Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/extending-a-serverless-event-driven-architecture-to-existing-container-workloads/
This post is written by Dhiraj Mahapatro, Principal Specialist SA, and Sascha Moellering, Principal Specialist SA, and Emily Shea, WW Lead, Integration Services.
Many serverless services are a natural fit for event-driven architectures (EDA), as events invoke them and only run when there is an event to process. When building in the cloud, many services emit events by default and have built-in features for managing events. This combination allows customers to build event-driven architectures easier and faster than ever before.
The insurance claims processing sample application in this blog series uses event-driven architecture principles and serverless services like AWS Lambda, AWS Step Functions, Amazon API Gateway, Amazon EventBridge, and Amazon SQS.
When building an event-driven architecture, it’s likely that you have existing services to integrate with the new architecture, ideally without needing to make significant refactoring changes to those services. As services communicate via events, extending applications to new and existing microservices is a key benefit of building with EDA. You can write those microservices in different programming languages or running on different compute options.
This blog post walks through a scenario of integrating an existing, containerized service (a settlement service) to the serverless, event-driven insurance claims processing application described in this blog post.
Overview of sample event-driven architecture
The sample application uses a front-end to sign up a new user and allow the user to upload images of their car and driver’s license. Once signed up, they can file a claim and upload images of their damaged car. Previously, it did not yet integrate with a settlement service for completing the claims and settlement process.
In this scenario, the settlement service is a brownfield application that runs Spring Boot 3 on Amazon ECS with AWS Fargate. AWS Fargate is a serverless, pay-as-you-go compute engine that lets you focus on building container applications without managing servers.
The Spring Boot application exposes a REST endpoint, which accepts a POST request. It applies settlement business logic and creates a settlement record in the database for a car insurance claim. Your goal is to make settlement work with the new EDA application that is designed for claims processing without re-architecting or rewriting. Customer, claims, fraud, document, and notification are the other domains that are shown as blue-colored boxes in the following diagram:

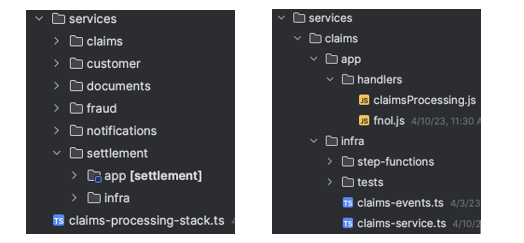
Project structure
The application uses AWS Cloud Development Kit (CDK) to build the stack. With CDK, you get the flexibility to create modular and reusable constructs imperatively using your language of choice. The sample application uses TypeScript for CDK.
The following project structure enables you to build different bounded contexts. Event-driven architecture relies on the choreography of events between domains. The object oriented programming (OOP) concept of CDK helps provision the infrastructure to separate the domain concerns while loosely coupling them via events.
You break the higher level CDK constructs down to these corresponding domains:

Application and infrastructure code are present in each domain. This project structure creates a seamless way to add new domains like settlement with its application and infrastructure code without affecting other areas of the business.
With the preceding structure, you can use the settlement-service.ts CDK construct inside claims-processing-stack.ts:
const settlementService = new SettlementService(this, "SettlementService", {
bus,
});
The only information the SettlementService construct needs to work is the EventBridge custom event bus resource that is created in the claims-processing-stack.ts.
To run the sample application, follow the setup steps in the sample application’s README file.
Existing container workload
The settlement domain provides a REST service to the rest of the organization. A Docker containerized Spring Boot application runs on Amazon ECS with AWS Fargate. The following sequence diagram shows the synchronous request-response flow from an external REST client to the service:

- External REST client makes POST /settlement call via an HTTP API present in front of an internal Application Load Balancer (ALB).
- SettlementController.java delegates to SettlementService.java.
- SettlementService applies business logic and calls SettlementRepository for data persistence.
- SettlementRepository persists the item in the Settlement DynamoDB table.
A request to the HTTP API endpoint looks like:
curl --location <settlement-api-endpoint-from-cloudformation-output> \
--header 'Content-Type: application/json' \
--data '{
"customerId": "06987bc1-1234-1234-1234-2637edab1e57",
"claimId": "60ccfe05-1234-1234-1234-a4c1ee6fcc29",
"color": "green",
"damage": "bumper_dent"
}'
The response from the API call is:

You can learn more here about optimizing Spring Boot applications on AWS Fargate.
Extending container workload for events
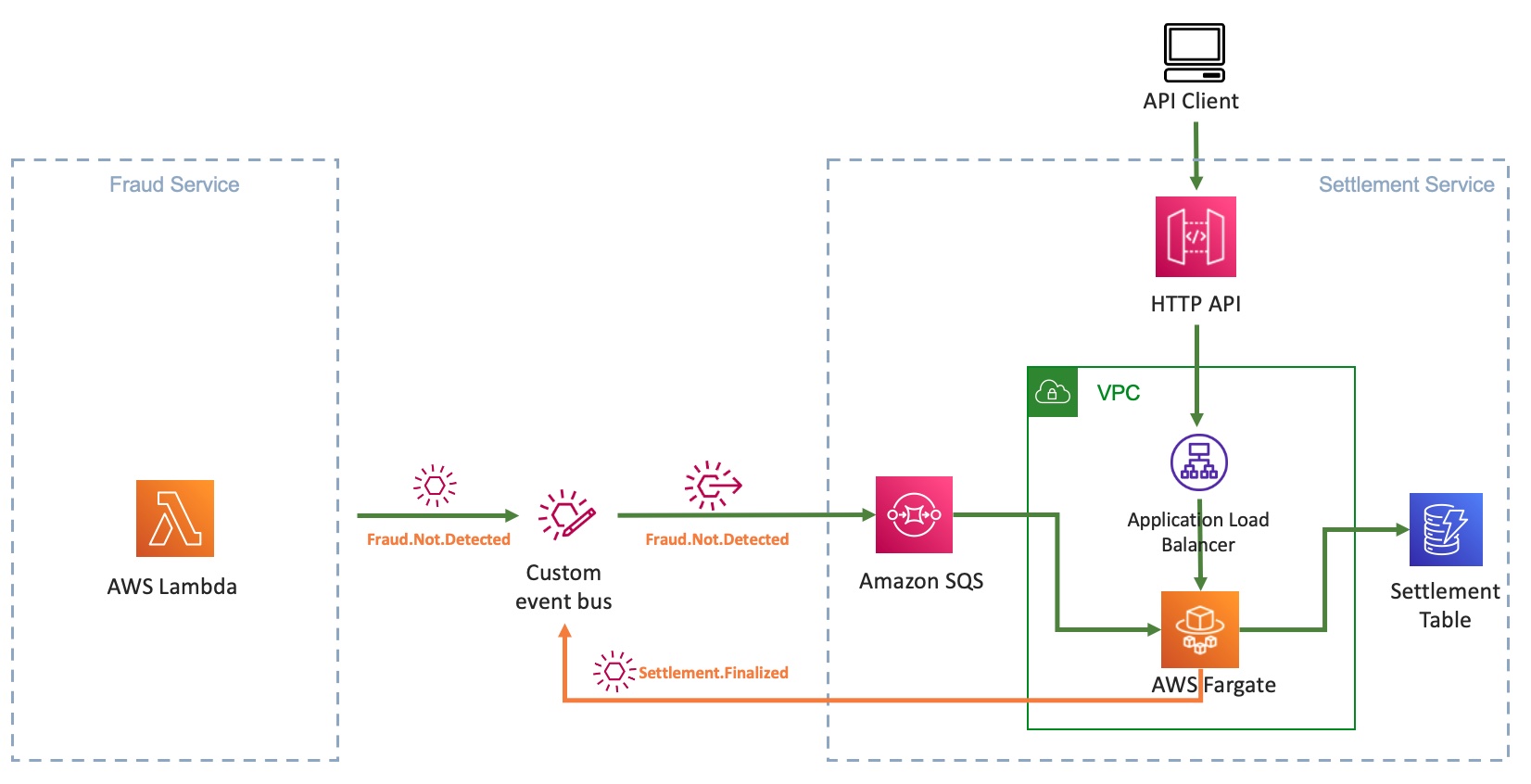
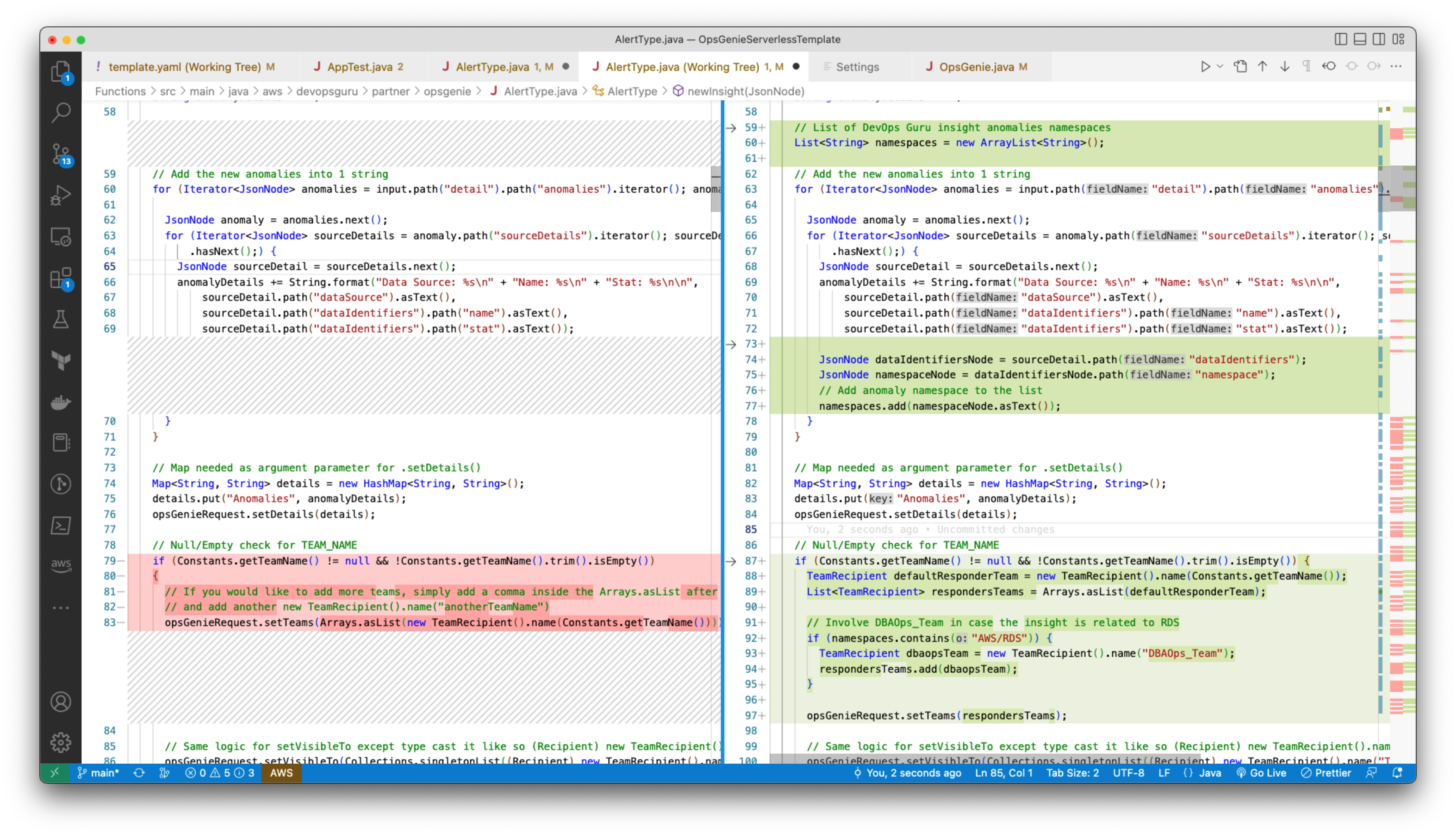
To integrate the settlement service, you must update the service to receive and emit events asynchronously. The core logic of the settlement service remains the same. When you file a claim, upload damaged car images, and the application detects no document fraud, the settlement domain subscribes to Fraud.Not.Detected event and applies its business logic. The settlement service emits an event back upon applying the business logic.
The following sequence diagram shows a new interface in settlement to work with EDA. The settlement service subscribes to events that a producer emits. Here, the event producer is the fraud service that puts an event in an EventBridge custom event bus.

- Producer emits Fraud.Not.Detected event to EventBridge custom event bus.
- EventBridge evaluates the rules provided by the settlement domain and sends the event payload to the target SQS queue.
- SubscriberService.java polls for new messages in the SQS queue.
- On message, it transforms the message body to an input object that is accepted by SettlementService.
- It then delegates the call to SettlementService, similar to how SettlementController works in the REST implementation.
- SettlementService applies business logic. The flow is like the REST use case from 7 to 10.
- On receiving the response from the SettlementService, the SubscriberService transforms the response to publish an event back to the event bus with the event type as
Settlement.Finalized.
The rest of the architecture consumes this Settlement.Finalized event.
Using EventBridge schema registry and discovery
Schema enforces a contract between a producer and a consumer. A consumer expects the exact structure of the event payload every time an event arrives. EventBridge provides schema registry and discovery to maintain this contract. The consumer (the settlement service) can download the code bindings and use them in the source code.
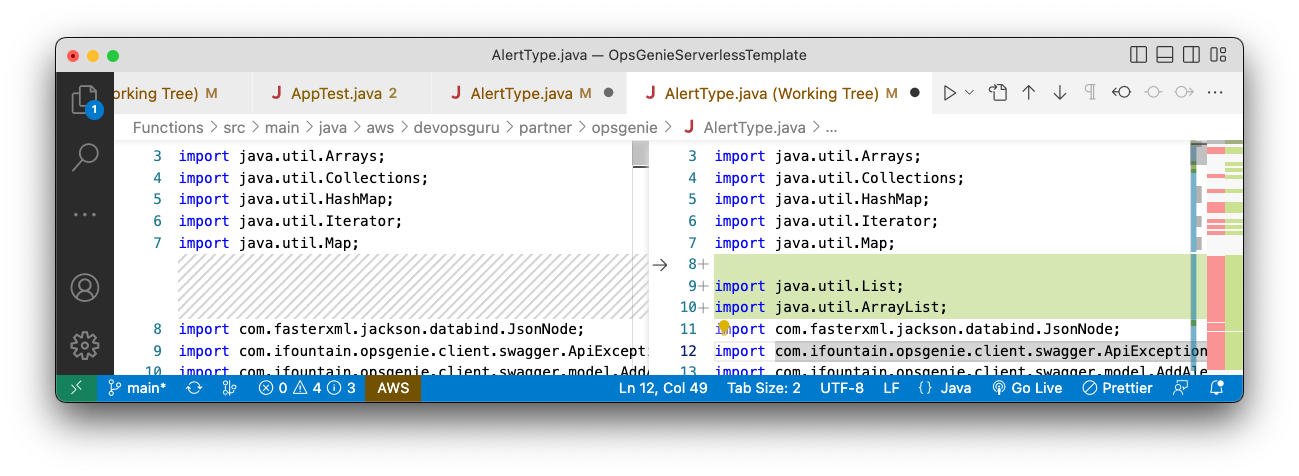
Enable schema discovery in EventBridge before downloading the code bindings and using them in your repository. The code bindings provide a marshaller that unmarshals the incoming event from SQS queue to a plain old Java object (POJO) FraudNotDetected.java. You download the code bindings using the choice of your IDE. AWS Toolkit for IntelliJ makes it convenient to download and use them.

The final architecture for the settlement service with REST and event-driven architecture looks like:

Transition to become fully event-driven
With the new capability to handle events, the Spring Boot application now supports both the REST endpoint and the event-driven architecture by running the same business logic through different interfaces. In this example scenario, as the event-driven architecture matures and the rest of the organization adopts it, the need for the POST endpoint to save a settlement may diminish. In the future, you can deprecate the endpoint and fully rely on polling messages from the SQS queue.
You start with using an ALB and Fargate service CDK ECS pattern:
const loadBalancedFargateService = new ecs_patterns.ApplicationLoadBalancedFargateService(
this,
"settlement-service",
{
cluster: cluster,
taskImageOptions: {
image: ecs.ContainerImage.fromDockerImageAsset(asset),
environment: {
"DYNAMODB_TABLE_NAME": this.table.tableName
},
containerPort: 8080,
logDriver: new ecs.AwsLogDriver({
streamPrefix: "settlement-service",
mode: ecs.AwsLogDriverMode.NON_BLOCKING,
logRetention: RetentionDays.FIVE_DAYS,
})
},
memoryLimitMiB: 2048,
cpu: 1024,
publicLoadBalancer: true,
desiredCount: 2,
listenerPort: 8080
});
To adapt to EDA, you update the resources to retrofit the SQS queue to receive messages and EventBridge to put events. Add new environment variables to the ApplicationLoadBalancerFargateService resource:
environment: {
"SQS_ENDPOINT_URL": queue.queueUrl,
"EVENTBUS_NAME": props.bus.eventBusName,
"DYNAMODB_TABLE_NAME": this.table.tableName
}
Grant the Fargate task permission to put events in the custom event bus and consume messages from the SQS queue:
props.bus.grantPutEventsTo(loadBalancedFargateService.taskDefinition.taskRole);
queue.grantConsumeMessages(loadBalancedFargateService.taskDefinition.taskRole);
When you transition the settlement service to become fully event-driven, you do not need the HTTP API endpoint and ALB anymore, as SQS is the source of events.
A better alternative is to use QueueProcessingFargateService ECS pattern for the Fargate service. The pattern provides auto scaling based on the number of visible messages in the SQS queue, besides CPU utilization. In the following example, you can also add two capacity provider strategies while setting up the Fargate service: FARGATE_SPOT and FARGATE. This means, for every one task that is run using FARGATE, there are two tasks that use FARGATE_SPOT. This can help optimize cost.
const queueProcessingFargateService = new ecs_patterns.QueueProcessingFargateService(this, 'Service', {
cluster,
memoryLimitMiB: 1024,
cpu: 512,
queue: queue,
image: ecs.ContainerImage.fromDockerImageAsset(asset),
desiredTaskCount: 2,
minScalingCapacity: 1,
maxScalingCapacity: 5,
maxHealthyPercent: 200,
minHealthyPercent: 66,
environment: {
"SQS_ENDPOINT_URL": queueUrl,
"EVENTBUS_NAME": props?.bus.eventBusName,
"DYNAMODB_TABLE_NAME": tableName
},
capacityProviderStrategies: [
{
capacityProvider: 'FARGATE_SPOT',
weight: 2,
},
{
capacityProvider: 'FARGATE',
weight: 1,
},
],
});
This pattern abstracts the automatic scaling behavior of the Fargate service based on the queue depth.
Running the application
To test the application, follow How to use the Application after the initial setup. Once complete, you see that the browser receives a Settlement.Finalized event:
{
"version": "0",
"id": "e2a9c866-cb5b-728c-ce18-3b17477fa5ff",
"detail-type": "Settlement.Finalized",
"source": "settlement.service",
"account": "123456789",
"time": "2023-04-09T23:20:44Z",
"region": "us-east-2",
"resources": [],
"detail": {
"settlementId": "377d788b-9922-402a-a56c-c8460e34e36d",
"customerId": "67cac76c-40b1-4d63-a8b5-ad20f6e2e6b9",
"claimId": "b1192ba0-de7e-450f-ac13-991613c48041",
"settlementMessage": "Based on our analysis on the damage of your car per claim id b1192ba0-de7e-450f-ac13-991613c48041, your out-of-pocket expense will be $100.00."
}
}
Cleaning up
The stack creates a custom VPC and other related resources. Be sure to clean up resources after usage to avoid the ongoing cost of running these services. To clean up the infrastructure, follow the clean-up steps shown in the sample application.
Conclusion
The blog explains a way to integrate existing container workload running on AWS Fargate with a new event-driven architecture. You use EventBridge to decouple different services from each other that are built using different compute technologies, languages, and frameworks. Using AWS CDK, you gain the modularity of building services decoupled from each other.
This blog shows an evolutionary architecture that allows you to modernize existing container workloads with minimal changes that still give you the additional benefits of building with serverless and EDA on AWS.
The major difference between the event-driven approach and the REST approach is that you unblock the producer once it emits an event. The event producer from the settlement domain that subscribes to that event is loosely coupled. The business functionality remains intact, and no significant refactoring or re-architecting effort is required. With these agility gains, you may get to the market faster
The sample application shows the implementation details and steps to set up, run, and clean up the application. The app uses ECS Fargate for a domain service, but you do not limit it to just Fargate. You can also bring container-based applications running on Amazon EKS similarly to event-driven architecture.
Learn more about event-driven architecture on Serverless Land.























 Debaprasun Chakraborty is an AWS Solutions Architect, specializing in the analytics domain. He has around 20 years of software development and architecture experience. He is passionate about helping customers in cloud adoption, migration and strategy.
Debaprasun Chakraborty is an AWS Solutions Architect, specializing in the analytics domain. He has around 20 years of software development and architecture experience. He is passionate about helping customers in cloud adoption, migration and strategy. Suraj Subramani Vineet is a Senior Cloud Architect at Amazon Web Services (AWS) Professional Services in Sydney, Australia. He specializes in designing and building scalable and cost-effective data platforms and AI/ML solutions in the cloud. Outside of work, he enjoys playing soccer on weekends.
Suraj Subramani Vineet is a Senior Cloud Architect at Amazon Web Services (AWS) Professional Services in Sydney, Australia. He specializes in designing and building scalable and cost-effective data platforms and AI/ML solutions in the cloud. Outside of work, he enjoys playing soccer on weekends.



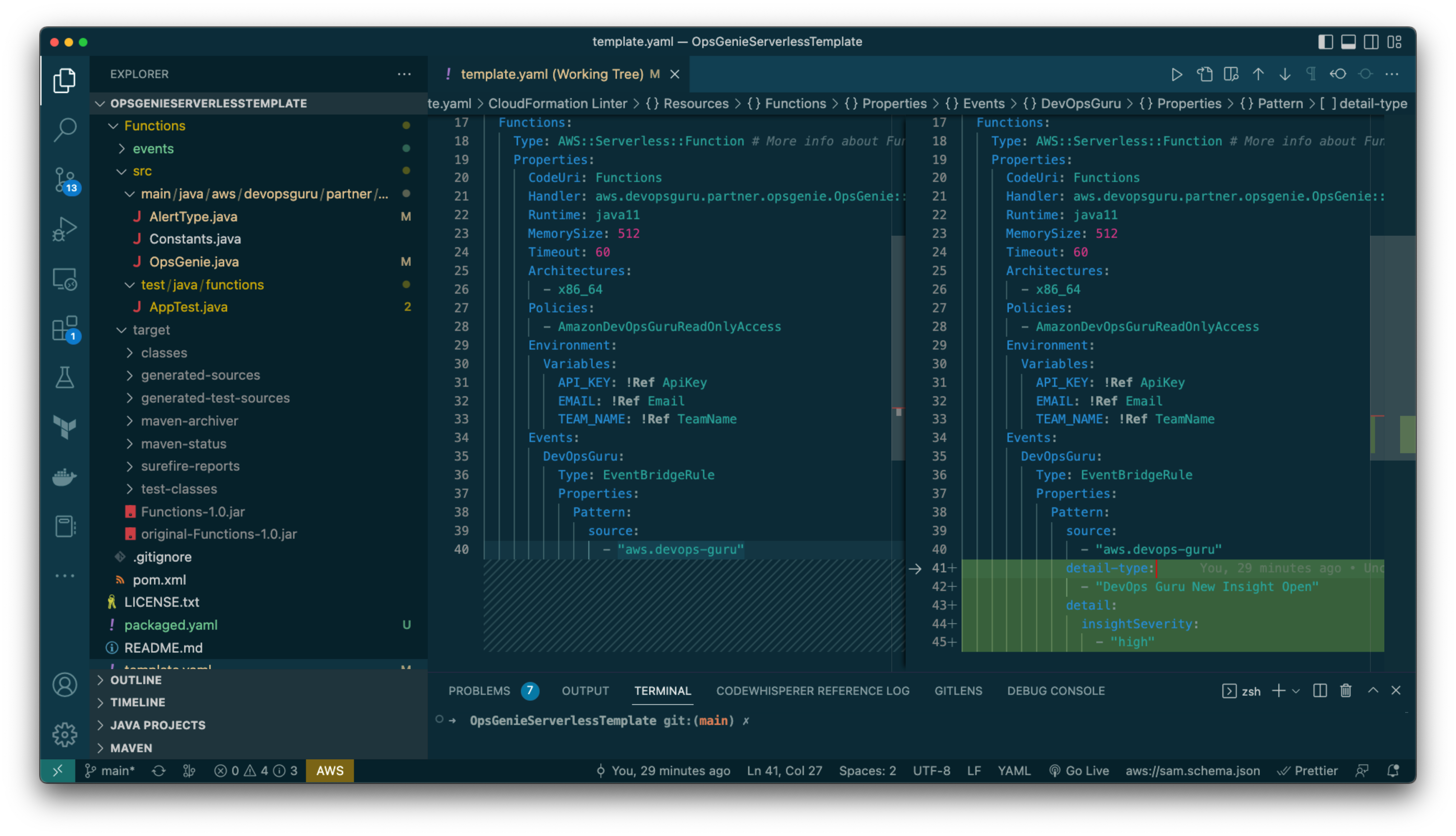
![As the user configures their EventBridge Rule, for the Creation method they have chosen "Custom pattern (JSON editor) write an event pattern in JSON." For the Event pattern editor just below they have entered {"source":["aws.devops-guru"]}](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2023/04/19/eventbridge.png)




















 Victor Gu is a Containers and Serverless Architect at AWS. He works with AWS customers to design microservices and cloud native solutions using Amazon EKS/ECS and AWS serverless services. His specialties are Kubernetes, Spark on Kubernetes, MLOps and DevOps.
Victor Gu is a Containers and Serverless Architect at AWS. He works with AWS customers to design microservices and cloud native solutions using Amazon EKS/ECS and AWS serverless services. His specialties are Kubernetes, Spark on Kubernetes, MLOps and DevOps. Michael Gasch is a Senior Product Manager for AWS EventBridge, driving innovations in event-driven architectures. Prior to AWS, Michael was a Staff Engineer at the VMware Office of the CTO, working on open-source projects, such as Kubernetes and Knative, and related distributed systems research.
Michael Gasch is a Senior Product Manager for AWS EventBridge, driving innovations in event-driven architectures. Prior to AWS, Michael was a Staff Engineer at the VMware Office of the CTO, working on open-source projects, such as Kubernetes and Knative, and related distributed systems research. Peter Dalbhanjan is a Solutions Architect for AWS based in Herndon, VA. Peter has a keen interest in evangelizing AWS solutions and has written multiple blog posts that focus on simplifying complex use cases. At AWS, Peter helps with designing and architecting variety of customer workloads.
Peter Dalbhanjan is a Solutions Architect for AWS based in Herndon, VA. Peter has a keen interest in evangelizing AWS solutions and has written multiple blog posts that focus on simplifying complex use cases. At AWS, Peter helps with designing and architecting variety of customer workloads.























































 Amazon EventBridge Scheduler | Schedule tasks over +200 targets!
Amazon EventBridge Scheduler | Schedule tasks over +200 targets!

{kind=link}