Post Syndicated from Ashutosh Upadhyay original https://aws.amazon.com/blogs/security/implement-tenant-isolation-for-amazon-s3-and-aurora-postgresql-by-using-abac/
In software as a service (SaaS) systems, which are designed to be used by multiple customers, isolating tenant data is a fundamental responsibility for SaaS providers. The practice of isolation of data in a multi-tenant application platform is called tenant isolation. In this post, we describe an approach you can use to achieve tenant isolation in Amazon Simple Storage Service (Amazon S3) and Amazon Aurora PostgreSQL-Compatible Edition databases by implementing attribute-based access control (ABAC). You can also adapt the same approach to achieve tenant isolation in other AWS services.
ABAC in Amazon Web Services (AWS), which uses tags to store attributes, offers advantages over the traditional role-based access control (RBAC) model. You can use fewer permissions policies, update your access control more efficiently as you grow, and last but not least, apply granular permissions for various AWS services. These granular permissions help you to implement an effective and coherent tenant isolation strategy for your customers and clients. Using the ABAC model helps you scale your permissions and simplify the management of granular policies. The ABAC model reduces the time and effort it takes to maintain policies that allow access to only the required resources.
The solution we present here uses the pool model of data partitioning. The pool model helps you avoid the higher costs of duplicated resources for each tenant and the specialized infrastructure code required to set up and maintain those copies.
Solution overview
In a typical customer environment where this solution is implemented, the tenant request for access might land at Amazon API Gateway, together with the tenant identifier, which in turn calls an AWS Lambda function. The Lambda function is envisaged to be operating with a basic Lambda execution role. This Lambda role should also have permissions to assume the tenant roles. As the request progresses, the Lambda function assumes the tenant role and makes the necessary calls to Amazon S3 or to an Aurora PostgreSQL-Compatible database. This solution helps you to achieve tenant isolation for objects stored in Amazon S3 and data elements stored in an Aurora PostgreSQL-Compatible database cluster.
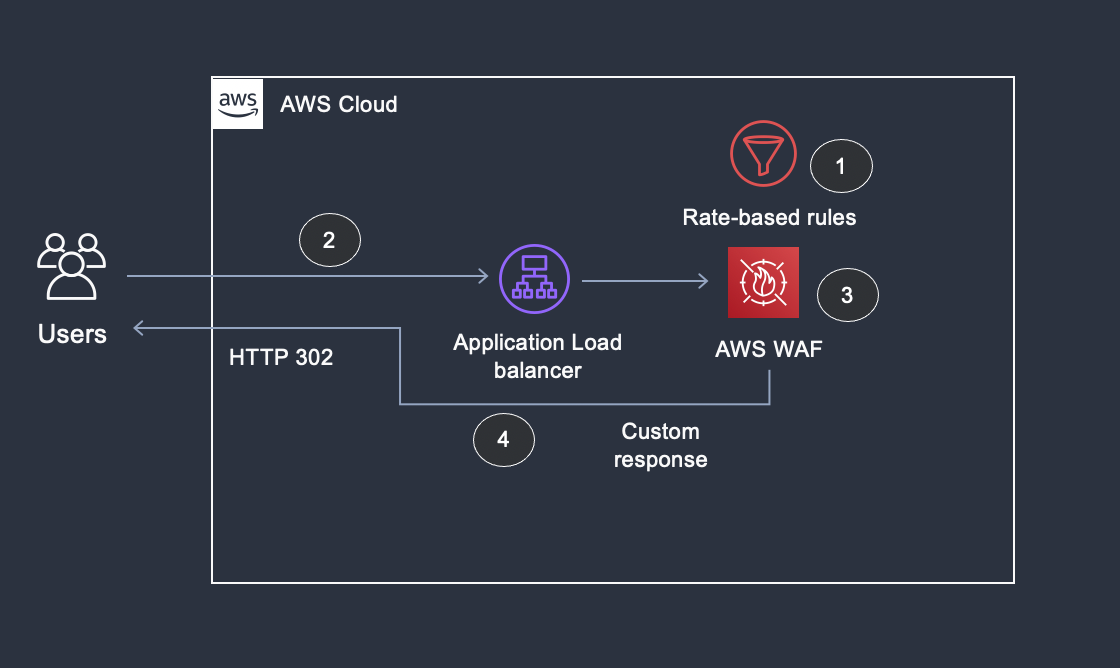
Figure 1 shows the tenant isolation architecture for both Amazon S3 and Amazon Aurora PostgreSQL-Compatible databases.
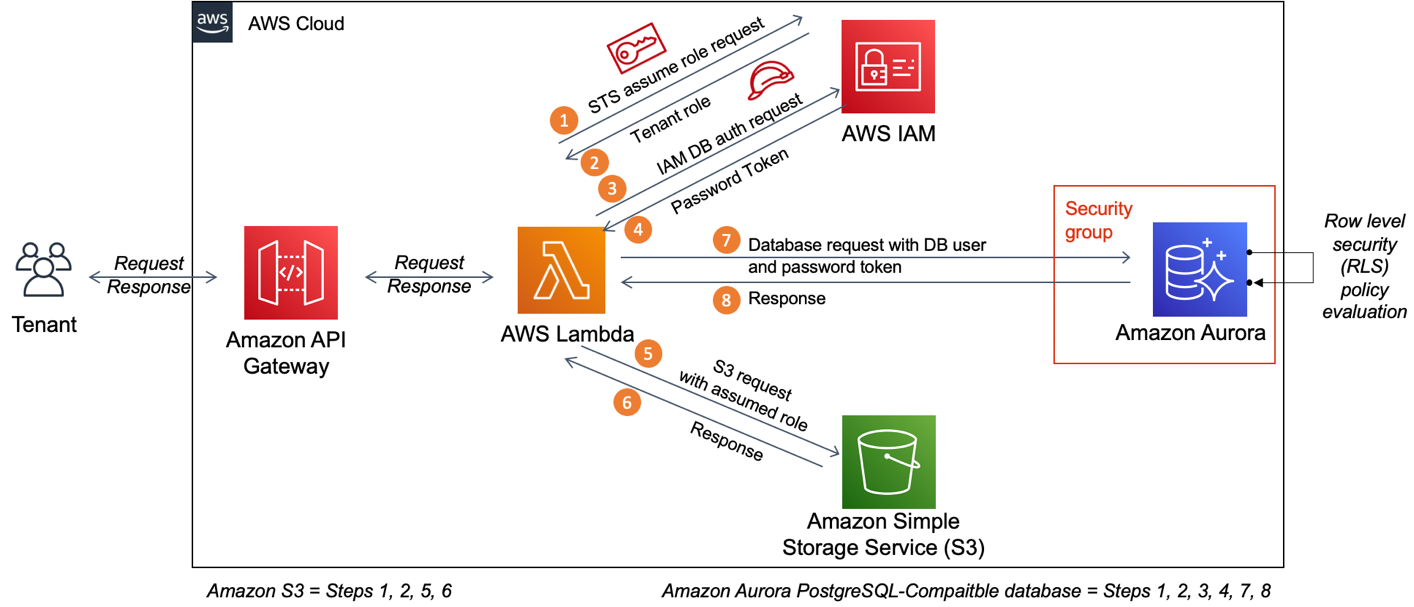
Figure 1: Tenant isolation architecture diagram
As shown in the numbered diagram steps, the workflow for Amazon S3 tenant isolation is as follows:
- AWS Lambda sends an AWS Security Token Service (AWS STS) assume role request to AWS Identity and Access Management (IAM).
- IAM validates the request and returns the tenant role.
- Lambda sends a request to Amazon S3 with the assumed role.
- Amazon S3 sends the response back to Lambda.
The diagram also shows the workflow steps for tenant isolation for Aurora PostgreSQL-Compatible databases, as follows:
- Lambda sends an STS assume role request to IAM.
- IAM validates the request and returns the tenant role.
- Lambda sends a request to IAM for database authorization.
- IAM validates the request and returns the database password token.
- Lambda sends a request to the Aurora PostgreSQL-Compatible database with the database user and password token.
- Aurora PostgreSQL-Compatible database returns the response to Lambda.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account for your workload.
- An Amazon S3 bucket.
- An Aurora PostgreSQL-Compatible cluster with a database created.
Note: Make sure to note down the default master database user and password, and make sure that you can connect to the database from your desktop or from another server (for example, from Amazon Elastic Compute Cloud (Amazon EC2) instances).
- A security group and inbound rules that are set up to allow an inbound PostgreSQL TCP connection (Port 5432) from Lambda functions. This solution uses regular non-VPC Lambda functions, and therefore the security group of the Aurora PostgreSQL-Compatible database cluster should allow an inbound PostgreSQL TCP connection (Port 5432) from anywhere (0.0.0.0/0).
Make sure that you’ve completed the prerequisites before proceeding with the next steps.
Deploy the solution
The following sections describe how to create the IAM roles, IAM policies, and Lambda functions that are required for the solution. These steps also include guidelines on the changes that you’ll need to make to the prerequisite components Amazon S3 and the Aurora PostgreSQL-Compatible database cluster.
Step 1: Create the IAM policies
In this step, you create two IAM policies with the required permissions for Amazon S3 and the Aurora PostgreSQL database.
To create the IAM policies
- Open the AWS Management Console.
- Choose IAM, choose Policies, and then choose Create policy.
- Use the following JSON policy document to create the policy. Replace the placeholder <111122223333> with the bucket name from your account.
- Save the policy with the name sts-ti-demo-s3-access-policy.

Figure 2: Create the IAM policy for Amazon S3 (sts-ti-demo-s3-access-policy)
- Open the AWS Management Console.
- Choose IAM, choose Policies, and then choose Create policy.
- Use the following JSON policy document to create a second policy. This policy grants an IAM role permission to connect to an Aurora PostgreSQL-Compatible database through a database user that is IAM authenticated. Replace the placeholders with the appropriate Region, account number, and cluster resource ID of the Aurora PostgreSQL-Compatible database cluster, respectively.

- Save the policy with the name sts-ti-demo-dbuser-policy.

Figure 3: Create the IAM policy for Aurora PostgreSQL database (sts-ti-demo-dbuser-policy)

Note: Make sure that you use the cluster resource ID for the clustered database. However, if you intend to adapt this solution for your Aurora PostgreSQL-Compatible non-clustered database, you should use the instance resource ID instead.
Step 2: Create the IAM roles
In this step, you create two IAM roles for the two different tenants, and also apply the necessary permissions and tags.
To create the IAM roles
- In the IAM console, choose Roles, and then choose Create role.
- On the Trusted entities page, choose the EC2 service as the trusted entity.
- On the Permissions policies page, select sts-ti-demo-s3-access-policy and sts-ti-demo-dbuser-policy.
- On the Tags page, add two tags with the following keys and values.
Tag key Tag value s3_home tenant1_home dbuser tenant1_dbuser - On the Review screen, name the role assumeRole-tenant1, and then choose Save.
- In the IAM console, choose Roles, and then choose Create role.
- On the Trusted entities page, choose the EC2 service as the trusted entity.
- On the Permissions policies page, select sts-ti-demo-s3-access-policy and sts-ti-demo-dbuser-policy.
- On the Tags page, add two tags with the following keys and values.
Tag key Tag value s3_home tenant2_home dbuser tenant2_dbuser - On the Review screen, name the role assumeRole-tenant2, and then choose Save.
Step 3: Create and apply the IAM policies for the tenants
In this step, you create a policy and a role for the Lambda functions. You also create two separate tenant roles, and establish a trust relationship with the role that you created for the Lambda functions.
To create and apply the IAM policies for tenant1
- In the IAM console, choose Policies, and then choose Create policy.
- Use the following JSON policy document to create the policy. Replace the placeholder <111122223333> with your AWS account number.
- Save the policy with the name sts-ti-demo-assumerole-policy.
- In the IAM console, choose Roles, and then choose Create role.
- On the Trusted entities page, select the Lambda service as the trusted entity.
- On the Permissions policies page, select sts-ti-demo-assumerole-policy and AWSLambdaBasicExecutionRole.
- On the review screen, name the role sts-ti-demo-lambda-role, and then choose Save.
- In the IAM console, go to Roles, and enter assumeRole-tenant1 in the search box.
- Select the assumeRole-tenant1 role and go to the Trust relationship tab.
- Choose Edit the trust relationship, and replace the existing value with the following JSON document. Replace the placeholder <111122223333> with your AWS account number, and choose Update trust policy to save the policy.
To verify that the policies are applied correctly for tenant1
In the IAM console, go to Roles, and enter assumeRole-tenant1 in the search box. Select the assumeRole-tenant1 role and on the Permissions tab, verify that sts-ti-demo-dbuser-policy and sts-ti-demo-s3-access-policy appear in the list of policies, as shown in Figure 4.
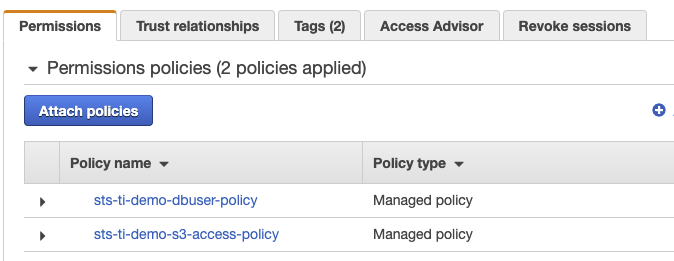
Figure 4: The assumeRole-tenant1 Permissions tab
On the Trust relationships tab, verify that sts-ti-demo-lambda-role appears under Trusted entities, as shown in Figure 5.
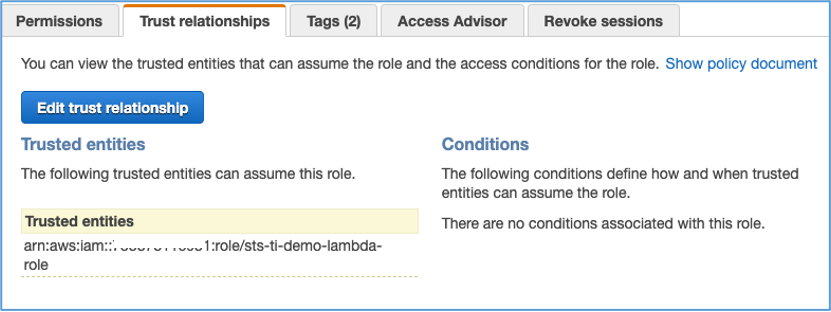
Figure 5: The assumeRole-tenant1 Trust relationships tab
On the Tags tab, verify that the following tags appear, as shown in Figure 6.
| Tag key | Tag value |
| dbuser | tenant1_dbuser |
| s3_home | tenant1_home |
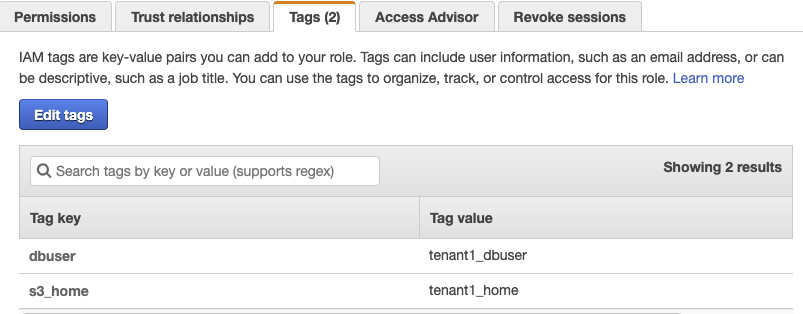
Figure 6: The assumeRole-tenant1 Tags tab
To create and apply the IAM policies for tenant2
- In the IAM console, go to Roles, and enter assumeRole-tenant2 in the search box.
- Select the assumeRole-tenant2 role and go to the Trust relationship tab.
- Edit the trust relationship, replacing the existing value with the following JSON document. Replace the placeholder <111122223333> with your AWS account number.
- Choose Update trust policy to save the policy.
To verify that the policies are applied correctly for tenant2
In the IAM console, go to Roles, and enter assumeRole-tenant2 in the search box. Select the assumeRole-tenant2 role and on the Permissions tab, verify that sts-ti-demo-dbuser-policy and sts-ti-demo-s3-access-policy appear in the list of policies, you did for tenant1. On the Trust relationships tab, verify that sts-ti-demo-lambda-role appears under Trusted entities.
On the Tags tab, verify that the following tags appear, as shown in Figure 7.
| Tag key | Tag value |
| dbuser | tenant2_dbuser |
| s3_home | tenant2_home |
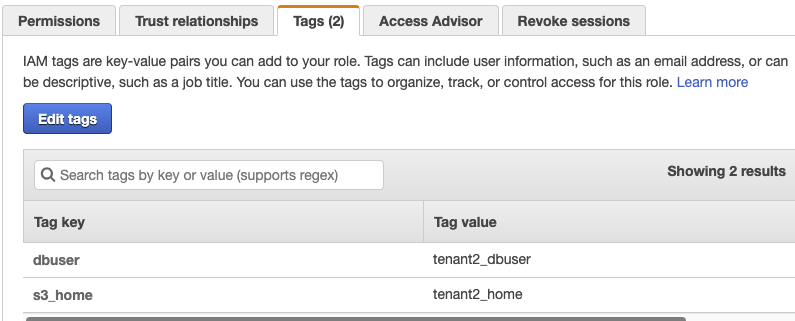
Figure 7: The assumeRole-tenant2 Tags tab
Step 4: Set up an Amazon S3 bucket
Next, you’ll set up an S3 bucket that you’ll use as part of this solution. You can either create a new S3 bucket or re-purpose an existing one. The following steps show you how to create two user homes (that is, S3 prefixes, which are also known as folders) in the S3 bucket.
- In the AWS Management Console, go to Amazon S3 and select the S3 bucket you want to use.
- Create two prefixes (folders) with the names tenant1_home and tenant2_home.
- Place two test objects with the names tenant.info-tenant1_home and tenant.info-tenant2_home in the prefixes that you just created, respectively.
Step 5: Set up test objects in Aurora PostgreSQL-Compatible database
In this step, you create a table in Aurora PostgreSQL-Compatible Edition, insert tenant metadata, create a row level security (RLS) policy, create tenant users, and grant permission for testing purposes.
To set up Aurora PostgreSQL-Compatible
- Connect to Aurora PostgreSQL-Compatible through a client of your choice, using the master database user and password that you obtained at the time of cluster creation.
- Run the following commands to create a table for testing purposes and to insert a couple of testing records.
- Run the following command to query the newly created database table.

Figure 8: The tenant_metadata table content
- Run the following command to create the row level security policy.
- Run the following commands to establish two tenant users and grant them the necessary permissions.
- Run the following commands to verify the newly created tenant users.

Figure 9: Verify the newly created tenant users output


Step 6: Set up the AWS Lambda functions
Next, you’ll create two Lambda functions for Amazon S3 and Aurora PostgreSQL-Compatible. You also need to create a Lambda layer for the Python package PG8000.
To set up the Lambda function for Amazon S3
- Navigate to the Lambda console, and choose Create function.
- Choose Author from scratch. For Function name, enter sts-ti-demo-s3-lambda.
- For Runtime, choose Python 3.7.
- Change the default execution role to Use an existing role, and then select sts-ti-demo-lambda-role from the drop-down list.
- Keep Advanced settings as the default value, and then choose Create function.
- Copy the following Python code into the lambda_function.py file that is created in your Lambda function.
- Under Basic settings, edit Timeout to increase the timeout to 29 seconds.
- Edit Environment variables to add a key called s3_bucket_name, with the value set to the name of your S3 bucket.
- Configure a new test event with the following JSON document, and save it as testEvent.
- Choose Test to test the Lambda function with the newly created test event testEvent. You should see status code 200, and the body of the results should contain the data for tenant1.

Figure 10: The result of running the sts-ti-demo-s3-lambda function

Next, create another Lambda function for Aurora PostgreSQL-Compatible. To do this, you first need to create a new Lambda layer.
To set up the Lambda layer
- Use the following commands to create a .zip file for Python package pg8000.
Note: This example is created by using an Amazon EC2 instance running the Amazon Linux 2 Amazon Machine Image (AMI). If you’re using another version of Linux or don’t have the Python 3 or pip3 packages installed, install them by using the following commands.
- Download the pg8000.zip file you just created to your local desktop machine or into an S3 bucket location.
- Navigate to the Lambda console, choose Layers, and then choose Create layer.
- For Name, enter pgdb, and then upload pg8000.zip from your local desktop machine or from the S3 bucket location.
Note: For more details, see the AWS documentation for creating and sharing Lambda layers.
- For Compatible runtimes, choose python3.6, python3.7, and python3.8, and then choose Create.
To set up the Lambda function with the newly created Lambda layer
- In the Lambda console, choose Function, and then choose Create function.
- Choose Author from scratch. For Function name, enter sts-ti-demo-pgdb-lambda.
- For Runtime, choose Python 3.7.
- Change the default execution role to Use an existing role, and then select sts-ti-demo-lambda-role from the drop-down list.
- Keep Advanced settings as the default value, and then choose Create function.
- Choose Layers, and then choose Add a layer.
- Choose Custom layer, select pgdb with Version 1 from the drop-down list, and then choose Add.
- Copy the following Python code into the lambda_function.py file that was created in your Lambda function.
- Add a certificate file called rds-ca-2019-root.pem into the Lambda project root by downloading it from https://s3.amazonaws.com/rds-downloads/rds-ca-2019-root.pem.
- Under Basic settings, edit Timeout to increase the timeout to 29 seconds.
- Edit Environment variables to add the following keys and values.
Key Value DBEndPoint Enter the database cluster endpoint URL DatabaseName Enter the database name RolePrefix assumeRole 
Figure 11: Example of environment variables display
- Configure a new test event with the following JSON document, and save it as testEvent.
- Choose Test to test the Lambda function with the newly created test event testEvent. You should see status code 200, and the body of the results should contain the data for tenant1.

Figure 12: The result of running the sts-ti-demo-pgdb-lambda function


Step 7: Perform negative testing of tenant isolation
You already performed positive tests of tenant isolation during the Lambda function creation steps. However, it’s also important to perform some negative tests to verify the robustness of the tenant isolation controls.
To perform negative tests of tenant isolation
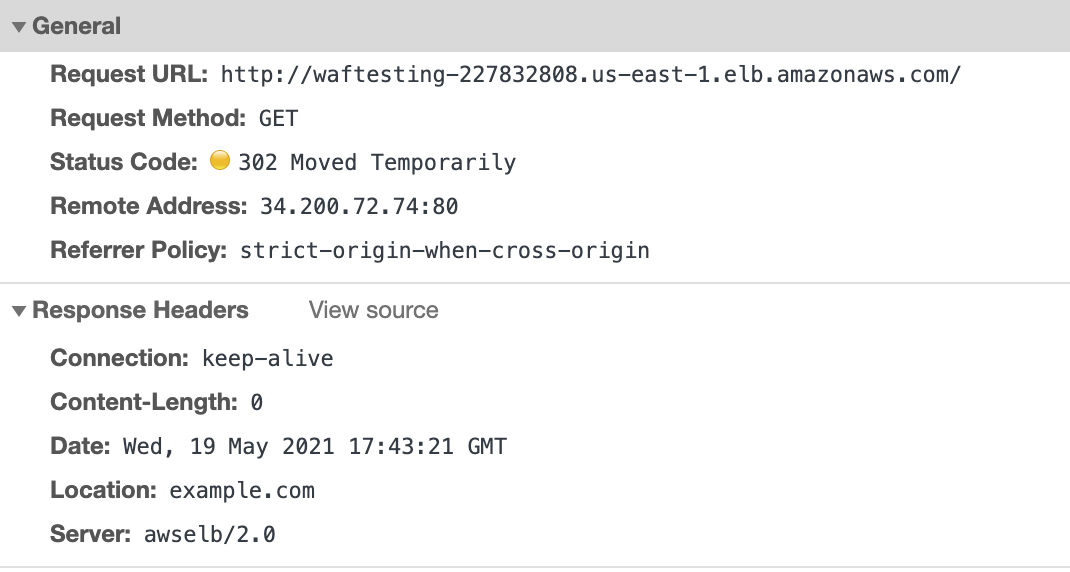
- In the Lambda console, navigate to the sts-ti-demo-s3-lambda function. Update the test event to the following, to mimic a scenario where tenant1 attempts to access other tenants’ objects.
- Choose Test to test the Lambda function with the updated test event. You should see status code 400, and the body of the results should contain an error message.

Figure 13: The results of running the sts-ti-demo-s3-lambda function (negative test)
- Navigate to the sts-ti-demo-pgdb-lambda function and update the test event to the following, to mimic a scenario where tenant1 attempts to access other tenants’ data elements.
- Choose Test to test the Lambda function with the updated test event. You should see status code 400, and the body of the results should contain an error message.

Figure 14: The results of running the sts-ti-demo-pgdb-lambda function (negative test)


Cleaning up
To de-clutter your environment, remove the roles, policies, Lambda functions, Lambda layers, Amazon S3 prefixes, database users, and the database table that you created as part of this exercise. You can choose to delete the S3 bucket, as well as the Aurora PostgreSQL-Compatible database cluster that we mentioned in the Prerequisites section, to avoid incurring future charges.
Update the security group of the Aurora PostgreSQL-Compatible database cluster to remove the inbound rule that you added to allow a PostgreSQL TCP connection (Port 5432) from anywhere (0.0.0.0/0).
Conclusion
By taking advantage of attribute-based access control (ABAC) in IAM, you can more efficiently implement tenant isolation in SaaS applications. The solution we presented here helps to achieve tenant isolation in Amazon S3 and Aurora PostgreSQL-Compatible databases by using ABAC with the pool model of data partitioning.
If you run into any issues, you can use Amazon CloudWatch and AWS CloudTrail to troubleshoot. If you have feedback about this post, submit comments in the Comments section below.
To learn more, see these AWS Blog and AWS Support articles:
- What is ABAC for AWS?
- Multi-tenant data isolation with PostGreSQL Row Level Security
- IAM role-based authentication to Amazon Aurora from serverless applications
- How do I connect to my RDS PostGreSQL instance using IAM authentication?
- Creating and sharing Lambda layers
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.