Post Syndicated from Anusha Challa original https://aws.amazon.com/blogs/big-data/automate-amazon-redshift-cluster-management-operations-using-aws-cloudformation/
Amazon Redshift is the fastest and most widely used cloud data warehouse. Tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift offers many features that enable you to build scalable, highly performant, cost-effective, and easy-to-manage workloads. For example, you can scale an Amazon Redshift cluster up or down based on your workload requirements, pause clusters when not in use to suspend on-demand billing, and enable relocation. You can automate these management activities either using the Amazon Redshift API, AWS Command Line Interface (AWS CLI), or AWS CloudFormation.
AWS CloudFormation helps you model and set up your AWS resources so that you can spend less time managing those resources and more time focusing on your applications that run in AWS. You create a template that describes all the AWS resources that you want, and AWS CloudFormation takes care of provisioning and configuring those resources for you.
In this post, we walk through how to use AWS CloudFormation to automate some of the most common Amazon Redshift cluster management operations:
- Create an Amazon Redshift cluster via the following methods:
- Restore a cluster from a snapshot
- Create an encrypted Amazon Redshift cluster
- Perform cluster management operations:
- Pause or resume a cluster
- Perform elastic resize or classic resize
- Add or remove Identity and Access Management (IAM) roles to cluster permissions
- Rotate encryption keys
- Modify snapshot retention period for automated and manual snapshots
- Enable or disable snapshot copy to another AWS Region
- Create a parameter group with required workload management (WLM) configuration and associate it to the Amazon Redshift cluster
- Enable concurrency scaling by modifying WLM configuration
- Enable or disable audit logging
For a complete list of operations that you can automate using AWS CloudFormation, see Amazon Redshift resource type reference.
Benefits of using CloudFormation templates
Many of our customers build fully automated production environments and use AWS CloudFormation to aid automation. AWS CloudFormation offers an easy way to create and manage AWS Infrastructure, by treating infrastructure as code. CloudFormation templates create infrastructure resources in a group called a stack, and allow you to define and customize all components. CloudFormation templates introduce the ability to implement version control, and the ability to quickly and reliably replicate your infrastructure. This significantly simplifies your continuous integration and continuous delivery (CI/CD) pipelines and keeps multiple environments in sync. The CloudFormation template becomes a repeatable, single source of truth for your infrastructure. You can create CloudFormation templates in YAML and JSON formats. The templates provided in this post use YAML format. Amazon Redshift clusters are one of the resources that you can provision and manage using AWS CloudFormation.
Create an Amazon Redshift cluster using AWS CloudFormation
With AWS CloudFormation, you can automate Amazon Redshift cluster creation. In this section, we describe two additional ways of creating Amazon Redshift clusters: by restoring from an existing snapshot or creating using default options. In the next section, we describe how you can manage the lifecycle of a cluster by performing cluster management operations using AWS CloudFormation.
Restore an Amazon Redshift cluster from a snapshot
Snapshots are point-in-time backups of a cluster. Amazon Redshift periodically takes automated snapshots of the cluster. You can also take a snapshot manually any time. A snapshot contains data from any databases that are running on the cluster. Snapshots enable data protection, and you can also use them to build new environments to perform application testing, data mining, and more. When you start a new development or enhancement project, you may want to build a new Amazon Redshift cluster that has the same code and data as that of your production, so you can develop and test your code there before deploying it. To do this, create the new cluster by restoring from your production cluster’s snapshot.
You can use AWS CloudFormation to automate the restore operation. If you have multiple projects with different timelines or requirements, you can build multiple Amazon Redshift clusters in an automatic and scalable fashion using AWS CloudFormation.
To create a new Amazon Redshift cluster by restoring from an existing snapshot, create a CloudFormation stack using a CloudFormation template that has the AWS::Redshift::Cluster resource with the following mandatory properties:
- SnapshotIdentifier – The name of the snapshot from which to create the new cluster
- ClusterIdentifier – A unique identifier of your choice for the cluster
- NodeType – The node type to be provisioned for the cluster
- ClusterType – The type of the cluster, either single-node or multi-node (recommended for production workloads)
- NumberofNodes – The number of compute nodes in the cluster
- DBName – The name of the first database to be created in the new cluster
- MasterUserName – The user name associated with the admin user account for the cluster that is being created
- MasterUserPassword – The password associated with the admin user account for the cluster that is being created
The following is a sample CloudFormation template that restores a snapshot with identifier cfn-blog-redshift-snapshot and creates a two-node Amazon Redshift cluster with identifier cfn-blog-redshift-cluster and node type ra3.4xlarge:
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
SnapshotIdentifier: "cfn-blog-redshift-snapshot"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Create an encrypted Amazon Redshift cluster
You can enable database encryption for your clusters to protect data at rest.
Use the following sample CloudFormation template to create an encrypted Amazon Redshift cluster. This template has basic properties only to make this walkthrough easy to understand. For your production workload, we recommend following the best practices as described in the post Automate Amazon Redshift cluster creation using AWS CloudFormation.
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password. Must be 8-64 characters long. Must contain at least one uppercase letter, one lowercase letter and one number. Can be any printable ASCII character except “/”, ““”, or “@”.
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
In AWS CloudFormation, create a stack using this template. When the creation of CloudFormation stack is complete, you can see a new encrypted Amazon Redshift cluster called cfn-blog-redshift-cluster. For the rest of this post, we use this CloudFormation template as the base and explore how to modify the template to perform various Amazon Redshift management operations.
To create a new CloudFormation stack that uses the preceding template via the AWS CloudFormation console, complete the following steps:
- On the AWS CloudFormation console, choose Create Stack.
- On the drop-down menu, choose With new resources (standard).
- For Prepare template, choose Template is ready.
- For Specify template, choose Upload a template file.
- Save the provided CloudFormation template in a .yaml file and upload it.
- Choose Next.
- Enter a name for the stack. For this post, we use
RedshiftClusterStack-CFNBlog.
- Choose Next.
- Choose Next again.
- Choose Create Stack.
To create the CloudFormation stack using the AWS CLI, run the following command:
aws cloudformation create-stack \
--stack-name RedshiftClusterStack-CFNBlog \
--template-body <<CloudFormation template’s file name>> \
The status of the stack changes to CREATE_IN_PROGRESS. After the Amazon Redshift cluster is created, the status changes to CREATE_COMPLETE. Navigate to the Amazon Redshift console to verify that the cluster is created and the status is Available.

Perform cluster management operations
Amazon Redshift customers have the flexibility to perform various cluster operations to implement workload security, perform cost-optimization, and manage scale. Often, we see our customers perform these operations in all their environments, such as DEV, QA, and PROD, to keep them in sync. You can automate these operations using CloudFormation stack updates by updating the CloudFormation template you used to create the cluster.
To perform these management operations using CloudFormation stack updates, you can create your initial CloudFormation stack in one of the two ways:
- If your cluster isn’t already created, you can create it using AWS CloudFormation.
- If you have an existing cluster, create a CloudFormation stack with the using existing resources option. Provide a template of the existing cluster and have a CloudFormation stack associated with the resource.
Each subsequent cluster management operation is an update to the base CloudFormation stack’s template. CloudFormation stack updates enable you to make changes to a stack’s resources by performing an update to the stack instead of deleting it and creating a new stack. Update to either add, modify, or remove relevant property values in the AWS::Redshift::Cluster resource to trigger the respective Amazon Redshift cluster management operation. AWS CloudFormation compares the changes you submit with the current state of your stack and applies only the changes. For a summary of the update workflow, see How does AWS CloudFormation work?
The following steps describe how to perform a CloudFormation stack update on the RedshiftClusterStack-CFNBlog stack that you created in the previous section.
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Choose the stack you want to update (for this post,
RedshiftClusterStack-CFNBlog).
- Choose Update.
- In the Prerequisite – Prepare template section, choose Replace current template.
- For Specify template, choose Upload a template file.
- Make changes to your current CloudFormation template based on the operation you wish to perform on the Amazon Redshift cluster.
- Save the updated CloudFormation template .yaml file and upload it.
- Choose Next.
- Choose Next again.
- Choose Next again.
- Choose Update Stack.
To update CloudFormation stack using the AWS CLI, run the following command:
aws cloudformation update-stack \
--stack-name RedshiftClusterStack-CFNBlog \
--template-body <<Updated CloudFormation template’s file name>> \
In this section, we look at some AWS CloudFormation properties available for Amazon Redshift clusters and dive deep to understand how to update the CloudFormation template and add, remove, or modify these properties to automate some of the most common cluster management operations. We use the RedshiftClusterStack-CFNBlog stack that you created in the previous section as an example.
Pause or resume cluster
If an Amazon Redshift cluster isn’t being used for a certain period of time, you can pause it easily and suspend on-demand billing. For example, you can suspend on-demand billing on a cluster that is used for development when it’s not in use. While the cluster is paused, you’re only charged for the cluster’s storage. This adds significant flexibility in managing operating costs for your Amazon Redshift clusters. You can resume a paused cluster when you’re ready to use it. To pause a cluster, update the cluster’s current CloudFormation stack template to add a new property called ResourceAction with the value pause-cluster. To pause the cluster created using the RedshiftClusterStack-CFNBlog stack, you can perform a stack update and use the following updated CloudFormation template:
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
#Added this property to pause cluster
ResourceAction: "pause-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Follow the steps in the previous section to update the stack. When the stack update operation is in progress, the cluster’s status changes from Available to Modifying, Pausing.

When the stack update is complete, the cluster’s status changes to Paused.
When you’re ready to use the cluster, you can resume it. To resume the cluster, update the cluster’s current CloudFormation stack template and change the value of the ResourceAction property to resume-cluster. You can use the following template to perform a stack update operation to resume the cluster created using the RedshiftClusterStack-CFNBlog stack:
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
#Added this property to resume cluster
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Follow the steps in the previous section to update the stack. When the stack update is in progress, the cluster’s status changes from Paused to Modifying, Resuming.

When the stack update is complete, the cluster’s status changes to Available.
Perform elastic resize or classic resize
Data warehouse workloads often have changing needs. You may add a new line of business and thereby ingest more data into the data warehouse, or you may have a new analytics application for your business users and add new ETL processes to support it. When your compute requirements change due to changing needs, you can resize your Amazon Redshift cluster using one of the following approaches:
- Elastic resize – This changes the node type, number of nodes, or both. Typically, it completes within 10–15 minutes when adding or removing nodes of the same type. Cross-instance elastic resize can take up to 45 minutes. We recommend using elastic resize whenever possible, because it completes much more quickly than classic resize. Elastic resize has some growth and reduction limits on the number of nodes.
- Classic resize – You can also use classic resize to change the node type, number of nodes, or both. We recommend this option only when you’re resizing to a configuration that isn’t available through elastic resize, because it takes considerably more time depending on your data size.
You can automate both elastic resize and classic resize operations on Amazon Redshift clusters using AWS CloudFormation. The default resize operation when initiated using a CloudFormation stack update is elastic resize. If elastic resize isn’t possible for your configuration, AWS CloudFormation throws an error. You can force the resize operation to be classic resize by specifying the value of the property Classic to Boolean true in the CloudFormation template provided in the update stack operation. If you don’t provide this parameter or set the value to false, the resize type is elastic. To initiate the resize operation, update the cluster’s current CloudFormation stack template and change the value of NodeType and NumberOfNodes properties as per your requirement.
To perform an elastic resize from the initial two-node RA3 4xlarge configuration to NumberOfNodes:2 and NodeType:ra3.16xlarge configuration on the Amazon Redshift cluster cfn-blog-redshift-cluster, you can update the current template of the RedshiftClusterStack-CFNBlog stack as shown in the following CloudFormation template:
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
#Modified the below 2 properties to perform elastic resize
NodeType: "ra3.16xlarge"
NumberOfNodes: "2"
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Alternatively, if you want to force this resize to be a classic resize, use the following CloudFormation template to update the RedshiftClusterStack-CFNBlog stack. This template has an additional property, Classic with Boolean value true, to initiate classic resize, in addition to having updated NodeType and NumberOfNodes properties.
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
#Modified the below 3 properties to perform classic resize
NodeType: "ra3.16xlarge"
NumberOfNodes: "2"
Classic: true
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Follow the steps earlier in this post to update the stack. For both elastic resize and classic resize, when the stack update is in progress, the cluster’s status changes from Available to Resizing.
Add or remove IAM roles to cluster permissions
Your Amazon Redshift cluster needs permissions to access other AWS services on your behalf. For the required permissions, add IAM roles to cluster permissions. You can add up to 10 IAM roles. For instructions on creating roles, see Create an IAM role.
To add IAM roles to the cluster, update the cluster’s current CloudFormation stack template and add the IamRoles property with a list of IAM roles you want to add. For example, to add IAM roles cfn-blog-redshift-role-1 and cfn-blog-redshift-role-2 to the cluster cfn-blog-redshift-cluster, you can update the RedshiftClusterStack-CFNBlog stack using the following CloudFormation template. In this template, the new array property IamRoles has been added with values cfn-blog-redshift-role-1 and cfn-blog-redshift-role-2.
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
#Added IAMRoles property with ARNs for 2 roles
IamRoles: [
!Sub "arn:${AWS::Partition}:iam::${AWS::AccountId}:role/cfn-blog-redshift-role-1",
!Sub "arn:${AWS::Partition}:iam::${AWS::AccountId}:role/cfn-blog-redshift-role-2"
]
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Now, if you want to remove the IAM role cfn-blog-redshift-role-2 from the cfn-blog-redshift-cluster cluster, you can perform another CloudFormation stack update on RedshiftClusterStack-CFNBlog using the following CloudFormation template. This template contains only those IAM roles you want to retain.
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
#Updated IAMRoles property to remove role-2
IamRoles: [
!Sub "arn:${AWS::Partition}:iam::${AWS::AccountId}:role/cfn-blog-redshift-role-1"
]
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Follow the steps earlier in this post to update the stack. When the stack update is in progress, the cluster’s status changes from Available to Available, Modifying.

Navigate to cluster’s properties tab and the Cluster Permissions section to validate that the IAM roles were associated to the cluster after the stack update is complete.
Rotate encryption keys on the cluster
You can enable database encryption for your Amazon Redshift clusters to protect data at rest. You can rotate encryption keys using AWS CloudFormation. To rotate encryption keys, update the base CloudFormation template to add the RotateEncryptionKey property and set it to Boolean true. For example, you can use the following CloudFormation template to rotate the encryption key for cfn-blog-redshift-cluster by performing an update on the CloudFormation stack RedshiftClusterStack-CFNBlog:
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
#Added RotateEncryptionKey property
RotateEncryptionKey: true
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Follow the steps earlier in this post to update the stack. When the stack update is in progress, the cluster’s status changes from Available to Modifying, Rotating Keys. It takes approximately 2 minutes to rotate the encryption keys.

Modify the snapshot retention period for automated and manual snapshots
Amazon Redshift takes periodic automated snapshots of the cluster. By default, automated snapshots are retained for 24 hours. You can change the retention period of automated snapshots to 0–35 days. Amazon Redshift deletes automated snapshots at the end of a snapshot’s retention period, when you disable automated snapshots for the cluster or delete the cluster.
If you set the automated snapshot retention period to 0 days, the automated snapshots feature is disabled and any existing automated snapshots are deleted. Exercise caution before setting the automated snapshot retention period to 0.
You can take manual snapshots of the cluster any time. By default, manual snapshots are retained indefinitely, even after you delete the cluster. You can also specify the retention period when you create a manual snapshot. When the snapshot retention period is modified on automated snapshots, it applies to both existing and new automated snapshots. In contrast, when the snapshot retention period is modified on manual snapshots, it applies to new manual snapshots only.
To modify the retention period on snapshots, update your current cluster’s CloudFormation stack template. Add or update the AutomatedSnapshotRetentionPeriod property with an integer value (must be between 0–35) indicating the new retention period in days for automated snapshots, and the ManualSnapshotRetentionPeriod property with an integer value (must be between 1–3653) indicating the new retention period in days for manual snapshots.
The following CloudFormation template sets the AutomatedSnapshotRetentionPeriod to 7 days and ManualSnapshotRetentionPeriod to 90 days on cfn-blog-redshift-cluster when you update the current CloudFormation stack RedshiftClusterStack-CFNBlog:
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
#Add snapshot retention properties
AutomatedSnapshotRetentionPeriod: 7
ManualSnapshotRetentionPeriod: 90
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Enable or disable snapshot copies to another Region
You can configure your Amazon Redshift cluster to copy all new manual and automated snapshots for a cluster to another Region. You can choose how long to keep copied automated or manual snapshots in the destination Region. If the cluster is encrypted, because AWS Key Management Service (AWS KMS) keys are specific to a Region, you must configure a snapshot copy grant for a primary key in the destination Region. For information on how to create a snapshot copy grant, see Copying AWS KMS–encrypted snapshots to another AWS Region. Make sure that the snapshot copy grant is created before enabling snapshot copy to another Region using CloudFormation templates.
To enable snapshot copy to another Region, update your current cluster’s CloudFormation stack template and add or update the following properties:
- DestinationRegion – Required to enable snapshot copy. It specifies the destination Region that snapshots are automatically copied to.
- SnapshotCopyRetentionPeriod – Optional. Modifies the number of days to retain snapshots in the destination Region. If this property is not specified, the retention period is the same as that of the source Region. By default, this operation only modifies the retention period of existing and new copied automated snapshots. To change the retention period of copied manual snapshots using this property, set the
SnapshotCopyManual property to true.
- SnapshotCopyManual – Indicates whether to apply the snapshot retention period to newly copied manual snapshots instead of automated snapshots. If you set this option, only newly copied manual snapshots have the new retention period.
- SnapshotCopyGrantName – The name of the snapshot copy grant.
To copy snapshots taken from cfn-blog-redshift-cluster into the Region us-west-1 and to modify the retention period of the newly copied manual snapshots to 90 days, update the current CloudFormation stack RedshiftClusterStack-CFNBlog with the following CloudFormation template:
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
#Add cross-region snapshot copy properties
DestinationRegion: "us-west-1"
SnapshotCopyGrantName: "cfn-blog-redshift-cross-region-snapshot-copy-grant"
SnapshotCopyManual: true
SnapshotCopyRetentionPeriod: 90
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
To disable cross-Region snapshot copy, update your current CloudFormation stack’s template and remove the properties DestinationRegion, SnapshotCopyRetentionPeriod, SnapshotCopyManual and SnapshotCopyGrantName.
Create a parameter group with required WLM configuration and assign it to an Amazon Redshift cluster
You can use AWS CloudFormation to create an Amazon Redshift parameter group and associate it to an Amazon Redshift cluster. If you don’t associate a parameter group, the default parameter group is assigned, which has the defaults for parameter values and WLM configuration. When you create a new parameter group, it also has the defaults for parameters, unless you override them. The following CloudFormation template overrides the default values for the require_ssl and wlm_json_configuration parameters. The WLM configuration is specified in JSON format. In this template, automatic WLM configuration is defined on cfn-blog-redshift-cluster with three queues: etl_queue, reporting_queue, and the default queue, with the following specifications:
- Priority for
etl_queue is set to highest. It’s configured to route all queries run by users belonging to the group named etl_group to etl_queue.
- Priority for
reporting_queue is set to normal. It’s configured to route all queries run by users belonging to any group name with the word report in it or any query having a query group with the word report in it to the reporting_queue.
- The following three query monitoring rules are defined to protect
reporting_queue from bad queries:
- When query runtime is greater than 7,200 seconds (2 hours), the query is stopped.
- If a query has a nested loop join with more than 1,000,000 rows, its priority is changed to lowest.
- If any query consumes more than 50% CPU utilization, it is logged.
- All other queries are routed to the default queue. Priority for
default_queue is set to lowest.
- The following three query monitoring rules are defined to protect the default queue from bad queries:
- If a query has a nested loop join with more than 1,000,000 rows, it is stopped.
- If a query has a large return set and is returning more than 1,000,000 rows, it is stopped.
- If more than 10 GB spilled to disk for a query, it is stopped.
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
#Add parameter group resource
RedshiftClusterParameterGroup:
Type: "AWS::Redshift::ClusterParameterGroup"
Properties:
Description: "CFNBlog-Redshift-Cluster-parameter-group"
ParameterGroupFamily: "redshift-1.0"
Parameters:
-
ParameterName: "require_ssl"
ParameterValue: "true"
-
ParameterName: "wlm_json_configuration"
ParameterValue: "[
{
\"name\":\"etl_queue\",
\"user_group\":[\"etl_user\"],
\"auto_wlm\":true,
\"queue_type\":\"auto\",
\"priority\":\"highest\"
},
{
\"name\":\"reporting_queue\",
\"user_group\":[\"%report%\"],
\"user_group_wild_card\":1,
\"query_group\":[\"%report%\"],
\"query_group_wild_card\":1,
\"auto_wlm\":true,
\"queue_type\":\"auto\",
\"priority\":\"normal\",
\"rules\":[
{
\"rule_name\":\"timeout_2hours\",
\"predicate\":[
{
\"metric_name\":\"query_execution_time\",
\"operator\":\">\",\"value\":7200
}
],
\"action\":\"abort\"
},
{
\"rule_name\":\"nested_loop_reporting\",
\"action\":\"change_query_priority\",
\"predicate\":[
{
\"metric_name\":\"nested_loop_join_row_count\",
\"operator\":\">\",\"value\":1000000
}
],
\"value\":\"lowest\"
},
{
\"rule_name\":\"expensive_computation\",
\"predicate\":[
{
\"metric_name\":\"query_cpu_usage_percent\",
\"operator\":\">\",\"value\":50
}
],
\"action\":\"log\"
}
]
},
{
\"name\":\"Default queue\",
\"auto_wlm\":true,
\"priority\":\"lowest\",
\"rules\":[
{
\"rule_name\":\"nested_loop\",
\"action\":\"abort\",
\"predicate\":[
{
\"metric_name\":\"nested_loop_join_row_count\",
\"operator\":\">\",\"value\":1000000
}
]
},
{
\"rule_name\":\"large_return_set\",
\"action\":\"abort\",
\"predicate\":[
{
\"metric_name\":\"return_row_count\",
\"operator\":\">\",\"value\":1000000
}
]
},
{
\"rule_name\":\"large_spill_to_disk\",
\"action\":\"abort\",
\"predicate\":[
{
\"metric_name\":\"query_temp_blocks_to_disk\",
\"operator\":\">\",
\"value\":10000
}
]
}
]
},
{
\"short_query_queue\":true
}
]"
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
#Add parameter to associate parameter group
ClusterParameterGroupName: !Ref RedshiftClusterParameterGroup
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Enable concurrency scaling by modifying WLM configuration
Concurrency scaling is an autoscaling feature of Amazon Redshift that enables you to support virtually unlimited concurrent users. When you turn on concurrency scaling, Amazon Redshift automatically adds additional cluster capacity to process an increase in both read queries and write queries.
You can enable concurrency scaling at an individual WLM queue level. To enable concurrency scaling using AWS CloudFormation, update you current stack’s CloudFormation template and change the parameter value for wlm_json_configuration to add a property called concurrency_scaling and set its value to auto.
The following CloudFormation template sets concurrency scaling to auto on reporting_queue. It also overrides the value for the max_concurrency_scaling_clusters parameter from default 1 to 5.
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftClusterParameterGroup:
Type: "AWS::Redshift::ClusterParameterGroup"
Properties:
Description: "CFNBlog-Redshift-Cluster-parameter-group"
ParameterGroupFamily: "redshift-1.0"
Parameters:
-
ParameterName: "require_ssl"
ParameterValue: "true"
#add parameter to change default value for max number of concurrency scaling clusters parameter
-
ParameterName: "max_concurrency_scaling_clusters"
ParameterValue: "5"
#Updated wlm configuration to set concurrency_scaling to auto
-
ParameterName: "wlm_json_configuration"
ParameterValue: "[
{
\"name\":\"etl_queue\",
\"user_group\":[\"etl_user\"],
\"auto_wlm\":true,
\"queue_type\":\"auto\",
\"priority\":\"highest\"
},
{
\"name\":\"reporting_queue\",
\"user_group\":[\"%report%\"],
\"user_group_wild_card\":1,
\"query_group\":[\"%report%\"],
\"query_group_wild_card\":1,
\"auto_wlm\":true,
\"queue_type\":\"auto\",
\"priority\":\"normal\",
\"concurrency_scaling\":\"auto\"
},
{
\"name\":\"Default queue\",
\"auto_wlm\":true,
\"priority\":\"lowest\"
},
{
\"short_query_queue\":true
}
]"
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
ClusterParameterGroupName: !Ref RedshiftClusterParameterGroup
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Enable or disable audit logging
When you enable audit logging, Amazon Redshift creates and uploads the connection log, user log, and user activity logs to Amazon Simple Storage Service (Amazon S3). You can automate enabling and disabling audit logging using AWS CloudFormation. To enable audit logging, update the base CloudFormation template to add the LoggingProperties property with the following sub-properties:
- BucketName – The name of an existing S3 bucket where the log files are to be stored.
- S3KeyPrefix – The prefix applied to the log file names
Also update the parameter group to change the value of the enable_user_activity_logging parameter to true.
To enable audit logging on cfn-blog-redshift-cluster and deliver log files to BucketName: cfn-blog-redshift-cluster-audit-logs with the S3KeyPrefix:cfn-blog, update the current CloudFormation stack RedshiftClusterStack-CFNBlog with the following CloudFormation template:
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftClusterParameterGroup:
Type: "AWS::Redshift::ClusterParameterGroup"
Properties:
Description: "CFNBlog-Redshift-Cluster-parameter-group"
ParameterGroupFamily: "redshift-1.0"
Parameters:
-
ParameterName: "require_ssl"
ParameterValue: "true"
-
ParameterName: "max_concurrency_scaling_clusters"
ParameterValue: "5"
#add parameter to enable user activity logging
-
ParameterName: "enable_user_activity_logging"
ParameterValue: "true"
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
NodeType: "ra3.4xlarge"
NumberOfNodes: "2"
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
#Add LoggingProperties and its sub-properties
LoggingProperties:
BucketName: "cfn-blog-redshift-cluster-audit-logs"
S3KeyPrefix: "cfn-blog/"
ClusterParameterGroupName: !Ref RedshiftClusterParameterGroup
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Follow the steps earlier in this post to update the stack. To disable audit logging, update the cluster’s CloudFormation stack template and remove the LoggingProperties property.
Concurrent operations
You can perform multiple cluster management operations using a single CloudFormation stack update. For example, you can perform elastic resize and rotate encryption keys on the cfn-blog-redshift-cluster using the following CloudFormation template. This template updates the values for NodeType and NumberOfNodes, which results in an elastic resize operation, and also sets the RotateEncryptionKey parameter value to Boolean true, which results in the encryption key rotation.
AWSTemplateFormatVersion: 2010-09-09
Description: Redshift CFN Blog Cluster Stack
Parameters:
MasterUserPasswordParam:
NoEcho: true
Type: String
Description: Enter Master User Password
Resources:
RedshiftCluster:
Type: "AWS::Redshift::Cluster"
Properties:
ResourceAction: "resume-cluster"
ClusterIdentifier: "cfn-blog-redshift-cluster"
ClusterType: "multi-node"
# Change Node type, number of nodes and rotate encryption
NodeType: "ra3.16xlarge"
NumberOfNodes: "2"
RotateEncryptionKey: true
DBName: "dev"
MasterUsername: "username"
Encrypted: true
MasterUserPassword: !Ref MasterUserPasswordParam
Outputs:
ClusterName:
Value: !Ref RedshiftCluster
Conclusion
You have now learned how to automate management operations on Amazon Redshift clusters using AWS CloudFormation. For a full list of properties you can update using this process, see Properties. For more sample CloudFormation templates, see Amazon Redshift template snippets.
About the Authors
 Anusha Challa is a Senior Analytics Specialist Solutions Architect at AWS. She has over a decade of experience in building large-scale data warehouses, both on-premises and in the cloud. She provides architectural guidance to our customers on end-to-end data warehousing implementations and migrations.
Anusha Challa is a Senior Analytics Specialist Solutions Architect at AWS. She has over a decade of experience in building large-scale data warehouses, both on-premises and in the cloud. She provides architectural guidance to our customers on end-to-end data warehousing implementations and migrations.
Shweta Yakkali is a Software Engineer for Amazon Redshift, where she works on developing features for Redshift Cloud infrastructure. She is passionate about innovations in cloud infrastructure and enjoys learning new technologies and building enhanced features for Redshift. She holds M.S in Computer Science from Rochester Institute of Technology, New York. Outside of work, she enjoys dancing, painting and playing badminton.
 Zirui Hua is a Software Development Engineer for Amazon Redshift, where he works on developing next generation features for Redshift. His main focuses are on networking and proxy of database. Outside of work, he likes to play tennis and basketball.
Zirui Hua is a Software Development Engineer for Amazon Redshift, where he works on developing next generation features for Redshift. His main focuses are on networking and proxy of database. Outside of work, he likes to play tennis and basketball.









































































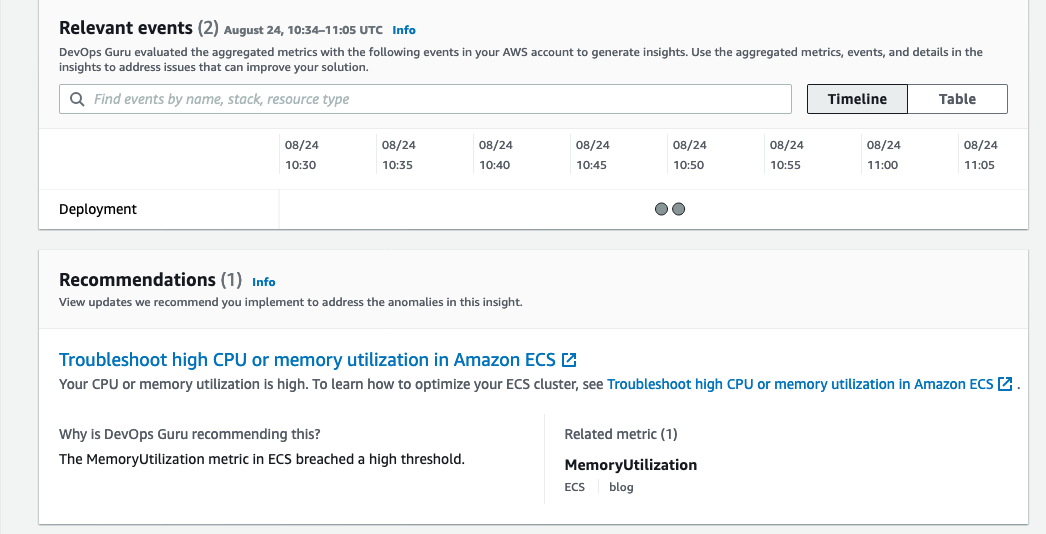
![Architecture Diagram showing the service “Test” using the container “brickwall-maker” with a desired count of two. The two ECS Task’s vended metrics are then processed by CloudWatch Container Insights. Both, CloudWatch Container Insights and CloudTrail, are ingested by Amazon DevOps Guru which then makes detected insights available to the user. [Image: DevOpsGuruBlog1.png]V1: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/LdkTqbmlZ8uNj7A44pZbnw?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz) V2: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/SvsNTJLEJOHHBls_kV7EwA?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz) V3: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/DqKTxtQvmOLrzM3KcF_oTg?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz)](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2021/10/29/DevOpsGuruBlog1-1-1.png)