Post Syndicated from Dalei Xu original https://aws.amazon.com/blogs/big-data/apache-hbase-online-migration-to-amazon-emr/
Apache HBase is an open source, non-relational distributed database developed as part of the Apache Software Foundation’s Hadoop project. HBase can run on Hadoop Distributed File System (HDFS) or Amazon Simple Storage Service (Amazon S3), and can host very large tables with billions of rows and millions of columns.
The followings are some typical use cases for HBase:
- In an ecommerce scenario, when retrieving detailed product information based on the product ID, HBase can provide a quick and random query function.
- In security assessment and fraud detection cases, the evaluation dimensions for users vary. HBase’s non-relational architectural design and ability to freely scale columns help cater to the complex needs.
- In a high-frequency, real-time trading platform, HBase can support highly concurrent reads and writes, resulting in higher productivity and business agility.
Recommended HBase deployment mode
Starting with Amazon EMR 5.2.0, you have the option to run Apache HBase on Amazon S3.
Running HBase on Amazon S3 has several added benefits, including lower costs, data durability, and easier scalability. And during HBase migration, you can export the snapshot files to S3 and use them for recovery.
Recommended HBase migration mode
For existing HBase clusters (including self-built based on open source HBase or provided by vendors or other cloud service providers), we recommend using HBase snapshot and replication technologies to migrate to Apache HBase on Amazon EMR without significant downtime of service.
This blog post introduces a set of typical HBase migration solutions with best practices based on real-world customers’ migration case studies. Additionally, we deep dive into some key challenges faced during migrations, such as:
- Using HBase snapshots to implement initial migration and HBase replication for real-time data migration.
- HBase provided by other cloud platforms doesn’t support snapshots.
- A single table with large amounts of data, for example more than 50 TB.
- Using BucketCache to improve read performance after migration.
HBase snapshots allow you to take a snapshot of a table without too much impact on region servers, snapshots, clones, and restore operations don’t involve data copying. Also, exporting a snapshot to another cluster has little impact on the region servers.
HBase replication is a way to copy data between HBase clusters. It allows you to keep one cluster’s state synchronized with that of another cluster, using the write-ahead log (WAL) of the source cluster to propagate changes. It can work as a disaster recovery solution and also provides higher availability in the architecture.
Prerequisites
To implement HBase migration, you must have the following prerequisites:
Solution summary
In this example, we walk through a typical migration solution, which is from the source HBase on HDFS cluster (Cluster A) to the target Amazon EMR HBase on S3 (Cluster B). The following diagram illustrates the solution architecture.

To demonstrate the best practice recommended to the HBase migration process, the following are the detailed steps we will walk through, as shown in the preceding diagram.
| Step |
Activity |
Description |
Estimated time |
| 1 |
Configure cluster A
(Source HBase)
|
Modify the configuration of the source HBase cluster to prepare for subsequent snapshot exports |
Less than 5 minutes |
| 2 |
Create cluster B
(Amazon EMR HBase on S3)
|
Create an EMR cluster with HBase on Amazon S3 as the migration target cluster |
Less than 10 minutes |
| 3 |
Configure replication |
Configure replication from the source HBase cluster to Amazon EMR HBase, but do not start |
Less than 1 minute |
| 4 |
Pause service |
Pause the service of the source HBase cluster |
Less than 1 minute |
| 5 |
Create snapshot |
Create a snapshot for each table on the source HBase cluster |
Less than 5 minutes |
| 6 |
Resume service |
Resume the service of the source HBase cluster |
Less than 1 minute |
| 7 |
Snapshot export and restore |
Use snapshot to migrate data from the source HBase cluster to the Amazon EMR HBase cluster |
Depends on the size of the table data volume |
| 8 |
Start replication |
Start the replication of the source HBase cluster to Amazon EMR HBase and synchronize incremental data |
Depends on the size of the data accumulated during the snapshot export restore. |
| 9 |
Test and verify |
Test the and verify the Amazon EMR HBase |
|
Solution walkthrough
In the preceding diagram and table, we have listed the operational steps of the solution. Next, we will elaborate the specific operations for each step shown in the preceding table.
1. Configure cluster A (source HBase)
When exporting a snapshot from the source HBase cluster to the Amazon EMR HBase cluster, you must modify the following settings on the source cluster to ensure the performance and stability of data transmission.
| Configuration classification |
Configuration item |
Suggested value |
Comment |
| core-site |
fs.s3.awsAccessKeyId |
Your AWS access key ID |
The snapshot export takes a relatively long time. Without an access key and secret key, the snapshot export to Amazon S3 will encounter errors such as com.amazon.aws.emr.hadoop.fs.shaded.com. amazonaws.SdkClientException: Unable to load AWS credentials from any provider in the chain. |
| core-site |
fs.s3.awsSecretAccessKey |
Your AWS secret access key |
| yarn-site |
yarn.nodemanager.resource.memory-mb |
Half of a single core node RAM |
The amount of physical memory, in MB, that can be allocated for containers. |
| yarn-site |
yarn.scheduler.maximum-allocation-mb |
Half of a single core node RAM |
The maximum allocation for every container request at the ResourceManager in MB. Because snapshot export runs in the YARN Map Reduce task, it’s necessary to allocate sufficient memory to YARN to ensure transmission speed. |
These values are set depending on the cluster resource, workload, and table data volume. The modification can be done using a web UI if available or by suing a standard configuration XML file. Restart the HBase service after the change is complete.
2. Create cluster B (EMR HBase on S3)
Use the following recommend settings to launch an EMR cluster:
| Configuration classification |
Configuration item |
Suggested value |
Comment |
| yarn-site |
yarn.nodemanager.resource.memory-mb |
20% of a single core node RAM |
Amount of physical memory, in MB, that can be allocated for containers. |
| yarn-site |
yarn.scheduler.maximum-allocation-mb |
20% of a single core node RAM |
The maximum allocation for every container request at the ResourceManager in MB. Because snapshot restore runs in the HBase, it’s necessary to allocate a small amount of small memory to YARN and leave sufficient memory to HBase to ensure restore. |
| hbase-env.export |
HBASE_MASTER_OPTS |
70% of a single core node RAM |
Set the Java heap size for the primary HBase. |
| hbase-env.export |
HBASE_REGIONSERVER_OPTS |
70% of a single core node RAM |
Set the Java heap size for the HBase region server. |
| hbase |
hbase.emr.storageMode |
S3 |
Indicates that HBase uses S3 to store data. |
| hbase-site |
hbase.rootdir |
<Your-HBase-Folder-on-S3> |
Your HBase data folder on S3. |
See Configure HBase for more details. Additionally, the default YARN configuration on Amazon EMR for each Amazon EC2 instance type can be found in Task configuration.
The configuration of our example is as shown in the following figure.

3. Config replication
Next, we configure the replication peer from the source HBase to the EMR cluster.
The operations include:
- Create a peer.
- Because the snapshot migration hasn’t been done, we start by disabling the peer.
- Specify the table that requires replication for the peer.
- Enable table replication.
Let’s use the table usertable as an example. The shell script is as follows:
MASTER_IP="<Master-IP>"
TABLE_NAME="usertable"
cat << EOF | sudo -u hbase hbase shell 2>/dev/null
add_peer 'PEER_$TABLE_NAME', CLUSTER_KEY => '$MASTER_IP:2181:/hbase'
disable_peer 'PEER_$TABLE_NAME'
enable_table_replication '$TABLE_NAME'
EOF
The result will like the following text.
hbase:001:0> add_peer 'PEER_usertable', CLUSTER_KEY => '<Master-IP>:2181:/hbase'
Took 13.4117 seconds
hbase:002:0> disable_peer 'PEER_usertable'
Took 8.1317 seconds
hbase:003:0> enable_table_replication 'usertable'
The replication of table 'usertable' successfully enabled
Took 168.7254 seconds
In this experiment, we’re using the table usertable as an example. If we have many tables that need to be configured for replication, we can use the following code:
MASTER_IP="<Master-IP>"
# Get all tables
TABLE_LIST=$(echo 'list' | sudo -u hbase hbase shell 2>/dev/null | sed -e '1,/TABLE/d' -e '/seconds/,$d' -e '/row/,$d')
# Iterate each table
for TABLE_NAME in $TABLE_LIST; do
# Add the operation
cat << EOF | sudo -u hbase hbase shell 2>/dev/null
add_peer 'PEER_$TABLE_NAME', CLUSTER_KEY => '$MASTER_IP:2181:/hbase'
disable_peer 'PEER_$TABLE_NAME'
enable_table_replication '$TABLE_NAME'
EOF
done
In the scripts of following steps, if you need to apply the operations for all tables, you can refer to the preceding code sample.
At this point, the status of the peer is Disabled, so replication won’t be started. And the data that needs to be synchronized from the source to the target EMR cluster will be backlogged at the source HBase cluster and won’t be synchronized to HBase on the EMR cluster.
After the snapshot restore (step 7) is completed on the HBase on Amazon EMR cluster, we can enable the peer to start synchronizing data.
If the source HBase version is 1.x, you must run the set_peer_tableCFs function. See HBase Cluster Replication.
4. Pause the service
To pause the service of the source HBase cluster, disable the HBase tables. You can use the following script:
sudo -u hbase bash /usr/lib/hbase/bin/disable_all_tables.sh 2>/dev/null
The result is shown in the following figure.

After disabling all tables, observe the HBase UI to ensure that no background tasks are being run, and then stop any services accessing the source HBase. This will take 5-10 minutes.
The HBase UI is as shown in the following figure.

5. Create a snapshot
Make sure the tables in the source HBase are disabled. Then, you can create a snapshot of the source. This process will take 1-5 minutes.
Let’s use the table usertable as an example. The shell script is as follows:
DATE=`date +"%Y%m%d"`
TABLE_NAME="usertable"
sudo -u hbase hbase snapshot create -n "${TABLE_NAME/:/_}-$DATE" -t ${TABLE_NAME} 2>/dev/null
You can check the snapshot with a script:
sudo -u hbase hbase snapshot info -list-snapshots 2>/dev/null
And the result is as shown in the following figure.

6. Resume service
After the snapshot is successfully created on the source HBase, you can enable the tables and resume the services that access the source HBase. These operations take several minutes, so the total data unavailability time on the source HBase during the implementation (steps 3 to step 6) will be approximately 10 minutes.
The command to enable the table is as follows:
TABLE_NAME="usertable"
echo -e "enable '$TABLE_NAME'" | sudo -u hbase hbase shell 2>/dev/null
The result is shown in the following figure.

At this point, you can write data to the source HBase, because the status of the replication peer is disabled, so the incremental data won’t be synchronized to the target cluster.
7. Snapshot export and restore
After the snapshot created in the source HBase, it’s time to export the snapshot to the HBase data directory on the target EMR cluster. The example script is as follows:
DATE=`date +"%Y%m%d"`
TABLE_NAME="usertable"
TARGET_BUCKET="<Your-HBase-Folder-on-S3>"
nohup sudo -u hbase hbase snapshot export -snapshot ${TABLE_NAME/:/_}-$DATE -copy-to $TARGET_BUCKET &> ${TABLE_NAME/:/_}-$DATE-export.log &
Exporting the snapshot will take from 10 minute to several hours to complete, depending on the amount of data to be exported. So we run it in the background. You can check the progress by using the yarn application -list command, as shown in the following figure.

As an example, if you’re using an HBase cluster with 20 r6g.4xlarge core nodes, it will take about 3 hours for 50 TB of data to be exported to Amazon S3 in same AWS Region.
After the snapshot export is completed at the source HBase, you can check the snapshot in the target EMR cluster using the following script:
sudo -u hbase hbase snapshot info -list-snapshots 2>/dev/null
The result is shown in the following figure.

Confirm the snapshot name—for example, usertable-20240710 and run snapshot restore on the target EMR cluster using the following script.
TABLE_NAME="usertable"
SNAPSHOT_NAME="usertable-20240710"
cat << EOF | nohup sudo -u hbase hbase shell &> restore-snapshot.out &
disable '$TABLE_NAME'
restore_snapshot '$SNAPSHOT_NAME'
enable '$TABLE_NAME'
EOF
The snapshot restore will take from 10 minute to several hours to complete, depending on the amount of data to be restored, so we run it in the background. The result is as shown in the following figure.

You can check the progress of the restore through The Amazon EMR web interface for HBase, as shown in the following figure.

From the Amazon EMR web interface for HBase, you can found it takes about 2 hours to run Clone Snapshot for a sample table with 50 TB of data, and then 1 additional hour to run . After these two stages, the snapshot restore is completed.
8. Start replication
After the snapshot restore is completed on the EMR cluster and the status of the table is set to enabled, you can enable HBase replication in the source HBase. The incremental data will be synchronized to the target EMR cluster.
In the source HBase, the example script is as follows:
TABLE_NAME="usertable"
echo -e "enable_peer 'PEER_$TABLE_NAME'" | sudo -u hbase hbase shell 2>/dev/null
The result is as shown in the following figure.

Wait for the incremental data to be synchronized from the source HBase to the HBase on EMR cluster. The time taken depends on the amount of data accumulated in the source HBase during the snapshot export and restore. In our example, it took about 10 minutes to complete the data synchronization.
You can check the replication status with scripts:
echo -e "status 'replication'" | sudo -u hbase hbase shell 2>/dev/null
The result is shown in the following figure.

9. Test and verify
After incremental data synchronization is complete, you can start testing and verifying the results. You can use the same HBase API to access both the source and the target HBase clusters and compare the results.
To guarantee the data integrity, you can check the number of HBase table region and store files for the replicated tables from the Amazon EMR web interface for HBase, as shown in the following figure.

For small tables, we recommend using the HBase command to verify the number of records. After signing in to the primary node of the Amazon EMR using SSH, you can run the following command:
sudo -u hbase hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'usertable'
Then, in the hbase.log file of the HBase log directory, find the number of records for the table usertable.
For large tables, you can use the HBase Java API to validate the row count in a range of row keys.
We provided sample Java code to implement this functionality. For example, we imported the demo data to usertable using the following script:
java -classpath hbase-utils-1.0-SNAPSHOT-jar-with-dependencies.jar HBaseAccess <Your-Zookeeper-IP> put 1000 20
The result is shown in the following figure.

You can run the script multiple times to import enough demo data into the table, then you can use the following script to count the number of records where the value of Row Key is between user1000 and user5000, and the value of the column family:field0 is value0
java -classpath hbase-utils-1.0-SNAPSHOT-jar-with-dependencies.jar HBaseRowCounter <Your-Zookeeper-IP> usertable "user1000" "user1100" "family:field0" "value0"
The result is shown in the following figure.

You can run the same code on both the source HBase and the target Amazon EMR HBase to verify that the results are consistent. See complete code.
After these steps are complete, you can switch from the source HBase to the target Amazon EMR Hbase, completing the migration.
Clean up
After you’re done with the solution walkthrough, complete the following steps to clean up your resources:
- Stop the Amazon EMR on EC2 cluster.
- Delete the S3 bucket that stores the HBase data.
- Stop the source HBase cluster, and release its related resource, for example, the Amazon EC2 cluster or resources provided by other vendors or cloud service providers.
Key challenges in HBase migration
In the previous sections, we have detailed the steps to implement HBase online migration through snapshots and replication for general scenario. Many customers’ scenarios may have some differences from the general scenario, and you need to make some modifications to the process steps in order to accomplish the migration.
HBase in the cloud doesn’t support snapshot
Many cloud providers have made modifications to the open source version of HBase, resulting in these versions of HBase not providing snapshot and replication functions. However, these cloud providers will provide data transfer tools for HBase, such as Lindorm Tunnel Service, that can be used to transfer HBase data to an HBase cluster with data on HDFS.
To deploy HBase on Amazon S3, you should follow the previous migration process as the best practice, using snapshot and replication techniques to migrate to an Amazon EMR environment. To solve the problem of HBase versions that don’t support snapshots and replication, you can create an HBase on HDFS as a jump or relay cluster, which can be used to synchronize the data from a source HBase to an HDFS-based HBase cluster, then migrate from the middle cluster to the target HBase on S3.
The following diagram illustrates the solution architecture.

You need to add three more steps in addition to the migration steps described previously.
| Step |
Activity |
Description |
Estimated time |
| 1 |
Create Cluster B
(EMR HBase on HDFS)
|
Create an EMR cluster with HBase on HDFS as the relay cluster. |
Less than 10 minutes |
| 2 |
Configure data transfer |
Configure the data transfer from the outer HBase cluster to Amazon EMR HBase on HDFS and start the data transfer. |
Less than 5 minutes |
| 3 |
HBase migration
(snapshot and replication)
|
Treat the outer HBase cluster as an application which writes data into the Amazon EMR HBase cluster, then you can use the steps in the previous scenario to complete the migration to Amazon EMR HBase on Amazon S3. |
Single table with large amounts of data
During the migration process, if the amount of data in a single table in the source HBase (Cluster A) is too large—such as 10 TB or even 50TB—you must modify the target Amazon EMR HBase cluster (Cluster B) configuration to ensure that there are no interruptions during the migration process, especially during the snapshot restore on the Amazon EMR HBase cluster. After the snapshot restore is complete, you can rebuild the Amazon EMR HBase cluster (Cluster C).
The following diagram illustrates the solution architecture for handling a very large table.

The following are the steps.
| Step |
Activity |
Description |
Estimated time |
| 1 |
Create Cluster B (EMR HBase on S3 for restore) |
Create an EMR cluster with the required configuration for a large table snapshot restore. |
Less than 10 minutes |
| 2 |
HBase migration
(snapshot and replication)
|
Consider the Amazon EMR HBase on Amazon S3 as the target cluster, then you can use the steps in the first scenario to complete the migration from the source HBase to the Amazon EMR HBase on S3. |
|
| 3 |
Recreate Cluster C
(EMR HBase on S3 for production)
|
After the migration is complete, Cluster B needs to be changed back to its previous configuration before migration. If it’s inconvenient to modify the parameters, you can use the previous configuration to recreate the EMR cluster (Cluster C). |
Less than 15 minutes |
| 4 |
Rebuild replication |
After recreating the EMR cluster, if replication is still needed to synchronize the data, the replication from the source HBase cluster to the new EMR HBase cluster must be rebuilt. Before building the new EMR cluster, the write service on the source HBase cluster should be paused to avoid data loss on the Amazon EMR HBase. |
Less than 1 minute |
In Step 1, create cluster B (EMR HBase on S3 for restore), use the following configuration for snapshot restore. All time values are in milliseconds.
| Configuration classification |
Configuration item |
Default value |
Suggested value |
Explanation |
| emrfs-site |
fs.s3.maxConnections |
1000 |
50000 |
The number of concurrent Amazon S3 connections that your applications need. The default value is 1000 and must be increased to avoid errors such as com. amazon. ws. emr. hadoop. fs. shaded. com. amazonaws. SdkClientException: Unable to execute HTTP request: timeout waiting for connection from pool. |
| hbase-site |
hbase.client.operation.timeout |
300000 |
18000000 |
Operation timeout is a top-level restriction that makes sure a blocking operation in a table will not be blocked for longer than the timeout. |
| hbase-site |
hbase.master.cleaner.interval |
60000 |
18000000 |
The default is to run HBase Clearer in 60,000 milliseconds, which will clear some files in the archive, resulting in an error that HFile cannot be found. |
| hbase-site |
hbase.rpc.timeout |
60000 |
18000000 |
This property limits how long a single RPC call can run before timing out. |
| hbase-site |
hbase.snapshot.master.timeout.millis |
300000 |
18000000 |
Timeout for the primary HBase for the snapshot procedure. |
| hbase-site |
hbase.snapshot.region.timeout |
300000 |
18000000 |
Timeout for region servers to keep threads in a snapshot request pool waiting. |
| hbase-site |
hbase.hregion.majorcompaction |
604800000 |
0 |
Default is 604,800,000 ms (1 week). Set to 0 to disable automatic triggering of compaction. Note that because of the change to manual triggering, you must make compaction one of the daily operation and maintenance tasks, and run it during periods of low activity to avoid impacting production. The following is the compaction script:
echo -e "major_compact '$TABLE_NAME'" | sudo -u hbase hbase shell
|
Adjust the suggested values based on the amount of table data, which requires conducting some experiments to determine the values to be used in the final migration plan.
Before you recreate a new EMR cluster in the production environment, disable the HBase table on the active EMR cluster. The command line is as follows:
sudo -u hbase bash /usr/lib/hbase/bin/disable_all_tables.sh 2>/dev/null
echo -e "flush 'hbase:meta'" | sudo -u hbase hbase shell 2>/dev/null
Wait for the command to execute successfully and terminate the current EMR cluster (Cluster B). Now the HBase data is kept in Amazon S3; create a new EMR cluster (Cluster C) with the previous configuration before migration, and specify HBase date folder on S3 to be the same as Cluster B.
Using Bucket Cache to improve read performance
To enhance HBase’s read performance, one of most effective method involves caching data. HBase uses BlockCache to implement caching mechanisms for the region server. Currently, HBase provides two different BlockCache implementations to cache data read from HDFS: the default on-heap LruBlockCache and the BucketCache, which is usually off-heap. Bucket cache is the most used method.
BucketCache can be deployed in offheap, file, or mmaped file mode. These three working modes are the same in terms of memory logical organization and caching process; however, the final storage media corresponding to these three working modes are different, that is, the IOEngine is different.
We recommend that customers use BucketCache in file mode, because the default storage type of Amazon Elastic Block Store (Amazon EBS) in Amazon EMR is SSD. You can put all hot data into BucketCache, which is on Amazon EBS. You can then determine the file size used by BucketCache based on the volume of hot data.
The following are the HBase configurations for BucketCache.
| Configuration classification |
Configuration item |
Suggested value |
Explanation |
| emrfs-site |
hbase.bucketcache.ioengine |
files:/mnt1/hbase/cache_01.data |
Where to store the contents of the bucket cache. You can use offheap, file, files, mmap, or pmem. If a file or files, set it to files. Note that some earlier Amazon EMR versions can only support using one file per core node. |
| hbase-site |
hbase.bucketcache.persistent.path |
file:/mnt1/hbase/cache.meta |
The path to store the metadata of the bucket cache, used to recover the cache during startup. |
| hbase-site |
hbase.bucketcache.size |
Depends on the hot data volume be cached |
The capacity in MBs of BucketCache for each core node. If you use multiple cache files, then this size is the sum of the capacities of multiple files. |
| hbase-site |
hbase.rs.prefetchblocksonopen |
TRUE |
Whether the server should asynchronously load all the blocks when a store file is opened (data, metadata, and index). Note that enabling this property contributes to the time the region server takes to open a region and therefore initialize. |
| hbase-site |
hbase.rs.cacheblocksonwrite |
TRUE |
Whether an HFile block should be added to the block cache when the block is finished. |
| hbase-site |
hbase.rs.cachecompactedblocksonwrite |
TRUE |
Whether to cache compressed blocks during writing. |
More configuration instructions for BucketCache would refer to Configuration properties.
We provided sample Java code to test HBase read performance. In the Java code, we use the putDemoData method to write test data to the table usertable, ensuring that the data is evenly distributed across HBase table regions, and then use the getDemoData method to read the data.
We tested three scenarios: HBase data stored on HDFS, on Amazon S3 without using BucketCache, and on S3 using BucketCache. To ensure that the written data isn’t cached in the first two scenarios, the cache can be cleared by restarting the the region servers.
We tested on the EMR HBase cluster, which has 10 r6g. 2xlarge core nodes. The command is as follows:
java -classpath hbase-utils-1.0-SNAPSHOT-jar-with-dependencies.jar HBaseAccess <Your-Zookeeper-IP> get 20 100
The result is shown in the following figure.

Benchmark results and key learning
For the three scenarios, we use 100 HBase record row keys as input, ensure these row keys distributed evenly in HBase table regions, we call the API consecutively with 20 times, 50 times, and 100 times, and we got the time cost result as the following figure. We found the read latency is the shortest when the data is on S3 and using BucketCache.

Above, we introduced four migration scenarios. In migration processes in production, we’ve gained invaluable knowledge and experience. We’re sharing the results here for you to use as best practices and a recommended run book.
Configuration parameters
In the configurations provided earlier, some are necessary for BucketCache settings while others mitigate known errors to reduce the snapshot duration. For example, the parameter hbase.snapshot.master.timeout.millis is related to the HBASE-14680 issue. It’s advisable to retain these configurations as much as possible throughout the migration process.
Version choice
When migrating to Amazon EMR and choosing a suitable HBase version, it is recommended to select a more recent minor version and patch version, while keeping the major version unchanged. That is to say:
- If the source HBase is version 1.x, we recommend using EMR 5.36.1, whose HBase version is 1.4.13, because the HBase 1.x API is compatible and won’t require you to make code changes.
- If the source HBase is version 2.x, we recommend using EMR 6.15.0, which has an HBase of 2.4.17.
The HBase API under the same major version can be universal. See HBase Version to learn more.
Allocating enough space
HDFS needs to leave enough space when exporting snapshots, it depends on the data volume. Data will be moved to the archive, causing double storage is needed for the table.
Replication
At present, there is compatibility problem if replication and WAL compression are used together. If you are using replication, set the hbase.regionserver.wal.enablecompression property to false. See HBASE-26849 for more information.
By default, replication in HBase is asynchronous, as the write-ahead log (WAL) is sent to another cluster in the background. This implies that when using replication for data recovery, some data loss may occur. Additionally, there is a potential for data overwrite conflicts when concurrently writing the same record within a short time frame. However, HBase v2.x introduces synchronous replication as a solution to this issue. For more details, refer to the Serial Replication documentation.
Disk type for BucketCache
Because BucketCache uses a portion of Amazon EBS IO and throughput to synchronize data, it’s recommended to choose Amazon EBS gp3 volumes for their higher IOPS and throughput.
Response latency when accessing to HBase
Users sometimes face the issue of high response latency from their Hbase on EMR clusters using API calls or the HBase shell tool.
In our testing, we found that the communication between HMaster and RegionServer takes an unusually long time to resolve through DNS. You can reduce latency by adding the host name and IP mapping to the /etc/hosts file in the HBase client host.
Conclusion
In this post, we used the results of real-world migration cases to introduce the process of migrating HBase to Amazon EMR HBase using HBase snapshot and replication and the deployment mode of HBase on Amazon S3. We included how to resolve challenges, such as how to configure the cluster to make the migration process smoother when migrating a single large table, or how to use BucketCache to improve reading performance. We also described techniques for testing performance.
We encourage you to migrate HBase to Amazon EMR HBase. For more information about HBase migration, see Amazon EMR HBase best practices.
About the Authors
 Dalei Xu is a Analytics Specialist Solution Architect at Amazon Web Services, responsible for consulting, designing, and implementing AWS data analytics solutions. With over 20 years of experience in data-related work, proficient in data development, migration to AWS, architecture design, and performance optimization. Hoping to promote AWS data analytics services to more customers, achieving a win-win situation and mutual growth with customers.
Dalei Xu is a Analytics Specialist Solution Architect at Amazon Web Services, responsible for consulting, designing, and implementing AWS data analytics solutions. With over 20 years of experience in data-related work, proficient in data development, migration to AWS, architecture design, and performance optimization. Hoping to promote AWS data analytics services to more customers, achieving a win-win situation and mutual growth with customers.
Zhiyong Su is a Migration Specialist Solution Architect at Amazon Web Services, primarily responsible for cloud migration or cross-cloud migration for enterprise-level clients. Has held positions such as R&D Engineer, Solutions Architect, and has years of practical experience in IT professional services and enterprise application architecture.
 Shijian Tang is a Analytics Specialist Solution Architect at Amazon Web Services.
Shijian Tang is a Analytics Specialist Solution Architect at Amazon Web Services.












































 Shaheer Mansoor is a Senior Machine Learning Engineer at AWS, where he specializes in developing cutting-edge machine learning platforms. His expertise lies in creating scalable infrastructure to support advanced AI solutions. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI.
Shaheer Mansoor is a Senior Machine Learning Engineer at AWS, where he specializes in developing cutting-edge machine learning platforms. His expertise lies in creating scalable infrastructure to support advanced AI solutions. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI. Anoop Kumar K M is a Data Architect at AWS with focus in the data and analytics area. He helps customers in building scalable data platforms and in their enterprise data strategy. His areas of interest are data platforms, data analytics, security, file systems and operating systems. Anoop loves to travel and enjoys reading books in the crime fiction and financial domains.
Anoop Kumar K M is a Data Architect at AWS with focus in the data and analytics area. He helps customers in building scalable data platforms and in their enterprise data strategy. His areas of interest are data platforms, data analytics, security, file systems and operating systems. Anoop loves to travel and enjoys reading books in the crime fiction and financial domains. Sreenivas Nettem is a Lead Database Consultant at AWS Professional Services. He has experience working with Microsoft technologies with a specialization in SQL Server. He works closely with customers to help migrate and modernize their databases to AWS.
Sreenivas Nettem is a Lead Database Consultant at AWS Professional Services. He has experience working with Microsoft technologies with a specialization in SQL Server. He works closely with customers to help migrate and modernize their databases to AWS.


























 Dalei Xu is a Analytics Specialist Solution Architect at Amazon Web Services, responsible for consulting, designing, and implementing AWS data analytics solutions. With over 20 years of experience in data-related work, proficient in data development, migration to AWS, architecture design, and performance optimization. Hoping to promote AWS data analytics services to more customers, achieving a win-win situation and mutual growth with customers.
Dalei Xu is a Analytics Specialist Solution Architect at Amazon Web Services, responsible for consulting, designing, and implementing AWS data analytics solutions. With over 20 years of experience in data-related work, proficient in data development, migration to AWS, architecture design, and performance optimization. Hoping to promote AWS data analytics services to more customers, achieving a win-win situation and mutual growth with customers. Zhiyong Su is a Migration Specialist Solution Architect at Amazon Web Services, primarily responsible for cloud migration or cross-cloud migration for enterprise-level clients. Has held positions such as R&D Engineer, Solutions Architect, and has years of practical experience in IT professional services and enterprise application architecture.
Zhiyong Su is a Migration Specialist Solution Architect at Amazon Web Services, primarily responsible for cloud migration or cross-cloud migration for enterprise-level clients. Has held positions such as R&D Engineer, Solutions Architect, and has years of practical experience in IT professional services and enterprise application architecture. Shijian Tang is a Analytics Specialist Solution Architect at Amazon Web Services.
Shijian Tang is a Analytics Specialist Solution Architect at Amazon Web Services.

 Madhan Kumar Baskaran works as a Search Engineer at AWS, specializing in Amazon OpenSearch Service. His primary focus involves assisting customers in constructing scalable search applications and analytics solutions. Based in Bellevue, Washington, Madhan has a keen interest in data engineering and DevOps.
Madhan Kumar Baskaran works as a Search Engineer at AWS, specializing in Amazon OpenSearch Service. His primary focus involves assisting customers in constructing scalable search applications and analytics solutions. Based in Bellevue, Washington, Madhan has a keen interest in data engineering and DevOps. Priyanshi Omer is a Customer Success Engineer at AWS OpenSearch, based in Bengaluru. Her primary focus involves assisting customers in constructing scalable search applications and analytics solutions. She works closely with customers to help them migrate their workloads and aids existing customers in fine-tuning their clusters to achieve better performance and cost savings. Outside of work, she enjoys spending time with her cats and playing video games
Priyanshi Omer is a Customer Success Engineer at AWS OpenSearch, based in Bengaluru. Her primary focus involves assisting customers in constructing scalable search applications and analytics solutions. She works closely with customers to help them migrate their workloads and aids existing customers in fine-tuning their clusters to achieve better performance and cost savings. Outside of work, she enjoys spending time with her cats and playing video games










 Mohammed Alkateb is an Engineering Manager at Amazon Redshift. Prior to joining Amazon, Mohammed had 12 years of industry experience in query optimization and database internals as an individual contributor and engineering manager. Mohammed has 18 US patents, and he has publications in research and industrial tracks of premier database conferences including EDBT, ICDE, SIGMOD and VLDB. Mohammed holds a PhD in Computer Science from The University of Vermont, and MSc and BSc degrees in Information Systems from Cairo University.
Mohammed Alkateb is an Engineering Manager at Amazon Redshift. Prior to joining Amazon, Mohammed had 12 years of industry experience in query optimization and database internals as an individual contributor and engineering manager. Mohammed has 18 US patents, and he has publications in research and industrial tracks of premier database conferences including EDBT, ICDE, SIGMOD and VLDB. Mohammed holds a PhD in Computer Science from The University of Vermont, and MSc and BSc degrees in Information Systems from Cairo University. Ramchandra Anil Kulkarni is a software development engineer who has been with Amazon Redshift for over 4 years. He is driven to develop database innovations that serve AWS customers globally. Kulkarni’s long-standing tenure and dedication to the Amazon Redshift service demonstrate his deep expertise and commitment to delivering cutting-edge database solutions that empower AWS customers worldwide.
Ramchandra Anil Kulkarni is a software development engineer who has been with Amazon Redshift for over 4 years. He is driven to develop database innovations that serve AWS customers globally. Kulkarni’s long-standing tenure and dedication to the Amazon Redshift service demonstrate his deep expertise and commitment to delivering cutting-edge database solutions that empower AWS customers worldwide. Mark Lyons is a Principal Product Manager on the Amazon Redshift team. He works on the intersection of data lakes and data warehouses. Prior to joining AWS, Mark held product leadership roles with Dremio and Vertica. He is passionate about data analytics and empowering customers to change the world with their data.
Mark Lyons is a Principal Product Manager on the Amazon Redshift team. He works on the intersection of data lakes and data warehouses. Prior to joining AWS, Mark held product leadership roles with Dremio and Vertica. He is passionate about data analytics and empowering customers to change the world with their data. Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.
Asser Moustafa is a Principal Worldwide Specialist Solutions Architect at AWS, based in Dallas, Texas. He partners with customers worldwide, advising them on all aspects of their data architectures, migrations, and strategic data visions to help organizations adopt cloud-based solutions, maximize the value of their data assets, modernize legacy infrastructures, and implement cutting-edge capabilities like machine learning and advanced analytics. Prior to joining AWS, Asser held various data and analytics leadership roles, completing an MBA from New York University and an MS in Computer Science from Columbia University in New York. He is passionate about empowering organizations to become truly data-driven and unlock the transformative potential of their data.







 Kalaiselvi Kamaraj is a Sr. Software Development Engineer with Amazon. She has worked on several projects within Redshift Query processing team and currently focusing on performance related projects for Redshift Data Lake.
Kalaiselvi Kamaraj is a Sr. Software Development Engineer with Amazon. She has worked on several projects within Redshift Query processing team and currently focusing on performance related projects for Redshift Data Lake.













 Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community. Paul Villena is a Senior Analytics Solutions Architect in AWS with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure as code, serverless technologies, and coding in Python.
Paul Villena is a Senior Analytics Solutions Architect in AWS with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure as code, serverless technologies, and coding in Python.








 Sean Bjurstrom is a Technical Account Manager in ISV accounts at Amazon Web Services, where he specializes in Analytics technologies and draws on his background in consulting to support customers on their analytics and cloud journeys. Sean is passionate about helping businesses harness the power of data to drive innovation and growth. Outside of work, he enjoys running and has participated in several marathons.
Sean Bjurstrom is a Technical Account Manager in ISV accounts at Amazon Web Services, where he specializes in Analytics technologies and draws on his background in consulting to support customers on their analytics and cloud journeys. Sean is passionate about helping businesses harness the power of data to drive innovation and growth. Outside of work, he enjoys running and has participated in several marathons. Seun Akinyosoye is a Sr. Technical Account Manager supporting public sector customer at Amazon Web Services. Seun has a background in analytics, data engineering which he uses to help customers achieve their outcomes and goals. Outside of work Seun enjoys spending time with his family, reading, traveling and supporting his favorite sports teams.
Seun Akinyosoye is a Sr. Technical Account Manager supporting public sector customer at Amazon Web Services. Seun has a background in analytics, data engineering which he uses to help customers achieve their outcomes and goals. Outside of work Seun enjoys spending time with his family, reading, traveling and supporting his favorite sports teams. Vinod Jayendra is a Enterprise Support Lead in ISV accounts at Amazon Web Services, where he helps customers in solving their architectural, operational, and cost optimization challenges. With a particular focus on Serverless technologies, he draws from his extensive background in application development to deliver top-tier solutions. Beyond work, he finds joy in quality family time, embarking on biking adventures, and coaching youth sports team.
Vinod Jayendra is a Enterprise Support Lead in ISV accounts at Amazon Web Services, where he helps customers in solving their architectural, operational, and cost optimization challenges. With a particular focus on Serverless technologies, he draws from his extensive background in application development to deliver top-tier solutions. Beyond work, he finds joy in quality family time, embarking on biking adventures, and coaching youth sports team. Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on  Chris Scull is a Solutions Architect dealing in orchestration tools and modern cloud technologies. With two years of experience at AWS, Chris has developed an interest in Amazon Managed Workflows for Apache Airflow, which allows for efficient data processing and workflow management. Additionally, he is passionate about exploring the capabilities of GenAI with Bedrock, a platform for building generative AI applications on AWS.
Chris Scull is a Solutions Architect dealing in orchestration tools and modern cloud technologies. With two years of experience at AWS, Chris has developed an interest in Amazon Managed Workflows for Apache Airflow, which allows for efficient data processing and workflow management. Additionally, he is passionate about exploring the capabilities of GenAI with Bedrock, a platform for building generative AI applications on AWS. Shengjie Luo is a Big data architect of Amazon Cloud Technology professional service team. Responsible for solutions consulting, architecture and delivery of AWS based data warehouse and data lake, and good at server-less computing, data migration, cloud data integration, data warehouse planning, data service architecture design and implementation.
Shengjie Luo is a Big data architect of Amazon Cloud Technology professional service team. Responsible for solutions consulting, architecture and delivery of AWS based data warehouse and data lake, and good at server-less computing, data migration, cloud data integration, data warehouse planning, data service architecture design and implementation. Qiushuang Feng is a Solutions Architect at AWS, responsible for Enterprise customers’ technical architecture design, consulting, and design optimization on AWS Cloud services. Before joining AWS, Qiushuang worked in IT companies such as IBM and Oracle, and accumulated rich practical experience in development and analytics.
Qiushuang Feng is a Solutions Architect at AWS, responsible for Enterprise customers’ technical architecture design, consulting, and design optimization on AWS Cloud services. Before joining AWS, Qiushuang worked in IT companies such as IBM and Oracle, and accumulated rich practical experience in development and analytics.






 Prasad Matkar is Database Specialist Solutions Architect at AWS based in the EMEA region. With a focus on relational database engines, he provides technical assistance to customers migrating and modernizing their database workloads to AWS.
Prasad Matkar is Database Specialist Solutions Architect at AWS based in the EMEA region. With a focus on relational database engines, he provides technical assistance to customers migrating and modernizing their database workloads to AWS. Arun Sankaranarayanan is a Database Specialist Solution Architect based in London, UK. With a focus on purpose-built database engines, he assists customers in migrating and modernizing their database workloads to AWS.
Arun Sankaranarayanan is a Database Specialist Solution Architect based in London, UK. With a focus on purpose-built database engines, he assists customers in migrating and modernizing their database workloads to AWS. Giorgio Bonzi is a Sr. Database Specialist Solutions Architect at AWS based in the EMEA region. With a focus on relational database engines, he provides technical assistance to customers migrating and modernizing their database workloads to AWS.
Giorgio Bonzi is a Sr. Database Specialist Solutions Architect at AWS based in the EMEA region. With a focus on relational database engines, he provides technical assistance to customers migrating and modernizing their database workloads to AWS.









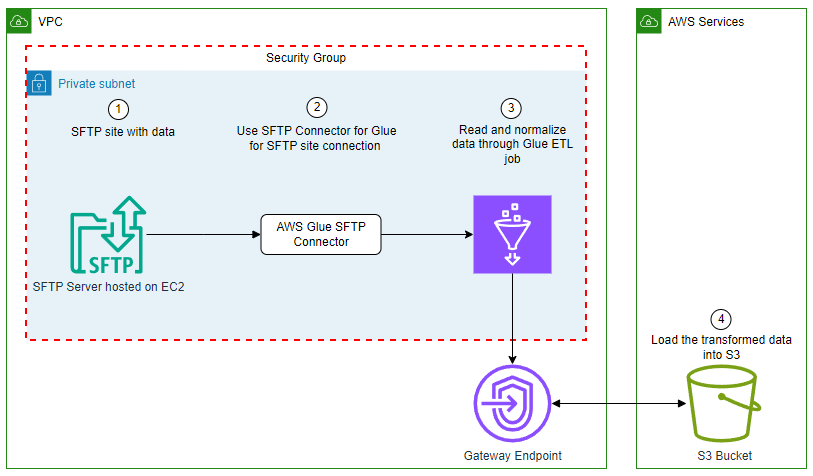
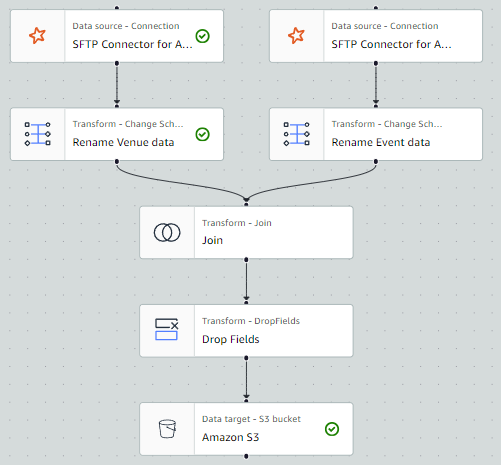
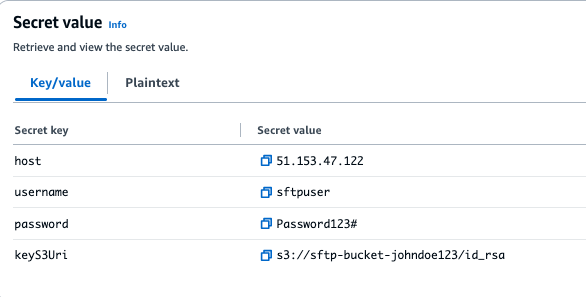
 This migration approach uses the following tools to perform the migration:
This migration approach uses the following tools to perform the migration: