Post Syndicated from Marco Guerriero original https://aws.amazon.com/blogs/big-data/detect-change-points-in-your-event-data-stream-using-amazon-kinesis-data-streams-amazon-dynamodb-and-aws-lambda/
The success of many modern streaming applications depends on the ability to sequentially detect each change as soon as possible after it occurs, while continuing to monitor the data stream as it evolves. Applications of change point detection range across genomics, marketing, and finance, to name a few. In genomics, change point detection can help identify genes that are damaged. In marketing, we can identify things like customer churns in real time or when customer engagement changes over time. This is very useful in areas like online retail where, if change detection is implemented, we can adapt much more quickly to customer behavior. In finance, we can detect moments in time when stock prices have significantly changed. As opposed to online batch methodologies that take a batch of historical data and look for the change points in that data, we use a streaming procedure where we detect change points as fast as possible in real time as new data comes in.
In this post, we demonstrate automated event detection (AED), a fully automated, non-parametric, multiple change point detection algorithm that can operate on massive streaming data with low computational complexity, quickly reacting to the changes. Quick change detection [1] can help a system raise a timely alarm. Quickly reacting to a sudden fault arising in an industrial process or a production process could lead to significant savings in unplanned downtime. Detecting the onset of the outbreak of a disease, or the effect of a bio-terrorist attack, is critical, both for effective initiation of public health intervention measures and to timely alert government agencies and the general public.
In AED, no statistical assumption (such as Gaussian) is made on the generative process of the time series or data streams being processed. We rely on a class of tests called non-parametric or distribution-free tests [2, 3, 4, 5]. These tests are the natural choice for performing change point detection on data streams with unknown statistical distribution, which represents a common scenario that applies to a wide variety of real-world processes. We demonstrate a Python implementation of AED embedded within AWS Lambda over a data stream processed and managed by Amazon Kinesis Data Streams.
Understanding event detection
Let’s talk for a moment about anomaly detection, data drift, and change point detection in time series.
In machine learning (ML), we hear a lot about anomaly detection. In the context of a time series, that often means a data point that is outside the expected range. That range may have a static definition, such as “we never expect the temperature to exceed 130F,” or a dynamic definition, such as “it should not vary from recent averages by more than three standard deviations.” An example of a dynamic anomaly detection algorithm is Random Cut Forest.
In contrast, data drift describes a slower shift in the stream’s data distribution. It may mean a shift in the mean of a variable, such as a shift in temperatures between summer and winter, or a change in behavior of visitors to a website as certain product categories fall out of favor and others become fashionable. A frequently recommended approach for dealing with data drift is frequent retraining of an ML model, to keep recommendations fresh and relevant based on recent data.
The events AED focuses on are in a different category altogether: sudden shifts in the data stream to a new level, sometimes called regime change. These are occasions where human intervention may be desired to see whether automated responses are appropriate. For example, a slow shift in readings from a temperature sensor may be normal, whereas a sudden large change may be a sign of a major malfunction in progress. Other data streams that constantly fluctuate but where a sudden large change may require oversight include equipment monitoring and malfunctions, cyber attacks, stock market movements, power grids and outages, and operational variations in manufacturing processes, to name a few [1].
Our goal is to automatically detect multiple events when the time series or the data streams change their behavior. In this version, we focus on sudden changes in mean or offset in time series. AED is an unsupervised, automatic, statistically rigorous, real-time procedure for detecting relevant events, which doesn’t require any training data. It can also be used as an automatic process for feature extraction (such as time series segmentation) that can be used in downstream ML systems.
Automated event detection
AED operates sequentially as data comes in, continuously performing a novel statistical test to identify a change event—a significant shift in the data from the data that preceded that point in time. If an event is detected at time ti, all the previous data prior to ti is discarded. AED is then reset to process new data points starting with the (ti +1)th data point, looking for a new change event. This procedure is repeated sequentially until no more data points are available.
The core of AED is represented by the statistical test called the Modified Practical Pettitt (MPP) test. The MPP test is a variant of the Pettitt test [6], which is a very powerful and robust non-parametrical statistical procedure to detect a single change point in data streams where the distribution is completely unknown. Pettitt’s test is based on Null Hypothesis Significance Testing (NHST), which comes with some constraints and fallacies. In fact, a very important problem with NHST is that the result of the test doesn’t provide information about the magnitude of the effect of the event—which is key information we’re interested in. A consequence of this limit is that an event (change point) can be detected despite a very small effect. But is an increase of 0.001 Celsius degrees in temperature data streams coming from some IoT devices or a decrease of $1 in a particular stock price noteworthy events? Statistical significance doesn’t tell us anything about practical relevance. The MPP test solves this problem by incorporating a practical significance threshold into the definition of the decision test statistic. In this way, only events that are both statistically and practically significant are detected and reported by AED.
The decision statistic of the MPP test can be computed recursively, resulting in a computational complexity that is linear in the number of data points processed by AED up to the reset time.
Prerequisites
To get started, we need the following:
- A continuous or discrete time series (data stream). No knowledge of the distribution of the data is needed.
- Some guidance for the algorithm in terms of when to alert us:
- The statistical confidence level we require that an event has occurred (p value).
- The practical significance level we require (our practical significance threshold).
The output of AED is a list of change points specified by their time of occurrence, their p-value, and the magnitude of the offset.
Solution overview
The following diagram illustrates the AWS services used to implement the solution.

The steps in the process are as follows:
- One or more programs, devices, or sensors generate events and place them into a Kinesis data stream. These events make up a time series. In our case, we provide a sample generator function.
- The event recorder Lambda function consumes records from the data stream.
- The Lambda function stores them in an Amazon DynamoDB events table.
- The DynamoDB table streams the inserted events to the event detection Lambda function.
- The Lambda function checks each event to see whether this is a change point. To do so, it performs the following actions:
- Reads the last change point recorded from the DynamoDB change points table (or creates one if this is the first data point for this device).
- Reads the prior events since the last change point from the events table, as a time series.
- Runs the event-detection algorithm over the retrieved time series.
- If a new change point is detected, the function does the following:
- Writes the change point into the DynamoDB change points table, for later use.
- Sends an Amazon Simple Notification Service (Amazon SNS) message to a topic with the change point details.
Setting up the solution infrastructure
To set up the infrastructure components and configure the connections, launch a predefined AWS CloudFormation stack. The stack sets up the following resources:
- A Kinesis data stream.
- Two Lambda functions: the event recorder, and the event detection. Each function has an associated AWS Identity and Access Management (IAM) role.
- Two DynamoDB tables: one to hold events, and one for detected change points.
- An SNS topic and a subscription, for notifying that a change point has been detected.
To see this solution in operation in the US East (N. Virginia) Region, launch the provided CloudFormation stack. The total solution costs approximately $0.02 per hour to run, depending on the volume of data sent to the components. Remember to delete the CloudFormation stack when you’re finished with the solution to avoid additional charges.
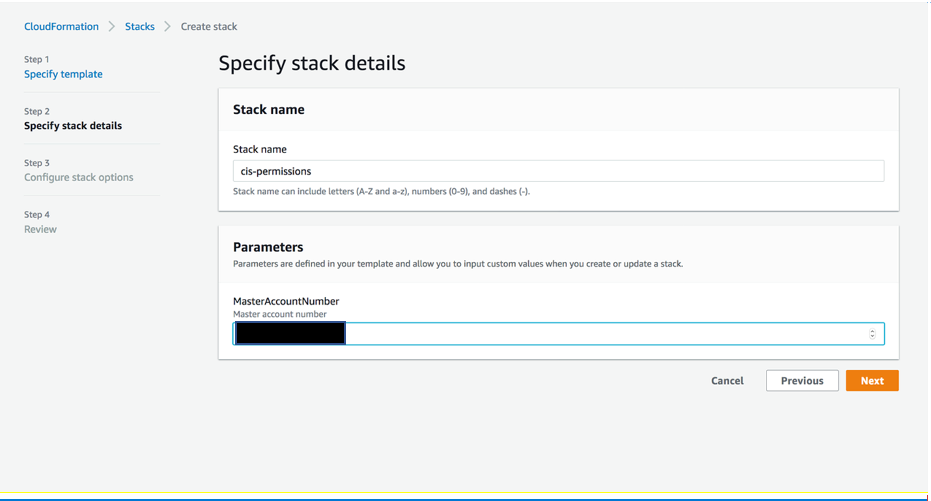
To run the stack, complete the following steps:
- Choose Launch Stack:

- Choose Next.
- Update the email address for notifications to be a valid email address of your choice.
- Update the following parameters for your environment if necessary, or, for now, leave the defaults:
- Environment parameters – Names for your DynamoDB tables, Kinesis stream, and SNS topic
- AED parameters – Startup, alpha level, change difference window, and practical significance threshold
- Choose Next.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
- Wait for the CloudFormation stack to reach a status of CREATE COMPLETE (around 5 minutes).
- Check the Outputs tab for the resources created.
If you want to receive the SNS messages for detected change points, remember to confirm your SNS subscription for the email address.
Generating data
After AWS CloudFormation creates the system resources for us, we’re ready to start generating some data. For this post, we provide a client that generates a time series with periodic regime shifts. For simplicity and to show generality, the client also runs AED over the time series it creates. At the end, it generates a time series plot of the generated data along with the detected change points. These should match the SNS notifications you receive.
- To download and set up the test clients, copy the following files to your local desktop:
- time series client.py
- time series validation client.py
- AmazonAED.py
- Install boto3, numpy, and matplotlib, if you don’t already have them installed.
Two test clients are provided:
- The
time_series_client.py generates data and puts it into Kinesis Data Streams; this is what your device does.
- For easier demonstration, we also provide a
time_series_validation_client. This version also runs AED locally and generates an annotated plot showing the input data, where the change points are detected, and where the change actually occurred.
To run the validation client, open a command prompt to the folder where you copied the client files and run the following code:
python time_series_validation_client.py -r us-east-1 -s aed_events_data_stream
You can pass the –h parameter to find out the other parameters. By default, the client generates 1 minute’s worth of data. The parameters let you configure the client for your environment, and, when running the validation client, for the local AED detection (which is independent of that being performed in the Lambda function).
You can use four parameters to configure AED’s behavior to match your environment:
- “-a”, “–alpha” – The AED alpha level, that is, the smallest change to identify. The default is 0.01.
- “-w”, “–window” – The AED change difference window, the number of points around the change to ignore. The default is 5.
- “-x”, “–startup” – The number of samples to include in the AED initialization stage. The default is 5.
- “-p”, “–practicalthreshold” – The AED practical significance threshold. Changes smaller than this are not designated as change points. The default is 0.
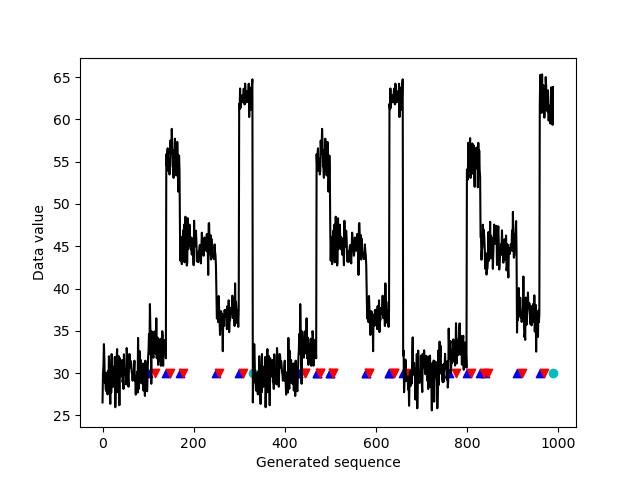
At the end of the time period, the client displays an image of the generated time series. The following time series is annotated with a small blue triangle whenever the client created a change point. The small red triangles mark the points where the AED algorithm, running independently over the generated data, detected the change points. The blue triangle always precedes the red triangle in our DetectBeforeDecide framework, where the AED algorithm has to first detect that something is changing (red triangle) and then work backwards to decide when in time the change most likely occurred (blue triangle).
The turquoise dot shows where the data generation was restarted; this change point may not be detected because AED isn’t running at that time. As you can see, each generated change point was detected. At the same time, the significant variation between the change points—in essence, within a single regime—didn’t cause a spurious change point detection.

The practical significance threshold additionally allows you to specify when the change is small enough that it’s not relevant and should be ignored.
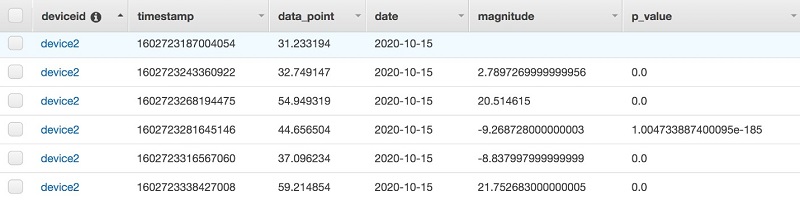
You can also review the contents of the DynamoDB tables on the AWS Management Console (see the following screenshot). The table aed_stream_data shows each event in the stream logged. The aed_change_points table shows the individual change points detected, along with the timestamp of the detection and the data point at the time the change was detected by the Lambda function running over the stream data. This data lets you construct a history of the event stream and the change points, and manipulate them according to your need.

Each Lambda function is started by the Kinesis stream; it checks to see when the last change point occurred. It then retrieves the data since that change point from the aed_stream_data table and reprocesses it, looking for a new change point. As the gaps between change points get very large, this may become a large sequence to retrieve and process. If this is your use case, you may wish to artificially create a new set point every so often to reduce the amount of data that must be reread.
Cleaning up
To avoid additional charges, you should delete the CloudFormation stack after walking through the solution.
To implement AED in a different Region or to adapt it to your own needs, download the aed.zip file.
Conclusion
In this post, we introduced automated event detection (AED), a new, fast, scalable, fully automated, non-parametric, multiple change point detection service that can operate on massive streaming data with low computational complexity. AED efficiently identifies shifts in the data stream that have both statistical and practical significance. This ability to locate the time and magnitude of a shift in the data stream, and to differentiate it from normal data fluctuations, is key in many applications. The appropriate action varies by use case: it may be appropriate to take automated action, or call a human to evaluate whether the preplanned actions should be taken. A natural extension of AED would be to add an algorithm to detect trends (gradual changes as opposed to sudden shifts) in data streams using non-parametric tests such as Mann-Kendall [7, 8]. Combining these functions allows you to identify both kinds of changes in your incoming data stream and distinguish between them, further broadening the use cases.
In this post, we demonstrated a Python implementation of AED embedded within Lambda over a data stream processed and managed by Kinesis Data Streams. We also provided a standalone client implementation to show an alternate implementation. The code is available for you to download and integrate into your applications. Do you have any data streams where sudden shifts may happen? Do you want to know when they happen? Are there automated actions that should be taken, or should someone be alerted? If your answer to any of these questions is “Yes!” then consider implementing AED.
If you have any comments about this post, submit them in the comments section.
References
[1] H. V. Poor and O. Hadjiliadis (2009). Quickest detection. Cambridge University Press, 2009.
[2] Brodsky, E., and Boris S. Darkhovsky (2013). Nonparametric methods in change point problems. Vol. 243. Springer Science & Business Media.
[3] Csörgö, Miklós, and Lajos Horváth (1997). Limit theorems in change-point analysis. Vol. 18. John Wiley & Sons Inc,.
[4] Ross GJ, Tasoulis DK, Adams NM (2011). Nonparametric Monitoring of Data Streams for Changes in Location and Scale. Technometrics, 53(4), 379–389.
[5] Chu, Lynna, and Hao Chen (2019). Asymptotic distribution-free change-point detection for multivariate and non-euclidean data. The Annals of Statistics 47.1, 382-414.
[6] Pettitt AN (1979). A Non-Parametric Approach to the Change-Point Problem. Journal of the Royal Statistical Society C, 28(2), 126–135.
[7] H. B. Mann (1945). Nonparametric tests against trend, Econometrica, vol. 13, pp. 245–259, 1945.
[8] M. G. Kendal (1975). Rank Correlation Methods, Griffin, London, UK, 1975
About the Authors
 Marco Guerriero, PhD, is a Practice Manager for Emergent Technologies and Intelligence Platform for AWS Professional Services. I love working on ways for emergent technologies such as AI/ML, Big Data, IoT, and Quantum to help businesses across different industry vertical succeed within their innovation journey.
Marco Guerriero, PhD, is a Practice Manager for Emergent Technologies and Intelligence Platform for AWS Professional Services. I love working on ways for emergent technologies such as AI/ML, Big Data, IoT, and Quantum to help businesses across different industry vertical succeed within their innovation journey.
 Veronika Megler, PhD, is Principal Data Scientist for Amazon.com Customer Packaging Experience. Until recently, she was the Principal Data Scientist for AWS Professional Services. She enjoys adapting innovative big data, AI, and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively. Her work has lately been focused more heavily on economic impacts of ML models and exploring causality.
Veronika Megler, PhD, is Principal Data Scientist for Amazon.com Customer Packaging Experience. Until recently, she was the Principal Data Scientist for AWS Professional Services. She enjoys adapting innovative big data, AI, and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively. Her work has lately been focused more heavily on economic impacts of ML models and exploring causality.









 Dylan Qu is an AWS solutions architect responsible for providing architectural guidance across the full AWS stack with a focus on Data Analytics, AI/ML and DevOps.
Dylan Qu is an AWS solutions architect responsible for providing architectural guidance across the full AWS stack with a focus on Data Analytics, AI/ML and DevOps. Vishwa Gupta is a Data and ML Engineer with AWS Professional Services Intelligence Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and playing badminton.
Vishwa Gupta is a Data and ML Engineer with AWS Professional Services Intelligence Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and playing badminton.
 This generates a sample workflow definition that you can change once the workflow is created.
This generates a sample workflow definition that you can change once the workflow is created.












 The Definition section shows the ASL that makes up the example workflow. The following example shows the new API Gateway resource and its parameters:
The Definition section shows the ASL that makes up the example workflow. The following example shows the new API Gateway resource and its parameters:
























 Marco Guerriero, PhD, is a Practice Manager for Emergent Technologies and Intelligence Platform for AWS Professional Services. I love working on ways for emergent technologies such as AI/ML, Big Data, IoT, and Quantum to help businesses across different industry vertical succeed within their innovation journey.
Marco Guerriero, PhD, is a Practice Manager for Emergent Technologies and Intelligence Platform for AWS Professional Services. I love working on ways for emergent technologies such as AI/ML, Big Data, IoT, and Quantum to help businesses across different industry vertical succeed within their innovation journey. Veronika Megler, PhD, is Principal Data Scientist for Amazon.com Customer Packaging Experience. Until recently, she was the Principal Data Scientist for AWS Professional Services. She enjoys adapting innovative big data, AI, and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively. Her work has lately been focused more heavily on economic impacts of ML models and exploring causality.
Veronika Megler, PhD, is Principal Data Scientist for Amazon.com Customer Packaging Experience. Until recently, she was the Principal Data Scientist for AWS Professional Services. She enjoys adapting innovative big data, AI, and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively. Her work has lately been focused more heavily on economic impacts of ML models and exploring causality.







 Manash Deb is a Senior Analytics Specialist Solutions Architect. He has worked in different database and data warehousing technologies for more than 15 years.
Manash Deb is a Senior Analytics Specialist Solutions Architect. He has worked in different database and data warehousing technologies for more than 15 years. Debu Panda, a senior product manager at AWS, is an industry leader in analytics, application platform, and database technologies. He has more than 20 years of experience in the IT industry and has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt).
Debu Panda, a senior product manager at AWS, is an industry leader in analytics, application platform, and database technologies. He has more than 20 years of experience in the IT industry and has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt). Fei Peng is a Software Dev Engineer working in the Amazon Redshift team.
Fei Peng is a Software Dev Engineer working in the Amazon Redshift team.


 Nuxt.js scaffolding tool inputs
Nuxt.js scaffolding tool inputs

























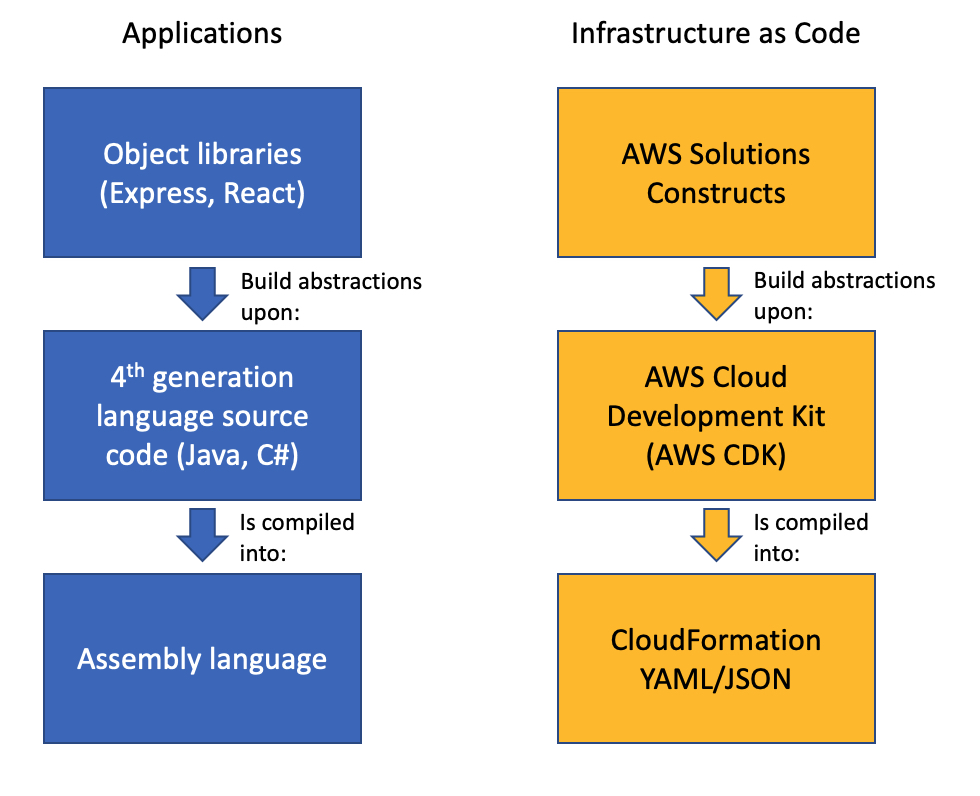



 Biff Gaut has been shipping software since 1983, from small startups to large IT shops. Along the way he has contributed to 2 books, spoken at several conferences and written many blog posts. He is now a Principal Solutions Architect at AWS working on the AWS Solutions Constructs team, helping customers deploy better architectures more quickly.
Biff Gaut has been shipping software since 1983, from small startups to large IT shops. Along the way he has contributed to 2 books, spoken at several conferences and written many blog posts. He is now a Principal Solutions Architect at AWS working on the AWS Solutions Constructs team, helping customers deploy better architectures more quickly.