Post Syndicated from Sid Vantair original https://aws.amazon.com/blogs/devops/accelerate-development-with-secure-access-to-amazon-q-developer-using-pingidentity/
Overview
Customers adopting Amazon Q Developer, a generative AI-powered coding companion, often need authentication through existing identity providers like PingIdentity. By leveraging AWS IAM Identity Center, organizations can enable their developers to access Amazon Q Developer with their existing PingIdentity credentials, streamlining authentication and removing the need for separate login procedures. Amazon Q Developer can chat about code, provide inline code completions, and generate new code. It also scans your code for security vulnerabilities and makes code improvements, including language updates, debugging, and optimizations. Amazon Q Developer comes in two tiers. The Free Tier is available at no cost for individual use. The Pro Tier is a paid version offering enterprise access controls, an analytics dashboard, customization, and higher usage limits. Organizations that enable the Pro tier of Amazon Q Developer for their developers typically authenticate with AWS IAM Identity Center. This approach is popular due to its ability to federate with external identity providers. In this blog, we will show you how to set up PingIdentity as an external IdP for IAM Identity Center and allow developers to access Amazon Q Developer using their existing PingIdentity login credentials.
How it works

Figure 1 – Solution Overview
The authentication workflow is as follows:
- The developer initiates an access request to Amazon Q Developer.
- IAM Identity center checks authentication status.
- If not authenticated, redirects to PingIdentity login.
- Developer provides PingIdentity Credentials.
- PingIdentity validates credentials and sends SAML response.
- IAM Identity Center verifies the SAML response.
- Upon successful verification, grants Amazon Q Developer access.
- Developer begins using Amazon Q Developer.
Prerequisites
- AWS account
- PingIdentity environment with users and groups already setup for Amazon Q Developer access
- IAM identity center
- Pro Tier subscription of Amazon Q Developer
Walkthrough
In this section, we demonstrate how to create a SAML-based connection between PingIdentity and IAM Identity Center, enabling you to access Amazon Q Developer seamlessly using your PingIdentity credentials.
Note: You will need to switch between PingIdentity portal and IAM Identity Center in your browser. We recommend opening a new browser tab for each console.
Step 1: Enable AWS Single Sign-On in PingIdentity
This step involves enabling AWS Single Sign-On application within PingIdentity.
-
- In the PingIdentity console, Navigate to the Applications Tab > Application Catalog
- Browse catalog for AWS Single Sign-On and select + to start the Quick Setup.

Figure 2 – PingIdentity Application Catalog
Alt Text: Screenshot of the PingIdentity Application Catalog interface. The search term “aws” is entered in the search bar, displaying three results: Amazon Web Services – AWS, AWS Gov-Cloud, and AWS Single Sign-On. The “AWS Single Sign-On” option is outlined with a red box and includes a plus button to add the application
-
- Provide Name, SSO Region and SSO Tenant ID and choose Next
- Name – Input an appropriate name for the connection
- SSO Region – Input the appropriate region
- Tenant ID – Identity Store ID
You can run the following CLI command to retrieve the value. It’s a 10-digit alphanumeric prefixed by “d-“.
- Provide Name, SSO Region and SSO Tenant ID and choose Next
-
- Navigate to PingOne Mappings and select Email Address from the drop down.

Figure 3 – AWS Single Sign-On attribute mapping
Alt Text: Screenshot of the AWS Single Sign-On configuration in PingIdentity. The screen shows Step 2 of the setup process where the SAML attribute SAML_SUBJECT is mapped to the PingOne attribute “Email Address”. A red box highlights the mapping section under “PingOne Mappings”.
-
- Search and select the group that you have created earlier for enabling access to Amazon Q Developer and select + to add the group.
- Choose Save

Figure 4 – Select PingIdentity directory Groups for Amazon Q Developer access
Alt Text: Screenshot of Step 3 in the AWS Single Sign-On setup process in PingIdentity. The screen shows the group selection interface where the “Amazon Q” group is listed. A plus icon is shown next to the group to add it, and a blue “Save” button is highlighted in the bottom-right corner to confirm the configuration.
Step 2: Connecting PingIdentity with IAM identity Center
This step involves configuring PingIdentity with the AWS IAM Identity Center sign-on details to complete the authentication setup.
- In the PingIdentity console, Navigate to the Applications Tab > Applications and select the application you created earlier in Step 1
- Select Enable Advanced Configuration and choose Enable.

Figure 5 – Enable Advanced configuration for AWS single Sign-On application
Alt Text: Screenshot of the PingIdentity Applications dashboard showing the AWS Single Sign-On application selected. The overview panel displays key configuration sections including protocol (SAML), mapped attributes, selected policies, and access group (Amazon Q). The option “Enable Advanced Configuration” is highlighted near the bottom of the panel.
- Scroll down and select Download Metadata. This will save the Metadata file to your local computer, which you will use later during the configuration process.
- In another browser tab login to your AWS IAM Identity Center console and Select Choose your identity source.
- Under Identity source, select Change identity source from the Actions drop-down menu.

Figure 6 – Change identity source in IAM Identity Center Console
Alt Text: Screenshot of the IAM Identity Center settings page, focused on the “Identity source” tab. The page displays details such as identity source, authentication method, AWS access portal URL, issuer URL, and identity store ID. A dropdown menu labeled “Actions” is expanded in the top-right corner, showing options to “Customize AWS access portal URL” and “Change identity source,” highlighted with a red box.
- On the next page, select External identity provider and choose Next.
- Under Service provider metadata copy the IAM Identity Center Assertion Consumer Service (ACS) URL.

Figure 7 – Copy IAM Identity Center ACS URL

Alt Text: Screenshot of the “Configure external identity provider” step in the AWS IAM Identity Center setup process. The screen displays service provider metadata including the AWS access portal sign-in URL, IAM Identity Center Assertion Consumer Service (ACS) URL (highlighted with a red box), and IAM Identity Center issuer URL. A button labeled “Download metadata file” is shown in the upper right.
- Now go back to the PingIdentity browser tab and Navigate to the Configuration tab and select pencil icon to edit the details.
- Paste the ACS URL you copied from the IAM identity center console and choose Save.

Figure 8 – Configuring AWS Single Sign-On SAML Settings in PingIdentity console
Alt Text: Two screenshots showing the configuration and editing of SAML settings for AWS Single Sign-On in PingIdentity. The first image displays the static configuration view, listing the ACS URL, signing key (“PingOne SSO Certificate for Administrators environment”), signing method (“Response”), and signing algorithm. The second image shows the editable configuration screen with the ACS URL input field highlighted in red, alongside dropdowns for selecting the signing key, options for signing method (Assertion, Response, or both), and the RSA_SHA256 signing algorithm. These screens guide users through setting up secure SAML integration with AWS SSO.
Step 3: Configure PingIdentity as external IdP in IAM identity Center
This step involves setting up PingIdentity as an external IdP in IAM Identity Center to enable federated access.
- Navigate back to the previous browser tab where you had IAM Identity Center console open.
- Upload the downloaded PingIdentity IdP SAML metadata file from step 3 of previous section and select Next.

Figure 9 – AWS IAM Identity Center metadata
Alt Text: Screenshot of the AWS Identity Center configuration screen where the user uploads the IdP SAML metadata XML file. The metadata file is shown as successfully selected. Below are empty fields for optional manual entry of IdP sign-in URL, IdP issuer URL, and IdP certificate. The “Next” button is highlighted in orange at the bottom right, indicating the next step in the setup process.
- Review the list of changes. Once you are ready to proceed, type ACCEPT, then select Change identity source.
Step 4: Enable provisioning and identity-aware sessions in IAM identity Center
This step involves configuring user provisioning and enabling identity-aware sessions in AWS IAM Identity Center to support dynamic access control.
- In IAM Identity Center Console, Choose Settings in the left navigation pane.
- On the Settings page, locate and enable automatic provisioning. This immediately enabled automatic provisioning in IAM Identity Center and displays the necessary SCIM endpoint and access token information.
- In the Inbound automatic provisioning dialog box, copy each of the values for the following options. You will need to paste these later when you configure provisioning in PingIdentity.
- SCIM endpoint
- Access token
- Choose Close.
- Next enable identity-aware sessions and automatic provisioning.

Figure 10 – IAM Identity Center Settings for identity aware sessions and automatic provisioning
Alt Text: Two options are displayed for further configuration: “Enable identity-aware sessions” and “Automatic provisioning.” Both options have an “Enable” button on the right-hand side, highlighted in red.
Step 5: Configure connections provisioning in PingIdentity
This step involves setting up connection provisioning in PingIdentity to enable automatic user and group management.
- In the PingIdentity console, Navigate to the Integrations > Provisioning.
- Select plus icon > New Connection
- Under connection type Select Identity Store.

Figure 11 – PingIdentity connection provisioning
Alt Text: PingIdentity Provisioning configuration screen. The left sidebar highlights the “Provisioning” tab. The main panel shows the “Create a New Connection” dialog with two connection type options: “Identity Store” and “Gateway.” The “Identity Store” option is selected using the “Select” button on the right. A plus (+) icon at the top indicates the option to add a new provisioning connection.
- Select SCIM outbound from the list of options and select Next.
- Provide a name for the connection and select Next.
- Paste the SCIM endpoint URL into the SCIM BASE URL field.
- Navigate to Authentication Method and select OAuth 2 Bearer Token.
- Paste the Access token into the Oauth Access Token field.
- Select Test Connection to validate the connectivity and select Next.

Figure 12 – Configure authentication details
Alt Text: PingIdentity interface showing the “Configure Authentication” step in the “Create a New Connection” wizard. Key fields include the SCIM Base URL, SCIM Version (2.0), Authentication Method (OAuth 2 Bearer Token), OAuth Access Token (obscured), and resource paths for Users and Groups. The “Test Connection” and “Next” buttons are visible at the bottom.
- Navigate to User Filter Expression and change to userName Eq “%s”.
- Choose Save. By default, the connection is created in a Disabled state.

Figure 13 – Edit UserFilter Expressions for the connection
Alt Text: Final step in the PingIdentity “Create a New Connection” wizard showing the “Configure Preferences” screen. The highlighted fields include “User Filter Expression” with the value userName Eq “%s”, “User Identifier” set to userName, and group membership handling options (“Merge” and “Overwrite” with “Overwrite” selected). A “Save” button is highlighted at the bottom right.
- Select the connection you created and select the toggle switch to enable the connection.

Figure 14 – Enable the connection
Alt Text: PingIdentity configuration screen showing the IAM Identity Store integration. The page displays the identity store name, and tabs for “Overview” and “Configuration.” A toggle switch in the top-right corner is highlighted, indicating the integration is currently enabled.
Step 6: Configure rules provisioning in PingIdentity
This step involves setting up provisioning rules in PingIdentity to define how users and groups are synchronized.
- In the PingIdentity console, Navigate to the Integrations > Provisioning.
- Select plus icon > New Rule
- Provide a Name and Description for the rule.
- Choose Create.
- Select plus icon to select the Connection you created in the previous step.
- Choose Save.

Figure 15 – Add the IAM identity center connection to the rule
Alt Text: Screenshots showing the final steps in connecting the IAM Identity Center to the IAM identity store using PingIdentity. The first image shows the IAM Identity Store connection listed under “Available Connections” with a plus (+) icon to initiate the link. The second image shows the selected connection from the PingOne Directory (P1) as the source and IAM identity store (SCIM) as the target, with the option to “Save” the configuration.
- If you want to sync users from your PingIdentity directory, create a user filter. To do so, navigate to User Filter and select pencil icon to edit the settings.
- Choose the appropriate filter from the drop down based on your use case and select Save. I have chosen Group Name which has been designated for Amazon Q Developer access.

Figure 16 – PingIdentity user filter
Alt Text: Screenshot of the “Edit User Filter” interface in IAM Identity Center. The user filter is configured to provision users who belong to a group with names that contain “Amazon Q Developer.” The condition logic is set to match if “Any” of the conditions are true.
- If you want to sync a group from your PingIdentity directory, create group provisioning. To do so, navigate to Group Provisioning and select pencil icon to edit the settings.
- Select the appropriate group which has been designated for Amazon Q Developer access and choose Save.

Figure 17 – PingIdentity Group Provisioning
Alt Text: Screenshot of the “Edit Group Provisioning” screen in IAM Identity Center. The group “Amazon Q Developer” is selected for outbound provisioning. A “Save” button is highlighted in the bottom-left corner.
- Navigate to Attribute Mapping and select the pencil icon to edit the settings.
- Delete the PingOne Directory attribute Primary Phone.
- Add a new attribute and select Username as PingOne Directory and displayName as IAM identity Store.
- Choose Save.

Figure 18 – PingIdentity attribute mapping
Alt Text: Two screenshots showing the editing of attribute mappings in IAM Identity Center. The first image displays default mappings such as ‘Email Address’ to ‘workEmail’ and ‘Username’ to ‘userName’, with an option to delete or update each field. The second image shows the addition of a new attribute mapping from ‘Username’ to ‘displayName’, along with highlighted ‘Add’ and ‘Save’ buttons.
- Select the rule you created and select the toggle switch to enable the rule.
- This automatically provisions the users/groups from PingIdentity to IAM identity Center using SCIM.

Figure 19 – PingIdentity Users and Groups Sync status using SCIM
Alt Text: IAM Identity Center sync summary showing successful user and group provisioning. The first image highlights two users impacted and successfully synced. The second image highlights one group impacted and successfully synced. Sync status is marked ‘ACTIVE’ in both views, confirming successful integration between PingOne and AWS IAM Identity Center.
Step 7: Provide access to Amazon Q Developer
This step involves locating and subscribing the groups that need permission to use Amazon Q Developer.
- In the Amazon Q Developer console, under Subscriptions add the IAM identity center groups which require access to Amazon Q Developer.
- Select Subscribe and search for the group name.
- Select Assign.

Figure 20 – Amazon Q Developer subscriptions page
Alt Text: Screenshot of the Amazon Q Developer Subscriptions page in the AWS Management Console. The “Groups” tab is selected, displaying “Amazon Q Developer,” with a subscription status of “Subscribed.” The “Amazon Q Developer” group is highlighted with a red box.
Setup Amazon Q Developer with IAM Identity Center
This section guides you through installing the Amazon Q Developer extension and setting up authentication with IAM Identity Center.
- To set up Amazon Q Developer extension in your integrated development environment (IDE), complete the steps in AWS documentation.
- Once extension is installed Choose Amazon Q icon in your IDE.
- Choose a sign-in option.
- Select Use with Pro license and choose
- Continue.
- Provide the Start URL. You can retrieve this AWS access portal URL from the IAM Identity Center Console.

Figure 21 – IAM identity center access portal URL
Alt Text: Screenshot of the IAM Identity Center settings page in the AWS Console, displaying the identity source configuration. It shows that the identity source is set to “External identity provider” with SAML 2.0 authentication and SCIM provisioning. The highlighted section includes the AWS access portal URL and the Identity Store ID. The “Settings” tab is selected in the left navigation pane.
- Provide the region that hosts the identity directory and choose Continue
- Select Open on the resulting pop up which redirects to your browser.
- The browser redirects you to the Pingone URL where you enter your PingIdentity credentials and select Sign On.
- Upon successful authentication, select Allow access on the resulting pop up to login successfully.

Figure 22 – Setup Visual Studio Code Amazon Q Developer extension
Alt Text: A screen recording of Visual Studio Code where the user selects the Amazon Q icon from the sidebar. The screen transitions to a login prompt indicating that the user must authenticate using their PingIdentity credentials via IAM Identity Center before accessing Amazon Q Developer features. The message highlights that authentication is required to continue.
Test Configuration
Upon successfully completing the previous step, you can now leverage the code suggestions by Amazon Q Developer.

Figure 23 – Amazon Q Developer example
Alt Text: A screen recording of Visual Studio Code where Amazon Q Developer generates a sample code inline.
Clean Up
To avoid ongoing charges after testing this solution, follow these steps to remove all provisioned resources:1. Remove PingIdentity Application Configuration
- In the PingIdentity console, navigate to Applications.
- Locate and delete the AWS Single Sign-On application that was configured for IAM Identity Center integration.
2. Reset IAM Identity Center Configuration
- In the AWS IAM Identity Center console:
- Navigate to Settings > Identity source.
- Change the identity source back to the default IAM Identity Center directory if no longer using PingIdentity.
- Remove any external metadata and configuration uploaded during the setup.
3. Revoke Subscriptions and Access
- In the Amazon Q Developer console:
- Go to Subscriptions and remove assigned groups such as Amazon Q Developer or code whisperer trial.
- This will deactivate access and prevent any future charges tied to those subscriptions.
4. Remove Amazon Q Developer Extension
- If desired, uninstall the Amazon Q Developer extension from Visual Studio Code to fully revert the development environment.
Conclusion
In this post, we demonstrated how to use existing PingIdentity credentials to access Amazon Q Developer through integration with IAM Identity Center. We provided a step-by-step guide for configuring PingIdentity as an external identity provider (IdP) with IAM Identity Center. Lastly, we demonstrated how to connect Amazon Q Developer extension within your IDE to AWS using your PingIdentity credentials, allowing seamless access to Amazon Q Developer.If you have any comments or questions, share them in the comments section.
To learn more about AWS Services
AWS Toolkit for Visual Studio Code
About the author
 Sid Vantair is a Solutions Architect with AWS covering Strategic accounts. He thrives on resolving complex technical issues to overcome customer hurdles. Outside of work, he cherishes spending time with his family and fostering inquisitiveness in his children.
Sid Vantair is a Solutions Architect with AWS covering Strategic accounts. He thrives on resolving complex technical issues to overcome customer hurdles. Outside of work, he cherishes spending time with his family and fostering inquisitiveness in his children.













 Fig 2: part of pom.xml changes after dependency upgrades
Fig 2: part of pom.xml changes after dependency upgrades
























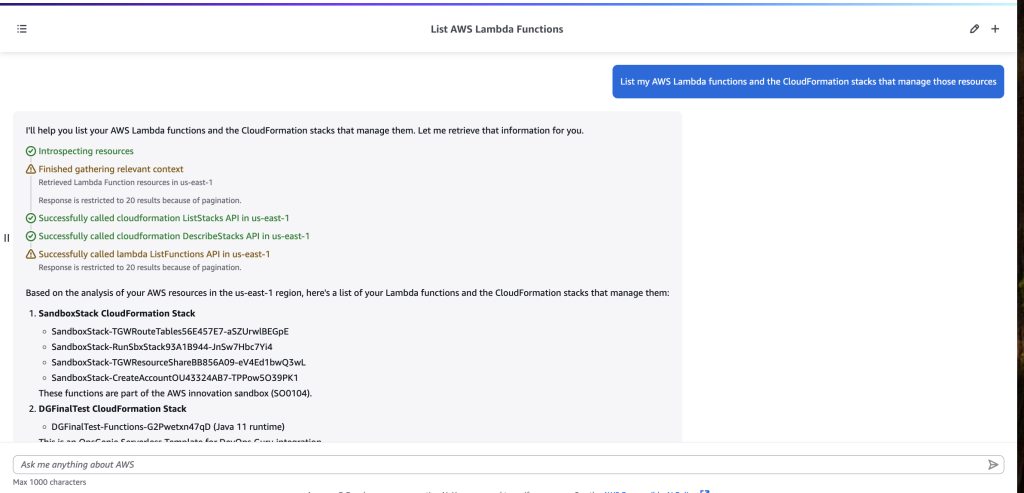
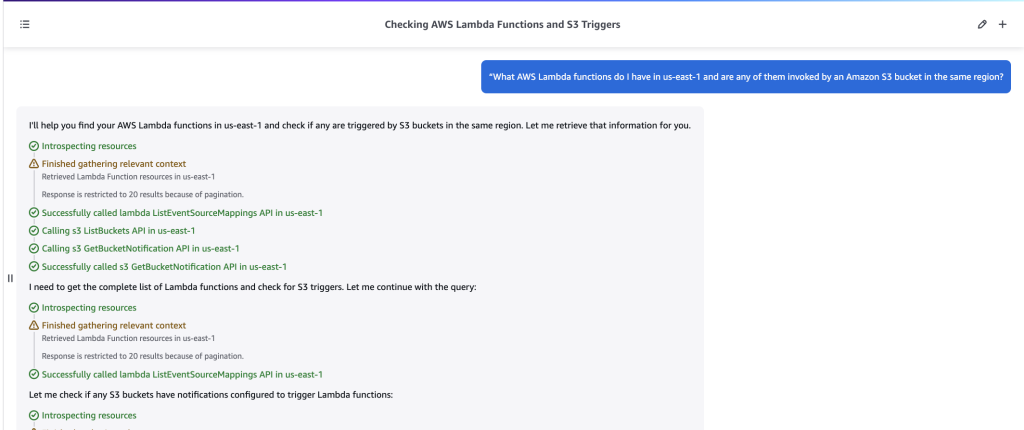
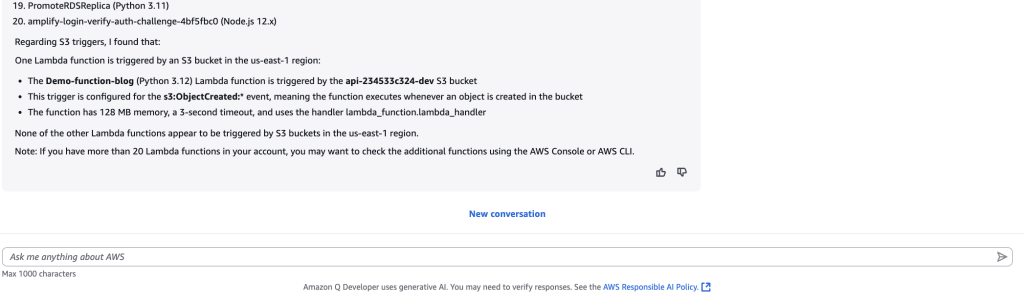
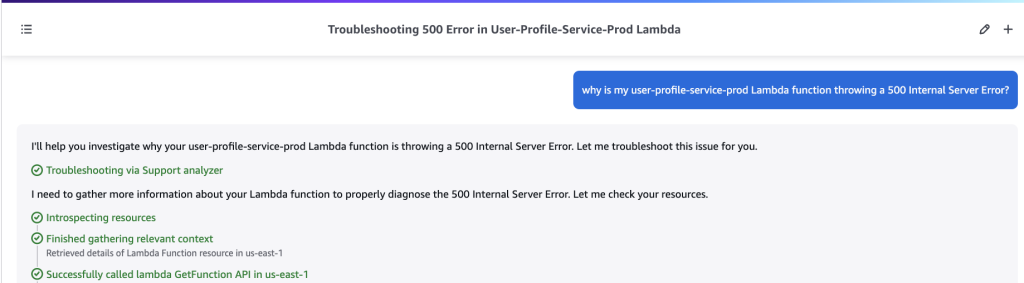








































 Fig 1 – Issue created with Amazon Q development agent label
Fig 1 – Issue created with Amazon Q development agent label Fig 2- PR created by Amazon Q Developer with change description
Fig 2- PR created by Amazon Q Developer with change description

 Fig 5 – Files updated for the pull request
Fig 5 – Files updated for the pull request

























