Post Syndicated from Marshall Jones original https://aws.amazon.com/blogs/security/how-to-detect-security-issues-in-amazon-eks-clusters-using-amazon-guardduty-part-1/
In this two-part blog post, we’ll discuss how to detect and investigate security issues in an Amazon Elastic Kubernetes Service (Amazon EKS) cluster with Amazon GuardDuty and Amazon Detective.
Amazon Elastic Kubernetes Service (Amazon EKS) is a managed service that you can use to run and scale container workloads by using Kubernetes in the AWS Cloud, which can help increase the speed of deployment and portability of modern applications. Amazon EKS provides secure, managed Kubernetes clusters on the AWS control plane by default. Kubernetes configurations such as pod security policies, runtime security, and network policies and configurations are specific for your organization’s use-case and securing them adequately would be a customer’s responsibility within AWS’ shared responsibility model.
Amazon GuardDuty can help you continuously monitor and detect suspicious activity related to AWS resources in your account. GuardDuty for EKS protection is a feature that you can enable within your accounts. When this feature is enabled, GuardDuty can help detect potentially unauthorized EKS activity resulting from misconfiguration of the control plane nodes or application.
In this post, we’ll walk through the events leading up to a real-world security issue that occurred due to EKS cluster misconfiguration, discuss how those misconfigurations could be used by a malicious actor, and how Amazon GuardDuty monitors and identifies suspicious activity throughout the EKS security event. In part 2 of the post, we’ll cover Amazon Detective investigation capabilities, possible remediation techniques, and preventative controls for EKS cluster related security issues.
Prerequisites
You must have AWS GuardDuty enabled in your AWS account in order to monitor and generate findings associated with an EKS cluster related security issue in your environment.
- Amazon GuardDuty, along with these features of GuardDuty:
EKS security issue walkthrough
Before jumping into the security issue, it is important to understand how the AWS shared responsibility model applies to the Amazon EKS managed service. AWS is responsible for the EKS managed Kubernetes control plane and the infrastructure to deliver EKS in a secure and reliable manner. You have the ability to configure EKS and how it interacts with other applications and services, where you are responsible for making sure that secure configurations are being used.
The following scenario is based on a real-world observed event, where a malicious actor used Kubernetes compromise tactics and techniques to expose and access an EKS cluster. We use this example to show how you can use AWS security services to identify and investigate each step of this security event. For a security event in your own environment, the order of operations and the investigative and remediation techniques used might be different. The scenario is broken down into the following phases and associated MITRE ATT&CK tactics:
- Phase 1 – EKS cluster misconfiguration
- Phase 2 (Discovery) – Discovery of vulnerable EKS clusters
- Phase 3 (Initial Access) – Credential access to obtain Kubernetes secrets
- Phase 4 (Persistence) – Impact to persist unauthorized access to the cluster
- Phase 5 (Impact) – Impact to manipulate resources for unauthorized activity
Phase 1 – EKS cluster misconfiguration
By default, when you provision an EKS cluster, the API cluster endpoint is set to public, meaning that it can be accessed from the internet. Despite being accessible from the internet, the endpoint is still considered secure because it requires all API requests to be authenticated by AWS Identity and Access Management (IAM) and then authorized by Kubernetes role-based access control (RBAC). Also, the entity (user or role) that creates the EKS cluster is automatically granted system:masters permissions, which allows the entity to modify the EKS cluster’s RBAC configuration.
This example scenario starts with a developer who has access to administer EKS clusters in an AWS account. The developer wants to work from their home network and doesn’t want to connect to their enterprise VPN for IAM role federation. They configure an EKS cluster API without setting up the proper authentication and authorization components. Instead, the developer grants explicit access to the system:anonymous user in the cluster’s RBAC configuration. (Alternatively, an unauthorized RBAC configuration could be introduced into your environment after a developer unknowingly installs a malicious helm chart from the internet without reviewing or inspecting it first.)
In Kubernetes anonymous requests, unauthenticated and unrejected HTTP requests are treated as anonymous access and are identified as a system:anonymous user belonging to a system:unauthenticated group. This means that any entity on the internet can access the cluster and make API requests that are permitted by the role. There aren’t many legitimate use cases for this type of activity, because it’s considered a best practice to use RBAC instead. Anonymous requests are primarily used for setting up health endpoints and custom authentication.
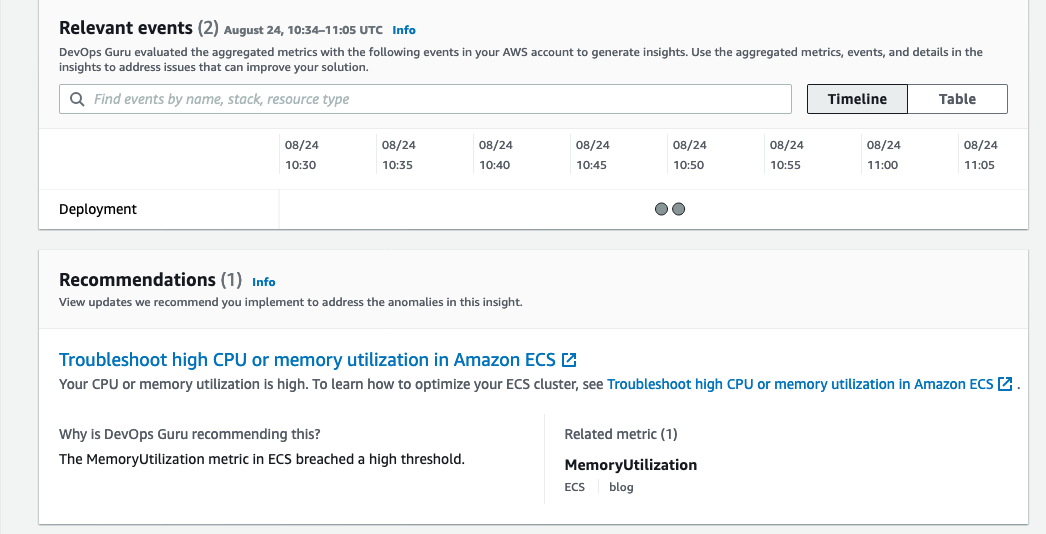
By monitoring EKS audit logs, GuardDuty identifies this activity and generates the finding Policy:Kubernetes/AnonymousAccessGranted, as shown in Figure 1. This finding informs you that a user on your Kubernetes cluster successfully created a ClusterRoleBinding or RoleBinding to bind the user system:anonymous to a role. This action enables unauthenticated access to the API operations permitted by the role.

Figure 1: Example GuardDuty finding for Kubernetes anonymous access granted
Phase 2 (Discovery) – Discovery of vulnerable EKS clusters
Port scanning is a method that malicious actors use to determine if resources are publicly exposed, with open ports and known vulnerabilities. As an increasing number of open-source tools allows users to search for endpoints connected to the internet, finding these endpoints has become even easier. Security teams can use these open-source tools to their advantage by proactively scanning for and identifying externally exposed resources in their organization.
This brings us to the discovery phase of our misconfigured EKS cluster. The discovery phase is defined by MITRE as follows: “Discovery consists of techniques an adversary may use to gain knowledge about the system and internal network. These techniques help adversaries observe the environment and orient themselves before deciding how to act.”
By granting system:anonymous access to the EKS cluster in our example, the developer allowed requests from any public unauthenticated source. This can result in external web crawlers probing the cluster API, which can often happen within seconds of the system:anonymous access being granted. GuardDuty identifies this activity and generates the finding Discovery:Kubernetes/SuccessfulAnonymousAccess, as shown in Figure 2. This finding informs you that an API operation to discover resources in a cluster was successfully invoked by the system:anonymous user. Remember, all API calls made by system:anonymous are unauthenticated, in addition to /healthz and /version calls that are always unauthenticated regardless of the user identity, and any entity can make use of this user within the EKS cluster.
In the screenshot, under the Action section in the finding details, you can see that the anonymous user made a get request to “/”. This is a generic request that is not specific to a Kubernetes cluster, which may indicate that the crawler is not specifically targeting Kubernetes clusters. You can further see that the Status code is 200, indicating that the request was successful. If this activity is malicious, then the actor is now aware that there is an exposed resource.

Figure 2: Example GuardDuty finding for Kubernetes successful anonymous access
Phase 3 (Initial Access) – Credential access to obtain Kubernetes secrets
Next, in this phase, you might start observing more targeted API calls for establishing initial access from unauthorized users. MITRE defines initial access as “techniques that use various entry vectors to gain their initial foothold within a network. Techniques used to gain a foothold include targeted spearphishing and exploiting weaknesses on public-facing web servers. Footholds gained through initial access may allow for continued access, like valid accounts and use of external remote services, or may be limited-use due to changing passwords.”
In our example, the malicious actor has established initial access for the EKS cluster which is evident in the next GuardDuty finding, CredentialAccess:Kubernetes/SuccessfulAnonymousAccess, as shown in Figure 3. This finding informs you that an API call to access credentials or secrets was successfully invoked by the system:anonymous user. The observed API call is commonly associated with the credential access tactic where an adversary is attempting to collect passwords, usernames, and access keys for a Kubernetes cluster.
You can see that in this GuardDuty finding, in the Action section, the Request uri is targeted at a Kubernetes cluster, specifically /api/v1/namespaces/kube-system/secrets. This request seems to be targeting the secrets management capabilities that are built into Kubernetes. You can find more information about this secrets management capability in the Kubernetes documentation.

Figure 3: Example GuardDuty finding for Kubernetes successful credential access from anonymous user
Phase 4 (Persistence) – Impact to persist unauthorized access to the cluster
The next phase of this scenario is likely to be an impact in the EKS cluster to enable persistence by the malicious actor. MITRE defines impact as “techniques that adversaries use to disrupt availability or compromise integrity by manipulating business and operational processes.” Following the MITRE definitions, “Persistence consists of techniques that adversaries use to keep access to systems across restarts, changed credentials, and other interruptions that could cut off their access. Techniques used for persistence include any access, action, or configuration changes that let them maintain their foothold on systems, such as replacing or hijacking legitimate code or adding startup code.”
In the GuardDuty finding Impact:Kubernetes/SuccessfulAnonymousAccess, shown in Figure 4, you can see the Kubernetes user details and Action sections that indicate that a successful Kubernetes API call was made to create a ClusterRoleBinding by the system:anonymous username. This finding informs you that a write API operation to tamper with resources was successfully invoked by the system:anonymous user. The observed API call is commonly associated with the impact stage of an attack, when an adversary is tampering with resources in your cluster. This activity shows that the system:anonymous user has now created their own role to enable persistent access the EKS cluster. If the user is malicious, they can now access the cluster even if access is removed in the RBAC configuration for the system:anonymous user.

Figure 4 Example GuardDuty finding for Kubernetes successful credential change by anonymous user
Phase 5 (Impact) – Impact to manipulate resources for unauthorized activity
The fifth phase of this scenario is where the unauthorized user is likely to focus on impact techniques in order to use the access for malicious purpose. MITRE says of the impact phase: “Techniques used for impact can include destroying or tampering with data. In some cases, business processes can look fine, but may have been altered to benefit the adversaries’ goals. These techniques might be used by adversaries to follow through on their end goal or to provide cover for a confidentiality breach.” Typically, once a malicious actor has access into a system, they will introduce malware to the system to manipulate the compromised resource and possibly also other resources.
With the introduction of GuardDuty Malware Protection, when an Amazon Elastic Compute Cloud (Amazon EC2) or container-related GuardDuty finding that indicates potentially suspicious activity is generated, an agentless scan on the volumes will initiate and detect the presence of malware. Existing GuardDuty customers need to enable Malware Protection, and for new customers this feature is on by default when they enable GuardDuty for the first time. Malware Protection comes with a 30-day free trial for both existing and new GuardDuty customers. You can see a list of findings that initiates a malware scan in the GuardDuty User Guide.
In this example, the malicious actor now uses access to the cluster to perform unauthorized cryptocurrency mining. GuardDuty monitors the DNS requests from the EC2 instances used to host the EKS cluster. This allows GuardDuty to identify a DNS request made to a domain name associated with a cryptocurrency mining pool, and generate the finding CryptoCurrency:EC2/BitcoinTool.B!DNS, as shown in Figure 5.

Figure 5: Example GuardDuty finding for EC2 instance querying bitcoin domain name
Because this is an EC2 related GuardDuty finding and GuardDuty Malware Protection is enabled in the account, GuardDuty then conducts an agentless scan on the volumes of the EC2 instance to detect malware. If the scan results in a successful detection of one or more malicious files, another GuardDuty finding for Execution:EC2/MaliciousFile is generated, as shown in Figure 6.

Figure 6: Example GuardDuty finding for detection of a malicious file on EC2
The first GuardDuty finding detects crypto mining activity, while the proceeding malware protection finding provides context on the malware associated with this activity. This context is very valuable for the incident response process.
Conclusion
In this post, we walked you through each of the five phases where we outlined how an initial misconfiguration could result in a malicious actor gaining control of EKS resources within an AWS account and how GuardDuty is able to continually monitor and detect the progression of the security event. As previously stated, this is just one example where a misconfiguration in an EKS cluster could result in a security event.
Now that you have a good understanding of GuardDuty capabilities to continuously monitor and detect EKS security events, you will need to establish processes and procedures to enable your security team to investigate these events. You can enable Amazon Detective to help accelerate your security team’s mean time to respond (MTTR) by providing an efficient mechanism to analyze, investigate, and identify the root cause of security events. Follow along in part 2 of this series, How to investigate and take action on an Amazon EKS cluster related security issue with Amazon Detective, where we’ll cover techniques you can use with Amazon Detective to identify impacted EKS resources in your AWS account, possible remediation actions to take on the cluster, and preventative controls you can implement.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a thread on Amazon GuardDuty re:Post.
Want more AWS Security news? Follow us on Twitter.











































![Architecture Diagram showing the service “Test” using the container “brickwall-maker” with a desired count of two. The two ECS Task’s vended metrics are then processed by CloudWatch Container Insights. Both, CloudWatch Container Insights and CloudTrail, are ingested by Amazon DevOps Guru which then makes detected insights available to the user. [Image: DevOpsGuruBlog1.png]V1: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/LdkTqbmlZ8uNj7A44pZbnw?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz) V2: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/SvsNTJLEJOHHBls_kV7EwA?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz) V3: DevOpsGuruBlog1.drawio (https://api.quip-amazon.com/2/blob/fbe9AAT37Ge/DqKTxtQvmOLrzM3KcF_oTg?name=DevOpsGuruBlog1.drawio&s=cVbmAWsXnynz)](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2021/10/29/DevOpsGuruBlog1-1-1.png)