Post Syndicated from Sheila Busser original https://aws.amazon.com/blogs/compute/capturing-gpu-telemetry-on-the-amazon-ec2-accelerated-computing-instances/
This post is written by Amr Ragab, Principal Solutions Architect EC2.
AWS is excited to announce the native integration of monitoring GPU metrics through the CloudWatch Agent. Customers can now easily monitor GPU utilization and its memory to scale their workloads more effectively without custom scripts. In this post, we’ll describe how to allow GPU monitoring and integrate it into your Amazon Machine Images (AMI). Furthermore, we’ll extend this to include the monitoring of GPU hardware events utilizing CloudWatch Log Streams. By combining this telemetry into the Amazon CloudWatch Console, customers can have a complete picture of GPU activity across their fleets.
Capturing GPU metrics
There is an extensive list of NVIDIA accelerator metrics that can be captured. Depending on the workload type, it may be unnecessary to capture all of the metrics at all times. The following table breaks down the suggested metrics to collect by workload type. This considers a balance of cost and impactful metrics at scale.
| Compute (Machine Learning (ML), High Performance Computing (HPC)) |
Graphics/Gaming |
utilization_gpu
power_draw
utilization_memory
memory_total
memory_used
memory_free
pcie_link_gen_current
pcie_link_width_current
clocks_current_smclocks_current_memory |
utilization_gpu
utilization_memory
memory_total
memory_usedmemory_free
pcie_link_gen_current
pcie_link_width_current
encoder_stats_session_count
encoder_stats_average_fps
encoder_stats_average_latency
clocks_current_graphics
clocks_current_memory
clocks_current_video |
Moreover, this is supported through custom AMIs that are deployed with managed service offerings, including Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Services (Amazon ECS), and AWS ParallelCluster w/ SLURM for HPC clusters.
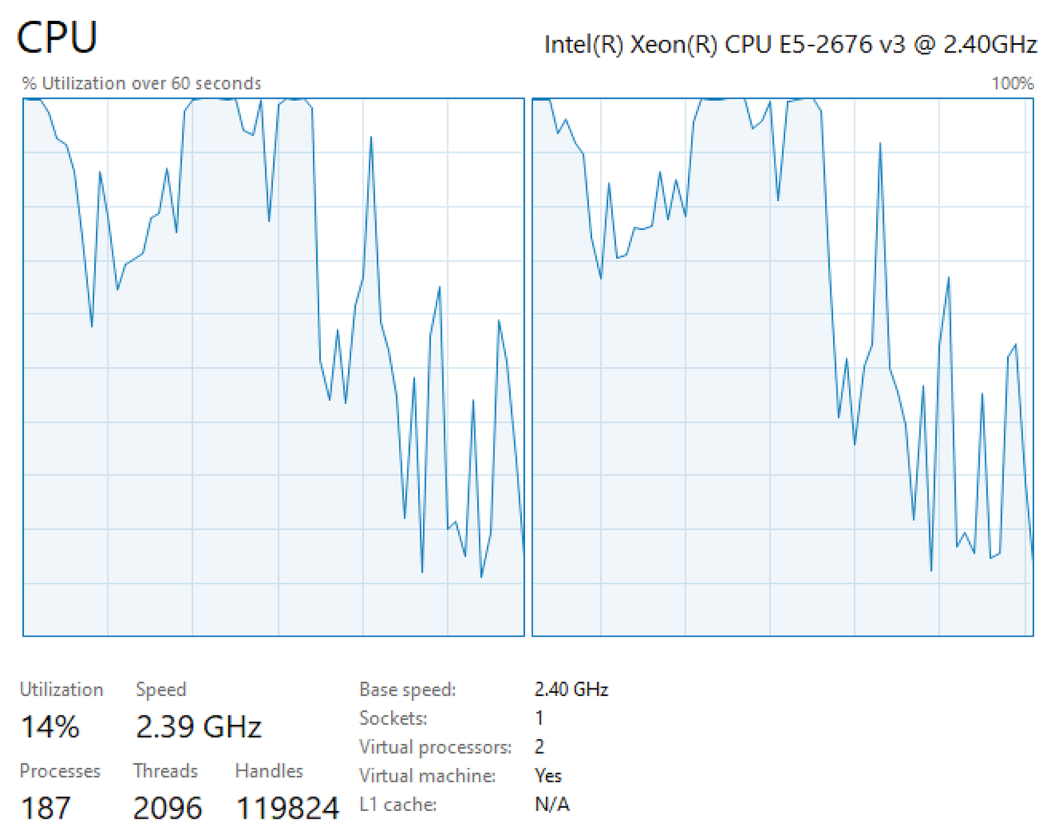
The following is an example screenshot from the CloudWatch Console showcasing the telemetry captured for a P4d instance. You can see that we captured the preceding metrics on a per-GPU index. Each Amazon Elastic Compute Cloud (Amazon EC2) P4d instance has 8x A100 GPUs.

Capturing GPU Xid events
Xid events are a reporting mechanism from GPU hardware vendors that emit notable events from the device to the OS in this case we are capturing the events through the NVRM kernel module. Current GPU architecture requires that the full GPU with protections are passed into the running instance. Thus, most errors that manifest inside of the customer instance aren’t directly visible to the Amazon EC2 virtualization stack. Although some of these errors are benign, others indicate problems with the customer application, the NVIDIA driver, and under rare circumstances a defect in the GPU hardware.
For NVIDIA-based Amazon EC2 instances, these errors will be logged in the system journal with an “NVRM:” regular expression.
These events can be collected and pushed to Amazon CloudWatch Logs as a stream. When an Xid event occurs on the GPU, it will parse the event and push it the log stream for that instance ID in the Region in which the instance is running. The following steps are required to get started capturing those events.
Deployment
We’ll cover the deployment in two different use-cases: 1. You have an existing instance running and you want to start to capture metrics and XID events. 2. You want to build and an AMI and use it within Amazon EC2 or additional services.
I. On a running Amazon EC2 instance
Step 1. Attach an IAM Role to the EC2 instance that has permission to CloudWatch Metrics/Logs. The following is an IAM policy that you can attach to your IAM Role.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "1",
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricStream",
"logs:CreateLogDelivery",
"logs:CreateLogStream",
"cloudwatch:PutMetricData",
"logs:UpdateLogDelivery",
"logs:CreateLogGroup",
"logs:PutLogEvents",
"cloudwatch:ListMetrics"
],
"Resource": "*"
}
]
}
Step 2. Connect to a shell on the EC2 instance (through SSM or SSH). Install the CloudWatch Agent following the instructions here. There is support across architectures and distributions.
Step 3. Next, we can create our CloudWatch Agent JSON configuration file. The following JSON snippet will capture the logs from gpuerrors.log and push to CloudWatch Logs. Save the contents of the following JSON snippet to a file on the instance at /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json.
{
"agent": {
"run_as_user": "root"
},
"metrics": {
"append_dimensions": {
"AutoScalingGroupName": "${aws:AutoScalingGroupName}",
"ImageId": "${aws:ImageId}",
"InstanceId": "${aws:InstanceId}",
"InstanceType": "${aws:InstanceType}"
},
"aggregation_dimensions": [["InstanceId"]],
"metrics_collected": {
"nvidia_gpu": {
"measurement": [
"utilization_gpu",
"utilization_memory",
"memory_total",
"memory_used",
"memory_free",
"clocks_current_graphics",
"clocks_current_sm",
"clocks_current_memory"
]
}
}
},
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/gpuevent.log",
"log_group_name": "/ec2/accelerated/accel-event-log",
"log_stream_name": "{instance_id}"
}
]
}
}
}
}
Step 4. To start capturing the logs, restart the aws cloudwatch systemd service.
sudo systemctl restart amazon-cloudwatch-agent.service
At this point, if you navigate to the CloudWatch Console in the Region that the instance is running, – All metrics – CWAgent, you should see a table of metrics similar to the following screenshot.

Step 5. To capture the XID events it’s possible to use the same CloudWatch Log directive used in the preceding image were set the GPU metrics to capture. The JSON following snippet defines that we will stream the log in /var/log/gpuevent.log to CloudWatch.
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/gpuevent.log",
"log_group_name": "/ec2/accelerated/accel-event-log",
"log_stream_name": "{instance_id}"
}
]
}
}
}
The GitHub project is an open source reference design for capturing these errors in the CloudWatch agent.
https://github.com/aws-samples/aws-efa-nccl-baseami-pipeline
Step 6. Save the following file as /opt/aws/aws-hwaccel-event-parser.py|.go with the following contents, which will write the Xid errors parsed to /var/log/gpuevent.log:
The code is available in either Python3 or Go (> 1.16).
Golang code of the hwaccel-event-parser: https://github.com/aws-samples/aws-efa-nccl-baseami-pipeline/blob/master/nvidia-efa-ami_base/cloudwatch/nvidia/aws-hwaccel-event-parser.go
Python3 code: https://github.com/aws-samples/aws-efa-nccl-baseami-pipeline/blob/master/nvidia-efa-ami_base/cloudwatch/nvidia/aws-hwaccel-event-parser.py
As you can see from the code, this is a blocking thread, and it will be running during the lifetime of the instance or container.
Step 7. For ease of deployment, you can also create a systemd service (aws-hw-monitor.service), which will run at startup before the CloudWatch agent.
[Unit]
Description=HW Error Monitor
Before=amazon-cloudwatch-agent.service
After=syslog.target network-online.target
[Service]
Type=simple
ExecStart=/opt/aws/cloudwatch/aws-cloudwatch-wrapper.sh
RemainAfterExit=1
TimeoutStartSec=0
[Install]
WantedBy=multi-user.target
Where /opt/aws/cloudwatch/aws-cloudwatch-wrapper.sh is a script which contains:
#!/bin/bash
python3 /opt/aws/aws-hwaccel-event-parser.py &
Finally, enable and start the hw monitor service
sudo systemctl enable aws-hw-monitor.service –now
II. Building an AMI
For convenience, the following repo has what is needed to build the AMI for Amazon EC2, Amazon EKS, Amazon ECS, Amazon Linux 2, and Ubuntu 18.04/20.04 distributions. You must have Packer installed on your machine, and it must be authenticated to make API calls on your behalf to AWS. Generally you need to modify the variables:{} json and execute the packer build.
"variables": {
"region": "us-east-1",
"flag": "<flag>",
"subnet_id": "<subnetid>",
"security_groupids": "<security_group_id,security_group_id",
"build_ami": "<buildami>",
"efa_pkg": "aws-efa-installer-latest.tar.gz",
"intel_mkl_version": "intel-mkl-2020.0-088",
"nvidia_version": "510.47.03",
"cuda_version": "cuda-toolkit-11-6 nvidia-gds-11-6",
"cudnn_version": "libcudnn8",
"nccl_version": "v2.12.7-1"
},
After filling in the variables, check that the packer script is validated.
packer validate nvidia-efa-ml-al2.yml
packer build nvidia-efa-ml-al2.yml
The log group namespace is /ec2/accelerated/accel-event-log. However, you may change this to the namespace of your preference in the CloudWatch Agent config file created earlier.
Navigate to the CloudWatch Console – Logs – Log groups – /ec2/accelerated/accel-event-log. It’s sorted by instance ID, where the instance ID of the latest stream is on top.

We can see in the preceding screenshot that an example workload ran on instance i-03a7b66de3198977e, which was a p4d.24xlarge triggered a Xid 63 event. Capturing these events is the first step. Next, we must interpret what these events mean. With each Xid error, there is a number associated with each event. As previously mentioned, these can be hardware errors, driver, and/or application errors. If you’re running on an Amazon EC2 accelerated instance, and after code execution run into one of these errors, contact AWS Support with the instance ID and Xid error. The following is a list of the more common Xid errors that you may encounter.
| Xid Error |
Name |
Description |
Action |
| 48 |
Double Bit ECC error |
Hardware memory error |
Contact AWS Support with Xid error and instance ID |
| 74 |
GPU NVLink error |
Further SXid errors should also be populated which will inform on the error seen with the NVLink fabric |
Get information on which links are causing the issue by running nvidia-smi nvlink -e |
| 63 |
GPU Row Remapping Event |
Specific to Ampere architecture –- a row bank is pending a memory remap |
Stop all CUDA processes, and reset the GPU (nvidia-smi -r), and make sure thatensure the remap is cleared in nvidia-smi -q |
| 13 |
Graphics Engine Exception |
User application fault , illegal instruction or register |
Rerun the application with CUDA_LAUNCH_BLOCKING=1 enabled which should determine if it’s a NVIDIA driver or hardware issue |
| 31 |
GPU memory page fault |
Illegal memory address access error |
Rerun the application with CUDA_LAUNCH_BLOCKING=1 enabled which should determine if it’s a NVIDIA driver or hardware issue |
A quick way to check for row remapping failures is to run the below command on the instance.
nvidia-smi --query-remapped-
rows=gpu_name,gpu_bus_id,remapped_rows.failure,remapped_rows.pending,remapped_rows.correctable,remapped_rows.uncorrectable --format=csv
gpu_name, gpu_bus_id, remapped_rows.failure, remapped_rows.pending, remapped_rows.correctable, remapped_rows.uncorrectable
NVIDIA A100-SXM4-40GB, 00000000:10:1C.0, 0, 0, 0, 0
NVIDIA A100-SXM4-40GB, 00000000:10:1D.0, 0, 0, 0, 0
NVIDIA A100-SXM4-40GB, 00000000:20:1C.0, 0, 0, 0, 0
NVIDIA A100-SXM4-40GB, 00000000:20:1D.0, 0, 0, 0, 0
NVIDIA A100-SXM4-40GB, 00000000:90:1C.0, 0, 0, 0, 0
NVIDIA A100-SXM4-40GB, 00000000:90:1D.0, 0, 0, 0, 0
NVIDIA A100-SXM4-40GB, 00000000:A0:1C.0, 0, 0, 0, 0
NVIDIA A100-SXM4-40GB, 00000000:A0:1D.0, 0, 0, 0, 0
This isn’t an exhaustive list of Xid events, but it provides some of the more common ones that you may come across as you develop your accelerated workload. You can find a more complete table of events here. Furthermore, if you have questions, you can reach out to AWS Support with the output of the tar ball created by executing the nvidia-bug-report.sh script included with the NVIDIA driver.
Conclusion
Get started with integrating this monitoring into your AMIs if you use custom AMIs specifically for key services, such as Amazon EKS, Amazon ECS, or Amazon EC2 with AWS ParallelCluster. This will help you discover utilization metrics for your accelerated computing workloads. If you have any questions about this post, then reach out to your account team.