create will authenticate into your account as the role that was created in Step 2: Create the IAM role and scope the trust policy.
To create a GitHub action to invoke the AWS CLI:
Create a basic workflow file, such as main.yml, in the .github/workflows directory of your repository. This sample workflow will assume the GitHubAction-AssumeRoleWithAction role, to perform the action aws sts get-caller-identity. Your repository can have multiple workflows, each performing different sets of tasks. After GitHub is authenticated to the role with the workflow, you can use AWS CLI commands in your account.
Paste the following example workflow into the file.
# This is a basic workflow to help you get started with Actions
name:Connect to an AWS role from a GitHub repository
# Controls when the action will run. Invokes the workflow on push events but only for the main branch
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
env:
AWS_REGION : <"us-east-1"> #Change to reflect your Region
# Permission can be added at job level or workflow level
permissions:
id-token: write # This is required for requesting the JWT
contents: read # This is required for actions/checkout
jobs:
AssumeRoleAndCallIdentity:
runs-on: ubuntu-latest
steps:
- name: Git clone the repository
uses: actions/checkout@v3
- name: configure aws credentials
uses: aws-actions/[email protected]
with:
role-to-assume: <arn:aws:iam::111122223333:role/GitHubAction-AssumeRoleWithAction> #change to reflect your IAM role’s ARN
role-session-name: GitHub_to_AWS_via_FederatedOIDC
aws-region: ${{ env.AWS_REGION }}
# Hello from AWS: WhoAmI
- name: Sts GetCallerIdentity
run: |
aws sts get-caller-identity
Modify the workflow to reflect your AWS account information:
AWS_REGION: Enter the AWS Region for your AWS resources.
role-to-assume: Replace the ARN with the ARN of the AWS GitHubAction role that you created previously.
In the example workflow, if there is a push or pull on the repository’s “main” branch, the action that you just created will be invoked.
Figure 5 shows the workflow steps in which GitHub does the following:
Authenticates to the IAM role with the OIDC IdP in the Region that was defined in the workflow file in the step configure aws credentials.
Calls aws sts get-caller-identity in the step Hello from AWS. WhoAmI… Run AWS CLI sts GetCallerIdentity.
Figure 5: Results of GitHub action
Step 5: Audit the role usage: Query CloudTrail logs
The final step is to view the AWS CloudTrail logs in your account to audit the use of this role.
To view the event logs for the GitHub action:
In the AWS Management Console, open CloudTrail and choose Event History.
In the Lookup attributes list, choose Event source.
In the search bar, enter sts.amazonaws.com.
Figure 6: Find event history in CloudTrail
You should see the GetCallerIdentity and AssumeRoleWithWebIdentity events, as shown in Figure 6. The GetCallerIdentity event is the Hello from AWS. step in the GitHub workflow file. This event shows the workflow as it calls aws sts get-caller-identity. The AssumeRoleWithWebIdentity event shows GitHub authenticating and assuming your IAM role GitHubAction-AssumeRoleWithAction.
You can also view one event at a time.
To view the AWS CLI GetCallerIdentity event:
In the Lookup attributes list, choose User name.
In the search bar, enter the role-session-name, defined in the workflow file in your repository. This is not the IAM role name, because this role-session-name is defined in line 30 of the workflow example. In the workflow example for this blog post, the role-session-name is GitHub_to_AWS_via_FederatedOIDC.
You can now see the first event in the CloudTrail history.
Figure 7: View the get caller identity in CloudTrail
To view the AssumeRoleWithWebIdentity event
In the Lookup attributes list, choose User name.
In the search bar, enter the GitHub organization, repository, and branch that is defined in the IAM role’s trust policy. In the example outlined earlier, the user name is repo:aws-samples/EXAMPLE:ref:refs/heads/main.
You can now see the individual event in the CloudTrail history.
Figure 8: View the assume role call in CloudTrail
Conclusion
When you use IAM roles with OIDC identity providers, you have a trusted way to provide access to your AWS resources. GitHub and other OIDC providers can generate temporary security credentials to update resources and infrastructure inside your accounts.
In this post, you learned how to use the federated access to assume a role inside AWS directly from a workflow action file in a GitHub repository. With this new IdP in place, you can begin to delete AWS access keys from your IAM users and use short-term credentials.
After you read this post, we recommend that you follow the AWS Well Architected Security Pillar IAM directive to use programmatic access to AWS services using temporary and limited-privilege credentials. If you deploy IAM federated roles instead of AWS user access keys, you follow this guideline and issue tokens by the AWS Security Token Service. If you have feedback on this post, leave a comment below and let us know how you would like to see OIDC workflows expanded to help your IAM needs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS Graviton Processors are designed by AWS to deliver the best price performance for your cloud workloads running in Amazon Elastic Compute Cloud (Amazon EC2). Amazon CodeCatalyst recently added support to run workflow actions using on-demand or pre-provisioned compute powered by AWS Graviton processors. Customers can now access high performance AWS Graviton processors to build artifacts for Arm, or improve their price performance. In this post I will show you how to create a multi-architecture docker image using CodeCatalyst that can run on both amd64 and arm64 processors.
Background
Container images only run on a system with the same CPU architecture for which they were targeted. For example, an amd64 image runs on Intel and AMD processors, while an arm64 image runs on AWS Graviton. Note that amd64 and x86_64 are often used interchangeable, and I have chosen to use amd64 in this post. Rather than maintaining multiple repositories for each image type, you can combine variants for multiple architectures in the same repository. In addition, you can create a manifest describing which image to use for each architecture. This is known as multi-architecture, or multi-platform images.
Let us look at an example to further understand multi-arch images. In this screenshot from Amazon Elastic Container Registry (Amazon ECR), I have created two images for a simple hello-world application. One image is tagged latest-amd64 for AMD architectures and one tagged latest-arm64 for ARM architectures.
In addition, I have created an Image Index tagged latest. The image index is a map describing which image to use for each architecture. This allows my users to simply pull hello-world:latest and the index will identify the correct image based on the target platform. The image index contains the following manifest.
Now that I have explained what a multi-arch image is, I will explain how to create one in a CodeCatalyst workflow. A CodeCatalyst workflow is an automated procedure that describes how to build, test, and deploy your code as part of a continuous integration and continuous delivery (CI/CD) system. A workflow defines a series of steps, or actions, to take during a workflow run. Let’s get started.
Prerequisites
If you would like to follow along with this walkthrough, you will need:
In this walkthrough I will create a simple application using an Apache HTTP Server serving a static hello world page. The workload is inconsequential. I will focus on the process of building the container image using a CodeCatalyst workflow. The Workflow will build two container images, one for amd64 and one for arm64. The two build tasks will run in parallel on different compute architectures. When both builds are complete, the workflow will build the docker manifest. At the end of this post, my workflow will look like this.
Note that docker also offers a plugin called buildx that will allow you to build a multi-architecture image with a single command. In a real-world application, the workflow would also build the source code, run unit tests, etc. on each architecture. The sample application used in this post is so simple that there is no need to build and test the source code. Let’s examine the sample application now.
Sample Application
Initially the empty repository will only have a README.md file. By the end of this post, my repository will look like this.
I’ll begin by creating the file named index.html. I used the Create file button in CodeCatalyst console shown previously. My index.html file has the following content:
<html>
<head>
<title>Hello World!</title>
</head>
<body>
<h1>Hello World!</h1>
<p>Hello from a multi-architecture container created in CodeCatalyst.</p>
</body>
</html>
I’ll also create a Dockerfile that contains two commands. The first command instructs Docker to build a new image from the Apache HTTP Server Project image called httpd. It is important to note that the httpd image already supports multiple architectures including amd64 and arm64. When creating a multi-architecture image, the base image must also support these architectures. The second command simply copies the index.html file above into the new image. My Dockerfile file has the following content.
FROM httpd
COPY ./index.html /usr/local/apache2/htdocs/
With the source code for my sample application complete, I can turn my attention to the workflow.
CI/CD Workflow
To create a new workflow, select CI/CD from navigation on the left and then select Workflows (1). Then, select Create workflow (2), leave the default options, and select Create (3).
If the workflow editor opens in YAML mode, select Visual to open the visual designer. Now, I can start adding actions to the workflow.
Build Action for the AMD64 Variant
I’ll begin by adding a build action for the amd64 container. Select “+ Actions” to open the actions list. Find the Build action and click “+” to add a new build action to the workflow.
On the Inputs tab, create three variable named AWS_DEFAULT_REGION,IMAGE_REPO_NAME, and IMAGE_TAG. Set the first two values equal to the region and **** name of your Amazon ECR repository**.** Set the third to latest-amd64. For example:
Now select the Configuration tab and rename the action docker_build_amd64. Select the Environment, AWS account connection, and Role for the associated AWS account where you created the Amazon ECR repository. For example:
Then, copy and paste the following code into the Shell commands. This code will build the image using the Dockerfile you created previously. Then, it logs into Amazon ECR, and finally, pushes the new image to ECR.
With the amd64 image complete, you can move on to the arm64 image.
Build Action for the ARM64 Variant
Add a second build action named docker_build_arm64 for the arm64 container. The configuration is nearly identical to the previous action with two minor changes. First, on the Inputs tab, I set the IMAGE_TAG to latest-arm64.
Second, on the Configuration tab, change the compute fleet to Linux.Arm64.Large. That is all you need to do to run your action on AWS Graviton. For example:
The Shell commands are identical to the arm64 build action. In addition, don’t forget to select the Environment, AWS account connection, and Role on the configuration tab. The complete configuration for the second action looks like this:
Now that you have a build action for the amd64 and arm64 images, you simply need to create a manifest file describing which image to use for each architecture.
Build Action for the Manifest
The final step in the workflow is to create the Docker manifest. Create a third build action named docker_manifest. You want this action to wait for the prior two actions to complete. Therefore, select the prior two actions from the Depends on drop down, like this:
Also configure four variables. AWS_DEFAULT_REGION and IMAGE_REPO_NAME are identical to the prior actions. In addition, IMAGE_TAG_AMD64 and IMAGE_TAG_ARM64 include the tags you created in the prior actions.
On the configuration tab, select the Environment, AWS account connection, and Role as you did in the prior actions. Then, copy and paste the following Shell commands.
I now have a complete CI/CD workflow that creates a container images for both amd64 and arm64. When I commit the changes, CodeCatalyst will execute my workflow, build the images, and push to ECR.
Cleanup
If you have been following along with this workflow, you should delete the resources you deployed so you do not continue to incur charges. First, delete the Amazon ECR repository using the AWS console. Second, delete the project from CodeCatalyst by navigating to Project settings and choosing Delete project.
Conclusion
AWS Graviton processors are custom-built by AWS to deliver the best price performance for cloud workloads. In this post I explained how to configure CodeCatalyst workflow actions to run on AWS Graviton. I used CodeCatalyst to create a workflow that builds a multi-architecture container image that can run on both amd64 and arm64 architectures. Get started building your multi-arch containers in Amazon CodeCatalyst today! You can read more about CodeCatalyst workflows in the documentation.
For the permissions already in place, one of IAM Access Analyzer’s capabilities is that it helps you identify resources in your AWS Organizations organization and AWS accounts that are shared with an external entity.
For each external entity that has access to a resource in your account, IAM Access Analyzer generates a finding. Findings display information about the resource and the policy statement that generated the finding, with details such as the list of actions in the policy granting access, level of access, and conditions that allow the access. You can review the findings to determine if the access is intended or unintended.
As your use of AWS services grows and the number of accounts in your organization increases, the number of findings that you have might also increase. To help reduce noise and allow you to focus on unintended access findings, you can filter findings and create archive rules for intended access.
This blog post provides step-by-step guidance on how to get started with IAM Access Analyzer findings by using different filtering techniques that can help you filter approved use cases that result in access findings. For example, you might see a finding generated for an S3 bucket that hosts images for your website and thus allows public access, as approved by your organization, apply a filter so that you can concentrate on unintended access. IAM Access Analyzer offers a wide range of filters; for a complete list, see the IAM documentation.
In this post, we also share example archive rules for approved use cases that result in access findings. Archive rules automatically archive new findings that meet the criteria you define when you create the rule. You can also apply archive rules retroactively to archive existing findings that meet the archive rule criteria. Finally, we have included an example implementation of archive rules using an AWS CloudFormation template.
IAM Access Analyzer findings overview
To get started, create an analyzer for your entire organization or your account. The organization or account that you choose is known as the zone of trust for the analyzer. The zone of trust determines the type of access that IAM Access Analyzer considers to be trusted. IAM Access Analyzer continuously monitors to identify resource policies, access control lists, and other access controls that grant public or cross-account access from outside the zone of trust, and generates findings. For this blog post, we’ll demonstrate an organization as the zone of trust, showcasing findings from a large-scale, multi-account AWS deployment.
Prerequisites
This blog post assumes that you have the following in place:
IAM Access Analyzer is enabled in your organization or account in the AWS Regions where you operate. For more details on how to enable IAM Access Analyzer, see Enabling IAM Access Analyzer.
Access to the AWS Organizations management account or to a member account in the organization with delegated administrator access for creating and updating IAM Access Analyzer resources.
How to filter the findings
To start filtering your findings and create archive rules, you should complete the following steps:
Review public access findings
Filter by removing permissions errors
Filter for known identity providers
Filter cross-account access from trusted external accounts
We’ll walk you through each step.
1. Review public access findings
Some AWS resources allow public access on the resource by means of a resource-based policy—for example, an Amazon Simple Storage Service (Amazon S3) bucket policy that has the “Principal:*” permission added to its bucket policy. For resources such as Amazon Elastic Block Store (Amazon EBS) snapshots, you can share these by using a flag on the resource permission. IAM Access Analyzer looks for such sharing and reports it in the findings.
From the global report, you can generate a list of resources that allow public access by using the Public access: true query in the IAM console.
If the access is intended, you can archive the findings by creating an archive rule using the AWS Management Console, AWS CLI, or API. When you archive a security finding, IAM Access Analyzer removes it from the Active findings list and changes its status to Archived. For instructions on how to automatically archive expected findings, see How to automatically archive expected IAM Access Analyzer findings.
Example: Known S3 bucket that hosts public website images
If you have resources for which public access is expected, such as an S3 bucket that hosts images for your website, you can add an archive rule with Resource criteria equal to the bucket name, as shown in Figure 1.
Figure 1: Create IAM Access Analyzer archive rule using the console
Is the public access unintended?
If the finding results from policies that were misconfigured to allow unintended public access, you can constrain the access by using AWS global condition context keys or a specific IAM principal ARN. The findings show the account and resource that contain the policy.
For example, if the finding shows a misconfigured S3 bucket, the following policy shows how you can modify the S3 bucket policy to only allow IAM principals from your organization to access the bucket by using the PrincipalOrgID condition key. Replace <DOC-EXAMPLE-BUCKET> with the name of your S3 bucket, and <ORGANIZATION_ID> with your organization ID.
Before you further investigate the IAM Access Analyzer findings, you should make sure that IAM Access Analyzer has enough permissions to access the resources in your accounts to be able to provide the analysis.
IAM Access Analyzer uses an AWS service-linked role to call other AWS services on your behalf. When IAM Access Analyzer analyzes a resource, it reads resource metadata, such as a resource-based policy, access control lists, and other access controls that grant public or cross-account access. If the policies don’t allow an IAM Access Analyzer role to read the resource metadata, it generates an Access Denied error finding, as shown in Figure 2.
Figure 2: IAM Access Analyzer access denied error example
To view these error findings from the IAM Access Analyzer console, filter the findings by using the Error: Access Denied property.
Resolution
To resolve the access issue, make sure that the IAM Access Analyzer service-linked role is not denied access. Review the resource-based policy attached to the resource that IAM Access Analyzer isn’t able to access. For a list of services that support resource-based policies, see the IAM documentation.
For example, if the analyzer can’t access an AWS Key Management Service (AWS KMS) key because of an explicit deny, add an exception for the IAM Access Analyzer service-linked role to the policy statement, similar to the following. Make sure that you change the <ACCOUNT_ID> to your account id.
With SAML 2.0 or Open ID Connect (OIDC)—which are open federation standards that many identity providers (IdPs) use—users can log in to the console or call the AWS API operations without you having to create an IAM user for everyone in your organization.
To set up federation, you must perform a one-time configuration so that your organization’s IdP and your account trust each other. To configure this trust, you must register AWS as a service provider (SP) with the IdP of your organization and set up metadata and key exchange.
The role or roles that you create in IAM define what the federated users from your organization are allowed to use on AWS. When you create the trust policy for the role, you specify the SAML or OIDC provider as the Principal. To only allow users that match certain attributes to access the role, you can scope the trust policy with a Condition.
Example 1: Federation with Okta
Let’s walk through an example that uses Okta as the IdP. Although access to a trusted IdP is intended, IAM Access Analyzer creates a finding for an IAM role that has trust policy granting access to a SAML provider because the trust policy allows access outside of the known zone of trust for the analyzer. You will see findings created for the IAM role granting access to Okta using the IAM trust policy, as shown in Figure 3.
Figure 3: IAM Access Analyzer identity provider finding example
Resolution
Setting access through SAML providers is a privileged operation, so we recommend that you analyze each finding to decide if an exception is acceptable. If you approve of the SAML-provided access setup, you can implement an archive rule to archive such findings with conditions for federation used in combination with your SAML provider. The filter for the Federated User rule depends on the name that you gave to the SAML IdP in your federation setup. For example, if your SAML IdP name is Okta, the rule should have a filter for arn:aws:iam::<ACCOUNT_ID>:saml-provider/Okta, where <ACCOUNT_ID> is your account number, as shown in Figure 4.
Figure 4: Archive rule example for using an IdP-related finding
Note: To include additional values for a multi-account setup, use the Add another value filter.
Example 2: IAM Identity Center
With AWS IAM Identity Center (successor to AWS Single Sign-On), you can manage sign-in security for your workforce. IAM Identity Center provides a central place to define your permission sets, assign them to your users and groups, and give your users a portal where they can access their assigned accounts.
With IAM Identity Center, you manage access to accounts by creating and assigning permission sets. These are IAM role templates that define (among other things) which policies to include in a role. When you create a permission set in IAM Identity Center and associate it to an account, IAM Identity Center creates a role in that account with a trust policy that allows a federated IdP as a principal — in this case, IAM Identity Center.
IAM Access Analyzer generates a finding for this setup because the allowed access is outside of the known zone of trust for the analyzer, as shown in Figure 5.
Figure 5: IAM Access Analyzer finding example for IAM Identity Center
To filter this finding, you need to implement an archive rule.
Resolution
You can implement an archive rule with conditions for federation used in combination with IAM Identity Center as the SAML provider. The roles created by IAM Identity Center in member accounts use a reserved path on AWS: arn:aws:iam::<ACCOUNT_ID>:role/aws-reserved/sso.amazonaws.com/. Hence, you can create an archive rule with a filter that contains :saml-provider/AWSSSO in the Federated User name and aws-reserved/sso.amazonaws.com/ in the Resource, as shown in Figure 6.
Figure 6: Archive rule example for IAM Identity Center generated findings
4. Filter cross-account access findings from trusted external accounts
We recommend that you identify and document accounts and principals that should be allowed access outside of the zone of trust for IAM Access Analyzer.
When a resource-based policy attached to a resource allows cross-account access from outside the zone of trust, IAM Access Analyzer generates cross-account access findings.
Is the cross-account access intended?
When you review cross-account access findings, you need to determine whether the access is intended or not. For example, you might have access provided to your auditor’s account or a partner account for visibility and monitoring of your AWS applications.
For trusted external accounts, you can create an archive rule that includes the AWS account in the criteria for the rule. Figure 7 shows an example of how to create the archive rule for a trusted external account (EXTERNAL_ACCOUNT_ID). In your own rule, replace EXTERNAL_ACCOUNT_ID with the trusted account id.
Figure 7: Archive rule example for trusted account findings
Is the cross-account access unintended?
After you have archived the intended access findings, you can start analyzing the findings initiated from unintended access. When you confirm that the findings show unintended access, you should take steps to remove the access by altering or deleting the policy or access control that granted access. You can expand the solution outlined in the blog post Automate resolution for IAM Access Analyzer cross-account access findings on IAM roles by adding an explicit deny statement.
You can also use AWS CloudTrail to track API calls that could have changed access configuration on your AWS resources.
Deploy IAM Access Analyzer and archive rules with a CloudFormation template
In this section, we demonstrate a sample CloudFormation template that creates an IAM access analyzer and archive rules for findings that are created for identified intended access to resources.
Important: When you create an archive rule using the AWS console, the existing findings and new findings that match criteria mentioned in the rules will be archived. However, archive rules created through CloudFormation or the AWS CLI will only archive the new findings that meet the criteria defined. You need to perform the access-analyzer:ApplyArchiveRule API after you create the archive rule to archive existing findings as well.
The sample CloudFormation template takes the following values as inputs and creates archive rules for findings that are created for identified intended access to resources shared outside of your zone of trust for the specified analyzer:
Analyzer name
Zone of trust
Known public S3 buckets, if you have any (for example, a bucket that hosts public website images).
Note: We use S3 buckets as an example. You can edit the rule to include resource types that are supported by IAM Access Analyzer, if public access is intended.
Trusted accounts — AWS accounts that don’t belong to your organization, but you trust them to have access to resources in your organization
SAML provider — The SAML provider approved to have access to your resources
Note: If you don’t use federation, you can remove the rule SAMLFederatedUsers.
AWSTemplateFormatVersion: 2010-09-09
Description: >+
Sample CloudFormation template creates archive rules for findings
created for resources shared outside of your zone of trust for specified
analyzer.
Metadata:
AWS::CloudFormation::Interface:
ParameterGroups:
- Label:
default: Define Configuration
Parameters:
- AccessAnalyzerName
- ZoneOfTrust
- KnownPublicS3Buckets
- TrustedAccounts
- SAMLProvider
Parameters:
AccessAnalyzerName:
Description: Provide name of the analyzer you would like to create archive rules for.
Type: String
ZoneOfTrust:
Description: Select the zone of trust of AccessAnalyzer
AllowedValues:
- ACCOUNT
- ORGANIZATION
Type: String
KnownPublicS3Buckets:
Description: List of comma-separated known S3 bucket arns, that should allow
public access Example -
arn:aws:s3:::DOC-EXAMPLE-BUCKET,arn:aws:s3:::DOC-EXAMPLE-BUCKET2
Type: CommaDelimitedList
TrustedAccounts:
Description: List of comma-separated account IDs, that do not belong to your
organization but you trust them to have access to resources in your
organization. [Example - Your auditor’s AWS account]
Type: List<Number>
TrustedFederationPrincipals:
Description: List of comma-separated trusted federated principals that are able
to assume roles in your accounts. [Example -
arn:aws:iam::012345678901:saml-provider/Okta,
arn:aws:iam::1111222233334444:saml-provider/Okta]
Type: CommaDelimitedList
Resources:
AccessAnalyzer:
Type: AWS::AccessAnalyzer::Analyzer
Properties:
AnalyzerName: ${AccessAnalyzerName}-${AWS::Region}
Type: ZoneOfTrust
ArchiveRules:
- RuleName: ArchivePublicS3BucketsAccess
Filter:
- Property: resource
Eq: KnownPublicS3Buckets
- RuleName: AccountAccessNecessaryForBusinessProcesses
Filter:
- Property: principal.AWS
Eq: TrustedAccounts
- Property: isPublic
Eq:
- "false"
- RuleName: SAMLFederatedUsers
Filter:
- Property: principal.Federated
Eq: TrustedFederationPrincipals
To download this sample template, download the file IAMAccessAnalyzer.yaml from Amazon S3.
Conclusion
In this blog post, you learned how to start with IAM Access Analyzer findings, filter them based on the level of access given outside of your zone of trust, and create archive rules for intended access findings. By using different filtering techniques to remediate intended access findings, you can concentrate on unintended access.
As organizations operate day-to-day, having insights into their cloud infrastructure state can be crucial for the durability and availability of their systems. Industry research estimates[1] that downtime costs small businesses around $427 per minute of downtime, and medium to large businesses an average of $9,000 per minute of downtime. Amazon DevOps Guru customers want to monitor and generate alerts using a single dashboard. This allows them to reduce context switching between applications, providing them an opportunity to respond to operational issues faster.
DevOps Guru can integrate with Amazon Managed Grafana to create and display operational insights. Alerts can be created and communicated for any critical events captured by DevOps Guru and notifications can be sent to operation teams to respond to these events. The key telemetry data types of logs and metrics are parsed and filtered to provide the necessary insights into observability.
Furthermore, it provides plug-ins to popular open-source databases, third-party ISV monitoring tools, and other cloud services. With Amazon Managed Grafana, you can easily visualize information from multiple AWS services, AWS accounts, and Regions in a single Grafana dashboard.
In this post, we will walk you through integrating the insights generated from DevOps Guru with Amazon Managed Grafana.
Solution Overview:
This architecture diagram shows the flow of the logs and metrics that will be utilized by Amazon Managed Grafana, starting with DevOps Guru and then using Amazon EventBridge to save the insight event logs to Amazon CloudWatch Log Group DevOps Guru service metrics to be parsed by Amazon Managed Grafana and create new dashboards in Grafana from these logs and Metrics.
Now we will walk you through how to do this and set up notifications to your operations team.
Prerequisites:
The following prerequisites are required for this walkthrough:
Enabled DevOps Guru on your account with CloudFormation stack, or tagged resources monitored.
Using Amazon CloudWatch Metrics
DevOps Guru sends service metrics to CloudWatch Metrics. We will use these to track metrics for insights and metrics for your DevOps Guru usage; the DevOps Guru service reports the metrics to the AWS/DevOps-Guru namespace in CloudWatch by default.
First, we will provision an Amazon Managed Grafana workspace and then create a Dashboard in the workspace that uses Amazon CloudWatch as a data source.
Setting up Amazon CloudWatch Metrics
Create Grafana Workspace Navigate to Amazon Managed Grafana from AWS console, then click Create workspace
For other insights outside of the service metrics, such as a number of insights per specific service or the average for a region or for a specific AWS account, we will need to parse the event logs. These logs first need to be sent to Amazon CloudWatch Logs. We will go over the details on how to set this up and how we can parse these logs in Amazon Managed Grafana using CloudWatch Logs Query Syntax. In this post, we will show a couple of examples. For more details, please check out this User Guide documentation. This is not done by default and we will need to use Amazon EventBridge to pass these logs to CloudWatch.
DevOps Guru logs include other details that can be helpful when building Dashboards, such as region, Insight Severity (High, Medium, or Low), associated resources, and DevOps guru dashboard URL, among other things. For more information, please check out this User Guide documentation.
EventBridge offers a serverless event bus that helps you receive, filter, transform, route, and deliver events. It provides one to many messaging solutions to support decoupled architectures, and it is easy to integrate with AWS Services and 3rd-party tools. Using Amazon EventBridge with DevOps Guru provides a solution that is easy to extend to create a ticketing system through integrations with ServiceNow, Jira, and other tools. It also makes it easy to set up alert systems through integrations with PagerDuty, Slack, and more.
Setting up Amazon CloudWatch Logs
Let’s dive in to creating the EventBridge rule and enhance our Grafana dashboard:
a. First head to Amazon EventBridge in the AWS console.
b. Click Createrule.
Type in rule Name and Description. You can leave the Event bus to default and Rule type to Rule with an event pattern.
c. Select AWS events or EventBridge partner events.
For event Pattern change to Customer patterns (JSON editor) and use:
{"source": ["aws.devops-guru"]}
This filters for all events generated from DevOps Guru. You can use the same mechanism to filter out specific messages such as new insights, or insights closed to a different channel. For this demonstration, let’s consider extracting all events.
d. Next, for Target, select AWS service.
Then use CloudWatch log Group.
For the Log Group, give your group a name, such as “devops-guru”.
e. Click Createrule.
f. Navigate back to Amazon Managed Grafana. It’s time to add a couple more additional Panels to our dashboard. Click Add panel. Then Select Amazon CloudWatch, and change from metrics to CloudWatch Logs and select the Log Group we created previously.
g. For the query use the following to get the number of closed insights:
Next, depending on the visualizations, you can work with the Logs and metrics data types to parse and filter the data.
i. For our fourth panel, we will add DevOps Guru dashboard direct link to the AWS Console.
Repeat the same process as demonstrated previously one more time with this query:
fields detail.messageType, detail.insightSeverity, detail.insightUrlfilter
| filter detail.messageType="CLOSED_INSIGHT" or detail.messageType="NEW_INSIGHT"
Switch to table when prompted on the panel.
This will give us a direct link to the DevOps Guru dashboard and help us get to the insight details and Recommendations.
Save your dashboard.
You can extend observability by sending notifications through alerts on dashboards of panels providing metrics. The alerts will be triggered when a condition is met. The Alerts are communicated with Amazon SNS notification mechanism. This is our SNS notification channel setup.
A previously created notification is used next to communicate any alerts when the condition is met across the metrics being observed.
Cleanup
To avoid incurring future charges, delete the resources.
Navigate to EventBridge in AWS console and delete the rule created in step 4 (a-e) “devops-guru”.
Navigate to CloudWatch logs in AWS console and delete the log group created as results of step 4 (a-e) named “devops-guru”.
Amazon Managed Grafana: Navigate to Amazon Managed Grafana service and delete the Grafana services you created in step 1.
Conclusion
In this post, we have demonstrated how to successfully incorporate Amazon DevOps Guru insights into Amazon Managed Grafana and use Grafana as the observability tool. This will allow Operations team to successfully observe the state of their AWS resources and notify them through Alarms on any preset thresholds on DevOps Guru metrics and logs. You can expand on this to create other panels and dashboards specific to your needs. If you don’t have DevOps Guru, you can start monitoring your AWS applications with AWS DevOps Guru today using this link.
Data mesh is a new approach to data management. Companies across industries are using a data mesh to decentralize data management to improve data agility and get value from data. However, when a data producer shares data products on a data mesh self-serve web portal, it’s neither intuitive nor easy for a data consumer to know which data products they can join to create new insights. This is especially true in a large enterprise with thousands of data products.
This post shows how to use machine learning (ML) and Amazon Neptune to create automated recommendations to join data products and display those recommendations alongside the existing data products. This allows data consumers to easily identify new datasets and provides agility and innovation without spending hours doing analysis and research.
Background
The success of a data-driven organization recognizes data as a key enabler to increase and sustain innovation. It follows what is called a distributed system architecture. The goal of a data product is to solve the long-standing issue of data silos and data quality. Independent data products often only have value if you can connect them, join them, and correlate them to create a higher order data product that creates additional insights. A modern data architecture is critical in order to become a data-driven organization. It allows stakeholders to manage and work with data products across the organization, enhancing the pace and scale of innovation.
Solution overview
A data mesh architecture starts to solve for the decoupled architecture by decoupling the data infrastructure from the application infrastructure, which is a common challenge in traditional data architectures. It focuses on decentralized ownership, domain design, data products, and self-serve data infrastructure. This allows for a new way of thinking and new organizational elements—namely, a modern data community.
However, today’s data mesh platform contains largely independent data products. Even with well-documented data products, knowing how to connect or join data products is a time-consuming job. Data consumers spend hours, days, or months to understand and analyze the data. Identifying links or relationships between data products is critical to create value from the data mesh and enable a data-driven organization.
The solution in this post illustrates an approach to solving these challenges. It uses a fictional insurance company with several data products shared on their data mesh marketplace. The following figure shows the sample data products used in our solution.
Suppose a consumer is browsing the customer data product in the data mesh marketplace. The consumer wonders if the customer data could be linked to claim, policy, or encounter data. Because these data products come from different lines of business (LOBs) or silos, it’s hard to know. A consumer would have to review each data product and do the necessary analysis and research to know this with any certainty.
To solve this problem, our solution uses ML and Neptune to create recommendations for the data consumer. The solution generates a list of data products, product attributes, and the associated probability scores to show join ability. This reduces the time to discover, analyze, and create new insights.
We use Valentine, a data science algorithm for comparing datasets, to improve data product recommendations. Neptune, the managed AWS graph database service, stores information about explicit connections between datasets, improving the recommendations.
Example use case
Let’s walk through a concrete example. Suppose a consumer is browsing the Customer data product in the data mesh marketplace. Customer is similar to the Policy and Encounter data products, but these products come from different silos. Their similarity to the Customer is hard to gauge. To expedite the consumer’s work, the mesh recommends how the Policy and Encounter products can be connected to the Customer product.
Let’s consider two cases. First, is Customer similar to Claim? The following is a sample of the data in each product.
Intuitively, these two products have lots of overlap. Every Cust_Nbr in Claim has a corresponding Customer_ID in Customer. There is no foreign key constraint in Claim that assures us it points to Customer. We think there is enough similarity to infer a join relationship.
The data science algorithm Valentine is an effective tool for this. Valentine is presented in the paper Valentine: Evaluating Matching Techniques for Dataset Discovery (2021, Koutras et al.). Valentine determines if two datasets are joinable or unionable. We focus on the former. Two datasets are joinable if a record from one dataset has a link to a record in the other dataset using one or more columns. Valentine addresses the use case where data is messy: there is no foreign key constraint in place, and data doesn’t match perfectly between datasets. Valentine looks for similarities, and its findings are probabilistic. It scores its proposed matches.
This solution uses an implementation of Valentine available in the following GitHub repo. The first step is to load each data product from its source into a Pandas data frame. If the data is large, load a representative subset of it, at most a few million records. Pass the frames to the valentine_match() function and select the matching method. We use COMA, one of several methods that Valentine supports. The function’s result indicates the similarity of columns and the score. In this case, it tells us that the Customer_ID for Customer matches the Cust_Nbr for Claim, with a very high score. We then instruct the data mesh to recommend Claim to the consumer browsing Customer.
A graph database isn’t required to recommend Claim; the two products could be directly compared. But let’s consider Encounter. Is Customer similar to Encounter? This case is more complicated. Many encounters in the Encounter product don’t link to a customer. An encounter occurs when someone contacts the contact center, which could be by phone or email. The party may or may not be a customer, and if they are a customer, we may not know their customer ID during this encounter. Additionally, sometimes the phone or email they use isn’t the same as the one from a customer record in the Customer product.
In the following sample encounter set, encounters 1 and 2 match to Customer_ID 4. Note that encounter 2’s inbound_email doesn’t exactly match the inbound_email in that customer’s record in the Customer product. Encounter 3 has no Customer_ID, but its inbound_email matches the customer with ID 8. Encounter 4 appears to refer to the customer with ID 8, but the email doesn’t match, and no Customer_ID is given. Encounter 5 only has Inbound_Phone, but that matches the customer with ID 1. Encounter 6 only has an Inbound_Phone, and it doesn’t appear to match any of the customers we’ve listed so far.
We don’t have a strong enough comparison to infer similarity.
But we know more about the customer than the Customer product tells us. In the Neptune database, we maintain a knowledge graph that combines multiple products and links them through relationships. A knowledge graph allows us to combine data from different sources to gain a better understanding of a specific problem domain. In Neptune, we combine the Customer product data with an additional data product: Sales Opportunity. We ingest each product from its source into the knowledge graph and model a hasSalesOpportunity relationship between Customer and SalesOpportunity resources. The following figure shows these resources, their attributes, and their relationship.
With the AWS SDK for Pandas, we combine this data by running a query against the Neptune graph. We use a graph query language (such as SPARQL) to wrangle a representative subset of customer and sales opportunity data into a Pandas data frame (shown as Enhanced Customer View in the following figure). In the following example, we enhance customers 7 and 8 with alternate phone or email contact data from sales opportunities.
We pass that frame to Valentine and compare it to Encounter. This time, two additional encounters match a customer.
The score meets our threshold, and is high enough to share with the consumer as a possible match. To the customer browsing Customer in the mesh marketplace, we present the recommendation of Encounter, along with scoring details to support the recommendation. With this recommendation, the consumer can explore the Encounter product with greater confidence.
Conclusion
Data-driven organizations are transitioning to a data product way of thinking. Utilizing strategies like data mesh generates value on a large scale. We took this a step further by creating a blueprint to create smart recommendations by linking similar data products using graph technology and ML. In this post, we showed how an organization can augment a data catalog with additional metadata by using ML and Neptune with an automated process.
This solution solves the interoperability and linkage problem for data products. Additionally, it gives organizations real-time insights, agility, and innovation without spending time on data analysis and research. This approach creates a truly connected ecosystem with simplified access to delight your data consumers. The current solution is platform agnostic; however, in a future post we will show how to implement this using data.all (open-source software) and Amazon DataZone.
Moira Lennox is a Senior Data Strategy Technical Specialist for AWS with 27 years’ experience helping companies innovate and modernize their data strategies to achieve new heights and allow for strategic decision-making. She has experience working in large enterprises and technology providers, in both business and technical roles across multiple industries, including health care live sciences, financial services, communications, digital entertainment, energy, and manufacturing.
Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data strategy, and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and data governance.
Mike Havey is a Solutions Architect for AWS with over 25 years of experience building enterprise applications. Mike is the author of two books and numerous articles. His Amazon author page
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a data warehouse on Hadoop. Apache Hive has performed pretty well for a long time. But with advancements in infrastructure such as cloud computing and multicore machines with large RAM, Apache Spark started to gain visibility by performing better than Apache Hive.
Customers now want to migrate their Apache Hive workloads to Apache Spark in the cloud to get the benefits of optimized runtime, cost reduction through transient clusters, better scalability by decoupling the storage and compute, and flexibility. However, migration from Apache Hive to Apache Spark needs a lot of manual effort to write migration scripts and maintain different Spark job configurations.
In this post, we walk you through a solution that automates the migration from HiveQL to Spark SQL. The solution was used to migrate Hive with Oozie workloads to Spark SQL and run them on Amazon EMR for a large gaming client. You can also use this solution to develop new jobs with Spark SQL and process them on Amazon EMR. This post assumes that you have a basic understanding of Apache Spark, Hive, and Amazon EMR.
Solution overview
In our example, we use Apache Oozie, which schedules Apache Hive jobs as actions to collect and process data on a daily basis.
We migrate these Oozie workflows with Hive actions by extracting the HQL files, and dynamic and static parameters, and converting them to be Spark compliant. Manual conversion is both time consuming and error prone. To convert the HQL to Spark SQL, you’ll need to sort through existing HQLs, replace the parameters, and change the syntax for a bunch of files.
Instead, we can use automation to speed up the process of migration and reduce heavy lifting tasks, costs, and risks.
We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The first component (metadata setup) consumes existing Hive job configurations and generates metadata such as number of parameters, number of actions (steps), and file formats. The second component consumes the generated metadata from the first component and prepares the run order of Spark SQL within a Spark session. With this solution, we support basic orchestration and scheduling with the help of AWS services like Amazon DynamoDB and Amazon Simple Storage Service (Amazon S3). We can validate the solution by running queries in Amazon Athena.
In the following sections, we walk through these components and how to use these automations in detail.
Generate Spark SQL metadata
Our batch job consists of Hive steps scheduled to run sequentially. For each step, we run HQL scripts that extract, transform, and aggregate input data into one final Hive table, which stores data in HDFS. We use the following Oozie workflow parser script, which takes the input of an existing Hive job and generates configurations artifacts needed for running SQL using PySpark.
Oozie workflow XML parser
We create a Python script to automatically parse the Oozie jobs, including workflow.xml, co-ordinator.xml, job properties, and HQL files. This script can handle many Hive actions in a workflow by organizing the metadata at the step level into separate folders. Each step includes the list of SQLs, SQL paths, and their static parameters, which are input for the solution in the next step.
The process consists of two steps:
The Python parser script takes input of the existing Oozie Hive job and its configuration files.
The script generates a metadata JSON file for each step.
The following diagram outlines these steps and shows sample output.
The Python script parses only HiveQL actions from the Oozie workflow.xml.
The Python script generates one file for each SQL statement and uses the sequence ID for file names. It doesn’t name the SQL based on the functionality of the SQL.
Run Spark SQL on Amazon EMR
After we create the SQL metadata files, we use another automation script to run them with Spark SQL on Amazon EMR. This automation script supports custom UDFs by adding JAR files to spark submit. This solution uses DynamoDB for logging the run details of SQLs for support and maintenance.
Architecture overview
The following diagram illustrates the solution architecture.
You can check on the DynamoDB console that the table dw-etl-pipelinelog is successfully created.
The log table has the following attributes.
Attributes
Type
Comments
job_run_id
String
partition_key
id
String
sort_key (UUID)
end_time
String
End time
error_description
String
Error in case of failure
expire
Number
Time to Live
sql_seq
Number
SQL sequence number
start_time
String
Start time
Status
String
Status of job
step_id
String
Job ID SQL belongs
The log table can grow quickly if there are too many jobs or if they are running frequently. We can archive them to Amazon S3 if they are no longer used or use the Time to Live feature of DynamoDB to clean up old records.
Run the first command to set the variable in case you have an existing bucket that can be reused. If not, create a S3 bucket to store the Spark SQL code, which will be run by Amazon EMR.
export s3_bucket_name=unique-code-bucket-name # Change unique-code-bucket-name to a valid bucket name
To create the source tables in the base database, run the DDLs present in the repo in the Athena query editor:
Run the ./sample_data/ddl/states_current.q file by modifying the S3 path to the bucket you created.
Run the ./sample_data/ddl/us_current.q file by modifying the S3 path to the bucket you created.
The ETL driver file implements the Spark driver logic. It can be invoked locally or on an EMR instance.
Launch an EMR cluster.
Make sure to select Use for Spark table metadata under AWS Glue Data Catalog settings.
Add the following steps to EMR cluster.
aws emr add-steps --cluster-id <<cluster id created above>> --steps 'Type=CUSTOM_JAR,Name="boto3",ActionOnFailure=CONTINUE,Jar=command-runner.jar,Args=[bash,-c,"sudo pip3 install boto3"]'
aws emr add-steps --cluster-id <<cluster id created above>> --steps 'Name="sample_oozie_job_name",Jar="command-runner.jar",Args=[spark-submit,--py-files,s3://unique-code-bucket-name-#####/framework/code.zip,s3://unique-code-bucket-name-#####/framework/etl_driver.py,--step_id,sample_oozie_job_name#step1,--job_run_id,sample_oozie_job_name#step1#2022-01-01-12-00-01, --code_bucket=s3://unique-code-bucket-name-#####/DW,--metadata_table=dw-etl-metadata,--log_table_name=dw-etl-pipelinelog,--sql_parameters,DATE=2022-02-02::HOUR=12::code_bucket=s3://unique-code-bucket-name-#####]' # Change unique-code-bucket-name to a valid bucket name
The following table summarizes the parameters for the spark step.
The following table summarizes the script arguments.
Script Argument
Argument Description
deploy-mode
Spark deploy mode. Client/Cluster.
name <jobname>#<stepname>
Unique name for the Spark job. This can be used to identify the job on the Spark History UI.
py-files <s3 path for code>/code.zip
S3 path for the code.
<s3 path for code>/etl_driver.py
S3 path for the driver module. This is the entry point for the solution.
step_id <jobname>#<stepname>
Unique name for the step. This refers to the step_id in the metadata entered in DynamoDB.
job_run_id <random UUID>
Unique ID to identify the log entries in DynamoDB.
log_table_name <DynamoDB Log table name>
DynamoDB table for storing the job run details.
code_bucket <s3 bucket>
S3 path for the SQL files that are uploaded in the job setup.
metadata_table <DynamoDB Metadata table name>
DynamoDB table for storing the job metadata.
sql_parameters DATE=2022-07-04::HOUR=00
Any additional or dynamic parameters expected by the SQL files.
Validation
After completion of EMR step you should have data on S3 bucket for the table base.states_daily. We can validate the data by querying the table base.states_daily in Athena.
Congratulations, you have converted an Oozie Hive job to Spark and run on Amazon EMR successfully.
Solution highlights
This solution has the following benefits:
It avoids boilerplate code for any new pipeline and offers less maintenance of code
Onboarding any new pipeline only needs the metadata set up—the DynamoDB entries and SQL to be placed in the S3 path
Any common modifications or enhancements can be done at the solution level, which will be reflected across all jobs
DynamoDB metadata provides insight into all active jobs and their optimized runtime parameters
For each run, this solution persists the SQL start time, end time, and status in a log table to identify issues and analyze runtimes
It supports Spark SQL and UDF functionality. Custom UDFs can be provided externally to the spark submit command
Limitations
This method has the following limitations:
The solution only supports SQL queries on Spark
Each SQL should be a Spark action like insert, create, drop, and so on
In this post, we explained the scenario of migrating an existing Oozie job. We can use the PySpark solution independently for any new development by creating DynamoDB entries and SQL files.
Clean up
Delete all the resources created as part of this solution to avoid ongoing charges for the resources:
Stop the EMR cluster if it wasn’t a transient cluster:
aws emr terminate-clusters --cluster-ids <<cluster id created above>>
Conclusion
In this post, we presented two automated solutions: one for parsing Oozie workflows and HiveQL files to generate metadata, and a PySpark solution for running SQLs using generated metadata. We successfully implemented these solutions to migrate a Hive workload to EMR Spark for a major gaming customer and achieved about 60% effort reduction.
For a Hive with Oozie to Spark migration, these solutions help complete the code conversion quickly so you can focus on performance benchmark and testing. Developing a new pipeline is also quick—you only need to create SQL logic, test it using Spark (shell or notebook), add metadata to DynamoDB, and test via the PySpark SQL solution. Overall, you can use the solution in this post to accelerate Hive to Spark code migration.
About the authors
Vinay Kumar Khambhampati is a Lead Consultant with the AWS ProServe Team, helping customers with cloud adoption. He is passionate about big data and data analytics.
Sandeep Singh is a Lead Consultant at AWS ProServe, focused on analytics, data lake architecture, and implementation. He helps enterprise customers migrate and modernize their data lake and data warehouse using AWS services.
Amol Guldagad is a Data Analytics Consultant based in India. He has worked with customers in different industries like banking and financial services, healthcare, power and utilities, manufacturing, and retail, helping them solve complex challenges with large-scale data platforms. At AWS ProServe, he helps customers accelerate their journey to the cloud and innovate using AWS analytics services.
Amazon OpenSearch Serverless is a serverless option of Amazon OpenSearch Service that makes it easy for you to run large-scale search and analytics workloads without having to configure, manage, or scale OpenSearch clusters. It automatically provisions and scales the underlying resources to deliver fast data ingestion and query responses for even the most demanding and unpredictable workloads. With OpenSearch Serverless, you can configure SAML to enable users to access data through OpenSearch Dashboards using an external SAML identity provider (IdP).
AWS IAM Identity Center (Successor to AWS Single Sign-On) helps you securely create or connect your workforce identities and manage their access centrally across AWS accounts and applications, OpenSearch Dashboards being one of them.
In this post, we show you how to configure SAML authentication for OpenSearch Dashboards using IAM Identity Center as its IdP.
Solution overview
The following diagram illustrates how the solution allows users or groups to authenticate into OpenSearch Dashboards using single sign-on (SSO) with IAM Identity Center using its built-in directory as the identity source.
The workflow steps are as follows:
A user accesses the OpenSearch Dashboard URL in their browser and chooses the SAML provider.
OpenSearch Serverless redirects the login to the specified IdP.
The IdP provides a login form for the user to specify the credentials for authentication.
After the user is authenticated successfully, a SAML assertion is sent back to OpenSearch Serverless.
OpenSearch Serverless validates the SAML assertion, and the user logs in to OpenSearch Dashboards.
IAM Identity Center should be enabled, and you should have the relevant IAM permissions to create an application in IAM Identity Center and create and manage users and groups.
Create and configure the application in IAM Identity Center
To set up your application in IAM Identity Center, complete the following steps:
On the IAM Identity Center dashboard, choose Applications in the navigation pane.
Choose Add application
For Custom application, select Add custom SAML 2.0 application.
Choose Next.
Under Configure application, enter a name and description for the application.
Under IAM Identity Center metadata, choose Download under IAM Identity Center SAML metadata file.
We use this metadata file to create a SAML provider under OpenSearch Serverless. It contains the public certificate used to verify the signature of the IAM Identity Center SAML assertions.
Under Application properties, leave Application start URL and Relay state blank.
For Session duration, choose 1 hour (the default value).
Note that the session duration you configure in this step takes precedence over the OpenSearch Dashboards timeout setting specified in the configuration of the SAML provider details on the OpenSearch Serverless end.
Under Application metadata, select Manually type your metadata values.
For Application ACS URL, enter your URL using the format https://collection.<REGION>.aoss.amazonaws.com/_saml/acs. For example, we enter https://collection.us-east-1.aoss.amazonaws.com/_saml/acs for this post.
For Application SAML audience, enter your service provider in the format aws:opensearch:<aws account id>.
Choose Submit.
Now you modify the attribute settings. The attribute mappings you configure here become part of the SAML assertion that is sent to the application.
On the Actions menu, choose Edit attribute mappings.
Configure Subject to map to ${user:email}, with the format unspecified.
Using ${user:email} here ensures that the email address for the user in IAM Identity Center is passed in the <NameId> tag of the SAML response.
Choose Save changes.
Now we assign a user to the application.
Create a user in IAM Identity Center to use to log in to OpenSearch Dashboards.
Alternatively, you can use an existing user.
On the IAM Identity Center console, navigate to your application and choose Assign Users and select the user(s) you would like to assign.
You have now created a custom SAML application. Next, you will configure the SAML provider in OpenSearch Serverless.
Create a SAML provider
The SAML provider you create in this step can be assigned to any collection in the same Region. Complete the following steps:
On the OpenSearch Service console, under Serverless in the navigation pane, choose SAML authentication under Security.
Choose Create SAML provider.
Enter a name and description for your SAML provider.
Enter the metadata from your IdP that you downloaded earlier.
Under Additional settings, you can optionally add custom user ID and group attributes. We leave these settings blank for now.
Choose Create a SAML provider.
You have now configured a SAML provider for OpenSearch Serverless. Next, we walk you through configuring the data access policy for accessing collections.
Create the data access policy
In this section, you set up data access policies for OpenSearch Serverless and allow access to the users. Complete the following steps:
On the OpenSearch Service console, under Serverless in the navigation pane, choose Data access policies under Security.
Choose Create access policy.
Enter a name and description for your access policy.
For Policy definition method, select Visual Editor.
In the Rules section, enter a rule name.
Under Select principals, for Add principals, choose SAML users and groups.
For SAML provider name, choose the SAML provider you created earlier.
Specify the user in the format user/<email> (for example, user/[email protected]).
The value of the email address should match the email address in IAM Identity Center.
Choose Save.
Choose Grant and specify the permissions.
You can configure what access you want to provide for the specific user at the collection level and specific indexes at the index pattern level.
Choose Save and configure any additional rules, if required.
You can now review and edit your configuration if needed.
Choose Create to create the data access policy.
Now you have the data access policy that will allow the users to perform the allowed actions on OpenSearch Dashboards.
Access OpenSearch Dashboards
To sign in to OpenSearch Dashboards, complete the following steps:
On the OpenSearch Service dashboard, under Serverless in the navigation pane, choose Dashboard.
Locate your dashboard and copy the OpenSearch Dashboards URL (in the format <collection-endpoint>/_dashboards).
Enter this URL into a new browser tab.
On the OpenSearch login page, choose your IdP and specify your SSO credentials.
Choose Login.
Configure SAML authentication using groups in IAM Identity Center
Groups can help you organize your users and permissions in a coherent way. With groups, you can add multiple users from the IdP, and then use groupid as the identifier in the data access policy. For more information, refer to Add groups and Add users to groups.
To configure group access to OpenSearch Dashboards, complete the following steps:
On the IAM Identity Center console, navigate to your application.
In the Attribute mappings section, add an additional user as group and map it to ${user:groups}, with the format unspecified.
Choose Save changes.
For the SAML provider in OpenSearch Serverless, under Additional settings, for Group attribute, enter group.
For the data access policy, create a new rule or add an additional principal in the previous rule.
Choose the SAML provider name and enter group/<GroupId>.
You can fetch the value for the group ID by navigating to the Group section on the IAM Identity Center console.
Clean up
If you don’t want to continue using the solution, be sure to delete the resources you created:
In this post, you learned how to set up IAM Identity Center as an IdP to access OpenSearch Dashboards using SAML as SSO. You also learned on how to set up users and groups within IAM Identity Center and control the access of users and groups for OpenSearch Dashboards. For more details, refer to SAML authentication for Amazon OpenSearch Serverless.
Stay tuned for a series of posts focusing on the various options available for you to build effective log analytics and search solutions using OpenSearch Serverless. You can also refer to the Getting started with Amazon OpenSearch Serverless workshop to know more about OpenSearch Serverless.
If you have feedback about this post, submit it in the comments section. If you have questions about this post, start a new thread on the OpenSearch Service forum or contact AWS Support.
About the Authors
Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree.
Ravi Bhatane is a software engineer with Amazon OpenSearch Serverless Service. He is passionate about security, distributed systems, and building scalable services. When he’s not coding, Ravi enjoys photography and exploring new hiking trails with his friends.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
With AWS Secrets Manager, you can securely store, manage, retrieve, and rotate the secrets required for your applications and services running on AWS. A secret can be a password, API key, OAuth token, or other type of credential used for authentication purposes. You can control access to secrets in Secrets Manager by using AWS Identity and Access Management (IAM) permission policies. In this blog post, I will show you how to use principles of attribute-based access control (ABAC) to define dynamic IAM permission policies in AWS IAM Identity Center (successor to AWS Single Sign-On) by using user attributes from an external identity provider (IdP) and resource tags in Secrets Manager.
What is ABAC and why use it?
Attribute-based access control (ABAC) is an authorization strategy that defines permissions based on attributes or characteristics of the user, the data, or the environment, such as the department, business unit, or other factors that could affect the authorization outcome. In the AWS Cloud, these attributes are called tags. By assigning user attributes as principal tags, you can simplify the process of creating fine-grained permissions on AWS.
With ABAC, you can use attributes to build more dynamic policies that provide access based on matching attribute conditions. ABAC rules are evaluated dynamically at runtime, which means that the users’ access to applications and data and the type of allowed operations automatically change based on the contextual factors in the policy. For example, if a user changes department, access is automatically adjusted without the need to update permissions or request new roles. You can use ABAC in conjunction with role-based access control (RBAC) to combine the ease of policy administration with flexible policy specification and dynamic decision-making capability to enforce least privilege.
AWS IAM Identity Center (successor to AWS Single Sign-On) expands the capabilities of IAM to provide a central place that brings together the administration of users and their access to AWS accounts and cloud applications. With IAM Identity Center, you can define user permissions and manage access to accounts and applications in your AWS Organizations organization centrally. You can also create ABAC permission policies in a central place. ABAC will work with attributes from a supported identity source in IAM Identity Center. For a list of supported external IdPs for identity synchronization through the System for Cross-domain Identity Management (SCIM) and Security Assertion Markup Language (SAML) 2.0, see Supported identity providers.
The following are key benefits of using ABAC with IAM Identity Center and Secrets Manager:
Fewer permission sets — With ABAC, multiple users who use the same IAM Identity Center permission set and the same IAM role can still get unique permissions, because permissions are now based on user attributes. Administrators can author IAM policies that grant users access only to secrets that have matching attributes. This helps reduce the number of distinct permissions that you need to create and manage in IAM Identity Center and, in turn, reduces your permission management complexity.
Teams can change and grow quickly — When you create new secrets, you can apply the appropriate tags, which will automatically grant access without requiring you to update the permission policies.
Use employee attributes from your corporate directory to define access — You can use existing employee attributes from a supported identity source configured in IAM Identity Center to make access control decisions on AWS.
Figure 1 shows a framework to control access to Secrets Manager secrets using IAM Identity Center and ABAC principles.
Figure 1: ABAC framework to control access to secrets using IAM Identity Center
The following is a brief introduction to the basic components of the framework:
User attribute source or identity source — This is where your users and groups are administered. You can configure a supported identity source with IAM Identity Center. You can then define and manage supported user attributes in the identity source.
Policy management — You can create and maintain policy definitions (permission sets) centrally in IAM Identity Center. You can assign access to a user or group to one or more accounts in IAM Identity Center with these permission sets. You can then use attributes defined in your identity source to build ABAC policies for managing access to secrets.
Policy evaluation — When you assign a permission set, IAM Identity Center creates corresponding IAM Identity Center-controlled IAM roles in each account, and attaches the policies specified in the permission set to those roles. IAM Identity Center manages the role, and allows the authorized users that you’ve defined to assume the role. When users try to access a secret, IAM dynamically evaluates ABAC policies on the target account to determine access based on the attributes assigned to the user and resource tags assigned to that secret.
How to configure ABAC with IAM Identity Center
To configure ABAC with IAM Identity Center, you need to complete the following high-level steps. I will walk you through these steps in detail later in this post.
Identify and set up identities that are created and managed in the identity source with user attributes, such as project, team, AppID or department.
In IAM Identity Center, enable Attributes for access control and configure select attributes (such as department) to use for access control. For a list of supported attributes, see Supported external identity provider attributes.
If you are using an external IdP and choose to use custom attributes from your IdP for access controls, configure your IdP to send the attributes through SAML assertions to IAM Identity Center.
Assign appropriate tags to secrets in Secrets Manager.
Create permission sets based on attributes added to identities and resource tags.
Define guardrails to enforce access using ABAC.
ABAC enforcement and governance
Because an ABAC authorization model is based on tags, you must have a tagging strategy for your resources. To help prevent unintended access, you need to make sure that tagging is enforced and that a governance model is in place to protect the tags from unauthorized updates. By using service control policies (SCPs) and AWS Organizations tag policies, you can enforce tagging and tag governance on resources.
When you implement ABAC for your secrets, consider the following guidance for establishing a tagging strategy:
During secret creation, secrets must have an ABAC tag applied (tag-on-create).
During secret creation, the provided ABAC tag key must be the same case as the principal’s ABAC tag key.
After secret creation, the ABAC tag cannot be modified or deleted.
Only authorized principals can do tagging operations on secrets.
You enforce the permissions that give access to secrets through tags.
For more information on tag strategy, enforcement, and governance, see the following resources:
In this post, I will walk you through the steps to enable the IdP that is supported by IAM Identity Center.
Figure 2: Sample solution implementation
In the sample architecture shown in Figure 2, Arnav and Ana are users who each have the attributes department and AppID. These attributes are created and updated in the external directory—Okta in this case. The attribute department is automatically synchronized between IAM Identity Center and Okta using SCIM. The attribute AppID is a custom attribute configured on Okta, and is passed to AWS as a SAML assertion. Both users are configured to use the same IAM Identity Center permission set that allows them to retrieve the value of secrets stored in Secrets Manager. However, access is granted based on the tags associated with the secret and the attributes assigned to the user.
For example, user Arnav can only retrieve the value of the RDS_Master_Secret_AppAlpha secret. Although both users work in the same department, Arnav can’t retrieve the value of the RDS_Master_Secret_AppBeta secret in this sample architecture.
Prerequisites
Before you implement the solution in this blog post, make sure that you have the following prerequisites in place:
You have IAM Identity Center enabled for your organization and connected to an external IdP using SAML 2.0 identity federation.
You have IAM Identity Center configured for automatic provisioning with an external IdP using the SCIM v2.0 standard. SCIM keeps your IAM Identity Center identities in sync with identities from the external IdP.
Solution implementation
In this section, you will learn how to enable access to Secrets Manager using ABAC by completing the following steps:
Configure ABAC in IAM Identity Center
Define custom attributes in Okta
Update configuration for the IAM Identity Center application on Okta
Make sure that required tags are assigned to secrets in Secrets Manager
Create and assign a permission set with an ABAC policy in IAM Identity Center
Define guardrails to enforce access using ABAC
Step 1: Configure ABAC in IAM Identity Center
The first step is to set up attributes for your ABAC configuration in IAM Identity Center. This is where you will be mapping the attribute coming from your identity source to an attribute that IAM Identity Center passes as a session tag. The Key represents the name that you are giving to the attribute for use in the permission set policies. You need to specify the exact name in the policies that you author for access control. For the example in this post, you will create a new attribute with Key of department and Value of ${path:enterprise.department}. For supported external IdP attributes, see Attribute mappings.
To configure ABAC in IAM Identity Center (console)
Open the IAM Identity Center console.
In the Settings menu, enable Attributes for access control.
Choose the Attributes for access control tab, select Add attribute, and then enter the Key and Value details as follows.
The sample architecture in this post uses a custom attribute (AppID) on an external IdP for access control. In this step, you will create a custom attribute in Okta.
To define custom attributes in Okta (console)
Open the Okta console.
Navigate to Directory and then select Profile Editor.
On the Profile Editor page, choose Okta User (default).
Select Add Attribute and create a new custom attribute with the following parameters.
For Data type, enter string
For Display name, enter AppID
For Variable name, enter user.AppID
For Attribute length, select Less Than from the dropdown and enter a value.
For User permission, enter Read Only
Navigate to Directory, select People, choose in-scope users, and enter a value for Department and AppID attributes. The following shows these values for the users in our example.
Step 3: Update SAML configuration for IAM Identity Center application on Okta
Automatic provisioning (through the SCIM v2.0 standard) of user and group information from Okta into IAM Identity Center supports a set of defined attributes. A custom attribute that you create on Okta won’t be automatically synchronized to IAM Identity Center through SCIM. You can, however, define the attribute in the SAML configuration so that it is inserted into the SAML assertions.
To update the SAML configuration in Okta (console)
Open the Okta console and navigate to Applications.
On the Applications page, select the app that you defined for IAM Identity Center.
Under the Sign On tab, choose Edit.
Under SAML 2.0, expand the Attributes (Optional) section, and add an attribute statement with the following values, as shown in Figure 3:
Figure 3: Sample SAML configuration with custom attributes
To check that the newly added attribute is reflected in the SAML assertion, choose Preview SAML, review the information, and then choose Save.
Step 4: Make sure that required tags are assigned to secrets in Secrets Manager
The next step is to make sure that the required tags are assigned to secrets in Secrets Manager. You will review the required tags from the Secrets Manager console.
To verify required tags on secrets (console)
Open the Secrets Manager console in the target AWS account and then choose Secrets.
Verify that the required tags are assigned to the secrets in scope for this solution, as shown in Figure 4. In our example, the tags are as follows:
Key: department
Value: Digital
Key: AppID
Value: Alpha or Beta
Figure 4: Sample secret configuration with required tags
Step 5a: Create a permission set in IAM Identity Center using ABAC policy
In this step, you will create a new permission set that allows access to secrets based on the principal attributes and resource tags.
When you enable ABAC and specify attributes, IAM Identity Center passes the attribute value of the authenticated user to AWS Security Token Service (AWS STS) as session tags when an IAM role is assumed. You can use access control attributes in your permission sets by using the aws:PrincipalTag condition key to create access control rules.
To create a permission set (console)
Open the IAM Identity Center console and navigate to Multi-account permissions.
Choose Permission sets, and then select Create permission set.
On the Specify policies and permissions boundary page, choose Inline policy.
For Inline policy, paste the following sample policy document and then choose Next. This policy allows users to retrieve the value of only those secrets that have resource tags that match the required user attributes (department and AppID in our example).
Configure the session duration, and optionally provide a description and tags for the permission set.
Review and create the permission set.
Step 5b: Assign permission set to users in IAM Identity Center
Now that you have created a permission set with ABAC policy, complete the configuration by assigning the permission set to users to grant them access to secrets in one or more accounts in your organization.
To assign a permission set (console)
Open the IAM Identity Center console and navigate to Multi-account permissions.
Choose AWS accounts and select one or more accounts to which you want to assign access.
Choose Assign users or groups.
On the Assign users and groups page, select the users, groups, or both to which you want to assign access. For this example, I select both Arnav and Ana.
On the Assign permission sets page, select the permission set that you created in the previous section.
Review your changes, as shown in Figure 5, and then select Submit.
Figure 5: Sample permission set assignment
Step 6: Define guardrails to enforce access using ABAC
To govern access to secrets to your workforce users only through ABAC and to help prevent unauthorized access, you can define guardrails. In this section, I will show you some sample service control policies (SCPs) that you can use in your organization.
Note: Before you use these sample SCPs, you should carefully review, customize, and test them for your unique requirements. For additional instructions on how to attach an SCP, see Attaching and detaching service control policies.
Guardrail 1 – Enforce ABAC to access secrets
The following sample SCP requires the use of ABAC to access secrets in Secrets Manager. In this example, users and secrets must have matching values for the attributes department and AppID. Access is denied if those attributes don’t exist or if they don’t have matching values. Also, this example SCP allows only the admin role to access secrets without matching tags. Replace <arn:aws:iam::*:role/secrets-manager-admin-role> with your own information.
The following sample SCP denies the creation of new secrets that don’t have the required tag key-value pairs. In this example, the SCP denies creation of a new secret if it doesn’t include department and AppID tag keys. It also denies access if the tag department doesn’t have the value Digital and the tag AppID doesn’t have either Alpha or Beta assigned to it. Also, this example SCP allows only the admin role to create secrets without matching tags. Replace <arn:aws:iam::*:role/secrets-manager-admin-role> with your own information.
The following sample SCP denies the ability to delete the tags used for ABAC. In this example, only the admin role can delete the tags department and AppID after they are attached to a secret. Replace <arn:aws:iam::*:role/secrets-manager-admin-role> with your own information.
Guardrail 4 – Restrict modification of ABAC tags
The following sample SCP denies the ability to modify required tags for ABAC after they are attached to a secret. In this example, only the admin role can modify the tags department and AppID after they are attached to a secret. Replace <arn:aws:iam::*:role/secrets-manager-admin-role> with your own information.
In this section, you will test the solution by retrieving a secret using the Secrets Manager console. Your attempt to retrieve the secret value will be successful only when the required resource and principal tags exist, and have matching values (AppID and department in our example).
Test scenario 1: Retrieve and view the value of an authorized secret
In this test, you will verify whether you can successfully retrieve the value of a secret that belongs to your application.
To test the scenario
Sign in to IAM Identity Center and log in with your external IdP user. For this example, I log in as Arnav.
On the IAM Identity Center dashboard, select the target account.
From the list of available roles that the user has access to, choose the role that you created in Step 5a and select Management console, as shown in Figure 6. For this example, I select the SecretsManagerABACTest permission set.
Figure 6: Sample IAM Identity Center dashboard
Open the Secrets Manager console and select a secret that belongs to your application. For this example, I select RDS_Master_Secret_AppAlpha.
Because the AppID and department tags exist on both the secret and the user, the ABAC policy allowed the user to describe the secret, as shown in Figure 7.
Figure 7: Sample secret that was described successfully
In the Secret value section, select Retrieve secret value.
Because the value of the resource tags, AppID and department, matches the value of the corresponding user attributes (in other words, the principal tags), the ABAC policy allows the user to retrieve the secret value, as shown in Figure 8.
Figure 8: Sample secret value that was retrieved successfully
Test scenario 2: Retrieve and view the value of an unauthorized secret
In this test, you will verify whether you can retrieve the value of a secret that belongs to a different application.
Open the Secrets Manager console and select a secret that belongs to a different application. For this example, I select RDS_Master_Secret_AppBeta.
Because the value of the resource tag AppID doesn’t match the value of the corresponding user attribute (principal tag), the ABAC policy denies access to describe the secret, as shown in Figure 9.
Figure 9: Sample error when describing an unauthorized secret
Conclusion
In this post, you learned how to implement an ABAC strategy using attributes and to build dynamic policies that can simplify access management to Secrets Manager using IAM Identity Center configured with an external IdP. You also learned how to govern resource tags used for ABAC and establish guardrails to enforce access to secrets using ABAC. To learn more about ABAC and Secrets Manager, see Attribute-Based Access Control (ABAC) for AWS and the Secrets Manager documentation.
If you have feedback about this blog post, submit comments in the Comments section below. If you have questions about this blog post, start a new thread on AWS Secrets Manager re:Post.
Want more AWS Security news? Follow us on Twitter.
This blog post shows you how to use AWS CloudTrail Lake capabilities to investigate CloudTrail activity across AWS Organizations in response to a security incident scenario. We will walk you through two security-related scenarios while we investigate CloudTrail activity. The method described in this post will help you with the investigation process, allowing you to gain comprehensive understanding of the incident and its implications. CloudTrail Lake is a managed audit and security lake that allows you to aggregate, immutably store, and query your activity logs for auditing, security investigation, and operational troubleshooting.
Prerequisites
You must have the following AWS services enabled before you start the investigation.
CloudTrail Lake — To learn how to enable this service and use sample queries, see the blog post Announcing AWS CloudTrail Lake – a managed audit and security Lake. When you create a new event data store at the organization level, you will need to enable CloudTrail Lake for all of the accounts in the organization. We advise that you include not only management events but also data events.
When you use CloudTrail Lake with AWS Organizations, you can designate an account within the organization to be the CloudTrail Lake delegated administrator. This provides a convenient way to perform queries from a designated AWS security account—for example, you can avoid granting access to your AWS management account.
Amazon GuardDuty — This is a threat detection service that continuously monitors your AWS accounts and workloads for malicious activity and delivers detailed security findings for visibility and remediation. To learn about the benefits of the service and how to get started, see Amazon GuardDuty.
Incident scenario 1: AWS access keys compromised
In the first scenario, you have observed activity within your AWS account from an unauthorized party. This example covers a situation where a threat actor has obtained and misused one of your AWS access keys that was exposed publicly by mistake. This investigation starts after Amazon GuardDuty generates an IAM finding identifying that the malicious activity came from the exposed AWS access key. Following the Incident Response Playbook Compromised IAM Credentials, focusing on step 12 in the playbook ([DETECTION AND ANALYSIS] Review CloudTrail Logs), you will use CloudTrail Lake capabilities to investigate the activity that was performed with this key. To do so, you will use the following nine query examples that we provide for this first scenario.
Query 1.1: Activity performed by access key during a specific time window
The first query is aimed at obtaining the specific activity that was performed by this key, either successfully or not, during the time the malicious activity took place. You can use the GuardDuty finding details “EventFirstSeen” and “EventLastSeen” to define the time window of the query. Also, and for further queries, you want to fetch artifacts that could be considered possible indicators of compromise (IoC) related to this security incident, such as IP addresses.
SELECT eventSource,eventName,sourceIPAddress,eventTime,errorCode FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE userIdentity.accessKeyId = 'AKIAIOSFODNN7EXAMPLE' AND eventTime > '2022-03-15 13:10:00' AND eventTime < '2022-03-16 00:00:00' order by eventTime;
The results of the query are as follows:
Figure 1: Sample query 1.1 and results in the AWS Management Console
The results demonstrate that the activity performed by the access key tried to unsuccessfully list Amazon Simple Storage Services (Amazon S3) buckets and CloudTrail trails. You can also see specific write activity related to AWS Identity and Access Management (IAM) that was denied, and afterwards there was activity possibly related to reconnaissance tactics in IAM to finally be able to assume a role, which indicates a possible attempt to perform an escalation of privileges. You can observe only one source IP from which this activity was performed.
Query 1.2: Confirm which IAM role was assumed by the threat actor during a specific time window
As you observed from the previous query results, the threat actor was able to assume an IAM role. In this query, you would like to confirm which IAM role was assumed during the security incident.
Query 1.2
SELECT requestParameters,responseElements FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE eventName = 'AssumeRole' AND eventTime > '2022-03-15 13:10:00' AND eventTime < '2022-03-16 00:00:00' AND userIdentity.accessKeyId = 'AKIAIOSFODNN7EXAMPLE'
The results of the query are as follows:
Figure 2: Sample query 1.2 and results in the console
The results show that an IAM role named “Alice” was assumed in a second account. For future queries, keep the temporary access key from the responseElements result to obtain activity performed by this role session.
Query 1.3: Activity performed from an IP address in an expanded time window search
Investigating the incident only from the time of discovery may result in overlooking signs or indicators of potential past incidents that were not detected related to this threat actor. For this reason, you want to expand the investigation window time, which might result in expanding the search back weeks, months, or even years, depending on factors such as the nature and severity of the incident, available resources, and so on. In this example, for balance and urgency, the window of time searched is expanded to a month. You want to also review whether there is past activity related to this account by the IP you previously observed.
Query 1.3
The results of the query are as follows:
SELECT eventSource,eventName,sourceIPAddress,eventTime,errorCode FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE sourceIPAddress = '192.0.2.76' AND useridentity.accountid = '555555555555 AND eventTime > '2022-02-15 13:10:00' AND eventTime < '2022-03-15 13:10:00' order by eventTime;
Figure 3: Sample query 1.3 and results in the console
As you can observe from the results, there is no activity coming from this IP address in this account in the previous month.
Query 1.4: Activity performed from an IP address in any other account in your organization during a specific time window
Before you start investigating what activity was performed by the role assumed in the second account, and considering that this malicious activity now involves cross-account access, you will want to review whether any other account in your organization has activity related to the specific IP address observed. You will need to expand the window of time to an entire month in order to see if previous activity was performed before this incident from this source IP, and you will need to exclude activity coming from the first account.
Query 1.4
SELECT useridentity.accountid,eventTime FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE sourceIPAddress = '192.0.2.76' AND eventTime > '2022-02-15 13:10:00' AND eventTime < '2022-03-16 00:00:00' AND useridentity.accountid != '555555555555'GROUP by useridentity.accountid
The results of the query are as follows:
Figure 4: Sample query 1.4 and results in the console
As you can observe from the results, there is activity only in the second account where the role was assumed. You can also confirm that there was no activity performed in other accounts in the previous month from this IP address.
Query 1.5: Count activity performed by an IAM role during a specific time period
For the next query example, you want to count and group activity based on the API actions that were performed in each service by the role assumed. This query helps you quantify and understand the impact of the possible unauthorized activity that might have happened in this second account.
Query 1.5
SELECT count (*) as NumberEvents, eventSource, eventName FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE eventTime > '2022-03-15 13:10:00' AND eventTime < '2022-03-16 00:00:00' AND useridentity.type = 'AssumedRole' AND useridentity.sessioncontext.sessionissuer.arn = 'arn:aws:iam::111122223333:role/Alice' GROUP by eventSource, eventName order by NumberEvents desc;
The results of the query are as follows:
Figure 5: Sample query 1.5 and results in the console
You observe that the activity is consistent with what was shown in the first account, and the threat actor seems to be targeting trails, S3 buckets, and IAM activity related to possible further escalation of privileges.
Query 1.6: Confirm successful activity performed by an IAM role during a specific time window
Following the example in query 1.1, you will fetch the information related to activity that was successful or denied. This helps you confirm modifications that took place in the environment, or the creation of new resources. For this example, you will also want to obtain the event ID in case you need to dig further into one specific API call. You will then filter out activity done by any other session by using the temporary access key obtained from query 1.2.
Query 1.6
SELECT eventSource, eventName, eventTime, eventID, errorCode FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE eventTime > '2022-03-15 13:10:00' AND eventTime < '2022-03-16 00:00:00' AND useridentity.type = 'AssumedRole' AND useridentity.sessioncontext.sessionissuer.arn = 'arn:aws:iam::111122223333:role/Alice' AND userIdentity.accessKeyId = 'ASIAZNYXHMZ37EXAMPLE '
The results of the query are as follows:
Figure 6: Sample query 1.6 and results in the console
You can observe that the threat actor was again not able to perform activity upon the trails, S3 buckets, or IAM roles. But as you can see, the threat actor was able to perform specific IAM activity, which led to the creation of a new IAM user, policy attachment, and access key.
Query 1.7: Obtain new access key ID created
By making use of the event ID from the CreateAccesskey event displayed in the previous query, you can obtain the access key ID so that you can further dig into what activity was performed by it.
Query 1.7
SELECT responseElements FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE eventID = 'bd29bab7-1153-4510-9e7f-9ff9bba4bd9a'
The results of the query are as follows:
Figure 7: Sample query 1.7 and results in the console
Query 1.8: Obtain successful API activity that was performed by the access key during a specific time window
Following previous examples, you will count and group the API activity that was successfully performed by this access key ID. This time, you will exclude denied activity in order to understand the activity that actually took place.
Query 1.8
SELECT count (*) as NumberEvents, eventSource, eventName FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE eventTime > '2022-03-15 13:10:00' AND eventTime < '2022-03-16 00:00:00' AND userIdentity.accessKeyId = 'AKIAI44QH8DHBEXAMPLE' AND errorcode IS NULL GROUP by eventSource, eventName order by NumberEvents desc;
The results of the query are as follows:
Figure 8: Sample query 1.8 and results in the console
You can observe that this time, the threat actor was able to perform specific activities targeting your trails and buckets due to privilege escalation. In these results, you observe that a trail was successfully stopped, and S3 objects were downloaded and deleted.
You can also see bucket deletion activity. At first glance, this might indicate activity related to a data exfiltration scenario in the case where the bucket was not properly secured, and possible future ransom demands could be made if proper preventive controls and measures to recover the data were not in place. For more details on this scenario, see this AWS Security blog post.
Query 1.9: Obtain bucket and object names affected during a specific time window
After you obtain the activities on the S3 buckets by using sample query 1.8, you can use the following query to show what objects this activity was related to, and from which buckets. You can expand the query to exclude denied activity.
Query 1.9
SELECT element_at(requestParameters, 'bucketName') as BucketName, element_at(requestParameters, 'key') as ObjectName, eventName FROM 1994bee2-d4a0-460e-8c07-1b5ee04765d8 WHERE (eventName = 'GetObject' OR eventName = 'DeleteObject') AND eventTime > '2022-03-15 13:10:00' AND eventTime < '2022-03-16 00:00:00' AND userIdentity.accessKeyId = 'AKIAI44QH8DHBEXAMPLE' AND errorcode IS NULL
The results of the query are as follows:
Figure 9: Sample query 1.9 and results in the console
As you can observe, the unauthorized user was able to first obtain and exfiltrate S3 objects, and then delete them afterwards.
Summary of incident scenario 1
This scenario describes a security incident involving a publicly exposed AWS access key that is exploited by a threat actor. Here is a summary of the steps taken to investigate this incident by using CloudTrail Lake capabilities:
Investigated AWS activity that was performed by the compromised access key
Observed possible adversary tactics and techniques that were used by the threat actor
Collected artifacts that could be potential indicators of compromise (IoC), such as IP addresses
Confirmed role assumption by the threat actor in a second account
Expanded the time window of your investigation and the scope to your entire organization in AWS Organizations; and searched for any activity that might have taken place originating from the IP address related to the unauthorized activity
Investigated AWS activity that was performed by the role assumed in the second account
Identified new resources that were created by the threat actor, and malicious activity performed by the actor
Confirmed the modifications caused by the threat actor and their impact in your environment
Incident scenario 2: AWS IAM Identity Center user credentials compromised
In this second scenario, you start your investigation from a GuardDuty finding stating that an Amazon Elastic Compute Cloud (Amazon EC2) instance is querying an IP address that is associated with cryptocurrency-related activity. There are several sources of logs that you might want to explore when you conduct this investigation, including network, operation system, or application logs, among others. In this example, you will use CloudTrail Lake capabilities to investigate API activity logged in CloudTrail for this security event. To understand what exactly happened and when, you start by querying information from the resource involved, in this case an EC2 instance, and then continue digging into the AWS IAM Identity Center (successor to AWS Single Sign-On) credentials that were used to launch that EC2 instance, to finally confirm what other actions were performed.
Query 2.1: Confirm who has launched the EC2 instance involved in the cryptocurrency-related activity
You can begin by looking at the finding CryptoCurrency:EC2/BitcoinTool.B to get more information related to this event, for example when (timestamp), where (AWS account and AWS Region), and also which resource (EC2 instance ID) was involved with the security incident and when it was launched. With this information, you can perform the first query for this scenario, which will confirm what type of user credentials were used to launch the instance involved.
Query 2.1
SELECT userIdentity.principalid, eventName, eventTime, recipientAccountId, awsRegion FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE responseElements IS NOT NULL AND element_at(responseElements, 'instancesSet') like '%"instanceId":"i-053a7e6164c0f0473"%' AND eventTime > '2022-09-13 12:45:59' AND eventName='RunInstances'
The results of the query are as follows:
Figure 10: Sample query 2.1 and results in the console
The results demonstrate that the IAM Identity Center user as principal ID AROASVPO5CIEXAMPLE:[email protected] was used to launch the EC2 instance that was involved in the incident.
Query 2.2: Confirm in which AWS accounts the IAM Identity Center user has federated and authenticated
You want to confirm which AWS accounts this specific IAM Identity Center user has federated and authenticated with, and also which IAM role was assumed. This is important information to make sure that the security event happened only within the affected AWS account. The window of time for this query is based on the maximum value for the permission sets’ session duration in IAM Identity Center.
Query 2.2
SELECT element_at(serviceEventDetails, 'account_id') as AccountID, element_at(serviceEventDetails, 'role_name') as SSORole, eventID, eventTime FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE eventSource = 'sso.amazonaws.com' AND eventName = 'Federate' AND userIdentity.username = '[email protected]' AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00'
The results of the query are as follows:
Figure 11: Sample query 2.2 and results in the console
The results show that only one AWS account has been accessed during the time of the incident, and only one AWS role named AdministratorAccess has been used.
Query 2.3: Count and group activity based on API actions that were performed by the user in each AWS service
You now know exactly where the user has gained access, so next you can count and group the activity based on the API actions that were performed in each AWS service. This information helps you confirm the types of activity that were performed.
Query 2.3
SELECT eventSource, eventName, COUNT(*) AS apiCount FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE userIdentity.principalId = 'AROASVPO5CIEXAMPLE:[email protected]' AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00' GROUP BY eventSource, eventName ORDER BY apiCount DESC
The results of the query are as follows:
Figure 12: Sample query 2.3 and results in the console
You can see that the list of APIs includes the read activities Get, Describe, and List. This activity is commonly associated with the discovery stage, when the unauthorized user is gathering information to determine credential permissions.
Query 2.4: Obtain mutable activity based on API actions performed by the user in each AWS service
To get a better understanding of the mutable actions performed by the user, you can add a new condition to hide the read-only actions by setting the readOnly parameter to false. You will want to focus on mutable actions to know whether there were new AWS resources created or if existing AWS resources were deleted or modified. Also, you can add the possible error code from the response element to the query, which will tell you if the actions were denied.
Query 2.4
SELECT eventSource, eventName, eventTime, eventID, errorCode FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE userIdentity.principalId = 'AROASVPO5CIEXAMPLE:[email protected]' AND readOnly = false AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00'
The results of the query are as follows:
Figure 13: Sample query 2.4 and results in the console
You can confirm that some actions, like EC2 RunInstances, EC2 CreateImage, SSM StartSession, IAM CreateUser, and IAM PutRolePolicy were allowed. And in contrast, IAM CreateAccessKey, IAM CreateRole, IAM AttachRolePolicy, and GuardDuty DeleteDetector were denied. The IAM-related denied actions are commonly associated with persistence tactics, where an unauthorized user may try to maintain access to the environment. The GuardDuty denied action is commonly associated with defense evasion tactics, where the unauthorized user is trying to cover their tracks and avoid detection.
Query 2.5: Obtain more information about API action EC2 RunInstances
You can focus first on the API action EC2 RunInstances to understand how many EC2 instances were created by the same user. This information will confirm which other EC2 instances were involved in the security event.
Query 2.5
SELECT awsRegion, recipientAccountId, eventID, element_at(responseElements, 'instancesSet') as instances FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE userIdentity.principalId = 'AROASVPO5CIEXAMPLE:[email protected]' AND eventName='RunInstances' AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00'
The results of the query are as follows:
Figure 14: Sample query 2.5 and results in the console
You can confirm that the API was called twice, and if you expand the column InstanceSet in the response element, you will see the exact number of EC2 instances that were launched. Also, you can find that these EC2 instances were launched with an IAM instance profile called ec2-role-ssm-core. By checking in the IAM console, you can confirm that the IAM role associated has only the AWS managed policy AmazonSSMManagedInstanceCore attached, which enables AWS Systems Manager core functionality.
Query 2.6: Get the list of denied API actions performed by the user for each AWS service
Now, you can filter more to focus only on those denied API actions by performing the following query. This is important because it can help you to identify what kind of malicious event was attempted.
Query 2.6
SELECT recipientAccountId, awsRegion, eventSource, eventName, eventID, eventTime FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE userIdentity.principalId = 'AROASVPO5CIEXAMPLE:[email protected]' AND errorCode = 'AccessDenied' AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00'
The results of the query are as follows:
Figure 15: Sample query 2.6 and results in the console
You can see that the user has tried to stop GuardDuty by calling DeleteDetector, and has also performed actions within IAM that you should examine more closely to know if new unwanted access to the environment was created.
Query 2.7: Obtain more information about API action IAM CreateUserAccessKeys
With the previous query, you confirmed that more actions were denied within IAM. You can now focus on the failed attempt to create IAM user access keys that could have been used to gain persistent and programmatic access to the AWS account. With the following query, you can make sure that the actions were denied and determine the reason why.
Query 2.7
SELECT recipientAccountId, awsRegion, eventID, eventTime, errorCode, errorMessage FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE userIdentity.principalId = 'AROASVPO5CIEXAMPLE:[email protected]' AND eventName='CreateAccessKey' AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00'
The results of the query are as follows:
Figure 16: Sample query 2.7 and results in the console
If you copy the errorMessage element from the response, you can confirm that the action was denied by a service control policy, as shown in the following example.
"errorMessage":"User: arn:aws:sts::111122223333:assumed-role/AWSReservedSSO_AdministratorAccess_f53d10b0f8a756ac/[email protected] is not authorized to perform: iam:CreateAccessKey on resource: user production-user with an explicit deny in a service control policy"
Query 2.8: Obtain more information about API IAM CreateUser
From the query error message in query 2.7, you can confirm the name of the IAM user that was used. Now you can check the allowed API action IAM CreateUser that you observed before to see if the IAM users match. This helps you confirm that there were no other IAM users involved in the security event.
Query 2.8
SELECT recipientAccountId, awsRegion, eventID, eventTime, element_at(responseElements, 'user') as userInfo FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE userIdentity.principalId = 'AROASVPO5CIEXAMPLE:[email protected]' AND eventName='CreateUser' AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00'
The results of the query are as follows:
Figure 17: Sample query 2.8 and results in the console
Based on this output, you can confirm that the IAM user is indeed the same. This user was created successfully but was denied the creation of access keys, confirming the failed attempt to get new persistent and programmatic credentials.
Query 2.9: Get more information about the IAM role creation attempt
Now you can figure out what happened with the IAM CreateRole denied action. With the following query, you can see the full error message for the denied action.
Query 2.9
SELECT recipientAccountId, awsRegion, eventID, eventTime, errorCode, errorMessage FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE userIdentity.principalId = 'AROASVPO5CIEXAMPLE:[email protected]' AND eventName='CreateRole' AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00'
The results of the query are as follows:
Figure 18: Sample query 2.9 and results in the console
If you copy the output of this query, you will see that the role was denied by a service control policy, as shown in the following example:
"errorMessage":"User: arn:aws:sts::111122223333:assumed-role/AWSReservedSSO_AdministratorAccess_f53d10b0f8a756ac/[email protected] is not authorized to perform: iam:CreateRole on resource: arn:aws:iam::111122223333:role/production-ec2-role with an explicit deny in a service control policy"
Query 2.10: Get more information about IAM role policy changes
With the previous query, you confirmed that the unauthorized user failed to create a new IAM role to replace the existing EC2 instance profile in an attempt to grant more permissions. And with another of the previous queries, you confirmed that the IAM API action AttachRolePolicy was also denied, in another attempt for the same goal, but this time trying to attach a new AWS managed policy directly. However, with this new query, you can confirm that the unauthorized user successfully applied an inline policy to the EC2 role associated with the existing EC2 instance profile, with full admin access.
Query 2.10
SELECT recipientAccountId, eventID, eventTime, element_at(requestParameters, 'roleName') as roleName, element_at(requestParameters, 'policyDocument') as policyDocument FROM 467f2e52-84b9-4d41-8049-bc8f8fad35dd WHERE userIdentity.principalId = 'AROASVPO5CIEXAMPLE:[email protected]' AND eventName = 'PutRolePolicy' AND eventTime > '2022-09-13 00:00:00' AND eventTime < '2022-09-14 00:00:00'
The results of the query are as follows:
Figure 19: Sample query 2.10 and results in the console
Summary of incident scenario 2
This second scenario describes a security incident that involves an IAM Identity Center user that has been compromised. To investigate this incident by using CloudTrail Lake capabilities, you did the following:
Started the investigation by looking at metadata from the GuardDuty EC2 finding
Confirmed the AWS credentials that were used for the creation of that resource
Looked at whether the IAM Identity Center user credentials were used to access other AWS accounts
Did further investigation on the AWS APIs that were called by the IAM Identity Center user
Obtained the list of denied actions, confirming the unauthorized user’s attempt to get persistent access and cover their tracks
Obtained the list of EC2 resources that were successfully created in this security event
Conclusion
In this post, we’ve shown you how to use AWS CloudTrail Lake capabilities to investigate CloudTrail activity in response to security incidents across your organization. We also provided sample queries for two security incident scenarios. You now know how to use the capabilities of CloudTrail Lake to assist you and your security teams during the investigation process in a security incident. Additionally, you can find some of the sample queries related to this post and other topics in the following GitHub repository, and additional examples in the sample queries tab in the CloudTrail console. To learn more, see Working with CloudTrail Lake in the CloudTrail User Guide.
Regarding pricing for CloudTrail Lake, you pay for ingestion and storage together, where the billing is based on the amount of uncompressed data ingested. If you’re a new customer, you can try AWS CloudTrail Lake for a 30-day free trial or when you reach the free usage limits of 5GB of data. For more information, see see AWS CloudTrail pricing.
Finally, in combination with the investigation techniques shown in this post, we also recommend that you explore the use of Amazon Detective, an AWS managed and dedicated service that simplifies the investigative process and helps security teams conduct faster and more effective investigations. With the Amazon Detective prebuilt data aggregations, summaries, and context, you can quickly analyze and determine the nature and extent of possible security issues.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed, highly available, and secure Apache Kafka service. Amazon MSK reduces the work needed to set up, scale, and manage Apache Kafka in production. With Amazon MSK, you can create a cluster in minutes and start sending data.
With Amazon MSK Serverless, you can run Apache Kafka without having to manage the underlying infrastructure. Amazon MSK will automatically provision, scale, and manage your Apache Kafka clusters, so you can focus on your applications without worrying about the operational overhead. Additionally, MSK Serverless offers fine-grained, pay-as-you-go pricing, making it a cost-effective option for organizations with unpredictable workloads.
Connecting to MSK Serverless is easy. You can set up a serverless cluster using the API or AWS Management Console in minutes. MSK Serverless provides bootstrap information as a private DNS endpoint, allowing clients to connect to the serverless Apache Kafka cluster. A common use case of using MSK Serverless is an on-premises client that needs to process real-time data streams. However, the private DNS endpoint is only accessible from virtual private clouds (VPCs) that have been configured to connect and isn’t directly resolvable from an on-premises network. This can pose a challenge for on-premises clients to discover and connect to the MSK Serverless cluster. In this post, we guide you through a step-by-step process to connect your on-premises client to MSK Serverless, overcoming this challenge.
Solution overview
The following diagram illustrates the solution architecture.
The flow of the solution is as follows:
The DNS query for your MSK endpoint is routed to a locally configured on-premises DNS server.
The on-premises DNS as configured performs conditional forwarding for kafka-serverless.REPLACE-MSK-SERVERLESS-REGION.amazonaws.com to an Amazon Route 53 inbound resolver endpoint IP address.
The inbound resolver endpoint performs DNS resolution by forwarding the query to the private hosted zone that was created along with the MSK Serverless cluster.
The IP addresses returned by the DNS query are the private IP addresses of the interface VPC endpoint, which allow your on-premises host to establish private connectivity over AWS VPN or AWS Direct Connect.
The interface endpoint is a collection of one or more elastic network interfaces with a private IP address in your account that serves as an entry point for traffic destined to a MSK Serverless service.
Note that at this time, this solution works only for MSK Serverless clusters with a single VPC.
Prerequisites
In this section, we discuss the prerequisite steps to complete in order to implement this solution.
Establish network connectivity between on premises and the AWS Cloud
To use MSK Serverless from your on-premises network, you need to establish a network connection between your on-premises environment and the VPC that you have set up for MSK Serverless. Various secure methods are available to connect your on-premises network to the AWS Cloud. Refer to Network-to-Amazon VPC connectivity options for more information.
Create a security group for allowing inbound TCP/UDP connections from your on-premises network
Create a security group with the following configurations on the same VPC that you configured for MSK Serverless:
Update the MSK security group for inbound connections from your on-premises network
To ensure that your MSK Serverless cluster can be accessed from your on-premises network, you need to adjust the cluster’s security group settings to allow incoming traffic from your network on TCP port 9098. Complete the following steps:
On the Amazon MSK console, choose Clusters in the navigation pane.
Navigate to your serverless MSK cluster’s properties.
Choose the security group associated with your MSK cluster.
Because MSK Serverless supports configuring multiple VPCs, make sure to choose the security group associated with the VPC that you configured for connecting from your on-premises network.
To enable connections from your on-premises CIDR block to MSK Serverless, add an inbound rule that allows traffic on TCP port 9098 from your on-premises CIDR.
This ensures that your on-premises network can communicate with MSK Serverless on the specified port.
Configure a Route 53 inbound resolver endpoint
MSK Serverless provides a DNS endpoint that serves as the starting point for an Apache Kafka client to connect to the cluster. However, this endpoint isn’t publicly discoverable and can only be accessed from within the configured VPC. To resolve the serverless DNS endpoint outside of your VPC, you can set up a Route 53 resolver endpoint. This allows you to access the endpoint securely by creating a hybrid cloud setup over VPN or Direct Connect.
To configure the Route 53 resolver using the console, complete the following steps:
On the Route 53 console, under Resolver in the navigation pane, choose Inbound endpoints.
Choose Create inbound endpoint.
For Endpoint name, enter the endpoint name.
For VPC in the Region, choose the VPC where you configured MSK Serverless.
For Security group for this endpoint, choose the security group that you created as a prerequisite for inbound TCP/UDP connections.
The security group of the inbound resolver endpoint should allow traffic from the on-premises DNS Server IP address on TCP/UDP port 53. In the next step, you add your IP addresses, ensuring that the number of IP addresses matches the number of subnets in your MSK cluster.
Choose the Availability Zones and subnets that are the same as your MSK Serverless network configuration.
Select Use anIP address that is selected automatically.
Choose Create inbound endpoint.
Copy the inbound endpoint IP addresses.
Configure the on-premises DNS server
In this example, we use a Microsoft DNS server. To configure a conditional forwarder, complete the following steps:
Open DNS Manager.
Run the following command in the Run command window:
dnsmgmt.msc
Choose (right-click) Conditional Forwarders under the server of your choosing, then choose New Conditional Forwarder.
In the next step, you enter kafka-serverless.REPLACE-MSK-SERVERLESS-REGION.amazonaws.com, using the IP address of Route 53 inbound resolver endpoints that you created earlier. You can find the MSK endpoint information by accessing the cluster’s client information. To learn more about getting client information, refer to Getting the bootstrap brokers for an Amazon MSK cluster.
For DNS Domain, enter your endpoint name. For example, kafka-serverless.ap-southeast-2.amazonaws.com. Do not enter the entire endpoint name.
Choose OK.
Test the DNS resolution
DNS (Domain Name System) uses TCP/UDP port 53. To test whether you can connect any of the Route 53 inbound endpoints, run the following command from your on-premises client:
telnet Route53-INBOUND-ENDPOINT-IP 53
For example: telnet 10.1.0.133 53
The following is a sample output:
Trying 10.1.0.133...
Connected to 10.1.0.133.
Escape character is '^]'.
Connection closed by foreign host.
Run the following command to check whether you can connect with the MSK Serverless endpoint from your on-premises client. To get the MSK Serverless endpoint information, refer to Create an MSK Serverless cluster.
After you create a serverless MSK cluster, the service automatically creates an interface VPC endpoint for the cluster. You can use the dig command as shown above to retrieve the VPC endpoint ID and its associated IP address, which confirms that you are now able to connect to the MSK Serverless cluster from your on-premises environment.
Test your Kafka client
Once you complete the configuration of the Route 53 inbound resolver endpoint and on-premises DNS server, you can test your Kafka client from an on-premises network. For instructions, refer to Create a client machine. This documentation guides you through the necessary steps to set up your client machine and verify that it can successfully connect to your MSK cluster from your on-premises network.
Conclusion
MSK Serverless makes it easy for you to manage your data. You don’t have to worry about setting up and running your own Kafka cluster, which saves time and effort. In this post, we explored the option of on-premises connectivity with MSK Serverless and how it can greatly benefit organizations. By establishing this connection, you can gain access to a wide range of real-time analytics use case possibilities and unlock the full potential of your data.
We encourage you to try on-premises connectivity with MSK serverless.
About the Authors
Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.
Akeef Khan is a Solutions Architect at Amazon Web Services. He helps SMB Greenfield customers adopt the cloud. Whilst being a generalist SA, Akeef is passionate about networking.
Amazon OpenSearch Service is used for a broad set of use cases like real-time application monitoring, log analytics, and website search at scale. As your domain ages and you add additional consumers, you need to reevaluate and change the domain’s configuration to handle additional storage and compute needs. You want to minimize downtime and performance impact as you make these changes.
Customers have been seeking guidance on best practices and patterns for changing index settings without an index maintenance window or affecting overall performance of the OpenSearch Service domain. This is part one of a two-part series, in which we show how to make settings changes to OpenSearch Service indexes with little to no downtime while supporting active producers and consumers of the data.
Indexes in OpenSearch Service
In OpenSearch Service, data must be indexed before it can be queried. Indexing is the method by which search engines organize data for fast retrieval. The resulting structure is called, fittingly, an index. All operations performed on an index are done via index APIs. Also, each index contains index mappings, which define field names and data types in the index. Data producers can add new fields with data types to an index. Index mappings can’t change throughout the index lifecycle.
OpenSearch Service indexes have two types of settings that periodically need adjustments as the profile of your workload changes:
Dynamic – Settings that can be changed on the index at any time
Static – Settings that can only be defined at the index creation time and can’t be changed throughout the index lifecycle
Dynamic index settings can be changed at any time using the update settings API. While the OpenSearch Service domain is performing instructed operations on dynamic index settings, the index doesn’t require a downtime. Changes to most dynamic index settings won’t trigger background tasks that affect the overall utilization of domain resources; however, some settings such as increasing the number of replicas via index.number_of_replicas or index.auto_expand_replicas, and depending on the domain’s configuration, can cause a temporary increase in resource utilization while the domain adds replicas. We recommend maintaining at least one replica for redundancy reasons, and multiple replicas for high query throughput use cases.
Static index settings such as mapping and shard count are defined at index creation time and can’t be changed throughout the index lifecycle. In this post, we focus on patterns and best practices for working with static index settings, such as changing shard count and patterns for updating index mappings.
As with any use case, there is a spectrum of solutions and constraints to be considered. We start with a few simple foundational patterns and build on them, accounting for use cases with more operational constraints and working with large datasets.
Solution overview
OpenSearch Service has a default sharding strategy of 5:1, where each index is divided into five primary shards. Within each index, each primary shard also has its own replica. OpenSearch Service automatically assigns primary shards and replica shards to separate data nodes.
It’s not possible to increase the primary shard number of an existing index, meaning an index must be recreated if you want to increase the primary shard count.
The _reindex operation is ideal for creating destination indexes with updated shards and mapping settings. The _reindex operation is resource intensive. We recommend disabling replicas in your destination index by setting number_of_replicas to 0 and re-enable replicas when the reindex process is complete. If you have your data in a second, durable store, the simplest thing to do is pause updates and reindex from the source. But that’s not always possible. In this post, we share several patterns that enable you to update even static index settings like shard count.
One the major advantages of using the _reindex operation is that it doesn’t require placing the source index in a read-only mode (data producers may continue to write the data while reindexing is in progress). Also, the _reindex operation enables reprocessing, transformation, and reindexing a subset of documents and even selectively combining documents from multiple indexes. With the _reindex operation, you can copy all or a subset of documents that you select through a query to another index. In its most basic form, the _reindex operation requires you to specify a source and a destination index and configuration parameters.
The following are the some of the use cases supported by the reindex API:
Reindexing all documents
Reindexing from a remote cluster when transferring data between clusters
Reindexing a subset of documents that match a search query
Combining one or more indexes
Transforming documents during reindexing
To increase the shard count, you create a new index, set number_of_shards to your desired primary shard count, set number_of_replicas to 0, update the new index mapping based on your requirement, and run the reindex API operation. After the _reindex operation is complete, we recommend updating number_of_replicas in the destination index settings to achieve your desired level of replica shards.
In the following sections, we provide a walkthrough of the reindex API operation. Note that the patterns and procedures presented in this post have been validated on Amazon OpenSearch Service version 1.3.
Prerequisites
The source of the documents must be stored in the index (the “_source” setting at the index mappings level must be set to “enabled”:true, which is the default). The _reindex operation can’t be used without source documents.
Create the destination index with your desired mapping (field or data type). For demonstration purposes, our source index has a field ratings defined as long, and we want the same field to use the float data type in the destination index:
Ensure that you have sufficient disk space on each hot tier data node to house the new index primary shards and, depending on your configuration, replica shards. If disk space is insufficient, perform an update operation on the OpenSearch Service domain to add the required storage capacity. Depending on storage requirements, you may need to migrate the OpenSearch Service domain to a different instance type, because nodes have constraints on the EBS volume size that can be mounted to each instance type. Issue the following operation to validate available disk space:
GET _cat/allocation?v
The following screenshot shows the output.
Check the disk.avail metric for hot storage tier nodes to validate your available disk space.
Use the reindex API operation
The _reindex operation snapshots the index at the beginning of its run and performs processing on a snapshot to minimize impact on the source index. The source index can still be used for querying and processing the data. Although the _reindex operation can run both synchronously and asynchronously, we recommend using an asynchronous run. You can monitor the progress of the _reindex operation, cancel its run, or throttle its run using the _task, _cancel, and _rethrottle operations, respectively.
Because the _reindex operation doesn’t require the source index placed in a read-only mode, query and index update operations are free to continue.
The source indexes as part of the _reindex API operation can be supplemented with a query for reindexing a subset of documents and storing them in the destination index. Progress of the re-indexing operation can be monitored via tasks API operation:
GET _tasks
Note that the _reindex operation can be throttled via a _rethrottle API or settings passed as a parameter. You can cancel the task with the _cancel operation:
POST _tasks/TASK_ID/_cancel
The following screenshot shows the output of the _reindex operation for reindexing from source_index_name to destination_index_name.
When the operation is complete, both consumers and producers of the source indexes or aliases need to re-point to the destination index and the same _reindex operation needs to run again to catch up on any create, update, or delete operations performed on the source indexes while the initial _reindex operation was running. This step is required because the _reindex operation is running on a snapshot of the index. At this time, the _reindex operation needs to run with “op_type”:”create” to realign missing and out-of-version documents. See the following API command:
After the operation is complete and data integrity in the destination index is confirmed, you can delete the source index to reclaim disk space.
Increase index shard count using the split index API
The split index API and shrink index API cover a large array of use cases and present with low resource utilization in the domain. However, these APIs require closing the index for write operations and don’t address use cases that require changes to the mapping settings.
In OpenSearch Service, the number_of_shards index setting is immutable and defined at the time when the index is created. However, although this setting is immutable, there are several patterns to increase or decrease index shard count without needing to explicitly reindex the data. You can alternatively use the split index API to increase index shard count in the environments that can suspend write operations. The split index API provides a simplified way of creating a new index with a different shard setting and without reindexing your data. The split index API operation creates a new index based off of a read-only index with a desired number of primary shards.
In OpenSearch Service, an index alias is a virtual index name that can point to one or more indexes. Referencing to indexes using aliases in your applications allows you to avoid index name changes. Index aliases are used to point consumers and producers to a new index after the split index API operation is complete.
Although the majority of use cases focus on increasing a number of shards on an existing index due to data growth, there are also instances where you need to reduce the number of shards on an existing index. Such cases occasionally happen when an actual index size is less than what was anticipated when the index was created, and you want to align with a shard strategy for operational best practices for OpenSearch Service. In cases where you need to reduce a number of shards on an index, you can use the shrink index API to achieve this task.
Conclusion
In this post, we reviewed best practices when reindexing data for making changes in OpenSearch Service static index settings and mappings that require little or no index downtime. We also covered use of the split index and shrink index APIs for changing the primary index shard count for use cases where the index can be placed in a read-only state.
In our next post, we’ll explore patterns for remote indexing to alleviate load and resource utilization on the source OpenSearch Service domain.
About the Authors
Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare and life sciences customers to build solutions that help improve patients’ outcomes. Mikhail specializes in data analytics services.
Sukhomoy Basak is a Solutions Architect at Amazon Web Services, with a passion for data and analytics solutions. Sukhomoy works with enterprise customers to help them architect, build, and scale applications to achieve their business outcomes.
The fleet management market is expected to grow at a Compound Annual Growth Rate (CAGR) of 15.5 percent—from 25.5 billion US dollars in 2022 to USD 52.4 billion in 2027. Optimizing how your organization uses its vehicle fleet is important for logistics and service providers such as last mile, middle mile, and field services.
In this post, we demonstrate how to build and run a solution for many-to-many vehicle routing using HERE Tour Planning and Amazon Location Service. HERE Technologies is a data provider for Amazon Location Service and provides it with map rendering, geocoding, search, and routing. HERE Tour Planning expands on functionality such as geocoding, basic routing, and matrix routing to consider parameters such as time windows, job requirements or priorities, vehicle capabilities, range, and traffic information. They also support immediate re-planning when conditions change.
The architecture described in this post can help you optimize your fleets for delivering shipments, such as perishable items on pallets, from a central distribution center to multiple retail locations. The architecture uses the AWS Cloud Development Kit (AWS CDK) to help you provision and version control your infrastructure. The architecture also uses Event Driven Architecture (EDA) based on AWS Lambda and Amazon DynamoDB. It uses Amazon Simple Storage Service (Amazon S3) and DynamoDB to store the artifacts generated and integrates with Amazon Location Service to plot the routes visually on a map for each delivery driver.
Solution overview
This post will help you:
Configure the many-to-many vehicle routing architecture using HERE Tour Planning and Amazon Location Service
This is needed to invoke the HERE Tour Planning API for generating solutions to new routing problems.
The GitHub sample repository includes a problem and pre-solved solution file, so you don’t need to acquire a HERE API key to learn about these offerings.
There can be additional charges based on API key use. For more details, see the HERE Tour Planning section within HERE service rates.
Walkthrough
Provision the infrastructure
The architecture uses NPM node modules. Run the following commands to install the dependencies:
# AWS Lambda function dependencies cd lib/lambda/calculate-route npm install
# Sample Frontend application dependencies cd frontend/here-driver-app npm install
If you have never used AWS CDK in your AWS account, you must first bootstrap the solution, which creates Amazon S3 buckets and metadata to support AWS CDK operations. Note: Architectural components described in this article are covered under AWS Free Tier and HERE Free monthly usage, but additional charges can occur based on usage beyond the Free Tier limits. We recommend following the Cleanup instructions after completing the walkthrough.
From the root of the repository, run the following command to generate the needed infrastructure:
cdk bootstrap
Output similar to the following indicates that you successfully bootstrapped the AWS account with what AWS CDK requires.
Figure 2. Successful bootstrap of AWS account with AWS CDK requirements
Deploy the infrastructure for this solution by running the following command. This provisions much of the infrastructure required for this solution such as DynamoDB, Lambda functions, and Amazon S3 buckets:
cdk deploy
Next, Amplify provisions the remaining resources to complete the architecture. Navigate to the folder for the frontend by running the following command:
To accept the defaults, run the following command:
amplify init
To push the infrastructure out to the AWS account, run the following command:
amplify push
To publish the environment, run the following command:
amplify publish
Create problem and generate architecture files
The next step is to create the HERE Tour Planning problem file and submit it to the HERE Tour Planning API to solve. Note: You can either sign up for the HERE Developer program to receive an API key to test this solution live or use the problem and pre-solved solution provided in the /data folder of the repository.
Open the Amazon S3 bucket that the previous step created.
Upload a problem file (in JSON format) to the bucket.
An Amazon S3 event notification invokes a Lambda function that performs a synchronous call to the HERE Tour Planning API and generates vehicle routing problem solution file in JSON format.
The Lambda function saves the solution file to the Amazon S3 bucket and additional details about the solution to a DynamoDB table.
The delivery drivers can use the example React app to view the list of vehicles and the routes.
Figure 3. Creating a problem file and submitting it to HERE Tour Planning API
Frontend
The next step is to run the React Frontend app to see the results. Access to the app and the API Gateway is secured with Amazon Cognito.
To run the web application, run the following command:
npm start
A local web server runs on http://localhost:3000.
To use the system, the user must authenticate. Amazon Cognito allows users to sign in or create a new account.
After you authenticate, the Home screen displays a list of available vehicles and routes.
Figure 4. Available vehicles and routes
Choose a vehicle to see the detail of the route. Each red marker is a stop.
Figure 5. Vehicle route details
Cleanup
To avoid incurring future charges, delete all resources created.
Run the following commands to delete the application in AWS Amplify. As an alternative, you can use the Amplify console to delete Amplify resources:
cd frontend/here-driver-app amplify pull amplify delete
With AWS CDK, run the following command to delete the AWS CloudFormation stack that was used to provision the resources. Note: You can leave the AWS CLI, Amplify CLI, and CDK CLI installed on your computer for future development:
cdk destroy
Conclusion
In this post, using shipment delivery from a central distribution center use case, we’ve demonstrated how you can build your own serverless solution for optimizing middle and last mile operations. The solution uses multi-vehicle and multi-stop optimization services provided by HERE Tour Planning and Amazon Location Service to visualize the generated routes for each delivery vehicle driver. For additional details about HERE’s offerings on AWS Marketplace, see AWS Marketplace: HERE Technologies.
To respond to emerging threats, you will often need to sort through large datasets rapidly to prioritize security findings. Amazon Detective recently released two new features to help you do this. New visualizations in Detective show the connections between entities related to multiple Amazon GuardDuty findings, and a new export data feature helps you use the data from Detective in your other tools and automated workflows.
In this post, we’ll show you how you can use these new features to help reduce the time it takes to assess, investigate, and prioritize a security incident.
If GuardDuty detects potential malicious activity, such as anomalous behavior, credential exfiltration, or command and control (C2) infrastructure communication, it generates detailed security incidents called findings.
Depending on the severity and complexity of the GuardDuty finding, the resolution might require deep investigation. Consider an example that involves cryptocurrency mining. If you frequently see a cryptocurrency finding on your EC2 instances, you might have a recurring malware issue that has enabled a backdoor. If a threat actor is attempting to compromise your AWS environment, they typically perform a sequence of actions that lead to multiple findings and unusual behavior. When security findings are investigated in isolation, it can lead to a misinterpretation of their significance and difficulty in finding the root cause. When you need more context around a finding, Detective can help.
Detective automatically collects log data and events from sources like CloudTrail logs, Amazon VPC Flow Logs, GuardDuty findings, and Amazon EKS audit logs and maintains up to a year of aggregated data for analysis. Detective uses machine learning to create a behavioral graph for these data sources that helps show how security issues have evolved. It highlights what AWS resources might be compromised and flags unusual activity like new API calls, new user agents, and new AWS Regions.
The search capabilities work across AWS workloads, providing the information required to show the potential impact of an incident. Detective helps you answer questions like: How did this security incident happen? What AWS resources were affected? How can we prevent this from happening again?
Finding groups help connect the dots of an incident
You can use finding groups, a recent feature of Detective, to help with your investigations. A finding group is a collection of entities related to a single potential security incident that should be investigated together. An entity can be an AWS resource like an EC2 instance, IAM role, or GuardDuty finding, but it can also be an IP address or user agent. For a full list of entities collected, see Searching for a finding or entity in the Detective User Guide.
Grouping these entities together helps provide context and a more complete understanding of the threat landscape. This makes it simpler for you to identify relationships between different events and to assess the overall impact of a potential threat.
In the cryptocurrency mining example described previously, finding groups could show the relationship between the cryptocurrency mining finding and a C2 finding so that you know the two are related and the AWS resources affected. To learn more about working with Detective finding groups, see How to improve security incident investigations using Amazon Detective finding groups.
Figure 1 shows the finding groups overview page on the Detective console, with a list of finding groups filtered by status. The dashboard also shows the severity, title, observed tactics, accounts, entities, and the total number of findings for each finding group. For more information about the attributes of finding groups, see Analyzing finding groups.
Figure 1: Finding groups overview
To see details about the finding group, select the title of the finding group to access the details page, which includes Details, Visualization, Involved entities, and Involved findings. On this panel, you can view entities and findings included in a finding group and interact with them. The information presented is the same in the Visualization panel, the Involved entities panel, and the Involved findings panel. The different views allow you to view the information in the way that is helpful for you. Figure 2 shows an example of the Details and Visualization for a specific finding group.
Figure 2: Details and Visualization
Note: Finding groups with over 100 nodes (findings and entities) do not include a graph visualization.
Visualizations to show you the situation
The new visualizations in Detective provide three layouts that display the same information from finding groups, but allow you to choose and arrange the different entities so that you can focus on the highest priority finding or resources.
To determine what each visual element represents, choose the Legend in the bottom left corner of the panel. You can change the placement of findings in the Visualization panel by selecting a different layout from the Select layout dropdown menu. Figure 2 in the preceding section shows the Force-directed layout, where the positioning of entities and findings presents an even distribution of links with minimal overlap, while maintaining consistent distance between items.
Figure 3 shows the Visualization panel with the Circle layout, where nodes are displayed in a circular layout. You can use the Legend to understand the different categories of Findings, Compute, Network, Identity, Storage, or Other.
Figure 3: Visualization panel with Circle layout and Legend
Figure 4 shows the Visualization panel with the Grid layout, where nodes are divided into four different columns: evidence, identity entities, GuardDuty findings, and other entities (compute, network, and storage).
Figure 4: Visualization panel with Grid layout
In the Visualization panel, you can select one or more (using ctrl/cmd+click) nodes. Selected nodes are listed next to the graph, and you can select each node’s title for more information. Selecting an entity’s title opens a new page that displays detailed information about that entity, whereas selecting a finding or evidence expands the right sidebar to show details on the selected finding or evidence.
You can rearrange chosen entities and findings as needed to help improve your understanding of their connections. This can help speed up your assessment of findings. Figure 5 shows the Visualization panel with four nodes selected and the sidebar displaying information relevant to the selected finding.
Figure 5: Visualization panel with evidence selected
Finding groups and visualizations provide an overview of the entities and resources related to a security activity. Presenting the information in this way highlights the interconnections between various activities. This means that you no longer have to use multiple tools or query different services to collect information or investigate entities and resources. This can help you reduce triage and scoping times and make your investigations faster and more comprehensive.
Increased flexibility for investigation with simpler data access
To expand the scope of your investigation or confirm if a security incident has taken place, you might want to combine data from Detective with your own tools or different services. This is where export data comes into play.
Detective has several Summary page panels that you can use as a starting point for your investigations because they highlight potentially suspicious activity. The panels include roles and users with the most API call volume, EC2 instances with the most traffic volume, and EKS clusters with the most Kubernetes pods created.
With export data, you can now export these panels as common-separated values (CSV) files and import the data into other AWS services or third-party applications, or manipulate the data with spreadsheet programs.
Export from the Detective console Summary screen
In the Detective console, on the Summary page, you will see an Export option on several summary panes. This is enabled and available for anyone with access to Detective. Figure 6 shows summary information for the roles and users with the most API call volume.
Figure 6: Detective console Summary screen
Choose Export to download a CSV file containing the data for the summary information. The file is downloaded to your browser’s default download folder on your local device. When you view the data, it will look something like the spreadsheet in Figure 7:
Figure 7: Example CSV data export from Detective console Summary
Export from the Detective console Search screen
You can also export data using the Search capability of Detective. After you apply specific filters to search for findings or entities based on your use case, an Export button appears at the top of the search results in Detective. Figure 8 shows an example of filtering for a particular CIDR range. Choose Export to download the CSV file containing the filtered data.
Figure 8: Detective search results filtering for a CIDR range
Conclusion
In this blog post, you learned how to use the two new features of Detective to visualize findings and export data. By using these new features, you and your teams can investigate an incident in the way that best fits your workflow. New visualizations show the entities involved in an issue and surface nuanced connections that can be difficult to find when you’re faced with line after line of log data. The new data export feature makes it simpler to integrate the insights discovered in Detective with the tools and automations that your team is already using.
These features are automatically enabled for both existing and new customers in AWS Regions that support Detective. There is no additional charge for finding groups. If you don’t currently use Detective, you can start a free 30-day trial. For more information on finding groups, see Analyzing finding groups in the Amazon Detective User Guide.
Amazon Redshift is a massively parallel processing (MPP), fully managed petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using existing business intelligence tools.
When businesses are modernizing their data warehousing solutions to Amazon Redshift, implementing additional data protection mechanisms for sensitive data, such as personally identifiable information (PII) or protected health information (PHI), is a common requirement, especially for those in highly regulated industries with strict data security and privacy mandates. Amazon Redshift provides role-based access control, row-level security, column-level security, and dynamic data masking, along with other database security features to enable organizations to enforce fine-grained data security.
Security-sensitive applications often require column-level (or field-level) encryption to enforce fine-grained protection of sensitive data on top of the default server-side encryption (namely data encryption at rest). In other words, sensitive data should be always encrypted on disk and remain encrypted in memory, until users with proper permissions request to decrypt the data. Column-level encryption provides an additional layer of security to protect your sensitive data throughout system processing so that only certain users or applications can access it. This encryption ensures that only authorized principals that need the data, and have the required credentials to decrypt it, are able to do so.
In this post, we demonstrate how you can implement your own column-level encryption mechanism in Amazon Redshift using AWS Glue to encrypt sensitive data before loading data into Amazon Redshift, and using AWS Lambda as a user-defined function (UDF) in Amazon Redshift to decrypt the data using standard SQL statements. Lambda UDFs can be written in any of the programming languages supported by Lambda, such as Java, Go, PowerShell, Node.js, C#, Python, Ruby, or a custom runtime. You can use Lambda UDFs in any SQL statement such as SELECT, UPDATE, INSERT, or DELETE, and in any clause of the SQL statements where scalar functions are allowed.
Solution overview
The following diagram describes the solution architecture.
To illustrate how to set up this architecture, we walk you through the following steps:
A sample 256-bit data encryption key is generated and securely stored using AWS Secrets Manager.
An AWS Glue job reads the data file from the S3 bucket, retrieves the data encryption key from Secrets Manager, performs data encryption for the PII columns, and loads the processed dataset into an Amazon Redshift table.
We create a Lambda function to reference the same data encryption key from Secrets Manager, and implement data decryption logic for the received payload data.
We can validate the data decryption functionality by issuing sample queries using Amazon Redshift Query Editor v2.0. You may optionally choose to test it with your own SQL client or business intelligence tools.
Prerequisites
To deploy the solution, make sure to complete the following prerequisites:
Have an AWS account. For this post, you configure the required AWS resources using AWS CloudFormation in the us-east-2 Region.
Have an IAM user with permissions to manage AWS resources including Amazon S3, AWS Glue, Amazon Redshift, Secrets Manager, Lambda, and AWS Cloud9.
Deploy the solution using AWS CloudFormation
Provision the required AWS resources using a CloudFormation template by completing the following steps:
Sign in to your AWS account.
Choose Launch Stack:
Navigate to an AWS Region (for example, us-east-2).
For Stack name, enter a name for the stack or leave as default (aws-blog-redshift-column-level-encryption).
For RedshiftMasterUsername, enter a user name for the admin user account of the Amazon Redshift cluster or leave as default (master).
For RedshiftMasterUserPassword, enter a strong password for the admin user account of the Amazon Redshift cluster.
Select I acknowledge that AWS CloudFormation might create IAM resources.
Choose Create stack.
The CloudFormation stack creation process takes around 5–10 minutes to complete.
When the stack creation is complete, on the stack Outputs tab, record the values of the following:
AWSCloud9IDE
AmazonS3BucketForDataUpload
IAMRoleForRedshiftLambdaUDF
LambdaFunctionName
Upload the sample data file to Amazon S3
To test the column-level encryption capability, you can download the sample synthetic data generated by Mockaroo. The sample dataset contains synthetic PII and sensitive fields such as phone number, email address, and credit card number. In this post, we demonstrate how to encrypt the credit card number field, but you can apply the same method to other PII fields according to your own requirements.
An AWS Cloud9 instance is provisioned for you during the CloudFormation stack setup. You may access the instance from the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key AWSCloud9IDE.
On the AWS Cloud9 terminal, copy the sample dataset to your S3 bucket by running the following command:
Generate a secret and secure it using Secrets Manager
We generate a 256-bit secret to be used as the data encryption key. Complete the following steps:
Create a new file in the AWS Cloud9 environment.
Enter the following code snippet. We use the cryptography package to create a secret, and use the AWS SDK for Python (Boto3) to securely store the secret value with Secrets Manager:
Run the Python script via the following command to generate the secret:
python generate_secret.py
Create a target table in Amazon Redshift
A single-node Amazon Redshift cluster is provisioned for you during the CloudFormation stack setup. To create the target table for storing the dataset with encrypted PII columns, complete the following steps:
On the Amazon Redshift console, navigate to the list of provisioned clusters, and choose your cluster.
To connect to the cluster, on the Query data drop-down menu, choose Query in query editor v2.
If this is the first time you’re using the Amazon Redshift Query Editor V2, accept the default setting by choosing Configure account.
To connect to the cluster, choose the cluster name.
For Database, enter demodb.
For User name, enter master.
For Password, enter your password.
You may need to change the user name and password according to your CloudFormation settings.
Choose Create connection.
In the query editor, run the following DDL command to create a table named pii_table:
We recommend using the smallest possible column size as a best practice, and you may need to modify these table definitions per your specific use case. Creating columns much larger than necessary will have an impact on the size of data tables and affect query performance.
Create the source and destination Data Catalog tables in AWS Glue
The CloudFormation stack provisioned two AWS Glue data crawlers: one for the Amazon S3 data source and one for the Amazon Redshift data source. To run the crawlers, complete the following steps:
On the AWS Glue console, choose Crawlers in the navigation pane.
Select the crawler named glue-s3-crawler, then choose Run crawler to trigger the crawler job.
Select the crawler named glue-redshift-crawler, then choose Run crawler.
When the crawlers are complete, navigate to the Tables page to verify your results. You should see two tables registered under the demodb database.
Author an AWS Glue ETL job to perform data encryption
An AWS Glue job is provisioned for you as part of the CloudFormation stack setup, but the extract, transform, and load (ETL) script has not been created. We create and upload the ETL script to the /glue-script folder under the provisioned S3 bucket in order to run the AWS Glue job.
Return to your AWS Cloud9 environment either via the AWS Cloud9 console, or by visiting the URL obtained from the CloudFormation stack output with the key AWSCloud9IDE.
We use the Miscreant package for implementing a deterministic encryption using the AES-SIV encryption algorithm, which means that for any given plain text value, the generated encrypted value will be always the same. The benefit of using this encryption approach is to allow for point lookups, equality joins, grouping, and indexing on encrypted columns. However, you should also be aware of the potential security implication when applying deterministic encryption to low-cardinality data, such as gender, boolean values, and status flags.
Create a new file in the AWS Cloud9 environment and enter the following code snippet:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrameCollection
from awsglue.dynamicframe import DynamicFrame
import boto3
import base64
from miscreant.aes.siv import SIV
from pyspark.sql.functions import udf, col
from pyspark.sql.types import StringType
args = getResolvedOptions(sys.argv, ["JOB_NAME", "SecretName", "InputTable"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# retrieve the data encryption key from Secrets Manager
secret_name = args["SecretName"]
sm_client = boto3.client('secretsmanager')
get_secret_value_response = sm_client.get_secret_value(SecretId = secret_name)
data_encryption_key = get_secret_value_response['SecretBinary']
siv = SIV(data_encryption_key) # Without nonce, the encryption becomes deterministic
# define the data encryption function
def pii_encrypt(value):
if value is None:
value = ""
ciphertext = siv.seal(value.encode())
return base64.b64encode(ciphertext).decode('utf-8')
# register the data encryption function as Spark SQL UDF
udf_pii_encrypt = udf(lambda z: pii_encrypt(z), StringType())
# define the Glue Custom Transform function
def Encrypt_PII (glueContext, dfc) -> DynamicFrameCollection:
newdf = dfc.select(list(dfc.keys())[0]).toDF()
# PII fields to be encrypted
pii_col_list = ["registered_credit_card"]
for pii_col_name in pii_col_list:
newdf = newdf.withColumn(pii_col_name, udf_pii_encrypt(col(pii_col_name)))
encrypteddyc = DynamicFrame.fromDF(newdf, glueContext, "encrypted_data")
return (DynamicFrameCollection({"CustomTransform0": encrypteddyc}, glueContext))
# Script generated for node S3 bucket
S3bucket_node1 = glueContext.create_dynamic_frame.from_catalog(
database="demodb",
table_name=args["InputTable"],
transformation_ctx="S3bucket_node1",
)
# Script generated for node ApplyMapping
ApplyMapping_node2 = ApplyMapping.apply(
frame=S3bucket_node1,
mappings=[
("id", "long", "id", "long"),
("full_name", "string", "full_name", "string"),
("gender", "string", "gender", "string"),
("job_title", "string", "job_title", "string"),
("spoken_language", "string", "spoken_language", "string"),
("contact_phone_number", "string", "contact_phone_number", "string"),
("email_address", "string", "email_address", "string"),
("registered_credit_card", "long", "registered_credit_card", "string"),
],
transformation_ctx="ApplyMapping_node2",
)
# Custom Transform
Customtransform_node = Encrypt_PII(glueContext, DynamicFrameCollection({"ApplyMapping_node2": ApplyMapping_node2}, glueContext))
# Script generated for node Redshift Cluster
RedshiftCluster_node3 = glueContext.write_dynamic_frame.from_catalog(
frame=Customtransform_node,
database="demodb",
table_name="demodb_public_pii_table",
redshift_tmp_dir=args["TempDir"],
transformation_ctx="RedshiftCluster_node3",
)
job.commit()
Save the script with the file name pii-data-encryption.py.
Copy the script to the desired S3 bucket location by running the following command:
To verify the script is uploaded successfully, navigate to the Jobs page on the AWS Glue console.You should be able to find a job named pii-data-encryption-job.
Choose Run to trigger the AWS Glue job.It will first read the source data from the S3 bucket registered in the AWS Glue Data Catalog, then apply column mappings to transform data into the expected data types, followed by performing PII fields encryption, and finally loading the encrypted data into the target Redshift table. The whole process should be completed within 5 minutes for this sample dataset.You can switch to the Runs tab to monitor the job status.
Configure a Lambda function to perform data decryption
A Lambda function with the data decryption logic is deployed for you during the CloudFormation stack setup. You can find the function on the Lambda console.
The following is the Python code used in the Lambda function:
import boto3
import os
import json
import base64
import logging
from miscreant.aes.siv import SIV
logger = logging.getLogger()
logger.setLevel(logging.INFO)
secret_name = os.environ['DATA_ENCRYPT_KEY']
sm_client = boto3.client('secretsmanager')
get_secret_value_response = sm_client.get_secret_value(SecretId = secret_name)
data_encryption_key = get_secret_value_response['SecretBinary']
siv = SIV(data_encryption_key) # Without nonce, the encryption becomes deterministic
# define lambda function logic
def lambda_handler(event, context):
ret = dict()
res = []
for argument in event['arguments']:
encrypted_value = argument[0]
try:
de_val = siv.open(base64.b64decode(encrypted_value)) # perform decryption
except:
de_val = encrypted_value
logger.warning('Decryption for value failed: ' + str(encrypted_value))
res.append(json.dumps(de_val.decode('utf-8')))
ret['success'] = True
ret['results'] = res
return json.dumps(ret) # return decrypted results
If you want to deploy the Lambda function on your own, make sure to include the Miscreant package in your deployment package.
Register a Lambda UDF in Amazon Redshift
You can create Lambda UDFs that use custom functions defined in Lambda as part of your SQL queries. Lambda UDFs are managed in Lambda, and you can control the access privileges to invoke these UDFs in Amazon Redshift.
Navigate back to the Amazon Redshift Query Editor V2 to register the Lambda UDF.
Use the CREATE EXTERNAL FUNCTION command and provide an IAM role that the Amazon Redshift cluster is authorized to assume and make calls to Lambda:
CREATE OR REPLACE EXTERNAL FUNCTION pii_decrypt (value varchar(max))
RETURNS varchar STABLE
LAMBDA '<--Replace-with-your-lambda-function-name-->'
IAM_ROLE '<--Replace-with-your-redshift-lambda-iam-role-arn-->';
You can find the Lambda name and Amazon Redshift IAM role on the CloudFormation stack Outputs tab:
LambdaFunctionName
IAMRoleForRedshiftLambdaUDF
Validate the column-level encryption functionality in Amazon Redshift
By default, permission to run new Lambda UDFs is granted to PUBLIC. To restrict usage of the newly created UDF, revoke the permission from PUBLIC and then grant the privilege to specific users or groups. To learn more about Lambda UDF security and privileges, see Managing Lambda UDF security and privileges.
You must be a superuser or have the sys:secadmin role to run the following SQL statements:
GRANT SELECT ON "demodb"."public"."pii_table" TO PUBLIC;
CREATE USER regular_user WITH PASSWORD '1234Test!';
CREATE USER privileged_user WITH PASSWORD '1234Test!';
REVOKE EXECUTE ON FUNCTION pii_decrypt(varchar) FROM PUBLIC;
GRANT EXECUTE ON FUNCTION pii_decrypt(varchar) TO privileged_user;
First, we run a SELECT statement to verify that our highly sensitive data field, in this case the registered_credit_card column, is now encrypted in the Amazon Redshift table:
SELECT * FROM "demodb"."public"."pii_table";
For regular database users who have not been granted the permission to use the Lambda UDF, they will see a permission denied error when they try to use the pii_decrypt() function:
SET SESSION AUTHORIZATION regular_user;
SELECT *, pii_decrypt(registered_credit_card) AS decrypted_credit_card FROM "demodb"."public"."pii_table";
For privileged database users who have been granted the permission to use the Lambda UDF for decrypting the data, they can issue a SQL statement using the pii_decrypt() function:
SET SESSION AUTHORIZATION privileged_user;
SELECT *, pii_decrypt(registered_credit_card) AS decrypted_credit_card FROM "demodb"."public"."pii_table";
The original registered_credit_card values can be successfully retrieved, as shown in the decrypted_credit_card column.
Cleaning up
To avoid incurring future charges, make sure to clean up all the AWS resources that you created as part of this post.
You can delete the CloudFormation stack on the AWS CloudFormation console or via the AWS Command Line Interface (AWS CLI). The default stack name is aws-blog-redshift-column-level-encryption.
Conclusion
In this post, we demonstrated how to implement a custom column-level encryption solution for Amazon Redshift, which provides an additional layer of protection for sensitive data stored on the cloud data warehouse. The CloudFormation template gives you an easy way to set up the data pipeline, which you can further customize for your specific business scenarios. You can also modify the AWS Glue ETL code to encrypt multiple data fields at the same time, and to use different data encryption keys for different columns for enhanced data security. With this solution, you can limit the occasions where human actors can access sensitive data stored in plain text on the data warehouse.
Aaron Chong is an Enterprise Solutions Architect at Amazon Web Services Hong Kong. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization.
August 13, 2018: Date this post was first published, on the Front-End Web and Mobile Blog. We updated the CloudFormation template, provided additional clarification on implementation steps, and revised to account for the new Amazon Cognito UI.
User authentication and authorization can be challenging when you’re building web and mobile apps. The challenges include handling user data and passwords, token-based authentication, federating identities from external identity providers (IdPs), managing fine-grained permissions, scalability, and more.
In this blog post, we will show you how to federate identities from Windows Server Active Directory to authenticate users into your web app by using AWS services. The main AWS service that we’ll use for this purpose is Amazon Cognito.
With Amazon Cognito user pools, you can add user sign-up and sign-in to your mobile and web apps by using a secure and scalable user directory. In addition, you can federate users from a SAML IdP with Amazon Cognito user pools, map these users to a user directory, and get standard authentication tokens from a user pool after the user authenticates with a SAML IdP.
This post explains how to integrate Amazon Cognito user pools with Microsoft Active Directory Federation Services (AD FS) to obtain JSON web tokens (JWTs) in your web app—which in turn can be used for downstream authentication. To demonstrate the complete authentication flow, we’ve created a simple REST API that’s built on Amazon API Gateway. The REST API retrieves data from an Amazon DynamoDB table with the help of an AWS Lambda function. We’ll use the JWT tokens that are vended from user pools to authenticate to the REST API, which is hosted on API Gateway.
A benefit of using Amazon Cognito user pools to federate users from a SAML provider is that a user pool supports SAML 2.0 post-binding endpoints. This helps eliminate the need for client-side parsing of the SAML assertion response, and the user pool directly receives the SAML response from your IdP through a user agent.
As part of the SAML federation feature, the user pool acts as a service provider on behalf of your application. The user pool becomes a single point of identity management for your application, and your application doesn’t need to integrate with multiple SAML IdPs.
Solution overview
Figure 1 shows the authentication flow that we present throughout this blog post.
Figure 1: Authentication flow with Amazon Cognito user pool
As shown in the figure, the authentication flow involves the following steps:
The app starts the sign-up and sign-in process by directing the user to the Cognito user pools hosted web UI. For a mobile app, you can use a web view to show the hosted web UI. For this post, you will use a web app that is hosted on Amazon Simple Storage Service (Amazon S3) fronted by Amazon CloudFront.
The Amazon Cognito user pool determines the appropriate IdP based on your configuration. For AD FS, the IdP is determined by the metadata file or metadata endpoint URL from your SAML IdP. For example, if you use AD FS, the metadata URL looks like the following: https://<yourservername>/FederationMetadata/2007-06/FederationMetadata.xml
The user is redirected to the IdP—in this case, Active Directory.
The IdP authenticates the user if necessary. If the IdP recognizes that the user has an active session, then the IdP skips the authentication to provide a single sign-on experience.
The IdP sends the SAML assertion to Amazon Cognito.
The user’s profile is created in the user pool.
After verifying the SAML assertion and collecting the user attributes (claims) from the assertion, Amazon Cognito returns OIDC tokens (ID, access, and refresh tokens) to the app for the user who is now signed in.
The app then makes a GET request to API Gateway, passing along the JWT token for authorization. If authorized, the request is forwarded to Lambda for data retrieval from DynamoDB.
Installation and configuration walkthrough
To build the authentication flow that we described in the previous section, complete the following steps.
Step 1: Install Active Directory and AD FS
Step 2: Create an Amazon Cognito user pool
Step 3: Configure Active Directory and AD FS
Step 4: Complete the Amazon Cognito configuration
Step 5: Deploy and configure the web app
Step 1: Install Active Directory and AD FS
You will need to set up Active Directory and AD FS. For instructions on how to install both with an AWS CloudFormation template, see Enabling Federation to AWS Using Windows Active Directory, ADFS, and SAML 2.0. To complete the walkthrough in this blog post, you will need to have a working Active Directory service and AD FS service, and a user created within Active Directory. For this walkthrough, we created a user named bob with an email address of [email protected].
If you have an existing user pool, in the left navigation pane, choose User pools and then choose Create user pool to create a new user pool for this walkthrough.
If you don’t have an existing user pool, you will see a landing page. Keep the dropdown list as default and choose Create user pool.
In the Configure sign-in experience section, for Cognito user pool sign-in options, select Email, and then choose Next.
In the Configure security requirements section, under Multi-factor authentication, select No MFA, leave the other fields as default, and then choose Next.
In the Configure sign-up experience section, under Attribute verification and user account confirmation, deselect Allow Cognito to automatically send messages to verifyandconfirm, and choose Next.
In the Configure message delivery section, under Email, select Send email with Cognito, leave the other fields as default, and then choose Next.
In the Integrate your app section, enter a user pool name, select Use the Cognito Hosted UI, and create a domain name using a Cognito domain.
In the Initial app client section as shown in Figure 2, for App client name, enter SAML-IdP; and for Allowed callback URLs, enter https://localhost. Then choose Next.
Figure 2: Set up the initial app client to create the Cognito user pool
In the Review and create section, review all settings, and then scroll to the bottom of the page and choose Create user pool.
Step 3: Configure Active Directory and AD FS
Now that you’ve created an Amazon Cognito user pool, you need to set up Amazon Cognito as a relying party in the SAML identity provider (in this case, AD FS). After you configure AD FS, you will return to Amazon Cognito to complete the final configurations for the application to work.
Connect to the Windows Server instance where you installed AD FS as an administrator through the remote desktop protocol (RDP).
Open the AD FS 2.0 console.
To make sure that the user you created in Step 1 has an email address, in the user property window for your user, choose General. Figure 3 shows our user named bob in Active Directory with an email address of [email protected].
Figure 3: User properties of bob in the Active Directory
Determine the Uniform Resource Name (URN) for the Amazon Cognito user pool. The form of the URN is urn:amazon:cognito:sp:<user-pool-id>. You can find the user pool ID in the General settings tab.
Configure AD FS as follows to work with the Amazon Cognito user pool:
Go to Trust Relationships > Relying Party Trusts > Add relying party trusts. This will start a wizard.
Select Enter data about the relying party manually.
Enter a display name for the relying party configuration.
On the next screen, do not configure a certificate.
Enable support for the SAML 2.0 single sign-on service URL.
Add the Amazon Cognito user pool URN as the relying party trust identifier.
Configure the SAML POST binding. The SAML 2.0 post-binding endpoint (also known as the assertion consumer URL) for the Amazon Cognito user pool is https://<domain-prefix>.auth.<<region>.amazoncognito.com/saml2/idpresponse. You configured this as the domain name in Step 2.6.
Select Permit all users to access this relying party.
Choose Finish.
Navigate to Trust Relationships > Relying Party Trusts. You should see that the URN of Amazon Cognito is configured as the relying party, as shown in Figure 4:
Figure 4: Amazon Cognito trusted as the relying party
In a SAML federation, the IdP can pass various attributes about the user, the authentication method, or other points of context to the service provider (in this case, Amazon Cognito) in the form of SAML attributes. In AD FS, claim rules are used to assemble these required attributes using a combination of Active Directory lookups, simple transformations, and regular expression-based custom rules. In this example, you will configure two claim rules: Name ID and E-Mail.
The Edit Claim Rules window should already be open. If it isn’t, select your relying party trust from the Trust Relationships > Relying Party Trusts screen, and then, in the Actions tab on the right side, choose Edit Claim Rules.
On the Configure Claim Rule page, enter the following values for each configuration element, and then choose OK.
Claim rule name: Name ID
Incoming claim type: Windows account name
Outgoing claim type: Name ID
Outgoing name ID format: Persistent identifier
Repeat the preceding steps for the E-mail claim:
Claim rule name: Email
Attribute Directory: Active Directory
LDAP Attributes: Email Addresses
Outgoing Claim Type:Email Address
Before leaving the AD FS configuration, download the metadata file for the AD FS. The metadata URL for AD FS looks like the following: https://<servername>/FederationMetadata/2007-06/FederationMetadata.xmlM. The metadata file describes the endpoint of your SAML IdP (the AD FS service) to the service provider (Amazon Cognito).
Select the Amazon Cognito user pool that you created earlier, navigate to Sign-in experience > Federated identity provider sign-in, and choose Add identity provider, as shown in Figure 5.
Figure 5: Add a federated identity provider in the Amazon Cognito console
Choose SAML as the identity provider.
As shown in Figure 6, enter a name for your identity provider, choose Select file, and then upload the FederationMetadata.xml file that you downloaded at the end of Step 3.
Figure 6: Set up SAML federation with the user pool
Provide the SAML attribute to map attributes between your SAML provider and your user pool as follows:
For User pool attribute, select email.
For SAML attribute, enter http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress
These mappings map the claims from the SAML assertion from AD FS to the user pool attributes. You configured an E-mail claim in AD FS, so you need to map this with the appropriate attribute in the user pool.
Choose Add identity provider.
Step 5: Deploy and configure a web app
To reduce the number of steps required for this walkthrough, we have provided a CloudFormation template that you can use to complete the deployment, which deploys the architecture shown in Figure 7:
Figure 7: Web app architecture deployed by the CloudFormation template
This architecture is essentially the same as step 8 from the authentication flow diagram (Figure 1) earlier in this post. In Figure 7, we have added Amazon S3 and Amazon CloudFront to the diagram, which is where your static website is hosted. Complete the following steps for this walkthrough:
Step 5.1: Create the AWS CloudFormation stack
Step 5.2: Manually integrate Amazon Cognito user pools with API Gateway
Step 5.3: Update the configuration for Amazon Cognito
Step 5.4: Update the configuration for the client-side application and upload to Amazon S3
Step 5.5: Insert a row into a DynamoDB table to help you test the application
Step 5.1: Create the AWS CloudFormation stack
Let’s deploy this infrastructure:
Download the code repository, which includes the CloudFormation template named prerequisites.yaml and the sample code for a web app named DataManager.
Navigate to the CloudFormation console in the Region where you deployed the user pool, and choose Create Stack.
To upload the template to Amazon S3, choose Browse and select prerequisites.yaml in the folder where you downloaded it.
Provide a Stack name and a unique Bucket name.
Note: S3 bucket names should not contain uppercase characters.
Choose Next, and select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
Choose Create and then wait for the resources to be deployed.
Note: If the deployment fails with the error message API: s3:CreateBucket Access Denied, review the IAM permissions available for the IAM user or the role used and make sure that the s3:CreateBucket permission has been granted.
Step 5.2: Manually integrate the Amazon Cognito user pool with API Gateway
Open the API Gateway console. You should see that an API named DataManager has been created by CloudFormation, as shown in Figure 8:
Figure 8: APIs in the API Gateway console
Under APIs, choose DataManager, and then choose Authorizers.
Choose Create new Authorizer, and then populate the relevant details:
For Name, enter SamlAuthorizer (Make sure that the name of the user pool is the same as the one that you created).
For Type, select Cognito.
For Cognito user pool, enter Samlfederation.
For Token source, enter Authorization.
With this configuration, you use the user pools authorizer to authenticate Get requests to your Rest API that’s hosted on API Gateway. In the dropdown for Cognito User Pool, add the user pool that you created in Step 2: Create an Amazon Cognito user pool. Choose Create.
Navigate back to APIs > Resources, choose GET, and then choose Method Request.
To add the authorizer that you just created, under Settings, in the Authorization dropdown, choose your authorizer. Remember to save the setting by choosing the small tick symbol on the right side. If you don’t see the Cognito authorizer, just wait for several minutes for updates from API Gateway.
Figure 9: Add the Cognito authorizer for the API GET method
Step 5.3: Update the configuration for Amazon Cognito
Now you need to update the Amazon Cognito configuration based on the CloudFront distribution that you deployed using the CloudFormation template in Step 5.1.
Navigate to the CloudFormation console and locate the CloudFormation stack that was deployed. As shown in Figure 10, in the Outputs tab, copy the values for CloudfrontEndpoint and DataManagerApiInvokeUrl because you will need them later.
Figure 10: Outputs of the CloudFormation template deployment
Navigate to the Amazon Cognito console and go to your user pool. Choose the App integration tab, scroll to the bottom of the page, and for App client name, choose the App client that you added during user pool creation.
On the page for your App client, in the Hosted UI section, choose Edit, and then do the following:
For both the Allowed callback URLs and Allowed sign-out URLs, enter the CloudFront endpoint.
For OAuth grant types, select Implicit grant.
For OpenID Connect scopes, select Email and OpenID.
Figure 11: Configure the hosted UI for the app client
The Amazon Cognito hosted UI provides an OAuth 2.0 compliant authorization server. It includes the default implementation of end user flows, such as registration and authentication. Because the application interacts with Amazon Cognito through an OAuth 2.0 implicit flow, which requires a redirect, the website needs to use HTTPS.
Note: In a production scenario, instead of implicit flow, an authorization code grant is the preferred method in the OAuth 2.0 framework because it’s more secure.
To have an HTTPS endpoint for the Amazon S3 static website, you can use the CloudFront distribution that was deployed by the CloudFormation template in Step 5.1.
When one of your users successfully logs in to the Active Directory infrastructure, the user is automatically redirected to the callback URL. In this case, this is a CloudFront distribution URL with an Amazon Cognito ID token, access token, and refresh token.
Step 5.4: Update the configuration for your client-side application, and upload it to Amazon S3
Navigate to the code that you previously cloned in Step 5.1, and perform the following steps:
With a file manager, navigate to the folder where the cloned content is located. Open the DataManager directory.
Open the js folder. Using a text editor, open the config.js file.
From the Amazon Cognito console, copy the client app application ID as the value of the userPoolClientId property. You can find the application ID in the App clients menu of the Amazon Cognito console.
Change the value of the Region property to the Region that you are using (for example, us-east-2)
While you are still in the Amazon Cognito console, open the Domain name page, and copy the custom prefix into the value for the authDomainPrefix property.
Open the CloudFormation console and choose the stack that was created in Step 5.1. With the stack selected, open the Outputs tab.
Copy the value of the CloudfrontEndpoint output variable to the redirect_uri property.
Copy the value of the DataManagerApiInvokeUrl output variable to the invokeUri property.
Step 5.5: Insert a row into the DynamoDB table to help test your application
The CloudFormation template that you used in Step 5.1 created a DynamoDB table that you can use to test your application. Now you need to add a row to the table (as shown in the Items returned section of Figure 12), so that you can get some results when you test your application. To add a row, in the left menu, choose Tables > Update settings to find the table, and then choose Actions > Create item.
The Lambda function that retrieves data from the ADFSSecretData DynamoDB table only retrieves data from rows where the email matches the one used to log in to Active Directory. To achieve this, you pass the event.requestContext.authorizer.claims.email.object within the Lambda function. This object contains the email that you used to log in to Active Directory.
Figure 12: Search result of DynamoDB table
Now you’re ready to test the application.
Open the CloudFront URL in your browser and choose Enter. This should immediately take you to the web app landing page. From there, you’re automatically redirected to the Amazon Cognito hosted UI. You should see a screen similar to the following that says Sign in with your corporate ID:
Figure 13: Cognito hosted UI sign-in page
After you choose your SAML provider, you are redirected to your AD FS infrastructure that shows a login screen similar to the following:
Figure 14: AD FS sign-in page
Note: If there’s an error, make sure that there’s a mapping in the host file for your AD FS server, with the appropriate hostname or public IP address of the EC2 instance where the AD FS infrastructure is hosted
On the login screen, for Username, enter the user’s email address (in our example, that’s Bob’s email address), and for Password, enter the password that you defined in Active Directory, as shown in Figure 14. If the login is successful, you’re redirected back to the web app with a valid ID and access tokens.
Figure 15: Sample web app home page
Choose Refresh to see the data that you stored in DynamoDB.
Figure 16: Retrieval of the data from DynamoDB
Summary
In this walkthrough, you federated users from AD FS, and successfully authenticated those users to our REST API that’s hosted on API Gateway.
The SAML federation feature in Amazon Cognito helps you set up and integrate your apps with multiple SAML IdPs. By using the SAML federation capabilities of Amazon Cognito, your apps don’t need to handle the type of SAML IdP that they are interacting with. Amazon Cognito takes care of it on behalf of your application.
This article was originally written by Adrian Hall, who was an AWS Solutions Architect when he wrote it.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
We often need our text search to be agnostic of accent marks. Accent-insensitive search, also called diacritics-agnostic search, is where search results are the same for queries that may or may not contain Latin characters such as à, è, Ê, ñ, and ç. Diacritics are English letters with an accent to mark a difference in pronunciation. In recent years, words with diacritics have trickled into the mainstream English language, such as café or protégé. Well, touché! OpenSearch has the answer!
OpenSearch is a scalable, flexible, and extensible open-source software suite for your search workload. OpenSearch can be deployed in three different modes: the self-managed open-source OpenSearch, the managed Amazon OpenSearch Service, and Amazon OpenSearch Serverless. All three deployment modes are powered by Apache Lucene, and offer text analytics using the Lucene analyzers.
In this post, we demonstrate how to perform accent-insensitive search using OpenSearch to handle diacritics.
Solution overview
Lucene Analyzers are Java libraries that are used to analyze text while indexing and searching documents. These analyzers consist of tokenizers and filters. The tokenizers split the incoming text into one or more tokens, and the filters are used to transform the tokens by modifying or removing the unnecessary characters.
OpenSearch supports custom analyzers, which enable you to configure different combinations of tokenizers and filters. It can consist of character filters, tokenizers, and token filters. In order to enable our diacritic-insensitive search, we configure custom analyzers that use the ASCII folding token filter.
ASCIIFolding is a method used to covert alphabetic, numeric, and symbolic Unicode characters that aren’t in the first 127 ASCII characters (the Basic Latin Unicode block) into their ASCII equivalents, if one exists. For example, the filter changes “à” to “a”. This allows search engines to return results agnostic of the accent.
In this post, we configure accent-insensitive search using the ASCIIFolding filter supported in OpenSearch Service. We ingest a set of European movie names with diacritics and verify search results with and without the diacritics.
Create an index with a custom analyzer
We first create the index asciifold_movies with custom analyzer custom_asciifolding:
Similarly, try comparing results for “señora” and “senora” or “sorcière” and “sorciere.” The accent-insensitive results are due to the ASCIIFolding filter used with the custom analyzers.
Enable aggregations for fields with accents
Now that we have enabled accent-insensitive search, let’s look at how we can make aggregations work with accents.
"aggregations" : {
"test" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Jour de fete",
"doc_count" : 1
},
{
"key" : "Jour de fête",
"doc_count" : 1
},
{
"key" : "Kirikou et la sorcière",
"doc_count" : 1
},
{
"key" : "La gloire de mon père",
"doc_count" : 1
},
{
"key" : "Le roi et l’oiseau",
"doc_count" : 1
},
{
"key" : "Señora Acero",
"doc_count" : 1
},
{
"key" : "Señora garçon",
"doc_count" : 1
},
{
"key" : "Être et avoir",
"doc_count" : 1
}
]
}
}
Create accent-insensitive aggregations using a normalizer
In the previous example, the aggregation returns two different buckets, one for “Jour de fête” and one for “Jour de fete.” We can enable aggregations to create one bucket for the field, regardless of the diacritics. This is achieved using the normalizer filter.
The normalizer supports a subset of character and token filters. Using just the defaults, the normalizer filter is a simple way to standardize Unicode text in a language-independent way for search, thereby standardizing different forms of the same character in Unicode and allowing diacritic-agnostic aggregations.
Let’s modify the index mapping to include the normalizer. Delete the previous index, then create a new index with the following mapping and ingest the same dataset:
"aggregations" : {
"test" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Jour de fete",
"doc_count" : 2
},
{
"key" : "Etre et avoir",
"doc_count" : 1
},
{
"key" : "Kirikou et la sorciere",
"doc_count" : 1
},
{
"key" : "La gloire de mon pere",
"doc_count" : 1
},
{
"key" : "Le roi et l'oiseau",
"doc_count" : 1
},
{
"key" : "Senora Acero",
"doc_count" : 1
},
{
"key" : "Senora garcon",
"doc_count" : 1
}
]
}
}
Now we compare the results, and we can see the aggregations with term “Jour de fête” and “Jour de fete” are rolled up into one bucket with doc_count=2.
Summary
In this post, we showed how to enable accent-insensitive search and aggregations by designing the index mapping to do ASCII folding for search tokens and normalize the keyword field for aggregations. You can use the OpenSearch query DSL to implement a range of search features, providing a flexible foundation for structured and unstructured search applications. The Open Source OpenSearch community has also extended the product to enable support for natural language processing, machine learning algorithms, custom dictionaries, and a wide variety of other plugins.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open-source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience. Her favorite pastime is hiking the New England trails and mountains.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

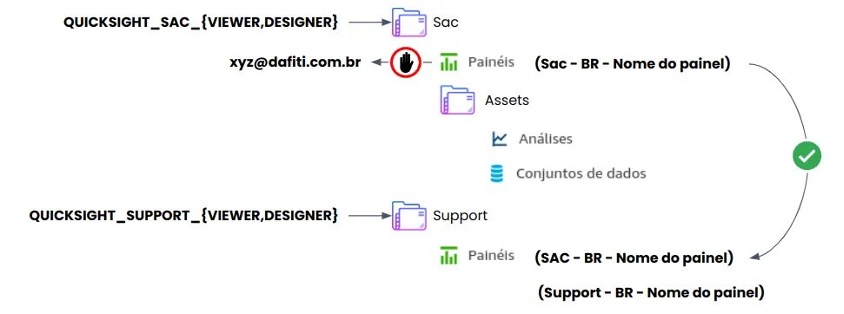
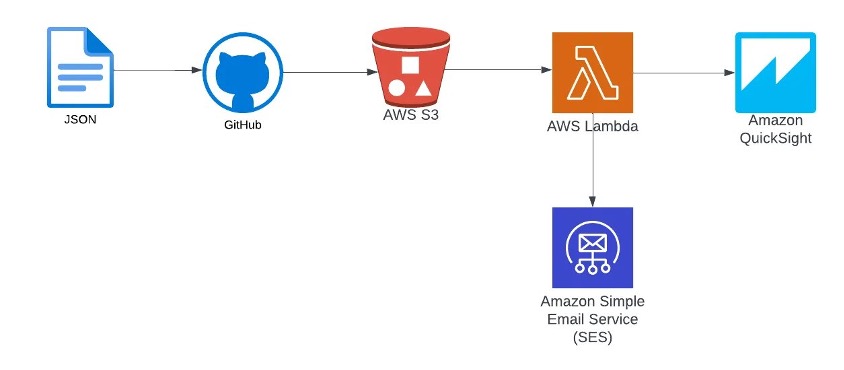
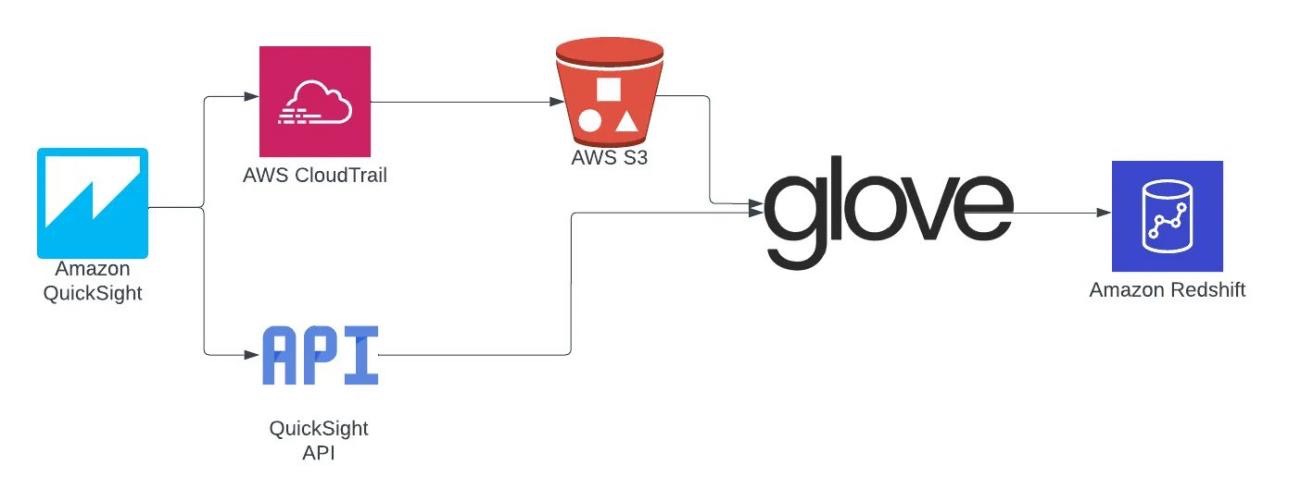

 Valdiney Gomes is Data Engineering Coordinator at Dafiti. He worked for many years in software engineering, migrated to data engineering, and currently leads an amazing team responsible for the data platform for Dafiti in Latin America.
Valdiney Gomes is Data Engineering Coordinator at Dafiti. He worked for many years in software engineering, migrated to data engineering, and currently leads an amazing team responsible for the data platform for Dafiti in Latin America. Hélio Leal is a Data Engineering Specialist at Dafiti, responsible for maintaining and evolving the entire data platform at Dafiti using AWS solutions.
Hélio Leal is a Data Engineering Specialist at Dafiti, responsible for maintaining and evolving the entire data platform at Dafiti using AWS solutions. Flávia Lima is a Data Engineer at Dafiti, responsible for sustaining the data platform and providing the data from many sources to internal customers.
Flávia Lima is a Data Engineer at Dafiti, responsible for sustaining the data platform and providing the data from many sources to internal customers.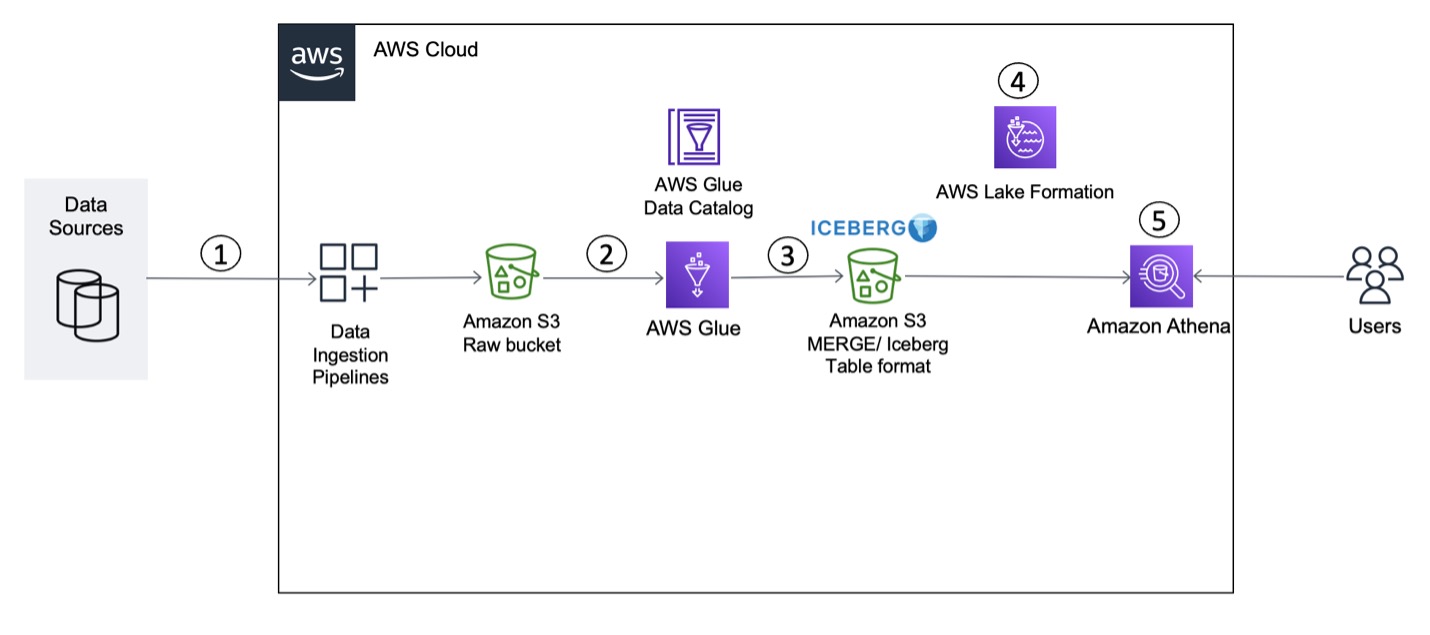































 Vikram Sahadevan is a Senior Resident Architect on the AWS Data Lab team. He enjoys efforts that focus around providing prescriptive architectural guidance, sharing best practices, and removing technical roadblocks with joint engineering engagements between customers and AWS technical resources that accelerate data, analytics, artificial intelligence, and machine learning initiatives.
Vikram Sahadevan is a Senior Resident Architect on the AWS Data Lab team. He enjoys efforts that focus around providing prescriptive architectural guidance, sharing best practices, and removing technical roadblocks with joint engineering engagements between customers and AWS technical resources that accelerate data, analytics, artificial intelligence, and machine learning initiatives. Suvendu Kumar Patra possesses 18 years of experience in infrastructure, database design, and data engineering, and he currently holds the position of Senior Resident Architect at Amazon Web Services. He is a member of the specialized focus group, AWS Data Lab, and his primary duties entail working with executive leadership teams of strategic AWS customers to develop their roadmaps for data, analytics, and AI/ML. Suvendu collaborates closely with customers to implement data engineering, data hub, data lake, data governance, and EDW solutions, as well as enterprise data strategy and data management.
Suvendu Kumar Patra possesses 18 years of experience in infrastructure, database design, and data engineering, and he currently holds the position of Senior Resident Architect at Amazon Web Services. He is a member of the specialized focus group, AWS Data Lab, and his primary duties entail working with executive leadership teams of strategic AWS customers to develop their roadmaps for data, analytics, and AI/ML. Suvendu collaborates closely with customers to implement data engineering, data hub, data lake, data governance, and EDW solutions, as well as enterprise data strategy and data management.

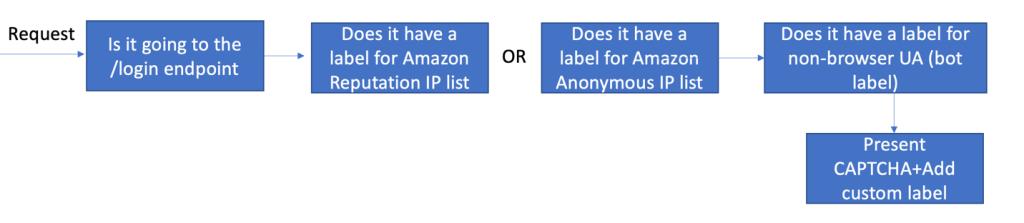
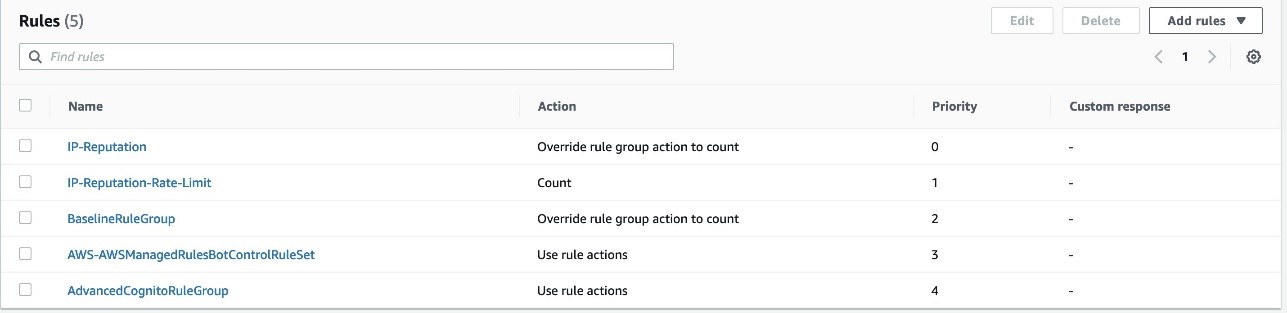
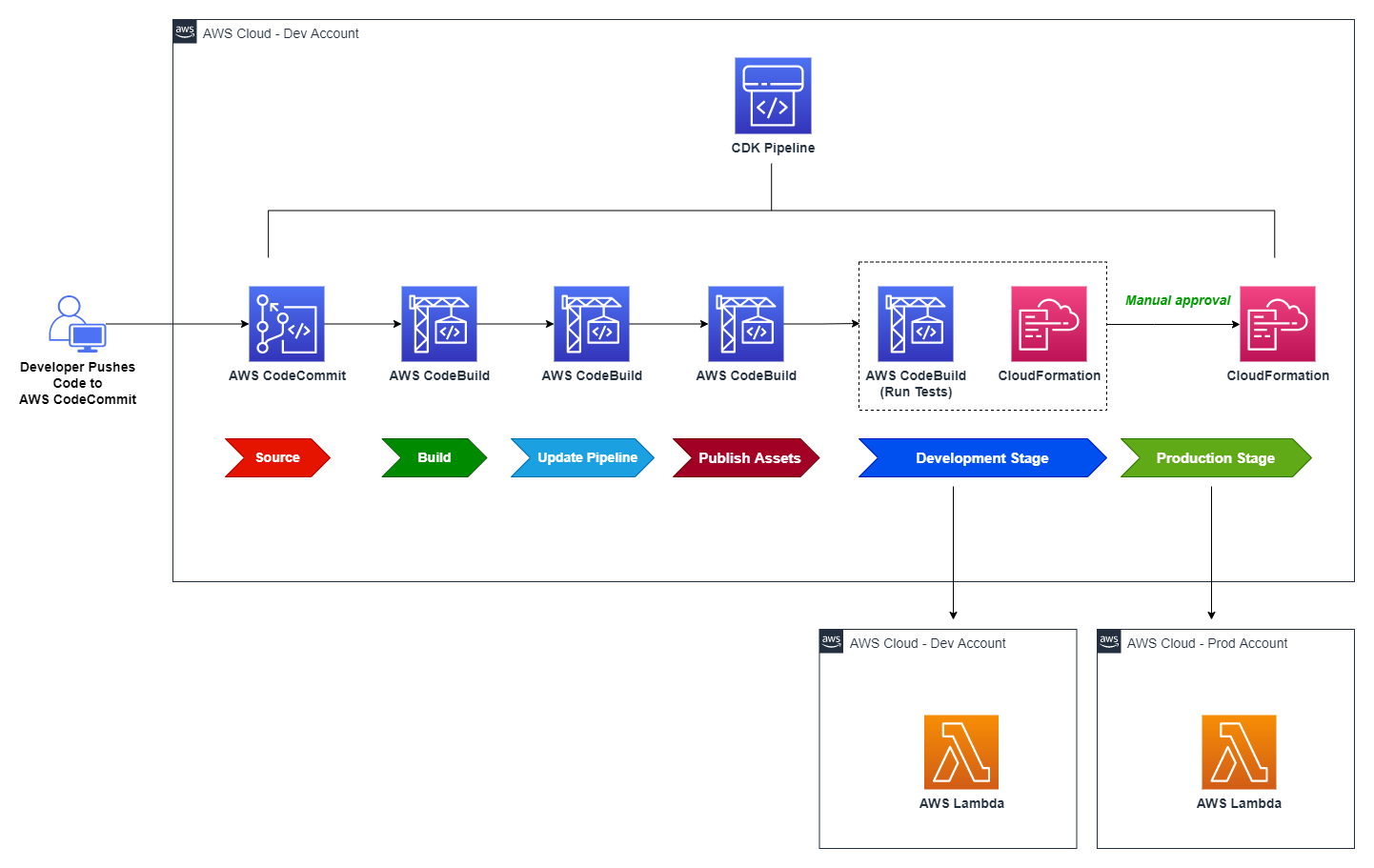
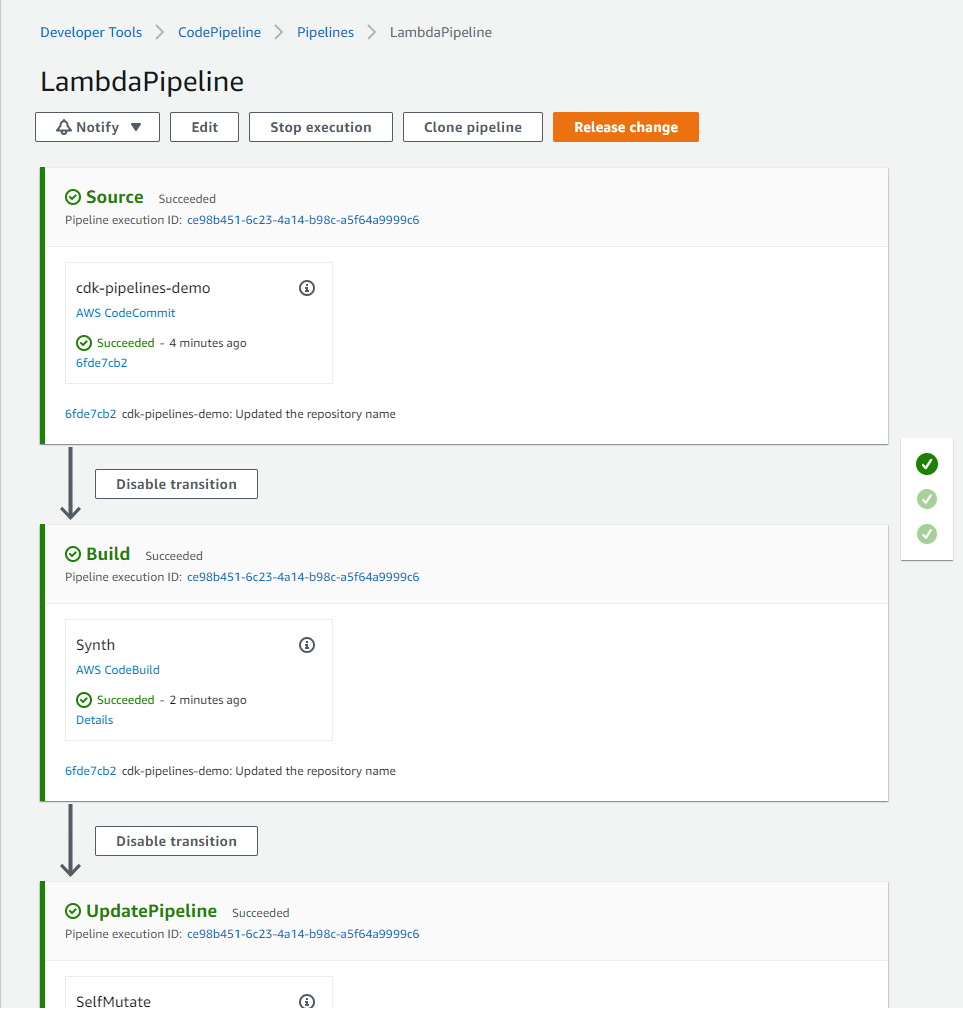
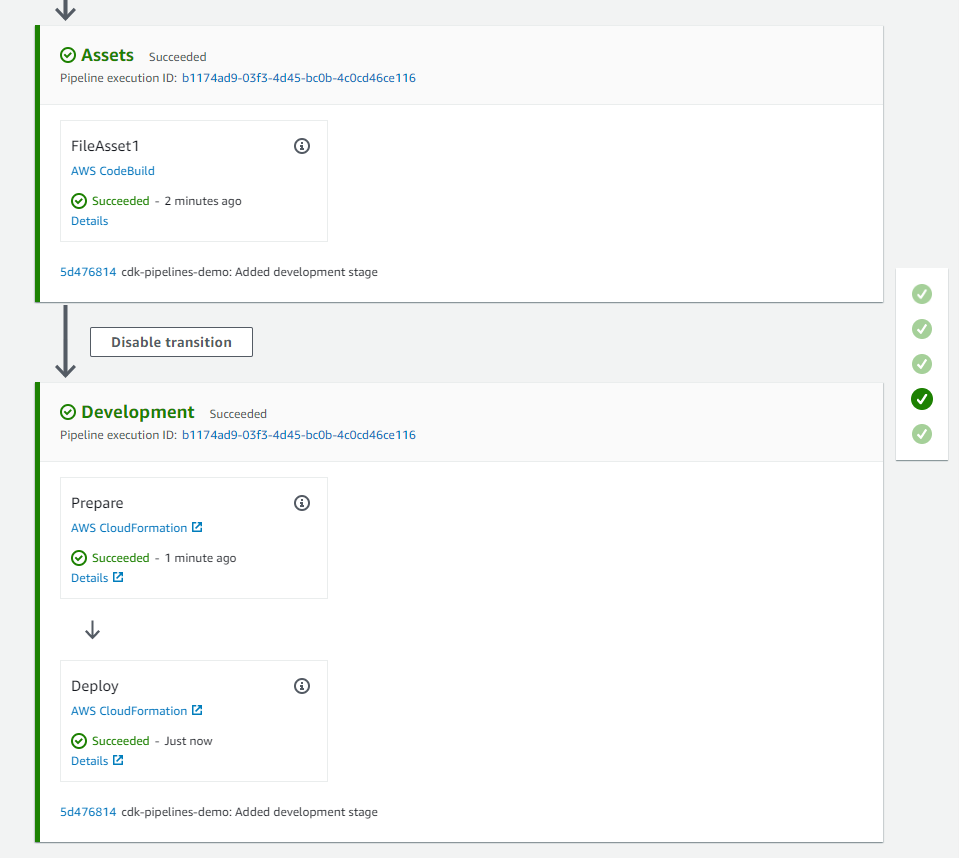
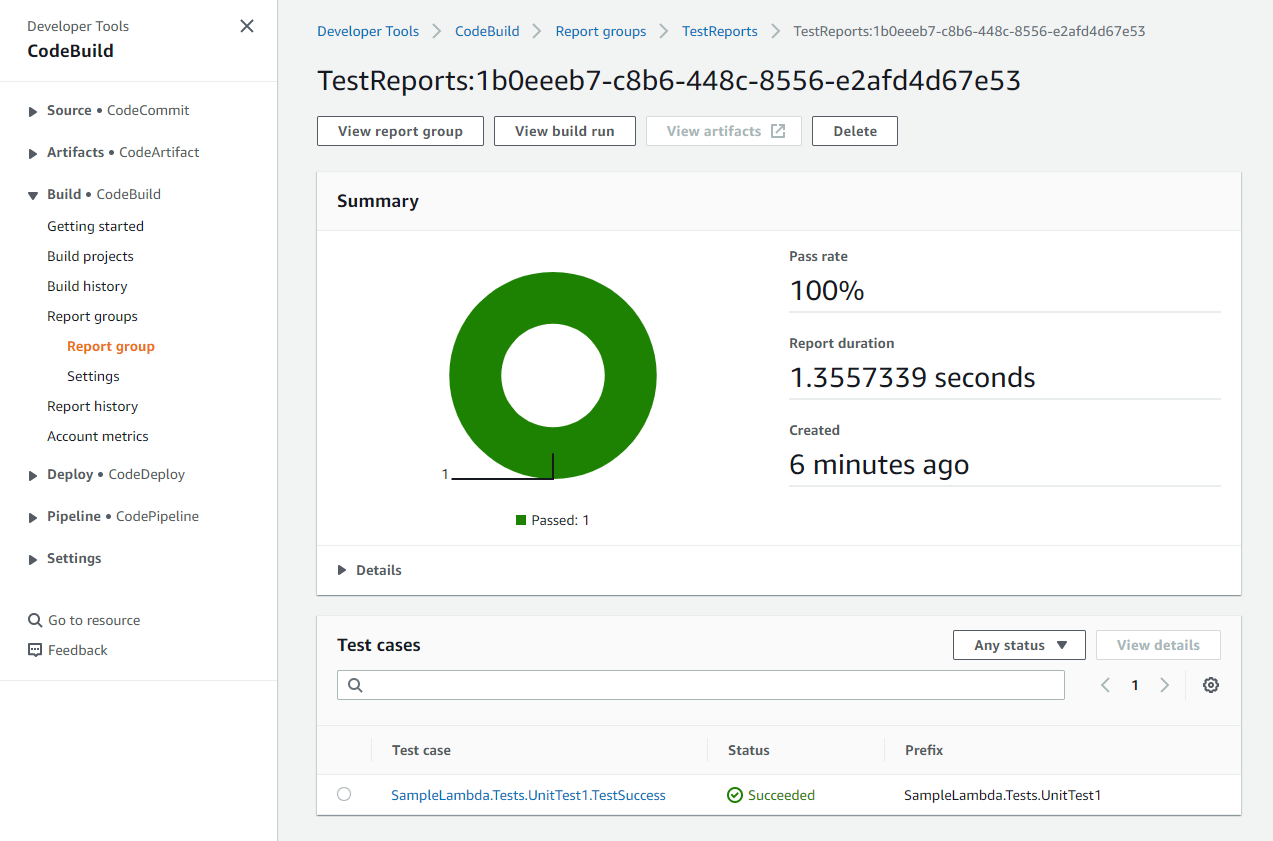
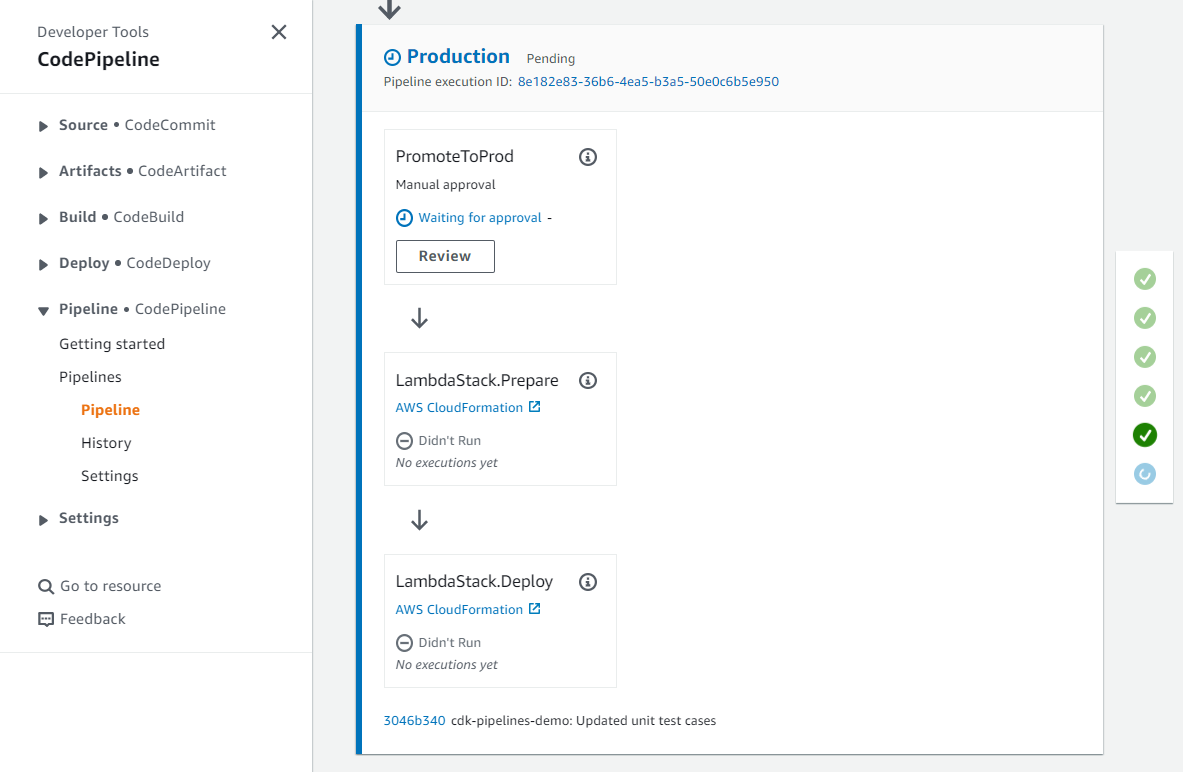
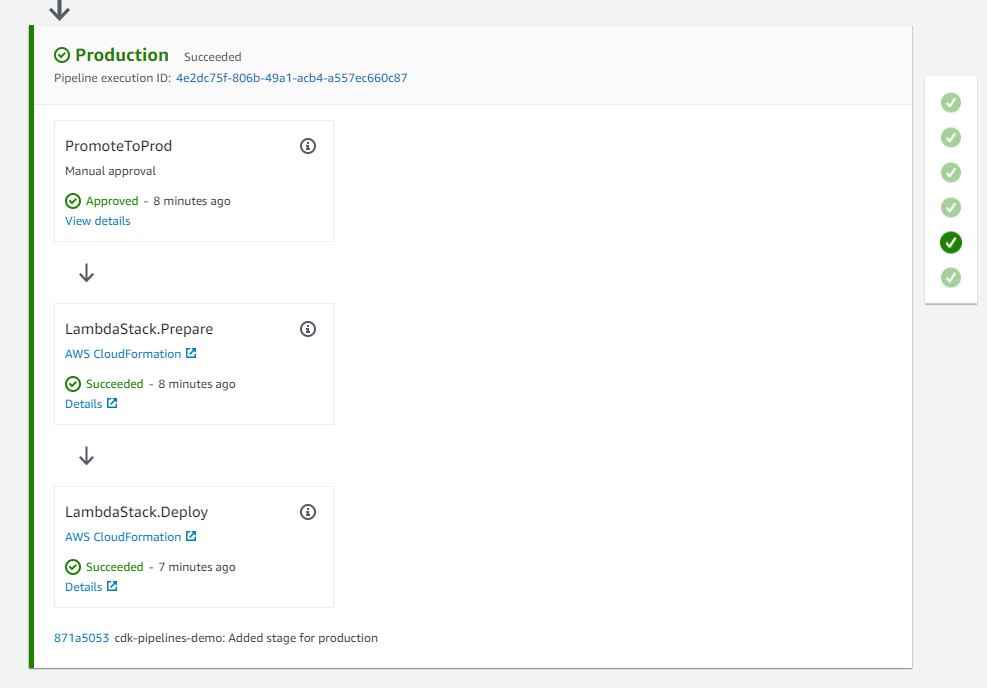


















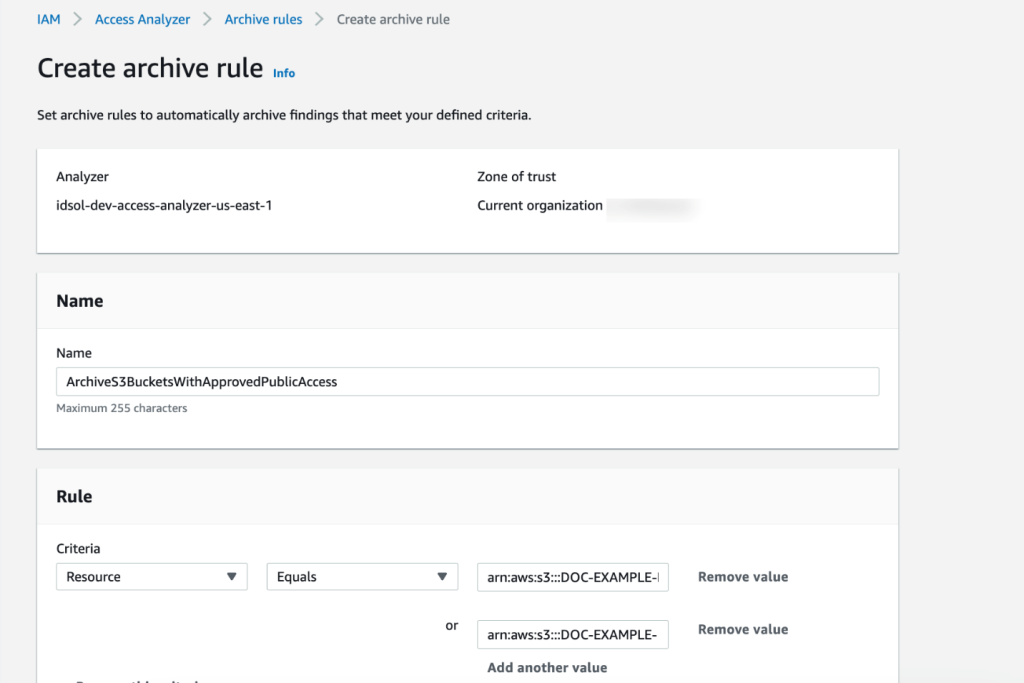

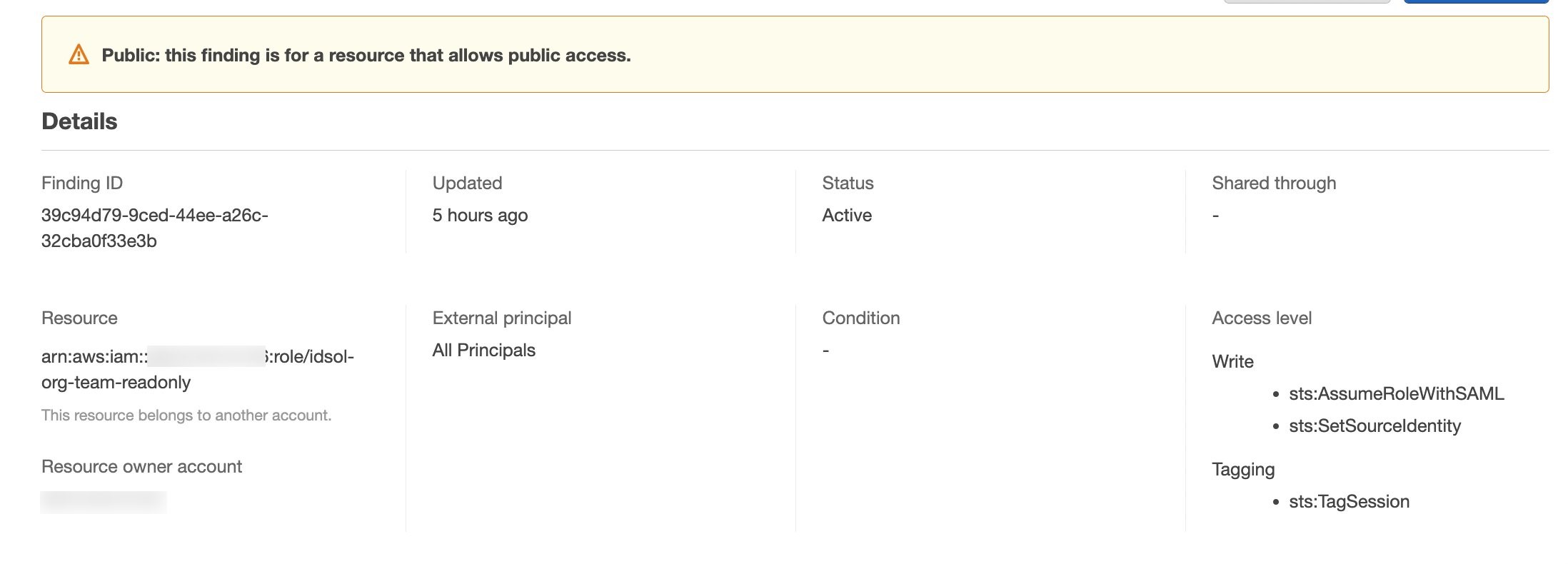
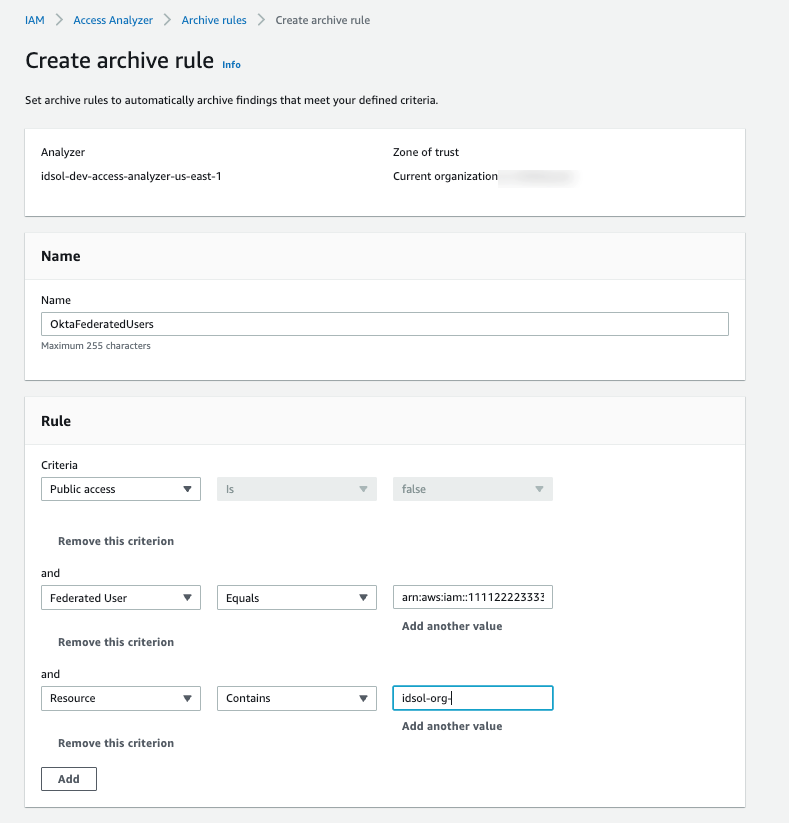
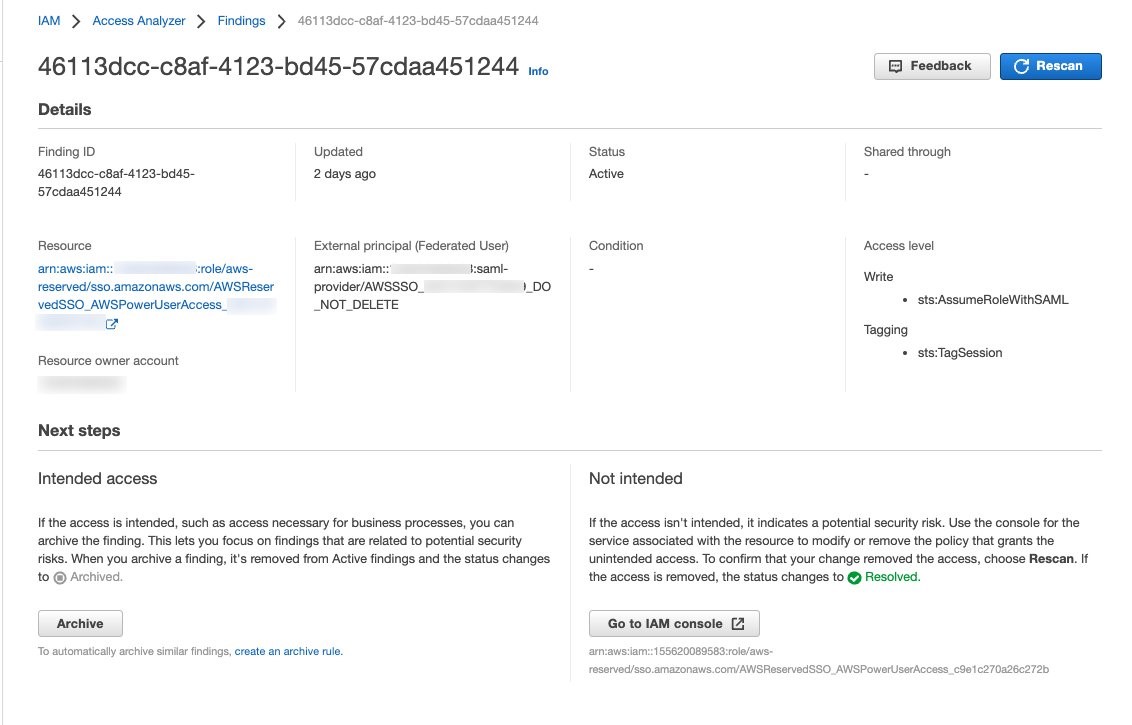
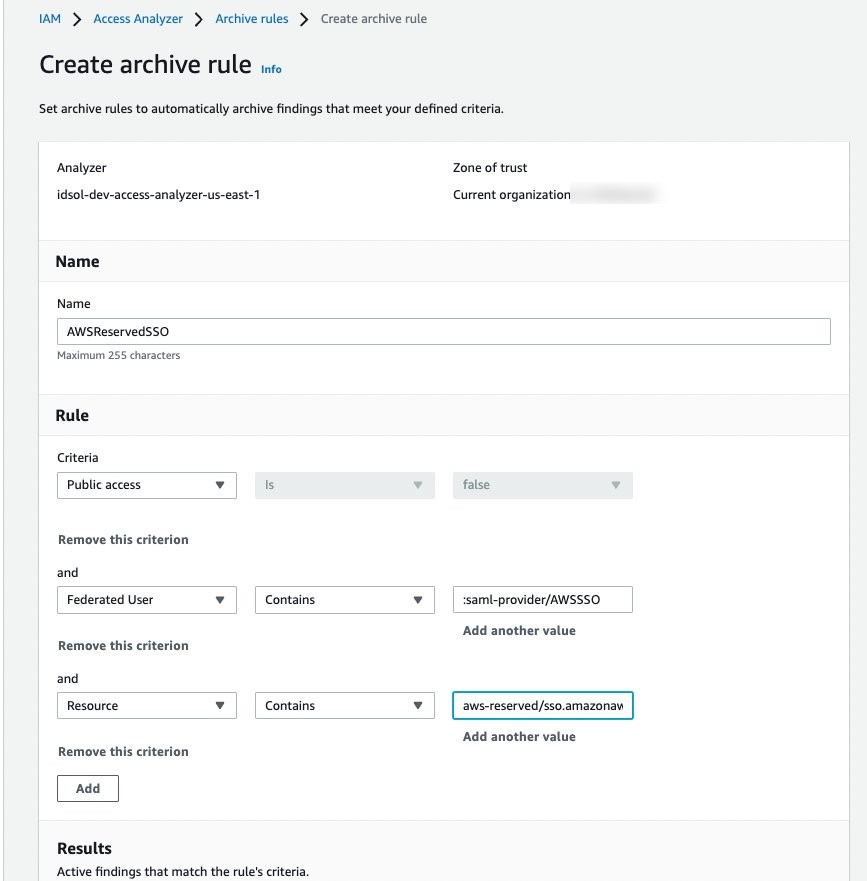
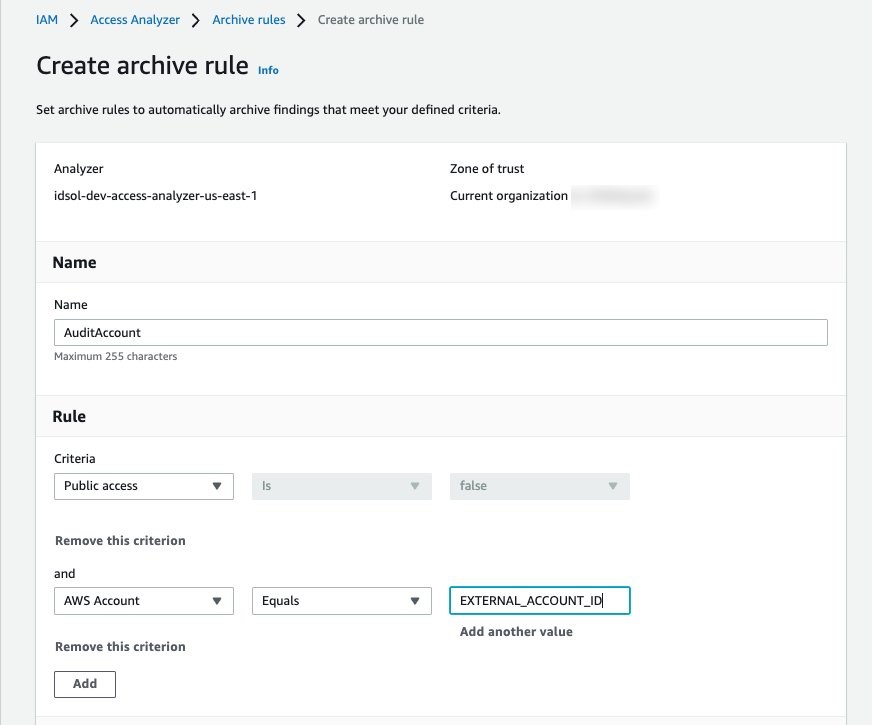




![As the user configures their EventBridge Rule, for the Creation method they have chosen "Custom pattern (JSON editor) write an event pattern in JSON." For the Event pattern editor just below they have entered {"source":["aws.devops-guru"]}](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2023/04/19/eventbridge.png)











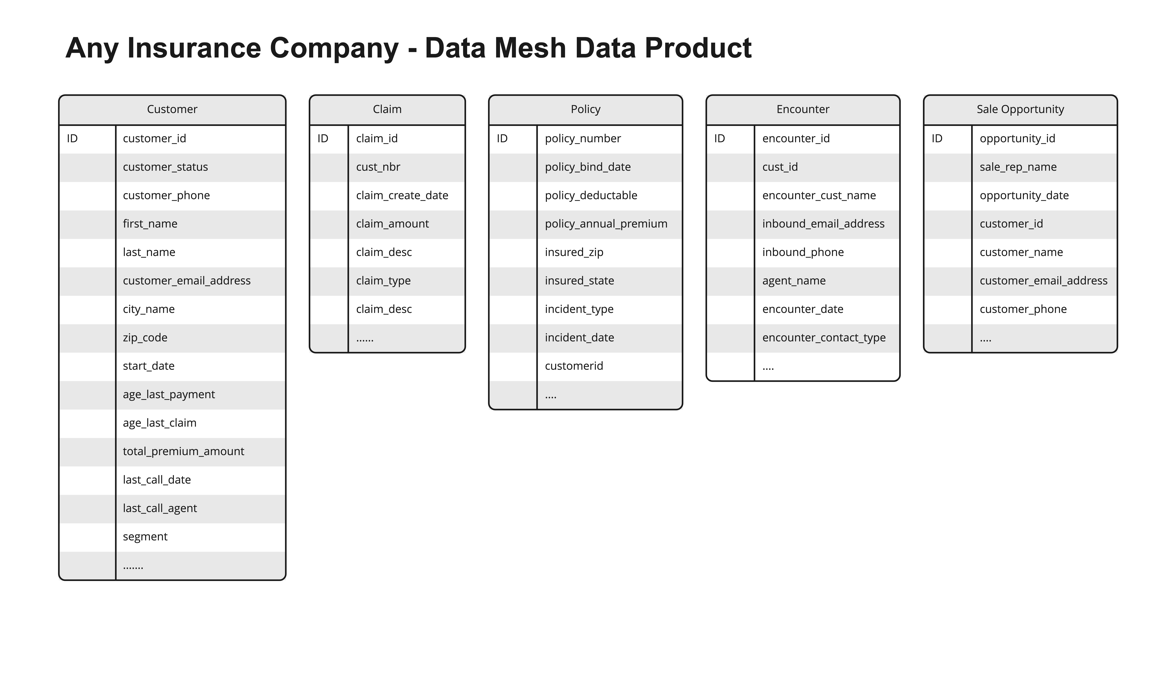
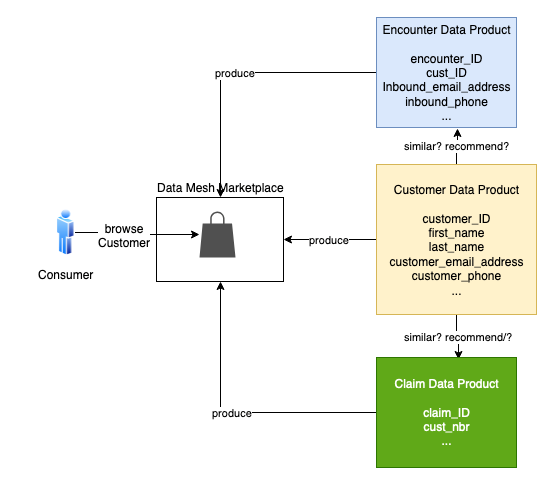



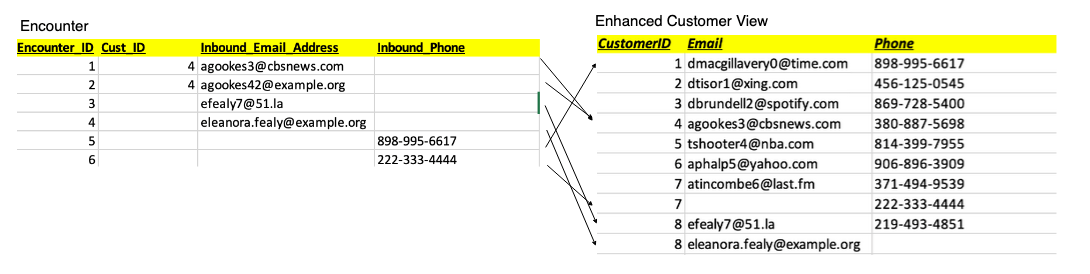
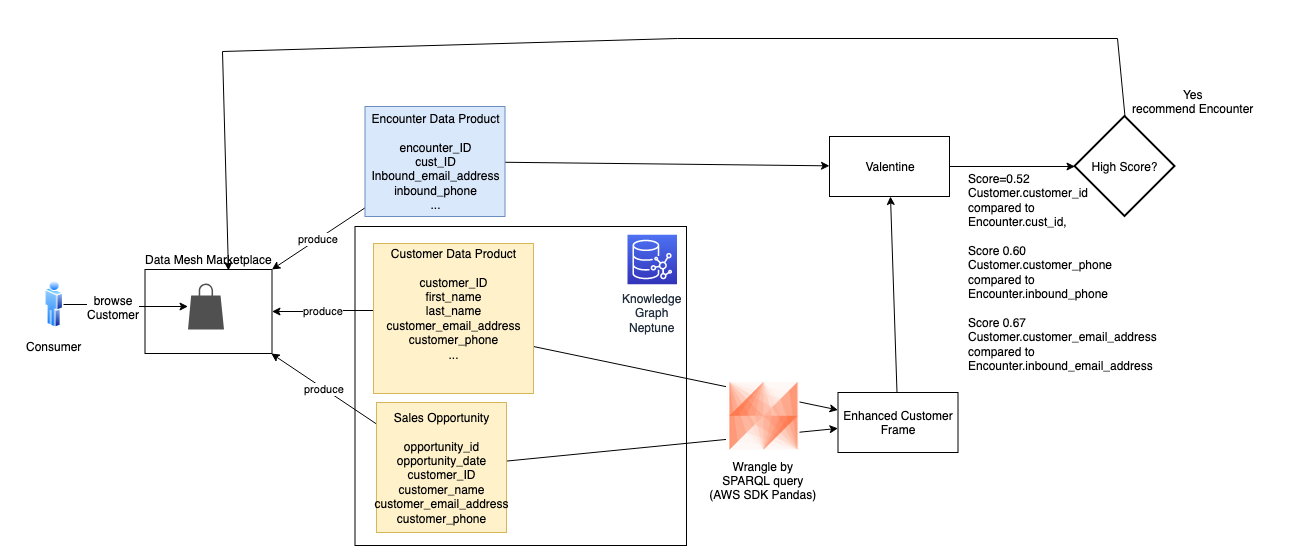
 Moira Lennox is a Senior Data Strategy Technical Specialist for AWS with 27 years’ experience helping companies innovate and modernize their data strategies to achieve new heights and allow for strategic decision-making. She has experience working in large enterprises and technology providers, in both business and technical roles across multiple industries, including health care live sciences, financial services, communications, digital entertainment, energy, and manufacturing.
Moira Lennox is a Senior Data Strategy Technical Specialist for AWS with 27 years’ experience helping companies innovate and modernize their data strategies to achieve new heights and allow for strategic decision-making. She has experience working in large enterprises and technology providers, in both business and technical roles across multiple industries, including health care live sciences, financial services, communications, digital entertainment, energy, and manufacturing. Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data strategy, and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and data governance.
Joel Farvault is Principal Specialist SA Analytics for AWS with 25 years’ experience working on enterprise architecture, data strategy, and analytics, mainly in the financial services industry. Joel has led data transformation projects on fraud analytics, claims automation, and data governance. Mike Havey is a Solutions Architect for AWS with over 25 years of experience building enterprise applications. Mike is the author of two books and numerous articles. His
Mike Havey is a Solutions Architect for AWS with over 25 years of experience building enterprise applications. Mike is the author of two books and numerous articles. His 













 Vinay Kumar Khambhampati is a Lead Consultant with the AWS ProServe Team, helping customers with cloud adoption. He is passionate about big data and data analytics.
Vinay Kumar Khambhampati is a Lead Consultant with the AWS ProServe Team, helping customers with cloud adoption. He is passionate about big data and data analytics. Sandeep Singh is a Lead Consultant at AWS ProServe, focused on analytics, data lake architecture, and implementation. He helps enterprise customers migrate and modernize their data lake and data warehouse using AWS services.
Sandeep Singh is a Lead Consultant at AWS ProServe, focused on analytics, data lake architecture, and implementation. He helps enterprise customers migrate and modernize their data lake and data warehouse using AWS services. Amol Guldagad is a Data Analytics Consultant based in India. He has worked with customers in different industries like banking and financial services, healthcare, power and utilities, manufacturing, and retail, helping them solve complex challenges with large-scale data platforms. At AWS ProServe, he helps customers accelerate their journey to the cloud and innovate using AWS analytics services.
Amol Guldagad is a Data Analytics Consultant based in India. He has worked with customers in different industries like banking and financial services, healthcare, power and utilities, manufacturing, and retail, helping them solve complex challenges with large-scale data platforms. At AWS ProServe, he helps customers accelerate their journey to the cloud and innovate using AWS analytics services.





















 Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree.
Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree. Ravi Bhatane is a software engineer with Amazon OpenSearch Serverless Service. He is passionate about security, distributed systems, and building scalable services. When he’s not coding, Ravi enjoys photography and exploring new hiking trails with his friends.
Ravi Bhatane is a software engineer with Amazon OpenSearch Serverless Service. He is passionate about security, distributed systems, and building scalable services. When he’s not coding, Ravi enjoys photography and exploring new hiking trails with his friends. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.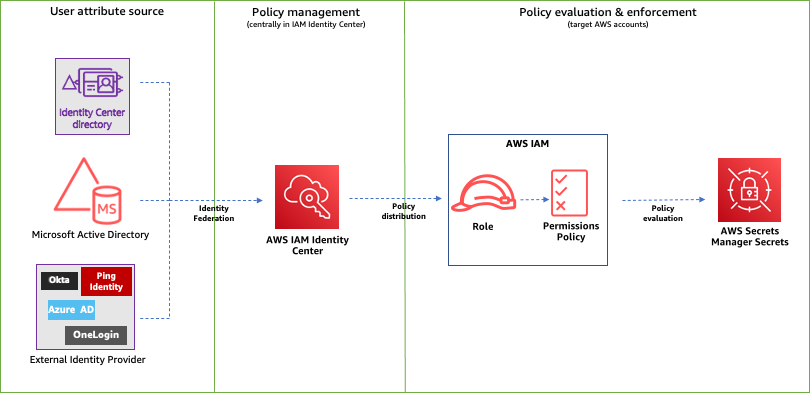
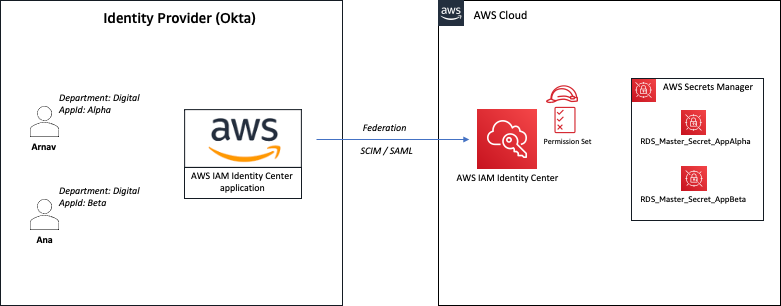


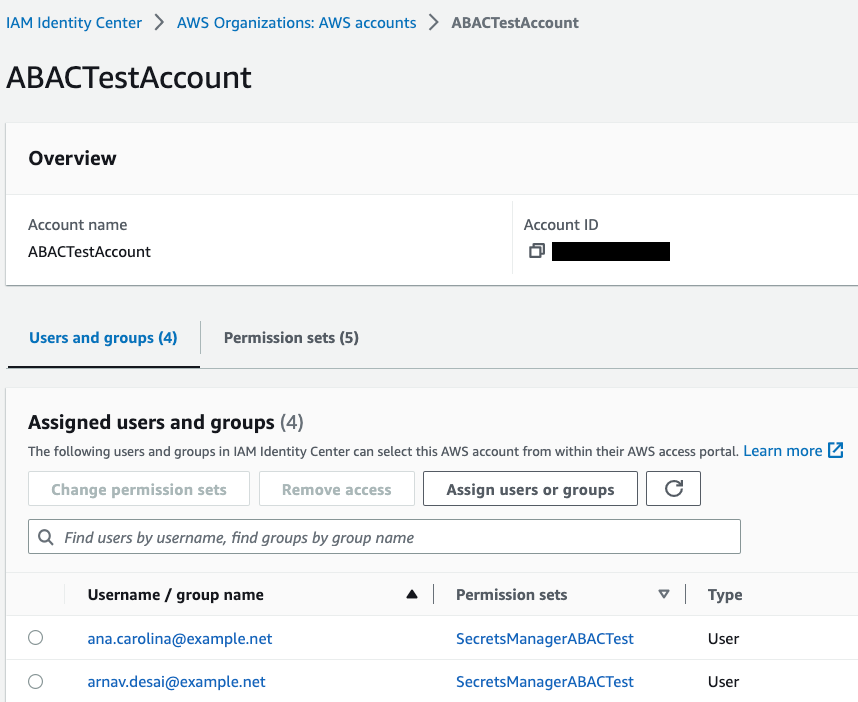





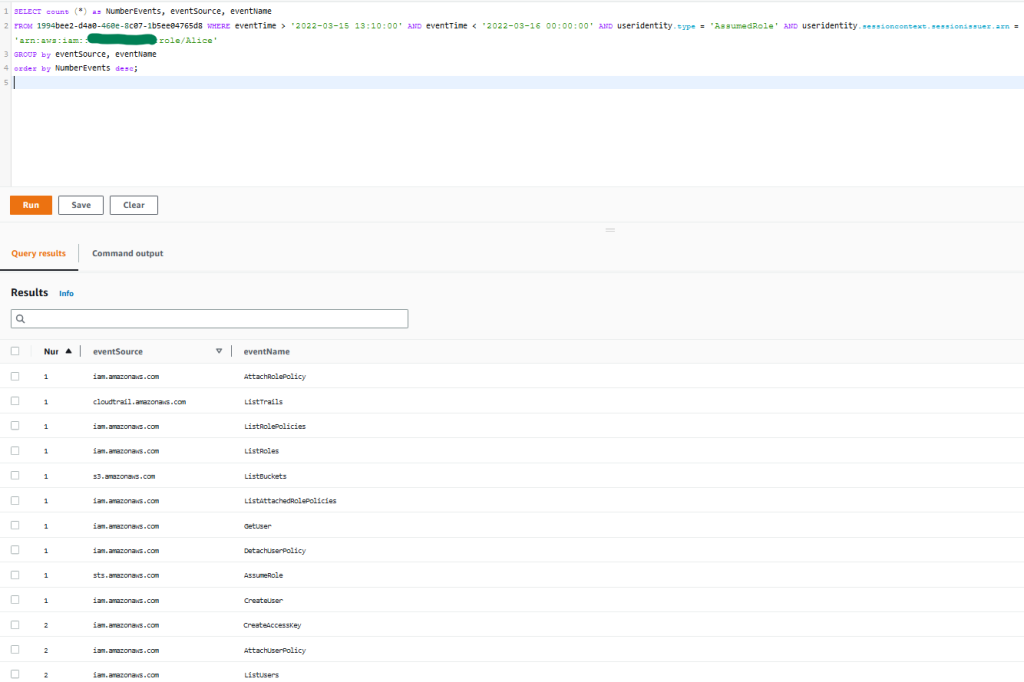
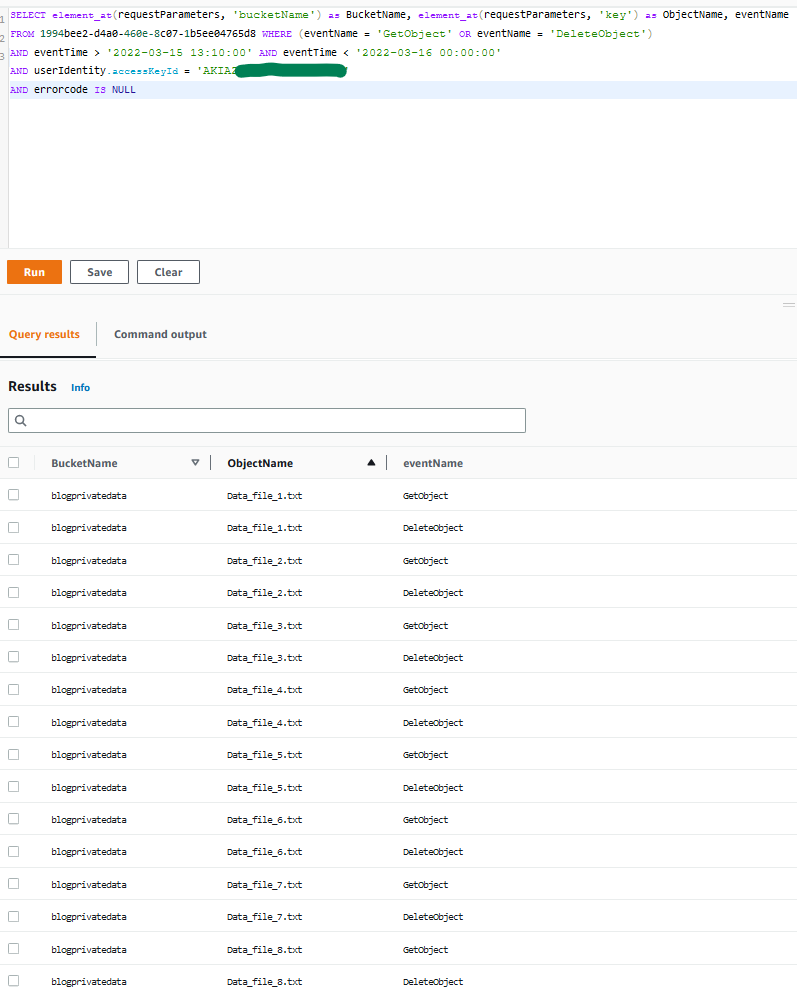
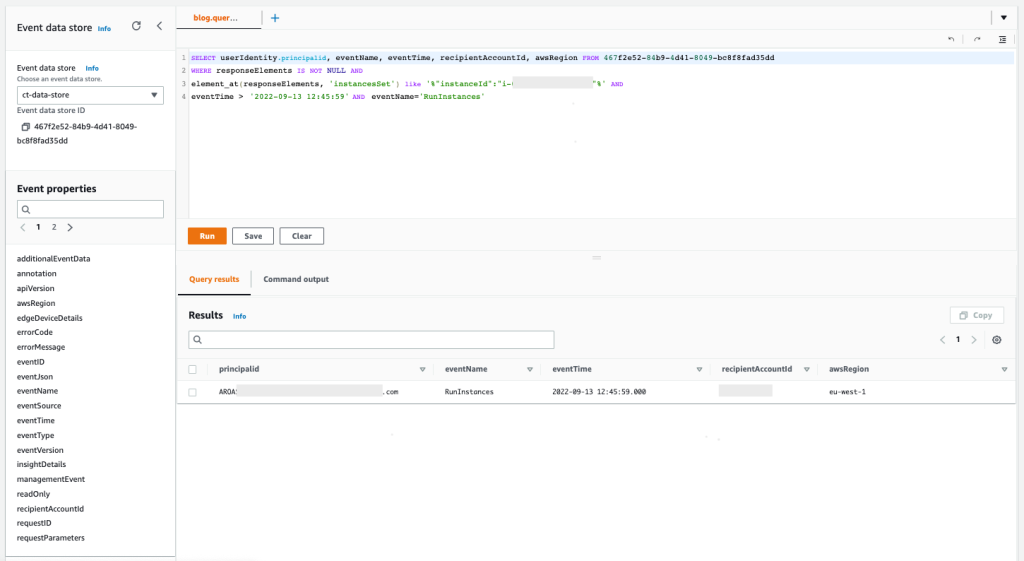
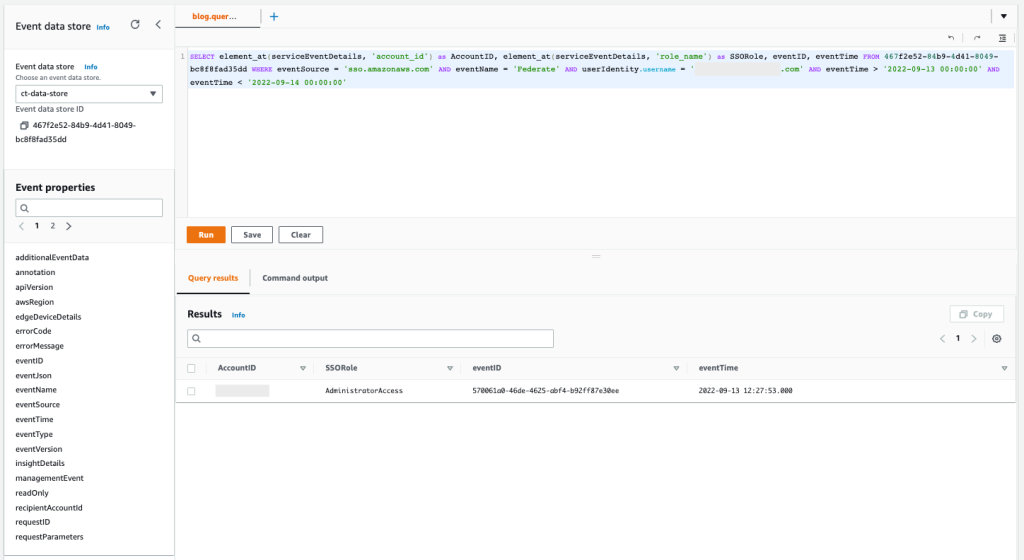
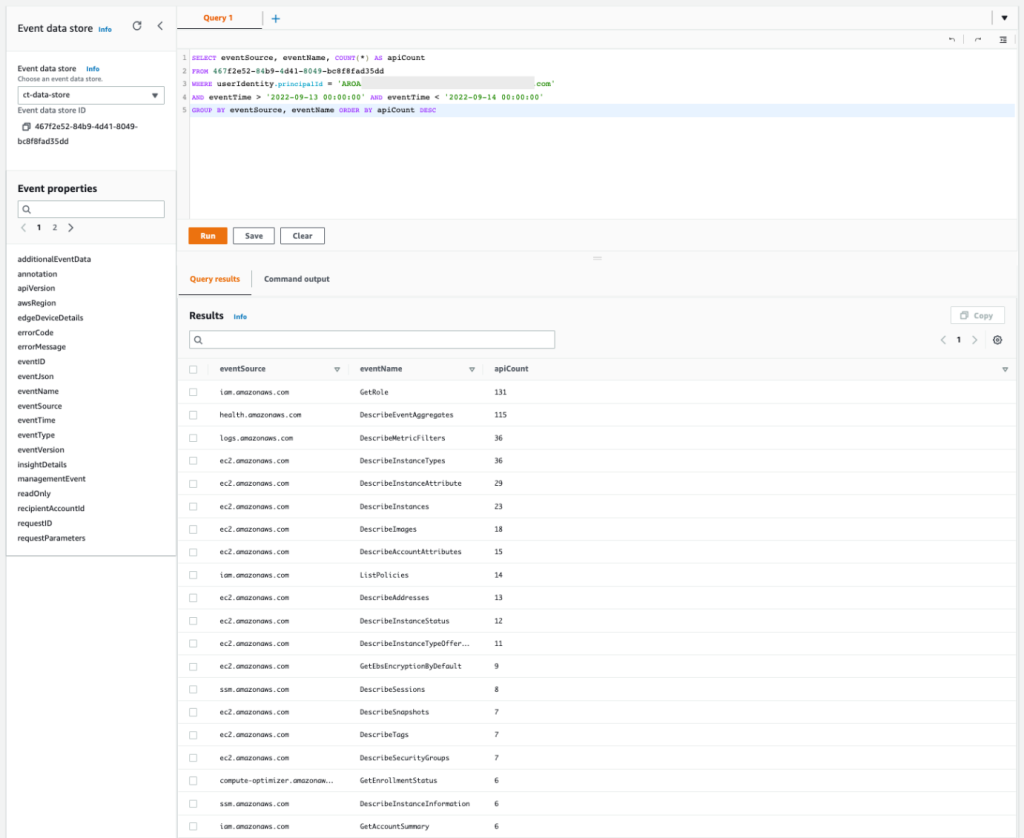
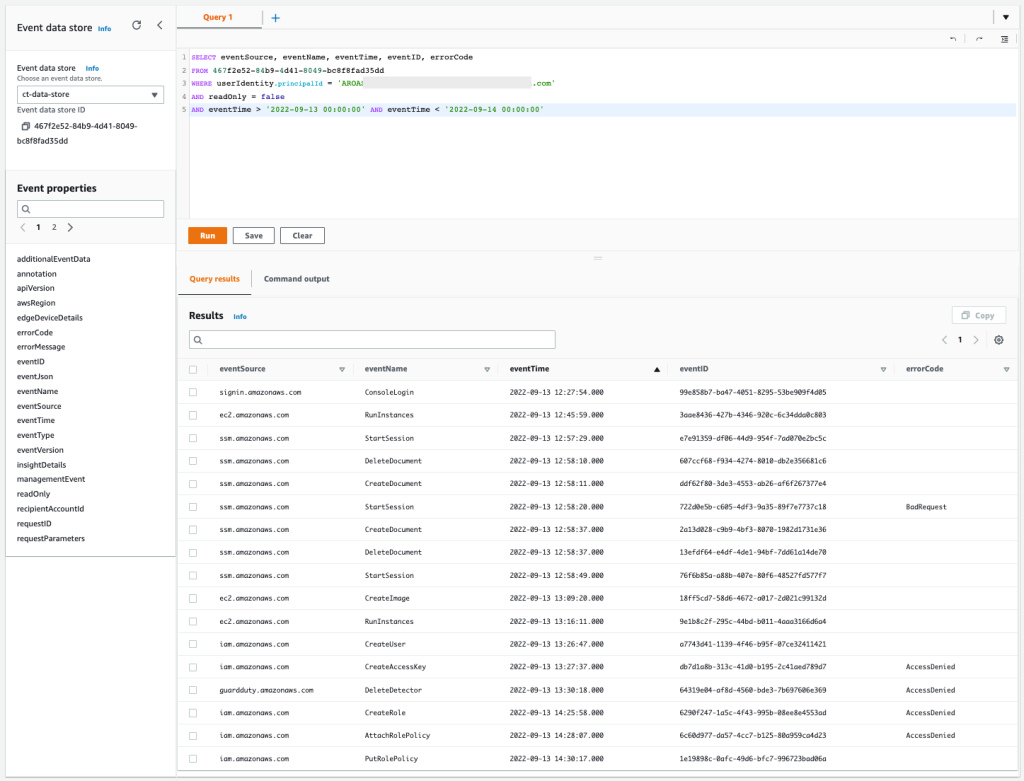
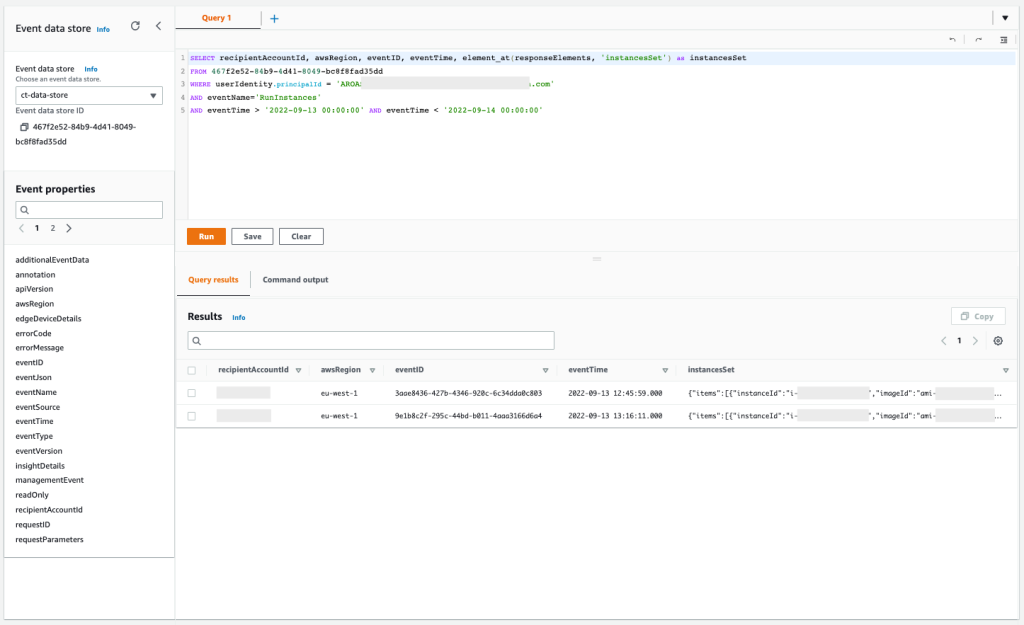
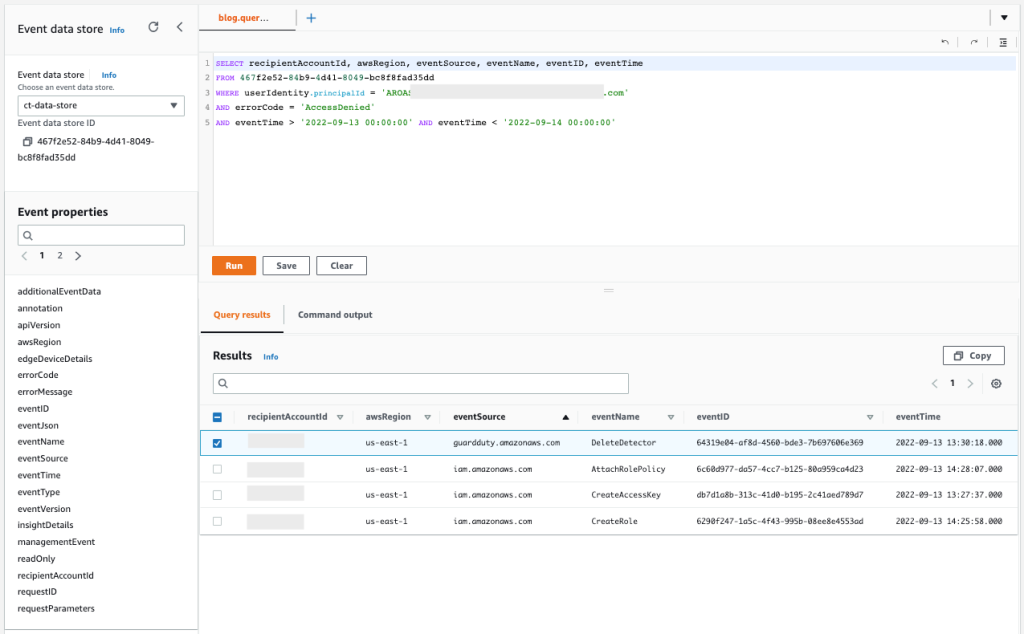
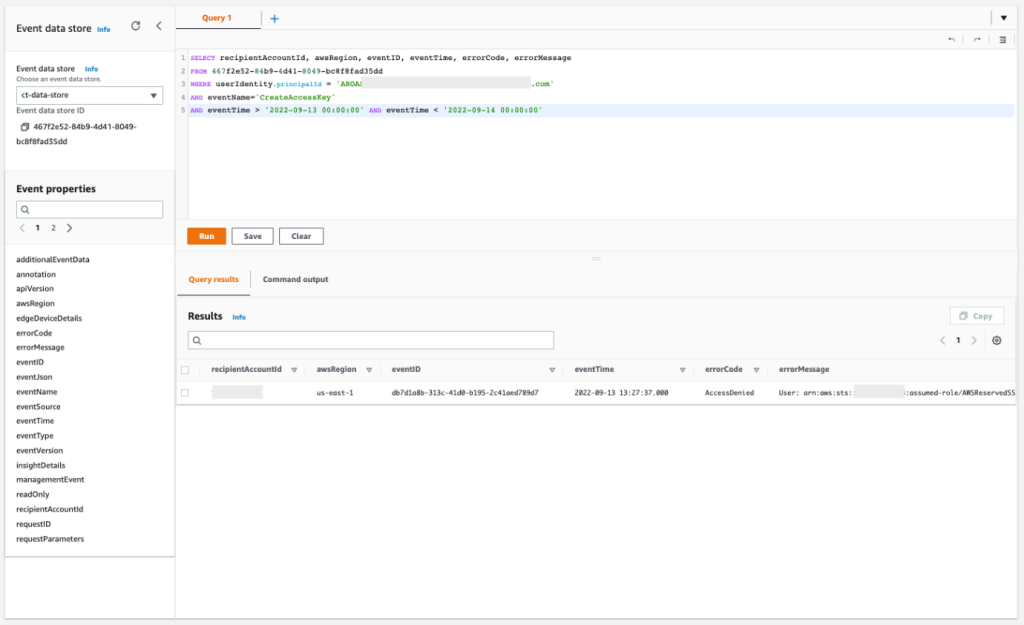
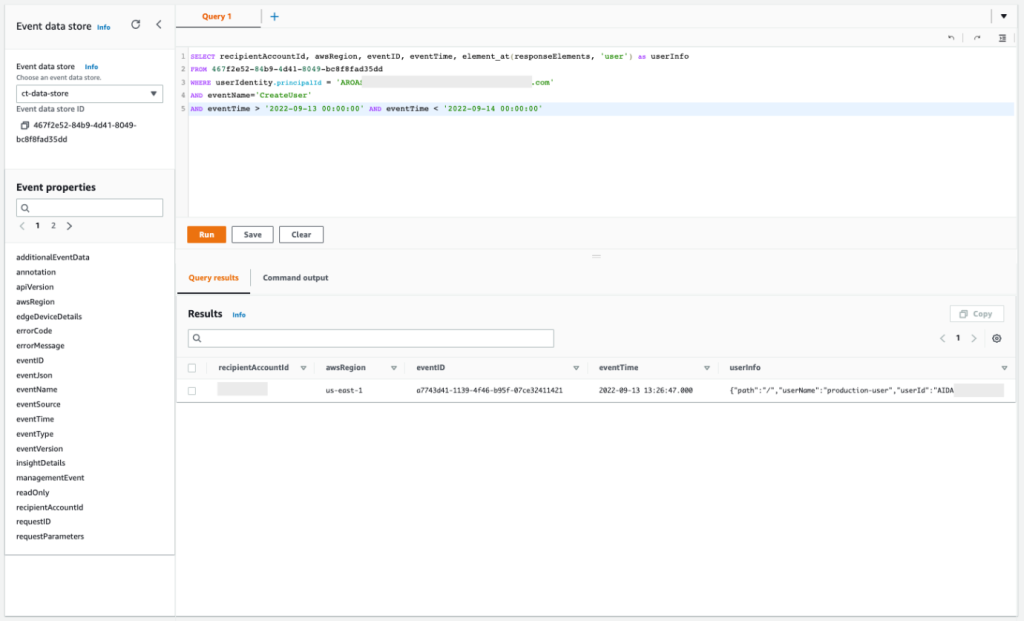
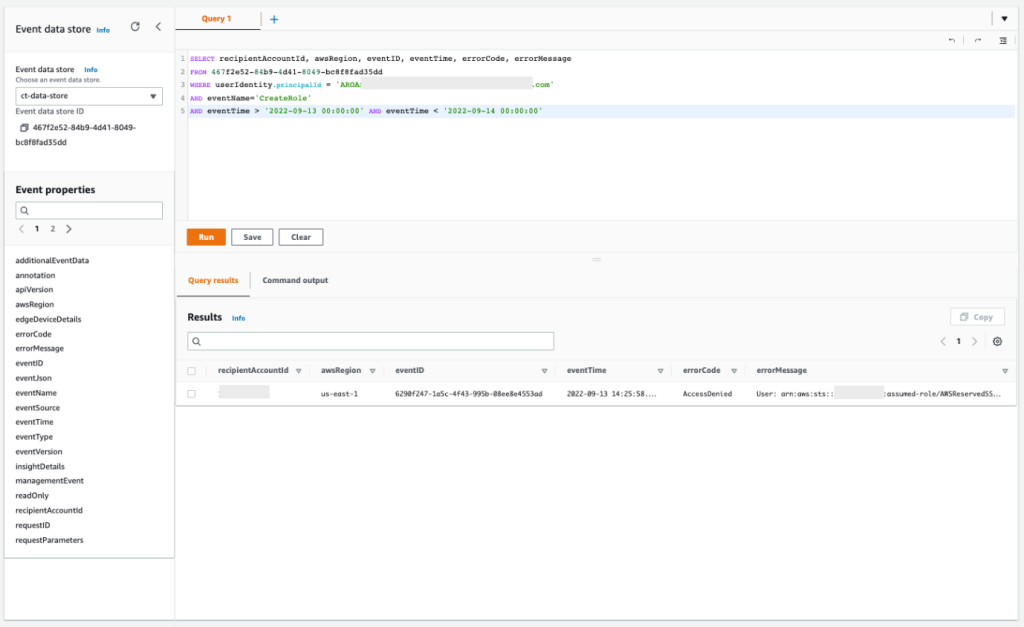
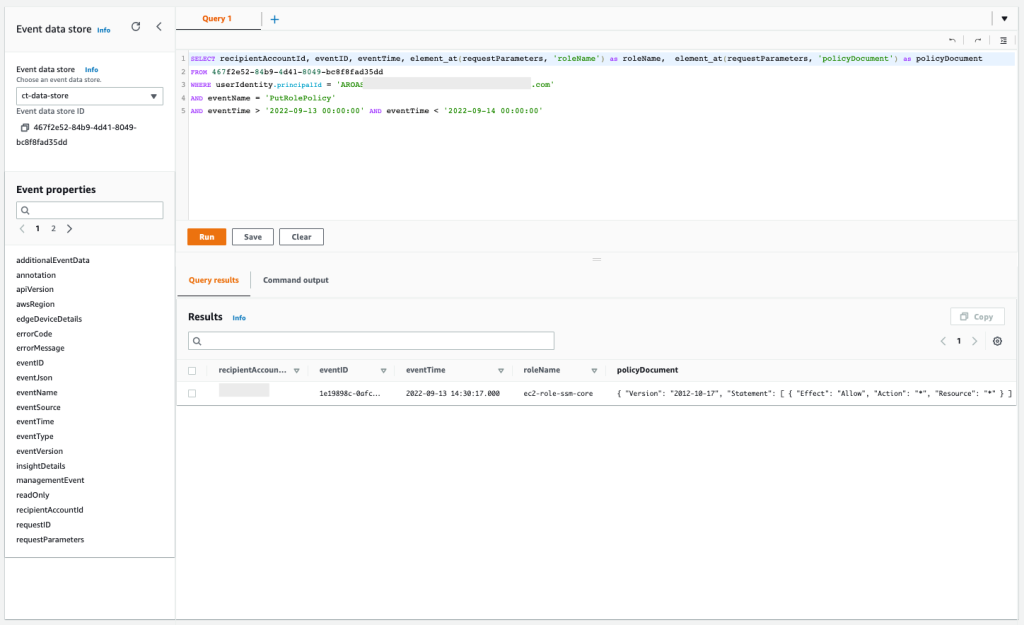













 Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.
Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing. Akeef Khan is a Solutions Architect at Amazon Web Services. He helps SMB Greenfield customers adopt the cloud. Whilst being a generalist SA, Akeef is passionate about networking.
Akeef Khan is a Solutions Architect at Amazon Web Services. He helps SMB Greenfield customers adopt the cloud. Whilst being a generalist SA, Akeef is passionate about networking.

 Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare and life sciences customers to build solutions that help improve patients’ outcomes. Mikhail specializes in data analytics services.
Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare and life sciences customers to build solutions that help improve patients’ outcomes. Mikhail specializes in data analytics services. Sukhomoy Basak is a Solutions Architect at Amazon Web Services, with a passion for data and analytics solutions. Sukhomoy works with enterprise customers to help them architect, build, and scale applications to achieve their business outcomes.
Sukhomoy Basak is a Solutions Architect at Amazon Web Services, with a passion for data and analytics solutions. Sukhomoy works with enterprise customers to help them architect, build, and scale applications to achieve their business outcomes.




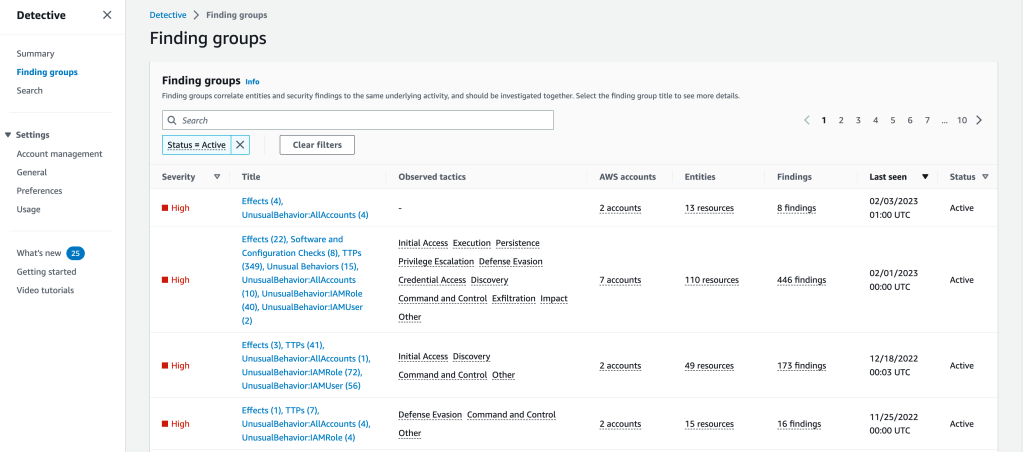
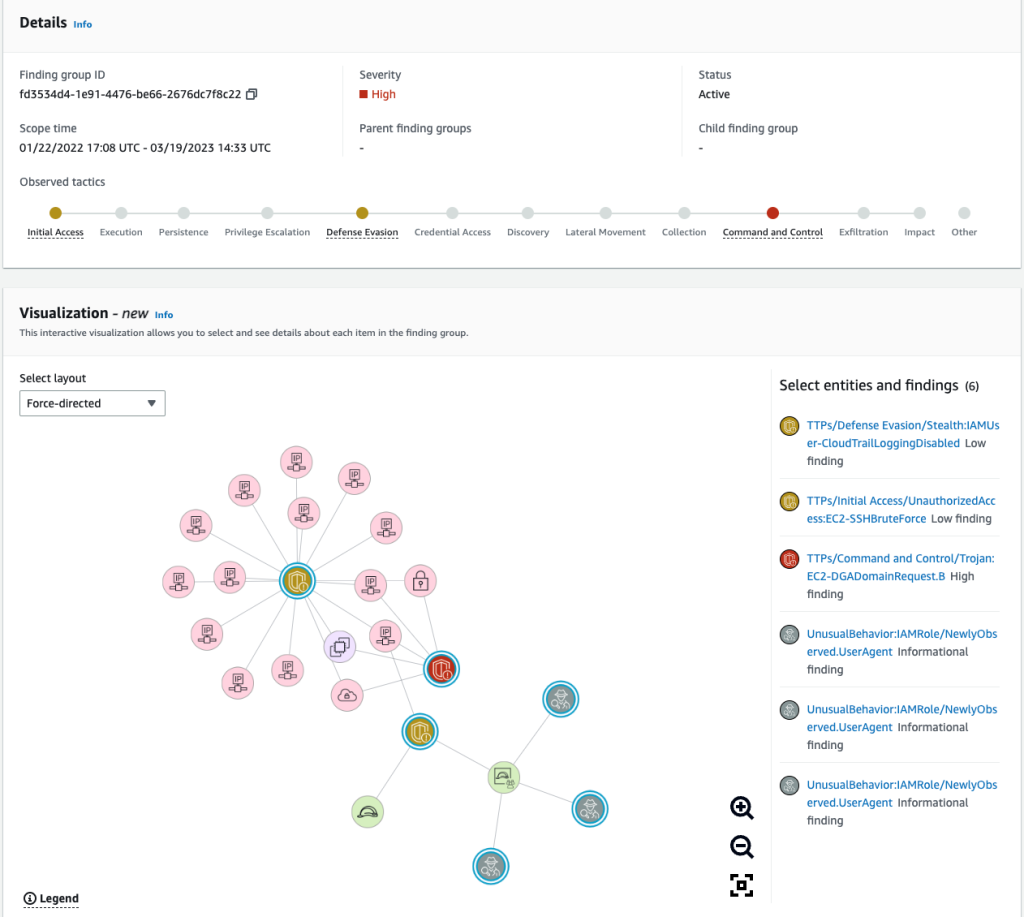
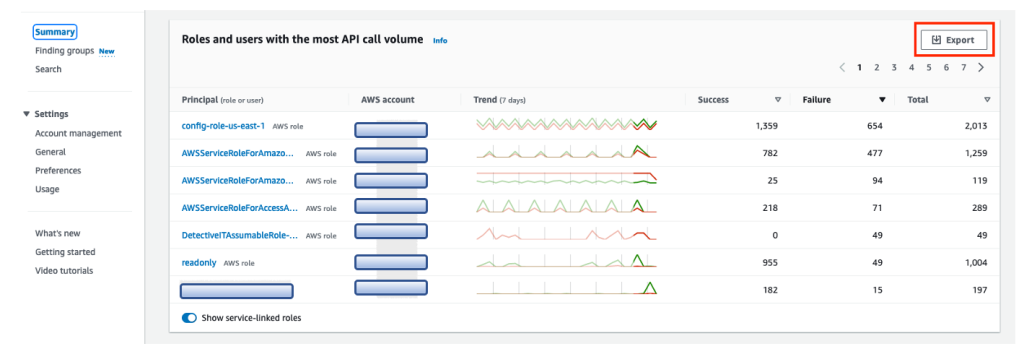












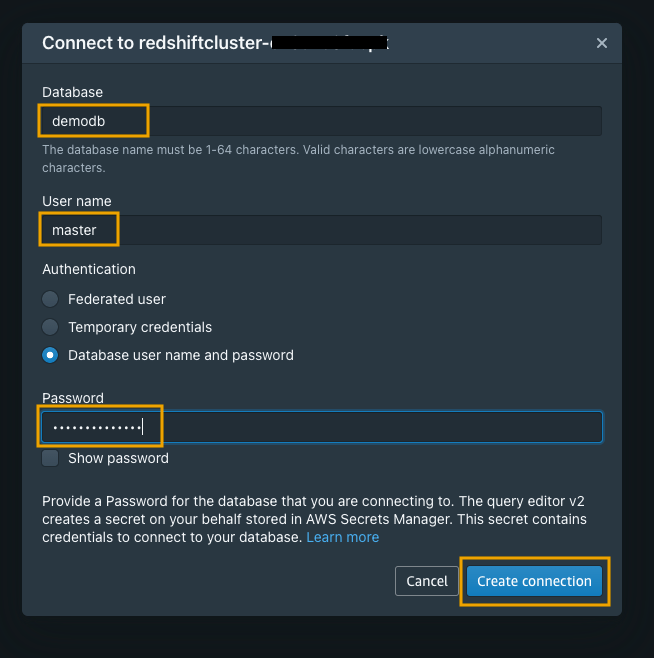











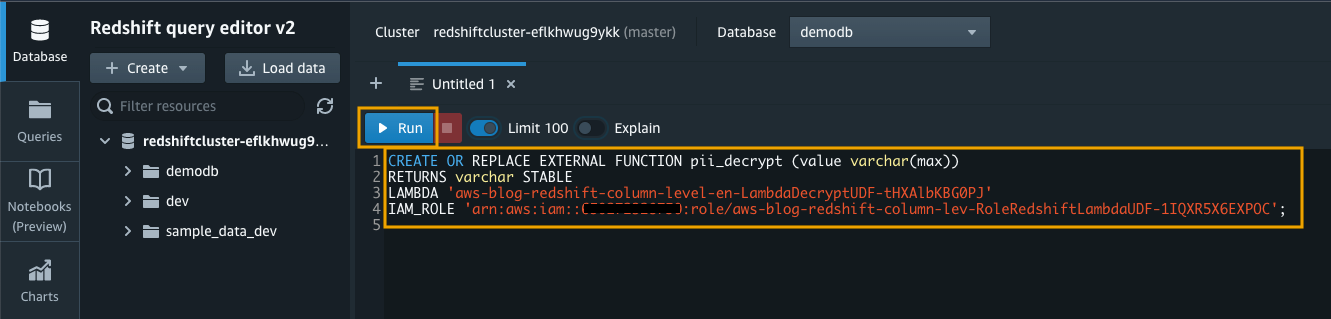


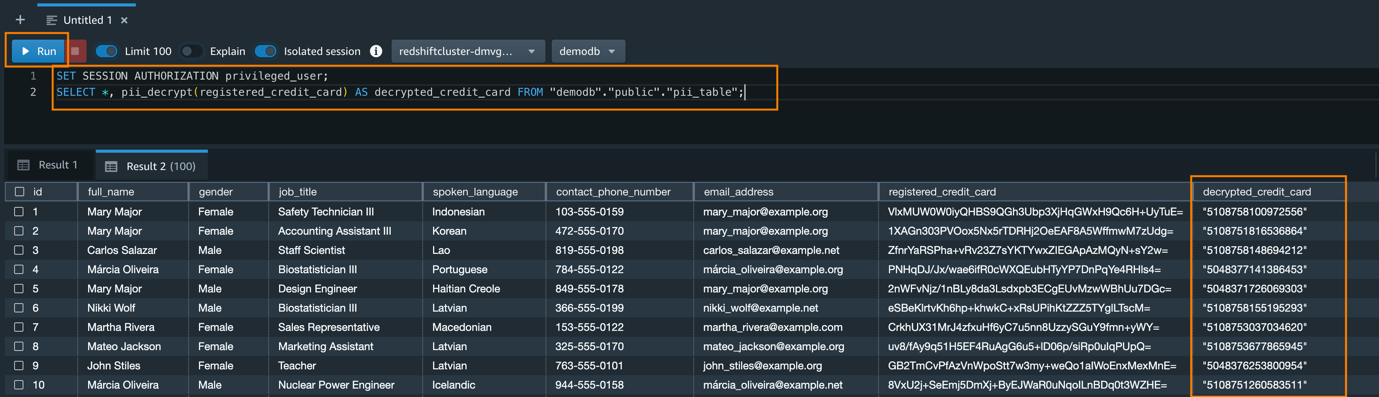
 Aaron Chong is an Enterprise Solutions Architect at Amazon Web Services Hong Kong. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization.
Aaron Chong is an Enterprise Solutions Architect at Amazon Web Services Hong Kong. He specializes in the data analytics domain, and works with a wide range of customers to build big data analytics platforms, modernize data engineering practices, and advocate AI/ML democratization.















 Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open-source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience. Her favorite pastime is hiking the New England trails and mountains.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open-source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience. Her favorite pastime is hiking the New England trails and mountains.