Everything fails all the time — Werner Vogels, AWS CTO
At the moment of imminent failure, you want to avoid an unlucky deployment. I’ll start here with a short story that demonstrates the purpose of this post.
The DevOps team has just started a database upgrade with a planned outage of 30 minutes. The team automated the entire upgrade flow, triggered a CI/CD pipeline with no human intervention, and the upgrade is progressing smoothly. Then, 20 minutes in, the pipeline is stuck, and your upgrade isn’t progressing. The maintenance window has expired and customers can’t transact. You’ve created a support case, and the AWS engineer confirmed that the upgrade is failing because of a running AWS Health incident in the us-west-2 Region. The engineer has directed the DevOps team to continue monitoring the status.aws.amazon.com page for updates regarding incident resolution. The event continued running for three hours, during which time customers couldn’t transact. Once resolved, the DevOps team retried the failed pipeline, and it completed successfully.
After the incident, the DevOps team explored the possibilities for avoiding these types of incidents in the future. The team was made aware of AWS Health API that provides programmatic access to AWS Health information. In this post, we’ll help the DevOps team make the most of the AWS Health API to proactively prevent unintended outages.
AWS provides Business and Enterprise Support customers with access to the AWS Health API. Customers can have access to running events in the AWS infrastructure that may impact their service usage. Incidents could be Regional, AZ-specific, or even account specific. During these incidents, it isn’t recommended to deploy or change services that are impacted by the event.
In this post, I will walk you through how to embed AWS Health API insights into your CI/CD pipelines to automatically stop deployments whenever an AWS Health event is reported in a Region that you’re operating in. Furthermore, I will demonstrate how you can automate detection and remediation.
The Demo
In this demo, I will use AWS CodePipeline to demonstrate the idea. I will build a simple pipeline that demonstrates the concept without going into the build, test, and deployment specifics.
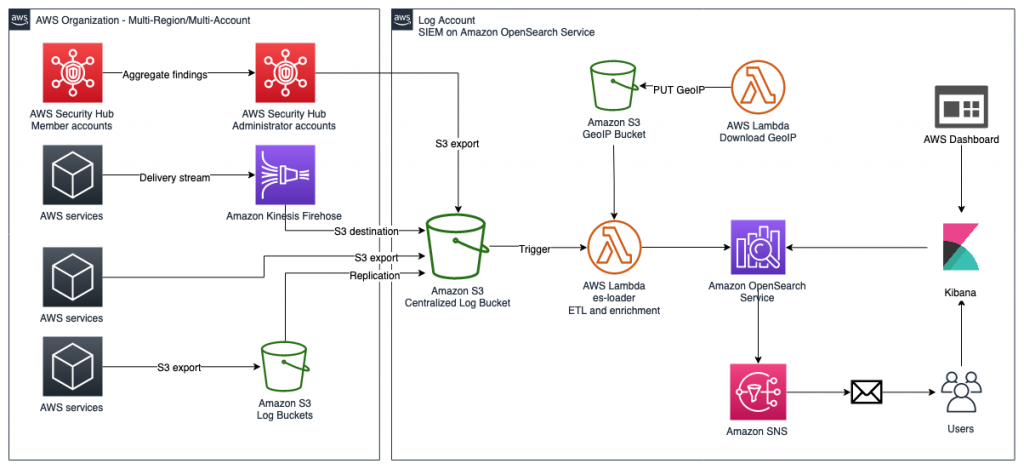
CodePipeline Flow
The CodePipeline flow consists of three steps:
Source stage that downloads a CloudFormation template from AWS CodeCommit. The template will be deployed in the last stage.
Custom stage that invokes the AWS Lambda function to evaluate the AWS Health. The Lambda function calls the AWS Health API, evaluates the health risk, and calls back CodePipeline with the assessment result.
Deploy stage that deploys the CloudFormation templates downloaded from CodeCommit in the first stage.
Figure 1. CodePipeline workflow.
Lambda evaluation logic
The Lambda function evaluates whether or not a running AWS Health event may be impacted by the deployment. In this case, the following criteria must be met to consider it as safe to deploy:
Deployment will take place in the North Virginia Region and accordingly the Lambda function will filter on the us-east-1 Region.
A closed event is irrelevant. The Lambda function will filter events with only the open status.
AWS Health API can return different event types that may not be relevant, such as: Scheduled Maintenance, and Account and Billing notifications. The Lambda function will filter only “Issue” type events.
The AWS Health API follows a multi-Region application architecture and has two regional endpoints in an active-passive configuration. To support active-passive DNS failover, AWS Health provides a global endpoint. The Python code is available on GitHub with more information in the README on how to build the Lambda code package.
The Lambda function requires the following AWS Identity and Access Management (IAM) permissions to access AWS Health API, CodePipeline, and publish logs to CloudWatch:
In CodePipeline, create a new stage with a single action to asynchronously invoke a Lambda function. The function will call AWS Health DescribeEvents API to retrieve the list of active health incidents. Then, the function will complete the event analysis and decide whether or not it may impact the running deployment. Finally, the function will call back CodePipeline with the evaluation results through either PutJobSuccessResult or PutJobFailureResult API operations.
If the Lambda evaluation succeeds, then it will call back the pipeline with a PutJobSuccessResult API. In turn, the pipeline will mark the step as successful and complete the execution.
If the Lambda evaluation fails, then it will call back the pipeline with a PutJobFailureResult API specifying a failure message. Once the DevOps team is made aware that the event has been resolved, select the Retry button to re-evaluate the health status.
Your DevOps team must be aware of failed deployments. Therefore, it’s a good idea to configure alerts to notify concerned stakeholders with failed stage executions. Create a notification rule that posts a Slack message if a stage fails. For detailed steps, see Create a notification rule – AWS CodePipeline. In case of failure, a Slack notification will be sent through AWS Chatbot.
Figure 5. Slack UI snapshot notification for a failed deployment.
A more elegant solution involves pushing the notification to an SNS topic that in turns calls a Lambda function to retry the failed stage. The Lambda function extracts the pipeline failed stage identifier, and then calls the RetryStageExecution CodePipeline API.
Conclusion
We’ve learned how to create an automation that evaluates the risk associated with proceeding with a deployment in conjunction with a running AWS Health event. Then, the automation decides whether to proceed with the deployment or block the progress to avoid unintended downtime. Accordingly, this results in the improved availability of your application.
This solution isn’t exclusive to CodePipeline. However, the pattern can be applied to other CI/CD tools that your DevOps team uses.
It’s critical for your enterprise to understand where sensitive data is stored in your organization and how and why it is shared. The ability to efficiently find data that is shared with entities outside your account and the contents of that data is paramount. You need a process to quickly detect and report which accounts have access to sensitive data. Amazon Macie is an AWS service that can detect many sensitive data types. Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and help protect your sensitive data in AWS.
AWS Identity and Access Management (IAM)Access Analyzer helps to identify resources in your organization and accounts, such as S3 buckets or IAM roles, that are shared with an external entity. When you enable IAM Access Analyzer, you create an analyzer for your entire organization or your account. The organization or account you choose is known as the zone of trust for the analyzer. The analyzer monitors the supported resources within your zone of trust. This analyzer enables IAM Access Analyzer to detect each instance of a resource shared outside the zone of trust and generates a finding about the resource and the external principals that have access to it.
Currently, you can use IAM Access Analyzer and Macie to detect external access and discover sensitive data as separate processes. You can join the findings from both to best evaluate the risk. The solution in this post integrates IAM Access Analyzer, Macie, and AWS Security Hub to automate the process of correlating findings between the services and presenting them in Security Hub.
How does the solution work?
First, IAM Access Analyzer discovers S3 buckets that are shared outside the zone of trust. Next, the solution schedules a Macie sensitive data discovery job for each of these buckets to determine if the bucket contains sensitive data. Upon discovery of shared sensitive data in S3, a custom high severity finding is created in Security Hub for review and incident response.
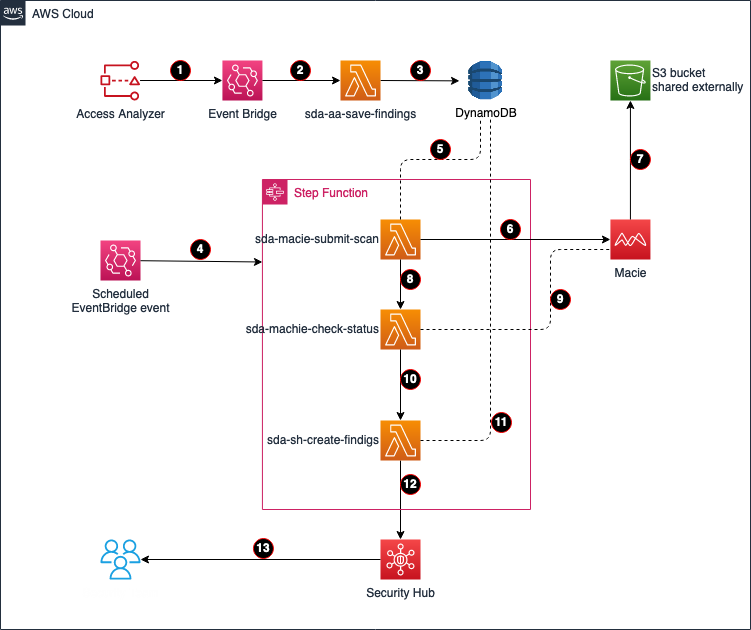
Solution architecture
This solution is based on a serverless architecture, and uses the following services:
IAM Access Analyzer detects shared S3 buckets outside of the zone of trust—the organization or account you choose is known as a zone of trust for the analyzer—and creates the event Access Analyzer Finding in EventBridge.
EventBridge triggers the Lambda function sda-aa-save-findings.
The sda-aa-save-findings function records each finding in DynamoDB.
An EventBridge scheduled event periodically starts a new cycle of the Step Function state machine, which immediately runs the Lambda function sda-macie-submit-scan. The template sets a 15-minute interval, but this is configurable.
The sda-macie-submit-scan function reads the IAM Access Analyzer findings that were created by sda-aa-save-findings from DynamoDB.
sda-macie-submit-scan launches a Macie classification job for each distinct S3 bucket that is related to one or more recent IAM Access Analyzer findings.
Macie performs a sensitive discovery scan on each requested S3 bucket.
The sda-macie-submit-scan function initiates the Lambda function sda-macie-check-status.
sda-macie-check-status periodically checks the status of each Macie classification job, waiting for all the Macie jobs initiated by this solution to complete.
Upon completion of the sda-macie-check-status function, the step function runs the Lambda function sda-sh-create-findings.
sda-sh-create-findings joins the resulting IAM Access Analyzer and Macie datasets for each S3 bucket.
sda-sh-create-findings publishes a finding to Security Hub for each bucket that has both external access and sensitive data.
Note: The Macie scan is skipped if the S3 bucket is tagged to be excluded or if it was recently scanned by Macie. See the Cost considerations section for more information on custom configurations.
Information security can review and act on the findings shown in Security Hub.
Sample Security Hub output
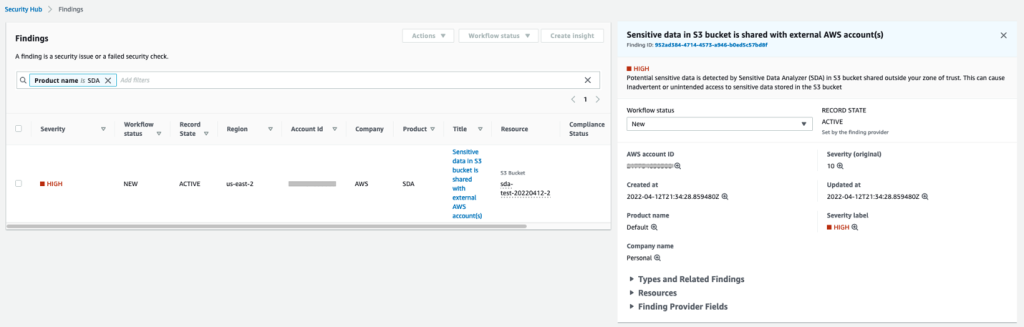
Figure 2 shows the sample findings that Security Hub will present. Each finding includes:
Severity
Workflow status
Record state
Company
Product
Title
Resource
Figure 2: Sample Security Hub findings
The output to Security Hub will display a severity of HIGH with workflow NEW, because this is the first time the event has been observed. The record state is ACTIVE because the workflow state is NEW. The title explains the reason for the event.
For example, if potentially sensitive data is discovered in a bucket that is shared outside a zone of trust, selecting an event will display the resources involved in the finding so you can investigate. For more information, see the Security Hub User Guide.
Notes:
Detection of public S3 buckets by IAM Access Analyzer will still occur through Security Hub and will be marked as critical severity. This solution does not add to or augment this finding in Security Hub.
If a finding in IAM Access Analyzer is archived, the solution does not update the related finding in Security Hub.
The Application code location, S3 Bucket and S3 Key fields will be pre-filled.
Under Service Activations, modify the activations based on the services you presently have running in your account.
Modify the Logging and Monitoring settings if required.
(Optional) Set an alert email address for errors.
Choose Next, then choose Next again.
Under Capabilities, select the check box.
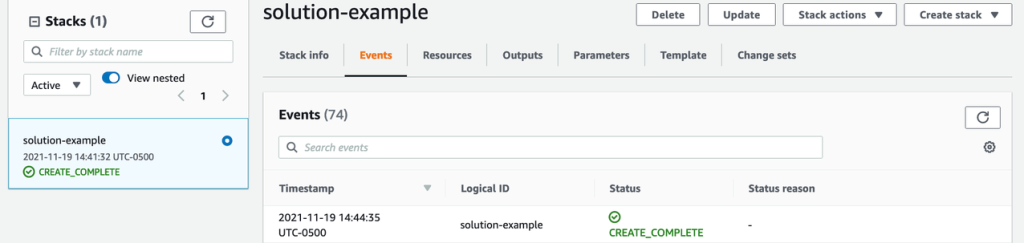
Choose Create Stack. The solution will begin deploying; watch for the CREATE_COMPLETE message.
Figure 3: Sample CloudFormation deployment status
The solution is now deployed and will start monitoring for sensitive data that is being shared. It will send the findings to Security Hub for your teams to investigate.
Cost considerations
When you scan large S3 buckets with sensitive data, remember that Macie cost is based on the amount of data scanned. For more information on Macie costs, see Amazon Macie pricing.
This solution allows the following options, which you can use to help manage costs:
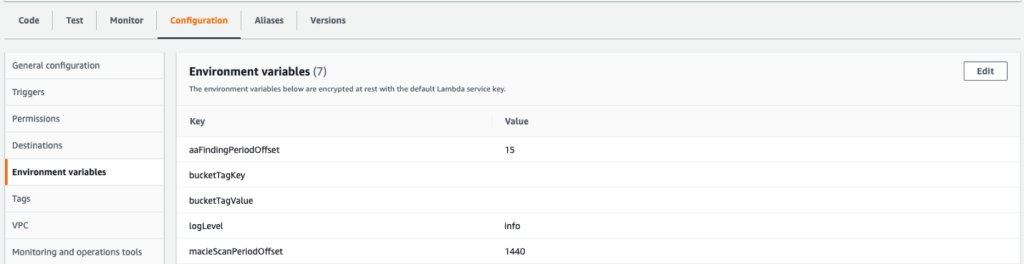
Use environment variables in Lambda to skip specific tagged buckets
Skip recently scanned S3 buckets and reuse prior findings
Figure 4: Screen shot of configurable environment variable
Conclusion
In this post, we discussed how the solution uses Lambda, Step Functions and EventBridge to integrate IAM Access Analyzer with Macie discovery jobs. We reviewed the components of the application, deployed it by using CloudFormation, and reviewed the output a security team would use to take the appropriate actions. We also provided two ways that you can manage the costs associated with the solution.
After you deploy this project, you can modify it to meet your organization’s needs. For example, you can modify the tags to skip specific S3 buckets your organization has already classified to hold sensitive data. Customers who use multiple AWS accounts can designate a centralized Security Hub administrator account to receive the solution alerts from each member account. For more information on this option, see Designating a Security Hub administrator account.
If you have feedback about this post, please submit it in the Comments section below. If you have questions about this post, please start a new thread on the AWS Identity and Access Management forum.
Other resources
For more information on correlating security findings with AWS Security Hub and Amazon EventBridge, refer to this blog post.
Want more AWS Security news? Follow us on Twitter.
Customers often ask for guidance on permissions boundaries in AWS Identity and Access Management (IAM) and when, where, and how to use them. A permissions boundary is an IAM feature that helps your centralized cloud IAM teams to safely empower your application developers to create new IAM roles and policies in Amazon Web Services (AWS). In this blog post, we cover this common use case for permissions boundaries, some best practices to consider, and a few things to avoid.
Background
Developers often need to create new IAM roles and policies for their applications because these applications need permissions to interact with AWS resources. For example, a developer will likely need to create an IAM role with the correct permissions for an Amazon Elastic Compute Cloud (Amazon EC2) instance to report logs and metrics to Amazon CloudWatch. Similarly, a role with accompanying permissions is required for an AWS Glue job to extract, transform, and load data to an Amazon Simple Storage Service (Amazon S3) bucket, or for an AWS Lambda function to perform actions on the data loaded to Amazon S3.
Before the launch of IAM permissions boundaries, central admin teams, such as identity and access management or cloud security teams, were often responsible for creating new roles and policies. But using a centralized team to create and manage all IAM roles and policies creates a bottleneck that doesn’t scale, especially as your organization grows and your centralized team receives an increasing number of requests to create and manage new downstream roles and policies. Imagine having teams of developers deploying or migrating hundreds of applications to the cloud—a centralized team won’t have the necessary context to manually create the permissions for each application themselves.
Because the use case and required permissions can vary significantly between applications and workloads, customers asked for a way to empower their developers to safely create and manage IAM roles and policies, while having security guardrails in place to set maximum permissions. IAM permissions boundaries are designed to provide these guardrails so that even if your developers created the most permissive policy that you can imagine, such broad permissions wouldn’t be functional.
By setting up permissions boundaries, you allow your developers to focus on tasks that add value to your business, while simultaneously freeing your centralized security and IAM teams to work on other critical tasks, such as governance and support. In the following sections, you will learn more about permissions boundaries and how to use them.
Permissions boundaries
A permissions boundary is designed to restrict permissions on IAM principals, such as roles, such that permissions don’t exceed what was originally intended. The permissions boundary uses an AWS or customer managed policy to restrict access, and it’s similar to other IAM policies you’re familiar with because it has resource, action, and effect statements. A permissions boundary alone doesn’t grant access to anything. Rather, it enforces a boundary that can’t be exceeded, even if broader permissions are granted by some other policy attached to the role. Permissions boundaries are a preventative guardrail, rather than something that detects and corrects an issue. To grant permissions, you use resource-based policies (such as S3 bucket policies) or identity-based policies (such as managed or in-line permissions policies).
The predominant use case for permissions boundaries is to limit privileges available to IAM roles created by developers (referred to as delegated administrators in the IAM documentation) who have permissions to create and manage these roles. Consider the example of a developer who creates an IAM role that can access all Amazon S3 buckets and Amazon DynamoDB tables in their accounts. If there are sensitive S3 buckets in these accounts, then these overly broad permissions might present a risk.
To limit access, the central administrator can attach a condition to the developer’s identity policy that helps ensure that the developer can only create a role if the role has a permissions boundary policy attached to it. The permissions boundary, which AWS enforces during authorization, defines the maximum permissions that the IAM role is allowed. The developer can still create IAM roles with permissions that are limited to specific use cases (for example, allowing specific actions on non-sensitive Amazon S3 buckets and DynamoDB tables), but the attached permissions boundary prevents access to sensitive AWS resources even if the developer includes these elevated permissions in the role’s IAM policy. Figure 1 illustrates this use of permissions boundaries.
Figure 1: Implementing permissions boundaries
The central IAM team adds a condition to the developer’s IAM policy that allows the developer to create a role only if a permissions boundary is attached to the role.
The developer creates a role with accompanying permissions to allow access to an application’s Amazon S3 bucket and DynamoDB table. As part of this step, the developer also attaches a permissions boundary that defines the maximum permissions for the role.
Resource access is granted to the application’s resources.
Resource access is denied to the sensitive S3 bucket.
You can use the following policy sample for your developers to allow the creation of roles only if a permissions boundary is attached to them. Make sure to replace <YourAccount_ID> with an appropriate AWS account ID; and the <DevelopersPermissionsBoundary>, with your permissions boundary policy.
Put together, you can use the following permissions policy for your developers to get started with permissions boundaries. This policy allows your developers to create downstream roles with an attached permissions boundary. The policy further denies permissions to detach, delete, or modify the attached permissions boundary policy. Remember, nothing is implicitly allowed in IAM, so you need to allow access permissions for any other actions that your developers require. To learn about allowing access permissions for various scenarios, see Example IAM identity-based policies in the documentation.
You can build on these concepts and apply permissions boundaries to different organizational structures and functional units. In the example shown in Figure 2, the developer can only create IAM roles if a permissions boundary associated to the business function is attached to the IAM roles. In the example, IAM roles in function A can only perform Amazon EC2 actions and Amazon DynamoDB actions, and they don’t have access to the Amazon S3 or Amazon Relational Database Service (Amazon RDS) resources of function B, which serve a different use case. In this way, you can make sure that roles created by your developers don’t exceed permissions outside of their business function requirements.
Figure 2: Implementing permissions boundaries in multiple organizational functions
Best practices
You might consider restricting your developers by directly applying permissions boundaries to them, but this presents the risk of you running out of policy space. Permissions boundaries use a managed IAM policy to restrict access, so permissions boundaries can only be up to 6,144 characters long. You can have up to 10 managed policies and 1 permissions boundary attached to an IAM role. Developers often need larger policy spaces because they perform so many functions. However, the individual roles that developers create—such as a role for an AWS service to access other AWS services, or a role for an application to interact with AWS resources—don’t need those same broad permissions. Therefore, it is generally a best practice to apply permissions boundaries to the IAM roles created by developers, rather than to the developers themselves.
There are better mechanisms to restrict developers, and we recommend that you use IAM identity policies and AWS Organizations service control policies (SCPs) to restrict access. In particular, the Organizations SCPs are a better solution here because they can restrict every principal in the account through one policy, rather than separately restricting individual principals, as permissions boundaries and IAM identity policies are confined to do.
You should also avoid replicating the developer policy space to a permissions boundary for a downstream IAM role. This, too, can cause you to run out of policy space. IAM roles that developers create have specific functions, and the permissions boundary can be tailored to common business functions to preserve policy space. Therefore, you can begin to group your permissions boundaries into categories that fit the scope of similar application functions or use cases (such as system automation and analytics), and allow your developers to choose from multiple options for permissions boundaries, as shown in the following policy sample.
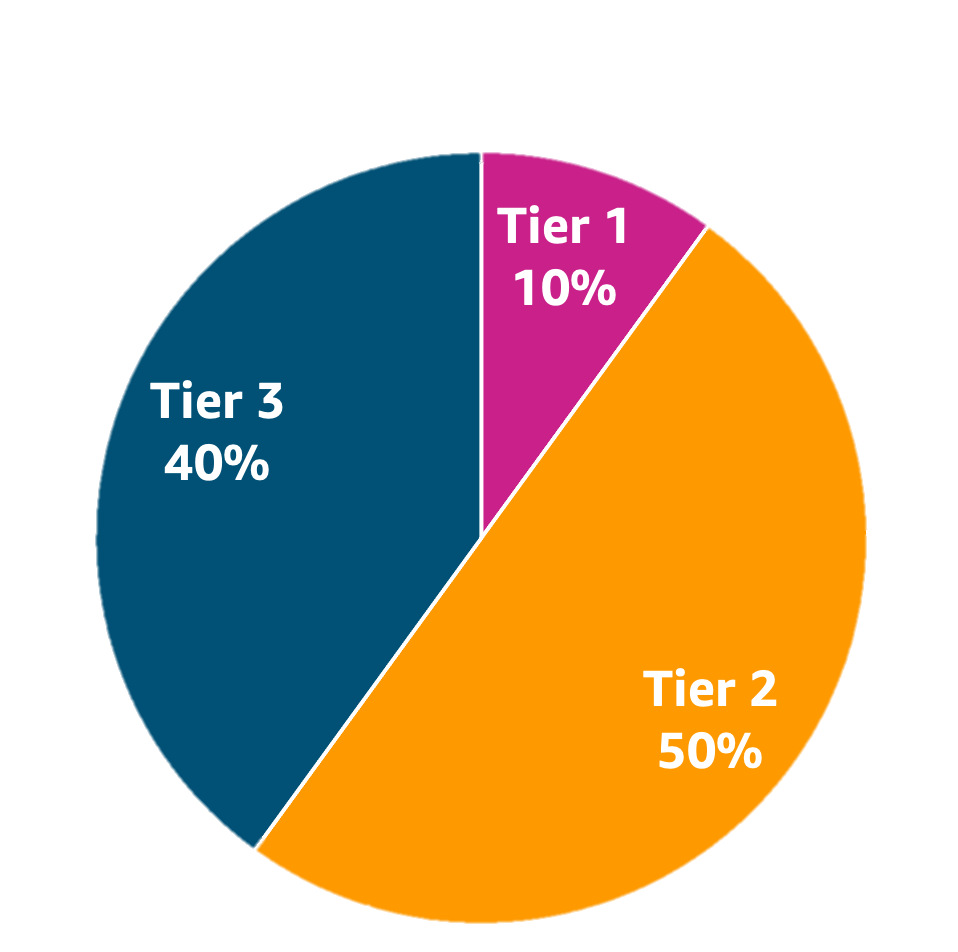
Finally, it is important to understand the differences between the various IAM resources available. The following table lists these IAM resources, their primary use cases and managing entities, and when they apply. Even if your organization uses different titles to refer to the personas in the table, you should have separation of duties defined as part of your security strategy.
IAM resource
Purpose
Owner/maintainer
Applies to
Federated roles and policies
Grant permissions to federated users for experimentation in lower environments
Central team
People represented by users in the enterprise identity provider
IAM workload roles and policies
Grant permissions to resources used by applications, services
Developer
IAM roles representing specific tasks performed by applications
Permissions boundaries
Limit permissions available to workload roles and policies
Central team
Workload roles and policies created by developers
IAM users and policies
Allowed only by exception when there is no alternative that satisfies the use case
Central team plus senior leadership approval
Break-glass access; legacy workloads unable to use IAM roles
Conclusion
This blog post covered how you can use IAM permissions boundaries to allow your developers to create the roles that they need and to define the maximum permissions that can be given to the roles that they create. Remember, you can use AWS Organizations SCPs or deny statements in identity policies for scenarios where permissions boundaries are not appropriate. As your organization grows and you need to create and manage more roles, you can use permissions boundaries and follow AWS best practices to set security guard rails and decentralize role creation and management. Get started using permissions boundaries in IAM.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Watts S. Humphrey, the father of Software Quality, had famously quipped, “Every business is a software business”. Software is indeed integral to any industry. The engineers who create software are also responsible for making sure that the underlying code adheres to industry and organizational standards, are performant, and are absolved of any security vulnerabilities that could make them susceptible to attack.
Traditionally, security testing has been the forte of a specialized security testing team, who would conduct their tests toward the end of the Software Development lifecycle (SDLC). The adoption of DevSecOps practices meant that security became a shared responsibility between the development and security teams. Now, development teams can, on their own or as advised by their security team, setup and configure various code scanning tools to detect security vulnerabilities much earlier in the software delivery process (aka “Shift Left”). Meanwhile, the practice of Static code analysis and security application testing (SAST) has become a standard part of the SDLC. Furthermore, it’s imperative that the development teams expect SAST tools that are easy to set-up, seamlessly fit into their DevOps infrastructure, and can be configured without requiring assistance from security or DevOps experts.
In this post, we’ll demonstrate how you can leverage Amazon CodeGuru Reviewer Command Line Interface (CLI) to integrate CodeGuru Reviewer into your Jenkins Continuous Integration & Continuous Delivery (CI/CD) pipeline. Note that the solution isn’t limited to Jenkins, and it would be equally useful with any other build automation tool. Moreover, it can be integrated at any stage of your SDLC as part of the White-box testing. For example, you can integrate the CodeGuru Reviewer CLI as part of your software development process, as well as run it on your dev machine before committing the code.
Launched in 2020, CodeGuru Reviewer utilizes machine learning (ML) and automated reasoning to identify security vulnerabilities, inefficient uses of AWS APIs and SDKs, as well as other common coding errors. CodeGuru Reviewer employs a growing set of detectors for Java and Python to provide recommendations via the AWS Console. Customers that leverage the CodeGuru Reviewer CLI within a CI/CD pipeline also receive recommendations in a machine-readable JSON format, as well as HTML.
CodeGuru Reviewer offers native integration with Source Code Management (SCM) systems, such as GitHub, BitBucket, and AWS CodeCommit. However, it can be used with any SCM via its CLI. The CodeGuru Reviewer CLI is a shim layer on top of the AWS Command Line Interface (AWS CLI) that simplifies the interaction with the tool by handling the uploading of artifacts, triggering of the analysis, and fetching of the results, all in a single command.
Many customers, including Mastercard, are benefiting from this new CodeGuru Reviewer CLI.
“During one of our technical retrospectives, we noticed the need to integrate Amazon CodeGuru recommendations in our build pipelines hosted on Jenkins. Not all our developers can run or check CodeGuru recommendations through the AWS console. Incorporating CodeGuru CLI in our build pipelines acts as an important quality gate and ensures that our developers can immediately fix critical issues.” Claudio Frattari, Lead DevOps at Mastercard
Solution overview
The application deployment workflow starts by placing the application code on a GitHub SCM. To automate the scenario, we have added GitHub to the Jenkins project under the “Source Code” section. We chose the GitHub option, which would clone the chosen GitHub repository in the Jenkins local workspace directory.
In the build stage of the pipeline (see Figure 1), we configure the appropriate build tool to perform the code build and security analysis. In this example, we will be using Maven as the build tool.
Figure 1: Jenkins pipeline with Amazon CodeGuru Reviewer
In the post-build stage, we configure the CodeGuru Reviewer CLI to generate the recommendations based on the review.
Lastly, in the concluding stage of the pipeline, we’ll be analyzing the JSON results using jq – a lightweight and flexible command-line JSON processor, and then failing the Jenkins job if we encounter observations that are of a “Critical” severity.
Jenkins will trigger the “CodeGuru Reviewer” (see Figure 1) based review process in the post-build stage, i.e., after the build finishes. Furthermore, you can configure other stages, such as automated testing or deployment, after this stage. Additionally, passing the location of the build artifacts to the CLI lets CodeGuru Reviewer perform a more in-depth security analysis. Build artifacts are either directories containing jar files (e.g., build/lib for Gradle or /target for Maven) or directories containing class hierarchies (e.g., build/classes/java/main for Gradle).
Walkthrough
Now that we have an overview of the workflow, let’s dive deep and walk you through the following steps in detail:
To run the CLI, we must have Git, Java, Maven, and the AWS CLI installed. Verify that they’re installed on our machine by running the following commands:
If they aren’t installed, then download and install Java here (Amazon Corretto is a no-cost, multiplatform, production-ready distribution of the Open Java Development Kit), Maven from here, and Git from here. Instructions for installing AWS CLI are available here.
We would need to create an Amazon Simple Storage Service (Amazon S3) bucket with the prefix codeguru-reviewer-. Note that the bucket name must begin with the mentioned prefix, since we have used the name pattern in the following AWS Identity and Access Management (IAM) permissions, and CodeGuru Reviewer expects buckets to begin with this prefix. Refer to the following section 4(a) “Specifying S3 bucket name” for more details.
Furthermore, we’ll need working credentials on our machine to interact with our AWS account. Learn more about setting up credentials for AWS here. You can find the minimal permissions to run the CodeGuru Reviewer CLI as follows.
b. Required Permissions
To use the CodeGuru Reviewer CLI, we need at least the following AWS IAM permissions, attached to an AWS IAM User or an AWS IAM role:
The CodeGuru Reviewer CLI only has one required parameter –root-dir (or just -r) to specify to the local directory that should be analyzed. Furthermore, the –src option can be used to specify one or more files in this directory that contain the source code that should be analyzed. In turn, for Java applications, the –build option can be used to specify one or more build directories.
For a demonstration, we’ll analyze the demo application. This will make sure that we’re all set for when we leverage the CLI in Jenkins. To proceed, first we download and install the sample application, as follows:
git clone https://github.com/aws-samples/amazon-codeguru-reviewer-sample-app
cd amazon-codeguru-reviewer-sample-app
mvn clean compile
Now that we have built our demo application, we can use the aws-codeguru-cli CLI command that we added to the path to trigger the code scan:
For additional assistance on the CLI command, reference the readme here.
2. Creating a Jenkins Pipeline job
CodeGuru Reviewer can be integrated in a Jenkins Pipeline as well as a Freestyle project. In this example, we’re leveraging a Pipeline.
a. Pipeline Job Configuration
Log in to Jenkins, choose “New Item”, then select “Pipeline” option.
Enter a name for the project (for example, “CodeGuruPipeline”), and choose OK.
Figure 2: Creating a new Jenkins pipeline
On the “Project configuration” page, scroll down to the bottom and find your pipeline. In the pipeline script, paste the following script (or use your own Jenkinsfile). The following example is a valid Jenkinsfile to integrate CodeGuru Reviewer with a project built using Maven.
pipeline {
agent any
stages {
stage('Build') {
steps {
// Get code from a GitHub repository
git clone https://github.com/aws-samples/amazon-codeguru-reviewer-java-detectors.git
// Run Maven on a Unix agent
sh "mvn clean compile"
// To run Maven on a Windows agent, use following
// bat "mvn -Dmaven.test.failure.ignore=true clean package"
}
}
stage('CodeGuru Reviewer') {
steps{
sh 'ls -lsa *'
sh 'pwd'
// Here we’re setting an absolute path, but we can
// also use JENKINS environment variables
sh '''
export BASE=/var/jenkins_home/workspace/CodeGuruPipeline/amazon-codeguru-reviewer-java-detectors
export SRC=${BASE}/src
export OUTPUT = ./output
/home/codeguru/aws-codeguru-cli/bin/aws-codeguru-cli --root-dir $BASE --build $BASE/target/classes --src $SRC --output $OUTPUT -c $GIT_PREVIOUS_COMMIT:$GIT_COMMIT --no-prompt
'''
}
}
stage('Checking findings'){
steps{
// In this example we are stopping our pipline on
// detecting Critical findings. We are using jq
// to count occurrences of Critical severity
sh '''
CNT = $(cat ./output/recommendations.json |jq '.[] | select(.severity=="Critical")|.severity' | wc -l)'
if (( $CNT > 0 )); then
echo "Critical findings discovered. Failing."
exit 1
fi
'''
}
}
}
}
Save the configuration and select “Build now” on the side bar to trigger the build process (see Figure 3).
Figure 3: Jenkins pipeline in triggered state
3. Reviewing the CodeGuru Reviewer recommendations
Once the build process is finished, you can view the review results from CodeGuru Reviewer by selecting the Jenkins build history for the most recent build job. Then, browse to Workspace output. The output is available in JSON and HTML formats (Figure 4).
Figure 4: CodeGuru CLI Output
Snippets from the HTML and JSON reports are displayed in Figure 5 and 6 respectively.
In this example, our pipeline analyzes the JSON results with jq based on severity equal to critical and failing the job if there are any critical findings. Note that this output path is set with the –output option. For instance, the pipeline will fail on noticing the “critical” finding at Line 67 of the EventHandler.java class (Figure 5), flagged due to use of an insecure code. Till the time the code is remediated, the pipeline would prevent the code deployment. The vulnerability could have gone to production undetected, in absence of the tool.
CodeGuru Reviewer needs one Amazon S3 bucket for the CLI to store the artifacts while the analysis is running. The artifacts are deleted after the analysis is completed. The same bucket will be reused for all the repositories that are analyzed in the same account and region (unless specified otherwise by the user). Note that CodeGuru Reviewer expects the S3 bucket name to begin with codeguru-reviewer-. At this time, you can’t use a different naming pattern. However, if you want to use a different bucket name, then you can use the –bucket-name option.
Select the Permissions tab of your S3 bucket. Update the Block public access and add the following S3 bucket policy.
Figure 7: S3 bucket settings
S3 bucket policy:
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"PublicRead",
"Effect":"Allow",
"Principal":"*",
"Action":"s3:GetObject",
"Resource":"[Change to ARN for your S3 bucket]/*"
}
]
}
Note that if you must change the bucket’s name, then you can remove the associated S3 bucket in the AWS console under CodeGuru → CI workflows and select Disassociate Workflow.
b. Analyzing a single commit
The CLI also lets us specify a specific commit range to analyze. This can lead to faster and more cost-effective scans for the incremental code changes, instead of a full repository scan. For example, if we just want to analyze the last commit, we can run:
Here, we use the -c option to specify that we only want to analyze the commits between HEAD^ (the previous commit) and HEAD (the current commit). Moreover, we add the –no-prompt option to automatically answer questions by the CLI with yes. This option is useful if we plan to use the CLI in an automated way, such as in our CI/CD workflow.
c. Encrypting artifacts
CodeGuru Reviewer lets us use a customer managed key to encrypt the content of the S3 bucket that is used to store the source and build artifacts. To achieve this, create a customer owned key in AWS Key Management Service (AWS KMS) (see Figure 8).
Figure 8: KMS settings
We must grant CodeGuru Reviewer the permission to decrypt artifacts with this key by adding the following Statement to your Key policy:
{
"Sid":"Allow CodeGuru to use the key to decrypt artifact",
"Effect":"Allow",
"Principal":{
"AWS":"*"
},
"Action":[
"kms:Decrypt",
"kms:DescribeKey"
],
"Resource":"*",
"Condition":{
"StringEquals":{
"kms:ViaService":"codeguru-reviewer.amazonaws.com",
"kms:CallerAccount":[
"YOUR AWS ACCOUNT ID"
]
}
}
}
Then, enable server-side encryption for the S3 bucket that we’re using with CodeGuru Reviewer (Figure 9).
S3 bucket settings:
Figure 9: S3 bucket encryption settings
After we enable encryption on the bucket, we must delete all the CodeGuru repository associations that use this bucket, and then recreate them by analyzing the repositories while providing the key (as in the following example, Figure 10):
Figure 10: CodeGuru CI Workflow
Note that the first time you check out your repository, it will always trigger a full repository scan. Consider setting the -c option, as this will allow a commit range.
Cleaning Up
At this stage, you may choose to delete the resources created while following this blog, to avoid incurring any unwanted costs.
Delete the Jenkins installation, if not required further.
Conclusion
In this post, we outlined how you can integrate Amazon CodeGuru Reviewer CLI with the Jenkins open-source build automation tool to perform code analysis as part of your code build pipeline and act as a quality gate. We showed you how to create a Jenkins pipeline job and integrate the CodeGuru Reviewer CLI to detect issues in your Java and Python code, as well as access the recommendations for remediating these issues. We presented an example where you can stop the build upon finding critical violations. Furthermore, we discussed how you can specify a commit range to avoid a full repo scan, and how the S3 bucket used by CodeGuru Reviewer to store artifacts can be encrypted using customer managed keys.
The CodeGuru Reviewer CLI offers you a one-line command to scan any code on your machine and retrieve recommendations. You can run the CLI anywhere where you can run AWS commands. In other words, you can use the CLI to integrate CodeGuru Reviewer into your favourite CI tool, as a pre-commit hook, or anywhere else in your workflow. In turn, you can combine CodeGuru Reviewer with Dynamic Application Security Testing (DAST) and Software Composition Analysis (SCA) tools to achieve a hybrid application security testing method that helps you combine the inside-out and outside-in testing approaches, cross-reference results, and detect vulnerabilities that both exist and are exploitable.
Hopefully, you have found this post informative, and the proposed solution useful. If you need helping hands, then AWS Professional Services can help implement this solution in your enterprise, as well as introduce you to our AWS DevOps services and offerings.
Many Amazon Web Services (AWS) customers choose to use federation with SAML 2.0 in order to use their existing identity provider (IdP) and avoid managing multiple sources of identities. Some customers have previously configured federation by using AWS Identity and Access Management (IAM) with the endpoint signin.aws.amazon.com. Although this endpoint is highly available, it is hosted in a single AWS Region, us-east-1. This blog post provides recommendations that can improve resiliency for customers that use IAM federation, in the unlikely event of disrupted availability of one of the regional endpoints. We will show you how to use multiple SAML sign-in endpoints in your configuration and how to switch between these endpoints for failover.
How to configure federation with multi-Region SAML endpoints
AWS Sign-In allows users to log in into the AWS Management Console. With SAML 2.0 federation, your IdP portal generates a SAML assertion and redirects the client browser to an AWS sign-in endpoint, by default signin.aws.amazon.com/saml. To improve federation resiliency, we recommend that you configure your IdP and AWS federation to support multiple SAML sign-in endpoints, which requires configuration changes for both your IdP and AWS. If you have only one endpoint configured, you won’t be able to log in to AWS by using federation in the unlikely event that the endpoint becomes unavailable.
Let’s take a look at the Region code SAML sign-in endpoints in the AWS General Reference. The table in the documentation shows AWS regional endpoints globally. The format of the endpoint URL is as follows, where <region-code> is the AWS Region of the endpoint: https://<region-code>.signin.aws.amazon.com/saml
All regional endpoints have a region-code value in the DNS name, except for us-east-1. The endpoint for us-east-1 is signin.aws.amazon.com—this endpoint does not contain a Region code and is not a global endpoint. AWS documentation has been updated to reference SAML sign-in endpoints.
In the next two sections of this post, Configure your IdP and Configure IAM roles, I’ll walk through the steps that are required to configure additional resilience for your federation setup.
Important: You must do these steps before an unexpected unavailability of a SAML sign-in endpoint.
Configure your IdP
You will need to configure your IdP and specify which AWS SAML sign-in endpoint to connect to.
To configure your IdP
If you are setting up a new configuration for AWS federation, your IdP will generate a metadata XML configuration file. Keep track of this file, because you will need it when you configure the AWS portion later.
Register the AWS service provider (SP) with your IdP by using a regional SAML sign-in endpoint. If your IdP allows you to import the AWS metadata XML configuration file, you can find these files available for the public,GovCloud, and China Regions.
If you are manually setting the Assertion Consumer Service (ACS) URL, we recommend that you pick the endpoint in the same Region where you have AWS operations.
In SAML 2.0, RelayState is an optional parameter that identifies a specified destination URL that your users will access after signing in. When you set the ACS value, configure the corresponding RelayState to be in the same Region as the ACS. This keeps the Region configurations consistent for both ACS and RelayState. Following is the format of a Region-specific console URL.
https://<region-code>.console.aws.amazon.com/
For more information, refer to your IdP’s documentation on setting up the ACS and RelayState.
Configure IAM roles
Next, you will need to configure IAM roles’ trust policies for all federated human access roles with a list of all the regional AWS Sign-In endpoints that are necessary for federation resiliency. We recommend that your trust policy contains all Regions where you operate. If you operate in only one Region, you can get the same resiliency benefits by configuring an additional endpoint. For example, if you operate only in us-east-1, configure a second endpoint, such as us-west-2. Even if you have no workloads in that Region, you can switch your IdP to us-west-2 for failover. You can log in through AWS federation by using the us-west-2 SAML sign-in endpoint and access your us-east-1 AWS resources.
To configure IAM roles
Log in to the AWS Management Console with credentials to administer IAM. If this is your first time creating the identity provider trust in AWS, follow the steps in Creating IAM SAML identity providers to create the identity providers.
Next, create or update IAM roles for federated access. For each IAM role, update the trust policy that lists the regional SAML sign-in endpoints. Include at least two for increased resiliency.
The following example is a role trust policy that allows the role to be assumed by a SAML provider coming from any of the four US Regions.
When you use a regional SAML sign-in endpoint, the corresponding regional AWS Security Token Service (AWS STS) endpoint is also used when you assume an IAM role. If you are using service control policies (SCP) in AWS Organizations, check that there are no SCPs denying the regional AWS STS service. This will prevent the federated principal from being able to obtain an AWS STS token.
Switch regional SAML sign-in endpoints
In the event that the regional SAML sign-in endpoint your ACS is configured to use becomes unavailable, you can reconfigure your IdP to point to another regional SAML sign-in endpoint. After you’ve configured your IdP and IAM role trust policies as described in the previous two sections, you’re ready to change to a different regional SAML sign-in endpoint. The following high-level steps provide guidance on switching the regional SAML sign-in endpoint.
To switch regional SAML sign-in endpoints
Change the configuration in the IdP to point to a different endpoint by changing the value for the ACS.
Change the configuration for the RelayState value to match the Region of the ACS.
Log in with your federated identity. In the browser, you should see the new ACS URL when you are prompted to choose an IAM role.
Figure 1: New ACS URL
The steps to reconfigure the ACS and RelayState will be different for each IdP. Refer to the vendor’s IdP documentation for more information.
Conclusion
In this post, you learned how to configure multiple regional SAML sign-in endpoints as a best practice to further increase resiliency for federated access into your AWS environment. Check out the updates to the documentation for AWS Sign-In endpoints to help you choose the right configuration for your use case. Additionally, AWS has updated the metadata XML configuration for the public,GovCloud, and China AWS Regions to include all sign-in endpoints.
The simplest way to get started with SAML federation is to use AWS Single Sign-On (AWS SSO). AWS SSO helps manage your permissions across all of your AWS accounts in AWS Organizations.
AWS Service Catalog enables organizations to create and manage Information Technology (IT) services catalogs that are approved for use on AWS. These IT services can include resources such as virtual machine images, servers, software, and databases to complete multi-tier application architectures. AWS Service Catalog lets you centrally manage deployed IT services and your applications, resources, and metadata , which helps you achieve consistent governance and meet your compliance requirements. In addition, this configuration enables users to quickly deploy only approved IT services.
In large organizations, as more products are created, Service Catalog management can become exponentially complicated when different teams work on various products. The following solution simplifies Service Catalog products provisioning by considering elements such as shared accounts, roles, or users who can run portfolios or tags in the form of best practices via Continuous Integrations and Continuous Deployment (CI/CD) patterns.
This post demonstrates how Service Catalog Products can be delivered by taking advantage of the main benefits of CI/CD principles along with reducing complexity required to sync services. In this scenario, we have built a CI/CD Pipeline exclusively using AWS Services and the AWS Cloud Development Kit (CDK) Framework to provision the necessary Infrastructure.
Customers need the capability to consume services in a self-service manner, with services built on patterns that follow best practices, including focus areas such as compliance and security. The key tenants for these customers are: the use of infrastructure as code (IaC), and CI/CD. For these reasons, we built a scalable and automated deployment solution covered in this post.Furthermore, this post is also inspired from another post from the AWS community, Building a Continuous Delivery Pipeline for AWS Service Catalog.
Solution Overview
The solution is built using a unified AWS CodeCommit repository with CDK v1 code, which manages and deploys the Service Catalog Product estate. The solution supports the following scenarios: 1) making Products available to accounts and 2) provisioning these Products directly into accounts. The configuration provides flexibility regarding which components must be deployed in accounts as opposed to making a collection of these components available to account owners/users who can in turn build upon and provision them via sharing.
The pipeline created is comprised of the following stages:
Retrieving the code from the repository
Synthesize the CDK code to transform it into a CloudFormation template
Ensure the pipeline is defined correctly
Deploy and/or share the defined Portfolios and Products to a hub account or multiple accounts
Deploying and using the solution
Deploy the pipeline
We have created a Python AWS Cloud Development Kit (AWS CDK) v1 application hosted in a Git Repository. Deploying this application will create the required components described in this post. For a list of the deployment prerequisites, see the project README.
Clone the repository to your local machine. Then, bootstrap and deploy the CDK stack following the next steps.
The infrastructure creation takes around 3-5 minutes to complete deploying the AWS CodePipelines and repository creation. Once CDK has deployed the components, you will have a new empty repository where we will define the target Service Catalog estate. To do so, clone the new repository and push our sample code into it:
git clone https://git-codecommit.eu-west-1.amazonaws.com/v1/repos/service-catalog-repo
git checkout -b main
cd service-catalog-repo
cp -aR ../cdk-service-catalog-pipeline/* .
git add .
git commit -am "First commit"
git push origin main
Review and update configuration
Our cdk.json file is used to manage context settings such as shared accounts, permissions, region to deploy, etc.
shared_accounts_ecs: AWS account IDs where the ECS portfolio will be shared
shared_accounts_storage: AWS account IDs where the Storage portfolio will be shared
roles: ARN for the roles who will have permissions to access to the Portfolio
users: ARN for the users who will have permissions to access to the Portfolio
groups: ARN for the groups who will have permissions to access to the Portfolio
hub_account: AWS account ID where the Portfolio will be created
pipeline_account: AWS account ID where the main Infrastructure Pipeline will be created
region: the AWS region to be used for the deployment of the account
There are two mechanisms that can be used to create Service Catalog Products in this solution: 1) providing a CloudFormation template or 2) declaring a CDK stack (that will be transformed as part of the pipeline). Our sample contains two Products, each demonstrating one of these options: an Amazon Elastic Container Services (ECS) deployment and an Amazon Simple Storage Service (S3) product.
These Products are automatically shared with accounts specified in the shared_accounts_storage variable. Each product is managed by a CDK Python file in the cdk_service_catalog folder.
The Pipeline stages that AWS CodePipeline runs through are as follows:
Download the AWS CodeCommit code
Synthesize the CDK code to transform it into a CloudFormation template
Auto-modify the Pipeline in case you have made manual changes to it
Display the different Portfolios and Products associated in a Hub account in a Region or in multiple accounts
Adding new Portfolios and Products
To add a new Portfolio to the Pipeline, we recommend creating a new class under cdk_service_catalog similar to cdk_service_catalog_ecs_stack.py from our sample. Once the new class is created with the products you wish to associate, we instantiate the new class inside cdk_pipelines.py, and then add it inside the wave in the stage. There are two ways to create portfolio products. The first one is by creating a CloudFormation template, as can be seen in the Amazon Elastic Container Service (ECS) example. The second way is by creating a CDK stack that will be transformed into a template, as can be seen in the Storage example.
Product and Portfolio definition:
class ECSCluster(servicecatalog.ProductStack):
def __init__(self, scope, id):
super().__init__(scope, id)
# Parameters for the Product Template
cluster_name = cdk.CfnParameter(self, "clusterName", type="String", description="The name of the ECS cluster")
container_insights_enable = cdk.CfnParameter(self, "container_insights", type="String",default="False",allowed_values=["False","True"],description="Enable Container Insights")
vpc = cdk.CfnParameter(self, "vpc", type="AWS::EC2::VPC::Id", description="VPC")
ecs.Cluster(self,"ECSCluster_template", enable_fargate_capacity_providers=True,cluster_name=cluster_name.value_as_string,container_insights=bool(container_insights_enable.value_as_string),vpc=vpc)
cdk.Tags.of(self).add("key", "value")
Clean up
The following will help you clean up all necessary parts of this post: After completing your demo, feel free to delete your stack using the CDK CLI:
cdk destroy --all
Conclusion
In this post, we demonstrated how Service Catalog deployments can be accelerated by building a CI/CD pipeline using self-managed services. The Portfolio & Product estate is defined in its entirety by using Infrastructure-as-Code and automatically deployed based on your configuration. To learn more about AWS CDK Pipelines or AWS Service Catalog, visit the appropriate product documentation.
AWS Certificate Manager Private Certificate Authority (ACM PCA) is a highly available, fully managed private certificate authority (CA) service that allows you to create CA hierarchies and issue X.509 certificates from the CAs you create in ACM PCA. You can then use these certificates for scenarios such as encrypting TLS communication channels, cryptographically signing code, authenticating users, and more. But what happens if you decide to change your TLS endpoint or update your code signing entity? How do you revoke a certificate so that others no longer accept it?
In this blog post, we will cover two fully managed certificate revocation status checking mechanisms provided by ACM PCA: the Online Certificate Status Protocol (OCSP) and certificate revocation lists (CRLs). OCSP and CRLs both enable you to manage how you can notify services and clients about ACM PCA–issued certificates that you revoke. We’ll explain how these standard mechanisms work, we’ll highlight appropriate deployment use cases, and we’ll identify the advantages and downsides of each. We won’t cover configuration topics directly, but will provide you with links to that information as we go.
Certificate revocation
An X.509 certificate is a static, cryptographically signed document that represents a user, an endpoint, an IoT device, or a similar end entity. Because certificates provide a mechanism to authenticate these end entities, they are valid for a fixed period of time that you specify in the expiration date attribute when you generate a certificate. The expiration attribute is important, because it validates and regulates an end entity’s identity, and provides a means to schedule the termination of a certificate’s validity. However, there are situations where a certificate might need to be revoked before its scheduled expiration. These scenarios can include a compromised private key, the end of agreement between signed and signing organizations, user or configuration error when issuing certificates, and more. Although you can use certificates in many ways, we will refer to the predominant use case of TLS-based client-server implementations for the remainder of this blog post.
Certificate revocation can be used to identify certificates that are no longer trusted, and CRLs and OCSP are the standard mechanisms used to publish the revocation information. In addition, the special use case of OCSP stapling provides a more efficient mechanism that is supported in TLS 1.2 and later versions.
ACM PCA gives you the flexibility to use either of these mechanisms, or both. More importantly, as an ACM PCA administrator, the mechanism you choose to use is reflected in the certificate, and you must know how you want to manage revocation before you create the certificate. Therefore, you need to understand how the mechanisms work, select your strategy based on its appropriateness to your needs, and then create and deploy your certificates. Let’s look at how each mechanism works, the use cases for each, and issues to be aware of when you select a revocation strategy.
Certificate revocation using CRLs
As the name suggests, a CRL contains a list of revoked certificates. A CRL is cryptographically signed and issued by a CA, and made available for download by clients (for example, web browsers for TLS) through a CRL distribution point (CDP) such as a web server or a Lightweight Directory Access Point (LDAP) endpoint.
A CRL contains the revocation date and the serial number of revoked certificates. It also includes extensions, which specify whether the CA administrator temporarily suspended or irreversibly revoked the certificate. The CRL is signed and timestamped by the CA and can be verified by using the public key of the CA and the cryptographic algorithm included in the certificate. Clients download the CRL by using the address provided in the CDP extension and trust a certificate by verifying the signature, expiration date, and revocation status in the CRL.
CRLs provide an easy way to verify certificate validity. They can be cached and reused, which makes them resilient to network disruptions, and are an excellent choice for a server that is getting requests from many clients for the same CA. All major web browsers, OpenSSL, and other major TLS implementations support the CRL method of validating certificates.
However, the size of CRLs can lead to inefficiency for clients that are validating server identities. An example is the scenario of browsing multiple websites and downloading a CRL for each site that is visited. CRLs can also grow large over time as you revoke more certificates. Consider the World Wide Web and the number of invalidations that take place daily, which makes CRLs an inefficient choice for small-memory devices (for example, mobile, IoT, and similar devices). In addition, CRLs are not suited for real-time use cases. CRLs are downloaded periodically, a value that can be hours, days, or weeks, and cached for memory management. Many default TLS implementations, such as Mozilla, Chrome, Windows OS, and similar, cache CRLs for 24 hours, leaving a window of up to a day where an endpoint might incorrectly trust a revoked certificate. Cached CRLs also open opportunities for non-trusted sites to establish secure connections until the server refreshes the list, leading to security risks such as data breaches and identity theft.
Implementing CRLs by using ACM PCA
ACM PCA supports CRLs and stores them in an Amazon Simple Storage Service (Amazon S3) bucket for high availability and durability. You can refer to this blog post for an overview of how to securely create and store your CRLs for ACM PCA. Figure 1 shows how CRLs are implemented by using ACM PCA.
Figure 1: Certificate validation with a CRL
The workflow in Figure 1 is as follows:
On certificate revocation, ACM PCA updates the Amazon S3 CRL bucket with a new CRL.
Note: An update to the CRL may take up to 30 minutes after a certificate is revoked.
The client requests a TLS connection and receives the server’s certificate.
The client retrieves the current CRL file from the Amazon S3 bucket and validates it.
The refresh interval is the period between when an administrator revokes a certificate and when all parties consider that certificate revoked. The length of the refresh interval can depend on how quickly new information is published and how long clients cache revocation information to improve performance.
When you revoke a certificate, ACM PCA publishes a new CRL. ACM PCA waits 5 minutes after a RevokeCertificate API call before publishing a new CRL. This process exists to accommodate multiple revocation requests in a short time frame. An update to the CRL can take up to 30 minutes to propagate. If the CRL update fails, ACM PCA makes further attempts every 15 minutes.
CRLs also have a validity period, which you define as part of the CRL configuration by using ExpirationInDays. ACM PCA uses the value in the ExpirationInDays parameter to calculate the nextUpdate field in the CRL (the day and time when ACM PCA will publish the next CRL). If there are no changes to the CRL, the CRL is refreshed at half the interval of the next update. Clients may cache CRLs while they are still valid, so not all clients will have the updated CRL with the newly revoked certificates until the previous published CRL has expired.
Certificate revocation using OCSP
OCSP removes the burden of downloading the CRL from the client. With OCSP, clients provide the serial number and obtain the certificate status for a single certificate from an OCSP Responder. The OCSP Responder can be the CA or an endpoint managed by the CA. The certificate that is returned to the client contains an authorityInfoAccess extension, which provides an accessMethod (for example, OCSP), and identifies the OCSP Responder by a URL (for example, http://example-responder:<port>) in the accessLocation. You can also specify the OCSP Responder location manually in the CA profile. The certificate status response that is returned by the OCSP Responder can be good, revoked, or unknown, and is signed by using a process similar to the CRL for protection against forgery.
OCSP status checks are conducted in real time and are a good choice for time-sensitive devices, as well as mobile and IoT devices with limited memory.
However, the certificate status needs to be checked against the OCSP Responder for every connection, therefore requiring an extra hop. This can overwhelm the responder endpoint that needs to be designed for high availability, low latency, and protection against network and system failures. We will cover how ACM PCA addresses these availability and latency concerns in the next section.
Another thing to be mindful of is that the OCSP protocol implements OCSP status checks over unencrypted HTTP that poses privacy risks. When a client requests a certificate status, the CA receives information regarding the endpoint that is being connected to (for example, domain, IP address, and related information), which can easily be intercepted by a middle party. We will address how OCSP stapling can be used to address these privacy concerns in the OCSP stapling section.
Implementing OCSP by using ACM PCA
ACM PCA provides a highly available, fully managed OCSP solution to notify endpoints that certificates have been revoked. The OCSP implementation uses AWS managed OCSP responders and a globally available Amazon CloudFront distribution that caches OCSP responses closer to you, so you don’t need to set up and operate any infrastructure by yourself. You can enable OCSP on new or existing CAs using the ACM PCA console, the API, the AWS Command Line Interface (AWS CLI), or through AWS CloudFormation. Figure 2 shows how OCSP is implemented on ACM PCA.
Note: OCSP Responders, and the CloudFront distribution that caches the OCSP response for client requests, are managed by AWS.
Figure 2: Certificate validation with OCSP
The workflow in Figure 2 is as follows:
On certificate revocation, the ACM PCA updates the OCSP Responder, which generates the OCSP response.
The client requests a TLS connection and receives the server’s certificate.
The client sends a query to the OCSP endpoint on CloudFront.
Note: If the response is still valid in the CloudFront cache, it will be served to the client from the cache.
If the response is invalid or missing in the CloudFront cache, the request is forwarded to the OCSP Responder.
The OCSP Responder sends the OCSP response to the CloudFront cache.
CloudFront caches the OCSP response and returns it to the client.
The ACM PCA OCSP Responder generates an OCSP response that gets cached by CloudFront for 60 minutes. When a certificate is revoked, ACM PCA updates the OCSP Responder to generate a new OCSP response. During the caching interval, clients continue to receive responses from the CloudFront cache. As with CRLs, clients may also cache OCSP responses, which means that not all clients will have the updated OCSP response for the newly revoked certificate until the previously published (client-cached) OCSP response has expired. Another thing to be mindful of is that while the response is cached, a compromised certificate can be used to spoof a client.
Certificate revocation using OCSP stapling
With both CRLs and OCSP, the client is responsible for validating the certificate status. OCSP stapling addresses the client validation overhead and privacy concerns that we mentioned earlier by having the server obtain status checks for certificates that the server holds, directly from the CA. These status checks are periodic (based on a user-defined value), and the responses are stored on the web server. During TLS connection establishment, the server staples the certificate status in the response that is sent to the client. This improves connection establishment speed by combining requests and reduces the number of requests that are sent to the OCSP endpoint. Because clients are no longer directly connecting to OCSP Responders or the CAs, the privacy risks that we mentioned earlier are also mitigated.
Implementing OCSP stapling by using ACM PCA
OCSP stapling is supported by ACM PCA. You simply use the OCSP Certificate Status Response passthrough to add the stapling extension in the TLS response that is sent from the server to the client. Figure 3 shows how OCSP stapling works with ACM PCA.
Figure 3: Certificate validation with OCSP stapling
The workflow in Figure 3 is as follows:
On certificate revocation, the ACM PCA updates the OCSP Responder, which generates the OCSP response.
The client requests a TLS connection and receives the server’s certificate.
In the case of server’s cache miss, the server will query the OCSP endpoint on CloudFront.
Note: If the response is still valid in the CloudFront cache, it will be returned to the server from the cache.
If the response is invalid or missing in the CloudFront cache, the request is forwarded to the OCSP Responder.
The OCSP Responder sends the OCSP response to the CloudFront cache.
CloudFront caches the OCSP response and returns it to the server, which also caches the response.
The server staples the certificate status in its TLS connection response (for TLS 1.2 and later versions).
OCSP stapling is supported with TLS 1.2 and later versions.
Selecting the correct path with OCSP and CRLs
All certificate revocation offerings from AWS run on a highly available, distributed, and performance-optimized infrastructure. We strongly recommend that you enable a certificate validation and revocation strategy in your environment that best reflects your use case. You can opt to use CRLs, OCSP, or both. Without a revocation and validation process in place, you risk unauthorized access. We recommend that you review your business requirements and evaluate the risk profile of access with an invalid certificate versus the availability requirements for your application.
In the following sections, we’ll provide some recommendations on when to select which certificate validation and revocation strategy. We’ll cover client-server TLS communication, and also provide recommendations for mutual TLS (mTLS) authentication scenarios.
Recommended scenarios for OCSP stapling and OCSP Must-Staple
If your organization requires support for TLS 1.2 and later versions, you should use OCSP stapling. If you want to reduce the application availability risk for a client that is configured to fail the TLS connection establishment when it is unable to validate the certificate, you should consider using the OCSP Must-Staple extension.
OCSP stapling
If your organization requires support for TLS 1.2 and later versions, you should use OCSP stapling. With OCSP stapling, you reduce your client’s load and connectivity requirements, which helps if your network connectivity is unpredictable. For example, if your application client is a mobile device, you should anticipate network failures, low bandwidth, limited processing capacity, and impatient users. In this scenario, you will likely benefit the most from a system that relies on OCSP stapling.
Although the majority of web browsers support OCSP stapling, not all servers support it. OCSP stapling is, therefore, typically implemented together with CRLs that provide an alternate validation mechanism or as a passthrough for when the OCSP response fails or is invalid.
OCSP Must-Staple
If you want to rely on OCSP alone and avoid implementing CRLs, you can use the OCSP Must-Staple certificate extension, which tells the connecting client to expect a stapled response. You can then use OCSP Must-Staple as a flag for your client to fail the connection if the client does not receive a valid OCSP response during connection establishment.
Recommended scenarios for CRLs, OCSP (without stapling), and combinational strategies
If your application needs to support legacy, now deprecated protocols such as TLS 1.0 or 1.1, or if your server doesn’t support OCSP stapling, you could use a CRL, OCSP, or both together. To determine which option is best, you should consider your sensitivity to CA availability, recently revoked certificates, the processing capacity of your application client, and network latency.
CRLs
If your application needs to be available independent of your CA connectivity, you should consider using a CRL. CRLs are much larger files that, from a practical standpoint, require much longer cache times to be of use, but they will be present and available for verification on your system regardless of the status of your network connection. In addition, the lookup time of a certificate within a CRL is local and therefore shorter than a network round trip to an OCSP Responder, because there are no network connection or DNS lookup times.
OCSP (without stapling)
If you are sensitive to the processing capacity of your application client, you should use OCSP. The size of an OCSP message is much smaller compared to a CRL, which allows you to configure shorter caching times that are better suited for your risk profile. To optimize your OCSP and OCSP stapling process, you should review your DNS configuration because it plays a significant role in the amount of time your application will take to receive a response.
For example, if you’re building an application that will be hosted on infrastructure that doesn’t support OCSP stapling, you will benefit from clients making an OCSP request and caching it for a short period. In this scenario, your application client will make a single OCSP request during its connection setup, cache the response, and reuse the certificate state for the duration of its application session.
Combining CRLs and OCSP
You can also choose to implement both CRLs and OCSP for your certificate revocation and validation needs. For example, if your application needs to support legacy TLS protocols while providing resiliency to network failures, you can implement both CRLs and OCSP. When you use CRLs and OCSP together, you verify certificates primarily by using OCSP; however, in case your client is unable to reach the OCSP endpoint, you can fail over to an alternative validation method (for example, CRL). This approach of combining CRLs and OCSP gives you all the benefits of OCSP mentioned earlier, while providing a backup mechanism for failure scenarios such as an unreachable OCSP Responder, invalid response from the OCSP Responder, and similar. However, while this approach adds resilience to your application, it will add management overhead because you will need to set up CRL-based and OCSP-based revocation separately. Also, remember that clients with reduced computing power or poor network connectivity might struggle as they attempt to download and process the CRL.
Recommendations for mTLS authentication scenarios
You should consider network latency and revocation propagation delays when optimizing your server infrastructure for mTLS authentication. In a typical scenario, server certificate changes are infrequent, so caching an OCSP response or CRL on your client and an OCSP-stapled response on a server will improve performance. For mTLS, you can revoke a client certificate at any time; therefore, cached responses could introduce the risk of invalid access. You should consider designing your system such that a copy of a CRL for client certificates is maintained on the server and refreshed based on your business needs. For example, you can use S3 ETags to determine whether an object has changed, and flush the server’s cache in response.
Conclusion
This blog post covered two certificate revocation methods, OCSP and CRLs, that are available on ACM PCA. Remember, when you deploy CA hierarchies for public key infrastructure (PKI), it’s important to define how to handle certificate revocation. The certificate revocation information must be included in the certificate when it is issued, so the choice to enable either CRL or OCSP, or both, has to happen before the certificate is issued. It’s also important to have highly available CRL and OCSP endpoints for certificate lifecycle management. ACM PCA provides a highly available, fully managed CA service that you can use to meet your certificate revocation and validation requirements. Get started using ACM PCA.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
The Relational Database Management System (RDBMS) is a popular choice among organizations running critical applications that supports online transaction processing (OLTP) use-cases. But managing the RDBMS database comes with its own challenges. AWS has made it easier for organizations to operate these databases in the cloud, thereby addressing the undifferentiated heavy lifting with managed databases (Amazon Aurora, Amazon RDS). Although using managed services has freed up engineering from provisioning hardware, database setup, patching, and backups, they still face the challenges that come with running a highly performant database. As applications scale in size and sophistication, it becomes increasingly challenging for customers to detect and resolve relational database performance bottlenecks and other operational issues quickly.
Amazon RDS Performance Insights is a database performance tuning and monitoring feature, that lets you quickly assess your database load and determine when and where to take action. Performance Insights lets non-experts in database administration diagnose performance problems with an easy-to-understand dashboard that visualizes database load. Furthermore, Performance Insights expands on the existing Amazon RDS monitoring features to illustrate database performance and help analyze any issues that affect it. The Performance Insights dashboard also lets you visualize the database load and filter the load by waits, SQL statements, hosts, or users.
On Dec 1st, 2021, we announced Amazon DevOps Guru for RDS, a new capability for Amazon DevOps Guru. It’s a fully-managed machine learning (ML)-powered service that detects operational and performance related issues for Amazon Aurora engines. It uses the data that it collects from Performance Insights, and then automatically detects and alerts customers of application issues, including database problems. When DevOps Guru detects an issue in an RDS database, it publishes an insight in the DevOps Guru dashboard. The insight contains an anomaly for the resource AWS/RDS. If DevOps Guru for RDS is turned on for your instances, then the anomaly contains a detailed analysis of the problem. DevOps Guru for RDS also recommends that you perform an investigation, or it provides a specific corrective action. For example, the recommendation might be to investigate a specific high-load SQL statement or to scale database resources.
In this post, we’ll deep-dive into some of the common issues that you may encounter while running your workloads against Amazon Aurora MySQL-Compatible Edition databases, with simulated performance issues. We’ll also look at how DevOps Guru for RDS can help identify and resolve these issues. Simulating a performance issue is resource intensive, and it will cost you money to run these tests. If you choose the default options that are provided, and clean up your resources using the following clean-up instructions, then it will cost you approximately $15 to run the first test only. If you wish to run all of the tests, then you can choose “all” in the Tests parameter choice. This will cost you approximately $28 to run all three tests.
Prerequisites
To follow along with this walkthrough, you must have the following prerequisites:
An AWS account with a role that has sufficient access to provision the required infrastructure. The account should also not have exceeded its quota for the resources being deployed (VPCs, Amazon Aurora, etc.).
Credentials that enable you to interact with your AWS account.
If you already have Amazon DevOps Guru turned on, then make sure that it’s tagged properly to detect issues for the resource being deployed.
Solution overview
You will clone the project from GitHub and deploy an AWS CloudFormation template, which will set up the infrastructure required to run the tests. If you choose to use the defaults, then you can run only the first test. If you would like to run all of the tests, then choose the “all” option under Tests parameter.
We simulate some common scenarios that your database might encounter when running enterprise applications. The first test simulates locking issues. The second test simulates the behavior when the AUTOCOMMIT property of the database driver is set to: True. This could result in statement latency. The third test simulates performance issues when an index is missing on a large table.
Solution walk through
Clone the repo and deploy resources
Utilize the following command to clone the GitHub repository that contains the CloudFormation template and the scripts necessary to simulate the database load. Note that by default, we’ve provided the command to run only the first test.
If you wish to run all four of the tests, then flip the ParameterValue of the Tests ParameterKey to “all”.
If Amazon DevOps Guru is already enabled in your account, then change the ParameterValue of the EnableDevOpsGuru ParameterKey to “n”.
It may take up to 30 minutes for CloudFormation to provision the necessary resources. Visit the CloudFormation console (make sure to choose the region where you have deployed your resources), and make sure that DevOpsGuru-Stack is in the CREATE_COMPLETE state before proceeding to the next step.
Navigate to AWS Cloud9, then choose Your environments. Next, choose DevOpsGuruMySQLInstance followed by Open IDE. This opens a cloud-based IDE environment where you will be running your tests. Note that in this setup, AWS Cloud9 inherits the credentials that you used to deploy the CloudFormation template.
Open a new terminal window which you will be using to clone the repository where the scripts are located.
Clone the repo into your Cloud9 environment, then navigate to the directory where the scripts are located, and run initial setup.
git clone https://github.com/aws-samples/amazon-devops-guru-rds.git
cd amazon-devops-guru-rds/scripts
sh setup.sh
# NOTE: If you are running all test cases, use sh setup.sh all command instead.
source ~/.bashrc
Initialize databases for all of the test cases, and add random data into them. The script to insert random data takes approximately five hours to complete. Your AWS Cloud9 instance is set up to run for up to 24 hours before shutting down. You can exit the browser and return between 5–24 hours to validate that the script ran successfully, then continue to the next step.
source ./connect.sh test 1
USE devopsgurusource;
CREATE TABLE IF NOT EXISTS test1 (id int, filler char(255), timer timestamp);
exit;
python3 ct.py
If you chose to run all test cases, and you ran the sh setup.sh all command in Step 4, open two new terminal windows and run the following commands to insert random data for test cases 2 and 3.
# Test case 2 – Open a new terminal window to run the commands
cd amazon-devops-guru-rds/scripts
source ./connect.sh test 2
USE devopsgurusource;
CREATE TABLE IF NOT EXISTS test1 (id int, filler char(255), timer timestamp);
exit;
python3 ct.py
# Test case 3 - Open a new terminal window to run the commands
cd amazon-devops-guru-rds/scripts
source ./connect.sh test 3
USE devopsgurusource;
CREATE TABLE IF NOT EXISTS test1 (id int, filler char(255), timer timestamp);
exit;
python3 ct.py
Return between 5-24 hours to run the next set of commands.
Add an index to the first database.
source ./connect.sh test 1
CREATE UNIQUE INDEX test1_pk ON test1(id);
INSERT INTO test1 VALUES (-1, 'locker', current_timestamp);
exit;
If you chose to run all test cases, and you ran the sh setup.sh all command in Step 4, add an index to the second database. NOTE: Do no add an index to the third database.
source ./connect.sh test 2
CREATE UNIQUE INDEX test1_pk ON test1(id);
INSERT INTO test1 VALUES (-1, 'locker', current_timestamp);
exit;
DevOps Guru for RDS uses Performance Insights, and it establishes a baseline for the database metrics. Baselining involves analyzing the database performance metrics over a period of time to establish a “normal” behavior. DevOps Guru for RDS then uses ML to detect anomalies against the established baseline. If your workload pattern changes, then DevOps Guru for RDS establishes a new baseline that it uses to detect anomalies against the new “normal”. For new database instances, DevOps Guru for RDS takes up to two days to establish an initial baseline, as it requires an analysis of the database usage patterns and establishing what is considered a normal behavior.
Allow two days before you start running the following tests.
Scenario 1: Locking Issues
In this scenario, multiple sessions compete for the same (“locked”) record, and they must wait for each other. In real life, this often happens when:
A database session gets disconnected due to a (i.e., temporary network) malfunction, while still holding a critical lock.
Other sessions become stuck while waiting for the lock to be released.
The problem is often exacerbated by the application connection manager that keeps spawning additional sessions (because the existing sessions don’t complete the work on time), thus creating a distinct “inclined slope” pattern that you’ll see in this scenario.
Here’s how you can reproduce it:
Connect to the database.
cd amazon-devops-guru-rds/scripts
source ./connect.sh test 1
In your MySQL, enter the following SQL, and don’t exit the shell.
START TRANSACTION;
UPDATE test1 SET timer=current_timestamp WHERE id=-1;
-- Do NOT exit!
Open a new terminal, and run the command to simulate competing transactions. Give it approximately five minutes before you run the commands in this step.
cd amazon-devops-guru-rds/scripts
source ./connect.sh test 1
exit;
python3 locking_scenario.py 1 1200 2
After the program completes its execution, navigate to the Amazon DevOps Guru console, choose Insights, and then choose RDS DB Load Anomalous. You’ll notice a summary of the insight under Description.
Choose the View Recommendations link on the top right, and observe the databases for which it’s showing the recommendations.
Next, choose View detailed analysis for database performance anomaly for the following resources.
Under To view a detailed analysis, choose a resource name, choose the database associated with the first test.
Observe the recommendations under Analysis and recommendations. It provides you with analysis, recommendations, and links to troubleshooting documentation.
In this example, DevOps Guru for RDS has detected a high and unusual spike of database load, and then marked it as “performance anomaly”.
Note that the relative size of the anomaly is significant: 490 times higher than the “typical” database load, which is why it’s deemed: “HIGH severity”.
In the analysis section, note that a single “wait event”, wait/synch/mutex/innodb/aurora_lock_thread_slot_futex, is dominating the entire spike. Moreover, a single SQL is “responsible” (or more precisely: “suffering”) from this wait event at the time of the problem. Select the wait event name and see a simple explanation of what’s happening in the database. For example, it’s “record locking”, where multiple sessions are competing for the same database records. Additionally, you can select the SQL hash and see the exact text of the SQL that’s responsible for the issue.
If you’re interested in why DevOps Guru for RDS detected this problem, and why these particular wait events and an SQL were selected, the Why is this a problem? and Why do we recommend this? links will provide the answer.
Finally, the most relevant part of this analysis is a View troubleshooting doc link. It references a document that contains a detailed explanation of the likely causes for this problem, as well as the actions that you can take to troubleshoot and address it.
Scenario 2: Autocommit: ON
In this scenario, we must run multiple batch updates, and we’re using a fairly popular driver setting: AUTOCOMMIT: ON.
This setting can sometimes lead to performance issues as it causes each UPDATE statement in a batch to be “encased” in its own “transaction”. This leads to data changes being frequently synchronized to disk, thus dramatically increasing batch latency.
Here’s how you can reproduce the scenario:
On your Cloud9 terminal, run the following commands:
cd amazon-devops-guru-rds/scripts
source ./connect.sh test 2
exit;
python3 batch_autocommit.py 50 1200 1000 10000000
Once the program completes its execution, or after an hour, navigate to the Amazon DevOps Guru console, choose Insights, and then choose RDS DB Load Anomalous. Then choose Recommendations and choose View detailed analysis for database performance anomaly for the following resources. Under To view a detailed analysis, choose a resource name, choose the database associated with the second test.
Observe the recommendations under Analysis and recommendations. It provides you with analysis, recommendations, and links to troubleshooting documentation.
Note that DevOps Guru for RDS detected a significant (and unusual) spike of database load and marked it as a HIGH severity anomaly.
The spike looks similar to the previous example (albeit, “smaller”), but it describes a different database problem (“COMMIT slowdowns”). This is because of a different database wait event that dominates the spike: wait/io/aurora_redo_log_flush.
As in the previous example, you can select the wait event name to see a simple description of what’s going on, and you can select the SQL hash to see the actual statement that is slow. Furthermore, just as before, the View troubleshooting doc link references the document that describes what you can do to troubleshoot the problem further and address it.
Scenario 3: Missing index
Have you ever wondered what would happen if you drop a frequently accessed index on a large table?
In this relatively simple scenario, we’re testing exactly that – an index gets dropped causing queries to switch from fast index lookups to slow full table scans, thus dramatically increasing latency and resource use.
Here’s how you can reproduce this problem and see it for yourself:
On your Cloud9 terminal, run the following commands:
cd amazon-devops-guru-rds/scripts
source ./connect.sh test 3
exit;
python3 no_index.py 50 1200 1000 10000000
Once the program completes its execution, or after an hour, navigate to the Amazon DevOps Guru console, choose Insights, and then choose RDS DB Load Anomalous. Then choose Recommendations and choose View detailed analysis for database performance anomaly for the following resources. Under To view a detailed analysis, choose a resource name, choose the database associated with the third test.
Observe the recommendations under Analysis and recommendations. It provides you with analysis, recommendations, and links to troubleshooting documentation.
As with the previous examples, DevOps Guru for RDS detected a high and unusual spike of database load (in this case, ~ 50 times larger than the “typical” database load). It also identified that a single wait event, wait/io/table/sql/handler, and a single SQL, are responsible for this issue.
The analysis highlights the SQL that you must pay attention to, and it links a detailed troubleshooting document that lists the likely causes and recommended actions for the problems that you see. While it doesn’t tell you that the “missing index” is the real root cause of the issue (this is planned in future versions), it does offer many relevant details that can help you come to that conclusion yourself.
Cleanup
On your terminal where you originally ran the AWS Command Line Interface (AWS CLI) command to create the CloudFormation resources, run the following command:
In this post, you learned how to leverage DevOps Guru for RDS to alert you of any operational issues with recommendations. You simulated some of the commonly encountered, real-world production issues, such as locking contentions, AUTOCOMMIT, and missing indexes. Moreover, you saw how DevOps Guru for RDS helped you detect and resolve these issues. Try this out, and let us know how DevOps Guru for RDS was able to address your use-case.
In Part 1 of this blog series, we demonstrated why tiering and throttling become necessary at scale for multi-tenant REST APIs, and explored tiering strategy and throttling with Amazon API Gateway.
In this post, Part 2, we will examine tenant isolation strategies at scale with API Gateway and extend the sample code from Part 1.
Enhancing the sample code
To enable this functionality in the sample code (Figure 1), we will make manual changes. First, create one API key for the Free Tier and five API keys for the Basic Tier. Currently, these API keys are private keys for your Amazon Cognito login, but we will make a further change in the backend business logic that will promote them to pooled resources. Note that all of these modifications are specific to this sample code’s implementation; the implementation and deployment of a production code may be completely different (Figure 1).
Figure 1. Cloud architecture of the sample code
Next, in the business logic for thecreateKey(), find the AWS Lambda function in lambda/create_key.js. It appears like this:
The getPoolForPlanId() function does a search for a pool of keys associated with the usage plan. If there is a pool, we “create” a kind of reference to the pooled resource, rather than a completely new key that is created by the API Gateway service directly. The lambda/api_key_pools.js should be empty.
exports.apiKeyPools = [];
In effect, all usage plans were considered as siloed keys up to now. To change that, populate the data structure with values from the six API keys that were created manually. You will have to look up the IDs of the API keys and usage plans that were created in API Gateway (Figures 2 and 3). Using the AWS console to navigate to API Gateway is the most intuitive.
Figure 2. A view of the AWS console when inspecting the ID for the Basic usage plan
Figure 3. A view of the AWS Console when looking up the API key value (not the ID)
When done, your code in lambda/api_key_pools.js should be the following, but instead of ellipses (…), the IDs for the user plans and API keys specific to your environment will appear.
After making the code changes, run cdk deploy from the command line to update the Lambda functions. This change will only affect key creation and deletion because of the system implementation. Updates affect only the user’s specific reference to the key, not the underlying resource managed by API Gateway.
When the web application is run now, it will look similar to before—tenants should not be aware what tiering strategy they have been assigned to. The only way to notice the difference would be to create two Free Tier keys, test them, and note that the value of the X-API-KEY header is unchanged between the two.
Now, you have a virtually unlimited number of users who can have API keys in the Free or Basic Tier. By keeping the Premium Tier siloed, you are subject to the 10,000-API-key maximum (less any keys allocated for the lower tiers). You may consider additional techniques to continue to scale, such as replicating your service in another AWS account.
Other production considerations
The sample code is minimal, and it illustrates just one aspect of scaling a Software-as-a-service (SaaS) application. There are many other aspects be considered in a production setting that we explore in this section.
The throttled endpoint, GET /api rely only on API key for authorization for demonstration purpose. For any production implementation consider authentication options for your REST APIs. You may explore and extend to require authentication with Cognito similar to /admin/* endpoints in the sample code.
One API key for Free Tier access and five API keys for Basic Tier access are illustrative in a sample code but not representative of production deployments. Number of API keys with service quota into consideration, business and technical decisions may be made to minimize noisy neighbor effect such as setting blast radius upper threshold of 0.1% of all users. To satisfy that requirement, each tier would need to spread users across at least 1,000 API keys. The number of keys allocated to Basic or Premium Tier would depend on market needs and pricing strategies. Additional allocations of keys could be held in reserve for troubleshooting, QA, tenant migrations, and key retirement.
In the planning phase of your solution, you will decide how many tiers to provide, how many usage plans are needed, and what throttle limits and quotas to apply. These decisions depend on your architecture and business.
To define API request limits, examine the system API Gateway is protecting and what load it can sustain. For example, if your service will scale up to 1,000 requests per second, it is possible to implement three tiers with a 10/50/40 split: the lowest tier shares one common API key with a 100 request per second limit; an intermediate tier has a pool of 25 API keys with a limit of 20 requests per second each; and the highest tier has a maximum of 10 API keys, each supporting 40 requests per second.
Metrics play a large role in continuously evolving your SaaS-tiering strategy (Figure 4). They provide rich insights into how tenants are using the system. Tenant-aware and SaaS-wide metrics on throttling and quota limits can be used to: assess tiering in-place, if tenants’ requirements are being met, and if currently used tenant usage profiles are valid (Figure 5).
Figure 4. Tiering strategy example with 3 tiers and requests allocation per tier
Figure 5. An example SaaS metrics dashboard
API Gateway provides options for different levels of granularity required, including detailed metrics, and execution and access logging to enable observability of your SaaS solution. Granular usage metrics combined with underlying resource consumption leads to managing optimal experience for your tenants with throttling levels and policies per method and per client.
Cleanup
To avoid incurring future charges, delete the resources. This can be done on the command line by typing:
cd ${TOP}/cdk
cdk destroy
cd ${TOP}/react
amplify delete
${TOP} is the topmost directory of the sample code. For the most up-to-date information, see the README.md file.
Conclusion
In this two-part blog series, we have reviewed the best practices and challenges of effectively guarding a tiered multi-tenant REST API hosted in AWS API Gateway. We also explored how throttling policy and quota management can help you continuously evaluate the needs of your tenants and evolve your tiering strategy to protect your backend systems from being overwhelmed by inbound traffic.
Many software-as-a-service (SaaS) providers adopt throttling as a common technique to protect a distributed system from spikes of inbound traffic that might compromise reliability, reduce throughput, or increase operational cost. Multi-tenant SaaS systems have an additional concern of fairness; excessive traffic from one tenant needs to be selectively throttled without impacting the experience of other tenants. This is also known as “the noisy neighbor” problem. AWS itself enforces some combination of throttling and quota limits on nearly all its own service APIs. SaaS providers building on AWS should design and implement throttling strategies in all of their APIs as well.
In this two-part blog series, we will explore tiering and throttling strategies for multi-tenant REST APIs and review tenant isolation models with hands-on sample code. In part 1, we will look at why a tiering and throttling strategy is needed and show how Amazon API Gateway can help by showing sample code. In part 2, we will dive deeper into tenant isolation models as well as considerations for production.
We selected Amazon API Gateway for this architecture since it is a fully managed service that helps developers to create, publish, maintain, monitor, and secure APIs. First, let’s focus on how Amazon API Gateway can be used to throttle REST APIs with fine granularity using Usage Plans and API Keys. Usage Plans define the thresholds beyond which throttling should occur. They also enable quotas, which sets a maximum usage per a day, week, or month. API Keys are identifiers for distinguishing traffic and determining which Usage Plans to apply for each request. We limit the scope of our discussion to REST APIs because other protocols that API Gateway supports — WebSocket APIs and HTTP APIs — have different throttling mechanisms that do not employ Usage Plans or API Keys.
SaaS providers must balance minimizing cost to serve and providing consistent quality of service for all tenants. They also need to ensure one tenant’s activity does not affect the other tenants’ experience. Throttling and quotas are a key aspect of a tiering strategy and important for protecting your service at any scale. In practice, this impact of throttling polices and quota management is continuously monitored and evaluated as the tenant composition and behavior evolve over time.
Architecture Overview
Figure 1 – Architecture of the sample code
To get a firm foundation of the basics of throttling and quotas with API Gateway, we’ve provided sample code in AWS-Samples on GitHub. Not only does it provide a starting point to experiment with Usage Plans and API Keys in the API Gateway, but we will modify this code later to address complexity that happens at scale. The sample code has two main parts: 1) a web frontend and, 2) a serverless backend. The backend is a serverless architecture using Amazon API Gateway, AWS Lambda, Amazon DynamoDB, and Amazon Cognito. As Figure I illustrates, it implements one REST API endpoint, GET /api, that is protected with throttling and quotas. There are additional APIs under the /admin/* resource to provide Read access to Usage Plans, and CRUD operations on API Keys.
All these REST endpoints could be tested with developer tools such as curl or Postman, but we’ve also provided a web application, to help you get started. The web application illustrates how tenants might interact with the SaaS application to browse different tiers of service, purchase API Keys, and test them. The web application is implemented in React and uses AWS Amplify CLI and SDKs.
Prerequisites
To deploy the sample code, you should have the following prerequisites:
An AWS CLI profile with permissions to deploy the architecture
For clarity, we’ll use the environment variable, ${TOP}, to indicate the top-most directory in the cloned source code or the top directory in the project when browsing through GitHub.
Detailed instructions on how to install the code are in ${TOP}/INSTALL.md file in the code. After installation, follow the ${TOP}/WALKTHROUGH.md for step-by-step instructions to create a test key with a very small quota limit of 10 requests per day, and use the client to hit that limit. Search for HTTP 429: Too Many Requests as the signal your client has been throttled.
Figure 2: The web application (with browser developer tools enabled) shows that a quick succession of API calls starts returning an HTTP 429 after the quota for the day is exceeded.
Responsibilities of the Client to support Throttling
The Client must provide an API Key in the header of the HTTP request, labelled, “X-Api-Key:”. If a resource in API Gateway has throttling enabled and that header is missing or invalid in the request, then API Gateway will reject the request.
Important: API Keys are simple identifiers, not authorization tokens or cryptographic keys. API keys are for throttling and managing quotas for tenants only and not suitable as a security mechanism. There are many ways to properly control access to a REST API in API Gateway, and we refer you to the AWS documentation for more details as that topic is beyond the scope of this post.
Clients should always test for the response to any network call, and implement logic specific to an HTTP 429 response. The correct action is almost always “try again later.” Just how much later, and how many times before giving up, is application dependent. Common approaches include:
Retry – With simple retry, client retries the request up to defined maximum retry limit configured
Exponential backoff – Exponential backoff uses progressively larger wait time between retries for consecutive errors. As the wait time can become very long quickly, maximum delay and a maximum retry limits should be specified.
Jitter – Jitter uses a random amount of delay between retry to prevent large bursts by spreading the request rate.
AWS SDK is an example client-responsibility implementation. Each AWS SDK implements automatic retry logic that uses a combination of retry, exponential backoff, jitter, and maximum retry limit.
SaaS Considerations: Tenant Isolation Strategies at Scale
While the sample code is a good start, the design has an implicit assumption that API Gateway will support as many API Keys as we have number of tenants. In fact, API Gateway has a quota on available per region per account. If the sample code’s requirements are to support more than 10,000 tenants (or if tenants are allowed multiple keys), then the sample implementation is not going to scale, and we need to consider more scalable implementation strategies.
This is one instance of a general challenge with SaaS called “tenant isolation strategies.” We highly recommend reviewing this white paper ‘SasS Tenant Isolation Strategies‘. A brief explanation here is that the one-resource-per-customer (or “siloed”) model is just one of many possible strategies to address tenant isolation. While the siloed model may be the easiest to implement and offers strong isolation, it offers no economy of scale, has high management complexity, and will quickly run into limits set by the underlying AWS Services. Other models besides siloed include pooling, and bridged models. Again, we recommend the whitepaper for more details.
Figure 3- Tiered multi-tenant architectures often employ different tenant isolation strategies at different tiers. Our example is specific to API Keys, but the technique generalizes to storage, compute, and other resources.
In this example, we implement a range of tenant isolation strategies at different tiers of service. This allows us to protect against “noisy-neighbors” at the highest tier, minimize outlay of limited resources (namely, API-Keys) at the lowest tier, and still provide an effective, bounded “blast radius” of noisy neighbors at the mid-tier.
A concrete development example helps illustrate how this can be implemented. Assume three tiers of service: Free, Basic, and Premium. One could create a single API Key that is a pooled resource among all tenants in the Free Tier. At the other extreme, each Premium customer would get their own unique API Key. They would protect Premium tier tenants from the ‘noisy neighbor’ effect. In the middle, the Basic tenants would be evenly distributed across a set of fixed keys. This is not complete isolation for each tenant, but the impact of any one tenant is contained within “blast radius” defined.
In production, we recommend a more nuanced approach with additional considerations for monitoring and automation to continuously evaluate tiering strategy. We will revisit these topics in greater detail after considering the sample code.
Conclusion
In this post, we have reviewed how to effectively guard a tiered multi-tenant REST API hosted in Amazon API Gateway. We also explored how tiering and throttling strategies can influence tenant isolation models. In Part 2 of this blog series, we will dive deeper into tenant isolation models and gaining insights with metrics.
If you’d like to know more about the topic, the AWS Well-Architected SaaS Lens Performance Efficiency pillar dives deep on tenant tiers and providing differentiated levels of performance to each tier. It also provides best practices and resources to help you design and reduce impact of noisy neighbors your SaaS solution.
This post is intended to assist users in understanding and replicating a method to unit test Python-based ETL Glue Jobs, using the PyTest Framework in AWS CodePipeline. In the current practice, several options exist for unit testing Python scripts for Glue jobs in a local environment. Although a local development environment may be set up to build and unit test Python-based Glue jobs, by following the documentation, replicating the same procedure in a DevOps pipeline is difficult and time consuming.
Unit test scripts are one of the initial quality gates used by developers to provide a high-quality build. One must reuse these scripts during regression testing to make sure that all of the existing functionality is intact, and that new releases don’t disrupt key application functionality. The majority of the regression test suites are expected to be integrated with the DevOps Pipeline for its execution. Unit testing an application code is a fundamental task that evaluates whether each (unit) code written by a programmer functions as expected. Unit testing of code provides a mechanism to determine that software quality hasn’t been compromised. One of the difficulties in building Python-based Glue ETL tasks is their ability for unit testing to be incorporated within DevOps Pipeline, especially when there are modernization of mainframe ETL process to modern tech stacks in AWS
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue provides all of the capabilities needed for data integration. This means that you can start analyzing your data and putting it to use in minutes rather than months. AWS Glue provides both visual and code-based interfaces to make data integration easier.
A typical enterprise-scale DevOps pipeline is illustrated in the following diagram. This solution describes how to incorporate the unit testing of Python-based AWS Glue ETL processes into the AWS DevOps Pipeline.
The GitHub repository aws-glue-jobs-unit-testing has a sample Python-based Glue job in the src folder. Its associated unit test cases built using the Pytest Framework are accessible in the tests folder. An AWS CloudFormation template written in YAML is included in the deploy folder. As a runtime environment, AWS CodeBuild utilizes custom container images. This feature is used to build a project utilizing Glue libraries from Public ECR repository, that can run the code package to demonstrate unit testing integration.
The container image at the Public ECR repository for AWS Glue libraries includes all of the binaries required to run PySpark-based AWS Glue ETL tasks locally, as well as unit test them. The public container repository has three image tags, one for each AWS Glue version supported by AWS Glue. To demonstrate the solution, we use the image tag glue_libs_3.0.0_image_01 in this post. To utilize this container image as a runtime image in CodeBuild, copy the Image URI corresponding to the image tag that you intend to use, as shown in the following image.
The aws-glue-jobs-unit-testing GitHub repository contains a CloudFormation template, pipeline.yml, which deploys a CodePipeline with CodeBuild projects to create, test, and publish the AWS Glue job. As illustrated in the following, use the copied image URL from Amazon ECR public to create and test a CodeBuild project.
It uses the CodeCommit repository as the source and transfers the most recent code from the main branch to the CodeBuild project for further processing.
The following stage is build and test, in which the most recent code from the previous phase is unit tested and the test report is published to CodeBuild report groups.
Following the successful completion of the publish phase, the final step is to deploy the AWS Glue task using the CloudFormation template in the deploy folder.
Deploying the solution
Set up
Now we’ll deploy the solution using a CloudFormation template.
Using the GitHub Web, download the code.zip file from the aws-glue-jobs-unit-testing repository. This zip file contains the GitHub repository’s src, tests, and deploy folders. You may also create the zip file yourself using command-line tools, such as git and zip. To create the zip file on Linux or Mac, open the terminal and enter the following commands.
git clone https://github.com/aws-samples/aws-glue-jobs-unit-testing.git
cd aws-glue-jobs-unit-testing
git checkout master
zip -r code.zip src/ tests/ deploy/
Upload the downloaded zip package, code.zip, to the Amazon S3 bucket that you created.
In this example, I created an Amazon S3 bucket named aws-glue-artifacts-us-east-1 in the N. Virginia (us-east-1) Region, and used the console to upload the zip package from the GitHub repository to the Amazon S3 bucket.
On the Specify template page, choose Upload a template file, and then choose the pipeline.yml template, downloaded from the GitHub repository
Specify the following parameters:.
Stack name: glue-unit-testing-pipeline (Choose a stack name of your choice)
ApplicationStackName: glue-codepipeline-app (This is the name of the CloudFormation stack that will be created by the pipeline)
BranchName: master (This is the name of the branch to be created in the CodeCommit repository to check-in the code from the Amazon S3 bucket zip file)
BucketName: aws-glue-artifacts-us-east-1 (This is the name of the Amazon S3 bucket that contains the zip file. This bucket will also be used by the pipeline for storing code artifacts)
CodeZipFile: lambda.zip (This is the key name of the sample code Amazon S3 object. The object should be a zip file)
RepositoryName: aws-glue-unit-testing (This is the name of the CodeCommit repository that will be created by the stack)
TestReportGroupName: glue-unittest-report (This is the name of the CodeBuild test report group that will be created to store the unit test reports)
Choose Next, and again Next.
On the Review page, under Capabilities, choose the following options:
I acknowledge that CloudFormation might create IAM resources with custom names.
Choose Create stack to begin the stack creation process. Once the stack creation is complete, the resources that were created are displayed on the Resources tab. The stack creation takes approximately 5-7 minutes.
The stack automatically creates a CodeCommit repository with the initial code checked-in from the zip file uploaded to the Amazon S3 bucket. Furthermore, it creates a CodePipeline view using the CodeCommit repository as the source. In the above example, the CodeCommit repository is aws-glue-unit-test, and the pipeline is aws-glue-unit-test-pipeline.
Testing the solution
To test the deployed pipeline, open the CodePipeline console and select the pipeline created by the CloudFormation stack. Select the Release Change button on the pipeline page.
The pipeline begins its execution with the most recent code in the CodeCommit repository.
When the Test_and_Build phase is finished, select the Details link to examine the execution logs.
Select the Reports tab, and choose the test report from Report history to view the unit execution results.
Finally, after the deployment stage is complete, you can see, run, and monitor the deployed AWS Glue job on the AWS Glue console page. For more information, refer to the Running and monitoring AWS Glue documentation
Cleanup
To avoid additional infrastructure costs, make sure that you delete the stack after experimenting with the examples provided in the post. On the CloudFormation console, select the stack that you created, and then choose Delete. This will delete all of the resources that it created, including CodeCommit repositories, IAM roles/policies, and CodeBuild projects.
Summary
In this post, we demonstrated how to unit test and deploy Python-based AWS Glue jobs in a pipeline with unit tests written with the PyTest framework. The approach is not limited to CodePipeline, and it can be used to build up a local development environment, as demonstrated in the Big Data blog. The aws-glue-jobs-unit-testing GitHub repository contains the example’s CloudFormation template, as well as sample AWS Glue Python code and Pytest code used in this post. If you have any questions or comments regarding this example, please open an issue or submit a pull request.
We’re excited to announce the Developer Preview of Smithy’s server and client generators for TypeScript. This enables developers to write concise, type-safe code in the same model-first manner that AWS has used to develop its services. Smithy is AWS’s open-source Interface Definition Language (IDL) for web services. AWS uses Smithy and its internal predecessor to model services, generate server scaffolding, and generate rich clients in multiple languages, such as the AWS SDKs.
If you’re unfamiliar with Smithy, check out the Smithy website and watch an introductory talk from Michael Dowling, Smithy’s Principal Engineer.
This post will demonstrate how you can write a simple Smithy model, write a service that implements the model, deploy it to AWS Lambda, and call it using a generated client.
What can the server generator do for me?
Using Smithy and its server generator unlocks model-first development. Model-first development puts your customers first. This forces you to define your interface first rather than let your API to become implicitly defined by your implementation choices.
Smithy’s server generator for TypeScript enables development at a higher level of abstraction. By making serialization, deserialization, and routing an implementation detail in generated code, service developers can focus on writing code against modeled types, rather than against raw HTTP requests. Your business logic and unit tests will be cleaner and more readable, and the way that your messages are represented on the wire is defined explicitly by a protocol, not implicitly by your JSON parser.
The server generator also lets you leverage TypeScript’s type safety. Not only is the business logic of your service written against strongly typed interfaces, but also you can reference your service’s types in your AWS Cloud Development Kit (AWS CDK) definition. This makes sure that your stack will fail at build time rather than deployment time if it’s out of sync with your model.
Finally, using Smithy for service generation lets you ship clients in Smithy’s growing portfolio of generated clients. We’re unveiling a developer preview of the client generator for TypeScript today as well, and we’ll continue to unveil more implementations in the future.
The architecture of a Smithy service
A Smithy service looks much like any other web service running on Lambda behind Amazon API Gateway. The difference lies in the code itself. Where a standard service might use a generic deserializer to parse an incoming request and bind it to an object, a Smithy service relies on code generation for deserialization, serialization, validation, and the object model itself. These functions are generated into a standalone library known as a Smithy server SDK. Using a server SDK with one of AWS’s prepackaged request converters, service developers can focus on their business logic, rather than the undifferentiated heavy lifting of parsing and generating HTTP requests and responses.
Walkthrough
This post will walk you through the process of building and using a Smithy service, from modeling to deployment.
By the end, you should be able to:
Model a simple REST service in Smithy
Generate a Smithy server SDK for TypeScript
Implement a service in Lambda using the generated server SDK
Deploy the service to AWS using the AWS CDK
Generate a client SDK, and use it to call the deployed service
The complete example described in this post can be found here.
Prerequisites
For this walkthrough, you should have the following prerequisites:
Select “Use this template” in the top right-hand corner
Fill out the form, and select “Create repository from template”
Clone your new repository from GitHub by following the instructions in the “Code” dropdown
Exploring and setting up the sample application
The sample application is split into three separate submodules:
model – contains the Smithy model that defines the service
Server – contains the code generation setup, application logic, and CDK stack for the service
typescript-client – contains the code generation setup for a rich client generated in TypeScript
To bootstrap the sample application and run the initial build
Open a terminal and navigate to the root of the sample application
Run the following command:
./gradlew build && yarn install
Wait until the build finishes successfully
Modeling a service using Smithy
In an IDE of your choice, open the file at model/src/main/smithy/main.smithy. This file defines the interface for the sample web service, a service that can echo strings back to the caller, as well as provide the string length.
The service definition forms the root of a Smithy model. It defines the operations that are available to clients, as well as common errors that are thrown by all of the operations in a service.
This service uses the @sigv4 trait to indicate that calls must be signed with AWS Signature V4. In the sample application, API Gateway’s Identity and Access Management (IAM) Authentication support provides this functionality.
@restJson1 indicates the protocol supported by this service. RestJson1 is Smithy’s built-in protocol for RESTful web services that use JSON for requests and responses.
This service advertises two operations: Echo and Length. Furthermore, it indicates that every operation on the service must be expected to throw ValidationException, if an invalid input is supplied.
Next, let’s look at the definition of the Length operation and its input type.
/// An operation that computes the length of a string
/// provided on the URI path
@readonly
@http(code: 200, method: "GET", uri: "/length/{string}",)
operation Length {
input: LengthInput,
output: LengthOutput,
errors: [PalindromeException],
}
@input
structure LengthInput {
@required
@httpLabel
string: String,
}
This operation uses the @http trait to model how requests are processed with restJson1, including the method (GET) and how the URI is formed (using a label to bind the string field from LengthInput to a path segment). HTTP binding with Smithy can be explored in depth at Smithy’s documentation page.
Note that this operation can also throw a PalindromeException, which we’ll explore in more detail when we check out the business logic.
Updating the Smithy model to add additional constraints to the input
Smithy constraint traits are used to enable additional validation for input types. Server SDKs automatically perform validation based on the Smithy constraints in the model. Let’s add a new constraint to the input for the Length operation. Moreover, let’s make sure that only alphanumeric characters can be passed in by the caller.
Open model/src/main/smithy/main.smithy in an editor
Add a @pattern constraint to the string member of Length input. It should look like this:
Open a terminal, and navigate to the root of the sample application
Run the following command:
yarn build
Wait for the build to finish successfully
Using the Smithy Server Generator for TypeScript
The key component of a Smithy web service is its code generator, which translates the Smithy model into actual code. You’ve already run the code generator – it runs every time that you build the sample application.
The codegen directory inside of the server submodule is where the Smithy Server Generator for TypeScript is configured and run. The server generator uses Smithy Build to build, and it’s configured by smithy-build.json.
This smithy-build configures two projections. The ts-server projection generates the server SDK by invoking the typescript-ssdk-codegen plugin. The package and packageVersion arguments are used to generate an npm package that you can add as a dependency in your server code.
The OpenAPI projection configures Smithy’s OpenAPI converter to generate a file that can be imported into API Gateway to host this service. It uses Smithy’s ability to extend models via the imports keyword to extend the base model with an additional API Gateway configuration. The generated OpenAPI specification is used by the CDK stack, which we’ll explore later.
If you open package.json in the server submodule, then you’ll notice this line in the dependencies section:
The key, @smithy-demo/string-wizard-service-ssdk, matches the package key in the smithy-build.json file. The value uses Yarn’s workspaces feature to set up a local dependency on the generated server SDK. This lets you use the server SDK as a standalone npm dependency without publishing it to a repository. Since we bundle the server application into a zip file before uploading it to Lambda, you can treat the server SDK as an implementation detail that isn’t published externally.
We won’t get into the details here, but you can see the specifics of how the code generator is invoked by looking at the regenerate:ssdk script in the server’s package.json, as well as the build.gradle file in the server’s codegen directory.
Implementing an operation using a server SDK
The server generator takes care of the undifferentiated heavy lifting of writing a Smithy service. However, there are still two tasks left for the service developer: writing the Lambda entrypoint, and implementing the operation’s business logic.
First, let’s look at the entrypoint for the Length operation. Open server/src/length_handler.ts in an editor. You should see the following content:
import { getLengthHandler } from "@smithy-demo/string-wizard-service-ssdk";
import { APIGatewayProxyHandler } from "aws-lambda";
import { LengthOperation } from "./length";
import { getApiGatewayHandler } from "./apigateway";
// This is the entry point for the Lambda Function that services the LengthOperation
export const lambdaHandler: APIGatewayProxyHandler = getApiGatewayHandler(getLengthHandler(LengthOperation));
If you’ve written a Lambda entry-point before, then exporting a function of type APIGatewayProxyHandler will be familiar to you. However, there are a few new pieces here. First, we have a function from the server SDK, called getLengthHandler, that takes a Smithy Operation type and returns a ServiceHandler. Operation is the interface that the server SDK uses to encapsulate business logic. The core task of implementing a Smithy service is to implement Operations. ServiceHandler is the interface that encapsulates the generated logic of a server SDK. It’s the black box that handles serialization, deserialization, error handling, validation, and routing.
The getApiGatewayHandler function simply invokes the request and response conversion logic, and then builds a custom context for the operation. We won’t go into their details here.
Next, let’s explore the operation implementation. Open server/src/length.ts in an editor. You should see the following content:
import { Operation } from "@aws-smithy/server-common";
import {
LengthServerInput,
LengthServerOutput,
PalindromeException,
} from "@smithy-demo/string-wizard-service-ssdk";
import { HandlerContext } from "./apigateway";
import { reverse } from "./util";
// This is the implementation of business logic of the LengthOperation
export const LengthOperation: Operation<LengthServerInput, LengthServerOutput, HandlerContext> = async (
input,
context
) => {
console.log(`Received Length operation from: ${context.user}`);
if (input.string != undefined && input.string === reverse(input.string)) {
throw new PalindromeException({ message: "Cannot handle palindrome" });
}
return {
length: input.string?.length,
};
};
Let’s look at this implementation piece-by-piece. First, the function type Operation<LengthServerInput, LengthServerOutput, HandlerContext> provides the type-safe interface for our business logic. LengthServerInput and LengthServerOutput are the code generated types that correspond to the input and output types for the Length operation in our Smithy model. If we use the wrong type arguments for the Operation, then it will fail type checks against the getLengthHandler function in the entry-point. If we try to access the incorrect properties on the input, then we’ll also see type checker failures. This is one of the core tenets of the Smithy Server Generator for TypeScript: writing a web service should be as strongly typed as writing anything else.
Next, let’s look at the section that validates that the input isn’t a palindrome:
if (input.string != undefined && input.string === reverse(input.string)) {
throw new PalindromeException({ message: "Cannot handle palindrome" });
}
Although the server SDK can validate the input against Smithy’s constraint traits, there is no constraint trait for rejecting palindromes. Therefore, we must include this validation in our business logic. Our Smithy model includes a PalindromeException definition that includes a message member. This is generated as a standard subclass of Error with a constructor that takes in a message that your operation implementation can throw like any other error. This will be caught and properly rendered as a response by the server SDK.
Finally, there’s the return statement. Since the Smithy model defines LengthOutput as a structure containing an integer member called length, we return an object that has the same structural type here.
Note that this business logic doesn’t have to consider serialization, or the wire format of the request or response, let alone anything else related to HTTP or API Gateway. The unit tests in src/length/length.spec.ts reflect this. They’re the same standard unit tests as you would write against any other TypeScript class. The server SDK lets you write your business logic at a higher level of abstraction, thus simplifying your unit testing and letting your developers focus on their business logic rather than the messy details.
Deploying the sample application
The sample application utilizes the AWS CDK to deploy itself to your AWS account. Explore the CDK definition in server/lib/cdk-stack.ts. An in-depth exploration of the stack is out of the scope for this post, but it looks largely like any other AWS application that deploys TypeScript code to Lambda behind API Gateway.
The key difference is that the cdk stack can rely on a generated OpenAPI definition for the API Gateway resource. This makes sure that your deployed application always matches your Smithy model. Furthermore, it can use the server SDK’s generated types to make sure that every modeled operation has an implementation deployed to Lambda. This means that forgetting to wire up the implementation for a new operation becomes a compile-time failure, rather than a runtime one.
To deploy the sample application from the command line
Open a terminal and navigate to the server directory of your sample application.
Run the following command:
yarn cdk deploy
The cdk will display a list of security-sensitive resources that will be deployed to your account. These consist mostly of AWS Identity and Access Management (IAM) roles used by your Lambda functions for execution. Enter y to continue deploying the application to your account.
When it has completed, the CDK will print your new application’s endpoint and the CloudFormation stack containing your application to the console. It will look something like the following:
Log on to your AWS account in the AWS Management Console.
Navigate to the Lambda console. You should see two new functions: one that starts with StringWizardService-EchoFunction, and one that starts with StringWizardService-EchoFunction. These are the implementations of your Smithy service’s operations.
Navigate to the Amazon API Gateway console. You should see a new REST API named StringWizardAPI, with Resources POST /echo and GET /length/{string}, corresponding to your Smithy model.
Calling the sample application with a generated client
The last piece of the Smithy puzzle is the strongly-typed generated client generated by the Smithy Client Generator for TypeScript. It’s located in the typescript-client folder, which has a codegen folder that uses SmithyBuild to generate a client in much the same manner as the server.
The sample application ships with a simple wrapper script for the length operation that uses the generated client to build a rudimentary CLI. Open the typescript-client/bin/length.ts file in your editor. The contents will look like the following:
If you’ve used the AWS SDK for JavaScript v3, this will look familiar. This is because it’s generated using the Smithy Client Generator for TypeScript!
From the code, you can see that the CLI takes two positional arguments: the endpoint for the deployed application, and an input string. Let’s give it a spin.
To call the deployed application using the generated client
Open a terminal and navigate to the typescript-client directory.
Run the following command to build the client:
yarn build
Using the endpoint output by the CDK in the Deploying the sample application section above, run the following command:
yarn run str-length https://RANDOMSTRING.execute-api.us-west-2.amazonaws.com/prod/ foo
You should see an output of 3, the length of foo.
Next, trigger anerror by calling your endpoint with a palindrome by running the following command:
yarn run str-length https://RANDOMSTRING.execute-api.us-west-2.amazonaws.com/prod/ kayak
You should see the following output:
Failed with error: PalindromeException: Cannot handle palindrome
Cleaning up
To avoid incurring future charges, delete the resources.
To delete the sample application using the CDK
Open a terminal and navigate to the server directory.
Run the following command:
yarn cdk destroy StringWizardService
Answer y to the prompt Are you sure you want to delete: StringWizardService (y/n)?
Wait for the CDK to complete the deletion of your CloudFormation stack. You should see the following when it has completed:
✅ StringWizardService: destroyed
Conclusion
You have now used a Smithy model to define a service, explored how a generated server SDK can simplify your web service development, deployed the service to the AWS Cloud using the AWS CDK, and called the service using a strongly-typed generated client.
If you aren’t familiar with Smithy, but you want to learn more, then don’t forget to check out the documentation or the introductory video.
To learn more about the Smithy Server Generator for TypeScript, check out its documentation.
If you have feature requests, bug reports, feedback of any kind, or would like to contribute, head over to the GitHub repository.
AWS Identity and Access Management (IAM) recently launched new condition keys to make it simpler to control access to your resources along your Amazon Web Services (AWS) organizational boundaries. AWS recommends that you set up multiple accounts as your workloads grow, and you can use multiple AWS accounts to isolate workloads or applications that have specific security requirements. By using the new conditions, aws:ResourceOrgID, aws:ResourceOrgPaths, and aws:ResourceAccount, you can define access controls based on an AWS resource’s organization, organizational unit (OU), or account. These conditions make it simpler to require that your principals (users and roles) can only access resources inside a specific boundary within your organization. You can combine the new conditions with other IAM capabilities to restrict access to and from AWS accounts that are not part of your organization.
This post will help you get started using the new condition keys. We’ll show the details of the new condition keys and walk through a detailed example based on the following scenario. We’ll also provide references and links to help you learn more about how to establish access control perimeters around your AWS accounts.
Consider a common scenario where you would like to prevent principals in your AWS organization from adding objects to Amazon Simple Storage Service (Amazon S3) buckets that don’t belong to your organization. To accomplish this, you can configure an IAM policy to deny access to S3 actions unless aws:ResourceOrgID matches your unique AWS organization ID. Because the policy references your entire organization, rather than individual S3 resources, you have a convenient way to maintain this security posture across any number of resources you control. The new conditions give you the tools to create a security baseline for your IAM principals and help you prevent unintended access to resources in accounts that you don’t control. You can attach this policy to an IAM principal to apply this rule to a single user or role, or use service control policies (SCPs) in AWS Organizations to apply the rule broadly across your AWS accounts. IAM principals that are subject to this policy will only be able to perform S3 actions on buckets and objects within your organization, regardless of their other permissions granted through IAM policies or S3 bucket policies.
New condition key details
You can use the aws:ResourceOrgID, aws:ResourceOrgPaths, and aws:ResourceAccount condition keys in IAM policies to place controls on the resources that your principals can access. The following table explains the new condition keys and what values these keys can take.
Condition key
Description
Operator
Single/multi value
Value
aws:ResourceOrgID
AWS organization ID of the resource being accessed
Note: Of the three keys, only aws:ResourceOrgPaths is a multi-value condition key, while aws:ResourceAccount and aws:ResourceOrgID are single-value keys. For information on how to use multi-value keys, see Creating a condition with multiple keys or values in the IAM documentation.
Resource owner keys compared to principal owner keys
The new IAM condition keys complement the existing principal condition keys aws:PrincipalAccount, aws:PrincipalOrgPaths, and aws:PrincipalOrgID. The principal condition keys help you define which AWS accounts, organizational units (OUs), and organizations are allowed to access your resources. For more information on the principal conditions, see Use IAM to share your AWS resources with groups of AWS accounts in AWS Organizations on the AWS Security Blog.
Using the principal and resource keys together helps you establish permission guardrails around your AWS principals and resources, and makes it simpler to keep your data inside the organization boundaries you define as you continue to scale. For example, you can define identity-based policies that prevent your IAM principals from accessing resources outside your organization (by using the aws:ResourceOrgID condition). Next, you can define resource-based policies that prevent IAM principals outside your organization from accessing resources that are inside your organization boundary (by using the aws:PrincipalOrgID condition). The combination of both policies prevents any access to and from AWS accounts that are not part of your organization. In the next sections, we’ll walk through an example of how to configure the identity-based policy in your organization. For the resource-based policy, you can follow along with the example in An easier way to control access to AWS resources by using the AWS organization of IAM principals on the AWS Security blog.
Setup for the examples
In the following sections, we’ll show an example IAM policy for each of the new conditions. To follow along with Example 1, which uses aws:ResourceAccount, you’ll just need an AWS account.
To follow along with Examples 2 and 3 that use aws:ResourceOrgPaths and aws:ResourceOrgID respectively, you’ll need to have an organization in AWS Organizations and at least one OU created. This blog post assumes that you have some familiarity with the basic concepts in IAM and AWS Organizations. If you need help creating an organization or want to learn more about AWS Organizations, visit Getting Started with AWS Organizations in the AWS documentation.
Which IAM policy type should I use?
You can implement the following examples as identity-based policies, or in SCPs that are managed in AWS Organizations. If you want to establish a boundary for some of your IAM principals, we recommend that you use identity-based policies. If you want to establish a boundary for an entire AWS account or for your organization, we recommend that you use SCPs. Because SCPs apply to an entire AWS account, you should take care when you apply the following policies to your organization, and account for any exceptions to these rules that might be necessary for some AWS services to function properly.
Example 1: Restrict access to AWS resources within a specific AWS account
Let’s look at an example IAM policy that restricts access along the boundary of a single AWS account. For this example, say that you have an IAM principal in account 222222222222, and you want to prevent the principal from accessing S3 objects outside of this account. To create this effect, you could attach the following IAM policy.
Note: This policy is not meant to replace your existing IAM access controls, because it does not grant any access. Instead, this policy can act as an additional guardrail for your other IAM permissions. You can use a policy like this to prevent your principals from access to any AWS accounts that you don’t know or control, regardless of the permissions granted through other IAM policies.
This policy uses a Deny effect to block access to S3 actions unless the S3 resource being accessed is in account 222222222222. This policy prevents S3 access to accounts outside of the boundary of a single AWS account. You can use a policy like this one to limit your IAM principals to access only the resources that are inside your trusted AWS accounts. To implement a policy like this example yourself, replace account ID 222222222222 in the policy with your own AWS account ID. For a policy you can apply to multiple accounts while still maintaining this restriction, you could alternatively replace the account ID with the aws:PrincipalAccount condition key, to require that the principal and resource must be in the same account (see example #3 in this post for more details how to accomplish this).
Organization setup: Welcome to AnyCompany
For the next two examples, we’ll use an example organization called AnyCompany that we created in AWS Organizations. You can create a similar organization to follow along directly with these examples, or adapt the sample policies to fit your own organization. Figure 1 shows the organization structure for AnyCompany.
Figure 1: Organization structure for AnyCompany
Like all organizations, AnyCompany has an organization root. Under the root are three OUs: Media, Sports, and Governance. Under the Sports OU, there are three more OUs: Baseball, Basketball, and Football. AWS accounts in this organization are spread across all the OUs based on their business purpose. In total, there are six OUs in this organization.
Example 2: Restrict access to AWS resources within my organizational unit
Now that you’ve seen what the AnyCompany organization looks like, let’s walk through another example IAM policy that you can use to restrict access to a specific part of your organization. For this example, let’s say you want to restrict S3 object access within the following OUs in the AnyCompany organization:
Media
Sports
Baseball
Basketball
Football
To define a boundary around these OUs, you don’t need to list all of them in your IAM policy. Instead, you can use the organization structure to your advantage. The Baseball, Basketball, and Football OUs share a parent, the Sports OU. You can use the new aws:ResourceOrgPaths key to prevent access outside of the Media OU, the Sports OU, and any OUs under it. Here’s the IAM policy that achieves this effect.
Note: Like the earlier example, this policy does not grant any access. Instead, this policy provides a backstop for your other IAM permissions, preventing your principals from accessing S3 objects outside an OU-defined boundary. If you want to require that your IAM principals consistently follow this rule, we recommend that you apply this policy as an SCP. In this example, we attached this policy to the root of our organization, applying it to all principals across all accounts in the AnyCompany organization.
The policy denies access to S3 actions unless the S3 resource being accessed is in a specific set of OUs in the AnyCompany organization. This policy is identical to Example 1, except for the condition block: The condition requires that aws:ResourceOrgPaths contains any of the listed OU paths. Because aws:ResourceOrgPaths is a multi-value condition, the policy uses the ForAllValues:StringNotLike operator to compare the values of aws:ResourceOrgPaths to the list of OUs in the policy.
The first OU path in the list is for the Media OU. The second OU path is the Sports OU, but it also adds the wildcard character * to the end of the path. The wildcard * matches any combination of characters, and so this condition matches both the Sports OU and any other OU further down its path. Using wildcards in the OU path allows you to implicitly reference other OUs inside the Sports OU, without having to list them explicitly in the policy. For more information about wildcards, refer to Using wildcards in resource ARNs in the IAM documentation.
Example 3: Restrict access to AWS resources within my organization
Finally, we’ll look at a very simple example of a boundary that is defined at the level of an entire organization. This is the same use case as the preceding two examples (restrict access to S3 object access), but scoped to an organization instead of an account or collection of OUs.
Note: Like the earlier examples, this policy does not grant any access. Instead, this policy provides a backstop for your other IAM permissions, preventing your principals from accessing S3 objects outside your organization regardless of their other access permissions. If you want to require that your IAM principals consistently follow this rule, we recommend that you apply this policy as an SCP. As in the previous example, we attached this policy to the root of our organization, applying it to all accounts in the AnyCompany organization.
The policy denies access to S3 actions unless the S3 resource being accessed is in the same organization as the IAM principal that is accessing it. This policy is identical to Example 1, except for the condition block: The condition requires that aws:ResourceOrgID and aws:PrincipalOrgID must be equal to each other. With this requirement, the principal making the request and the resource being accessed must be in the same organization. This policy also applies to S3 resources that are created after the policy is put into effect, so it is simple to maintain the same security posture across all your resources.
In this post, we explored the new conditions, and walked through a few examples to show you how to restrict access to S3 objects across the boundary of an account, OU, or organization. These tools work for more than just S3, though: You can use the new conditions to help you protect a wide variety of AWS services and actions. Here are a few links that you may want to look at:
Whitepaper: Building an AWS Perimeter provides an in-depth overview of how to use these keys as part of a broader strategy to secure your AWS resources.
If you have any questions, comments, or concerns, contact AWS Support or start a new thread on the AWS Identity and Access Management forum. Thanks for reading about this new feature. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
Git hooks are scripts that extend Git functionality when certain events and actions occur during code development. Developer teams often use Git hooks to perform quality checks before they commit their code changes. For example, see the blog post Use Git pre-commit hooks to avoid AWS CloudFormation errors for a description of how the AWS Integration and Automation team uses various pre-commit hooks to help reduce effort and errors when they build AWS Quick Starts.
This blog post shows you how to extend your Git hooks to validate your AWS CloudFormation templates against policy-as-code rules by using AWS CloudFormation Guard. This can help you verify that your code follows organizational best practices for security, compliance, and more by preventing you from commit changes that fail validation rules.
We will also provide patterns you can use to centrally maintain a list of rules that security teams can use to roll out new security best practices across an organization. You will learn how to configure a pre-commit framework by using an example repository while you store Guard rules in both a central Amazon Simple Storage Service (Amazon S3) bucket or in versioned code repositories (such as AWS CodeCommit, GitHub, Bitbucket, or GitLab).
Prerequisites
To complete the steps in this blog post, first perform the following installations.
In this section, we walk you through an exercise to extend a Java service on an Amazon EKS example repository with Git hooks by using AWS CloudFormation Guard. You can choose to upload your Guard rules in either a separate GitHub repository or your own S3 bucket.
First, download the sample repository that you will add the pre-commit framework to.
To clone the test repository
Clone the repo to a local directory by running the following command in your local terminal.
where <account-id> is the ID of the AWS account you’re using and <aws-region> is the AWS Region you want to use.
(Optional) Alternatively, you can follow the Getting started with Amazon S3 tutorial to create the bucket and upload the object (as described in step 4 that follows) by using the AWS Management Console.
When you store your Guard rules in an S3 bucket, you can make the rules accessible to other member accounts in your organization by using the aws:PrincipalOrgID condition and setting the value to your organization ID in the bucket policy.
Create a file that contains a Guard rule named rules.guard, with the following content.
let eks_cluster = Resources.* [ Type == 'AWS::EKS::Cluster' ]
rule eks_public_disallowed when %eks_cluster !empty {
%eks_cluster.Properties.ResourcesVpcConfig.EndpointPublicAccess == false
}
This rule will verify that public endpoints are disabled by checking that resources that are created by using the AWS::EKS::Cluster resource type have the EndpointPublicAccess property set to false. For more information about authoring your own rules using Guard domain-specific language (DSL), see Introducing AWS CloudFormation Guard 2.0.
Upload the rule set to your S3 bucket by running the following command in the AWS CLI.
In the next step, you will set up the pre-commit framework in the repository to run CloudFormation Guard against code changes.
To configure your pre-commit hook to use Guard
Run the following command to create a new branch where you will test your changes. git checkout -b feature/guard-hook
Navigate to the root directory of the project that you cloned earlier and create a .pre-commit-config.yaml file with the following configuration.
repos:
- repo: local
hooks:
- id: cfn-guard-rules
name: Rules for AWS
description: Download Organization rules
entry: aws s3 cp --recursive s3://<account-id>-cfn-guard-rules/rules guard-rules/org-rules/
language: system
pass_filenames: false
- id: cfn-guard
name: AWS CloudFormation Guard
description: Validate code against your Guard rules
entry: bash -c 'for template in "$@"; do cfn-guard validate -r guard-rules -d "$template" || SCAN_RESULT="FAILED"; done; if [[ "$SCAN_RESULT" = "FAILED" ]]; then exit 1; fi'
language: rust
files: \.(json|yaml|yml|template\.json|template)$
additional_dependencies:
- cli:cfn-guard
You will need to replace the <account-id> placeholder value with the AWS account ID you entered in the To set up an S3 bucket with your Guard rules procedure.
This hook configuration uses local pre-commit hooks to download the latest version of Guard rules from the bucket you created previously. This allows you to set up a centralized set of Guard rules across your organization.
Alternatively, you can create and use a code repository such as GitHub, AWS CodeCommit, or Bitbucket to keep your rules in version control. To do so, replace the command in the Download Organization rules step of the .pre-commit-config.yaml file with:
bash -c ‘if [ -d guard-rules/org-rules ]; then cd guard-rules/org-rules && git pull; else git clone <guard-rules-repository-target> guard-rules/org-rules; fi’
Where <guard-rules-repository-target> is the HTTPS or SSH URL of your repository. This command will clone or pull the latest rules from your Git repo by using your Git credentials.
The hook will also install Guard as an additional dependency by using a Rust hook. Using Guard, it will run the code changes in the repository directory against the downloaded rule set. When misconfigurations are detected, the hook stops the commit.
You can further extend your organization rules with your own Guard rules by adding them to the cfn-guard-rules folder. You should commit these rules in your repository and add cfn-guard-rules/org-rules/* to your .gitignore file.
Run a pre-commit install command to install the hooks you just created.
Finally, test that the pre-commit’s Guard hook fails commits of code changes that do not follow organizational best practices.
To test pre-commit hooks
Add EndpointPublicAccess: true in cloudformation/eks.template.yaml, as shown following. This describes the test-only intent (meaning that you want to detect and flag errors in your rule) of adding public access to the Amazon Elastic Kubernetes Service (Amazon EKS) cluster.
You should see the following error that disallows the commit to the local repository and shows which one of your Guard rules failed.
amazon-eks-controlplane.template.yaml Status = FAIL
FAILED rules
rules.guard/eks_public_disallowed FAIL
---
Evaluation of rules rules.guard against data amazon-eks-controlplane.template.yaml
---
Property
[/Resources/EKS/Properties/ResourcesVpcConfig/EndpointPublicAccess] in data
[eks.template.yaml] is not compliant with [rules.guard/eks_public_disallowed]
because provided value [true] did not match expected value [false].
Error Message []
(Optional) You can also test hooks before committing by using the pre-commit run command to see similar output.
Cleanup
To avoid incurring ongoing charges, follow these cleanup steps to delete the resources and files you created as you followed along with this blog post.
To clean up resources and files
Remove your local repository.
rm -rf /path/to/repository
Delete the S3 bucket you created by running the following command.
(Optional) Remove the pre-commit hooks framework by running this command.
pip uninstall pre-commit
Conclusion
In this post, you learned how to use AWS CloudFormation Guard with the pre-commit framework locally to validate your infrastructure-as-code solutions before you push remote changes to your repositories.
You also learned how to extend the solution to use a centralized list of security rules that is stored in versioned code repositories (GitHub, Bitbucket, or GitLab) or an S3 bucket. And you learned how to further extend the solution with your own rules. You can find examples of rules to use in Guard’s Github repository or refer to write preventative compliance rules for AWS CloudFormation templates the cfn-guard way. You can then further configure other repositories to prevent misconfigurations by using the same Guard rules.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the KMS re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
The General Data Protection Law (LGPD) in Brazil was first published on 14 August 2018, and started its applicability on 18 August 2020. Companies that manage personally identifiable information (PII) in Brazil as defined by LGPD will have to comply with and attend to the law.
To better help customers prepare and implement controls that focus on LGPD Chapter VII Security and Best Practices, AWS created a workbook based on industry best practices, AWS service offerings, and controls.
Amongst other topics, this workbook covers information security and AWS controls from:
AWS adheres to a shared responsibility model. Customers will have to observe which services offer privacy features and determine their applicability to their specific compliance requirements. Further information about data privacy at AWS can be found at our Data Privacy Center. Specific information about LGPD and data privacy at AWS in Brazil can be found on our Brazil Data Privacy page.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below. Want more AWS Security news? Follow us on Twitter.
Portuguese
Workbook da LGPD para Clientes AWS que gerenciam Informações de Identificação Pessoal no Brasil
A Lei Geral de Proteção de Dados (LGPD) teve sua primeira publicação em 14 de agosto de 2018 no Brasil e iniciou sua aplicabilidade em 18 de agosto de 2020. Empresas que gerenciam informações pessoais identificáveis (PII) conforme definido na LGPD terão que cumprir e atender às cláusulas da lei.
Para ajudar melhor os clientes a preparar e implementar controles que se concentram no Capítulo VII da LGPD “da Segurança e Boas Práticas”, a AWS criou uma pasta de trabalho com base nas melhores práticas do setor, ofertas de serviços e controles da AWS.
Entre outros tópicos, esta pasta de trabalho aborda a segurança da informação e os controles da AWS de:
CIS v8.0 – framework contendo 18 domínios de controles
NIST Cybersecurity Framework (CSF) – informações adicionais sobre NIST CSF disponíveis para consulta
Para saber mais sobre nossos programas de conformidade e segurança, consulte Programas de conformidade da AWS. Como sempre, valorizamos seus comentários e perguntas; entre em contato com a equipe de conformidade da AWS por meio da página Fale conosco.
Se você tiver feedback sobre esta postagem, envie comentários na seção Comentários abaixo.
Quer mais notícias sobre segurança da AWS? Siga-nos no Twitter.
We are pleased to announce that in all AWS Regions that support Amazon Cognito, you can now integrate Amazon Cognito with Amazon Simple Email Service (Amazon SES) and Amazon Simple Notification Service (Amazon SNS) in the same Region. By integrating these services in the same Region, you can more easily achieve lower latency, and remove cross-Region dependencies in your architecture. Amazon Cognito lets you add authentication, authorization, and user management to your web and mobile apps. Amazon Cognito scales to millions of users and supports sign-in with social identity providers such as Apple, Facebook, Google, and Amazon, and enterprise identity providers that support SAML 2.0 and OpenID Connect (OIDC).
Amazon Cognito launched new console experience in 2021 that makes it even easier for you to manage Amazon Cognito user pools and add sign-in and sign-up functionality to your applications. The new console has now been further enhanced to configure the in-Region Amazon SES options as shown in Figure 1, and Amazon SNS options as shown in Figure 2. Also you can configure the same via Amazon Cognito APIs. Thus you can update your in-Region Amazon SES, Amazon SNS configuration options through the console, API, or CLI. You can use Amazon Cognito in a Region that suits your business requirements and sustainability goals, and extend your Amazon Cognito architecture to additional Regions.
Figure 1: Amazon SES Region drop-down selection with new options
Figure 2: Amazon SNS Region selection drop-down selection with new options
In-Region integration with Amazon SES and Amazon SNS is currently available in all Regions where Amazon SES, Amazon SNS and Amazon Cognito are available. For up to date information, see the AWS Regional Services List. To learn more, see What is Amazon Cognito?.
Frequently asked questions (FAQs)
What Region will Amazon Cognito console default to when I configure Amazon SES and Amazon SNS Regions?
When creating new user pools, the Amazon Cognito console auto-populates the Region to in-Region, but you still have to select the identity. Existing user pools with cross-Region Amazon SES or Amazon SNS integration will not be affected.
Can I update an existing user pool to integrate with Amazon SES or Amazon SNS in the same Region?
Yes, you can change your configuration so that Amazon Cognito integrates with either Amazon SES or Amazon SNS, or both, in the same Region.
What Regions can I use with Amazon Cognito for Amazon SNS and Amazon SES?
Why should I change from cross-Region to same-Region Amazon SES or Amazon SNS?
Amazon Cognito is designed to scale to millions of users. Your users expect prompt delivery of their messages for multi-factor authentication and account setup. Using Amazon SES and Amazon SNS in the same Region as your user pool improves performance by reducing the round-trip time of the call that Amazon Cognito makes to Amazon SES or Amazon SNS.
What are the key benefits of using in-Region integration?
Availability: Availability is improved as you no longer will have cross-Region dependency for Amazon SES or Amazon SNS.
Latency: Transit time for API requests is most efficient within a single AWS Region.
Usability: Billing, logging, and setup are more transparent when you consolidate resources in the same Region.
Which version of Amazon Cognito user pools console does this change apply to?
This change applies to current version of the new Amazon Cognito user pool console experience. Also this change applies to current version of Amazon Cognito APIs.
Will my current cross-Region integration change?
No. Your AWS resources are your own and will not be changed. If you want to make use of the new in-Region integration, you must update your user pool configuration to integrate with Amazon SES or Amazon SNS in the same AWS Region.
Will I be placed in the SMS sandbox if I change my Amazon SNS Region?
The SMS sandbox status is Region dependent, so whether or not your user pool is in the SMS sandbox depends on the SNS Region you configure in your user pool. When your account is in the SMS sandbox, Amazon Cognito can send SMS text messages only to verified phone numbers and not to all of your users. When you move to a new Region, verified phone numbers will also need to be re-verified. For more information, see SMS message settings for Amazon Cognito user pools.
To find info about whether your user pool is configured in an SNS Region that is in the SMS sandbox, you can view the SmsConfigurationFailure field in DescribeUserPool API.
Which API parameters can developers use to make the in-Region changes?
Will my automation scripts break due to this change?
This change to support in-Region integration will not break your automation scripts. If future updates include changing the default Region value to in-Region, we plan to inform all Amazon Cognito customers about this change with sufficient time to transition to the new default Region value.
Can I revert to my original Region integration if I run into an issue?
Yes, the ability to use Amazon SES or Amazon SNS resources in a different AWS Region is still supported.
Next steps
If your Amazon Cognito user pool is currently configured to make cross-Region calls to Amazon SES or Amazon SNS, you can update your configuration through the console, API, or CLI.
If you have any questions or issues, you can start a new thread on AWS re:Post, contact AWS Support, or your technical account manager (TAM).
Want more AWS Security news? Follow us on Twitter.
You can use third-party identity providers (IdPs) such as Okta, Ping, or OneLogin to federate with the AWS Identity and Access Management (IAM) service using SAML 2.0, allowing your workforce to configure services by providing authorization access to the AWS Management Console or Command Line Interface (CLI). When you federate to AWS, you assume a role through the AWS Security Token Service (AWS STS), which through the AssumeRole API returns a set of temporary security credentials you then use to access AWS resources. The use of temporary credentials can make it challenging for administrators to trace which identity was responsible for actions performed.
To address this, with AWS STS you set a unique attribute called SourceIdentity, which allows you to easily see which identity is responsible for a given action.
This post will show you how to set up the AWS STS SourceIdentity attribute when using Okta, Ping, or OneLogin as your IdP. Your IdP administrator can configure a corporate directory attribute, such as an email address, to be passed as the SourceIdentity value within the SAML assertion. This value is stored as the SourceIdentity element in AWS CloudTrail, along with the activity performed by the assumed role. This post will also show you how to set up a sample policy for setting the SourceIdentity when switching roles. Finally, as an administrator reviewing CloudTrail activity, you can use the source identity information to determine who performed which actions. We will walk you through CloudTrail logs from two accounts to demonstrate the continuance of the source identity attribute, showing you how the SourceIdentity will appear in both accounts’ logs.
Configure the SourceIdentity attribute with Okta integration
You will do this portion of the configuration within the Okta administrative console. This procedure assumes that you have a previously configured AWS and Okta integration. If not, you can configure your integration by following the instructions in the Okta AWS Multi-Account Configuration Guide. You will use the Okta to SAML integration and configure an optional attribute to map as the SourceIdentity.
To set up Okta with SourceIdentity
Log in to the Okta admin console.
Navigate to Applications–AWS.
In the top navigation bar, select the Sign On tab, as shown in Figure 1.
Figure 1 – Navigate to attributes in SAML settings on the Okta applications page
Under Sign on methods, select SAML 2.0, and choose the arrow next to Attributes (Optional) to expand, as shown in Figure 2.
Figure 2 – Add new attribute SourceIdentity and map it to Okta provided attribute of your choice
Add the optional attribute definition for SourceIdentity using the following parameters:
For Name, enter: https://aws.amazon.com/SAML/Attributes/SourceIdentity
For Name format, choose URI Reference.
For Value, enter user.login.
Note: The Name format options are the following: Unspecified – can be any format defined by the Okta profile and must be interpreted by your application. URI Reference – the name is provided as a Uniform Resource Identifier string. Basic – a simple string; the default if no other format is specified.
The examples shown in Figure 1 and Figure 2 show how to map an email address to the SourceIdentity attribute by using an on-premises Active Directory sync. The SourceIdentity can be mapped to other attributes from your Active Directory.
Configure the SourceIdentity attribute with PingOne integration
You do this portion of the configuration in the Ping Identity administrative console. This procedure assumes that you have a previously configured AWS and Ping integration. If not, you can set up the PingFederate AWS Connector by following the Ping Identity instructions Configuring an SSO connection to Amazon Web Services.
You’re using the Ping to SAML integration and configuring an optional attribute to map as the source identity.
Configuring PingOne as an IdP involves setting up an identity repository (in this case, the PingOne Directory), creating a user group, and adding users to the individual groups.
Choose the My Applications tab, as shown in Figure 3.
Figure 3. PingOne My Applications tab
On the Amazon Web Services line, choose on the arrow on the right side to show application details to edit and add a new attribute for the source identity.
Choose Continue to Next Step to open the Attribute Mapping section, as shown in Figure 4.
Figure 4. Attribute mappings
In the Attribute Mapping section line 1, for SAML_SUBJECT, choose Advanced.
On the Advanced Attribute Options page, for Name ID Format to send to SP select urn:oasis:names:tc:SAML:2.0:nameid-format:persistent. For IDP Attribute Name or Literal Value, select SAML_SUBJECT, as shown in Figure 4.
Figure 5. Advanced Attribute Options for SAML_SUBJECT
In the Attribute Mapping section line 2 as shown in Figure 4, for the application attribute https://aws.amazon.com/SAML/Attributes/Role, select Advanced.
On the Advanced Attribute Options page, for Name Format, select urn:oasis:names:tc:SAML:2.0:attrname-format:uri, as shown in Figure 6.
Figure 6. Advanced Attribute Options for https://aws.amazon.com/SAML/Attributes/Role
In the Attribute Mapping section line 2 as shown in Figure 4, select As Literal.
For IDP Attribute Name or Literal Value, format the role and provider ARNs (which are not yet created on the AWS side) in the following format. Be sure to replace the placeholders with your own values. Make a note of the role name and SAML provider name, as you will be using these exact names to create an IAM role and an IAM provider on the AWS side.
In the Attribute Mapping section line 3 as shown in Figure 4, for the application attribute https://aws.amazon.com/SAML/Attributes/RoleSessionName, enter Email (Work).
In the Attribute Mapping section as shown in Figure 4, to create line 5, choose Add a new attribute in the lower left.
In the newly added Attribute Mapping section line 5 as shown in Figure 4, add the SourceIdentity.
For Application Attribute, enter: https://aws.amazon.com/SAML/Attributes/SourceIdentity
For Identity Bridge Attribute or Literal Value, enter: SAML_SUBJECT
Choose Continue to Next Step in the lower right.
For Group Access, add your existing PingOne Directory Group to this application.
Review your setup configuration, as shown in Figure 7, and choose Finish.
Figure 7. Review mappings
Configure the SourceIdentity attribute with OneLogin integration
For the OneLogin SAML integration with AWS, you use the Amazon Web Services Multi Account application and configure an optional attribute to map as the SourceIdentity. You do this portion of the configuration in the OneLogin administrative console.
This procedure assumes that you already have a previously configured AWS and OneLogin integration. For information about how to configure the OneLogin application for AWS authentication and authorization, see the OneLogin KB article Configure SAML for Amazon Web Services (AWS) with Multiple Accounts and Roles.
After the OneLogin Multi Account application and AWS are correctly configured for SAML login, you can further customize the application to pass the SourceIdentity parameter upon login.
To change OneLogin configuration to add SourceIdentity attribute
In the OneLogin administrative console, in the Amazon Web Services Multi Account application, on the app administration page, navigate to Parameters, as shown in Figure 8.
Figure 8. OneLogin AWS Multi Account Application Configuration Parameters
To add a parameter, choose the + (plus) icon to the right of Value.
As shown in Figure 9, for Field Name enter https://aws.amazon.com/SAML/Attributes/SourceIdentity, select Include in SAML assertion, then choose Save.
Figure 9. OneLogin AWS Multi Account Application add new field
In the Edit Field page, select the default value you want to use for SourceIdentity. For the example in this blog post, for Value, select Email, then choose Save, as shown in Figure 10.
Figure 10. OneLogin AWS Multi Account Application map new field to email
After you’ve completed this procedure, review the final mapping details, as shown in Figure 11, to confirm that you see the additional parameter that will be passed into AWS through the SAML assertion.
Figure 11. OneLogin AWS Multi Account Application final mapping details
Configuring AWS IAM role trust policy
Now that the IdP configuration is complete, you can enable your AWS accounts to use SourceIdentity by modifying the IAM role trust policy.
For the workforce identity or application to be able to define their source identity when they assume IAM roles, you must first grant them permission for the sts:SetSourceIdentity action, as illustrated in the sample policy document below. This will permit the workforce identity or application to set the SourceIdentity themselves without any need for manual intervention.
To modify an AWS IAM role trust policy
Log in to the AWS Management Console for your account as a user with privileges to configure an IdP, typically an administrator.
Navigate to the AWS IAM service.
For trusted identity, choose SAML 2.0 federation.
From the SAML Provider drop down menu, select the IAM provider you created previously.
Modify the role trust policy and add the SetSourceIdentity action.
Sample policy document
This is a sample policy document attached to a role you assume when you log in to Account1 from the Okta dashboard. Edit your Account1/Role1 trust policy document and add sts:AssumeRoleWithSAML and sts:setSourceIdentity to the Action section.
Notes: The SetSourceIdentity action has to be allowed in the trust policy for assumeRole to work when the IdP is set up to pass SourceIdentity in the assertion. Future version of the sign-in URL may contain a Region code. When this occurs, you will need to modify the URL appropriately.
Policy statement
The following are examples of how the line “Federated”: “arn:aws:iam::<AccountId>:saml-provider/<IdP>” should look, based on the different IdPs specified in this post:
The following is a sample access control policy document in Account2 for Role2 that allows you to switchRole from Account1. Edit the control policy and add sts:AssumeRole and sts:SetSourceIdentity in the Action section.
Validate that the CloudTrail log entries for Account1 contain the Active Directory mapped SourceIdentity.
Use the Switch Role feature to switch to a second account Account2 (444455556666), using a role named Role2.
Create a new Amazon S3 bucket in Account2.
To summarize what you’ve done so far, you have:
Configured your corporate directory to pass a unique attribute to AWS as the source identity.
Configured a role that will persist the SourceIdentity attribute in AWS STS, which an employee will use to federate into your account.
Configured an Amazon S3 bucket that user will access.
Now you’ll observe in CloudTrail the SourceIdentity attribute that will be associated with every IAM action.
To see the SourceIdentity attribute in CloudTrail
From the your preferred IdP dashboard, select the AWS tile to log into the AWS console. The example in Figure 12 shows the Okta dashboard.
Figure 12. Login to AWS from IdP dashboard
Choose the AWS icon, which will take you to the AWS Management Console. Notice how the user has assumed the role you created earlier.
To test the SourceIdentity action, you will create a new Amazon S3 bucket.
Amazon S3 bucket names are globally unique, and the namespace is shared by all AWS accounts, so you will need to create a unique bucket name in your account. For this example, we used a bucket named DOC-EXAMPLE-BUCKET1 to validate CloudTrail log entries containing the SourceIdentity attribute.
Log into an account Account1 (111122223333) using a role named Role1.
Next, create a new Amazon S3 bucket in Account1, and validate that the Account1 CloudTrail logs entries contain the SourceIdentity attribute.
Create an Amazon S3 bucket called DOC-EXAMPLE-BUCKET1, as shown in Figure 13.
Figure 13. Create S3 bucket
In the AWS Management Console go to CloudTrail and check the log entry for bucket creation event, as shown in Figure 14.
Switch to Account2 (444455556666) using assume role, and switch to Account2/assumeRoleSourceIdentity.
Create a new Amazon S3 bucket in Account2 and validate that the Account2 CloudTrail log entries contain the SourceIdentity attribute, as shown in Figure 15.
Figure 15 – Switch role to assumeRoleSourceIdentity
Create a new Amazon S3 bucket in account2 called DOC-EXAMPLE-BUCKET2, as shown in Figure 16.
Figure 16 – Create DOC-EXAMPLE-BUCKET2 bucket while logged into account2 using assumeRoleSourceIdentity
Check the CloudTrail logs for account2 (444455556666) to see if the original SourceIdentity is logged, as shown in Figure 17.
Figure 17 – CloudTrail log entry for the above action
CloudTrail entry showing original SourceIdentity after assuming a role
You logged into Account1/Role1 and switched to Account2/Role2. All the user activities performed in AWS using the Assume Role were also logged with the original user’s sourceIdentity attribute. This makes it simple to trace user activity in CloudTrail.
Conclusion
Now that you have configured your SourceIdentity, you have made it easier for the security team of your organization to use CloudTrail logs to investigate and identify the originating identity of a user. In this post, you learned how to configure the AWS STSSourceIdentity attribute for three different popular IdPs, as well as how to configure each IdP using SAML and their optional attributes. We also provided sample control policy documents outlining how to configure the SourceIdentity for each provider. Additionally, we provide a sample policy for setting the SourceIdentity when switching roles. Lastly, the post walks through how the source identity will show in CloudTrail logs, and provides logs from two accounts to demonstrate the continuance of the source identity attribute. You can now test this capability yourself in your own environment, validate activity in your CloudTrail logs, and determine which user performed a specific action while using the assumeRole functionality.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS Glue Schema Registry now supports Protocol buffers (protobuf) schemas in addition to JSON and Avro schemas. This allows application teams to use protobuf schemas to govern the evolution of streaming data and centrally control data quality from data streams to data lake. AWS Glue Schema Registry provides an open-source library that includes Apache-licensed serializers and deserializers for protobuf that integrate with Java applications developed for Apache Kafka, Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Kinesis Data Streams, and Kafka Streams. Similar to Avro and JSON schemas, Protocol buffers schemas also support compatibility modes, schema sourcing via metadata, auto-registration of schemas, and AWS Identity and Access Management (IAM) compatibility.
In this post, we focus on Protocol buffers schema support in AWS Glue Schema Registry and how to use Protocol buffers schemas in stream processing Java applications that integrate with Apache Kafka, Amazon Managed Streaming for Apache Kafka and Amazon Kinesis Data Streams
Introduction to Protocol buffers
Protocol buffers is a language and platform-neutral, extensible mechanism for serializing and deserializing structured data for use in communications protocols and data storage. A protobuf message format is defined in the .proto file. Protobuf is recommended over other data formats when you need language interoperability, faster serialization and deserialization, type safety, schema adherence between data producer and consumer applications, and reduced coding effort. With protobuf, you can use generated code from the schema using the protobuf compiler (protoc) to easily write and read your data to and from data streams using a variety of languages. You can also use build tools plugins such as Maven and Gradle to generate code from protobuf schemas as part of your CI/CD pipelines. We use the following schema for code examples in this post, which defines an employee with a gRPC service definition to find an employee by ID:
Employee.proto
syntax = "proto2";
package gsr.proto.post;
import "google/protobuf/wrappers.proto";
import "google/protobuf/duration.proto";
import "google/protobuf/timestamp.proto";
import "google/type/money.proto";
service EmployeeSearch {
rpc FindEmployee(EmployeeSearchParams) returns (Employee);
}
message EmployeeSearchParams {
required int32 id = 1;
}
message Employee {
required int32 id = 1;
required string name = 2;
required string address = 3;
required google.protobuf.Int32Value employee_age = 4;
required google.protobuf.Timestamp start_date = 5;
required google.protobuf.Duration total_time_span_in_company = 6;
required google.protobuf.BoolValue is_certified = 7;
required Team team = 8;
required Project project = 9;
required Role role = 10;
required google.type.Money total_award_value = 11;
}
message Team {
required string name = 1;
required string location = 2;
}
message Project {
required string name = 1;
required string state = 2;
}
enum Role {
MANAGER = 0;
DEVELOPER = 1;
ARCHITECT = 2;
}
AWS Glue Schema Registry supports both proto2 and proto3 syntax. The preceding protobuf schema using version 2 contains three message types: Employee, Team, and Project using scalar, composite, and enumeration data types. Each field in the message definitions has a unique number, which is used to identify fields in the message binary format, and should not be changed once your message type is in use. In a proto2 message, a field can be required, optional, or repeated; in proto3, the options are repeated and optional. The package declaration makes sure generated code is namespaced to avoid any collisions. In addition to scalar, composite, and enumeration types, AWS Glue Schema Registry also supports protobuf schemas with common types such as Money, PhoneNumber,Timestamp, Duration, and nullable types such as BoolValue and Int32Value. It also supports protobuf schemas with gRPC service definitions with compatibility rules, such as EmployeeSearch, in the preceding schema. To learn more about the Protocol buffers, refer to its documentation.
Supported Protocol buffers specification and features
AWS Glue Schema Registry supports all the features of Protocol buffers for versions 2 and 3 except for groups, extensions, and importing definitions. AWS Glue Schema Registry APIs and its open-source library supports the latest protobuf runtime version. The protobuf schema operations in AWS Glue Schema Registry are supported via the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS Glue Schema Registry API, AWS SDK, and AWS CloudFormation.
How AWS Glue Schema Registry works
The following diagram illustrates a high-level view of how AWS Glue Schema Registry works. AWS Glue Schema Registry allows you to register and evolve JSON, Apache Avro, and Protocol buffers schemas with compatibility modes. You can register multiple versions of each schema as the business needs or stream processing application’s requirements evolve. The AWS Glue Schema Registry open-source library provides JSON, Avro, and protobuf serializers and deserializers that you configure in producer and consumer stream processing applications, as shown in the following diagram. The open-source library also supports optional compression and caching configuration to save on data transfers.
To accommodate various business use cases, AWS Glue Schema Registry supports multiple compatibility modes. For example, if a consumer application is updated to a new schema version but is still able to consume and process messages based on the previous version of the same schema, then the schema is backward-compatible. However, if a schema version has bumped up in the producer application and the consumer application is not updated yet but can still consume and process the old and new message, then the schema is configured as forward-compatible. For more information, refer to How the Schema Registry Works.
Create a Protocol buffers schema in AWS Glue Schema Registry
In this section, we create a protobuf schema in AWS Glue Schema Registry via the console and AWS CLI.
Create a schema via the console
Make sure you have the required AWS Glue Schema Registry IAM permissions.
On the AWS Glue console, choose Schema registries in the navigation pane.
Click Add registry.
For Registry name, enter employee-schema-registry.
Click Add Registry.
After the registry is created, click Add schema to register a new schema.
For Schema name, enter Employee.proto.
The schema must be either Employee.proto or Employee if the protobuf schema doesn’t have the options option java_multiple_files = true; and option java_outer_classname = "<Outer class name>"; and if you decide to use protobuf schema generated code (POJOs) in your stream processing applications. We cover this with an example in a subsequent section of this post. For more information on protobuf options, refer to Options.
For Registry, choose the registry employee-schema-registry.
For Data format, choose Protocol buffers.
For Compatibility mode, choose Backward.
You can choose other compatibility modes as per your use case.
For First schema version, enter the preceding protobuf schema, then click Create schema and version.
After the schema is registered successfully, its status will be Available, as shown in the following screenshot.
Create a schema via the AWS CLI
Make sure you have IAM credentials with AWS Glue Schema Registry permissions.
Run the following AWS CLI command to create a schema registry employee-schema-registry (for this post, we use the Region us-east-2):
Using a Protocol buffers schema with Amazon MSK and Kinesis Data Streams
Like Apache Avro’s SpecificRecord and GenericRecord, protobuf also supports working with POJOs to ensure type safety and DynamicMessage to create generic data producer and consumer applications. The following examples showcase the use of a protobuf schema registered in AWS Glue Schema Registry with Kafka and Kinesis Data Streams producer and consumer applications.
Use a protobuf schema with Amazon MSK
Create an Amazon MSK or Apache Kafka cluster with a topic called protobuf-demo-topic. If creating an Amazon MSK cluster, you can use the console. For instructions, refer to Getting Started Using Amazon MSK.
Use protobuf schema-generated POJOs
To use protobuf schema-generated POJOs, complete the following steps:
Install the protobuf compiler (protoc) on your local machine from GitHub and add it in the PATH variable.
Add the following plugin configuration to your application’s pom.xml file. We use the xolstice protobuf Maven plugin for this post to generate code from the protobuf schema.
Create a schema registry employee-schema-registry in AWS Glue Schema Registry and register the Employee.proto protobuf schema with it. Name your schema Employee.proto (or Employee).
Run the following command to generate the code from Employee.proto. Make sure you have the schema file in the ${basedir}/src/main/resources/proto directory or change it as per your application directory structure in the application’s pom.xml <protoSourceRoot> tag value:
mvn clean compile
Next, we configure the Kafka producer publishing protobuf messages to the Kafka topic on Amazon MSK.
public static void main(String args[]){
ConsumerProtobuf consumer = new ConsumerProtobuf();
consumer.startConsumer();
}
Use protobuf’s DynamicMessage
You can use DynamicMessage to create generic producer and consumer applications without generating the code from the protobuf schema. To use DynamicMessage, you first need to create a protobuf schema file descriptor.
Generate a file descriptor from the protobuf schema using the following command:
Consume protobuf dynamic messages from the Kafka topic protobuf-demo-topic. Because we’re using DYNAMIC_MESSAGE, the retrieved objects are of type DynamicMessage.
public void startConsumer() {
logger.info("starting consumer...");
String topic = "protobuf-demo-topic";
KafkaConsumer<String, DynamicMessage> consumer = new KafkaConsumer<String, DynamicMessage>(getConsumerConfig());
consumer.subscribe(Collections.singletonList(topic));
while (true) {
final ConsumerRecords<String, DynamicMessage> records = consumer.poll(Duration.ofMillis(1000));
for (final ConsumerRecord<String, DynamicMessage> record : records) {
for (Descriptors.FieldDescriptor field : record.value().getAllFields().keySet()) {
logger.info(field.getName() + ": " + record.value().getField(field));
}
}
}
}
Start the Kafka consumer:
public static void main(String args[]){
ConsumerProtobuf consumer = new ConsumerProtobuf();
consumer.startConsumer();
}
Install the protobuf compiler (protoc) on your local machine from GitHub and add it in the PATH variable.
Add the following plugin configuration to your application’s pom.xml file. We’re using the xolstice protobuf Maven plugin for this post to generate code from the protobuf schema.
Because the KPL and KCL latest versions have the AWS Glue Schema Registry open-source library (schema-registry-serde) and protobuf runtime (protobuf-java) included, you only need to add the following dependencies to your application’s pom.xml:
Create a schema registry employee-schema-registry and register the Employee.proto protobuf schema with it. Name your schema Employee.proto (or Employee).
Run the following command to generate the code from Employee.proto. Make sure you have the schema file in the ${basedir}/src/main/resources/proto directory or change it as per your application directory structure in the application’s pom.xml <protoSourceRoot> tag value.
mvn clean compile
The following Kinesis producer code with the KPL uses the Schema Registry open-source library to publish protobuf messages to Kinesis Data Streams.
The following is the Kinesis consumer code with the KCL using the Schema Registry open-source library to consume protobuf messages from the Kinesis Data Streams.
Initialize the application:
public void run(){
logger.info("Starting KCL client with Glue Schema Registry Integration...");
Region region = Region.of(ObjectUtils.firstNonNull(REGION_NAME, "us-east-2"));
KinesisAsyncClient kinesisClient = KinesisClientUtil.createKinesisAsyncClient(KinesisAsyncClient.builder().region(region));
DynamoDbAsyncClient dynamoClient = DynamoDbAsyncClient.builder().region(region).build();
CloudWatchAsyncClient cloudWatchClient = CloudWatchAsyncClient.builder().region(region).build();
EmployeeRecordProcessorFactory employeeRecordProcessorFactory = new EmployeeRecordProcessorFactory();
ConfigsBuilder configsBuilder =
new ConfigsBuilder(STREAM_NAME,
APPLICATION_NAME,
kinesisClient,
dynamoClient,
cloudWatchClient,
APPLICATION_NAME,
employeeRecordProcessorFactory);
//Creating Glue Schema Registry configuration and Glue Schema Registry Deserializer object.
GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration(region.toString());
gsrConfig.setEndPoint(REGISTRY_ENDPOINT);
gsrConfig.setProtobufMessageType(ProtobufMessageType.POJO);
GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer =
new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), gsrConfig);
/*
Setting Glue Schema Registry deserializer in the Retrieval Config for
Kinesis Client Library to use it while deserializing the protobuf messages.
*/
RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(STREAM_NAME, kinesisClient));
retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer);
Scheduler scheduler = new Scheduler(
configsBuilder.checkpointConfig(),
configsBuilder.coordinatorConfig(),
configsBuilder.leaseManagementConfig(),
configsBuilder.lifecycleConfig(),
configsBuilder.metricsConfig(),
configsBuilder.processorConfig(),
retrievalConfig);
Thread schedulerThread = new Thread(scheduler);
schedulerThread.setDaemon(true);
schedulerThread.start();
logger.info("Press enter to shutdown");
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
try {
reader.readLine();
Future<Boolean> gracefulShutdownFuture = scheduler.startGracefulShutdown();
logger.info("Waiting up to 20 seconds for shutdown to complete.");
gracefulShutdownFuture.get(20, TimeUnit.SECONDS);
} catch (Exception e) {
logger.info("Interrupted while waiting for graceful shutdown. Continuing.");
}
logger.info("Completed, shutting down now.");
}
Consume protobuf messages from Kinesis Data Streams:
We covered examples of data producer and consumer applications integrating with Amazon MSK, Apache Kafka, and Kinesis Data Streams, and using a Protocol buffers schema registered with AWS Glue Schema Registry. You can further enhance these examples with schema evolution using the following rules, which are supported by AWS Glue Schema Registry. For example, the following protobuf schema shown is a backward-compatible updated version of Employee.proto. We have added another gRPC service definition CreateEmployee under EmployeeSearch and added an Optional field in the Employee message type. If you upgrade the consumer application with this version of the protobuf schema, the consumer application can still consume old and new protobuf messages.
In this post, we introduced Protocol buffers schema support in AWS Glue Schema Registry. AWS Glue Schema Registry now supports Apache Avro, JSON, and Protocol buffers schemas with different compatible modes. The examples in this post demonstrated how to use Protocol buffers schemas registered with AWS Glue Schema Registry in stream processing applications integrated with Apache Kafka, Amazon MSK, and Kinesis Data Streams. We used the schema-generated POJOs for type safety and protobuf’s DynamicMessage to create generic producer and consumer applications. The examples in this post contain the basic components of the stream processing pattern; you can adapt these examples to your use case needs.
Vikas Bajaj is a Principal Solutions Architect at AWS. Vikas works with digital native customers and advises them on technology architecture and solutions to meet strategic business objectives.
Location data is subjected to heavy scrutiny by security experts. Knowing the current position of a person, vehicle, or asset can provide industries with many benefits, whether to understand where a current delivery is, how many people are inside a venue, or to optimize routing for a fleet of vehicles. This blog post explains how Amazon Web Services (AWS) helps keep location data secured in transit and at rest, and how you can leverage additional security features to help keep information safe and compliant.
The General Data Protection Regulation (GDPR) defines personal data as “any information relating to an identified or identifiable natural person (…) such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.” Also, many companies wish to improve transparency to users, making it explicit when a particular application wants to not only track their position and data, but also to share that information with other apps and websites. Your organization needs to adapt to these changes quickly to maintain a secure stance in a competitive environment.
On June 1, 2021, AWS made Amazon Location Service generally available to customers. With Amazon Location, you can build applications that provide maps and points of interest, convert street addresses into geographic coordinates, calculate routes, track resources, and invoke actions based on location. The service enables you to access location data with developer tools and to move your applications to production faster with monitoring and management capabilities.
In this blog post, we will show you the features that Amazon Location provides out of the box to keep your data safe, along with best practices that you can follow to reach the level of security that your organization strives to accomplish.
Data control and data rights
Amazon Location relies on global trusted providers Esri and HERE Technologies to provide high-quality location data to customers. Features like maps, places, and routes are provided by these AWS Partners so solutions can have data that is not only accurate but constantly updated.
AWS anonymizes and encrypts location data at rest and during its transmission to partner systems. In parallel, third parties cannot sell your data or use it for advertising purposes, following our service terms. This helps you shield sensitive information, protect user privacy, and reduce organizational compliance risks. To learn more, see the Amazon Location Data Security and Control documentation.
Integrations
Operationalizing location-based solutions can be daunting. It’s not just necessary to build the solution, but also to integrate it with the rest of your applications that are built in AWS. Amazon Location facilitates this process from a security perspective by integrating with services that expedite the development process, enhancing the security aspects of the solution.
Encryption
Amazon Location uses AWS owned keys by default to automatically encrypt personally identifiable data. AWS owned keys are a collection of AWS Key Management Service (AWS KMS) keys that an AWS service owns and manages for use in multiple AWS accounts. Although AWS owned keys are not in your AWS account, Amazon Location can use the associated AWS owned keys to protect the resources in your account.
If customers choose to use their own keys, they can benefit from AWS KMS to store their own encryption keys and use them to add a second layer of encryption to geofencing and tracking data.
Authentication and authorization
Amazon Location also integrates with AWS Identity and Access Management (IAM), so that you can use its identity-based policies to specify allowed or denied actions and resources, as well as the conditions under which actions are allowed or denied on Amazon Location. Also, for actions that require unauthenticated access, you can use unauthenticated IAM roles.
As an extension to IAM, Amazon Cognito can be an option if you need to integrate your solution with a front-end client that authenticates users with its own process. In this case, you can use Cognito to handle the authentication, authorization, and user management for you. You can use Cognito unauthenticated identity pools with Amazon Location as a way for applications to retrieve temporary, scoped-down AWS credentials. To learn more about setting up Cognito with Amazon Location, see the blog post Add a map to your webpage with Amazon Location Service.
Limit the scope of your unauthenticated roles to a domain
When you are building an application that allows users to perform actions such as retrieving map tiles, searching for points of interest, updating device positions, and calculating routes without needing them to be authenticated, you can make use of unauthenticated roles.
When using unauthenticated roles to access Amazon Location resources, you can add an extra condition to limit resource access to an HTTP referer that you specify in the policy. The aws:referer request context value is provided by the caller in an HTTP header, and it is included in a web browser request.
The following is an example of a policy that allows access to a Map resource by using the aws:referer condition, but only if the request comes from the domain example.com.
Encrypt tracker and geofence information using customer managed keys with AWS KMS
When you create your tracker and geofence collection resources, you have the option to use a symmetric customer managed key to add a second layer of encryption to geofencing and tracking data. Because you have full control of this key, you can establish and maintain your own IAM policies, manage key rotation, and schedule keys for deletion.
After you create your resources with customer managed keys, the geometry of your geofences and all positions associated to a tracked device will have two layers of encryption. In the next sections, you will see how to create a key and use it to encrypt your own data.
Create an AWS KMS symmetric key
First, you need to create a key policy that will limit the AWS KMS key to allow access to principals authorized to use Amazon Location and to principals authorized to manage the key. For more information about specifying permissions in a policy, see the AWS KMS Developer Guide.
To create the key policy
Create a JSON policy file by using the following policy as a reference. This key policy allows Amazon Location to grant access to your KMS key only when it is called from your AWS account. This works by combining the kms:ViaService and kms:CallerAccount conditions. In the following policy, replace us-west-2 with your AWS Region of choice, and the kms:CallerAccount value with your AWS account ID. Adjust the KMS Key Administrators statement to reflect your actual key administrators’ principals, including yourself. For details on how to use the Principal element, see the AWS JSON policy elements documentation.
Tip: AWS CLI will consider the Region you defined as the default during the configuration steps, but you can override this configuration by adding –region<your region> at the end of each command line in the following command. Also, make sure that your user has the appropriate permissions to perform those actions.
To create the symmetric key
Now, create a symmetric key on AWS KMS by running the create-key command and passing the policy file that you created in the previous step.
Create an Amazon Location tracker and geofence collection resources
To create an Amazon Location tracker resource that uses AWS KMS for a second layer of encryption, run the following command, passing the key ID from the previous step.
By following these steps, you have added a second layer of encryption to your geofence collection and tracker.
Data retention best practices
Trackers and geofence collections are stored and never leave your AWS account without your permission, but they have different lifecycles on Amazon Location.
Trackers store the positions of devices and assets that are tracked in a longitude/latitude format. These positions are stored for 30 days by the service before being automatically deleted. If needed for historical purposes, you can transfer this data to another data storage layer and apply the proper security measures based on the shared responsibility model.
Geofence collections store the geometries you provide until you explicitly choose to delete them, so you can use encryption with AWS managed keys or your own keys to keep them for as long as needed.
Asset tracking and location storage best practices
After a tracker is created, you can start sending location updates by using the Amazon Location front-end SDKs or by calling the BatchUpdateDevicePosition API. In both cases, at a minimum, you need to provide the latitude and longitude, the time when the device was in that position, and a device-unique identifier that represents the asset being tracked.
Protecting device IDs
This device ID can be any string of your choice, so you should apply measures to prevent certain IDs from being used. Some examples of what to avoid include:
First and last names
Facility names
Documents, such as driver’s licenses or social security numbers
Emails
Addresses
Telephone numbers
Latitude and longitude precision
Latitude and longitude coordinates convey precision in degrees, presented as decimals, with each decimal place representing a different measure of distance (when measured at the equator).
Amazon Location supports up to six decimal places of precision (0.000001), which is equal to approximately 11 cm or 4.4 inches at the equator. You can limit the number of decimal places in the latitude and longitude pair that is sent to the tracker based on the precision required, increasing the location range and providing extra privacy to users.
Figure 1 shows a latitude and longitude pair, with the level of detail associated to decimals places.
Figure 1: Geolocation decimal precision details
Position filtering
Amazon Location introduced position filtering as an option to trackers that enables cost reduction and reduces jitter from inaccurate device location updates.
DistanceBased filtering ignores location updates wherein devices have moved less than 30 meters (98.4 ft).
TimeBased filtering evaluates every location update against linked geofence collections, but not every location update is stored. If your update frequency is more often than 30 seconds, then only one update per 30 seconds is stored for each unique device ID.
AccuracyBased filtering ignores location updates if the distance moved was less than the measured accuracy provided by the device.
By using filtering options, you can reduce the number of location updates that are sent and stored, thus reducing the level of location detail provided and increasing the level of privacy.
Logging and monitoring
Amazon Location integrates with AWS services that provide the observability needed to help you comply with your organization’s security standards.
To record all actions that were taken by users, roles, or AWS services that access Amazon Location, consider using AWS CloudTrail. CloudTrail provides information on who is accessing your resources, detailing the account ID, principal ID, source IP address, timestamp, and more. Moreover, Amazon CloudWatch helps you collect and analyze metrics related to your Amazon Location resources. CloudWatch also allows you to create alarms based on pre-defined thresholds of call counts. These alarms can create notifications through Amazon Simple Notification Service (Amazon SNS) to automatically alert teams responsible for investigating abnormalities.
Conclusion
At AWS, security is our top priority. Here, security and compliance is a shared responsibility between AWS and the customer, where AWS is responsible for protecting the infrastructure that runs all of the services offered in the AWS Cloud. The customer assumes the responsibility to perform all of the necessary security configurations to the solutions they are building on top of our infrastructure.
In this blog post, you’ve learned the controls and guardrails that Amazon Location provides out of the box to help provide data privacy and data protection to our customers. You also learned about the other mechanisms you can use to enhance your security posture.
Start building your own secure geolocation solutions by following the Amazon Location Developer Guide and learn more about how the service handles security by reading the security topics in the guide.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this blog post, start a new thread on Amazon Location Service forum or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS Security Hub provides you with a consolidated view of your security posture in Amazon Web Services (AWS) and helps you check your environment against security standards and current AWS security recommendations. Although Security Hub has some similarities to security information and event management (SIEM) tools, it is not designed as standalone a SIEM replacement. For example, Security Hub only ingests AWS-related security findings and does not directly ingest higher volume event logs, such as AWS CloudTrail logs. If you have use cases to consolidate AWS findings with other types of findings from on-premises or other non-AWS workloads, or if you need to ingest higher volume event logs, we recommend that you use Security Hub in conjunction with a SIEM tool.
There are also other benefits to using Security Hub and a SIEM tool together. These include being able to store findings for longer periods of time than Security Hub, aggregating findings across multiple administrator accounts, and further correlating Security Hub findings with each other and other log sources. In this blog post, we will show you how you can use Amazon OpenSearch Service (successor to Amazon Elasticsearch Service) as a SIEM and integrate Security Hub with it to accomplish these three use cases. Amazon OpenSearch Service is a fully managed service that makes it easier to deploy, manage, and scale Elasticsearch and Kibana. OpenSearch Service is a distributed, RESTful search and analytics engine that is capable of addressing a growing number of use cases. You can expand OpenSearch Service with AWS services like Kinesis or Kinesis Data Firehose, by integrating with other AWS services, or by using traditional agents like Beats and Logstash for log ingestion, and Kibana for data visualization. Although the OpenSearch Service also is not a SIEM out-of-the-box tool, with some customization, you can use it for SIEM tool use cases.
Security Hub plus SIEM use cases
By enabling Security Hub within your AWS Organizations account structure, you immediately start receiving the benefits of viewing all of your security findings from across various AWS and partner services on a single screen. Some organizations want to go a step further and use Security Hub in conjunction with a SIEM tool for the following reasons:
Correlate Security Hub findings with each other and other log sources – This is the most popular reason customers choose to implement this solution. If you have various log sources outside of Security Hub findings (such as application logs, database logs, partner logs, and security tooling logs), then it makes sense to consolidate these log sources into a single SIEM solution. Then you can view both your Security Hub findings and miscellaneous logs in the same place and create alerts based on interesting correlations.
Store findings for longer than 90 days after the last update date – Some organizations want or need to store Security Hub findings for longer than 90 days after the last update date. They may want to do this for historical investigation, or for audit and compliance needs. Either way, this solution offers you the ability to store Security Hub findings in a private Amazon Simple Storage Service (Amazon S3) bucket, which is then consumed by Amazon OpenSearch Service.
Aggregate findings across multiple administrator accounts – Security Hub has a feature customers can use to designate an administrator account if they have enabled Security Hub in multiple accounts. A Security Hub administrator account can view data from and manage configuration for its member accounts. This allows customers to view and manage all their findings from multiple member accounts in one place. Sometimes customers have multiple Security Hub administrator accounts, because they have multiple organizations in AWS Organizations. In this situation, you can use this solution to consolidate all of the Security Hub administrator accounts into a single OpenSearch Service with Kibana SIEM implementation to have a single view across your environments. This related blog post walks through this use case in more detail, and shows how to centralize Security Hub findings across multiple AWS Regions and administrators. However, this blog post takes this approach further by introducing OpenSearch Service with Kibana to the use case, for a full SIEM experience.
Solution architecture
Figure 1: SIEM implementation on Amazon OpenSearch Service
The solution represented in Figure 1 shows the flexibility of integrations that are possible when you create a SIEM by using Amazon OpenSearch Service. The solution allows you to aggregate findings across multiple accounts, store findings in an S3 bucket indefinitely, and correlate multiple AWS and non-AWS services in one place for visualization. This post focuses on Security Hub’s integration with the solution, but the following AWS services are also able to integrate:
Each of these services has its own dedicated dashboard within the OpenSearch SIEM solution. This makes it possible for customers to view findings and data that are relevant to each service that the SIEM tool is ingesting. OpenSearch Service also allows the customer to create aggregated dashboards, consolidating multiple services within a single dashboard, if needed.
Prerequisites
We recommend that you enable Security Hub and AWS Config across all of your accounts and Regions. For more information about how to do this, see the documentation for Security Hub and AWS Config. We also recommend that you use Security Hub and AWS Config integration with AWS Organizations to simplify the setup and automatically enable these services in all current and future accounts in your organization.
Launch the solution
In order to launch this solution within your environment, you can either launch the solution by using an AWS CloudFormation template, or by following the steps presented later in this post to customize the deployment to support integrations with non-AWS services, multi-Organization deployments, or launch within your existing OpenSearch Service environment.
Before you start using the solution, we’ll show you how this solution appears in the Security Hub dashboard, as shown in Figure 2. Navigate here by following Step 3 from the GitHub README.
Figure 2: Pre-built dashboards within solution
The Security Hub dashboard highlights all major components of the service within an OpenSearch Service dashboard environment. This includes supporting all of the service integrations that are available within Security Hub (such as GuardDuty, AWS Identity and Access Management (IAM) Access Analyzer, Amazon Inspector, Amazon Macie, and AWS Systems Manager Patch Manager). The dashboard displays both findings and security standards, and you can filter by AWS account, finding type, security standard, or service integration. Figure 3 shows an overview of the visual dashboard experience when you deploy the solution.
Figure 3: Dashboard preview
Use case 1: Correlate Security Hub findings with each other and other log sources and create alerts
This solution uses OpenSearch Service and Kibana to allow you to search through both Security Hub findings and logs from any other AWS and non-AWS systems. You can then create alerts within Kibana based on interesting correlations between Security Hub and any other logged events. Although Security Hub supports ingesting a vast number of integrations and findings, it cannot create correlation rules like a SIEM tool can. However, you can create such rules using SIEM on OpenSearch Service. It’s important to take a closer look when multiple AWS security services generate findings for a single resource, because this potentially indicates elevated risk or multiple risk vectors. Depending on your environment, the initial number of findings in Security Hub may be high, so you may need to prioritize which findings require immediate action. Security Hub natively gives you the ability to filterfindings by resource, account, severity, and many other details.
As part of the findings, you can send notifications through alerts that are generated by SIEM on OpenSearch Service in several ways: Amazon Simple Notification Service (Amazon SNS) by consuming messages in an appropriate tool or configuring recipient email addresses, Amazon Chime, Slack (using AWS Chatbot) or custom webhook to your organization’s ticketing system. You can then respond to these new security incident-oriented findings through ticketing, chat, or incident management systems.
Solution overview for use case 1
Figure 4: Solution overview diagram
Figure 4 gives an overview of the solution for use case 1. This solution requires that you have Security Hub and GuardDuty enabled in your AWS account. Logs from AWS services, including Security Hub, are ingested into an S3 bucket, then are automatically extracted, transformed, and loaded (ETL) and populated into the SIEM system that is running on OpenSearch Service using AWS Lambda. After capturing the logs, you will be able to visualize them on the dashboard and analyze correlations of multiple logs. Within the SIEM on OpenSearch Service solution, you will create a rule to detect failures, such as CloudTrail authentication failures in logs. Then, you will configure the solution to publish alerts to Amazon SNS and send emails when logs match rules.
Implement the solution for use case 1
You will now set up this workflow to alert you by email when logs in OpenSearch match certain rules that you create.
Step 1: Create and visualize findings in OpenSearch Dashboards
Security Hub and other AWS services export findings to Amazon S3 in a centralized log bucket. You can ingest logs from CloudTrail, VPC Flow Logs, and GuardDuty, which are often used in AWS security analytics. In this step, you import simulated security incident data in OpenSearch Dashboards, and use the dashboard to visualize the data in the logs.
In OpenSearch Dashboards, go to the Discover screen. The Discover screen is divided into three major sections: Search bar, index/display field list, and time-series display, as shown in Figure 5.
Figure 5: OpenSearch Dashboards
In OpenSearch Dashboards, select log-aws-securityhub-* or log-aws-vpcflowlogs-* or log-aws-cloudtrail-* or any other index patterns and add event.module to the display field. event.module is a field that indicates where the log originates from. If you are collecting other threat information, such as Security Hub, @log-type is Security Hub, and event.module indicates where the log originated from (either Amazon Inspector or Amazon Macie for example). After you have added event.module, filter the desired Security Hub integrated service (for example, Amazon Inspector) to display. When testing the environment covered in this blog post outside a production context, you can use Kinesis Data Generator to generate sample user traffic. Other tools are also available.
Select the following on the dashboard to see the visualized information:
CloudTrail Summary
VpcFlowLogs Summary
GuardDuty Summary
All – Threat Hunting
Step 2: Configure alerts to match log criteria
Next, you will configure alerts to match log criteria. First you need to set the destination for alerts, and then set what to monitor.
To configure alerts
In OpenSearch Dashboards, in the left menu, choose Alerting.
To add the details of SNS, on the Destinations tab, choose Add destinations, and enter the following parameters:
Replace <111111111111> with your AWS account ID and correct the Region name
Replace <AWS-REGION> with the Region you are using, for example, eu-west-1
IAM Role ARN:arn:aws:iam::<111111111111>:role/aes-siem-sns-role
Replace &<111111111111> with your AWS account ID
Choose Create to complete setting the alert destination.
Figure 6: Edit alert destination
In OpenSearch Dashboards, in the left menu, select Alerting. You will now set what to monitor. Here you monitor a CloudTrail trail authentication failure. There are two normalized log times: @timestamp and event.ingested. The difference is between the log occurrence time (@timestamp) and the SIEM reception time (event.ingested). Use event.ingested for logs with a large time lag from occurrence to reception. You can specify flexible conditions by selecting Define using extraction query for the filter definition.
On the Monitors tab, choose Create monitor.
Enter the following parameters. If there is no description, use the default value.
Name: Authentication failed
Method of definition: Define using extraction query
Indices:log-aws-cloudtrail-* (manual input, not pull-down)
Define extraction query: Enter the following query.
Enter the following remaining parameters of the monitor:
Frequency: By interval
Monitor schedule: Every 3 minutes
Choose Create to create the monitor.
Step 3: Set up trigger to send email via Amazon SNS
Now you will set the alert firing condition, known as the trigger. This is the setting for alerting when the monitored conditions (Monitors) are met. By default, the alert will be triggered if the number of hits is greater than 0. In this step , you will not change it, only give it a name.
To set up the trigger
Select Create trigger and for Trigger name, enter Authentication failed trigger.
Scroll down to Configure actions.
Figure 7: Create trigger
Set what the trigger should do (action). In this case, you want to publish to SNS. Set the following parameters for the body of the email
Action throttling: Select Enable action throttling, and set throttle action to only trigger every 10 minutes.
Message: Copy and paste the following message into the text box. After pasting, choose Send test message at the bottom right of the screen to confirm that you can receive the test email.
Monitor ctx.monitor.name just entered alert status. Please investigate the issue.
You will receive an alert email in a few minutes. You can check the occurrence status, including the history, by the following method:
In OpenSearch Dashboards, on the left menu, choose Alerting.
On the Monitors tab, choose Authentication failed.
You can check the status of the alert in the History pane.
Figure 9: Email alert
Use case 1 shows you how to correlate various Security Hub findings through this OpenSearch Service SIEM solution. However, you can take the solution a step further and build more complex correlation checks by following the procedure in the blog post Correlate security findings with AWS Security Hub and Amazon EventBridge. This information can then be ingested into this OpenSearch Service SIEM solution for viewing on a single screen.
Use case 2: Store findings for longer than 90 days after last update date
Security Hub has a maximum storage time of 90 days for events, but your organization might require data storage beyond that period, with flexibility to specify a custom retention period to meet your needs. The SIEM on Amazon OpenSearch Service solution creates a centralized S3 bucket where findings from Security Hub and various other services are collected and stored, and this bucket can be configured to store data as long as you require. The S3 bucket can persist data indefinitely, or you can create an S3 object lifecycle policy to set a custom retention timeframe. Lifecycle policies allow you to either transition objects between S3 storage classes or delete objects after a specified period. Alternatively, you can use S3 Intelligent-Tiering to allow the Amazon S3 service to move data between tiers, based on user access patterns.
Either lifecycle policies or S3 Intelligent-Tiering will allow you to optimize costs for data that is stored in S3, to keep data for archive or backup purposes when it is no longer available in Security Hub or OpenSearch Service. Within the solution, this centralized bucket is called aes-siem-xxxxxxxx-log and is configured to store data for OpenSearch Service to consume indefinitely. The Amazon S3 User Guide has instructions for configuring an S3 lifecycle policy that is explicitly defined by the user on the centralized bucket. Or you can follow the instructions for configuring intelligent tiering to allow the S3 service to manage which tier data is stored in automatically. After data is archived, you can use Amazon Athena to query the S3 bucket for historical information that has been removed from OpenSearch Service, because this S3 bucket acts as a centralized security event repository.
Use case 3: Aggregate findings across multiple administrator accounts
There are cases where you might have multiple Security Hub administrator accounts within one or multiple organizations. For these use cases, you can consolidate findings across these multiple Security Hub administrator accounts into a single S3 bucket for centralized storage, archive, backup, and querying. This gives you the ability to create a single SIEM on OpenSearch Service to minimize the number of monitoring tools you need. In order to do this, you can use S3 replication to automatically copy findings to a centralized S3 bucket. You can follow this detailed walkthrough on how to set up the correct bucket permissions in order to allow replication between the accounts. You can also follow this related blog post to configure cross-Region Security Hub findings that are centralized in a single S3 bucket, if cross-Region replication is appropriate for your security needs. With cross-account S3 replication set up for Security Hub archived event data, you can import data from the centralized S3 bucket into OpenSearch Service by using the Lambda function within the solution in this blog post. This Lambda function automatically normalizes and enriches the log data and imports it into OpenSearch Service, so that users only need to configure data storage in the S3 bucket, and the Lambda function will automatically import the data.
Conclusion
In this blog post, we showed how you can use Security Hub with a SIEM to store findings for longer than 90 days, aggregate findings across multiple administrator accounts, and correlate Security Hub findings with each other and other log sources. We used the solution to walk through building the SIEM and explained how Security Hub could be used within that solution to add greater flexibility. This post describes one solution to create your own SIEM using OpenSearch Service; however, we also recommend that you read the blog post Visualize AWS Security Hub Findings using Analytics and Business Intelligence Tools, in order to see a different method of consolidating and visualizing insights from Security Hub.
If you have feedback about this blog post, submit comments in the Comments section below. If you have questions about this blog post, please start a new thread on the Security Hub forum or contact AWS Support.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.