Post Syndicated from Alex Casalboni original https://aws.amazon.com/blogs/aws/s3-multi-region-access-points-accelerate-performance-availability/
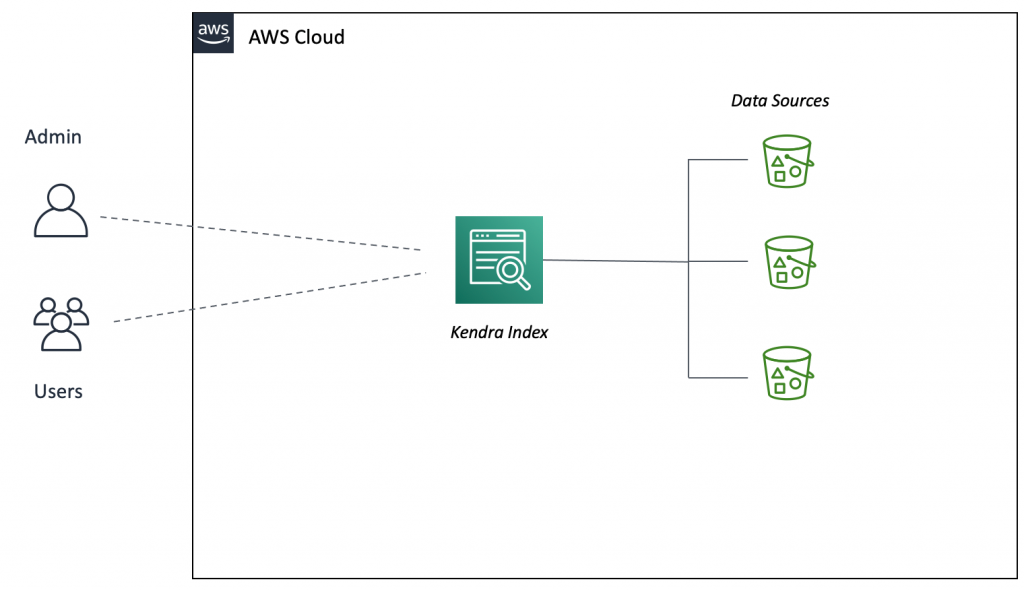
Building multi-region applications allows you to improve latency for end users, achieve higher availability and resiliency in case of unexpected disasters, and adhere to business requirements related to data durability and data residency. For example, you might want to reduce the overall latency of dynamic API calls to your backend services . Or you might want to extend a single-region deployment to handle internet routing issues, failures of submarine cables, or regional connectivity issues – and therefore avoid costly downtime. Today, thanks to multi-region data replication functions such as Amazon DynamoDB global tables, Amazon Aurora global database, Amazon ElastiCache global datastore, and Amazon Simple Storage Service (Amazon S3) cross-region replication, you can build multi-region applications across 25 AWS Regions worldwide.
Yet, when it comes to implementing multi-region applications, you often have to make your code region-aware and take care of the heavy lifting of interacting with the correct regional resources, whether it’s the closest or the most available. For example, you might have three S3 buckets with object replication across three AWS Regions. Your application code needs to be aware of how many copies of the bucket exist and where they are located, which bucket is the closest to the caller, and how to fall back to other buckets in case of issues. The complexity grows when you add new regions to your multi-region architecture and redeploy your stack in each region whenever a global configuration changes.
Today, I’m happy to announce the general availability of Amazon S3 Multi-Region Access Points, a new S3 feature that allows you to define global endpoints that span buckets in multiple AWS Regions. With S3 Multi-Region Access Points, you can build multi-region applications with the same simple architecture used in a single region.
S3 Multi-Region Access Points deliver built-in network resilience, building on top AWS Global Accelerator to route S3 requests over the AWS global network. This is especially important to minimize network congestion and overall latency, while maintaining a simple application architecture. AWS Global Accelerator constantly monitors for regional availability and can shift requests to another region within seconds. By dynamically routing your requests to the lowest latency copy of your data, S3 Multi-Region Access Points increase upload and download performance by up to 60%. This is great not just for server-side applications that rely on S3 for reading configuration files or application data, but also for edge applications that need a performant and reliable write-only endpoint, such as IoT devices or autonomous vehicles.
S3 Multi-Region Access Points in Action
To get started, you create an S3 Multi-Region Access Point in the S3 console, via API, or with AWS CloudFormation.
Let me show you how to create one using the S3 console. Each access point needs a name, unique at the account level.
After it’s created, you can access it through its alias, which is generated automatically and globally unique. The alias will look like a random string ending with .mrap – for example, mmqdt41e4bf6x.mrap. It can also be accessed over the internet via https://mmqdt41e4bf6x.mrap.s3-global.amazonaws.com, via VPC, or on-premises using AWS PrivateLink.

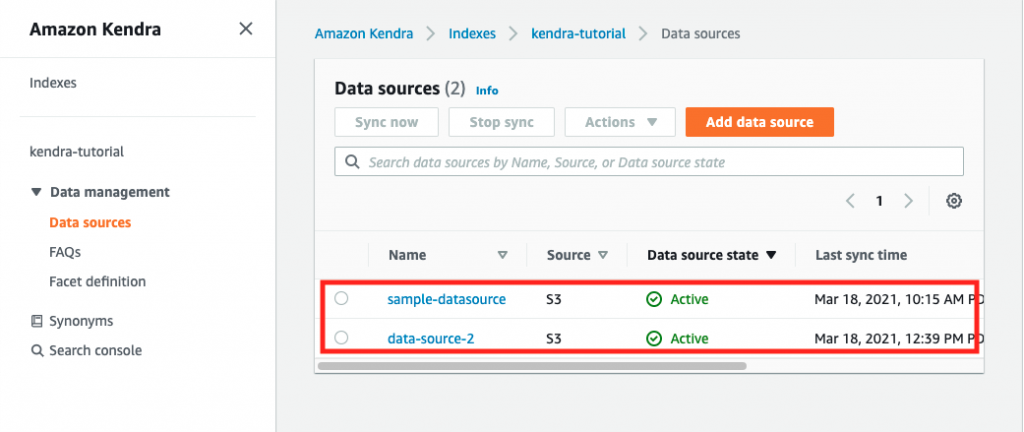
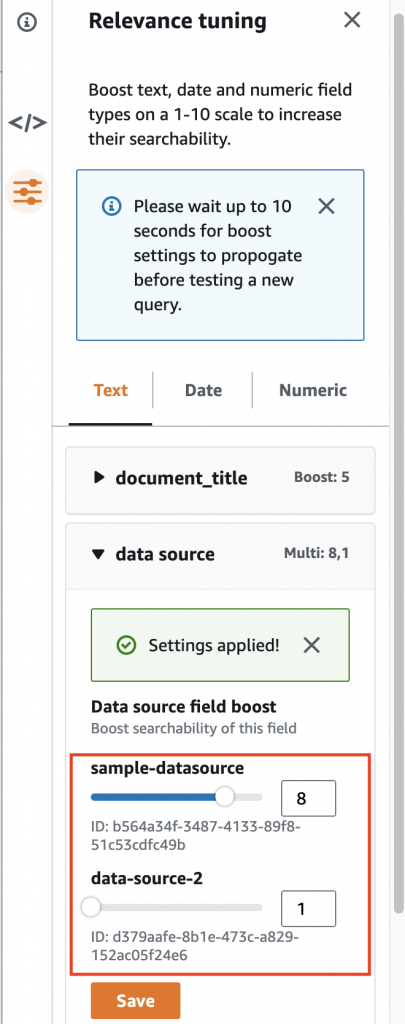
Then, you associate multiple buckets (new or existing) to the access point, one per Region. If you need data replication, you’ll need to enable bucket versioning too.

Finally, you configure the Block Public Access settings for the access point. By default, all public access is blocked, which works fine for most cases.
The creation process is asynchronous, you can view the creation status in the Console or by listing the S3 Multi-Region Access Points from the CLI. When it becomes Ready, you can configure optional settings for the access point policy and object replication.

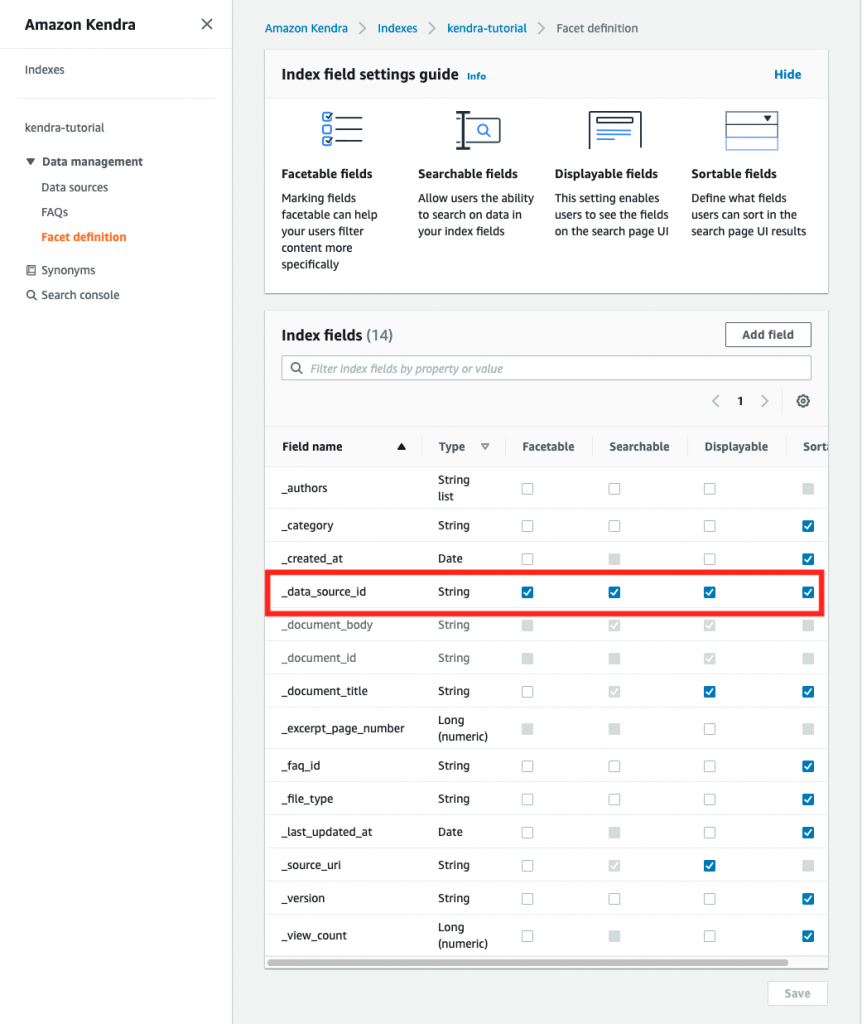
Similar to regular access points, you can customize the access control policy to limit the use of the access point with respect to the bucket’s permission. Keep in mind that both the access point and the underlying buckets must permit a request. S3 Multi-Region Access Points cannot extend the permissions, just limit (or equal) them. You can also use IAM Access Analyzer to verify public and cross-account access for buckets that use S3 Multi-Region Access Points and preview access to your buckets before deploying permissions changes.
Your S3 Multi-Region Access Point access policy might look like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Default",
"Effect": "Allow",
"Principal": {
"AWS": "YOUR_ACCOUNT_ID"
},
"Action": ["s3:GetObject", "s3:PutObject"],
"Resource": "arn:aws:s3::YOUR_ACCOUNT_ID:accesspoint/YOUR_ALIAS/object/*"
}
]
}To replicate data between buckets used with your S3 Multi-Region Access Point, you configure S3 Replication. In some cases, you might want to store different content in each bucket, or have a portion of a regional bucket for use with a global endpoint and other portions that aren’t replicated and used only with a regional access point or direct bucket access. For example, an IoT device configuration might include references to other regional API endpoints or regional resources that will be different for each bucket.
The new S3 console provides two basic templates that you can use to easily and centrally create replication rules:
- Replicate objects from one or more source bucket to one or more destination buckets: This is ideal for ready-only use cases where data is always generated in a specific AWS Region and you want it to be available in all other Regions, too.
- Replicate objects among all specified buckets: This is ideal for the IoT scenario I mentioned, where you’d define a write-only access point that devices use to upload data to the closest region, and you need this data to be available in all regions.
Of course, thanks to filters and conditions, you can create more sophisticated replication setups. For example, you might want to replicate only certain objects based on a prefix or tags.

Keep in mind that bucket versioning must be enabled for cross-region replication.
![]()
The console will take care of creating and configuring the replication rules and IAM roles. Note that to add or remove buckets, you would create a new the S3 Multi-Region Access Point with the revised list.
In addition to the replication rules, here is where you configure replication options such as Replication Time Control (RTC), replication metrics and notifications, and bidirectional sync. RTC allows you to replicate most new objects in seconds, and 99.99% of those objects within 15 minutes, for use cases where replication speed is important; replications metrics allow you to monitor how synchronized are your buckets in terms of object and byte count; bidirectional sync allows you to achieve an active-active configuration for put-heavy use cases in which object metadata needs to be replicated across buckets too.

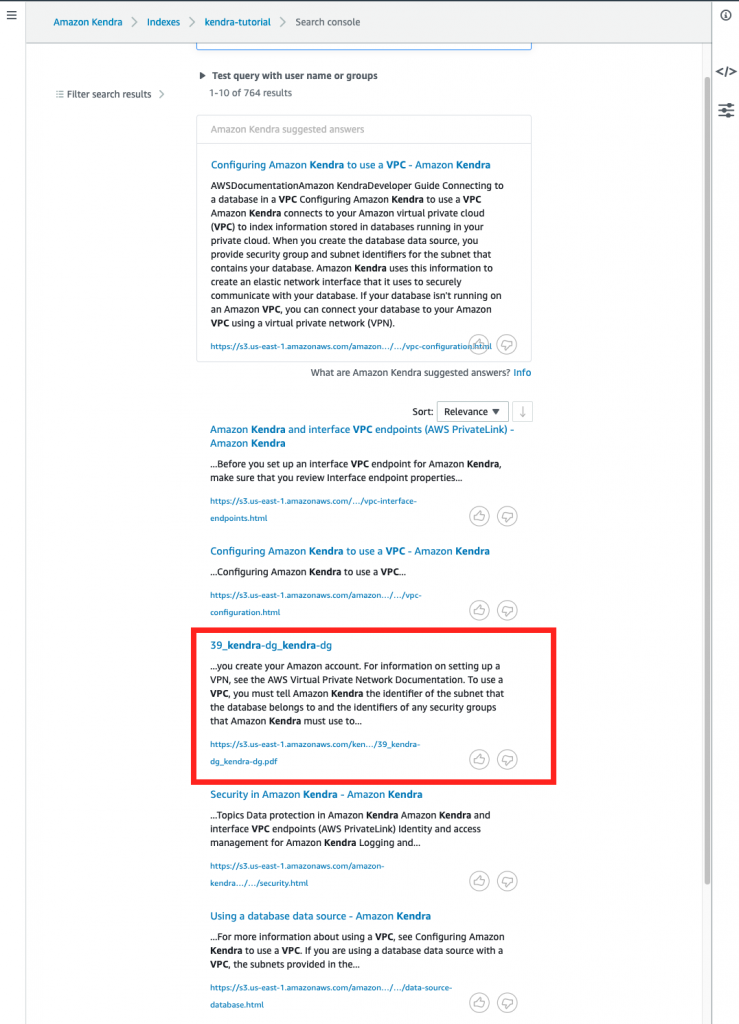
After replication is configured, you get a very useful visual and interactive summary that allows you to verify which AWS Regions are enabled. You’ll see where they are on the map, the name of the regional buckets, and which replication rules are being applied.

After the S3 Multi-Region Access Point is defined and correctly configured, you can start interacting with it through the S3 API, AWS CLI, or the AWS SDKs. For example, this is how you’d write and read a new object using the CLI (don’t forget to upgrade to the latest CLI version):
# create a new object
aws s3api put-object --bucket arn:aws:s3::YOUR_ACCOUNT_ID:accesspoint/YOUR_ALIAS --key test.png --body test.png
# retrieve the same object
aws s3api get-object --bucket arn:aws:s3::YOUR_ACCOUNT_ID:accesspoint/YOUR_ALIAS --key test.png test.png
Last but not least, you can use bucket metrics in Amazon CloudWatch to keep track of how user requests are distributed across buckets in multiple AWS Regions.
CloudFormation Support at Launch
Today, you can start using two new CloudFormation resources to easily define an S3 Multi-Region Access Point: AWS::S3::MultiRegionAccessPoint and AWS::S3::MultiRegionAccessPointPolicy.
Here is an example:
Resources:
MyS3MultiRegionAccessPoint:
Type: AWS::S3::MultiRegionAccessPoint
Properties:
Regions:
- Bucket: regional-bucket-ireland
- Bucket: regional-bucket-australia
- Bucket: regional-bucket-us-east
PublicAccessBlockConfiguration:
BlockPublicAcls: true
IgnorePublicAcls: true
BlockPublicPolicy: true
RestrictPublicBuckets: true
MyMultiRegionAccessPointPolicy:
Type: AWS::S3::MultiRegionAccessPointPolicy
Properties:
MrapName: !Ref MyS3MultiRegionAccessPoint
Policy:
Version: 2012-10-17
Statement:
- Action: '*'
Effect: Allow
Resource: !Sub
- 'arn:aws:s3::${AWS::AccountId}:accesspoint/${mrapalias}/object/*'
- mrapalias: !GetAtt
- MyS3MultiRegionAccessPoint
- Alias
Principal: {"AWS": !Ref "AWS::AccountId"}
The AWS::S3::MultiRegionAccessPoint resource depends only on the S3 bucket names. You don’t need to reference other regional stacks and you can easily centralize the S3 Multi-Region Access Point definition into its own stack. On the other hand, cross-region replication needs to be configured on each S3 bucket.
Cost considerations
When you use an S3 Multi-Region Access Point to route requests within the AWS global network, you pay a data routing cost of $0.0033 per GB processed, in addition to the standard charges for S3 requests, storage, data transfer, and replication. If your applications access the S3 Multi-Region Access Point over the internet, you’re also charged an internet acceleration cost per GB. This cost depends on the transfer type (upload or download) and whether the client and the bucket are in the same or different locations. For details, visit the S3 pricing page and select the data transfer tab.
Let me share a few practical examples:
- All traffic within an AWS Region: In this simple case, your application runs in US East (N. Virginia) and you configure two S3 buckets in US East (N. Virginia) and US West (Oregon). The application uploads 100GB of data and the lowest latency bucket is in US East(N. Virginia). All the data is routed by your S3 Multi-Region Access Point in the same region and the total cost is $0.33.
- All traffic across two AWS Regions: In this case, your application runs in US East (N. Virginia) and you configure two S3 buckets in US East (Ohio) and US West (Oregon). The application uploads 100GB of data and the lowest latency bucket is in US East (Ohio). All the data is routed by your S3 Multi-Region Access Point across two AWS Regions. The data routing cost for 100GB is the same of the previous example ($0.33), plus the S3 data transfer cost of $0.01 per GB, resulting in a total cost of $1.33.
- All traffic over the internet across North America, Europe, and Asia Pacific (download and upload): In this case, your application runs on customer devices in North America, Europe, and Asia, and you configure two S3 buckets in US East (N. Virginia) and Europe (Ireland). One customer in North America uploads 50GB of data, which is routed to the bucket in US East (N. Virginia); a second customer in Europe downloads 50GB of data from the bucket in Europe (Ireland); a third customer in Asia downloads 50GB of data from the bucket in Europe (Ireland). The data routing cost for 150GB is $0.495. Plus the data transfer out from S3 to Europe of $0.09 per GB ($9), the internet acceleration cost from North America to the S3 bucket in US East (N. Virginia) of $0.0025 per GB ($0.125), the internet acceleration cost from the S3 bucket in Europe (Ireland) to Europe of $0.005 per GB ($0.25), and the internet acceleration cost from the S3 bucket in Europe (Ireland) to Asia of $0.05 per GB ($2.5). The total cost is $12.37. Please note that this example is intended to demonstrate how the internet acceleration cost works across continents. Also note that the internet acceleration cost to Asia might be reduced by an order of magnitude with an additional S3 bucket in Asia (see next example).
- All the traffic over the internet across North America, Europe, and Asia Pacific (only upload): In this case, we consider the same conditions of the previous example. The only difference is that all customers only upload data and that you configure an additional bucket in Asia Pacific (Singapore). The data routing cost is the same ($0.495). Plus the internet acceleration cost from North America to the S3 bucket in US East (N. Virginia) of $0.0025 per GB ($0.125), the internet acceleration cost from Europe to the S3 bucket in Europe (Ireland) of $0.0025 per GB ($0.125), and the internet acceleration cost from Asia to the S3 bucket in Asia Pacific (Singapore) of $0.01 per GB ($0.5). The total cost is $1.24.
In other words, the routing cost is easy to estimate and doesn’t depend on the application type or data access pattern. The internet acceleration cost depends on the access pattern (downloads are more expensive than uploads) and on the client location with respect to the closest AWS Region. For global applications that upload or download data over the internet, you can minimize the internet acceleration cost by configuring at least one S3 bucket in each continent.
Available Today
Amazon S3 Multi-Region Access Points allow you to increase resiliency and accelerate application performance up to 60% when accessing data across multiple AWS Regions. We look forward to feedback about your use cases so that we can iterate quickly and simplify how you design and implement multi-region applications.
You can get started using the S3 API, CLI, SDKs, AWS CloudFormation or the S3 Console. This new functionality is available in 17 AWS Regions worldwide (see the full list of supported AWS Regions).
Learn More
Watch this video to hear more about S3 Multi-Region Access Points and see a short demo.
Check out the technical documentation for S3 Multi-Region Access Points.
— Alex




















































































 For more information, see
For more information, see 
















