Post Syndicated from Scott Ward original https://aws.amazon.com/blogs/security/get-to-know-amazon-guardduty-runtime-monitoring-for-amazon-ec2/
In this blog post, I take you on a deep dive into Amazon GuardDuty Runtime Monitoring for EC2 instances and key capabilities that are part of the feature. Throughout the post, I provide insights around deployment strategies for Runtime Monitoring and detail how it can deliver security value by detecting threats against your Amazon Elastic Compute Cloud (Amazon EC2) instances and the workloads you run on them. This post builds on the post by Channy Yun that outlines how to enable Runtime Monitoring, how to view the findings that it produces, and how to view the coverage it provides across your EC2 instances.
Amazon Web Services (AWS) launched Amazon GuardDuty at re:Invent 2017 with a focus on providing customers managed threat detection capabilities for their AWS accounts and workloads. When enabled, GuardDuty takes care of consuming and processing the necessary log data. Since its launch, GuardDuty has continued to expand its threat detection capabilities. This expansion has included identifying new threat types that can impact customer environments, identifying new threat tactics and techniques within existing threat types and expanding the log sources consumed by GuardDuty to detect threats across AWS resources. Examples of this expansion include the ability to detect EC2 instance credentials being used to invoke APIs from an IP address that’s owned by a different AWS account than the one that the associated EC2 instance is running in, and the ability to identify threats to Amazon Elastic Kubernetes Services (Amazon EKS) clusters by analyzing Kubernetes audit logs.
GuardDuty has continued to expand its threat detection capabilities beyond AWS log sources, providing a more comprehensive coverage of customers’ AWS resources. Specifically, customers needed more visibility around threats that might occur at the operating system level of their container and compute instances. To address this customer need, GuardDuty released the Runtime Monitoring feature, beginning with support on Amazon Elastic Kubernetes Service (Amazon EKS) workloads. Runtime Monitoring provides operating system insight for GuardDuty to use in detecting potential threats to workloads running on AWS and enabled the operating system visibility that customers were asking for. At re:Invent 2023, GuardDuty expanded Runtime Monitoring to include Amazon Elastic Container Service (Amazon ECS)—including serverless workloads running on AWS Fargate, and previewed support for Amazon EC2, which became generally available earlier this year. The release of EC2 Runtime Monitoring enables comprehensive compute coverage for GuardDuty across containers and EC2 instances, delivering breadth and depth for threat detection in these areas.
Features and functions
GuardDuty EC2 Runtime Monitoring relies on a lightweight security agent that collects operating system events—such as file access, processes, command line arguments, and network connections—from your EC2 instance and sends them to GuardDuty. After the operating system events are received by GuardDuty, they’re evaluated to identify potential threats related to the EC2 instance. In this section, we explore how GuardDuty is evaluating the runtime events it receives and how GuardDuty presents identified threat information.
Command arguments and event correlation
The runtime security agent enables GuardDuty to create findings that can’t be created using the foundational data sources of VPC Flow Logs, DNS logs, and CloudTrail logs. The security agent can collect detailed information about what’s happening at the instance operating system level that the foundational data sources don’t contain.
With the release of EC2 Runtime Monitoring, additional capabilities have been added to the runtime agent and to GuardDuty. The additional capabilities include collecting command arguments and correlation of events for an EC2 instance. These new capabilities help to rule out benign events and more accurately generate findings that are related to activities that are associated with a potential threat to your EC2 instance.
Command arguments
The GuardDuty security agent collects information on operating system runtime commands (curl, systemctl, cron, and so on) and uses this information to generate findings. The security agent now also collects the command arguments that were used as part of running a command. This additional information gives GuardDuty more capabilities to detect threats because of the additional context related to running a command.
For example, the agent will not only identify that systemctl (which is used to manage services on your Linux instance) was run but also which parameters the command was run with (stop, start, disable, and so on) and for which service the command was run. This level of detail helps identify that a threat actor might be changing security or monitoring services to evade detection.
Event correlation
GuardDuty can now also correlate multiple events collected using the runtime agent to identify scenarios that present themselves as a threat to your environment. There might be events that happen on your instance that, on their own, don’t present themselves as a clear threat. These are referred to as weak signals. However, when these weak signals are considered together and the sequence of commands aligns to malicious activity, GuardDuty uses that information to generate a finding. For example, a download of a file would present itself as a weak signal. If that download of a file is then piped to a shell command and the shell command begins to interact with additional operating system files or network configurations, or run known malware executables, then the correlation of all these events together can lead to a GuardDuty finding.
GuardDuty finding types
GuardDuty Runtime Monitoring currently supports 41 finding types to indicate potential threats based on the operating system-level behavior from the hosts and containers in your Amazon EKS clusters on Amazon EC2, Amazon ECS on Fargate and Amazon EC2, and EC2 instances. These findings are based on the event types that the security agent collects and sends to the GuardDuty service.
Five of these finding types take advantage of the new capabilities of the runtime agent and GuardDuty, which were discussed in the previous section of this post. These five new finding types are the following:
Each GuardDuty finding begins with a threat purpose, which is aligned with MITRE ATT&CK tactics. The Execution finding types are focused on observed threats to the actual running of commands or processes that align to malicious activity. The DefenseEvasion finding types are focused on situations where commands are run that are trying to disable defense mechanisms on the instance, which would normally be used to identify or help prevent the activity of a malicious actor on your instance.
In the following sections, I go into more detail about the new Runtime Monitoring finding types and the types of malicious activities that they are identifying.
Identifying suspicious tools and commands
The SuspiciousTool, SuspiciousCommand, and PtraceAntiDebugging finding types are focused on suspicious activities, or those that are used to evade detection. The approach to identify these types of activities is similar. The SuspiciousTool finding type is focused on tools such as backdoor tools, network scanners, and network sniffers. GuardDuty helps to identify the cases where malicious activities related to these tools are occurring on your instance.
The SuspiciousCommand finding type identifies suspicious commands with the threat purposes of DefenseEvasion or Execution. The DefenseEvasion findings are an indicator of an unauthorized user trying to hide their actions. These actions could include disabling a local firewall, modifying local IP tables, or removing crontab entries. The Execution findings identify when a suspicious command has been run on your EC2 instance. The findings related to Execution could be for a single suspicious command or a series of commands, which, when combined with a series of other commands along with additional context, becomes a clearer indicator of suspicious activity. An example of an Execution finding related to combining multiple commands could be when a file is downloaded and is then run in a series of steps that align with a known malicious pattern.
For the PtraceAntiDebugging finding, GuardDuty is looking for cases where a process on your instance has used the ptrace system call with the PTRACE_TRACEME option, which causes an attached debugger to detach from the running process. This is a suspicious activity because it allows a process to evade debugging using ptrace and is a known technique that malware uses to evade detection.
Identifying running malicious files
The updated GuardDuty security agent can also identify when malicious files are run. With the MaliciousFileExecuted finding type, GuardDuty can identify when known malicious files might have been run on your EC2 instance, providing a strong indicator that malware is present on your instance. This capability is especially important because it allows you to identify known malware that might have been introduced since your last malware scan.
Finding details
All of the findings mentioned so far are consumable through the AWS Management Console for GuardDuty, through the GuardDuty APIs, as Amazon EventBridge messages, or through AWS Security Hub. The findings that GuardDuty generates are meant to not only tell you that a suspicious event has been observed on your instance, but also give you enough context to formulate a response to the finding.
The GuardDuty security agent collects a variety of events from the operating system to use for threat detection. When GuardDuty generates a finding based on observed runtime activities, it will include the details of these observed events, which can help with confirmation on what the threat is and provide you a path for possible remediation steps based on the reported threat. The information provided in a GuardDuty runtime finding can be broken down into three main categories:
- Information about the impacted AWS resource
- Information about the observed processes that were involved in the activity
- Context related to the runtime events that were observed
Impacted AWS resources
In each finding that GuardDuty produces, information about the impacted AWS resource will be included. For EC2 Runtime Monitoring, the key information included will be information about the EC2 instance (such as name, instance type, AMI, and AWS Region), tags that are assigned to the instance, network interfaces, and security groups. This information will help guide your response and investigation to the specific instance that’s identified for the observed threat. It’s also useful in assessing key network configurations of the instance that could assist with confirming whether the network configuration of the instance is correct or assessing how the network configuration might factor into the response.
Process details
For each runtime finding, GuardDuty includes the details that were observed about the process attributed to the threat that the finding is for. Common items that you should expect to see include the name of the executable and the path to the executable that resulted in the finding being created, the ID of the operating system process, when the process started, and which operating system user ran the process. Additionally, process lineage is included in the finding. Process lineage helps identify operating system processes that are related to each other and provides insight into the parent processes that were run leading up to the identified process. Understanding this lineage can give you valuable insight into what the root cause of the malicious process identified in the finding might be; for example, being able to identify which other commands were run that ultimately led to the activation of the executable or command identified in the finding. If the process attributed to the finding is running inside a container, the finding also provides container details such as the container ID and image.
Runtime context
Runtime context provides insight on things such as file system type, flags that were used to control the behavior of the event, name of the potentially suspicious tool, path to the script that generated the finding, and the name of the security service that was disabled. The context information in the finding is intended to help you further understand the runtime activity that was identified as a threat and determine its potential impact and what your response might be. For example, a command that is detected by using the systemctl command to disable the apparmor utility would report the process information related to running the systemctl command, and then the runtime context would contain the name of the actual service that was impacted by the systemctl command call and the options used with the command.
See Runtime Monitoring finding details for a full list of the process and context details that might be present in your runtime findings.
Responding to runtime findings
With GuardDuty findings, it’s a best practice to enable an event-based response that can be invoked as soon as the runtime finding is generated. This approach holds true for runtime related findings as well. For every runtime finding that GuardDuty generates, a copy of the finding is sent to EventBridge. If you use Security Hub, a copy of the finding is sent to Security Hub as well. With EventBridge, you can define a rule with a pattern that matches the finding attributes you want to prioritize and respond to. This pattern could be very broad in looking for all runtime-related findings. Or, it could be more specific, only looking for certain finding types, findings of a certain severity, or even certain attributes related to the process or runtime context of a finding.
After the rule pattern is established, you can define a target that the finding should be sent to. This target can be one of over 20 AWS services, which gives you lots of flexibility in routing the finding into the operational tools or processes that are used by your company. The target could be an AWS Lambda function that’s responsible for evaluating the finding, adding some additional data to the finding, and then sending it to a ticketing or chat tool. The target could be an AWS Systems Manager runbook, which would be used on the actual operating system to perform additional forensics or to isolate or disable any processes that are identified in the finding.
Many customers take a stepped approach in their response to GuardDuty findings. The first step might be to make sure that the finding is enriched with as many supporting details as possible and sent to the right individual or team. This helps whoever’s investigating the finding to confirm that the finding is a true positive, further informing the decision on what action to take.
In addition to having an event-based response to GuardDuty findings, you can investigate each GuardDuty runtime finding in the GuardDuty or Security Hub console. Through the console, you can research the details of the finding and use the information to inform the next steps to respond to or remediate the finding.
Speed to detection
With its close proximity to your workloads, the GuardDuty security agent can produce findings more quickly when compared to processing log sources such as VPC Flow Logs and DNS logs. The security agent collects operating system events and forwards them directly to the GuardDuty service, examining events and generating findings more quickly. This helps you to formulate a response sooner so that you can isolate and stop identified threats to your EC2 instances.
Let’s examine a finding type that can be detected by both the runtime security agent and by the foundational log sources of AWS CloudTrail, VPC Flow Logs, and DNS logs. Backdoor:EC2/C&CActivity.B!DNS and Backdoor:Runtime/C&CActivity.B!DNS are the same finding with one coming from DNS logs and one coming from the runtime security agent. While GuardDuty doesn’t have a service-level agreement (SLA) on the time it takes to consume the findings for a log source or the security agent, testing for these finding types reveals that the runtime finding is generated in just a few minutes. Log file-based findings will take around 15 minutes to produce because of the latency of log file delivery and processing. In the end, these two findings mean the same thing, but the runtime finding will arrive faster and with additional process and context information, helping you implement a response to the threat sooner and improve your ability to isolate, contain, and stop the threat.
Runtime data and flow logs data
When exploring the Runtime Monitoring feature and its usefulness for your organization, a key item to understand is the foundational level of protection for your account and workloads. When you enable GuardDuty the foundational data sources of VPC Flow Logs, DNS logs, and CloudTrail logs are also enabled, and those sources cannot be turned off without fully disabling GuardDuty. Runtime Monitoring provides contextual information that allows for more precise findings that can help with targeted remediation compared to the information provided in VPC Flow Logs. When the Runtime Monitoring agent is deployed onto an instance, the GuardDuty service still processes the VPC Flow Logs and DNS logs for that instance. If, at any point in time, an unauthorized user tampers with your security agent or an instance is deployed without the security agent, GuardDuty will continue to use VPC Flow Logs and DNS logs data to monitor for potential threats and suspicious activity, providing you defense in depth to help ensure you have visibility and coverage for detecting threats.
Note: GuardDuty doesn’t charge you for processing VPC Flow Logs while the Runtime Monitoring agent is active on an instance.
Deployment strategies
There are multiple strategies that you can use to install the GuardDuty security agent on an EC2 instance, and it’s important to use the one that fits best based on how you deploy and maintain instances in your environment. The following are agent installation options that cover managed installation, tag-based installation, and manual installation techniques. The managed installation approach is a good fit for most customers, but the manual options are potentially better if you have existing processes that you want to maintain or you want the more fine-grained features provided by agent installation compared to the managed approach.
Note: GuardDuty requires that each VPC, with EC2 instances running the GuardDuty agent, has a VPC endpoint that allows the agent to communicate with the GuardDuty service. You aren’t charged for the cost of these VPC endpoints. When you’re using the GuardDuty managed agent feature, GuardDuty will automatically create and operate these VPC endpoints for you. For the other agent deployment options listed in this section, or other approaches that you take, you must manually configure the VPC endpoint for each VPC where you have EC2 instances that will run the GuardDuty agent. See Creating VPC endpoint manually for additional details.
GuardDuty-managed installation
If you want to use security agents to monitor runtime activity on your EC2 instances but don’t want to manage the installation and lifecycle of the agent on specific instances, then Automated agent configuration is the option for you. For GuardDuty to successfully manage agent installation, each EC2 instance must meet the operating system architectural requirements of the security agent. Additionally, each instance must have the Systems Manager agent installed and configured with the minimal instance permissions that System Manager requires.
In addition to making sure that your instances are configured correctly, you also need to enable automated agent configuration for your EC2 instances in the Runtime Monitoring section of the GuardDuty console. Figure 1 shows what this step looks like.

Figure 1: Enable GuardDuty automated agent configuration for Amazon EC2
After you have enabled automated agent configuration and have your instances correctly configured, GuardDuty will install and manage the security agent for every instance that is configured.
GuardDuty-managed with explicit tagging
If you want to selectively manage installation of the GuardDuty agent but still want automated deployment and updates, you can use inclusion or exclusion tags to control which instances the agent is installed to.
- Inclusion tags allow you to specify which EC2 instances the GuardDuty security agent should be installed to without having to enable automated agent configuration. To use inclusion tags, each instance where the security agent should be installed needs to have a key-value pair of
GuardDutyManaged/true. While you don’t need to turn on automated agent configuration to use inclusion tags, each instance that you tag for agent installation needs to have the Systems Manager agent installed and the appropriate permissions attached to the instance using an instance role.
- Exclusion tags allow you to enable automated agent configuration, and then selectively manage which instances the agent shouldn’t be deployed to. To use exclusion tags, each instance that shouldn’t have an instance installed needs to have a key-value pair of
GuardDutyManaged/false.
You can use selective installation for a variety of use cases. If you’re doing a proof of concept with EC2 Runtime Monitoring, you might want to deploy the solution to a subset of your instances and then gradually onboard additional instances. At times, you might want to limit agent installation to instances that are deployed into certain environments or applications that are a priority for runtime monitoring. Tagging resources associated with these workloads helps ensure that monitoring is in place for resources that you want to prioritize for runtime monitoring. This strategy gives you more fine-grained control but also requires more work and planning to help ensure that the strategy is implemented correctly.
With a tag-based strategy it is important to understand who is allowed to add or remove tags to your EC2 instances as this influences when security controls are enabled or disabled. A review of your IAM roles and policies for tagging permissions is recommended to help ensure that the appropriate principals have access to this tagging capability. This IAM document provides an example of how you may limit tagging capabilities within a policy. The approach you take will depend on how you are using policies within your environment.
Manual agent installation options
If you don’t want to run the Systems Manager agent that powers the automated agent configuration, or if you have your own strategy to install and configure software on your EC2 instances, there are other deployment options that are better suited for your situation. The following are multiple approaches that you can use to manually install the GuardDuty agent for Runtime Monitoring. See Installing the security agent manually for general pointers on the recommended manual installation steps. With manual installation, you’re responsible for updating the GuardDuty security agent when new versions of the agent are released. Updating the agent can often be performed using the same techniques as installing the agent.
EC2 Image Builder
Your EC2 deployment strategy might be to build custom Amazon EC2 machine images that are then used as the approved machine images for your organization’s workloads. One option for installing the GuardDuty runtime agent as part of a machine image build is to use EC2 Image Builder. Image Builder simplifies the building, testing, and deployment of virtual machine and container images for use on AWS. With Image Builder, you define an image pipeline that includes a recipe with a build component for installing the GuardDuty Runtime Monitoring RPM. This approach with Image Builder helps ensure that your pre-built machine image includes the necessary components for EC2 Runtime Monitoring so that the necessary security monitoring is in place as soon as your instances are launched.
Bootstrap
Some customers prefer to configure their EC2 instances as they’re launched. This is commonly done through the user data field of an EC2 instance definition. For EC2 Runtime Monitoring agent installation, you would add the steps related to download and install of the runtime RPM as part of your user data script. The steps that you would add to your user data script are outlined in the Linux Package Managers method of Installing the security agent manually.
Other tools
In addition to the preceding steps, there are other tools that you can use when you want to incorporate the installation of the GuardDuty runtime monitoring agent. Tools such as Packer for building EC2 images, and Ansible, Chef, and Puppet for instance automation can be used to run the necessary steps to install the runtime agent onto the necessary EC2 instances. See Installing the security agent manually for guidance on the installation commands you would use with these tools.
Conclusion
Through customer feedback, GuardDuty has enhanced its threat detection capabilities with the Runtime Monitoring feature and you can now use it to deploy the same security agent across different compute services in AWS for runtime threat detection. Runtime monitoring provides an additional level of visibility that helps you achieve your security goals for your AWS workloads.
This post outlined the GuardDuty EC2 Runtime Monitoring feature, how you can implement the feature on your EC2 instances, and the security value that the feature provides. The insight provided in this post is intended to help you better understand how EC2 Runtime Monitoring can benefit you in achieving your security goals related to identifying and responding to threats.
To learn more about GuardDuty and its Runtime Monitoring capabilities, see Runtime Monitoring in GuardDuty.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.



















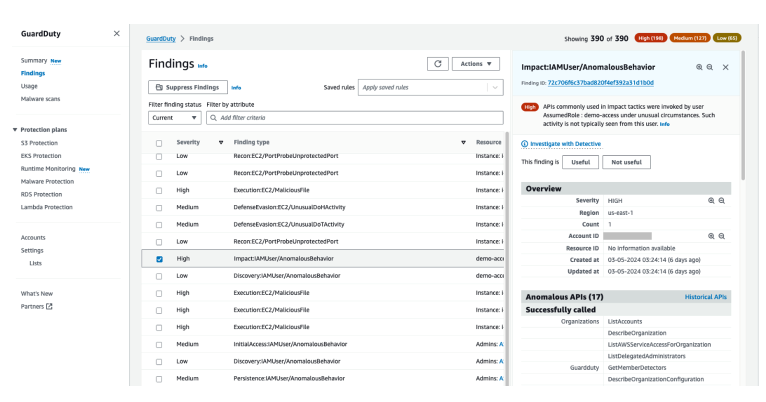
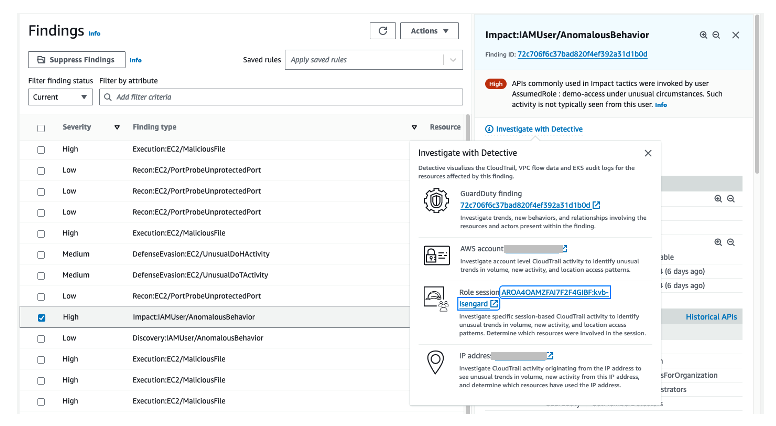
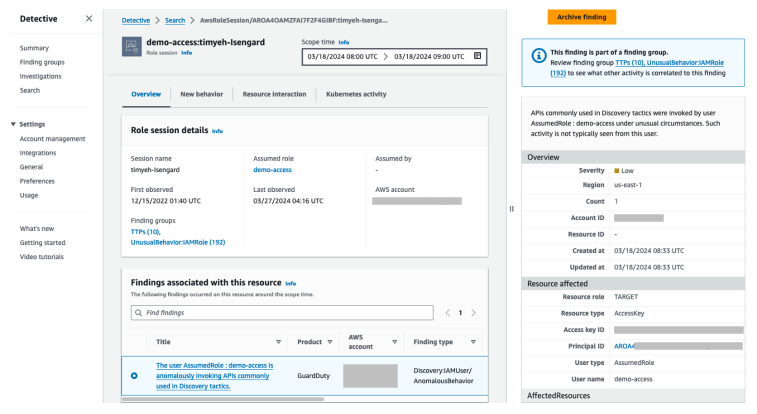
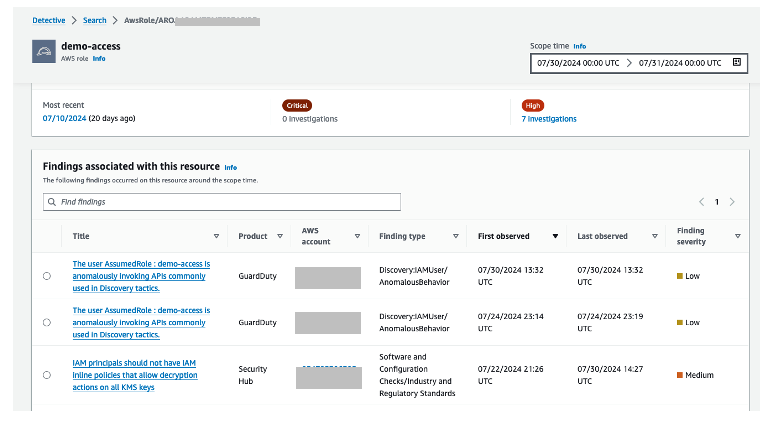
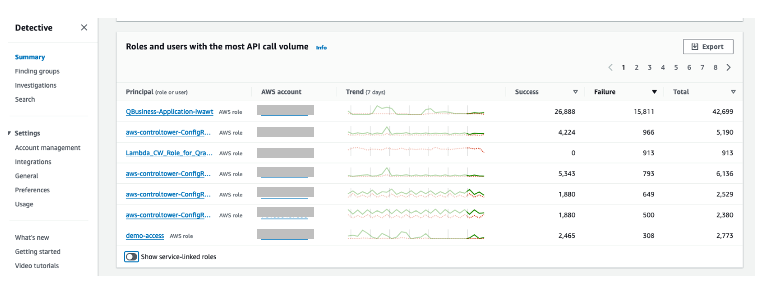
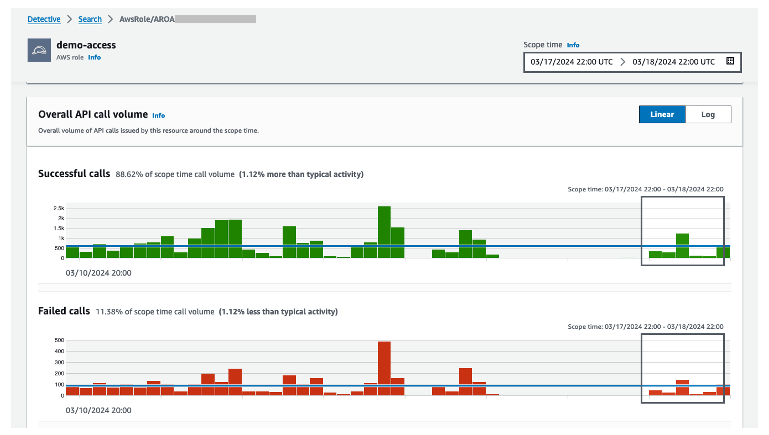
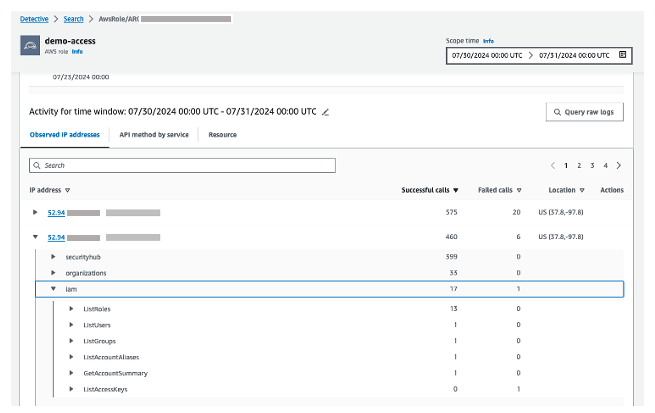
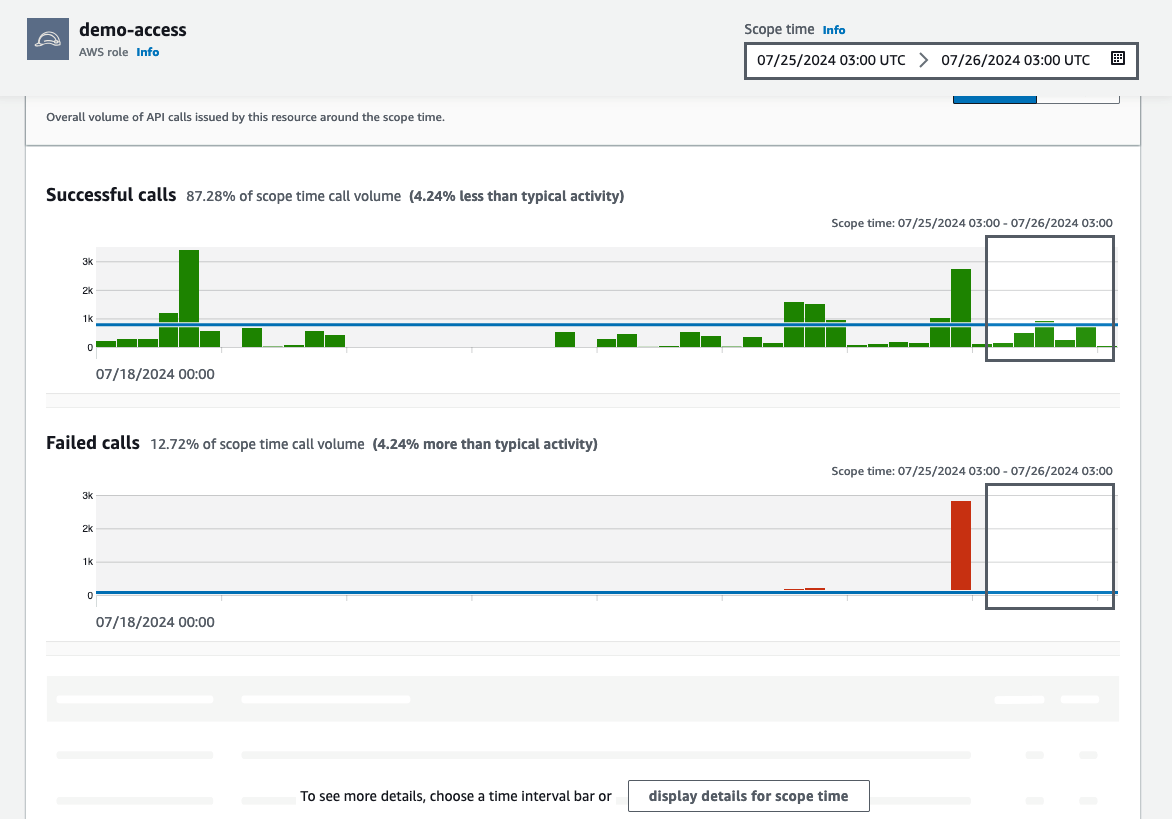 Figure 12: Overall API call volume during the specified scope time
Figure 12: Overall API call volume during the specified scope time







































 apc-crr
apc-crr
 Deployment time: 307.88s
Stack ARN:
arn:aws:cloudformation:<aws_region>:<aws_account>:stack/apc-crr/<stack_id>
Deployment time: 307.88s
Stack ARN:
arn:aws:cloudformation:<aws_region>:<aws_account>:stack/apc-crr/<stack_id>

