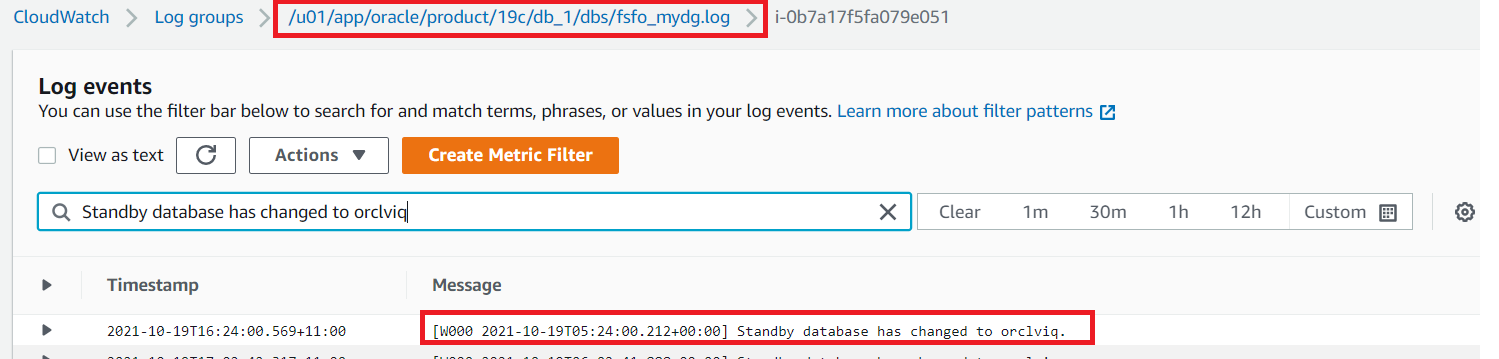
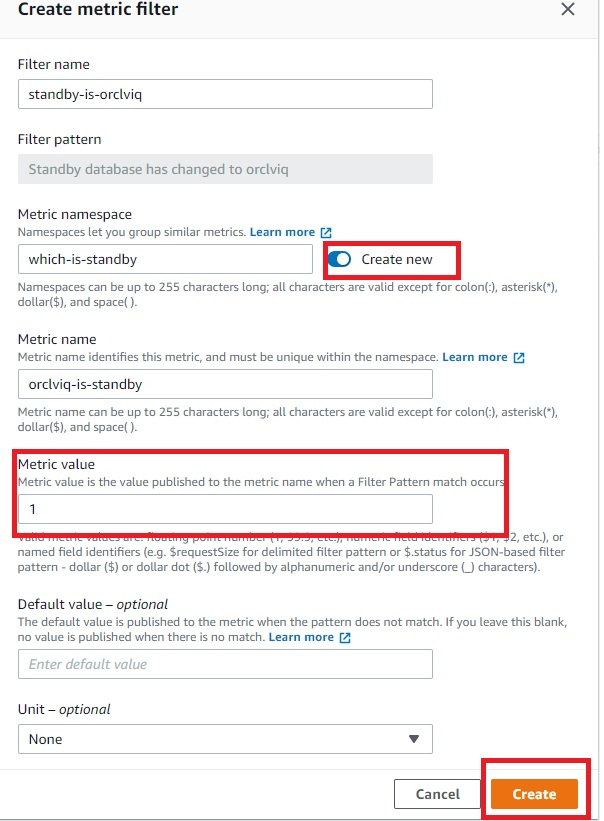
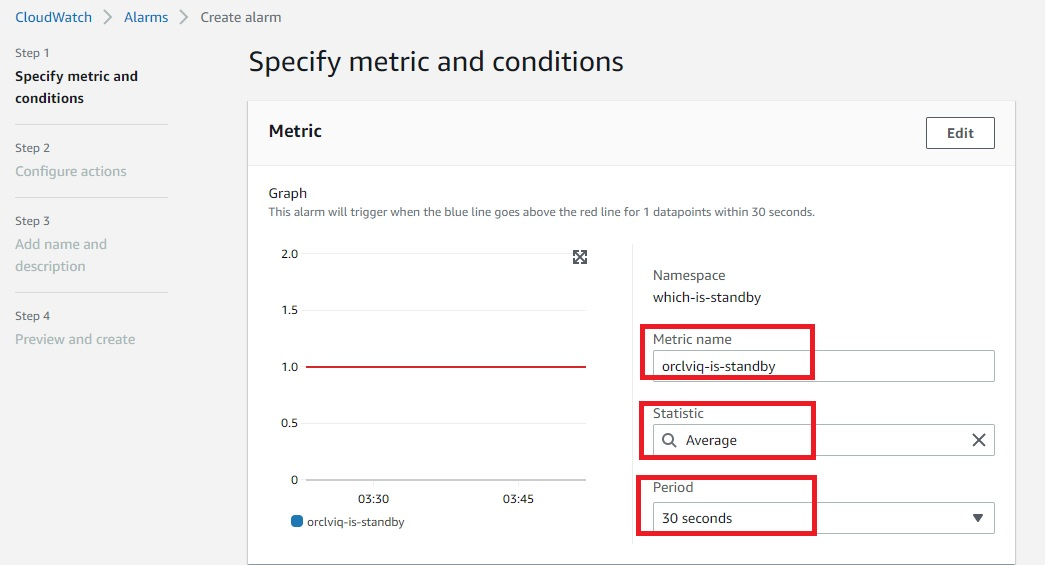
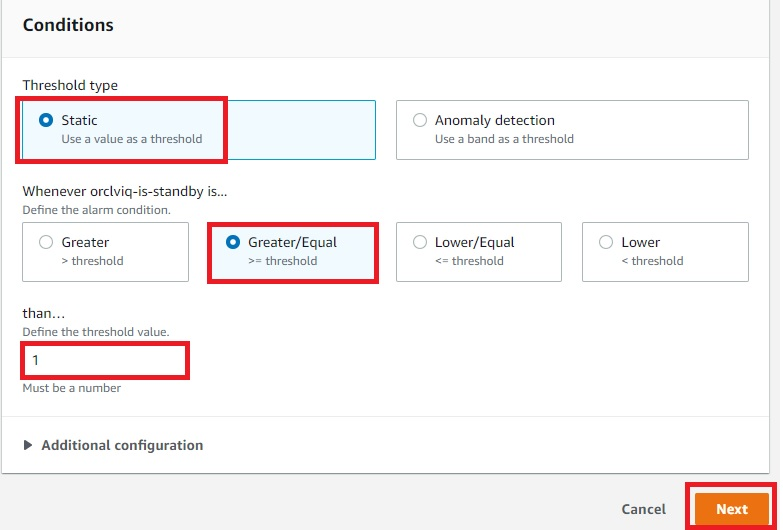
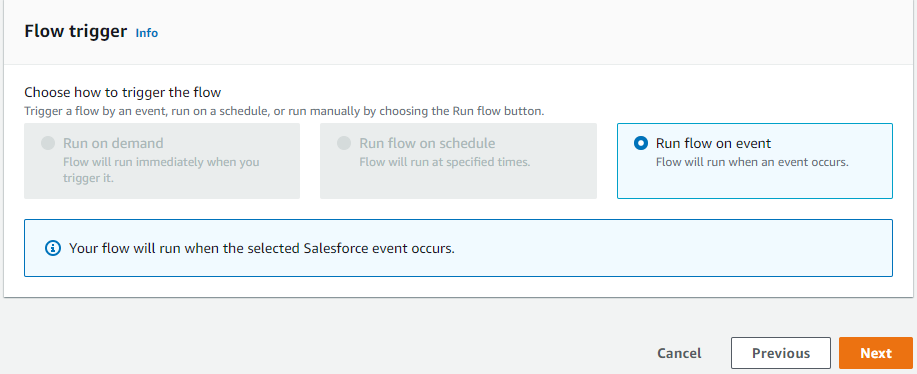
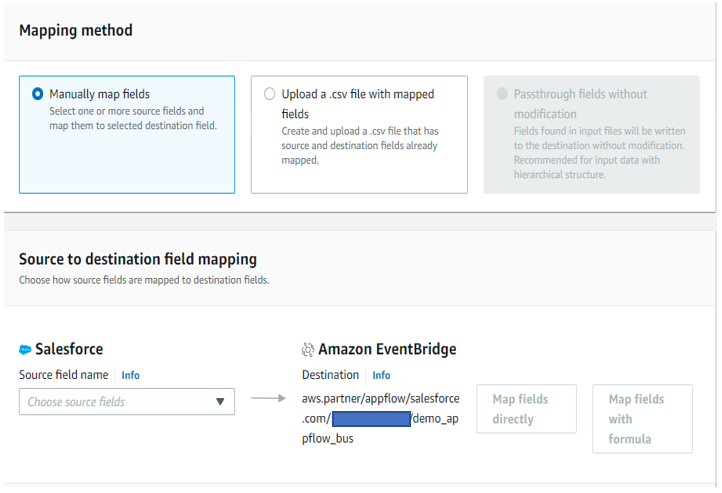
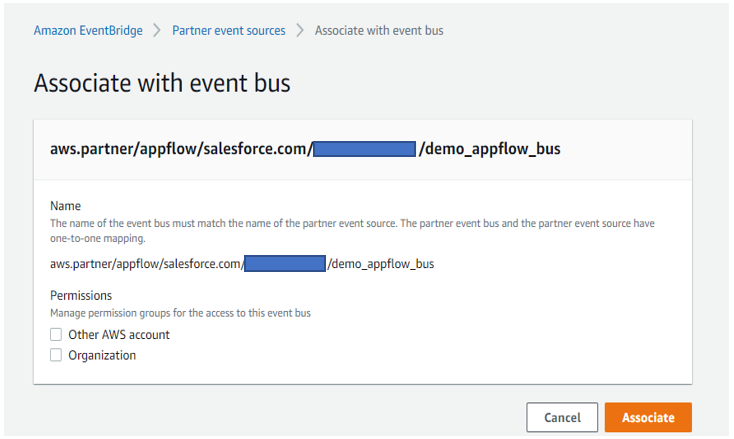
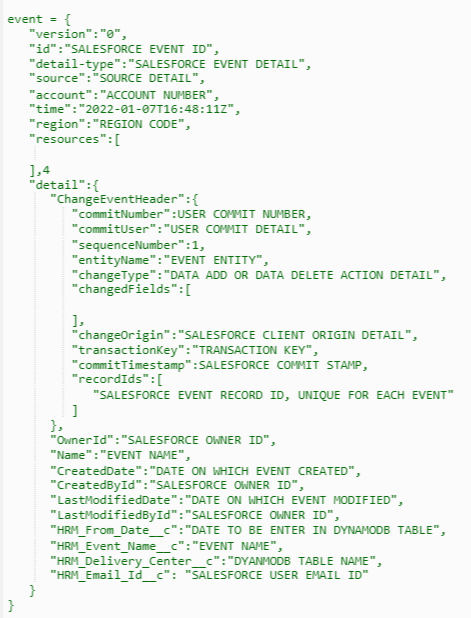
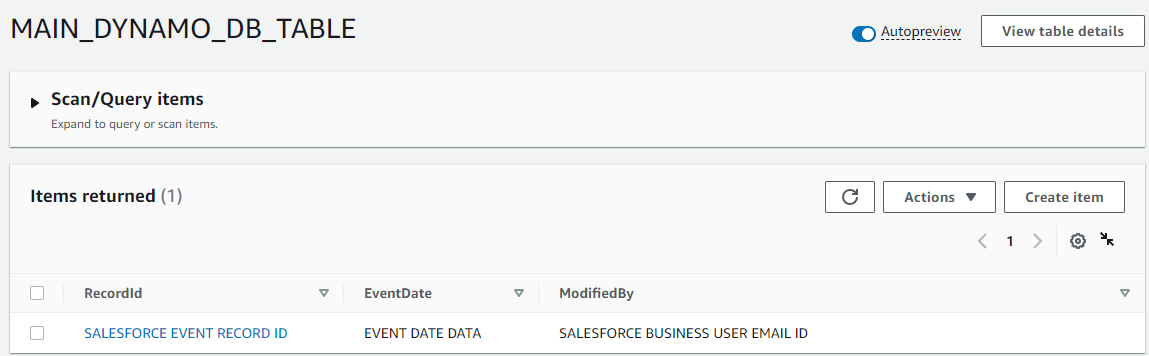
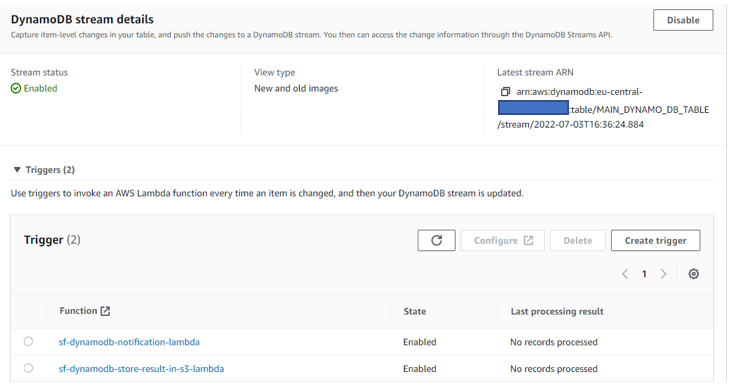
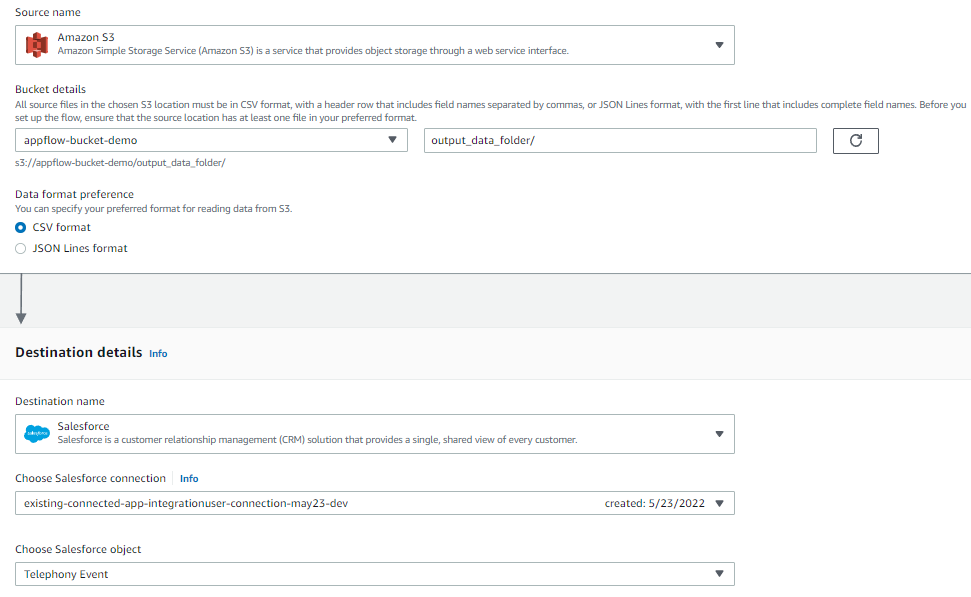
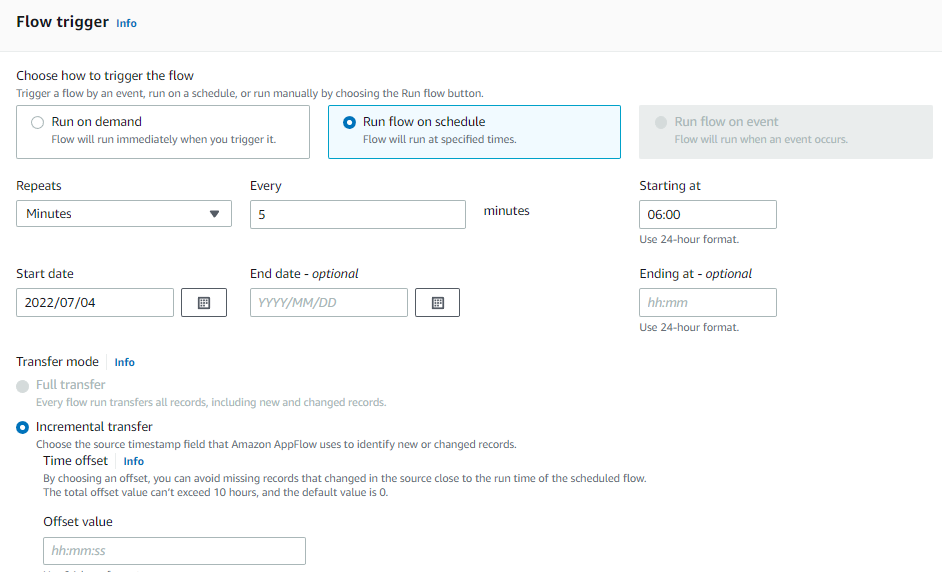
Post Syndicated from Elise Chahine original https://aws.amazon.com/blogs/architecture/author-spotlight-lewis-tang-senior-partner-solution-architect-in-transformation-and-modernization/
The Author Spotlight series pulls back the curtain on some of AWS’s most prolific authors. Read on to find out more about our very own Lewis Tang’s journey, in his own words!
I have been a Senior Partner Solution Architect since joining Amazon Web Services (AWS) in 2019. What I really enjoy about this role is helping AWS partners build successful businesses with AWS services. Not only does this satisfy the customer need, but it clearly demonstrates what we at Amazon use to drive every decision: customer obsession! At AWS, we are encouraged to pick an area of expertise and dive deep into it. I am passionate about helping AWS customers and partners to plan and drive transformation through cloud adoption: transformation and modernization are my areas of expertise!

Whether it’s an AWS service partner in consulting business or an AWS ISV partner offering software services, building products and winning customer mindshare can be very challenging. To Amazonians, every day is Day 1. Learning with partners about these challenges and collaborating on solving problems are big parts of my daily Day 1.
Prior to joining AWS, I was a transformation architect for close to a decade. I travelled to work with customers throughout Australia, New Zealand, and the ASEAN region on their cloud transformation strategy, cloud governance and management, and to build their cloud foundational capabilities. Learning with customers face-to-face, diving deep into the industry problems, and helping them invent and simplify their business practices taught me how to leverage the power of cloud technology to deliver results. These experiences made me want to pursue this with AWS.
Now, I collaborate with partners at AWS, working backwards from their target business outcomes to identify and implement the solutions that will boost their success rates. I also provide guidance on adopting wide range of AWS services to develop an offering that can scale and solve specific problems in an efficient and cost-effective manner.
Many folks know about the AWS 7Rs migration strategy. What you may not know is I am an enthusiastic practitioner of Replatform and Refactor/Re-architect to modernize business applications. To promote and scale the adoption of modernization best practices, I work with other subject-matter experts in the Application Modernization Technical Field Community to develop thought leadership content and publish whitepapers, blogs, and prescriptive guidance (I share my favorites a little later).
I have recently created a Back to Basics video, which explores multiple patterns of running Microsoft SQL data service on AWS and the automation that these options provide, allowing you to refocus on business innovation.
At events like AWS Global Summits or AWS re:Invent, I receive feedback on these publications and answer questions about application modernization. With partners who are present at these congresses, I am able to provide guidance on building and modernizing their applications with AWS services.
In my role with AWS, I am educated and rewarded daily: I learn a lot from my AWS partners when working with them to integrate AWS services into their intellectual property solutions and tool chains, which helps to accelerate AWS customer application modernization journey. Throughout these experiences, I became a SME of modernization. It’s educational and fulfilling to help builders, customers, and partners solve their most difficult problems.
Lewis’s favorite posts!
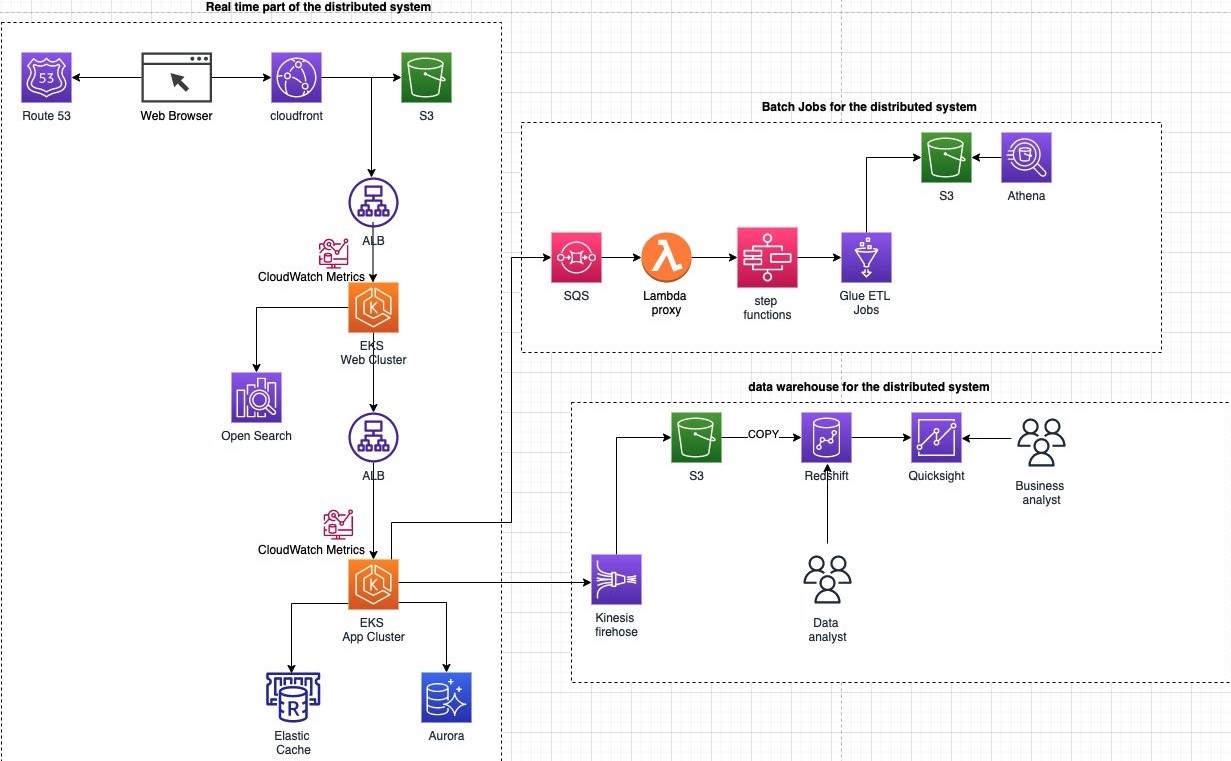
What to consider when migrating data warehouse to Amazon Redshift
My very first blog at AWS! Many customers are looking to modernize data warehouses by migrating to Amazon Redshift because their existing data warehouse is not built for today’s data analytics needs (like data types, volume, and velocity).
A data warehouse migration project can be challenging. This post helps you secure a successful delivery of a data warehouse migration project by discussing data warehouse migration strategies and the adoption of an optimal migration process for a presented use case and the best practices of AWS migration tools, such as AWS Schema Conversion Tool.

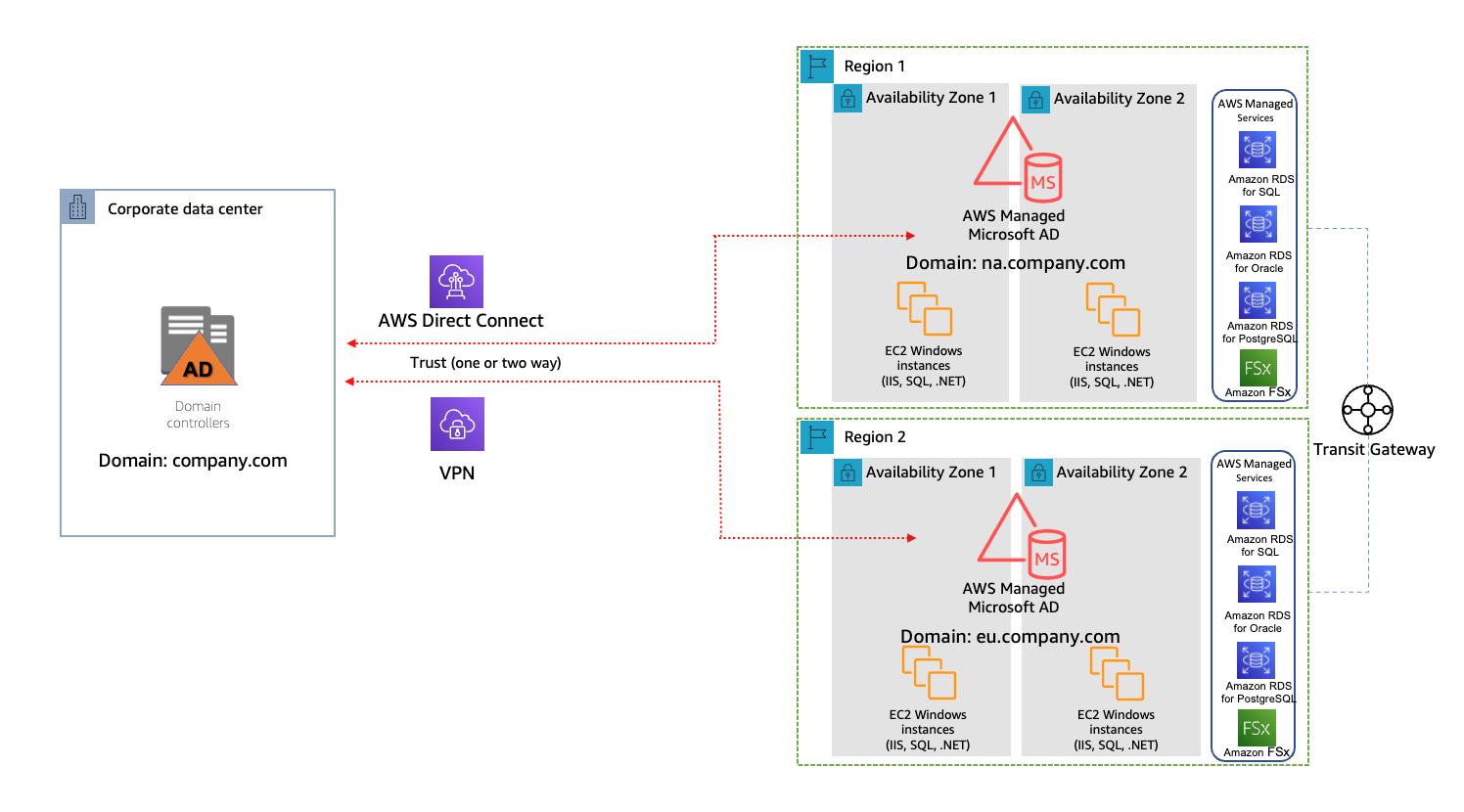
Running hybrid Active Directory service with AWS Managed Microsoft Active Directory
When migrating and modernizing application with AWS, customers often need to have applications on AWS to work with other applications located outside of AWS, such as an on-premise data center. Many of these applications use Microsoft Active Directory (AD) service for authentication, configuration, and management.
In this post, I discuss the benefits of using AWS Managed Microsoft Active Directory service and the design patterns of a hybrid AD service using AWS Managed Microsoft AD.
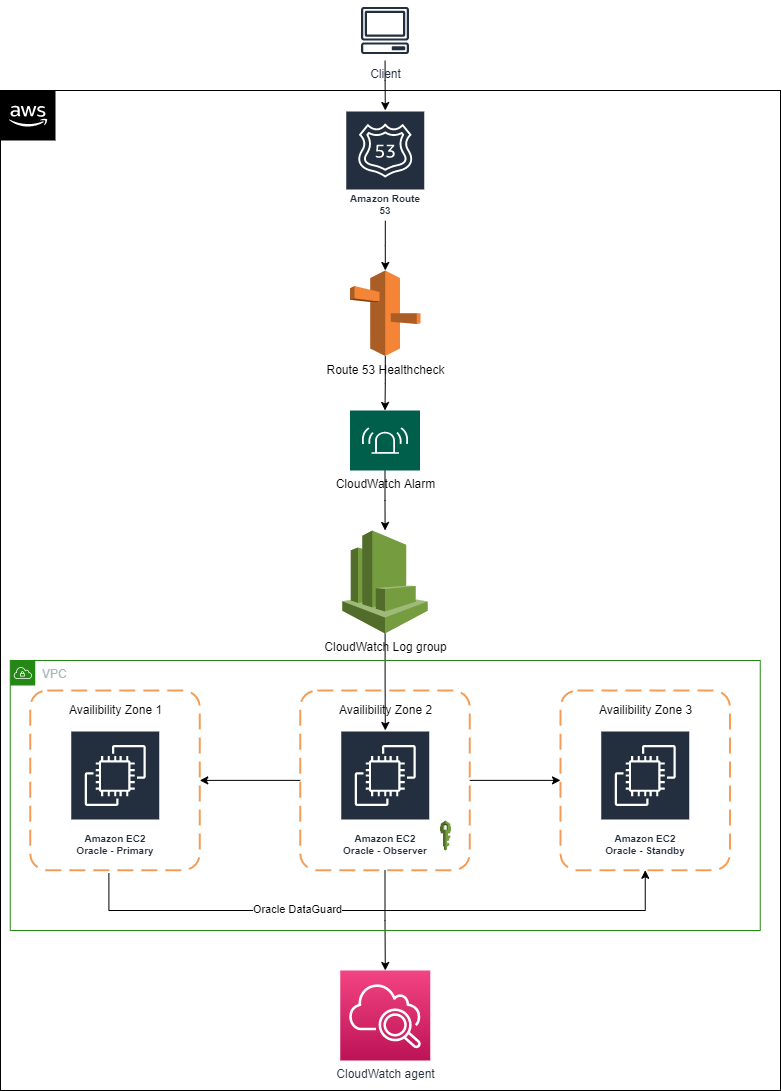
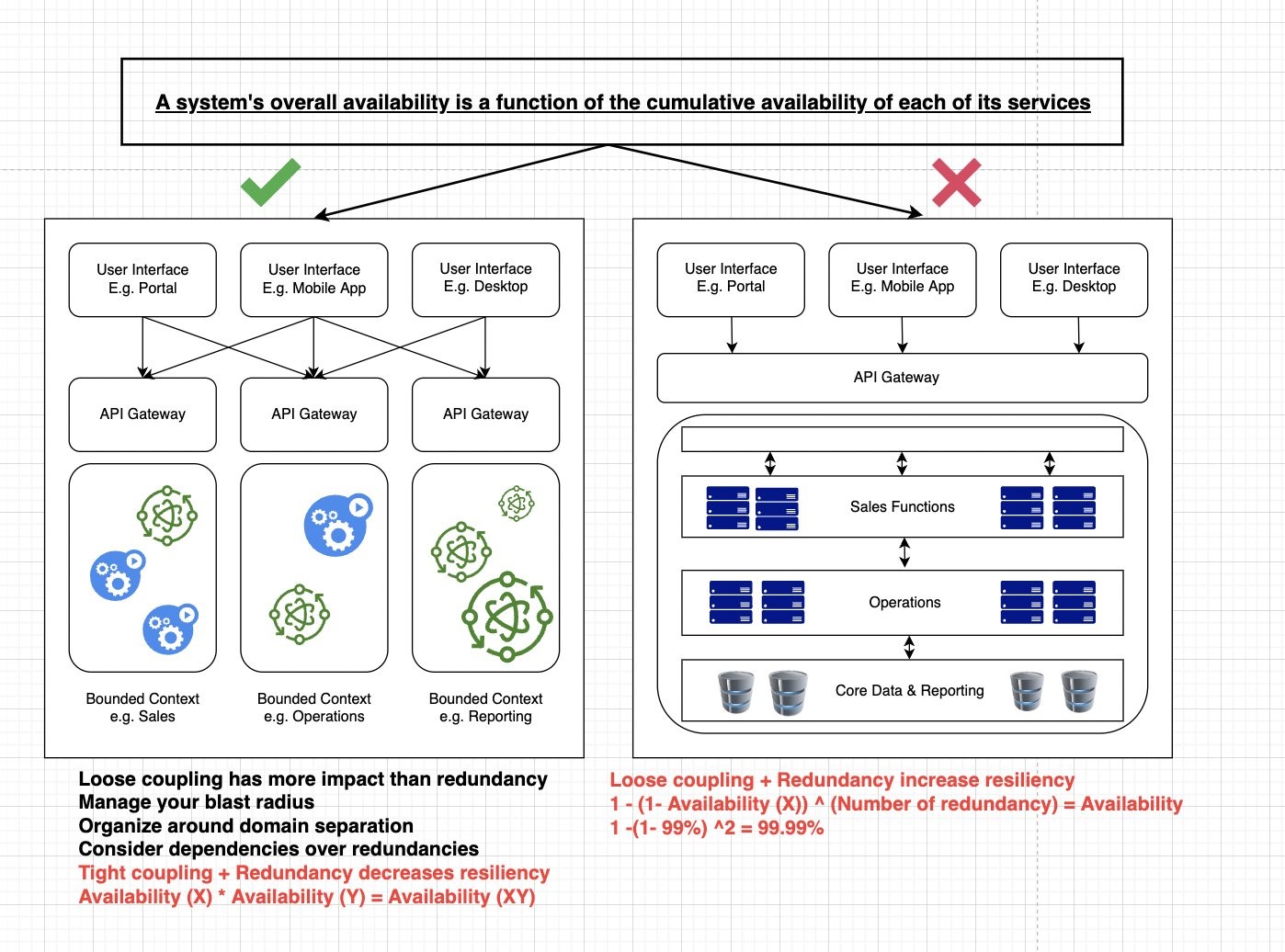
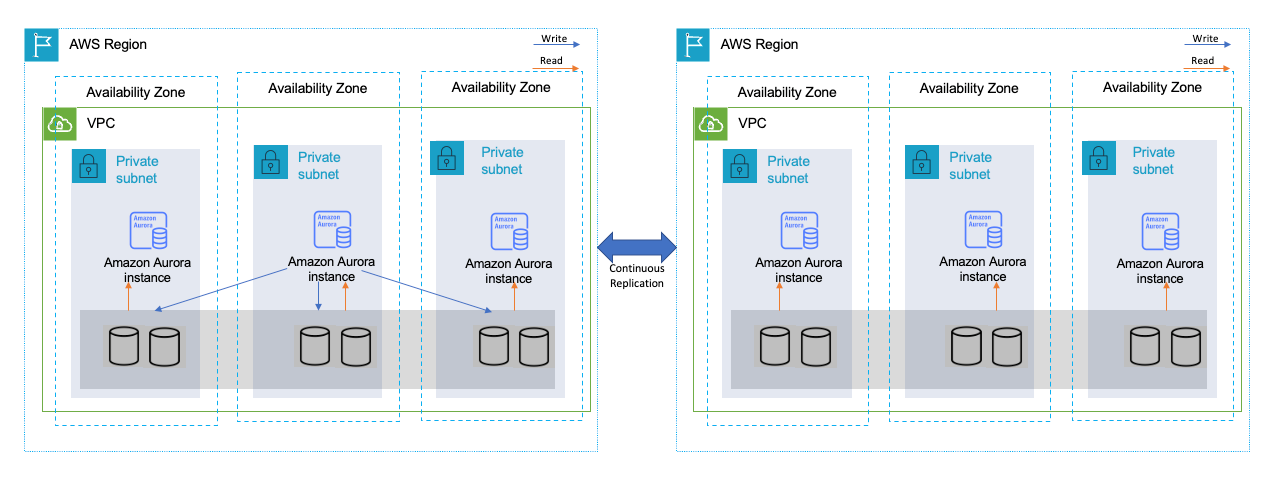
Considerations for modernizing Microsoft SQL database service with high availability on AWS
Microsoft SQL database is a common relational database service. AWS customers often lift-and-shift a Microsoft SQL database to AWS, and they seek guidance on how to architect high-availability database service on Amazon Elastic Compute Cloud (Amazon EC2) in single or multiple AWS region scenario.
In this post, I shared all the options of modernizing Microsoft SQL database service with high availability on AWS, including lift-and-shift to Amazon EC2, replatform with Amazon Relational Database Service, and refactor with Amazon Aurora.
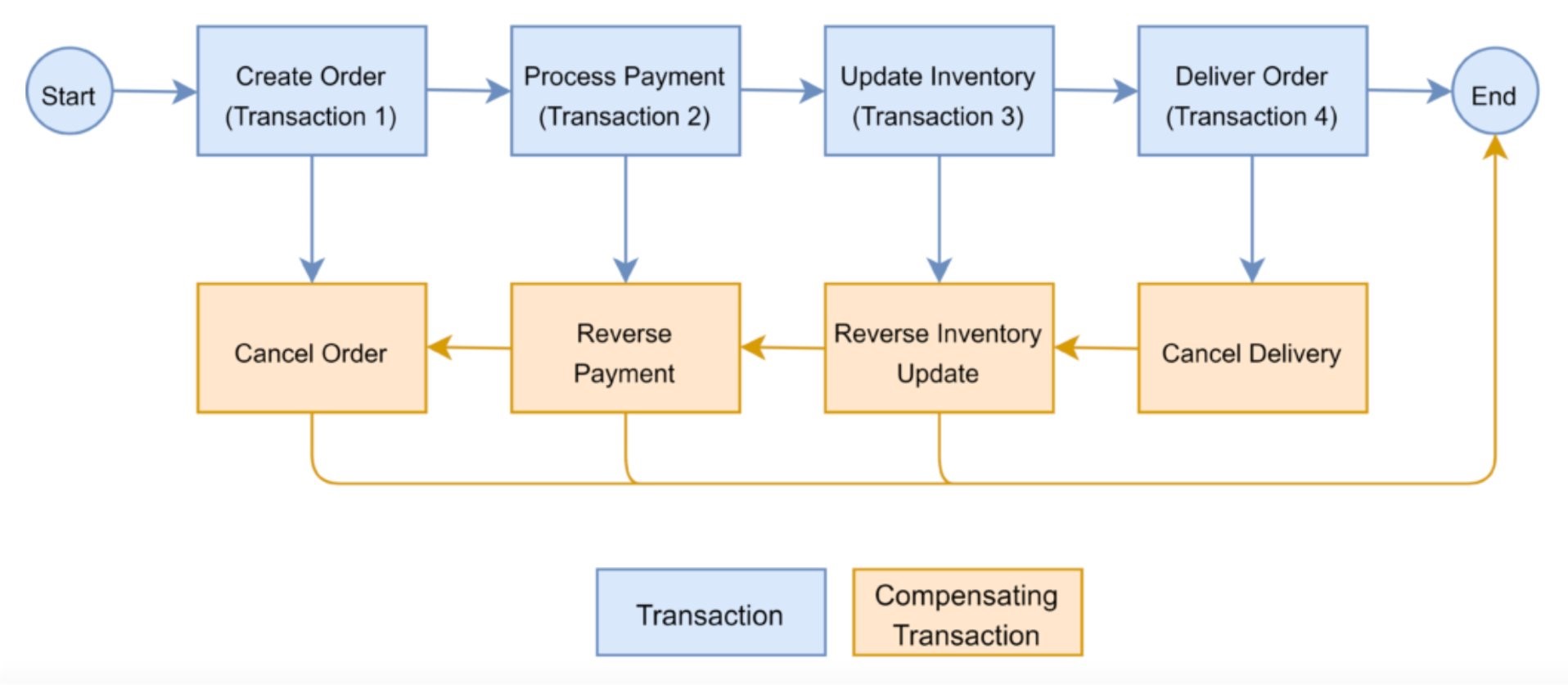
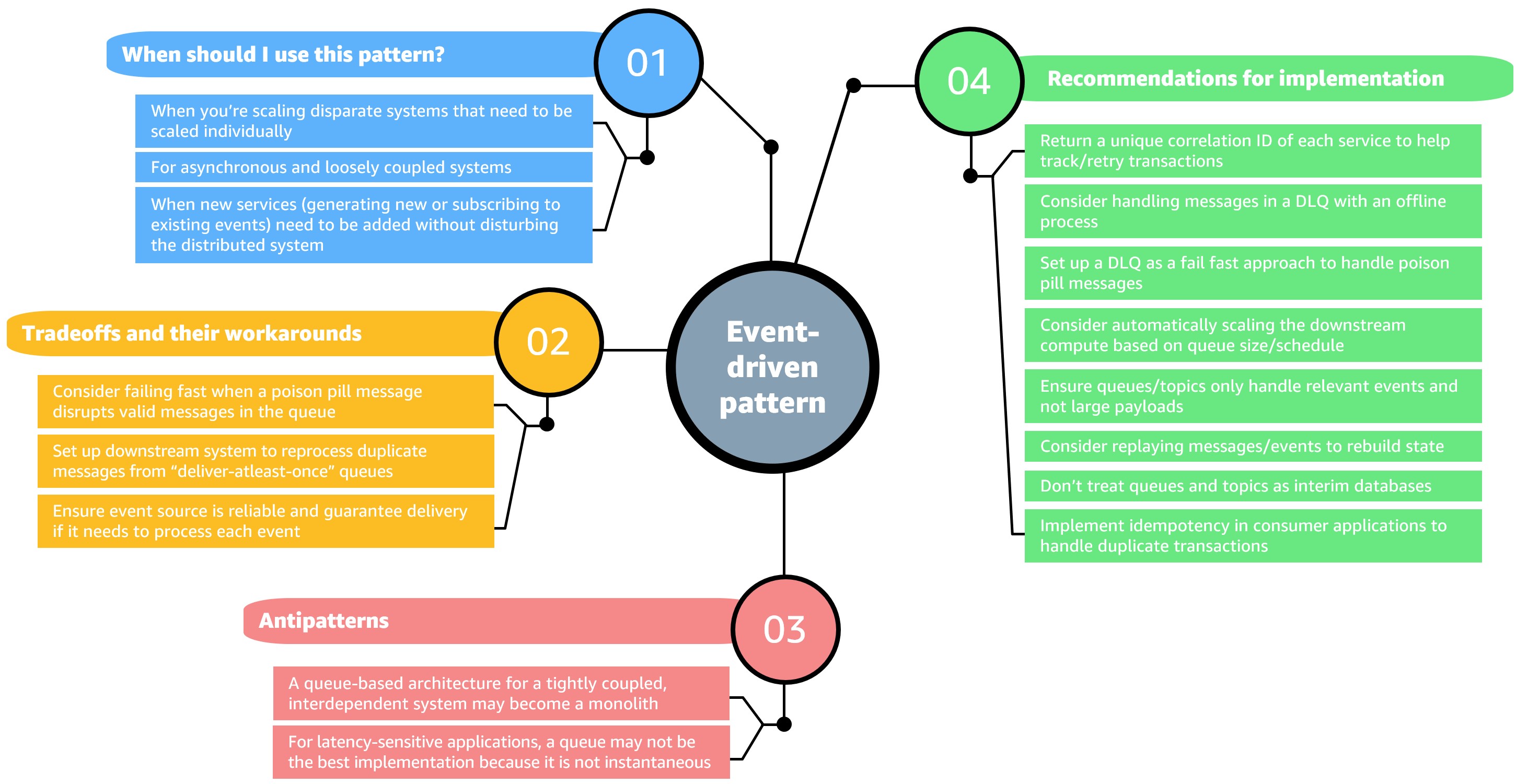
Augmentation patterns to modernize a mainframe on AWS
I’ve had pleasure working with an AWS partner on building an AWS-focused mainframe modernization practice. I learned side-by-side with my partner using mainframe modernization use cases. By working with AWS Mainframe Modernization service team and SMEs in Technical Field Community, I published this post to share the design patterns of modernizing a mainframe through building augmentation solutions on AWS. Plus, my partner is building service offerings based on these patterns!

Strengthening Cloud Governance and Optimizing FinOps with LTI Infinity Ensure
My very first AWS Partner Network blog, co-authored with my AWS partner Larsen and Toubro Infotech (LTI). At AWS, customer obsession is probably everyone’s favorite leadership principle—and, perhaps, it is the best-known leadership principle among AWS customers.
As a partner solution architect, AWS partners—like LTI—are my immediate customers. Nothing excites me more than working with my partner to make a solution better and publish a blog explaining it to all AWS readers!