Post Syndicated from Shahna Campbell original https://aws.amazon.com/blogs/security/how-to-manage-certificate-lifecycles-using-acm-event-driven-workflows/
With AWS Certificate Manager (ACM), you can simplify certificate lifecycle management by using event-driven workflows to notify or take action on expiring TLS certificates in your organization. Using ACM, you can provision, manage, and deploy public and private TLS certificates for use with integrated AWS services like Amazon CloudFront and Elastic Load Balancing (ELB), as well as for your internal resources and infrastructure. For a full list of integrated services, see Services integrated with AWS Certificate Manager.
By implementing event-driven workflows for certificate lifecycle management, you can help increase the visibility of upcoming and actual certificate expirations, and notify application teams that their action is required to renew a certificate. You can also use event-driven workflows to automate provisioning of private certificates to your internal resources, like a web server based on Amazon Elastic Compute Cloud (Amazon EC2).
In this post, we describe the ACM event types that Amazon EventBridge supports. EventBridge is a serverless event router that you can use to build event-driven applications at scale. ACM publishes these events for important occurrences, such as when a certificate becomes available, approaches expiration, or fails to renew. We also highlight example use cases for the event types supported by ACM. Lastly, we show you how to implement an event-driven workflow to notify application teams that they need to take action to renew a certificate for their workloads. You can also use these types of workflows to send the relevant event information to AWS Security Hub or to initiate certificate automation actions through AWS Lambda.
To view a video walkthrough and demo of this workflow, see AWS Certificate Manager: How to create event-driven certificate workflows.
ACM event types and selected use cases
In October 2022, ACM released support for three new event types:
- ACM Certificate Renewal Action Required
- ACM Certificate Expired
- ACM Certificate Available
Before this release, ACM had a single event type: ACM Certificate Approaching Expiration. By default, ACM creates Certificate Approaching Expiration events daily for active, ACM-issued certificates starting 45 days prior to their expiration. To learn more about the structure of these event types, see Amazon EventBridge support for ACM. The following examples highlight how you can use the different event types in the context of certificate lifecycle operations.
Notify stakeholders that action is required to complete certificate renewal
ACM emits an ACM Certificate Renewal Action Required event when customer action must be taken before a certificate can be renewed. For instance, if permissions aren’t appropriately configured to allow ACM to renew private certificates issued from AWS Private Certificate Authority (AWS Private CA), ACM will publish this event when automatic renewal fails at 45 days before expiration. Similarly, ACM might not be able to renew a public certificate because an administrator needs to confirm the renewal by email validation, or because Certification Authority Authorization (CAA) record changes prevent automatic renewal through domain validation. ACM will make further renewal attempts at 30 days, 15 days, 3 days, and 1 day before expiration, or until customer action is taken, the certificate expires, or the certificate is no longer eligible for renewal. ACM publishes an event for each renewal attempt.
It’s important to notify the appropriate parties — for example, the Public Key Infrastructure (PKI) team, security engineers, or application developers — that they need to take action to resolve these issues. You might notify them by email, or by integrating with your workflow management system to open a case that the appropriate engineering or support teams can track.
Notify application teams that a certificate for their workload has expired
You can use the ACM Certificate Expired event type to notify application teams that a certificate associated with their workload has expired. The teams should quickly investigate and validate that the expired certificate won’t cause an outage or cause application users to see a message stating that a website is insecure, which could impact their trust. To increase visibility for support teams, you can publish this event to Security Hub or a support ticketing system. For an example of how to publish these events as findings in Security Hub, see Responding to an event with a Lambda function.
Use automation to export and place a renewed private certificate
ACM sends an ACM Certificate Available event when a managed public or private certificate is ready for use. ACM publishes the event on issuance, renewal, and import. When a private certificate becomes available, you might still need to take action to deploy it to your resources, such as installing the private certificate for use in an EC2 web server. This includes a new private certificate that AWS Private CA issues as part of managed renewal through ACM. You might want to notify the appropriate teams that the new certificate is available for export from ACM, so that they can use the ACM APIs, AWS Command Line Interface (AWS CLI), or AWS Management Console to export the certificate and manually distribute it to your workload (for example, an EC2-based web server). For integrated services such as ELB, ACM binds the renewed certificate to your resource, and no action is required.
You can also use this event to invoke a Lambda function that exports the private certificate and places it in the appropriate directory for the relevant server, provide it to other serverless resources, or put it in an encrypted Amazon Simple Storage Service (Amazon S3) bucket to share with a third party for mutual TLS or a similar use case.
How to build a workflow to notify administrators that action is required to renew a certificate
In this section, we’ll show you how to configure notifications to alert the appropriate stakeholders that they need to take an action to successfully renew an ACM certificate.
To follow along with this walkthrough, make sure that you have an AWS Identity and Access Management (IAM) role with the appropriate permissions for EventBridge and Amazon Simple Notification Service (Amazon SNS). When a rule runs in EventBridge, a target associated with that rule is invoked, and in order to make API calls on Amazon SNS, EventBridge needs a resource-based IAM policy.
The following IAM permissions work for the example below (and for tidying up afterwards):
The following is a sample resource-based policy that allows EventBridge to publish to an Amazon SNS topic. Make sure to replace <region>, <account-id>, and <topic-name> with your own data.
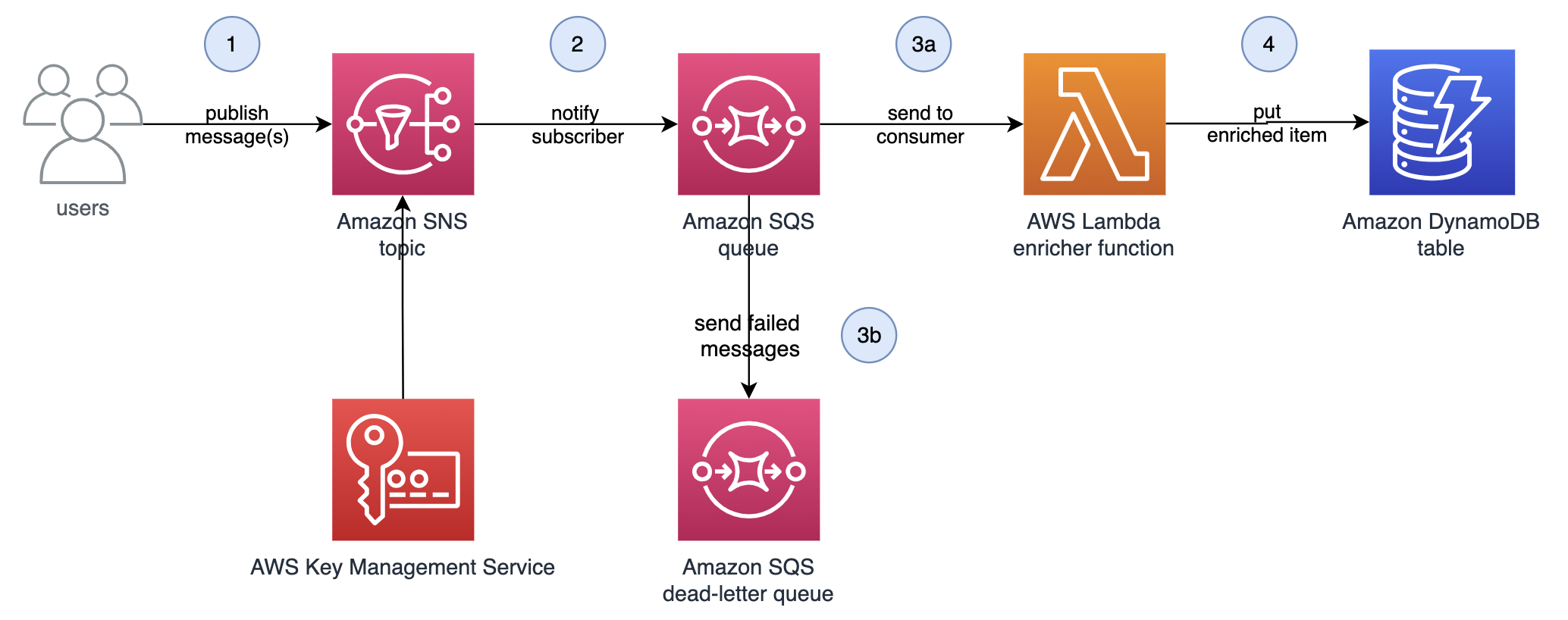
The first step is to create an SNS topic by using the console to link multiple endpoints such as AWS Lambda and Amazon Simple Queue Service (Amazon SQS), or send a notification to an email address.
To create an SNS topic
- Open the Amazon SNS console.
- In the left navigation pane, choose Topics.
- Choose Create Topic.
- For Type, choose Standard.
- Enter a name for the topic, and (optional) enter a display name.
- Choose the triangle next to the Encryption — optional panel title.
- Select the Encryption toggle (optional) to encrypt the topic. This will enable server-side encryption (SSE) to help protect the contents of the messages in Amazon SNS topics.
- For this demonstration, we are going to use the default AWS managed KMS key. Using Amazon SNS with AWS Key Management Service (AWS KMS) provides encryption at rest, and the data keys that encrypt the SNS message data are stored with the data protected. To learn more about SNS data encryption, see Data encryption.
- Keep the defaults for all other settings.
- Choose Create topic.
When the topic has been successfully created, a notification bar appears at the top of the screen, and you will be routed to the page for the newly created topic. Note the Amazon Resource Name (ARN) listed in the Details panel because you’ll need it for the next section.
Next, you need to create a subscription to the topic to set a destination endpoint for the messages that are pushed to the topic to be delivered.
To create a subscription to the topic
- In the Subscriptions section of the SNS topic page you just created, choose Create subscription.
- On the Create subscription page, in the Details section, do the following:
- For Protocol, choose Email.
- For Endpoint, enter the email address where the ACM Certificate Renewal Action Required event alerts should be sent.
- Keep the default Subscription filter policy and Redrive policy settings for this demonstration.
- Choose Create subscription.
- To finalize the subscription, an email will be sent to the email address that you entered as the endpoint. To validate your subscription, choose Confirm Subscription in the email when you receive it.
- A new web browser will open with a message verifying that the subscription status is Confirmed and that you have been successfully subscribed to the SNS topic.
Next, create the EventBridge rule that will be invoked when an ACM Certificate Renewal Action Required event occurs. This rule uses the SNS topic that you just created as a target.
To create an EventBridge rule
- Navigate to the EventBridge console.
- In the left navigation pane, choose Rules.
- Choose Create rule.
- In the Rule detail section, do the following:
- Define the rule by entering a Name and an optional Description.
- In the Event bus dropdown menu, select the default event bus.
- The default event bus in your AWS account only allows events from one account. If you want to add additional permissions, attach a resource-based policy to a new event bus. See Permissions for Amazon EventBridge event buses to find example policies for sending events.
- Keep the default values for the rest of the settings.
- Choose Next.
- For Event source, make sure that AWS events or EventBridge partner events is selected, because the event source is ACM.
- In the Sample event panel, under Sample events, choose ACM Certificate Renewal Action Required as the sample event. This helps you verify your event pattern.
- In the Event pattern panel, for Event Source, make sure that AWS services is selected.
- For AWS service, choose Certificate Manager.
- Under Event type, choose ACM Certificate Renewal Action Required.
- Choose Test pattern.
- In the Event pattern section, a notification will appear stating Sample event matched the event pattern to confirm that the correct event pattern was created.
- Choose Next.
- In the Target 1 panel, do the following:
- For Target types, make sure that AWS service is selected.
- Under Select a target, choose SNS topic.
- In the Topic dropdown list, choose your desired topic.
- Choose Next.
- (Optional) Add tags to the topic.
- Choose Next.
- Review the settings for the rule, and then choose Create rule.
Now you are listening to this event and will be notified when a customer action must be taken before a certificate can be renewed.
For another example of how to use Amazon SNS and email notifications, see How to monitor expirations of imported certificates in AWS Certificate Manager (ACM). For an example of how to use Lambda to publish findings to Security Hub to provide visibility to administrators and security teams, see Responding to an event with a Lambda function. Other options for responding to this event include invoking a Lambda function to export and distribute private certificates, or integrating with a messaging or collaboration tool for ChatOps.
Conclusion
In this blog post, you learned about the new EventBridge event types for ACM, and some example use cases for each of these event types. You also learned how to use these event types to create a workflow with EventBridge and Amazon SNS that notifies the appropriate stakeholders when they need to take action, so that ACM can automatically renew a TLS certificate.
By using these events to increase awareness of upcoming certificate lifecycle events, you can make it simpler to manage TLS certificates across your organization. For more information about certificate management on AWS, see the ACM documentation or get started using ACM today in the AWS Management Console.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.











 Bernard Verster is an experienced cloud engineer with years of exposure in creating scalable and efficient data models, defining data integration strategies, and ensuring data governance and security. He is passionate about using data to drive insights, while aligning with business requirements and objectives.
Bernard Verster is an experienced cloud engineer with years of exposure in creating scalable and efficient data models, defining data integration strategies, and ensuring data governance and security. He is passionate about using data to drive insights, while aligning with business requirements and objectives. Abhishek Pan is a WWSO Specialist SA-Analytics working with AWS India Public sector customers. He engages with customers to define data-driven strategy, provide deep dive sessions on analytics use cases, and design scalable and performant analytical applications. He has 12 years of experience and is passionate about databases, analytics, and AI/ML. He is an avid traveler and tries to capture the world through his camera lens.
Abhishek Pan is a WWSO Specialist SA-Analytics working with AWS India Public sector customers. He engages with customers to define data-driven strategy, provide deep dive sessions on analytics use cases, and design scalable and performant analytical applications. He has 12 years of experience and is passionate about databases, analytics, and AI/ML. He is an avid traveler and tries to capture the world through his camera lens.





















 Qiushuang Feng is a Solutions Architect at AWS, responsible for Enterprise customers’ technical architecture design, consulting, and design optimization on AWS Cloud services. Before joining AWS, Qiushuang worked in IT companies such as IBM and Oracle, and accumulated rich practical experience in development and analytics.
Qiushuang Feng is a Solutions Architect at AWS, responsible for Enterprise customers’ technical architecture design, consulting, and design optimization on AWS Cloud services. Before joining AWS, Qiushuang worked in IT companies such as IBM and Oracle, and accumulated rich practical experience in development and analytics. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data environments, diving deep into distributed big data software like Apache Spark, building reusable software artifacts for data lakes, and sharing knowledge in AWS Big Data blog posts.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data environments, diving deep into distributed big data software like Apache Spark, building reusable software artifacts for data lakes, and sharing knowledge in AWS Big Data blog posts. Greg Huang is a Senior Solutions Architect at AWS with expertise in technical architecture design and consulting for the China G1000 team. He is dedicated to deploying and utilizing enterprise-level applications on AWS Cloud services. He possesses nearly 20 years of rich experience in large-scale enterprise application development and implementation, having worked in the cloud computing field for many years. He has extensive experience in helping various types of enterprises migrate to the cloud. Prior to joining AWS, he worked for well-known IT enterprises such as Baidu and Oracle.
Greg Huang is a Senior Solutions Architect at AWS with expertise in technical architecture design and consulting for the China G1000 team. He is dedicated to deploying and utilizing enterprise-level applications on AWS Cloud services. He possesses nearly 20 years of rich experience in large-scale enterprise application development and implementation, having worked in the cloud computing field for many years. He has extensive experience in helping various types of enterprises migrate to the cloud. Prior to joining AWS, he worked for well-known IT enterprises such as Baidu and Oracle. Maciej Torbus is a Principal Customer Solutions Manager within Strategic Accounts at Amazon Web Services. With extensive experience in large-scale migrations, he focuses on helping customers move their applications and systems to highly reliable and scalable architectures in AWS. Outside of work, he enjoys sailing, traveling, and restoring vintage mechanical watches.
Maciej Torbus is a Principal Customer Solutions Manager within Strategic Accounts at Amazon Web Services. With extensive experience in large-scale migrations, he focuses on helping customers move their applications and systems to highly reliable and scalable architectures in AWS. Outside of work, he enjoys sailing, traveling, and restoring vintage mechanical watches.
 Ajay Vohra is a Principal Prototyping Architect specializing in perception machine learning for autonomous vehicle development. Prior to Amazon, Ajay worked in the area of massively parallel grid-computing for financial risk modeling.
Ajay Vohra is a Principal Prototyping Architect specializing in perception machine learning for autonomous vehicle development. Prior to Amazon, Ajay worked in the area of massively parallel grid-computing for financial risk modeling. Jaswanth Kumar is a customer-obsessed Cloud Application Architect at AWS in NY. Jaswanth excels in application refactoring and migration, with expertise in containers and serverless solutions, coupled with a Masters Degree in Applied Computer Science.
Jaswanth Kumar is a customer-obsessed Cloud Application Architect at AWS in NY. Jaswanth excels in application refactoring and migration, with expertise in containers and serverless solutions, coupled with a Masters Degree in Applied Computer Science. Aneel Murari is a Sr. Serverless Specialist Solution Architect at AWS based in the Washington, D.C. area. He has over 18 years of software development and architecture experience and holds a graduate degree in Computer Science. Aneel helps AWS customers orchestrate their workflows on Amazon Managed Apache Airflow (MWAA) in a secure, cost effective and performance optimized manner.
Aneel Murari is a Sr. Serverless Specialist Solution Architect at AWS based in the Washington, D.C. area. He has over 18 years of software development and architecture experience and holds a graduate degree in Computer Science. Aneel helps AWS customers orchestrate their workflows on Amazon Managed Apache Airflow (MWAA) in a secure, cost effective and performance optimized manner. Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.
Parnab Basak is a Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.

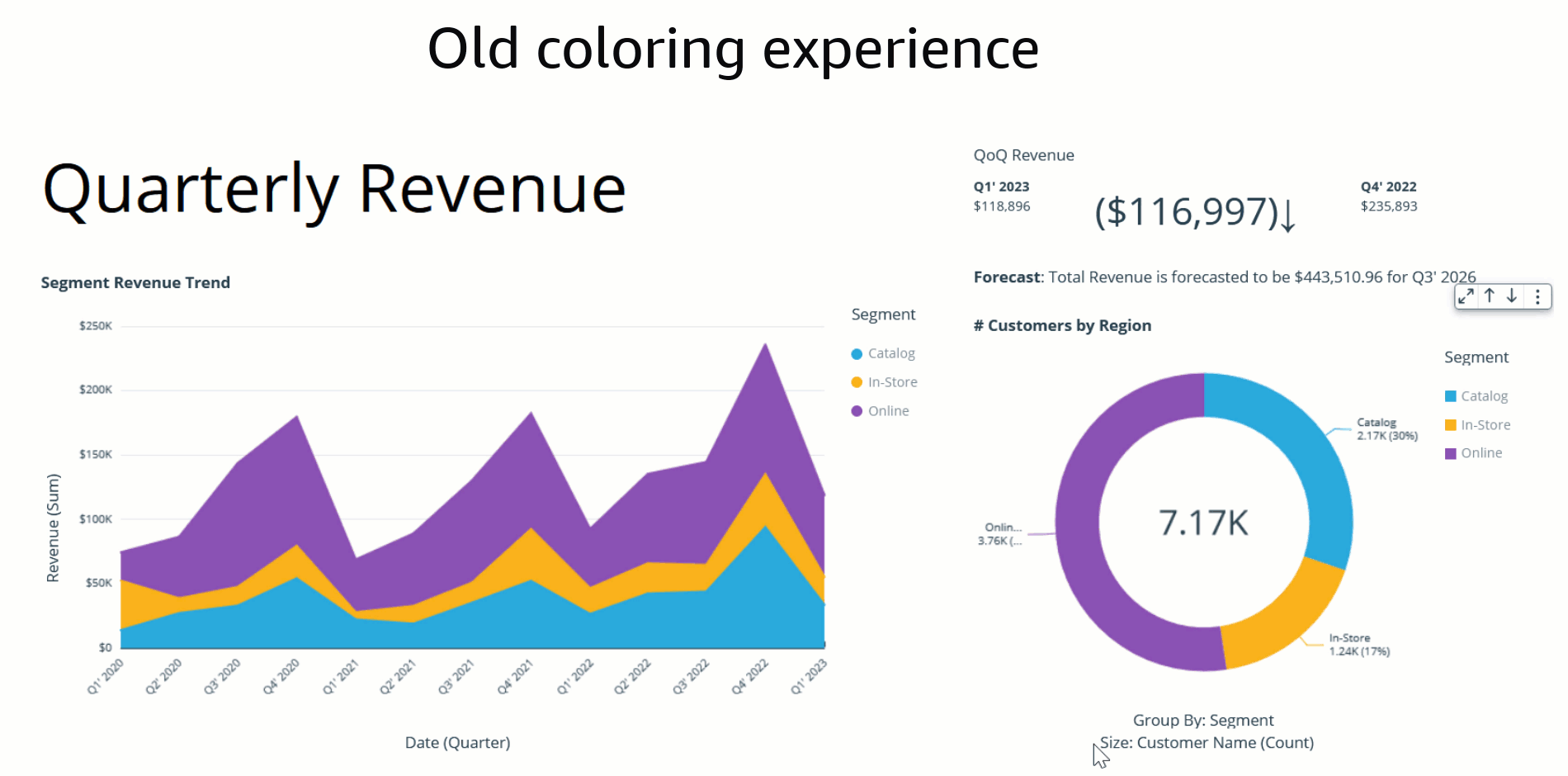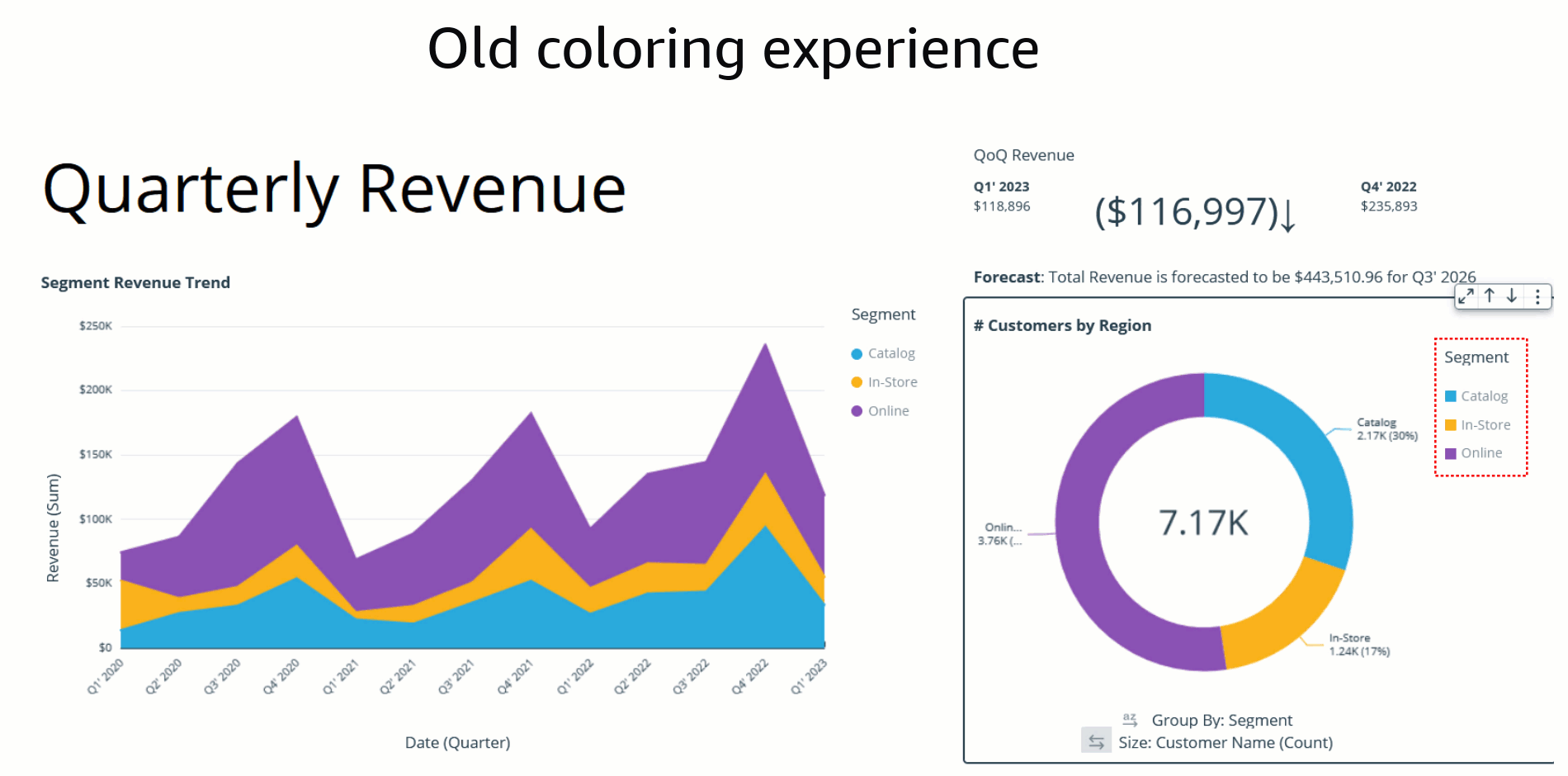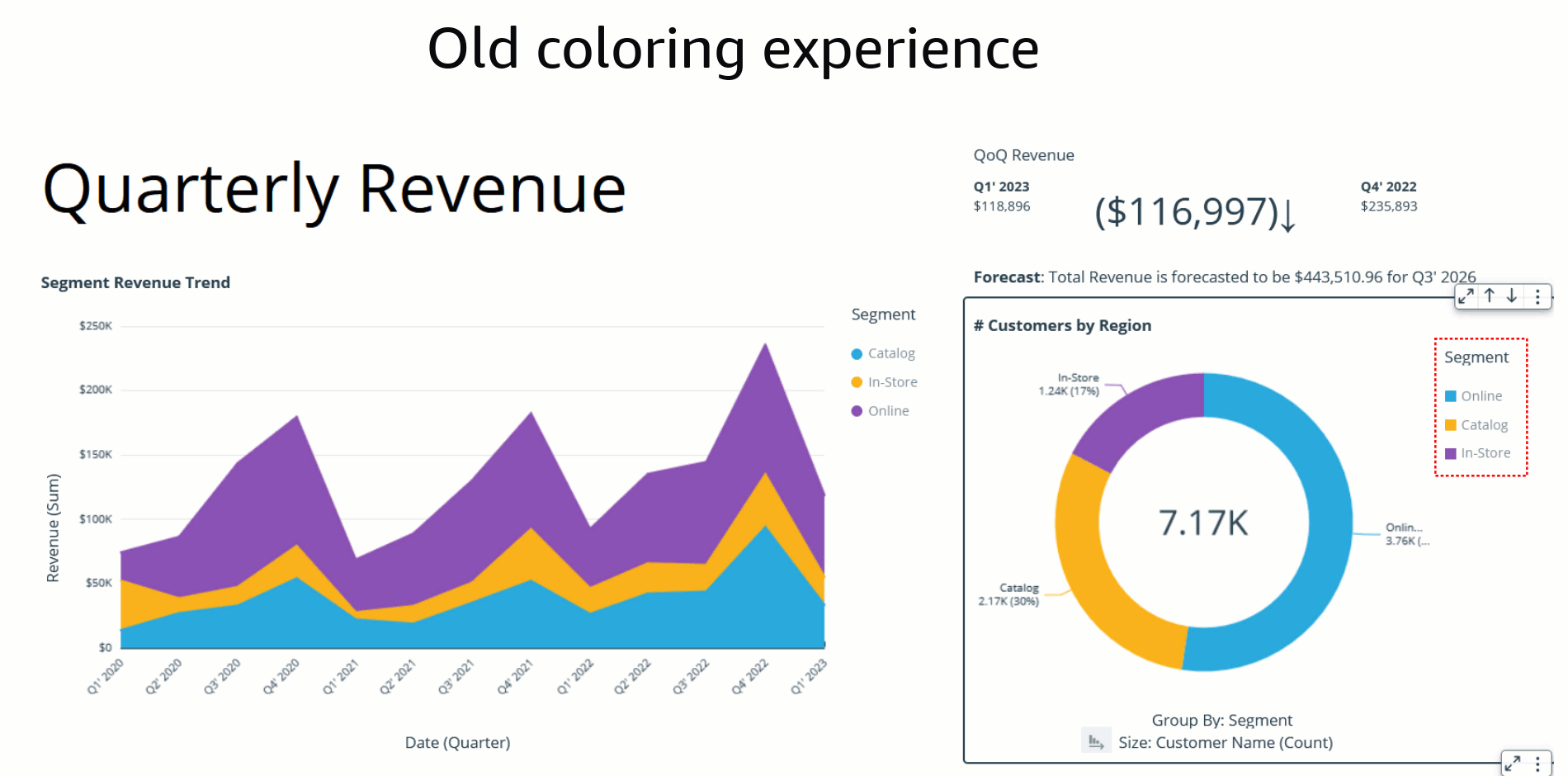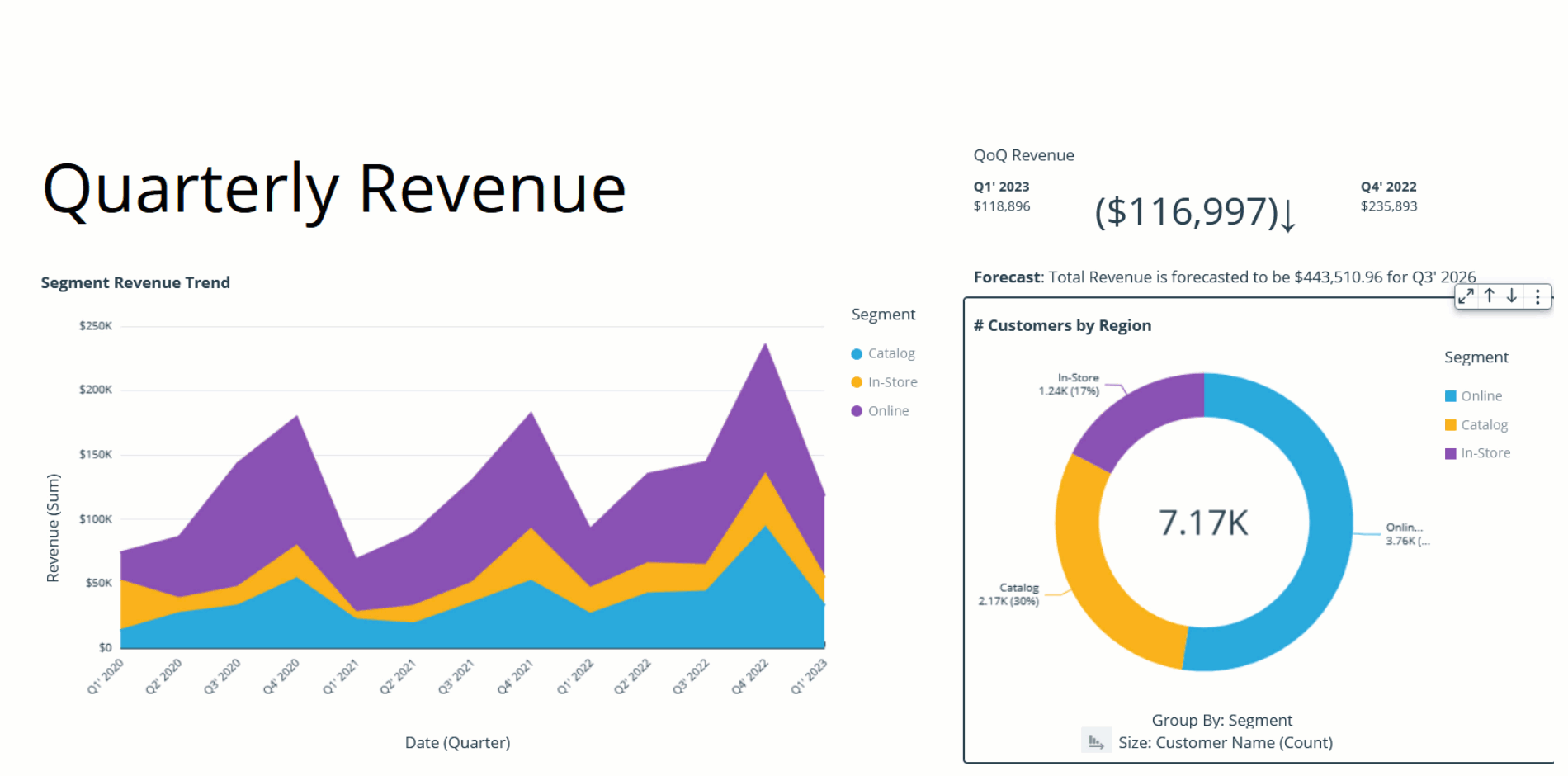
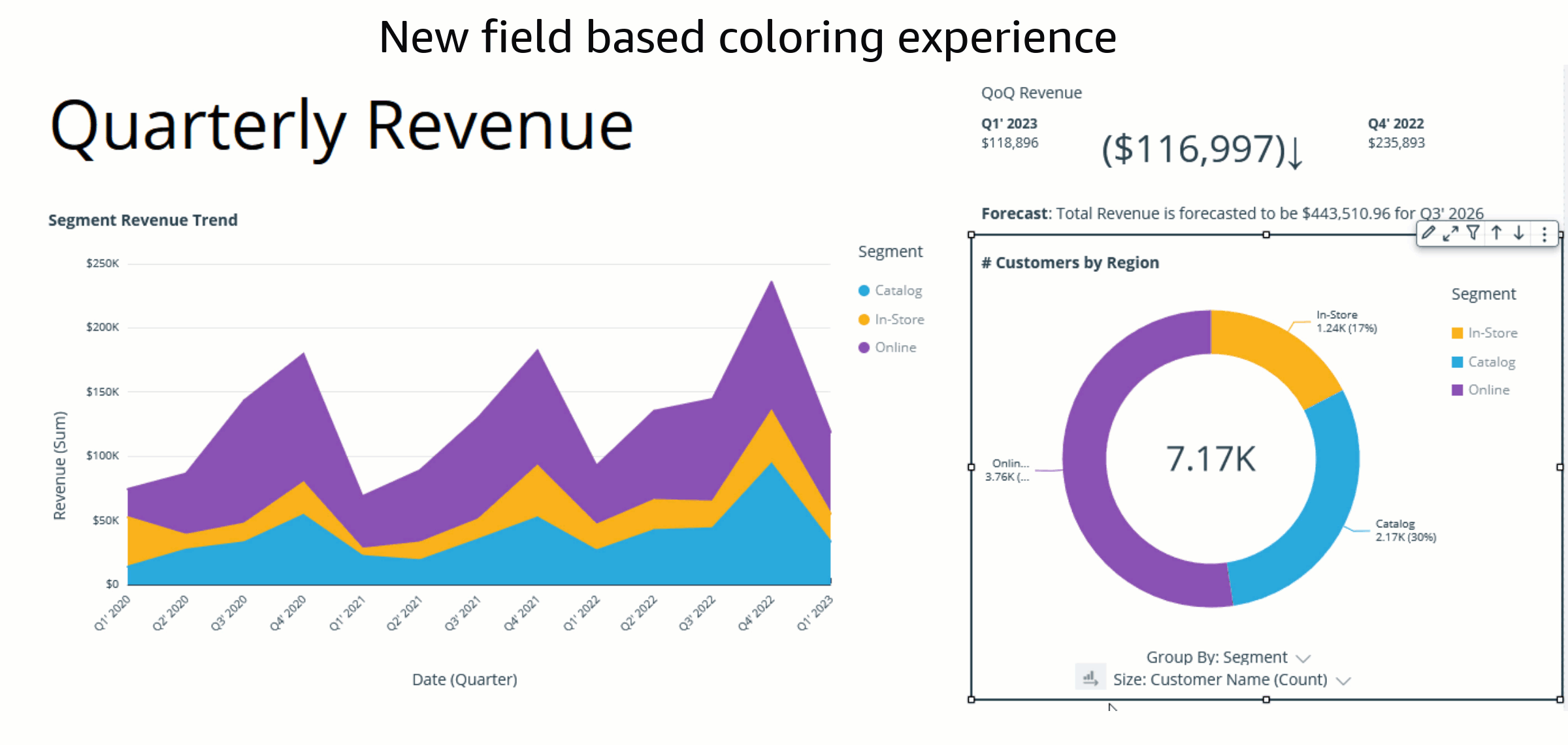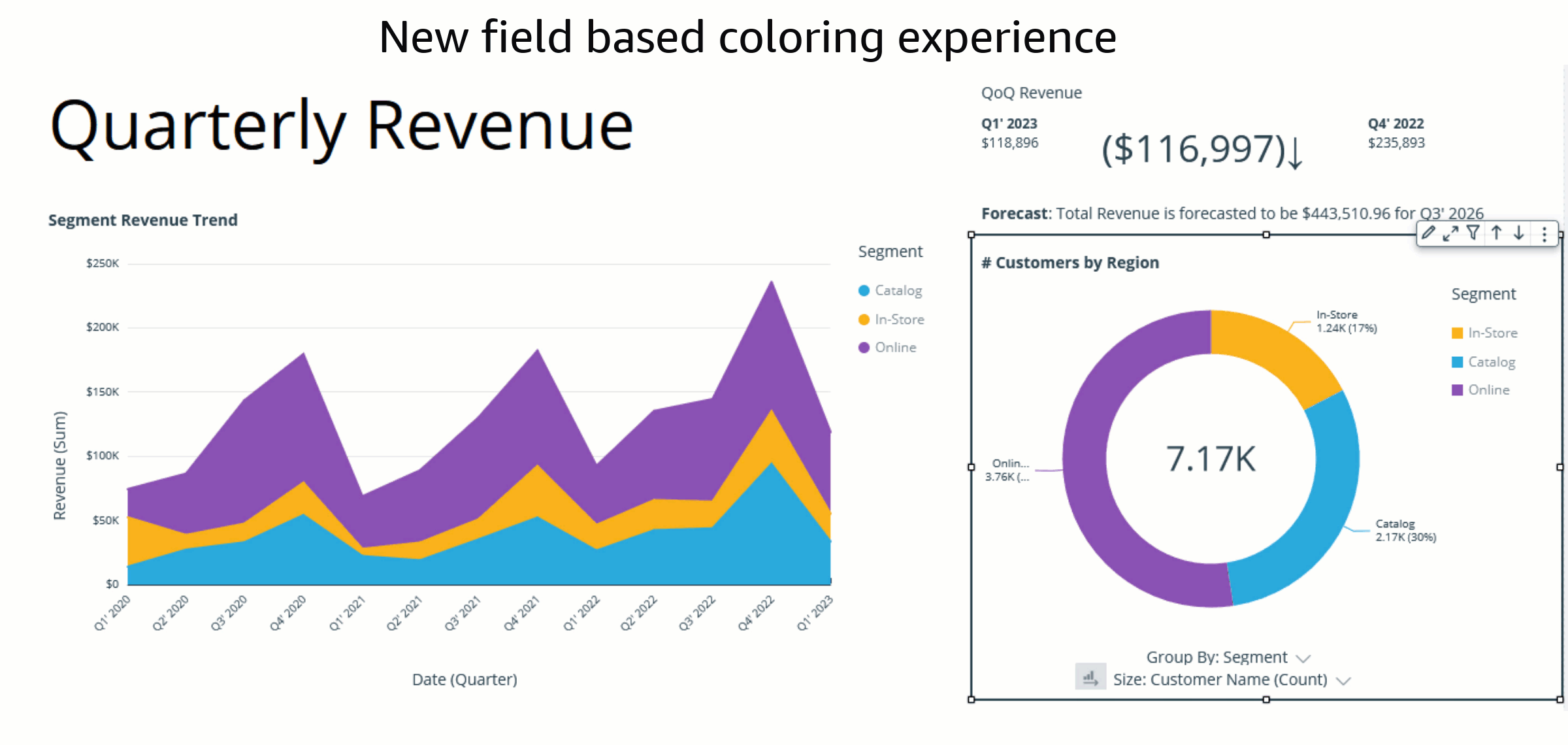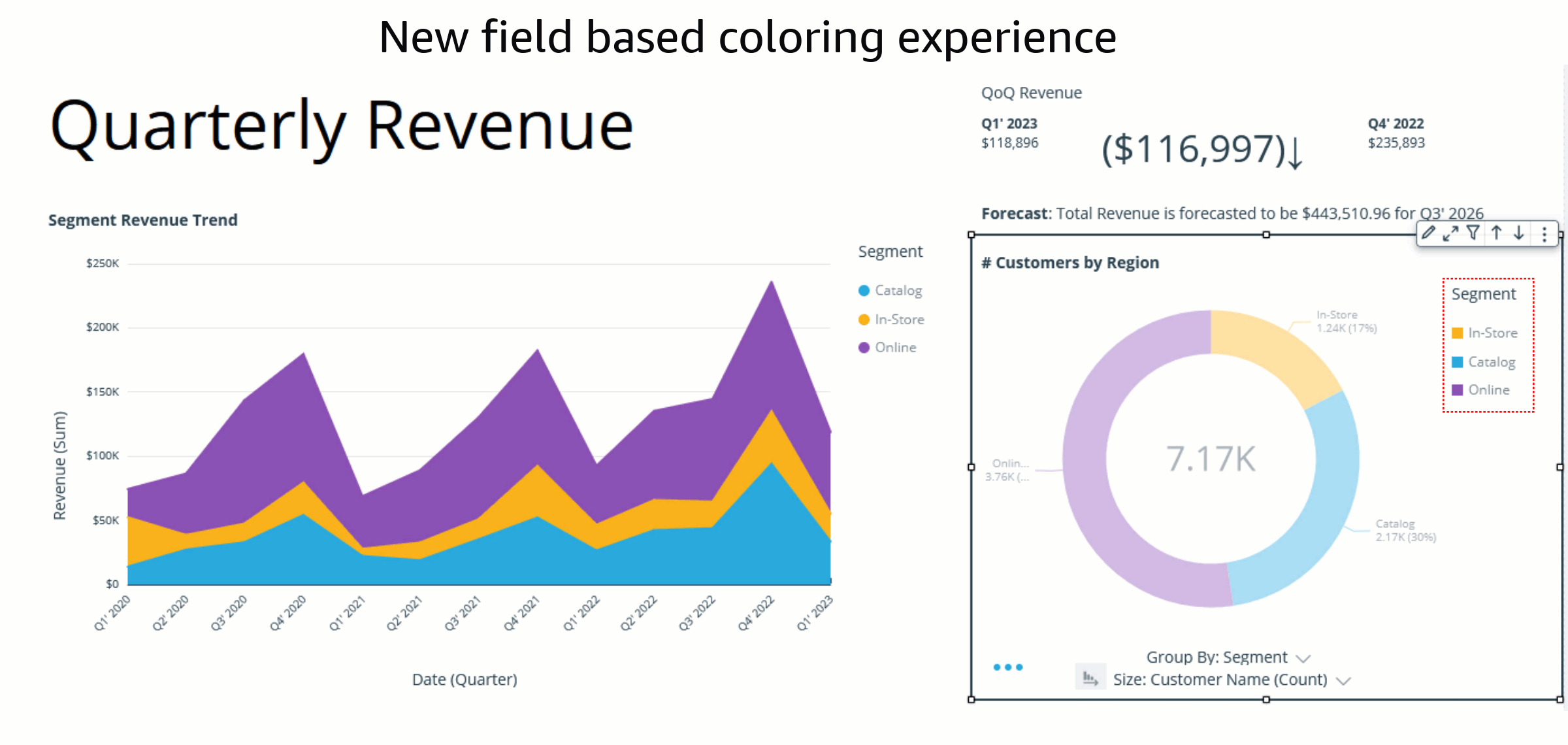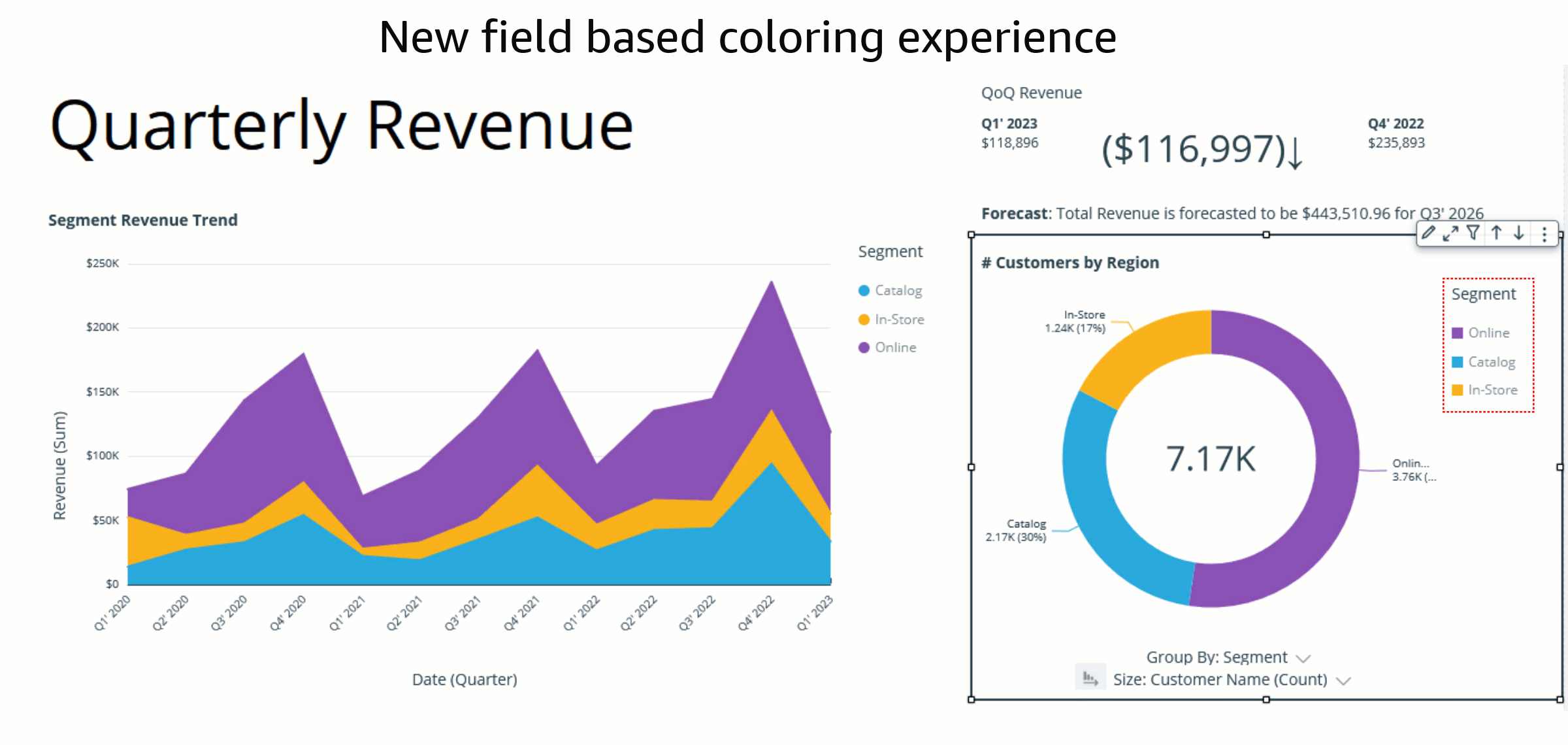


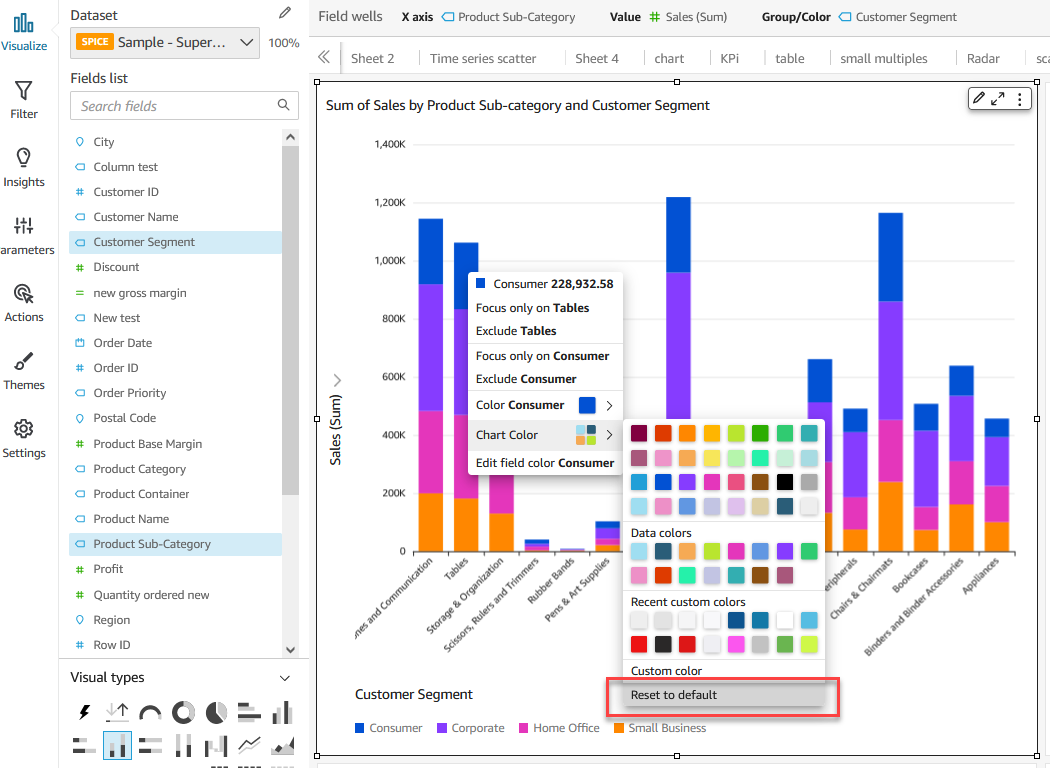
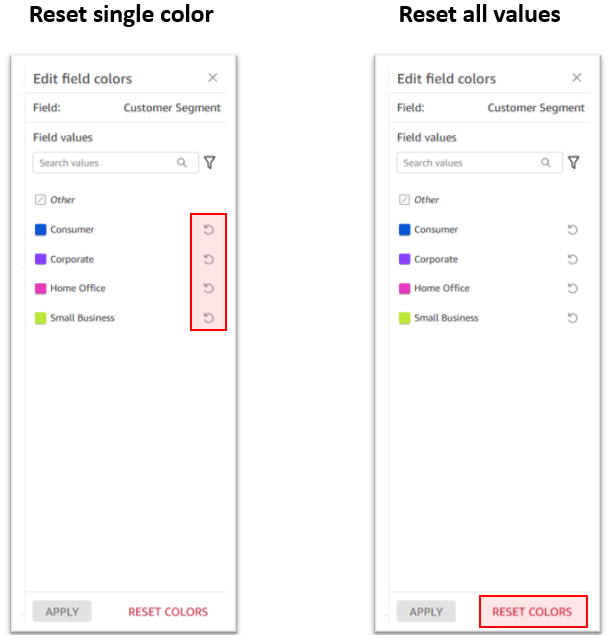

 Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.
Bhupinder Chadha is a senior product manager for Amazon QuickSight focused on visualization and front end experiences. He is passionate about BI, data visualization and low-code/no-code experiences. Prior to QuickSight he was the lead product manager for Inforiver, responsible for building a enterprise BI product from ground up. Bhupinder started his career in presales, followed by a small gig in consulting and then PM for xViz, an add on visualization product.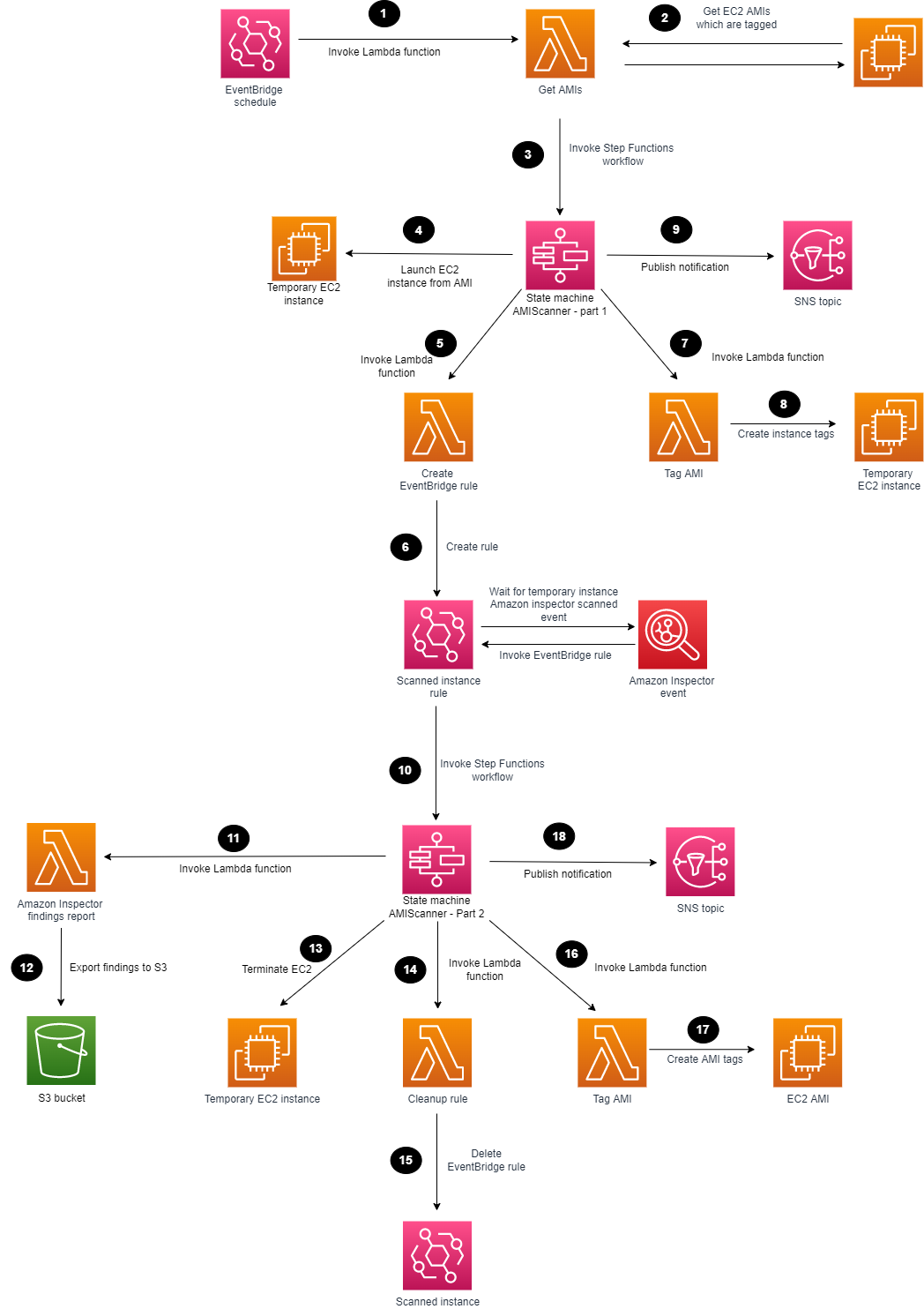


 Nitin Arora is a Sr. Software Development Manager for Finance Automation in Amazon. He has over 18 years of experience building business critical, scalable, high-performance software. Nitin leads several data and analytics initiatives within Finance, which includes building Data Mesh. In his spare time, he enjoys listening to music and read.
Nitin Arora is a Sr. Software Development Manager for Finance Automation in Amazon. He has over 18 years of experience building business critical, scalable, high-performance software. Nitin leads several data and analytics initiatives within Finance, which includes building Data Mesh. In his spare time, he enjoys listening to music and read. Pradeep Misra is a Specialist Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments with his daughters.
Pradeep Misra is a Specialist Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML. Outside of work, Pradeep likes exploring new places, trying new cuisines, and playing board games with his family. He also likes doing science experiments with his daughters. Rajesh Rao is a Sr. Technical Program Manager in Amazon Finance. He works with Data Services teams within Amazon to build and deliver data processing and data analytics solutions for Financial Operations teams. He is passionate about delivering innovative and optimal solutions using AWS to enable data-driven business outcomes for his customers.
Rajesh Rao is a Sr. Technical Program Manager in Amazon Finance. He works with Data Services teams within Amazon to build and deliver data processing and data analytics solutions for Financial Operations teams. He is passionate about delivering innovative and optimal solutions using AWS to enable data-driven business outcomes for his customers. Andrew Long, the lead developer for data mesh, has designed and built many of the big data processing systems that have fueled Amazon’s financial data processing infrastructure. His work encompasses a range of areas, including S3-based table formats for Spark, diverse Spark performance optimizations, distributed orchestration engines and the development of data cataloging systems. Additionally, Andrew finds pleasure in sharing his knowledge of partner acrobatics.
Andrew Long, the lead developer for data mesh, has designed and built many of the big data processing systems that have fueled Amazon’s financial data processing infrastructure. His work encompasses a range of areas, including S3-based table formats for Spark, diverse Spark performance optimizations, distributed orchestration engines and the development of data cataloging systems. Additionally, Andrew finds pleasure in sharing his knowledge of partner acrobatics. Kumar Satyen Gaurav, is an experienced Software Development Manager at Amazon, with over 16 years of expertise in big data analytics and software development. He leads a team of engineers to build products and services using AWS big data technologies, for providing key business insights for Amazon Finance Operations across diverse business verticals. Beyond work, he finds joy in reading, traveling and learning strategic challenges of chess.
Kumar Satyen Gaurav, is an experienced Software Development Manager at Amazon, with over 16 years of expertise in big data analytics and software development. He leads a team of engineers to build products and services using AWS big data technologies, for providing key business insights for Amazon Finance Operations across diverse business verticals. Beyond work, he finds joy in reading, traveling and learning strategic challenges of chess.
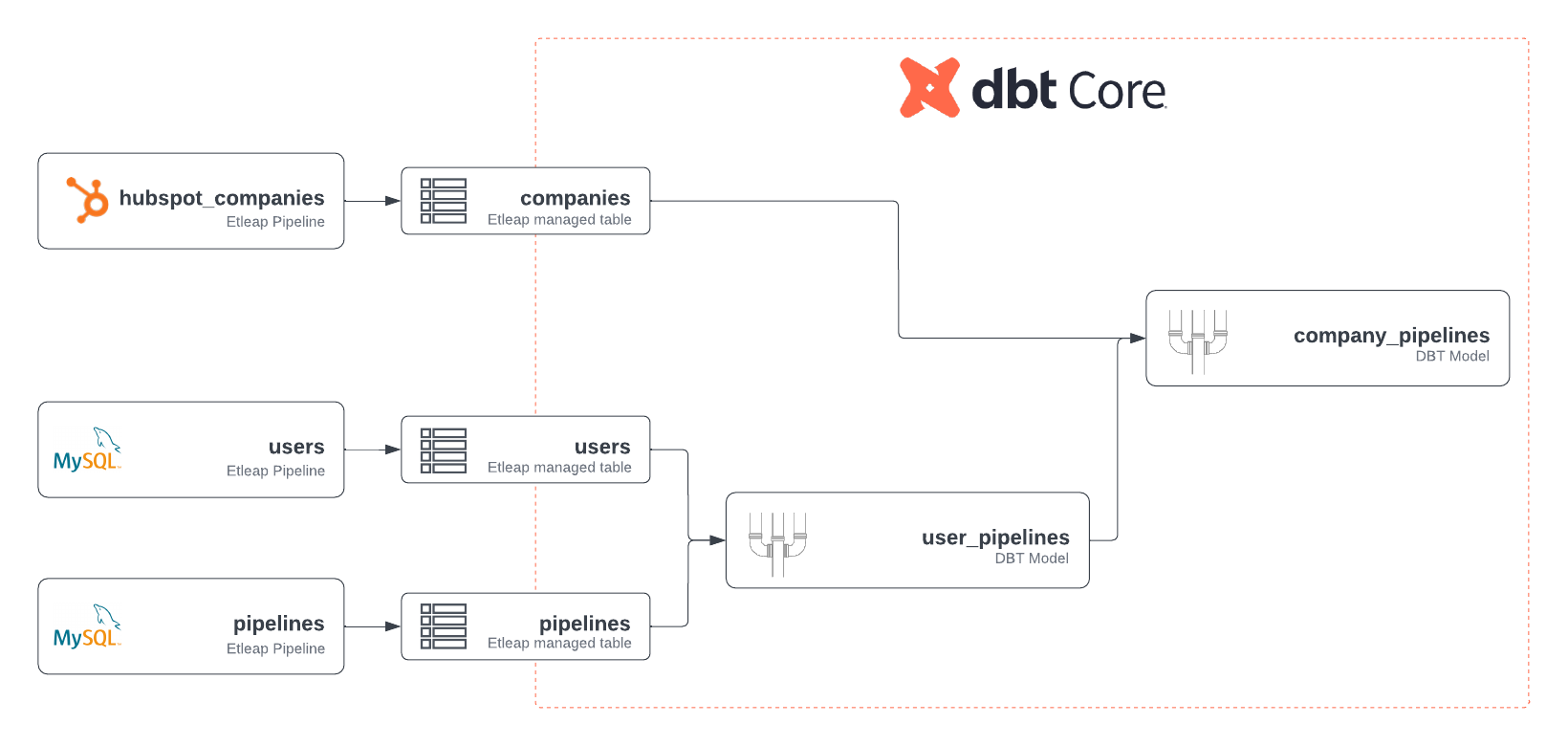
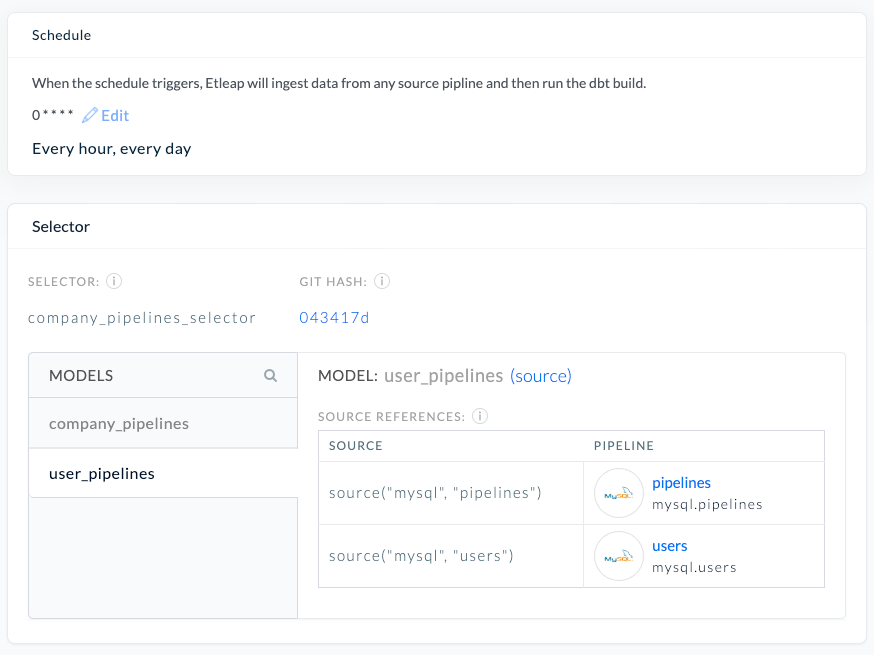
 Zygimantas Koncius is an engineer at Etleap with 3 years of experience in developing robust and performant ETL software. In addition to development work, he maintains Etleap infrastructure and provides deep-level technical customer support.
Zygimantas Koncius is an engineer at Etleap with 3 years of experience in developing robust and performant ETL software. In addition to development work, he maintains Etleap infrastructure and provides deep-level technical customer support. Sudhir Gupta is a Principal Partner Solutions Architect, Analytics Specialist at AWS with over 18 years of experience in Databases and Analytics. He helps AWS partners and customers design, implement, and migrate large-scale data & analytics (D&A) workloads. As a trusted advisor to partners, he enables partners globally on AWS D&A services, builds solutions/accelerators, and leads go-to-market initiatives.
Sudhir Gupta is a Principal Partner Solutions Architect, Analytics Specialist at AWS with over 18 years of experience in Databases and Analytics. He helps AWS partners and customers design, implement, and migrate large-scale data & analytics (D&A) workloads. As a trusted advisor to partners, he enables partners globally on AWS D&A services, builds solutions/accelerators, and leads go-to-market initiatives.









































































 Rohit Vashishtha is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has 17 years of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance.
Rohit Vashishtha is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has 17 years of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance. Vijay Karumajji is a Database Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Vijay Karumajji is a Database Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS. BP Yau is a Sr Partner Solutions Architect at AWS. He is passionate about helping customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies.
BP Yau is a Sr Partner Solutions Architect at AWS. He is passionate about helping customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies. Jyoti Aggarwal is a Product Manager on the Amazon Redshift team based in Seattle. She has spent the last 10 years working on multiple products in the data warehouse industry.
Jyoti Aggarwal is a Product Manager on the Amazon Redshift team based in Seattle. She has spent the last 10 years working on multiple products in the data warehouse industry. Adam Levin is a Product Manager on the Amazon Aurora team based in California. He has spent the last 10 years working on various cloud database services.
Adam Levin is a Product Manager on the Amazon Aurora team based in California. He has spent the last 10 years working on various cloud database services.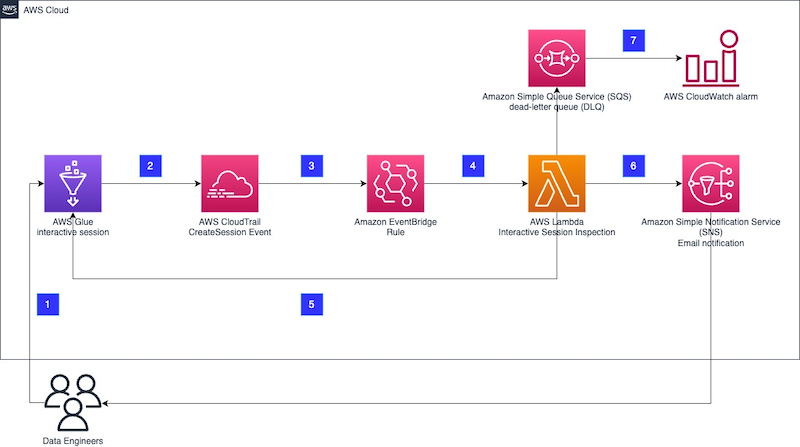
 Nicolas Jacob Baer is a Senior Cloud Application Architect with a strong focus on data engineering and machine learning, based in Switzerland. He works closely with enterprise customers to design data platforms and build advanced analytics/ml use-cases.
Nicolas Jacob Baer is a Senior Cloud Application Architect with a strong focus on data engineering and machine learning, based in Switzerland. He works closely with enterprise customers to design data platforms and build advanced analytics/ml use-cases. Luca Mazzaferro is a Senior DevOps Architect at Amazon Web Services. He likes to have infrastructure automated, reproducible and secured. In his free time he likes to cook, especially pizza.
Luca Mazzaferro is a Senior DevOps Architect at Amazon Web Services. He likes to have infrastructure automated, reproducible and secured. In his free time he likes to cook, especially pizza. Kemeng Zhang is a Cloud Application Architect with a strong focus on machine learning and UX, based in Switzerland. She works closely with customers to design user experiences and build advanced analytics/ml use-cases.
Kemeng Zhang is a Cloud Application Architect with a strong focus on machine learning and UX, based in Switzerland. She works closely with customers to design user experiences and build advanced analytics/ml use-cases. Mark Walser, a Senior Global Data Architect at Amazon Web Services, collaborates with customers to develop innovative Big Data solutions that solve business problems and speed up the adoption of AWS services. Outside of work, he finds pleasure in running, swimming, and all things related to technology.
Mark Walser, a Senior Global Data Architect at Amazon Web Services, collaborates with customers to develop innovative Big Data solutions that solve business problems and speed up the adoption of AWS services. Outside of work, he finds pleasure in running, swimming, and all things related to technology. Gal Heyne is a Product Manager for AWS Glue with a strong focus on AI/ML, data engineering and BI, based in California. She is passionate about developing a deep understanding of customer’s business needs and collaborating with engineers to design easy to use data products.
Gal Heyne is a Product Manager for AWS Glue with a strong focus on AI/ML, data engineering and BI, based in California. She is passionate about developing a deep understanding of customer’s business needs and collaborating with engineers to design easy to use data products.
























 Anderson Santos is a Senior Solutions Architect at Amazon Web Services. He works with AWS Enterprise customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS.
Anderson Santos is a Senior Solutions Architect at Amazon Web Services. He works with AWS Enterprise customers to provide guidance and technical assistance, helping them improve the value of their solutions when using AWS. Arun Pradeep Selvaraj is a Senior Solutions Architect and is part of Analytics TFC at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build and reinvent. He is creative, fast-paced, deeply customer-obsessed and leverages the working backwards process to build modern architectures to help customers solve their unique challenges.
Arun Pradeep Selvaraj is a Senior Solutions Architect and is part of Analytics TFC at AWS. Arun is passionate about working with his customers and stakeholders on digital transformations and innovation in the cloud while continuing to learn, build and reinvent. He is creative, fast-paced, deeply customer-obsessed and leverages the working backwards process to build modern architectures to help customers solve their unique challenges. Patrick Muller is a Senior Solutions Architect and a valued member of the Datalab. With over 20 years of expertise in analytics, data warehousing, and distributed systems, he brings extensive knowledge to the table. Patrick’s passion lies in evaluating new technologies and assisting customers with innovative solutions. During his free time, he enjoys watching soccer.
Patrick Muller is a Senior Solutions Architect and a valued member of the Datalab. With over 20 years of expertise in analytics, data warehousing, and distributed systems, he brings extensive knowledge to the table. Patrick’s passion lies in evaluating new technologies and assisting customers with innovative solutions. During his free time, he enjoys watching soccer.
 Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a Ph. D. in Computer Science and Artificial Intelligence from Northwestern University. Jianwei Li is a Principal Analytics Specialist TAM at Amazon Web Services. Jianwei provides consultant service for customers to help customer design and build modern data platform. Jianwei has been working in big data domain as software developer, consultant and tech leader.
Jianwei Li is a Principal Analytics Specialist TAM at Amazon Web Services. Jianwei provides consultant service for customers to help customer design and build modern data platform. Jianwei has been working in big data domain as software developer, consultant and tech leader. Dylan Tong is a Senior Product Manager at AWS. He works with customers to help drive their success on the AWS platform through thought leadership and guidance on designing well architected solutions. He has spent most of his career building on his expertise in data management and analytics by working for leaders and innovators in the space.
Dylan Tong is a Senior Product Manager at AWS. He works with customers to help drive their success on the AWS platform through thought leadership and guidance on designing well architected solutions. He has spent most of his career building on his expertise in data management and analytics by working for leaders and innovators in the space. Vamshi Vijay Nakkirtha is a Software Engineering Manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems. He is an active contributor to various plugins, like k-NN, GeoSpatial, and dashboard-maps.
Vamshi Vijay Nakkirtha is a Software Engineering Manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems. He is an active contributor to various plugins, like k-NN, GeoSpatial, and dashboard-maps.











 Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community. Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
 Ketan Verma is a Senior SDE working on Amazon OpenSearch Service. He is passionate about building large-scale distributed systems, improving performance, and simplifying complex ideas with simple abstractions. Outside work, he likes to read and improve his home barista skills.
Ketan Verma is a Senior SDE working on Amazon OpenSearch Service. He is passionate about building large-scale distributed systems, improving performance, and simplifying complex ideas with simple abstractions. Outside work, he likes to read and improve his home barista skills. Suresh N S is a Senior SDE working on Amazon OpenSearch Service. He is passionate towards solving problems in large scale distributed systems.
Suresh N S is a Senior SDE working on Amazon OpenSearch Service. He is passionate towards solving problems in large scale distributed systems. Pritkumar Ladani is an SDE-2 working on Amazon OpenSearch Service. He likes to contribute to open source software development, and is passionate about distributed systems. He is an amateur badminton player and enjoys trekking.
Pritkumar Ladani is an SDE-2 working on Amazon OpenSearch Service. He likes to contribute to open source software development, and is passionate about distributed systems. He is an amateur badminton player and enjoys trekking. Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.