Post Syndicated from Sheila Busser original https://aws.amazon.com/blogs/compute/architecting-for-data-residency-with-aws-outposts-rack-and-landing-zone-guardrails/
This blog post was written by Abeer Naffa’, Sr. Solutions Architect, Solutions Builder AWS, David Filiatrault, Principal Security Consultant, AWS and Jared Thompson, Hybrid Edge SA Specialist, AWS.
In this post, we will explore how organizations can use AWS Control Tower landing zone and AWS Organizations custom guardrails to enable compliance with data residency requirements on AWS Outposts rack. We will discuss how custom guardrails can be leveraged to limit the ability to store, process, and access data and remain isolated in specific geographic locations, how they can be used to enforce security and compliance controls, as well as, which prerequisites organizations should consider before implementing these guardrails.
Data residency is a critical consideration for organizations that collect and store sensitive information, such as Personal Identifiable Information (PII), financial, and healthcare data. With the rise of cloud computing and the global nature of the internet, it can be challenging for organizations to make sure that their data is being stored and processed in compliance with local laws and regulations.
One potential solution for addressing data residency challenges with AWS is to use Outposts rack, which allows organizations to run AWS infrastructure on premises and in their own data centers. This lets organizations store and process data in a location of their choosing. An Outpost is seamlessly connected to an AWS Region where it has access to the full suite of AWS services managed from a single plane of glass, the AWS Management Console or the AWS Command Line Interface (AWS CLI). Outposts rack can be configured to utilize landing zone to further adhere to data residency requirements.
The landing zones are a set of tools and best practices that help organizations establish a secure and compliant multi-account structure within a cloud provider. A landing zone can also include Organizations to set policies – guardrails – at the root level, known as Service Control Policies (SCPs) across all member accounts. This can be configured to enforce certain data residency requirements.
When leveraging Outposts rack to meet data residency requirements, it is crucial to have control over the in-scope data movement from the Outposts. This can be accomplished by implementing landing zone best practices and the suggested guardrails. The main focus of this blog post is on the custom policies that restrict data snapshots, prohibit data creation within the Region, and limit data transfer to the Region.
Prerequisites
Landing zone best practices and custom guardrails can help when data needs to remain in a specific locality where the Outposts rack is also located. This can be completed by defining and enforcing policies for data storage and usage within the landing zone organization that you set up. The following prerequisites should be considered before implementing the suggested guardrails:
1. AWS Outposts rack
AWS has installed your Outpost and handed off to you. An Outpost may comprise of one or more racks connected together at the site. This means that you can start using AWS services on the Outpost, and you can manage the Outposts rack using the same tools and interfaces that you use in AWS Regions.
2. Landing Zone Accelerator on AWS
We recommend using Landing Zone Accelerator on AWS (LZA) to deploy a landing zone for your organization. Make sure that the accelerator is configured for the appropriate Region and industry. To do this, you must meet the following prerequisites:
-
- A clear understanding of your organization’s compliance requirements, including the specific Region and industry rules in which you operate.
- Knowledge of the different LZAs available and their capabilities, such as the compliance frameworks with which you align.
- Have the necessary permissions to deploy the LZAs and configure it for your organization’s specific requirements.
Note that LZAs are designed to help organizations quickly set up a secure, compliant multi-account environment. However, it’s not a one-size-fits-all solution, and you must align it with your organization’s specific requirements.
3. Set up the data residency guardrails
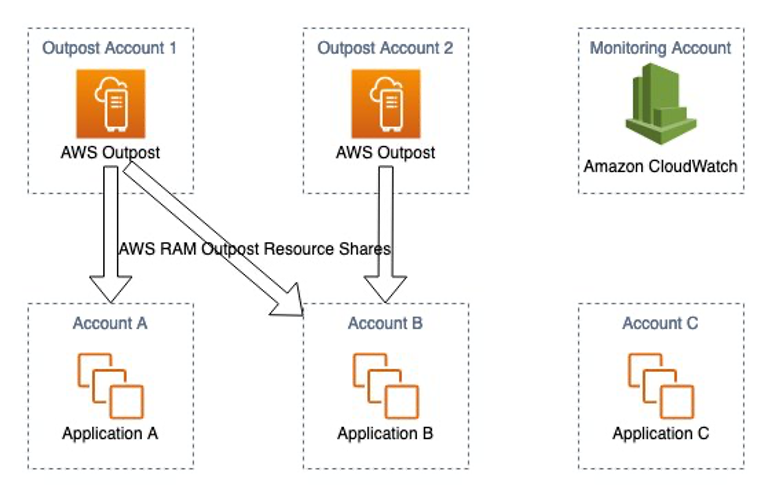
Using Organizations, you must make sure that the Outpost is ordered within a workload account in the landing zone.

Figure 1: Landing Zone Accelerator – Outposts workload on AWS high level Architecture
Utilizing Outposts rack for regulated components
When local regulations require regulated workloads to stay within a specific boundary, or when an AWS Region or AWS Local Zone isn’t available in your jurisdiction, you can still choose to host your regulated workloads on Outposts rack for a consistent cloud experience. When opting for Outposts rack, note that, as part of the shared responsibility model, customers are responsible for attesting to physical security, access controls, and compliance validation regarding the Outposts, as well as, environmental requirements for the facility, networking, and power. Utilizing Outposts rack requires that you procure and manage the data center within the city, state, province, or country boundary for your applications’ regulated components, as required by local regulations.
Procuring two or more racks in the diverse data centers can help with the high availability for your workloads. This is because it provides redundancy in case of a single rack or server failure. Additionally, having redundant network paths between Outposts rack and the parent Region can help make sure that your application remains connected and continue to operate even if one network path fails.
However, for regulated workloads with strict service level agreements (SLA), you may choose to spread Outposts racks across two or more isolated data centers within regulated boundaries. This helps make sure that your data remains within the designated geographical location and meets local data residency requirements.
In this post, we consider a scenario with one data center, but consider the specific requirements of your workloads and the regulations that apply to determine the most appropriate high availability configurations for your case.
Outposts rack workload data residency guardrails
Organizations provide central governance and management for multiple accounts. Central security administrators use SCPs with Organizations to establish controls to which all AWS Identity and Access Management (IAM) principals (users and roles) adhere.
Now, you can use SCPs to set permission guardrails. A suggested preventative controls for data residency on Outposts rack that leverage the implementation of SCPs are shown as follows. SCPs enable you to set permission guardrails by defining the maximum available permissions for IAM entities in an account. If an SCP denies an action for an account, then none of the entities in the account can take that action, even if their IAM permissions let them. The guardrails set in SCPs apply to all IAM entities in the account, which include all users, roles, and the account root user.
Upon finalizing these prerequisites, you can create the guardrails for the Outposts Organization Unit (OU).
| Note that while the following guidelines serve as helpful guardrails – SCPs – for data residency, you should consult internally with legal and security teams for specific organizational requirements. |
To exercise better control over workloads in the Outposts rack and prevent data transfer from Outposts to the Region or data storage outside the Outposts, consider implementing the following guardrails. Additionally, local regulations may dictate that you set up these additional guardrails.
- When your data residency requirements require restricting data transfer/saving to the Region, consider the following guardrails:
a. Deny copying data from Outposts to the Region for Amazon Elastic Compute Cloud (Amazon EC2), Amazon Relational Database Service (Amazon RDS), Amazon ElastiCache and data sync “DenyCopyToRegion”.
b. Deny Amazon Simple Storage Service (Amazon S3) put action to the Region “DenyPutObjectToRegionalBuckets”.
|
If your data residency requirements mandate restrictions on data storage in the Region, consider implementing this guardrail to prevent the use of S3 in the Region.
Note: You can use Amazon S3 for Outposts.
|
c. If your data residency requirements mandate restrictions on data storage in the Region, consider implementing “DenyDirectTransferToRegion” guardrail.
|
Out of Scope is metadata such as tags, or operational data such as KMS keys.
|
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenyCopyToRegion",
"Action": [
"ec2:ModifyImageAttribute",
"ec2:CopyImage",
"ec2:CreateImage",
"ec2:CreateInstanceExportTask",
"ec2:ExportImage",
"ec2:ImportImage",
"ec2:ImportInstance",
"ec2:ImportSnapshot",
"ec2:ImportVolume",
"rds:CreateDBSnapshot",
"rds:CreateDBClusterSnapshot",
"rds:ModifyDBSnapshotAttribute",
"elasticache:CreateSnapshot",
"elasticache:CopySnapshot",
"datasync:Create*",
"datasync:Update*"
],
"Resource": "*",
"Effect": "Deny"
},
{
"Sid": "DenyDirectTransferToRegion",
"Action": [
"dynamodb:PutItem",
"dynamodb:CreateTable",
"ec2:CreateTrafficMirrorTarget",
"ec2:CreateTrafficMirrorSession",
"rds:CreateGlobalCluster",
"es:Create*",
"elasticfilesystem:C*",
"elasticfilesystem:Put*",
"storagegateway:Create*",
"neptune-db:connect",
"glue:CreateDevEndpoint",
"glue:UpdateDevEndpoint",
"datapipeline:CreatePipeline",
"datapipeline:PutPipelineDefinition",
"sagemaker:CreateAutoMLJob",
"sagemaker:CreateData*",
"sagemaker:CreateCode*",
"sagemaker:CreateEndpoint",
"sagemaker:CreateDomain",
"sagemaker:CreateEdgePackagingJob",
"sagemaker:CreateNotebookInstance",
"sagemaker:CreateProcessingJob",
"sagemaker:CreateModel*",
"sagemaker:CreateTra*",
"sagemaker:Update*",
"redshift:CreateCluster*",
"ses:Send*",
"ses:Create*",
"sqs:Create*",
"sqs:Send*",
"mq:Create*",
"cloudfront:Create*",
"cloudfront:Update*",
"ecr:Put*",
"ecr:Create*",
"ecr:Upload*",
"ram:AcceptResourceShareInvitation"
],
"Resource": "*",
"Effect": "Deny"
},
{
"Sid": "DenyPutObjectToRegionalBuckets",
"Action": [
"s3:PutObject"
],
"Resource": ["arn:aws:s3:::*"],
"Effect": "Deny"
}
]
}
- If your data residency requirements require limitations on data storage in the Region, consider implementing this guardrail “DenySnapshotsToRegion” and “DenySnapshotsNotOutposts” to restrict the use of snapshots in the Region.
a. Deny creating snapshots of your Outpost data in the Region “DenySnapshotsToRegion”
Make sure to update the Outposts “<outpost_arn_pattern>”.
b. Deny copying or modifying Outposts Snapshots “DenySnapshotsNotOutposts”
Make sure to update the Outposts “<outpost_arn_pattern>”.
Note: “<outpost_arn_pattern>” default is arn:aws:outposts:*:*:outpost/*
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenySnapshotsToRegion",
"Effect":"Deny",
"Action":[
"ec2:CreateSnapshot",
"ec2:CreateSnapshots"
],
"Resource":"arn:aws:ec2:*::snapshot/*",
"Condition":{
"ArnLike":{
"ec2:SourceOutpostArn":"<outpost_arn_pattern>"
},
"Null":{
"ec2:OutpostArn":"true"
}
}
},
{
"Sid": "DenySnapshotsNotOutposts",
"Effect":"Deny",
"Action":[
"ec2:CopySnapshot",
"ec2:ModifySnapshotAttribute"
],
"Resource":"arn:aws:ec2:*::snapshot/*",
"Condition":{
"ArnLike":{
"ec2:OutpostArn":"<outpost_arn_pattern>"
}
}
}
]
}
- This guardrail helps to prevent the launch of Amazon EC2 instances or creation of network interfaces in non-Outposts subnets. It is advisable to keep data residency workloads within the Outposts rather than the Region to ensure better control over regulated workloads. This approach can help your organization achieve better control over data residency workloads and improve governance over your AWS Organization.
Make sure to update the Outposts subnets “<outpost_subnet_arns>”.
{
"Version": "2012-10-17",
"Statement":[{
"Sid": "DenyNotOutpostSubnet",
"Effect":"Deny",
"Action": [
"ec2:RunInstances",
"ec2:CreateNetworkInterface"
],
"Resource": [
"arn:aws:ec2:*:*:network-interface/*"
],
"Condition": {
"ForAllValues:ArnNotEquals": {
"ec2:Subnet": ["<outpost_subnet_arns>"]
}
}
}]
}
Additional considerations
When implementing data residency guardrails on Outposts rack, consider backup and disaster recovery strategies to make sure that your data is protected in the event of an outage or other unexpected events. This may include creating regular backups of your data, implementing disaster recovery plans and procedures, and using redundancy and failover systems to minimize the impact of any potential disruptions. Additionally, you should make sure that your backup and disaster recovery systems are compliant with any relevant data residency regulations and requirements. You should also test your backup and disaster recovery systems regularly to make sure that they are functioning as intended.
Additionally, the provided SCPs for Outposts rack in the above example do not block the “logs:PutLogEvents”. Therefore, even if you implemented data residency guardrails on Outpost, the application may log data to CloudWatch logs in the Region.
|
Highlights
By default, application-level logs on Outposts rack are not automatically sent to Amazon CloudWatch Logs in the Region. You can configure CloudWatch logs agent on Outposts rack to collect and send your application-level logs to CloudWatch logs.
logs: PutLogEvents does transmit data to the Region, but it is not blocked by the provided SCPs, as it’s expected that most use cases will still want to be able to use this logging API. However, if blocking is desired, then add the action to the first recommended guardrail. If you want specific roles to be allowed, then combine with the ArnNotLike condition example referenced in the previous highlight.
|
Conclusion
The combined use of Outposts rack and the suggested guardrails via AWS Organizations policies enables you to exercise better control over the movement of the data. By creating a landing zone for your organization, you can apply SCPs to your Outposts racks that will help make sure that your data remains within a specific geographic location, as required by the data residency regulations.
Note that, while custom guardrails can help you manage data residency on Outposts rack, it’s critical to thoroughly review your policies, procedures, and configurations to make sure that they are compliant with all relevant data residency regulations and requirements. Regularly testing and monitoring your systems can help make sure that your data is protected and your organization stays compliant.
References
 Amazon S3 – Last week there was AWS Pi Day 2023 celebrating 17 years of innovation since Amazon S3 was introduced on March 14, 2006. For the occasion, the team released many new capabilities:
Amazon S3 – Last week there was AWS Pi Day 2023 celebrating 17 years of innovation since Amazon S3 was introduced on March 14, 2006. For the occasion, the team released many new capabilities: Women founders Q&A – We’re talking to six women founders and leaders about how they’re making impacts in their communities, industries, and beyond.
Women founders Q&A – We’re talking to six women founders and leaders about how they’re making impacts in their communities, industries, and beyond.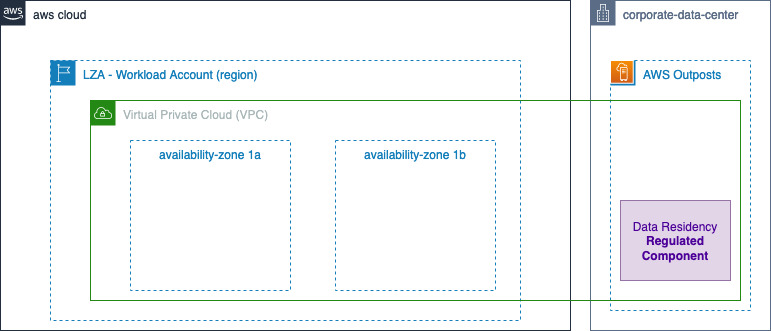











 AWS and Hugging Face collaborate to make generative AI more accessible and cost-efficient – This previous week, we announced an expanded collaboration between AWS and
AWS and Hugging Face collaborate to make generative AI more accessible and cost-efficient – This previous week, we announced an expanded collaboration between AWS and 
 AWS Pi Day – Join me on March 14 for the third annual
AWS Pi Day – Join me on March 14 for the third annual 















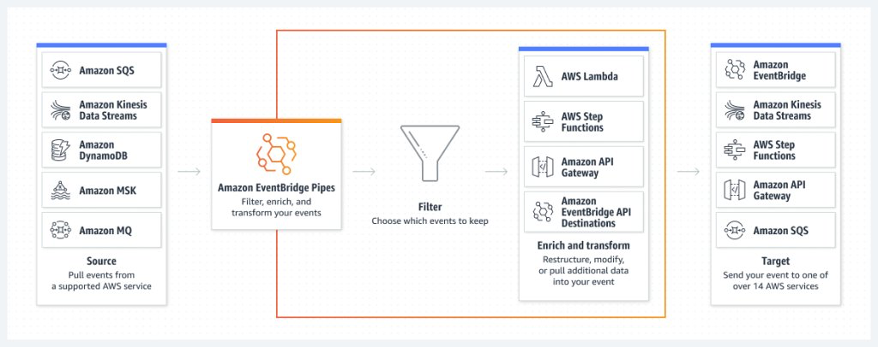




 Amazon EventBridge Scheduler | Schedule tasks over +200 targets!
Amazon EventBridge Scheduler | Schedule tasks over +200 targets!




 Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.
Kinnar Kumar Sen is a Sr. Solutions Architect at Amazon Web Services (AWS) focusing on Flexible Compute. As a part of the EC2 Flexible Compute team, he works with customers to guide them to the most elastic and efficient compute options that are suitable for their workload running on AWS. Kinnar has more than 15 years of industry experience working in research, consultancy, engineering, and architecture.