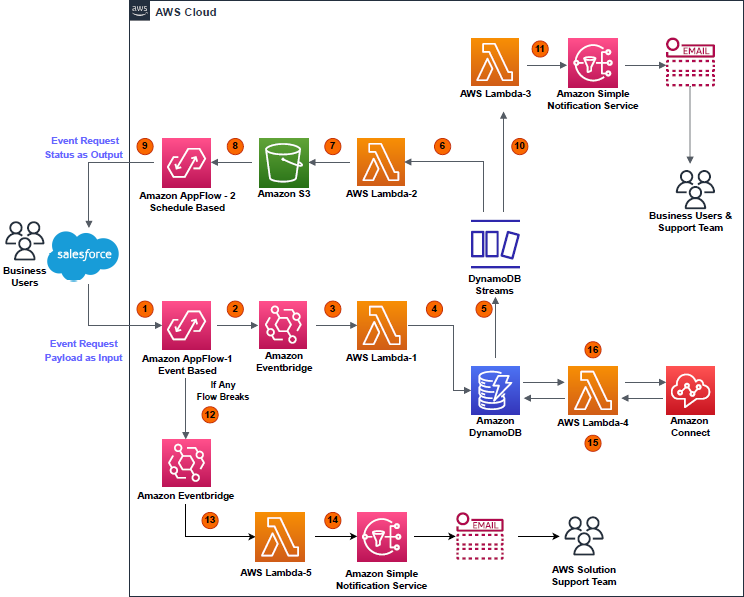
Post Syndicated from Marcia Villalba original https://aws.amazon.com/blogs/compute/introducing-amazon-eventbridge-scheduler/
Today, we are announcing Amazon EventBridge Scheduler. This is a new capability from Amazon EventBridge that allows you to create, run, and manage scheduled tasks at scale. With EventBridge Scheduler, you can schedule one-time or recurrently tens of millions of tasks across many AWS services without provisioning or managing underlying infrastructure.
Previously, many customers used commercial off-the-shelf tools or built their own scheduling capabilities. This can increase application complexity, slow application development, and increase costs, which are magnified at scale. Most of these solutions are limited in what services they can trigger and create complexity in managing concurrency limitations of invoked targets that can affect application performance.
When to use EventBridge Scheduler?
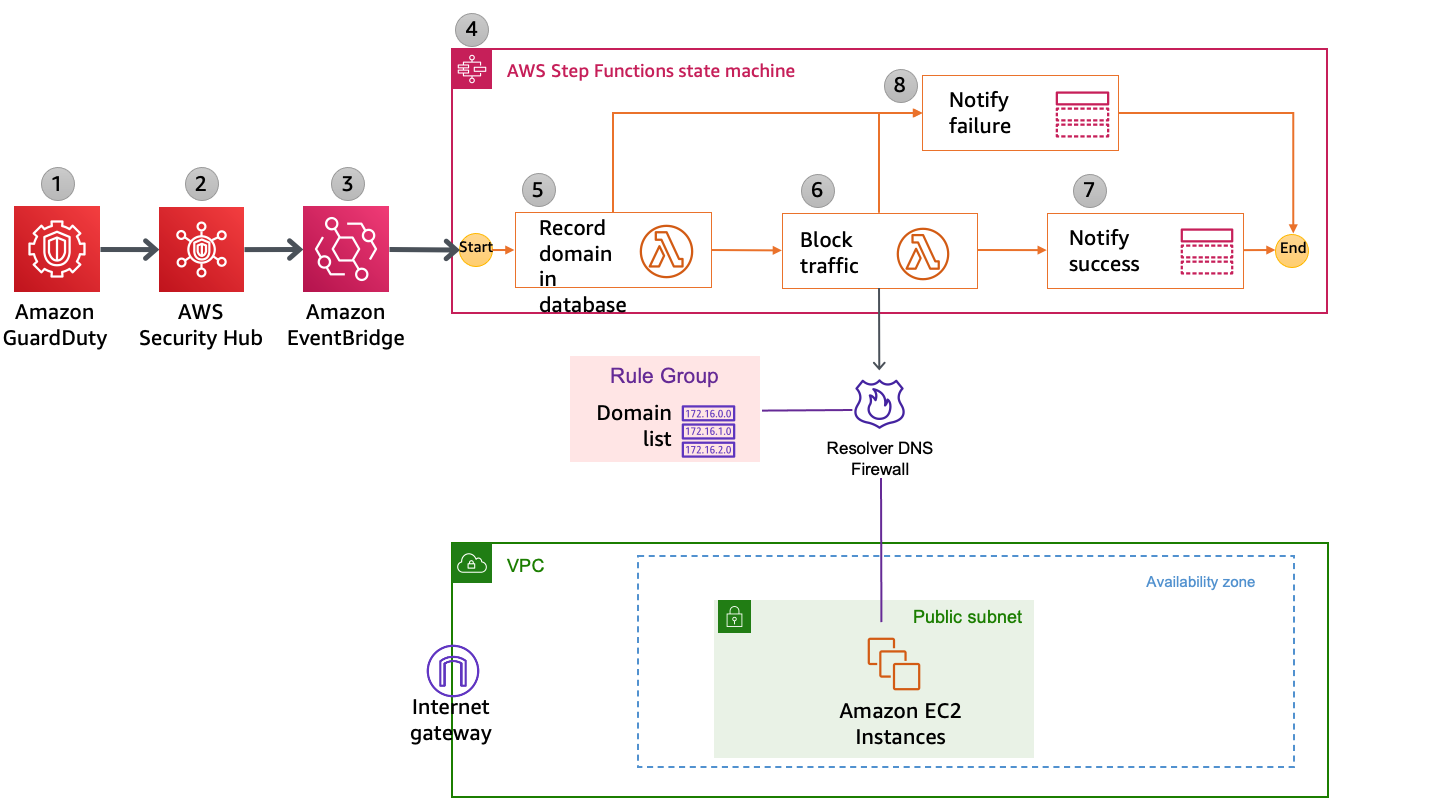
For example, consider a company that develops a task management system. One feature that the application provides is that users can add a reminder for a task and be reminded by email one week before, two days before, or on the day of the task due date. You can automate the creation of all the schedules with EventBridge Scheduler, create the task for each of the reminders, and send it to Amazon SNS to send the notifications.
Or consider a large organization, like a supermarket, with thousands of AWS accounts and tens of thousands of Amazon EC2 instances. These instances are used in different parts of the world during business hours. You want to make sure that all the instances are started before the stores open and terminated after the business hours to reduce costs as much as possible. You can use EventBridge Scheduler to start and stop all the thousands of instances and also respect time zones.
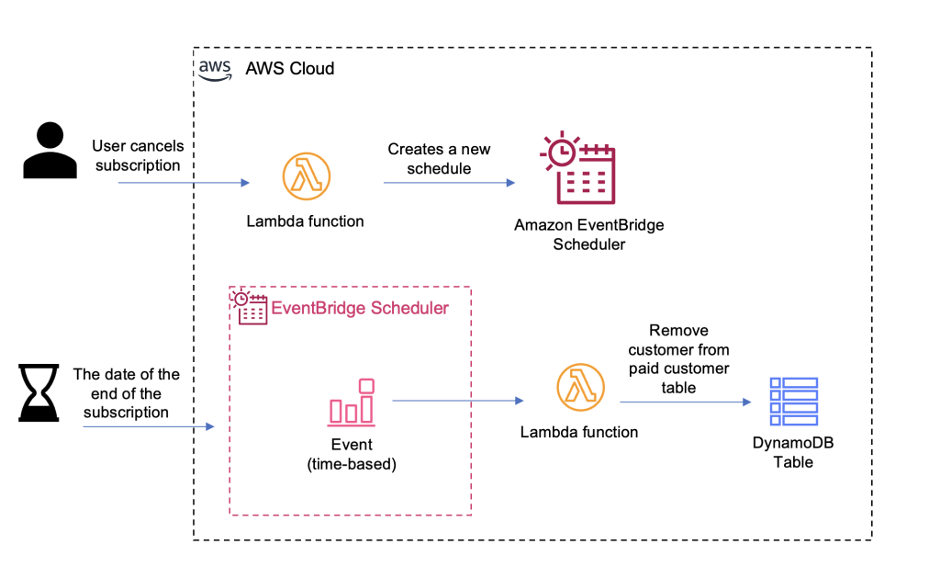
SaaS providers can also benefit from EventBridge Scheduler, as now they can more easily manage all the different scheduled tasks that their customers have. For example, consider a SaaS provider with a subscription model for your customers paying a monthly or annual fee. You want to ensure that their license key is valid until the end of their current billing period. With Scheduler, you can create a schedule that removes the access to the service when the billing period is over, or when the user cancels their subscription. Also, you can create a series of emails that let your customer knows that their license is expiring so they can purchase a renewal. 
Use cases for EventBridge Scheduler are diverse, from simplifying new feature development to improving your infrastructure operations.
How does EventBridge Scheduler work?
With EventBridge Scheduler, you can now create single or recurrent schedules that trigger over 200 services with more than 6,000 APIs. EventBridge Scheduler allows you to configure schedules with a minimum granularity of one minute.
EventBridge Scheduler provides at-least-once event delivery to targets, and you can create schedules that adjust to different delivery patterns by setting the window of delivery, the number of retries, the time for the event to be retained, and the dead letter queue (DLQ). You can learn more about each configuration from the Scheduler User Guide.
- Time window allows you to start a schedule within a window of time. This means that the scheduled tasks are dispersed across the time window to reduce the impact of multiple requests on downstream services.
- Maximum retention time of the event is the maximum time to keep an unprocessed event in the scheduler. If the target is not responding during this time, the event is dropped or sent to a DLQ.
- Retries with exponential backoff help to retry a failed task with delayed attempts. This improves the success of the task when the target is available.
- A dead letter queue is an Amazon SQS queue where events that failed to get delivered to the target are routed.
By default, EventBridge Scheduler tries to send the event for 24 hours and a maximum of 185 times. You can configure these values. If that fails, the message is dropped, since by default there is not a DLQ configured.
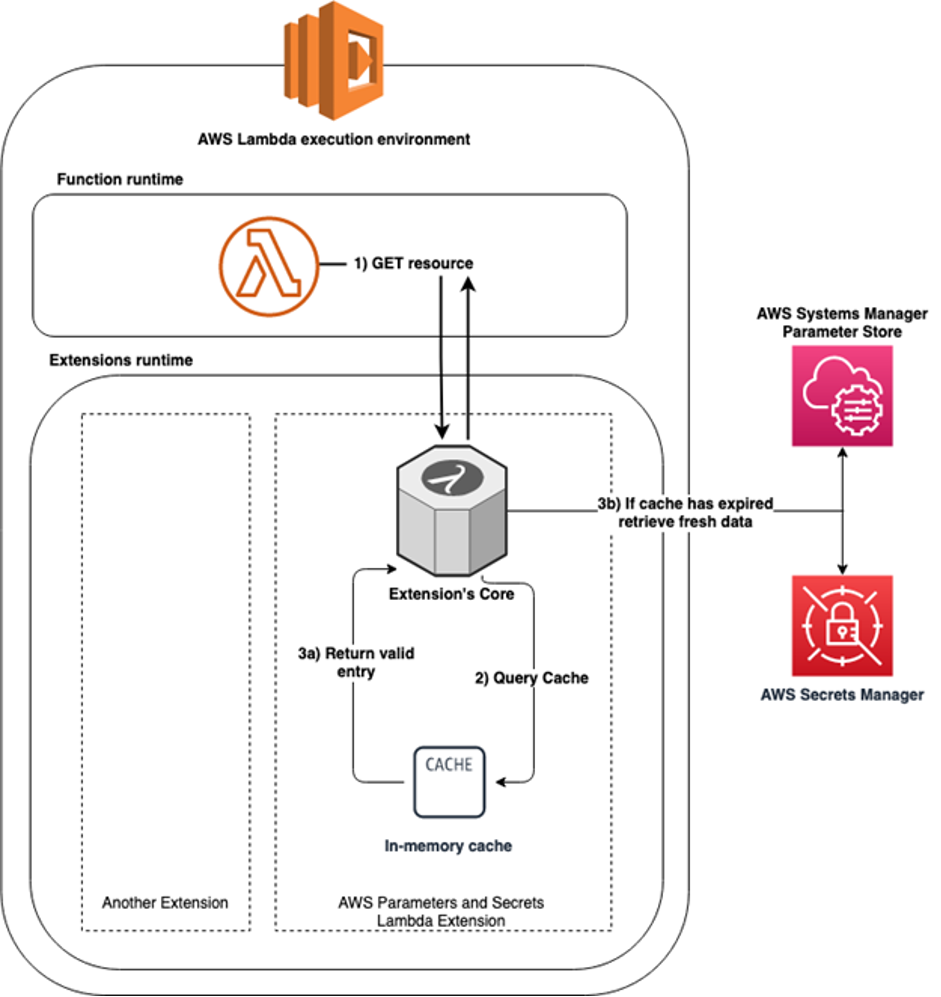
In addition, by default, all events in Scheduler are encrypted with a key that AWS owns and manages. You can also use your own AWS KMS encryption keys.
You can also schedule tasks using Amazon EventBridge rules. But to schedule tasks at scale, EventBridge Scheduler is better suited for this task. The following table shows the main differences between EventBridge Scheduler and EventBridge rules:
|
Amazon EventBridge Scheduler |
Amazon EventBridge rules |
| Quota on schedules |
1 million per account |
300 rule limit per account per Region |
| Event invocation throughput |
Able to support throughput in 1,000s of TPS |
Because of the schedule limit, you can only have 300 1-minute schedules for max throughput of 5 TPS |
| Targets |
Over 270 services and over 6,000 API Actions with AWS SDK targets |
20+ targets supported by EventBridge |
| Time expression and time-zones |
at(), cron(), rate()
All time-zones and DST
|
cron(), rate(), UTC
No support for DST
|
| One-time schedules |
Yes |
No |
| Time window schedules |
Yes |
No |
| Event bus support |
No event bus is needed |
Default bus only |
| Rule quota consumption |
No. 1 million schedules soft limit |
Yes, consumes from 2,000 rules per bus |
Getting started with EventBridge Scheduler
This walkthrough builds a series of schedules to get started with EventBridge Scheduler. For that, you use the AWS Command Line (AWS CLI) to configure the schedules that send notifications using Amazon SNS.
Prerequisites
Update your AWS CLI to the latest version (v1.27.7).
As a prerequisite, you must create an SNS topic with an email subscription and an AWS IAM role that EventBridge Scheduler can assume to publish messages on your behalf. You can deploy these AWS resources using AWS SAM. Follow the instructions in the README file.
Scheduling a one-time schedule
Once configured, create your first schedule. This is a one-time schedule that publishes an event for the SNS topic you created.
For creating the schedule, run this command in your terminal and replace the schedule expression and time zone with values for your task:
$ aws scheduler create-schedule --name SendEmailOnce \
--schedule-expression "at(2022-11-01T11:00:00)" \
--schedule-expression-timezone "Europe/Helsinki" \
--flexible-time-window "{\"Mode\": \"OFF\"}" \
--target "{\"Arn\": \"arn:aws:sns:us-east-1:xxx:test-chronos-send-email\", \"RoleArn\": \" arn:aws:iam::xxxx:role/sam_scheduler_role\" }"
Let’s analyze the different parts of this command. The first parameter is the name of the schedule.
In the schedule expression attribute, you can define if the event is a one-time schedule or a recurrent schedule. Because this is a one-time schedule, it uses the at() expression with the date and time you want this schedule to run. Also, you must configure the schedule expression time zone in which this schedule run:
--schedule-expression "at(2022-11-01T11:00:00)" --schedule-expression-timezone "Europe/Helsinki"
Another setting that you can configure is the flexible time window. It’s not used for this example, but if you choose a time window, EventBridge Scheduler invokes the task within that timeframe. This setting helps to distribute the invocations across time and manage the downstream service limits.
--flexible-time-window "{\"Mode\": \"OFF\"}"
Finally, pass the IAM role ARN. This is the role previously created with the AWS SAM template. This role is the one that EventBridge Scheduler assumes when publishing events to SNS and it has permissions to publish messages on that topic.
Finally, you must configure the target. Scheduler comes with predefined targets with simpler APIs, that include actions like putting events for Amazon EventBridge, invoke a Lambda function, send a message to an Amazon SQS queue. For this example, use the universal target, which allows you to invoke almost any AWS services. Learn more about the targets from the User Guide.
--target "{\"Arn\": \"arn:aws:sns:us-east-1:xxx:test-chronos-send-email\", \"RoleArn\": \" arn:aws:iam::xxxx:role/sam_scheduler_role\" }"
Scheduling groups
Scheduling groups help you organize your schedules. Scheduling groups support tags that you can use for cost allocation, access control, and resource organization. When creating a new schedule, you can add it to a scheduling group.
To create a new scheduling group, run:
$ aws scheduler create-schedule-group --name ScheduleGroupTest
Scheduling a recurrent schedule
Now let’s create a recurrent schedule for that scheduling group. This schedule runs every five minutes and publishes a message to the SNS topic you created during the prerequisites.
$ aws scheduler create-schedule --name SendEmailTest \
--group-name ScheduleGroupTest \
--schedule-expression "rate(5minutes)" \
--flexible-time-window "{\"Mode\": \"OFF\"}" \
--target "{\"Arn\": \"arn:aws:sns:us-east-1:xxxx:test-chronos-send-email\", \"RoleArn\": \" arn:aws:iam::xxxx:role/sam_scheduler_role \" }"
Recurrent schedules can be configured with a cron expression or rate expression, to define the frequency that this schedule should be triggered. For scheduling this to run every five minutes, you can use an expression like this one:
--schedule-expression "rate(5minutes)"
Because you have selected the recurring schedule, you can define the timeframe in which this schedule runs. You can optionally choose a start and end date and time for your schedule. If you don’t do it, the schedule starts as soon as you create the task. These times are formatted in the same way as other AWS CLI timestamps.
--start-date "2022-11-01T18:48:00Z" --end-date "2022-11-01T19:00:00Z"
If you run the previous recurrent schedule for some time, and then check Amazon CloudWatch metrics, you find a metric called InvocationAttemptCount, for the schedule invocations that happened within the scheduling group you just created.
You can graph that metric in a dashboard and see how many times this schedule run. Also, you can create alarms to get notified if the number of invocations exceeds a threshold. For example, you can set this threshold to be close to the limits of your downstream service, to prevent reaching those limits.

Cleaning up
Make sure that you delete all the recurrent schedules that you created without an end time.
To check all the schedules that you have configured:
$ aws scheduler list-schedules
To delete a schedule using the AWS CLI:
$ aws scheduler delete-schedule --name <name-of-schedule> --group <name-of-group>
Also delete the CloudFormation stack with the prerequisite infrastructure when you complete this demo, as is defined in the README file of that project.
Conclusion
This blog post introduces the new Amazon EventBridge Scheduler, its use cases and its differences with existing scheduling options. It shows you how to create a new schedule using Amazon EventBridge Scheduler to simplify the creation, execution, and managing of scheduled tasks at scale.
You can get started today with EventBridge Scheduler from the AWS Management Console, AWS CLI, AWS CloudFormation, AWS SDK, and AWS SAM.
For more serverless learning resources, visit Serverless Land.






































 Do not delete unsent messages from the queues. These messages will become visible after their queue’s visibility timeout is reached.
Do not delete unsent messages from the queues. These messages will become visible after their queue’s visibility timeout is reached.






















 to securely and efficiently access the remote macOS machines. You can connect from anywhere, using a PCoIP client application or from thin terminals such as
to securely and efficiently access the remote macOS machines. You can connect from anywhere, using a PCoIP client application or from thin terminals such as