Post Syndicated from Jonathan Herzog original https://aws.amazon.com/blogs/security/share-and-query-encrypted-data-in-aws-clean-rooms/
In this post, we’d like to introduce you to the cryptographic computing feature of AWS Clean Rooms. With AWS Clean Rooms, customers can run collaborative data-query sessions on sensitive data sets that live in different AWS accounts, and can do so without having to share, aggregate, or replicate the data. When customers also use the cryptographic computing feature, their data remains cryptographically protected even while it is being processed by an AWS Clean Rooms collaboration.
Where would AWS Clean Rooms be useful? Consider a scenario where two different insurance companies want to identify duplicate claims so they can identify potential fraud. This would be simple if they could compare their claims with each other, but they might not be able to do so due to privacy constraints.
Alternately, consider an advertising network and a client that want to measure the effectiveness of an advertising campaign. To that end, they would like to know how many of the people who saw the campaign (exposures) went on to make a purchase from the client (purchasers). However, confidentiality concerns might prevent the advertising network from sharing their list of exposures with the client or prevent the client from sharing their list of purchasers with the advertising network.
As these examples show, there can be many situations in which different organizations want to collaborate on a joint analysis of their pooled data, but cannot share their individual datasets directly. One solution to this problem is a data clean room, which is a service trusted by a collaboration’s participants to do the following:
- Hold the data of individual parties
- Enforce access-control rules that collaborators specify regarding their data
- Perform analyses over the pooled data
To serve customers with these needs, AWS recently launched a new data clean-room service called AWS Clean Rooms. This service provides AWS customers with a way to collaboratively analyze data (stored in other AWS services as SQL tables) without having to replicate the data, move the data outside of the AWS Cloud, or allow their collaborators to see the data itself.
Additionally, AWS Clean Rooms provides a feature that gives customers even more control over their data: cryptographic computing. This feature allows AWS Clean Rooms to operate over data that customers encrypt themselves and that the service cannot actually read. Specifically, customers can use this feature to select which portions of their data should be encrypted and to encrypt that data themselves. Collaborators can continue to analyze that data as if it were in the clear, however, even though the data in question remains encrypted while it is being processed in AWS Clean Rooms collaborations. In this way, customers can use AWS Clean Rooms to securely collaborate on data they may not have been able to share due to internal policies or regulations.
Cryptographic computing
Using the cryptographic computing feature of AWS Clean Rooms involves these steps:
- Users create AWS Clean Rooms collaborations and set collaboration-wide encryption settings. They then invite collaborators to support the analysis process.
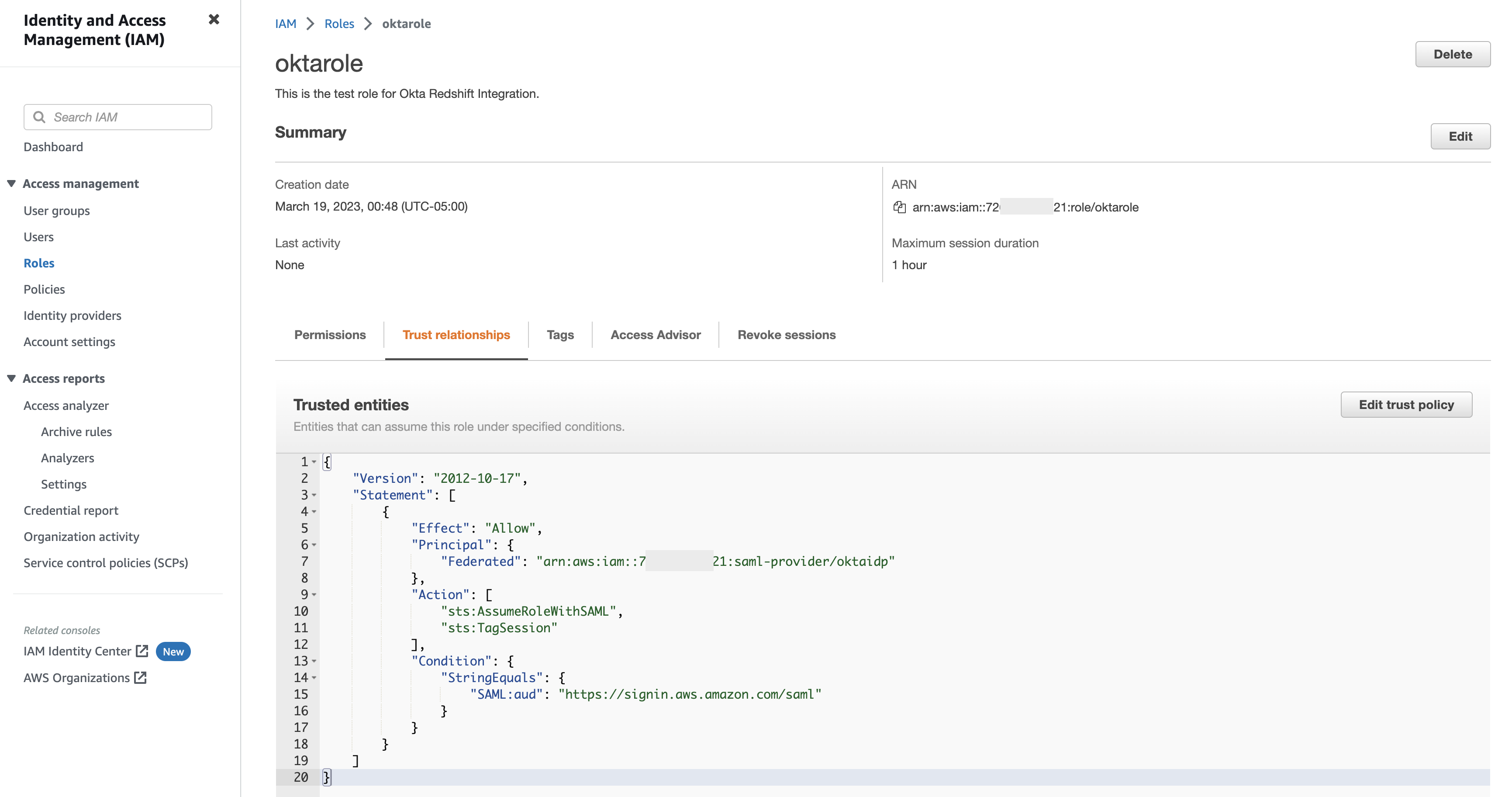
- Outside of AWS Clean Rooms, those collaborators agree on a shared secret: a common, secret, cryptographic key.
- Collaborators individually encrypt their tables outside of the AWS Cloud (typically on their own premises) using the shared secret, the collaboration ID of the intended collaboration, and the Cryptographic Computing for Clean Rooms (C3R) encryption client (which AWS provides as an open-source package). Collaborators then provide the encrypted tables to AWS Clean Rooms, just as they would have provided plaintext tables.
- Collaborators continue to use AWS Clean Rooms for their data analysis. They impose access-control rules on their tables, submit SQL queries over the tables in the collaboration, and retrieve results.
- These results might contain encrypted columns, and so collaborators decrypt the results by using the shared secret and the C3R encryption client.
As a result, data that enters AWS Clean Rooms in encrypted format will remain encrypted from input tables to intermediate values to result sets. AWS Clean Rooms will be unable to decrypt or read the data even while performing the queries.
Note: For those interested in the academic aspects of this process, the cryptographic computing feature of AWS Clean Rooms is based on server-aided private set intersection (PSI). Server-aided PSI allows two or more participants to submit sets of values to a server and learn which elements are found in all sets, but without (1) allowing the participants to learn anything about the other (non-shared) elements, or (2) allowing the server to learn anything about the underlying data (aside from the degrees to which the sets overlap). PSI is just one example of the field of cryptographic computing, which provides a variety of new methods by which encrypted data can be processed for various purposes and without decryption. These techniques allow our customers to use the scale and power of AWS systems on data that AWS will not be able to read. See our Cryptographic Computing webpage for more about our work in this area.
Let’s dive deeper into each new step in the process for using cryptographic computing in AWS Clean Rooms.
Key agreement. Each collaboration needs its own shared secret: a secure cryptographic secret (of at least 256 bits). Customers sometimes have a regulatory need to maintain ownership of their encryption keys. Therefore, the cryptographic computing feature supports the case where customers generate, distribute, and store their collaboration’s secret themselves. In this way, customers’ encryption keys are never stored on an AWS system.
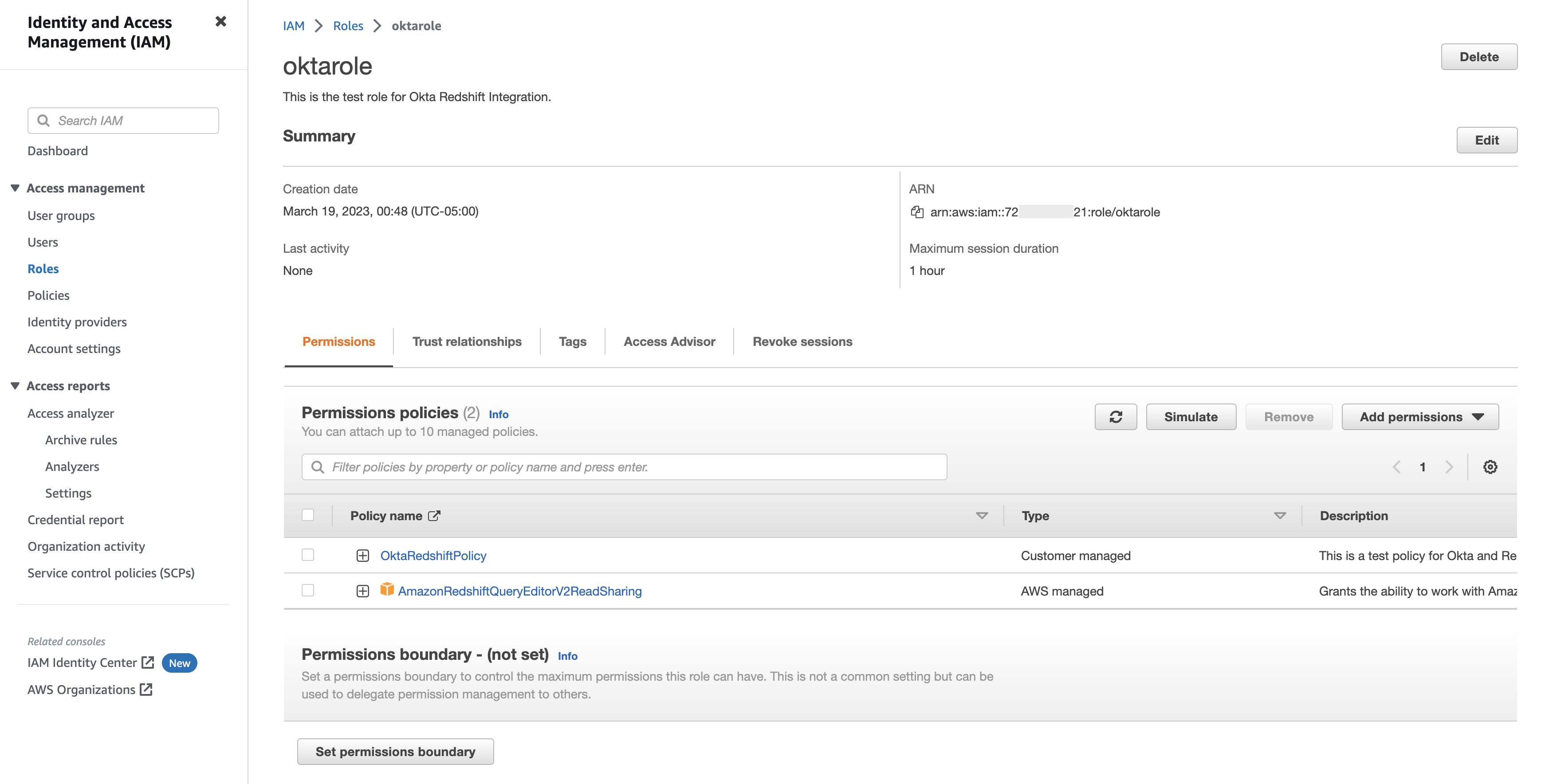
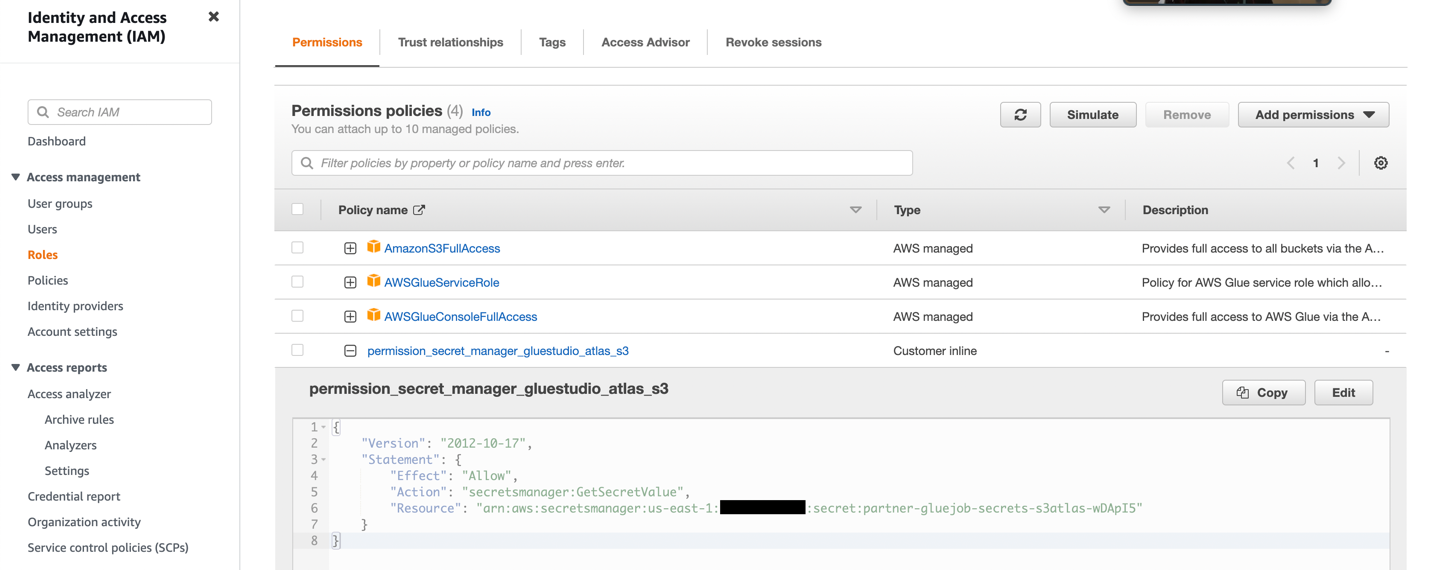
Encryption. AWS Clean Rooms allows table owners to control how tables are encrypted on a column-by-column basis. In particular, each column in an encrypted table will be one of three types: cleartext, sealed, or fingerprint. These types map directly to both how columns are used in queries and how they are protected with cryptography, described as follows:
- Cleartext columns are not cryptographically processed at all. They are copied to encrypted tables verbatim, and can be used anywhere in a SQL query.
- Sealed columns are encrypted. The encryption scheme used (AES-GCM) is randomized, meaning that encrypting the same value multiple times yields different ciphertexts each time. This helps prevent the statistical analysis of these columns, but also means that these columns cannot be used in JOIN clauses. They can be used in SELECT clauses, however, which allows them to appear in query results.
- Fingerprint columns are hashed using the Hash-based Message Authentication Code (HMAC) algorithm. There is no way to decrypt these values, and therefore no reason for them to appear in the SELECT clause of a query. They can, however, be used in JOIN clauses: HMAC will map a given value to the same fingerprint every time, meaning that JOINs will be able to unify common values across different fingerprint columns.
Encryption settings. This last point—that fingerprint values will always map a given plaintext value to the same fingerprint—might give pause to some readers. If this is true, won’t the encrypted table be vulnerable to statistical analysis? That is absolutely correct: it will. For this reason, users might wish to set collaboration-wide encryption settings to control these forms of analysis.
To see how statistical analysis might be a concern, imagine a table where one fingerprint column is named US_State. In this case, a simple frequency analysis will reverse-engineer the plaintext values relatively quickly: the most common fingerprint is almost certain to be “California”, followed by “Texas”, “Florida”, and so on. Also, imagine that the same table has another fingerprint column called US_City, and that a given fingerprint appears in both columns. In that case, the fingerprint in question is almost certain to be “New York”. If a row has a fingerprint in the US_City column but a NULL in the US_State column, furthermore, it’s very likely that the fingerprint is for “District of Columbia”. And finally, imagine that the table has a cleartext column called Time_Zone. In this case, values of “HST” (Hawaii standard time) or “AKST” (Alaska standard time) reveal the value in the US_State column regardless of the cryptography.
Not all datasets will be vulnerable to these kinds of statistical analysis, but some will. Only customers can determine which types of analysis may reveal their data and which may not. Because of this, the cryptographic computing feature allows the customer to decide which protections will be needed. At the time of collaboration creation, that is, the creator of the AWS Clean Rooms collaboration can configure the following collaboration-wide encryption settings:
- Whether or not fingerprint columns can contain duplicate plaintext values (addressing the “California” example)
- Whether or not fingerprint columns with different names should fingerprint values in the same way (addressing the “New York” example)
- Whether or not NULL values in the plaintext table should be left as NULL in the encrypted table (addressing the “District of Columbia” example)
- Whether or not encrypted tables should be allowed to have cleartext columns at all (addressing the time zone example)
Security is maximized when all of these options are set to “no,” but each “no” will limit the queries that C3R will be able to support. For example, the choice of whether or not encrypted tables should be allowed to have cleartext columns will determine which WHERE clauses will be supported: If cleartext columns are not supported, then the Time_Zone column must be cryptographically processed — meaning that the clause WHERE Time_Zone=”EST” will not act as intended. There might be reasons to set these options to “yes” in order to enable a wider variety of queries, which we discuss in the Query behavior section later in this post.
Decryption. AWS Clean Rooms will write query results to an Amazon Simple Storage Service (Amazon S3) bucket. The recipient copies these results from the bucket to some on-premises storage and then runs the C3R encryption client. The client will find encrypted elements of the output and decrypt them. Note that the client can only decrypt elements from sealed columns. If the output contains elements from a fingerprint column, the client will warn you, but will also leave these elements untouched, as cryptographic fingerprints can’t be decrypted.
Having finished our overview, let’s return to the discussion regarding how encryption can affect the behavior of queries.
Query behavior
Implicit in the discussion so far is something worth calling out explicitly: AWS Clean Rooms runs queries over the data that is provided to it. If the data given to AWS Clean Rooms is encrypted, therefore, queries will be run on the ciphertexts and not the plaintexts. This will not affect the results returned, so long as the columns are used for their intended purposes:
- Fingerprint columns are used in JOIN clauses
- Sealed columns are used in SELECT clauses
(Cleartext columns can be used anywhere.) Queries might produce unexpected results, however, if the columns are used outside of their intended purposes:
- Sometimes queries will fail when they would have succeeded on the plaintext. For example, ciphertexts and fingerprints will be string values, even if the original plaintext values were another type. Therefore, SUM() or AVG() calls on fingerprint or sealed columns will yield errors even if the corresponding plaintext columns were numeric.
- Sometimes queries will omit results that would have been found by querying the plaintext. For example, attempting to JOIN on sealed columns will yield empty result sets: no two ciphertexts will be the same, even if they encrypt the same plaintext value. (Also, performing a JOIN on fingerprint columns with different names will exhibit the same behavior, if the collaboration-wide encryption settings specified that fingerprint columns of different names should fingerprint values differently.)
- Sometimes results will include rows that would not be found by querying the plaintext. As mentioned, ciphertexts and fingerprints will be string values—base64 encodings of random-looking bytes, specifically. This means that a clause such as WHERE ‘US_State’ CONTAINS ‘CA’ will match some ciphertexts or fingerprints even when they would not match the plaintext.
To avoid these issues, fingerprint and sealed columns should only be used for their intended purposes (JOIN and SELECT clauses, respectively).
Conclusion
In this blog post, you have learned how AWS Clean Rooms can help you harness the power of AWS services to query and analyze your most-sensitive data. By using cryptographic computing, you can work with collaborators to perform joint analyses over pooled data without sharing your “raw” data with each other—or with AWS. If you believe that you can benefit from cryptographic computing (in AWS Clean Rooms or elsewhere), we’d like to hear from you. Please contact us with any questions or feedback. Also, we invite you to learn more about AWS Clean Rooms (including its use of cryptographic computing). Finally, the C3R client is open source, and can be downloaded from its GitHub page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.

 Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education.
Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education. Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment.
Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment. Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family.
Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family. Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.
Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.






 Srikanth Baheti is a Specialized World Wide Principal Solutions Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.
Srikanth Baheti is a Specialized World Wide Principal Solutions Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing. Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics.
Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics.























 Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team.
Gonzalo Herreros is a Senior Big Data Architect on the AWS Glue team.
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.



































 Hari Thatavarthy is a Senior Solutions Architect on the AWS Data Lab team. He helps customers design and build solutions in the data and analytics space. He believes in data democratization and loves to solve complex data processing-related problems. In his spare time, he loves to play table tennis.
Hari Thatavarthy is a Senior Solutions Architect on the AWS Data Lab team. He helps customers design and build solutions in the data and analytics space. He believes in data democratization and loves to solve complex data processing-related problems. In his spare time, he loves to play table tennis. Krishna Maddileti is a Senior Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey and helps them with data engineering, data lakes, and analytics. In his spare time, he enjoys spending time with his family and playing video games with his 7-year-old.
Krishna Maddileti is a Senior Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey and helps them with data engineering, data lakes, and analytics. In his spare time, he enjoys spending time with his family and playing video games with his 7-year-old. Yadukishore Tatavarthi is a Senior Partner Solutions Architect at AWS. He works closely with global system integrator partners to enable and support customers moving their workloads to AWS.
Yadukishore Tatavarthi is a Senior Partner Solutions Architect at AWS. He works closely with global system integrator partners to enable and support customers moving their workloads to AWS. Manish Kola is a Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey.
Manish Kola is a Solutions Architect on the AWS Data Lab team. He partners with customers on their AWS journey. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.





























 Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.
Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.













 Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in the data analytics domain.
Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in the data analytics domain. Shu Sia Lukito is a Partner Solutions Architect at AWS. She is on a mission to help AWS partners build successful AWS practices and help their customers accelerate their journey to the cloud. In her spare time, she enjoys spending time with her family and making spicy food.
Shu Sia Lukito is a Partner Solutions Architect at AWS. She is on a mission to help AWS partners build successful AWS practices and help their customers accelerate their journey to the cloud. In her spare time, she enjoys spending time with her family and making spicy food.


 Daren Wong is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Daren Wong is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS. Aleksandr Pilipenko is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Aleksandr Pilipenko is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS. Hong Liang Teoh is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.
Hong Liang Teoh is a Software Development Engineer in AWS. He works on Amazon Kinesis Data Analytics, the managed offering for running Apache Flink applications on AWS.






 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.

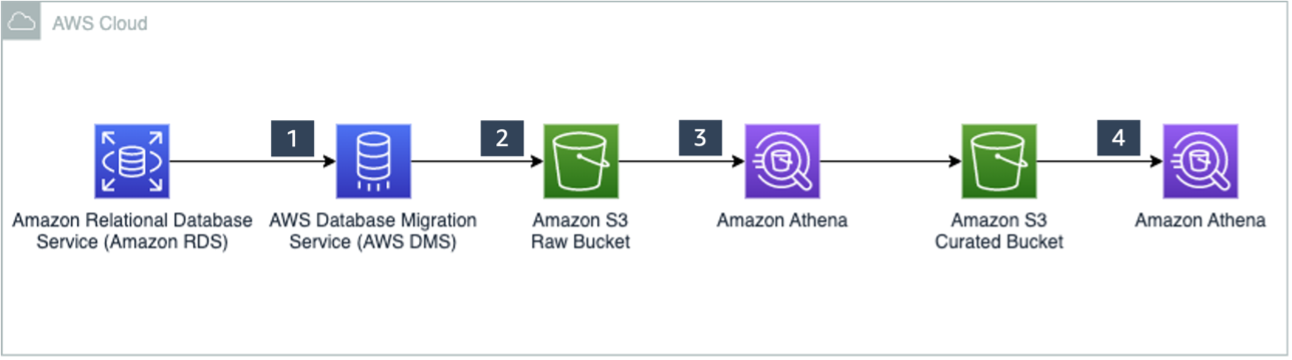

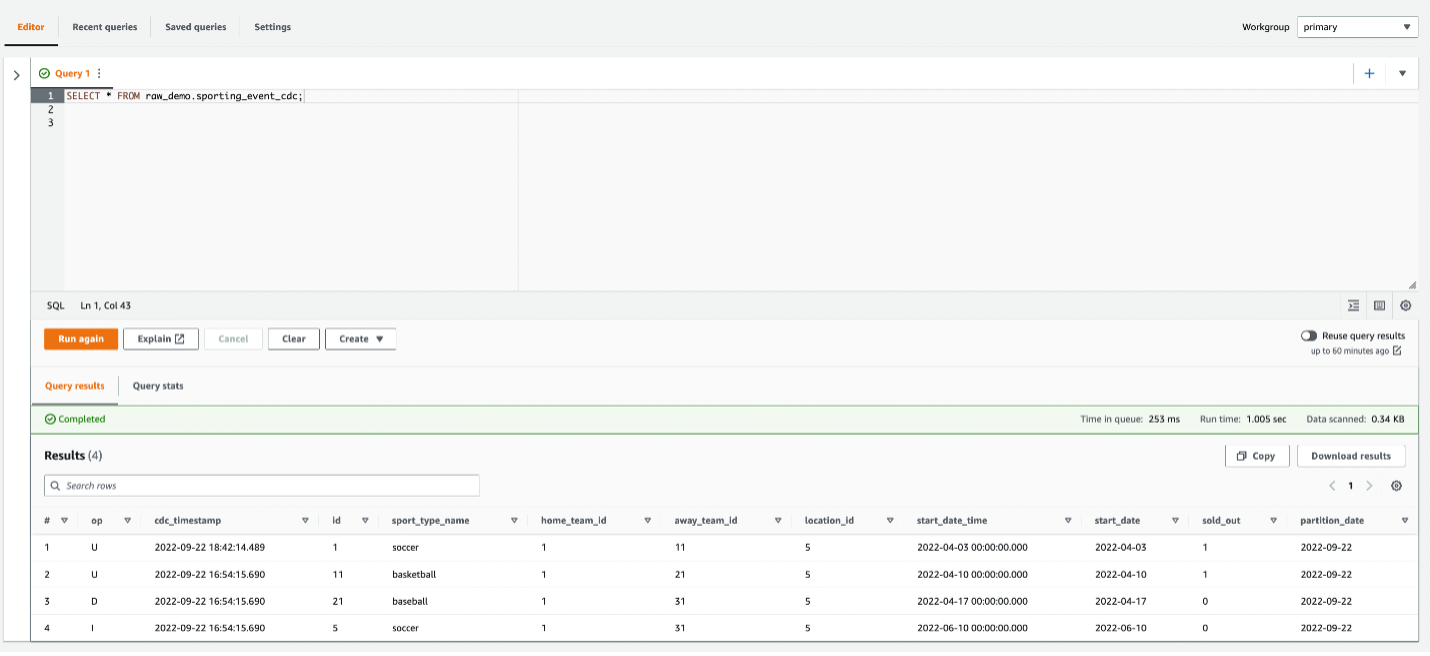
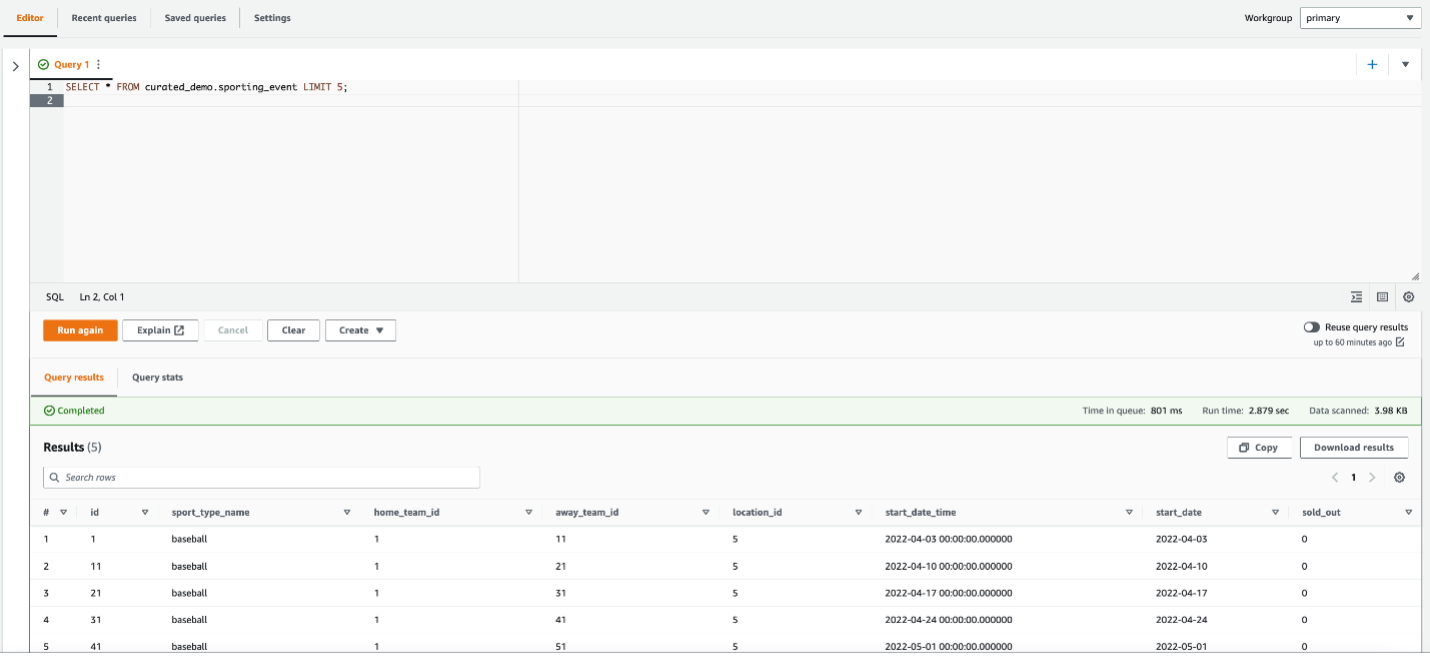

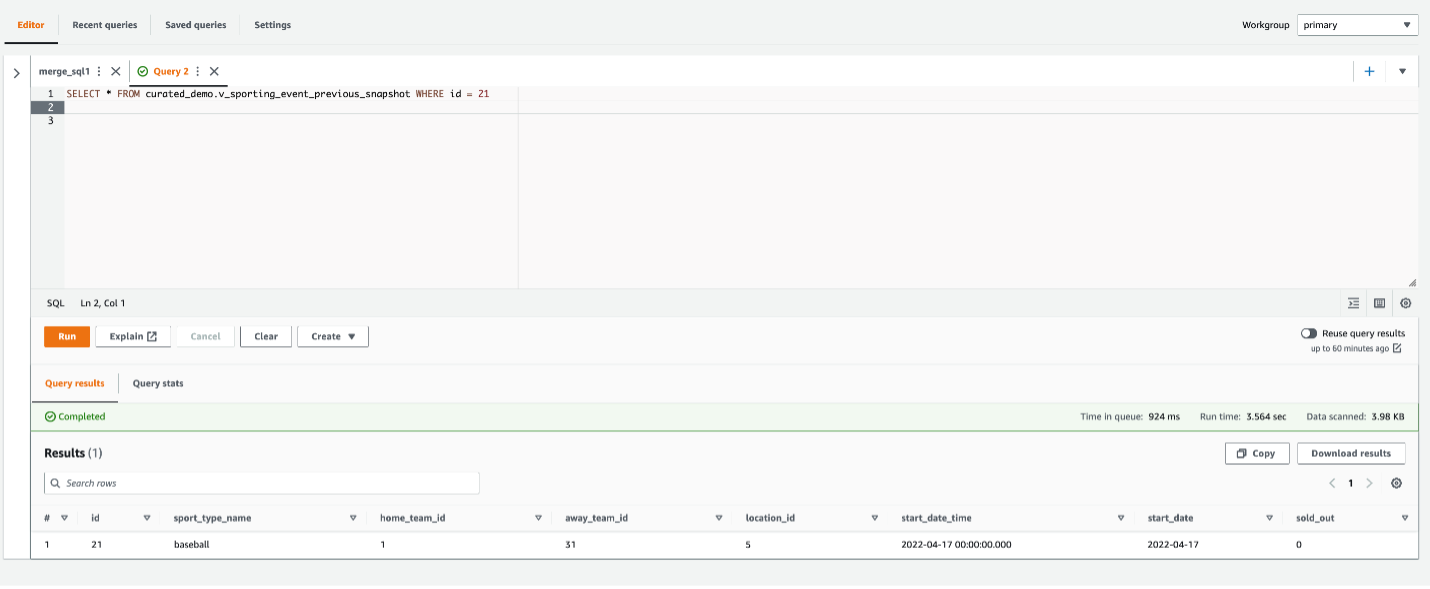
 Ranjit Rajan is a Principal Data Lab Solutions Architect with AWS. Ranjit works with AWS customers to help them design and build data and analytics applications in the cloud.
Ranjit Rajan is a Principal Data Lab Solutions Architect with AWS. Ranjit works with AWS customers to help them design and build data and analytics applications in the cloud. Kannan Iyer is a Senior Data Lab Solutions Architect with AWS. Kannan works with AWS customers to help them design and build data and analytics applications in the cloud.
Kannan Iyer is a Senior Data Lab Solutions Architect with AWS. Kannan works with AWS customers to help them design and build data and analytics applications in the cloud. Alexandre Rezende is a Data Lab Solutions Architect with AWS. Alexandre works with customers on their Business Intelligence, Data Warehouse, and Data Lake use cases, design architectures to solve their business problems, and helps them build MVPs to accelerate their path to production.
Alexandre Rezende is a Data Lab Solutions Architect with AWS. Alexandre works with customers on their Business Intelligence, Data Warehouse, and Data Lake use cases, design architectures to solve their business problems, and helps them build MVPs to accelerate their path to production.

 Arun Lakshmanan is a Search Specialist with Amazon OpenSearch Service based out of Chicago, IL. He has over 20 years of experience working with enterprise customers and startups. He loves to travel and spend quality time with his family.
Arun Lakshmanan is a Search Specialist with Amazon OpenSearch Service based out of Chicago, IL. He has over 20 years of experience working with enterprise customers and startups. He loves to travel and spend quality time with his family.