Post Syndicated from Shubham Gupta original https://aws.amazon.com/blogs/compute/aws-lambda-standardizes-billing-for-init-phase/
Effective August 1, 2025, AWS will standardize billing for the initialization (INIT) phase across all AWS Lambda function configurations. This change specifically affects on-demand invocations of Lambda functions packaged as ZIP files that use managed runtimes, for which the INIT phase duration was previously unbilled. This update standardizes billing of the INIT phase across all runtime types, deployment packages, and invocation modes. Most users will see minimal impact on their overall Lambda bill from this change, as the INIT phase typically occurs for a very small fraction of function invocations. In this post, we discuss the Lambda Function Lifecycle and upcoming changes to INIT phase billing. You will learn what happens in the INIT phase and when it occurs, how to monitor your INIT phase duration, and strategies to optimize this phase and minimize costs.
Understanding the Lambda function execution lifecycle
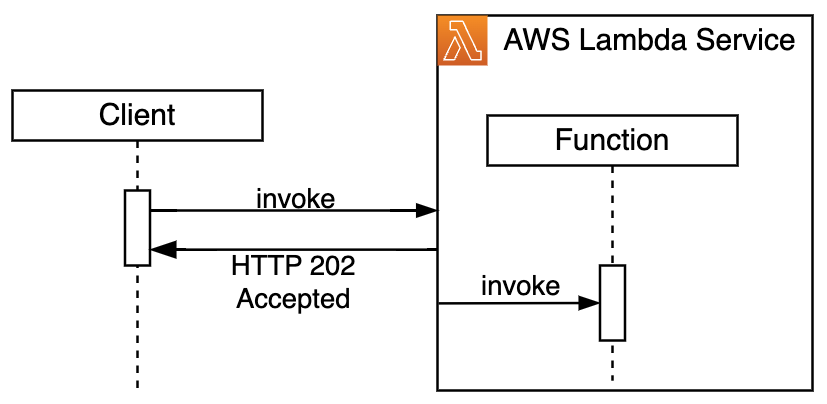
The Lambda function execution lifecycle consists of three distinct phases: INIT, INVOKE, and SHUTDOWN. The INIT phase is triggered during a “cold start” when Lambda creates a new execution environment for a function in response to an invocation. This is followed by the INVOKE phase where the request is processed, and finally, the SHUTDOWN phase where the execution environment is terminated. For a summary of the execution lifecycle, watch AWS Lambda execution environment lifecycle.
During the INIT phase, Lambda performs a series of preparatory steps within a maximum duration of 10 seconds. The service retrieves the function code from an internal Amazon S3 bucket, or from Amazon Elastic Container Registry (Amazon ECR) for functions using container packaging. Then, it configures an environment with the specified memory, runtime, and other settings. When the execution environment is prepared, Lambda executes four key tasks in sequence:
- Initiate any extensions configured (Extension INIT)
- Bootstrap the runtime (Runtime INIT)
- Execute the function’s static code (Function INIT)
- Run any before-checkpoint runtime hooks (applicable only for Lambda SnapStart)

Understanding the billing changes
Lambda charges are based on the number of requests and the duration it takes for the code to run. The duration is calculated from the moment the function code begins running until it completes or terminates, rounded up to the nearest millisecond. Duration cost depends on the amount of memory that you allocate to your function.
https://docs.aws.amazon.com/lambda/latest/dg/provisioned-concurrency.html
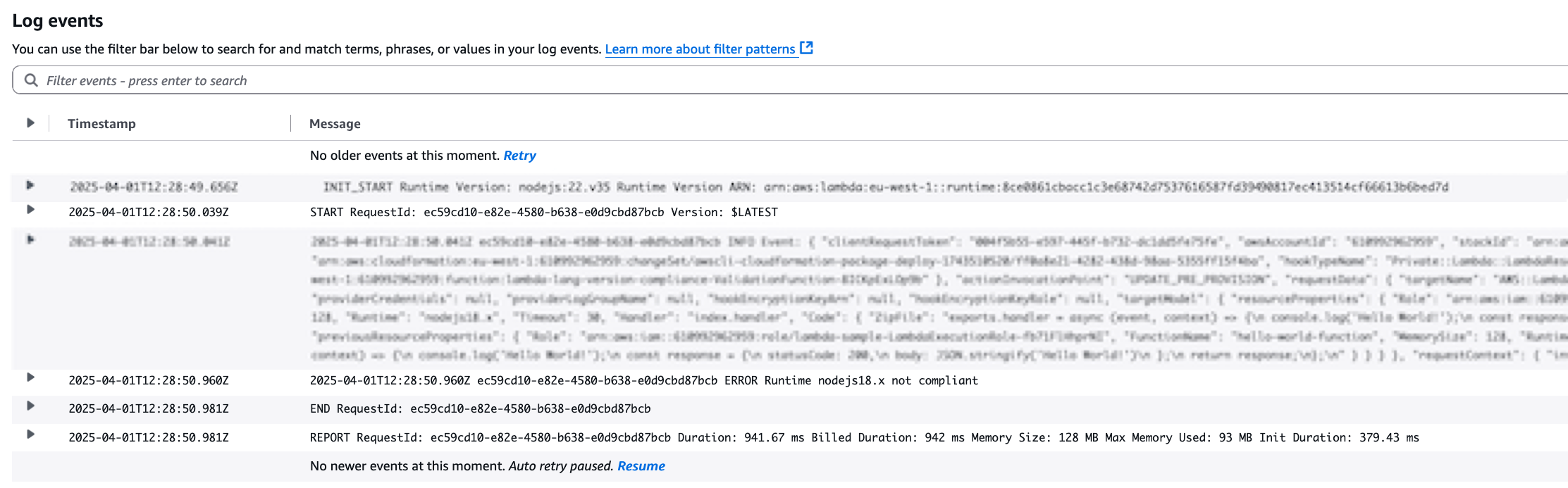
Previously, the INIT phase duration wasn’t included in the Billed Duration for functions using managed runtimes with ZIP archive packaging, as evidenced in Amazon CloudWatch logs:
However, functions configured with custom runtimes, Provisioned Concurrency (PC), or OCI packaging already included the INIT phase duration in their Billed Duration. Effective August 1, 2025, INIT phase will be billed across all configuration types and the INIT phase duration will be included in the Billed Duration for on-demand invocations of functions using managed runtimes with ZIP archive packaging as well. After this change, the REPORT Request ID log line will show the following:
The further INIT phase duration charges will follow the standard on-demand duration pricing that is specific to each AWS Region, which can be found on the Lambda pricing page. For AWS Lambda@Edge functions, the INIT phase duration will be billed according to Lambda@Edge duration rates.
Finding the INIT phase duration and impact to Lambda billing
You can already monitor the time spent in the INIT phase of your function invocations using the “init_duration” CloudWatch metric. This metric is also reported as “Init Duration” in the “REPORT RequestId” log line within CloudWatch Logs. These tools offer valuable insights into the INIT time of Lambda functions, which will now be factored into billing calculations.
For a more comprehensive analysis, you can use the following CloudWatch Log Insights query to generate a detailed report estimating the previously unbilled duration of the INIT phase. The query helps you understand the proportion of the unbilled INIT phase time relative to your overall Lambda usage, enabling more accurate cost projections following this billing change.
The CloudWatch Log Insights query provides three essential metrics:
- BilledGBs: Represents the total GB-s (gigabyte-seconds) currently being billed for the chosen log groups.
- UnbilledInitGBs: Shows the total GB-s consumed during INIT phase that was previously not included in billing.
- Ratio: Indicates the percentage of total GB-s attributed to previously unbilled INIT phase duration.

Using these existing monitoring capabilities allows you to proactively assess and optimize your Lambda function INIT times, potentially minimizing the impact of the new billing structure on your overall costs.
Understanding and optimizing Lambda INIT phase
The Lambda INIT phase is triggered in two specific scenarios: during the creation of a new execution environment and when a function scales up to meet demand. This INIT code runs only during these “cold starts” and is bypassed during subsequent invocations that use existing warm environments. After the INIT phase, Lambda runs the function handler code to process the invocation.
Following the handler execution, Lambda freezes the execution environment. To improve resource management and performance, the Lambda service retains the execution environment for a non-deterministic period of time. During this time, if another request arrives for the same function, then the service may reuse the environment. This second request typically finishes faster, because the execution environment already exists and it isn’t necessary to download the code and run the INIT code. This is called a “warm start.”
Developers can use the INIT phase to create, initialize, and configure objects expected to be reused across multiple invocations during function INIT instead of doing it in the handler. Initializing the dependencies/shared objects upfront reduces the latency of subsequent invocations. For example:
- Download more libraries or dependencies
- Establish client connections to other AWS services such as Amazon S3 or Amazon DynamoDB
- Create database connections to be shared across invocations
- Retrieve application parameters or secrets from Amazon Systems Manager Parameter Store or AWS Secrets Manager
When developing Lambda functions, it’s important to strategically decide what code runs during the INIT phase as opposed to the handler phase, because it affects both performance and costs.
Optimizing package/library size
The INIT phase includes creating an execution environment, downloading the function code and initializing it. Three main factors influence its performance:
- The size of the function package, in terms of imported libraries and dependencies, and Lambda layers.
- The amount of code and INIT work.
- The performance of libraries and other services in setting up connections and other resources.
Larger function packages increase code download times. You can decrease INIT phase duration by reducing package size, resulting in faster cold starts and lower INIT costs. Furthermore, optimizing loading of libraries can also significantly impact package size. For example, in Node.js functions, you should use specific path imports (for example import DynamoDB from "aws-sdk/clients/dynamodb") rather than wildcard imports (for example import {* as AWS} from "aws-sdk") to speed up the INIT phase. Tools such as esbuild can further optimize performance by minifying and bundling packages. For details, read Optimizing node.js dependencies in AWS Lambda.
Optimizing INIT phase execution and cost efficiency
The frequency of INIT phase executions (or cold starts) directly impacts both performance and cost efficiency. According to an analysis of production Lambda workloads, INITs (cold starts) typically occur in under 1% of invocations—meaning code in the INIT phase may execute just once per hundred invocations.
You can use the INIT phase to perform one-time operations that benefit subsequent invocations. Common optimization patterns include pre-calculating lookup tables or transforming static datasets. For example, downloading static data from Amazon S3 or DynamoDB during INIT, making it available for all subsequent function invocations without repeated downloads.
Lambda SnapStart
Lambda SnapStart provides an effective solution for reducing cold start latency and INIT phase costs. When it’s enabled, SnapStart creates a snapshot during the first function INIT and reuses it for subsequent cold starts, eliminating the need for repeated INIT phase executions. This approach is particularly valuable for functions with longer INIT times due to loading module dependencies/frameworks, initializing the runtime, or executing one-time INIT code. SnapStart is supported for Java, .NET, and Python runtimes. You can implement SnapStart through the Lambda console or AWS Command Line Interface (AWS CLI), making sure that your code adheres to the AWS serialization guidelines for snapshot restoration compatibility. Using SnapStart allows you to significantly improve function startup times and optimize costs across multiple popular programming languages.
Provisioned Concurrency
Provisioned Concurrency is a Lambda feature that pre-initializes execution environments before any invocations occur. This proactive approach effectively eliminates the performance impact of the INIT phase on individual function calls, because the INIT is completed in advance.
Although all functions using the Provisioned Concurrency benefit from reduced startup times as compared to on-demand execution, the impact is particularly pronounced for certain runtime environments. For example, C# and Java functions—which typically experience slower INIT but faster execution times as compared to Node.js or Python—can achieve significant performance gains through this feature. Implementing Provisioned Concurrency allows you to effectively manage both consistent traffic patterns and expected usage spikes, thereby minimizing cold start latency across your serverless applications. This optimization strategy is particularly valuable for functions with complex INIT requirements or those serving latency-sensitive workloads. From a cost optimization perspective, Provisioned Concurrency is most suitable for workloads with sustained usage patterns above 60% usage, because this typically provides better cost efficiency compared to on-demand execution.
Conclusion
Effective August 1, 2025, AWS is standardizing the INIT phase billing for AWS Lambda. AWS provides multiple ways for you to optimize both the performance and costs of your Lambda functions. Whether you’re using SnapStart, implementing Provisioned Concurrency, or optimizing INIT code, we recommend working closely with AWS support teams to identify the most suitable optimization approach for your specific workload requirements.
For more support and guidance, consider participating in AWS Cost Optimization workshops or consulting the Lambda documentation.






































































 Michael Davies is a Data Engineer at OUA. He has extensive experience within the education industry, with a particular focus on building robust and efficient data architecture and pipelines.
Michael Davies is a Data Engineer at OUA. He has extensive experience within the education industry, with a particular focus on building robust and efficient data architecture and pipelines. Emma Arrigo is a Solutions Architect at AWS, focusing on education customers across Australia. She specializes in leveraging cloud technology and machine learning to address complex business challenges in the education sector. Emma’s passion for data extends beyond her professional life, as evidenced by her dog named Data.
Emma Arrigo is a Solutions Architect at AWS, focusing on education customers across Australia. She specializes in leveraging cloud technology and machine learning to address complex business challenges in the education sector. Emma’s passion for data extends beyond her professional life, as evidenced by her dog named Data.









































 Xu Feng is a Senior Industry Solution Architect at AWS, responsible for designing, building, and promoting industry solutions for the Media & Entertainment and Advertising sectors, such as intelligent customer service and business intelligence. With 20 years of software industry experience, currently focused on researching and implementing generative AI and AI-powered data solutions.
Xu Feng is a Senior Industry Solution Architect at AWS, responsible for designing, building, and promoting industry solutions for the Media & Entertainment and Advertising sectors, such as intelligent customer service and business intelligence. With 20 years of software industry experience, currently focused on researching and implementing generative AI and AI-powered data solutions. Xu Da is a Amazon Web Services (AWS) Partner Solutions Architect based out of Shanghai, China. He has more than 25 years of experience in IT industry, software development and solution architecture. He is passionate about collaborative learning, knowledge sharing, and guiding community in their cloud technologies journey.
Xu Da is a Amazon Web Services (AWS) Partner Solutions Architect based out of Shanghai, China. He has more than 25 years of experience in IT industry, software development and solution architecture. He is passionate about collaborative learning, knowledge sharing, and guiding community in their cloud technologies journey.

