Post Syndicated from Robbie Cooray original https://aws.amazon.com/blogs/architecture/how-wesfarmers-health-implemented-upstream-event-buffering-using-amazon-sqs-fifo/
Customers of all sizes and industries use Software-as-a-Service (SaaS) applications to host their workloads. Most SaaS solutions take care of maintenance and upgrades of the application for you, and get you up and running in a relatively short timeframe. Why spend time, money, and your precious resources to build and maintain applications when this could be offloaded?
However, working with SaaS solutions can introduce new requirements for integration. This blog post shows you how Wesfarmers Health was able to introduce an upstream architecture using serverless technologies in order to work with integration constraints.
At the end of the post, you will see the final architecture and a sample repository for you to download and adjust for your use case.
Let’s get started!
Consent capture problem
Wesfarmers Health used a SaaS solution to capture consent. When capturing consent for a user, order guarantee and delivery semantics become important. Failure to correctly capture consent choice can lead to downstream systems making non-compliant decisions. This can end up in penalties, financial or otherwise, and might even lead to brand reputation damage.
In Wesfarmers’ case, the integration options did not support a queue with order guarantee nor exactly-once processing. This meant that, with enough load and chance, a user’s preference might be captured incorrectly. Let’s look at two scenarios where this could happen.
In both of these scenarios, the user makes a choice, and quickly changes their mind. These are considered two discreet events:
- Event 1 – User confirms “yes.”
- Event 2 – User then quickly changes their mind to confirm “no.”
Scenario 1: Incorrect order
In this scenario, two events end up in a queue with no order guarantee. Event 2 might be processed before Event 1, so although the user provided a “no,” the system has now captured a “yes.” This is now considered a non-compliant consent capture.

Figure 1. Animation showing messages processed in the wrong order
Scenario 2 – events processed multiple times
In this scenario, perhaps due to the load, Event 1 was transmitted twice, once before and once after Event 2, due to at least once processing. In this scenario, the user’s record could be updated three times, first with Event 1 with “yes,” then Event 2 with “no,” then again with retransmitted Event 1 with “yes,” which ultimately ends up with a “yes,” also considered a non-compliant consent capture.

Figure 2. Animation showing messages processed multiple times
How did Amazon SQS and Amazon DynamoDB help with order?
With Amazon Amazon Simple Queue Service (Amazon SQS), queues come in two flavors: standard and first-in-first-out (FIFO). Standard queues provide best effort ordering and at-least once processing with high throughput, whereas FIFO delivers order and processes exactly once with relatively low throughput, as shown in Figure 3.

Figure 3. Animation showing FIFO queue processing in the correct order
In Wesfarmers Health’s scenario with relatively few events per user, it made sense to deploy a FIFO queue to deliver messages in the order they arrived and also have them delivered once for each event (see more details on quotas at Amazon SQS FIFO queue quotas).
Wesfarmers Health also employed the use of message group IDs to parallelize all users using a unique userID. This means that they can guarantee order and exactly-once processing at the user level, while processing all users in parallel, as shown in Figure 4.

Figure 4. Animation showing a FIFO queue partitioned per user, in the correct order per user
The buffer implementation
Wesfarmers Health also opted to buffer messages for the same user in order to minimize race conditions. This was achieved by employing an Amazon DynamoDB table to capture the timestamp of the last message that was processed. For this, Wesfarmers Health designed the DynamoDB table shown in Figure 5.

Figure 5. Example DynamoDB schema with messageGroupId based on user, and TTL
The messageGroupId value corresponds to a unique identifier for a user. The time-to-live (TTL) value serves dual functions. First, the TTL is the value of the Unix timestamp for the last time a message from a specific user was processed, plus the desired message buffer interval (for example, 60 seconds). It also serves a secondary function of allowing DynamoDB to remove obsolete entries to minimize table size, thus improving cost for certain DynamoDB operations.
In between the Amazon SQS FIFO queue and the Amazon DynamoDB table sits an AWS Lambda function that listens to all events and transmits to the downstream SaaS solution. The main responsibility of this Lambda function is to check the DynamoDB table for the last processed timestamp for the user before processing the event. If, by chance, a user event for the user was already processed within the buffer interval, then that event is sent back to the queue with a visibility timeout that matches the interval, so that the user events for that user is not processed until the buffer interval is passed.

Figure 6. Amazon DynamoDB table and AWS Lambda function introducing the buffer
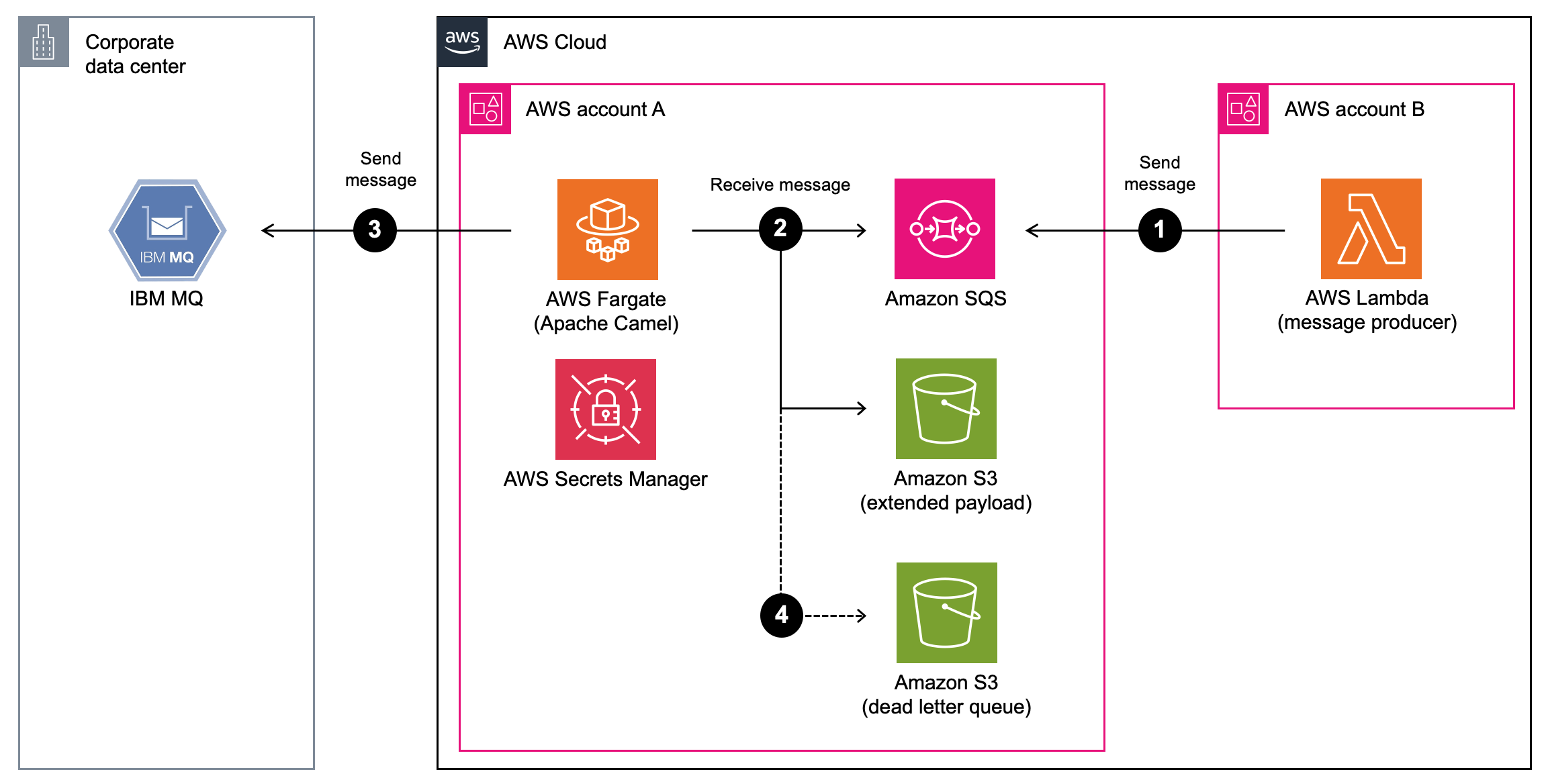
Final architecture
Figure 7 shows the high-level architecture diagram that powers this integration. When users send their consent events, it is sent to the SQS FIFO queue first. The AWS Lambda function determines, based on the timestamp stored in the DynamoDB table, whether to process it or delay the message. Once the outcome is determined, the function passes through the event downstream.

Figure 7. Final architecture diagram
Why serverless services were used
The Wesfarmers Health Digital Innovations team is strategically aligned towards a serverless first approach where appropriate. This team builds, maintains, and owns these solutions end-to-end. Using serverless technologies, the team gets to focus on delivering business outcomes while leaving the undifferentiated heavy lifting of managing infrastructure to AWS.
In this specific scenario, the number of requests for consent is sporadic. With serverless technologies, you pay as you go. This is a great use case for workloads that have requests fluctuate throughout the day, providing the customer a great option to be cost efficient.
The team at Wesfarmers Health has been on the serverless journey for a while, and are quite mature in developing and managing these workloads in a production setting using best practices mentioned above and employing the AWS Well Architected Framework to guide their solutions.
Conclusion
SaaS solutions are a great mechanism to move fast and reduce the undifferentiated heavy lifting of building and maintaining solutions. However, integrations play a crucial part as to how these solutions work with your existing ecosystem.
Using AWS services, you can build these integration patterns that is fit for purpose, for your unique requirements.
AWS Serverless Patterns is a great place to get started to see what other patterns exist for your use case.
Next steps
Check out the repository hosted on AWS Patterns that sets up this architecture. You can review, modify, and extend it for your own use case.


























 John Jackson has over 25 years of software experience as a developer, systems architect, and product manager in both startups and large corporations and is the AWS Principal Product Manager responsible for Amazon MWAA.
John Jackson has over 25 years of software experience as a developer, systems architect, and product manager in both startups and large corporations and is the AWS Principal Product Manager responsible for Amazon MWAA.




























 Ravi Itha is a Principal Consultant at AWS Professional Services with specialization in data and analytics and generalist background in application development. Ravi helps customers with enterprise data strategy initiatives across insurance, airlines, pharmaceutical, and financial services industries. In his 6-year tenure at Amazon, Ravi has helped the AWS builder community by publishing approximately 15 open-source solutions (accessible via
Ravi Itha is a Principal Consultant at AWS Professional Services with specialization in data and analytics and generalist background in application development. Ravi helps customers with enterprise data strategy initiatives across insurance, airlines, pharmaceutical, and financial services industries. In his 6-year tenure at Amazon, Ravi has helped the AWS builder community by publishing approximately 15 open-source solutions (accessible via  Srinivas Kandi is a Data Architect at AWS Professional Services. He leads customer engagements related to data lakes, analytics, and data warehouse modernizations. He enjoys reading history and civilizations.
Srinivas Kandi is a Data Architect at AWS Professional Services. He leads customer engagements related to data lakes, analytics, and data warehouse modernizations. He enjoys reading history and civilizations.