Post Syndicated from Guy Bachar original https://aws.amazon.com/blogs/big-data/backtesting-index-rebalancing-arbitrage-with-amazon-emr-and-apache-iceberg/
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance.
Index rebalancing arbitrage takes advantage of short-term price discrepancies resulting from ETF managers’ efforts to minimize index tracking error. Major market indexes, such as S&P 500, are subject to periodic inclusions and exclusions for reasons beyond the scope of this post (for an example, refer to CoStar Group, Invitation Homes Set to Join S&P 500; Others to Join S&P 100, S&P MidCap 400, and S&P SmallCap 600). The arbitrage trade looks to profit from going long on stocks added to an index and shorting the ones that are removed, with the aim of generating profit from these price differences.
In this post, we look into the process of using backtesting to evaluate the performance of an index arbitrage profitability strategy. We specifically explore how Amazon EMR and the newly developed Apache Iceberg branching and tagging feature can address the challenge of look-ahead bias in backtesting. This will enable a more accurate evaluation of the performance of the index arbitrage profitability strategy.
Terminology
Let’s first discuss some of the terminology used in this post:
- Research data lake on Amazon S3 – A data lake is a large, centralized repository that allows you to manage all your structured and unstructured data at any scale. Amazon Simple Storage Service (Amazon S3) is a popular cloud-based object storage service that can be used as the foundation for building a data lake.
- Apache Iceberg – Apache Iceberg is an open-source table format that is designed to provide efficient, scalable, and secure access to large datasets. It provides features such as ACID transactions on top of Amazon S3-based data lakes, schema evolution, partition evolution, and data versioning. With scalable metadata indexing, Apache Iceberg is able to deliver performant queries to a variety of engines such as Spark and Athena by reducing planning time.
- Look–ahead bias – This is a common challenge in backtesting, which occurs when future information is inadvertently included in historical data used to test a trading strategy, leading to overly optimistic results.
- Iceberg tags – The Iceberg branching and tagging feature allows users to tag specific snapshots of their data tables with meaningful labels using SQL syntax or the Iceberg library, which correspond to specific events notable to internal investment teams. This, combined with Iceberg’s time travel functionality, ensures that accurate data enters the research pipeline and guards it from hard-to-detect problems such as look-ahead bias.
Testing scope
For our testing purposes, consider the following example, in which a change to the S&P Dow Jones Indices is announced on September 2, 2022, becomes effective on September 19, 2022, and doesn’t become observable in the ETF holdings data that we will be using in the experiment until September 30, 2022. We use Iceberg tags to label market data snapshots to avoid look-ahead bias in the research data lake, which will enable us to test various trade entry and exit scenarios and assess the respective profitability of each.
Experiment
As part of our experiment, we utilize a paid, third-party data provider API to identify SPY ETF holdings changes and construct a portfolio. Our model portfolio will buy stocks that are added to the index, known as going long, and will sell an equivalent amount of stocks removed from the index, known as going short.
We will test short-term holding periods, such as 1 day and 1, 2, 3, or 4 weeks, because we assume that the rebalancing effect is very short-lived and new information, such as macroeconomics, will drive performance beyond the studied time horizons. Lastly, we simulate different entry points for this trade:
- Market open the day after announcement day (AD+1)
- Market close of effective date (ED0)
- Market open the day after ETF holdings registered the change (MD+1)
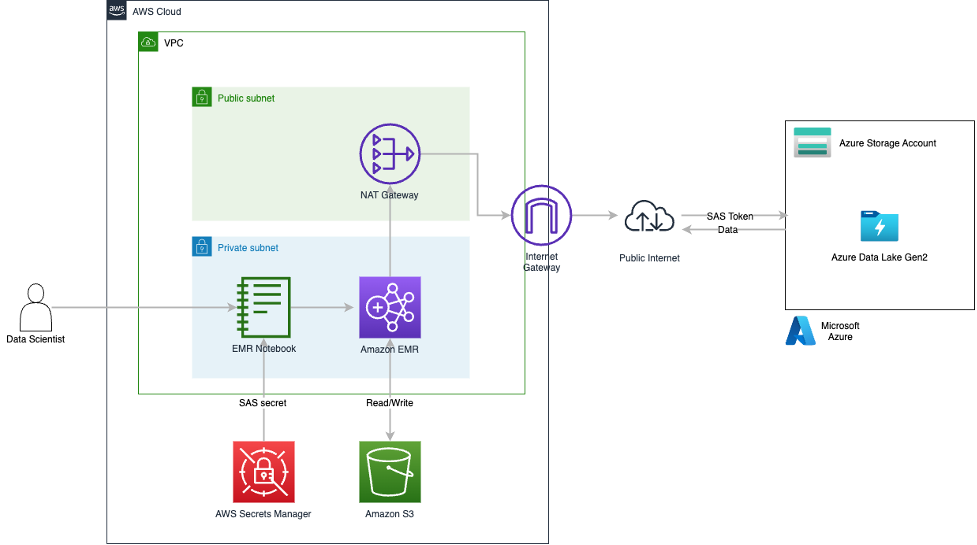
Research data lake
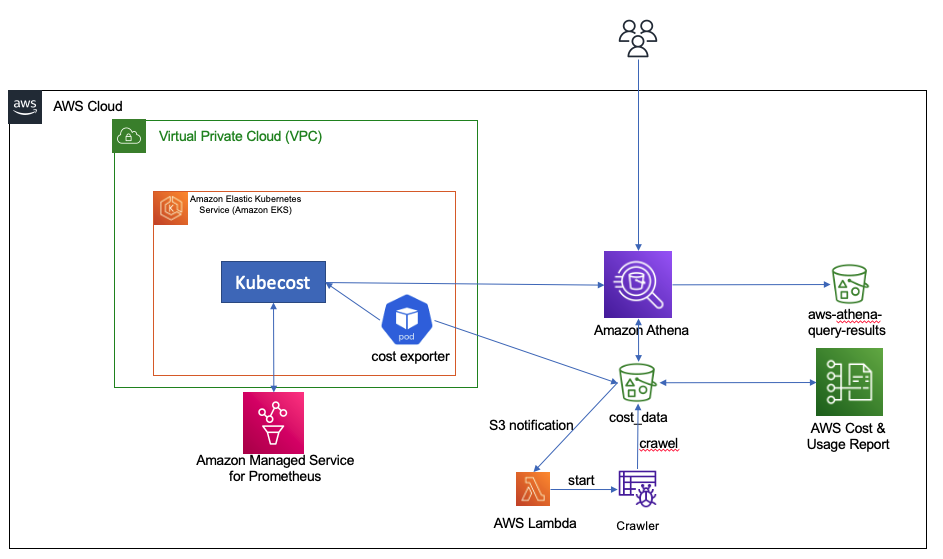
To run our experiment, we have have used the following research data lake environment.
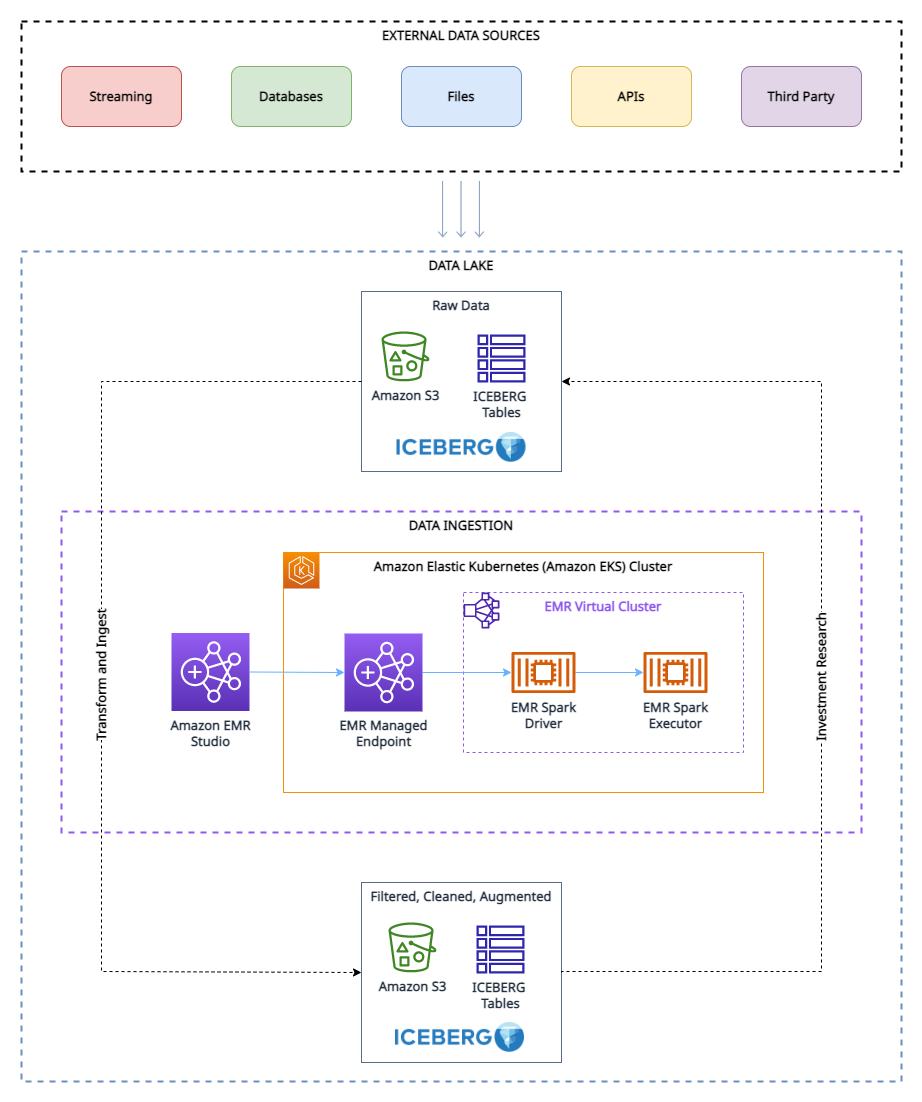
As shown in the architecture diagram, the research data lake is built on Amazon S3 and managed using Apache Iceberg, which is an open table format bringing the reliability and simplicity of relational database management service (RDBMS) tables to data lakes. To avoid look-ahead bias in backtesting, it’s essential to create snapshots of the data at different points in time. However, managing and organizing these snapshots can be challenging, especially when dealing with a large volume of data.
This is where the tagging feature in Apache Iceberg comes in handy. With tagging, researchers can create differently named snapshots of market data and track changes over time. For example, they can create a snapshot of the data at the end of each trading day and tag it with the date and any relevant market conditions.
By using tags to organize the snapshots, researchers can easily query and analyze the data based on specific market conditions or events, without having to worry about the specific dates of the data. This can be particularly helpful when conducting research that is not time-sensitive or when looking for trends over long periods of time.
Furthermore, the tagging feature can also help with other aspects of data management, such as data retention for GDPR compliance, and maintaining lineages of the table via different branches. Researchers can use Apache Iceberg tagging to ensure the integrity and accuracy of their data while also simplifying data management.
Prerequisites
To follow along with this walkthrough, you must have the following:
- An AWS account with an IAM role that has sufficient access to provision the required resources.
- To comply with licensing considerations, we cannot provide a sample of the ETF constituents data. Therefore, it must be purchased separately for the dataset onboarding purposes.
Solution overview
To set up and test this experiment, we complete the following high-level steps:
- Create an S3 bucket.
- Load the dataset into Amazon S3. For this post, the ETF data referred to was obtained via API call through a third-party provider, but you can also consider the following options:
- You can use the following prescriptive guidance, which describes how to automate data ingestion from various data providers into a data lake in Amazon S3 using AWS Data Exchange.
- You can also utilize AWS Data Exchange to select from a range of third-party dataset providers. It simplifies the usage of data files, tables, and APIs for your specific needs.
- Lastly, you can also refer to the following post on how to use AWS Data Exchange for Amazon S3 to access data from a provider bucket: Analyzing impact of regulatory reform on the stock market using AWS and Refinitiv data.
- Create an EMR cluster. You can use this Getting Started with EMR tutorial or we used CDK to deploy an EMR on EKS environment with a custom managed endpoint.
- Create an EMR notebook using EMR Studio. For our testing environment, we used a custom build Docker image, which contains Iceberg v1.3. For instructions on attaching a cluster to a Workspace, refer to Attach a cluster to a Workspace.
- Configure a Spark session. You can follow along via the following sample notebook.
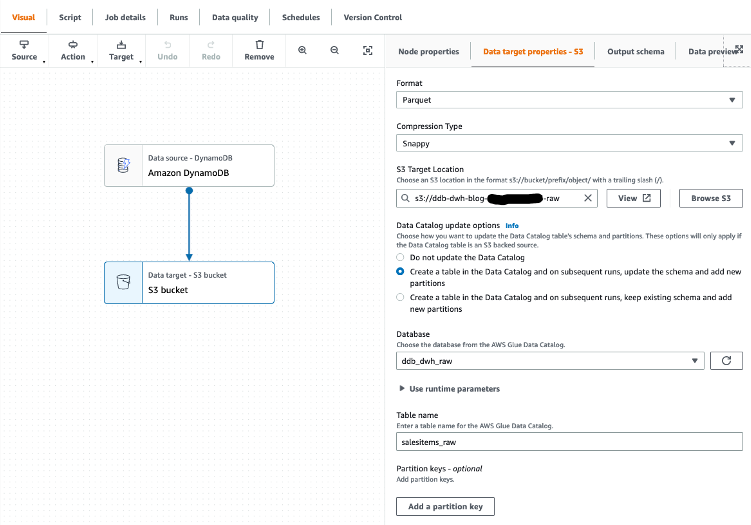
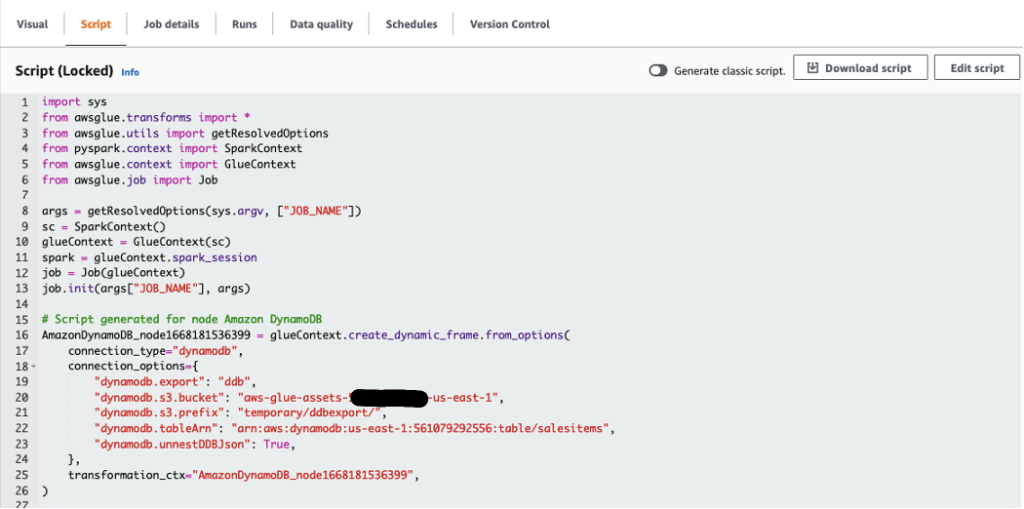
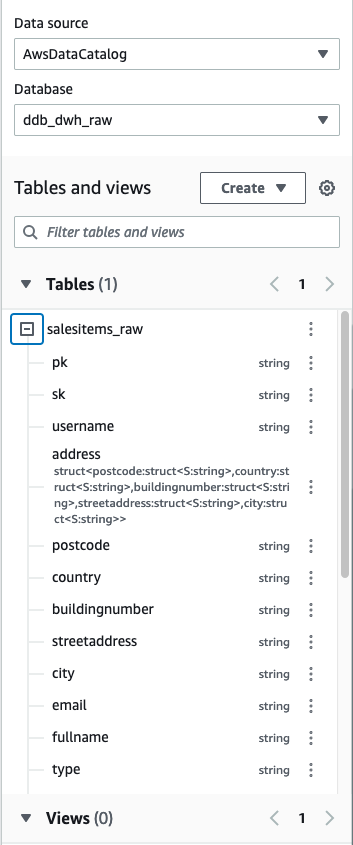
- Create an Iceberg table and load the test data from Amazon S3 into the table.
- Tag this data to preserve a snapshot of it.
- Perform updates to our test data and tag the updated dataset.
- Run simulated backtesting on our test data to find the most profitable entry point for a trade.
Create the experiment environment
We can get up and running with Iceberg by creating a table via Spark SQL from an existing view, as shown in the following code:
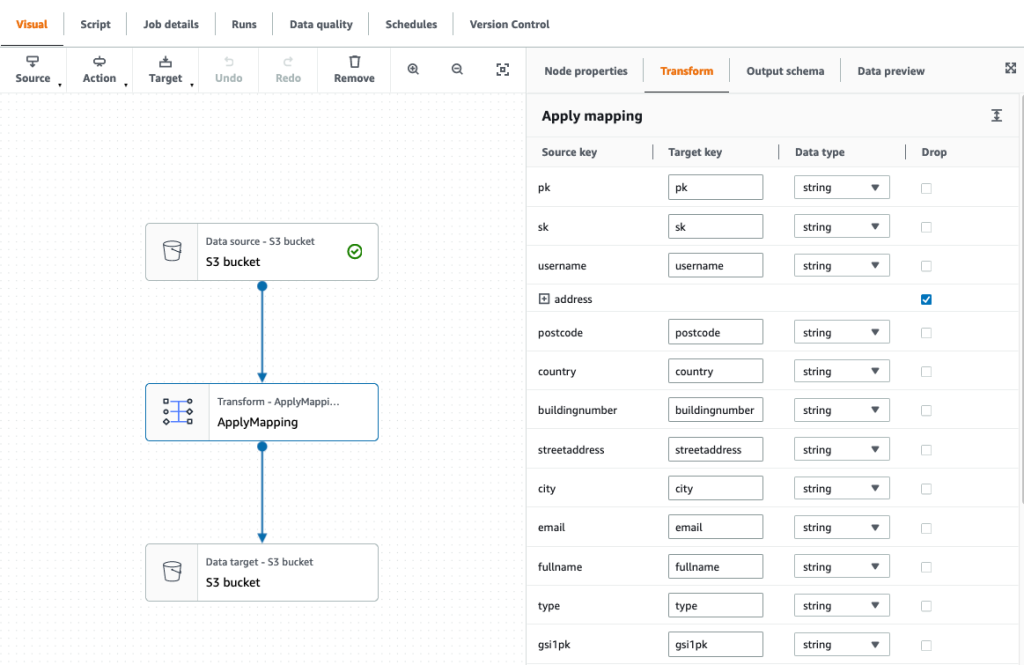
Now that we’ve created an Iceberg table, we can use it for investment research. One of the key features of Iceberg is its support for scalable data versioning. This means that we can easily track changes to our data and roll back to previous versions without making additional copies. Because this data gets updated periodically, we want to be able to create named snapshots of the data so that quant traders have easy access to consistent snapshots of data that have their own retention policy. In this case, let’s tag the dataset to indicate that it represents the ETF holdings data as of Q1 2022:
As we move forward in time and new data becomes available by Q3, we may need to update existing datasets to reflect these changes. In the following example, we first use an UPDATE statement to mark the stocks as expired in the existing ETF holdings dataset. Then we use the MERGE INTO statement based on matching conditions such as ISIN code. If a match is not found between the existing dataset and the new dataset, the new data will be inserted as new records in the table and status code will be set to ‘new’ for these records. Similarly, if the existing dataset has stocks that are not present in the new dataset, those records will remain expired with a status code of ‘expired’. Finally, for records where a match is found, the data in the existing dataset will be updated with the data from the new dataset, and record will have an unchanged status code. With Iceberg’s support for efficient data versioning and transactional consistency, we can be confident that our data updates will be applied correctly and without data corruption.
Because we now have a new version of the data, we use Iceberg tagging to provide isolation for each new version of data. In this case, we tag this as Q3_2022 and allow quant traders and other users to work on this snapshot of the data without being affected by ongoing updates to the pipeline:
This makes it very easy to see which stocks are being added and deleted. We can use Iceberg’s time travel feature to read the data at a given quarterly tag. First, let’s look at which stocks are added to the index; these are the rows that are in the Q3 snapshot but not in the Q1 snapshot. Then we will look at which stocks are removed; these are the rows that are in the Q1 snapshot but not in the Q3 snapshot:
Now we use the delta obtained in the preceding code to backtest the following strategy. As part of the index rebalancing arbitrage process, we’re going to long stocks that are added to the index and short stocks that are removed from the index, and we’ll test this strategy for both the effective date and announcement date. As a proof of concept from the two different lists, we picked PVH and PENN as removed stocks, and CSGP and INVH as added stocks.
To follow along with the examples below, you will need to use the notebook provided in the Quant Research example GitHub repository.
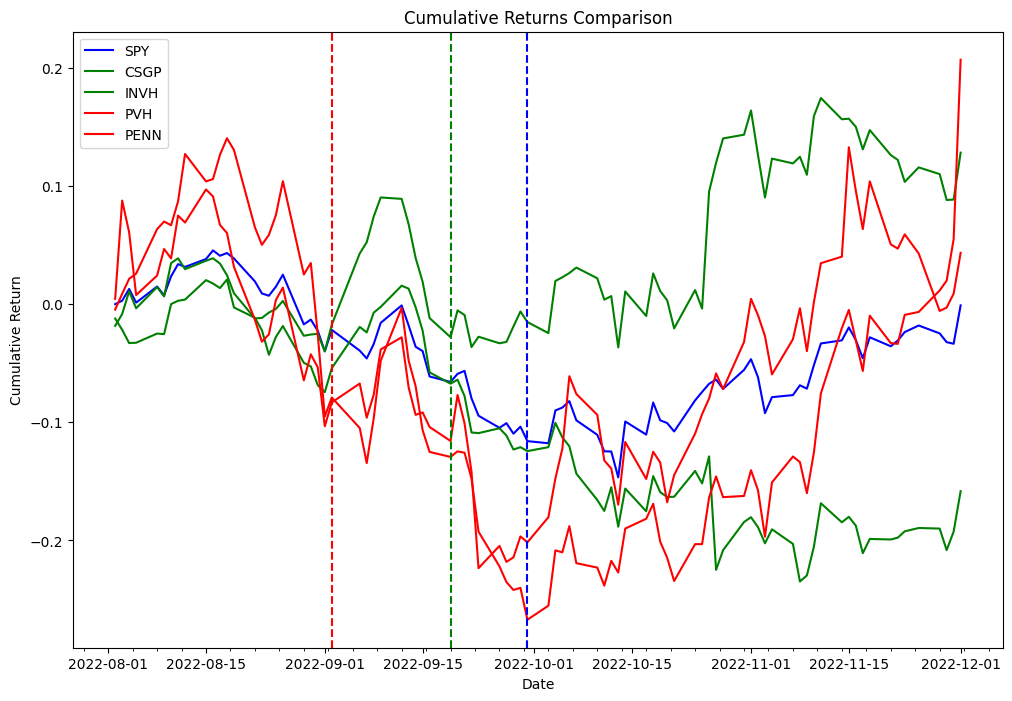
The following table represent the portfolio orders records:
| Order Id | Column | Timestamp | Size | Price | Fees | Side |
|---|---|---|---|---|---|---|
| 0 | (PENN, PENN) | 2022-09-06 | 31948.881789 | 31.66 | 0.0 | Sell |
| 1 | (PVH, PVH) | 2022-09-06 | 18321.729571 | 55.15 | 0.0 | Sell |
| 2 | (INVH, INVH) | 2022-09-06 | 27419.797094 | 38.20 | 0.0 | Buy |
| 3 | (CSGP, CSGP) | 2022-09-06 | 14106.361969 | 75.00 | 0.0 | Buy |
| 4 | (CSGP, CSGP) | 2022-11-01 | 14106.361969 | 83.70 | 0.0 | Sell |
| 5 | (INVH, INVH) | 2022-11-01 | 27419.797094 | 31.94 | 0.0 | Sell |
| 6 | (PVH, PVH) | 2022-11-01 | 18321.729571 | 52.95 | 0.0 | Buy |
| 7 | (PENN, PENN) | 2022-11-01 | 31948.881789 | 34.09 | 0.0 | Buy |
Experimentation findings
The following table shows Sharpe Ratios for various holding periods and two different trade entry points: announcement and effective dates.
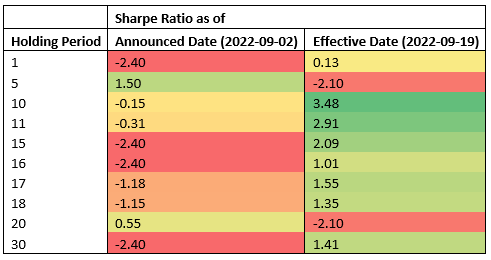
The data suggests that the effective date is the most profitable entry point across most holding periods, whereas the announcement date is an effective entry point for short-term holding periods (5 calendar days, 2 business days). Because the results are obtained from testing a single event, this is not statistically significant to accept or reject a hypothesis that index rebalancing events can be used to generate consistent alpha. The infrastructure we used for our testing can be used to run the same experiment required to do hypothesis testing at scale, but index constituents data is not readily available.
Conclusion
In this post, we demonstrated how the use of backtesting and the Apache Iceberg tagging feature can provide valuable insights into the performance of index arbitrage profitability strategies. By using a scalable Amazon EMR on Amazon EKS stack, researchers can easily handle the entire investment research lifecycle, from data collection to backtesting. Additionally, the Iceberg tagging feature can help address the challenge of look-ahead bias, while also providing benefits such as data retention control for GDPR compliance and maintaining lineage of the table via different branches. The experiment findings demonstrate the effectiveness of this approach in evaluating the performance of index arbitrage strategies and can serve as a useful guide for researchers in the finance industry.
About the Authors
 Boris Litvin is Principal Solution Architect, responsible for financial services industry innovation. He is a former Quant and FinTech founder, and is passionate about systematic investing.
Boris Litvin is Principal Solution Architect, responsible for financial services industry innovation. He is a former Quant and FinTech founder, and is passionate about systematic investing.
 Guy Bachar is a Solutions Architect at AWS, based in New York. He accompanies greenfield customers and helps them get started on their cloud journey with AWS. He is passionate about identity, security, and unified communications.
Guy Bachar is a Solutions Architect at AWS, based in New York. He accompanies greenfield customers and helps them get started on their cloud journey with AWS. He is passionate about identity, security, and unified communications.
 Noam Ouaknine is a Technical Account Manager at AWS, and is based in Florida. He helps enterprise customers develop and achieve their long-term strategy through technical guidance and proactive planning.
Noam Ouaknine is a Technical Account Manager at AWS, and is based in Florida. He helps enterprise customers develop and achieve their long-term strategy through technical guidance and proactive planning.
 Sercan Karaoglu is Senior Solutions Architect, specialized in capital markets. He is a former data engineer and passionate about quantitative investment research.
Sercan Karaoglu is Senior Solutions Architect, specialized in capital markets. He is a former data engineer and passionate about quantitative investment research.
 Jack Ye is a software engineer in the Athena Data Lake and Storage team. He is an Apache Iceberg Committer and PMC member.
Jack Ye is a software engineer in the Athena Data Lake and Storage team. He is an Apache Iceberg Committer and PMC member.
 Amogh Jahagirdar is a Software Engineer in the Athena Data Lake team. He is an Apache Iceberg Committer.
Amogh Jahagirdar is a Software Engineer in the Athena Data Lake team. He is an Apache Iceberg Committer.































 Nicholas Tunney is a Partner Solutions Architect for Worldwide Public Sector at AWS. He works with global SI partners to develop architectures on AWS for clients in the government, nonprofit healthcare, utility, and education sectors.
Nicholas Tunney is a Partner Solutions Architect for Worldwide Public Sector at AWS. He works with global SI partners to develop architectures on AWS for clients in the government, nonprofit healthcare, utility, and education sectors.



























 Rajdip Chaudhuri is a Senior Solutions Architect with Amazon Web Services specializing in data and analytics. He enjoys working with AWS customers and partners on data and analytics requirements. In his spare time, he enjoys soccer and movies.
Rajdip Chaudhuri is a Senior Solutions Architect with Amazon Web Services specializing in data and analytics. He enjoys working with AWS customers and partners on data and analytics requirements. In his spare time, he enjoys soccer and movies. Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.
Dhiraj Thakur is a Solutions Architect with Amazon Web Services. He works with AWS customers and partners to provide guidance on enterprise cloud adoption, migration, and strategy. He is passionate about technology and enjoys building and experimenting in the analytics and AI/ML space.













 Chaitanya Shah is a Sr. Technical Account Manager(TAM) with AWS, based out of New York. He has over 22 years of experience working with enterprise customers. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their AWS Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.
Chaitanya Shah is a Sr. Technical Account Manager(TAM) with AWS, based out of New York. He has over 22 years of experience working with enterprise customers. He loves to code and actively contributes to the AWS solutions labs to help customers solve complex problems. He provides guidance to AWS customers on best practices for their AWS Cloud migrations. He is also specialized in AWS data transfer and the data and analytics domain.






























 Kiran Anand is a Principal Solutions Architect with the AWS Data Lab. He is a seasoned professional with more than 20 years of experience in information technology. His areas of expertise are databases and big data solutions for data engineering and analytics. He enjoys music, watching movies, and traveling with his family.
Kiran Anand is a Principal Solutions Architect with the AWS Data Lab. He is a seasoned professional with more than 20 years of experience in information technology. His areas of expertise are databases and big data solutions for data engineering and analytics. He enjoys music, watching movies, and traveling with his family. Andre Hass is a Sr. Solutions Architect with the AWS Data Lab. He has more than 20 years of experience in the databases and data analytics field. Andre enjoys camping, hiking, and exploring new places with his family on the weekends, or whenever he gets a chance. He also loves technology and electronic gadgets.
Andre Hass is a Sr. Solutions Architect with the AWS Data Lab. He has more than 20 years of experience in the databases and data analytics field. Andre enjoys camping, hiking, and exploring new places with his family on the weekends, or whenever he gets a chance. He also loves technology and electronic gadgets. Stefan Marinov is a Sr. Solutions Architecture Manager with the AWS Data Lab. He is passionate about big data solutions and distributed computing. Outside of work, he loves spending active time outdoors with his family.
Stefan Marinov is a Sr. Solutions Architecture Manager with the AWS Data Lab. He is passionate about big data solutions and distributed computing. Outside of work, he loves spending active time outdoors with his family. Hari Thatavarthy is a Senior Solutions Architect on the AWS Data Lab team. He helps customers design and build solutions in the data and analytics space. He believes in data democratization and loves to solve complex data processing-related problems.
Hari Thatavarthy is a Senior Solutions Architect on the AWS Data Lab team. He helps customers design and build solutions in the data and analytics space. He believes in data democratization and loves to solve complex data processing-related problems. Hao Wang is a Senior Big Data Architect at AWS. Hao actively works with customers building large scale data platforms on AWS. He has a background as a software architect on implementing distributed software systems. In his spare time, he enjoys reading and outdoor activities with his family.
Hao Wang is a Senior Big Data Architect at AWS. Hao actively works with customers building large scale data platforms on AWS. He has a background as a software architect on implementing distributed software systems. In his spare time, he enjoys reading and outdoor activities with his family.










 Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running.
Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running. Hamza Mimi Principal Solutions Architect in the French Public sector team at Amazon Web Services (AWS). With a long experience in the telecommunications industry. He is currently working as a customer advisor on topics ranging from digital transformation to architectural guidance.
Hamza Mimi Principal Solutions Architect in the French Public sector team at Amazon Web Services (AWS). With a long experience in the telecommunications industry. He is currently working as a customer advisor on topics ranging from digital transformation to architectural guidance.
















 Vetri Natarajan is a Specialist Solutions Architect for Amazon QuickSight. Vetri has 15 years of experience implementing enterprise business intelligence (BI) solutions and greenfield data products. Vetri specializes in integration of BI solutions with business applications and enable data-driven decisions.
Vetri Natarajan is a Specialist Solutions Architect for Amazon QuickSight. Vetri has 15 years of experience implementing enterprise business intelligence (BI) solutions and greenfield data products. Vetri specializes in integration of BI solutions with business applications and enable data-driven decisions. Zhao Pan is a software development manager for Amazon QuickSight. He is working to provide a delightful developer experience to our customers to automate and streamline their BI operations. He has 20 years of software development experience in various tech stacks. Prior to QuickSight he was a people and technical leader at ADP building a next-gen platform for human capital management. When he is not at his desk, he can usually be found in his garage building one contraption or another.
Zhao Pan is a software development manager for Amazon QuickSight. He is working to provide a delightful developer experience to our customers to automate and streamline their BI operations. He has 20 years of software development experience in various tech stacks. Prior to QuickSight he was a people and technical leader at ADP building a next-gen platform for human capital management. When he is not at his desk, he can usually be found in his garage building one contraption or another. Mayank Agarwal is a product manager for Amazon QuickSight, AWS’ cloud-native, fully managed BI service. He focuses on embedded analytics and developer experience. He started his career as an embedded software engineer developing handheld devices. Prior to QuickSight he was leading engineering teams at Credence ID, developing custom mobile embedded device and web solutions using AWS services that make biometric enrollment and identification fast, intuitive, and cost-effective for Government sector, healthcare and transaction security applications.
Mayank Agarwal is a product manager for Amazon QuickSight, AWS’ cloud-native, fully managed BI service. He focuses on embedded analytics and developer experience. He started his career as an embedded software engineer developing handheld devices. Prior to QuickSight he was leading engineering teams at Credence ID, developing custom mobile embedded device and web solutions using AWS services that make biometric enrollment and identification fast, intuitive, and cost-effective for Government sector, healthcare and transaction security applications.
 Vara Bonthu is a dedicated technology professional and Worldwide Tech Leader for Data on EKS, specializing in assisting AWS customers ranging from strategic accounts to diverse organizations. He is passionate about open-source technologies, data analytics, AI/ML, and Kubernetes, and boasts an extensive background in development, DevOps, and architecture. Vara’s primary focus is on building highly scalable data and AI/ML solutions on Kubernetes platforms, helping customers harness the full potential of cutting-edge technology for their data-driven pursuits.
Vara Bonthu is a dedicated technology professional and Worldwide Tech Leader for Data on EKS, specializing in assisting AWS customers ranging from strategic accounts to diverse organizations. He is passionate about open-source technologies, data analytics, AI/ML, and Kubernetes, and boasts an extensive background in development, DevOps, and architecture. Vara’s primary focus is on building highly scalable data and AI/ML solutions on Kubernetes platforms, helping customers harness the full potential of cutting-edge technology for their data-driven pursuits.












 Zack Zhou is a Software Development Engineer on the AWS Glue team.
Zack Zhou is a Software Development Engineer on the AWS Glue team.
 Avik Bhattacharjee is a Senior Partner Solutions Architect at AWS. He works with customers to build IT strategy, making digital transformation through the cloud more accessible, focusing on big data and analytics and AI/ML.
Avik Bhattacharjee is a Senior Partner Solutions Architect at AWS. He works with customers to build IT strategy, making digital transformation through the cloud more accessible, focusing on big data and analytics and AI/ML. Amit Kumar Panda is a Data Architect at AWS Professional Services who is passionate about helping customers build scalable data analytics solutions to enable making critical business decisions.
Amit Kumar Panda is a Data Architect at AWS Professional Services who is passionate about helping customers build scalable data analytics solutions to enable making critical business decisions.










 Neel Patel is a software engineer working within GlueML. He has contributed to the AWS Glue Data Quality feature and hopes it will expand the repertoire for all AWS CloudFormation users along with displaying the power and usability of AWS Glue as a whole.
Neel Patel is a software engineer working within GlueML. He has contributed to the AWS Glue Data Quality feature and hopes it will expand the repertoire for all AWS CloudFormation users along with displaying the power and usability of AWS Glue as a whole. Edward Cho is a Software Development Engineer at AWS Glue. He has contributed to the AWS Glue Data Quality feature as well as the underlying open-source project Deequ.
Edward Cho is a Software Development Engineer at AWS Glue. He has contributed to the AWS Glue Data Quality feature as well as the underlying open-source project Deequ.
























 Navnit Shukla is AWS Specialist Solutions Architect in Analytics. He is passionate about helping customers uncover insights from their data. He builds solutions to help organizations make data-driven decisions.
Navnit Shukla is AWS Specialist Solutions Architect in Analytics. He is passionate about helping customers uncover insights from their data. He builds solutions to help organizations make data-driven decisions. Rahul Sharma is a Software Development Engineer at AWS Glue. He focuses on building distributed systems to support features in AWS Glue. He has a passion for helping customers build data management solutions on the AWS Cloud.
Rahul Sharma is a Software Development Engineer at AWS Glue. He focuses on building distributed systems to support features in AWS Glue. He has a passion for helping customers build data management solutions on the AWS Cloud. Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.
Shriya Vanvari is a Software Developer Engineer in AWS Glue. She is passionate about learning how to build efficient and scalable systems to provide better experience for customers. Outside of work, she enjoys reading and chasing sunsets.














 Stuti Deshpande is an Analytics Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in Big Data, ETL, and Analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends.
Stuti Deshpande is an Analytics Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in Big Data, ETL, and Analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends. Aniket Jiddigoudar is a Big Data Architect on the AWS Glue team. He works with customers to help improve their big data workloads. In his spare time, he enjoys trying out new food, playing video games, and kickboxing.
Aniket Jiddigoudar is a Big Data Architect on the AWS Glue team. He works with customers to help improve their big data workloads. In his spare time, he enjoys trying out new food, playing video games, and kickboxing. Joseph Barlan is a Frontend Engineer at AWS Glue. He has over 5 years of experience helping teams build reusable UI components and is passionate about frontend design systems. In his spare time, he enjoys pencil drawing and binge watching tv shows.
Joseph Barlan is a Frontend Engineer at AWS Glue. He has over 5 years of experience helping teams build reusable UI components and is passionate about frontend design systems. In his spare time, he enjoys pencil drawing and binge watching tv shows. Jesus Max Hernandez is a Software Development Engineer at AWS Glue. He joined the team in August after graduating from The University of Texas at El Paso. Outside of work, you can find him practicing guitar or playing softball in Central Park.
Jesus Max Hernandez is a Software Development Engineer at AWS Glue. He joined the team in August after graduating from The University of Texas at El Paso. Outside of work, you can find him practicing guitar or playing softball in Central Park. Divya Gaitonde
Divya Gaitonde







 Srikanth Baheti is a Specialized World Wide Principal Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.
Srikanth Baheti is a Specialized World Wide Principal Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing. Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics.
Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics.



 Jeremy Ber has been working in the telemetry data space for the past 9 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. At AWS, he is a Streaming Specialist Solutions Architect, supporting both Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed offering for Apache Flink.
Jeremy Ber has been working in the telemetry data space for the past 9 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. At AWS, he is a Streaming Specialist Solutions Architect, supporting both Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed offering for Apache Flink. Deepthi Mohan is a Principal Product Manager for Amazon Kinesis Data Analytics, AWS’s managed offering for Apache Flink.
Deepthi Mohan is a Principal Product Manager for Amazon Kinesis Data Analytics, AWS’s managed offering for Apache Flink. Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
Gaurav Rele is a Data Scientist at the Amazon ML Solution Lab, where he works with AWS customers across different verticals to accelerate their use of machine learning and AWS Cloud services to solve their business challenges.
 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.