In November 2013, we announced AWS CloudTrail to track user activity and API usage. AWS CloudTrail enables auditing, security monitoring, and operational troubleshooting. CloudTrail records user activity and API calls across AWS services as events. CloudTrail events help you answer the questions of “who did what, where, and when?”.
Recently we have improved the ability for you to simplify your auditing and security analysis by using AWS CloudTrail Lake. CloudTrail Lake is a managed data lake for capturing, storing, accessing, and analyzing user and API activity on AWS for audit, security, and operational purposes. You can aggregate and immutably store your activity events, and run SQL-based queries for search and analysis.
We have heard your feedback that aggregating activity information from diverse applications across hybrid environments is complex and costly, but important for a comprehensive picture of your organization’s security and compliance posture.
Today we are announcing support of ingestion for activity events from non-AWS sources using CloudTrail Lake, making it a single location of immutable user and API activity events for auditing and security investigations. Now you can consolidate, immutably store, search, and analyze activity events from AWS and non-AWS sources, such as in-house or SaaS applications, in one place.
Using the new PutAuditEvents API in CloudTrail Lake, you can centralize user activity information from disparate sources into CloudTrail Lake, enabling you to analyze, troubleshoot and diagnose issues using this data. CloudTrail Lake records all events in standardized schema, making it easier for users to consume this information to comprehensively and quickly respond to security incidents or audit requests.
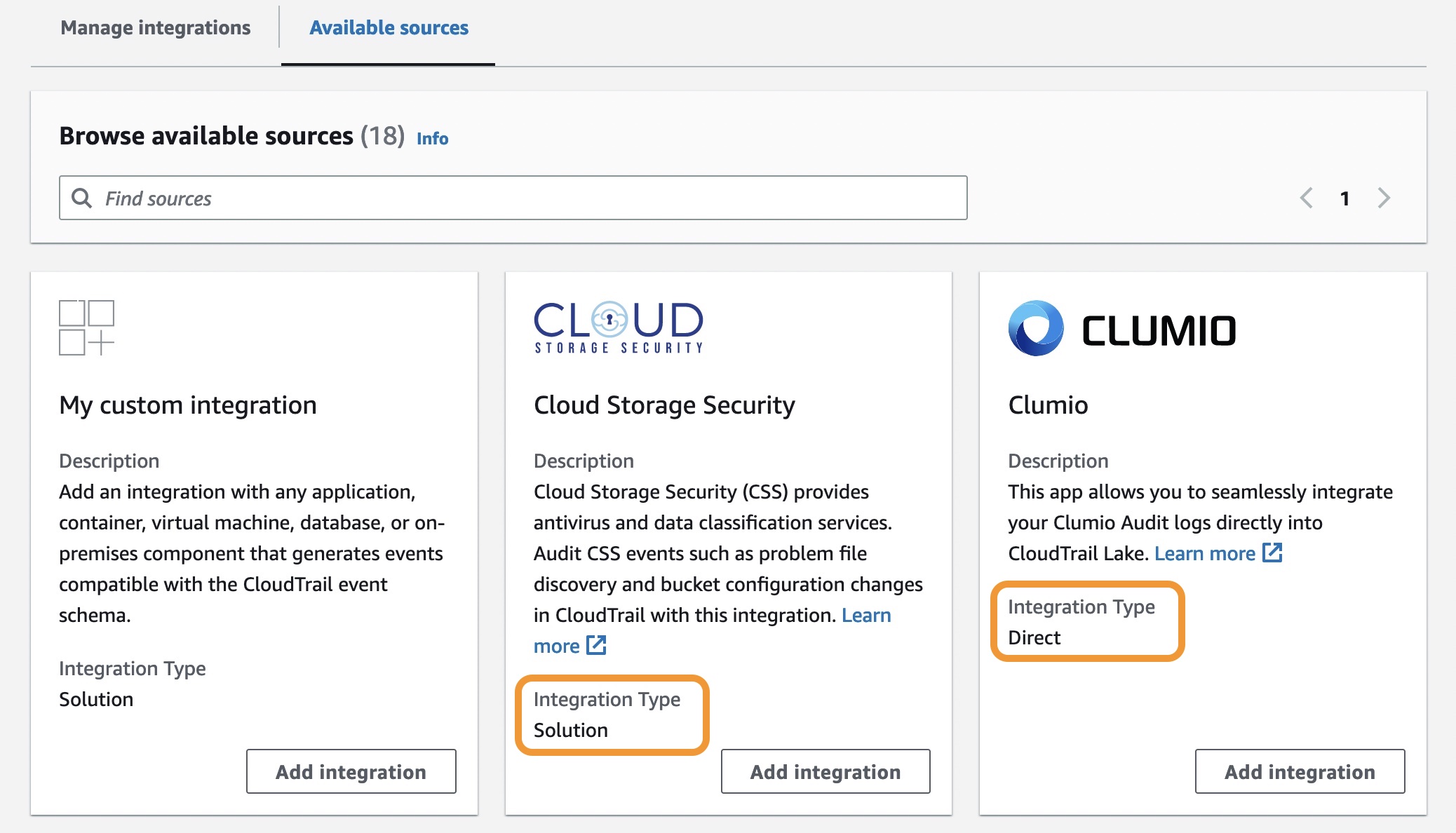
CloudTrail Lake is also integrated with selected AWS Partners, such as Cloud Storage Security, Clumio, CrowdStrike, CyberArk, GitHub, Kong Inc, LaunchDarkly, MontyCloud, Netskope, Nordcloud, Okta, One Identity, Shoreline.io, Snyk, and Wiz, allowing you to easily enable audit logging through the CloudTrail console.
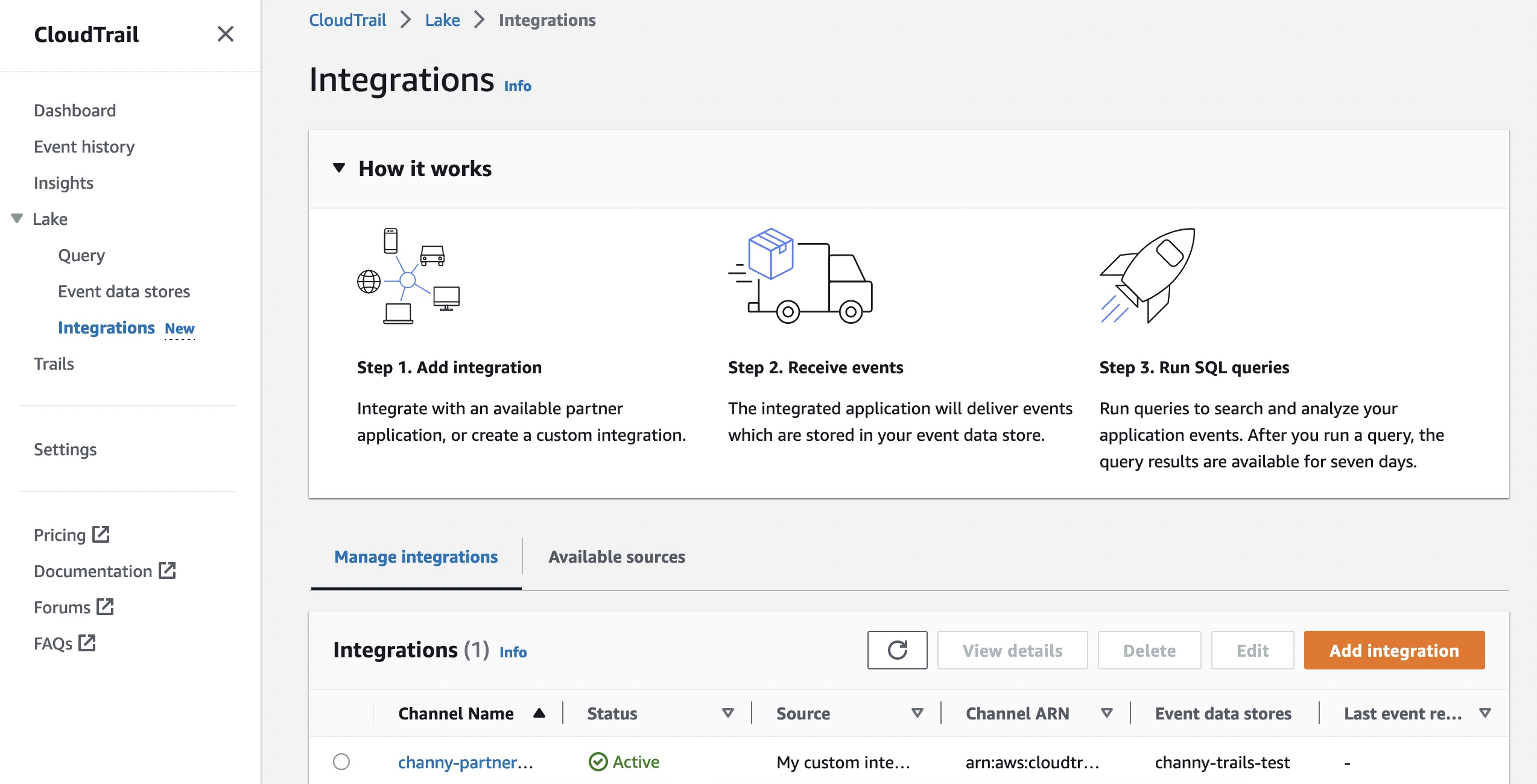
Getting Started to Integrate External Sources You can start to ingest activity events from your own data sources or partner applications by choosing Integrations under the Lake menu in the AWS CloudTrail console.
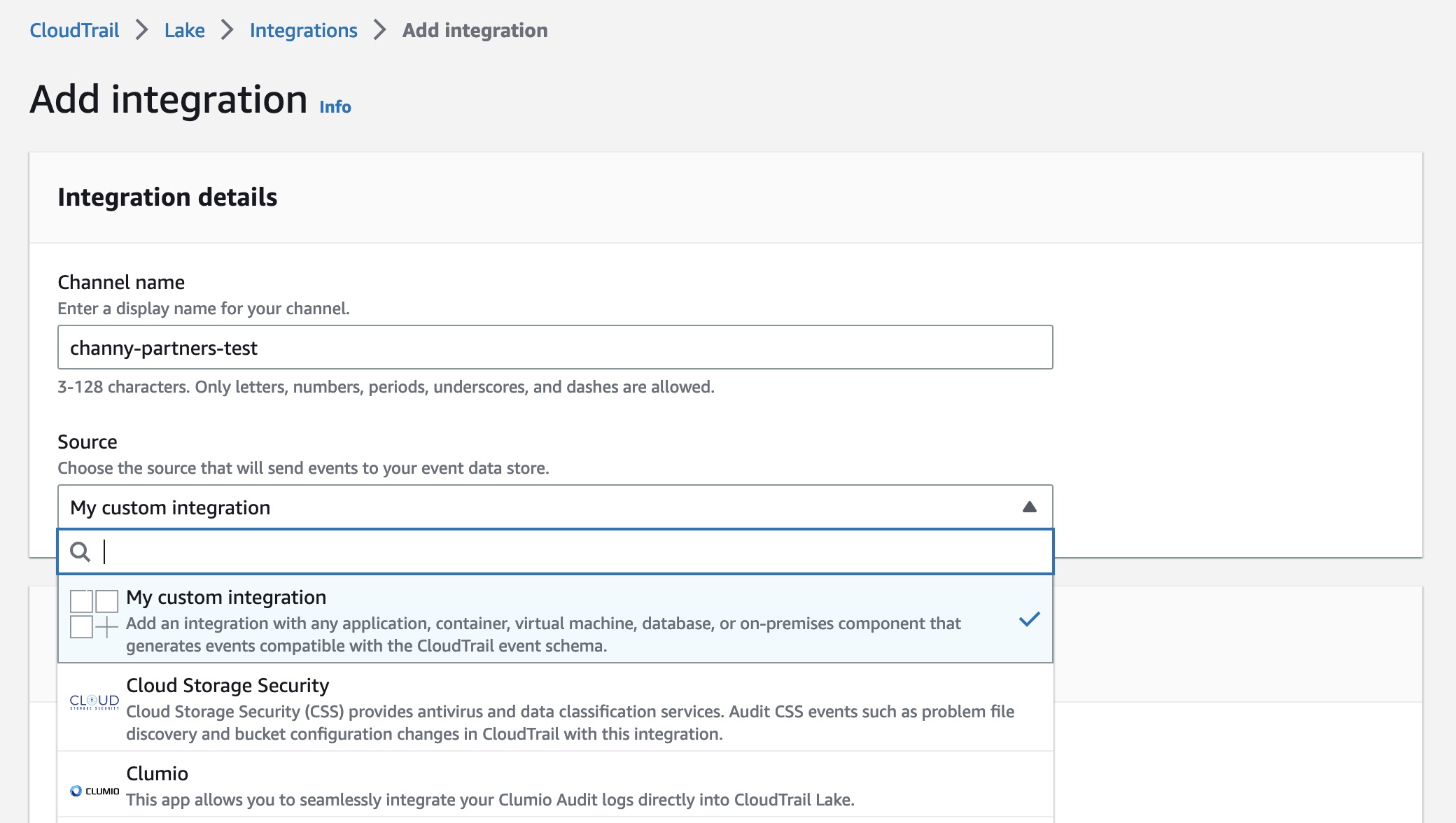
To create a new integration, choose Add integration and enter your channel name. You can choose the partner application source from which you want to get events. If you’re integrating with events from your own applications hosted on-premises or in the cloud, choose My custom integration.
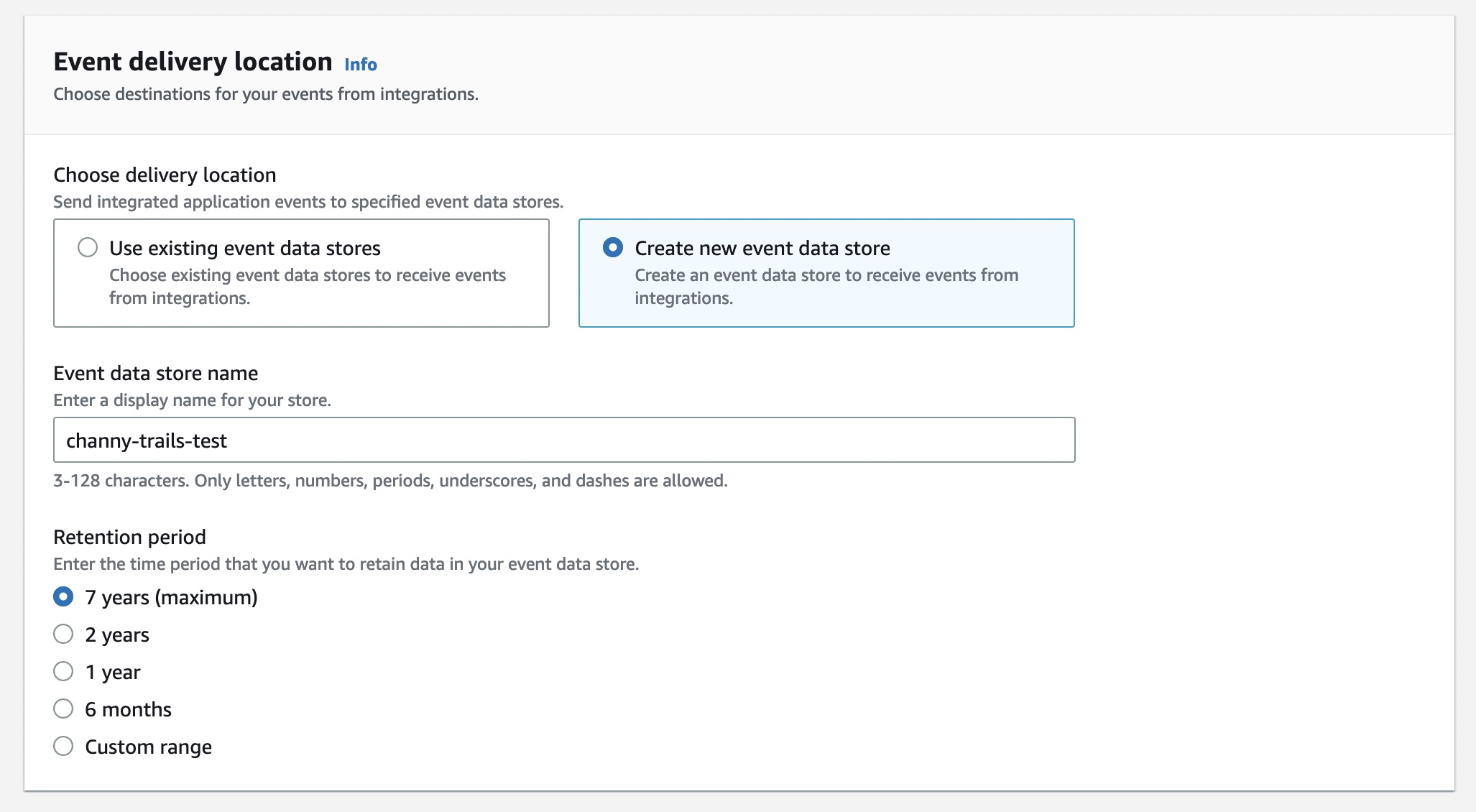
For Event delivery location, you can choose destinations for your events from this integration. This allows your application or partners to deliver events to your event data store of CloudTrail Lake. An event data store can retain your activity events for a week to up to seven years. Then you can run queries on the event data store.
Choose either Use existing event data stores or Create new event data store—to receive events from integrations. To learn more about event data store, see Create an event data store in the AWS documentation.
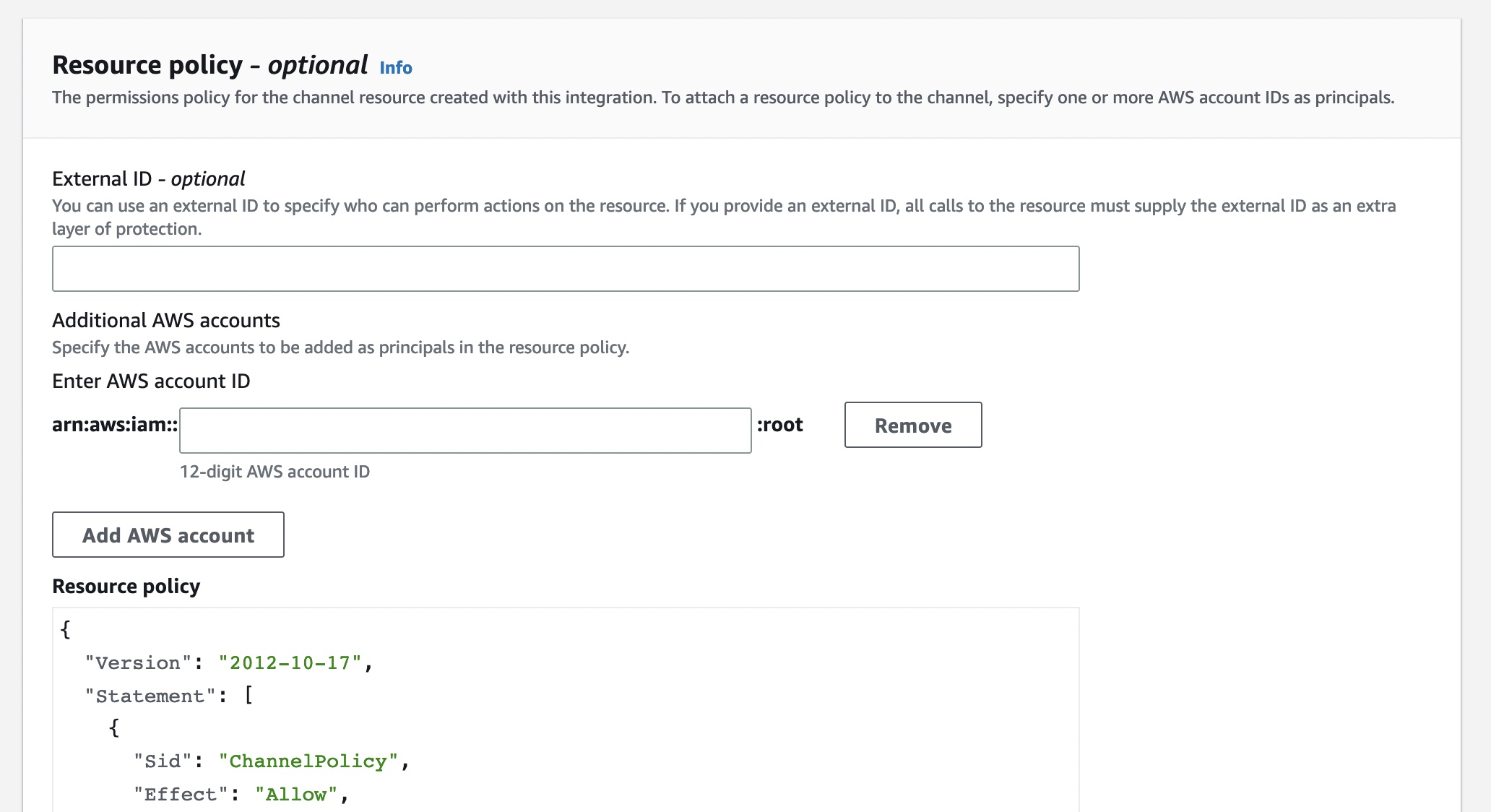
You can also set up the permissions policy for the channel resource created with this integration. The information required for the policy is dependent on the integration type of each partner applications.
There are two types of integrations: direct and solution. With direct integrations, the partner calls the PutAuditEvents API to deliver events to the event data store for your AWS account. In this case, you need to provide External ID, the unique account identifier provided by the partner. You can see a link to partner website for the step-by-step guide. With solution integrations, the application runs in your AWS account and the application calls the PutAuditEvents API to deliver events to the event data store for your AWS account.
To find the Integration type for your partner, choose the Available sources tab from the integrations page.
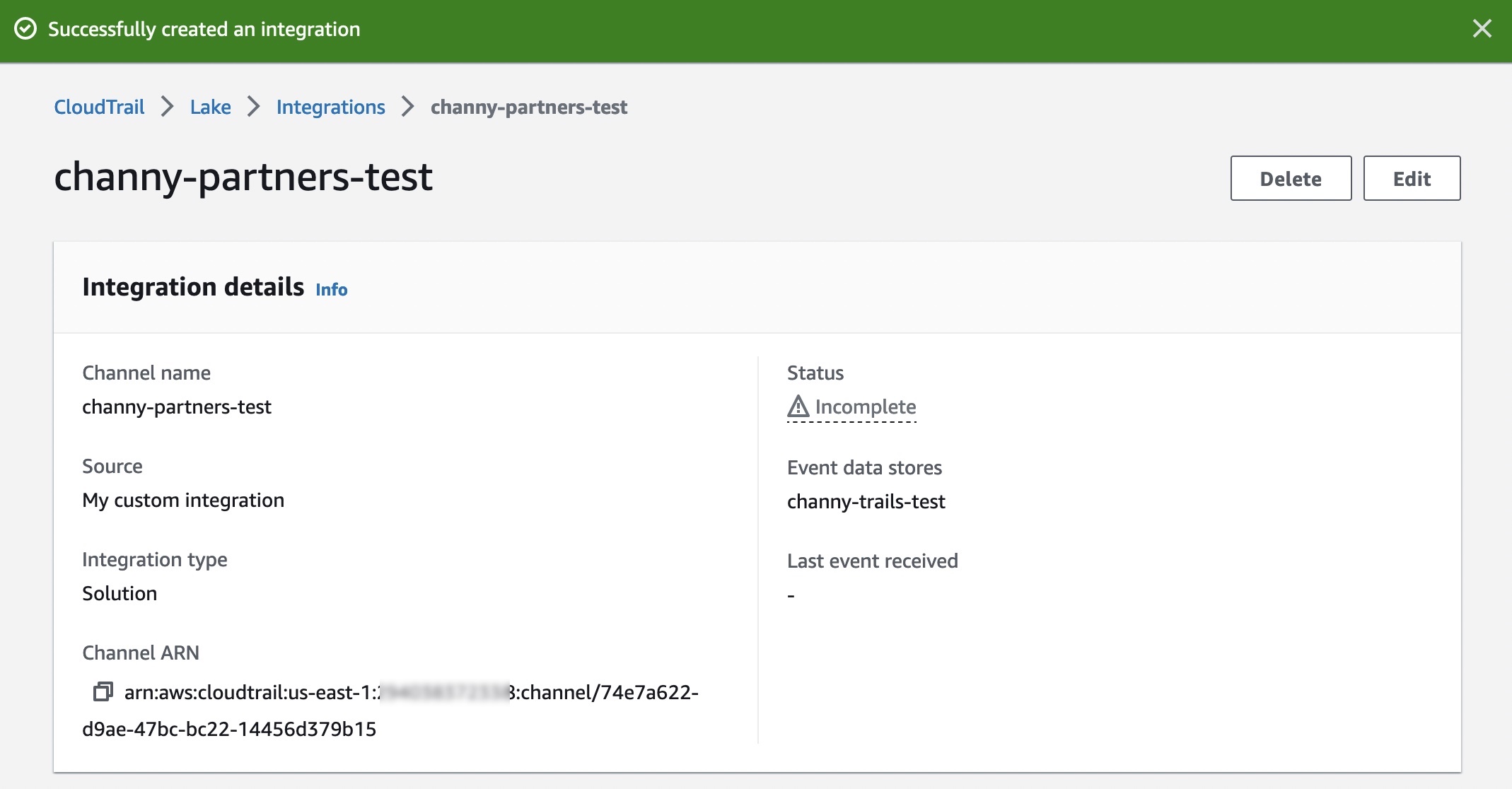
After creating an integration, you will need to provide this Channel ARN to the source or partner application. Until these steps are finished, the status will remain as incomplete. Once CloudTrail Lake starts receiving events for the integrated partner or application, the status field will be updated to reflect the current state.
To ingest your application’s activity events into your integration, call the PutAuditEvents API to add the payload of events. Be sure that there is no sensitive or personally identifying information in the event payload before ingesting it into CloudTrail Lake.
You can make a JSON array of event objects, which includes a required user-generated ID from the event, the required payload of the event as the value of EventData, and an optional checksum to help validate the integrity of the event after ingestion into CloudTrail Lake.
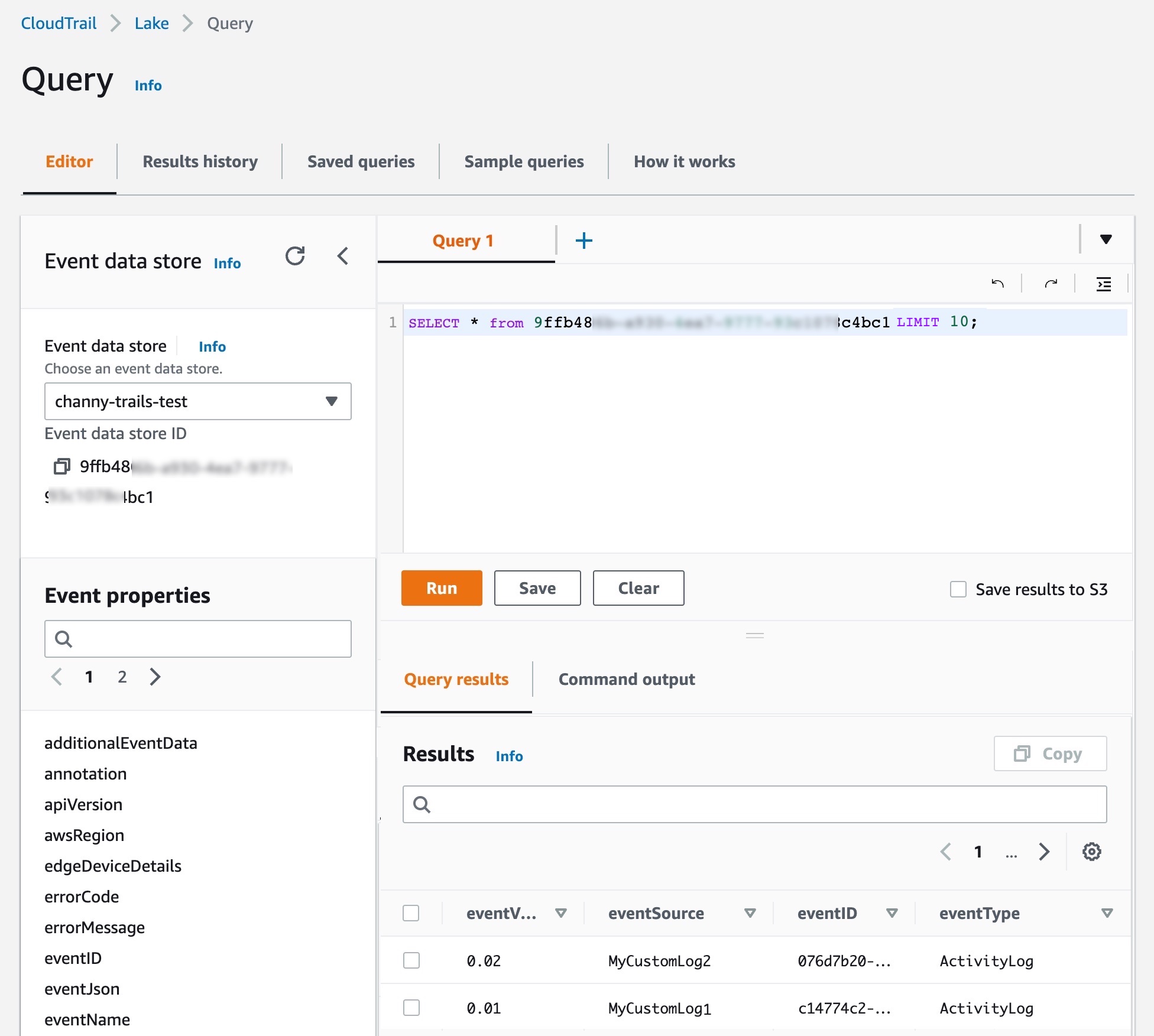
On the Editor tab in the CloudTrail Lake, write your own queries for a new integrated event data store to check delivered events.
You can make your own integration query, like getting all principals across AWS and external resources that have made API calls after a particular date:
SELECT userIdentity.principalId FROM $AWS_EVENT_DATA_STORE_ID
WHERE eventTime > '2022-09-24 00:00:00'
UNION ALL
SELECT eventData.userIdentity.principalId FROM $PARTNER_EVENT_DATA_STORE_ID
WHRERE eventData.eventTime > '2022-09-24 00:00:00'
Launch Partners You can see the list of our launch partners to support a CloudTrail Lake integration option in the Available applications tab. Here are blog posts and announcements from our partners who collaborated on this launch (some will be added in the next few days).
Cloud Storage Security
Clumio
CrowdStrike
CyberArk
GitHub
Kong Inc
LaunchDarkly
MontyCloud
Netskope
Nordcloud
Okta
One Identity
Shoreline.io
Snyk
Wiz
Now Available AWS CloudTrail Lake now supports ingesting activity events from external sources in all AWS Regions where CloudTrail Lake is available today. To learn more, see the AWS documentation and each partner’s getting started guides.
If you are interested in becoming an AWS CloudTrail Partner, you can contact your usual partner contacts.
As we kick off 2023, I wanted to take a moment to highlight the top posts from 2022. Without further ado, here are the top 10 AWS DevOps Blog posts of 2022.
Sylvia Qi, Senior DevOps Architect, and Sebastian Carreras, Senior Cloud Application Architect, guide us through utilizing infrastructure as code (IaC) to automate GitLab Runner deployment on Amazon EC2.
Lerna Ekmekcioglu, Senior Solutions Architect, and Jack Iu, Global Solutions Architect, demonstrate best practices for multi-Region deployments using HashiCorp Terraform, AWS CodeBuild, and AWS CodePipeline.
Praveen Kumar Jeyarajan, Senior DevOps Consultant, and Vaidyanathan Ganesa Sankaran, Sr Modernization Architect, discuss unit testing Python-based AWS Glue Jobs in AWS CodePipeline.
James Bland, APN Global Tech Lead for DevOps, and Welly Siauw, Sr. Partner solutions architect, discuss the challenges of architecting Jenkins for scale and high availability (HA).
Harish Vaswani, Senior Cloud Application Architect, and Rafael Ramos, Solutions Architect, explain how you can configure and use tfdevops to easily enable Amazon DevOps Guru for your existing AWS resources created by Terraform.
Arun Donti, Senior Software Engineer with Twitch, demonstrates how to integrate cdk-nag into an AWS Cloud Development Kit (AWS CDK) application to provide continual feedback and help align your applications with best practices.
Adam Thomas, Senior Software Development Engineer, demonstrate how you can use Smithy to define services and SDKs and deploy them to AWS Lambda using a generated client.
A big thank you to all our readers! Your feedback and collaboration are appreciated and help us produce better content.
Over the past year, AWS CIRT has responded to hundreds of such security events, including the unauthorized use of AWS Identity and Access Management (IAM) credentials, ransomware and data deletion in an AWS account, and billing increases due to the creation of unauthorized resources to mine cryptocurrency.
We are excited to release five workshops that simulate these security events to help you learn the tools and procedures that AWS CIRT uses on a daily basis to detect, investigate, and respond to such security events. The workshops cover AWS services and tools, such as Amazon GuardDuty, Amazon CloudTrail, Amazon CloudWatch, Amazon Athena, and AWS WAF, as well as some open source tools written and published by AWS CIRT.
To access the workshops, you just need an AWS account, an internet connection, and the desire to learn more about incident response in the AWS Cloud! Choose the following links to access the workshops.
During this workshop, you will simulate the unauthorized use of IAM credentials by using a script invoked within AWS CloudShell. The script will perform reconnaissance and privilege escalation activities that have been commonly seen by AWS CIRT and that are typically performed during similar events of this nature. You will also learn some tools and processes that AWS CIRT uses, and how to use these tools to find evidence of unauthorized activity by using IAM credentials.
During this workshop, you will use an AWS CloudFormation template to replicate an environment with multiple IAM users and five Amazon Simple Storage Service (Amazon S3) buckets. AWS CloudShell will then run a bash script that simulates data exfiltration and data deletion events that replicate a ransomware-based security event. You will also learn the tools and processes that AWS CIRT uses to respond to similar events, and how to use these tools to find evidence of unauthorized S3 bucket and object deletions.
During this workshop, you will simulate a cryptomining security event by using a CloudFormation template to initialize three Amazon Elastic Compute Cloud (Amazon EC2) instances. These EC2 instances will mimic cryptomining activity by performing DNS requests to known cryptomining domains. You will also learn the tools and processes that AWS CIRT uses to respond to similar events, and how to use these tools to find evidence of unauthorized creation of EC2 instances and communication with known cryptomining domains.
During this workshop, you will simulate the unauthorized use of a web application that is hosted on an EC2 instance configured to use Instance Metadata Service Version 1 (IMDSv1) and vulnerable to server side request forgery (SSRF). You will learn how web application vulnerabilities, such as SSRF, can be used to obtain credentials from an EC2 instance. You will also learn the tools and processes that AWS CIRT uses to respond to this type of access, and how to use these tools to find evidence of the unauthorized use of EC2 instance credentials through web application vulnerabilities such as SSRF.
During this workshop, you will install and experiment with some common tools and utilities that AWS CIRT uses on a daily basis to detect security misconfigurations, respond to active events, and assist customers with protecting their infrastructure.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Healthcare data is being generated at an increased rate with the proliferation of connected medical devices and clinical systems. Some examples of these data are time-sensitive patient information, including results of laboratory tests, pathology reports, X-rays, digital imaging, and medical devices to monitor a patient’s vital signs, such as blood pressure, heart rate, and temperature.
These different types of data can be difficult to work with, but when combined they can be used to build data pipelines and machine learning (ML) models to address various challenges in the healthcare industry, like the prediction of patient outcome, readmission rate, or disease progression.
In this post, we demonstrate how to bring data from different sources, like Snowflake and connected health devices, to form a healthcare data lake on Amazon Web Services (AWS). We also explore how to use this data with IBM Watson to build, train, and deploy ML models. You can learn how to integrate model endpoints with clinical health applications to generate predictions for patient health conditions.
Solution overview
The main parts of the architecture we discuss are (Figure 1):
Using patient data to improve health outcomes
Healthcare data lake formation to store patient health information
Analyzing clinical data to improve medical research
Gaining operational insights from healthcare provider data
Providing data governance to maintain the data privacy
Building, training, and deploying an ML model
Integration with the healthcare system
Figure 1. Data pipeline for the healthcare industry using IBM CP4D on AWS
Connected health devices, on the edge, use sensors and wireless connectivity to gather patient health data, such as biometrics, and send it to the AWS Cloud through Amazon Kinesis Data Firehose. AWS Lambda transforms the data that is persisted to Amazon Simple Storage Service (Amazon S3), making that information available to healthcare providers.
Amazon Simple Notification Service (Amazon SNS) is used to send notifications whenever there is an issue with the real-time data ingestion from the connected health devices. In case of failures, messages are sent via Amazon SNS topics for rectifying and reprocessing of failure messages.
DataStage performs ETL operations and move patient historical information from Snowflake into Amazon S3. This data, combined with the data from the connected health devices, form a healthcare data lake, which is used in IBM CP4D to build and train ML models.
The pipeline described in architecture uses Watson Knowledge Catalogue, which provides data governance framework and artifacts to enrich our data assets. It protects sensitive patient information from unauthorized access, like individually identifiable information, medical history, test results, or insurance information.
Data protection rules define how to control access to data, mask sensitive values, or filter rows from data assets. The rules are automatically evaluated and enforced each time a user attempts to access a data asset in any governed catalog of the platform.
After this, the datasets are published to Watson Studio projects, where they are used to train ML models. You can develop models using Jupyter Notebook, IBM AutoAI (low-code), or IBM SPSS modeler (no-code).
For the purpose of this use case, we used logistic regression algorithm for classifying and predicting the probability of an event, such as disease risk management to assist doctors in making critical medical decisions. You can also build ML models using algorithms like Classification, Random Forest, and K-Nearest Neighbor. These are widely used to predict disease risk.
Once the models are trained, they are exposed as endpoints with Watson Machine Learning and integrated with the healthcare application to generate predictions by analyzing patient symptoms.
The healthcare applications are a type of clinical software that offer crucial physiological insights and predict the effects of illnesses and possible treatments. It provides built-in dashboards that display patient information together with the patient’s overall metrics for outcomes and treatments. This can help healthcare practitioners gain insights into patient conditions. It also can help medical institutions prioritize patients with more risk factors and curate clinical and behavioral health plans.
A healthcare data lake can help health organizations turn data into insights. It is centralized, curated, and securely stores data on Amazon S3. It also enables you to break down data silos and combine different types of analytics to gain insights. We are using the DataStage, Kinesis Data Firehose, and Amazon S3 services to build the healthcare data lake.
Data governance
Watson Knowledge Catalogue provides an ML catalogue for data discovery, cataloging, quality, and governance. We define policies in Watson Knowledge Catalogue to enable data privacy and overall access to and utilization of this data. This includes sensitive data and personal information that needs to be handled through data protection, quality, and automation rules. To learn more about IBM data governance, please refer to Running a data quality analysis (Watson Knowledge Catalogue).
Build, train, and deploy the ML model
Watson Studio empowers data scientists, developers, and analysts to build, run, and manage AI models on IBM CP4D.
In this solution, we are building models using Watson Studio by:
Promoting the governed data from Watson Knowledge Catalogue to Watson Studio for insights
Using ETL features, such as built-in search, automatic metadata propagation, and simultaneous highlighting, to process and transform large amounts of data
Training the model, including model technique selection and application, hyperparameter setting and adjustment, validation, ensemble model development and testing; algorithm selection; and model optimization
Evaluating the model based on metric evaluation, confusion matrix calculations, KPIs, model performance metrics, model quality measurements for accuracy and precision
Deploying the model on Watson Machine Learning using online deployments, which create an endpoint to generate a score or prediction in real time
Integrating the endpoint with applications like health applications, as demonstrated in Figure 1
Conclusion
In this blog, we demonstrated how to use patient data to improve health outcomes by creating a healthcare data lake and analyzing clinical data. This can help patients and healthcare practitioners make better, faster decisions and prioritize cases. We also discussed how to build an ML model using IBM Watson and integrate it with healthcare applications for health analysis.
AWS Identity and Access Management (IAM) Access Analyzer provides tools to simplify permissions management by making it simpler for you to set, verify, and refine permissions. One such tool is IAM Access Analyzer policy generation, which creates fine-grained policies based on your AWS CloudTrail access activity—for example, the actions you use with Amazon Elastic Compute Cloud (Amazon EC2), AWS Lambda, and Amazon Simple Storage Service (Amazon S3). AWS has expanded policy generation capabilities to support the identification of actions used from over 140 services. New additions include services such as AWS CloudFormation, Amazon DynamoDB, and Amazon Simple Queue Service (Amazon SQS). When you request a policy, IAM Access Analyzer generates a policy by analyzing your CloudTrail logs to identify actions used from this group of over 140 services. The generated policy makes it efficient to grant only the required permissions for your workloads. For other services, Access Analyzer helps you by identifying the services used and guides you to add the necessary actions.
In this post, we will show how you can use Access Analyzer to generate an IAM permissions policy that restricts CloudFormation permissions to only those actions that are necessary to deploy a given template, in order to follow the principle of least privilege.
Permissions for AWS CloudFormation
AWS CloudFormation lets you create a collection of related AWS and third-party resources and provision them in a consistent and repeatable fashion. A common access management pattern is to grant developers permission to use CloudFormation to provision resources in the production environment and limit their ability to do so directly. This directs developers to make infrastructure changes in production through CloudFormation, using infrastructure-as-code patterns to manage the changes.
CloudFormation can create, update, and delete resources on the developer’s behalf by assuming an IAM role that has sufficient permissions. Cloud administrators often grant this IAM role broad permissions–in excess of what’s necessary to just create, update, and delete the resources from the developer’s template–because it’s not clear what the minimum permissions are for the template. As a result, the developer could use CloudFormation to create or modify resources outside of what’s required for their workload.
The best practice for CloudFormation is to acquire permissions by using the credentials from an IAM role you pass to CloudFormation. When you attach a least-privilege permissions policy to the role, the actions CloudFormation is allowed to perform can be scoped to only those that are necessary to manage the resources in the template. In this way, you can avoid anti-patterns such as assigning the AdministratorAccess or PowerUserAccess policies—both of which grant excessive permissions—to the role.
The following section will describe how to set up your account and grant these permissions.
Prepare your development account
Within your development account, you will configure the same method for deploying infrastructure as you use in production: passing a role to CloudFormation when you launch a stack. First, you will verify that you have the necessary permissions, and then you will create the role and the role’s permissions policy.
Get permissions to use CloudFormation and IAM Access Analyzer
You will need the following minimal permissions in your development account:
Permission to use CloudFormation, in particular to create, update, and delete stacks
Permission to pass an IAM role to CloudFormation
Permission to create IAM roles and policies
Permission to use Access Analyzer, specifically the GetGeneratedPolicy, ListPolicyGenerations, and StartPolicyGeneration actions
The following IAM permissions policy can be used to grant your identity these permissions.
Note: If your identity already has these permissions through existing permissions policies, there is no need to apply the preceding policy to your identity.
Create a role for CloudFormation
Creating a service role for CloudFormation in the development account makes it less challenging to generate the least-privilege policy, because it becomes simpler to identify the actions CloudFormation is taking as it creates and deletes resources defined in the template. By identifying the actions CloudFormation has taken, you can create a permissions policy to match.
To create an IAM role in your development account for CloudFormation
For the trusted entity, choose AWS service. From the list of services, choose CloudFormation.
Choose Next: Permissions.
Select one or more permissions policies that align with the types of resources your stack will create. For example, if your stack creates a Lambda function and an IAM role, choose the AWSLambda_FullAccess and IAMFullAccess policies.
Note: Because you have not yet created the least-privilege permissions policy, the role is granted broader permissions than required. You will use this role to launch your stack and evaluate the resulting actions that CloudFormation takes, in order to build a lower-privilege policy.
Choose Next: Tags to proceed.
Enter one or more optional tags, and then choose Next: Review.
Enter a name for the role, such as CloudFormationDevExecRole.
Choose Create role.
Create and destroy the stack
To have CloudFormation exercise the actions required by the stack, you will need to create and destroy the stack.
To create and destroy the stack
Navigate to CloudFormation in the console, expand the menu in the left-hand pane, and choose Stacks.
On the Stacks page, choose Create Stack, and then choose With new resources.
Choose Template is ready, choose Upload a template file, and then select the file for your template. Choose Next.
Enter a Stack name, and then choose Next.
For IAM execution role name, select the name of the role you created in the previous section (CloudFormationDevExecRole). Choose Next.
Review the stack configuration. If present, select the check box(es) in the Capabilities section, and then choose Create stack.
Wait for the stack to reach the CREATE_COMPLETE state before continuing.
From the list of stacks, select the stack you just created, choose Delete, and then choose Delete stack.
Wait until the stack reaches the DELETE_COMPLETE state (at which time it will also disappear from the list of active stacks).
Note: It’s recommended that you also modify the CloudFormation template and update the stack to initiate updates to the deployed resources. This will allow Access Analyzer to capture actions that update the stack’s resources, in addition to create and delete actions. You should also review the API documentation for the resources that are being used in your stack and identify any additional actions that may be required.
Now that the development environment is ready, you can create the least-privilege permissions policy for the CloudFormation role.
Use Access Analyzer to generate a fine-grained identity policy
Access Analyzer reviews the access history in AWS CloudTrail to identify the actions an IAM role has used. Because CloudTrail delivers logs within an average of about 15 minutes of an API call, you should wait at least that long after you delete the stack before you attempt to generate the policy, in order to properly capture all of the actions.
Note: CloudTrail must be enabled in your AWS account in order for policy generation to work. To learn how create a CloudTrail trail, see Creating a trail for your AWS account in the AWS CloudTrail User Guide.
To generate a permissions policy by using Access Analyzer
Open the IAM console and choose Roles. In the search box, enter CloudFormationDevExecRole and select the role name in the list.
On the Permissions tab, scroll down and choose Generate policy based on CloudTrail events to expand this section. Choose Generate policy.
Select the time period of the CloudTrail logs you want analyzed.
Select the AWS Region where you created and deleted the stack, and then select the CloudTrail trail name in the drop-down list.
If this is your first time generating a policy, choose Create and use a new service role to have an IAM role automatically created for you. You can view the permissions policy the role will receive by choosing View permission details. Otherwise, choose Use an existing service role and select a role in the drop-down list.
The policy generation options are shown in Figure 1.
Figure 1: Policy generation options
Choose Generate policy.
You will be redirected back to the page that shows the CloudFormationDevExecRole role. The Status in the Generate policy based on CloudTrail events section will show In progress. Wait for the policy to be generated, at which time the status will change to Success.
Review the generated policy
You must review and save the generated policy before it can be applied to the role.
To review the generated policy
While you are still viewing the CloudFormationDevExecRole role in the IAM console, under Generate policy based on CloudTrail events, choose View generated policy.
The Generated policy page will open. The Actions included in the generated policy section will show a list of services and one or more actions that were found in the CloudTrail log. Review the list for omissions. Refer to the IAM documentation for a list of AWS services for which an action-level policy can be generated. An example list of services and actions for a CloudFormation template that creates a Lambda function is shown in Figure 2.
Figure 2: Actions included in the generated policy
Use the drop-down menus in the Add actions for services used section to add any necessary additional actions to the policy for the services that were identified by using CloudTrail. This might be needed if an action isn’t recorded in CloudTrail or if action-level information isn’t supported for a service.
Note: The iam:PassRole action will not show up in CloudTrail and should be added manually if your CloudFormation template assigns an IAM role to a service (for example, when creating a Lambda function). A good rule of thumb is: If you see iam:CreateRole in the actions, you likely need to also allow iam:PassRole. An example of this is shown in Figure 3.
Figure 3: Adding PassRole as an IAM action
When you’ve finished adding additional actions, choose Next.
Generated policies contain placeholders that need to be filled in with resource names, AWS Region names, and other variable data. The actual values for these placeholders should be determined based on the content of your CloudFormation template and the Region or Regions you plan to deploy the template to.
To replace placeholders with real values
In the generated policy, identify each of the Resource properties that use placeholders in the value, such as ${RoleNameWithPath} or ${Region}. Use your knowledge of the resources that your CloudFormation template creates to properly fill these in with real values.
${RoleNameWithPath} is an example of a placeholder that reflects the name of a resource from your CloudFormation template. Replace the placeholder with the actual name of the resource.
${Region} is an example of a placeholder that reflects where the resource is being deployed, which in this case is the AWS Region. Replace this with either the Region name (for example, us-east-1), or a wildcard character (*), depending on whether you want to restrict the policy to a specific Region or to all Regions, respectively.
For example, a statement from the policy generated earlier is shown following.
This statement allows the Lambda actions to be performed on a function named MyLambdaFunction in AWS account 123456789012 in any Region (*). Substitute the correct values for Region, Account, and FunctionName in your policy.
The IAM policy editor window will automatically identify security or other issues in the generated policy. Review and remediate the issues identified in the Security, Errors, Warnings, and Suggestions tabs across the bottom of the window.
To review and remediate policy issues
Use the Errors tab at the bottom of the IAM policy editor window (powered by IAM Access Analyzer policy validation) to help identify any placeholders that still need to be replaced. Access Analyzer policy validation reviews the policy and provides findings that include security warnings, errors, general warnings, and suggestions for your policy. To find more information about the different checks, see Access Analyzer policy validation. An example of policy errors caused by placeholders still being present in the policy is shown in Figure 4.
Figure 4: Errors identified in the generated policy
Use the Security tab at the bottom of the editor window to review any security warnings, such as passing a wildcard (*) resource with the iam:PassRole permission. Choose the Learn more link beside each warning for information about remediation. An example of a security warning related to PassRole is shown in Figure 5.
Figure 5: Security warnings identified in the generated policy
Remediate the PassRole With Star In Resource warning by modifying Resource in the iam:PassRole statement to list the Amazon Resource Name (ARN) of any roles that CloudFormation needs to pass to other services. Additionally, add a condition to restrict which service the role can be passed to. For example, to allow passing a role named MyLambdaRole to the Lambda service, the statement would look like the following.
The generated policy can now be saved as an IAM policy.
To save the generated policy
In the IAM policy editor window, choose Next.
Enter a name for the policy and an optional description.
Review the Summary section with the list of permissions in the policy.
Enter optional tags in the Tags section.
Choose Create and attach policy.
Test this policy by replacing the existing role policy with this newly generated policy. Then create and destroy the stack again so that the necessary permissions are granted. If the stack fails during creation or deletion, follow the steps to generate the policy again and make sure that the correct values are being used for any iam:PassRole statements.
Deploy the CloudFormation role and policy
Now that you have the least-privilege policy created, you can give this policy to the cloud administrator so that they can deploy the policy and CloudFormation service role into production.
To create a CloudFormation template that the cloud administrator can use
Open the IAM console, choose Policies, and then use the search box to search for the policy you created. Select the policy name in the list.
On the Permissions tab, make sure that the {}JSON button is activated. Select the policy document by highlighting from line 1 all the way to the last line in the policy, as shown in Figure 6.
Figure 6: Highlighting the generated policy
With the policy still highlighted, use your keyboard to copy the policy into the clipboard (Ctrl-C on Linux or Windows, Option-C on macOS).
Paste the permissions policy JSON object into the following CloudFormation template, replacing the <POLICY-JSON-GOES-HERE> marker. Be sure to indent the left-most curly braces of the JSON object so that they are to the right of the PolicyDocument keyword.
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
PolicyName:
Type: String
Description: The name of the IAM policy that will be created
RoleName:
Type: String
Description: The name of the IAM role that will be created
Resources:
CfnPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
ManagedPolicyName: !Ref PolicyName
Path: /
PolicyDocument: >
<POLICY-JSON-GOES-HERE>
CfnRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Ref RoleName
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Action:
- sts:AssumeRole
Effect: Allow
Principal:
Service:
- cloudformation.amazonaws.com
ManagedPolicyArns:
- !Ref CfnPolicy
Path: /
For example, after pasting the policy, the CfnPolicy resource in the template will look like the following.
Save the CloudFormation template and share it with the cloud administrator. They can use this template to create an IAM role and permissions policy that CloudFormation can use to deploy resources in the production account.
Note: Verify that in addition to having the necessary permissions to work with CloudFormation, your production identity also has permission to perform the iam:PassRole action with CloudFormation for the role that the preceding template creates.
As you continue to develop your stack, you will need to repeat the steps in the Use Access Analyzer to create a permissions policy and Deploy the CloudFormation role and policy sections of this post in order to make sure that the permissions policy remains up-to-date with the permissions required to deploy your stack.
Considerations
If your CloudFormation template uses custom resources that are backed by AWS Lambda, you should also run Access Analyzer on the IAM role that is created for the Lambda function in order to build an appropriate permissions policy for that role.
To generate a permissions policy for a Lambda service role
Launch the stack in your development AWS account to create the Lamba function’s role.
Make a note of the name of the role that was created.
Destroy the stack in your development AWS account.
Follow the instructions from the Use Access Analyzer to generate a fine-grained identity policy and Review the generated policy sections of this post to create the least-privilege policy for the role, substituting the Lambda function’s role name for CloudFormationDevExecRole.
Build the resulting least-privilege policy into the CloudFormation template as the Lambda function’s permission policy.
Conclusion
IAM Access Analyzer helps generate fine-grained identity policies that you can use to grant CloudFormation the permissions it needs to create, update, and delete resources in your stack. By granting CloudFormation only the necessary permissions, you can incorporate the principle of least privilege, developers can deploy their stacks in production using reduced permissions, and cloud administrators can create guardrails for developers in production settings.
If you have feedback about this blog post, submit comments in the Comments section below. You can also start a new thread on AWS Identity and Access Management re:Post to get answers from the community.
Want more AWS Security news? Follow us on Twitter.
AWS Identity and Access Management (IAM) Access Analyzer provides many tools to help you set, verify, and refine permissions. One part of IAM Access Analyzer—policy validation—helps you author secure and functional policies that grant the intended permissions. Now, I’m excited to announce that AWS has updated the IAM console experience for role trust policies to make it simpler for you to author and validate the policy that controls who can assume a role. In this post, I’ll describe the new capabilities and show you how to use them as you author a role trust policy in the IAM console.
Overview of changes
A role trust policy is a JSON policy document in which you define the principals that you trust to assume the role. The principals that you can specify in the trust policy include users, roles, accounts, and services. The new IAM console experience provides the following features to help you set the right permissions in the trust policy:
An interactive policy editor prompts you to add the right policy elements, such as the principal and the allowed actions, and offers context-specific documentation.
As you author the policy, IAM Access Analyzer runs over 100 checks against your policy and highlights issues to fix. This includes new policy checks specific to role trust policies, such as a check to make sure that you’ve formatted your identity provider correctly. These new checks are also available through the IAM Access Analyzer policy validation API.
Before saving the policy, you can preview findings for the external access granted by your trust policy. This helps you review external access, such as access granted to a federated identity provider, and confirm that you grant only the intended access when you create the policy. This functionality was previously available through the APIs, but now it’s also available in the IAM console.
In the following sections, I’ll walk you through how to use these new features.
Example scenario
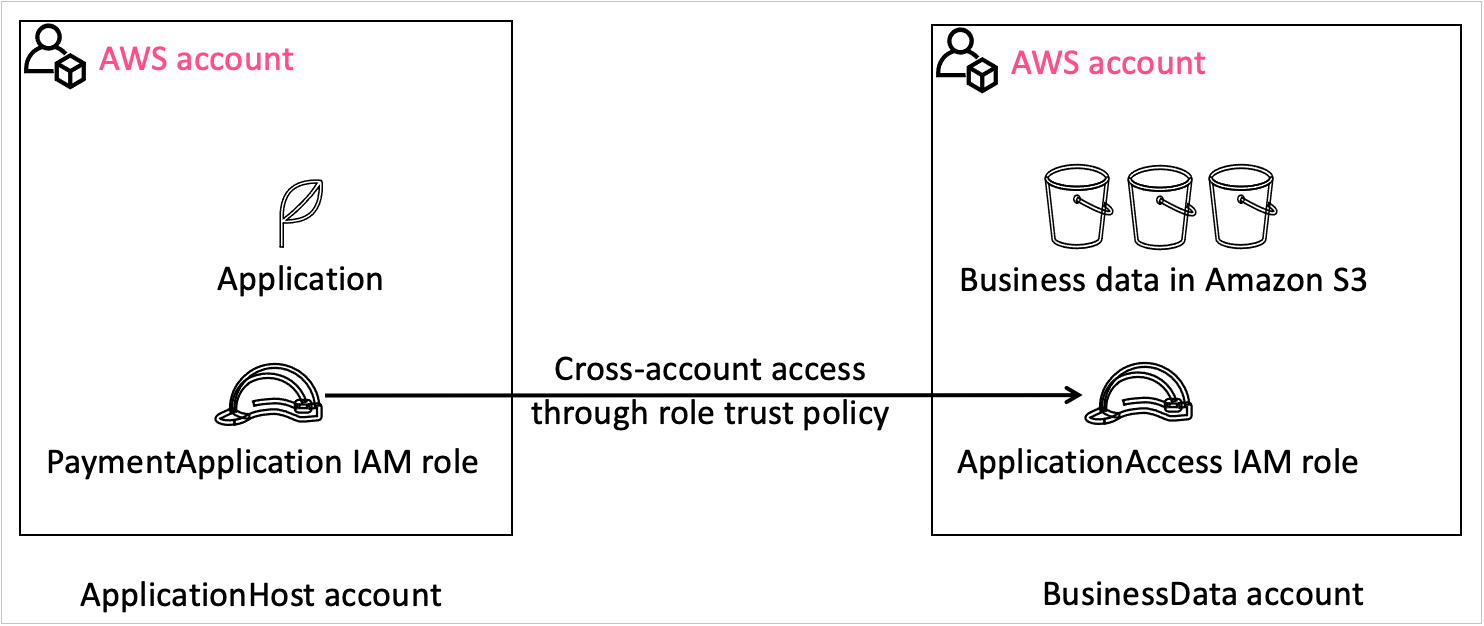
For the walkthrough, consider the following example, which is illustrated in Figure 1. You are a developer for Example Corp., and you are working on a web application. You want to grant the application hosted in one account—the ApplicationHost account—access to data in another account—the BusinessData account. To do this, you can use an IAM role in the BusinessData account to grant temporary access to the application through a role trust policy. You will grant a role in the ApplicationHost account—the PaymentApplication role—to access the BusinessData account through a role—the ApplicationAccess role. In this example, you create the ApplicationAccess role and grant cross-account permissions through the trust policy by using the new IAM console experience that helps you set the right permissions.
Figure 1: Visual explanation of the scenario
Create the role and grant permissions through a role trust policy with the policy editor
In this section, I will show you how to create a role trust policy for the ApplicationAccess role to grant the application access to the data in your account through the policy editor in the IAM console.
To create a role and grant access
In the BusinessData account, open the IAM console, and in the left navigation pane, choose Roles.
Choose Create role, and then select Custom trust policy, as shown in Figure 2.
Figure 2: Select “Custom trust policy” when creating a role
In the Custom trust policy section, for 1. Add actions for STS, select the actions that you need for your policy. For example, to add the action sts:AssumeRole, choose AssumeRole.
Figure 3: JSON role trust policy
For 2. Add a principal, choose Add to add a principal.
In the Add principal box, for Principal type, select IAM roles. This populates the ARN field with the format of the role ARN that you need to add to the policy, as shown in Figure 4.
Figure 4: Add a principal to your role trust policy
Update the role ARN template with the actual account and role information, and then choose Add principal. In our example, the account is ApplicationHost with an AWS account number of 111122223333, and the role is PaymentApplication role. Therefore, the role ARN is arn:aws:iam:: 111122223333: role/PaymentApplication. Figure 5 shows the role trust policy with the action and principal added.
Figure 5: Sample role trust policy
(Optional) To add a condition, for 3. Add a condition, choose Add, and then complete the Add condition box according to your needs.
Author secure policies by reviewing policy validation findings
As you author the policy, you can see errors or warnings related to your policy in the policy validation window, which is located below the policy editor in the console. With this launch, policy validation in IAM Access Analyzer includes 13 new checks focused on the trust relationship for the role. The following are a few examples of these checks and how to address them:
Role trust policy unsupported wildcard in principal – you can’t use a * in your role trust policy.
Invalid federated principal syntax in role trust policy – you need to fix the format of the identity provider.
Missing action for condition key – you need to add the right action for a given condition, such as the sts:TagSession when there are session tag conditions.
In the policy validation window, do the following:
Choose the Security tab to check if your policy is overly permissive.
Choose the Errors tab to review any errors associated with the policy.
Choose the Warnings tab to review if aspects of the policy don’t align with AWS best practices.
Choose the Suggestions tab to get recommendations on how to improve the quality of your policy.
Figure 6: Policy validation window in IAM Access Analyzer with a finding for your policy
For each finding, choose Learn more to review the documentation associated with the finding and take steps to fix it. For example, Figure 6 shows the error Mismatched Action For Principal. To fix the error, remove the action sts:AssumeRoleWithWebIdentity.
Preview external access by reviewing cross-account access findings
IAM Access Analyzer also generates findings to help you assess if a policy grants access to external entities. You can review the findings before you create the policy to make sure that the policy grants only intended access. To preview the findings, you create an analyzer and then review the findings.
To preview findings for external access
Below the policy editor, in the Preview external access section, choose Go to Access Analyzer, as shown in Figure 7.
Note: IAM Access Analyzer is a regional service, and you can create a new analyzer in each AWS Region where you operate. In this situation, IAM Access Analyzer looks for an analyzer in the Region where you landed on the IAM console. If IAM Access Analyzer doesn’t find an analyzer there, it asks you to create an analyzer.
Figure 7: Preview external access widget without an analyzer
On the Create analyzer page, do the following to create an analyzer:
For Name, enter a name for your analyzer.
For Zone of trust, select the correct account.
Choose Create analyzer.
Figure 8: Create an analyzer to preview findings
After you create the analyzer, navigate back to the role trust policy for your role to review the external access granted by this policy. The following figure shows that external access is granted to PaymentApplication.
Figure 9: Preview finding
If the access is intended, you don’t need to take any action. In this example, I want the PaymentApplication role in the ApplicationHost account to assume the role that I’m creating.
If the access is unintended, resolve the finding by updating the role ARN information.
Select Next and grant the required IAM permissions for the role.
Name the role ApplicationAccess, and then choose Save to save the role.
Now the application can use this role to access the BusinessData account.
Conclusion
By using the new IAM console experience for role trust policies, you can confidently author policies that grant the intended access. IAM Access Analyzer helps you in your least-privilege journey by evaluating the policy for potential issues to make it simpler for you to author secure policies. IAM Access Analyzer also helps you preview external access granted through the trust policy to help ensure that the granted access is intended. To learn more about how to preview IAM Access Analyzer cross-account findings, see Preview access in the documentation. To learn more about IAM Access Analyzer policy validation checks, see Access Analyzer policy validation. These features are also available through APIs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread at AWS IAM re:Post or contact AWS Support.
Cloud platform and enterprise architecture teams use architecture patterns to provide guidance for different use cases. Cloud architecture patterns are typically aggregates of multiple Amazon Web Services (AWS) resources, such as Elastic Load Balancing with Amazon Elastic Compute Cloud, or Amazon Relational Database Service with Amazon ElastiCache. In a large organization, cloud platform teams often have limited governance over cloud deployments, and, therefore, lack control or visibility over the actual cloud pattern adoption in their organization.
While having decentralized responsibility for cloud deployments is essential to scale, a lack of visibility or controls leads to inefficiencies, such as proliferation of infrastructure templates, misconfigurations, and insufficient feedback loops to inform cloud platform roadmap.
To address this, we present an integrated approach that allows cloud platform engineers to share and track use of cloud architecture patterns with:
AWS Service Catalog to publish an IT service catalog of codified cloud architecture patterns that are pre-approved for use in the organization.
Amazon QuickSight to track and visualize actual use of service catalog products across the organization.
This solution enables cloud platform teams to maintain visibility into the adoption of cloud architecture patterns in their organization and build a release management process around them.
Publish architectural patterns in your IT service catalog
We use AWS Service Catalog to create portfolios of pre-approved cloud architecture patterns and expose them as self-service to end users. This is accomplished in a shared services AWS account where cloud platform engineers manage the lifecycle of portfolios and publish new products (Figure 1). Cloud platform engineers can publish new versions of products within a portfolio and deprecate older versions, without affecting already-launched resources in end-user AWS accounts. We recommend using organizational sharing to share portfolios with multiple AWS accounts.
Application engineers launch products by referencing the AWS Service Catalog API. Access can be via infrastructure code, like AWS CloudFormation and TerraForm, or an IT service management tool, such as ServiceNow. We recommend using a multi-account setup for application deployments, with an application deployment account hosting the deployment toolchain: in our case, using AWS developer tools.
Although not explicitly depicted, the toolchain can be launched as an AWS Service Catalog product and include pre-populated infrastructure code to bootstrap initial product deployments, as described in the blog post Accelerate deployments on AWS with effective governance.
Figure 1. Launching cloud architecture patterns as AWS Service Catalog products
Track the adoption of cloud architecture patterns
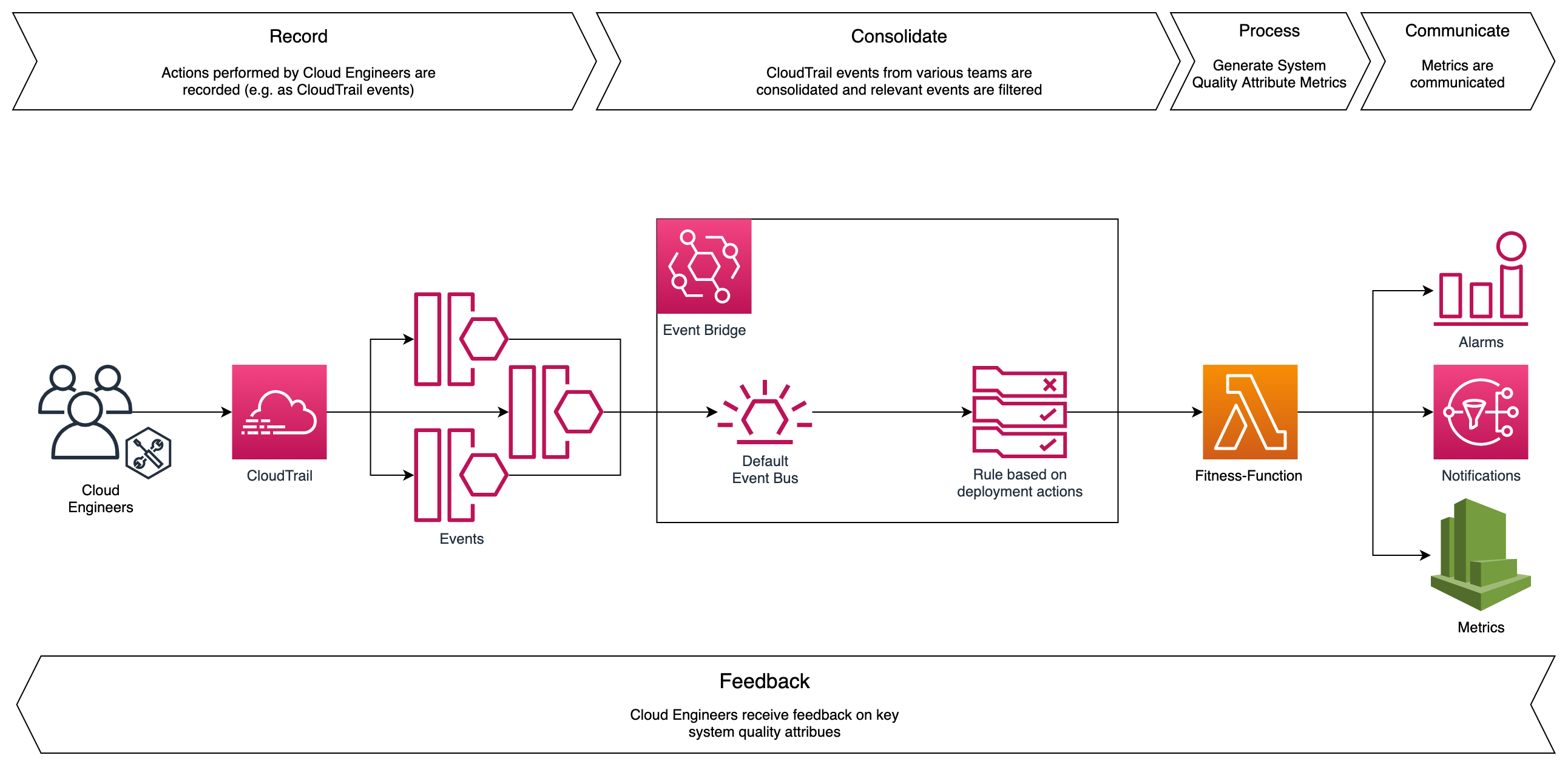
Track the usage of AWS Service Catalog products by analyzing the corresponding AWS CloudTrail logs. The latter can be forwarded to an Amazon EventBridge rule with a filter on the following events: CreateProduct, UpdateProduct, DeleteProduct, ProvisionProduct and TerminateProvisionedProduct.
The logs are generated no matter how you interact with the AWS Service Catalog API, such as through ServiceNow or TerraForm. Once in EventBridge, Amazon Kinesis Data Firehose delivers the events to Amazon Simple Storage Service (Amazon S3) from where QuickSight can access them. Figure 2 depicts the end-to-end flow.
Figure 2. Tracking adoption of AWS Service Catalog products with Amazon QuickSight
Depending on your AWS landing zone setup, CloudTrail logs from all relevant AWS accounts and regions need to be forwarded to a central S3 bucket in your shared services account or, otherwise, centralized logging account. Figure 3 provides an overview of this cross-account log aggregation.
Figure 3. Aggregating AWS Service Catalog product logs across AWS accounts
If your landing zone allows, consider giving permissions to EventBridge in all accounts to write to a central event bus in your shared services AWS account. This avoids having to set up Kinesis Data Firehose delivery streams in all participating AWS accounts and further simplifies the solution (Figure 4).
Figure 4. Aggregating AWS Service Catalog product logs across AWS accounts to a central event bus
If you are already using an organization trail, you can use Amazon Athena or AWS Lambda to discover the relevant logs in your QuickSight dashboard, without the need to integrate with EventBridge and Kinesis Data Firehose.
Reporting on product adoption can be customized in QuickSight. The S3 bucket storing AWS Service Catalog logs can be defined in QuickSight as datasets, for which you can create an analysis and publish as a dashboard.
In the past, we have reported on the top ten products used in the organization (if relevant, also filtered by product version or time period) and the top accounts in terms of product usage. The following figure offers an example dashboard visualizing product usage by product type and number of times they were provisioned. Note: the counts of provisioned and terminated products differ slightly, as logging was activated after the first products were created and provisioned for demonstration purposes.
Figure 5. Example Amazon QuickSight dashboard tracking AWS Service Catalog product adoption
Conclusion
In this blog, we described an integrated approach to track adoption of cloud architecture patterns using AWS Service Catalog and QuickSight. The solution has a number of benefits, including:
Building an IT service catalog based on pre-approved architectural patterns
Maintaining visibility into the actual use of patterns, including which patterns and versions were deployed in the organizational units’ AWS accounts
Compliance with organizational standards, as architectural patterns are codified in the catalog
In our experience, the model may compromise on agility if you enforce a high level of standardization and only allow the use of a few patterns. However, there is the potential for proliferation of products, with many templates differing slightly without a central governance over the catalog. Ideally, cloud platform engineers assume responsibility for the roadmap of service catalog products, with formal intake mechanisms and feedback loops to account for builders’ localization requests.
In Part 1 and Part 2 of this series, we discussed how to build application layer and infrastructure layer resiliency.
In Part 3, we explore how to develop resilient applications, and the need to test and break our operational processes and run books. Processes are needed to capture baseline metrics and boundary conditions. Detecting deviations from accepted baselines requires logging, distributed tracing, monitoring, and alerting. Testing automation and rollback are part of continuous integration/continuous deployment (CI/CD) pipelines. Keeping track of network, application, and system health requires automation.
In order to meet recovery time and point objective (RTO and RPO, respectively) requirements of distributed applications, we need automation to implement failover operations across multiple layers. Let’s explore how a distributed system’s operational resiliency needs to be addressed before it goes into production, after it’s live in production, and when a failure happens.
Pattern 1: Standardize and automate AWS account setup
Create processes and automation for onboarding users and providing access to AWS accounts according to their role and business unit, as defined by the organization. Federated access to AWS accounts and organizations simplifies cost management, security implementation, and visibility. Having a strategy for a suitable AWS account structure can reduce the blast radius in case of a compromise.
Have auditing mechanisms in place. AWS CloudTrail monitors compliance, improving security posture, and auditing all the activity records across AWS accounts.
Practice the least privilege security model when setting up access to the CloudTrail audit logs plus network and applications logs. Follow best practices on service control policies and IAM boundaries to help ensure your AWS accounts stay within your organization’s access control policies.
Use AWS CloudFormation and AWS Config to detect infrastructure drift and take corrective actions to make resources compliant, as demonstrated in Figure 1.
Figure 1. Compliance control and drift detection
Pattern 2: Documenting knowledge about the distributed system
Document high-level infrastructure and dependency maps.
Define availability characteristics of distributed system. Systems have components with varying RTO and RPO needs. Document application component boundaries and capture dependencies with other infrastructure components, including Domain Name System (DNS), IAM permissions; and access patterns, secrets, and certificates. Discover dependencies through solutions, such as Workload Discovery on AWS, to plan resiliency methods and ensure the order of execution of various steps during failover are correct.
Capture non-functional requirements (NFRs), such as business key performance indicators (KPIs), RTO, and RPO, for your composing services. NFRs are quantifiable and define system availability, reliability, and recoverability requirements. They should include throughput, page-load, and response time requirements. Quantify the RTO and RPO of different components of the distributed system by defining them. The KPIs measure if you are meeting the business objectives. As mentioned in Part 2: Infrastructure layer, RTO and RPO help define the failover and data recovery procedures.
Pattern 3: Define CI/CD pipelines for application code and infrastructure components
Establish a branching strategy. Implement automated checks for version and tagging compliance in feature/sprint/bug fix/hot fix/release candidate branches, according to your organization’s policies. Define appropriate release management processes and responsibility matrices, as demonstrated in Figures 2 and 3.
Test at all levels as part of an automated pipeline. This includes security, unit, and system testing. Create a feedback loop that provides the ability to detect issues and automate rollback in case of production failures, which are indicated by business KPI negative impact and other technical metrics.
Figure 2. Define the release management process
Figure 3. Sample roles and responsibility matrix
Pattern 4: Keep code in a source control repository, regardless of GitOps
Merge requests and configuration changes follow the same process as application software. Just like application code, manage infrastructure as code (IaC) by checking the code into a source control repository, submitting pull requests, scanning code for vulnerabilities, alerting and sending notifications, running validation tests on deployments, and having an approval process.
You can audit your infrastructure drift, design reusable and repeatable patterns, and adhere to your distributed application’s RTO objectives by building your IaC (Figure 4). IaC is crucial for operational resilience.
Figure 4. CI/CD pipeline for deploying IaC
Pattern 5: Immutable infrastructure
An immutable deployment pipeline launches a set of new instances running the new application version. You can customize immutability at different levels of granularity depending on which infrastructure part is being rebuilt for new application versions, as in Figure 5.
The more immutable infrastructure components being rebuilt, the more expensive deployments are in both deployment time and actual operational costs. Immutable infrastructure also is easier to rollback.
Figure 5. Different granularity levels of immutable infrastructure
Pattern 6: Test early, test often
In a shift-left testing approach, begin testing in the early stages, as demonstrated in Figure 6. This can surface defects that can be resolved in a more time- and cost-effective manner compared with after code is released to production.
Figure 6. Shift-left test strategy
Continuous testing is an essential part of CI/CD. CI/CD pipelines can implement various levels of testing to reduce the likelihood of defects entering production. Testing can include: unit, functional, regression, load, and chaos.
Continuous testing requires testing and breaking existing boundary conditions, and updating test cases if the boundaries have changed. Test cases should test distributed systems’ idempotency. Chaos testing benefits our incidence response mechanisms for distributed systems that have multiple integration points. By testing our auto scaling and failover mechanisms, chaos testing improves application performance and resiliency.
AWS Fault Injection Simulator (AWS FIS) is a service for chaos testing. An experiment template contains actions, such as StopInstance and StartInstance, along with targets on which the test will be performed. In addition, you can mention stop conditions and check if they triggered the required Amazon CloudWatch alarms, as demonstrated in Figure 7.
Figure 7. AWS Fault Injection Simulator architecture for chaos testing
Pattern 7: Providing operational visibility
In production, operational visibility across multiple dimensions is necessary for distributed systems (Figure 8). To identify performance bottlenecks and failures, use AWS X-Ray and other open-source libraries for distributed tracing.
Write application, infrastructure, and security logs to CloudWatch. When metrics breach alarm thresholds, integrate the corresponding alarms with Amazon Simple Notification Service or a third-party incident management system for notification.
Monitoring services, such as Amazon GuardDuty, are used to analyze CloudTrail, virtual private cloud flow logs, DNS logs, and Amazon Elastic Kubernetes Service audit logs to detect security issues. Monitor AWS Health Dashboard for maintenance, end-of-life, and service-level events that could affect your workloads. Follow the AWS Trusted Advisor recommendations to ensure your accounts follow best practices.
Figure 8. Dimensions for operational visibility (click the image to enlarge)
Figure 9 explores various application and infrastructure components integrating with AWS logging and monitoring components for increased problem detection and resolution, which can provide operational visibility.
Figure 9. Tooling architecture to provide operational visibility
Having an incident response management plan is an important mechanism for providing operational visibility. Successful execution of this requires educating the stakeholders on the AWS shared responsibility model, simulation of anticipated and unanticipated failures, documentation of the distributed system’s KPIs, and continuous iteration. Figure 10 demonstrates the features of a successful incidence response management plan.
Figure 10. An incidence response management plan (click the image to enlarge)
Conclusion
In Part 3, we discussed continuous improvement of our processes by testing and breaking them. In order to understand the baseline level metrics, service-level agreements, and boundary conditions of our system, we need to capture NFRs. Operational capabilities are required to capture deviations from baseline, which is where alerting, logging, and distributed tracing come in. Processes should be defined for automating frequent testing in CI/CD pipelines, detecting network issues, and deploying alternate infrastructure stacks in failover regions based on RTOs and RPOs. Automating failover steps depends on metrics and alarms, and by using chaos testing, we can simulate failover scenarios.
Prepare for failure, and learn from it. Working to maintain resilience is an ongoing task.
When building serverless applications using AWS Lambda, there are a number of considerations regarding security, governance, and compliance. This post highlights how Lambda, as a serverless service, simplifies cloud security and compliance so you can concentrate on your business logic. It covers controls that you can implement for your Lambda workloads to ensure that your applications conform to your organizational requirements.
The Shared Responsibility Model
The AWS Shared Responsibility Model distinguishes between what AWS is responsible for and what customers are responsible for with cloud workloads. AWS is responsible for “Security of the Cloud” where AWS protects the infrastructure that runs all the services offered in the AWS Cloud. Customers are responsible for “Security in the Cloud”, managing and securing their workloads. When building traditional applications, you take on responsibility for many infrastructure services, including operating systems and network configuration.
Traditional application shared responsibility
One major benefit when building serverless applications is shifting more responsibility to AWS so you can concentrate on your business applications. AWS handles managing and patching the underlying servers, operating systems, and networking as part of running the services.
Serverless application shared responsibility
For Lambda, AWS manages the application platform where your code runs, which includes patching and updating the managed language runtimes. This reduces the attack surface while making cloud security simpler. You are responsible for the security of your code and AWS Identity and Access Management (IAM) to the Lambda service and within your function.
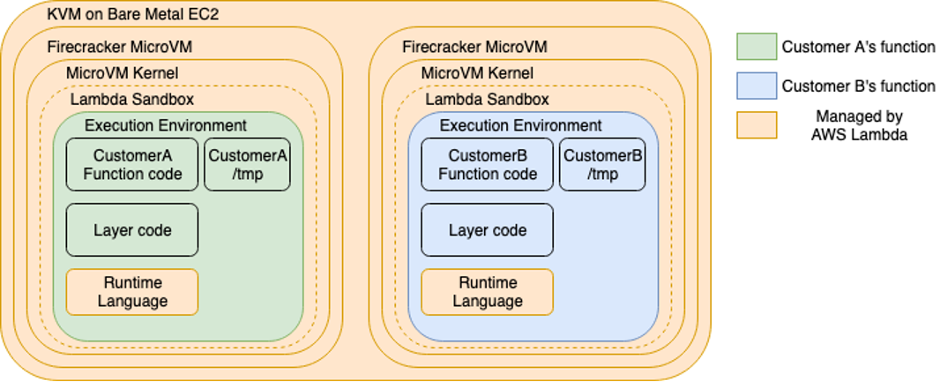
Lambda functions run in separate isolated AWS accounts that are dedicated to the Lambda service. Lambda invokes your code in a secure and isolated runtime environment within the Lambda service account. A runtime environment is a collection of resources running in a dedicated hardware-virtualized Micro Virtual Machines (MVM) on a Lambda worker node.
Lambda workers are bare metalEC2 Nitro instances, which are managed and patched by the Lambda service team. They have a maximum lease lifetime of 14 hours to keep the underlying infrastructure secure and fresh. MVMs are created by Firecracker, an open source virtual machine monitor (VMM) that uses Linux’s Kernel-based Virtual Machine (KVM) to create and manage MVMs securely at scale.
MVMs maintain a strong separation between runtime environments at the virtual machine hardware level, which increases security. Runtime environments are never reused across functions, function versions, or AWS accounts.
Isolation model for AWS Lambda workers
Network security
Lambda functions always run inside secure Amazon Virtual Private Cloud (Amazon VPCs) owned by the Lambda service. This gives the Lambda function access to AWS services and the public internet. There is no direct network inbound access to Lambda workers, runtime environments, or Lambda functions. All inbound access to a Lambda function only comes via the Lambda Invoke API, which sends the event object to the function handler.
You can configure a Lambda function to connect to private subnets in a VPC in your account if necessary, which you can control with IAM condition keys . The Lambda function still runs inside the Lambda service VPC but sends all network traffic through your VPC. Function outbound traffic comes from your own network address space.
AWS Lambda service VPC with VPC-to-VPC NAT to customer VPC
To give your VPC-connected function access to the internet, route outbound traffic to a NAT gateway in a public subnet. Connecting a function to a public subnet doesn’t give it internet access or a public IP address, as the function is still running in the Lambda service VPC and then routing network traffic into your VPC.
All internal AWS traffic uses the AWS Global Backbone rather than traversing the internet. You do not need to connect your functions to a VPC to avoid connectivity to AWS services over the internet. VPC connected functions allow you to control and audit outbound network access.
You can use security groups to control outbound traffic for VPC-connected functions and network ACLs to block access to CIDR IP ranges or ports. VPC endpoints allow you to enable private communications with supported AWS services without internet access.
You can use VPC Flow Logs to audit traffic going to and from network interfaces in your VPC.
Runtime environment re-use
Each runtime environment processes a single request at a time. After Lambda finishes processing the request, the runtime environment is ready to process an additional request for the same function version. For more information on how Lambda manages runtime environments, see Understanding AWS Lambda scaling and throughput.
Data can persist in the local temporary filesystem path, in globally scoped variables, and in environment variables across subsequent invocations of the same function version. Ensure that you only handle sensitive information within individual invocations of the function by processing it in the function handler, or using local variables. Do not re-use files in the local temporary filesystem to process unencrypted sensitive data. Do not put sensitive or confidential information into Lambda environment variables, tags, or other freeform fields such as Name fields.
AWS recommends using multiple accounts to isolate your resources because they provide natural boundaries for security, access, and billing. Use AWS Organizations to manage and govern individual member accounts centrally. You can use AWS Control Tower to automate many of the account build steps and apply managed guardrails to govern your environment. These include preventative guardrails to limit actions and detective guardrails to detect and alert on non-compliance resources for remediation.
Lambda access controls
Lambda permissions define what a Lambda function can do, and who or what can invoke the function. Consider the following areas when applying access controls to your Lambda functions to ensure least privilege:
Execution role
Lambda functions have permission to access other AWS resources using execution roles. This is an AWS principal that the Lambda service assumes which grants permissions using identity policy statements assigned to the role. The Lambda service uses this role to fetch and cache temporary security credentials, which are then available as environment variables during a function’s invocation. It may re-use them across different runtime environments that use the same execution role.
Ensure that each function has its own unique role with the minimum set of permissions..
Identity/user policies
IAM identity policies are attached to IAM users, groups, or roles. These policies allow users or callers to perform operations on Lambda functions. You can restrict who can create functions, or control what functions particular users can manage.
Resource policies
Resource policies define what identities have fine-grained inbound access to managed services. For example, you can restrict which Lambda function versions can add events to a specific Amazon EventBridge event bus. You can use resource-based policies on Lambda resources to control what AWS IAM identities and event sources can invoke a specific version or alias of your function. You also use a resource-based policy to allow an AWS service to invoke your function on your behalf. To see which services support resource-based policies, see “AWS services that work with IAM”.
Attribute-based access control (ABAC)
With attribute-based access control (ABAC), you can use tags to control access to your Lambda functions. With ABAC, you can scale an access control strategy by setting granular permissions with tags without requiring permissions updates for every new user or resource as your organization scales. You can also use tag policies with AWS Organizations to standardize tags across resources.
Permissions boundaries
Permissions boundaries are a way to delegate permission management safely. The boundary places a limit on the maximum permissions that a policy can grant. For example, you can use boundary permissions to limit the scope of the execution role to allow only read access to databases. A builder with permission to manage a function or with write access to the applications code repository cannot escalate the permissions beyond the boundary to allow write access.
Service control policies
When using AWS Organizations, you can use Service control policies (SCPs) to manage permissions in your organization. These provide guardrails for what actions IAM users and roles within the organization root or OUs can do. For more information, see the AWS Organizations documentation, which includes example service control policies.
Code signing
As you are responsible for the code that runs in your Lambda functions, you can ensure that only trusted code runs by using code signing with the AWS Signer service. AWS Signer digitally signs your code packages and Lambda validates the code package before accepting the deployment, which can be part of your automated software deployment process.
Auditing Lambda configuration, permissions and access
You should audit access and permissions regularly to ensure that your workloads are secure. Use the IAM console to view when an IAM role was last used.
IAM last used
IAM access advisor
Use IAM access advisor on the Access Advisor tab in the IAM console to review when was the last time an AWS service was used from a specific IAM user or role. You can use this to remove IAM policies and access from your IAM roles.
You can validate policies using IAM Access Analyzer, which provides over 100 policy checks with security warnings for overly permissive policies. To learn more about policy checks provided by IAM Access Analyzer, see “IAM Access Analyzer policy validation”.
You can also generate IAM policies based on access activity from CloudTrail logs, which contain the permissions that the role used in your specified date range.
IAM Access Analyzer
AWS Config
AWS Config provides you with a record of the configuration history of your AWS resources. AWS Config monitors the resource configuration and includes rules to alert when they fall into a non-compliant state.
For Lambda, you can track and alert on changes to your function configuration, along with the IAM execution role. This allows you to gather Lambda function lifecycle data for potential audit and compliance requirements. For more information, see the Lambda Operators Guide.
Lambda makes cloud security simpler by taking on more responsibility using the AWS Shared Responsibility Model. Lambda implements strict workload security at scale to isolate your code and prevent network intrusion to your functions. This post provides guidance on assessing and implementing best practices and tools for Lambda to improve your security, governance, and compliance controls. These include permissions, access controls, multiple accounts, and code security. Learn how to audit your function permissions, configuration, and access to ensure that your applications conform to your organizational requirements.
For more serverless learning resources, visit Serverless Land.
AWS Lambda functions often need to access secrets, such as certificates, API keys, or database passwords. Storing secrets outside the function code in an external secrets manager helps to avoid exposing secrets in application source code. Using a secrets manager also allows you to audit and control access, and can help with secret rotation. Do not store secrets in Lambda environment variables, as these are visible to anyone who has access to view function configuration.
This post highlights some solutions to store secrets securely and retrieve them from within your Lambda functions.
AWS Partner Network (APN) member Hashicorp provides Vault to secure secrets and application data. Vault allows you to control access to your secrets centrally, across applications, systems, and infrastructure. You can store secrets in Vault and access them from a Lambda function to access a database, for example. The Vault Agent for AWS helps you authenticate with Vault, retrieve the database credentials, and then perform the queries. You can also use the Vault AWS Lambda extension to manage connectivity to Vault.
AWS Systems Manager Parameter Store enables you to store configuration data securely, including secrets, as parameter values. For information on Parameter Store pricing, see the documentation.
AWS Secrets Manager allows you to replace hardcoded credentials in your code with an API call to Secrets Manager to retrieve the secret programmatically. You can generate, protect, rotate, manage, and retrieve secrets throughout their lifecycle. By default, Secrets Manager does not write or cache the secret to persistent storage. Secrets Manager supports cross-account access to secrets. For information on Secrets Manager pricing, see the documentation.
Parameter Store integrates directly with Secrets Manager as a pass-through service for references to Secrets Manager secrets. Use this integration if you prefer using Parameter Store as a consistent solution for calling and referencing secrets across your applications. For more information, see “Referencing AWS Secrets Manager secrets from Parameter Store parameters.”
When Lambda first invokes your function, it creates a runtime environment. It runs the function’s initialization (init) code, which is the code outside the main handler. Lambda then runs the function handler code as the invocation. This receives the event payload and processes your business logic. Subsequent invocations can use the same runtime environment.
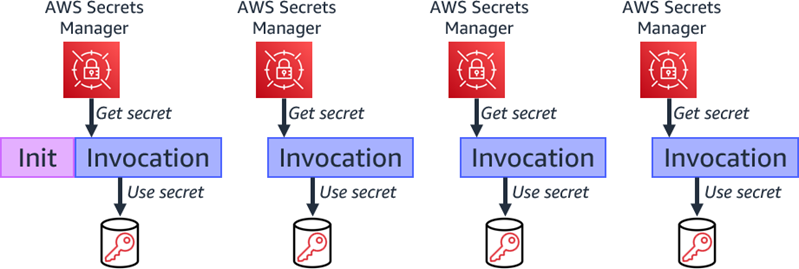
You can retrieve secrets during each function invocation from within your handler code. This ensures that the secret value is always up to date but can lead to increased function duration and cost, as the function calls the secret manager during each invocation. There may also be additional retrieval costs from Secret Manager.
Retrieving secret during each invocation
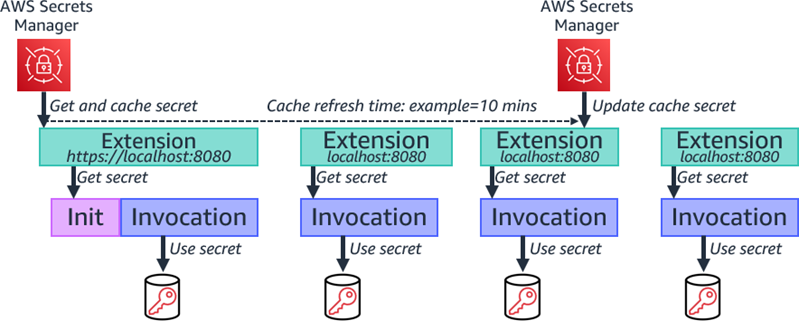
You can reduce costs and improve performance by retrieving the secret during the function init process. During subsequent invocations using the same runtime environment, your handler code can use the same secret.
Retrieving secret during function initialization.
The Serverless Land pattern example shows how to retrieve a secret during the init phase using Node.js and top-level await.
If a secret may change between subsequent invocations, ensure that your handler can check for the secret validity and, if necessary, retrieve the secret again.
Retrieve changed secret during subsequent invocation.
You can also use Lambda extensions to retrieve secrets from Secrets Manager, cache them, and automatically refresh the cache based on a time value. The extension retrieves the secret from Secrets Manager before the init process and makes it available via a local HTTP endpoint. The function then retrieves the secret from the local HTTP endpoint, rather than directly from Secrets Manager, increasing performance. You can also share the extension with multiple functions, which can reduce function code. The extension handles refreshing the cache based on a configurable timeout value. This ensures that the function has the updated value, without handling the refresh in your function code, which increases reliability.
Using Lambda extensions to cache and refresh secret.
Lambda Powertools provides a suite of utilities for Lambda functions to simplify the adoption of serverless best practices. AWS Lambda Powertools for Python and AWS Lambda Powertools for Java both provide a parameters utility that integrates with Secrets Manager.
from aws_lambda_powertools.utilities import parameters
def handler(event, context):
# Retrieve a single secret
value = parameters.get_secret("my-secret")
import software.amazon.lambda.powertools.parameters.SecretsProvider;
import software.amazon.lambda.powertools.parameters.ParamManager;
public class AppWithSecrets implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
// Get an instance of the Secrets Provider
SecretsProvider secretsProvider = ParamManager.getSecretsProvider();
// Retrieve a single secret
String value = secretsProvider.get("/my/secret");
Rotating secrets
You should rotate secrets to prevent the misuse of your secrets. This helps you to replace long-term secrets with short-term ones, which reduces the risk of compromise.
Secrets Manager has built-in functionality to rotate secrets on demand or according to a schedule. Secrets Manager has native integrations with Amazon RDS, Amazon DocumentDB, and Amazon Redshift, using a Lambda function to manage the rotation process for you. It deploys an AWS CloudFormation stack and populates the function with the Amazon Resource Name (ARN) of the secret. You specify the permissions to rotate the credentials, and how often you want to rotate the secret. You can view and edit Secrets Manager rotation settings in the Secrets Manager console.
Secrets Manager rotation settings
You can also create your own rotation Lambda function for other services.
Auditing secrets access
You should continually review how applications are using your secrets to ensure that the usage is as you expect. You should also log any changes to them so you can investigate any potential issues, and roll back changes if necessary.
When using Hashicorp Vault, use Audit devices to log all requests and responses to Vault. Audit devices can append logs to a file, write to syslog, or write to a socket.
Secrets Manager supports logging API calls using AWS CloudTrail. CloudTrail monitors and records all API calls for Secrets Manager as events. This includes calls from code calling the Secrets Manager APIs and access via the Secrets Manager console. CloudTrail data is considered sensitive, so you should use AWS KMS encryption to protect it.
The CloudTrail event history shows the requests to secretsmanager.amazonaws.com.
Viewing CloudTrail access to Secrets Manager
You can use Amazon EventBridge to respond to alerts based on specific operations recorded in CloudTrail. These include secret rotation or deleted secrets. You can also generate an alert if someone tries to use a version of a secret version while it is pending deletion. This may help identify and alert you when an outdated certificate is used.
Securing secrets
You must tightly control access to secrets because of their sensitive nature. Create AWS Identity and Access Management (IAM) policies and resource policies to enable minimal access to secrets. You can use role-based, as well as attribute-based, access control. This can prevent credentials from being accidentally used or compromised. For more information, see “Authentication and access control for AWS Secrets Manager”.
Secrets Manager supports encryption at rest using AWS Key Management Service (AWS KMS) using keys that you manage. Secrets are encrypted in transit using TLS by default, which requires request signing.
Do not store plaintext secrets in Lambda environment variables. Ensure that you do not embed secrets directly in function code, commit these secrets to code repositories, or log the secret to CloudWatch.
Conclusion
Using a secrets manager to store secrets such as certificates, API keys or database passwords helps to avoid exposing secrets in application source code. This post highlights some AWS and third-party solutions, such as Hashicorp Vault, to store secrets securely and retrieve them from within your Lambda functions.
Secrets Manager is the preferred AWS solution for storing and managing secrets. I explain when to retrieve secrets, including using Lambda extensions to cache secrets, which can reduce cost and improve performance.
You can use the Lambda Powertools parameters utility, which integrates with Secrets Manager. Rotating secrets reduces the risk of compromise and you can audit secrets using CloudTrail and respond to alerts using EventBridge. I also cover security considerations for controlling access to your secrets.
For more serverless learning resources, visit Serverless Land.
AWS re:Inforce returned to Boston last week, kicking off with a keynote from Amazon Chief Security Officer Steve Schmidt and AWS Chief Information Security officer C.J. Moses:
Be sure to take some time to watch this video and the other leadership sessions, and to use what you learn to take some proactive steps to improve your security posture.
Last Week’s Launches Here are some launches that caught my eye last week:
AWS Wickr uses 256-bit end-to-end encryption to deliver secure messaging, voice, and video calling, including file sharing and screen sharing, across desktop and mobile devices. Each call, message, and file is encrypted with a new random key and can be decrypted only by the intended recipient. AWS Wickr supports logging to a secure, customer-controlled data store for compliance and auditing, and offers full administrative control over data: permissions, ephemeral messaging options, and security groups. You can now sign up for the preview.
AWS Marketplace Vendor Insights helps AWS Marketplace sellers to make security and compliance data available through AWS Marketplace in the form of a unified, web-based dashboard. Designed to support governance, risk, and compliance teams, the dashboard also provides evidence that is backed by AWS Config and AWS Audit Manager assessments, external audit reports, and self-assessments from software vendors. To learn more, read the What’s New post.
GuardDuty Malware Protection protects Amazon Elastic Block Store (EBS) volumes from malware. As Danilo describes in his blog post, a malware scan is initiated when Amazon GuardDuty detects that a workload running on an EC2 instance or in a container appears to be doing something suspicious. The new malware protection feature creates snapshots of the attached EBS volumes, restores them within a service account, and performs an in-depth scan for malware. The scanner supports many types of file systems and file formats and generates actionable security findings when malware is detected.
Amazon Neptune Global Database lets you build graph applications that run across multiple AWS Regions using a single graph database. You can deploy a primary Neptune cluster in one region and replicate its data to up to five secondary read-only database clusters, with up to 16 read replicas each. Clusters can recover in minutes in the result of an (unlikely) regional outage, with a Recovery Point Objective (RPO) of 1 second and a Recovery Time Objective (RTO) of 1 minute. To learn a lot more and see this new feature in action, read Introducing Amazon Neptune Global Database.
Amazon Detective now Supports Kubernetes Workloads, with the ability to scale to thousands of container deployments and millions of configuration changes per second. It ingests EKS audit logs to capture API activity from users, applications, and the EKS control plane, and correlates user activity with information gleaned from Amazon VPC flow logs. As Channy notes in his blog post, you can enable Amazon Detective and take advantage of a free 30 day trial of the EKS capabilities.
AWS SSO is Now AWS IAM Identity Center in order to better represent the full set of workforce and account management capabilities that are part of IAM. You can create user identities directly in IAM Identity Center, or you can connect your existing Active Directory or standards-based identify provider. To learn more, read this post from the AWS Security Blog.
AWS Config Conformance Packs now provide you with percentage-based scores that will help you track resource compliance within the scope of the resources addressed by the pack. Scores are computed based on the product of the number of resources and the number of rules, and are reported to Amazon CloudWatch so that you can track compliance trends over time. To learn more about how scores are computed, read the What’s New post.
Amazon Macie now lets you perform one-click temporary retrieval of sensitive data that Macie has discovered in an S3 bucket. You can retrieve up to ten examples at a time, and use these findings to accelerate your security investigations. All of the data that is retrieved and displayed in the Macie console is encrypted using customer-managed AWS Key Management Service (AWS KMS) keys. To learn more, read the What’s New post.
AWS Control Tower was updated multiple times last week. CloudTrail Organization Logging creates an org-wide trail in your management account to automatically log the actions of all member accounts in your organization. Control Tower now reduces redundant AWS Config items by limiting recording of global resources to home regions. To take advantage of this change you need to update to the latest landing zone version and then re-register each Organizational Unit, as detailed in the What’s New post. Lastly, Control Tower’s region deny guardrail now includes AWS API endpoints for AWS Chatbot, Amazon S3 Storage Lens, and Amazon S3 Multi Region Access Points. This allows you to limit access to AWS services and operations for accounts enrolled in your AWS Control Tower environment.
Other AWS News Here are some other news items and customer stories that you may find interesting:
AWS Open Source News and Updates – My colleague Ricardo Sueiras writes a weekly open source newsletter and highlights new open source projects, tools, and demos from the AWS community. Read installment #122 here.
Growy Case Study – This Netherlands-based company is building fully-automated robot-based vertical farms that grow plants to order. Read the case study to learn how they use AWS IoT and other services to monitor and control light, temperature, CO2, and humidity to maximize yield and quality.
Cutting Cardboard Waste – Bin packing is almost certainly a part of every computer science curriculum! In the linked article from the Amazon Science site, you can learn how an Amazon Principal Research Scientist developed PackOpt to figure out the optimal set of boxes to use for shipments from Amazon’s global network of fulfillment centers. This is an NP-hard problem and the article describes how they build a parallelized solution that explores a multitude of alternative solutions, all running on AWS.
Upcoming Events Check your calendar and sign up for these online and in-person AWS events:
AWS Global Summits – AWS Global Summits are free events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Registrations are open for the following AWS Summits in August:
IMAGINE 2022 – The IMAGINE 2022 conference will take place on August 3 at the Seattle Convention Center, Washington, USA. It’s a no-cost event that brings together education, state, and local leaders to learn about the latest innovations and best practices in the cloud. You can register here.
That’s all for this week. Check back next Monday for another Week in Review!
In Part 1 of this two-part series, we shared an overview of some of the most important 2021 Amazon Web Services (AWS) Security service and feature launches. In this follow-up, we’ll dive deep into additional launches that are important for security professionals to be aware of and understand across all AWS services. There have already been plenty in the first half of 2022, so we’ll highlight those soon, as well.
AWS Identity
You can use AWS Identity Services to build Zero Trust architectures, help secure your environments with a robust data perimeter, and work toward the security best practice of granting least privilege. In 2021, AWS expanded the identity source options, AWS Region availability, and support for AWS services. There is also added visibility and power in the permission management system. New features offer new integrations, additional policy checks, and secure resource sharing across AWS accounts.
AWS Single Sign-On
For identity management, AWS Single Sign-On (AWS SSO) is where you create, or connect, your workforce identities in AWS once and manage access centrally across your AWS accounts in AWS Organizations. In 2021, AWS SSO announced new integrations for JumpCloud and CyberArk users. This adds to the list of providers that you can use to connect your users and groups, which also includes Microsoft Active Directory Domain Services, Okta Universal Directory, Azure AD, OneLogin, and Ping Identity.
For access management, there have been a range of feature launches with AWS Identity and Access Management (IAM) that have added up to more power and visibility in the permissions management system. Here are some key examples.
IAM made it simpler to relate a user’s IAM role activity to their corporate identity. By setting the new source identity attribute, which persists through role assumption chains and gets logged in AWS CloudTrail, you can find out who is responsible for actions that IAM roles performed.
IAM added support for policy conditions, to help manage permissions for AWS services that access your resources. This important feature launch of service principal conditions helps you to distinguish between API calls being made on your behalf by a service principal, and those being made by a principal inside your account. You can choose to allow or deny the calls depending on your needs. As a security professional, you might find this especially useful in conjunction with the aws:CalledVia condition key, which allows you to scope permissions down to specify that this account principal can only call this API if they are calling it using a particular AWS service that’s acting on their behalf. For example, your account principal can’t generally access a particular Amazon Simple Storage Service (Amazon S3) bucket, but if they are accessing it by using Amazon Athena, they can do so. These conditions can also be used in service control policies (SCPs) to give account principals broader scope across an account, organizational unit, or organization; they need not be added to individual principal policies or resource policies.
Another very handy new IAM feature launch is additional information about the reason for an access denied error message. With this additional information, you can now see which of the relevant access control policies (for example, IAM, resource, SCP, or VPC endpoint) was the cause of the denial. As of now, this new IAM feature is supported by more than 50% of all AWS services in the AWS SDK and AWS Command Line Interface, and a fast-growing number in the AWS Management Console. We will continue to add support for this capability across services, as well as add more features that are designed to make the journey to least privilege simpler.
IAM Access Analyzer also launched the ability to generate fine-grained policies based on analyzing past AWS CloudTrail activity. This feature provides a great new capability for DevOps teams or central security teams to scope down policies to just the permissions needed, making it simpler to implement least privilege permissions. IAM Access Analyzer launched further enhancements to expand policy checks, and the ability to generate a sample least-privilege policy from past activity was expanded beyond the account level to include an analysis of principal behavior within the entire organization by analyzing log activity stored in AWS CloudTrail.
AWS Resource Access Manager
AWS Resource Access Manager (AWS RAM) helps you securely share your resources across unrelated AWS accounts within your organization or organizational units (OUs) in AWS Organizations. Now you can also share your resources with IAM roles and IAM users for supported resource types. This update enables more granular access using managed permissions that you can use to define access to shared resources. In addition to the default managed permission defined for each shareable resource type, you now have more flexibility to choose which permissions to grant to whom for resource types that support additional managed permissions. Additionally, AWS RAM added support for global resource types, enabling you to provision a global resource once, and share that resource across your accounts. A global resource is one that can be used in multiple AWS Regions; the first example of a global resource is found in AWS Cloud WAN, currently in preview as of this publication. AWS RAM helps you more securely share an AWS Cloud WAN core network, which is a managed network containing AWS and on-premises networks. With AWS RAM global resource sharing, you can use the Cloud WAN core network to centrally operate a unified global network across Regions and accounts.
AWS Directory Service
AWS Directory Service for Microsoft Active Directory, also known as AWS Managed Microsoft Active Directory (AD), was updated to automatically provide domain controller and directory utilization metrics in Amazon CloudWatch for new and existing directories. Analyzing these utilization metrics helps you quantify your average and peak load times to identify the need for additional domain controllers. With this, you can define the number of domain controllers to meet your performance, resilience, and cost requirements.
Amazon Cognito
Amazon Cognitoidentity pools (federated identities) was updated to enable you to use attributes from social and corporate identity providers to make access control decisions and simplify permissions management in AWS resources. In Amazon Cognito, you can choose predefined attribute-tag mappings, or you can create custom mappings using the attributes from social and corporate providers’ access and ID tokens, or SAML assertions. You can then reference the tags in an IAM permissions policy to implement attribute-based access control (ABAC) and manage access to your AWS resources. Amazon Cognito also launched a new console experience for user pools and now supports targeted sign out through refresh token revocation.
Governance, control, and logging services
There were a number of important releases in 2021 in the areas of governance, control, and logging services.
This approach provides a powerful new middle ground between the older security models of prevention (which provide developers only an access denied message, and often can’t distinguish between an acceptable and an unacceptable use of the same API) and a detect and react model (when undesired states have already gone live). The Cfn-Guard 2.0 model gives builders the freedom to build with IaC, while allowing central teams to have the ability to reject infrastructure configurations or changes that don’t conform to central policies—and to do so with completely custom error messages that invite dialog between the builder team and the central team, in case the rule is unnuanced and needs to be refined, or if a specific exception needs to be created.
For example, a builder team might be allowed to provision and attach an internet gateway to a VPC, but the team can do this only if the routes to the internet gateway are limited to a certain pre-defined set of CIDR ranges, such as the public addresses of the organization’s branch offices. It’s not possible to write an IAM policy that takes into account the CIDR values of a VPC route table update, but you can write a Cfn-Guard 2.0 rule that allows the creation and use of an internet gateway, but only with a defined and limited set of IP addresses.
AWS Systems Manager Incident Manager
An important launch that security professionals should know about is AWS Systems Manager Incident Manager. Incident Manager provides a number of powerful capabilities for managing incidents of any kind, including operational and availability issues but also security issues. With Incident Manager, you can automatically take action when a critical issue is detected by an Amazon CloudWatch alarm or Amazon EventBridge event. Incident Manager runs pre-configured response plans to engage responders by using SMS and phone calls, can enable chat commands and notifications using AWS Chatbot, and runs automation workflows with AWS Systems Manager Automation runbooks. The Incident Manager console integrates with AWS Systems Manager OpsCenter to help you track incidents and post-incident action items from a central place that also synchronizes with third-party management tools such as Jira Service Desk and ServiceNow. Incident Manager enables cross-account sharing of incidents using AWS RAM, and provides cross-Region replication of incidents to achieve higher availability.
Amazon Simple Storage Service (Amazon S3) is one of the most important services at AWS, and its steady addition of security-related enhancements is always big news. Here are the 2021 highlights.
Access Points aliases
Amazon S3 introduced a new feature, Amazon S3 Access Points aliases. With Amazon S3 Access Points aliases, you can make the access points backwards-compatible with a large amount of existing code that is programmed to interact with S3 buckets rather than access points.
To understand the importance of this launch, we have to go back to 2019 to the launch of Amazon S3 Access Points. Access points are a powerful mechanism for managing S3 bucket access. They provide a great simplification for managing and controlling access to shared datasets in S3 buckets. You can create up to 1,000 access points per Region within each of your AWS accounts. Although bucket access policies remain fully enforced, you can delegate access control from the bucket to its access points, allowing for distributed and granular control. Each access point enforces a customizable policy that can be managed by a particular workgroup, while also avoiding the problem of bucket policies needing to grow beyond their maximum size. Finally, you can also bind an access point to a particular VPC for its lifetime, to prevent access directly from the internet.
With the 2021 launch of Access Points aliases, Amazon S3 now generates a unique DNS name, or alias, for each access point. The Access Points aliases look and acts just like an S3 bucket to existing code. This means that you don’t need to make changes to older code to use Amazon S3 Access Points; just substitute an Access Points aliases wherever you previously used a bucket name. As a security team, it’s important to know that this flexible and powerful administrative feature is backwards-compatible and can be treated as a drop-in replacement in your various code bases that use Amazon S3 but haven’t been updated to use access point APIs. In addition, using Access Points aliases adds a number of powerful security-related controls, such as permanent binding of S3 access to a particular VPC.
S3 Bucket Keys were launched at the end of 2020, another great launch that security professionals should know about, so here is an overview in case you missed it. S3 Bucket Keys are data keys generated by AWS KMS to provide another layer of envelope encryption in which the outer layer (the S3 Bucket Key) is cached by S3 for a short period of time. This extra key layer increases performance and reduces the cost of requests to AWS KMS. It achieves this by decreasing the request traffic from Amazon S3 to AWS KMS from a one-to-one model—one request to AWS KMS for each object written to or read from Amazon S3—to a one-to-many model using the cached S3 Bucket Key. The S3 Bucket Key is never stored persistently in an unencrypted state outside AWS KMS, and so Amazon S3 ultimately must always return to AWS KMS to encrypt and decrypt the S3 Bucket Key, and thus, the data. As a result, you still retain control of the key hierarchy and resulting encrypted data through AWS KMS, and are still able to audit Amazon S3 returning periodically to AWS KMS to refresh the S3 Bucket Keys, as logged in CloudTrail.
Returning to our review of 2021, S3 Bucket Keys gained the ability to use Amazon S3 Inventory and Amazon S3 Batch Operations automatically to migrate objects from the higher cost, slightly lower-performance SSE-KMS model to the lower-cost, higher-performance S3 Bucket Keys model.
To understand this launch, we need to go in time to the origins of Amazon S3, which is one of the oldest services in AWS, created even before IAM was launched in 2011. In those pre-IAM days, a storage system like Amazon S3 needed to have some kind of access control model, so Amazon S3 invented its own: Amazon S3 access control lists (ACLs). Using ACLs, you could add access permissions down to the object level, but only with regard to access by other AWS account principals (the only kind of identity that was available at the time), or public access (read-only or read-write) to an object. And in this model, objects were always owned by the creator of the object, not the bucket owner.
After IAM was introduced, Amazon S3 added the bucket policy feature, a type of resource policy that provides the rich features of IAM, including full support for all IAM principals (users and roles), time-of-day conditions, source IP conditions, ability to require encryption, and more. For many years, Amazon S3 access decisions have been made by combining IAM policy permissions and ACL permissions, which has served customers well. But the object-writer-is-owner issue has often caused friction. The good news for security professionals has been that a deny by either type of access control type overrides an allow by the other, so there were no security issues with this bi-modal approach. The challenge was that it could be administratively difficult to manage both resource policies—which exist at the bucket and access point level—and ownership and ACLs—which exist at the object level. Ownership and ACLs might potentially impact the behavior of only a handful of objects, in a bucket full of millions or billions of objects.
With the features released in 2021, Amazon S3 has removed these points of friction, and now provides the features needed to reduce ownership issues and to make IAM-based policies the only access control system for a specified bucket. The first step came in 2020 with the ability to make object ownership track bucket ownership, regardless of writer. But that feature applied only to newly-written objects. The final step is the 2021 launch we’re highlighting here: the ability to disable at the bucket level the evaluation of all existing ACLs—including ownership and permissions—effectively nullifying all object ACLs. From this point forward, you have the mechanisms you need to govern Amazon S3 access with a combination of S3 bucket policies, S3 access point policies, and (within the same account) IAM principal policies, without worrying about legacy models of ACLs and per-object ownership.
Additional database and storage service features
AWS Backup Vault Lock
AWS Backup added an important new additional layer for backup protection with the availability of AWS Backup Vault Lock. A vault lock feature in AWS is the ability to configure a storage policy such that even the most powerful AWS principals (such as an account or Org root principal) can only delete data if the deletion conforms to the preset data retention policy. Even if the credentials of a powerful administrator are compromised, the data stored in the vault remains safe. Vault lock features are extremely valuable in guarding against a wide range of security and resiliency risks (including accidental deletion), notably in an era when ransomware represents a rising threat to data.
ACM Private CA achieved FedRAMP authorization for six additional AWS Regions in the US.
Additional certificate customization now allows administrators to tailor the contents of certificates for new use cases, such as identity and smart card certificates; or to securely add information to certificates instead of relying only on the information present in the certificate request.
Additional capabilities were added for sharing CAs across accounts by using AWS RAM to help administrators issue fully-customized certificates, or revoke them, from a shared CA.
Integration with Kubernetes provides a more secure certificate authority solution for Kubernetes containers.
Online Certificate Status Protocol (OCSP) provides a fully-managed solution for notifying endpoints that certificates have been revoked, without the need for you to manage or operate infrastructure yourself.
Network and application protection
We saw a lot of enhancements in network and application protection in 2021 that will help you to enforce fine-grained security policies at important network control points across your organization. The services and new capabilities offer flexible solutions for inspecting and filtering traffic to help prevent unauthorized resource access.
AWS WAF
AWS WAF launched AWS WAF Bot Control, which gives you visibility and control over common and pervasive bots that consume excess resources, skew metrics, cause downtime, or perform other undesired activities. The Bot Control managed rule group helps you monitor, block, or rate-limit pervasive bots, such as scrapers, scanners, and crawlers. You can also allow common bots that you consider acceptable, such as status monitors and search engines. AWS WAF also added support for custom responses, managed rule group versioning, in-line regular expressions, and Captcha. The Captcha feature has been popular with customers, removing another small example of “undifferentiated work” for customers.
AWS Shield Advanced
AWS Shield Advanced now automatically protects web applications by blocking application layer (L7) DDoS events with no manual intervention needed by you or the AWS Shield Response Team (SRT). When you protect your resources with AWS Shield Advanced and enable automatic application layer DDoS mitigation, Shield Advanced identifies patterns associated with L7 DDoS events and isolates this anomalous traffic by automatically creating AWS WAF rules in your web access control lists (ACLs).
Amazon CloudFront
In other edge networking news, Amazon CloudFront added support for response headers policies. This means that you can now add cross-origin resource sharing (CORS), security, and custom headers to HTTP responses returned by your CloudFront distributions. You no longer need to configure your origins or use custom Lambda@Edge or CloudFront Functions to insert these headers.
Following Route 53 Resolver’s much-anticipated launch of DNS logging in 2020, the big news for 2021 was the launch of its DNS Firewall capability. Route 53 Resolver DNS Firewall lets you create “blocklists” for domains you don’t want your VPC resources to communicate with, or you can take a stricter, “walled-garden” approach by creating “allowlists” that permit outbound DNS queries only to domains that you specify. You can also create alerts for when outbound DNS queries match certain firewall rules, allowing you to test your rules before deploying for production traffic. Route 53 Resolver DNS Firewall launched with two managed domain lists—malware domains and botnet command and control domains—enabling you to get started quickly with managed protections against common threats. It also integrated with Firewall Manager (see the following section) for easier centralized administration.
AWS Network Firewall and Firewall Manager
Speaking of AWS Network Firewall and Firewall Manager, 2021 was a big year for both. Network Firewall added support for AWS Managed Rules, which are groups of rules based on threat intelligence data, to enable you to stay up to date on the latest security threats without writing and maintaining your own rules. AWS Network Firewall features a flexible rules engine enabling you to define firewall rules that give you fine-grained control over network traffic. As of the launch in late 2021, you can enable managed domain list rules to block HTTP and HTTPS traffic to domains identified as low-reputation, or that are known or suspected to be associated with malware or botnets. Prior to that, another important launch was new configuration options for rule ordering and default drop, making it simpler to write and process rules to monitor your VPC traffic. Also in 2021, Network Firewall announced a major regional expansion following its initial launch in 2020, and a range of compliance achievements and eligibility including HIPAA, PCI DSS, SOC, and ISO.
Elastic Load Balancing now supports forwarding traffic directly from Network Load Balancer (NLB) to Application Load Balancer (ALB). With this important new integration, you can take advantage of many critical NLB features such as support for AWS PrivateLink and exposing static IP addresses for applications that still require ALB.
The AWS Networking team also made Amazon VPC private NAT gateways available in both AWS GovCloud (US) Regions. The expansion into the AWS GovCloud (US) Regions enables US government agencies and contractors to move more sensitive workloads into the cloud by helping them to address certain regulatory and compliance requirements.
Compute
Security professionals should also be aware of some interesting enhancements in AWS compute services that can help improve their organization’s experience in building and operating a secure environment.
Amazon Elastic Compute Cloud (Amazon EC2) launched the Global View on the console to provide visibility to all your resources across Regions. Global View helps you monitor resource counts, notice abnormalities sooner, and find stray resources. A few days into 2022, another simple but extremely useful EC2 launch was the new ability to obtain instance tags from the Instance Metadata Service (IMDS). Many customers run code on Amazon EC2 that needs to introspect about the EC2 tags associated with the instance and then change its behavior depending on the content of the tags. Prior to this launch, you had to associate an EC2 role and call the EC2 API to get this information. That required access to API endpoints, either through a NAT gateway or a VPC endpoint for Amazon EC2. Now, that information can be obtained directly from the IMDS, greatly simplifying a common use case.
Amazon EC2 launched sharing of Amazon Machine Images (AMIs) with AWS Organizations and Organizational Units (OUs). Previously, you could share AMIs only with specific AWS account IDs. To share AMIs within AWS Organizations, you had to explicitly manage sharing of AMIs on an account-by-account basis, as they were added to or removed from AWS Organizations. With this new feature, you no longer have to update your AMI permissions because of organizational changes. AMI sharing is automatically synchronized when organizational changes occur. This feature greatly helps both security professionals and governance teams to centrally manage and govern AMIs as you grow and scale your AWS accounts. As previously noted, this feature was also added to EC2 Image Builder. Finally, Amazon Data Lifecycle Manager, the tool that manages all your EBS volumes and AMIs in a policy-driven way, now supports automatic deprecation of AMIs. As a security professional, you will find this helpful as you can set a timeline on your AMIs so that, if the AMIs haven’t been updated for a specified period of time, they will no longer be considered valid or usable by development teams.
Looking ahead
In 2022, AWS continues to deliver experiences that meet administrators where they govern, developers where they code, and applications where they run. We will continue to summarize important launches in future blog posts. If you’re interested in learning more about AWS services, join us for AWS re:Inforce, the AWS conference focused on cloud security, identity, privacy, and compliance. AWS re:Inforce 2022 will take place July 26–27 in Boston, MA. Registration is now open. Register now with discount code SALxUsxEFCw to get $150 off your full conference pass to AWS re:Inforce. For a limited time only and while supplies last. We look forward to seeing you there!
To stay up to date on the latest product and feature launches and security use cases, be sure to read the What’s New with AWS announcements (or subscribe to the RSS feed) and the AWS Security Blog.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
At Amazon Web Services (AWS), we continuously innovate to deliver you a cloud computing environment that works to help meet the requirements of the most security-sensitive organizations. To respond to evolving technology and regulatory standards for Transport Layer Security (TLS), we will be updating the TLS configuration for all AWS service API endpoints to a minimum of version TLS 1.2. This update means you will no longer be able to use TLS versions 1.0 and 1.1 with all AWS APIs in all AWS Regions by June 28, 2023. In this post, we will tell you how to check your TLS version, and what to do to prepare.
We have continued AWS support for TLS versions 1.0 and 1.1 to maintain backward compatibility for customers that have older or difficult to update clients, such as embedded devices. Furthermore, we have active mitigations in place that help protect your data for the issues identified in these older versions. Now is the right time to retire TLS 1.0 and 1.1, because increasing numbers of customers have requested this change to help simplify part of their regulatory compliance, and there are fewer and fewer customers using these older versions.
If you are one of the more than 95% of AWS customers who are already using TLS 1.2 or later, you will not be impacted by this change. You are almost certainly already using TLS 1.2 or later if your client software application was built after 2014 using an AWS Software Development Kit (AWS SDK), AWS Command Line Interface (AWS CLI), Java Development Kit (JDK) 8 or later, or another modern development environment. If you are using earlier application versions, or have not updated your development environment since before 2014, you will likely need to update.
If you are one of the customers still using TLS 1.0 or 1.1, then you must update your client software to use TLS 1.2 or later to maintain your ability to connect. It is important to understand that you already have control over the TLS version used when connecting. When connecting to AWS API endpoints, your client software negotiates its preferred TLS version, and AWS uses the highest mutually agreed upon version.
To minimize the availability impact of requiring TLS 1.2, AWS is rolling out the changes on an endpoint-by-endpoint basis over the next year, starting now and ending in June 2023. Before making these potentially breaking changes, we monitor for connections that are still using TLS 1.0 or TLS 1.1. If you are one of the AWS customers who may be impacted, we will notify you on your AWS Health Dashboard, and by email. After June 28, 2023, AWS will update our API endpoint configuration to remove TLS 1.0 and TLS 1.1, even if you still have connections using these versions.
What should you do to prepare for this update?
To minimize your risk, you can self-identify if you have any connections using TLS 1.0 or 1.1. If you find any connections using TLS 1.0 or 1.1, you should update your client software to use TLS 1.2 or later.
AWS CloudTrail records are especially useful to identify if you are using the outdated TLS versions. You can now search for the TLS version used for your connections by using the recently added tlsDetails field. The tlsDetails structure in each CloudTrail record contains the TLS version, cipher suite, and the fully qualified domain name (FQDN, also known as the URL) field used for the API call. You can then use the data in the records to help you pinpoint your client software that is responsible for the TLS 1.0 or 1.1 call, and update it accordingly. Nearly half of AWS services currently provide the TLS information in the CloudTrail tlsDetails field, and we are continuing to roll this out for the remaining services in the coming months.
We recommend you use one of the following options for running your CloudTrail TLS queries:
Amazon CloudWatch Log Insights: There are two built-in CloudWatch Log Insights sample CloudTrail TLS queries that you can use, as shown in Figure 1.
Figure 1: Available sample TLS queries for CloudWatch Log Insights
Amazon Athena: You can query AWS CloudTrail logs in Amazon Athena, and we will be adding support for querying the TLS values in your CloudTrail logs in the coming months. Look for updates and announcements about this in future AWS Security Blog posts.
In addition to using CloudTrail data, you can also identify the TLS version used by your connections by performing code, network, or log analysis as described in the blog post TLS 1.2 will be required for all AWS FIPS endpoints. Note that while this post refers to the FIPS API endpoints, the information about querying for TLS versions is applicable to all API endpoints.
Will I be notified if I am using TLS 1.0 or TLS 1.1?
If we detect that you are using TLS 1.0 or 1.1, you will be notified on your AWS Health Dashboard, and you will receive email notifications. However, you will not receive a notification for connections you make anonymously to AWS shared resources, such as a public Amazon Simple Storage Service (Amazon S3) bucket, because we cannot identify anonymous connections. Furthermore, while we will make every effort to identify and notify every customer, there is a possibility that we may not detect infrequent connections, such as those that occur less than monthly.
How do I update my client to use TLS 1.2 or TLS 1.3?
If you are using an AWS Software Developer Kit (AWS SDK) or the AWS Command Line Interface (AWS CLI), follow the detailed guidance about how to examine your client software code and properly configure the TLS version used in the blog post TLS 1.2 to become the minimum for FIPS endpoints.
We encourage you to be proactive in order to avoid an impact to availability. Also, we recommend that you test configuration changes in a staging environment before you introduce them into production workloads.
What is the most common use of TLS 1.0 or TLS 1.1?
The most common use of TLS 1.0 or 1.1 are .NET Framework versions earlier than 4.6.2. If you use the .NET Framework, please confirm you are using version 4.6.2 or later. For information about how to update and configure the .NET Framework to support TLS 1.2, see How to enable TLS 1.2 on clients in the .NET Configuration Manager documentation.
What is Transport Layer Security (TLS)?
Transport Layer Security (TLS) is a cryptographic protocol that secures internet communications. Your client software can be set to use TLS version 1.0, 1.1, 1.2, or 1.3, or a subset of these, when connecting to service endpoints. You should ensure that your client software supports TLS 1.2 or later.
Is there more assistance available to help verify or update my client software?
If you have any questions or issues, you can start a new thread on the AWS re:Post community, or you can contact AWS Support or your Technical Account Manager (TAM).
Additionally, you can use AWS IQ to find, securely collaborate with, and pay AWS certified third-party experts for on-demand assistance to update your TLS client components. To find out how to submit a request, get responses from experts, and choose the expert with the right skills and experience, see the AWS IQ page. Sign in to the AWS Management Console and select Get Started with AWS IQ to start a request.
What if I can’t update my client software?
If you are unable to update to use TLS 1.2 or TLS 1.3, contact AWS Support or your Technical Account Manager (TAM) so that we can work with you to identify the best solution.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
In this post, we describe a practical approach that you can use to detect anomalous behaviors within Amazon Web Services (AWS) cloud workloads by using behavioral analysis techniques that can be used to augment existing threat detection solutions. Anomaly detection is an advanced threat detection technique that should be considered when a mature security baseline as described in the security pillar of the AWS Well-Architected framework is in place.
Why you should consider behavior-based detection in the cloud
Traditionally, threat detection solutions focus on the endpoint and the network and analyze log events for known indicators of attack and indicators of compromise Other forms of threat detection focus on the user and data using products such as data loss prevention and user and endpoint behavior analytics to detect suspicious user behavior at the data layer. Both solution types analyze operating system, application level, and network logs and focus on the detection of known tactics, techniques, and procedures, but the cloud control plane and other cloud native log sources are outside the use case of traditional threat detection solutions
Being able to detect malicious behavior in your environment is necessary to stay secure in the cloud. This includes the detection of events when cloud services might have been misused. The challenge is that related activities are logged on a control plane level and don’t leave any traces in log sources that are traditionally analyzed for threat detection. For example, unwanted data movements between cloud services or cloud accounts use the cloud backplane for data transfers and don’t necessarily touch any endpoint or network gateway. Therefore, related events only appear within cloud native logs such as AWS CloudTrail or AWS Config and not in network or operating system logs.
Figure 1: Solution architecture example
In the simplified example shown in Figure 1, only data streams that pass from the cloud to the firewall and then to AWS services are visible to the endpoint (an Amazon EC2 instance) or the gateway security solution.
Data streams that pass through serverless solutions and activities of cloud native services are only visible in cloud native logs.
Amazon GuardDuty is a threat detection service that continuously monitors for malicious activity and unauthorized behavior to protect AWS accounts, and analyzes not only the network flow logs but also the cloud control plane. GuardDuty uses threat intelligence coupled with machine learning and behavior models to detect threats such as account compromise and unusual data access or communications, and should be activated in each cloud account.
But not all unwanted behavior follows known attack patterns. Unwanted behaviors can also include normal activity inside a cloud environment that is different from the intended behavior of a particular workload. Each activity or log entry by itself might not look malicious, but a series of events can reveal possible malicious intent when compared to the individual context of the application. Because there are no bad events as such in CloudTrail like in a firewall or antivirus log, the challenge is to detect threats based on noncompliant behaviors in the context of the application use case and not on known threat vectors.
Anomaly detection is playing an increasingly important role in defense strategies because of the constantly evolving attack and obfuscation techniques that make it hard to detect threats based on known tactics, techniques, and procedures.
What does unwanted behavior look like?
One approach to identifying key events that are related to unwanted behaviors is to identify a set of anomaly-related questions around common cloud activities that consider the workload context. Depending on the workload type, unwanted cloud API events and related questions could look like the following:
Event: An EC2 instance was launched. Question: Was an unexpected user or role used or was the EC2 instance launched outside the pipeline?
Event: A user or role performs many API list and describe events within a short timeframe. Questions: Does the application normally generate list and describe API calls in production? If not, this could be reconnaissance activity performed by an intruder.
Event: A user or role creates and shares an Amazon Elastic Block Store (Amazon EBS) snapshot with another account. Question: Is the snapshot sharing event expected? If not, it could be an attempt to exfiltrate data.
Event: Many failed API calls are detected in CloudTrail. Question: Are these failed calls around sensitive services or information? If yes, an unauthorized user could be exploring the environment.
Event: Many ListBucket events are detected for a sensitive Amazon Simple Storage Service (Amazon S3) bucket. Question: Are these events unexpected and performed by an unexpected identity? If yes, an unauthorized user performing an S3 bucket enumeration might indicate a reconnaissance activity.
After a set of questions has been identified, they can be converted into application specific threat detection use cases, which can be applied to sensitive production environments. This is a useful strategy because these environments typically have a predictable usage pattern. The predictable patterns reduce the chance of false positives, making it worth the effort of developing use cases for monitoring anomalies. Threat detection use cases can be identified within CloudTrail logs using security information and event management (SIEM) tools or Amazon CloudWatch rules.
Detecting anomalies in CloudTrail with CloudWatch
Activities within your AWS account can be recorded with CloudTrail, which makes it the ideal service not only for deeper investigations into past cloud activities but also to detect unwanted behaviors in near real time. CloudTrail sends logs to an S3 bucket and can forward events to CloudWatch. Using CloudWatch, you can perform searches across all CloudTrail events and define CloudWatch alarms for automatic notifications.
You can create alerts for individual CloudTrail events that you consider an anomaly by creating CloudWatch filters and alarms. A filter defines the events that you want to monitor and an alarm defines the threshold when you want to be notified.
To create a filter for the preceding S3 bucket enumeration example, you would select the CloudTrail log group, and then select Metric Filters and create a new metric filter, as shown in Figure 2.
Figure 2: Create CloudWatch metric filter
Excluding the userAgentAWS Internal excludes S3 access activities performed by other AWS services such as AWS Access Analyzer or Amazon Macie which can be considered normal behavior.
Save this metric filter in a new name space that you use for all of your anomaly detection monitoring. After you have created the filter, create a new CloudWatch alarm based on your filter. Depending on your filter and alarm thresholds, you will receive CloudWatch alarm notifications through a Amazon Simple Notification Service (Amazon SNS) topic and have the opportunity to automatically launch other actions that can perform incident response activities.
After an alert is raised, you can use the same filter pattern to search for the relevant events in CloudWatch. The CloudTrail events will provide more information about who performed the S3 ListBucket events such as IP address (sourceIPAddress), who performed the action (userIdentity), or if the action was performed through the AWS Management Console or AWS Command Line Interface (AWS CLI) (userAgent = aws-internal or aws-cli). Figure 3 that follows is an example of a CloudTrail log.
Figure 3: CloudTrail example log
Detecting anomalies using traps
Another simple, but effective technique to detect intruders based on unwanted behaviors is to use decoy services such as canaries or honey pots. Honey pots are designed to provide information about the behavior of attackers by providing them fake production environments that they can explore—such as hosts within a subnet or data stores such as databases or storage services with dummy data. Canaries are identities or access tokens within honey pot environments that look like privileged identities. Honey pots and canaries both appear attractive to attackers due to the names that are used for users, databases, or host names, but don’t expose the organization to risk if compromised.
Using CloudWatch alarms, you can monitor CloudTrail for events that indicate that attackers have started to explore the honey pot or tried to laterally move using the canary access token. By acting like an attacker yourself, you can generate test events within CloudTrail that will help you to identify the event details—such as event sources, event names, and parameters—that you want to monitor. Here are some examples of CloudTrail events you can monitor for different kinds of traps.
Trap
Event source
Event name
Example instance or user name
Login attempt using a canary identity
signin.amazonaws.com
ConsoleLogin
Backup_Admin
Assume role attempt using a canary role
sts.amazonaws.com
AssumeRole
DevOps_role
Exploration of a honey pot database
dynamodb.amazonaws.com
ListTable
CustomerAccounts
Exploration of a honey pot storage service
s3.amazonaws.com
GetObject
PasswordBackup
Traps are typically deployed in production environments where access and use patterns are predictable and strictly controlled. They’re a cost effective and easy to implement solution that can provide alarms with a high degree of certainty. Traps also offer a good chance to catch even the most sophisticated threat actors; especially when they use highly automated attacks.
Detecting statistical anomalies
AWS CloudTrail Insights is a feature of CloudTrail that can be used to identify unusual operational activity in your AWS accounts such as spikes in resource provisioning, bursts of AWS Identity and Access Management (IAM) activity, or gaps in periodic maintenance activity.
CloudTrail Insights can provide primary indicators for noncompliant behaviors by establishing a baseline for normal behavior and then generating Insights events when it detects unusual patterns. Primary indicators are events that initiate an investigation.
But even when statistical changes haven’t reached alert thresholds and no issue is raised, statistical insights can be used as a supporting secondary indicator during investigations to better understand the context of an incident. Even minor changes of specific API calls around sensitive data can provide valuable information after an alert from another solution such as GuardDuty, or when the previously described anomaly detection techniques have been raised.
Figure 4 that follows is an example of an Insights chart showing API calls over time.
Figure 4: CloudTrail Insights example chart
Conclusion
In this post I described the importance of monitoring sensitive workloads for noncompliant or unwanted behaviors to complement existing security solutions. Anomaly detection in the cloud monitors cloud service activities on the control plane and checks to see if the behavior is expected in the context of each workload. The effort to set up and support the tools described in this blog post leads to an affordable, practical, and powerful mechanism for the detection of sophisticated threat actors in the cloud. To learn more about how you can analyze API activities in the cloud, see Analyzing AWS CloudTrail in Amazon CloudWatch in the AWS Management & Governance Blog.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the Amazon ADD FORUM NAME AND LINK or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
Building a multi-Region application requires lots of preparation and work. Many AWS services have features to help you build and manage a multi-Region architecture, but identifying those capabilities across 200+ services can be overwhelming.
In this 3-part blog series, we’ll explore AWS services with features to assist you in building multi-Region applications. In Part 1, we’ll build a foundation with AWS security, networking, and compute services. In Part 2, we’ll add in data and replication strategies. Finally, in Part 3, we’ll look at the application and management layers.
Considerations before getting started
AWS Regions are built with multiple isolated and physically separate Availability Zones (AZs). This approach allows you to create highly available Well-Architected workloads that span AZs to achieve greater fault tolerance. There are three general reasons that you may need to expand beyond a single Region:
Expansion to a global audience as an application grows and its user base becomes more geographically dispersed, there can be a need to reduce latencies for different parts of the world.
Local laws and regulations may have strict data residency and privacy requirements that must be followed.
Ensuring security, identity, and compliance
Creating a security foundation starts with proper authentication, authorization, and accounting to implement the principle of least privilege. AWS Identity and Access Management (IAM) operates in a global context by default. With IAM, you specify who can access which AWS resources and under what conditions. For workloads that use directory services, the AWS Directory Service for Microsoft Active Directory Enterprise Edition can be set up to automatically replicate directory data across Regions. This allows applications to reduce lookup latencies by using the closest directory and creates durability by spanning multiple Regions.
AWS KMS can be used to encrypt data at rest, and is used extensively for encryption across AWS services. By default, keys are confined to a single Region. AWS KMS multi-Region keys can be created to replicate keys to a second Region, which eliminates the need to decrypt and re-encrypt data with a different key in each Region.
As your application expands to new Regions, AWS Security Hub can aggregate and link findings to a single Region to create a centralized view across accounts and Regions. These findings are continuously synced between Regions to keep you updated on global findings.
We put these features together in Figure 1.
Figure 1. Multi-Region security, identity, and compliance services
Building a global network
For resources launched into virtual networks in different Regions, Amazon Virtual Private Cloud (Amazon VPC) allows private routing between Regions and accounts with VPC peering. These resources can communicate using private IP addresses and do not require an internet gateway, VPN, or separate network appliances. This works well for smaller networks that only require a few peering connections. However, as the number of peered connections increases, the mesh of peered connections can become difficult to manage and troubleshoot.
AWS Transit Gateway can help reduce these difficulties by creating a central transitive hub to act as a cloud router. A Transit Gateway’s routing capabilities can expand to additional Regions with Transit Gateway inter-Region peering to create a globally distributed private network.
Building a reliable, cost-effective way to route users to distributed Internet applications requires highly available and scalable Domain Name System (DNS) records. Amazon Route 53 does exactly that.
Route 53 routing policies can route traffic to a record with the lowest latency, or automatically fail over a record. If a larger failure occurs, the Route 53 Application Recovery Controller can simplify the monitoring and failover process for application failures across Regions, AZs, and on-premises.
Amazon CloudFront’s content delivery network is truly global, built across 300+ points of presence (PoP) spread throughout the world. Applications that have multiple possible origins, such as across Regions, can use CloudFront origin failover to automatically fail over the origin. CloudFront’s capabilities expand beyond serving content, with the ability to run compute at the edge. CloudFront functions make it easy to run lightweight JavaScript functions, and AWS Lambda@Edge makes it easy to run Node.js and Python functions across these 300+ PoPs.
Although EC2 instances and their associated Amazon Elastic Block Store (Amazon EBS) volumes live in a single AZ, Amazon Data Lifecycle Manager can automate the process of taking and copying EBS snapshots across Regions. This can enhance DR strategies by providing a relatively easy cold backup-and-restore option for EBS volumes.
As an architecture expands into multiple Regions, it can become difficult to track where instances are provisioned. Amazon EC2 Global View helps solve this by providing a centralized dashboard to see Amazon EC2 resources such as instances, VPCs, subnets, security groups, and volumes in all active Regions.
Microservice-based applications that use containers benefit from quicker start-up times. Amazon Elastic Container Registry (Amazon ECR) can help ensure this happens consistently across Regions with private image replication at the registry level. An ECR private registry can be configured for either cross-Region or cross-account replication to ensure your images are ready in secondary Regions when needed.
We bring these compute layer features together in Figure 3.
Figure 3. AMI and EBS snapshot copy across Regions
Summary
It’s important to create a solid foundation when architecting a multi-Region application. These foundations pave the way for you to move fast in a secure, reliable, and elastic way as you build out your application. In this post, we covered options across AWS security, networking, and compute services that have built-in functionality to take away some of the undifferentiated heavy lifting. We’ll cover data, application, and management services in future posts.
Looking for more architecture content?AWS Architecture Center provides reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more!
Businesses are expanding their footprint on Amazon Web Services (AWS) and are adopting a multi-account strategy to help isolate and manage business applications and data. In the multi-account strategy, it is common to have business applications deployed in one account accessing an Amazon Simple Storage Service (Amazon S3) encrypted bucket from another AWS account.
When an application in an AWS account uses a AWS Key Management Service (AWS KMS) key owned by a different account, it’s known as a cross-account call. For cross-account requests, AWS KMS throttles the account that makes the requests, not the account that owns the AWS KMS key. These requests count toward the request quota of the caller account. Sometimes it’s essential to identify or track cross-account AWS KMS API usage. In this blog, you will learn about use cases to track these requests and steps to identify cross-account AWS KMS calls.
To understand the problem better, consider a scenario where you have multiple AWS accounts set up in a hub and spoke configuration as shown in the following diagram. Each account is administered by a different administrator. Amazon S3 data lake is located in the centralized hub account. The data lake bucket is encrypted using server-side encryption with AWS KMS (SSE-KMS) with customer-managed keys. Multiple spoke accounts access datasets from this data lake bucket. When a spoke account uploads or downloads objects from the data lake, Amazon S3 makes a GenerateDataKey (for uploads) or Decrypt (for downloads) API request to AWS KMS on behalf of the spoke account. These API requests get applied toward AWS KMS quota of the spoke account.
In the following diagram (figure 1), spoke accounts B, C, and D are uploading/downloading files from the encrypted data lake located in hub account A. Related AWS KMS API quotas will get applied to spoke accounts even though encryption/decryption is happening at the data lake S3 bucket. For example, the centralized Amazon S3 data lake is located in hub account A with an account ID 111111111111. Amazon S3 data lake bucket is encrypted using AWS KMS key ARN ending in 3aa3c82a2174.
Spoke account B with account ID 222222222222 is downloading 1,811 files and uploading 749 files from the centralized data lake. A total of 2,560 AWS KMS API calls will be counted against the request quota for account B.
Spoke account C with account ID 33333333333 is downloading 997 files and uploading 271 files from centralized data lake. A total of 1,268 AWS KMS API calls will be counted against the request quota for account C.
Spoke account D with account ID 444444444444 is downloading 638 files and uploading 306 files from centralized data lake from centralized data lake. The total 944 AWS KMS API quotas will get applied to account D.
Spoke and hub accounts are owned by separate business units and owned by different account administrators.
Note: when you configure your bucket to use an S3 Bucket Key for SSE-KMS, you may not see separate Decrypt or GenerateDataKey for each file upload or download.
Figure 1: Architecture outlining the hub and spoke accounts
This architecture design works for the following three use cases.
Use case #1:
A spoke account administrator wants to track the individual AWS KMS key-wise encryption/decryption costs using AWS Cost Explorer and cost allocation tags. Tracking costs this way works well for the AWS KMS API calls made within the same spoke account and related costs will be displayed under appropriate cost allocation tags. However, for the cross account AWS KMS API calls, cost allocation tags will not be visible outside of the hub account and will be displayed under cost allocation tag “None.” Analyzing cross-account AWS KMS API calls will help administrator determine approximate percentage usage by each cross account KMS key.
Use case # 2:
The spoke account has multiple applications, and each application has a unique AWS Identity and Access Management (IAM) principal. The spoke account administrator would like to track encryption/decryption usage. Identifying IAM principal-wise cross account calls will help the administrator determine approximate percent usage by each IAM principal /each application.
Use case # 3:
The spoke account administrator wants to understand how much AWS KMS quota is used for the cross-account specific KMS keys.
Solution Overview
Let’s discuss how we can track cross-account AWS KMS calls using AWS CloudTrail and Amazon Athena. For this solution, we will reuse your existing CloudTrail or create new CloudTrail in a Region where the hub account Amazon S3 data lake is located. As shown in the following diagram, we will use Athena to query the CloudTrail data to identify cross account AWS KMS calls used for S3 encryption/decryption.
Figure 2: Architecture outlining the CloudTrail and Athena Solution
Prerequisites
For this walkthrough, you should have the following prerequisites:
AWS accounts (one for hub and at least one for spoke)
AWS KMS (SSE-KMS) with customer managed keys encrypted S3 bucket
Walkthrough
Step 1: Activate AWS CloudTrail for the hub account
CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log, continuously monitor, and retain account activity across your AWS accounts. If you have already activated CloudTrail, you can reuse the same. If you haven’t, you can activate it using the steps in this tutorial. For the proposed solution, you must enable CloudTrail for management events only. You don’t require CloudTrail for data events or insight events. Also, be aware that you need only single CloudTrail and creating duplicate cloud trails can increase the service cost.
Note: you can analyze the data in Athena only when the CloudTrail data is available. Any access requests made prior to enabling CloudTrail cannot be analyzed. It takes up to 15 minutes for events to get to CloudTrail, and up to 5 minutes for CloudTrail to write to S3.
Step 2: Create Amazon Athena table to query the CloudTrail data
Amazon Athena is an interactive query service that analyzes data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Create an Athena table in any database or default database in a Region where your hub account S3 data lake bucket resides.
If you are using Athena for the first time, follow these steps to create a database. Once the database is created you need to create Athena table. Follow these steps to create a table:
Open the Athena built-in query editor,
copy the following query,
modify as suggested,
run the query.
In the LOCATION and storage.location.template clauses, replace the bucket with CloudTrail bucket. Replace accountId with hub account’s ID and replace awsRegion with region where data lake S3 bucket is located. For projection.timestamp.range, replace 2020/01/01 with the start date you want to use.
After successful initiation of the query, you will see the CloudTrail_logs table created in Athena.
CREATE EXTERNAL TABLE cloudtrail_logs_region(
eventVersion STRING,
userIdentity STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
invokedBy: STRING,
accessKeyId: STRING,
userName: STRING,
sessionContext: STRUCT<
attributes: STRUCT<
mfaAuthenticated: STRING,
creationDate: STRING>,
sessionIssuer: STRUCT<
type: STRING,
principalId: STRING,
arn: STRING,
accountId: STRING,
userName: STRING>>>,
eventTime STRING,
eventSource STRING,
eventName STRING,
awsRegion STRING,
sourceIpAddress STRING,
userAgent STRING,
errorCode STRING,
errorMessage STRING,
requestParameters STRING,
responseElements STRING,
additionalEventData STRING,
requestId STRING,
eventId STRING,
readOnly STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING>>,
eventType STRING,
apiVersion STRING,
recipientAccountId STRING,
serviceEventDetails STRING,
sharedEventID STRING,
vpcEndpointId STRING
)
PARTITIONED BY (
`timestamp` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
Once the Athena table is created, you can run the following query to find out cross-account AWS KMS calls made for S3 encryption /decryption.
Query:
SELECT useridentity.accountid as requestor_account_id,
resources[1].accountid as owner_account_id,
resources[1].arn as key_arn,
count(resources) as count
FROM CloudTrail_logs_us_east_2
WHERE eventsource='kms.amazonaws.com'
AND timestamp between '2021/04/01' and '2021/08/30'
AND eventname in ('Decrypt','Encrypt','GenerateDataKey')
AND useridentity.accountid!= resources[1].accountid
AND json_extract(json_extract(requestparameters , '$.encryptionContext'),'$.aws:s3:arn') is not null
GROUP BY useridentity.accountid,resources[1].accountid,resources[1].arn
ORDER BY key_arn,count desc
Result:
Result displays the cross account AWS KMS calls made for S3 encryption /decryption i.e. where caller account is not the key owner account for time period between April 1, 2021 and August 30, 2021.
The preceding example shows cross-account AWS KMS API calls generated by downloading /uploading files from centralized Amazon S3 data lake located in account A (111111111111) from spoke accounts B (222222222222), C (333333333333), and D (444444444444).
These AWS KMS quotas will get applied to caller (spoke) accounts even though key owner is hub account.
For example:
2,560 AWS KMS API call quotas will be applied to account B.
1,644 AWS KMS API call quotas will be applied to account C.
944 AWS KMS API call quotas will be applied to account D.
To identify IAM principal-wise cross account Amazon S3 encryption /decryption calls, you can run following query.
Query:
SELECT useridentity.accountid as requestor_account_id, useridentity.principalid as requestor_principal, resources[1].accountid as owner_account_id, resources[1].arn as key_arn, count(resources) as count FROM CloudTrail_logs_us_east_2 WHERE eventsource='kms.amazonaws.com' AND timestamp between '2021/04/01' and '2021/08/30' AND eventname in ('Decrypt','Encrypt','GenerateDataKey') AND useridentity.accountid!= resources[1].accountid AND json_extract(json_extract(requestparameters , '$.encryptionContext'),'$.aws:s3:arn') is not null GROUP BY useridentity.accountid,useridentity.principalid,resources[1].accountid,resources[1].arn ORDER BY requestor_account_id,count desc
Result:
The preceding result shows AWS Identity and Access Management (IAM) principal-wise cross-account AWS KMS API calls made between hub and spoke accounts. For example, Account B (22222222222) has two applications configured with IAM principals ids ending with 4C5VIMGI2, 4YFPRTQMP are accessing the centralized S3 bucket located in hub account A (111111111111).
For the time period between ‘2021/04/01’ and ‘2021/08/30’, the application configured with IAM principal ending in 4C5VIMGI2 made 1622 cross-account AWS KMS API calls. During this same time period, the application configured with IAM principal 4YFPRTQMP made 936 cross-account AWS KMS API calls.
We can further filter the results to see only KMS key ARN ending with 3aa3c82a2174 to get application- wise % of AWS KMS API calls made to the Amazon S3 centralized data lake from all the spoke accounts.
Note: we assume that each application is configured with a unique IAM principal.
SELECT useridentity.accountid as requestor_account_id,
resources[1].accountid as owner_account_id,
resources[1].arn as key_arn,
eventname as eventname,
count(resources) as count
FROM CloudTrail_logs_us_east_2
WHERE eventsource='kms.amazonaws.com'
AND timestamp between '2021/04/01' and '2021/08/30'
AND useridentity.accountid!= resources[1].accountid
AND json_extract(json_extract(requestparameters , '$.encryptionContext'),'$.aws:s3:arn') is not null
GROUP BY useridentity.accountid, resources [1].accountid,resources[1].arn,eventname
ORDER BY requestor_account_id,count desc
Result:
Amazon S3 makes decrypt API requests when you download the files and GenerateDataKey API request when you upload the file to encrypted S3 bucket. The result shows that:
Spoke account B (22222222222) made 1811 decrypt API requests to download 1811 files and 749 GenerateDataKey API requests to uploaded 749 files.
Spoke account C (33333333333) made 1373 decrypt API requests to download 1373 files and 271 GenerateDataKey API requests to uploaded 271 files.
Spoke account D (444444444444) made 638 decrypt API requests to download 638 files and 306 GenerateDataKey API requests to uploaded 306 files.
Note: When you configure your bucket to use an S3BucketKey for SSE-KMS, you may not have a separate Decrypt or GenerateDataKey for each file upload or download.
Step 6: Identify all the AWS KMS Calls.
To analyze the hub account for all the AWS KMS API calls made, run following query.
Query:
SELECT useridentity.accountid as requestor_account_id,
resources[1].accountid as owner_account_id,
resources[1].arn as key_arn,
count(resources) as count
FROM CloudTrail_logs_us_east_2
WHERE eventsource='kms.amazonaws.com'
AND timestamp between '2021/04/01' and '2021/08/30'
GROUP BY useridentity.accountid, resources [1].accountid,resources[1].arn
ORDER BY requestor_account_id,count desc
Result:
Results show all the AWS KMS API calls made in the hub account both within the account and across accounts. From this result, we can analyze that for centralized S3 data lake (KMS key ARN ending with 3aa3c82a2174), the majority of the calls are cross account AWS KMS API call and only 303 calls are made within account. You can do further analysis by refining the Amazon Athena queries based on your needs.
Cleaning up
To avoid incurring future charges, delete the resources that are no longer required.
Step 1: Delete the CloudTrail created in hub account
If you have created CloudTrail specifically for this solution, you can delete the CloudTrail by following the instructions in this user guide.
Step 2: Drop the Amazon Athena table
Log in to the Amazon Athena console and run the following drop table query:
Drop table < CloudTrail_logs_aws_region_1>
Conclusion
Tracking use of the cross-account AWS KMS APIs can be challenging in a multi-account scenario. In this blog, we learned how to use AWS CloudTrail and Amazon Athena to analyze AWS KMS API usage. In a hub and spoke account model, cross-account AWS KMS API quotas are applied to the spoke account when the spoke account accesses SSE-KMS encrypted S3 bucket in the hub account. You learned to analyze cross-account AWS KMS API quotas using AWS CloudTrail and Amazon Athena. Finally, we learned how we can identify all the AWS KMS API call within account for period of time and analyze AWS KMS API traffic within account and across account. You can repeat the process and aggregate the data across Regions.
By integrating Amazon EventBridge with Falcon Horizon, CrowdStrike has developed a real-time, cloud-based solution that allows you to detect threats in less than a second. This solution uses AWS CloudTrail and EventBridge. CloudTrail allows governance, compliance, operational auditing, and risk auditing of your AWS account. EventBridge is a serverless event bus that makes it easier to build event-driven applications at scale.
In this blog post, we’ll cover the challenges presented by using traditional log file-based security monitoring. We will also discuss how CrowdStrike used EventBridge to create an innovative, real-time cloud security solution that enables high-speed, event-driven alerts that detect malicious actors in milliseconds.
Challenges of log file-based security monitoring
Being able to detect malicious actors in your environment is necessary to stay secure in the cloud. With the growing volume, velocity, and variety of cloud logs, log file-based monitoring makes it difficult to reveal adverse behaviors in time to stop breaches.
When an attack is in progress, a security operations center (SOC) analyst has an average of one minute to detect the threat, ten minutes to understand it, and one hour to contain it. If you cannot meet this 1/10/60 minute rule, you may have a costly breach that may move laterally and explode exponentially across the cloud estate.
Let’s look at a real-life scenario. When a malicious actor attempts a ransom attack that targets high-value data in an Amazon Simple Storage Service (Amazon S3) bucket, it can involve activities in various parts of the cloud services in a brief time window.
Amazon S3: bucket and object enumeration; impair bucket encryption and versioning; bucket policy manipulation; getObject, putObject, and deleteObject APIs, etc.
With siloed log file-based monitoring, detecting, understanding, and containing a ransom attack while still meeting the 1/10/60 rule is difficult. This is because log files are written in batches, and files are typically only created every 5 minutes. Once the log file is written, it still needs to be fetched and processed. This means that you lose the ability to dynamically correlate disparate activities.
To summarize, top-level challenges of log file-based monitoring are:
Lag time between the breach and the detection
Inability to correlate disparate activities to reveal sophisticated attack patterns
Frequent false positive alarms that obscure true positives
High operational cost of log file synchronizations and reprocessing
Log analysis tool maintenance for fast growing log volume
Security and compliance is a shared responsibility between AWS and the customer. We protect the infrastructure that runs all of the services offered in the AWS Cloud. For abstracted services, such as Amazon S3, we operate the infrastructure layer, the operating system, and platforms, and customers access the endpoints to store and retrieve data.
You are responsible for managing your data (including encryption options), classifying assets, and using IAM tools to apply the appropriate permissions.
Indicators of attack by CrowdStrike with Amazon EventBridge
In real-world cloud breach scenarios, timeliness of observation, detection, and remediation is critical. CrowdStrike Falcon Horizon IOA is built on an event-driven architecture based on EventBridge and operates at a velocity that can outpace attackers.
CrowdStrike Falcon Horizon IOA performs the following core actions:
Observe: EventBridge streams CloudTrail log files across accounts to the CrowdStrike platform as activity occurs. Parallelism is enabled via event bus rules, which enables CrowdStrike to avoid the five-minute lag in fetching the log files and dynamically correlate disparate activities. The CrowdStrike platform observes end-to-end activities from AWS services and infrastructure hosted in the accounts protected by CrowdStrike.
Detect: Falcon Horizon invokes indicators of attack (IOA) detection algorithms that reveal adversarial or anomalous activities from the log file streams. It correlates new and historical events in real time while enriching the events with CrowdStrike threat intelligence data. Each IOA is prioritized with the likelihood of activity being malicious via scoring and mapped to the MITRE ATT&CK framework.
Remediate: The detected IOA is presented with remediation steps. Depending on the score, applying the remediations quickly can be critical before the attack spreads.
Prevent: Unremediated insecure configurations are revealed via indicators of misconfiguration (IOM) in Falcon Horizon. Applying the remediation steps from IOM can prevent future breaches.
Key differentiators of IOA from Falcon Horizon are:
Observability of wider attack surfaces with heterogeneous event sources
Detection of sophisticated tactics, techniques, and procedures (TTPs) with dynamic event correlation
Event enrichment with threat intelligence that aids prioritization and reduces alert fatigue
Low latency between malicious activity occurrence and corresponding detection
Insight into attacks for each adversarial event from MITRE ATT&CK framework
High-level architecture
Event-driven architectures provide advantages for integrating varied systems over legacy log file-based approaches. For securing cloud attack surfaces against the ever-evolving TTPs, a robust event-driven architecture at scale is a key differentiator.
CrowdStrike maximizes the advantages of event-driven architecture by integrating with EventBridge, as shown in Figure 1. EventBridge allows observing CloudTrail logs in event streams. It also simplifies log centralization from a number of accounts with its direct source-to-target integration across accounts, as follows:
CrowdStrike hosts an EventBridge with central event buses that consume the stream of CloudTrail log events from a multitude of customer AWS accounts.
Within customer accounts, EventBridge rules listen to the local CloudTrail and stream each activity as an event to the centralized EventBridge hosted by CrowdStrike.
CrowdStrike’s event-driven platform detects adversarial behaviors from the event streams in real time. The detection is performed against incoming events in conjunction with historical events. The context that comes from connecting new and historical events minimizes false positives and improves alert efficacy.
Events are enriched with CrowdStrike threat intelligence data that provides additional insight of the attack to SOC analysts and incident responders.
As data is received by the centralized EventBridge, CrowdStrike relies on unique customer ID and AWS Region in each event to provide integrity and isolation.
EventBridge allows relatively hassle-free customer onboarding by using cross account rules to transfer customer CloudTrail data into one common event bus that can then be used to filter and selectively forward the data into the Falcon Horizon platform for analysis and mitigation.
Conclusion
As your organization’s cloud footprint grows, visibility into end-to-end activities in a timely manner is critical for maintaining a safe environment for your business to operate. EventBridge allows event-driven monitoring of CloudTrail logs at scale.
CrowdStrike Falcon Horizon IOA, powered by EventBridge, observes end-to-end cloud activities at high speeds at scale. Paired with targeted detection algorithms from in-house threat detection experts and threat intelligence data, Falcon Horizon IOA combats emerging threats against the cloud control plane with its cutting-edge event-driven architecture.
Incident response is a core security capability for organizations to develop, and a core element in the AWS Cloud Adoption Framework (AWS CAF). Responding to security incidents quickly is important to minimize their impacts. Automating incident response helps you scale your capabilities, rapidly reduce the scope of compromised resources, and reduce repetitive work by your security team.
In this post, I show you how to use Incident Manager, a capability of AWS Systems Manager, to build an effective automated incident management and response solution to security events.
You’ll walk through three common security-related events and how you can use Incident Manager to automate your response.
AWS account root user activity: An Amazon Web Services (AWS) account root user has full access to all your resources for all AWS services, including billing information. It’s therefore elemental to adhere to the best practice of using the root user only to create your first IAM user and securely lock away the root user credentials and use them to perform only a few account and service management tasks. And it is critical to be aware when root user activity occurs in your AWS account.
Amazon GuardDuty high severity findings: Amazon GuardDuty is a threat detection service that continuously monitors for malicious or unauthorized behavior to help protect your AWS accounts and workloads. In this blog post, you’ll learn how to initiate an incident response plan whenever a high severity finding is discovered.
AWS Config rule change and S3 bucket allowing public access: AWS Config enables continuous monitoring of your AWS resources, making it simple to assess, audit, and record resource configurations and changes. You will use AWS Config to monitor your Amazon Simple Storage Service (S3) bucket ACLs and policies for settings that allow public read or public write access.
Incident Manager can start managing incidents automatically using Amazon CloudWatch or Amazon EventBridge. For the solution in this blog post, you will use EventBridge to capture events and start an incident.
To complete the steps in this walkthrough, you need the following:
An AWS account and AWS Identity Access and Management (IAM) permissions to access Systems Manager, GuardDuty, Config, S3, and EventBridge. Your IAM user or role should also have iam:CreateServiceLinkedRole permissions. Incident Manager uses this permission to create the service-linked role AWSServiceRoleforIncidentManager in your account. For more information, see Using service-linked roles for Incident Manager.
A response plan ties together the contacts, escalation plan, and runbook. When an incident occurs, a response plan defines who to engage, how to engage, which runbook to initiate, and which metrics to monitor. By creating a well-defined response plan, you can save your security team time down the road.
Add contacts
Your contacts should include everyone who might be involved in the incident. Follow these steps to add a contact.
On Contact information, enter names and define contact channels for your contacts.
Under Contact channel, you can select Email, SMS, or Voice. You can also add multiple contact channels.
In Engagement plan, specify how fast to engage your responders. In the example illustrated below, the incident responder will be engaged through email immediately (0 minutes) when an incident is detected and then through SMS 10 minutes into an incident. Complete the fields and then choose Create.
Figure 2: Engagement plan
Create a response plan
Once you’ve created your contacts, you can create a response plan to define how to respond to incidents. Refer to the Best Practices for Response Plans.
Note: (Optional) You can also create an escalation plan that lets you further define the escalation path for your contacts. You can learn more in Create an escalation plan.
Enter a unique and identifiable name for your response plan.
Enter an incident title. The incident title helps to identify an incident on the incidents home page.
Select an appropriate Impact based on the potential scope of the incident.
Figure 3: Selecting your impact level
(Optional) Choose a chat channel for the incident responders to interact in during an incident. For more information about chat channels, see Chat channels.
(Optional) For Engagement, you can choose any number of contacts and escalation plans. For this solution, select the security team responder that you created earlier as one of your contacts.
Figure 4: Adding engagements
(Optional) You can also create a runbook that can drive the incident mitigation and response. For further information, refer to Runbooks and automation.
Under Execution permissions, choose Create an IAM role using a template. Under Role name, select the IAM role you created in the prerequisites that allows Incident Manager to run SSM automation documents, and then choose Create response plan.
Monitor AWS account root activity
When you first create an AWS account, you begin with a single sign-in identity that has complete access to all AWS services and resources in the account. This identity is called the root user and is accessed by signing in with the email address and password that you used to create the account.
An AWS account root user has full access to all your resources for all AWS services, including billing information. It is critical to prevent root user access from unauthorized use and to be aware whenever root user activity occurs in your AWS account. For more information about AWS recommendations, see Security best practices in IAM.
To be certain that all root user activity is authorized and expected, it’s important to monitor root API calls to a given AWS account and to be notified when root user activity is detected.
Create an EventBridge rule
Create and validate an EventBridge rule to capture AWS account root activity.
In the navigation pane, choose Rules, and then choose Create rule.
Enter a name and description for the rule.
For Define pattern, choose Event pattern.
Choose Custom pattern.
Enter the following event pattern:
{
"detail-type": [
"AWS API Call via CloudTrail",
"AWS Console Sign In via CloudTrail"
],
"detail": {
"userIdentity": {
"type": [
"Root"
]
}
}
}
For Select targets, choose Incident Manager response plan.
For Response plan, choose SecurityEventResponsePlan, which you created when you set up Incident Manager.
To create an IAM role automatically, choose Create a new role for this specific resource. To use an existing IAM role, choose Use existing role.
(Optional) Enter one or more tags for the rule.
Choose Create.
To validate the rule
Sign in using root credentials.
This console login activity by a root user should invoke the Incident Manager response plan and show an open incident as illustrated below. The respective contact channels that you defined earlier in your Engagement Plan, will be engaged.
GuardDuty integrates with EventBridge, which can be used to send findings data to other applications and services for processing. With EventBridge, you can use GuardDuty findings to invoke automatic responses to your findings by connecting finding events to targets such as Incident Manager response plan.
Create an EventBridge rule
You’ll use an EventBridge rule to capture GuardDuty high severity findings.
For Select targets, choose Incident Manager response plan.
For Response plan, select SecurityEventResponsePlan, which you created when you set up Incident Manager.
To create an IAM role automatically, choose Create a new role for this specific resource. To use an IAM role that you created before, choose Use existing role.
(Optional) Enter one or more tags for the rule.
Choose Create.
To validate the rule
To test and validate whether the above rule is now functional, you can generate sample findings within the GuardDuty console.
On the Settings page, under Sample findings, choose Generate sample findings.
In the navigation pane, choose Findings. The sample findings are displayed on the Current findings page with the prefix [SAMPLE].
Once you have generated sample findings, your Incident Manager response plan will be invoked almost immediately and the engagement plan with your contacts will begin.
You can select an open incident in the Incident Manager console to see additional details from the GuardDuty finding. Figure 6 shows a high severity finding.
Figure 6: Incident Manager open incident for GuardDuty high severity finding
Monitor S3 bucket settings for public access
AWS Config enables continuous monitoring of your AWS resources, making it easier to assess, audit, and record resource configurations and changes. AWS Config does this through rules that define the desired configuration state of your AWS resources. AWS Config provides a number of AWS managed rules that address a wide range of security concerns such as checking that your Amazon Elastic Block Store (Amazon EBS) volumes are encrypted, your resources are tagged appropriately, and multi-factor authentication (MFA) is enabled for root accounts.
Set up AWS Config and EventBridge
You will use AWS Config to monitor your S3 bucket ACLs and policies for violations which could allow public read or public write access. If AWS Config finds a policy violation, it will initiate an AWS EventBridge rule to invoke your Incident Manager response plan.
To create the AWS Config rule to capture S3 bucket public access
If this is your first time in the AWS Config console, refer to the Getting Started guide for more information.
Select Rules from the menu and choose Add Rule.
On the AWS Config rules page, enter S3 in the search box and select the s3-bucket-public-read-prohibited and s3-bucket-public-write-prohibited rules, and then choose Next.
Figure 7: AWS Config rules
Leave the Configure rules page as default and select Next.
On the Review page, select Add Rule. AWS Config is now analyzing your S3 buckets, capturing their current configurations, and evaluating the configurations against the rules you selected.
For Select targets, choose Incident Manager response plan.
For Response plan, choose SecurityEventResponsePlan, which you created earlier when setting up Incident Manager.
To create an IAM role automatically, choose Create a new role for this specific resource. To use an existing IAM role, choose Use existing role.
(Optional) Enter one or more tags for the rule.
Choose Create.
To validate the rule
Create a compliant test S3 bucket with no public read or write access through either an ACL or a policy.
Change the ACL of the bucket to allow public listing of objects so that the bucket is non-compliant.
Figure 8: Amazon S3 console
After a few minutes, you should see the AWS Config rule initiated which invokes the EventBridge rule and therefore your Incident Manager response plan.
Summary
In this post, I showed you how to use Incident Manager to monitor for security events and invoke a response plan via Amazon CloudWatch or Amazon EventBridge. AWS CloudTrail API activity (for a root account login), Amazon GuardDuty (for high severity findings), and AWS Config (to enforce policies like preventing public write access to an S3 bucket). I demonstrated how you can create an incident management and response plan to ensure you have used the power of cloud to create automations that respond to and mitigate security incidents in a timely manner. To learn more about Incident Manager, see What Is AWS Systems Manager Incident Manager in the AWS documentation.
If you have feedback about this post, submit comments in the comments section below. If you have questions about this post, start a new thread on the Systems Manager forum or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
“It is not the strongest of the species that survives, nor the most intelligent. It is the one that is most adaptable to change.” – often attributed to Charles Darwin
One common strategy for businesses that operate in dynamic market conditions (and thus need to continuously correct their course) is to aim for smaller, independent development teams. Microservices and two-pizza teams at Amazon are prominent examples of this strategy. But having smaller units is not the only success factor: to reduce organizational bottlenecks and make high-quality decisions quickly, these two-pizza teams need to be autonomous in most of their decision making.
Architects can no longer rely on static upfront design to meet the change rate required to be successful in such an environment.
This blog shows enterprise architects a mechanism to align decentralized architectural decision making with overall architecture goals.
Gathering data from your fitness functions
“Evolutionary architecture” was coined by Neal Ford and his colleagues from AWS Partner ThoughtWorks in their work on Building Evolutionary Architectures. It is defined as “supporting guided, incremental change as a first principle across multiple dimensions.”
Fitness functions help you obtain the necessary data to allow for the planned evolution of your architecture. They set measurable values to assess how close your solution is to achieving your set goals.
Fitness functions can and should be adapted as the architecture evolves to guide a desired change process. This provides architects with a tool to guide their teams while maintaining team autonomy.
Example of a regression fitness function in action
You’ve identified shorter time-to-market as a key non-functional requirement. You want to lower the risk of regressions and rollbacks after deployments. So, you and your team write automated test cases. To ensure that they have a good set of test cases in place, they measure test coverage. This test coverage measures the percentage of code that is tested automatically. This steers the team toward writing tests to mitigate the risk of regressions so they have fewer rollbacks and shorter time to market.
Fitness functions like this work best when they’re as automated as possible. But how do you acquire the necessary data points to use this mechanism outside of software architecture? We’ll show you how in the following sections.
AWS Cloud services with built-in fitness functions
AWS Cloud services are highly standardized, fully automated via API operations, and are built with observability in mind. This allows you to generate measurements for fitness functions automatically for areas such as availability, responsiveness, and security.
To start building your evolutionary architecture with fitness functions, use something that can be easily measured. AWS has services that can be used as inputs to fitness functions, including:
Amazon CloudWatch aggregates logs and metrics to check for availability, responsiveness, and reliability fitness functions.
AWS Security Hub provides a comprehensive view of your security alerts and security posture across your AWS accounts. Security Architects could, for example, define the fitness function of critical and high findings to be zero. Teams then would be guided into reducing the number of these findings, resulting in better security.
AWS Cost Explorer ensures your costs stay in line with value generated.
Amazon SageMakerModel Monitor continuously monitors the quality of SageMaker machine learning models in production. Detecting deviations early allows you to take corrective actions like retraining models, auditing upstream systems, or fixing quality issues.
Using the observability that the cloud provides
Fitness functions can be derived by evaluating the AWS account activity such as configuration changes. AWS CloudTrail is useful for this. It records account activity and service events from most AWS services, which can then be analyzed with Amazon Athena.
Figure 1. Fitness functions provide feedback to engineers via metrics
Example of a cloud fitness function in action
In this example, we implement a fitness function that monitors the operability of your system.
You have had certain outages due to manual tasks in operations, and you have anecdotal evidence that engineers are spending time on manual work during application rollouts. To improve operations, you want to reduce manual interactions via the shell in favor of automation. First, you prevent direct secure shell (SSH) access by blocking SSH traffic via the managed AWS Config rule restricted-ssh. Second, you make use of AWS Systems Manager Session Manager, which provides a secure and auditable way to access Amazon Elastic Compute Cloud (Amazon EC2) instances.
By counting the logged API events in CloudTrail you can measure the number of shell sessions. This is shown in this sample Athena query to count the number of shell sessions:
SELECT count(*),
DATE(from_iso8601_timestamp(eventTime)),
userIdentity.type,
eventSource,
eventName
FROM "cloudtrail_logs_partition_projection"
WHERE readonly = 'false'
AND eventsource = 'ssm.amazonaws.com'
AND eventname in ('StartSession',
'ResumeSession',
'TerminateSession')
GROUP BY DATE(from_iso8601_timestamp(eventTime)),
userIdentity.type,
eventSource,
eventName
ORDER BY DATE(from_iso8601_timestamp(eventTime)) DESC
The number of shell sessions now act as fitness function to improve operational excellence through operations as code. Coincidently, the fitness function you defined also rewards teams moving to serverless compute services such as AWS Fargate or AWS Lambda.
Fitness through exercising
Similar to people, your architecture’s fitness can be improved by exercising. It does not take much equipment, but you need to take the first step. To get started, we encourage you to think of the desired outcomes for your architecture that you can measure (and thus guide) through fitness functions. The following lessons learned will help you focus your goals:
Requirements and business goals may differ per domain. Thus, your fitness functions might differ. Work closely with your teams when defining fitness functions.
Start by taking something that can be easily measured and communicated as a goal.
Focus on a positive trendline rather than absolute values.
Make sure you and your teams are using the same metrics and the same way to measure them. We have seen examples where central governance departments had access to data the individual teams did not, leading to frustration on all sides.
Ensure that your architecture goals fit well into the current context and time horizon.
Continuously re-visit the fitness functions to ensure that they evolve with the changing business goals.
Conclusion
Fitness functions help architects focus on building. Once established, teams can use the data points from fitness functions to make decisions and work towards a common and measurable goal. The architects in turn can use the data points they get from fitness functions to confirm their hypothesis of the current state of the architecture. Get started building your fitness functions today by:
Gathering the most important system quality attributes.
Beginning with approximately three meaningful fitness functions relying on the API operations available.
Building a dashboard that shows progress over time, share it with your teams, and rely on this data in your daily work.
This series of blog posts uses the AWS Well-Architected Tool with the Serverless Lens to help customers build and operate applications using best practices. In each post, I address the serverless-specific questions identified by the Serverless Lens along with the recommended best practices. See the introduction post for a table of contents and explanation of the example application.
Security question SEC3: How do you implement application security in your workload?
This post continues part 1 of this security question. Previously, I cover reviewing security awareness documentation such as the Common Vulnerabilities and Exposures (CVE) database. I show how to use GitHub security features to inspect and manage code dependencies. I then show how to validate inbound events using Amazon API Gateway request validation.
Required practice: Store secrets that are used in your code securely
Store secrets such as database passwords or API keys in a secrets manager. Using a secrets manager allows for auditing access, easier rotation, and prevents exposing secrets in application source code. There are a number of AWS and third-party solutions to store and manage secrets.
AWS Partner Network (APN) member Hashicorp provides Vault to keep secrets and application data secure. Vault has a centralized workflow for tightly controlling access to secrets across applications, systems, and infrastructure. You can store secrets in Vault and access them from an AWS Lambda function to, for example, access a database. You can use the Vault Agent for AWS to authenticate with Vault, receive the database credentials, and then perform the necessary queries. You can also use the Vault AWS Lambda extension to manage the connectivity to Vault.
AWS Secrets Manager enables you to replace hardcoded credentials in your code with an API call to Secrets Manager to retrieve the secret programmatically. You can protect, rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle. You can also generate secure secrets. By default, Secrets Manager does not write or cache the secret to persistent storage.
The AWS CloudFormation stack deploys an Amazon RDS MySQL database with a randomly generated password. This is stored in Secrets Manager using a secret resource. A Lambda function behind an API Gateway endpoint returns the record count in a table from the database, using the required credentials. Lambda function environment variables store the database connection details and which secret to return for the database password. The password is not stored as an environment variable, nor in the Lambda function application code.
Lambda environment variables for Secrets Manager
The application flow is as follows:
Clients call the API Gateway endpoint
API Gateway invokes the Lambda function
The Lambda function retrieves the database secrets using the Secrets Manager API
The Lambda function connects to the RDS database using the credentials from Secrets Manager and returns the query results
View the password secret value in the Secrets Manager console, which is randomly generated as part of the stack deployment.
Example password stored in Secrets Manager
The Lambda function includes the following code to retrieve the secret from Secrets Manager. The function then uses it to connect to the database securely.
Browsing to the endpoint URL specified in the CloudFormation output displays the number of records. This confirms that the Lambda function has successfully retrieved the secure database credentials and queried the table for the record count.
Lambda function retrieving database credentials
Audit secrets access through a secrets manager
Monitor how your secrets are used to confirm that the usage is expected, and log any changes to them. This helps to ensure that any unexpected usage or change can be investigated, and unwanted changes can be rolled back.
Hashicorp Vault uses Audit devices that keep a detailed log of all requests and responses to Vault. Audit devices can append logs to a file, write to syslog, or write to a socket.
Secrets Manager supports logging API calls with AWS CloudTrail. CloudTrail captures all API calls for Secrets Manager as events. This includes calls from the Secrets Manager console and from code calling the Secrets Manager APIs.
Viewing the CloudTrail event history shows the requests to secretsmanager.amazonaws.com. This shows the requests from the console in addition to the Lambda function.
CloudTrail showing access to Secrets Manager
Secrets Manager also works with Amazon EventBridge so you can trigger alerts when administrator-specified operations occur. You can configure EventBridge rules to alert on deleted secrets or secret rotation. You can also create an alert if anyone tries to use a secret version while it is pending deletion. This can identify and alert when there is an attempt to use an out-of-date secret.
Enforce least privilege access to secrets
Access to secrets must be tightly controlled because the secrets contain sensitive information. Create AWS Identity and Access Management (IAM) policies that enable minimal access to secrets to prevent credentials being accidentally used or compromised. Secrets that have policies that are too permissive could be misused by other environments or developers. This can lead to accidental data loss or compromised systems. For more information, see “Authentication and access control for AWS Secrets Manager”.
Rotate secrets frequently.
Rotating your workload secrets is important. This prevents misuse of your secrets since they become invalid within a configured time period.
Secrets Manager allows you to rotate secrets on a schedule or on demand. This enables you to replace long-term secrets with short-term ones, significantly reducing the risk of compromise. Secrets Manager creates a CloudFormation stack with a Lambda function to manage the rotation process for you. Secrets Manager has native integrations with Amazon RDS, Amazon Redshift, and Amazon DocumentDB. It populates the function with the Amazon Resource Name (ARN) of the secret. You specify the permissions to rotate the credentials, and how often you want to rotate the secret.
The CloudFormation stack creates a MySecretRotationSchedule resource with a MyRotationLambda function to rotate the secret every 30 days.
MySecretRotationSchedule:
Type: AWS::SecretsManager::RotationSchedule
DependsOn: SecretRDSInstanceAttachment
Properties:
SecretId: !Ref MyRDSInstanceRotationSecret
RotationLambdaARN: !GetAtt MyRotationLambda.Arn
RotationRules:
AutomaticallyAfterDays: 30
MyRotationLambda:
Type: AWS::Serverless::Function
Properties:
Runtime: python3.7
Role: !GetAtt MyLambdaExecutionRole.Arn
Handler: mysql_secret_rotation.lambda_handler
Description: 'This is a lambda to rotate MySql user passwd'
FunctionName: 'cfn-rotation-lambda'
CodeUri: 's3://devsecopsblog/code.zip'
Environment:
Variables:
SECRETS_MANAGER_ENDPOINT: !Sub 'https://secretsmanager.${AWS::Region}.amazonaws.com'
View and edit the rotation settings in the Secrets Manager console.
Secrets Manager rotation settings
Manually rotate the secret by selecting Rotate secret immediately. This invokes the Lambda function, which updates the database password and updates the secret in Secrets Manager.
View the updated secret in Secrets Manager, where the password has changed.
Secrets Manager password change
Browse to the endpoint URL to confirm you can still access the database with the updated credentials.
Access endpoint with updated Secret Manager password
You can provide your own code to customize a Lambda rotation function for other databases or services. The code includes the commands required to interact with your secured service to update or add credentials.
Conclusion
Implementing application security in your workload involves reviewing and automating security practices at the application code level. By implementing code security, you can protect against emerging security threats. You can improve the security posture by checking for malicious code, including third-party dependencies.
In this post, I continue from part 1, looking at securely storing, auditing, and rotating secrets that are used in your application code.
In the next post in the series, I start to cover the reliability pillar from the Well-Architected Serverless Lens with regulating inbound request rates.
For more serverless learning resources, visit Serverless Land.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.