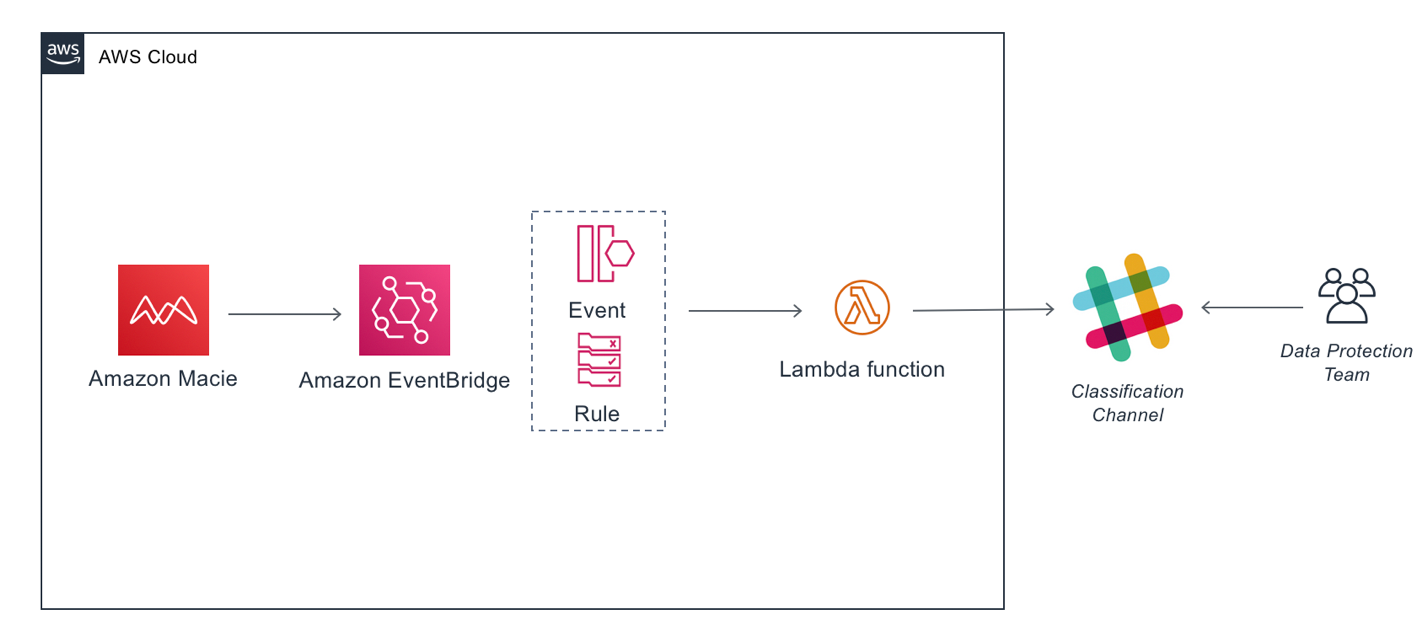
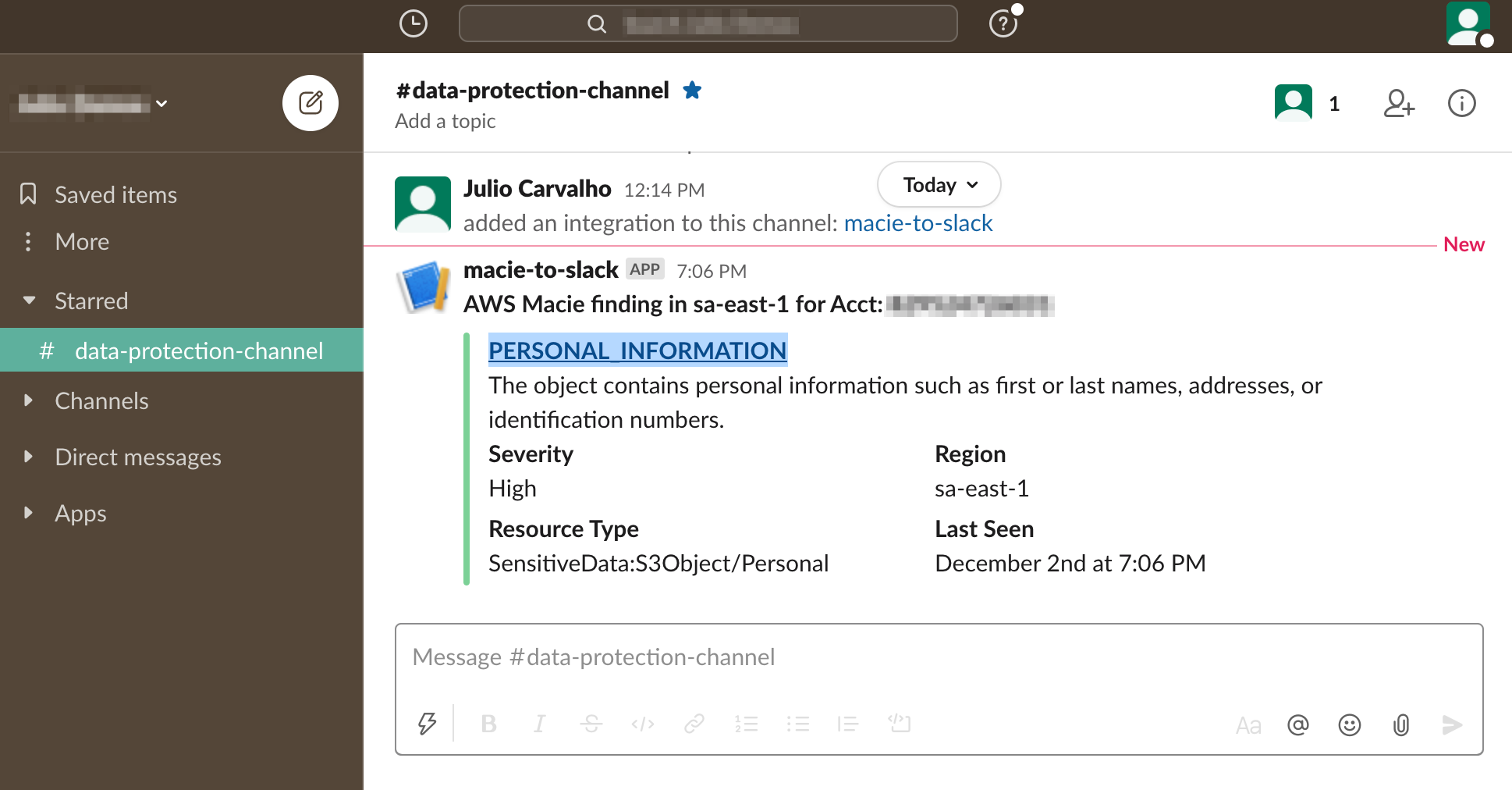
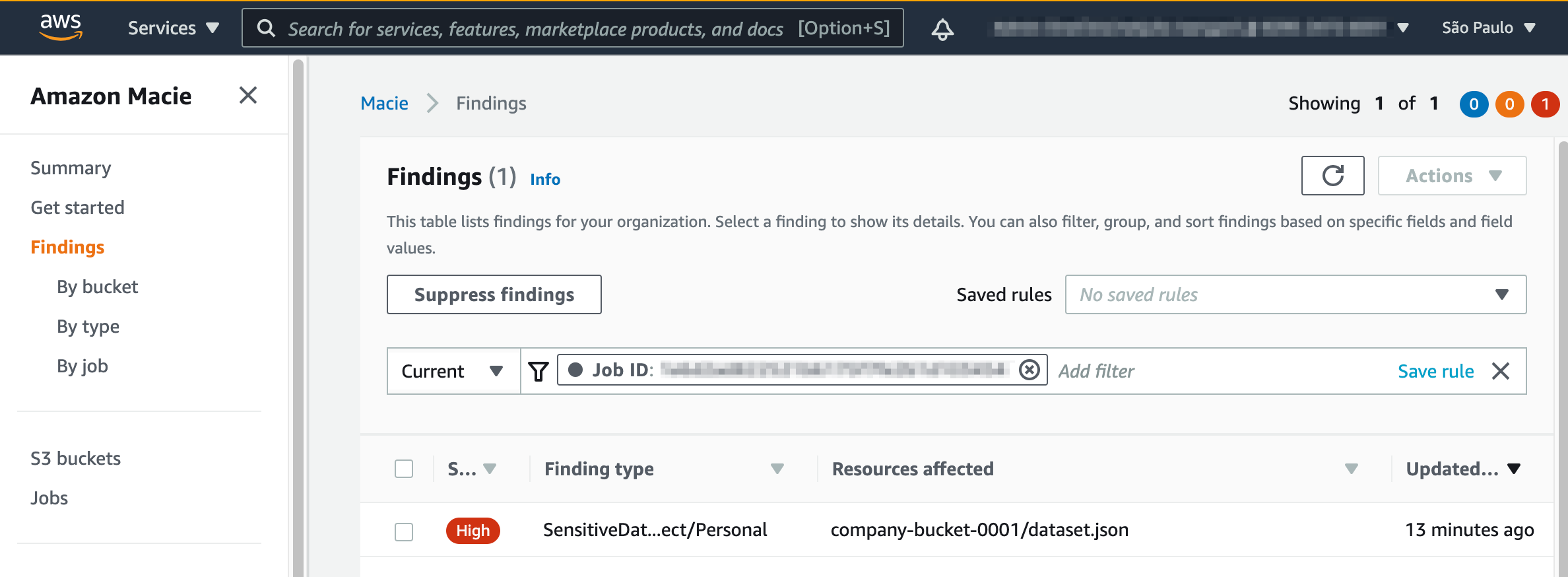
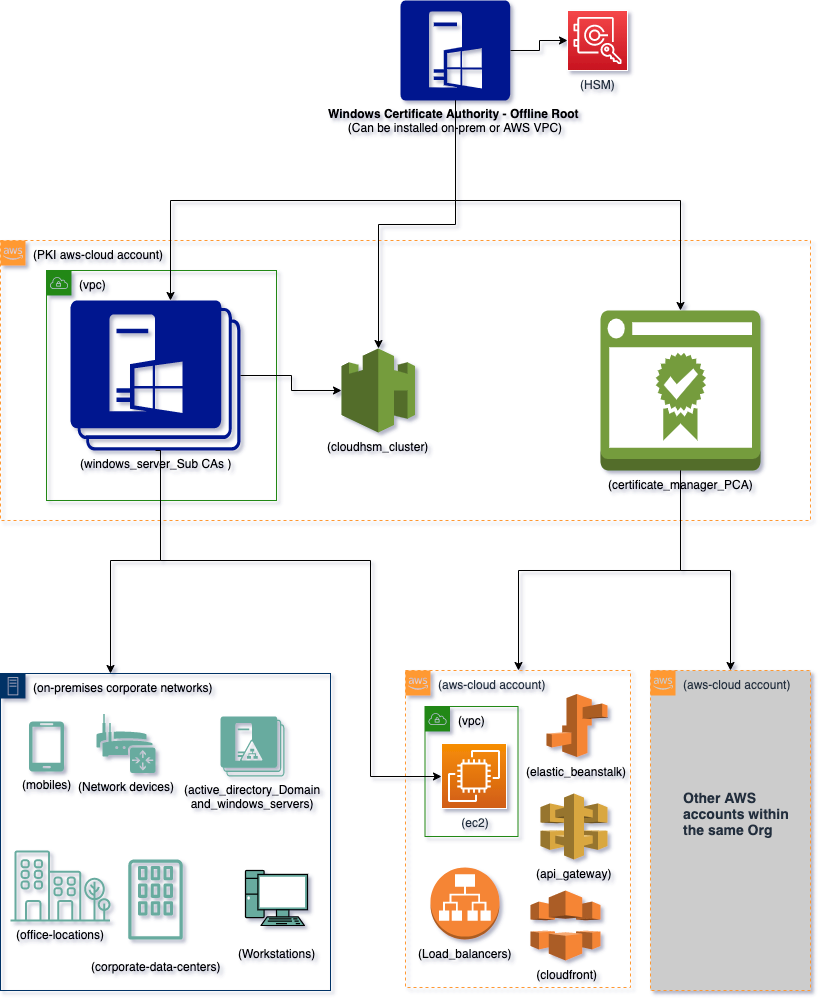
Post Syndicated from John Hildebrandt original https://aws.amazon.com/blogs/security/approaches-to-meeting-australian-government-gateway-requirements-on-aws/
Australian Commonwealth Government agencies are subject to specific requirements set by the Protective Security Policy Framework (PSPF) for securing connectivity between systems that are running sensitive workloads, and for accessing less trusted environments, such as the internet. These agencies have often met the requirements by using some form of approved gateway solution that provides network-based security controls.
This post examines the types of controls you need to provide a gateway that can meet Australian Government requirements defined in the Protective Security Policy Framework (PSPF) and the challenges of using traditional deployment models to support cloud-based solutions. PSPF requirements are mandatory for non-corporate Commonwealth entities, and represent better practice for corporate Commonwealth entities, wholly-owned Commonwealth companies, and state and territory agencies. We discuss the ability to deploy gateway-style solutions in the cloud, and show how you can meet the majority of gateway requirements by using standard cloud architectures plus services. We provide guidance on deploying gateway solutions in the AWS Cloud, and highlight services that can support such deployments. Finally, we provide an illustrative AWS web architecture pattern to show how to meet the majority of gateway requirements through Well-Architected use of services.
Australian Government gateway requirements
The Australian Government Protective Security Policy Framework (PSPF) highlights the requirement to use secure internet gateways (SIGs) and references the Australian Information Security Manual (ISM) control framework to guide agencies. The ISM has a chapter on gateways, which includes the following recommendations for gateway architecture and operations:
- Provide a central control point for traffic in and out of the system.
- Inspect and filter traffic.
- Log and monitor traffic and gateway operation to a secure location. Use appropriate security event alerting.
- Use secure administration practices, including multi-factor authentication (MFA) access control, minimum privilege, separation of roles, and network segregation.
- Perform appropriate authentication and authorization of users, traffic, and equipment. Use MFA when possible.
- Use demilitarized zone (DMZ) patterns to limit access to internal networks.
- Test security controls regularly.
- Set up firewalls between security domains and public network infrastructure.
Since the PSPF references the ISM, the agency should apply the overall ISM framework to meet ISM requirements such as governance and security patching for the environment. The ISM is a risk-based framework, and the risk posture of the workload and organization should inform how to assess the controls. For example, requirements for authentication of users might be relaxed for a public-facing website.
In traditional on-premises environments, some Australian Government agencies have mandated centrally assessed and managed gateway capabilities in order to drive economies of scale across multiple government agencies. However, the PSPF does provide the option for gateways used only by a single government agency to undertake their own risk-based assessment for the single agency gateway solution.
Other government agencies also have specific requirements to connect with cloud providers. For example, the U.S. Government Office of Management and Budget (OMB) mandates that U.S. government users access the cloud through a specific agency connection.
Connecting to the cloud through on-premises gateways
Given the existence of centrally managed off-cloud gateways, one approach by customers has been to continue to use these off-cloud gateways and then connect to AWS through the on-premises gateway environment by using AWS Direct Connect, as shown in Figure 1.

Figure 1: Connecting to the AWS Cloud through an agency gateway and then through AWS Direct Connect
Although this approach does work, and makes use of existing gateway capability, it has a number of downsides:
- A potential single point of failure: If the on-premises gateway capability is unavailable, the agency can lose connectivity to the cloud-based solution.
- Bandwidth limitations: The agency is limited by the capacity of the gateway, which might not have been developed with dynamically scalable and bandwidth-intensive cloud-based workloads in mind.
- Latency issues: The requirement to traverse multiple network hops, in addition to the gateway, will introduce additional latency. This can be particularly problematic with architectures that involve API communications being sent back and forth across the gateway environment.
- Castle-and-moat thinking: Relying only on the gateway as the security boundary can discourage agencies from using and recognizing the cloud-based security controls that are available.
Some of these challenges are discussed in the context of US Trusted Internet Connection (TIC) programs in this whitepaper.
Moving gateways to the cloud
In response to the limitations discussed in the last section, both customers and AWS Partners have built gateway solutions on AWS to meet gateway requirements while remaining fully within the cloud environment. See this type of solution in Figure 2.

Figure 2: Moving the gateway to the AWS Cloud
With this approach, you can fully leverage the scalable bandwidth that is available from the AWS environment, and you can also reduce latency issues, particularly when multiple hops to and from the gateway are required. This blog post describes a pilot program in the US that combines AWS services and AWS Marketplace technologies to provide a cloud-based gateway.
You can use AWS Transit Gateway (released after the referenced pilot program) to provide the option to centralize such a gateway capability within an organization. This makes it possible to utilize the gateway across multiple cloud solutions that are running in their own virtual private clouds (VPCs) and accounts. This approach also facilitates the principle of the gateway being the central control point for traffic flowing in and out. For more information on using AWS Transit Gateway with security appliances, see the Appliance VPC topic in the Amazon VPC documentation.
More recently, AWS has released additional services and features that can assist with delivering government gateway requirements.
Elastic Load Balancing Gateway Load Balancer provide the capability to deploy third-party network appliances in a scalable fashion. With this capability, you can leverage existing investment in licensing, use familiar tooling, reuse intellectual property (IP) such as rule sets, and reuse skills, because staff are already trained in configuring and managing the chosen device. You have one gateway for distributing traffic across multiple virtual appliances, while scaling the appliances up and down based on demand. This reduces the potential points of failure in your network and increases availability. Gateway Load Balancer is a straightforward way to use third-party network appliances from industry leaders in the cloud. You benefit from the features of these devices, while Gateway Load Balancer makes them automatically scalable and easier to deploy. You can find an AWS Partner with Gateway Load Balancer expertise on the AWS Marketplace. For more information on combining Transit Gateway and Gateway Load Balancer for a centralized inspection architecture, see this blog post. The post shows centralized architecture for East-West (VPC-to-VPC) and North-South (internet or on-premises bound) traffic inspection, plus processing.
To further simplify this area for customers, AWS has introduced the AWS Network Firewall service. Network Firewall is a managed service that you can use to deploy essential network protections for your VPCs. The service is simple to set up and scales automatically with your network traffic so you don’t have to worry about deploying and managing any infrastructure. You can combine Network Firewall with Transit Gateway to set up centralized inspection architecture models, such as those described in this blog post.
Reviewing a typical web architecture in the cloud
In the last section, you saw that SIG patterns can be created in the cloud. Now we can put that in context with the layered security controls that are implemented in a typical web application deployment. Consider a web application hosted on Amazon Elastic Compute Cloud (Amazon EC2) instances, as shown in Figure 3, within the context of other services that will support the architecture.

Figure 3: Security controls in a web application hosted on EC2
Although this example doesn’t include a traditional SIG-type infrastructure that inspects and controls traffic before it’s sent to the AWS Cloud, the architecture has many of the technical controls that are called for in SIG solutions as a result of using the AWS Well-Architected Framework. We’ll now step through some of these services to highlight the relevant security functionality that each provides.
Network control services
Amazon Virtual Private Cloud (Amazon VPC) is a service you can use to launch AWS resources in a logically isolated virtual network that you define. You have complete control over your virtual networking environment, including selection of your own IP address range, creation of subnets, and configuration of route tables and network gateways. Amazon VPC lets you use multiple layers of security, including security groups and network access control lists (network ACLs), to help control access to Amazon EC2 instances in each subnet. Security groups act as a firewall for associated EC2 instances, controlling both inbound and outbound traffic at the instance level. A network ACL is an optional layer of security for your VPC that acts as a firewall for controlling traffic in and out of one or more subnets. You might set up network ACLs with rules similar to your security groups to add an additional layer of security to your VPC. Read about the specific differences between security groups and network ACLs.
Having this level of control throughout the application architecture has advantages over relying only on a central, border-style gateway pattern, because security groups for each tier of the application architecture can be locked down to only those ports and sources required for that layer. For example, in the architecture shown in Figure 3, only the application load balancer security group would allow web traffic (ports 80, 443) from the internet. The web-tier-layer security group would only accept traffic from the load-balancer layer, and the database-layer security group would only accept traffic from the web tier.
If you need to provide a central point of control with this model, you can use AWS Firewall Manager, which simplifies the administration and maintenance of your VPC security groups across multiple accounts and resources. With Firewall Manager, you can configure and audit your security groups for your organization using a single, central administrator account. Firewall Manager automatically applies rules and protections across your accounts and resources, even as you add new resources. Firewall Manager is particularly useful when you want to protect your entire organization, or if you frequently add new resources that you want to protect via a central administrator account.
To support separation of management plan activities from data plane aspects in workloads, agencies can use multiple elastic network interface patterns on EC2 instances to provide a separate management network path.
Edge protection services
In the example in Figure 3, several services are used to provide edge-based protections in front of the web application. AWS Shield is a managed distributed denial of service (DDoS) protection service that safeguards applications that are running on AWS. AWS Shield provides always-on detection and automatic inline mitigations that minimize application downtime and latency, so there’s no need to engage AWS Support to benefit from DDoS protection. There are two tiers of AWS Shield: Standard and Advanced. When you use Shield Advanced, you can apply protections at both the Amazon CloudFront, Amazon EC2 and application load balancer layers. Shield Advanced also gives you 24/7 access to the AWS DDoS Response Team (DRT).
AWS WAF is a web application firewall that helps protect your web applications or APIs against common web exploits that can affect availability, compromise security, or consume excessive resources. AWS WAF gives you control over how traffic reaches your applications by enabling you to create security rules that block common attack patterns, such as SQL injection or cross-site scripting, and rules that filter out specific traffic patterns that you define. Again, you can apply this protection at both the Amazon CloudFront and application load balancer layers in our illustrated solution. Agencies can also use managed rules for WAF to benefit from rules developed and maintained by AWS Marketplace sellers.
Amazon CloudFront is a fast content delivery network (CDN) service. CloudFront seamlessly integrates with AWS Shield, AWS WAF, and Amazon Route 53 to help protect against multiple types of unauthorized access, including network and application layer DDoS attacks.
Logging and monitoring services
The example application in Figure 3 shows several services that provide logging and monitoring of network traffic, application activity, infrastructure, and AWS API usage.
At the VPC level, the VPC Flow Logs feature provides you with the ability to capture information about the IP traffic going to and from network interfaces in your VPC. Flow log data can be published to Amazon CloudWatch Logs or Amazon Simple Storage Service (Amazon S3). Traffic Mirroring is a feature that you can use in a VPC to capture traffic if needed for inspection. This allows agencies to implement full packet capture on a continuous basis, or in response to a specific event within the application.
Amazon CloudWatch provides a monitoring service with alarms and analytics. In the example application, AWS WAF can also be configured to log activity as described in the AWS WAF Developer Guide.
AWS Config provides a timeline view of the configuration of the environment. You can also define rules to provide alerts and remediation when the environment moves away from the desired configuration.
AWS CloudTrail is a service that you can use to handle governance, compliance, operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log, continuously monitor, and retain account activity that is related to actions across your AWS infrastructure.
Amazon GuardDuty is a threat detection service that continuously monitors for malicious activity and unauthorized behavior to protect your AWS accounts. GuardDuty analyzes tens of billions of events across multiple AWS data sources, such as AWS CloudTrail event logs, Amazon VPC Flow Logs, and DNS logs. This blog post highlights a third-party assessment of GuardDuty that compares its performance to other intrusion detection systems (IDS).
Route 53 Resolver Query Logging lets you log the DNS queries that originate in your VPCs. With query logging turned on, you can see which domain names have been queried, the AWS resources from which the queries originated—including source IP and instance ID—and the responses that were received.
With Route 53 Resolver DNS Firewall, you can filter and regulate outbound DNS traffic for your VPCs. To do this, you create reusable collections of filtering rules in DNS Firewall rule groups, associate the rule groups to your VPC, and then monitor activity in DNS Firewall logs and metrics. Based on the activity, you can adjust the behavior of DNS Firewall accordingly.
Mapping services to control areas
Based on the above description of the use of additional services, we can summarize which services contribute to the control and recommendation areas in the gateway chapter in the Australian ISM framework.
| Control and recommendation areas | Contributing services |
| Inspect and filter traffic | AWS WAF, VPC Traffic Mirroring |
| Central control point | Infrastructure as code, AWS Firewall Manager |
| Authentication and authorization (MFA) | AWS Identity and Access Management (IAM), solution and application IAM, VPC security groups |
| Logging and monitoring | Amazon CloudWatch, AWS CloudTrail, AWS Config, Amazon VPC (flow logs and mirroring), load balancer logs, Amazon CloudFront logs, Amazon GuardDuty, Route 53 Resolver Query Logging |
| Secure administration (MFA) | IAM, directory federation (if used) |
| DMZ patterns | VPC subnet layout, security groups, network ACLs |
| Firewalls | VPC security groups, network ACLs, AWS WAF, Route 53 Resolver DNS Firewall |
| Web proxy; site and content filtering and scanning | AWS WAF, Firewall Manager |
Note that the listed AWS service might not provide all relevant controls in each area, and it is part of the customer’s risk assessment and design to determine what additional controls might need to be implemented.
As you can see, many of the recommended practices and controls from the Australian Government gateway requirements are already encompassed in a typical Well-Architected solution. The implementing agency has the choice of two options: it can continue to place such a solution behind a gateway that runs either within or outside of AWS, leveraging the gateway controls that are inherent in the application architecture as additional layers of defense. Otherwise, the agency can conduct a risk assessment to understand which gateway controls can be supplied by means of the application architecture to reduce the gateway control requirements at any gateway layer in front of the application.
Summary
In this blog post, we’ve discussed the requirements for Australian Government gateways which provide network controls to secure workloads. We’ve outlined the downsides of using traditional on-premises solutions and illustrated how services such as AWS Transit Gateway, Elastic Load Balancing, Gateway Load Balancer, and AWS Network Firewall facilitate moving gateway solutions into the cloud. These are services you can evaluate against your network control requirements. Finally, we reviewed a typical web architecture running in the AWS Cloud with associated services to illustrate how many of the typical gateway controls can be met by using a standard Well-Architected approach.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on one of the AWS Security or Networking forums or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.