As cloud adoption continues to accelerate, organizations are realizing that the journey to the cloud is just the beginning. The real challenge—and opportunity—lies in optimizing cloud usage to drive maximum business value. At AWS, we’re committed to helping our customers navigate this journey successfully. Let’s explore some key insights and best practices for cloud optimization from the recent MIT Technology Review publication, Driving business value by optimizing the cloud.
The cloud optimization imperative
Recent data shows that global cloud infrastructure spending reached $84 billion in Q3 2024, marking a 23% year-over-year increase. This growth underscores the critical role of the cloud in driving business agility and innovation. However, to truly harness the power of the cloud, organizations must strike the right balance between cost, security, resilience, and innovation.
André Dufour, AWS Director and General Manager for AWS Cloud Optimization, emphasizes that cloud optimization involves making cloud spending efficient so that freed-up resources can be redirected to fund new innovations, such as generative AI initiatives.
Cloud optimization should be viewed as a continuous process rather than a one-time event, requiring regular assessment whenever business conditions or technical requirements change significantly. The approach should be comprehensive, addressing not just costs but all six pillars (operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability), while also recognizing that different workloads require tailored optimization strategies rather than a one-size-fits-all approach.
Best practices for success
Consider the following best practices:
Upskill your team – Empower your employees with cloud, cost management, and optimization skills. As Dufour notes, “Every engineer or builder plays a role in cloud optimization.”
Establish a cloud center of excellence – Create a centralized body responsible for developing and distributing cloud best practices throughout your organization.
Align finance and business – Make cloud KPIs business-centric rather than purely technical, so cloud optimization efforts support overall business goals.
Embrace automation – Use tools to automate cloud provisioning, monitoring, and optimization, reducing human error and effort.
Use AI services and solutions for efficiency – Use AI technologies to automate visualization, enhance decision-making, and optimize resource utilization.
Real-world success stories
Our customers are already seeing significant benefits from strategic cloud optimization:
DreamCasino achieved 30% cost savings and a 50% reduction in API response times, enabling expansion into new markets
BMC Software reduced cloud costs by 25% while improving security and reliability, reinvesting savings into new business opportunities
Even within AWS, our use of Amazon Q for application modernization saved an estimated 4,500 years of development work and $260 million in performance benefits
Business impact
Effective cloud optimization delivers more than just cost savings. It enables the following:
Faster innovation through reinvestment of saved resources
Enhanced security and operational efficiency
Improved ability to scale and adapt to business needs
Better customer experiences and faster time-to-market
The capability to make informed architecture and design decisions by balancing trade-offs across AWS Well-Architected pillars
AWS resources for your optimization journey
To help you accelerate your cloud optimization efforts, AWS provides several tools and resources:
Use AWS re:Post as an authoritative, knowledge-sharing service designed to help you quickly remove technical roadblocks, accelerate innovation, and operate more efficiently
Additionally, you can engage with the AWS Cloud Optimization Success (COS) team for more detailed guidance and to help identify what to do next in your cloud optimization journey. The COS team has Solutions Architects who specialize in the Cloud Adoption Framework and Well-Architected Framework and deliver workshops and training sessions though customer and partner engagements. The team can help drive adoption of AWS services through the use of the Well-Architected and Cloud Adoption Frameworks and support other services like AWS Trusted Advisor and AWS Health to optimize cost and cloud architectures. Whether you’re just starting or looking to enhance existing implementations, the AWS COS team provides the guidance, tools, and expertise you need to succeed.
Conclusion
At AWS, we’re dedicated to helping you optimize your cloud journey. By implementing these strategies and best practices, you can unlock the full potential of the cloud, driving innovation and growth while maintaining security and operational excellence.
Ready to take your cloud optimization to the next level? Refer to the resources included in this post and contact your AWS COS team to learn how we can help you maximize the value of your cloud investments.
This blog post discusses the AWS Lambda as orchestrator anti-pattern and how to redesign serverless solutions using AWS Step Functions with native integrations.
Step Functions is a serverless workflow service that you can use to build distributed applications, automate processes, orchestrate microservices, and create data and machine learning (ML) pipelines. Step Functions provides native integrations with over 200 AWS services in addition to external third-party APIs. You can use these integrations to deploy production-ready solutions with less effort, reducing code complexity, improving long-term maintainability, and minimizing technical debt when operating at scale.
The Lambda as orchestrator anti-pattern
Let’s examine a common anti-pattern: using a Lambda function as an orchestrator for message distribution across multiple channels. Consider this real-world scenario where a system needs to send notifications through SMS or email channels based on user preferences, as shown in the following diagram.
Here’s how it typically starts—with a Lambda function acting as an orchestrator:
import boto3
import json
# Initialize Lambda client
# You can specify region if needed: boto3.client('lambda', region_name='us-east-1')
lambda_client = boto3.client('lambda')
def lambda_handler(event, context):
try:
# Parse the incoming event
body = json.loads(event['body'])
# Validate required fields
if 'channel' not in body:
return {
'statusCode': 400,
'body': json.dumps('Missing channel parameter')
}
if 'message' not in body:
return {
'statusCode': 400,
'body': json.dumps('Missing message content')
}
if body['channel'] == 'both':
# Invoke SMS Lambda function
lambda_client.invoke(
FunctionName='send-sns',
InvocationType='Event',
Payload=json.dumps(body)
)
# Invoke Email Lambda function
lambda_client.invoke(
FunctionName='send-email',
InvocationType='Event',
Payload=json.dumps(body)
)
else:
# Validate channel value
if body['channel'] not in ['sms', 'email']:
return {
'statusCode': 400,
'body': json.dumps('Invalid channel specified')
}
# Invoke function based on specified channel
function_name = 'send-sns' if body['channel'] == 'sms' else 'send-email'
lambda_client.invoke(
FunctionName=function_name,
InvocationType='Event',
Payload=json.dumps(body)
)
return {
'statusCode': 200,
'body': json.dumps('Messages sent successfully')
}
except json.JSONDecodeError:
return {
'statusCode': 400,
'body': json.dumps('Invalid JSON in request body')
}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps(f'Error: {str(e)}')
}
This approach has the following problems:
Complex error handling: The orchestrator needs to manage errors from multiple function invocations.
Tight coupling: Functions are directly dependent on each other.
Limited execution time: The orchestrator Lambda function continues running while sub Lambda functions execute. This could lead to the orchestrator Lambda function timing out.
Idle resources: Because the orchestrator Lambda function is sitting idle waiting for returns from other Lambda functions, in this case, the user is now paying for idle resources.
Rearchitecting with Step Functions
You can rebuild the logic using Step Functions and Amazon States Language to replace the Lambda orchestrator function. You can use the Choice state in Amazon States Language to define logical conditions to follow a specific path. This approach reduces code maintenance complexity because you define the conditions using Amazon States Language. You can also use it to to extend the functionality with minimal changes to the codebase.
The following Step Functions workflow diagram shows the rearchitected version of the previous Orchestrator Lambda function:
The following Amazon State Language represents the workflow:
Visual workflow: The execution flow is visible and maintainable through the AWS Management Console
Built-in error handling: Retry policies and error states can be defined declaratively
Parallel execution: The Parallel state handles multiple channel delivery efficiently
Simplified logic: The Choice state replaces complex if-else statements
Centralized data flow: Input and output are managed consistently across states
Enhanced workflow duration capabilities: Step Functions Standard workflows support executions that run for up to one year, compared to the 15-minute maximum execution time for Lambda functions
Comparing Lambda function as orchestrator to Step Functions
The summary of different features implemented on Lambda function as orchestrator and Step Functions is reflected in the following table:
Feature
Lambda function as orchestrator
Step Functions
Orchestration logic
Implemented in Python with nested if-else statements.
Defined declaratively using the Choice state
Multi-channel delivery
Sequential function invocations. Parallel execution using function’s logic.
Parallel execution using the Parallel state
Service integration
Requires SDK calls or separate Lambda functions.
Direct integration with AWS services (Amazon SNS, DynamoDB)
Error handling
Custom try-except blocks in Python.
Built-in error states and retry policies
Data persistance
Custom code to interact with DynamoDB.
Native DynamoDB integration with putItem task
Metrics logging
Custom code to call CloudWatch.
CloudWatch Metrics SDK integration
Implementation considerations
Review the following considerations when re-architecting a Lambda function orchestrator to Step Functions:
State machine type: Choose between Standard (up to 1 year runtime) and Express (up to 5 minutes) workflows based on your needs.
Input/output management: Parameters manipulation reduces the development effort and give flexible alternatives to implement the workflow:
Parameters: Selects specific input fields to pass to the next state
ResultSelector: Filters the state response to include only relevant fields
ResultPath: Stores the processed result in a specific path of the state input
OutputPath: Determines what data passes to the next state A code snippet for these features is:
Error handling: Implement retry policies and catch errors at both the task and state machine levels.
Monitoring: Set up CloudWatch logs and metrics for your state machine to track executions and performance.
Benefits of using Step Functions
Using Step Functions for rearchitecting scenarios bring the following benefits:
Reduced code complexity: The business logic is now defined in Amazon States Language rather than distributed across multiple Lambda functions.
Improved maintainability: Developers can make workflow changes by modifying the Amazon States Language, often modifying several Lambda functions.
Native AWS service integrations: Step Functions offers direct integrations with over 200 AWS services, which you can use to connect and coordinate AWS resources without writing custom integration code.
Cost optimization: By using direct service integrations, there are fewer Lambda invocations and reduced costs.
Long-running processes: Step Functions can manage workflows that run for up to a year, beyond the 15-minute limit for Lambda functions.
Conclusion
Rearchitecting Lambda-based applications with Step Functions can significantly improve maintainability, scalability, and operational efficiency. By moving orchestration logic into Step Functions and using its native service integrations, you can create more robust and manageable serverless applications.
While this post focused on a message distribution workflow, the principles apply to many serverless architectures. As you develop your applications, consider how Step Functions can help you build more resilient and scalable solutions.
To learn more about serverless architectures visit Serverless Land.
Recent security research has highlighted the importance of CI/CD pipeline configurations, as documented in AWS Security Bulletin AWS-2025-016. This post pulls together existing guidance and recommendations into one guide.
Continuous integration and continuous deployment (CI/CD) practices help development teams deliver software efficiently and reliably. AWS CodeBuild provides managed build services that integrate with source code repositories like GitHub, GitLab, and other Source Control Management (SCM) systems. While this guide uses GitHub examples, the security principles and webhook configuration approaches apply to other supported source control systems.
However, certain configurations require careful attention. We strongly recommend that you do not use automatic pull request builds from untrusted repository contributors without proper security controls and a clear understanding of your threat model. This configuration allows untrusted code to execute in your build environment with access to repository credentials and environment variables. Webhook configurations determine which repository events trigger builds and what code gets executed during the build process. Understanding these configurations is essential for maintaining appropriate security boundaries while preserving the automation benefits that make CI/CD valuable.
Security teams and DevOps engineers can use these practical approaches to configure AWS CodeBuild to meet their security goals while maintaining development velocity. We’ll explore webhook configurations, trust boundaries, and implementation strategies that emphasize threat model assessment, least-privilege access, and proactive monitoring of your pipeline configurations.
Security of the pipeline implications
Under the shared responsibility model, while AWS manages the security of the underlying AWS CodeBuild infrastructure, customers are responsible for securing their pipeline configurations, access controls, and the code that runs within their build environments. This shared responsibility is critical when considering the security of the pipeline itself.
When AWS CodeBuild processes pull requests automatically, it builds the code in an environment with access to repository credentials, environment variables, and potentially sensitive information. This creates specific security of the pipeline considerations:
Repository access: AWS CodeBuild projects require repository credentials to read source code and create webhooks. These credentials provide specific permissions that vary based on your configuration.
Build execution: The build process runs the retrieved source code, which may include build scripts, dependency definitions, or test files from pull requests.
Build environment: AWS CodeBuild environments may have access to environment variables, AWS credentials, or other configuration data needed for the build process.
Establishing trust boundaries
Effective security of the pipeline starts with clearly defining trust boundaries for different types of code contributions:
Internal contributors: Team members with repository write access who have been verified through your organization’s access management processes.
External contributors: Contributors from outside your organization who submit pull requests from forked repositories.
Automated processing: Code that runs without manual review as part of the build process.
These trust boundaries form the foundation for threat modeling your specific environment. Internal and trusted environments can often rely more heavily on automation with contributor filtering and least-privilege controls. Public and open source projects require more stringent controls due to the inherent risks of processing untrusted contributions – these environments benefit from stricter webhook filtering, comprehensive approval gates, or the self-hosted GitHub Actions runner approach discussed later.
The key principle is finding the appropriate balance between security controls and development velocity based on your specific risk profile and contributor trust levels. With these considerations in mind, let’s examine how to assess and configure your current AWS CodeBuild webhook settings.
Configuring secure webhooks
Webhooks represent the preferred mechanism by which external events trigger AWS CodeBuild processes. When properly configured, webhooks provide a powerful and efficient way to automate your build processes in response to repository changes. However, improper webhook configuration can create security vulnerabilities by allowing untrusted code to execute in privileged environments.The security of your webhook configuration depends on understanding exactly which events trigger builds, what level of access those builds have, and what code gets executed during the build process. This section provides a comprehensive approach to authoring, assessing, configuring, and maintaining secure webhook configurations.
Assessing current webhook configurations
Begin by reviewing your existing AWS CodeBuild projects to understand their current webhook configurations. The following AWS CLI commands provide a systematic approach to gathering this information:
# List all CodeBuild projects in your region
aws codebuild list-projects --region us-west-2
# Retrieve detailed configuration for analysis
aws codebuild batch-get-projects --region us-west-2 \
--names $(aws codebuild list-projects --region us-west-2 \
--query 'projects[*]' --output text | tr '\n' ' ')
When you run these commands, pay particular attention to the webhook section in the output. This section contains the filterGroups configuration, which determines exactly which repository events trigger builds.
Now that you understand how to review your current setup, let’s examine common configuration patterns and their security implications.
Webhook configuration patterns
Understanding common webhook configuration patterns helps you quickly identify potential security concerns and implement appropriate improvements. The following patterns represent different approaches to webhook configuration, each with specific security implications.
Note: These patterns are not recommended for use and are shown here to help you identify configurations that may need attention.
This configuration allows contributors who can create a pull request to trigger code execution in your build environment. We strongly recommend that you do not use automatic pull request builds from untrusted repository contributors.
Configuration requiring immediate review – No event filtering
Without filtering, this configuration can trigger builds for a wide variety of repository events.
Recommended secure webhook configurations
The following configurations represent security best practices that balance automation benefits with appropriate security controls. These patterns help to reduce security risks while maintaining the development velocity that makes CI/CD valuable.
Push-based builds (Recommended for most use cases)
Push-based builds make sure that only users with repository write access can trigger builds, which means contributors have already been vetted through your repository’s access control mechanisms.
Organizations that rely heavily on external open-source contributions may find this approach too restrictive. For example, a popular open-source project that receives dozens of pull requests daily from external contributors would need to manually merge each contribution before builds can run, significantly slowing down the contribution review process. In such cases, contributor-filtered builds or the self-hosted GitHub Actions runner approach may be more appropriate.
Contributor-filtered builds (Recommended for trusted contributors only)
This configuration allows pull request builds from specific, trusted contributors.
Important: Filtering applies to the GitHub account ID, not repository ownership. Contributors working from forked repositories can still introduce untrusted code that executes in your build environment.
Before implementing these configurations in your environment, consider these key factors that will help facilitate a smooth transition.
Webhook configuration implementation steps
While implementing the webhook security measures below, consider these broader practices:
Threat modeling: Assess your specific risk profile before selecting approaches.
Infrastructure as code: Use Infrastructure as Code (IaC) tools for production implementations.
Gradual implementation: Implement changes incrementally with observation periods.
Testing and rollback: Validate changes in non-production environments first.
The following implementation approach moves from most restrictive to more automated configurations. Choose the approach that best fits your organization’s risk tolerance and operational requirements. This three-step process moves from the most restrictive approach to more automated configurations while maintaining security controls. Each step builds upon the previous one, creating layers of security that work together to protect your pipeline.
Note: The following examples use the AWS CLI for demonstration purposes. Similar configuration steps can be performed using the AWS Management Console through the AWS CodeBuild project settings.
Step 1: Configure push-only builds
Push-based builds help make sure that only verified contributors can trigger builds. This approach is more secure, because contributors must already be vetted through your repository’s access control mechanisms before they can push code. Configure your webhook to trigger only on push events:
Branch-based filtering adds an additional layer of security by making sure that builds are triggered only for changes to specific branches. This approach recognizes that not all branches in a repository have the same security requirements or risk profiles.
For example, changes to main or production branches typically require more stringent security controls than changes to feature or development branches. By implementing branch-based filtering, you can apply appropriate security measures based on the criticality and exposure of different branches.
Contributor filtering can be used to manage pull request builds by allowing automation for trusted contributors while requiring manual review for others. This approach recognizes that different contributors represent different risk profiles and should be treated accordingly.
The first step in implementing contributor filtering is identifying the GitHub user IDs of your trusted contributors.
Retrieve GitHub user IDs for trusted contributors:
Important: Contributor allowlists require ongoing maintenance as team membership changes. Consider using Infrastructure as Code templates like the Cloudformation examples to manage webhook configurations and contributor lists in version control.
Webhook filtering provides the first layer of security by controlling which events trigger builds. However, comprehensive pipeline security requires additional controls around the permissions and credentials available to those builds once they execute. The following section covers how to implement defense-in-depth security through proper access controls and credential management.
Access control and credential management
This section covers specific approaches to limit the permissions available to build processes, scope repository access tokens appropriately, and create isolated environments that help contain potential security issues. These practices work together to implement defense-in-depth security while maintaining the operational benefits of automated CI/CD workflows.
Implementing least-privilege access
AWS CodeBuild projects require IAM service roles to access AWS resources during the build process. The principle of least privilege dictates that each role should have only the minimum permissions necessary to perform its intended function. By creating separate, purpose-built IAM roles for different types of builds, you can help reduce the potential impact of unauthorized access to build environments.
The following examples demonstrate how to structure minimal IAM roles for different build scenarios. These examples serve as starting points that you should customize based on your specific requirements, adding only the permissions your builds actually need.
Service role configuration
Create minimal IAM roles that provide only the permissions required for specific build types:
Leveraging IAM Access Analyzer for CodeBuild security
AWS IAM Access Analyzer can generate least-privilege policies for your AWS CodeBuild service roles based on actual CloudTrail activity from your build executions. This eliminates guesswork by analyzing the specific AWS API calls your builds make, rather than requiring you to predict what permissions might be needed.
After running your CodeBuild projects for a representative period, use Access Analyzer’s policy generation feature to create refined policies. This approach proves particularly valuable for complex build processes where the required permissions might not be immediately obvious.
When processing external contributions, the principle of least privilege becomes important for repository access tokens. If an unauthorized user gains access to a token through an untrusted build, properly scoped tokens limit the potential impact to only the permissions necessary for the build process.
Configure fine-grained GitHub Personal Access Tokens with minimal permissions to help reduce this risk. Even if accessed inappropriately, a properly scoped token can only read source code (already accessible through the PR) and write status messages – it cannot push code, modify repository settings, or access other repositories.
The following permissions represent the minimum required access for processing external pull requests, demonstrating how to limit token scope to only essential operations:
contents:read – Read-only access to repository source code (already accessible through the PR)
statuses:write – Write commit status messages only (cannot modify code or settings)
metadata:read – Access basic repository information (name, description, public status)
Important: Use fine-grained personal access tokens restricted to the target repository only. Otherwise, this could allow access to other repositories beyond what is necessary for the build process.
This scoped approach ensures that even if a token is accessed inappropriately, the potential impact is limited to reading already-accessible information and writing status messages. The token cannot push code, modify repository settings, create webhooks, or access other repositories.
Credential storage and rotation
The following examples demonstrate how to securely store and reference these tokens using AWS Secrets Manager. AWS Secrets Manager provides automatic rotation capabilities, encryption at rest and in transit, and fine-grained access controls that help prevent tokens from being exposed in build logs or configuration files. This approach also enables centralized token management across multiple CodeBuild projects while maintaining audit trails of token access.
The centralized storage enables credential rotation capabilities, helping to minimize the window of exposure compared to hardcoded tokens that would require infrastructure updates to rotate.
Build environment isolation
Establishing proper build environment security controls helps maintain pipeline integrity. The foundation of this approach involves implementing separation between test and release builds, which helps prevent credential escalation and limits the scope of potential unauthorized access.
Network isolation represents another layer of protection. Configure VPC settings specifically for builds that process external code by creating dedicated security groups with carefully restricted outbound access. These security groups should permit only necessary connections, such as HTTPS traffic for downloading legitimate dependencies, while blocking unnecessary network access that could be exploited by untrusted code.
Update your AWS CodeBuild projects to leverage this network isolation through proper VPC configuration, including specified subnets and the restricted security groups you’ve established.
Multi-stage pipeline security with human review gates
Implementing security controls across multiple pipeline stages helps provide proper validation and approval processes, especially when processing external contributions. This approach combines automated scanning with human oversight to identify issues before they reach production.
Code inspection integration
Configure your build specification to automatically run security tools like Automated Security Helper during the build process. These tools scan for code security issues and dependency problems, generating detailed reports for review.
Structure the build to continue execution even when issues are found, allowing all scans to complete while automatically failing builds that contain security problems requiring attention. Store all scan artifacts to provide security teams with detailed information for approval decisions.
Manual approval gates
After code passes automated security scans, configure manual approval gates to involve human reviewers for final validation. This helps provide appropriate human review before proceeding to sensitive environments.
The access control and credential management practices outlined in this section provide specific, actionable approaches to implementing defense-in-depth security for AWS CodeBuild pipelines. These controls work together to create multiple layers of protection while maintaining the operational benefits that make CI/CD automation valuable.
Alternative approach – Self-hosted GitHub Actions runners
AWS CodeBuild’s self-hosted GitHub Actions runner capability addresses the configuration issues described in this guide by isolating repository credentials from the build environment and using GitHub Actions’ execution framework instead of AWS CodeBuild webhook processing.
For organizations that need to process external contributions automatically, configure runners with proper access controls, use ephemeral runners to minimize persistent access, and apply standard security practices for runner management.
The security controls outlined in previous sections provide protection at build time, but comprehensive defense-in-depth security requires ongoing visibility into your pipeline activities and configuration changes. Monitoring and compliance tracking serve as the final layer of your security framework, helping you detect configuration drift, audit access patterns, and maintain security posture over time.
AWS CloudTrail provides detailed logging of API calls made to AWS services, including AWS CodeBuild. Enable CloudTrail logging to create a comprehensive audit trail of all build-related activities in your environment.
AWS Config tracks AWS CodeBuild project configurations over time, providing an inventory of projects and a complete history of configuration changes. This includes webhook modifications, resource relationships, and compliance tracking across your environment. Configure AWS Config to monitor AWS CodeBuild projects and receive notifications when security-critical configurations like webhook filters are modified. For more information, see the AWS Config sample with CodeBuild documentation.
Conclusion
Implementing defense-in-depth security for AWS CodeBuild pipelines requires layered controls that address different security considerations. The most effective approach combines webhook filtering, access controls, credential management, and monitoring to provide comprehensive protection. By implementing these layered practices outlined in this guide, you can maintain development velocity while establishing robust pipeline security. Key principles to remember:
Assess your threat model first – different projects require different security approaches
Establish clear trust boundaries between different types of contributors
Use webhook filtering to control when builds are triggered
Implement least-privilege access for build environments
Monitor and audit configurations regularly using AWS Config and CloudTrail
Store secrets in AWS Secrets Manager or SSM Parameter Store and enable rotation
AWS CodeBuild provides the flexibility to implement these security measures while maintaining the operational benefits that make pipelines valuable. Apply the configurations and mitigations in this guide based on your specific risk profile and operational requirements. Regular review and updates of your configurations will help your pipelines remain secure as your organization’s needs evolve.
Stay tuned for additional practical guides for implementing CI/CD security best practices. If you have questions or feedback about this post, including suggestions for topics that would help you most, start a new thread on re:Post : Begimher or contact AWS Support.
As introduced in Part 1 of this series, implementing secure file sharing solutions in AWS requires a comprehensive understanding of your organization’s needs and constraints. Before selecting a specific solution, organizations must evaluate five fundamental areas: access patterns and scale, technical requirements, security and compliance, operational requirements, and business constraints. These areas cover everything from how files will be shared and what protocols are needed, to security measures, day-to-day operations, and business limitations.
See Part 1 of this series for detailed information about each of these fundamental areas and their specific considerations. Part 1 also covers solutions including AWS Transfer Family, Transfer Family web apps, and Amazon Simple Storage Service (Amazon S3) pre-signed URLs. This part continues our analysis with additional AWS file sharing solutions to help you make an informed decision based on your specific requirements.
Solutions
Let’s start by looking at the various file sharing mechanisms that AWS supports. The following table identifies the key AWS services needed for each solution, describes the security and cost implications of the solutions, and describes their complexity and protocol support capabilities.
Solution
AWS services
Security features
Cost*
Region control
CloudFront signed URLs
CloudFront, Amazon S3, and Lambda
Optional edge security using AWS Lambda@Edge, WAF integration, SSL/TLS, geo restrictions, and AWS Shield Standard (included automatically)
Content delivery network (CDN) costs, request pricing, and data transfer fees
Global service by design; origin can be AWS Region-specific
Amazon VPC endpoint service
AWS PrivateLink, Amazon VPC, and Network Load Balancer (NLB)
Complete network isolation, private connectivity, and multi-layer security
Endpoint hourly charges, NLB costs, and data processing fees
Service endpoints are strictly Region-specific; must create endpoints in each Region where access is needed
Data transfer fees apply based on standard S3 rates
Amazon VPC endpoint charges apply when using VPC endpoints with access points
Access points are Region-specific
Each access point is created in the same Region as its S3 bucket
Cross-Region access requires separate access points in each Region
VPC-specific access points are limited to the VPC’s Region
The following table shows the solutions described in Part 1.
Solution
AWS services
Security features
Cost*
Region control
AWS Transfer Family
Transfer Family, Amazon S3, API Gateway, and Lambda
Managed security, encryption in transit and at rest, IAM integration, and custom authentication
$0.30 per hour per protocol, data transfer fees, and storage costs
Can deploy to specific AWS Regions, can only transfer files to and from S3 buckets in the same Region
Transfer Family web apps
Transfer Family, S3, and CloudFront
Browser-based access, IAM Identity Center integration, and S3 Access Grants
Pay-per-file operation, CloudFront costs, and storage costs
Uses CloudFront (global) for web access, but backend components can be Region-specific
Amazon S3 pre-signed URLs
S3
Time-limited URLs, IAM controls for URL generation, and HTTPS
S3 request and data transfer fees
Can be restricted to specific Regions
Serverless application with Amazon S3 presigned URLs
S3, Lambda, and API Gateway
Time-limited URLs, HTTPS, IAM controls, customizable authentication
Pay per request and minimal infrastructure cost
Components can be Region-specific
* Pricing information provided is based on AWS service rates at the time of publication and is intended as an estimation only. Additional costs may be incurred depending on your specific implementation and usage patterns. For the most current and accurate pricing details, please consult the official AWS pricing pages for each service mentioned.
Let’s examine each of the solutions in detail. Part 1 talked about AWS Transfer Family, Transfer Family web apps, and Amazon S3 pre-signed URLs. Here in Part 2, we explain the remaining solutions to help you make the right choice for your use case.
CloudFront signed URLs with Amazon S3
Amazon CloudFront signed URLs combine Amazon S3 storage with the global edge network of CloudFront to deliver files securely with lower latency.
CloudFront edge locations cache content geographically closer to users, which usually reduces latency and gives better performance for users. CloudFront also reduces the number of origin requests to Amazon S3. CloudFront integration with AWS Shield and AWS WAF provides options for additional security layers, helping to protect against DDoS events and unintended requests. You can use custom domains with AWS-provided or your own SSL/TLS certificates managed through AWS Certificate Manager (ACM), helping to facilitate secure connections from users to edge locations.
When a user requests a file, the system generates a signed URL using either a CloudFront key pair or a custom trusted signer (such as Lambda Edge) that includes security parameters such as IP restrictions, time windows, and custom policies. The major difference is the content distribution network (CDN) making performance faster by caching data geographically close to the user downloading it.
The built-in logging and monitoring capabilities of CloudFront provide detailed insights into content access patterns, cache hit ratios, and security events. CloudFront integrates seamlessly with Amazon S3 to support origin access identity (OAI), helping to make sure that the S3 objects can be accessed only through CloudFront and not directly through S3 APIs.
Figure 1: CloudFront signed URLs with Amazon S3 architecture
Pros
If Amazon S3 pre-signed URLs sound good, but you need higher performance at a global scale, CloudFront signed URLs are the right choice. The AWS global edge network has points of presence (POPs) all over the world, which significantly reduces latency for users and minimizes data transfer costs through caching. This architecture provides substantial cost savings for frequently accessed content, because edge locations serve cached copies without retrieving objects from the S3 origin. The integration with AWS security services offers protection against various threats, including sophisticated distributed denial of service (DDoS) events and web application issues, making it particularly suitable for public-facing file sharing applications. Choose CloudFront instead of S3 if you tend to make the same file available to many people who download it many times, such as in software distribution or documentation distribution.
The solution’s security model provides extensive flexibility in access control implementation. You can define granular permissions through custom policies, implement geo-restriction rules, and enforce IP-based access controls. The ability to use custom TLS certificates and domains maintains brand consistency while helping to facilitate secure communications. The integration with AWS WAF enables advanced request filtering and rate limiting, while detailed access logging and real-time metrics provide visibility into content delivery and security events. The solution’s support for both signed URLs and signed cookies offers flexibility in implementing various access control scenarios. Signed cookies are used when you want to provide access to multiple restricted files. For example, if you need to provide access to many files in a private directory, you can use signed cookies to avoid having to create individual signed URLs for each file. When choosing between CloudFront signed URLs (ideal for individual file access) or signed cookies (better for providing access to multiple files, like a subscriber’s content library), consider your content distribution needs and whether your clients support cookies.
Cons
If you implement CloudFront, you must develop expertise in its configuration options, including robust key management processes and secure key rotation procedures. Self-managed certificates don’t automatically renew. You must track expiration dates and make sure you renew on time, or your users will get warnings and errors when they try to download. ACM can simplify TLS certificate management and automatically renew certificates before they expire. while trusted signer workflows enhance your security posture.
Note: To create signed URLs, you need a signer. A signer is either a trusted key group that you create in CloudFront, or an AWS account that contains a CloudFront key pair.
Misconfigured web caches have many surprising and frustrating effects for users. Understanding and configuring CloudFront cache behavior is key to helping to prevent unintended content exposure or availability issues. You need to add cache invalidation to your publication workflows so that old versions are no longer available from the cache. This might introduce additional costs and operational overhead, especially in scenarios with frequent content changes. If you frequently change the content that you share, if the content is unique to an individual (such as a personalized report), or if the same content isn’t downloaded many times by many people in many locations, you won’t realize much cost savings or reduced latency from CloudFront caching. The additional complexity added by cache configuration might not be justified unless the cache is used a lot.
If you use the CloudFront global content delivery network, your content will be stored in caches in hundreds of locations around the world. ACM will store your TLS certificates for CloudFront (whether ACM is issuing them or you manage them yourself) in the us-east-1 AWS Region. Because CloudFront is a global service, it automatically distributes the certificate from the us-east-1 Region to the Regions associated with your CloudFront distribution. Caching data and keys around the world might not be acceptable if you have data sovereignty requirements to keep your data in one country.
From a cost perspective, while CloudFront can provide savings through caching, the pricing model has other variables to consider. Data transfer costs vary by Region and can be significant for large-scale distributions. If you need custom domain names and custom TLS certificates, that might introduce additional costs. Implementation expertise is needed when dealing with dynamic content or when specific origin request handling is required. CloudFront only delivers via HTTPS and HTTP protocols, so you won’t be able to use it if you require support for other file transfer protocols. CloudFront distributions provide statistics on cache hit-and-miss rates—pay attention to these because low cache hit rates mean that you’re pulling data from the origin frequently, which limits the possible cost savings.
Amazon VPC endpoint service with custom application
Amazon VPC endpoint services, powered by AWS PrivateLink, enable private connectivity between VPCs without requiring internet access, VPN connections, or direct physical connections. This solution creates a highly secure, private network path for file sharing by exposing services through Network Load Balancers (NLB) and allowing other VPCs to access them through interface endpoints. The architecture isolates the file sharing service from the public internet, operating entirely within the AWS private network infrastructure.
The best use cases for this architecture involve sharing data or distributing software around your AWS infrastructure without exposing it to the public internet.
Figure 2: Amazon VPC endpoint service architecture
The solution, shown in Figure 2, typically involves deploying a custom file sharing application behind an NLB in the service VPC, which is then exposed as an endpoint service. Consumer VPCs create interface endpoints to connect to this service, establishing private connectivity through the AWS backbone network. Traffic remains within the AWS network, is encrypted in transit, and is subject to security controls at both the endpoint and VPC levels. The architecture supports many TCP-based protocols, making it versatile for various file transfer requirements.
This architecture provides secure pathways for data to travel by using multiple layers, including VPC security groups, network access control lists (ACLs), endpoint policies, and the custom application’s authentication mechanisms. The built-in security features of PrivateLink are designed so that only approved AWS principals can create interface endpoints to connect to the service, while detailed VPC flow logs provide network traffic visibility.
Pros
Amazon VPC endpoint services provide complete network isolation and private connectivity that’s inaccessible from the public internet. This reduces the exposure footprint and helps meet security requirements for sensitive data transfer operations. The solution maintains private connectivity across different AWS accounts and Regions while keeping traffic within the AWS network infrastructure.
This solution also provides the most flexible protocol support. Other solutions require you to use HTTPS, AWS API calls (which are HTTPS), or one of the protocols supported by Transfer Family (such as SFTP). If you have software that uses custom protocols, and you need security controls and network isolation, this architecture provides predictable performance through dedicated network paths and supports high throughput requirements without internet bandwidth constraints. The granular control over network security through VPC security groups, network ACLs, and endpoint policies enables organizations to implement defense-in-depth strategies effectively. Additionally, the solution’s integration with AWS Organizations facilitates centralized management and governance across multiple accounts.
Cons
Setting up and maintaining VPC endpoints requires significant expertise in AWS networking, including VPC design, PrivateLink configuration, and network security controls. The initial architecture design must carefully consider IP address management, service quotas, and Regional availability to provide scalability and reliability. Organizations must also develop and maintain the custom file sharing application in addition to the VPC endpoints.
This solution has many components that incur hourly and bandwidth-related charges. Each interface endpoint incurs hourly charges and data processing fees, which can accumulate significantly in multi-VPC or multi-Region deployments. NLBs add another cost component, and you must maintain sufficient capacity for peak loads. The solution also has operational costs because of the need for specialized expertise and ongoing maintenance. Additionally, while the private connectivity model provides superior security, it can make troubleshooting more challenging and might require additional tooling for effective monitoring and diagnostics. The Regional nature of VPC endpoints might necessitate additional architecture for multi-Region deployments, potentially increasing both costs and operational overhead. This solution is most suitable when private network security considerations are the highest priority, and cost considerations are secondary.
Amazon S3 Access Points
Amazon S3 Access Points simplify managing data access at scale for applications using shared data sets on S3. Access points are named network endpoints attached to S3 buckets that streamline managing access to shared datasets. Each access point has its own AWS Identity and Access Management (IAM) policy that controls access to the data, allowing you to create custom access permissions for different applications or user groups accessing the same bucket.
The architecture uses S3 buckets with access points providing dedicated access paths to the data. Each access point has its own hostname (URL) and access policy that works in conjunction with the bucket policy. You can create access points that only allow connections from your Amazon Virtual Private Cloud (Amazon VPC) for private network access to Amazon S3 or create access points with Internet connectivity. You can use this flexibility to implement sophisticated access control patterns while maintaining a single source of truth in S3.
Figure 3: S3 Access Points with VPC endpoints
Pros
Amazon S3 Access Points simplify permissions management and security to accommodate multiple access patterns and use cases. For example, if an S3 bucket contains data that needs to be accessed by multiple applications, each requiring different levels of access, you can create a dedicated access point for each application with precisely the permissions it needs, rather than managing a long monolithic bucket policy.
You can implement access control workflows, such as restricting access to specific VPCs, encryption, or limit access to specific objects or prefixes. The service requires no new infrastructure management, reducing operational overhead and allowing you to focus on business logic implementation.
Access points provide a way to enforce network controls through VPC-only access points, helping to make sure that data can only be accessed from within your private network. IAM permissions management becomes more granular and straightforward to audit when each application or user group has its own access point with a dedicated policy. You can associate different access points with different network origins.
Another possible use case is when you need to provide temporary access to specific data within a bucket without modifying the bucket policy. You can create a temporary access point with the necessary permissions and delete it when the access is no longer needed.
Cons
Access points add another layer to your Amazon S3 architecture that needs to be managed and monitored. Each access point has its own Amazon Resource Name (ARN) and hostname that applications need to use instead of the bucket name, which might require changes to your application code.
There are limits to the number of access points you can create for each bucket, which might be a constraint for large-scale applications. Access points can only control access to the bucket they’re associated with, not across multiple buckets, so if your application needs to access data across buckets, you’ll need multiple access points.
When implementing this solution, you need to design your access point policies to make sure that they work correctly with your bucket policy. Think of your S3 bucket policy as the primary security framework, while access point policies act as specialized gatekeepers. These two layers of security must work in harmony. The bucket policy takes precedence. For example, if your bucket policy explicitly denies access from specific IP ranges, an access point policy can’t override this restriction. This hierarchical relationship requires strategic planning. Start by defining your broad security boundaries in the bucket policy—perhaps allowing access only from specific VPCs or requiring encryption. Then create your access point policies within these boundaries.
While Amazon S3 Access Points offer powerful flexibility, understanding their boundaries is crucial. Cross-account scenarios, common in large enterprises or partner collaborations, require careful configuration. Imagine you’re working with an external auditing firm that needs temporary access to your financial data stored in S3. Setting up a cross-account access point requires creating the access point in your account, configuring a trust policy to allow the external account, verifying that the bucket policy permits access from the access point, and providing the auditors with the access point ARN and necessary IAM permissions in their account. This process maintains tight control over your data while enabling secure cross-account access.
Some Amazon S3 operations are only controlled at the bucket level and can’t be controlled by access points. Core bucket operations such as configuring versioning, logging, managing lifecycle policies, and setting up cross-Region replication require direct bucket access. For these operations, you need to interact directly with the bucket through the appropriate permissions. This limitation helps make sure that fundamental bucket configurations remain centralized and controlled by bucket owners.
Creating a dedicated IAM role for bucket administration tasks—separate from the roles that interact with data through access points—enhances security and aligns with the principle of least privilege.
Conclusion
In this second part of a two-part post, you’ve learned about multiple solutions for secure file sharing using AWS services and the pros and cons of each. You can find additional options and a full decision matrix in Part 1. The optimal solution depends on your specific organizational requirements, technical capabilities, and budget constraints. You don’t have to choose just one option, you can implement multiple solutions to address different use cases, creating a file sharing strategy that balances security, cost, and operational efficiency.
Organizations face mounting challenges in building and maintaining effective security incident response programs. Studies from IBM and Morning Consult show security teams face two major challenges: over 50 percent of security alerts go unaddressed because of resource constraints and alert fatigue, while false positives consume 30 percent of investigation time, delaying responses to true positive threats
According to the 2024 IBM Cost of a Data Breach Report, organizations now take an average of 258 days to identify and contain security events. The report also reveals that nearly half of SOC teams report increased detection and response times over the past two years, with 80 percent indicating that manual threat investigation significantly impacts their response times.
Despite these challenges, according to the 2024 IBM Security Services Benchmark Report, organizations with mature incident response capabilities demonstrate a 50 percent reduction in mean time to resolution (MTTR) and achieve cost savings of up to 58 percent per incident. These improvements are driven by the adoption of automated workflows, integrated tools, and streamlined communication processes that accelerate threat detection and containment.
In this post, we walk you through a real-world scenario to show how AWS Security Incident Response can immediately generate benefits by accelerating every step of your incident response lifecycle, how it integrates with other native AWS services such as Amazon GuardDuty, AWS Security Hub, and AWS Systems Manager, and how to integrate third-party threat detection findings for inclusion in your automated monitoring, triage, and containment capabilities.
How AWS Security Incident Response can help
AWS Security Incident Response is a Tier 1 service that launched in December 2024. The service is an AWS-native, purpose-built security incident response solution for customers that can be used as a better-together experience with other AWS services in the areas of detection and response (GuardDuty and Security Hub), networking and content delivery (AWS WAF and AWS Shield), and management and governance (Systems Manager). AWS Security Incident Response is also integrated across AWS Partners through a service specific Partner Specialization program. More detailed information is available in the AWS Security Incident Response documentation.
AWS Security Incident Response complements existing services by enhancing your security posture through streamlined incident management capabilities before, during, and after security events.
Key challenges
AWS Security Incident Response addresses three common challenges:
Alert fatigue: It can reduce alert fatigue and accelerate security investigations through automated monitoring and intelligent triage, reducing false positives and helping to prevent security team burnout.
Fragmented access and communications: By simplifying AWS Management Console permissions management and unifying incident response team communications, it can resolve fragmented access issues.
Security skills gaps: It can bridge cloud security skills gaps by providing 24/7 access to AWS security experts who support the incidents including credential compromise, data exfiltration, and ransomware. The AWS Security Incident Response service allows security teams to handle immediate security challenges while maintaining focus on strategic long-term preparedness and operational improvements.
Service integration
AWS Security Incident Response complements and integrates with AWS security services to provide comprehensive incident response capabilities. The service works seamlessly with:
This integration helps you build efficient incident response capabilities that can minimize the time, cost, and impact of security events throughout your organization’s cloud journey, while helping to reduce investments in additional staffing, training, and tool maintenance.
Distinct capabilities
The AWS Security Incident Response service offers:
Expert knowledge from the AWS Customer Incident Response Team (CIRT)
Tools through APIs and the console
Streamlined processes for handling security incidents
Prerequisites
Before implementing the capabilities described in this post, make sure that you have:
These prerequisites help make sure that you can fully utilize the service’s automated detection, triage, and response capabilities.
The service provides automated monitoring and analysis capabilities within its own service infrastructure, enabling automatic triage of findings from GuardDuty and Security Hub.
For automated containment actions in your AWS accounts, you must first deploy the required CloudFormation StackSets and configure the appropriate IAM permissions. This helps make sure that you maintain full control over automated actions taken in your environment while benefiting from the service’s detection capabilities. This automation can be customized based on variables you establish, such as known CIDR ranges (specific ranges of IP addresses that define your network) and IP addresses, and you can implement GuardDuty suppression rules to help reduce false positives and alert volumes. As a result, the service can serve as a powerful augmentation to your existing security incident response programs and tools.
Setting up AWS Security Incident Response
Your cloud administrator, with AWSSecurityIncidentResponseFullAccess permissions, has established the incident response team in the service. The service notifies individuals, your partners or managed security service provider (MSSP), and other contacts added to the team, supporting a rapid escalation to alert the required parties and respond to the event.
As a best practice, your team establishes minimal privileges for accessing and managing information within AWS Security Incident Response cases. This helps make sure that team members have appropriate access levels to case details, findings, and investigation data while maintaining security and compliance requirements. AWS Security Incident Response provides multiple API actions, such as CreateCaseComment (to add notes to investigations) and GetCase (to retrieve case metadata), to limit whom and which actions can be performed against differing cases. For development and testing environments, AWS provides role-based policies that you can use such as AWSSecurityIncidentResponseCaseFullAccess and AWSSecurityIncidentResponseReadOnlyAccess for role-based access control (as shown in Figure 1). For production environments, we recommend creating custom IAM policies following the principle of least privilege based on your security requirements.
Figure 1: Permissions policies for security incident response
Following your configuration of the AWS Security Incident Response service, your security team reviews the email distribution list or alias for notifications for notifications from the service, as shown in Figure 2. You have developed items in your backlog to take advantage of Amazon EventBridge integrations to add in pager duty, Jira, and other services in the future for additional notification mechanisms.
Figure 2: Use the console to manage your incident response team membership
Detecting and responding to suspicious activity
At 2:00 AM, days after AWS Security Incident Response has been set up, the service detects a combination of suspicious activities through GuardDuty findings, including anomalous IAM user behavior (such as shown in Figure 3), unusual API calls from unknown IP addresses, and a surge of Amazon Elastic Compute Cloud (Amazon EC2) instance creations that deviate from your account’s normal baseline. This pattern of activities matches known threat behaviors monitored by GuardDuty Extended Threat Detection. Without the service, security teams would need to manually analyze and correlate these separate findings across accounts and Regions. Instead, the service automatically identifies the pattern of suspicious activities.
Figure 3: Pattern of potentially suspicious activity
One of the anomalous behaviors is a surge of unrecognized EC2 instance creations, complete with SSH keys (secure credentials used for remote access) and security group configurations (firewall rules that control network traffic) allowing internet connectivity. Using this example scenario, let’s walk through how the service’s automated monitoring, triage and containment capabilities, access management, API actions for custom integrations, collaboration tools, and 24/7 AWS security experts work together to help you navigate security incident response challenges across your AWS environment.
With the initial detection complete, the next phase focuses on centralizing and analyzing the security findings to understand the full scope of the incident.
Centralizing security findings: A systematic approach
GuardDuty begins to generate findings in your enabled Regions.
Note: GuardDuty must be enabled in your accounts and Regions. For setup instructions, see the GuardDuty documentation.
Because AWS Security Incident Response is integrated with GuardDuty, these findings are automatically sent to the service for internal processing, analysis, and auto-triage without manual effort. The service’s proactive response and alert triaging feature analyzes multiple factors, including your account’s historical baseline activity, specific GuardDuty finding types, and correlation patterns across accounts. In this case, it identified anomalous EC2 instance creation activity that deviated significantly from your environment’s normal patterns.
When the service identifies a true positive, an AWS Security Incident Response case is opened automatically (see Figure 4), resulting in a notification to the incident response team you configured earlier. A central benefit is how the service correlates disparate events—connecting the instance creations with the security group modifications—to paint a complete picture of the potential security event.
Figure 4: Automated incident remediation flow
This proactive monitoring and analysis, as documented in your monthly service reports, demonstrates tangible benefits by reducing alert fatigue, and providing intelligent triage capabilities to SOC teams every day. The service’s automated analysis and correlation capabilities set the stage for rapid response when security events occur, which means that your team can focus on strategic security initiatives instead of spending time manually investigating alerts. The service feature helps you maintain strong security in two ways:
Comprehensive monitoring across configured Regions.
Integration with third-party security tools. This automated approach reduces the time, cost, and impact of security events.
As the investigation progresses from initial detection to detailed analysis, the GuardDuty integration provides crucial insights into the threat patterns.
From detection to action: The GuardDuty integration story
As your security team responds to the internal detection mechanisms, AWS Security Incident Response processes security findings in three key steps:
It analyzes GuardDuty alerts to identify genuine security threats
Using GuardDuty Extended Threat Detection, it correlates related events to identify threat patterns
It tracks the threat sequence, from initial actions (deleting logs or creating unauthorized access) through to potential data theft attempts
For this event, the sequence started with the deletion of CloudTrail logs, followed by the creation of unauthorized access keys. As the threat progressed, the service identified suspicious Amazon Simple Storage Service (Amazon S3) object access patterns and potential data exfiltration attempts, along with sophisticated evasion techniques and persistence mechanisms. Each of these signals maps directly to specific MITRE ATT&CK® tactics, techniques and procedures (TTPs), revealing the systematic nature of a potential ransomware threat. For detailed mapping of AWS Security Incident Response findings to MITRE ATT&CK® frameworks, see Mapping AWS security services to MITRE frameworks for threat detection and mitigation.
The service assists in correlation and analysis, evaluating patterns such as deletion of CloudTrail trails, creation of new access keys, and suspicious actions targeting S3 objects. When the AI and machine learning (AI/ML) capabilities of GuardDuty detect these concerning patterns over periods of time, the service automatically elevates the situation by creating an AWS Security Incident Response case on your behalf, bringing additional resources and focused attention to the situation. The incident response team defined in the earlier steps are then notified by email or other methods (shown in Figure 5) that a new triaged event has been created and to begin their investigations.
The benefits include the service coordinating communication across your affected accounts. Instead of juggling multiple alerts and trying to piece together the scope of the potential ransomware incident, GuardDuty Extended Threat Detection provides a comprehensive view of the threat sequence, while the AWS Security Incident Response case offers a single, coherent channel for triaging these signals and providing coordination as your global team comes online to join the response effort.
Note: For brevity, Security Hub’s workflow details have been omitted because they mirror the monitoring and escalation processes described above for GuardDuty. Both services integrate closely and share similar operational patterns, with GuardDuty findings being sent to Security Hub within five minutes of detection. Security Hub enhances security coverage by aggregating findings from multiple AWS services and third-party partners.
With the threat patterns identified, your team moves to the next phase—engaging AWS CIRT for specialized expertise and advanced investigation capabilities.
Partnering with AWS CIRT through the incident response case
Your team continues investigating the event and discovers that they need additional assistance. An authorized user in your account opens a service supported case to request assistance from AWS.
The AWS Security Incident Response case establishes a direct communication channel with AWS CIRT (shown in Figure 6) with a one-click escalation of the case within the console, providing immediate access to specialized expertise. Upon case escalation, AWS CIRT engages through the incident response case with a 15-minute acknowledgement timeframe, bringing their advanced tooling and specialized knowledge to analyze patterns across your accounts—even in environments with limited logging capabilities. This partnership delivers:
Real-time collaboration through conference bridge video calls
Advanced artifact analysis and pattern recognition
Technical guidance for investigation and containment
Recommendations for improving security posture
Figure 6: Connect with the AWS CIRT
Figure 6 is an example of how this would appear in your account, with the resolver set to Self for a self-managed case.
Returning to the scenario, you discover that multiple accounts have insufficient logging enabled—which limits the available investigation data. While AWS CIRT can provide additional insights through specialized tooling, maintaining comprehensive logging across your accounts remains crucial for security visibility, compliance requirements, and thorough incident investigations. The capabilities of AWS CIRT complement—but do not replace—proper logging practices. This capability provides an understanding of the scope of the incident, as they see patterns and activities otherwise invisible to you.
The collaboration begins with AWS CIRT analyzing your environment using their tooling, looking for anomalous patterns beyond what you see in your immediate logs. Through the incident response case, they help you understand the scope of your situation by:
Communicating their findings
Recommending additional investigation paths
Sharing analysis showing similar EC2 instance creation patterns from other environments
AWS CIRT uses the incident response case to establish a bridge call, bringing together their team and yours for real-time collaboration. During these calls, AWS CIRT shares their ongoing analysis of artifacts and service data, helping you understand what happened, why it happened, and how to prevent similar issues in the future. They also provide guidance on implementing proper logging across your accounts to improve your future security posture.
Managing the incident through intelligent tagging
As AWS CIRT begins their analysis, your team implements real-time resource tagging using the incident case ID. This systematic tagging approach proves crucial for tracking and managing the suspicious EC2 instances across your accounts. By using tags, you can quickly implement isolation policies and track costs while maintaining clear documentation of affected resources throughout the investigation.
Your tag-based approach helps track affected resources to implement isolation policies. You used the incident case ID tags to quickly identify resources connected to the incident, which you use to apply targeted access controls and containment measures. The tags also help you track costs associated with the incident, giving your finance team precise visibility into the event’s financial impact.
Working alongside the AWS Security Incident Response service, you find that using the incident case ID as your primary tag key (shown in Figure 7) created a consistent way to correlate resources across affected accounts. This proves especially helpful when coordinating with AWS CIRT, because you can quickly direct them to specific resources requiring investigation. Even after containment, these tags continue to provide value in supporting your post-incident analysis and helping you implement targeted security controls based on what you learn from the incident.
Figure 7: Incident tags
Automated containment options through Systems Manager integration
While working with AWS CIRT to understand the incident scope, you can also use Systems Manager to help automatically contain threats. Your team previously deployed the required CloudFormation StackSets across your organization, enabling Amazon EC2 containment actions through Systems Manager.
The setup process required deploying CloudFormation StackSets with specific IAM roles and Systems Manager configurations across your accounts. This infrastructure allows the AWS Security Incident Response service to make containment actions on your behalf. These actions can be reversed if needed—similar to using an undo function—so that you can restore systems to their previous state.
When authorized through your pre-deployed CloudFormation StackSets, AWS Security Incident Response service can request Systems Manager to implement containment measures. Containment actions require explicit customer authorization and proper IAM permissions to be configured in advance. The service isolates the tagged suspicious instances by modifying their security groups and network access, while preserving their state to maintain forensic integrity for analysis.
The containment process happens in three steps:
Isolate: Remove compromised instances from security groups
Preserve: Create backup copies (snapshots) of affected systems
Investigate: Collect system information using Systems Manager
These actions can be reversed if needed, supporting containment decisions for legitimate workloads.
The automation capabilities help streamline containment procedures across multiple instances, reducing the time taken to contain impacted resources. The service maintains detailed logs of each action in the incident response case, providing your team with clear visibility into the containment efforts.
Through this response capability, combined with the guidance from AWS CIRT, you can contain the incident’s spread within minutes rather than hours. The Systems Manager integration provides a reliable way to implement containment actions while preserving evidence for investigation (shown in Figure 8).
Figure 8: Systems Manager documents for containment actions
Resolution and lessons learned
As the incident moves toward resolution, your team works through a systematic process to verify containment, alleviate threats, and restore services. Working alongside AWS CIRT through the AWS Security Incident Response case, you implement a structured approach to make sure that affected resources are secured and normal operations can safely resume. The immediate resolution actions fall into three main categories:
Containment confirmation through Systems Manager verification
Verify security group modifications are in place
Confirm network isolation of affected instances
Validate that automated containment actions were successful
Review Systems Manager logs for containment action completion
Verification of threat alleviation across affected resources
Analyze GuardDuty findings to confirm that there’s no new suspicious activity
Review tagged resources for complete containment
Verify termination of unauthorized access attempts
Confirm removal of persistence mechanisms
Check for remaining unauthorized IAM access
Service restoration and access control normalization
Restore legitimate workload access based on verified baselines
Implement updated security group configurations
Reset affected IAM credentials and access keys
Re-establish normal network connectivity for verified clean resources
Update resource tags to reflect post-incident status
Documentation and reporting:
As the incident reaches resolution, AWS Security Incident Response service compiles a comprehensive incident timeline. This documentation accelerates your reporting process, helping you quickly generate required reports for executives, regulators, and cyber insurance providers—all from within the incident response case.
The incident response case captures the complete timeline of events, starting with GuardDuty Extended Threat Detection identifying the initial threat sequences. Each step of the incident response is documented, from the moment suspicious EC2 instance creations were detected, through the MITRE ATT&CK® tactics observed, to the containment actions implemented through Systems Manager integration, and finally to the resolution steps that proved effective.
Long-term Improvements: Through this collaborative post-incident review process, your team:
Implements enhanced logging based on AWS CIRT recommendations
Updates security controls to help prevent similar incidents
Improves incident response processes based on lessons learned
Strengthens your security posture through targeted improvements
Conclusion
This example illustrates how AWS Security Incident Response service can enhance security operations through automated detection, triage, containment, access, and coordinated response capabilities. The service’s integration with AWS Security Hub and Amazon GuardDuty provides efficient handling of security events, while the optional escalation to the AWS CIRT can provide valuable expertise and specialized tooling to help accelerate every stage of your incident response lifecycle and strengthen your security posture.
AWS Security Incident Response service serves as a critical component of a comprehensive security operations strategy, delivering measurable benefits through:
Continuous threat monitoring for automated correlation and machine learning to identify high-priority security risks while minimizing false positives.
Reduced incident response times through automated detection and coordinated response
Enhanced investigation capabilities through direct AWS CIRT collaboration
Streamlined, rapid containment
Comprehensive incident documentation and audit trails to support and accelerate reporting requirements
To prepare for, respond to and recover from security incidents faster and more efficiently today, visit AWS Security Incident Response or contact your AWS account team to schedule a discussion.
Additional resources
Here are some additional AWS resources that your teams can use to further improve your security incident response capabilities:
Before an event:
AWS Customer Playbook Framework: Publicly available response frameworks that use AWS CIRT lessons learned from security events
Assisted Log Enabler: A tool that assists customers to enable logs, including the following: Amazon VPC Flow Logs, AWS CloudTrail, Amazon Elastic Kubernetes Service audit and authenticator logs, Amazon Route 53 Resolver Query Logs, Amazon S3 server access logs, and Elastic Load Balancing logs
During an event:
Athena Security Analytics Bootstrap: A tool for customers who need a quick method to set up Amazon Athena and perform investigations on AWS service logs archived in S3 buckets
When it comes to AWS authentication, relying on long-term credentials, such as AWS Identity and Access Management (IAM) access keys, introduces unnecessary risks; including potential credential exposure, unauthorized sharing, or theft. In this post, I present five common use cases where AWS customers traditionally use IAM access keys and present more secure alternatives that you should consider.
AWS CLI access: Embrace CloudShell
If you’re primarily using access keys for AWS Command Line Interface (AWS CLI) access, consider AWS CloudShell—a browser-based CLI that minimizes the need for local credential management while providing the same powerful CLI capabilities that you’re accustomed to.
AWS CLI with enhanced security: IAM Identity Center
If you need a more robust solution, AWS CLI v2 combined with AWS IAM Identity Center offers a superior authentication approach. This integration enables:
For developers working in local environments, modern integrated development environments (IDEs) such as Visual Studio Code, with AWS Toolkit support offer secure authentication through IAM Identity Center. This alleviates the need for static access keys while maintaining a smooth development experience. Learn more about AWS IDE integrations.
AWS compute services and CI/CD access
When your applications and automation pipelines need AWS resource access, whether running on AWS compute services (Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), or AWS Lambda) or through continuous integration and delivery (CI/CD) tools, IAM roles can provide the ideal solution. These roles automatically manage temporary credential rotation and follow security best practices.
For AWS compute services: Use standard IAM roles with your compute resources. Review the EC2 IAM roles documentation for implementation details.
For CI/CD tools self-hosted on Amazon EC2: If you’re running tools such as Jenkins or GitLab on AWS resources, use the instance profile roles the same as you would with other compute services.
For third-party CI/CD services (such as GitHub Actions, CircleCI, and so on), see External access requirements.
External access requirements
For scenarios involving third-party applications or on-premises workloads, AWS offers three methods:
Third-party applications: Implement temporary security credentials through IAM roles instead of static access keys. Never use root account access keys. See third-party access documentation.
CI/CD software as a service (SaaS): For cloud-based CI/CD services, use OpenID Connect (OIDC) integration with IAM roles to minimize the need for long-term credentials. This allows your CI/CD pipelines to obtain temporary credentials through trust relationships. See the AWS OIDC provider documentation for implementation details.
Best practice: Principle of least privilege
Regardless of your authentication method, always implement the principle of least privilege. This helps make sure that users and applications have only the permissions they need. For guidance on crafting precise IAM policies, see Techniques for writing least privilege IAM policies.
Note: AWS also offers policy generation based on AWS CloudTrail logs, helping you create permission templates based on actual usage patterns. Learn about this feature in the IAM policy generation documentation.
Conclusion
As you’ve seen, there are numerous secure alternatives to IAM access keys that you can use to enhance your AWS authentication strategy while reducing security risks. By using tools such as CloudShell, IAM Identity Center, IDE integrations, IAM roles, and IAM Roles Anywhere, you can implement robust authentication mechanisms that align with modern security best practices.Key takeaways:
Prefer temporary credentials over long-term access keys
Choose the authentication method that best fits your use case
Implement the principle of least privilege across all access methods
Take advantage of the built-in tools provided by AWS for policy generation and management
Regularly review and update your authentication methods as new solutions become available
By making these changes, you can not only improve your security posture but also streamline your authentication processes across your AWS environment. Start small by identifying your current IAM access key use cases and gradually transition to these more secure alternatives. Your future self—and your security team—will thank you.
If you have feedback about this post, submit comments in the Comments section below.
In this post, we show you how to implement comprehensive monitoring for Amazon Elastic Kubernetes Service (Amazon EKS) workloads using AWS managed services. Amazon EKS offers compelling solutions with EKS Auto Mode and AWS Fargate, each designed for different use cases. This solution demonstrates building an EKS platform that combines flexible compute options with enterprise-grade observability using AWS native services and OpenTelemetry.
Modern containerized environments require observability that goes beyond basic CPU and memory metrics. Our approach addresses three critical challenges: reducing compute management complexity, closing observability gaps, and enabling metrics-driven automatic scaling that responds to real application demand rather than infrastructure utilization alone.
Architecture components
Amazon Managed Service for Prometheus is a fully managed Prometheus-compatible service that alleviates the operational overhead of running Prometheus infrastructure while providing automatic scaling to handle billions of metrics, built-in high availability across multiple Availability Zones, 150 days of metrics retention by default, and native integration with Grafana and other visualization tools.
AWS Distro for OpenTelemetry (ADOT) is a secure, enterprise-grade distribution of OpenTelemetry that provides standardized metrics, traces, and logs collection, native AWS service integration, automatic instrumentation for popular frameworks, and efficient data processing and export.
Amazon CloudWatch is a centralized logging and monitoring service offering structured log aggregation and search, custom metrics and alarms, integration with AWS services, and long-term log retention and analysis.
Solution overview
This section outlines the comprehensive monitoring solution architecture and its key components. We explore how the different AWS services work together to provide complete observability for your Amazon EKS workloads.
Our solution addresses key challenges through a comprehensive observability pipeline using Amazon Managed Service for Prometheus, AWS X-Ray, and Amazon CloudWatch; real metrics-based automatic scaling using custom Prometheus metrics instead of basic resource utilization; and cost optimization through strategic virtual private cloud (VPC) endpoints and compute mode selection.
The architecture showcases a Kubernetes environment with two distinct compute modes, each optimized for different use cases. EKS Auto Mode represents AWS’s latest approach to managed Kubernetes compute. It eliminates the need for node management by removing the requirement to configure node groups or instance types. The platform automatically scales compute resources based on your actual workload demands, ensuring you pay only for the resources your applications consume. It comes with integrated services including automatic configuration of VPC CNI, EBS CSI driver, and load balancer integration, making it ideal for general workloads and cost-optimized deployments. The Amazon EKS Auto Mode architecture (shown in the following diagram) provides zero node management with automatic scaling based on workload demands. This mode includes integrated networking, storage, and load balancing capabilities, making it ideal for general workloads and cost-optimized deployments.
AWS Fargate takes a different approach by providing true serverless container execution. With Fargate, you don’t need to manage any Amazon EC2 instances, as each pod runs in its own isolated compute environment. This isolation extends to billing, where costs are tracked at the individual pod level, providing granular control over your expenses. Pods can scale independently without requiring capacity planning, making Fargate particularly well-suited for security-sensitive workloads and applications requiring strict resource isolation.The Amazon EKS Fargate architecture (shown in the following diagram) offers serverless container execution with strong isolation, where each pod runs in its own compute environment. This approach works best for security-sensitive workloads and applications requiring granular cost control.
The key architectural difference lies in networking and scaling behavior. Auto Mode uses shared node networking with cluster-wide scaling decisions, whereas Fargate provides isolated pod networking with individual pod scaling.
Comprehensive observability pipeline
The following diagram illustrates the workflow of the observability pipeline.
The observability architecture implements the three pillars of observability using AWS native services:
Metrics collection and storage:
Dual collection strategy combining direct Prometheus scraping and OpenTelemetry SDK
Local Prometheus server for Horizontal Pod Autoscaler (HPA) metrics and Prometheus Adapter integration
Amazon Managed Service for Prometheus for long-term storage and querying
Custom metrics exposed through Kubernetes custom metrics API
Distributed tracing:
OpenTelemetry SDK integration for automatic trace collection
AWS X-Ray for trace storage and service map visualization
End-to-end transaction monitoring across microservices
Centralized logging:
OpenTelemetry SDK for structured application logging
FluentBit for container log collection
CloudWatch Logs with proper retention policies
Log correlation with traces and metrics for comprehensive debugging
The below diagram demonstrates a modern cloud-native monitoring solution that collects and analyzes performance data from containerized applications, with data flowing from the Kubernetes workloads through the metrics pipeline to CloudWatch for centralized monitoring and observability.
In the following sections, we walk you through deploying the complete observability stack. We start with the foundational AWS services, then configure the collection agents, and finally instrument your applications.
Prerequisites
Before implementing this solution, you must have the following:
The first step to implement the observability stack involves creating the core AWS services that will store and process your observability data using the AWS CDK:
from aws_cdk import (
Stack,
aws_logs as logs,
aws_aps as aps,
aws_iam as iam,
RemovalPolicy,
CfnOutput
)
class ObservabilityStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Create workspace for storing Prometheus metrics
self.prometheus_workspace = aps.CfnWorkspace(
self, "AmpWorkspace",
alias="eks-observability-platform"
)
# Create CloudWatch Log Groups for storing Application Logs
self.app_log_group = logs.LogGroup(
self, "ApplicationLogGroup",
log_group_name="/aws/eks/observability/applications",
removal_policy=RemovalPolicy.DESTROY,
retention=logs.RetentionDays.ONE_WEEK
)
# Create Otel Log Group for OpenTelemetry Logs
self.otel_log_group = logs.LogGroup(
self, "OtelLogGroup",
log_group_name="/aws/eks/observability/otel",
removal_policy=RemovalPolicy.DESTROY,
retention=logs.RetentionDays.ONE_WEEK
)
Deploy the infrastructure stack using the following commands:
This step configures Prometheus for service discovery and remote write to Amazon Managed Service for Prometheus. The local Prometheus instance enables the HPA to access custom metrics:
Deploy the ADOT Collector with proper AWS service integration. This collector processes telemetry data from your applications and exports it to AWS services:
This section shows how to instrument your applications to emit telemetry data. We cover both Python and Java applications.
Instrument a Python Flask application
The following code demonstrates how to add OpenTelemetry instrumentation to a Python Flask application:
from opentelemetry import trace, metrics
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.resources import Resource
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
# Configure OpenTelemetry
resource = Resource.create({
"service.name": "flask-app",
"service.version": "1.0.0",
"deployment.environment": "production"
})
# Setup tracing
trace_provider = TracerProvider(resource=resource)
otlp_trace_exporter = OTLPSpanExporter(endpoint="http://otel-collector.opentelemetry:4317")
trace_provider.add_span_processor(BatchSpanProcessor(otlp_trace_exporter))
trace.set_tracer_provider(trace_provider)
tracer = trace.get_tracer(__name__)
# Setup metrics
metric_provider = MeterProvider(resource=resource)
otlp_metric_exporter = OTLPMetricExporter(endpoint="http://otel-collector.opentelemetry:4317")
metric_provider.add_metric_reader(PeriodicExportingMetricReader(otlp_metric_exporter))
metrics.set_meter_provider(metric_provider)
meter = metrics.get_meter(__name__)
# Create application metrics
request_counter = meter.create_counter(
name="http_requests_total",
description="Total HTTP requests",
unit="1"
)
@app.route('/api/users')
def users():
with tracer.start_as_current_span("get_users") as span:
span.set_attribute("endpoint", "api_users")
# Record metrics
request_counter.add(1, {"endpoint": "api_users", "status": "success"})
return jsonify({"users": ["user1", "user2", "user3"]})
Instrument a Java application
For Java applications using Spring Boot, add the following instrumentation:
@RestController
public class ApiController {
private final Counter httpRequestsTotal;
public ApiController(MeterRegistry meterRegistry) {
this.httpRequestsTotal = Counter.builder("http_requests_total")
.description("Total HTTP requests")
.register(meterRegistry);
}
@GetMapping("/api/users")
public Map<String, Object> getUsers() {
httpRequestsTotal.increment();
Map<String, Object> response = new HashMap<>();
response.put("users", Arrays.asList("user1", "user2", "user3"));
return response;
}
}
Build and deploy your instrumented applications to the EKS cluster with the appropriate annotations for Prometheus scraping.
Configure the Prometheus Adapter for custom metrics
The Prometheus Adapter exposes custom metrics from Prometheus to the Kubernetes custom metrics API, enabling the HPA to use application-specific metrics:
After implementing this solution, you can create custom dashboards in Amazon Managed Grafana to monitor the following:
Application performance metrics
Request rates and latencies
Resource utilization
Error rates
For dashboard examples and templates, refer to the Amazon Managed Grafana documentation. The following screenshots are examples of some of the dashboards you can build:
OpenTelemetry Prometheus Dashboard – This dashboard displays Python application performance with request rate by endpoints, response time percentiles (P50, P95, P99), CPU utilization trends, memory usage patterns, and error rates segmented by HTTP status codes.
Go OpenTelemetry Application Dashboard – This dashboard focuses on Go-specific metrics including HTTP request rate, active concurrent users, goroutine counts, CPU usage, and memory allocation patterns with garbage collection insights.
Java OTEL Sample App Monitoring – This dashboard shows JVM-specific metrics like heap memory utilization, alongside application-level metrics such as requests per second, garbage collection insights, and thread pool utilization.
The dashboards enable real-time application performance monitoring, infrastructure resource utilization tracking, error rate monitoring and alerting, and automatic scaling visualization and trends.
Best practices and recommendations
Choose Amazon EKS Auto Mode for the following use cases and features:
You’re building general-purpose applications that benefit from cost optimization and operational simplicity
You’re managing mixed workload types and want to use integrated AWS service features
Teams want to avoid the complexity of node management
Cost-efficiency and ease of operations are priorities for production workloads
Choose Amazon EKS with Fargate in the following scenarios:
Security isolation is paramount for your applications
You’re running batch or event-driven workloads that require strong container isolation
Your organization requires granular cost attribution at the pod level
Compliance mandates dictate complete container isolation from the underlying infrastructure
For your observability strategy, consider the following monitoring approach:
Use business metrics for HPA scaling decisions
Implement proper metric labeling for filtering and aggregation
Monitor both application and infrastructure metrics
Set up alerting based on Service Level Indicator (SLI) and Service Level Objective (SLO) definitions
Additionally, implement the following tracing approach:
Instrument critical code paths with OpenTelemetry
Use consistent trace context propagation
Monitor service dependencies through AWS X-Ray service maps
Implement proper error handling and trace sampling
Benefits of the solution
Instead of relying on basic CPU and memory metrics, this solution configures the Prometheus Adapter to expose custom metrics to the Kubernetes HPA. The HPA configuration shown in this post enables more intelligent scaling decisions based on actual application load, resulting in better resource efficiency and improved application performance. This approach allows your applications to scale based on business-relevant metrics such as request rate, queue length, or custom application metrics rather than generic infrastructure utilization. This solution offers reduced management overhead through the following features:
Fully managed – Amazon Managed Service for Prometheus eliminates infrastructure management
Automatic scaling – Built-in high availability and scaling
Integrated security – Native IAM integration
Cost-effective – Pay only for metrics ingested and stored
You also benefit from enhanced observability:
Three pillars – Complete metrics, traces, and logs coverage
Real-time monitoring – Custom metrics for intelligent automatic scaling
Correlation – Trace IDs link logs, metrics, and traces
Business metrics – Scale based on application behavior, not just infrastructure
Troubleshooting
If the ADOT Collector isn’t receiving data, troubleshoot as follows:
Verify the collector service is running: $ kubectl get pods -n opentelemetry
Check application configuration for correct endpoint URLs
Verify IAM roles have proper permissions for AWS services
If the custom metrics aren’t available in the HPA, check the following:
Confirm the Prometheus Adapter is deployed and running
Verify metrics are being scraped by Prometheus: $ kubectl port-forward svc/prometheus 9090:9090
Check the Prometheus Adapter configuration for correct metric queries
Deployment cost considerations
In this section, we provide an estimate of the cost that will incur with the preceding solutions:
Amazon Managed Service for Prometheus – $0.90 per million samples ingested + $0.03 per GB-month storage
AWS X-Ray – $5.00 per million traces recorded
Amazon CloudWatch Logs – $0.50 per GB ingested + $0.03 per GB-month storage
For a medium-scale application (5 microservices, 2 million samples/hour, 100,000 traces/day, 10 GB logs/day), the costs are as follows:|
Service
Cost
Amazon Managed Prometheus
~$80
AWS X-Ray
~$45
CloudWatch Logs
~$165
EKS Control Plane
~$73
Compute costs
~$200-400
Total
~$563-763/month
Costs are estimates based on US East (N. Virginia) pricing as of 2025 and might vary based on AWS Region, usage patterns, and AWS pricing changes. Consider the following cost optimization methods:
Sampling – Implement intelligent sampling for high-cardinality metrics
Retention – Set appropriate log retention (7–30 days for debug logs)
Monitoring – Use CloudWatch billing alarms to track spending
Regional – Deploy in single Region to minimize data transfer costs
Clean up
To avoid ongoing charges, delete the resources created in this walkthrough:
Remove IAM roles and policies created for this solution through the IAM console or AWS CLI.
Delete the AWS CDK stack:
cdk destroy ObservabilityStack
Conclusion
This solution demonstrates how organizations can achieve enterprise-grade Kubernetes deployments that balance flexibility, observability, and cost optimization. By combining Amazon EKS Auto Mode or Fargate with comprehensive AWS native observability services, teams can focus on application development while maintaining deep visibility into system performance. The real metrics-based automatic scaling approach represents a significant improvement over traditional resource-based scaling, enabling more intelligent infrastructure decisions that align with actual application behavior. Combined with the flexible compute options and modular architecture, this platform provides a robust foundation for modern containerized applications at scale. Key takeaways include:
Use AWS managed services – Reduce operational overhead with Amazon Managed Service for Prometheus and CloudWatch
Implement OpenTelemetry – Standardize observability across all applications
Custom metrics for HPA – Scale based on business metrics, not just CPU/memory
Structured logging – Enable better debugging and correlation
Security first – Implement proper IAM roles and network isolation
Organizations implementing this solution can expect reduced operational complexity, improved cost-efficiency, and enhanced visibility into their containerized applications, enabling faster development cycles and more reliable production deployments.
Amazon SageMaker Unified Studio is a single data and AI development environment where you can find and access your data and act on it using AWS resources for SQL analytics, data processing, model development, and generative AI application development.
SageMaker Unified Studio is part of the next generation of Amazon SageMaker. SageMaker brings together AWS artificial intelligence and machine learning (AI/ML) and analytics capabilities and delivers an integrated experience for analytics and AI with unified access to data.
With SageMaker Unified Studio, you can create domains and projects, providing a single interface to build, deploy, execute, and monitor end-to-end workflows. This approach helps drive collaboration across teams and facilitates agile development.
SageMaker Unified Studio implements resource tagging when AWS resources are provisioned. You can use these tags to track and allocate costs for the various resources created as part of the domains and projects within SageMaker Unified Studio.
This post demonstrates how to perform cost allocation using these resource tags, so finance analysts and business analysts can implement and follow Financial Operations (FinOps) best practices to control and track cloud infrastructure costs.
Solution overview
The following diagram illustrates how tagging works within SageMaker domains.
Before reviewing the implementation details, let’s explore several key SageMaker concepts: domain, project, project profile, and environment blueprint. For more information, refer to the SageMaker Unified Studio Administrator Guide.
Domain – A domain is an organizing entity created by an administrator. Administrators assign users to domains to enable collaboration using similar tools, assets, and resources. A domain can represent a business organization or a business unit containing people who collaborate and share resources. After creating a domain, administrators share the URL with users to access the portal.
Projects – Projects exist within each domain. A project provides a boundary where users can collaborate on a business use case. Users can create and share data, computing, and other resources within projects.
Project profile – When you create a project, you must select a project profile. A project profile is a template that governs infrastructure for the project, simplifying project creation with preconfigured settings and resources ready for use.
Environment blueprints – Environment blueprints are reusable templates for creating environments. They define settings for resource deployment and provide information for provisioning. Each blueprint uses an AWS CloudFormation template to create resources in a repeatable and scalable manner.
As of this writing, SageMaker domains support tagging at the blueprint, domain, project, and environment level. When you create projects or add resources within an existing project, the following tags are automatically added to resources through CloudFormation resource tags, configured for each blueprint stack:
AmazonDataZoneBlueprint – Type of blueprint corresponding to this blueprint’s CloudFormation template (for example, Tooling)
AmazonDataZoneDomain – Amazon DataZone domain associated with this CloudFormation template
AmazonDataZoneEnvironment – Amazon DataZone environment ID associated with this CloudFormation template
AmazonDataZoneProject – Amazon DataZone project associated with this CloudFormation template
To track costs in SageMaker Unified Studio, you will perform the following steps:
Create a SageMaker domain and project.
Configure cost and billing settings by enabling cost allocation tags.
(Optional) Generate costs for your project.
Track costs using Cost Explorer and Data Exports.
Prerequisites
This post requires the following configurations in your AWS account:
AWS IAM Identity Center enabled in your organization management account (preferred) or in the member account where you will use SageMaker Unified Studio. For instructions on enabling IAM Identity Center, refer to Enable IAM Identity Center.
Cost Explorer enabled in your organization management account (preferred) or in the member account where you will use SageMaker Unified Studio. For configuration steps, refer to Enabling Cost Explorer.
On the AWS Billing and Cost Management console, under Cost organization in the navigation pane, choose Cost allocation tags.
Select the following tags and choose Activate:
AmazonDataZoneDomain
AmazonDataZoneProject
AmazonDataZoneEnvironment
AmazonDataZoneBlueprint
The AmazonDataZoneProject and AmazonDataZoneDomain tags correspond to the project and domain ID values you recorded earlier.
Cost allocation tags configuration doesn’t apply retroactively. If you want to monitor costs associated with these tags in the AWS Billing and Cost Management tools before the activation date, you must request a cost allocation tag backfill. The backfill operation can take several hours to complete.
Generate costs for the project
This section explains how to generate costs associated with the underlying data backend (Amazon Redshift in this case) to examine them using AWS billing tools. You can skip this section if you’re tracking costs on an active project.
To generate costs, we use the table structure used in the Redshift Immersion Labs. Refer to Create Tables for more details.
To run queries in SageMaker Unified Studio, follow these steps:
Copy and execute the SQL statements provided in the following GitHub repo into the SageMaker Unified Studio query editor to create, load, and validate data on the tables.
After running these steps, you will have generated some Amazon Redshift costs that will be present for further analysis in AWS Billing and Cost Management tools. However, these tools (Cost Explorer and Data Exports) are refreshed least one time every 24 hours, so you might need to wait up to 24 hours before proceeding to the next section.
Tracking costs in AWS Billing and Cost Management tools
With the cost allocation tags enabled, you can use AWS Billing and Cost Management tools to analyze and track costs, including Cost Explorer and Data Exports. For more information about using these tools, refer to the AWS Billing and Cost Management User Guide.
Check costs in Cost Explorer
You can check your SageMaker Unified Studio costs using Cost Explorer. With this tool, you can view and analyze your costs and usage through an interface with pre-built filters and aggregation capabilities for various metrics. For more information, refer to the Analyzing your costs and usage with AWS Cost Explorer.
To access Cost Explorer, complete the following steps:
On the AWS Management Console, choose your account name in the top right corner and choose Billing Dashboard, or search for “Cost Explorer” in the console search bar.
On the Billing Dashboard, choose Cost Explorer in the navigation pane.
For first-time users, choose Launch Cost Explorer to enable the service.
AWS can take up to 24 hours to prepare your cost data.
To view overall costs per project, configure the following report parameters:
For Date Range, enter your range.
For Granularity, choose Monthly.
For Dimension, choose Tag.
For Tag, enter your tag (AmazonDataZoneProject).
The following screenshot shows a sample report.
To view different service costs for a specific project, update the following parameters:
For Dimension, choose Service.
For Tag¸ choose AmazonDataZoneProject and choose the value of the project you want to inspect (in this case, 4z9d694nbsnyqx).
The results should look similar to the following screenshot.
Check costs using Data Exports
With Data Exports, you can query your cost and usage in AWS with the maximum flexibility degree compared to other tools such as Cost Explorer. It provides a comprehensive set of measures and dimensions that you can include in the export to create a personalized report. This report is then delivered to Amazon Simple Storage Service (Amazon S3) so you can configure it with Athena, so it can be queried using SQL or business intelligence (BI) tools such as Amazon QuickSight.
Use the following query to check costs by project:
SELECT product_servicecode,
product_product_family,
resource_tags[ 'user_amazon_data_zone_project' ] as user_amazon_data_zone_project,
round(sum(line_item_unblended_cost), 2) costs,
line_item_line_item_description
FROM "data_exports"."data_exportdata"
where resource_tags [ 'user_amazon_data_zone_project' ] != ''
group by product_product_family,
product_servicecode,
resource_tags[ 'user_amazon_data_zone_project' ],
line_item_line_item_description
order by round(sum(line_item_unblended_cost), 2) DESC;
Results will look similar to the following screenshot on the Athena console.
The preceding query shows your costs grouped by:
Project (using tags)
Service
Product family, which corresponds to the subtype for a given product usage charge (for example, ML Instance for SageMaker, or Managed Storage for Amazon Redshift)
Check costs for individual projects
To check costs for a specific SageMaker Unified Studio project (for example, the sample project 4z9d694nbsnyqx created during this walkthrough), you can use the following query:
SELECT product_servicecode,
product_product_family,
resource_tags[ 'user_amazon_data_zone_project' ] as user_amazon_data_zone_project,
round(sum(line_item_unblended_cost), 2) costs,
line_item_line_item_description
FROM "data_exports"."data_exportdata"
where resource_tags [ 'user_amazon_data_zone_project' ] != ''
and resource_tags [ 'user_amazon_data_zone_project' ] = <provide the project id here>
group by product_product_family,
product_servicecode,
resource_tags[ 'user_amazon_data_zone_project' ],
line_item_line_item_description
order by round(sum(line_item_unblended_cost), 2) DESC;
Monitor costs with Data Exports and QuickSight
If you enabled Athena to work with Data Exports, you can also configure QuickSight to query this data source. With QuickSight, you can create interactive dashboards to track SageMaker costs in SageMaker Unified Studio at scale.
Configure access and permissions
To create CUR dashboards in QuickSight, first complete the following steps:
Enable access to Athena and your CUR S3 bucket in the Security & permissions section of the QuickSight administration console. You need QuickSight administrator permissions to access this console.
The next step is to create a dataset in QuickSight using a SQL query. For instructions on creating a dataset with SQL, refer to Using SQL to customize data. Use the following SQL expression:
SELECT product_servicecode,
product_product_family,
resource_tags[ 'user_amazon_data_zone_environment' ] as user_amazon_data_zone_environment,
resource_tags[ 'user_amazon_data_zone_project' ] as user_amazon_data_zone_project,
resource_tags[ 'user_amazon_data_zone_domain' ] as user_amazon_data_zone_domain,
line_item_unblended_cost,
line_item_usage_start_date,
line_item_line_item_description
FROM "data_exports"."data_exportdata"
where resource_tags [ 'user_amazon_data_zone_environment' ] != '' or resource_tags [ 'user_amazon_data_zone_project' ] != ''
The preceding query includes only cost and usage data that’s tagged with either user_amazon_data_zone_environment or user_amazon_data_zone_project to focus on SageMaker associated costs. To include other AWS costs, you must modify these filters.
Create QuickSight dashboards
Using the authoring capabilities of QuickSight, you can create interactive dashboards where business stakeholders can explore and track costs associated with SageMaker Unified Studio projects. You can use these dashboards to review relevant cost metrics at a glance that are derived from the Data Exports dimensions and metrics included in your dataset, as shown in the following screenshot. For more information about adding visuals to analyses, refer to Adding visuals to Amazon QuickSight analyses.
The preceding example shows a dashboard built using QuickSight connected to a Data Exports dataset. The dashboard contains the following visuals:
KPI visual showing the current monthly costs for SageMaker Unified Studio along with the month over month (MoM) variation and history
Autonarrative visual analyzing SageMaker Unified Studio costs (highest) by month
Using this approach (QuickSight and Data Exports), you can create highly customizable dashboards to explore and monitor your SageMaker Unified Studio costs. Furthermore, you can create automated reports using the QuickSight reporting feature to send these by email to the relevant stakeholders.
Clean up
Delete the resources you created as part of this post when you’re done with them to avoid monthly charges. This includes SageMaker resources, created Data Export reports and the QuickSight subscription (in case it was created to visualize costs).
Delete SageMaker resources
Log in to the SageMaker domain using an admin role.
Delete the project you created.
Delete the SageMaker domain.
Delete Data Exports reports
On the AWS Billing console, in the navigation pane, choose Cost & Usage Reports.
Select the report you want to delete.
Choose Delete.
Confirm the deletion by choosing Delete report.
For more information about managing Data Exports, refer to Deleting exports.
Unsubscribe from QuickSight
On the QuickSight console, choose your profile name in the top right corner.
Choose Manage QuickSight.
Choose Account settings.
At the bottom of the page, choose Delete your QuickSight account.
Review the information about data deletion.
Enter delete to confirm.
Choose Delete.
IMPORTANT NOTE: Before unsubscribing, make sure you backed up any dashboards or analyses you want to keep. After deletion, you can’t recover your QuickSight assets. For more information about managing your QuickSight subscription, refer to Deleting your Amazon QuickSight subscription and closing the account.
Conclusion
Managing costs on a unified platform like SageMaker can seem challenging because it aggregates many tools and services with different cost models. In this post, we showed how to use AWS Billing and Cost Management tools to aggregate and categorize costs across the various services used within SageMaker. With this approach, you can monitor and track respective service costs, either in aggregate or focusing on a particular project.
Start taking control of your analytics and ML costs today. With AWS Billing and Cost Management tools with SageMaker, you can:
Track and monitor your service costs
Break down expenses by project or service
Implement efficient back charging mechanisms to the different business units or organizations using SageMaker within your organization
Enrique Salgado Hernández is a Senior Specialist Solutions Architect at AWS with more than 10 years of experience working in the cloud. He specializes in designing and implementing large-scale analytics architectures across various industry sectors. He is passionate about working with customers to solve their problems by supporting them during their cloud journey.
Angel Conde Manjon is a Senior EMEA Data & AI PSA, based in Madrid. He previously worked on research related to data analytics and AI in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.
Stifel Financial Corp. is an American multinational independent investment bank and financial services company, founded in 1890 and headquartered in downtown St. Louis, Missouri. Stifel offers securities-related financial services in the United States and Europe through several wholly owned subsidiaries. Stifel provides both equity and fixed income research and is the largest provider of US equity research.
In this post, we show you how Stifel implemented a modern data platform using AWS services and open data standards, building an event-driven architecture for domain data products while centralizing the metadata to facilitate discovery and sharing of data products.
Stifel’s modern data platform use case
Stifel envisioned a data platform that delivers accurate, timely, and properly governed data, providing consistency throughout the organization whenever users access the information. This approach showed limitations as the data complexity increased, data volumes grew, and demand for quick, business-driven insights rose. These challenges are encountered by financial institutions worldwide, leading to a reassessment of traditional data management practices. Under the federated governance model, Stifel developed a modern data strategy based on the following objectives:
Managing ingestion and metadata
Creating source-aligned data products complying with Stifel business streams
Integrating source-aligned data products from other domains (Stifel business units)
Producing consumer-aligned data products for specific business purposes
Publishing data products to a centralized data catalog
Some of the Stifel challenges highlighted in the preceding list required building a data platform that can:
Boost agility by democratizing data, thus reducing time to market and enhancing the customer experience
Improve data quality and trust in the data
Standardize tools and eliminate the shadow information technology (IT) culture to increase scalability, reduce risk, and minimize operational inefficiencies
Following the federated governance model, Stifel has organized its domain structure to provide autonomy to various functional teams while preserving the core values of data mesh. The following diagram depicts a high-level architecture of the data mesh implementation at Stifel.
Each data domain has the flexibility to create data products that can be published to the centralized catalog, while maintaining the autonomy for teams to develop data products that are exclusively accessible to teams within the domain. These products aren’t available to others until they are deemed ready for broader enterprise use. Domains have the freedom to decide which data they want to share. They can either:
Make their data products visible to everyone through the central catalog
Keep their data products visible only within their own domain
By implementing an event-driven domain architecture, organizations can achieve significant business advantages while positioning themselves for future growth and innovation. Stifel data products refreshes were dependent on data assets with variable cadence. Event-driven architecture enables real-time or near real-time updates by allowing data products to automatically respond to changes in underlying data assets as they occur, rather than relying on fixed batch schedules that might miss critical updates or waste resources on unnecessary refreshes. The key is to carefully plan the implementation and make sure of alignment with business objectives while considering both technical and organizational factors. This architecture style particularly suits organizations that:
Need real-time processing capabilities
Have complex domain interactions
Require high scalability
Want to improve business agility
Need better system integration
Are pursuing digital transformation
The following are some of the key AWS Services that helped Stifel to build their modern data platform.
AWS Glue is a serverless data integration service that’s used for data processing to build data assets and data products in the domains. Data is also cataloged in AWS Glue Catalog, making it straightforward to discover and query with supported engines.
Amazon EventBridge provides a scalable and flexible serverless event bus that facilitates seamless communication between different domains and services. By using EventBridge, Stifel was able to implement a publish-subscribe model where domain events can be emitted, filtered, and routed to appropriate consumers based on configurable rules. EventBridge supports custom event buses for domain-specific events, enabling clear separation of concerns and improved manageability.
AWS Lake Formation helped in providing centralized security, governance, and catalog capabilities while preserving domain autonomy in data product creation and management. With Lake Formation, data domains were able to maintain their independent data products within a federated structure while enforcing consistent access controls, data quality standards, and metadata management across the organization.
The following diagram illustrates the data mesh architecture that Stifel uses to build a domain-driven architecture. In this system, various domains create data products and share them with other domains through a central governance account that uses Lake Formation.
Let’s look at some of the key design components that are being used to enable and implement data mesh and event driven design
Data ingestion framework
The data ingestion framework consists of several processor modules that are built using several AWS services and metadata driven architecture. The following diagram shows the architecture of the raw data ingestion framework.
The framework gets raw data files from both internal Stifel systems and third-party data sources. These files are processed and stored in a raw data ingestion account on Amazon S3 in open table format Apache Hudi. This stored data is then shared with different parts of the organization, called data domains. Each domain can use this shared data to create their own data products.
As a file (in CSV, XML, JSON and custom formats) lands into the landing bucket, an Amazon S3 event notification is created and placed in an Amazon Simple Queue Service (Amazon SQS)queue. The Amazon SQS queue triggers an AWS Lambda function and saves the metadata (such as the name of the file, date and time the file was received, and the file size) to a file audit data store (Amazon Aurora PostgreSQL-Compatible Edition).
An EventBridge time scheduler invokes an AWS Step Functions workflow at pre-determined intervals. The Step Functions workflow orchestrates the batch ingestion from raw to staging layer.
The Step Functions workflow orchestrates a set of Lambda functions to get the list of unprocessed raw files from the audit data store and create batches of raw files to process them in parallel. The Step Functions workflow then triggers parallel AWS Glue jobs that process each batch of raw files.
Each raw file is validated for any data quality checks and the data is saved to staging tables in Hudi format. Any errors encountered are logged into an audit table and a notification is generated for support team. For all successfully processed raw files, the file status is updated to PROCESSED and logged into an audit table.
After the Hudi table is updated, a data refresh event is sent to EventBridge and then passed to the Central Mesh Account. The Central Mesh Account forwards these events to the data domains to notify them that the raw tables are refreshed, allowing the data domains to use this data for creating their own data products.
Event driven data product refresh
The Stifel data lake is based on a data mesh architecture where several data producers share data across data domains. A mechanism is needed to alert consumers who depend on other data producers’ data products when those source data products are refreshed, so that the consumers can update their own data products accordingly. The following diagram describes the technical architecture of event-based data processing. The central governance account acts as the central event bus, which receives all data refresh events from all data producers. The central event bus forwards the events to consumer accounts. The consumer accounts filter the events consumers are interested in from data producers for their data processing needs.
Orchestration design
Stifel designed and implemented an event-based data pipeline orchestration system that triggers data pipelines when specific events occur. This system processes data immediately after receiving all required dependency events, enabling efficient workflow management.
The following diagram describes the logical architecture of the domain data pipeline orchestration framework.
The orchestration framework includes the components described in the following list. The data dependencies and data pipeline state management metadata are hosted in an Aurora PostgreSQL database.
Data refresh processor: Receives data refresh events from central mesh and local data domain and evaluates if the domain data products data dependencies are met
Data product dependency processor: Retrieves metadata for the product, kicks off a corresponding data domain AWS Glue job, and updates metadata with the job information
Data pipeline state change processor: Monitors the domain data jobs and takes actions based on the job’s final status (SUCCEED or FAILED) and then creates incident tickets for failed jobs
Conclusion
Stifel has improved its data management and reduced data silos by adopting a data product approach. This strategy has positioned Stifel to become a data-driven, customer-centric organization. The company combines federated platform practices with AWS and open standards. As a result, Stifel is achieving its decentralization objectives through a scalable data platform. This platform empowers domain teams to make informed decisions, drive innovation, and maintain a competitive edge. Here are the some of the advantages Stifel got from an event-driven domain architecture (EDDA):
Business agility: Rapid market response, new business capability integration, scalable domains, quicker feature deployment, and flexible process modification
Customer experience: Real-time processing, responsive interactions, personalized services, consistent omnichannel presence, and enhanced service availability
Operational efficiency: Reduced system coupling, optimal resource use, scalable systems, lower maintenance overhead, and efficient data processing
Cost benefits: Lower development costs, reduced infrastructure expenses, decreased maintenance costs, efficient resource usage, and a better ROI on technology investments
In this post, we demonstrated how Stifel is building a modern data platform by recognizing the critical importance of data in today’s financial landscape. This strategic approach not only enhances operational efficiency but also positions Stifel at the forefront of technological innovation in the financial services industry. To learn more and get started, see the following resources:
Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing.
Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance.
Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines.
Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.
Amazon OpenSearch Service is a managed service that you can use to secure, deploy, and operate OpenSearch clusters at scale in the AWS Cloud. With OpenSearch Service, you can configure clusters with different types of node options such as data nodes, dedicated cluster manager nodes, dedicated coordinator nodes, and UltraWarm nodes. When configuring your OpenSearch Service domain, you can exercise different node options to manage your cluster’s overall stability, performance, and resiliency.
In this post, we show how to enhance the stability of your OpenSearch Service domain with dedicated cluster manager nodes and how using these in deployment enhances your cluster’s stability and reliability.
The benefit of dedicated cluster manager nodes
A dedicated cluster manager node handles the behind-the-scenes work of running an OpenSearch Service cluster, but it doesn’t store actual data or process search requests. In the absence of dedicated cluster manager nodes, OpenSearch Service will use data nodes for cluster management; combining these responsibilities on the data nodes can impact performance and stability because data operations (like indexing and searching) compete with critical cluster management tasks for computing resources. The dedicated cluster manager node is responsible for several key tasks: monitoring and keeping track of all the data nodes in the cluster, knowing how many indexes and shards there are and where they’re located, and routing data to the correct places. They also update and share the cluster state whenever something changes, like creating an index or adding and removing nodes. The problem, however, is that when traffic gets heavy, the cluster manager node can get overloaded and become unresponsive. If this happens, your cluster will not respond to write requests until it elects a new cluster manager, at which point the cycle might repeat itself. You can alleviate this issue by deploying dedicated cluster manager instances, whereby this separation of duties between the manager node and the data nodes results in a much more stable cluster.
Calculating the number of dedicated cluster manager nodes
In OpenSearch Service, a single node is elected as the cluster manager from all eligible nodes through a quorum-based voting process, confirming consensus before taking on the responsibility of coordinating cluster-wide operations and maintaining the cluster’s state. Quorum is the minimum number of nodes that need to agree before the cluster makes important decisions. It helps keep your data consistent and your cluster running smoothly. When you use dedicated cluster manager nodes, only those nodes are eligible for election and OpenSearch Service sets the quorum to half of the nodes, rounded down to the nearest whole number, plus one. One dedicated cluster manager node is explicitly prohibited by OpenSearch Service because you have no backup in the event of a failure. Using three dedicated cluster manager nodes makes sure that even if one node fails, the remaining two can still reach a quorum and maintain cluster operations. We recommend three dedicated cluster manager nodes for production use cases. Multi-AZ with standby is an OpenSearch Service feature designed to deliver four 9s of availability using a third AWS Availability Zone as a standby. When you use Multi-AZ with standby, the service requires three dedicated cluster manager nodes. If you deploy with Multi-AZ without standby or Single-AZ, we still recommend three dedicated cluster manager nodes. It provides two backup nodes in the event of one cluster manager node failure and the necessary quorum (two) to elect a new manager. You can choose three or five dedicated cluster manager nodes.
Having five dedicated cluster manager nodes works as well as three, and you can lose two nodes while maintaining a quorum. But because only one dedicated cluster manager node is active at any given time, this configuration means you pay for four idle nodes.
Cluster manager node configurations for different domain creation methods
This section explains the resources each domain creation method and template deploy when you set up an OpenSearch Service domain.
With the Easy create option, you can quickly create a domain using ‘multi-AZ with standby’ for high availability three-cluster manager nodes distributed across three Availability Zones. The following table summarizes the configuration.
Domain Creation Method
Output
Easy Create
Dedicated cluster manager node: Yes
Number of cluster manager nodes: 3
Availability Zones: 3
Standby: Yes
The Standard create option provides templates for ‘Production’ and ‘Dev/test’workloads. Both templates come with a Domain with standby and a Domain without standby deployment choice. The following table summarizes these configuration options.
Domain Creation Method
Template
Deployment Option
Output
Standard Create
Production
Domain with standby
Requires dedicated cluster manager node
Number of cluster manager nodes: 3
Availability Zones: 3
Standby: Yes
Instance type choice: Yes
Standard create
Production
Domain without standby
Requires dedicated cluster manager node
Number of cluster manager nodes: 3, 5
Availability Zones: 3
Standby: No
Instance type choice: Yes
Standard Create
Dev/test
Domain with standby
Requires dedicated cluster manager node
Number of cluster manager nodes: 3
Availability Zones: 3
Standby: Yes
Instance type choice: Yes
Standard create
Dev/test
Domain without standby
Does not require dedicated cluster manager node
Choosing a dedicated cluster manager instance type
Dedicated cluster manager instances typically handle critical cluster operations like shard distribution and index management and track cluster state changes. It’s recommended to select a comparatively smaller instance type. Refer to Choosing instance types for dedicated master nodes for more information on instance types for dedicated cluster manager nodes.
You should expect to occasionally adjust cluster manager instance size and type as your workload evolves over time. As with all scale questions, you need to monitor performance and make sure you have enough CPU and Java virtual machine (JVM) heap for your dedicated cluster managers. We recommend using Amazon CloudWatch alarms to monitor the following CloudWatch metrics, and adjust according to the alarm state:
ManagerCPUUtilization – Maximum is greater than or equal to 50% for 15 minutes, three consecutive times
ManagerJVMMemoryPressure – Maximum is greater than or equal to 95% for 1 minute, three consecutive times
Conclusion
Dedicated cluster manager nodes provide added stability and protection against split-brain situations, can be of a different instance type than data nodes, and are an obvious benefit when OpenSearch Service is backing mission-critical applications for production workloads. They are typically not required for development workloads like proof of concept because the cost of running a dedicated cluster manager node exceeds the tangible benefits of keeping the cluster up and running. To learn more about OpenSearch best practices, see link.
About the authors
Imtiaz (Taz) Sayed is the WW Tech Leader for Analytics at AWS. He enjoys engaging with the community on all things data and analytics. He can be reached through LinkedIn.
Chinmayi Narasimhadevara is a Senior Solutions Architect focused on Data Analytics and AI at AWS. She helps customers build advanced, highly scalable, and performant solutions.
Amazon Web Services (AWS) customers can enable secure remote access to their cloud resources, supporting business operations with both speed and agility. As organizations embrace flexible work environments, employees can safely connect to AWS resources from various locations using different devices. AWS provides comprehensive security solutions that help organizations maintain strong protection of corporate resources, manage appropriate access controls, and meet compliance requirements while enabling productive remote work environments.
Because there are different types of workloads—from Amazon Elastic Compute Cloud (Amazon EC2) instances to web applications—running in the AWS Cloud, there are correspondingly multiple remote access use cases for using or operating these workloads. For example, access to an EC2 instance and its operating system to perform operations such as troubleshooting, log analysis, and data retrieval. Other use cases require access to web applications such as Jenkins, Salesforce, or the Kubernetes UI deployed on AWS.
To support these use cases, AWS provides multiple services and features that help you address access patterns using different approaches. One of the key challenges that you might face when implementing remote access solutions is understanding the tradeoffs of the different approaches and solutions. This post is designed to help you decide which remote access approach is best for your use-case.
Use cases
In this post, we address the following use cases:
User access to internal web applications deployed in a virtual private cloud (VPC).
User access to SAML 2.0 and OAuth 2.0 applications.
Challenges associated with remote access
Cost: The cost of a remote access solution is a key factor for businesses.
Increased exposure surface: Securing a VPC with several EC2 instances, S3 buckets, and a database is a different task than securing the identities, devices, and communications channels used for remote access to the infrastructure.
Increased risk: Susceptibility to social engineering threats. Humans accessing workloads are the weakest link in any security program, introducing risks to data and infrastructure that otherwise wouldn’t have existed.
User experience (UX): The UX is a key factor in remote access. Lacking a well-designed UX can introduce risks by making it difficult to conduct day-to-day operations or respond quickly to incidents that affect users at scale.
A solution to mitigate the risks associated with remote access is to not provide it at certain levels, and you might sometimes choose this approach. In these cases, access to workloads that must be secure is only possible from trusted locations (such as company offices) and managed devices (such as company-issued laptops). For the remainder of this post, we talk about approaches and solutions available for you when you need to provide remote access from various locations and devices.
The different approaches
Before diving deeper into the services and features, let’s explore the different approaches for providing remote access to your users (shown in Figure 1). The main differentiator among them is where the trust boundary lies.
Figure 1: The different approaches along with the corresponding solutions
Network-based approach: Users are given access to your network through VPCs and are granted broad access to the actual target resource, web application, or EC2 instances. The trust boundary in this case is the VPC.
Host-based approach: Users have access to the host running the application. This is commonly used for operator access. The trust boundary is the host.
Application-based approach: Users access the application using their corporate credentials. This is commonly the case for software as a service (SaaS) applications. The trust boundary is the application.
End-user computing approach: End-user computing (EUC) is a combination of technologies, policies, and processes that gives users secure, remote access to applications, desktops, and data that they need to get their work done. Desktops are operated centrally in the cloud and interacted with using streamed pixels to users’ devices. This approach shifts the trust boundary from the user device to desktops and data residing in the cloud.
These approaches aren’t mutually exclusive and occasionally overlap or can be combined in a zero trust model. Zero trust is centered on the idea that access to resources shouldn’t be based solely on the network location but on authentication and authorization of each request using multiple factors; including the user identity, device, and location, among others.
The trust boundary primarily depends on the criticality of the target resource, the risk tolerance of the organization, and the complexity of the implementation. Wider trust boundaries (such as in a network-based approach) increase the exposed surface area—because the whole network is exposed to trusted users and access to the network grants access to all the resources inside it—but are the simplest to implement. Tighter trust boundaries (such as a zero trust model) considerably reduce the exposed surface area but require implementing multiple factors that feed into the authorization context.
For example, organizations might provide network-based access from trusted devices to operators for a VPC with web-servers and databases, but only allow end-user computing based access for contractors or third-party users using non-corporate devices, also known as bring your own device (BYOD).
When selecting your remote access solution, you need to consider the desired trust boundary, authentication, authorization, user experience, access visibility and cost, which we explore in the following sections.
Network-based approach
The network-based approach is popular when users need access to multiple resources residing in specific networks in a straightforward manner, while keeping the networks disconnected from the public internet. When providing access at the network level, managing security configurations such as authorization, authentication, and auditing happens at the resource (application or machine) and client device, introducing challenges at scale.
AWS Client VPN is a fully managed service that you can use to securely connect users to VPCs from virtually any location using OpenVPN-based clients. Users can authenticate using your organization’s identity provider (IdP) in combination with certificate-based authentication. The service supports authorization rules that act as firewall rules to grant users access to specific CIDR blocks based on membership in an Active Directory group or a group defined in a SAML-based IdP. Additionally, you can use client connect handlers to run custom authorization logic based on device, user, and connection attributes.
After the required infrastructure is set up, users can connect to the target VPC and access EC2 instances or web applications at the network level inside their authorization scope. The UX is as straightforward as connecting using client software installed on the user’s device and authenticating using corporate authentication policies. A client VPN provides visibility into users’ connections to the VPN through connection logs, which are streamed to an Amazon CloudWatch log group. Connection logging provides visibility into each user’s initial VPN connection; getting visibility into what happened during the connection requires gathering the data from the target resource, network, or the user’s device.
After the user is authenticated and authorized, their device gains network access to the relevant VPC—and potentially other VPCs that are peered—or is connected through AWS Transit Gateway to that VPC. This can potentially provide network access to resources and networks outside the scope of the user.
A client VPN-based solution should be implemented when the network is the intended trust boundary around resources (for example, at the subnet or security group level) and group-level access control is sufficient. See Get started with AWS Client VPN.
Host-based approach
Providing access to hosts isn’t always necessary. One way to mitigate risks related to unauthorized host access is to not allow it and rely on fully automated operations instead. In practice, operators and developers still require access to hosts for visibility, tuning the operating system settings, applying patches, or manually restarting a service.
These two features mainly differ in the way they operate. Session Manager requires an agent, which is installed by default on several Amazon Machine Images (AMIs). The agent establishes an outbound connection—through the internet or a VPC endpoint—to the service endpoints, so you don’t have to modify the host’s inbound security group rules. It allows SSH connections tunneled over a proxy connection and provides in-session logging providing visibility into users’ commands within a session.
EC2 Instance Connect doesn’t require that you install an agent; it allows a secure native SSH connection, using short-lived SSH keys. As such, it requires that inbound connections from the EC2 Instance Connect service on port 22 be allowed on the host’s security group.
Most customers use Session Manager unless they don’t want to have an agent installed on the virtual machine or require a native SSH experience.
End-user computing approach
End-user computing services like the Amazon WorkSpaces Family or Amazon AppStream 2.0 stream desktops and applications as encrypted pixels to remote users while keeping data safely within your Amazon Virtual Private Cloud (Amazon VPC) and connected private networks. Unauthorized access to the client device is exposed only to encrypted pixels, which essentially moves the trust boundary from the device accessing the resources to the virtual desktop running in the cloud.
These services are particularly popular among customers who want to minimize the user’s device as the trust boundary. This can improve operational efficiency, especially when dealing with untrusted devices or highly sensitive data, because you significantly narrow the scope of what needs to be protected. This can also reduce the use (and costs) of expensive hardware.
The idea is that a user first authenticates using credentials provided by the corporate Active Directory or a SAML federation to the corporate identity provider. After the user is authenticated and authorized, an encrypted streaming session begins and the client is remotely operating a desktop or application that’s deployed in an Amazon VPC, with an elastic network interface (ENI) deployed to the customer’s managed VPC.
When adopting end-user computing for remote access, you can choose the UX and the cost structure that best fit your use case (for example, persistent access to a desktop or on-demand access to specific applications). You can also select different compute and storage options depending on the desired performance.
AWS End User Computing provides different machine types to accommodate different UX requirements and with different pricing models depending on the consumption model being used.
IAM Identity Center is primarily known for simplifying user access to AWS accounts within an organization at scale. It also provides single sign-on (SSO) access to supported web applications, giving users seamless access to these applications after they sign in using their directory credentials. Identity Center supports two application types:
If you use customer managed applications that support SAML 2.0 and OAuth 2.0, you can federate your IdP to IAM Identity Center through SAML 2.0 and use Identity Center to manage user access to those applications.
For organizations operating AWS environments at scale with multiple accounts, using IAM Identity Center is the recommended service to provide access to web applications and is provided at no additional cost.
Combining multiple approaches in a zero trust model
The zero trust model combines multiple factors including the user identity, device, location, and others, to evaluate and grant access requests. One way that you can implement this model to provide remote access to workloads deployed in a VPC is to use AWS Verified Access. With Verified Access, you can provide secure access to corporate applications without a client VPN and support TCP-based connections to a VPC, be it to web applications or EC2 or RDS instances. Authentication can be done using an existing IdP or AWS IAM Identity Center and a device management service that can provide additional information to improve authorization decisions based on context from the device. Those authorization decisions are expressed as Cedar policies that you author based on your access requirements. The service provides extensive logging for each web request, so you can investigate anomalies and view information about the access that was granted. For more information, see Get Started with Amazon Verified Access.
Understanding the tradeoffs
To select the right solution for your workforce, work backwards from the use case. Start by identifying and classifying the asset inventory and mapping the users accessing it and their access patterns.
Things to consider based on the classification:
Visibility: Determine the level of visibility into remote access activities and the type of information that you’ll need to detect and recover from a security event or to comply with regulatory and compliance requirements.
Authentication and authorization: Determine if your existing IAM mechanisms are sufficient. You might need to identify a temporary access management system or include information coming from user devices to address risks of compromised employees.
Network access: Know your users and what type of network access, if any, they need. When considering network access, include the potential risks of overly permissive access.
Cost: To determine costs, you need to know how many users and resources will be supported by remote access. Also, how many connections you expect and for how much time. Use that information to help determine the total cost of ownership of your solution.
Endpoint security: For each resource, understand risks associated with providing access to it from a user’s device. Know what mechanisms you have (or can implement) to detect threats and unauthorized access or provide additional context for the authorization decision granting access to a resource.
User experience: Compare the cost of a streamed user experience to one that’s locally installed to see if any additional cost is balanced by the improved security of the streamed UX.
The following provides an overview of the different solutions and the factors that can help you make an informed decision.
Solution
Use cases
Trust Boundary
Provides access to
Protocol
User experience
Authentication
Authorization
Visibility
Cost
Client VPN
User access to internal applications
Operator access to IP resources in VPC
Network
VPCs, subnets, security groups
IP
Client based,native
Single sign-on (SAML-based)
Active Directory
Mutual (certificate based)
Per CIDR (Authorization rules)
Lambda Authorizer for custom code
Connection logging (CloudWatch)
Connection time and endpoint association
AWS Session Manager
Operator access to EC2 or on-premises instances
Host
EC2 Instances: Linux, Windows, or MacOS (EC2 only)
SSH or RDP
Native
IAM
IAM
CloudTrail, or in-session logging using CloudWatch and Amazon S3)
No additional cost for accessing EC2 instances
EC2 Instance Connect Endpoint
Operator access to EC2 instances
Host
EC2 Instances: Linux or Windows
SSH or RDP
Native
IAM
IAM
CloudTrail
No additional cost
IAM Identity Center
User access to SAML 2.0 and OAuth 2.0 applications
Application
Web applications
HTTP(S)
Native
IAM Identity Center
IAM Identity Center
CloudTrail
No additional cost
Amazon Verified Access
User accesses web or TCP-based applications deployed in a VPC
Amazon Verified Access
Web applications
TCP resources
HTTP(S) or TCP
Native
IAM Identity Center or OIDC
Custom using Cedar policies
Allows device signals
Per request logging
Per application or bandwidth
Amazon Workspaces
User accesses a virtual persistent desktop in a VPC
Cloud desktop
Persistent virtual desktop
WSP or PCoIP
Client based, or non-native
Identity provider
Group membership
CloudTrail
Per instance
Amazon AppStream 2.0
User accesses a virtual desktop in a VPC
Cloud desktop
Non persistent virtual desktops and applications
NICE DCV
Client based or non-native
Identity provider
Group membership
CloudTrail
Per instance
Conclusion
In this post, you learned about different approaches and solutions for providing remote access for your organization’s workforce. This included tactical recommendations on how to find the remote access solution that suits your needs best based on factors such as costs, user experience, and risk. By understanding those tradeoffs, you can now map out the different use-cases based on your infrastructure and threat model and build a remote access strategy to meet your needs. As you experiment and adopt the different tools, careful planning is required when designing and deploying the services. For example, which account to deploy the service to or how to provision access to the services. Use resources such as the AWS Security Reference Architecture (AWS SRA) and the individual service documentation pages to help guide your journey.
If you have feedback about this post, submit comments in the Comments section below.
As organizations build modern applications with event-driven architectures (EDA), they often seek solutions that minimize infrastructure management overhead while maximizing developer productivity. Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS Lambda together provide a serverless, scalable, and cost-efficient platform for real-time event-driven processing.
In this post, we describe how you can simplify your event-driven application architecture using AWS Lambda with Amazon MSK. We demonstrate how to configure Lambda as a consumer for Kafka topics, including a cross-account setup and how to optimize price and performance for these applications.
Why use Lambda with Amazon MSK?
Customers building event-driven applications have several key priorities when it comes to their architecture choices. They typically seek to reduce their operational overhead by using Amazon Web Services (AWS) to handle the complex, underlying infrastructure components so their teams can focus on core business logic. Additionally, developers prefer a streamlined experience that minimizes the need for repetitive boilerplate code, enabling them to be more productive and focus on creating value. Furthermore, these customers want to achieve both scalability and cost-effectiveness without the burden of managing compute infrastructure directly. Lambda integration with Amazon MSK effectively addresses these requirements, delivering a comprehensive solution that combines the benefits of serverless computing with managed Kafka services. For example, an ecommerce company can use Amazon MSK to collect real-time clickstream data from its website and process those events using AWS Lambda. With this integration, they can trigger Lambda functions to update recommendation models, send personalized offers, or analyze user behavior instantly—without provisioning or managing servers. The key benefits of using Lambda with Amazon MSK include:
Simplicity through native integration – AWS Lambda offers native integration with Amazon MSK through a connector resource called event source mapping. You can use this integration to directly associate a Kafka topic—whether it’s on Amazon MSK or a self-managed Kafka cluster—as an event source for a Lambda function without writing custom consumer logic. With just a few configuration steps, event source mapping handles partition assignment, offset tracking, and parallelized batch processing under the hood. It uses the Kafka consumer group protocol to distribute topic partitions across multiple concurrent Lambda invocations, supports batch windowing, and enables at-least-once delivery semantics. Moreover, it automatically commits offsets upon successful function execution while handling retries and dead-letter queue (DLQ) routing for failed records, significantly reducing the operational overhead traditionally associated with Kafka consumers.
Auto scaling and throughput controls – When using AWS Lambda with Amazon MSK through event source mapping, Lambda automatically scales by assigning a dedicated event poller per Kafka partition, enabling parallel, partition-based processing. This allows the system to elastically handle varying traffic without manual intervention. For advanced control, provisioned concurrency pre-initializes Lambda execution environments, eliminating cold starts and delivering consistent low-latency performance. Additionally, with provisioned event source mapping, you can configure the minimum and maximum number of Kafka pollers, providing precise control over throughput and concurrency. This is ideal for applications with unpredictable traffic patterns or strict latency requirements.
Cost-effectiveness – AWS Lambda uses a pay-per-use model in which you only pay for compute time and number of invocations. When integrated with Amazon MSK, there are no charges for idle time, making it ideal for bursty or low-frequency Kafka workloads. You can further optimize costs by tuning batch size and batch window settings. For mission-critical workloads, provisioned concurrency provides consistent performance with controlled pricing.
Event filtering – AWS Lambda supports event filtering for Amazon MSK event sources, which means you can process only the Kafka records that match specific criteria. This reduces unnecessary function invocations and optimizes your function costs. You can define up to five filters per event source mapping (with the option to request an increase to ten). Each filter uses a JSON-based pattern to specify the conditions a record must meet to be processed. Filters can be applied using the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS Serverless Application Model (AWS SAM) templates. For more details and examples, refer to the AWS Lambda documentation on event filtering with Amazon MSK.
Handling Availability Zone outage for your consumer – Amazon MSK enables high availability for your Kafka brokers by distributing them across multiple Availability Zones within a Region. To maintain high availability across your application, you similarly need a consumer that offers high availability. AWS Lambda offers high availability and resilience by running your consumer functions across multiple Availability Zones in a Region. This means that even if one Availability Zone experiences an outage, your Lambda function will continue to operate in other healthy Availability Zones. While Lambda manages security patching and Availability Zone failure scenarios, you can focus on your application logic.
Cross-account event processing – Cross-account connectivity between AWS Lambda and Amazon MSK allows a Lambda function in one AWS account to consume data from an MSK cluster in another account using MSK multi-VPC private connectivity powered by AWS PrivateLink. This setup is particularly beneficial for organizations that centralize Kafka infrastructure while maintaining separate accounts for different applications or teams.
Support for JSON, Avro, Protobuf, and Schema Registries – AWS Lambda supports Kafka events in JSON, Avro and Protobuf formats via event source mapping. It integrates with AWS Glue Schema registry, Confluent Cloud Schema registry, and self-managed Confluent Schema registry , enabling native schema validation, filtering, and deserialization without custom code.
How Lambda processes messages from your Kafka topic
Lambda uses event source mappings to process records from Amazon MSK by actively polling Kafka topics through event pollers that invoke Lambda functions with batches of records. These mappings are Lambda managed resources designed for high-throughput, stream-based processing. By default, Lambda detects the OffsetLag for all partitions in your Kafka topic and automatically scales pollers based on traffic. For high-throughput applications, you can enable provisioned mode to define minimum and maximum pollers, and your event source mapping auto scales between the minimum and maximum defined values. In the provisioned mode, each poller can process up to 5 MBps and supports concurrent Lambda invocations.
After Lambda processes each batch, it commits the offsets of the messages in that batch. If your function returns an error for a message in a batch, Lambda retries the whole batch of messages until processing succeeds or the messages expire. You can send records that fail all retry attempts to an on-failure destination for later processing. To maintain ordered processing within a partition, Lambda limits the maximum event pollers to the number of partitions in the topic. When setting up Kafka as a Lambda event source, you can specify a consumer group ID to let Lambda join an existing Kafka consumer group. If other consumers are active in that group, Lambda will receive only part of the topic’s messages. If the group exists, Lambda starts from the group’s committed offset, ignoring the StartingPosition. The following diagram illustrates this flow.
Walkthrough: Build a serverless Kafka app with AWS Lambda
Follow these steps to build a serverless application that consumes messages from an MSK cluster using AWS Lambda:
Create an Amazon MSK cluster. Use the AWS Management Console or AWS CLI to create your MSK cluster. When the cluster is up, create your Kafka topic(s). For detailed instructions, refer to the Amazon MSK documentation.
Create a Lambda function using the AWS Management Console or the AWS CLI. To learn more about creating a Lambda function, refer to Create your first Lambda function. The Lambda function’s execution role needs to have the following permissions:
Access to connect to your MSK cluster
Permissions to manage elastic network interfaces in your VPC
To connect Lambda to Amazon MSK as a consumer, set up event source mapping to link your MSK topic with the Lambda function. This allows Lambda to automatically poll for new messages and process them. Follow the guide on how to configure event source mapping.
For reference, configuring event source mapping involves three steps:
Network setup – In the default event source mapping mode, you need to configure a networking setup using a PrivateLink endpoint or NAT gateway for event source mapping to invoke Lambda functions. In provisioned mode, no networking configuration is needed (and you don’t incur the cost of networking components).
Event source mapping parameter configuration – This involves setting necessary configuration parameters for the event source mapping to be able to poll messages from your Kafka cluster. This includes the MSK cluster, topic name, consumer group ID, authentication method, and optionally, schema registry, scaling mode. You can configure the scaling mode for provisioned throughput, along with batch size, batch window, and event filtering for your event source mapping.
Access permissions – This involves configuring required permissions to access the required AWS resources, and includes configuring permissions for the function to execute the code, permissions for the event source mapping to access your MSK cluster, and permissions for Lambda to access your VPC resources.
The following screenshot shows the console setup for configuring Amazon MSK event source mapping, including the Amazon MSK trigger related fields.
The following screenshot shows event poller configuration.
The following screenshot shows additional settings you can use, depending on your use case.
Optimizing AWS Lambda for stream processing with Amazon MSK
When building real-time data processing pipelines with Amazon MSK and AWS Lambda, it’s important to tune your setup for both performance and cost-efficiency. Lambda offers powerful serverless compute capabilities, but to get the most out of it in a streaming context, you need to make a few key optimizations:
Enable provisioned concurrency for low-latency processing – For workloads that are sensitive to latency—cold starts can introduce unwanted delays. By enabling provisioned concurrency, you can pre-warm a specified number of Lambda instances so they’re always ready to handle traffic immediately. This eliminates cold starts and provides consistent response times, which is crucial for latency-critical use cases.
Enable provisioned mode for event source mapping for high-throughput processing – For Kafka workloads with stringent throughput requirements, activate the provisioned mode. The optimal configuration of minimum and maximum event pollers for your Kafka event source mapping depends on your application’s performance requirements. Start with the default minimum event pollers to baseline the performance profile and adjust event pollers based on observed message processing patterns and your application’s performance requirements. For workloads with spiky traffic and strict performance needs, increase the minimum event pollers to handle sudden surges. You can fine-tune the minimum event pollers by evaluating your desired throughput, your observed throughput, which depends on factors such as the ingested messages per second and average payload size, and using the throughput capacity of one event poller (up to 5 MB/s) as reference. To maintain ordered processing within a partition, Lambda caps the maximum event pollers at the number of partitions in the topic.
Optimize message batching using size and windowing – By integrating Lambda with Amazon MSK, you can control how messages are batched before they’re sent to your function. Tuning parameters such as batch size (the number of records per invocation: 1–10,000 records) and maximum batching window (how long to wait for a full batch: 0–300 seconds) can significantly impact performance. Larger batches mean fewer invocations, which reduces overhead and improves throughput. However, it’s important to strike a balance—too large a batch or window might introduce unwanted processing delays. Monitor your stream’s behavior and adjust these settings based on throughput requirements and acceptable latency.
Apply filters to reduce unnecessary invocations – Not every record in your Kafka topic might require processing. To avoid unnecessary Lambda invocations (and associated costs), apply filtering logic directly when configuring the event source mapping. With Lambda, you can define filtering (up to 10 filters) criteria so that only relevant records trigger your function. This helps reduce compute time, minimize noise, and optimize your budget, especially when dealing with high-throughput topics with mixed content. For Amazon MSK, Lambda commits offsets for matched and unmatched messages after successfully invoking the function.
Conclusion
By combining Amazon MSK with AWS Lambda, you can seamlessly build modern, serverless event-driven applications. This integration eliminates the need to manage consumer groups, compute infrastructure, or scaling logic so teams can focus on delivering business value faster.
Whether you’re integrating Kafka into microservices, transforming data pipelines, or building reactive applications, Lambda with Amazon MSK is a powerful and flexible serverless solution. For detailed documentation on how to configure Lambda with Amazon MSK, refer to the AWS Lambda Developer Guide. For more serverless learning resources, visit Serverless Land.
About the Authors
Tarun Rai Madan is a Principal Product Manager at Amazon Web Services (AWS). He specializes in serverless technologies and leads product strategy to help customers achieve accelerated business outcomes with event-driven applications, using services like AWS Lambda, AWS Step Functions, Apache Kafka, and Amazon SQS/SNS. Prior to AWS, he was an engineering leader in the semiconductor industry, and led development of high-performance processors for wireless, automotive, and data center applications.
Masudur Rahaman Sayem is a Streaming Data Architect at AWS with over 25 years of experience in the IT industry. He collaborates with AWS customers worldwide to architect and implement sophisticated data streaming solutions that address complex business challenges. As an expert in distributed computing, Sayem specializes in designing large-scale distributed systems architecture for maximum performance and scalability. He has a keen interest and passion for distributed architecture, which he applies to designing enterprise-grade solutions at internet scale.
As email continues to be a critical communication channel for businesses, ensuring proper authentication and maintaining high deliverability rates are increasingly difficult challenges. This post explores how Amazon Simple Email Service (SES) and Valimail work together to provide a robust solution for email authentication and deliverability, with a focus on meeting Microsoft’s new sender requirements.
The evolving landscape of email authentication
Email authentication protocols such as SPF and DKIM play a crucial role in preventing email spoofing and phishing attacks, with DMARC reports providing visibility into email authentication status. However, implementing and maintaining these protocols can be challenging, especially as major mailbox providers like Microsoft implement stricter requirements.
As of May 5, 2025, Microsoft began enforcing new authentication standards for bulk senders targeting their consumer domains. Senders who don’t meet these requirements now face SMTP rejections, potentially impacting their email deliverability and business communications.
Addressing authentication challenges
To help customers navigate these changes and maintain strong deliverability, Amazon SES is collaborating with Valimail, a leader in email authentication. This collaboration offers two flexible solutions:
Valimail Monitor (Free): Monitor helps you identify the sending services sending from your domains and provides a dynamic real-time check into compliance for Google, Microsoft, & Yahoo’s DKIM, SPF, and DMARC requirements.
Valimail Enforce (Premium): Enforce is an automated DMARC solution that helps simplify and speed up the process of getting to DMARC enforcement and includes unlimited SPF, in-depth reporting, notifications and expert product support.
Both solutions complement Amazon SES, allowing customers to leverage the scalability and reliability of SES while helping align their email sending with the latest authentication requirements.
Email authentication flow and security
The combination of Amazon SES and Valimail enhances the email sending process:
Emails are sent through Amazon SES.
Valimail continuously monitors the authentication status of these emails.
For Valimail Enforce users, automatic adjustments are made to SPF, DKIM, and DMARC configurations as needed.
Detailed reports provide insights into authentication issues and potential threats.
Emails that pass authentication checks are delivered to recipients with improved inbox placement.
This process helps customers properly authenticate emails sent via Amazon SES, reducing the risk of spoofing and improving overall deliverability.
Gaining visibility into your domain with Valimail Monitor:
Continuously protecting your domain with Valimail Enforce:
Combined benefits of Amazon SES and Valimail
When you combine Amazon SES with Valimail, you gain comprehensive visibility into your email ecosystem while maintaining the robust sending capabilities of SES. The combination enables you to assess your compliance with the latest sender requirements from major providers like Microsoft, Google, and Yahoo. You’ll have clear insights into which of your domains are successfully passing DMARC, SPF, and DKIM authentication checks, and which ones need attention.
Beyond basic authentication status, Valimail provides a global view of all email traffic being sent on your behalf, helping you maintain control over your sending reputation. For organizations looking to strengthen their email security, this serves as the first step towards achieving DMARC enforcement, while seamlessly fitting into your existing Amazon SES workflows.
With Valimail Enforce, you get the added benefit of automated management of your authentication protocols, helping you comply with evolving standards while maintaining optimal deliverability rates. This not only helps improve your inbox placement but also helps enhance your protection against email-based threats and spoofing attempts.
Conclusion
The combination of Amazon SES and Valimail provides a powerful solution for organizations looking to enhance their email authentication and maintain high deliverability rates. This collaboration allows businesses to leverage the scalability of Amazon SES while helping them comply with the latest email authentication standards.
Additional resources
Take the next step in optimizing your email authentication and deliverability:
Since launch, Amazon Inspector has helped customers automate vulnerability management for their running workloads on Amazon Elastic Compute Cloud (Amazon EC2), container workloads, and AWS Lambda functions. Today, we’re taking a step forward into more proactive security with the latest addition to Amazon Inspector: code security capabilities. By using this powerful new feature you can get a proactive view of the security health of your code. With native integration to source code managers (SCM) such as GitHub and GitLab, Amazon Inspector helps you identify and prioritize security vulnerabilities and misconfigurations across your application source-code, dependencies, and infrastructure as code (IaC).
Even if you make no changes to your code, there can be vulnerabilities in libraries that it depends on, creating risks for you and your users. By scanning repositories, you can continually monitor the security of your code and its dependencies. With Amazon Inspector, you can define consistent security controls throughout your software development lifecycle, so your security and development teams can collaborate effectively while reducing risk and remediation costs.
Overview of Amazon Inspector code security capabilities
Amazon Inspector now provides three additional security analysis capabilities: static application security testing (SAST), software composition analysis (SCA), and infrastructure as code (IaC) scanning. To use these features, you must establish a connection with your SCM tool (as shown in Figure 1). If you use GitHub, you can get started by installing and configuring the Amazon Inspector App from the GitHub Marketplace, which enables automated code analysis and delivers security findings directly within pull requests. If you use a self-managed GitLab, implementation is straightforward using a personal access token with the necessary permissions.
Figure 1: Code security landing page for Amazon Inspector
Static application security testing
Static application security testing (SAST) is the process of analyzing source code to identify insecure patterns or methods without needing to compile or execute the code. Amazon Inspector SAST scans analyze your source code to identify potential security vulnerabilities such as hardcoded secrets, cross-site scripting, or injection attacks across a wide range of programming languages including, JavaScript, Python, C#. The service also analyzes Bash shell scripts, extending security coverage beyond application code to include deployment and configuration scripts.
Software composition analysis
Software composition analysis (SCA) helps you understand and manage risks related to software dependencies. Every programming language has its own method of finding, importing, and updating contributed libraries. For example, PyPI for Python, NPM for NodeJS, and Cargo for Rust. Sometimes vulnerabilities are discovered in libraries distributed through the language-specific package distributions, or sometimes a library that you’re using depends on another library, and that dependency has the vulnerability. Amazon Inspector supports the major environments for Python, .Net, PHP, JavaScript, Java, Ruby, Rust, and Go. It automatically analyzes dependencies to identify known vulnerabilities and show you which code is affected. When vulnerabilities are detected, Amazon Inspector provides detailed information about the impact, available fixes, and upgrade paths to help you quickly remediate issues.
Infrastructure as code security
Just as applications are constructed from code, cloud infrastructure can be deployed and managed through code-based methods. Amazon Inspector now also analyzes IaC templates (as shown in Figure 2) to identify potential security misconfigurations, for example, the use of AWS Identity and Access Management (IAM) wildcards in action statements or disabled Glue Data Catalog encryption. This way identified risks can be fixed before the code is executed and the incorrect infrastructure is deployed. The new feature analyzes AWS CloudFormation, Terraform, and AWS CDK, helping you maintain secure infrastructure definitions throughout their development process. This capability helps make sure that security best practices are followed, and potential issues are caught before the infrastructure is deployed.
For the most up-to-date list of programming languages supported across Amazon Inspector code security capabilities, see the online documentation.
Improved security governance and visibility
Amazon Inspector lets you choose which scan types to run across which repositories (as shown in Figure 3). You can initiate a scan based on any of the following:
On-demand: Initiates an immediate scan of the selected repository
Change based: Initiates a scan on push to main branch, or on a pull request or merge request
Scheduled: Initiates a scan weekly or monthly
Figure 3: Overview of scan configurations
Amazon Inspector integrates code security findings into a unified dashboard that you can use to manage and enforce scanning policies across repositories using customizable scan configurations. As part of the integration workflow with the SCM platform, you can set up a default scan configuration that can be applied to existing or new repositories. Alternatively, you also have an option to create custom scan configurations that match specific existing repositories through inclusions tags.
Upon successful scheduled or event-based scans, Amazon Inspector generates detailed findings that pinpoint specific lines of code within repositories, including commit IDs and file locations where vulnerabilities are detected. Amazon Inspector empowers your security teams with customizable filtering through intelligent suppression rules. By using these options, you can tailor your security view to match your organization’s unique priorities, showing exactly what matters most to your team while preserving findings data for reporting and auditing. Through native Amazon EventBridge integration, these detailed security findings can be automatically routed into existing security workflows, enabling alerting and response capabilities.
Code fix recommendations
Amazon Inspector streamlines security remediation by providing specific code fix recommendations directly where developers work. The two-way integration with your SCM automatically suggests fixes as comments within pull requests (PRs) and merge requests (MRs) for Critical and High findings, alerting developers to the most important vulnerabilities to address without disrupting their workflow. Simultaneously, security teams benefit from a consolidated dashboard in the Amazon Inspector console that aggregates findings from scheduled or event-based scans across in-scope repositories. Each finding comes with tailored remediation guidance based on scan type (as shown in Figure 4): specific code suggestions for IAC and SAST findings, or recommended version upgrades and dependency update paths for SCA findings.
Figure 4: Code fix recommendation on a finding in the Amazon Inspector dashboard
Conclusion
These expanded security capabilities now deliver end-to-end visibility of the security health of your cloud applications, from initial code development through to production deployment. Security teams can use the unified dashboard in Amazon Inspector to track and manage vulnerabilities across repositories and application components, facilitating consistent security controls throughout the software lifecycle. Meanwhile, development teams receive immediate, actionable feedback within their source code repositories, creating a seamless security experience that bridges both security and development workflows. This approach is designed to help you maintain robust security practices while keeping development velocity high.
To get started with the new capabilities of Amazon Inspector, visit the Amazon Inspector console. For pricing details and implementation guidance, see documentation. These new features are now available in 10 AWS commercial Regions.
Today, Amazon Web Service (AWS) introduces the Security Champion Knowledge Path on AWS Skill Builder, featuring training and a digital badge. The Security Champion Knowledge path is a comprehensive educational framework designed to empower developers and software engineers with essential AWS cloud security knowledge and best practices. The structured learning path enables development teams to accelerate their delivery while maintaining robust security standards in cloud environments, addressing customers’ need for a structured curriculum to develop and validate security expertise across their organizations.
A new era of security education
The AWS Security Champion Knowledge Path complements the existing AWS security training offerings, providing a structured, self-paced journey to security expertise. Hart Rossman, Vice President of Global Services Security at AWS, emphasizes the program’s significance: “Security in the cloud isn’t a destination; it’s an ongoing journey. The AWS Security Champion Knowledge Path equips our customers with the tools and knowledge to navigate this journey confidently, fostering a culture where security is woven into every aspect of cloud operations.”
Designed for a diverse audience including software developers, solutions architects, technical leaders, and cloud practitioners, the training plan covers a wide range of topics that are critical for a strong security posture in the cloud. This AWS security learning journey begins with essential fundamentals and progressively builds toward advanced concepts across a well-structured curriculum. Starting with AWS Security Fundamentals and the AWS Shared Responsibility Model, learners establish core principles before diving into AWS Identity and Access Management (IAM), including detailed troubleshooting scenarios. The curriculum advances to critical security elements such as encryption and comprehensive threat modeling through the AWS Builders Workshop. Security governance and auditing form the next tier, followed by practical implementations of monitoring, alerting, and network infrastructure best practices. The learning path then covers specialized areas including web-facing workload protection, network control, and incident response procedures. The knowledge path culminates with deep dives into container security and core security concepts through AWS SimuLearn, providing hands-on experience with real-world scenarios. This carefully orchestrated progression helps facilitate a thorough understanding of AWS security principles while maintaining a practical, implementation-focused approach.
What is a Security Champion?
A Security Champion is a bridge between security teams and development teams, promoting security best practices and making sure that security is embedded into every stage of the development lifecycle. However, Security Champion isn’t just a role—it’s a mindset. In today’s distributed and agile cloud environments, having Security Champions across different teams provides a competitive advantage for releasing products quickly and securely.
This distributed ownership of security brings numerous benefits: faster development cycles because teams can address security requirements proactively, reduced security incidents through early detection, and improved collaboration between security and development teams. Most importantly, it creates a culture of security where every team member understands their role in protecting the organization’s assets and data.
By becoming a Security Champion, you’ll gain valuable expertise, earn recognized credentials, and develop leadership skills that can accelerate your career growth. Most importantly, you’ll be empowered to make meaningful contributions to your organization’s security posture by promoting best practices, identifying potential vulnerabilities early in the development cycle, and fostering collaboration between teams—ultimately helping your organization deliver products that are both innovative and secure.
How can I become an AWS Security Champion?
Security enthusiasts can enroll into the AWS Security Champion Knowledge Badge Readiness Path on AWS Skill Builder and complete the assessment successfully to earn the AWS Security Champion digital badge available on Credly.
AWS Security Champion training is a self-paced, hands-on, and interactive approach to upskilling on security concepts. As a participant, you’re introduced to security best practices, performing basic audits, planning for governance at scale, incident response concepts and more. You can engage with real-world scenarios through hands-on labs, interactive game-based learning, gain access to AWS sandbox environments, and conduct practical security assessments. This applied learning helps make sure that knowledge isn’t just acquired, but truly internalized and ready for immediate application.
“The AWS Security Champion Knowledge Path represents a significant milestone in democratizing security expertise. We’ve designed this program to transform how organizations approach security training, making it accessible, practical, and immediately applicable. This isn’t just about learning security concepts—it’s about creating a culture where security becomes second nature to every team member.” – Jenni Troutman, Training and Certification Director at AWS
Recognition and community
Upon successfully completing the assessment in this training path, participants earn the prestigious AWS Security Champion knowledge badge in Credly to showcase their accomplishment, such as on LinkedIn, and join a growing community of security professionals. This recognition not only validates individual expertise but also signals an organization’s commitment to security excellence, and helps organizations identify qualified security champions within their team.
Getting started
To begin your journey to becoming an AWS Security Champion, log in or create an account with AWS Skill Builder and enroll in the Security Champion Knowledge Badge Readiness Path. The training plan is available through flexible pricing options, including individual subscriptions at $29 per month and team subscriptions at $449 per month with enterprise volume pricing available.
Rossman concludes, “The AWS Security Champion Knowledge Path represents a paradigm shift in how organizations approach security education. It’s about creating a shared language of security across teams, enabling faster, more secure development cycles, and ultimately, delivering better outcomes for our customers.”
Ready to elevate your organization’s security capabilities? Visit AWS Skill Builder to enroll and start your journey towards becoming an AWS Security Champion. For enterprise inquiries, reach out to your AWS account team.
Stay tuned to the AWS Security Blog for more updates on AWS Security services, features, and best practices. Together, we’re building a more secure cloud for all.
If you have feedback about this post, submit comments in the Comments section below.
Amazon OpenSearch Service recently introduced a new Transport Layer Security (TLS) policy Policy-Min-TLS-1-2-PFS-2023-10, which supports the latest TLS 1.3 protocol and TLS 1.2 with Perfect Forward Secrecy (PFS) cipher suites. This new policy improves security and enhances OpenSearch performance.
OpenSearch Service previously offered predefined TLS policies for domain endpoint security, making it possible to encrypt your traffic end-to-end by enforcing HTTPS. However, these policies were limited to older versions of TLS, such as TLS 1.0 and TLS 1.2, without any PFS offerings.
In this post, we discuss the benefits of this new policy and how to enable it using the AWS Command Line Interface (AWS CLI).
Solution overview
The new TLS security policy provides an upgraded security posture for OpenSearch Service domains by implementing TLS 1.3 and PFS. This makes it possible to enhance the confidentiality and integrity of traffic between clients and your OpenSearch Service domains, providing a more secure and efficient communication channel for your sensitive data. TLS 1.3 is the latest version of the Transport Layer Security protocol, designed to prevent certain attacks targeting legacy TLS ciphers and provide improvements like 0-RTT resumption for faster connection times. TLS 1.3 can establish secure connections faster than TLS 1.2, resulting in reduced latency for your applications. PFS is an important security enhancement that makes sure past communications remain secure, even if the server’s long-term secret key is compromised in the future. By using a unique, randomly generated session key for each connection, PFS adds an extra layer of protection against potential eavesdropping or decryption of encrypted data. Compared to the older TLS 1.2 policy Policy-Min-TLS-1-2-2019-07, TLS 1.2 with PFS offers stronger security by protecting against potential key compromises, while still maintaining compatibility with older clients that don’t support TLS 1.3.
Prerequisites
To start using this new policy, you need the following prerequisites:
To create new domains with the new TLS policy enabled, add --domain-endpoint-options '{"TLSSecurityPolicy": "Policy-Min-TLS-1-2-PFS-2023-10"}' to the create-domain AWS CLI command:
Most modern clients and libraries should support TLS 1.3 and TLS 1.2 with PFS out of the box. However, if you encounter issues or compatibility concerns, you might need to update your client libraries or configurations to enable support for the new TLS policy.
Conclusion
The new Policy-Min-TLS-1-2-PFS-2023-10 security policy for OpenSearch Service offers significant improvements in security and performance. By supporting TLS 1.3 and TLS 1.2 with PFS, this policy helps protect your data in transit and provides faster connection times. We recommend that you start using this new TLS security policy for improved security posture and performance when connecting to your OpenSearch Service domains. To get started, follow the steps outlined in this post to enable the new policy on your existing or new domains.
At Amazon, security is our top priority, and we are continuously working to enhance the security and performance of our services. Stay tuned for more exciting updates!
About the authors
Shubham Kumar is a Software Development Engineer at Amazon OpenSearch Service, specializing in the security domain. He is passionate about developing robust security features to enhance the protection of customer data and infrastructure.
Sachet Alva is a Software Development Manager at Amazon OpenSearch Service, overseeing the infrastructure security and custom package initiatives. His team’s innovations contribute to the enhanced security and flexibility of Amazon OpenSearch Service deployments.
Naveen Negi is a Senior Tech Product Manager for Amazon OpenSearch Service. He works closely with engineering teams and customers to shape the future of OpenSearch Service, making sure it meets evolving security and performance needs.
Managing AWS End User Messaging SMS registrations can be challenging, especially when dealing with multiple registrations in various states and countries. This post introduces an automated monitoring solution that helps you stay on top of your registration statuses. By leveraging AWS Lambda, EventBridge, and Simple Email Service (SES), you’ll create a system that provides regular updates about registrations that need attention, are under review, in draft pending submission, or have recently been completed.
Whether you’re managing Sender IDs, United States 10DLC campaigns, toll-free numbers, or short codes, this solution will help you maintain visibility across all your registrations and respond promptly to status changes. The setup takes approximately 15-20 minutes and requires no ongoing maintenance beyond occasional adjustments to meet your evolving needs.
Estimated Setup Time: 15-20 minutes
Prerequisites
An AWS account with access to Lambda, IAM, EventBridge, End User Messaging SMS, and SES
A verified email address in Amazon SES for sending reports.
Figure 1: AWS End User Messaging SMS registrations in the console. This view shows registrations in various states that our Lambda function will monitor.
Step 1: Set up Amazon SES
Open the Amazon SES console
Navigate to “Verified identities”
If you have an identity verified you can skip this section
If you do not already have an identity verified Click “Create identity”
Review this post to learn how to verify an identity NOTE: Best practice is to verify a domain identity. This will authenticate your domain and improve deliverability. An email address identity, while more simple, will not be authenticated through DKIM which may decrease deliverability.
Name your rule (e.g., “EndUserMessagingRegistrationsMonitorSchedule”)
For the event pattern, choose “Schedule” then select “Continue in EventBridge Scheduler”
Configure your schedule pattern to your requirements (for example, Cron-based schedule to run at specific days and times or rate-based schedule such as every 1 day). Click “Next”.
Select “Lambda” for “Target detail” and select the Lambda function created in Step 3 as the target from the dropdown. Click “Next”.
For permissions:
Select “Create new role for this schedule”
EventBridge will automatically create a role with the necessary permissions to invoke your Lambda function
Figure 2: The generated email report provides a clear summary of all registrations, categorized by their status.
Understanding the Lambda Function
Let’s break down the key components of our Lambda function:
Initialization: The script sets up necessary AWS clients and defines constants.
categorize_registrations(): This function fetches all registrations and categorizes them based on their status and type.
generate_html_output(): Creates a formatted HTML report of the registration statuses.
send_email(): Uses Amazon SES to send the HTML report via email.
lambda_handler(): The main entry point for the Lambda function, orchestrating the entire process.
The function categorizes registrations into four main statuses:
REQUIRES_UPDATES: Registrations that need attention or modifications
CREATED: Newly created registrations
REVIEWING: Registrations currently under review
COMPLETED: Registrations that have been approved recently (within the last 7 days by default)
Figure 3: Detailed view of a registration requiring updates and created registrations pending submission, including specific denial reasons if applicable and direct console links.
Customization Options
Lookback Period: Modify the COMPLETED_LOOKBACK_DAYS constant to change how far back the function checks for completed registrations.
Email Formatting: Adjust the HTML and CSS in generate_html_output() to customize the email report’s appearance.
Additional Data: Modify the reg_info dictionary in categorize_registrations() to include more data fields in your report.
Monitoring and Maintenance
CloudWatch Logs: Regularly check the Lambda function’s CloudWatch Logs for any errors or unexpected behavior.
Adjusting Schedule: If you find the current schedule doesn’t meet your needs, adjust the EventBridge rule accordingly.
Conclusion
You now have an automated system that monitors your End User Messaging SMS registrations and sends you regular, detailed status reports. This setup provides:
Automated visibility into registrations requiring updates or attention
Clear tracking of draft registrations awaiting your submission
Monitoring of registrations under review
Notifications of recently completed registrations
A consolidated view of all registration states through formatted email reports
This automated solution eliminates the need for manual status checking and helps ensure timely responses to registration changes. As your messaging needs grow, you can easily customize the monitoring frequency, lookback period, and report format to match your requirements.
Next Steps:
Consider adjusting the EventBridge schedule based on your registration volume
Customize the email format to highlight information most relevant to your team
Set up CloudWatch alarms to monitor the Lambda function’s health
Review and update the completed registrations lookback period as needed
For more complex scenarios, consider extending this solution with additional features like Slack notifications, registration metrics tracking, or integration with your ticketing system.
Amazon Web Services (AWS) customers value business continuity while building modern data governance solutions. A resilient data solution helps maximize business continuity by minimizing solution downtime and making sure that critical information remains accessible to users. This post provides guidance on how you can use event driven architecture to enhance the resiliency of data solutions built on the next generation of Amazon SageMaker, a unified platform for data, analytics, and AI. SageMaker is a managed service with high availability and durability. If customers want to build a backup and recovery system on their end, we show you how to do this in this blog. It provides three design principles to improve the data solution resiliency of your organization. In addition, it contains guidance to formulate a robust disaster recovery strategy based on event driven architecture. It contains code samples to back up the system metadata of your data solution built on SageMaker, enabling disaster recovery.
The AWS Well-Architected Framework defines resilience as the ability of a system to recover from infrastructure or service disruptions. You can enhance the resiliency of your data solution by adopting three design principles that are highlighted in this post and by establishing a robust disaster recovery strategy. Recovery point objective (RPO) and recovery time objective (RTO) are industry standard metrics to measure the resilience of a system. RPO indicates how much data loss your organization can accept in case of solution failure. RTO refers to the time for the solution to recover after failure. You can measure these metrics in seconds, minutes, hours, or days. The next section discusses how you can align your data solution resiliency strategy to meet the needs of your organization.
Formulating a strategy to enhance data solution resilience
To develop a robust resiliency strategy for your data solution built on SageMaker, start with how users interact with the data solution. The user interaction influences the data solution architecture, the degree of automation, and determines your resiliency strategy. Here are a few aspects you might consider while designing the resiliency of your data solution.
Data solution architecture – The data solution of your organization might follow a centralized, decentralized, or hybrid architecture. This architecture pattern reflects the distribution of responsibilities of the data solution based on the data strategy of your organization. This shift in responsibilities is reflected in the structure of the teams that perform activities in the Amazon DataZone data portal, SageMaker Unified Studio portal, AWS Management Console, and underlying infrastructure. Examples of such activities include configuring and running the data sources, publishing data assets in the data catalog, subscribing to data assets, and assigning members to projects.
User persona – The user persona, their data, and cloud maturity influence their preferences for interacting with the data solution. The users of a data governance solution fall into two categories: business users and technical users. Business users of your organization might include data owners, data stewards, and data analysts. They might find the Amazon DataZone data portal and SageMaker Unified Studio portal more convenient for tasks such as approving or rejecting subscription requests and performing one-time queries. Technical users such as data solution administrators, data engineers, and data scientists might opt for automation when making system changes. Examples of such activities include publishing data assets, managing glossary and metadata forms in the Amazon DataZone data portal or in SageMaker Unified Studio portal. A robust resiliency strategy accounts for tasks performed by both user groups.
Empowerment of self-service – The data strategy of your organization determines autonomy granted to the users. Increased user autonomy demands a high level of abstraction of the cloud infrastructure powering the data solution. SageMaker empowers self-service by enabling users to perform regular data management activities in the Amazon DataZone data portal and in the SageMaker Unified Studio portal. The level of self-service maturity of the data solution depends on the data strategy and user maturity of your organization. At an early stage, you might limit the self-service features to the use cases for onboarding the data solution. As the data solution scales, consider increasing the self-service capabilities. See Data Mesh Strategy Framework to learn about the different phases of a data mesh-based data solution.
Adopt the following design principles to enhance the resiliency of your data solution:
Choose serverless services – Use serverless AWS services to build your data solution. Serverless services scale automatically with increasing system load, provide fault isolation, and have built-in high-availability. Serverless services minimize the need for infrastructure management, reducing the need to design resiliency into the infrastructure. SageMaker seamlessly integrates with several serverless services such Amazon Simple Storage Service (Amazon S3), AWS Glue, AWS Lake Formation, and Amazon Athena.
Document system metadata – Document the system metadata of your data solution using infrastructure-as-code (IaC) and automation. Consider how users interact with the data solution. If the users prefer to perform certain activities through the Amazon DataZone data portal and SageMaker Unified Studio portal, implement automation to capture and store the metadata that’s relevant for disaster recovery. Use Amazon Relational Database Service (Amazon RDS) and Amazon DynamoDB to store the system metadata of your data solution.
Monitor system health – Implement a monitoring and alerting solution for your data solution so that you can respond to service interruptions and initiate the recovery process. Make sure that system activities are logged so that you can troubleshoot the system interruption. Amazon CloudWatch helps you monitor AWS resources and the applications you run on AWS in real time.
The next section presents disaster recovery strategies to recover your data solution built on SageMaker.
Disaster recovery strategies
Disaster recovery focuses on one-time recovery objectives in response to natural disasters, large-scale technical failures, or human threats such as attack or error. Disaster recovery is a crucial part of your business continuity plan. As shown in the following figure, AWS offers the following options for disaster recovery: Backup and restore, pilot light, warm standby, and multi-site active/active.
The business continuity requirements and cost of recovery should guide your organization’s disaster recovery strategy. As a general guideline, the recovery cost of your data solution increases with reduced RPO and RTO requirements. The next section provides architecture patterns to implement a robust backup and recovery solution for a data solution built on SageMaker.
Solution overview
This section provides event-driven architecture patterns following the backup and restore approach to enhance resiliency of your data solution. This active/passive strategy-based solution stores the system metadata in a DynamoDB table. You can use the system metadata to restore your data solution. The following architecture patterns provide regional resilience. You can simplify the architecture of this solution to restore data in a single AWS Region.
Pattern 1: Point-in-time backup
The point-in-time backup captures and stores system metadata of a data solution built on SageMaker when a user or an automation performs an action. In this pattern, a user activity or an automation initiates an event that captures the system metadata. This pattern is suited for low RPO requirements, ranging from seconds to minutes. The following architecture diagram shows the solution for the point-in-time backup process.
The steps comprise the following.
User or automation performs an activity on an Amazon DataZone domain or Amazon Unified Studio domain.
The CloudTrail event is sent to Amazon EventBridge. Alternatively, you can use Amazon DataZone as the event source for the EventBridge rule.
AWS Lambda transforms and stores this event in a DynamoDB global table where the Amazon DataZone domain is hosted.
The information is replicated into the replica DynamoDB table in a secondary Region. The replica DynamoDB table can be used to restore the data solution based on SageMaker in the secondary Region.
Pattern 2: Scheduled backup
The scheduled backup captures and stores system metadata of a data solution built on SageMaker at regular intervals. In this pattern, an event is initiated based on a defined time schedule. This pattern is suited for RPO requirements in the order of hours. The following architecture diagram displays the solution for point-in-time backup process.
The steps comprise the following.
EventBridge triggers an event at regular interval and sends this event to AWS Step Functions.
The Step Functions state machine contains multiple Lambda functions. These Lambda functions get the system metadata from either a SageMaker Unified Studio domain or an Amazon DataZone domain.
The system metadata is stored in an DynamoDB global table in the primary Region where the Amazon DataZone domain is hosted.
The information is replicated into the replica DynamoDB table in a secondary Region. The data solution can be restored in the secondary Region using the replica DynamoDB table.
The next section provides step by step instructions to deploy a code sample that implements the scheduled backup pattern. This code sample stores asset information of a data solution built on a SageMaker Unified Studio domain and an Amazon DataZone domain in an DynamoDB global table. The data in the DynamoDB table is encrypted at rest using a customer managed key stored in AWS Key Management Service (AWS KMS). A multi-Region replica key encrypts the data in the secondary Region. The asset uses the data lake blueprint that contains the definition for launching and configuring a set of services (AWS Glue, Lake Formation, and Athena) to publish and use data lake assets in the business data catalog. The code sample uses the AWS Cloud Development Kit (AWS CDK) to deploy the cloud infrastructure.
Prerequisites
An active AWS account.
AWS administrator credentials for the central governance account in your development environment
Node.js and Node Package Manager (npm) installed to manage AWS CDK applications
AWS CDK Toolkit installed globally in your development environment by using npm, to synthesize and deploy AWS CDK applications
npm install -g aws-cdk
TypeScript installed in your development environment or installed globally by using npm compiler:
npm install -g typescript
Docker installed in your development environment (recommended)
An integrated development environment (IDE) or text editor with support for Python and TypeScript (recommended)
Walkthrough for data solutions built on a SageMaker Unified Studio domain
This section provides step by step instructions to deploy a code sample that implements the scheduled backup pattern for data solutions built on a SageMaker Unfied Studio domain.
Set up SageMaker Unified Studio
Sign into the IAM console. Create an IAM role that trusts Lambda with the following policy.
Note down the Amazon Resource Name (ARN) of the Lambda role. Navigate to SageMaker and choose Create a Unified Studio domain.
Select Quick setup and expand the Quick setup settings section. Enter a domain name, for example, CORP-DEV-SMUS. Select the Virtual private cloud (VPC) and Subnets. Choose Continue.
Enter the email address of the SageMaker Unified Studio user in the Create IAM Identity Center user section. Choose Create domain.
After the domain is created, choose Open unified studio in the top right corner.
Sign in to SageMaker Unified Studio using the single sign-on (SSO) credentials of your user. Choose Create project at the top right corner. Enter a project name and description, choose Continue twice, and choose Create project. Wait unti project creation is complete.
After the project is created, go into the project by selecting the project name. Select Query Editor from the Build drop-down menu on the top left. Paste the following create table as select (CTAS) query script in the query editor window and run it to create a new table named mkt_sls_table as described in Produce data for publishing. The script creates a table with sample marketing and sales data.
CREATE TABLE mkt_sls_table AS
SELECT 146776932 AS ord_num, 23 AS sales_qty_sld, 23.4 AS wholesale_cost, 45.0 as lst_pr, 43.0 as sell_pr, 2.0 as disnt, 12 as ship_mode,13 as warehouse_id, 23 as item_id, 34 as ctlg_page, 232 as ship_cust_id, 4556 as bill_cust_id
UNION ALL SELECT 46776931, 24, 24.4, 46, 44, 1, 14, 15, 24, 35, 222, 4551
UNION ALL SELECT 46777394, 42, 43.4, 60, 50, 10, 30, 20, 27, 43, 241, 4565
UNION ALL SELECT 46777831, 33, 40.4, 51, 46, 15, 16, 26, 33, 40, 234, 4563
UNION ALL SELECT 46779160, 29, 26.4, 50, 61, 8, 31, 15, 36, 40, 242, 4562
UNION ALL SELECT 46778595, 43, 28.4, 49, 47, 7, 28, 22, 27, 43, 224, 4555
UNION ALL SELECT 46779482, 34, 33.4, 64, 44, 10, 17, 27, 43, 52, 222, 4556
UNION ALL SELECT 46779650, 39, 37.4, 51, 62, 13, 31, 25, 31, 52, 224, 4551
UNION ALL SELECT 46780524, 33, 40.4, 60, 53, 18, 32, 31, 31, 39, 232, 4563
UNION ALL SELECT 46780634, 39, 35.4, 46, 44, 16, 33, 19, 31, 52, 242, 4557
UNION ALL SELECT 46781887, 24, 30.4, 54, 62, 13, 18, 29, 24, 52, 223, 4561
Navigate to Data sources from the Project. Choose Run in the Actions section next to the project.default_lakehouse connection. Wait until the run is complete.
Navigate to Assets in the left side bar. Select the mkt_sls_table in the Inventory section and review the metadata that was generated. Choose Accept All if you’re satisfied with the metadata.
Choose Publish Asset to publish the mkt_sls_table table to the business data catalog, making it discoverable and understandable across your organization.
Choose Members in the navigation pane. Choose Add members and select the IAM role you created in Step 1. Add the role as a Contributor in the project.
Deployment steps
After setting up SageMaker Unified Studio, use the AWS CDK stack provided on GitHub to deploy the solution to back up the asset metadata that is created in the previous section.
Clone the repository from GitHub to your preferred integrated development environment (IDE) using the following commands.
git clone https://github.com/aws-samples/sample-event-driven-resilience-data-solutions-sagemaker.git
cd sample-event-driven-resilience-data-solutions-sagemaker
Export AWS credentials and the primary Region to your development environment for the IAM role with administrative permissions, use the following format
Bootstrap the AWS account in the primary and secondary Regions by using AWS CDK and running the following command.
cdk bootstrap aws://<AWS_ACCOUNT_ID>/<AWS_REGION>
cdk bootstrap aws://<AWS_ACCOUNT_ID>/<AWS_SECONDARY_REGION>
cd unified-studio
Modify the following parameters in the config/Config.ts file.
SMUS_APPLICATION_NAME – Name of the application.
SMUS_SECONDARY_REGION – Secondary AWS region for backup.
SMUS_BACKUP_INTERVAL_MINUTES – Minutes before each backup interval.
SMUS_STAGE_NAME – Name of the stage.
SMUS_DOMAIN_ID – Domain identifier of the Amazon SageMaker Unified Studio.
SMUS_PROJECT_ID – Project identifier of the Amazon SageMaker Unified Studio.
SMUS_ASSETS_REGISTRAR_ROLE_ARN – ARN of the AWS Lambda role created in step 1 of the preceding section.
Install the dependencies by running the following command:
npm install
Synthesize the CloudFormation template by running the following command.
cdk synth
Deploy the solution by running the following command.
cdk deploy –all
After the deployment is complete, sign in to your AWS account and navigate to the CloudFormation console to verify that the infrastructure deployed.
When deployment is complete, wait for the duration of DZ_BACKUP_INTERVAL_MINUTES. Navigate to the <DZ_APPLICATION_NAME >AssetsInfo DynamoDB table. Retrieve the data from the DynamoDB table. The following screenshot shows the data in the Items returned section. Verify the same data in the secondary Region.
Clean up
Use the following steps to clean up the resources deployed.
Empty the S3 buckets that were created as part of this deployment.
In your local development environment (Linux or macOS):
Navigate to the unified-studio directory of your repository.
Export the AWS credentials for the IAM role that you used to create the AWS CDK stack.
To destroy the cloud resources, run the following command:
cdk destroy --all
Go to the SageMaker Unified Studio and delete the published data assets that were created in the project.
Use the console to delete the SageMaker Unified Studio domain.
Walkthrough for data solutions built on an Amazon DataZone domain
This section provides step by step instructions to deploy a code sample that implements the scheduled backup pattern for data solutions built on an Amazon DataZone domain.
Deployment steps
After completing the prerequisites, use the AWS CDK stack provided on GitHub to deploy the solution to backup system metadata of the data solution built on Amazon DataZone domain
Clone the repository from GitHub to your preferred IDE using the following commands.
git clone https://github.com/aws-samples/sample-event-driven-resilience-data-solutions-sagemaker.git
cd event-driven-resilience-sagemaker
Export AWS credentials and the primary Region information to your development environment for the AWS Identity and Access Management (IAM) role with administrative permissions, use the following format:
Bootstrap the AWS account in the primary and secondary Regions by using AWS CDK and running the following command:
cdk bootstrap aws://<AWS_ACCOUNT_ID>/<AWS_REGION>
cdk bootstrap aws://<AWS_ACCOUNT_ID>/<AWS_SECONDARY_REGION>
cd datazone
From the console for IAM, note the Amazon Resource Name (ARN) of the CDK execution role. Update the trust relationship of the IAM role so that Lambda can assume the role.
Modify the following parameters in the config/Config.ts file.
DZ_APPLICATION_NAME – Name of the application.
DZ_SECONDARY_REGION – Secondary Region for backup.
DZ_BACKUP_INTERVAL_MINUTES – Minutes before each backup interval.
DZ_STAGE_NAME – Name of the stage (dev, qa, or prod).
DZ_DOMAIN_NAME – Name of the Amazon DataZone domain
DZ_DOMAIN_DESCRIPTION – Description of the Amazon DataZone domain
DZ_DOMAIN_TAG – Tag of the Amazon DataZone domain
DZ_PROJECT_NAME – Name of the Amazon DataZone project
DZ_PROJECT_DESCRIPTION – Description of the Amazon DataZone project
CDK_EXEC_ROLE_ARN – ARN of the CDK execution role
DZ_ADMIN_ROLE_ARN – ARN of the administrator role
Install the dependencies by running the following command:
npm install
Synthesize the AWS CloudFormation template by running the following command:
cdk synth
Deploy the solution by running the following command:
cdk deploy --all
After the deployment is complete, sign in to your AWS account and navigate to the CloudFormation console to verify that the infrastructure deployed.
Document system metadata
This section provides instructions to create an asset and demonstrates how you can retrive the metadata of the asset. Perform the following steps to retrieve the systems metadata.
Sign in to the Amazon DataZone data portal from the console. Select the project and choose Query data at the upper right.
Choose Open Athena and make sure that <DZ_PROJECT_NAME>_DataLakeEnvironment is selected in the Amazon DataZone environment dropdown at the upper right and that on the left, and that <DZ_PROJECT_NAME>_datalakeenvironment_pub_db is selected as the Database.
Create a new AWS Glue table for publishing to Amazon DataZone. Paste the following create table as select (CTAS) query script in the Query window and run it to create a new table named mkt_sls_table as described in Produce data for publishing. The script creates a table with sample marketing and sales data.
CREATE TABLE mkt_sls_table AS
SELECT 146776932 AS ord_num, 23 AS sales_qty_sld, 23.4 AS wholesale_cost, 45.0 as lst_pr, 43.0 as sell_pr, 2.0 as disnt, 12 as ship_mode,13 as warehouse_id, 23 as item_id, 34 as ctlg_page, 232 as ship_cust_id, 4556 as bill_cust_id
UNION ALL SELECT 46776931, 24, 24.4, 46, 44, 1, 14, 15, 24, 35, 222, 4551
UNION ALL SELECT 46777394, 42, 43.4, 60, 50, 10, 30, 20, 27, 43, 241, 4565
UNION ALL SELECT 46777831, 33, 40.4, 51, 46, 15, 16, 26, 33, 40, 234, 4563
UNION ALL SELECT 46779160, 29, 26.4, 50, 61, 8, 31, 15, 36, 40, 242, 4562
UNION ALL SELECT 46778595, 43, 28.4, 49, 47, 7, 28, 22, 27, 43, 224, 4555
UNION ALL SELECT 46779482, 34, 33.4, 64, 44, 10, 17, 27, 43, 52, 222, 4556
UNION ALL SELECT 46779650, 39, 37.4, 51, 62, 13, 31, 25, 31, 52, 224, 4551
UNION ALL SELECT 46780524, 33, 40.4, 60, 53, 18, 32, 31, 31, 39, 232, 4563
UNION ALL SELECT 46780634, 39, 35.4, 46, 44, 16, 33, 19, 31, 52, 242, 4557
UNION ALL SELECT 46781887, 24, 30.4, 54, 62, 13, 18, 29, 24, 52, 223, 4561
Go to the Tables and Views section and verify that the mkt_sls_table table was successfully created.
In the Amazon DataZone Data Portal, go to Data sources, select the <DZ_PROJECT_NAME>-DataLakeEnvironment-default-datasource, and choose Run. The mkt_sls_table will be listed in the inventory and available to publish.
Select the mkt_sls_table table and review the metadata that was generated. Choose Accept All if you’re satisfied with the metadata.
Choose Publish Asset and the mkt_sls_table table will be published to the business data catalog, making it discoverable and understandable across your organization.
After the table is published, wait for the duration of DZ_BACKUP_INTERVAL_MINUTES. Navigate to the <DZ_APPLICATION_NAME >AssetsInfo DynamoDB table and retrieve the data from the table. The following screenshot shows the data in the Items returned section. Verify the same data in the secondary Region.
Clean up
Use the following steps to clean up the resources deployed.
Go to the Amazon DataZone domain portal and delete the published data assets that were created in the Amazon DataZone project.
In your local development environment (Linux or macOS):
Navigate to the datazone directory of your repository.
Export the AWS credentials for the IAM role that you used to create the AWS CDK stack.
To destroy the cloud resources, run the following command:
cdk destroy --all
Conclusion
This post explores how to build a resilient data governance solution on Amazon SageMaker. Resilient design principles and a robust disaster recovery strategy are central to the business continuity of AWS customers. The code samples included in this post implement a backup process of the data solution at regular time interval. They store the Amazon SageMaker asset information in Amazon DynamoDB Global tables. You can extend the backup solution by identifying the system metadata that is relevant for the data solution of your organization and by using Amazon SageMaker APIs to capture and store the metadata. The DynamoDB Global table replicates the changes in the DynamoDB table in the primary region to the secondary region in an asynchronous manner. Consider Implementing an additional layer of resiliency by using AWS Backup to back up the DynamoDB table at regular interval. In the next post, we show how you can use the system metadata to restore your data solution in the secondary region.
To build a data mesh based data solution using Amazon DataZone domain, see our GitHub repository. This open source project provides a step-by-step blueprint for constructing a data mesh architecture using the powerful capabilities of Amazon SageMaker, AWS Cloud Development Kit (AWS CDK), and AWS CloudFormation.
About the authors
Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data governance, and artificial intelligence at Amazon Web Services (AWS). He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure cloud solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains.
Tens of thousands of customers use Amazon Redshift as a fully managed, petabyte-scale data warehouse service in the cloud. As an organization’s business data grows in volume, the data analytics need also grows. Amazon Redshift performance needs to be optimized at scale to achieve faster, near real-time business intelligence (BI). You might also consider optimizing Amazon Redshift performance when your data analytics workloads or user base increases, or to meet a data analytics performance service level agreement (SLA). You can also look for ways to optimize Amazon Redshift data warehouse performance after you complete an online analytical processing (OLAP) migration from another system to Amazon Redshift.
Use Amazon Redshift Serverless to automatically provision and scale your data warehouse capacity
To start, let’s review using Amazon Redshift Serverless to automatically provision and scale your data warehouse capacity. The architecture is shown in the following diagram and includes different components within Amazon Redshift Serverless like ML-based workload monitoring and automatic workload management.
Amazon Redshift Serverless architecture diagram
Amazon Redshift Serverless is a deployment model that you can use to run and scale your Redshift data warehouse without managing infrastructure. Amazon Redshift Serverless will automatically provision and scale your data warehouse capacity to deliver fast performance for even the most demanding, unpredictable, or massive workloads.
Amazon Redshift Serverless scaling is automatic and based on your RPU capacity. To further optimize scaling operations for large scale datasets, Amazon Redshift Serverless has AI-driven scaling and optimization. It uses AI to scale automatically with workload changes across key metrics such as data volume changes, concurrent users, and query complexity, accurately meeting your price performance targets.
There is no maintenance window in Amazon Redshift Serverless, because software version updates are applied automatically. This maintenance occurs with no interruptions for any existing connections or query executions. Make sure to consult the considerations guide to better understand the operation of Amazon Redshift Serverless.
You can migrate from an existing provisioned Amazon Redshift data warehouse to Amazon Redshift Serverless by creating a snapshot of your current provisioned data warehouse and then restoring that snapshot in Amazon Redshift Serverless. Amazon Redshift will automatically convert interleaved keys to compound keys when you restore a provisioned data warehouse snapshot to a Serverless namespace. You can also get started with a new Amazon Redshift Serverless data warehouse.
Amazon Redshift Serverless use cases
You can use Amazon Redshift Serverless for:
Self-service analytics
Auto scaling for unpredictable or variable workloads
You can also use Amazon Redshift Serverless with Amazon Redshift data sharing, which can automatically scale your large dataset in independent datashares and maintain workload isolation controls.
Amazon Redshift data sharing to share live data between separate Amazon Redshift data warehouses
Next, we will look at an Amazon Redshift data sharing architecture pattern, shown in below diagram, to share data between a hub Amazon Redshift data warehouse and spoke Amazon Redshift data warehouses , and to share data across multiple Amazon Redshift data warehouses with each other.
Amazon Redshift data sharing architecture patterns diagram
With Amazon Redshift data sharing, you can securely share access to live data between separate Amazon Redshift data warehouses without manually moving or copying the data. Because the data is live, all users can see the most up-to-date and consistent information in Amazon Redshift as soon as it’s updated using separate dedicated resources. Because the compute accessing the data is isolated, you can size the data warehouse configurations to individual workload price performance requirements rather than the aggregate of all workloads. This also provides additional flexibility to scale with new workloads without affecting the workloads already being run on Amazon Redshift.
A datashare is the unit of sharing data in Amazon Redshift. A producer data warehouse administrator can create datashares and add datashare objects to share data with other data warehouses, referred to as outbound shares. A consumer data warehouse administrator can receive datashares from other data warehouses, referred to as inbound shares.
To get started, a producer data warehouse needs to add all objects (and potential permissions) that need to be accessed by another data warehouse to a datashare, and share that datashare with a consumer. After that consumer creates a database from the datashare, the shared objects can be accessed using three-part notation consumer_database_name.schema_name.table_name on the consumer, using the consumer’s compute.
Support different kinds of business-critical workloads, including workload isolation and chargeback for individual workloads.
Enable cross-group collaboration across teams for broader analytics, data science, and cross-product impact analysis.
Deliver data as a service.
Share data between environments to improve team agility by sharing data at different granularity levels such as development, test, and production.
License access to data in Amazon Redshift by listing Amazon Redshift data sets in the AWS Data Exchange catalog so that customers can find, subscribe to, and query the data in minutes.
Update business source data on the producer. You can share data as a service across your organization, but then consumers can also perform actions on the source data.
Insert additional records on the producer. Consumers can add records to the original source data.
The following articles provide examples of how you can use Amazon Redshift data sharing to scale performance:
Amazon Redshift Spectrum to query data in Amazon S3
You can use Amazon Redshift Spectrum to query data in , as shown in below diagram using AWS Glue Data Catalog.
Amazon Redshift Spectrum architecture diagram
You can use Amazon Redshift Spectrum to efficiently query and retrieve structured and semi-structured data from files in Amazon S3 without having to directly load data into Amazon Redshift tables. Using the large, parallel scale of the Amazon Redshift Spectrum layer, you can run massive, fast, parallel queries against large datasets while most of the data remains in Amazon S3. This can significantly improve the performance and cost-effectiveness of massive analytics workloads, because you can use the scalable storage of Amazon S3 to handle large volumes of data while still benefiting from the powerful query processing capabilities of Amazon Redshift.
Amazon Redshift Spectrum uses separate infrastructure independent of your Amazon Redshift data warehouse, offloading many compute-intensive tasks, such as predicate filtering and aggregation. This means that you can use significantly less data warehouse processing capacity than other queries. Amazon Redshift Spectrum can also automatically scale to potentially thousands of instances, based on the demands of your queries.
When implementing Amazon Redshift Spectrum, make sure to consult the considerations guide which details how to configure your networking, external table creation, and permissions requirements.
To get started with Amazon Redshift Spectrum, you define the structure for your files and register them as an external table in an external data catalog (AWS Glue, Amazon Athena, and Apache Hive metastore are supported). After creating your external table, you can query your data in Amazon S3 directly from Amazon Redshift.
Amazon Redshift Spectrum use cases
You can use Amazon Redshift Spectrum in the following use cases:
Huge volume but less frequently accessed data, build lake house architecture to query exabytes of data in an S3 data lake
Heavy scan- and aggregation-intensive queries
Selective queries that can use partition pruning and predicate pushdown, so the output is fairly small
Zero-ETL to unify all data and achieve near real-time analytics
You can use Zero-ETL integration with Amazon Redshift to integrate with your transactional databases like Amazon Aurora MySQL-Compatible Edition, so you can run near real-time analytics in Amazon Redshift, or BI in Amazon QuickSight, or machine learning workload in Amazon SageMaker AI, shown in below diagram.
Zero-ETL integration with Amazon Redshift architecture diagram
Zero-ETL integration with Amazon Redshift removes the undifferentiated heavy lifting to build and manage complex extract, transform, and load (ETL) data pipelines; unifies data across databases, data lakes, and data warehouses; and makes data available in Amazon Redshift in near real time for analytics, artificial intelligence (AI) and machine learning (ML) workloads.
Currently Amazon Redshift supports the following zero-ETL integrations:
Applications such as Salesforce, SAP, ServiceNow, and Zendesk
To create a zero-ETL integration, you specify an integration source, such as an Amazon Aurora DB cluster, and an Amazon Redshift data warehouse, such as Amazon Redshift Serverless workgroup or a provisioned data warehouse (including Multi-AZ deployment on RA3 clusters to automatically recover from any infrastructure or Availability Zone failures and help ensure that your workloads remain uninterrupted), as the target. The integration replicates data from the source to the target and makes data available in the target data warehouse within seconds. The integration also monitors the health of the integration pipeline and recovers from issues when possible.
Make sure to review considerations, limitations, and quotas on both the data source and target when using zero-ETL integrations with Amazon Redshift.
Zero-ETL integration use cases
You can use zero-ETL integration with Amazon Redshift as an architecture pattern to boost analytical query performance at scale, enable a straightforward and secure way to create near real-time analytics on petabytes of transactional data, with continuous change-data-capture (CDC). Plus, you can use other Amazon Redshift capabilities such as built-in machine learning, materialized views, data sharing, and federated access to multiple data stores and data lakes. You can see more other zero-ETL integrations use cases at What is ETL.
Ingest streaming data into Amazon Redshift data warehouse for near real-time analytics
Amazon Redshift data streaming architecture diagram
Amazon Redshift streaming ingestion provides low-latency, high-speed data ingestion directly from Amazon Kinesis Data Streams or Amazon MSK to an Amazon Redshift provisioned or Amazon Redshift Serverless data warehouse, without staging data in Amazon S3. You can connect to and access the data from the stream using standard SQL and simplify data pipelines by creating materialized views in Amazon Redshift on top of the data stream. For best practices, you can review these blog posts:
You can use Amazon Redshift streaming ingestion to:
Improve gaming experience by analyzing real-time data from gamers
Analyze real-time IoT data and use machine learning (ML) within Amazon Redshift to improve operations, predict customer churn, and grow your business
Analyze clickstream user data
Conduct real-time troubleshooting by analyzing streaming data from log files
Perform near real-time retail analytics on streaming point of sale (POS) data
Other Amazon Redshift features to optimize performance
There are other Amazon Redshift features that you can use to optimize performance.
You can resize Amazon Redshift provisioned clusters to optimize data warehouse compute and storage use.
You can use concurrency scaling, where Amazon Redshift provisioning automatically adds additional capacity to process increases in read, such as dashboard queries; and write operations, such as data ingestion and processing.
You can also consider materialized views in Amazon Redshift, applicable to both provisioned and serverless data warehouses, which contains a precomputed result set, based on an SQL query over one or more base tables. They are especially useful for speeding up queries that are predictable and repeated.
You can use auto-copy for Amazon Redshift to set up continuous file ingestion from your Amazon S3 prefix and automatically load new files to tables in your Amazon Redshift data warehouse without the need for additional tools or custom solutions.
Cloud security at AWS is the highest priority. Amazon Redshift offers broad security-related configurations and controls to help ensure information is appropriately protected. See Amazon Redshift Security Best Practices for a comprehensive guide to Amazon Redshift security best practices.
Conclusion
In this post, we reviewed Amazon Redshift architecture patterns and features that you can use to help scale your data warehouse to dynamically accommodate different workload combinations, volumes, and data sources to achieve optimal price performance. You can use them alone or together—choosing the best infrastructural set up for your use case requirements—and scale to accommodate for any future growth.
Get started with these Amazon Redshift architecture patterns and features today by following the instructions provided in each section. If you have questions or suggestions, leave a comment below.
About the authors
Eddie Yao is a Principal Technical Account Manager (TAM) at AWS. He helps enterprise customers build scalable, high-performance cloud applications and optimize cloud operations. With over a decade of experience in web application engineering, digital solutions, and cloud architecture, Eddie currently focuses on Media & Entertainment (M&E) and Sports industries and AI/ML and generative AI.
Julia Beck is an Analytics Specialist Solutions Architect at AWS. She supports customers in validating analytics solutions by architecting proof of concept workloads designed to meet their specific needs.
Scott St. Martin is a Solutions Architect at AWS who is passionate about helping customers build modern applications. Scott uses his decade of experience in the cloud to guide organizations in adopting best practices around operational excellence and reliability, with a focus the manufacturing and financial services spaces. Outside of work, Scott enjoys traveling, spending time with family, and playing piano.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) has become a cornerstone for organizations embracing data-driven decision-making. As a scalable solution for managing complex data pipelines, Amazon MWAA enables seamless orchestration across AWS services and on-premises systems. Although AWS manages the underlying infrastructure, you must carefully plan and execute your Amazon MWAA environment updates according to the shared responsibility model. Upgrading to the latest Amazon MWAA version can provide significant advantages, including enhanced security through critical security patches and potential improvements in performance with faster DAG parsing and reduced database load. You can use advanced features while maintaining ecosystem compatibility and receiving prioritized AWS support. The key to successful upgrades lies in choosing the right solution and following a methodical implementation approach.
In this post, we explore best practices for upgrading your Amazon MWAA environment and provide a step-by-step guide to seamlessly transition to the latest version.
Solution overview
Amazon MWAA provides two primary upgrade solutions:
In-place upgrade – This method works best when you can accommodate planned downtime. You deploy the new version directly on your existing infrastructure. In-place version upgrades on Amazon MWAA are supported for environments running Apache Airflow version 2.x and later. However, if you’re running version 1.10.z or older versions, you must create a new environment and migrate your resources, because these versions don’t support in-place upgrades.
Cutover upgrade – This method helps minimize disruption to production environments. You create a new Amazon MWAA environment with the target version and then transition from your old environment to the new one.
Each solution offers a different approach to help you upgrade while working to maintain data integrity and system reliability.
In-place upgrade
In-place upgrades work well for environments where you can schedule a maintenance window for the upgrade process. During this window, Amazon MWAA preserves your workflow history. This method works best when you can accommodate planned downtime. It helps maintain historical data, provides a straightforward upgrade process, and includes rollback capabilities if issues occur during provisioning. You also use fewer resources because you don’t need to create a new environment.
You can perform in-place upgrades through the AWS Management Console with a single operation. This process helps reduce operational overhead by managing many upgrade steps for you.
During the upgrade process, your environment can’t schedule or run new tasks. Amazon MWAA helps manage the upgrade process and implements safety measures—if issues occur during the provisioning phase, the service attempts to revert to the previous stable version.
Before you begin an in-place upgrade, we recommend testing your DAGs for compatibility with the target version, because DAG compatibility issues can affect the upgrade process. You can use the Amazon MWAA local runner to test DAG compatibility before you start the upgrade. You can start the upgrade using either the console and specifying the new version or the AWS Command Line Interface (AWS CLI). The following is an example Amazon MWAA upgrade command using the AWS CLI:
A cutover upgrade provides an alternative solution when you need to minimize downtime, though it requires more manual steps and operational planning. With this approach, you create a new Amazon MWAA environment, migrate your metadata, and manage the transition between environments. Although this method offers more control over the upgrade process, it requires additional planning and execution effort compared to an in-place upgrade.
This method can work well for environments with complex workflows, particularly when you plan to make significant changes alongside the version upgrade. The approach offers several benefits: you can minimize production downtime, perform comprehensive testing before switching environments, and maintain the ability to return to your original environment if needed. You can also review and update your configurations during the transition.
Consider the following aspects of the cutover approach. When you run two environments simultaneously, you pay for both environments. The pricing for each Amazon MWAA environment depends on:
Duration of environment uptime (billed hourly with per-second resolution)
Environment size configuration
Automatic scaling capacity for workers
Scheduler capacity
AWS calculates the cost of additional automatic scaled workers separately. You can estimate costs for your specific configuration using the AWS Pricing Calculator.
To help prevent data duplication or corruption during parallel operation, we recommend implementing idempotent DAGs. The Airflow scheduler automatically populates some metadata tables (dag, dag_tag, and dag_code) in your new environment. However, you need to plan the migration of the following additional metadata components:
DAG history
Variables
Slot pool configurations
SLA miss records
XCom data
Job records
Log tables
You can choose this approach when your requirements prioritize minimal downtime and you can manage the additional operational complexity.
The cutover upgrade process involves three main steps: creating a new environment, restoring it with the existing data, and performing the upgrade. The following diagram illustrates the full workflow.
In the following sections, we walk through the key steps to perform a cutover upgrade.
Prerequisites
Before you begin the upgrade process, complete the following steps:
Plan your transition timing carefully. When your original environment continues to process workflows during this upgrade, the metadata between environments can change.
Clean up
After you verify the stability of your upgraded environment through monitoring, you can begin the cleanup process:
Remove your original Amazon MWAA environment using the AWS CLI command:
aws mwaa delete-environment --name <old-env-name>
Clean up your associated resources by removing unused backup data from S3 buckets, deleting temporary AWS Identity and Access Management (IAM) roles and policies created for the upgrade, and updating your DNS or routing configurations.
Before removing any resources, make sure you follow your organization’s backup retention policies, maintain necessary backup data for your compliance requirements, and document configuration changes made during the upgrade.
This approach helps you perform a controlled upgrade with opportunities for testing and the ability to return to your original environment if needed.
Monitoring and validation
You can track your upgrade progress using Amazon CloudWatch metrics, with a focus on DAG processing metrics and scheduler heartbeat. Your environment transitions through several states during the upgrade process, including UPDATING and CREATING. When your environment shows the AVAILABLE state, you can begin validation testing. We recommend checking system accessibility, testing critical workflow operations, and verifying external connections. For detailed monitoring guidance, see Monitoring and metrics for Amazon Managed Workflows for Apache Airflow.
Key considerations
Consider using infrastructure as code (IaC) practices to help maintain consistent environment management and support repeatable deployments. Schedule metadata backups using mwaa-dr during periods of low activity to help protect your data. When designing your workflows, implement idempotent pipelines to help manage potential interruptions, and maintain documentation of your configurations and dependencies.
Conclusion
A successful Amazon MWAA upgrade starts with selecting an approach that aligns with your operational requirements. Whether you choose an in-place or cutover upgrade, thorough preparation and testing help support a controlled transition. Using available tools, monitoring capabilities, and recommended practices can help you upgrade to the latest Amazon MWAA features while working to maintain your workflow operations.
Apache, Apache Airflow, and Airflow are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
About the Authors
Anurag Srivastava works as a Senior Big Data Cloud Engineer at Amazon Web Services (AWS), specializing in Amazon MWAA. He’s passionate about helping customers build scalable data pipelines and workflow automation solutions on AWS.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Venu Thangalapally is a Senior Solutions Architect at AWS, based in Chicago, with deep expertise in cloud architecture, data and analytics, containers, and application modernization. He partners with Financial Services industry customers to translate business goals into secure, scalable, and compliant cloud solutions that deliver measurable value. Venu is passionate about leveraging technology to drive innovation and operational excellence. Outside of work, he enjoys spending time with his family, reading, and taking long walks.
Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
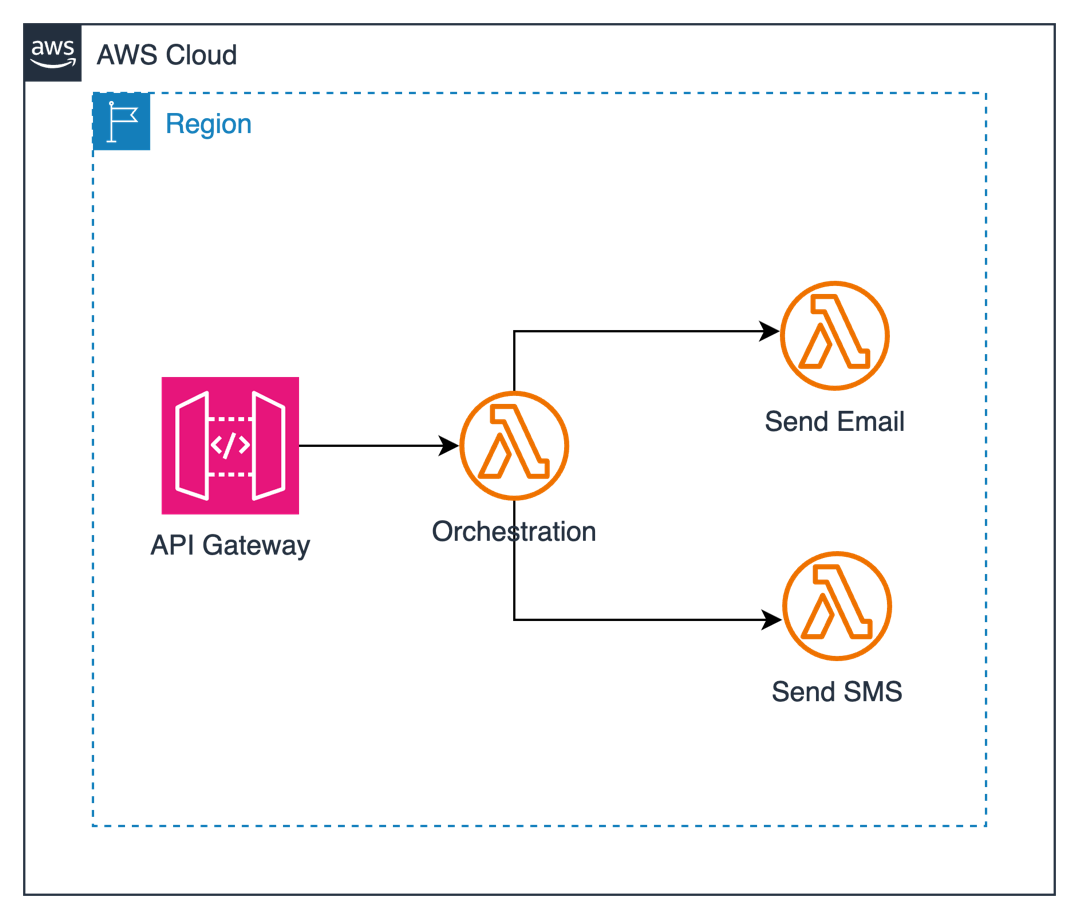
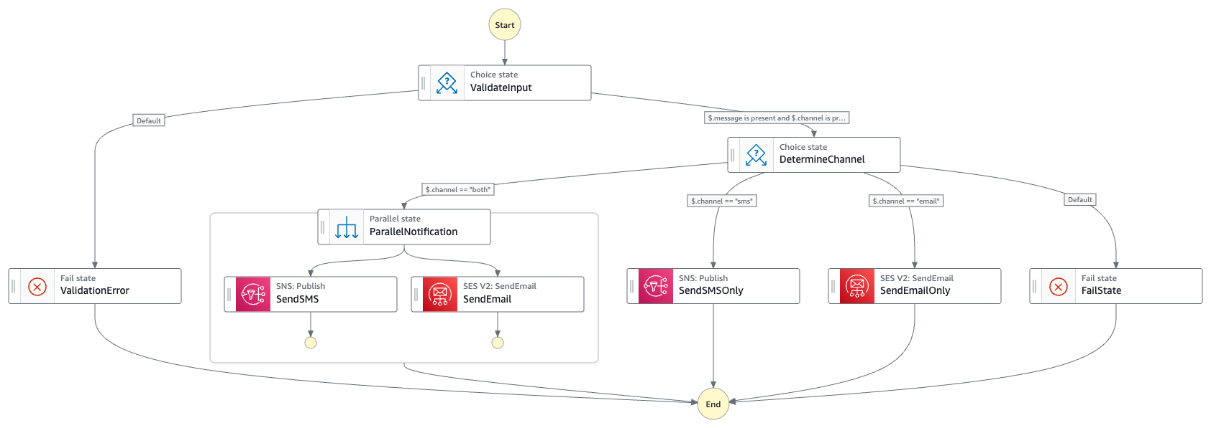
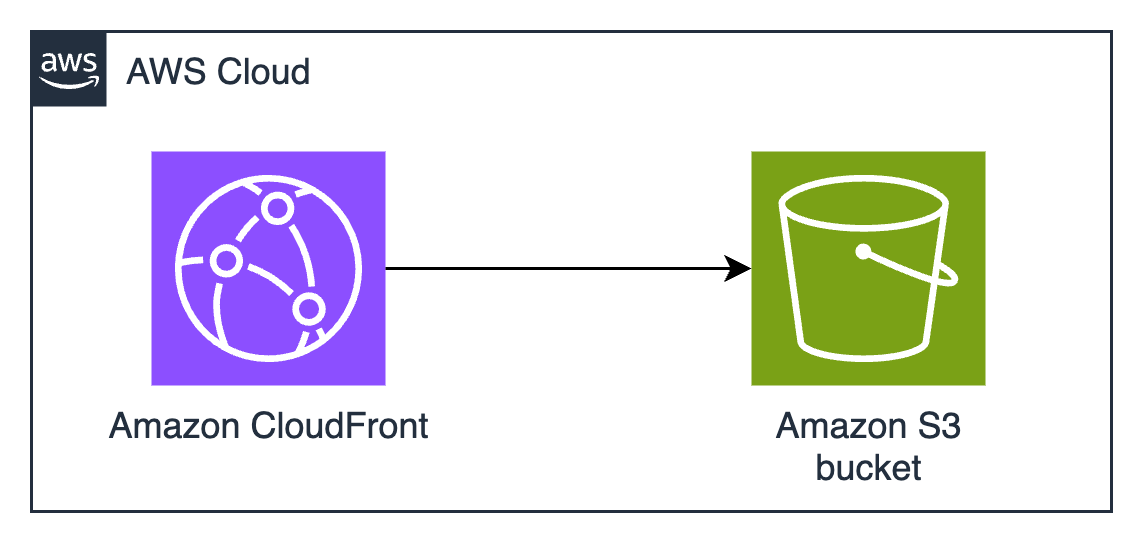
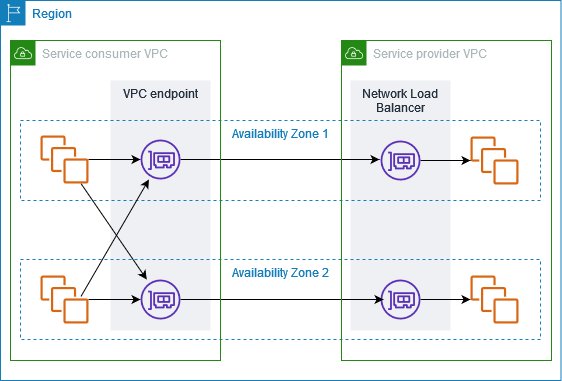
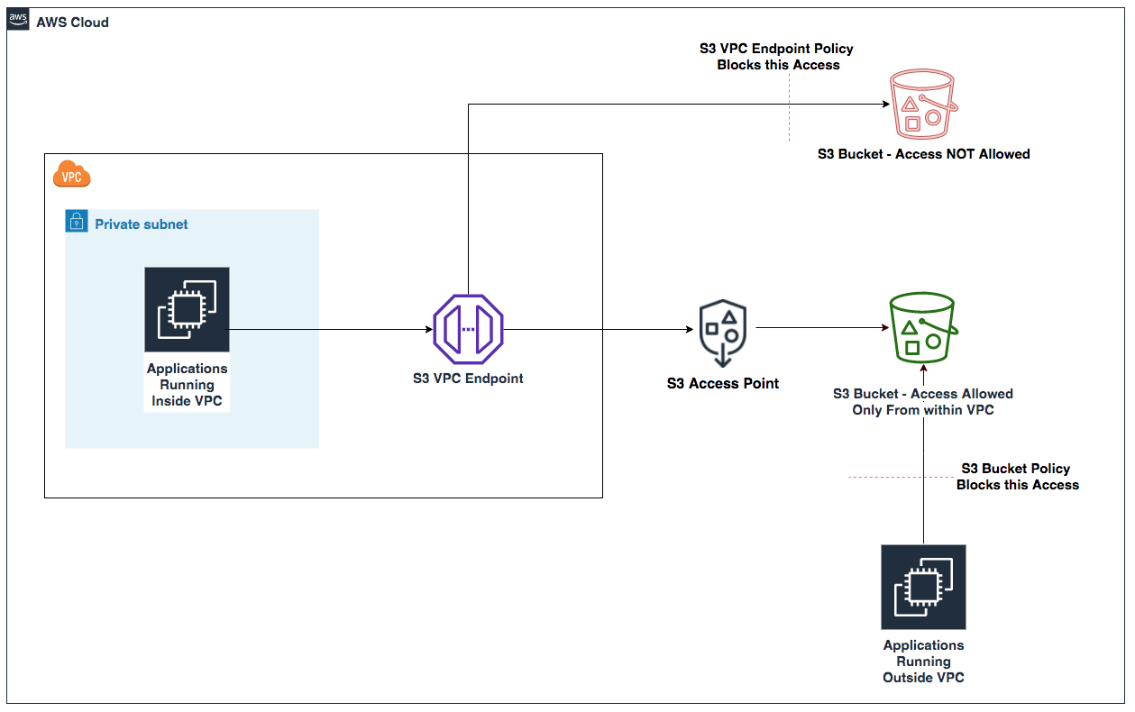
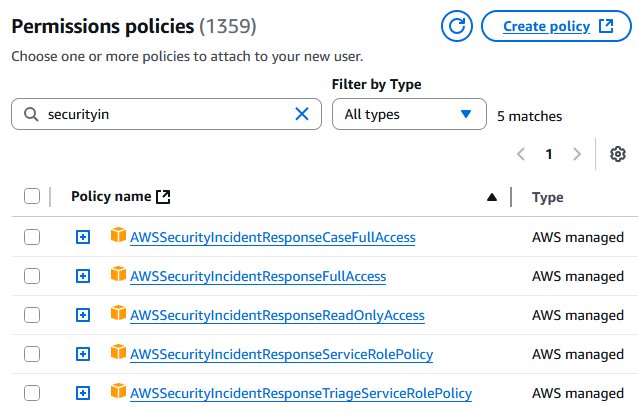
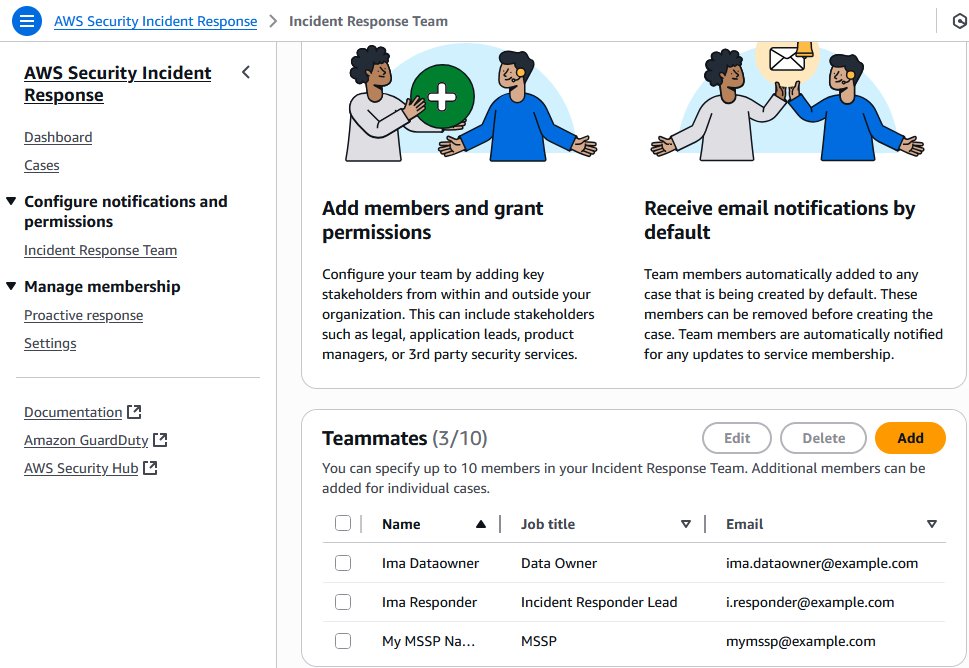
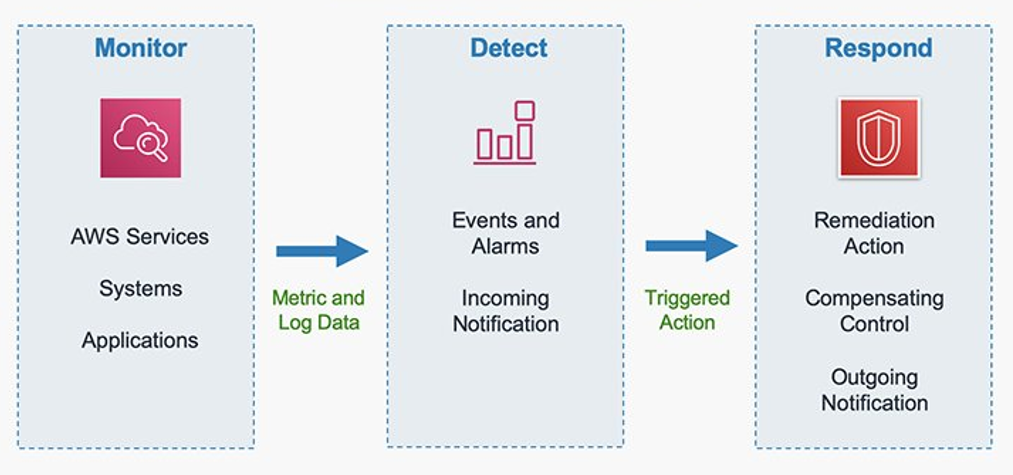

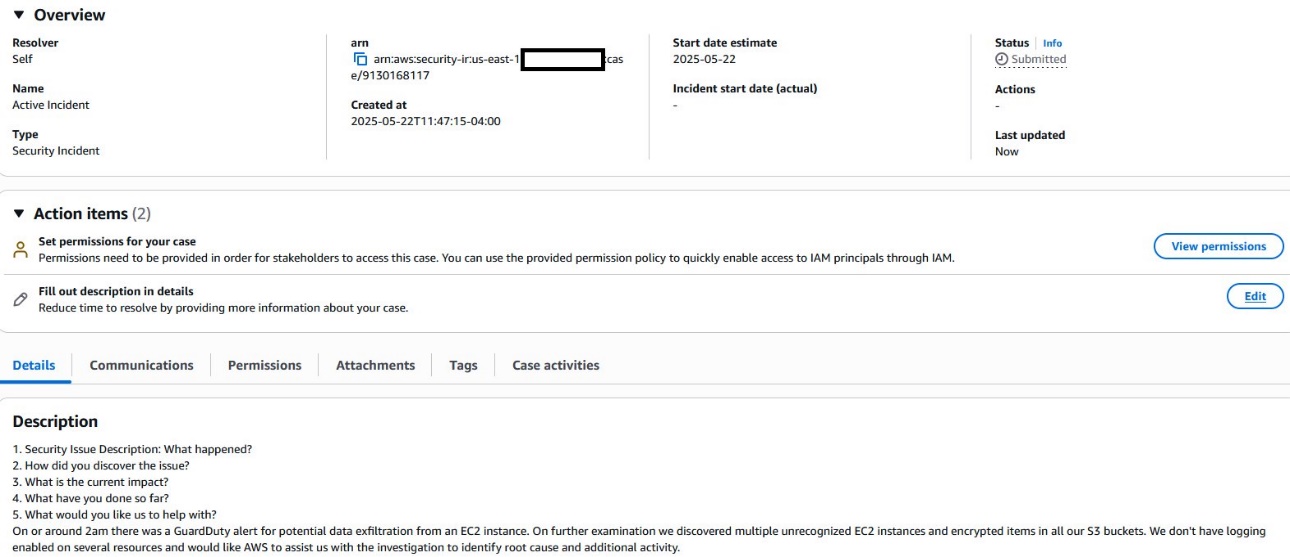
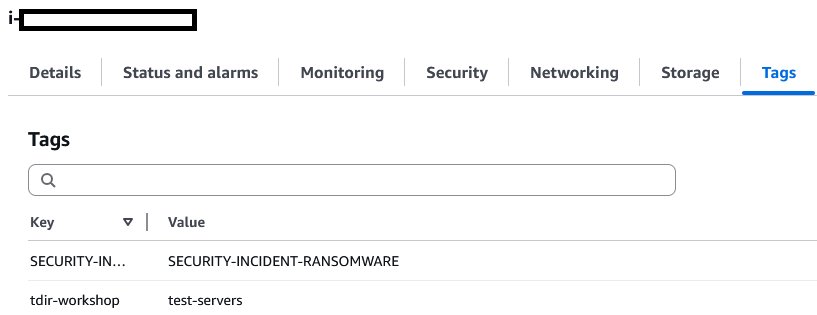
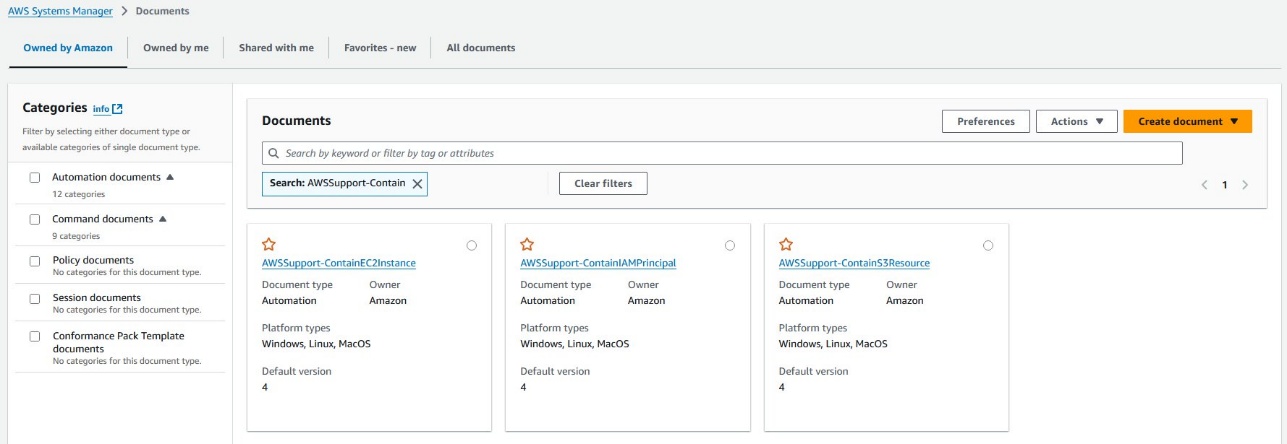
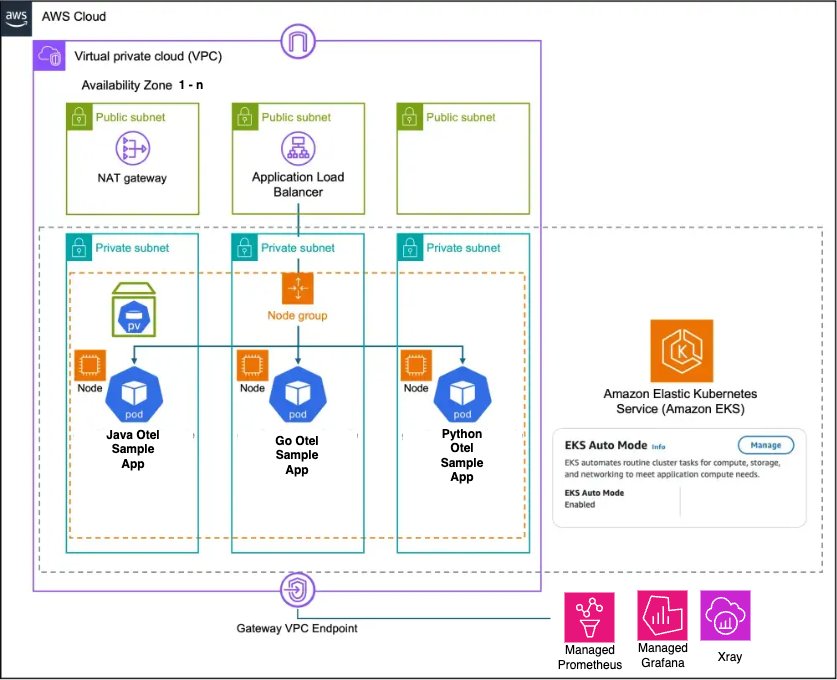
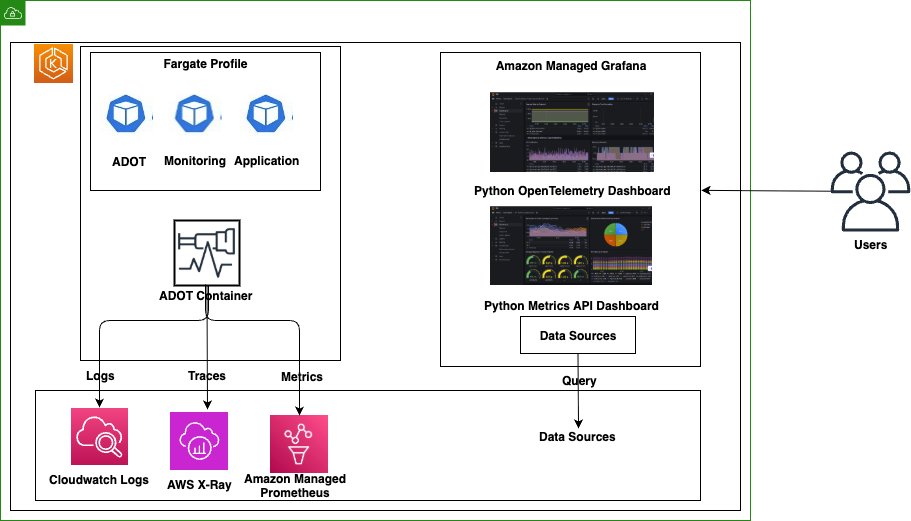
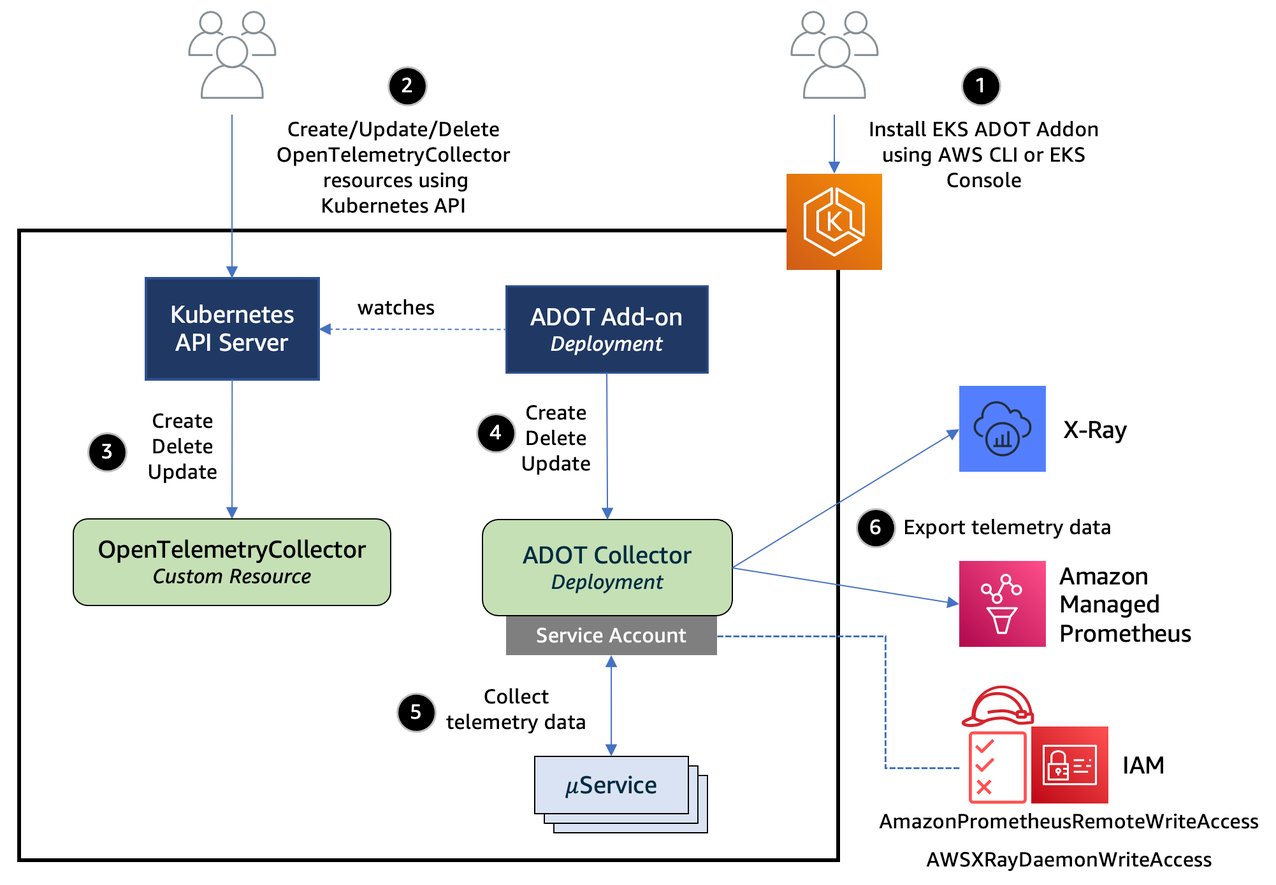
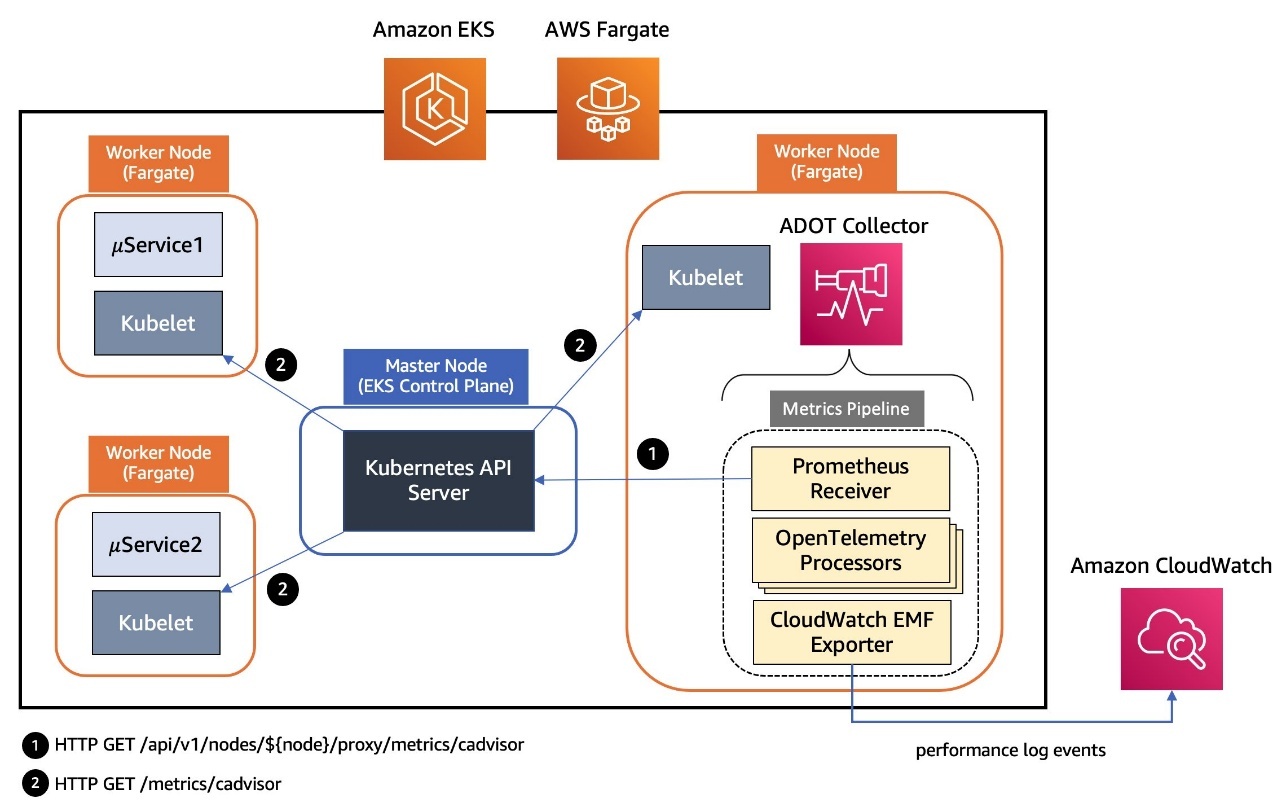
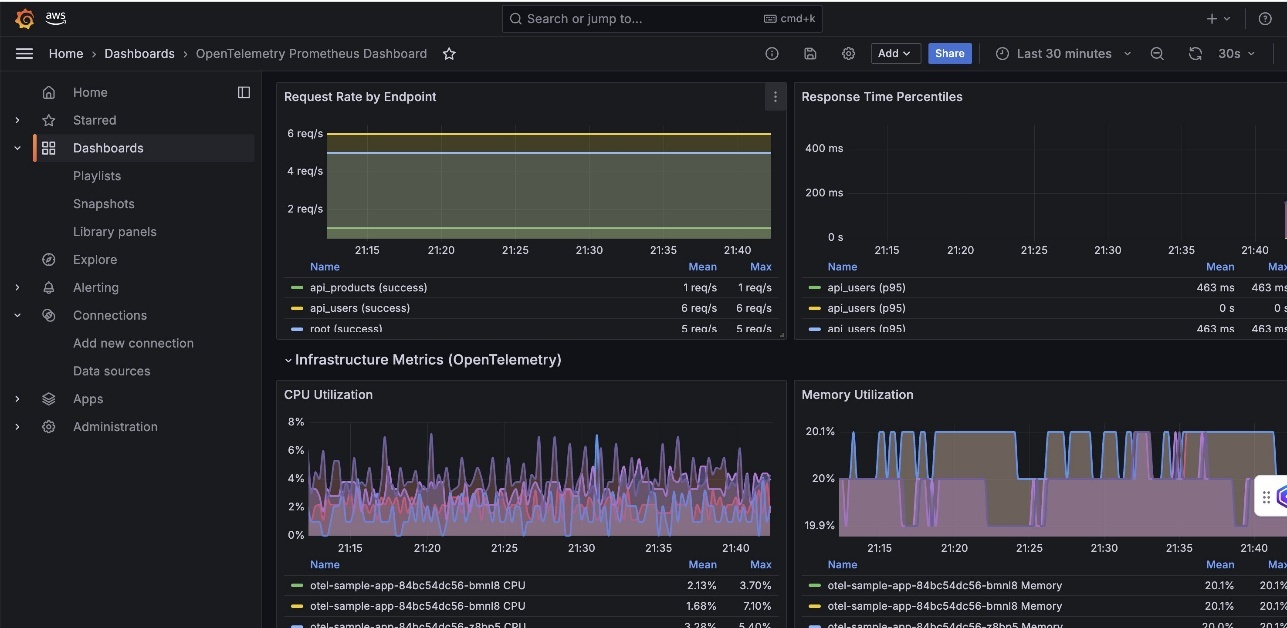
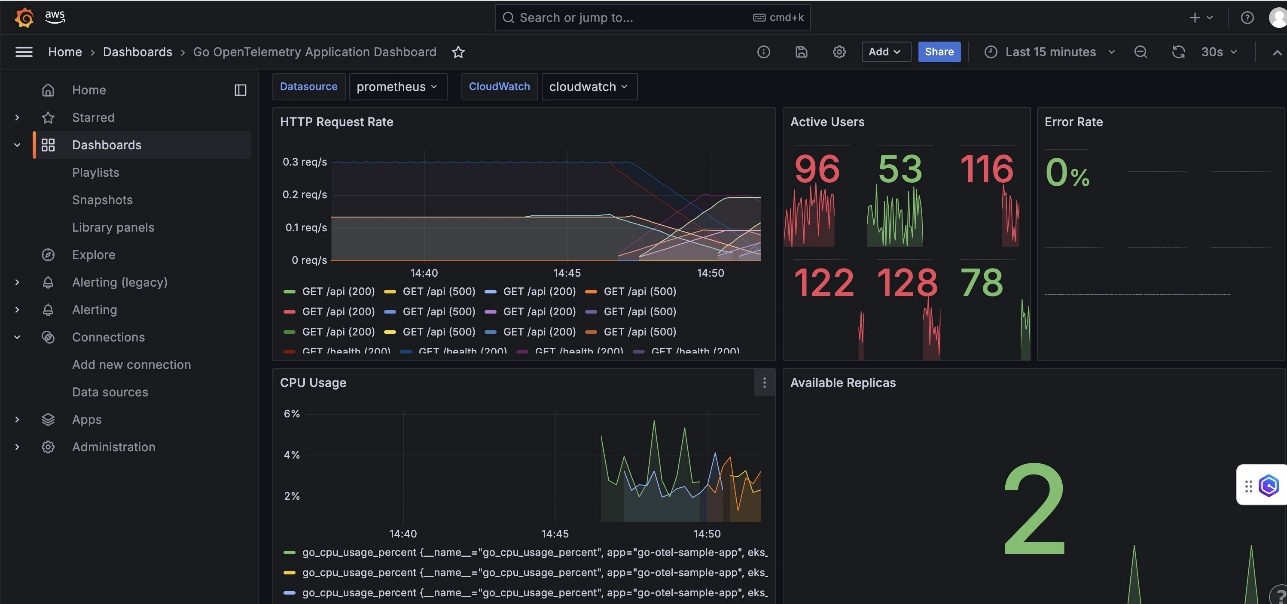
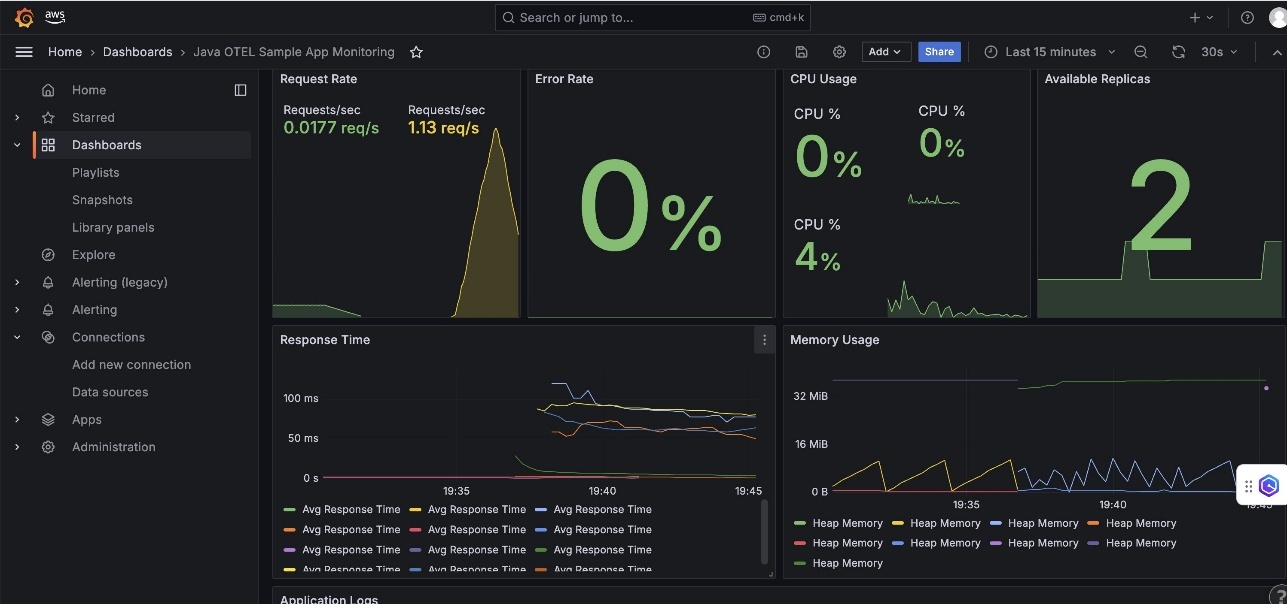

















 Enrique Salgado Hernández is a Senior Specialist Solutions Architect at AWS with more than 10 years of experience working in the cloud. He specializes in designing and implementing large-scale analytics architectures across various industry sectors. He is passionate about working with customers to solve their problems by supporting them during their cloud journey.
Enrique Salgado Hernández is a Senior Specialist Solutions Architect at AWS with more than 10 years of experience working in the cloud. He specializes in designing and implementing large-scale analytics architectures across various industry sectors. He is passionate about working with customers to solve their problems by supporting them during their cloud journey. Angel Conde Manjon is a Senior EMEA Data & AI PSA, based in Madrid. He previously worked on research related to data analytics and AI in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.
Angel Conde Manjon is a Senior EMEA Data & AI PSA, based in Madrid. He previously worked on research related to data analytics and AI in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.




 Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions. Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing.
Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing. Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance.
Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance. Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines.
Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines. Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.
Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems. Imtiaz (Taz) Sayed is the WW Tech Leader for Analytics at AWS. He enjoys engaging with the community on all things data and analytics. He can be reached through
Imtiaz (Taz) Sayed is the WW Tech Leader for Analytics at AWS. He enjoys engaging with the community on all things data and analytics. He can be reached through  Chinmayi Narasimhadevara is a Senior Solutions Architect focused on Data Analytics and AI at AWS. She helps customers build advanced, highly scalable, and performant solutions.
Chinmayi Narasimhadevara is a Senior Solutions Architect focused on Data Analytics and AI at AWS. She helps customers build advanced, highly scalable, and performant solutions.




 Tarun Rai Madan is a Principal Product Manager at Amazon Web Services (AWS). He specializes in serverless technologies and leads product strategy to help customers achieve accelerated business outcomes with event-driven applications, using services like AWS Lambda, AWS Step Functions, Apache Kafka, and Amazon SQS/SNS. Prior to AWS, he was an engineering leader in the semiconductor industry, and led development of high-performance processors for wireless, automotive, and data center applications.
Tarun Rai Madan is a Principal Product Manager at Amazon Web Services (AWS). He specializes in serverless technologies and leads product strategy to help customers achieve accelerated business outcomes with event-driven applications, using services like AWS Lambda, AWS Step Functions, Apache Kafka, and Amazon SQS/SNS. Prior to AWS, he was an engineering leader in the semiconductor industry, and led development of high-performance processors for wireless, automotive, and data center applications. Masudur Rahaman Sayem is a Streaming Data Architect at AWS with over 25 years of experience in the IT industry. He collaborates with AWS customers worldwide to architect and implement sophisticated data streaming solutions that address complex business challenges. As an expert in distributed computing, Sayem specializes in designing large-scale distributed systems architecture for maximum performance and scalability. He has a keen interest and passion for distributed architecture, which he applies to designing enterprise-grade solutions at internet scale.
Masudur Rahaman Sayem is a Streaming Data Architect at AWS with over 25 years of experience in the IT industry. He collaborates with AWS customers worldwide to architect and implement sophisticated data streaming solutions that address complex business challenges. As an expert in distributed computing, Sayem specializes in designing large-scale distributed systems architecture for maximum performance and scalability. He has a keen interest and passion for distributed architecture, which he applies to designing enterprise-grade solutions at internet scale.
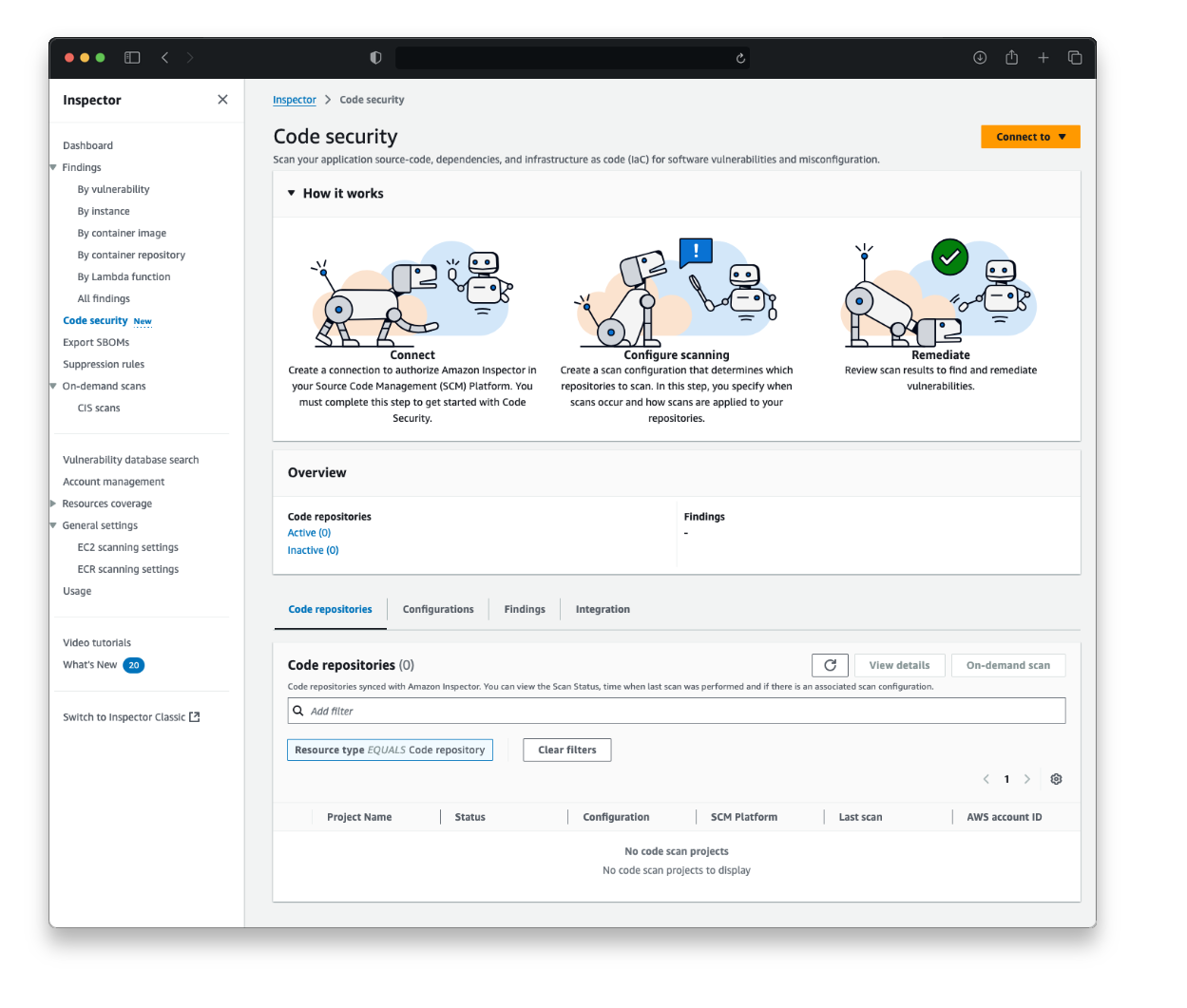
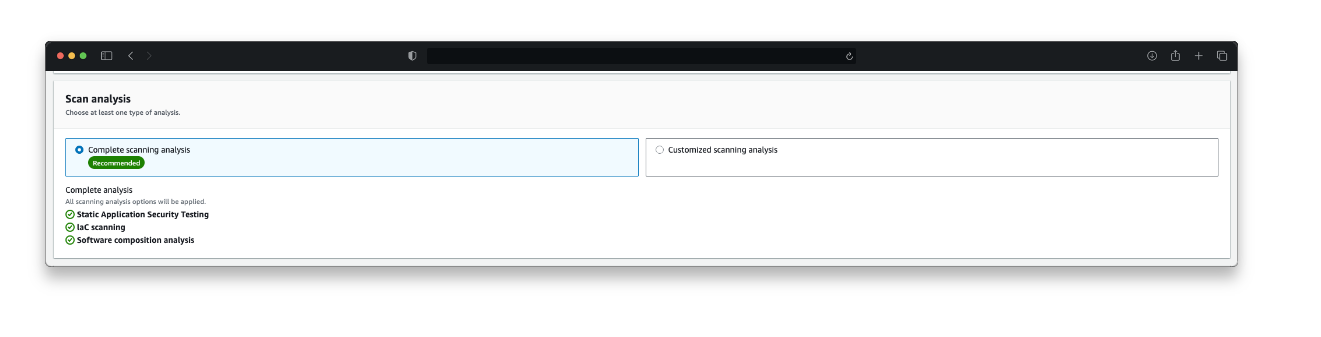
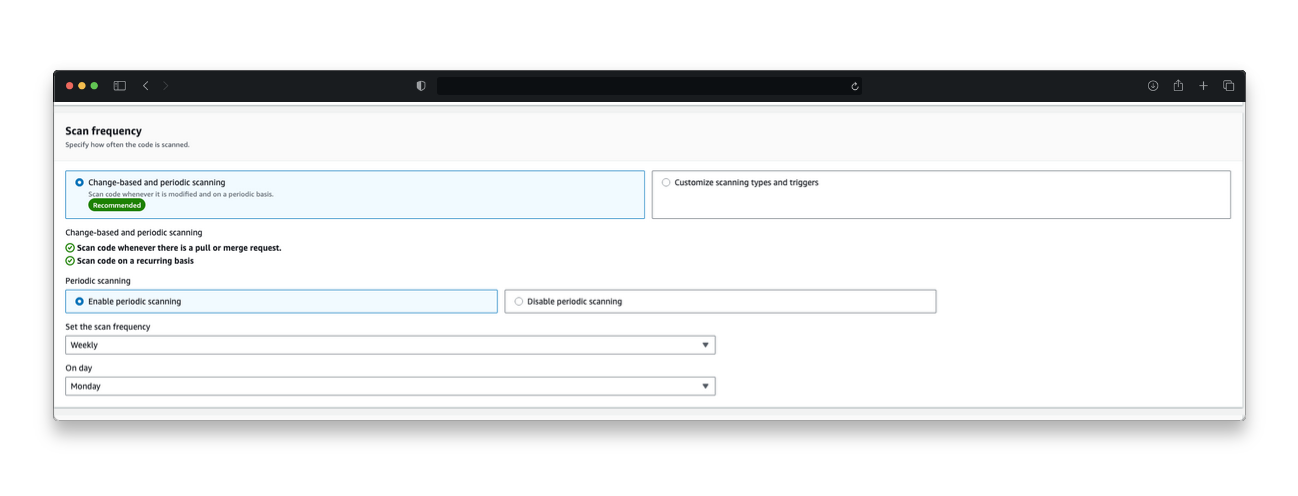
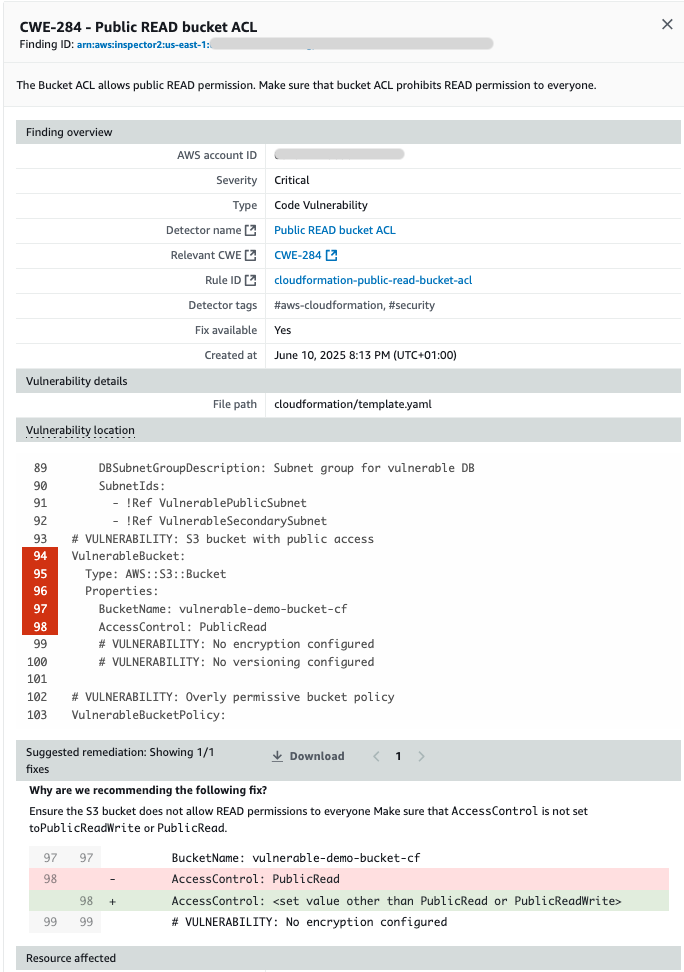


 Shubham Kumar is a Software Development Engineer at Amazon OpenSearch Service, specializing in the security domain. He is passionate about developing robust security features to enhance the protection of customer data and infrastructure.
Shubham Kumar is a Software Development Engineer at Amazon OpenSearch Service, specializing in the security domain. He is passionate about developing robust security features to enhance the protection of customer data and infrastructure. Sachet Alva is a Software Development Manager at Amazon OpenSearch Service, overseeing the infrastructure security and custom package initiatives. His team’s innovations contribute to the enhanced security and flexibility of Amazon OpenSearch Service deployments.
Sachet Alva is a Software Development Manager at Amazon OpenSearch Service, overseeing the infrastructure security and custom package initiatives. His team’s innovations contribute to the enhanced security and flexibility of Amazon OpenSearch Service deployments. Naveen Negi is a Senior Tech Product Manager for Amazon OpenSearch Service. He works closely with engineering teams and customers to shape the future of OpenSearch Service, making sure it meets evolving security and performance needs.
Naveen Negi is a Senior Tech Product Manager for Amazon OpenSearch Service. He works closely with engineering teams and customers to shape the future of OpenSearch Service, making sure it meets evolving security and performance needs.
















 Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data governance, and artificial intelligence at Amazon Web Services (AWS). He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure cloud solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains.
Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data governance, and artificial intelligence at Amazon Web Services (AWS). He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure cloud solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains.





 Julia Beck is an Analytics Specialist Solutions Architect at AWS. She supports customers in validating analytics solutions by architecting proof of concept workloads designed to meet their specific needs.
Julia Beck is an Analytics Specialist Solutions Architect at AWS. She supports customers in validating analytics solutions by architecting proof of concept workloads designed to meet their specific needs. Scott St. Martin is a Solutions Architect at AWS who is passionate about helping customers build modern applications. Scott uses his decade of experience in the cloud to guide organizations in adopting best practices around operational excellence and reliability, with a focus the manufacturing and financial services spaces. Outside of work, Scott enjoys traveling, spending time with family, and playing piano.
Scott St. Martin is a Solutions Architect at AWS who is passionate about helping customers build modern applications. Scott uses his decade of experience in the cloud to guide organizations in adopting best practices around operational excellence and reliability, with a focus the manufacturing and financial services spaces. Outside of work, Scott enjoys traveling, spending time with family, and playing piano.

 Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla. Venu Thangalapally is a Senior Solutions Architect at AWS, based in Chicago, with deep expertise in cloud architecture, data and analytics, containers, and application modernization. He partners with Financial Services industry customers to translate business goals into secure, scalable, and compliant cloud solutions that deliver measurable value. Venu is passionate about leveraging technology to drive innovation and operational excellence. Outside of work, he enjoys spending time with his family, reading, and taking long walks.
Venu Thangalapally is a Senior Solutions Architect at AWS, based in Chicago, with deep expertise in cloud architecture, data and analytics, containers, and application modernization. He partners with Financial Services industry customers to translate business goals into secure, scalable, and compliant cloud solutions that deliver measurable value. Venu is passionate about leveraging technology to drive innovation and operational excellence. Outside of work, he enjoys spending time with his family, reading, and taking long walks. Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.